Spaces:
Running

Running
Migrated from GitHub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +12 -0
- INSTALL.md +54 -0
- LICENSE.txt +201 -0
- ORIGINAL_README.md +663 -0
- assets/comp_effic.png +3 -0
- assets/data_for_diff_stage.jpg +3 -0
- assets/i2v_res.png +3 -0
- assets/logo.png +0 -0
- assets/t2v_res.jpg +3 -0
- assets/vben_vs_sota.png +3 -0
- assets/video_dit_arch.jpg +3 -0
- assets/video_vae_res.jpg +3 -0
- examples/flf2v_input_first_frame.png +3 -0
- examples/flf2v_input_last_frame.png +3 -0
- examples/girl.png +3 -0
- examples/i2v_input.JPG +3 -0
- examples/snake.png +3 -0
- generate.py +572 -0
- gradio/fl2v_14B_singleGPU.py +252 -0
- gradio/i2v_14B_singleGPU.py +287 -0
- gradio/t2i_14B_singleGPU.py +205 -0
- gradio/t2v_1.3B_singleGPU.py +207 -0
- gradio/t2v_14B_singleGPU.py +205 -0
- gradio/vace.py +295 -0
- pyproject.toml +67 -0
- requirements.txt +16 -0
- tests/README.md +6 -0
- tests/test.sh +120 -0
- wan/__init__.py +5 -0
- wan/configs/__init__.py +53 -0
- wan/configs/shared_config.py +19 -0
- wan/configs/wan_i2v_14B.py +36 -0
- wan/configs/wan_t2v_14B.py +29 -0
- wan/configs/wan_t2v_1_3B.py +29 -0
- wan/distributed/__init__.py +0 -0
- wan/distributed/fsdp.py +41 -0
- wan/distributed/xdit_context_parallel.py +230 -0
- wan/first_last_frame2video.py +370 -0
- wan/image2video.py +347 -0
- wan/modules/__init__.py +18 -0
- wan/modules/attention.py +179 -0
- wan/modules/clip.py +542 -0
- wan/modules/model.py +630 -0
- wan/modules/t5.py +513 -0
- wan/modules/tokenizers.py +82 -0
- wan/modules/vace_model.py +233 -0
- wan/modules/vae.py +663 -0
- wan/modules/xlm_roberta.py +170 -0
- wan/text2video.py +267 -0
- wan/utils/__init__.py +10 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,15 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/comp_effic.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/data_for_diff_stage.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/i2v_res.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/t2v_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/vben_vs_sota.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/video_dit_arch.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/video_vae_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
examples/flf2v_input_first_frame.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
examples/flf2v_input_last_frame.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
examples/girl.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
examples/i2v_input.JPG filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
examples/snake.png filter=lfs diff=lfs merge=lfs -text
|
INSTALL.md
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Installation Guide
|
| 2 |
+
|
| 3 |
+
## Install with pip
|
| 4 |
+
|
| 5 |
+
```bash
|
| 6 |
+
pip install .
|
| 7 |
+
pip install .[dev] # Installe aussi les outils de dev
|
| 8 |
+
```
|
| 9 |
+
|
| 10 |
+
## Install with Poetry
|
| 11 |
+
|
| 12 |
+
Ensure you have [Poetry](https://python-poetry.org/docs/#installation) installed on your system.
|
| 13 |
+
|
| 14 |
+
To install all dependencies:
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
poetry install
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
### Handling `flash-attn` Installation Issues
|
| 21 |
+
|
| 22 |
+
If `flash-attn` fails due to **PEP 517 build issues**, you can try one of the following fixes.
|
| 23 |
+
|
| 24 |
+
#### No-Build-Isolation Installation (Recommended)
|
| 25 |
+
```bash
|
| 26 |
+
poetry run pip install --upgrade pip setuptools wheel
|
| 27 |
+
poetry run pip install flash-attn --no-build-isolation
|
| 28 |
+
poetry install
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
#### Install from Git (Alternative)
|
| 32 |
+
```bash
|
| 33 |
+
poetry run pip install git+https://github.com/Dao-AILab/flash-attention.git
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
---
|
| 37 |
+
|
| 38 |
+
### Running the Model
|
| 39 |
+
|
| 40 |
+
Once the installation is complete, you can run **Wan2.1** using:
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
poetry run python generate.py --task t2v-14B --size '1280x720' --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
#### Test
|
| 47 |
+
```bash
|
| 48 |
+
pytest tests/
|
| 49 |
+
```
|
| 50 |
+
#### Format
|
| 51 |
+
```bash
|
| 52 |
+
black .
|
| 53 |
+
isort .
|
| 54 |
+
```
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
ORIGINAL_README.md
ADDED
|
@@ -0,0 +1,663 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Wan2.1
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<img src="assets/logo.png" width="400"/>
|
| 5 |
+
<p>
|
| 6 |
+
|
| 7 |
+
<p align="center">
|
| 8 |
+
💜 <a href="https://wan.video"><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.1">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2503.20314">Technical Report</a>    |    📑 <a href="https://wan.video/welcome?spm=a2ty_o02.30011076.0.0.6c9ee41eCcluqg">Blog</a>    |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat Group</a>   |    📖 <a href="https://discord.gg/AKNgpMK4Yj">Discord</a>  
|
| 9 |
+
<br>
|
| 10 |
+
|
| 11 |
+
-----
|
| 12 |
+
|
| 13 |
+
[**Wan: Open and Advanced Large-Scale Video Generative Models**](https://arxiv.org/abs/2503.20314) <be>
|
| 14 |
+
|
| 15 |
+
In this repository, we present **Wan2.1**, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. **Wan2.1** offers these key features:
|
| 16 |
+
- 👍 **SOTA Performance**: **Wan2.1** consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
|
| 17 |
+
- 👍 **Supports Consumer-grade GPUs**: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
|
| 18 |
+
- 👍 **Multiple Tasks**: **Wan2.1** excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
|
| 19 |
+
- 👍 **Visual Text Generation**: **Wan2.1** is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
|
| 20 |
+
- 👍 **Powerful Video VAE**: **Wan-VAE** delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
|
| 21 |
+
|
| 22 |
+
## Video Demos
|
| 23 |
+
|
| 24 |
+
<div align="center">
|
| 25 |
+
<video src="https://github.com/user-attachments/assets/4aca6063-60bf-4953-bfb7-e265053f49ef" width="70%" poster=""> </video>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
## 🔥 Latest News!!
|
| 29 |
+
|
| 30 |
+
* May 14, 2025: 👋 We introduce **Wan2.1** [VACE](https://github.com/ali-vilab/VACE), an all-in-one model for video creation and editing, along with its [inference code](#run-vace), [weights](#model-download), and [technical report](https://arxiv.org/abs/2503.07598)!
|
| 31 |
+
* Apr 17, 2025: 👋 We introduce **Wan2.1** [FLF2V](#run-first-last-frame-to-video-generation) with its inference code and weights!
|
| 32 |
+
* Mar 21, 2025: 👋 We are excited to announce the release of the **Wan2.1** [technical report](https://files.alicdn.com/tpsservice/5c9de1c74de03972b7aa657e5a54756b.pdf). We welcome discussions and feedback!
|
| 33 |
+
* Mar 3, 2025: 👋 **Wan2.1**'s T2V and I2V have been integrated into Diffusers ([T2V](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wan#diffusers.WanPipeline) | [I2V](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wan#diffusers.WanImageToVideoPipeline)). Feel free to give it a try!
|
| 34 |
+
* Feb 27, 2025: 👋 **Wan2.1** has been integrated into [ComfyUI](https://comfyanonymous.github.io/ComfyUI_examples/wan/). Enjoy!
|
| 35 |
+
* Feb 25, 2025: 👋 We've released the inference code and weights of **Wan2.1**.
|
| 36 |
+
|
| 37 |
+
## Community Works
|
| 38 |
+
If your work has improved **Wan2.1** and you would like more people to see it, please inform us.
|
| 39 |
+
- [Phantom](https://github.com/Phantom-video/Phantom) has developed a unified video generation framework for single and multi-subject references based on **Wan2.1-T2V-1.3B**. Please refer to [their examples](https://github.com/Phantom-video/Phantom).
|
| 40 |
+
- [UniAnimate-DiT](https://github.com/ali-vilab/UniAnimate-DiT), based on **Wan2.1-14B-I2V**, has trained a Human image animation model and has open-sourced the inference and training code. Feel free to enjoy it!
|
| 41 |
+
- [CFG-Zero](https://github.com/WeichenFan/CFG-Zero-star) enhances **Wan2.1** (covering both T2V and I2V models) from the perspective of CFG.
|
| 42 |
+
- [TeaCache](https://github.com/ali-vilab/TeaCache) now supports **Wan2.1** acceleration, capable of increasing speed by approximately 2x. Feel free to give it a try!
|
| 43 |
+
- [DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio) provides more support for **Wan2.1**, including video-to-video, FP8 quantization, VRAM optimization, LoRA training, and more. Please refer to [their examples](https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/wanvideo).
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
## 📑 Todo List
|
| 47 |
+
- Wan2.1 Text-to-Video
|
| 48 |
+
- [x] Multi-GPU Inference code of the 14B and 1.3B models
|
| 49 |
+
- [x] Checkpoints of the 14B and 1.3B models
|
| 50 |
+
- [x] Gradio demo
|
| 51 |
+
- [x] ComfyUI integration
|
| 52 |
+
- [x] Diffusers integration
|
| 53 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 54 |
+
- Wan2.1 Image-to-Video
|
| 55 |
+
- [x] Multi-GPU Inference code of the 14B model
|
| 56 |
+
- [x] Checkpoints of the 14B model
|
| 57 |
+
- [x] Gradio demo
|
| 58 |
+
- [x] ComfyUI integration
|
| 59 |
+
- [x] Diffusers integration
|
| 60 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 61 |
+
- Wan2.1 First-Last-Frame-to-Video
|
| 62 |
+
- [x] Multi-GPU Inference code of the 14B model
|
| 63 |
+
- [x] Checkpoints of the 14B model
|
| 64 |
+
- [x] Gradio demo
|
| 65 |
+
- [ ] ComfyUI integration
|
| 66 |
+
- [ ] Diffusers integration
|
| 67 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 68 |
+
- Wan2.1 VACE
|
| 69 |
+
- [x] Multi-GPU Inference code of the 14B and 1.3B models
|
| 70 |
+
- [x] Checkpoints of the 14B and 1.3B models
|
| 71 |
+
- [x] Gradio demo
|
| 72 |
+
- [x] ComfyUI integration
|
| 73 |
+
- [ ] Diffusers integration
|
| 74 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 75 |
+
|
| 76 |
+
## Quickstart
|
| 77 |
+
|
| 78 |
+
#### Installation
|
| 79 |
+
Clone the repo:
|
| 80 |
+
```sh
|
| 81 |
+
git clone https://github.com/Wan-Video/Wan2.1.git
|
| 82 |
+
cd Wan2.1
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
Install dependencies:
|
| 86 |
+
```sh
|
| 87 |
+
# Ensure torch >= 2.4.0
|
| 88 |
+
pip install -r requirements.txt
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
#### Model Download
|
| 93 |
+
|
| 94 |
+
| Models | Download Link | Notes |
|
| 95 |
+
|--------------|---------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------|
|
| 96 |
+
| T2V-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | Supports both 480P and 720P
|
| 97 |
+
| I2V-14B-720P | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | Supports 720P
|
| 98 |
+
| I2V-14B-480P | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | Supports 480P
|
| 99 |
+
| T2V-1.3B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | Supports 480P
|
| 100 |
+
| FLF2V-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-FLF2V-14B-720P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-FLF2V-14B-720P) | Supports 720P
|
| 101 |
+
| VACE-1.3B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-VACE-1.3B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-VACE-1.3B) | Supports 480P
|
| 102 |
+
| VACE-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-VACE-14B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-VACE-14B) | Supports both 480P and 720P
|
| 103 |
+
|
| 104 |
+
> 💡Note:
|
| 105 |
+
> * The 1.3B model is capable of generating videos at 720P resolution. However, due to limited training at this resolution, the results are generally less stable compared to 480P. For optimal performance, we recommend using 480P resolution.
|
| 106 |
+
> * For the first-last frame to video generation, we train our model primarily on Chinese text-video pairs. Therefore, we recommend using Chinese prompt to achieve better results.
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
Download models using huggingface-cli:
|
| 110 |
+
``` sh
|
| 111 |
+
pip install "huggingface_hub[cli]"
|
| 112 |
+
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Download models using modelscope-cli:
|
| 116 |
+
``` sh
|
| 117 |
+
pip install modelscope
|
| 118 |
+
modelscope download Wan-AI/Wan2.1-T2V-14B --local_dir ./Wan2.1-T2V-14B
|
| 119 |
+
```
|
| 120 |
+
#### Run Text-to-Video Generation
|
| 121 |
+
|
| 122 |
+
This repository supports two Text-to-Video models (1.3B and 14B) and two resolutions (480P and 720P). The parameters and configurations for these models are as follows:
|
| 123 |
+
|
| 124 |
+
<table>
|
| 125 |
+
<thead>
|
| 126 |
+
<tr>
|
| 127 |
+
<th rowspan="2">Task</th>
|
| 128 |
+
<th colspan="2">Resolution</th>
|
| 129 |
+
<th rowspan="2">Model</th>
|
| 130 |
+
</tr>
|
| 131 |
+
<tr>
|
| 132 |
+
<th>480P</th>
|
| 133 |
+
<th>720P</th>
|
| 134 |
+
</tr>
|
| 135 |
+
</thead>
|
| 136 |
+
<tbody>
|
| 137 |
+
<tr>
|
| 138 |
+
<td>t2v-14B</td>
|
| 139 |
+
<td style="color: green;">✔️</td>
|
| 140 |
+
<td style="color: green;">✔️</td>
|
| 141 |
+
<td>Wan2.1-T2V-14B</td>
|
| 142 |
+
</tr>
|
| 143 |
+
<tr>
|
| 144 |
+
<td>t2v-1.3B</td>
|
| 145 |
+
<td style="color: green;">✔️</td>
|
| 146 |
+
<td style="color: red;">❌</td>
|
| 147 |
+
<td>Wan2.1-T2V-1.3B</td>
|
| 148 |
+
</tr>
|
| 149 |
+
</tbody>
|
| 150 |
+
</table>
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
##### (1) Without Prompt Extension
|
| 154 |
+
|
| 155 |
+
To facilitate implementation, we will start with a basic version of the inference process that skips the [prompt extension](#2-using-prompt-extention) step.
|
| 156 |
+
|
| 157 |
+
- Single-GPU inference
|
| 158 |
+
|
| 159 |
+
``` sh
|
| 160 |
+
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
If you encounter OOM (Out-of-Memory) issues, you can use the `--offload_model True` and `--t5_cpu` options to reduce GPU memory usage. For example, on an RTX 4090 GPU:
|
| 164 |
+
|
| 165 |
+
``` sh
|
| 166 |
+
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
> 💡Note: If you are using the `T2V-1.3B` model, we recommend setting the parameter `--sample_guide_scale 6`. The `--sample_shift parameter` can be adjusted within the range of 8 to 12 based on the performance.
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 173 |
+
|
| 174 |
+
We use FSDP and [xDiT](https://github.com/xdit-project/xDiT) USP to accelerate inference.
|
| 175 |
+
|
| 176 |
+
* Ulysess Strategy
|
| 177 |
+
|
| 178 |
+
If you want to use [`Ulysses`](https://arxiv.org/abs/2309.14509) strategy, you should set `--ulysses_size $GPU_NUMS`. Note that the `num_heads` should be divisible by `ulysses_size` if you wish to use `Ulysess` strategy. For the 1.3B model, the `num_heads` is `12` which can't be divided by 8 (as most multi-GPU machines have 8 GPUs). Therefore, it is recommended to use `Ring Strategy` instead.
|
| 179 |
+
|
| 180 |
+
* Ring Strategy
|
| 181 |
+
|
| 182 |
+
If you want to use [`Ring`](https://arxiv.org/pdf/2310.01889) strategy, you should set `--ring_size $GPU_NUMS`. Note that the `sequence length` should be divisible by `ring_size` when using the `Ring` strategy.
|
| 183 |
+
|
| 184 |
+
Of course, you can also combine the use of `Ulysses` and `Ring` strategies.
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
``` sh
|
| 188 |
+
pip install "xfuser>=0.4.1"
|
| 189 |
+
torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
##### (2) Using Prompt Extension
|
| 194 |
+
|
| 195 |
+
Extending the prompts can effectively enrich the details in the generated videos, further enhancing the video quality. Therefore, we recommend enabling prompt extension. We provide the following two methods for prompt extension:
|
| 196 |
+
|
| 197 |
+
- Use the Dashscope API for extension.
|
| 198 |
+
- Apply for a `dashscope.api_key` in advance ([EN](https://www.alibabacloud.com/help/en/model-studio/getting-started/first-api-call-to-qwen) | [CN](https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen)).
|
| 199 |
+
- Configure the environment variable `DASH_API_KEY` to specify the Dashscope API key. For users of Alibaba Cloud's international site, you also need to set the environment variable `DASH_API_URL` to 'https://dashscope-intl.aliyuncs.com/api/v1'. For more detailed instructions, please refer to the [dashscope document](https://www.alibabacloud.com/help/en/model-studio/developer-reference/use-qwen-by-calling-api?spm=a2c63.p38356.0.i1).
|
| 200 |
+
- Use the `qwen-plus` model for text-to-video tasks and `qwen-vl-max` for image-to-video tasks.
|
| 201 |
+
- You can modify the model used for extension with the parameter `--prompt_extend_model`. For example:
|
| 202 |
+
```sh
|
| 203 |
+
DASH_API_KEY=your_key python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh'
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
- Using a local model for extension.
|
| 207 |
+
|
| 208 |
+
- By default, the Qwen model on HuggingFace is used for this extension. Users can choose Qwen models or other models based on the available GPU memory size.
|
| 209 |
+
- For text-to-video tasks, you can use models like `Qwen/Qwen2.5-14B-Instruct`, `Qwen/Qwen2.5-7B-Instruct` and `Qwen/Qwen2.5-3B-Instruct`.
|
| 210 |
+
- For image-to-video or first-last-frame-to-video tasks, you can use models like `Qwen/Qwen2.5-VL-7B-Instruct` and `Qwen/Qwen2.5-VL-3B-Instruct`.
|
| 211 |
+
- Larger models generally provide better extension results but require more GPU memory.
|
| 212 |
+
- You can modify the model used for extension with the parameter `--prompt_extend_model` , allowing you to specify either a local model path or a Hugging Face model. For example:
|
| 213 |
+
|
| 214 |
+
``` sh
|
| 215 |
+
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'zh'
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
##### (3) Running with Diffusers
|
| 220 |
+
|
| 221 |
+
You can easily inference **Wan2.1**-T2V using Diffusers with the following command:
|
| 222 |
+
``` python
|
| 223 |
+
import torch
|
| 224 |
+
from diffusers.utils import export_to_video
|
| 225 |
+
from diffusers import AutoencoderKLWan, WanPipeline
|
| 226 |
+
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
|
| 227 |
+
|
| 228 |
+
# Available models: Wan-AI/Wan2.1-T2V-14B-Diffusers, Wan-AI/Wan2.1-T2V-1.3B-Diffusers
|
| 229 |
+
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
|
| 230 |
+
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
|
| 231 |
+
flow_shift = 5.0 # 5.0 for 720P, 3.0 for 480P
|
| 232 |
+
scheduler = UniPCMultistepScheduler(prediction_type='flow_prediction', use_flow_sigmas=True, num_train_timesteps=1000, flow_shift=flow_shift)
|
| 233 |
+
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
|
| 234 |
+
pipe.scheduler = scheduler
|
| 235 |
+
pipe.to("cuda")
|
| 236 |
+
|
| 237 |
+
prompt = "A cat and a dog baking a cake together in a kitchen. The cat is carefully measuring flour, while the dog is stirring the batter with a wooden spoon. The kitchen is cozy, with sunlight streaming through the window."
|
| 238 |
+
negative_prompt = "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards"
|
| 239 |
+
|
| 240 |
+
output = pipe(
|
| 241 |
+
prompt=prompt,
|
| 242 |
+
negative_prompt=negative_prompt,
|
| 243 |
+
height=720,
|
| 244 |
+
width=1280,
|
| 245 |
+
num_frames=81,
|
| 246 |
+
guidance_scale=5.0,
|
| 247 |
+
).frames[0]
|
| 248 |
+
export_to_video(output, "output.mp4", fps=16)
|
| 249 |
+
```
|
| 250 |
+
> 💡Note: Please note that this example does not integrate Prompt Extension and distributed inference. We will soon update with the integrated prompt extension and multi-GPU version of Diffusers.
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
##### (4) Running local gradio
|
| 254 |
+
|
| 255 |
+
``` sh
|
| 256 |
+
cd gradio
|
| 257 |
+
# if one uses dashscope’s API for prompt extension
|
| 258 |
+
DASH_API_KEY=your_key python t2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-14B
|
| 259 |
+
|
| 260 |
+
# if one uses a local model for prompt extension
|
| 261 |
+
python t2v_14B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-14B
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
#### Run Image-to-Video Generation
|
| 267 |
+
|
| 268 |
+
Similar to Text-to-Video, Image-to-Video is also divided into processes with and without the prompt extension step. The specific parameters and their corresponding settings are as follows:
|
| 269 |
+
<table>
|
| 270 |
+
<thead>
|
| 271 |
+
<tr>
|
| 272 |
+
<th rowspan="2">Task</th>
|
| 273 |
+
<th colspan="2">Resolution</th>
|
| 274 |
+
<th rowspan="2">Model</th>
|
| 275 |
+
</tr>
|
| 276 |
+
<tr>
|
| 277 |
+
<th>480P</th>
|
| 278 |
+
<th>720P</th>
|
| 279 |
+
</tr>
|
| 280 |
+
</thead>
|
| 281 |
+
<tbody>
|
| 282 |
+
<tr>
|
| 283 |
+
<td>i2v-14B</td>
|
| 284 |
+
<td style="color: green;">❌</td>
|
| 285 |
+
<td style="color: green;">✔️</td>
|
| 286 |
+
<td>Wan2.1-I2V-14B-720P</td>
|
| 287 |
+
</tr>
|
| 288 |
+
<tr>
|
| 289 |
+
<td>i2v-14B</td>
|
| 290 |
+
<td style="color: green;">✔️</td>
|
| 291 |
+
<td style="color: red;">❌</td>
|
| 292 |
+
<td>Wan2.1-T2V-14B-480P</td>
|
| 293 |
+
</tr>
|
| 294 |
+
</tbody>
|
| 295 |
+
</table>
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
##### (1) Without Prompt Extension
|
| 299 |
+
|
| 300 |
+
- Single-GPU inference
|
| 301 |
+
```sh
|
| 302 |
+
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 303 |
+
```
|
| 304 |
+
|
| 305 |
+
> 💡For the Image-to-Video task, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 309 |
+
|
| 310 |
+
```sh
|
| 311 |
+
pip install "xfuser>=0.4.1"
|
| 312 |
+
torchrun --nproc_per_node=8 generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
##### (2) Using Prompt Extension
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
The process of prompt extension can be referenced [here](#2-using-prompt-extention).
|
| 319 |
+
|
| 320 |
+
Run with local prompt extension using `Qwen/Qwen2.5-VL-7B-Instruct`:
|
| 321 |
+
```
|
| 322 |
+
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 323 |
+
```
|
| 324 |
+
|
| 325 |
+
Run with remote prompt extension using `dashscope`:
|
| 326 |
+
```
|
| 327 |
+
DASH_API_KEY=your_key python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_method 'dashscope' --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 328 |
+
```
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
##### (3) Running with Diffusers
|
| 332 |
+
|
| 333 |
+
You can easily inference **Wan2.1**-I2V using Diffusers with the following command:
|
| 334 |
+
``` python
|
| 335 |
+
import torch
|
| 336 |
+
import numpy as np
|
| 337 |
+
from diffusers import AutoencoderKLWan, WanImageToVideoPipeline
|
| 338 |
+
from diffusers.utils import export_to_video, load_image
|
| 339 |
+
from transformers import CLIPVisionModel
|
| 340 |
+
|
| 341 |
+
# Available models: Wan-AI/Wan2.1-I2V-14B-480P-Diffusers, Wan-AI/Wan2.1-I2V-14B-720P-Diffusers
|
| 342 |
+
model_id = "Wan-AI/Wan2.1-I2V-14B-720P-Diffusers"
|
| 343 |
+
image_encoder = CLIPVisionModel.from_pretrained(model_id, subfolder="image_encoder", torch_dtype=torch.float32)
|
| 344 |
+
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
|
| 345 |
+
pipe = WanImageToVideoPipeline.from_pretrained(model_id, vae=vae, image_encoder=image_encoder, torch_dtype=torch.bfloat16)
|
| 346 |
+
pipe.to("cuda")
|
| 347 |
+
|
| 348 |
+
image = load_image(
|
| 349 |
+
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg"
|
| 350 |
+
)
|
| 351 |
+
max_area = 720 * 1280
|
| 352 |
+
aspect_ratio = image.height / image.width
|
| 353 |
+
mod_value = pipe.vae_scale_factor_spatial * pipe.transformer.config.patch_size[1]
|
| 354 |
+
height = round(np.sqrt(max_area * aspect_ratio)) // mod_value * mod_value
|
| 355 |
+
width = round(np.sqrt(max_area / aspect_ratio)) // mod_value * mod_value
|
| 356 |
+
image = image.resize((width, height))
|
| 357 |
+
prompt = (
|
| 358 |
+
"An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in "
|
| 359 |
+
"the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
|
| 360 |
+
)
|
| 361 |
+
negative_prompt = "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards"
|
| 362 |
+
|
| 363 |
+
output = pipe(
|
| 364 |
+
image=image,
|
| 365 |
+
prompt=prompt,
|
| 366 |
+
negative_prompt=negative_prompt,
|
| 367 |
+
height=height, width=width,
|
| 368 |
+
num_frames=81,
|
| 369 |
+
guidance_scale=5.0
|
| 370 |
+
).frames[0]
|
| 371 |
+
export_to_video(output, "output.mp4", fps=16)
|
| 372 |
+
|
| 373 |
+
```
|
| 374 |
+
> 💡Note: Please note that this example does not integrate Prompt Extension and distributed inference. We will soon update with the integrated prompt extension and multi-GPU version of Diffusers.
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
##### (4) Running local gradio
|
| 378 |
+
|
| 379 |
+
```sh
|
| 380 |
+
cd gradio
|
| 381 |
+
# if one only uses 480P model in gradio
|
| 382 |
+
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_480p ./Wan2.1-I2V-14B-480P
|
| 383 |
+
|
| 384 |
+
# if one only uses 720P model in gradio
|
| 385 |
+
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_720p ./Wan2.1-I2V-14B-720P
|
| 386 |
+
|
| 387 |
+
# if one uses both 480P and 720P models in gradio
|
| 388 |
+
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_480p ./Wan2.1-I2V-14B-480P --ckpt_dir_720p ./Wan2.1-I2V-14B-720P
|
| 389 |
+
```
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
#### Run First-Last-Frame-to-Video Generation
|
| 393 |
+
|
| 394 |
+
First-Last-Frame-to-Video is also divided into processes with and without the prompt extension step. Currently, only 720P is supported. The specific parameters and corresponding settings are as follows:
|
| 395 |
+
<table>
|
| 396 |
+
<thead>
|
| 397 |
+
<tr>
|
| 398 |
+
<th rowspan="2">Task</th>
|
| 399 |
+
<th colspan="2">Resolution</th>
|
| 400 |
+
<th rowspan="2">Model</th>
|
| 401 |
+
</tr>
|
| 402 |
+
<tr>
|
| 403 |
+
<th>480P</th>
|
| 404 |
+
<th>720P</th>
|
| 405 |
+
</tr>
|
| 406 |
+
</thead>
|
| 407 |
+
<tbody>
|
| 408 |
+
<tr>
|
| 409 |
+
<td>flf2v-14B</td>
|
| 410 |
+
<td style="color: green;">❌</td>
|
| 411 |
+
<td style="color: green;">✔️</td>
|
| 412 |
+
<td>Wan2.1-FLF2V-14B-720P</td>
|
| 413 |
+
</tr>
|
| 414 |
+
</tbody>
|
| 415 |
+
</table>
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
##### (1) Without Prompt Extension
|
| 419 |
+
|
| 420 |
+
- Single-GPU inference
|
| 421 |
+
```sh
|
| 422 |
+
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 423 |
+
```
|
| 424 |
+
|
| 425 |
+
> 💡Similar to Image-to-Video, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 429 |
+
|
| 430 |
+
```sh
|
| 431 |
+
pip install "xfuser>=0.4.1"
|
| 432 |
+
torchrun --nproc_per_node=8 generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 433 |
+
```
|
| 434 |
+
|
| 435 |
+
##### (2) Using Prompt Extension
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
The process of prompt extension can be referenced [here](#2-using-prompt-extention).
|
| 439 |
+
|
| 440 |
+
Run with local prompt extension using `Qwen/Qwen2.5-VL-7B-Instruct`:
|
| 441 |
+
```
|
| 442 |
+
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 443 |
+
```
|
| 444 |
+
|
| 445 |
+
Run with remote prompt extension using `dashscope`:
|
| 446 |
+
```
|
| 447 |
+
DASH_API_KEY=your_key python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --use_prompt_extend --prompt_extend_method 'dashscope' --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 448 |
+
```
|
| 449 |
+
|
| 450 |
+
|
| 451 |
+
##### (3) Running local gradio
|
| 452 |
+
|
| 453 |
+
```sh
|
| 454 |
+
cd gradio
|
| 455 |
+
# use 720P model in gradio
|
| 456 |
+
DASH_API_KEY=your_key python flf2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_720p ./Wan2.1-FLF2V-14B-720P
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
|
| 460 |
+
#### Run VACE
|
| 461 |
+
|
| 462 |
+
[VACE](https://github.com/ali-vilab/VACE) now supports two models (1.3B and 14B) and two main resolutions (480P and 720P).
|
| 463 |
+
The input supports any resolution, but to achieve optimal results, the video size should fall within a specific range.
|
| 464 |
+
The parameters and configurations for these models are as follows:
|
| 465 |
+
|
| 466 |
+
<table>
|
| 467 |
+
<thead>
|
| 468 |
+
<tr>
|
| 469 |
+
<th rowspan="2">Task</th>
|
| 470 |
+
<th colspan="2">Resolution</th>
|
| 471 |
+
<th rowspan="2">Model</th>
|
| 472 |
+
</tr>
|
| 473 |
+
<tr>
|
| 474 |
+
<th>480P(~81x480x832)</th>
|
| 475 |
+
<th>720P(~81x720x1280)</th>
|
| 476 |
+
</tr>
|
| 477 |
+
</thead>
|
| 478 |
+
<tbody>
|
| 479 |
+
<tr>
|
| 480 |
+
<td>VACE</td>
|
| 481 |
+
<td style="color: green; text-align: center; vertical-align: middle;">✔️</td>
|
| 482 |
+
<td style="color: green; text-align: center; vertical-align: middle;">✔️</td>
|
| 483 |
+
<td>Wan2.1-VACE-14B</td>
|
| 484 |
+
</tr>
|
| 485 |
+
<tr>
|
| 486 |
+
<td>VACE</td>
|
| 487 |
+
<td style="color: green; text-align: center; vertical-align: middle;">✔️</td>
|
| 488 |
+
<td style="color: red; text-align: center; vertical-align: middle;">❌</td>
|
| 489 |
+
<td>Wan2.1-VACE-1.3B</td>
|
| 490 |
+
</tr>
|
| 491 |
+
</tbody>
|
| 492 |
+
</table>
|
| 493 |
+
|
| 494 |
+
In VACE, users can input text prompt and optional video, mask, and image for video generation or editing. Detailed instructions for using VACE can be found in the [User Guide](https://github.com/ali-vilab/VACE/blob/main/UserGuide.md).
|
| 495 |
+
The execution process is as follows:
|
| 496 |
+
|
| 497 |
+
##### (1) Preprocessing
|
| 498 |
+
|
| 499 |
+
User-collected materials needs to be preprocessed into VACE-recognizable inputs, including `src_video`, `src_mask`, `src_ref_images`, and `prompt`.
|
| 500 |
+
For R2V (Reference-to-Video Generation), you may skip this preprocessing, but for V2V (Video-to-Video Editing) and MV2V (Masked Video-to-Video Editing) tasks, additional preprocessing is required to obtain video with conditions such as depth, pose or masked regions.
|
| 501 |
+
For more details, please refer to [vace_preproccess](https://github.com/ali-vilab/VACE/blob/main/vace/vace_preproccess.py).
|
| 502 |
+
|
| 503 |
+
##### (2) cli inference
|
| 504 |
+
|
| 505 |
+
- Single-GPU inference
|
| 506 |
+
```sh
|
| 507 |
+
python generate.py --task vace-1.3B --size 832*480 --ckpt_dir ./Wan2.1-VACE-1.3B --src_ref_images examples/girl.png,examples/snake.png --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇��头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
|
| 508 |
+
```
|
| 509 |
+
|
| 510 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 511 |
+
|
| 512 |
+
```sh
|
| 513 |
+
torchrun --nproc_per_node=8 generate.py --task vace-14B --size 1280*720 --ckpt_dir ./Wan2.1-VACE-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --src_ref_images examples/girl.png,examples/snake.png --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
|
| 514 |
+
```
|
| 515 |
+
|
| 516 |
+
##### (3) Running local gradio
|
| 517 |
+
- Single-GPU inference
|
| 518 |
+
```sh
|
| 519 |
+
python gradio/vace.py --ckpt_dir ./Wan2.1-VACE-1.3B
|
| 520 |
+
```
|
| 521 |
+
|
| 522 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 523 |
+
```sh
|
| 524 |
+
python gradio/vace.py --mp --ulysses_size 8 --ckpt_dir ./Wan2.1-VACE-14B/
|
| 525 |
+
```
|
| 526 |
+
|
| 527 |
+
#### Run Text-to-Image Generation
|
| 528 |
+
|
| 529 |
+
Wan2.1 is a unified model for both image and video generation. Since it was trained on both types of data, it can also generate images. The command for generating images is similar to video generation, as follows:
|
| 530 |
+
|
| 531 |
+
##### (1) Without Prompt Extension
|
| 532 |
+
|
| 533 |
+
- Single-GPU inference
|
| 534 |
+
```sh
|
| 535 |
+
python generate.py --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人'
|
| 536 |
+
```
|
| 537 |
+
|
| 538 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 539 |
+
|
| 540 |
+
```sh
|
| 541 |
+
torchrun --nproc_per_node=8 generate.py --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 0 --frame_num 1 --task t2i-14B --size 1024*1024 --prompt '一个朴素端庄的美人' --ckpt_dir ./Wan2.1-T2V-14B
|
| 542 |
+
```
|
| 543 |
+
|
| 544 |
+
##### (2) With Prompt Extention
|
| 545 |
+
|
| 546 |
+
- Single-GPU inference
|
| 547 |
+
```sh
|
| 548 |
+
python generate.py --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人' --use_prompt_extend
|
| 549 |
+
```
|
| 550 |
+
|
| 551 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 552 |
+
```sh
|
| 553 |
+
torchrun --nproc_per_node=8 generate.py --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 0 --frame_num 1 --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人' --use_prompt_extend
|
| 554 |
+
```
|
| 555 |
+
|
| 556 |
+
|
| 557 |
+
## Manual Evaluation
|
| 558 |
+
|
| 559 |
+
##### (1) Text-to-Video Evaluation
|
| 560 |
+
|
| 561 |
+
Through manual evaluation, the results generated after prompt extension are superior to those from both closed-source and open-source models.
|
| 562 |
+
|
| 563 |
+
<div align="center">
|
| 564 |
+
<img src="assets/t2v_res.jpg" alt="" style="width: 80%;" />
|
| 565 |
+
</div>
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
##### (2) Image-to-Video Evaluation
|
| 569 |
+
|
| 570 |
+
We also conducted extensive manual evaluations to evaluate the performance of the Image-to-Video model, and the results are presented in the table below. The results clearly indicate that **Wan2.1** outperforms both closed-source and open-source models.
|
| 571 |
+
|
| 572 |
+
<div align="center">
|
| 573 |
+
<img src="assets/i2v_res.png" alt="" style="width: 80%;" />
|
| 574 |
+
</div>
|
| 575 |
+
|
| 576 |
+
|
| 577 |
+
## Computational Efficiency on Different GPUs
|
| 578 |
+
|
| 579 |
+
We test the computational efficiency of different **Wan2.1** models on different GPUs in the following table. The results are presented in the format: **Total time (s) / peak GPU memory (GB)**.
|
| 580 |
+
|
| 581 |
+
|
| 582 |
+
<div align="center">
|
| 583 |
+
<img src="assets/comp_effic.png" alt="" style="width: 80%;" />
|
| 584 |
+
</div>
|
| 585 |
+
|
| 586 |
+
> The parameter settings for the tests presented in this table are as follows:
|
| 587 |
+
> (1) For the 1.3B model on 8 GPUs, set `--ring_size 8` and `--ulysses_size 1`;
|
| 588 |
+
> (2) For the 14B model on 1 GPU, use `--offload_model True`;
|
| 589 |
+
> (3) For the 1.3B model on a single 4090 GPU, set `--offload_model True --t5_cpu`;
|
| 590 |
+
> (4) For all testings, no prompt extension was applied, meaning `--use_prompt_extend` was not enabled.
|
| 591 |
+
|
| 592 |
+
> 💡Note: T2V-14B is slower than I2V-14B because the former samples 50 steps while the latter uses 40 steps.
|
| 593 |
+
|
| 594 |
+
|
| 595 |
+
-------
|
| 596 |
+
|
| 597 |
+
## Introduction of Wan2.1
|
| 598 |
+
|
| 599 |
+
**Wan2.1** is designed on the mainstream diffusion transformer paradigm, achieving significant advancements in generative capabilities through a series of innovations. These include our novel spatio-temporal variational autoencoder (VAE), scalable training strategies, large-scale data construction, and automated evaluation metrics. Collectively, these contributions enhance the model’s performance and versatility.
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
##### (1) 3D Variational Autoencoders
|
| 603 |
+
We propose a novel 3D causal VAE architecture, termed **Wan-VAE** specifically designed for video generation. By combining multiple strategies, we improve spatio-temporal compression, reduce memory usage, and ensure temporal causality. **Wan-VAE** demonstrates significant advantages in performance efficiency compared to other open-source VAEs. Furthermore, our **Wan-VAE** can encode and decode unlimited-length 1080P videos without losing historical temporal information, making it particularly well-suited for video generation tasks.
|
| 604 |
+
|
| 605 |
+
|
| 606 |
+
<div align="center">
|
| 607 |
+
<img src="assets/video_vae_res.jpg" alt="" style="width: 80%;" />
|
| 608 |
+
</div>
|
| 609 |
+
|
| 610 |
+
|
| 611 |
+
##### (2) Video Diffusion DiT
|
| 612 |
+
|
| 613 |
+
**Wan2.1** is designed using the Flow Matching framework within the paradigm of mainstream Diffusion Transformers. Our model's architecture uses the T5 Encoder to encode multilingual text input, with cross-attention in each transformer block embedding the text into the model structure. Additionally, we employ an MLP with a Linear layer and a SiLU layer to process the input time embeddings and predict six modulation parameters individually. This MLP is shared across all transformer blocks, with each block learning a distinct set of biases. Our experimental findings reveal a significant performance improvement with this approach at the same parameter scale.
|
| 614 |
+
|
| 615 |
+
<div align="center">
|
| 616 |
+
<img src="assets/video_dit_arch.jpg" alt="" style="width: 80%;" />
|
| 617 |
+
</div>
|
| 618 |
+
|
| 619 |
+
|
| 620 |
+
| Model | Dimension | Input Dimension | Output Dimension | Feedforward Dimension | Frequency Dimension | Number of Heads | Number of Layers |
|
| 621 |
+
|--------|-----------|-----------------|------------------|-----------------------|---------------------|-----------------|------------------|
|
| 622 |
+
| 1.3B | 1536 | 16 | 16 | 8960 | 256 | 12 | 30 |
|
| 623 |
+
| 14B | 5120 | 16 | 16 | 13824 | 256 | 40 | 40 |
|
| 624 |
+
|
| 625 |
+
|
| 626 |
+
|
| 627 |
+
##### Data
|
| 628 |
+
|
| 629 |
+
We curated and deduplicated a candidate dataset comprising a vast amount of image and video data. During the data curation process, we designed a four-step data cleaning process, focusing on fundamental dimensions, visual quality and motion quality. Through the robust data processing pipeline, we can easily obtain high-quality, diverse, and large-scale training sets of images and videos.
|
| 630 |
+
|
| 631 |
+

|
| 632 |
+
|
| 633 |
+
|
| 634 |
+
##### Comparisons to SOTA
|
| 635 |
+
We compared **Wan2.1** with leading open-source and closed-source models to evaluate the performance. Using our carefully designed set of 1,035 internal prompts, we tested across 14 major dimensions and 26 sub-dimensions. We then compute the total score by performing a weighted calculation on the scores of each dimension, utilizing weights derived from human preferences in the matching process. The detailed results are shown in the table below. These results demonstrate our model's superior performance compared to both open-source and closed-source models.
|
| 636 |
+
|
| 637 |
+

|
| 638 |
+
|
| 639 |
+
|
| 640 |
+
## Citation
|
| 641 |
+
If you find our work helpful, please cite us.
|
| 642 |
+
|
| 643 |
+
```
|
| 644 |
+
@article{wan2025,
|
| 645 |
+
title={Wan: Open and Advanced Large-Scale Video Generative Models},
|
| 646 |
+
author={Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
|
| 647 |
+
journal = {arXiv preprint arXiv:2503.20314},
|
| 648 |
+
year={2025}
|
| 649 |
+
}
|
| 650 |
+
```
|
| 651 |
+
|
| 652 |
+
## License Agreement
|
| 653 |
+
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
|
| 654 |
+
|
| 655 |
+
|
| 656 |
+
## Acknowledgements
|
| 657 |
+
|
| 658 |
+
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
|
| 659 |
+
|
| 660 |
+
|
| 661 |
+
|
| 662 |
+
## Contact Us
|
| 663 |
+
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/AKNgpMK4Yj) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
assets/comp_effic.png
ADDED
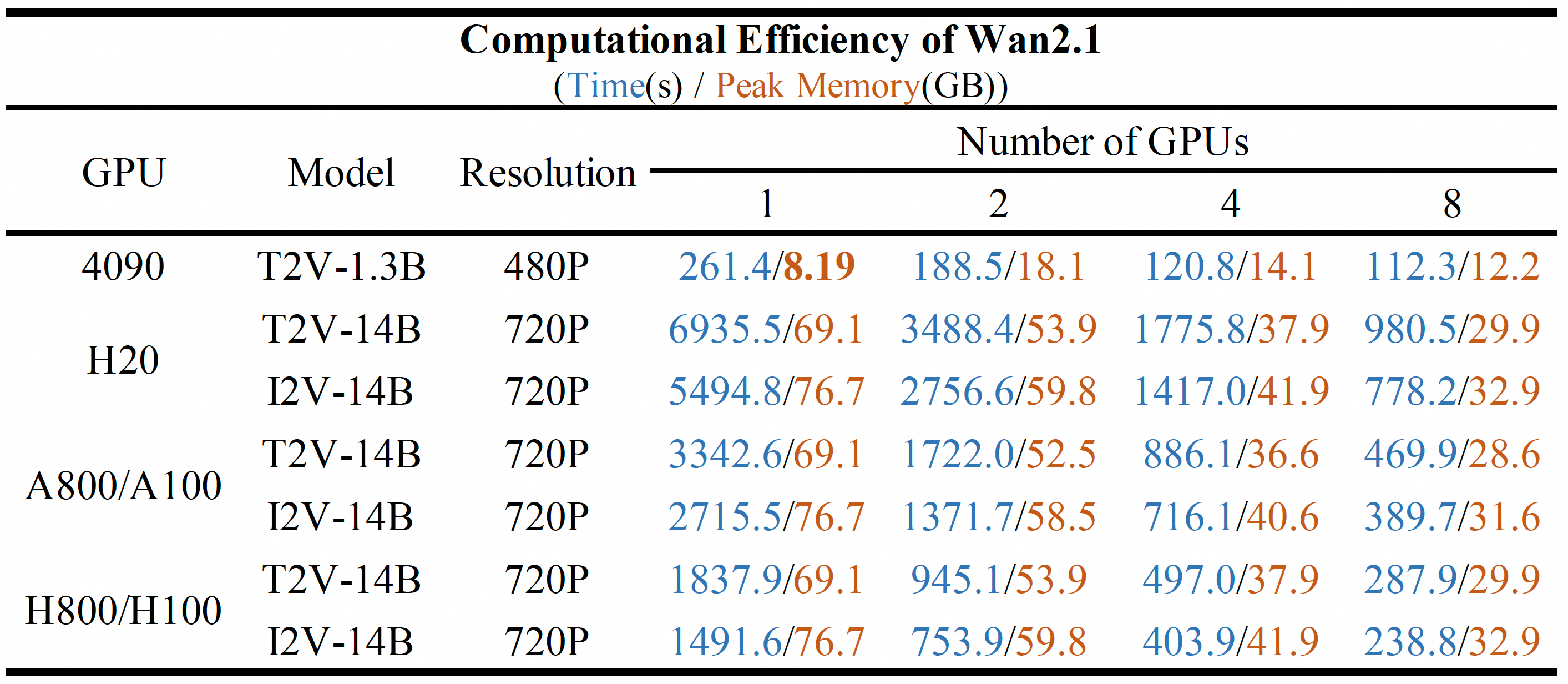
|
Git LFS Details
|
assets/data_for_diff_stage.jpg
ADDED
|
Git LFS Details
|
assets/i2v_res.png
ADDED
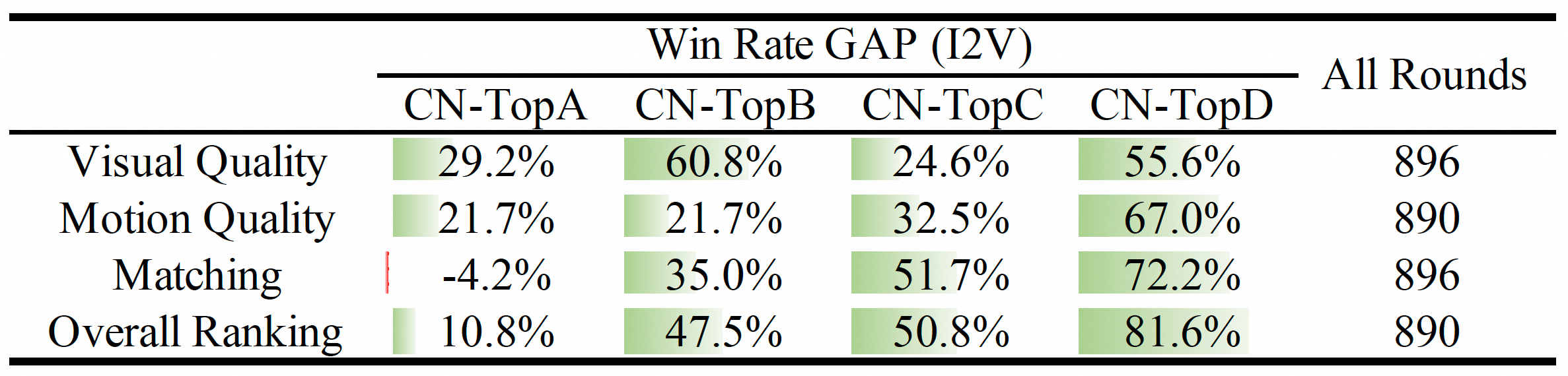
|
Git LFS Details
|
assets/logo.png
ADDED
|
|
assets/t2v_res.jpg
ADDED

|
Git LFS Details
|
assets/vben_vs_sota.png
ADDED

|
Git LFS Details
|
assets/video_dit_arch.jpg
ADDED

|
Git LFS Details
|
assets/video_vae_res.jpg
ADDED
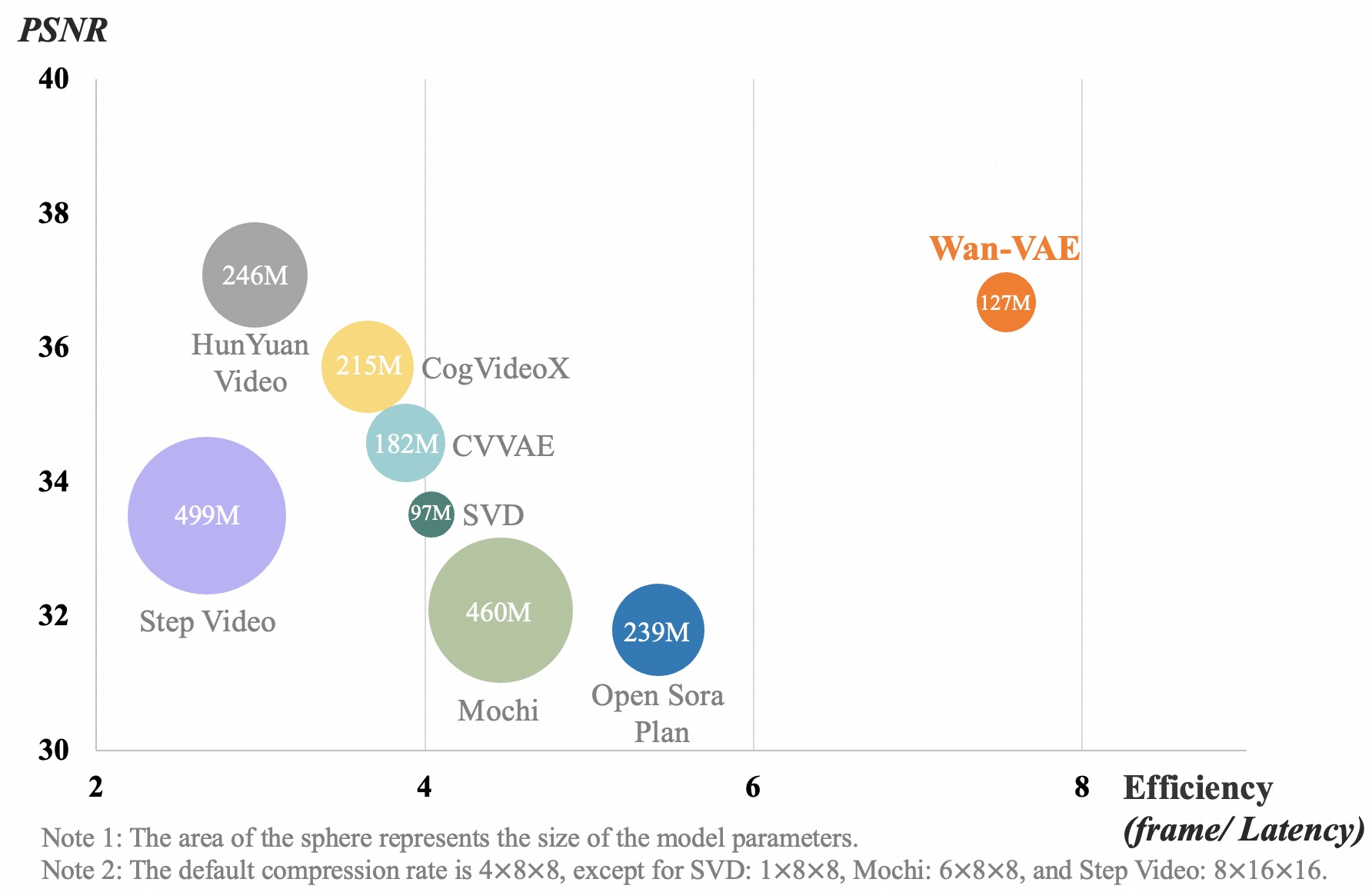
|
Git LFS Details
|
examples/flf2v_input_first_frame.png
ADDED

|
Git LFS Details
|
examples/flf2v_input_last_frame.png
ADDED

|
Git LFS Details
|
examples/girl.png
ADDED

|
Git LFS Details
|
examples/i2v_input.JPG
ADDED

|
Git LFS Details
|
examples/snake.png
ADDED

|
Git LFS Details
|
generate.py
ADDED
|
@@ -0,0 +1,572 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
from datetime import datetime
|
| 4 |
+
import logging
|
| 5 |
+
import os
|
| 6 |
+
import sys
|
| 7 |
+
import warnings
|
| 8 |
+
|
| 9 |
+
warnings.filterwarnings('ignore')
|
| 10 |
+
|
| 11 |
+
import torch, random
|
| 12 |
+
import torch.distributed as dist
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
import wan
|
| 16 |
+
from wan.configs import WAN_CONFIGS, SIZE_CONFIGS, MAX_AREA_CONFIGS, SUPPORTED_SIZES
|
| 17 |
+
from wan.utils.prompt_extend import DashScopePromptExpander, QwenPromptExpander
|
| 18 |
+
from wan.utils.utils import cache_video, cache_image, str2bool
|
| 19 |
+
|
| 20 |
+
EXAMPLE_PROMPT = {
|
| 21 |
+
"t2v-1.3B": {
|
| 22 |
+
"prompt": "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.",
|
| 23 |
+
},
|
| 24 |
+
"t2v-14B": {
|
| 25 |
+
"prompt": "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage.",
|
| 26 |
+
},
|
| 27 |
+
"t2i-14B": {
|
| 28 |
+
"prompt": "一个朴素端庄的美人",
|
| 29 |
+
},
|
| 30 |
+
"i2v-14B": {
|
| 31 |
+
"prompt":
|
| 32 |
+
"Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside.",
|
| 33 |
+
"image":
|
| 34 |
+
"examples/i2v_input.JPG",
|
| 35 |
+
},
|
| 36 |
+
"flf2v-14B": {
|
| 37 |
+
"prompt":
|
| 38 |
+
"CG动画风格,一只蓝色的小鸟从地面起飞,煽动翅膀。小鸟羽毛细腻,胸前有独特的花纹,背景是蓝天白云,阳光明媚。镜跟随小鸟向上移动,展现出小鸟飞翔的姿态和天空的广阔。近景,仰视视角。",
|
| 39 |
+
"first_frame":
|
| 40 |
+
"examples/flf2v_input_first_frame.png",
|
| 41 |
+
"last_frame":
|
| 42 |
+
"examples/flf2v_input_last_frame.png",
|
| 43 |
+
},
|
| 44 |
+
"vace-1.3B": {
|
| 45 |
+
"src_ref_images": 'examples/girl.png,examples/snake.png',
|
| 46 |
+
"prompt": "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
|
| 47 |
+
},
|
| 48 |
+
"vace-14B": {
|
| 49 |
+
"src_ref_images": 'examples/girl.png,examples/snake.png',
|
| 50 |
+
"prompt": "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
|
| 51 |
+
}
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def _validate_args(args):
|
| 56 |
+
# Basic check
|
| 57 |
+
assert args.ckpt_dir is not None, "Please specify the checkpoint directory."
|
| 58 |
+
assert args.task in WAN_CONFIGS, f"Unsupport task: {args.task}"
|
| 59 |
+
assert args.task in EXAMPLE_PROMPT, f"Unsupport task: {args.task}"
|
| 60 |
+
|
| 61 |
+
# The default sampling steps are 40 for image-to-video tasks and 50 for text-to-video tasks.
|
| 62 |
+
if args.sample_steps is None:
|
| 63 |
+
args.sample_steps = 50
|
| 64 |
+
if "i2v" in args.task:
|
| 65 |
+
args.sample_steps = 40
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if args.sample_shift is None:
|
| 69 |
+
args.sample_shift = 5.0
|
| 70 |
+
if "i2v" in args.task and args.size in ["832*480", "480*832"]:
|
| 71 |
+
args.sample_shift = 3.0
|
| 72 |
+
elif "flf2v" in args.task or "vace" in args.task:
|
| 73 |
+
args.sample_shift = 16
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
# The default number of frames are 1 for text-to-image tasks and 81 for other tasks.
|
| 77 |
+
if args.frame_num is None:
|
| 78 |
+
args.frame_num = 1 if "t2i" in args.task else 81
|
| 79 |
+
|
| 80 |
+
# T2I frame_num check
|
| 81 |
+
if "t2i" in args.task:
|
| 82 |
+
assert args.frame_num == 1, f"Unsupport frame_num {args.frame_num} for task {args.task}"
|
| 83 |
+
|
| 84 |
+
args.base_seed = args.base_seed if args.base_seed >= 0 else random.randint(
|
| 85 |
+
0, sys.maxsize)
|
| 86 |
+
# Size check
|
| 87 |
+
assert args.size in SUPPORTED_SIZES[
|
| 88 |
+
args.
|
| 89 |
+
task], f"Unsupport size {args.size} for task {args.task}, supported sizes are: {', '.join(SUPPORTED_SIZES[args.task])}"
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def _parse_args():
|
| 93 |
+
parser = argparse.ArgumentParser(
|
| 94 |
+
description="Generate a image or video from a text prompt or image using Wan"
|
| 95 |
+
)
|
| 96 |
+
parser.add_argument(
|
| 97 |
+
"--task",
|
| 98 |
+
type=str,
|
| 99 |
+
default="t2v-14B",
|
| 100 |
+
choices=list(WAN_CONFIGS.keys()),
|
| 101 |
+
help="The task to run.")
|
| 102 |
+
parser.add_argument(
|
| 103 |
+
"--size",
|
| 104 |
+
type=str,
|
| 105 |
+
default="1280*720",
|
| 106 |
+
choices=list(SIZE_CONFIGS.keys()),
|
| 107 |
+
help="The area (width*height) of the generated video. For the I2V task, the aspect ratio of the output video will follow that of the input image."
|
| 108 |
+
)
|
| 109 |
+
parser.add_argument(
|
| 110 |
+
"--frame_num",
|
| 111 |
+
type=int,
|
| 112 |
+
default=None,
|
| 113 |
+
help="How many frames to sample from a image or video. The number should be 4n+1"
|
| 114 |
+
)
|
| 115 |
+
parser.add_argument(
|
| 116 |
+
"--ckpt_dir",
|
| 117 |
+
type=str,
|
| 118 |
+
default=None,
|
| 119 |
+
help="The path to the checkpoint directory.")
|
| 120 |
+
parser.add_argument(
|
| 121 |
+
"--offload_model",
|
| 122 |
+
type=str2bool,
|
| 123 |
+
default=None,
|
| 124 |
+
help="Whether to offload the model to CPU after each model forward, reducing GPU memory usage."
|
| 125 |
+
)
|
| 126 |
+
parser.add_argument(
|
| 127 |
+
"--ulysses_size",
|
| 128 |
+
type=int,
|
| 129 |
+
default=1,
|
| 130 |
+
help="The size of the ulysses parallelism in DiT.")
|
| 131 |
+
parser.add_argument(
|
| 132 |
+
"--ring_size",
|
| 133 |
+
type=int,
|
| 134 |
+
default=1,
|
| 135 |
+
help="The size of the ring attention parallelism in DiT.")
|
| 136 |
+
parser.add_argument(
|
| 137 |
+
"--t5_fsdp",
|
| 138 |
+
action="store_true",
|
| 139 |
+
default=False,
|
| 140 |
+
help="Whether to use FSDP for T5.")
|
| 141 |
+
parser.add_argument(
|
| 142 |
+
"--t5_cpu",
|
| 143 |
+
action="store_true",
|
| 144 |
+
default=False,
|
| 145 |
+
help="Whether to place T5 model on CPU.")
|
| 146 |
+
parser.add_argument(
|
| 147 |
+
"--dit_fsdp",
|
| 148 |
+
action="store_true",
|
| 149 |
+
default=False,
|
| 150 |
+
help="Whether to use FSDP for DiT.")
|
| 151 |
+
parser.add_argument(
|
| 152 |
+
"--save_file",
|
| 153 |
+
type=str,
|
| 154 |
+
default=None,
|
| 155 |
+
help="The file to save the generated image or video to.")
|
| 156 |
+
parser.add_argument(
|
| 157 |
+
"--src_video",
|
| 158 |
+
type=str,
|
| 159 |
+
default=None,
|
| 160 |
+
help="The file of the source video. Default None.")
|
| 161 |
+
parser.add_argument(
|
| 162 |
+
"--src_mask",
|
| 163 |
+
type=str,
|
| 164 |
+
default=None,
|
| 165 |
+
help="The file of the source mask. Default None.")
|
| 166 |
+
parser.add_argument(
|
| 167 |
+
"--src_ref_images",
|
| 168 |
+
type=str,
|
| 169 |
+
default=None,
|
| 170 |
+
help="The file list of the source reference images. Separated by ','. Default None.")
|
| 171 |
+
parser.add_argument(
|
| 172 |
+
"--prompt",
|
| 173 |
+
type=str,
|
| 174 |
+
default=None,
|
| 175 |
+
help="The prompt to generate the image or video from.")
|
| 176 |
+
parser.add_argument(
|
| 177 |
+
"--use_prompt_extend",
|
| 178 |
+
action="store_true",
|
| 179 |
+
default=False,
|
| 180 |
+
help="Whether to use prompt extend.")
|
| 181 |
+
parser.add_argument(
|
| 182 |
+
"--prompt_extend_method",
|
| 183 |
+
type=str,
|
| 184 |
+
default="local_qwen",
|
| 185 |
+
choices=["dashscope", "local_qwen"],
|
| 186 |
+
help="The prompt extend method to use.")
|
| 187 |
+
parser.add_argument(
|
| 188 |
+
"--prompt_extend_model",
|
| 189 |
+
type=str,
|
| 190 |
+
default=None,
|
| 191 |
+
help="The prompt extend model to use.")
|
| 192 |
+
parser.add_argument(
|
| 193 |
+
"--prompt_extend_target_lang",
|
| 194 |
+
type=str,
|
| 195 |
+
default="zh",
|
| 196 |
+
choices=["zh", "en"],
|
| 197 |
+
help="The target language of prompt extend.")
|
| 198 |
+
parser.add_argument(
|
| 199 |
+
"--base_seed",
|
| 200 |
+
type=int,
|
| 201 |
+
default=-1,
|
| 202 |
+
help="The seed to use for generating the image or video.")
|
| 203 |
+
parser.add_argument(
|
| 204 |
+
"--image",
|
| 205 |
+
type=str,
|
| 206 |
+
default=None,
|
| 207 |
+
help="[image to video] The image to generate the video from.")
|
| 208 |
+
parser.add_argument(
|
| 209 |
+
"--first_frame",
|
| 210 |
+
type=str,
|
| 211 |
+
default=None,
|
| 212 |
+
help="[first-last frame to video] The image (first frame) to generate the video from.")
|
| 213 |
+
parser.add_argument(
|
| 214 |
+
"--last_frame",
|
| 215 |
+
type=str,
|
| 216 |
+
default=None,
|
| 217 |
+
help="[first-last frame to video] The image (last frame) to generate the video from.")
|
| 218 |
+
parser.add_argument(
|
| 219 |
+
"--sample_solver",
|
| 220 |
+
type=str,
|
| 221 |
+
default='unipc',
|
| 222 |
+
choices=['unipc', 'dpm++'],
|
| 223 |
+
help="The solver used to sample.")
|
| 224 |
+
parser.add_argument(
|
| 225 |
+
"--sample_steps", type=int, default=None, help="The sampling steps.")
|
| 226 |
+
parser.add_argument(
|
| 227 |
+
"--sample_shift",
|
| 228 |
+
type=float,
|
| 229 |
+
default=None,
|
| 230 |
+
help="Sampling shift factor for flow matching schedulers.")
|
| 231 |
+
parser.add_argument(
|
| 232 |
+
"--sample_guide_scale",
|
| 233 |
+
type=float,
|
| 234 |
+
default=5.0,
|
| 235 |
+
help="Classifier free guidance scale.")
|
| 236 |
+
|
| 237 |
+
args = parser.parse_args()
|
| 238 |
+
|
| 239 |
+
_validate_args(args)
|
| 240 |
+
|
| 241 |
+
return args
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def _init_logging(rank):
|
| 245 |
+
# logging
|
| 246 |
+
if rank == 0:
|
| 247 |
+
# set format
|
| 248 |
+
logging.basicConfig(
|
| 249 |
+
level=logging.INFO,
|
| 250 |
+
format="[%(asctime)s] %(levelname)s: %(message)s",
|
| 251 |
+
handlers=[logging.StreamHandler(stream=sys.stdout)])
|
| 252 |
+
else:
|
| 253 |
+
logging.basicConfig(level=logging.ERROR)
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
def generate(args):
|
| 257 |
+
rank = int(os.getenv("RANK", 0))
|
| 258 |
+
world_size = int(os.getenv("WORLD_SIZE", 1))
|
| 259 |
+
local_rank = int(os.getenv("LOCAL_RANK", 0))
|
| 260 |
+
device = local_rank
|
| 261 |
+
_init_logging(rank)
|
| 262 |
+
|
| 263 |
+
if args.offload_model is None:
|
| 264 |
+
args.offload_model = False if world_size > 1 else True
|
| 265 |
+
logging.info(
|
| 266 |
+
f"offload_model is not specified, set to {args.offload_model}.")
|
| 267 |
+
if world_size > 1:
|
| 268 |
+
torch.cuda.set_device(local_rank)
|
| 269 |
+
dist.init_process_group(
|
| 270 |
+
backend="nccl",
|
| 271 |
+
init_method="env://",
|
| 272 |
+
rank=rank,
|
| 273 |
+
world_size=world_size)
|
| 274 |
+
else:
|
| 275 |
+
assert not (
|
| 276 |
+
args.t5_fsdp or args.dit_fsdp
|
| 277 |
+
), f"t5_fsdp and dit_fsdp are not supported in non-distributed environments."
|
| 278 |
+
assert not (
|
| 279 |
+
args.ulysses_size > 1 or args.ring_size > 1
|
| 280 |
+
), f"context parallel are not supported in non-distributed environments."
|
| 281 |
+
|
| 282 |
+
if args.ulysses_size > 1 or args.ring_size > 1:
|
| 283 |
+
assert args.ulysses_size * args.ring_size == world_size, f"The number of ulysses_size and ring_size should be equal to the world size."
|
| 284 |
+
from xfuser.core.distributed import (initialize_model_parallel,
|
| 285 |
+
init_distributed_environment)
|
| 286 |
+
init_distributed_environment(
|
| 287 |
+
rank=dist.get_rank(), world_size=dist.get_world_size())
|
| 288 |
+
|
| 289 |
+
initialize_model_parallel(
|
| 290 |
+
sequence_parallel_degree=dist.get_world_size(),
|
| 291 |
+
ring_degree=args.ring_size,
|
| 292 |
+
ulysses_degree=args.ulysses_size,
|
| 293 |
+
)
|
| 294 |
+
|
| 295 |
+
if args.use_prompt_extend:
|
| 296 |
+
if args.prompt_extend_method == "dashscope":
|
| 297 |
+
prompt_expander = DashScopePromptExpander(
|
| 298 |
+
model_name=args.prompt_extend_model, is_vl="i2v" in args.task or "flf2v" in args.task)
|
| 299 |
+
elif args.prompt_extend_method == "local_qwen":
|
| 300 |
+
prompt_expander = QwenPromptExpander(
|
| 301 |
+
model_name=args.prompt_extend_model,
|
| 302 |
+
is_vl="i2v" in args.task,
|
| 303 |
+
device=rank)
|
| 304 |
+
else:
|
| 305 |
+
raise NotImplementedError(
|
| 306 |
+
f"Unsupport prompt_extend_method: {args.prompt_extend_method}")
|
| 307 |
+
|
| 308 |
+
cfg = WAN_CONFIGS[args.task]
|
| 309 |
+
if args.ulysses_size > 1:
|
| 310 |
+
assert cfg.num_heads % args.ulysses_size == 0, f"`{cfg.num_heads=}` cannot be divided evenly by `{args.ulysses_size=}`."
|
| 311 |
+
|
| 312 |
+
logging.info(f"Generation job args: {args}")
|
| 313 |
+
logging.info(f"Generation model config: {cfg}")
|
| 314 |
+
|
| 315 |
+
if dist.is_initialized():
|
| 316 |
+
base_seed = [args.base_seed] if rank == 0 else [None]
|
| 317 |
+
dist.broadcast_object_list(base_seed, src=0)
|
| 318 |
+
args.base_seed = base_seed[0]
|
| 319 |
+
|
| 320 |
+
if "t2v" in args.task or "t2i" in args.task:
|
| 321 |
+
if args.prompt is None:
|
| 322 |
+
args.prompt = EXAMPLE_PROMPT[args.task]["prompt"]
|
| 323 |
+
logging.info(f"Input prompt: {args.prompt}")
|
| 324 |
+
if args.use_prompt_extend:
|
| 325 |
+
logging.info("Extending prompt ...")
|
| 326 |
+
if rank == 0:
|
| 327 |
+
prompt_output = prompt_expander(
|
| 328 |
+
args.prompt,
|
| 329 |
+
tar_lang=args.prompt_extend_target_lang,
|
| 330 |
+
seed=args.base_seed)
|
| 331 |
+
if prompt_output.status == False:
|
| 332 |
+
logging.info(
|
| 333 |
+
f"Extending prompt failed: {prompt_output.message}")
|
| 334 |
+
logging.info("Falling back to original prompt.")
|
| 335 |
+
input_prompt = args.prompt
|
| 336 |
+
else:
|
| 337 |
+
input_prompt = prompt_output.prompt
|
| 338 |
+
input_prompt = [input_prompt]
|
| 339 |
+
else:
|
| 340 |
+
input_prompt = [None]
|
| 341 |
+
if dist.is_initialized():
|
| 342 |
+
dist.broadcast_object_list(input_prompt, src=0)
|
| 343 |
+
args.prompt = input_prompt[0]
|
| 344 |
+
logging.info(f"Extended prompt: {args.prompt}")
|
| 345 |
+
|
| 346 |
+
logging.info("Creating WanT2V pipeline.")
|
| 347 |
+
wan_t2v = wan.WanT2V(
|
| 348 |
+
config=cfg,
|
| 349 |
+
checkpoint_dir=args.ckpt_dir,
|
| 350 |
+
device_id=device,
|
| 351 |
+
rank=rank,
|
| 352 |
+
t5_fsdp=args.t5_fsdp,
|
| 353 |
+
dit_fsdp=args.dit_fsdp,
|
| 354 |
+
use_usp=(args.ulysses_size > 1 or args.ring_size > 1),
|
| 355 |
+
t5_cpu=args.t5_cpu,
|
| 356 |
+
)
|
| 357 |
+
|
| 358 |
+
logging.info(
|
| 359 |
+
f"Generating {'image' if 't2i' in args.task else 'video'} ...")
|
| 360 |
+
video = wan_t2v.generate(
|
| 361 |
+
args.prompt,
|
| 362 |
+
size=SIZE_CONFIGS[args.size],
|
| 363 |
+
frame_num=args.frame_num,
|
| 364 |
+
shift=args.sample_shift,
|
| 365 |
+
sample_solver=args.sample_solver,
|
| 366 |
+
sampling_steps=args.sample_steps,
|
| 367 |
+
guide_scale=args.sample_guide_scale,
|
| 368 |
+
seed=args.base_seed,
|
| 369 |
+
offload_model=args.offload_model)
|
| 370 |
+
|
| 371 |
+
elif "i2v" in args.task:
|
| 372 |
+
if args.prompt is None:
|
| 373 |
+
args.prompt = EXAMPLE_PROMPT[args.task]["prompt"]
|
| 374 |
+
if args.image is None:
|
| 375 |
+
args.image = EXAMPLE_PROMPT[args.task]["image"]
|
| 376 |
+
logging.info(f"Input prompt: {args.prompt}")
|
| 377 |
+
logging.info(f"Input image: {args.image}")
|
| 378 |
+
|
| 379 |
+
img = Image.open(args.image).convert("RGB")
|
| 380 |
+
if args.use_prompt_extend:
|
| 381 |
+
logging.info("Extending prompt ...")
|
| 382 |
+
if rank == 0:
|
| 383 |
+
prompt_output = prompt_expander(
|
| 384 |
+
args.prompt,
|
| 385 |
+
tar_lang=args.prompt_extend_target_lang,
|
| 386 |
+
image=img,
|
| 387 |
+
seed=args.base_seed)
|
| 388 |
+
if prompt_output.status == False:
|
| 389 |
+
logging.info(
|
| 390 |
+
f"Extending prompt failed: {prompt_output.message}")
|
| 391 |
+
logging.info("Falling back to original prompt.")
|
| 392 |
+
input_prompt = args.prompt
|
| 393 |
+
else:
|
| 394 |
+
input_prompt = prompt_output.prompt
|
| 395 |
+
input_prompt = [input_prompt]
|
| 396 |
+
else:
|
| 397 |
+
input_prompt = [None]
|
| 398 |
+
if dist.is_initialized():
|
| 399 |
+
dist.broadcast_object_list(input_prompt, src=0)
|
| 400 |
+
args.prompt = input_prompt[0]
|
| 401 |
+
logging.info(f"Extended prompt: {args.prompt}")
|
| 402 |
+
|
| 403 |
+
logging.info("Creating WanI2V pipeline.")
|
| 404 |
+
wan_i2v = wan.WanI2V(
|
| 405 |
+
config=cfg,
|
| 406 |
+
checkpoint_dir=args.ckpt_dir,
|
| 407 |
+
device_id=device,
|
| 408 |
+
rank=rank,
|
| 409 |
+
t5_fsdp=args.t5_fsdp,
|
| 410 |
+
dit_fsdp=args.dit_fsdp,
|
| 411 |
+
use_usp=(args.ulysses_size > 1 or args.ring_size > 1),
|
| 412 |
+
t5_cpu=args.t5_cpu,
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
logging.info("Generating video ...")
|
| 416 |
+
video = wan_i2v.generate(
|
| 417 |
+
args.prompt,
|
| 418 |
+
img,
|
| 419 |
+
max_area=MAX_AREA_CONFIGS[args.size],
|
| 420 |
+
frame_num=args.frame_num,
|
| 421 |
+
shift=args.sample_shift,
|
| 422 |
+
sample_solver=args.sample_solver,
|
| 423 |
+
sampling_steps=args.sample_steps,
|
| 424 |
+
guide_scale=args.sample_guide_scale,
|
| 425 |
+
seed=args.base_seed,
|
| 426 |
+
offload_model=args.offload_model)
|
| 427 |
+
elif "flf2v" in args.task:
|
| 428 |
+
if args.prompt is None:
|
| 429 |
+
args.prompt = EXAMPLE_PROMPT[args.task]["prompt"]
|
| 430 |
+
if args.first_frame is None or args.last_frame is None:
|
| 431 |
+
args.first_frame = EXAMPLE_PROMPT[args.task]["first_frame"]
|
| 432 |
+
args.last_frame = EXAMPLE_PROMPT[args.task]["last_frame"]
|
| 433 |
+
logging.info(f"Input prompt: {args.prompt}")
|
| 434 |
+
logging.info(f"Input first frame: {args.first_frame}")
|
| 435 |
+
logging.info(f"Input last frame: {args.last_frame}")
|
| 436 |
+
first_frame = Image.open(args.first_frame).convert("RGB")
|
| 437 |
+
last_frame = Image.open(args.last_frame).convert("RGB")
|
| 438 |
+
if args.use_prompt_extend:
|
| 439 |
+
logging.info("Extending prompt ...")
|
| 440 |
+
if rank == 0:
|
| 441 |
+
prompt_output = prompt_expander(
|
| 442 |
+
args.prompt,
|
| 443 |
+
tar_lang=args.prompt_extend_target_lang,
|
| 444 |
+
image=[first_frame, last_frame],
|
| 445 |
+
seed=args.base_seed)
|
| 446 |
+
if prompt_output.status == False:
|
| 447 |
+
logging.info(
|
| 448 |
+
f"Extending prompt failed: {prompt_output.message}")
|
| 449 |
+
logging.info("Falling back to original prompt.")
|
| 450 |
+
input_prompt = args.prompt
|
| 451 |
+
else:
|
| 452 |
+
input_prompt = prompt_output.prompt
|
| 453 |
+
input_prompt = [input_prompt]
|
| 454 |
+
else:
|
| 455 |
+
input_prompt = [None]
|
| 456 |
+
if dist.is_initialized():
|
| 457 |
+
dist.broadcast_object_list(input_prompt, src=0)
|
| 458 |
+
args.prompt = input_prompt[0]
|
| 459 |
+
logging.info(f"Extended prompt: {args.prompt}")
|
| 460 |
+
|
| 461 |
+
logging.info("Creating WanFLF2V pipeline.")
|
| 462 |
+
wan_flf2v = wan.WanFLF2V(
|
| 463 |
+
config=cfg,
|
| 464 |
+
checkpoint_dir=args.ckpt_dir,
|
| 465 |
+
device_id=device,
|
| 466 |
+
rank=rank,
|
| 467 |
+
t5_fsdp=args.t5_fsdp,
|
| 468 |
+
dit_fsdp=args.dit_fsdp,
|
| 469 |
+
use_usp=(args.ulysses_size > 1 or args.ring_size > 1),
|
| 470 |
+
t5_cpu=args.t5_cpu,
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
logging.info("Generating video ...")
|
| 474 |
+
video = wan_flf2v.generate(
|
| 475 |
+
args.prompt,
|
| 476 |
+
first_frame,
|
| 477 |
+
last_frame,
|
| 478 |
+
max_area=MAX_AREA_CONFIGS[args.size],
|
| 479 |
+
frame_num=args.frame_num,
|
| 480 |
+
shift=args.sample_shift,
|
| 481 |
+
sample_solver=args.sample_solver,
|
| 482 |
+
sampling_steps=args.sample_steps,
|
| 483 |
+
guide_scale=args.sample_guide_scale,
|
| 484 |
+
seed=args.base_seed,
|
| 485 |
+
offload_model=args.offload_model
|
| 486 |
+
)
|
| 487 |
+
elif "vace" in args.task:
|
| 488 |
+
if args.prompt is None:
|
| 489 |
+
args.prompt = EXAMPLE_PROMPT[args.task]["prompt"]
|
| 490 |
+
args.src_video = EXAMPLE_PROMPT[args.task].get("src_video", None)
|
| 491 |
+
args.src_mask = EXAMPLE_PROMPT[args.task].get("src_mask", None)
|
| 492 |
+
args.src_ref_images = EXAMPLE_PROMPT[args.task].get("src_ref_images", None)
|
| 493 |
+
|
| 494 |
+
logging.info(f"Input prompt: {args.prompt}")
|
| 495 |
+
if args.use_prompt_extend and args.use_prompt_extend != 'plain':
|
| 496 |
+
logging.info("Extending prompt ...")
|
| 497 |
+
if rank == 0:
|
| 498 |
+
prompt = prompt_expander.forward(args.prompt)
|
| 499 |
+
logging.info(f"Prompt extended from '{args.prompt}' to '{prompt}'")
|
| 500 |
+
input_prompt = [prompt]
|
| 501 |
+
else:
|
| 502 |
+
input_prompt = [None]
|
| 503 |
+
if dist.is_initialized():
|
| 504 |
+
dist.broadcast_object_list(input_prompt, src=0)
|
| 505 |
+
args.prompt = input_prompt[0]
|
| 506 |
+
logging.info(f"Extended prompt: {args.prompt}")
|
| 507 |
+
|
| 508 |
+
logging.info("Creating VACE pipeline.")
|
| 509 |
+
wan_vace = wan.WanVace(
|
| 510 |
+
config=cfg,
|
| 511 |
+
checkpoint_dir=args.ckpt_dir,
|
| 512 |
+
device_id=device,
|
| 513 |
+
rank=rank,
|
| 514 |
+
t5_fsdp=args.t5_fsdp,
|
| 515 |
+
dit_fsdp=args.dit_fsdp,
|
| 516 |
+
use_usp=(args.ulysses_size > 1 or args.ring_size > 1),
|
| 517 |
+
t5_cpu=args.t5_cpu,
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
src_video, src_mask, src_ref_images = wan_vace.prepare_source([args.src_video],
|
| 521 |
+
[args.src_mask],
|
| 522 |
+
[None if args.src_ref_images is None else args.src_ref_images.split(',')],
|
| 523 |
+
args.frame_num, SIZE_CONFIGS[args.size], device)
|
| 524 |
+
|
| 525 |
+
logging.info(f"Generating video...")
|
| 526 |
+
video = wan_vace.generate(
|
| 527 |
+
args.prompt,
|
| 528 |
+
src_video,
|
| 529 |
+
src_mask,
|
| 530 |
+
src_ref_images,
|
| 531 |
+
size=SIZE_CONFIGS[args.size],
|
| 532 |
+
frame_num=args.frame_num,
|
| 533 |
+
shift=args.sample_shift,
|
| 534 |
+
sample_solver=args.sample_solver,
|
| 535 |
+
sampling_steps=args.sample_steps,
|
| 536 |
+
guide_scale=args.sample_guide_scale,
|
| 537 |
+
seed=args.base_seed,
|
| 538 |
+
offload_model=args.offload_model)
|
| 539 |
+
else:
|
| 540 |
+
raise ValueError(f"Unkown task type: {args.task}")
|
| 541 |
+
|
| 542 |
+
if rank == 0:
|
| 543 |
+
if args.save_file is None:
|
| 544 |
+
formatted_time = datetime.now().strftime("%Y%m%d_%H%M%S")
|
| 545 |
+
formatted_prompt = args.prompt.replace(" ", "_").replace("/",
|
| 546 |
+
"_")[:50]
|
| 547 |
+
suffix = '.png' if "t2i" in args.task else '.mp4'
|
| 548 |
+
args.save_file = f"{args.task}_{args.size.replace('*','x') if sys.platform=='win32' else args.size}_{args.ulysses_size}_{args.ring_size}_{formatted_prompt}_{formatted_time}" + suffix
|
| 549 |
+
|
| 550 |
+
if "t2i" in args.task:
|
| 551 |
+
logging.info(f"Saving generated image to {args.save_file}")
|
| 552 |
+
cache_image(
|
| 553 |
+
tensor=video.squeeze(1)[None],
|
| 554 |
+
save_file=args.save_file,
|
| 555 |
+
nrow=1,
|
| 556 |
+
normalize=True,
|
| 557 |
+
value_range=(-1, 1))
|
| 558 |
+
else:
|
| 559 |
+
logging.info(f"Saving generated video to {args.save_file}")
|
| 560 |
+
cache_video(
|
| 561 |
+
tensor=video[None],
|
| 562 |
+
save_file=args.save_file,
|
| 563 |
+
fps=cfg.sample_fps,
|
| 564 |
+
nrow=1,
|
| 565 |
+
normalize=True,
|
| 566 |
+
value_range=(-1, 1))
|
| 567 |
+
logging.info("Finished.")
|
| 568 |
+
|
| 569 |
+
|
| 570 |
+
if __name__ == "__main__":
|
| 571 |
+
args = _parse_args()
|
| 572 |
+
generate(args)
|
gradio/fl2v_14B_singleGPU.py
ADDED
|
@@ -0,0 +1,252 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import gc
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import os
|
| 6 |
+
import sys
|
| 7 |
+
import warnings
|
| 8 |
+
|
| 9 |
+
import gradio as gr
|
| 10 |
+
|
| 11 |
+
warnings.filterwarnings('ignore')
|
| 12 |
+
|
| 13 |
+
# Model
|
| 14 |
+
sys.path.insert(0, os.path.sep.join(osp.realpath(__file__).split(os.path.sep)[:-2]))
|
| 15 |
+
import wan
|
| 16 |
+
from wan.configs import MAX_AREA_CONFIGS, WAN_CONFIGS
|
| 17 |
+
from wan.utils.prompt_extend import DashScopePromptExpander, QwenPromptExpander
|
| 18 |
+
from wan.utils.utils import cache_video
|
| 19 |
+
|
| 20 |
+
# Global Var
|
| 21 |
+
prompt_expander = None
|
| 22 |
+
wan_flf2v_720P = None
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Button Func
|
| 26 |
+
def load_model(value):
|
| 27 |
+
global wan_flf2v_720P
|
| 28 |
+
|
| 29 |
+
if value == '------':
|
| 30 |
+
print("No model loaded")
|
| 31 |
+
return '------'
|
| 32 |
+
|
| 33 |
+
if value == '720P':
|
| 34 |
+
if args.ckpt_dir_720p is None:
|
| 35 |
+
print("Please specify the checkpoint directory for 720P model")
|
| 36 |
+
return '------'
|
| 37 |
+
if wan_flf2v_720P is not None:
|
| 38 |
+
pass
|
| 39 |
+
else:
|
| 40 |
+
gc.collect()
|
| 41 |
+
|
| 42 |
+
print("load 14B-720P flf2v model...", end='', flush=True)
|
| 43 |
+
cfg = WAN_CONFIGS['flf2v-14B']
|
| 44 |
+
wan_flf2v_720P = wan.WanFLF2V(
|
| 45 |
+
config=cfg,
|
| 46 |
+
checkpoint_dir=args.ckpt_dir_720p,
|
| 47 |
+
device_id=0,
|
| 48 |
+
rank=0,
|
| 49 |
+
t5_fsdp=False,
|
| 50 |
+
dit_fsdp=False,
|
| 51 |
+
use_usp=False,
|
| 52 |
+
)
|
| 53 |
+
print("done", flush=True)
|
| 54 |
+
return '720P'
|
| 55 |
+
return value
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def prompt_enc(prompt, img_first, img_last, tar_lang):
|
| 59 |
+
print('prompt extend...')
|
| 60 |
+
if img_first is None or img_last is None:
|
| 61 |
+
print('Please upload the first and last frames')
|
| 62 |
+
return prompt
|
| 63 |
+
global prompt_expander
|
| 64 |
+
prompt_output = prompt_expander(
|
| 65 |
+
prompt, image=[img_first, img_last], tar_lang=tar_lang.lower())
|
| 66 |
+
if prompt_output.status == False:
|
| 67 |
+
return prompt
|
| 68 |
+
else:
|
| 69 |
+
return prompt_output.prompt
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def flf2v_generation(flf2vid_prompt, flf2vid_image_first, flf2vid_image_last, resolution, sd_steps,
|
| 73 |
+
guide_scale, shift_scale, seed, n_prompt):
|
| 74 |
+
|
| 75 |
+
if resolution == '------':
|
| 76 |
+
print(
|
| 77 |
+
'Please specify the resolution ckpt dir or specify the resolution'
|
| 78 |
+
)
|
| 79 |
+
return None
|
| 80 |
+
|
| 81 |
+
else:
|
| 82 |
+
if resolution == '720P':
|
| 83 |
+
global wan_flf2v_720P
|
| 84 |
+
video = wan_flf2v_720P.generate(
|
| 85 |
+
flf2vid_prompt,
|
| 86 |
+
flf2vid_image_first,
|
| 87 |
+
flf2vid_image_last,
|
| 88 |
+
max_area=MAX_AREA_CONFIGS['720*1280'],
|
| 89 |
+
shift=shift_scale,
|
| 90 |
+
sampling_steps=sd_steps,
|
| 91 |
+
guide_scale=guide_scale,
|
| 92 |
+
n_prompt=n_prompt,
|
| 93 |
+
seed=seed,
|
| 94 |
+
offload_model=True)
|
| 95 |
+
pass
|
| 96 |
+
else:
|
| 97 |
+
print(
|
| 98 |
+
'Sorry, currently only 720P is supported.'
|
| 99 |
+
)
|
| 100 |
+
return None
|
| 101 |
+
|
| 102 |
+
cache_video(
|
| 103 |
+
tensor=video[None],
|
| 104 |
+
save_file="example.mp4",
|
| 105 |
+
fps=16,
|
| 106 |
+
nrow=1,
|
| 107 |
+
normalize=True,
|
| 108 |
+
value_range=(-1, 1))
|
| 109 |
+
|
| 110 |
+
return "example.mp4"
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# Interface
|
| 114 |
+
def gradio_interface():
|
| 115 |
+
with gr.Blocks() as demo:
|
| 116 |
+
gr.Markdown("""
|
| 117 |
+
<div style="text-align: center; font-size: 32px; font-weight: bold; margin-bottom: 20px;">
|
| 118 |
+
Wan2.1 (FLF2V-14B)
|
| 119 |
+
</div>
|
| 120 |
+
<div style="text-align: center; font-size: 16px; font-weight: normal; margin-bottom: 20px;">
|
| 121 |
+
Wan: Open and Advanced Large-Scale Video Generative Models.
|
| 122 |
+
</div>
|
| 123 |
+
""")
|
| 124 |
+
|
| 125 |
+
with gr.Row():
|
| 126 |
+
with gr.Column():
|
| 127 |
+
resolution = gr.Dropdown(
|
| 128 |
+
label='Resolution',
|
| 129 |
+
choices=['------', '720P'],
|
| 130 |
+
value='------')
|
| 131 |
+
flf2vid_image_first = gr.Image(
|
| 132 |
+
type="pil",
|
| 133 |
+
label="Upload First Frame",
|
| 134 |
+
elem_id="image_upload",
|
| 135 |
+
)
|
| 136 |
+
flf2vid_image_last = gr.Image(
|
| 137 |
+
type="pil",
|
| 138 |
+
label="Upload Last Frame",
|
| 139 |
+
elem_id="image_upload",
|
| 140 |
+
)
|
| 141 |
+
flf2vid_prompt = gr.Textbox(
|
| 142 |
+
label="Prompt",
|
| 143 |
+
placeholder="Describe the video you want to generate",
|
| 144 |
+
)
|
| 145 |
+
tar_lang = gr.Radio(
|
| 146 |
+
choices=["ZH", "EN"],
|
| 147 |
+
label="Target language of prompt enhance",
|
| 148 |
+
value="ZH")
|
| 149 |
+
run_p_button = gr.Button(value="Prompt Enhance")
|
| 150 |
+
|
| 151 |
+
with gr.Accordion("Advanced Options", open=True):
|
| 152 |
+
with gr.Row():
|
| 153 |
+
sd_steps = gr.Slider(
|
| 154 |
+
label="Diffusion steps",
|
| 155 |
+
minimum=1,
|
| 156 |
+
maximum=1000,
|
| 157 |
+
value=50,
|
| 158 |
+
step=1)
|
| 159 |
+
guide_scale = gr.Slider(
|
| 160 |
+
label="Guide scale",
|
| 161 |
+
minimum=0,
|
| 162 |
+
maximum=20,
|
| 163 |
+
value=5.0,
|
| 164 |
+
step=1)
|
| 165 |
+
with gr.Row():
|
| 166 |
+
shift_scale = gr.Slider(
|
| 167 |
+
label="Shift scale",
|
| 168 |
+
minimum=0,
|
| 169 |
+
maximum=20,
|
| 170 |
+
value=5.0,
|
| 171 |
+
step=1)
|
| 172 |
+
seed = gr.Slider(
|
| 173 |
+
label="Seed",
|
| 174 |
+
minimum=-1,
|
| 175 |
+
maximum=2147483647,
|
| 176 |
+
step=1,
|
| 177 |
+
value=-1)
|
| 178 |
+
n_prompt = gr.Textbox(
|
| 179 |
+
label="Negative Prompt",
|
| 180 |
+
placeholder="Describe the negative prompt you want to add"
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
run_flf2v_button = gr.Button("Generate Video")
|
| 184 |
+
|
| 185 |
+
with gr.Column():
|
| 186 |
+
result_gallery = gr.Video(
|
| 187 |
+
label='Generated Video', interactive=False, height=600)
|
| 188 |
+
|
| 189 |
+
resolution.input(
|
| 190 |
+
fn=load_model, inputs=[resolution], outputs=[resolution])
|
| 191 |
+
|
| 192 |
+
run_p_button.click(
|
| 193 |
+
fn=prompt_enc,
|
| 194 |
+
inputs=[flf2vid_prompt, flf2vid_image_first, flf2vid_image_last, tar_lang],
|
| 195 |
+
outputs=[flf2vid_prompt])
|
| 196 |
+
|
| 197 |
+
run_flf2v_button.click(
|
| 198 |
+
fn=flf2v_generation,
|
| 199 |
+
inputs=[
|
| 200 |
+
flf2vid_prompt, flf2vid_image_first, flf2vid_image_last, resolution, sd_steps,
|
| 201 |
+
guide_scale, shift_scale, seed, n_prompt
|
| 202 |
+
],
|
| 203 |
+
outputs=[result_gallery],
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
return demo
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
# Main
|
| 210 |
+
def _parse_args():
|
| 211 |
+
parser = argparse.ArgumentParser(
|
| 212 |
+
description="Generate a video from a text prompt or image using Gradio")
|
| 213 |
+
parser.add_argument(
|
| 214 |
+
"--ckpt_dir_720p",
|
| 215 |
+
type=str,
|
| 216 |
+
default=None,
|
| 217 |
+
help="The path to the checkpoint directory.")
|
| 218 |
+
parser.add_argument(
|
| 219 |
+
"--prompt_extend_method",
|
| 220 |
+
type=str,
|
| 221 |
+
default="local_qwen",
|
| 222 |
+
choices=["dashscope", "local_qwen"],
|
| 223 |
+
help="The prompt extend method to use.")
|
| 224 |
+
parser.add_argument(
|
| 225 |
+
"--prompt_extend_model",
|
| 226 |
+
type=str,
|
| 227 |
+
default=None,
|
| 228 |
+
help="The prompt extend model to use.")
|
| 229 |
+
|
| 230 |
+
args = parser.parse_args()
|
| 231 |
+
assert args.ckpt_dir_720p is not None, "Please specify the checkpoint directory."
|
| 232 |
+
|
| 233 |
+
return args
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
if __name__ == '__main__':
|
| 237 |
+
args = _parse_args()
|
| 238 |
+
|
| 239 |
+
print("Step1: Init prompt_expander...", end='', flush=True)
|
| 240 |
+
if args.prompt_extend_method == "dashscope":
|
| 241 |
+
prompt_expander = DashScopePromptExpander(
|
| 242 |
+
model_name=args.prompt_extend_model, is_vl=True)
|
| 243 |
+
elif args.prompt_extend_method == "local_qwen":
|
| 244 |
+
prompt_expander = QwenPromptExpander(
|
| 245 |
+
model_name=args.prompt_extend_model, is_vl=True, device=0)
|
| 246 |
+
else:
|
| 247 |
+
raise NotImplementedError(
|
| 248 |
+
f"Unsupport prompt_extend_method: {args.prompt_extend_method}")
|
| 249 |
+
print("done", flush=True)
|
| 250 |
+
|
| 251 |
+
demo = gradio_interface()
|
| 252 |
+
demo.launch(server_name="0.0.0.0", share=False, server_port=7860)
|
gradio/i2v_14B_singleGPU.py
ADDED
|
@@ -0,0 +1,287 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import gc
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import os
|
| 6 |
+
import sys
|
| 7 |
+
import warnings
|
| 8 |
+
|
| 9 |
+
import gradio as gr
|
| 10 |
+
|
| 11 |
+
warnings.filterwarnings('ignore')
|
| 12 |
+
|
| 13 |
+
# Model
|
| 14 |
+
sys.path.insert(0, os.path.sep.join(osp.realpath(__file__).split(os.path.sep)[:-2]))
|
| 15 |
+
import wan
|
| 16 |
+
from wan.configs import MAX_AREA_CONFIGS, WAN_CONFIGS
|
| 17 |
+
from wan.utils.prompt_extend import DashScopePromptExpander, QwenPromptExpander
|
| 18 |
+
from wan.utils.utils import cache_video
|
| 19 |
+
|
| 20 |
+
# Global Var
|
| 21 |
+
prompt_expander = None
|
| 22 |
+
wan_i2v_480P = None
|
| 23 |
+
wan_i2v_720P = None
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# Button Func
|
| 27 |
+
def load_model(value):
|
| 28 |
+
global wan_i2v_480P, wan_i2v_720P
|
| 29 |
+
|
| 30 |
+
if value == '------':
|
| 31 |
+
print("No model loaded")
|
| 32 |
+
return '------'
|
| 33 |
+
|
| 34 |
+
if value == '720P':
|
| 35 |
+
if args.ckpt_dir_720p is None:
|
| 36 |
+
print("Please specify the checkpoint directory for 720P model")
|
| 37 |
+
return '------'
|
| 38 |
+
if wan_i2v_720P is not None:
|
| 39 |
+
pass
|
| 40 |
+
else:
|
| 41 |
+
del wan_i2v_480P
|
| 42 |
+
gc.collect()
|
| 43 |
+
wan_i2v_480P = None
|
| 44 |
+
|
| 45 |
+
print("load 14B-720P i2v model...", end='', flush=True)
|
| 46 |
+
cfg = WAN_CONFIGS['i2v-14B']
|
| 47 |
+
wan_i2v_720P = wan.WanI2V(
|
| 48 |
+
config=cfg,
|
| 49 |
+
checkpoint_dir=args.ckpt_dir_720p,
|
| 50 |
+
device_id=0,
|
| 51 |
+
rank=0,
|
| 52 |
+
t5_fsdp=False,
|
| 53 |
+
dit_fsdp=False,
|
| 54 |
+
use_usp=False,
|
| 55 |
+
)
|
| 56 |
+
print("done", flush=True)
|
| 57 |
+
return '720P'
|
| 58 |
+
|
| 59 |
+
if value == '480P':
|
| 60 |
+
if args.ckpt_dir_480p is None:
|
| 61 |
+
print("Please specify the checkpoint directory for 480P model")
|
| 62 |
+
return '------'
|
| 63 |
+
if wan_i2v_480P is not None:
|
| 64 |
+
pass
|
| 65 |
+
else:
|
| 66 |
+
del wan_i2v_720P
|
| 67 |
+
gc.collect()
|
| 68 |
+
wan_i2v_720P = None
|
| 69 |
+
|
| 70 |
+
print("load 14B-480P i2v model...", end='', flush=True)
|
| 71 |
+
cfg = WAN_CONFIGS['i2v-14B']
|
| 72 |
+
wan_i2v_480P = wan.WanI2V(
|
| 73 |
+
config=cfg,
|
| 74 |
+
checkpoint_dir=args.ckpt_dir_480p,
|
| 75 |
+
device_id=0,
|
| 76 |
+
rank=0,
|
| 77 |
+
t5_fsdp=False,
|
| 78 |
+
dit_fsdp=False,
|
| 79 |
+
use_usp=False,
|
| 80 |
+
)
|
| 81 |
+
print("done", flush=True)
|
| 82 |
+
return '480P'
|
| 83 |
+
return value
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def prompt_enc(prompt, img, tar_lang):
|
| 87 |
+
print('prompt extend...')
|
| 88 |
+
if img is None:
|
| 89 |
+
print('Please upload an image')
|
| 90 |
+
return prompt
|
| 91 |
+
global prompt_expander
|
| 92 |
+
prompt_output = prompt_expander(
|
| 93 |
+
prompt, image=img, tar_lang=tar_lang.lower())
|
| 94 |
+
if prompt_output.status == False:
|
| 95 |
+
return prompt
|
| 96 |
+
else:
|
| 97 |
+
return prompt_output.prompt
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def i2v_generation(img2vid_prompt, img2vid_image, resolution, sd_steps,
|
| 101 |
+
guide_scale, shift_scale, seed, n_prompt):
|
| 102 |
+
# print(f"{img2vid_prompt},{resolution},{sd_steps},{guide_scale},{shift_scale},{seed},{n_prompt}")
|
| 103 |
+
|
| 104 |
+
if resolution == '------':
|
| 105 |
+
print(
|
| 106 |
+
'Please specify at least one resolution ckpt dir or specify the resolution'
|
| 107 |
+
)
|
| 108 |
+
return None
|
| 109 |
+
|
| 110 |
+
else:
|
| 111 |
+
if resolution == '720P':
|
| 112 |
+
global wan_i2v_720P
|
| 113 |
+
video = wan_i2v_720P.generate(
|
| 114 |
+
img2vid_prompt,
|
| 115 |
+
img2vid_image,
|
| 116 |
+
max_area=MAX_AREA_CONFIGS['720*1280'],
|
| 117 |
+
shift=shift_scale,
|
| 118 |
+
sampling_steps=sd_steps,
|
| 119 |
+
guide_scale=guide_scale,
|
| 120 |
+
n_prompt=n_prompt,
|
| 121 |
+
seed=seed,
|
| 122 |
+
offload_model=True)
|
| 123 |
+
else:
|
| 124 |
+
global wan_i2v_480P
|
| 125 |
+
video = wan_i2v_480P.generate(
|
| 126 |
+
img2vid_prompt,
|
| 127 |
+
img2vid_image,
|
| 128 |
+
max_area=MAX_AREA_CONFIGS['480*832'],
|
| 129 |
+
shift=shift_scale,
|
| 130 |
+
sampling_steps=sd_steps,
|
| 131 |
+
guide_scale=guide_scale,
|
| 132 |
+
n_prompt=n_prompt,
|
| 133 |
+
seed=seed,
|
| 134 |
+
offload_model=True)
|
| 135 |
+
|
| 136 |
+
cache_video(
|
| 137 |
+
tensor=video[None],
|
| 138 |
+
save_file="example.mp4",
|
| 139 |
+
fps=16,
|
| 140 |
+
nrow=1,
|
| 141 |
+
normalize=True,
|
| 142 |
+
value_range=(-1, 1))
|
| 143 |
+
|
| 144 |
+
return "example.mp4"
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
# Interface
|
| 148 |
+
def gradio_interface():
|
| 149 |
+
with gr.Blocks() as demo:
|
| 150 |
+
gr.Markdown("""
|
| 151 |
+
<div style="text-align: center; font-size: 32px; font-weight: bold; margin-bottom: 20px;">
|
| 152 |
+
Wan2.1 (I2V-14B)
|
| 153 |
+
</div>
|
| 154 |
+
<div style="text-align: center; font-size: 16px; font-weight: normal; margin-bottom: 20px;">
|
| 155 |
+
Wan: Open and Advanced Large-Scale Video Generative Models.
|
| 156 |
+
</div>
|
| 157 |
+
""")
|
| 158 |
+
|
| 159 |
+
with gr.Row():
|
| 160 |
+
with gr.Column():
|
| 161 |
+
resolution = gr.Dropdown(
|
| 162 |
+
label='Resolution',
|
| 163 |
+
choices=['------', '720P', '480P'],
|
| 164 |
+
value='------')
|
| 165 |
+
|
| 166 |
+
img2vid_image = gr.Image(
|
| 167 |
+
type="pil",
|
| 168 |
+
label="Upload Input Image",
|
| 169 |
+
elem_id="image_upload",
|
| 170 |
+
)
|
| 171 |
+
img2vid_prompt = gr.Textbox(
|
| 172 |
+
label="Prompt",
|
| 173 |
+
placeholder="Describe the video you want to generate",
|
| 174 |
+
)
|
| 175 |
+
tar_lang = gr.Radio(
|
| 176 |
+
choices=["ZH", "EN"],
|
| 177 |
+
label="Target language of prompt enhance",
|
| 178 |
+
value="ZH")
|
| 179 |
+
run_p_button = gr.Button(value="Prompt Enhance")
|
| 180 |
+
|
| 181 |
+
with gr.Accordion("Advanced Options", open=True):
|
| 182 |
+
with gr.Row():
|
| 183 |
+
sd_steps = gr.Slider(
|
| 184 |
+
label="Diffusion steps",
|
| 185 |
+
minimum=1,
|
| 186 |
+
maximum=1000,
|
| 187 |
+
value=50,
|
| 188 |
+
step=1)
|
| 189 |
+
guide_scale = gr.Slider(
|
| 190 |
+
label="Guide scale",
|
| 191 |
+
minimum=0,
|
| 192 |
+
maximum=20,
|
| 193 |
+
value=5.0,
|
| 194 |
+
step=1)
|
| 195 |
+
with gr.Row():
|
| 196 |
+
shift_scale = gr.Slider(
|
| 197 |
+
label="Shift scale",
|
| 198 |
+
minimum=0,
|
| 199 |
+
maximum=10,
|
| 200 |
+
value=5.0,
|
| 201 |
+
step=1)
|
| 202 |
+
seed = gr.Slider(
|
| 203 |
+
label="Seed",
|
| 204 |
+
minimum=-1,
|
| 205 |
+
maximum=2147483647,
|
| 206 |
+
step=1,
|
| 207 |
+
value=-1)
|
| 208 |
+
n_prompt = gr.Textbox(
|
| 209 |
+
label="Negative Prompt",
|
| 210 |
+
placeholder="Describe the negative prompt you want to add"
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
run_i2v_button = gr.Button("Generate Video")
|
| 214 |
+
|
| 215 |
+
with gr.Column():
|
| 216 |
+
result_gallery = gr.Video(
|
| 217 |
+
label='Generated Video', interactive=False, height=600)
|
| 218 |
+
|
| 219 |
+
resolution.input(
|
| 220 |
+
fn=load_model, inputs=[resolution], outputs=[resolution])
|
| 221 |
+
|
| 222 |
+
run_p_button.click(
|
| 223 |
+
fn=prompt_enc,
|
| 224 |
+
inputs=[img2vid_prompt, img2vid_image, tar_lang],
|
| 225 |
+
outputs=[img2vid_prompt])
|
| 226 |
+
|
| 227 |
+
run_i2v_button.click(
|
| 228 |
+
fn=i2v_generation,
|
| 229 |
+
inputs=[
|
| 230 |
+
img2vid_prompt, img2vid_image, resolution, sd_steps,
|
| 231 |
+
guide_scale, shift_scale, seed, n_prompt
|
| 232 |
+
],
|
| 233 |
+
outputs=[result_gallery],
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
return demo
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
# Main
|
| 240 |
+
def _parse_args():
|
| 241 |
+
parser = argparse.ArgumentParser(
|
| 242 |
+
description="Generate a video from a text prompt or image using Gradio")
|
| 243 |
+
parser.add_argument(
|
| 244 |
+
"--ckpt_dir_720p",
|
| 245 |
+
type=str,
|
| 246 |
+
default=None,
|
| 247 |
+
help="The path to the checkpoint directory.")
|
| 248 |
+
parser.add_argument(
|
| 249 |
+
"--ckpt_dir_480p",
|
| 250 |
+
type=str,
|
| 251 |
+
default=None,
|
| 252 |
+
help="The path to the checkpoint directory.")
|
| 253 |
+
parser.add_argument(
|
| 254 |
+
"--prompt_extend_method",
|
| 255 |
+
type=str,
|
| 256 |
+
default="local_qwen",
|
| 257 |
+
choices=["dashscope", "local_qwen"],
|
| 258 |
+
help="The prompt extend method to use.")
|
| 259 |
+
parser.add_argument(
|
| 260 |
+
"--prompt_extend_model",
|
| 261 |
+
type=str,
|
| 262 |
+
default=None,
|
| 263 |
+
help="The prompt extend model to use.")
|
| 264 |
+
|
| 265 |
+
args = parser.parse_args()
|
| 266 |
+
assert args.ckpt_dir_720p is not None or args.ckpt_dir_480p is not None, "Please specify at least one checkpoint directory."
|
| 267 |
+
|
| 268 |
+
return args
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
if __name__ == '__main__':
|
| 272 |
+
args = _parse_args()
|
| 273 |
+
|
| 274 |
+
print("Step1: Init prompt_expander...", end='', flush=True)
|
| 275 |
+
if args.prompt_extend_method == "dashscope":
|
| 276 |
+
prompt_expander = DashScopePromptExpander(
|
| 277 |
+
model_name=args.prompt_extend_model, is_vl=True)
|
| 278 |
+
elif args.prompt_extend_method == "local_qwen":
|
| 279 |
+
prompt_expander = QwenPromptExpander(
|
| 280 |
+
model_name=args.prompt_extend_model, is_vl=True, device=0)
|
| 281 |
+
else:
|
| 282 |
+
raise NotImplementedError(
|
| 283 |
+
f"Unsupport prompt_extend_method: {args.prompt_extend_method}")
|
| 284 |
+
print("done", flush=True)
|
| 285 |
+
|
| 286 |
+
demo = gradio_interface()
|
| 287 |
+
demo.launch(server_name="0.0.0.0", share=False, server_port=7860)
|
gradio/t2i_14B_singleGPU.py
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import os.path as osp
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import warnings
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
warnings.filterwarnings('ignore')
|
| 11 |
+
|
| 12 |
+
# Model
|
| 13 |
+
sys.path.insert(0, os.path.sep.join(osp.realpath(__file__).split(os.path.sep)[:-2]))
|
| 14 |
+
import wan
|
| 15 |
+
from wan.configs import WAN_CONFIGS
|
| 16 |
+
from wan.utils.prompt_extend import DashScopePromptExpander, QwenPromptExpander
|
| 17 |
+
from wan.utils.utils import cache_image
|
| 18 |
+
|
| 19 |
+
# Global Var
|
| 20 |
+
prompt_expander = None
|
| 21 |
+
wan_t2i = None
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# Button Func
|
| 25 |
+
def prompt_enc(prompt, tar_lang):
|
| 26 |
+
global prompt_expander
|
| 27 |
+
prompt_output = prompt_expander(prompt, tar_lang=tar_lang.lower())
|
| 28 |
+
if prompt_output.status == False:
|
| 29 |
+
return prompt
|
| 30 |
+
else:
|
| 31 |
+
return prompt_output.prompt
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def t2i_generation(txt2img_prompt, resolution, sd_steps, guide_scale,
|
| 35 |
+
shift_scale, seed, n_prompt):
|
| 36 |
+
global wan_t2i
|
| 37 |
+
# print(f"{txt2img_prompt},{resolution},{sd_steps},{guide_scale},{shift_scale},{seed},{n_prompt}")
|
| 38 |
+
|
| 39 |
+
W = int(resolution.split("*")[0])
|
| 40 |
+
H = int(resolution.split("*")[1])
|
| 41 |
+
video = wan_t2i.generate(
|
| 42 |
+
txt2img_prompt,
|
| 43 |
+
size=(W, H),
|
| 44 |
+
frame_num=1,
|
| 45 |
+
shift=shift_scale,
|
| 46 |
+
sampling_steps=sd_steps,
|
| 47 |
+
guide_scale=guide_scale,
|
| 48 |
+
n_prompt=n_prompt,
|
| 49 |
+
seed=seed,
|
| 50 |
+
offload_model=True)
|
| 51 |
+
|
| 52 |
+
cache_image(
|
| 53 |
+
tensor=video.squeeze(1)[None],
|
| 54 |
+
save_file="example.png",
|
| 55 |
+
nrow=1,
|
| 56 |
+
normalize=True,
|
| 57 |
+
value_range=(-1, 1))
|
| 58 |
+
|
| 59 |
+
return "example.png"
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# Interface
|
| 63 |
+
def gradio_interface():
|
| 64 |
+
with gr.Blocks() as demo:
|
| 65 |
+
gr.Markdown("""
|
| 66 |
+
<div style="text-align: center; font-size: 32px; font-weight: bold; margin-bottom: 20px;">
|
| 67 |
+
Wan2.1 (T2I-14B)
|
| 68 |
+
</div>
|
| 69 |
+
<div style="text-align: center; font-size: 16px; font-weight: normal; margin-bottom: 20px;">
|
| 70 |
+
Wan: Open and Advanced Large-Scale Video Generative Models.
|
| 71 |
+
</div>
|
| 72 |
+
""")
|
| 73 |
+
|
| 74 |
+
with gr.Row():
|
| 75 |
+
with gr.Column():
|
| 76 |
+
txt2img_prompt = gr.Textbox(
|
| 77 |
+
label="Prompt",
|
| 78 |
+
placeholder="Describe the image you want to generate",
|
| 79 |
+
)
|
| 80 |
+
tar_lang = gr.Radio(
|
| 81 |
+
choices=["ZH", "EN"],
|
| 82 |
+
label="Target language of prompt enhance",
|
| 83 |
+
value="ZH")
|
| 84 |
+
run_p_button = gr.Button(value="Prompt Enhance")
|
| 85 |
+
|
| 86 |
+
with gr.Accordion("Advanced Options", open=True):
|
| 87 |
+
resolution = gr.Dropdown(
|
| 88 |
+
label='Resolution(Width*Height)',
|
| 89 |
+
choices=[
|
| 90 |
+
'720*1280', '1280*720', '960*960', '1088*832',
|
| 91 |
+
'832*1088', '480*832', '832*480', '624*624',
|
| 92 |
+
'704*544', '544*704'
|
| 93 |
+
],
|
| 94 |
+
value='720*1280')
|
| 95 |
+
|
| 96 |
+
with gr.Row():
|
| 97 |
+
sd_steps = gr.Slider(
|
| 98 |
+
label="Diffusion steps",
|
| 99 |
+
minimum=1,
|
| 100 |
+
maximum=1000,
|
| 101 |
+
value=50,
|
| 102 |
+
step=1)
|
| 103 |
+
guide_scale = gr.Slider(
|
| 104 |
+
label="Guide scale",
|
| 105 |
+
minimum=0,
|
| 106 |
+
maximum=20,
|
| 107 |
+
value=5.0,
|
| 108 |
+
step=1)
|
| 109 |
+
with gr.Row():
|
| 110 |
+
shift_scale = gr.Slider(
|
| 111 |
+
label="Shift scale",
|
| 112 |
+
minimum=0,
|
| 113 |
+
maximum=10,
|
| 114 |
+
value=5.0,
|
| 115 |
+
step=1)
|
| 116 |
+
seed = gr.Slider(
|
| 117 |
+
label="Seed",
|
| 118 |
+
minimum=-1,
|
| 119 |
+
maximum=2147483647,
|
| 120 |
+
step=1,
|
| 121 |
+
value=-1)
|
| 122 |
+
n_prompt = gr.Textbox(
|
| 123 |
+
label="Negative Prompt",
|
| 124 |
+
placeholder="Describe the negative prompt you want to add"
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
run_t2i_button = gr.Button("Generate Image")
|
| 128 |
+
|
| 129 |
+
with gr.Column():
|
| 130 |
+
result_gallery = gr.Image(
|
| 131 |
+
label='Generated Image', interactive=False, height=600)
|
| 132 |
+
|
| 133 |
+
run_p_button.click(
|
| 134 |
+
fn=prompt_enc,
|
| 135 |
+
inputs=[txt2img_prompt, tar_lang],
|
| 136 |
+
outputs=[txt2img_prompt])
|
| 137 |
+
|
| 138 |
+
run_t2i_button.click(
|
| 139 |
+
fn=t2i_generation,
|
| 140 |
+
inputs=[
|
| 141 |
+
txt2img_prompt, resolution, sd_steps, guide_scale, shift_scale,
|
| 142 |
+
seed, n_prompt
|
| 143 |
+
],
|
| 144 |
+
outputs=[result_gallery],
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
return demo
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
# Main
|
| 151 |
+
def _parse_args():
|
| 152 |
+
parser = argparse.ArgumentParser(
|
| 153 |
+
description="Generate a image from a text prompt or image using Gradio")
|
| 154 |
+
parser.add_argument(
|
| 155 |
+
"--ckpt_dir",
|
| 156 |
+
type=str,
|
| 157 |
+
default="cache",
|
| 158 |
+
help="The path to the checkpoint directory.")
|
| 159 |
+
parser.add_argument(
|
| 160 |
+
"--prompt_extend_method",
|
| 161 |
+
type=str,
|
| 162 |
+
default="local_qwen",
|
| 163 |
+
choices=["dashscope", "local_qwen"],
|
| 164 |
+
help="The prompt extend method to use.")
|
| 165 |
+
parser.add_argument(
|
| 166 |
+
"--prompt_extend_model",
|
| 167 |
+
type=str,
|
| 168 |
+
default=None,
|
| 169 |
+
help="The prompt extend model to use.")
|
| 170 |
+
|
| 171 |
+
args = parser.parse_args()
|
| 172 |
+
|
| 173 |
+
return args
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
if __name__ == '__main__':
|
| 177 |
+
args = _parse_args()
|
| 178 |
+
|
| 179 |
+
print("Step1: Init prompt_expander...", end='', flush=True)
|
| 180 |
+
if args.prompt_extend_method == "dashscope":
|
| 181 |
+
prompt_expander = DashScopePromptExpander(
|
| 182 |
+
model_name=args.prompt_extend_model, is_vl=False)
|
| 183 |
+
elif args.prompt_extend_method == "local_qwen":
|
| 184 |
+
prompt_expander = QwenPromptExpander(
|
| 185 |
+
model_name=args.prompt_extend_model, is_vl=False, device=0)
|
| 186 |
+
else:
|
| 187 |
+
raise NotImplementedError(
|
| 188 |
+
f"Unsupport prompt_extend_method: {args.prompt_extend_method}")
|
| 189 |
+
print("done", flush=True)
|
| 190 |
+
|
| 191 |
+
print("Step2: Init 14B t2i model...", end='', flush=True)
|
| 192 |
+
cfg = WAN_CONFIGS['t2i-14B']
|
| 193 |
+
wan_t2i = wan.WanT2V(
|
| 194 |
+
config=cfg,
|
| 195 |
+
checkpoint_dir=args.ckpt_dir,
|
| 196 |
+
device_id=0,
|
| 197 |
+
rank=0,
|
| 198 |
+
t5_fsdp=False,
|
| 199 |
+
dit_fsdp=False,
|
| 200 |
+
use_usp=False,
|
| 201 |
+
)
|
| 202 |
+
print("done", flush=True)
|
| 203 |
+
|
| 204 |
+
demo = gradio_interface()
|
| 205 |
+
demo.launch(server_name="0.0.0.0", share=False, server_port=7860)
|
gradio/t2v_1.3B_singleGPU.py
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import os.path as osp
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import warnings
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
warnings.filterwarnings('ignore')
|
| 11 |
+
|
| 12 |
+
# Model
|
| 13 |
+
sys.path.insert(0, os.path.sep.join(osp.realpath(__file__).split(os.path.sep)[:-2]))
|
| 14 |
+
import wan
|
| 15 |
+
from wan.configs import WAN_CONFIGS
|
| 16 |
+
from wan.utils.prompt_extend import DashScopePromptExpander, QwenPromptExpander
|
| 17 |
+
from wan.utils.utils import cache_video
|
| 18 |
+
|
| 19 |
+
# Global Var
|
| 20 |
+
prompt_expander = None
|
| 21 |
+
wan_t2v = None
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# Button Func
|
| 25 |
+
def prompt_enc(prompt, tar_lang):
|
| 26 |
+
global prompt_expander
|
| 27 |
+
prompt_output = prompt_expander(prompt, tar_lang=tar_lang.lower())
|
| 28 |
+
if prompt_output.status == False:
|
| 29 |
+
return prompt
|
| 30 |
+
else:
|
| 31 |
+
return prompt_output.prompt
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def t2v_generation(txt2vid_prompt, resolution, sd_steps, guide_scale,
|
| 35 |
+
shift_scale, seed, n_prompt):
|
| 36 |
+
global wan_t2v
|
| 37 |
+
# print(f"{txt2vid_prompt},{resolution},{sd_steps},{guide_scale},{shift_scale},{seed},{n_prompt}")
|
| 38 |
+
|
| 39 |
+
W = int(resolution.split("*")[0])
|
| 40 |
+
H = int(resolution.split("*")[1])
|
| 41 |
+
video = wan_t2v.generate(
|
| 42 |
+
txt2vid_prompt,
|
| 43 |
+
size=(W, H),
|
| 44 |
+
shift=shift_scale,
|
| 45 |
+
sampling_steps=sd_steps,
|
| 46 |
+
guide_scale=guide_scale,
|
| 47 |
+
n_prompt=n_prompt,
|
| 48 |
+
seed=seed,
|
| 49 |
+
offload_model=True)
|
| 50 |
+
|
| 51 |
+
cache_video(
|
| 52 |
+
tensor=video[None],
|
| 53 |
+
save_file="example.mp4",
|
| 54 |
+
fps=16,
|
| 55 |
+
nrow=1,
|
| 56 |
+
normalize=True,
|
| 57 |
+
value_range=(-1, 1))
|
| 58 |
+
|
| 59 |
+
return "example.mp4"
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# Interface
|
| 63 |
+
def gradio_interface():
|
| 64 |
+
with gr.Blocks() as demo:
|
| 65 |
+
gr.Markdown("""
|
| 66 |
+
<div style="text-align: center; font-size: 32px; font-weight: bold; margin-bottom: 20px;">
|
| 67 |
+
Wan2.1 (T2V-1.3B)
|
| 68 |
+
</div>
|
| 69 |
+
<div style="text-align: center; font-size: 16px; font-weight: normal; margin-bottom: 20px;">
|
| 70 |
+
Wan: Open and Advanced Large-Scale Video Generative Models.
|
| 71 |
+
</div>
|
| 72 |
+
""")
|
| 73 |
+
|
| 74 |
+
with gr.Row():
|
| 75 |
+
with gr.Column():
|
| 76 |
+
txt2vid_prompt = gr.Textbox(
|
| 77 |
+
label="Prompt",
|
| 78 |
+
placeholder="Describe the video you want to generate",
|
| 79 |
+
)
|
| 80 |
+
tar_lang = gr.Radio(
|
| 81 |
+
choices=["ZH", "EN"],
|
| 82 |
+
label="Target language of prompt enhance",
|
| 83 |
+
value="ZH")
|
| 84 |
+
run_p_button = gr.Button(value="Prompt Enhance")
|
| 85 |
+
|
| 86 |
+
with gr.Accordion("Advanced Options", open=True):
|
| 87 |
+
resolution = gr.Dropdown(
|
| 88 |
+
label='Resolution(Width*Height)',
|
| 89 |
+
choices=[
|
| 90 |
+
'480*832',
|
| 91 |
+
'832*480',
|
| 92 |
+
'624*624',
|
| 93 |
+
'704*544',
|
| 94 |
+
'544*704',
|
| 95 |
+
],
|
| 96 |
+
value='480*832')
|
| 97 |
+
|
| 98 |
+
with gr.Row():
|
| 99 |
+
sd_steps = gr.Slider(
|
| 100 |
+
label="Diffusion steps",
|
| 101 |
+
minimum=1,
|
| 102 |
+
maximum=1000,
|
| 103 |
+
value=50,
|
| 104 |
+
step=1)
|
| 105 |
+
guide_scale = gr.Slider(
|
| 106 |
+
label="Guide scale",
|
| 107 |
+
minimum=0,
|
| 108 |
+
maximum=20,
|
| 109 |
+
value=6.0,
|
| 110 |
+
step=1)
|
| 111 |
+
with gr.Row():
|
| 112 |
+
shift_scale = gr.Slider(
|
| 113 |
+
label="Shift scale",
|
| 114 |
+
minimum=0,
|
| 115 |
+
maximum=20,
|
| 116 |
+
value=8.0,
|
| 117 |
+
step=1)
|
| 118 |
+
seed = gr.Slider(
|
| 119 |
+
label="Seed",
|
| 120 |
+
minimum=-1,
|
| 121 |
+
maximum=2147483647,
|
| 122 |
+
step=1,
|
| 123 |
+
value=-1)
|
| 124 |
+
n_prompt = gr.Textbox(
|
| 125 |
+
label="Negative Prompt",
|
| 126 |
+
placeholder="Describe the negative prompt you want to add"
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
run_t2v_button = gr.Button("Generate Video")
|
| 130 |
+
|
| 131 |
+
with gr.Column():
|
| 132 |
+
result_gallery = gr.Video(
|
| 133 |
+
label='Generated Video', interactive=False, height=600)
|
| 134 |
+
|
| 135 |
+
run_p_button.click(
|
| 136 |
+
fn=prompt_enc,
|
| 137 |
+
inputs=[txt2vid_prompt, tar_lang],
|
| 138 |
+
outputs=[txt2vid_prompt])
|
| 139 |
+
|
| 140 |
+
run_t2v_button.click(
|
| 141 |
+
fn=t2v_generation,
|
| 142 |
+
inputs=[
|
| 143 |
+
txt2vid_prompt, resolution, sd_steps, guide_scale, shift_scale,
|
| 144 |
+
seed, n_prompt
|
| 145 |
+
],
|
| 146 |
+
outputs=[result_gallery],
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
return demo
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
# Main
|
| 153 |
+
def _parse_args():
|
| 154 |
+
parser = argparse.ArgumentParser(
|
| 155 |
+
description="Generate a video from a text prompt or image using Gradio")
|
| 156 |
+
parser.add_argument(
|
| 157 |
+
"--ckpt_dir",
|
| 158 |
+
type=str,
|
| 159 |
+
default="cache",
|
| 160 |
+
help="The path to the checkpoint directory.")
|
| 161 |
+
parser.add_argument(
|
| 162 |
+
"--prompt_extend_method",
|
| 163 |
+
type=str,
|
| 164 |
+
default="local_qwen",
|
| 165 |
+
choices=["dashscope", "local_qwen"],
|
| 166 |
+
help="The prompt extend method to use.")
|
| 167 |
+
parser.add_argument(
|
| 168 |
+
"--prompt_extend_model",
|
| 169 |
+
type=str,
|
| 170 |
+
default=None,
|
| 171 |
+
help="The prompt extend model to use.")
|
| 172 |
+
|
| 173 |
+
args = parser.parse_args()
|
| 174 |
+
|
| 175 |
+
return args
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
if __name__ == '__main__':
|
| 179 |
+
args = _parse_args()
|
| 180 |
+
|
| 181 |
+
print("Step1: Init prompt_expander...", end='', flush=True)
|
| 182 |
+
if args.prompt_extend_method == "dashscope":
|
| 183 |
+
prompt_expander = DashScopePromptExpander(
|
| 184 |
+
model_name=args.prompt_extend_model, is_vl=False)
|
| 185 |
+
elif args.prompt_extend_method == "local_qwen":
|
| 186 |
+
prompt_expander = QwenPromptExpander(
|
| 187 |
+
model_name=args.prompt_extend_model, is_vl=False, device=0)
|
| 188 |
+
else:
|
| 189 |
+
raise NotImplementedError(
|
| 190 |
+
f"Unsupport prompt_extend_method: {args.prompt_extend_method}")
|
| 191 |
+
print("done", flush=True)
|
| 192 |
+
|
| 193 |
+
print("Step2: Init 1.3B t2v model...", end='', flush=True)
|
| 194 |
+
cfg = WAN_CONFIGS['t2v-1.3B']
|
| 195 |
+
wan_t2v = wan.WanT2V(
|
| 196 |
+
config=cfg,
|
| 197 |
+
checkpoint_dir=args.ckpt_dir,
|
| 198 |
+
device_id=0,
|
| 199 |
+
rank=0,
|
| 200 |
+
t5_fsdp=False,
|
| 201 |
+
dit_fsdp=False,
|
| 202 |
+
use_usp=False,
|
| 203 |
+
)
|
| 204 |
+
print("done", flush=True)
|
| 205 |
+
|
| 206 |
+
demo = gradio_interface()
|
| 207 |
+
demo.launch(server_name="0.0.0.0", share=False, server_port=7860)
|
gradio/t2v_14B_singleGPU.py
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import os.path as osp
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import warnings
|
| 7 |
+
|
| 8 |
+
import gradio as gr
|
| 9 |
+
|
| 10 |
+
warnings.filterwarnings('ignore')
|
| 11 |
+
|
| 12 |
+
# Model
|
| 13 |
+
sys.path.insert(0, os.path.sep.join(osp.realpath(__file__).split(os.path.sep)[:-2]))
|
| 14 |
+
import wan
|
| 15 |
+
from wan.configs import WAN_CONFIGS
|
| 16 |
+
from wan.utils.prompt_extend import DashScopePromptExpander, QwenPromptExpander
|
| 17 |
+
from wan.utils.utils import cache_video
|
| 18 |
+
|
| 19 |
+
# Global Var
|
| 20 |
+
prompt_expander = None
|
| 21 |
+
wan_t2v = None
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
# Button Func
|
| 25 |
+
def prompt_enc(prompt, tar_lang):
|
| 26 |
+
global prompt_expander
|
| 27 |
+
prompt_output = prompt_expander(prompt, tar_lang=tar_lang.lower())
|
| 28 |
+
if prompt_output.status == False:
|
| 29 |
+
return prompt
|
| 30 |
+
else:
|
| 31 |
+
return prompt_output.prompt
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def t2v_generation(txt2vid_prompt, resolution, sd_steps, guide_scale,
|
| 35 |
+
shift_scale, seed, n_prompt):
|
| 36 |
+
global wan_t2v
|
| 37 |
+
# print(f"{txt2vid_prompt},{resolution},{sd_steps},{guide_scale},{shift_scale},{seed},{n_prompt}")
|
| 38 |
+
|
| 39 |
+
W = int(resolution.split("*")[0])
|
| 40 |
+
H = int(resolution.split("*")[1])
|
| 41 |
+
video = wan_t2v.generate(
|
| 42 |
+
txt2vid_prompt,
|
| 43 |
+
size=(W, H),
|
| 44 |
+
shift=shift_scale,
|
| 45 |
+
sampling_steps=sd_steps,
|
| 46 |
+
guide_scale=guide_scale,
|
| 47 |
+
n_prompt=n_prompt,
|
| 48 |
+
seed=seed,
|
| 49 |
+
offload_model=True)
|
| 50 |
+
|
| 51 |
+
cache_video(
|
| 52 |
+
tensor=video[None],
|
| 53 |
+
save_file="example.mp4",
|
| 54 |
+
fps=16,
|
| 55 |
+
nrow=1,
|
| 56 |
+
normalize=True,
|
| 57 |
+
value_range=(-1, 1))
|
| 58 |
+
|
| 59 |
+
return "example.mp4"
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
# Interface
|
| 63 |
+
def gradio_interface():
|
| 64 |
+
with gr.Blocks() as demo:
|
| 65 |
+
gr.Markdown("""
|
| 66 |
+
<div style="text-align: center; font-size: 32px; font-weight: bold; margin-bottom: 20px;">
|
| 67 |
+
Wan2.1 (T2V-14B)
|
| 68 |
+
</div>
|
| 69 |
+
<div style="text-align: center; font-size: 16px; font-weight: normal; margin-bottom: 20px;">
|
| 70 |
+
Wan: Open and Advanced Large-Scale Video Generative Models.
|
| 71 |
+
</div>
|
| 72 |
+
""")
|
| 73 |
+
|
| 74 |
+
with gr.Row():
|
| 75 |
+
with gr.Column():
|
| 76 |
+
txt2vid_prompt = gr.Textbox(
|
| 77 |
+
label="Prompt",
|
| 78 |
+
placeholder="Describe the video you want to generate",
|
| 79 |
+
)
|
| 80 |
+
tar_lang = gr.Radio(
|
| 81 |
+
choices=["ZH", "EN"],
|
| 82 |
+
label="Target language of prompt enhance",
|
| 83 |
+
value="ZH")
|
| 84 |
+
run_p_button = gr.Button(value="Prompt Enhance")
|
| 85 |
+
|
| 86 |
+
with gr.Accordion("Advanced Options", open=True):
|
| 87 |
+
resolution = gr.Dropdown(
|
| 88 |
+
label='Resolution(Width*Height)',
|
| 89 |
+
choices=[
|
| 90 |
+
'720*1280', '1280*720', '960*960', '1088*832',
|
| 91 |
+
'832*1088', '480*832', '832*480', '624*624',
|
| 92 |
+
'704*544', '544*704'
|
| 93 |
+
],
|
| 94 |
+
value='720*1280')
|
| 95 |
+
|
| 96 |
+
with gr.Row():
|
| 97 |
+
sd_steps = gr.Slider(
|
| 98 |
+
label="Diffusion steps",
|
| 99 |
+
minimum=1,
|
| 100 |
+
maximum=1000,
|
| 101 |
+
value=50,
|
| 102 |
+
step=1)
|
| 103 |
+
guide_scale = gr.Slider(
|
| 104 |
+
label="Guide scale",
|
| 105 |
+
minimum=0,
|
| 106 |
+
maximum=20,
|
| 107 |
+
value=5.0,
|
| 108 |
+
step=1)
|
| 109 |
+
with gr.Row():
|
| 110 |
+
shift_scale = gr.Slider(
|
| 111 |
+
label="Shift scale",
|
| 112 |
+
minimum=0,
|
| 113 |
+
maximum=10,
|
| 114 |
+
value=5.0,
|
| 115 |
+
step=1)
|
| 116 |
+
seed = gr.Slider(
|
| 117 |
+
label="Seed",
|
| 118 |
+
minimum=-1,
|
| 119 |
+
maximum=2147483647,
|
| 120 |
+
step=1,
|
| 121 |
+
value=-1)
|
| 122 |
+
n_prompt = gr.Textbox(
|
| 123 |
+
label="Negative Prompt",
|
| 124 |
+
placeholder="Describe the negative prompt you want to add"
|
| 125 |
+
)
|
| 126 |
+
|
| 127 |
+
run_t2v_button = gr.Button("Generate Video")
|
| 128 |
+
|
| 129 |
+
with gr.Column():
|
| 130 |
+
result_gallery = gr.Video(
|
| 131 |
+
label='Generated Video', interactive=False, height=600)
|
| 132 |
+
|
| 133 |
+
run_p_button.click(
|
| 134 |
+
fn=prompt_enc,
|
| 135 |
+
inputs=[txt2vid_prompt, tar_lang],
|
| 136 |
+
outputs=[txt2vid_prompt])
|
| 137 |
+
|
| 138 |
+
run_t2v_button.click(
|
| 139 |
+
fn=t2v_generation,
|
| 140 |
+
inputs=[
|
| 141 |
+
txt2vid_prompt, resolution, sd_steps, guide_scale, shift_scale,
|
| 142 |
+
seed, n_prompt
|
| 143 |
+
],
|
| 144 |
+
outputs=[result_gallery],
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
return demo
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
# Main
|
| 151 |
+
def _parse_args():
|
| 152 |
+
parser = argparse.ArgumentParser(
|
| 153 |
+
description="Generate a video from a text prompt or image using Gradio")
|
| 154 |
+
parser.add_argument(
|
| 155 |
+
"--ckpt_dir",
|
| 156 |
+
type=str,
|
| 157 |
+
default="cache",
|
| 158 |
+
help="The path to the checkpoint directory.")
|
| 159 |
+
parser.add_argument(
|
| 160 |
+
"--prompt_extend_method",
|
| 161 |
+
type=str,
|
| 162 |
+
default="local_qwen",
|
| 163 |
+
choices=["dashscope", "local_qwen"],
|
| 164 |
+
help="The prompt extend method to use.")
|
| 165 |
+
parser.add_argument(
|
| 166 |
+
"--prompt_extend_model",
|
| 167 |
+
type=str,
|
| 168 |
+
default=None,
|
| 169 |
+
help="The prompt extend model to use.")
|
| 170 |
+
|
| 171 |
+
args = parser.parse_args()
|
| 172 |
+
|
| 173 |
+
return args
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
if __name__ == '__main__':
|
| 177 |
+
args = _parse_args()
|
| 178 |
+
|
| 179 |
+
print("Step1: Init prompt_expander...", end='', flush=True)
|
| 180 |
+
if args.prompt_extend_method == "dashscope":
|
| 181 |
+
prompt_expander = DashScopePromptExpander(
|
| 182 |
+
model_name=args.prompt_extend_model, is_vl=False)
|
| 183 |
+
elif args.prompt_extend_method == "local_qwen":
|
| 184 |
+
prompt_expander = QwenPromptExpander(
|
| 185 |
+
model_name=args.prompt_extend_model, is_vl=False, device=0)
|
| 186 |
+
else:
|
| 187 |
+
raise NotImplementedError(
|
| 188 |
+
f"Unsupport prompt_extend_method: {args.prompt_extend_method}")
|
| 189 |
+
print("done", flush=True)
|
| 190 |
+
|
| 191 |
+
print("Step2: Init 14B t2v model...", end='', flush=True)
|
| 192 |
+
cfg = WAN_CONFIGS['t2v-14B']
|
| 193 |
+
wan_t2v = wan.WanT2V(
|
| 194 |
+
config=cfg,
|
| 195 |
+
checkpoint_dir=args.ckpt_dir,
|
| 196 |
+
device_id=0,
|
| 197 |
+
rank=0,
|
| 198 |
+
t5_fsdp=False,
|
| 199 |
+
dit_fsdp=False,
|
| 200 |
+
use_usp=False,
|
| 201 |
+
)
|
| 202 |
+
print("done", flush=True)
|
| 203 |
+
|
| 204 |
+
demo = gradio_interface()
|
| 205 |
+
demo.launch(server_name="0.0.0.0", share=False, server_port=7860)
|
gradio/vace.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
# Copyright (c) Alibaba, Inc. and its affiliates.
|
| 3 |
+
|
| 4 |
+
import argparse
|
| 5 |
+
import os
|
| 6 |
+
import sys
|
| 7 |
+
import datetime
|
| 8 |
+
import imageio
|
| 9 |
+
import numpy as np
|
| 10 |
+
import torch
|
| 11 |
+
import gradio as gr
|
| 12 |
+
|
| 13 |
+
sys.path.insert(0, os.path.sep.join(os.path.realpath(__file__).split(os.path.sep)[:-2]))
|
| 14 |
+
import wan
|
| 15 |
+
from wan import WanVace, WanVaceMP
|
| 16 |
+
from wan.configs import WAN_CONFIGS, SIZE_CONFIGS
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class FixedSizeQueue:
|
| 20 |
+
def __init__(self, max_size):
|
| 21 |
+
self.max_size = max_size
|
| 22 |
+
self.queue = []
|
| 23 |
+
def add(self, item):
|
| 24 |
+
self.queue.insert(0, item)
|
| 25 |
+
if len(self.queue) > self.max_size:
|
| 26 |
+
self.queue.pop()
|
| 27 |
+
def get(self):
|
| 28 |
+
return self.queue
|
| 29 |
+
def __repr__(self):
|
| 30 |
+
return str(self.queue)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class VACEInference:
|
| 34 |
+
def __init__(self, cfg, skip_load=False, gallery_share=True, gallery_share_limit=5):
|
| 35 |
+
self.cfg = cfg
|
| 36 |
+
self.save_dir = cfg.save_dir
|
| 37 |
+
self.gallery_share = gallery_share
|
| 38 |
+
self.gallery_share_data = FixedSizeQueue(max_size=gallery_share_limit)
|
| 39 |
+
if not skip_load:
|
| 40 |
+
if not args.mp:
|
| 41 |
+
self.pipe = WanVace(
|
| 42 |
+
config=WAN_CONFIGS[cfg.model_name],
|
| 43 |
+
checkpoint_dir=cfg.ckpt_dir,
|
| 44 |
+
device_id=0,
|
| 45 |
+
rank=0,
|
| 46 |
+
t5_fsdp=False,
|
| 47 |
+
dit_fsdp=False,
|
| 48 |
+
use_usp=False,
|
| 49 |
+
)
|
| 50 |
+
else:
|
| 51 |
+
self.pipe = WanVaceMP(
|
| 52 |
+
config=WAN_CONFIGS[cfg.model_name],
|
| 53 |
+
checkpoint_dir=cfg.ckpt_dir,
|
| 54 |
+
use_usp=True,
|
| 55 |
+
ulysses_size=cfg.ulysses_size,
|
| 56 |
+
ring_size=cfg.ring_size
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def create_ui(self, *args, **kwargs):
|
| 61 |
+
gr.Markdown("""
|
| 62 |
+
<div style="text-align: center; font-size: 24px; font-weight: bold; margin-bottom: 15px;">
|
| 63 |
+
<a href="https://ali-vilab.github.io/VACE-Page/" style="text-decoration: none; color: inherit;">VACE-WAN Demo</a>
|
| 64 |
+
</div>
|
| 65 |
+
""")
|
| 66 |
+
with gr.Row(variant='panel', equal_height=True):
|
| 67 |
+
with gr.Column(scale=1, min_width=0):
|
| 68 |
+
self.src_video = gr.Video(
|
| 69 |
+
label="src_video",
|
| 70 |
+
sources=['upload'],
|
| 71 |
+
value=None,
|
| 72 |
+
interactive=True)
|
| 73 |
+
with gr.Column(scale=1, min_width=0):
|
| 74 |
+
self.src_mask = gr.Video(
|
| 75 |
+
label="src_mask",
|
| 76 |
+
sources=['upload'],
|
| 77 |
+
value=None,
|
| 78 |
+
interactive=True)
|
| 79 |
+
#
|
| 80 |
+
with gr.Row(variant='panel', equal_height=True):
|
| 81 |
+
with gr.Column(scale=1, min_width=0):
|
| 82 |
+
with gr.Row(equal_height=True):
|
| 83 |
+
self.src_ref_image_1 = gr.Image(label='src_ref_image_1',
|
| 84 |
+
height=200,
|
| 85 |
+
interactive=True,
|
| 86 |
+
type='filepath',
|
| 87 |
+
image_mode='RGB',
|
| 88 |
+
sources=['upload'],
|
| 89 |
+
elem_id="src_ref_image_1",
|
| 90 |
+
format='png')
|
| 91 |
+
self.src_ref_image_2 = gr.Image(label='src_ref_image_2',
|
| 92 |
+
height=200,
|
| 93 |
+
interactive=True,
|
| 94 |
+
type='filepath',
|
| 95 |
+
image_mode='RGB',
|
| 96 |
+
sources=['upload'],
|
| 97 |
+
elem_id="src_ref_image_2",
|
| 98 |
+
format='png')
|
| 99 |
+
self.src_ref_image_3 = gr.Image(label='src_ref_image_3',
|
| 100 |
+
height=200,
|
| 101 |
+
interactive=True,
|
| 102 |
+
type='filepath',
|
| 103 |
+
image_mode='RGB',
|
| 104 |
+
sources=['upload'],
|
| 105 |
+
elem_id="src_ref_image_3",
|
| 106 |
+
format='png')
|
| 107 |
+
with gr.Row(variant='panel', equal_height=True):
|
| 108 |
+
with gr.Column(scale=1):
|
| 109 |
+
self.prompt = gr.Textbox(
|
| 110 |
+
show_label=False,
|
| 111 |
+
placeholder="positive_prompt_input",
|
| 112 |
+
elem_id='positive_prompt',
|
| 113 |
+
container=True,
|
| 114 |
+
autofocus=True,
|
| 115 |
+
elem_classes='type_row',
|
| 116 |
+
visible=True,
|
| 117 |
+
lines=2)
|
| 118 |
+
self.negative_prompt = gr.Textbox(
|
| 119 |
+
show_label=False,
|
| 120 |
+
value=self.pipe.config.sample_neg_prompt,
|
| 121 |
+
placeholder="negative_prompt_input",
|
| 122 |
+
elem_id='negative_prompt',
|
| 123 |
+
container=True,
|
| 124 |
+
autofocus=False,
|
| 125 |
+
elem_classes='type_row',
|
| 126 |
+
visible=True,
|
| 127 |
+
interactive=True,
|
| 128 |
+
lines=1)
|
| 129 |
+
#
|
| 130 |
+
with gr.Row(variant='panel', equal_height=True):
|
| 131 |
+
with gr.Column(scale=1, min_width=0):
|
| 132 |
+
with gr.Row(equal_height=True):
|
| 133 |
+
self.shift_scale = gr.Slider(
|
| 134 |
+
label='shift_scale',
|
| 135 |
+
minimum=0.0,
|
| 136 |
+
maximum=100.0,
|
| 137 |
+
step=1.0,
|
| 138 |
+
value=16.0,
|
| 139 |
+
interactive=True)
|
| 140 |
+
self.sample_steps = gr.Slider(
|
| 141 |
+
label='sample_steps',
|
| 142 |
+
minimum=1,
|
| 143 |
+
maximum=100,
|
| 144 |
+
step=1,
|
| 145 |
+
value=25,
|
| 146 |
+
interactive=True)
|
| 147 |
+
self.context_scale = gr.Slider(
|
| 148 |
+
label='context_scale',
|
| 149 |
+
minimum=0.0,
|
| 150 |
+
maximum=2.0,
|
| 151 |
+
step=0.1,
|
| 152 |
+
value=1.0,
|
| 153 |
+
interactive=True)
|
| 154 |
+
self.guide_scale = gr.Slider(
|
| 155 |
+
label='guide_scale',
|
| 156 |
+
minimum=1,
|
| 157 |
+
maximum=10,
|
| 158 |
+
step=0.5,
|
| 159 |
+
value=5.0,
|
| 160 |
+
interactive=True)
|
| 161 |
+
self.infer_seed = gr.Slider(minimum=-1,
|
| 162 |
+
maximum=10000000,
|
| 163 |
+
value=2025,
|
| 164 |
+
label="Seed")
|
| 165 |
+
#
|
| 166 |
+
with gr.Accordion(label="Usable without source video", open=False):
|
| 167 |
+
with gr.Row(equal_height=True):
|
| 168 |
+
self.output_height = gr.Textbox(
|
| 169 |
+
label='resolutions_height',
|
| 170 |
+
# value=480,
|
| 171 |
+
value=720,
|
| 172 |
+
interactive=True)
|
| 173 |
+
self.output_width = gr.Textbox(
|
| 174 |
+
label='resolutions_width',
|
| 175 |
+
# value=832,
|
| 176 |
+
value=1280,
|
| 177 |
+
interactive=True)
|
| 178 |
+
self.frame_rate = gr.Textbox(
|
| 179 |
+
label='frame_rate',
|
| 180 |
+
value=16,
|
| 181 |
+
interactive=True)
|
| 182 |
+
self.num_frames = gr.Textbox(
|
| 183 |
+
label='num_frames',
|
| 184 |
+
value=81,
|
| 185 |
+
interactive=True)
|
| 186 |
+
#
|
| 187 |
+
with gr.Row(equal_height=True):
|
| 188 |
+
with gr.Column(scale=5):
|
| 189 |
+
self.generate_button = gr.Button(
|
| 190 |
+
value='Run',
|
| 191 |
+
elem_classes='type_row',
|
| 192 |
+
elem_id='generate_button',
|
| 193 |
+
visible=True)
|
| 194 |
+
with gr.Column(scale=1):
|
| 195 |
+
self.refresh_button = gr.Button(value='\U0001f504') # 🔄
|
| 196 |
+
#
|
| 197 |
+
self.output_gallery = gr.Gallery(
|
| 198 |
+
label="output_gallery",
|
| 199 |
+
value=[],
|
| 200 |
+
interactive=False,
|
| 201 |
+
allow_preview=True,
|
| 202 |
+
preview=True)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def generate(self, output_gallery, src_video, src_mask, src_ref_image_1, src_ref_image_2, src_ref_image_3, prompt, negative_prompt, shift_scale, sample_steps, context_scale, guide_scale, infer_seed, output_height, output_width, frame_rate, num_frames):
|
| 206 |
+
output_height, output_width, frame_rate, num_frames = int(output_height), int(output_width), int(frame_rate), int(num_frames)
|
| 207 |
+
src_ref_images = [x for x in [src_ref_image_1, src_ref_image_2, src_ref_image_3] if
|
| 208 |
+
x is not None]
|
| 209 |
+
src_video, src_mask, src_ref_images = self.pipe.prepare_source([src_video],
|
| 210 |
+
[src_mask],
|
| 211 |
+
[src_ref_images],
|
| 212 |
+
num_frames=num_frames,
|
| 213 |
+
image_size=SIZE_CONFIGS[f"{output_width}*{output_height}"],
|
| 214 |
+
device=self.pipe.device)
|
| 215 |
+
video = self.pipe.generate(
|
| 216 |
+
prompt,
|
| 217 |
+
src_video,
|
| 218 |
+
src_mask,
|
| 219 |
+
src_ref_images,
|
| 220 |
+
size=(output_width, output_height),
|
| 221 |
+
context_scale=context_scale,
|
| 222 |
+
shift=shift_scale,
|
| 223 |
+
sampling_steps=sample_steps,
|
| 224 |
+
guide_scale=guide_scale,
|
| 225 |
+
n_prompt=negative_prompt,
|
| 226 |
+
seed=infer_seed,
|
| 227 |
+
offload_model=True)
|
| 228 |
+
|
| 229 |
+
name = '{0:%Y%m%d%-H%M%S}'.format(datetime.datetime.now())
|
| 230 |
+
video_path = os.path.join(self.save_dir, f'cur_gallery_{name}.mp4')
|
| 231 |
+
video_frames = (torch.clamp(video / 2 + 0.5, min=0.0, max=1.0).permute(1, 2, 3, 0) * 255).cpu().numpy().astype(np.uint8)
|
| 232 |
+
|
| 233 |
+
try:
|
| 234 |
+
writer = imageio.get_writer(video_path, fps=frame_rate, codec='libx264', quality=8, macro_block_size=1)
|
| 235 |
+
for frame in video_frames:
|
| 236 |
+
writer.append_data(frame)
|
| 237 |
+
writer.close()
|
| 238 |
+
print(video_path)
|
| 239 |
+
except Exception as e:
|
| 240 |
+
raise gr.Error(f"Video save error: {e}")
|
| 241 |
+
|
| 242 |
+
if self.gallery_share:
|
| 243 |
+
self.gallery_share_data.add(video_path)
|
| 244 |
+
return self.gallery_share_data.get()
|
| 245 |
+
else:
|
| 246 |
+
return [video_path]
|
| 247 |
+
|
| 248 |
+
def set_callbacks(self, **kwargs):
|
| 249 |
+
self.gen_inputs = [self.output_gallery, self.src_video, self.src_mask, self.src_ref_image_1, self.src_ref_image_2, self.src_ref_image_3, self.prompt, self.negative_prompt, self.shift_scale, self.sample_steps, self.context_scale, self.guide_scale, self.infer_seed, self.output_height, self.output_width, self.frame_rate, self.num_frames]
|
| 250 |
+
self.gen_outputs = [self.output_gallery]
|
| 251 |
+
self.generate_button.click(self.generate,
|
| 252 |
+
inputs=self.gen_inputs,
|
| 253 |
+
outputs=self.gen_outputs,
|
| 254 |
+
queue=True)
|
| 255 |
+
self.refresh_button.click(lambda x: self.gallery_share_data.get() if self.gallery_share else x, inputs=[self.output_gallery], outputs=[self.output_gallery])
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
if __name__ == '__main__':
|
| 259 |
+
parser = argparse.ArgumentParser(description='Argparser for VACE-WAN Demo:\n')
|
| 260 |
+
parser.add_argument('--server_port', dest='server_port', help='', type=int, default=7860)
|
| 261 |
+
parser.add_argument('--server_name', dest='server_name', help='', default='0.0.0.0')
|
| 262 |
+
parser.add_argument('--root_path', dest='root_path', help='', default=None)
|
| 263 |
+
parser.add_argument('--save_dir', dest='save_dir', help='', default='cache')
|
| 264 |
+
parser.add_argument("--mp", action="store_true", help="Use Multi-GPUs",)
|
| 265 |
+
parser.add_argument("--model_name", type=str, default="vace-14B", choices=list(WAN_CONFIGS.keys()), help="The model name to run.")
|
| 266 |
+
parser.add_argument("--ulysses_size", type=int, default=1, help="The size of the ulysses parallelism in DiT.")
|
| 267 |
+
parser.add_argument("--ring_size", type=int, default=1, help="The size of the ring attention parallelism in DiT.")
|
| 268 |
+
parser.add_argument(
|
| 269 |
+
"--ckpt_dir",
|
| 270 |
+
type=str,
|
| 271 |
+
# default='models/VACE-Wan2.1-1.3B-Preview',
|
| 272 |
+
default='models/Wan2.1-VACE-14B/',
|
| 273 |
+
help="The path to the checkpoint directory.",
|
| 274 |
+
)
|
| 275 |
+
parser.add_argument(
|
| 276 |
+
"--offload_to_cpu",
|
| 277 |
+
action="store_true",
|
| 278 |
+
help="Offloading unnecessary computations to CPU.",
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
args = parser.parse_args()
|
| 282 |
+
|
| 283 |
+
if not os.path.exists(args.save_dir):
|
| 284 |
+
os.makedirs(args.save_dir, exist_ok=True)
|
| 285 |
+
|
| 286 |
+
with gr.Blocks() as demo:
|
| 287 |
+
infer_gr = VACEInference(args, skip_load=False, gallery_share=True, gallery_share_limit=5)
|
| 288 |
+
infer_gr.create_ui()
|
| 289 |
+
infer_gr.set_callbacks()
|
| 290 |
+
allowed_paths = [args.save_dir]
|
| 291 |
+
demo.queue(status_update_rate=1).launch(server_name=args.server_name,
|
| 292 |
+
server_port=args.server_port,
|
| 293 |
+
root_path=args.root_path,
|
| 294 |
+
allowed_paths=allowed_paths,
|
| 295 |
+
show_error=True, debug=True)
|
pyproject.toml
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["setuptools>=61.0"]
|
| 3 |
+
build-backend = "setuptools.build_meta"
|
| 4 |
+
|
| 5 |
+
[project]
|
| 6 |
+
name = "wan"
|
| 7 |
+
version = "2.1.0"
|
| 8 |
+
description = "Wan: Open and Advanced Large-Scale Video Generative Models"
|
| 9 |
+
authors = [
|
| 10 |
+
{ name = "Wan Team", email = "[email protected]" }
|
| 11 |
+
]
|
| 12 |
+
license = { file = "LICENSE.txt" }
|
| 13 |
+
readme = "README.md"
|
| 14 |
+
requires-python = ">=3.10,<4.0"
|
| 15 |
+
dependencies = [
|
| 16 |
+
"torch>=2.4.0",
|
| 17 |
+
"torchvision>=0.19.0",
|
| 18 |
+
"opencv-python>=4.9.0.80",
|
| 19 |
+
"diffusers>=0.31.0",
|
| 20 |
+
"transformers>=4.49.0",
|
| 21 |
+
"tokenizers>=0.20.3",
|
| 22 |
+
"accelerate>=1.1.1",
|
| 23 |
+
"tqdm",
|
| 24 |
+
"imageio",
|
| 25 |
+
"easydict",
|
| 26 |
+
"ftfy",
|
| 27 |
+
"dashscope",
|
| 28 |
+
"imageio-ffmpeg",
|
| 29 |
+
"flash_attn",
|
| 30 |
+
"gradio>=5.0.0",
|
| 31 |
+
"numpy>=1.23.5,<2"
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
[project.optional-dependencies]
|
| 35 |
+
dev = [
|
| 36 |
+
"pytest",
|
| 37 |
+
"black",
|
| 38 |
+
"flake8",
|
| 39 |
+
"isort",
|
| 40 |
+
"mypy",
|
| 41 |
+
"huggingface-hub[cli]"
|
| 42 |
+
]
|
| 43 |
+
|
| 44 |
+
[project.urls]
|
| 45 |
+
homepage = "https://wanxai.com"
|
| 46 |
+
documentation = "https://github.com/Wan-Video/Wan2.1"
|
| 47 |
+
repository = "https://github.com/Wan-Video/Wan2.1"
|
| 48 |
+
huggingface = "https://huggingface.co/Wan-AI/"
|
| 49 |
+
modelscope = "https://modelscope.cn/organization/Wan-AI"
|
| 50 |
+
discord = "https://discord.gg/p5XbdQV7"
|
| 51 |
+
|
| 52 |
+
[tool.setuptools]
|
| 53 |
+
packages = ["wan"]
|
| 54 |
+
|
| 55 |
+
[tool.setuptools.package-data]
|
| 56 |
+
"wan" = ["**/*.py"]
|
| 57 |
+
|
| 58 |
+
[tool.black]
|
| 59 |
+
line-length = 88
|
| 60 |
+
|
| 61 |
+
[tool.isort]
|
| 62 |
+
profile = "black"
|
| 63 |
+
|
| 64 |
+
[tool.mypy]
|
| 65 |
+
strict = true
|
| 66 |
+
|
| 67 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch>=2.4.0
|
| 2 |
+
torchvision>=0.19.0
|
| 3 |
+
opencv-python>=4.9.0.80
|
| 4 |
+
diffusers>=0.31.0
|
| 5 |
+
transformers>=4.49.0
|
| 6 |
+
tokenizers>=0.20.3
|
| 7 |
+
accelerate>=1.1.1
|
| 8 |
+
tqdm
|
| 9 |
+
imageio
|
| 10 |
+
easydict
|
| 11 |
+
ftfy
|
| 12 |
+
dashscope
|
| 13 |
+
imageio-ffmpeg
|
| 14 |
+
flash_attn
|
| 15 |
+
gradio>=5.0.0
|
| 16 |
+
numpy>=1.23.5,<2
|
tests/README.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Put all your models (Wan2.1-T2V-1.3B, Wan2.1-T2V-14B, Wan2.1-I2V-14B-480P, Wan2.1-I2V-14B-720P) in a folder and specify the max GPU number you want to use.
|
| 3 |
+
|
| 4 |
+
```bash
|
| 5 |
+
bash ./test.sh <local model dir> <gpu number>
|
| 6 |
+
```
|
tests/test.sh
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
if [ "$#" -eq 2 ]; then
|
| 5 |
+
MODEL_DIR=$(realpath "$1")
|
| 6 |
+
GPUS=$2
|
| 7 |
+
else
|
| 8 |
+
echo "Usage: $0 <local model dir> <gpu number>"
|
| 9 |
+
exit 1
|
| 10 |
+
fi
|
| 11 |
+
|
| 12 |
+
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )"
|
| 13 |
+
REPO_ROOT="$(dirname "$SCRIPT_DIR")"
|
| 14 |
+
cd "$REPO_ROOT" || exit 1
|
| 15 |
+
|
| 16 |
+
PY_FILE=./generate.py
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
function t2v_1_3B() {
|
| 20 |
+
T2V_1_3B_CKPT_DIR="$MODEL_DIR/Wan2.1-T2V-1.3B"
|
| 21 |
+
|
| 22 |
+
# 1-GPU Test
|
| 23 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_1_3B 1-GPU Test: "
|
| 24 |
+
python $PY_FILE --task t2v-1.3B --size 480*832 --ckpt_dir $T2V_1_3B_CKPT_DIR
|
| 25 |
+
|
| 26 |
+
# Multiple GPU Test
|
| 27 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_1_3B Multiple GPU Test: "
|
| 28 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2v-1.3B --ckpt_dir $T2V_1_3B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS
|
| 29 |
+
|
| 30 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_1_3B Multiple GPU, prompt extend local_qwen: "
|
| 31 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2v-1.3B --ckpt_dir $T2V_1_3B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS --use_prompt_extend --prompt_extend_model "Qwen/Qwen2.5-3B-Instruct" --prompt_extend_target_lang "en"
|
| 32 |
+
|
| 33 |
+
if [ -n "${DASH_API_KEY+x}" ]; then
|
| 34 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_1_3B Multiple GPU, prompt extend dashscope: "
|
| 35 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2v-1.3B --ckpt_dir $T2V_1_3B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS --use_prompt_extend --prompt_extend_method "dashscope"
|
| 36 |
+
else
|
| 37 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> No DASH_API_KEY found, skip the dashscope extend test."
|
| 38 |
+
fi
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
function t2v_14B() {
|
| 42 |
+
T2V_14B_CKPT_DIR="$MODEL_DIR/Wan2.1-T2V-14B"
|
| 43 |
+
|
| 44 |
+
# 1-GPU Test
|
| 45 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_14B 1-GPU Test: "
|
| 46 |
+
python $PY_FILE --task t2v-14B --size 480*832 --ckpt_dir $T2V_14B_CKPT_DIR
|
| 47 |
+
|
| 48 |
+
# Multiple GPU Test
|
| 49 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_14B Multiple GPU Test: "
|
| 50 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2v-14B --ckpt_dir $T2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS
|
| 51 |
+
|
| 52 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2v_14B Multiple GPU, prompt extend local_qwen: "
|
| 53 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2v-14B --ckpt_dir $T2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS --use_prompt_extend --prompt_extend_model "Qwen/Qwen2.5-3B-Instruct" --prompt_extend_target_lang "en"
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
function t2i_14B() {
|
| 59 |
+
T2V_14B_CKPT_DIR="$MODEL_DIR/Wan2.1-T2V-14B"
|
| 60 |
+
|
| 61 |
+
# 1-GPU Test
|
| 62 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2i_14B 1-GPU Test: "
|
| 63 |
+
python $PY_FILE --task t2i-14B --size 480*832 --ckpt_dir $T2V_14B_CKPT_DIR
|
| 64 |
+
|
| 65 |
+
# Multiple GPU Test
|
| 66 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2i_14B Multiple GPU Test: "
|
| 67 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2i-14B --ckpt_dir $T2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS
|
| 68 |
+
|
| 69 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> t2i_14B Multiple GPU, prompt extend local_qwen: "
|
| 70 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task t2i-14B --ckpt_dir $T2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS --use_prompt_extend --prompt_extend_model "Qwen/Qwen2.5-3B-Instruct" --prompt_extend_target_lang "en"
|
| 71 |
+
}
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
function i2v_14B_480p() {
|
| 75 |
+
I2V_14B_CKPT_DIR="$MODEL_DIR/Wan2.1-I2V-14B-480P"
|
| 76 |
+
|
| 77 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> i2v_14B 1-GPU Test: "
|
| 78 |
+
python $PY_FILE --task i2v-14B --size 832*480 --ckpt_dir $I2V_14B_CKPT_DIR
|
| 79 |
+
|
| 80 |
+
# Multiple GPU Test
|
| 81 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> i2v_14B Multiple GPU Test: "
|
| 82 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task i2v-14B --ckpt_dir $I2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS
|
| 83 |
+
|
| 84 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> i2v_14B Multiple GPU, prompt extend local_qwen: "
|
| 85 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task i2v-14B --ckpt_dir $I2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS --use_prompt_extend --prompt_extend_model "Qwen/Qwen2.5-VL-3B-Instruct" --prompt_extend_target_lang "en"
|
| 86 |
+
|
| 87 |
+
if [ -n "${DASH_API_KEY+x}" ]; then
|
| 88 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> i2v_14B Multiple GPU, prompt extend dashscope: "
|
| 89 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task i2v-14B --ckpt_dir $I2V_14B_CKPT_DIR --size 832*480 --dit_fsdp --t5_fsdp --ulysses_size $GPUS --use_prompt_extend --prompt_extend_method "dashscope"
|
| 90 |
+
else
|
| 91 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> No DASH_API_KEY found, skip the dashscope extend test."
|
| 92 |
+
fi
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
function i2v_14B_720p() {
|
| 97 |
+
I2V_14B_CKPT_DIR="$MODEL_DIR/Wan2.1-I2V-14B-720P"
|
| 98 |
+
|
| 99 |
+
# 1-GPU Test
|
| 100 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> i2v_14B 1-GPU Test: "
|
| 101 |
+
python $PY_FILE --task i2v-14B --size 720*1280 --ckpt_dir $I2V_14B_CKPT_DIR
|
| 102 |
+
|
| 103 |
+
# Multiple GPU Test
|
| 104 |
+
echo -e "\n\n>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> i2v_14B Multiple GPU Test: "
|
| 105 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --task i2v-14B --ckpt_dir $I2V_14B_CKPT_DIR --size 720*1280 --dit_fsdp --t5_fsdp --ulysses_size $GPUS
|
| 106 |
+
}
|
| 107 |
+
|
| 108 |
+
function vace_1_3B() {
|
| 109 |
+
VACE_1_3B_CKPT_DIR="$MODEL_DIR/VACE-Wan2.1-1.3B-Preview/"
|
| 110 |
+
torchrun --nproc_per_node=$GPUS $PY_FILE --ulysses_size $GPUS --task vace-1.3B --size 480*832 --ckpt_dir $VACE_1_3B_CKPT_DIR
|
| 111 |
+
|
| 112 |
+
}
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
t2i_14B
|
| 116 |
+
t2v_1_3B
|
| 117 |
+
t2v_14B
|
| 118 |
+
i2v_14B_480p
|
| 119 |
+
i2v_14B_720p
|
| 120 |
+
vace_1_3B
|
wan/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from . import configs, distributed, modules
|
| 2 |
+
from .image2video import WanI2V
|
| 3 |
+
from .text2video import WanT2V
|
| 4 |
+
from .first_last_frame2video import WanFLF2V
|
| 5 |
+
from .vace import WanVace, WanVaceMP
|
wan/configs/__init__.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import copy
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
os.environ['TOKENIZERS_PARALLELISM'] = 'false'
|
| 6 |
+
|
| 7 |
+
from .wan_i2v_14B import i2v_14B
|
| 8 |
+
from .wan_t2v_1_3B import t2v_1_3B
|
| 9 |
+
from .wan_t2v_14B import t2v_14B
|
| 10 |
+
|
| 11 |
+
# the config of t2i_14B is the same as t2v_14B
|
| 12 |
+
t2i_14B = copy.deepcopy(t2v_14B)
|
| 13 |
+
t2i_14B.__name__ = 'Config: Wan T2I 14B'
|
| 14 |
+
|
| 15 |
+
# the config of flf2v_14B is the same as i2v_14B
|
| 16 |
+
flf2v_14B = copy.deepcopy(i2v_14B)
|
| 17 |
+
flf2v_14B.__name__ = 'Config: Wan FLF2V 14B'
|
| 18 |
+
flf2v_14B.sample_neg_prompt = "镜头切换," + flf2v_14B.sample_neg_prompt
|
| 19 |
+
|
| 20 |
+
WAN_CONFIGS = {
|
| 21 |
+
't2v-14B': t2v_14B,
|
| 22 |
+
't2v-1.3B': t2v_1_3B,
|
| 23 |
+
'i2v-14B': i2v_14B,
|
| 24 |
+
't2i-14B': t2i_14B,
|
| 25 |
+
'flf2v-14B': flf2v_14B,
|
| 26 |
+
'vace-1.3B': t2v_1_3B,
|
| 27 |
+
'vace-14B': t2v_14B,
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
SIZE_CONFIGS = {
|
| 31 |
+
'720*1280': (720, 1280),
|
| 32 |
+
'1280*720': (1280, 720),
|
| 33 |
+
'480*832': (480, 832),
|
| 34 |
+
'832*480': (832, 480),
|
| 35 |
+
'1024*1024': (1024, 1024),
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
MAX_AREA_CONFIGS = {
|
| 39 |
+
'720*1280': 720 * 1280,
|
| 40 |
+
'1280*720': 1280 * 720,
|
| 41 |
+
'480*832': 480 * 832,
|
| 42 |
+
'832*480': 832 * 480,
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
SUPPORTED_SIZES = {
|
| 46 |
+
't2v-14B': ('720*1280', '1280*720', '480*832', '832*480'),
|
| 47 |
+
't2v-1.3B': ('480*832', '832*480'),
|
| 48 |
+
'i2v-14B': ('720*1280', '1280*720', '480*832', '832*480'),
|
| 49 |
+
'flf2v-14B': ('720*1280', '1280*720', '480*832', '832*480'),
|
| 50 |
+
't2i-14B': tuple(SIZE_CONFIGS.keys()),
|
| 51 |
+
'vace-1.3B': ('480*832', '832*480'),
|
| 52 |
+
'vace-14B': ('720*1280', '1280*720', '480*832', '832*480')
|
| 53 |
+
}
|
wan/configs/shared_config.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import torch
|
| 3 |
+
from easydict import EasyDict
|
| 4 |
+
|
| 5 |
+
#------------------------ Wan shared config ------------------------#
|
| 6 |
+
wan_shared_cfg = EasyDict()
|
| 7 |
+
|
| 8 |
+
# t5
|
| 9 |
+
wan_shared_cfg.t5_model = 'umt5_xxl'
|
| 10 |
+
wan_shared_cfg.t5_dtype = torch.bfloat16
|
| 11 |
+
wan_shared_cfg.text_len = 512
|
| 12 |
+
|
| 13 |
+
# transformer
|
| 14 |
+
wan_shared_cfg.param_dtype = torch.bfloat16
|
| 15 |
+
|
| 16 |
+
# inference
|
| 17 |
+
wan_shared_cfg.num_train_timesteps = 1000
|
| 18 |
+
wan_shared_cfg.sample_fps = 16
|
| 19 |
+
wan_shared_cfg.sample_neg_prompt = '色调艳丽,过曝,静态,细节模糊不清,字幕,风格,作品,画作,画面,静止,整体发灰,最差质量,低质量,JPEG压缩残留,丑陋的,残缺的,多余的手指,画得不好的手部,画得不好的脸部,畸形的,毁容的,形态畸形的肢体,手指融合,静止不动的画面,杂乱的背景,三条腿,背景人很多,倒着走'
|
wan/configs/wan_i2v_14B.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import torch
|
| 3 |
+
from easydict import EasyDict
|
| 4 |
+
|
| 5 |
+
from .shared_config import wan_shared_cfg
|
| 6 |
+
|
| 7 |
+
#------------------------ Wan I2V 14B ------------------------#
|
| 8 |
+
|
| 9 |
+
i2v_14B = EasyDict(__name__='Config: Wan I2V 14B')
|
| 10 |
+
i2v_14B.update(wan_shared_cfg)
|
| 11 |
+
i2v_14B.sample_neg_prompt = "镜头晃动," + i2v_14B.sample_neg_prompt
|
| 12 |
+
|
| 13 |
+
i2v_14B.t5_checkpoint = 'models_t5_umt5-xxl-enc-bf16.pth'
|
| 14 |
+
i2v_14B.t5_tokenizer = 'google/umt5-xxl'
|
| 15 |
+
|
| 16 |
+
# clip
|
| 17 |
+
i2v_14B.clip_model = 'clip_xlm_roberta_vit_h_14'
|
| 18 |
+
i2v_14B.clip_dtype = torch.float16
|
| 19 |
+
i2v_14B.clip_checkpoint = 'models_clip_open-clip-xlm-roberta-large-vit-huge-14.pth'
|
| 20 |
+
i2v_14B.clip_tokenizer = 'xlm-roberta-large'
|
| 21 |
+
|
| 22 |
+
# vae
|
| 23 |
+
i2v_14B.vae_checkpoint = 'Wan2.1_VAE.pth'
|
| 24 |
+
i2v_14B.vae_stride = (4, 8, 8)
|
| 25 |
+
|
| 26 |
+
# transformer
|
| 27 |
+
i2v_14B.patch_size = (1, 2, 2)
|
| 28 |
+
i2v_14B.dim = 5120
|
| 29 |
+
i2v_14B.ffn_dim = 13824
|
| 30 |
+
i2v_14B.freq_dim = 256
|
| 31 |
+
i2v_14B.num_heads = 40
|
| 32 |
+
i2v_14B.num_layers = 40
|
| 33 |
+
i2v_14B.window_size = (-1, -1)
|
| 34 |
+
i2v_14B.qk_norm = True
|
| 35 |
+
i2v_14B.cross_attn_norm = True
|
| 36 |
+
i2v_14B.eps = 1e-6
|
wan/configs/wan_t2v_14B.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
from easydict import EasyDict
|
| 3 |
+
|
| 4 |
+
from .shared_config import wan_shared_cfg
|
| 5 |
+
|
| 6 |
+
#------------------------ Wan T2V 14B ------------------------#
|
| 7 |
+
|
| 8 |
+
t2v_14B = EasyDict(__name__='Config: Wan T2V 14B')
|
| 9 |
+
t2v_14B.update(wan_shared_cfg)
|
| 10 |
+
|
| 11 |
+
# t5
|
| 12 |
+
t2v_14B.t5_checkpoint = 'models_t5_umt5-xxl-enc-bf16.pth'
|
| 13 |
+
t2v_14B.t5_tokenizer = 'google/umt5-xxl'
|
| 14 |
+
|
| 15 |
+
# vae
|
| 16 |
+
t2v_14B.vae_checkpoint = 'Wan2.1_VAE.pth'
|
| 17 |
+
t2v_14B.vae_stride = (4, 8, 8)
|
| 18 |
+
|
| 19 |
+
# transformer
|
| 20 |
+
t2v_14B.patch_size = (1, 2, 2)
|
| 21 |
+
t2v_14B.dim = 5120
|
| 22 |
+
t2v_14B.ffn_dim = 13824
|
| 23 |
+
t2v_14B.freq_dim = 256
|
| 24 |
+
t2v_14B.num_heads = 40
|
| 25 |
+
t2v_14B.num_layers = 40
|
| 26 |
+
t2v_14B.window_size = (-1, -1)
|
| 27 |
+
t2v_14B.qk_norm = True
|
| 28 |
+
t2v_14B.cross_attn_norm = True
|
| 29 |
+
t2v_14B.eps = 1e-6
|
wan/configs/wan_t2v_1_3B.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
from easydict import EasyDict
|
| 3 |
+
|
| 4 |
+
from .shared_config import wan_shared_cfg
|
| 5 |
+
|
| 6 |
+
#------------------------ Wan T2V 1.3B ------------------------#
|
| 7 |
+
|
| 8 |
+
t2v_1_3B = EasyDict(__name__='Config: Wan T2V 1.3B')
|
| 9 |
+
t2v_1_3B.update(wan_shared_cfg)
|
| 10 |
+
|
| 11 |
+
# t5
|
| 12 |
+
t2v_1_3B.t5_checkpoint = 'models_t5_umt5-xxl-enc-bf16.pth'
|
| 13 |
+
t2v_1_3B.t5_tokenizer = 'google/umt5-xxl'
|
| 14 |
+
|
| 15 |
+
# vae
|
| 16 |
+
t2v_1_3B.vae_checkpoint = 'Wan2.1_VAE.pth'
|
| 17 |
+
t2v_1_3B.vae_stride = (4, 8, 8)
|
| 18 |
+
|
| 19 |
+
# transformer
|
| 20 |
+
t2v_1_3B.patch_size = (1, 2, 2)
|
| 21 |
+
t2v_1_3B.dim = 1536
|
| 22 |
+
t2v_1_3B.ffn_dim = 8960
|
| 23 |
+
t2v_1_3B.freq_dim = 256
|
| 24 |
+
t2v_1_3B.num_heads = 12
|
| 25 |
+
t2v_1_3B.num_layers = 30
|
| 26 |
+
t2v_1_3B.window_size = (-1, -1)
|
| 27 |
+
t2v_1_3B.qk_norm = True
|
| 28 |
+
t2v_1_3B.cross_attn_norm = True
|
| 29 |
+
t2v_1_3B.eps = 1e-6
|
wan/distributed/__init__.py
ADDED
|
File without changes
|
wan/distributed/fsdp.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import gc
|
| 3 |
+
from functools import partial
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
|
| 7 |
+
from torch.distributed.fsdp import MixedPrecision, ShardingStrategy
|
| 8 |
+
from torch.distributed.fsdp.wrap import lambda_auto_wrap_policy
|
| 9 |
+
from torch.distributed.utils import _free_storage
|
| 10 |
+
|
| 11 |
+
def shard_model(
|
| 12 |
+
model,
|
| 13 |
+
device_id,
|
| 14 |
+
param_dtype=torch.bfloat16,
|
| 15 |
+
reduce_dtype=torch.float32,
|
| 16 |
+
buffer_dtype=torch.float32,
|
| 17 |
+
process_group=None,
|
| 18 |
+
sharding_strategy=ShardingStrategy.FULL_SHARD,
|
| 19 |
+
sync_module_states=True,
|
| 20 |
+
):
|
| 21 |
+
model = FSDP(
|
| 22 |
+
module=model,
|
| 23 |
+
process_group=process_group,
|
| 24 |
+
sharding_strategy=sharding_strategy,
|
| 25 |
+
auto_wrap_policy=partial(
|
| 26 |
+
lambda_auto_wrap_policy, lambda_fn=lambda m: m in model.blocks),
|
| 27 |
+
mixed_precision=MixedPrecision(
|
| 28 |
+
param_dtype=param_dtype,
|
| 29 |
+
reduce_dtype=reduce_dtype,
|
| 30 |
+
buffer_dtype=buffer_dtype),
|
| 31 |
+
device_id=device_id,
|
| 32 |
+
sync_module_states=sync_module_states)
|
| 33 |
+
return model
|
| 34 |
+
|
| 35 |
+
def free_model(model):
|
| 36 |
+
for m in model.modules():
|
| 37 |
+
if isinstance(m, FSDP):
|
| 38 |
+
_free_storage(m._handle.flat_param.data)
|
| 39 |
+
del model
|
| 40 |
+
gc.collect()
|
| 41 |
+
torch.cuda.empty_cache()
|
wan/distributed/xdit_context_parallel.py
ADDED
|
@@ -0,0 +1,230 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import torch
|
| 3 |
+
import torch.cuda.amp as amp
|
| 4 |
+
from xfuser.core.distributed import (get_sequence_parallel_rank,
|
| 5 |
+
get_sequence_parallel_world_size,
|
| 6 |
+
get_sp_group)
|
| 7 |
+
from xfuser.core.long_ctx_attention import xFuserLongContextAttention
|
| 8 |
+
|
| 9 |
+
from ..modules.model import sinusoidal_embedding_1d
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def pad_freqs(original_tensor, target_len):
|
| 13 |
+
seq_len, s1, s2 = original_tensor.shape
|
| 14 |
+
pad_size = target_len - seq_len
|
| 15 |
+
padding_tensor = torch.ones(
|
| 16 |
+
pad_size,
|
| 17 |
+
s1,
|
| 18 |
+
s2,
|
| 19 |
+
dtype=original_tensor.dtype,
|
| 20 |
+
device=original_tensor.device)
|
| 21 |
+
padded_tensor = torch.cat([original_tensor, padding_tensor], dim=0)
|
| 22 |
+
return padded_tensor
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
@amp.autocast(enabled=False)
|
| 26 |
+
def rope_apply(x, grid_sizes, freqs):
|
| 27 |
+
"""
|
| 28 |
+
x: [B, L, N, C].
|
| 29 |
+
grid_sizes: [B, 3].
|
| 30 |
+
freqs: [M, C // 2].
|
| 31 |
+
"""
|
| 32 |
+
s, n, c = x.size(1), x.size(2), x.size(3) // 2
|
| 33 |
+
# split freqs
|
| 34 |
+
freqs = freqs.split([c - 2 * (c // 3), c // 3, c // 3], dim=1)
|
| 35 |
+
|
| 36 |
+
# loop over samples
|
| 37 |
+
output = []
|
| 38 |
+
for i, (f, h, w) in enumerate(grid_sizes.tolist()):
|
| 39 |
+
seq_len = f * h * w
|
| 40 |
+
|
| 41 |
+
# precompute multipliers
|
| 42 |
+
x_i = torch.view_as_complex(x[i, :s].to(torch.float64).reshape(
|
| 43 |
+
s, n, -1, 2))
|
| 44 |
+
freqs_i = torch.cat([
|
| 45 |
+
freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
|
| 46 |
+
freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
|
| 47 |
+
freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
|
| 48 |
+
],
|
| 49 |
+
dim=-1).reshape(seq_len, 1, -1)
|
| 50 |
+
|
| 51 |
+
# apply rotary embedding
|
| 52 |
+
sp_size = get_sequence_parallel_world_size()
|
| 53 |
+
sp_rank = get_sequence_parallel_rank()
|
| 54 |
+
freqs_i = pad_freqs(freqs_i, s * sp_size)
|
| 55 |
+
s_per_rank = s
|
| 56 |
+
freqs_i_rank = freqs_i[(sp_rank * s_per_rank):((sp_rank + 1) *
|
| 57 |
+
s_per_rank), :, :]
|
| 58 |
+
x_i = torch.view_as_real(x_i * freqs_i_rank).flatten(2)
|
| 59 |
+
x_i = torch.cat([x_i, x[i, s:]])
|
| 60 |
+
|
| 61 |
+
# append to collection
|
| 62 |
+
output.append(x_i)
|
| 63 |
+
return torch.stack(output).float()
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def usp_dit_forward_vace(
|
| 67 |
+
self,
|
| 68 |
+
x,
|
| 69 |
+
vace_context,
|
| 70 |
+
seq_len,
|
| 71 |
+
kwargs
|
| 72 |
+
):
|
| 73 |
+
# embeddings
|
| 74 |
+
c = [self.vace_patch_embedding(u.unsqueeze(0)) for u in vace_context]
|
| 75 |
+
c = [u.flatten(2).transpose(1, 2) for u in c]
|
| 76 |
+
c = torch.cat([
|
| 77 |
+
torch.cat([u, u.new_zeros(1, seq_len - u.size(1), u.size(2))],
|
| 78 |
+
dim=1) for u in c
|
| 79 |
+
])
|
| 80 |
+
|
| 81 |
+
# arguments
|
| 82 |
+
new_kwargs = dict(x=x)
|
| 83 |
+
new_kwargs.update(kwargs)
|
| 84 |
+
|
| 85 |
+
# Context Parallel
|
| 86 |
+
c = torch.chunk(
|
| 87 |
+
c, get_sequence_parallel_world_size(),
|
| 88 |
+
dim=1)[get_sequence_parallel_rank()]
|
| 89 |
+
|
| 90 |
+
hints = []
|
| 91 |
+
for block in self.vace_blocks:
|
| 92 |
+
c, c_skip = block(c, **new_kwargs)
|
| 93 |
+
hints.append(c_skip)
|
| 94 |
+
return hints
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def usp_dit_forward(
|
| 98 |
+
self,
|
| 99 |
+
x,
|
| 100 |
+
t,
|
| 101 |
+
context,
|
| 102 |
+
seq_len,
|
| 103 |
+
vace_context=None,
|
| 104 |
+
vace_context_scale=1.0,
|
| 105 |
+
clip_fea=None,
|
| 106 |
+
y=None,
|
| 107 |
+
):
|
| 108 |
+
"""
|
| 109 |
+
x: A list of videos each with shape [C, T, H, W].
|
| 110 |
+
t: [B].
|
| 111 |
+
context: A list of text embeddings each with shape [L, C].
|
| 112 |
+
"""
|
| 113 |
+
if self.model_type == 'i2v':
|
| 114 |
+
assert clip_fea is not None and y is not None
|
| 115 |
+
# params
|
| 116 |
+
device = self.patch_embedding.weight.device
|
| 117 |
+
if self.freqs.device != device:
|
| 118 |
+
self.freqs = self.freqs.to(device)
|
| 119 |
+
|
| 120 |
+
if self.model_type != 'vace' and y is not None:
|
| 121 |
+
x = [torch.cat([u, v], dim=0) for u, v in zip(x, y)]
|
| 122 |
+
|
| 123 |
+
# embeddings
|
| 124 |
+
x = [self.patch_embedding(u.unsqueeze(0)) for u in x]
|
| 125 |
+
grid_sizes = torch.stack(
|
| 126 |
+
[torch.tensor(u.shape[2:], dtype=torch.long) for u in x])
|
| 127 |
+
x = [u.flatten(2).transpose(1, 2) for u in x]
|
| 128 |
+
seq_lens = torch.tensor([u.size(1) for u in x], dtype=torch.long)
|
| 129 |
+
assert seq_lens.max() <= seq_len
|
| 130 |
+
x = torch.cat([
|
| 131 |
+
torch.cat([u, u.new_zeros(1, seq_len - u.size(1), u.size(2))], dim=1)
|
| 132 |
+
for u in x
|
| 133 |
+
])
|
| 134 |
+
|
| 135 |
+
# time embeddings
|
| 136 |
+
with amp.autocast(dtype=torch.float32):
|
| 137 |
+
e = self.time_embedding(
|
| 138 |
+
sinusoidal_embedding_1d(self.freq_dim, t).float())
|
| 139 |
+
e0 = self.time_projection(e).unflatten(1, (6, self.dim))
|
| 140 |
+
assert e.dtype == torch.float32 and e0.dtype == torch.float32
|
| 141 |
+
|
| 142 |
+
# context
|
| 143 |
+
context_lens = None
|
| 144 |
+
context = self.text_embedding(
|
| 145 |
+
torch.stack([
|
| 146 |
+
torch.cat([u, u.new_zeros(self.text_len - u.size(0), u.size(1))])
|
| 147 |
+
for u in context
|
| 148 |
+
]))
|
| 149 |
+
|
| 150 |
+
if self.model_type != 'vace' and clip_fea is not None:
|
| 151 |
+
context_clip = self.img_emb(clip_fea) # bs x 257 x dim
|
| 152 |
+
context = torch.concat([context_clip, context], dim=1)
|
| 153 |
+
|
| 154 |
+
# arguments
|
| 155 |
+
kwargs = dict(
|
| 156 |
+
e=e0,
|
| 157 |
+
seq_lens=seq_lens,
|
| 158 |
+
grid_sizes=grid_sizes,
|
| 159 |
+
freqs=self.freqs,
|
| 160 |
+
context=context,
|
| 161 |
+
context_lens=context_lens)
|
| 162 |
+
|
| 163 |
+
# Context Parallel
|
| 164 |
+
x = torch.chunk(
|
| 165 |
+
x, get_sequence_parallel_world_size(),
|
| 166 |
+
dim=1)[get_sequence_parallel_rank()]
|
| 167 |
+
|
| 168 |
+
if self.model_type == 'vace':
|
| 169 |
+
hints = self.forward_vace(x, vace_context, seq_len, kwargs)
|
| 170 |
+
kwargs['hints'] = hints
|
| 171 |
+
kwargs['context_scale'] = vace_context_scale
|
| 172 |
+
|
| 173 |
+
for block in self.blocks:
|
| 174 |
+
x = block(x, **kwargs)
|
| 175 |
+
|
| 176 |
+
# head
|
| 177 |
+
x = self.head(x, e)
|
| 178 |
+
|
| 179 |
+
# Context Parallel
|
| 180 |
+
x = get_sp_group().all_gather(x, dim=1)
|
| 181 |
+
|
| 182 |
+
# unpatchify
|
| 183 |
+
x = self.unpatchify(x, grid_sizes)
|
| 184 |
+
return [u.float() for u in x]
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def usp_attn_forward(self,
|
| 188 |
+
x,
|
| 189 |
+
seq_lens,
|
| 190 |
+
grid_sizes,
|
| 191 |
+
freqs,
|
| 192 |
+
dtype=torch.bfloat16):
|
| 193 |
+
b, s, n, d = *x.shape[:2], self.num_heads, self.head_dim
|
| 194 |
+
half_dtypes = (torch.float16, torch.bfloat16)
|
| 195 |
+
|
| 196 |
+
def half(x):
|
| 197 |
+
return x if x.dtype in half_dtypes else x.to(dtype)
|
| 198 |
+
|
| 199 |
+
# query, key, value function
|
| 200 |
+
def qkv_fn(x):
|
| 201 |
+
q = self.norm_q(self.q(x)).view(b, s, n, d)
|
| 202 |
+
k = self.norm_k(self.k(x)).view(b, s, n, d)
|
| 203 |
+
v = self.v(x).view(b, s, n, d)
|
| 204 |
+
return q, k, v
|
| 205 |
+
|
| 206 |
+
q, k, v = qkv_fn(x)
|
| 207 |
+
q = rope_apply(q, grid_sizes, freqs)
|
| 208 |
+
k = rope_apply(k, grid_sizes, freqs)
|
| 209 |
+
|
| 210 |
+
# TODO: We should use unpaded q,k,v for attention.
|
| 211 |
+
# k_lens = seq_lens // get_sequence_parallel_world_size()
|
| 212 |
+
# if k_lens is not None:
|
| 213 |
+
# q = torch.cat([u[:l] for u, l in zip(q, k_lens)]).unsqueeze(0)
|
| 214 |
+
# k = torch.cat([u[:l] for u, l in zip(k, k_lens)]).unsqueeze(0)
|
| 215 |
+
# v = torch.cat([u[:l] for u, l in zip(v, k_lens)]).unsqueeze(0)
|
| 216 |
+
|
| 217 |
+
x = xFuserLongContextAttention()(
|
| 218 |
+
None,
|
| 219 |
+
query=half(q),
|
| 220 |
+
key=half(k),
|
| 221 |
+
value=half(v),
|
| 222 |
+
window_size=self.window_size)
|
| 223 |
+
|
| 224 |
+
# TODO: padding after attention.
|
| 225 |
+
# x = torch.cat([x, x.new_zeros(b, s - x.size(1), n, d)], dim=1)
|
| 226 |
+
|
| 227 |
+
# output
|
| 228 |
+
x = x.flatten(2)
|
| 229 |
+
x = self.o(x)
|
| 230 |
+
return x
|
wan/first_last_frame2video.py
ADDED
|
@@ -0,0 +1,370 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import gc
|
| 3 |
+
import logging
|
| 4 |
+
import math
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
import sys
|
| 8 |
+
import types
|
| 9 |
+
from contextlib import contextmanager
|
| 10 |
+
from functools import partial
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
import torch.cuda.amp as amp
|
| 15 |
+
import torch.distributed as dist
|
| 16 |
+
import torchvision.transforms.functional as TF
|
| 17 |
+
from tqdm import tqdm
|
| 18 |
+
|
| 19 |
+
from .distributed.fsdp import shard_model
|
| 20 |
+
from .modules.clip import CLIPModel
|
| 21 |
+
from .modules.model import WanModel
|
| 22 |
+
from .modules.t5 import T5EncoderModel
|
| 23 |
+
from .modules.vae import WanVAE
|
| 24 |
+
from .utils.fm_solvers import (FlowDPMSolverMultistepScheduler,
|
| 25 |
+
get_sampling_sigmas, retrieve_timesteps)
|
| 26 |
+
from .utils.fm_solvers_unipc import FlowUniPCMultistepScheduler
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class WanFLF2V:
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
config,
|
| 34 |
+
checkpoint_dir,
|
| 35 |
+
device_id=0,
|
| 36 |
+
rank=0,
|
| 37 |
+
t5_fsdp=False,
|
| 38 |
+
dit_fsdp=False,
|
| 39 |
+
use_usp=False,
|
| 40 |
+
t5_cpu=False,
|
| 41 |
+
init_on_cpu=True,
|
| 42 |
+
):
|
| 43 |
+
r"""
|
| 44 |
+
Initializes the image-to-video generation model components.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
config (EasyDict):
|
| 48 |
+
Object containing model parameters initialized from config.py
|
| 49 |
+
checkpoint_dir (`str`):
|
| 50 |
+
Path to directory containing model checkpoints
|
| 51 |
+
device_id (`int`, *optional*, defaults to 0):
|
| 52 |
+
Id of target GPU device
|
| 53 |
+
rank (`int`, *optional*, defaults to 0):
|
| 54 |
+
Process rank for distributed training
|
| 55 |
+
t5_fsdp (`bool`, *optional*, defaults to False):
|
| 56 |
+
Enable FSDP sharding for T5 model
|
| 57 |
+
dit_fsdp (`bool`, *optional*, defaults to False):
|
| 58 |
+
Enable FSDP sharding for DiT model
|
| 59 |
+
use_usp (`bool`, *optional*, defaults to False):
|
| 60 |
+
Enable distribution strategy of USP.
|
| 61 |
+
t5_cpu (`bool`, *optional*, defaults to False):
|
| 62 |
+
Whether to place T5 model on CPU. Only works without t5_fsdp.
|
| 63 |
+
init_on_cpu (`bool`, *optional*, defaults to True):
|
| 64 |
+
Enable initializing Transformer Model on CPU. Only works without FSDP or USP.
|
| 65 |
+
"""
|
| 66 |
+
self.device = torch.device(f"cuda:{device_id}")
|
| 67 |
+
self.config = config
|
| 68 |
+
self.rank = rank
|
| 69 |
+
self.use_usp = use_usp
|
| 70 |
+
self.t5_cpu = t5_cpu
|
| 71 |
+
|
| 72 |
+
self.num_train_timesteps = config.num_train_timesteps
|
| 73 |
+
self.param_dtype = config.param_dtype
|
| 74 |
+
|
| 75 |
+
shard_fn = partial(shard_model, device_id=device_id)
|
| 76 |
+
self.text_encoder = T5EncoderModel(
|
| 77 |
+
text_len=config.text_len,
|
| 78 |
+
dtype=config.t5_dtype,
|
| 79 |
+
device=torch.device('cpu'),
|
| 80 |
+
checkpoint_path=os.path.join(checkpoint_dir, config.t5_checkpoint),
|
| 81 |
+
tokenizer_path=os.path.join(checkpoint_dir, config.t5_tokenizer),
|
| 82 |
+
shard_fn=shard_fn if t5_fsdp else None,
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
self.vae_stride = config.vae_stride
|
| 86 |
+
self.patch_size = config.patch_size
|
| 87 |
+
self.vae = WanVAE(
|
| 88 |
+
vae_pth=os.path.join(checkpoint_dir, config.vae_checkpoint),
|
| 89 |
+
device=self.device)
|
| 90 |
+
|
| 91 |
+
self.clip = CLIPModel(
|
| 92 |
+
dtype=config.clip_dtype,
|
| 93 |
+
device=self.device,
|
| 94 |
+
checkpoint_path=os.path.join(checkpoint_dir,
|
| 95 |
+
config.clip_checkpoint),
|
| 96 |
+
tokenizer_path=os.path.join(checkpoint_dir, config.clip_tokenizer))
|
| 97 |
+
|
| 98 |
+
logging.info(f"Creating WanModel from {checkpoint_dir}")
|
| 99 |
+
self.model = WanModel.from_pretrained(checkpoint_dir)
|
| 100 |
+
self.model.eval().requires_grad_(False)
|
| 101 |
+
|
| 102 |
+
if t5_fsdp or dit_fsdp or use_usp:
|
| 103 |
+
init_on_cpu = False
|
| 104 |
+
|
| 105 |
+
if use_usp:
|
| 106 |
+
from xfuser.core.distributed import \
|
| 107 |
+
get_sequence_parallel_world_size
|
| 108 |
+
|
| 109 |
+
from .distributed.xdit_context_parallel import (usp_attn_forward,
|
| 110 |
+
usp_dit_forward)
|
| 111 |
+
for block in self.model.blocks:
|
| 112 |
+
block.self_attn.forward = types.MethodType(
|
| 113 |
+
usp_attn_forward, block.self_attn)
|
| 114 |
+
self.model.forward = types.MethodType(usp_dit_forward, self.model)
|
| 115 |
+
self.sp_size = get_sequence_parallel_world_size()
|
| 116 |
+
else:
|
| 117 |
+
self.sp_size = 1
|
| 118 |
+
|
| 119 |
+
if dist.is_initialized():
|
| 120 |
+
dist.barrier()
|
| 121 |
+
if dit_fsdp:
|
| 122 |
+
self.model = shard_fn(self.model)
|
| 123 |
+
else:
|
| 124 |
+
if not init_on_cpu:
|
| 125 |
+
self.model.to(self.device)
|
| 126 |
+
|
| 127 |
+
self.sample_neg_prompt = config.sample_neg_prompt
|
| 128 |
+
|
| 129 |
+
def generate(self,
|
| 130 |
+
input_prompt,
|
| 131 |
+
first_frame,
|
| 132 |
+
last_frame,
|
| 133 |
+
max_area=720 * 1280,
|
| 134 |
+
frame_num=81,
|
| 135 |
+
shift=16,
|
| 136 |
+
sample_solver='unipc',
|
| 137 |
+
sampling_steps=50,
|
| 138 |
+
guide_scale=5.5,
|
| 139 |
+
n_prompt="",
|
| 140 |
+
seed=-1,
|
| 141 |
+
offload_model=True):
|
| 142 |
+
r"""
|
| 143 |
+
Generates video frames from input first-last frame and text prompt using diffusion process.
|
| 144 |
+
|
| 145 |
+
Args:
|
| 146 |
+
input_prompt (`str`):
|
| 147 |
+
Text prompt for content generation.
|
| 148 |
+
first_frame (PIL.Image.Image):
|
| 149 |
+
Input image tensor. Shape: [3, H, W]
|
| 150 |
+
last_frame (PIL.Image.Image):
|
| 151 |
+
Input image tensor. Shape: [3, H, W]
|
| 152 |
+
[NOTE] If the sizes of first_frame and last_frame are mismatched, last_frame will be cropped & resized
|
| 153 |
+
to match first_frame.
|
| 154 |
+
max_area (`int`, *optional*, defaults to 720*1280):
|
| 155 |
+
Maximum pixel area for latent space calculation. Controls video resolution scaling
|
| 156 |
+
frame_num (`int`, *optional*, defaults to 81):
|
| 157 |
+
How many frames to sample from a video. The number should be 4n+1
|
| 158 |
+
shift (`float`, *optional*, defaults to 5.0):
|
| 159 |
+
Noise schedule shift parameter. Affects temporal dynamics
|
| 160 |
+
[NOTE]: If you want to generate a 480p video, it is recommended to set the shift value to 3.0.
|
| 161 |
+
sample_solver (`str`, *optional*, defaults to 'unipc'):
|
| 162 |
+
Solver used to sample the video.
|
| 163 |
+
sampling_steps (`int`, *optional*, defaults to 40):
|
| 164 |
+
Number of diffusion sampling steps. Higher values improve quality but slow generation
|
| 165 |
+
guide_scale (`float`, *optional*, defaults 5.0):
|
| 166 |
+
Classifier-free guidance scale. Controls prompt adherence vs. creativity
|
| 167 |
+
n_prompt (`str`, *optional*, defaults to ""):
|
| 168 |
+
Negative prompt for content exclusion. If not given, use `config.sample_neg_prompt`
|
| 169 |
+
seed (`int`, *optional*, defaults to -1):
|
| 170 |
+
Random seed for noise generation. If -1, use random seed
|
| 171 |
+
offload_model (`bool`, *optional*, defaults to True):
|
| 172 |
+
If True, offloads models to CPU during generation to save VRAM
|
| 173 |
+
|
| 174 |
+
Returns:
|
| 175 |
+
torch.Tensor:
|
| 176 |
+
Generated video frames tensor. Dimensions: (C, N H, W) where:
|
| 177 |
+
- C: Color channels (3 for RGB)
|
| 178 |
+
- N: Number of frames (81)
|
| 179 |
+
- H: Frame height (from max_area)
|
| 180 |
+
- W: Frame width from max_area)
|
| 181 |
+
"""
|
| 182 |
+
first_frame_size = first_frame.size
|
| 183 |
+
last_frame_size = last_frame.size
|
| 184 |
+
first_frame = TF.to_tensor(first_frame).sub_(0.5).div_(0.5).to(self.device)
|
| 185 |
+
last_frame = TF.to_tensor(last_frame).sub_(0.5).div_(0.5).to(self.device)
|
| 186 |
+
|
| 187 |
+
F = frame_num
|
| 188 |
+
first_frame_h, first_frame_w = first_frame.shape[1:]
|
| 189 |
+
aspect_ratio = first_frame_h / first_frame_w
|
| 190 |
+
lat_h = round(
|
| 191 |
+
np.sqrt(max_area * aspect_ratio) // self.vae_stride[1] //
|
| 192 |
+
self.patch_size[1] * self.patch_size[1])
|
| 193 |
+
lat_w = round(
|
| 194 |
+
np.sqrt(max_area / aspect_ratio) // self.vae_stride[2] //
|
| 195 |
+
self.patch_size[2] * self.patch_size[2])
|
| 196 |
+
first_frame_h = lat_h * self.vae_stride[1]
|
| 197 |
+
first_frame_w = lat_w * self.vae_stride[2]
|
| 198 |
+
if first_frame_size != last_frame_size:
|
| 199 |
+
# 1. resize
|
| 200 |
+
last_frame_resize_ratio = max(
|
| 201 |
+
first_frame_size[0] / last_frame_size[0],
|
| 202 |
+
first_frame_size[1] / last_frame_size[1]
|
| 203 |
+
)
|
| 204 |
+
last_frame_size = [
|
| 205 |
+
round(last_frame_size[0] * last_frame_resize_ratio),
|
| 206 |
+
round(last_frame_size[1] * last_frame_resize_ratio),
|
| 207 |
+
]
|
| 208 |
+
# 2. center crop
|
| 209 |
+
last_frame = TF.center_crop(last_frame, last_frame_size)
|
| 210 |
+
|
| 211 |
+
max_seq_len = ((F - 1) // self.vae_stride[0] + 1) * lat_h * lat_w // (
|
| 212 |
+
self.patch_size[1] * self.patch_size[2])
|
| 213 |
+
max_seq_len = int(math.ceil(max_seq_len / self.sp_size)) * self.sp_size
|
| 214 |
+
|
| 215 |
+
seed = seed if seed >= 0 else random.randint(0, sys.maxsize)
|
| 216 |
+
seed_g = torch.Generator(device=self.device)
|
| 217 |
+
seed_g.manual_seed(seed)
|
| 218 |
+
noise = torch.randn(
|
| 219 |
+
16,
|
| 220 |
+
(F - 1) // 4 + 1,
|
| 221 |
+
lat_h,
|
| 222 |
+
lat_w,
|
| 223 |
+
dtype=torch.float32,
|
| 224 |
+
generator=seed_g,
|
| 225 |
+
device=self.device)
|
| 226 |
+
|
| 227 |
+
msk = torch.ones(1, 81, lat_h, lat_w, device=self.device)
|
| 228 |
+
msk[:, 1: -1] = 0
|
| 229 |
+
msk = torch.concat([torch.repeat_interleave(msk[:, 0:1], repeats=4, dim=1), msk[:, 1:]], dim=1)
|
| 230 |
+
msk = msk.view(1, msk.shape[1] // 4, 4, lat_h, lat_w)
|
| 231 |
+
msk = msk.transpose(1, 2)[0]
|
| 232 |
+
|
| 233 |
+
if n_prompt == "":
|
| 234 |
+
n_prompt = self.sample_neg_prompt
|
| 235 |
+
|
| 236 |
+
# preprocess
|
| 237 |
+
if not self.t5_cpu:
|
| 238 |
+
self.text_encoder.model.to(self.device)
|
| 239 |
+
context = self.text_encoder([input_prompt], self.device)
|
| 240 |
+
context_null = self.text_encoder([n_prompt], self.device)
|
| 241 |
+
if offload_model:
|
| 242 |
+
self.text_encoder.model.cpu()
|
| 243 |
+
else:
|
| 244 |
+
context = self.text_encoder([input_prompt], torch.device('cpu'))
|
| 245 |
+
context_null = self.text_encoder([n_prompt], torch.device('cpu'))
|
| 246 |
+
context = [t.to(self.device) for t in context]
|
| 247 |
+
context_null = [t.to(self.device) for t in context_null]
|
| 248 |
+
|
| 249 |
+
self.clip.model.to(self.device)
|
| 250 |
+
clip_context = self.clip.visual([first_frame[:, None, :, :], last_frame[:, None, :, :]])
|
| 251 |
+
if offload_model:
|
| 252 |
+
self.clip.model.cpu()
|
| 253 |
+
|
| 254 |
+
y = self.vae.encode([
|
| 255 |
+
torch.concat([
|
| 256 |
+
torch.nn.functional.interpolate(
|
| 257 |
+
first_frame[None].cpu(),
|
| 258 |
+
size=(first_frame_h, first_frame_w),
|
| 259 |
+
mode='bicubic'
|
| 260 |
+
).transpose(0, 1),
|
| 261 |
+
torch.zeros(3, F - 2, first_frame_h, first_frame_w),
|
| 262 |
+
torch.nn.functional.interpolate(
|
| 263 |
+
last_frame[None].cpu(),
|
| 264 |
+
size=(first_frame_h, first_frame_w),
|
| 265 |
+
mode='bicubic'
|
| 266 |
+
).transpose(0, 1),
|
| 267 |
+
], dim=1).to(self.device)
|
| 268 |
+
])[0]
|
| 269 |
+
y = torch.concat([msk, y])
|
| 270 |
+
|
| 271 |
+
@contextmanager
|
| 272 |
+
def noop_no_sync():
|
| 273 |
+
yield
|
| 274 |
+
|
| 275 |
+
no_sync = getattr(self.model, 'no_sync', noop_no_sync)
|
| 276 |
+
|
| 277 |
+
# evaluation mode
|
| 278 |
+
with amp.autocast(dtype=self.param_dtype), torch.no_grad(), no_sync():
|
| 279 |
+
|
| 280 |
+
if sample_solver == 'unipc':
|
| 281 |
+
sample_scheduler = FlowUniPCMultistepScheduler(
|
| 282 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 283 |
+
shift=1,
|
| 284 |
+
use_dynamic_shifting=False)
|
| 285 |
+
sample_scheduler.set_timesteps(
|
| 286 |
+
sampling_steps, device=self.device, shift=shift)
|
| 287 |
+
timesteps = sample_scheduler.timesteps
|
| 288 |
+
elif sample_solver == 'dpm++':
|
| 289 |
+
sample_scheduler = FlowDPMSolverMultistepScheduler(
|
| 290 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 291 |
+
shift=1,
|
| 292 |
+
use_dynamic_shifting=False)
|
| 293 |
+
sampling_sigmas = get_sampling_sigmas(sampling_steps, shift)
|
| 294 |
+
timesteps, _ = retrieve_timesteps(
|
| 295 |
+
sample_scheduler,
|
| 296 |
+
device=self.device,
|
| 297 |
+
sigmas=sampling_sigmas)
|
| 298 |
+
else:
|
| 299 |
+
raise NotImplementedError("Unsupported solver.")
|
| 300 |
+
|
| 301 |
+
# sample videos
|
| 302 |
+
latent = noise
|
| 303 |
+
|
| 304 |
+
arg_c = {
|
| 305 |
+
'context': [context[0]],
|
| 306 |
+
'clip_fea': clip_context,
|
| 307 |
+
'seq_len': max_seq_len,
|
| 308 |
+
'y': [y],
|
| 309 |
+
}
|
| 310 |
+
|
| 311 |
+
arg_null = {
|
| 312 |
+
'context': context_null,
|
| 313 |
+
'clip_fea': clip_context,
|
| 314 |
+
'seq_len': max_seq_len,
|
| 315 |
+
'y': [y],
|
| 316 |
+
}
|
| 317 |
+
|
| 318 |
+
if offload_model:
|
| 319 |
+
torch.cuda.empty_cache()
|
| 320 |
+
|
| 321 |
+
self.model.to(self.device)
|
| 322 |
+
for _, t in enumerate(tqdm(timesteps)):
|
| 323 |
+
latent_model_input = [latent.to(self.device)]
|
| 324 |
+
timestep = [t]
|
| 325 |
+
|
| 326 |
+
timestep = torch.stack(timestep).to(self.device)
|
| 327 |
+
|
| 328 |
+
noise_pred_cond = self.model(
|
| 329 |
+
latent_model_input, t=timestep, **arg_c)[0].to(
|
| 330 |
+
torch.device('cpu') if offload_model else self.device)
|
| 331 |
+
if offload_model:
|
| 332 |
+
torch.cuda.empty_cache()
|
| 333 |
+
noise_pred_uncond = self.model(
|
| 334 |
+
latent_model_input, t=timestep, **arg_null)[0].to(
|
| 335 |
+
torch.device('cpu') if offload_model else self.device)
|
| 336 |
+
if offload_model:
|
| 337 |
+
torch.cuda.empty_cache()
|
| 338 |
+
noise_pred = noise_pred_uncond + guide_scale * (
|
| 339 |
+
noise_pred_cond - noise_pred_uncond)
|
| 340 |
+
|
| 341 |
+
latent = latent.to(
|
| 342 |
+
torch.device('cpu') if offload_model else self.device)
|
| 343 |
+
|
| 344 |
+
temp_x0 = sample_scheduler.step(
|
| 345 |
+
noise_pred.unsqueeze(0),
|
| 346 |
+
t,
|
| 347 |
+
latent.unsqueeze(0),
|
| 348 |
+
return_dict=False,
|
| 349 |
+
generator=seed_g)[0]
|
| 350 |
+
latent = temp_x0.squeeze(0)
|
| 351 |
+
|
| 352 |
+
x0 = [latent.to(self.device)]
|
| 353 |
+
del latent_model_input, timestep
|
| 354 |
+
|
| 355 |
+
if offload_model:
|
| 356 |
+
self.model.cpu()
|
| 357 |
+
torch.cuda.empty_cache()
|
| 358 |
+
|
| 359 |
+
if self.rank == 0:
|
| 360 |
+
videos = self.vae.decode(x0)
|
| 361 |
+
|
| 362 |
+
del noise, latent
|
| 363 |
+
del sample_scheduler
|
| 364 |
+
if offload_model:
|
| 365 |
+
gc.collect()
|
| 366 |
+
torch.cuda.synchronize()
|
| 367 |
+
if dist.is_initialized():
|
| 368 |
+
dist.barrier()
|
| 369 |
+
|
| 370 |
+
return videos[0] if self.rank == 0 else None
|
wan/image2video.py
ADDED
|
@@ -0,0 +1,347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import gc
|
| 3 |
+
import logging
|
| 4 |
+
import math
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
import sys
|
| 8 |
+
import types
|
| 9 |
+
from contextlib import contextmanager
|
| 10 |
+
from functools import partial
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
import torch.cuda.amp as amp
|
| 15 |
+
import torch.distributed as dist
|
| 16 |
+
import torchvision.transforms.functional as TF
|
| 17 |
+
from tqdm import tqdm
|
| 18 |
+
|
| 19 |
+
from .distributed.fsdp import shard_model
|
| 20 |
+
from .modules.clip import CLIPModel
|
| 21 |
+
from .modules.model import WanModel
|
| 22 |
+
from .modules.t5 import T5EncoderModel
|
| 23 |
+
from .modules.vae import WanVAE
|
| 24 |
+
from .utils.fm_solvers import (FlowDPMSolverMultistepScheduler,
|
| 25 |
+
get_sampling_sigmas, retrieve_timesteps)
|
| 26 |
+
from .utils.fm_solvers_unipc import FlowUniPCMultistepScheduler
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class WanI2V:
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
config,
|
| 34 |
+
checkpoint_dir,
|
| 35 |
+
device_id=0,
|
| 36 |
+
rank=0,
|
| 37 |
+
t5_fsdp=False,
|
| 38 |
+
dit_fsdp=False,
|
| 39 |
+
use_usp=False,
|
| 40 |
+
t5_cpu=False,
|
| 41 |
+
init_on_cpu=True,
|
| 42 |
+
):
|
| 43 |
+
r"""
|
| 44 |
+
Initializes the image-to-video generation model components.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
config (EasyDict):
|
| 48 |
+
Object containing model parameters initialized from config.py
|
| 49 |
+
checkpoint_dir (`str`):
|
| 50 |
+
Path to directory containing model checkpoints
|
| 51 |
+
device_id (`int`, *optional*, defaults to 0):
|
| 52 |
+
Id of target GPU device
|
| 53 |
+
rank (`int`, *optional*, defaults to 0):
|
| 54 |
+
Process rank for distributed training
|
| 55 |
+
t5_fsdp (`bool`, *optional*, defaults to False):
|
| 56 |
+
Enable FSDP sharding for T5 model
|
| 57 |
+
dit_fsdp (`bool`, *optional*, defaults to False):
|
| 58 |
+
Enable FSDP sharding for DiT model
|
| 59 |
+
use_usp (`bool`, *optional*, defaults to False):
|
| 60 |
+
Enable distribution strategy of USP.
|
| 61 |
+
t5_cpu (`bool`, *optional*, defaults to False):
|
| 62 |
+
Whether to place T5 model on CPU. Only works without t5_fsdp.
|
| 63 |
+
init_on_cpu (`bool`, *optional*, defaults to True):
|
| 64 |
+
Enable initializing Transformer Model on CPU. Only works without FSDP or USP.
|
| 65 |
+
"""
|
| 66 |
+
self.device = torch.device(f"cuda:{device_id}")
|
| 67 |
+
self.config = config
|
| 68 |
+
self.rank = rank
|
| 69 |
+
self.use_usp = use_usp
|
| 70 |
+
self.t5_cpu = t5_cpu
|
| 71 |
+
|
| 72 |
+
self.num_train_timesteps = config.num_train_timesteps
|
| 73 |
+
self.param_dtype = config.param_dtype
|
| 74 |
+
|
| 75 |
+
shard_fn = partial(shard_model, device_id=device_id)
|
| 76 |
+
self.text_encoder = T5EncoderModel(
|
| 77 |
+
text_len=config.text_len,
|
| 78 |
+
dtype=config.t5_dtype,
|
| 79 |
+
device=torch.device('cpu'),
|
| 80 |
+
checkpoint_path=os.path.join(checkpoint_dir, config.t5_checkpoint),
|
| 81 |
+
tokenizer_path=os.path.join(checkpoint_dir, config.t5_tokenizer),
|
| 82 |
+
shard_fn=shard_fn if t5_fsdp else None,
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
self.vae_stride = config.vae_stride
|
| 86 |
+
self.patch_size = config.patch_size
|
| 87 |
+
self.vae = WanVAE(
|
| 88 |
+
vae_pth=os.path.join(checkpoint_dir, config.vae_checkpoint),
|
| 89 |
+
device=self.device)
|
| 90 |
+
|
| 91 |
+
self.clip = CLIPModel(
|
| 92 |
+
dtype=config.clip_dtype,
|
| 93 |
+
device=self.device,
|
| 94 |
+
checkpoint_path=os.path.join(checkpoint_dir,
|
| 95 |
+
config.clip_checkpoint),
|
| 96 |
+
tokenizer_path=os.path.join(checkpoint_dir, config.clip_tokenizer))
|
| 97 |
+
|
| 98 |
+
logging.info(f"Creating WanModel from {checkpoint_dir}")
|
| 99 |
+
self.model = WanModel.from_pretrained(checkpoint_dir)
|
| 100 |
+
self.model.eval().requires_grad_(False)
|
| 101 |
+
|
| 102 |
+
if t5_fsdp or dit_fsdp or use_usp:
|
| 103 |
+
init_on_cpu = False
|
| 104 |
+
|
| 105 |
+
if use_usp:
|
| 106 |
+
from xfuser.core.distributed import \
|
| 107 |
+
get_sequence_parallel_world_size
|
| 108 |
+
|
| 109 |
+
from .distributed.xdit_context_parallel import (usp_attn_forward,
|
| 110 |
+
usp_dit_forward)
|
| 111 |
+
for block in self.model.blocks:
|
| 112 |
+
block.self_attn.forward = types.MethodType(
|
| 113 |
+
usp_attn_forward, block.self_attn)
|
| 114 |
+
self.model.forward = types.MethodType(usp_dit_forward, self.model)
|
| 115 |
+
self.sp_size = get_sequence_parallel_world_size()
|
| 116 |
+
else:
|
| 117 |
+
self.sp_size = 1
|
| 118 |
+
|
| 119 |
+
if dist.is_initialized():
|
| 120 |
+
dist.barrier()
|
| 121 |
+
if dit_fsdp:
|
| 122 |
+
self.model = shard_fn(self.model)
|
| 123 |
+
else:
|
| 124 |
+
if not init_on_cpu:
|
| 125 |
+
self.model.to(self.device)
|
| 126 |
+
|
| 127 |
+
self.sample_neg_prompt = config.sample_neg_prompt
|
| 128 |
+
|
| 129 |
+
def generate(self,
|
| 130 |
+
input_prompt,
|
| 131 |
+
img,
|
| 132 |
+
max_area=720 * 1280,
|
| 133 |
+
frame_num=81,
|
| 134 |
+
shift=5.0,
|
| 135 |
+
sample_solver='unipc',
|
| 136 |
+
sampling_steps=40,
|
| 137 |
+
guide_scale=5.0,
|
| 138 |
+
n_prompt="",
|
| 139 |
+
seed=-1,
|
| 140 |
+
offload_model=True):
|
| 141 |
+
r"""
|
| 142 |
+
Generates video frames from input image and text prompt using diffusion process.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
input_prompt (`str`):
|
| 146 |
+
Text prompt for content generation.
|
| 147 |
+
img (PIL.Image.Image):
|
| 148 |
+
Input image tensor. Shape: [3, H, W]
|
| 149 |
+
max_area (`int`, *optional*, defaults to 720*1280):
|
| 150 |
+
Maximum pixel area for latent space calculation. Controls video resolution scaling
|
| 151 |
+
frame_num (`int`, *optional*, defaults to 81):
|
| 152 |
+
How many frames to sample from a video. The number should be 4n+1
|
| 153 |
+
shift (`float`, *optional*, defaults to 5.0):
|
| 154 |
+
Noise schedule shift parameter. Affects temporal dynamics
|
| 155 |
+
[NOTE]: If you want to generate a 480p video, it is recommended to set the shift value to 3.0.
|
| 156 |
+
sample_solver (`str`, *optional*, defaults to 'unipc'):
|
| 157 |
+
Solver used to sample the video.
|
| 158 |
+
sampling_steps (`int`, *optional*, defaults to 40):
|
| 159 |
+
Number of diffusion sampling steps. Higher values improve quality but slow generation
|
| 160 |
+
guide_scale (`float`, *optional*, defaults 5.0):
|
| 161 |
+
Classifier-free guidance scale. Controls prompt adherence vs. creativity
|
| 162 |
+
n_prompt (`str`, *optional*, defaults to ""):
|
| 163 |
+
Negative prompt for content exclusion. If not given, use `config.sample_neg_prompt`
|
| 164 |
+
seed (`int`, *optional*, defaults to -1):
|
| 165 |
+
Random seed for noise generation. If -1, use random seed
|
| 166 |
+
offload_model (`bool`, *optional*, defaults to True):
|
| 167 |
+
If True, offloads models to CPU during generation to save VRAM
|
| 168 |
+
|
| 169 |
+
Returns:
|
| 170 |
+
torch.Tensor:
|
| 171 |
+
Generated video frames tensor. Dimensions: (C, N H, W) where:
|
| 172 |
+
- C: Color channels (3 for RGB)
|
| 173 |
+
- N: Number of frames (81)
|
| 174 |
+
- H: Frame height (from max_area)
|
| 175 |
+
- W: Frame width from max_area)
|
| 176 |
+
"""
|
| 177 |
+
img = TF.to_tensor(img).sub_(0.5).div_(0.5).to(self.device)
|
| 178 |
+
|
| 179 |
+
F = frame_num
|
| 180 |
+
h, w = img.shape[1:]
|
| 181 |
+
aspect_ratio = h / w
|
| 182 |
+
lat_h = round(
|
| 183 |
+
np.sqrt(max_area * aspect_ratio) // self.vae_stride[1] //
|
| 184 |
+
self.patch_size[1] * self.patch_size[1])
|
| 185 |
+
lat_w = round(
|
| 186 |
+
np.sqrt(max_area / aspect_ratio) // self.vae_stride[2] //
|
| 187 |
+
self.patch_size[2] * self.patch_size[2])
|
| 188 |
+
h = lat_h * self.vae_stride[1]
|
| 189 |
+
w = lat_w * self.vae_stride[2]
|
| 190 |
+
|
| 191 |
+
max_seq_len = ((F - 1) // self.vae_stride[0] + 1) * lat_h * lat_w // (
|
| 192 |
+
self.patch_size[1] * self.patch_size[2])
|
| 193 |
+
max_seq_len = int(math.ceil(max_seq_len / self.sp_size)) * self.sp_size
|
| 194 |
+
|
| 195 |
+
seed = seed if seed >= 0 else random.randint(0, sys.maxsize)
|
| 196 |
+
seed_g = torch.Generator(device=self.device)
|
| 197 |
+
seed_g.manual_seed(seed)
|
| 198 |
+
noise = torch.randn(
|
| 199 |
+
16,
|
| 200 |
+
(F - 1) // 4 + 1,
|
| 201 |
+
lat_h,
|
| 202 |
+
lat_w,
|
| 203 |
+
dtype=torch.float32,
|
| 204 |
+
generator=seed_g,
|
| 205 |
+
device=self.device)
|
| 206 |
+
|
| 207 |
+
msk = torch.ones(1, 81, lat_h, lat_w, device=self.device)
|
| 208 |
+
msk[:, 1:] = 0
|
| 209 |
+
msk = torch.concat([
|
| 210 |
+
torch.repeat_interleave(msk[:, 0:1], repeats=4, dim=1), msk[:, 1:]
|
| 211 |
+
],
|
| 212 |
+
dim=1)
|
| 213 |
+
msk = msk.view(1, msk.shape[1] // 4, 4, lat_h, lat_w)
|
| 214 |
+
msk = msk.transpose(1, 2)[0]
|
| 215 |
+
|
| 216 |
+
if n_prompt == "":
|
| 217 |
+
n_prompt = self.sample_neg_prompt
|
| 218 |
+
|
| 219 |
+
# preprocess
|
| 220 |
+
if not self.t5_cpu:
|
| 221 |
+
self.text_encoder.model.to(self.device)
|
| 222 |
+
context = self.text_encoder([input_prompt], self.device)
|
| 223 |
+
context_null = self.text_encoder([n_prompt], self.device)
|
| 224 |
+
if offload_model:
|
| 225 |
+
self.text_encoder.model.cpu()
|
| 226 |
+
else:
|
| 227 |
+
context = self.text_encoder([input_prompt], torch.device('cpu'))
|
| 228 |
+
context_null = self.text_encoder([n_prompt], torch.device('cpu'))
|
| 229 |
+
context = [t.to(self.device) for t in context]
|
| 230 |
+
context_null = [t.to(self.device) for t in context_null]
|
| 231 |
+
|
| 232 |
+
self.clip.model.to(self.device)
|
| 233 |
+
clip_context = self.clip.visual([img[:, None, :, :]])
|
| 234 |
+
if offload_model:
|
| 235 |
+
self.clip.model.cpu()
|
| 236 |
+
|
| 237 |
+
y = self.vae.encode([
|
| 238 |
+
torch.concat([
|
| 239 |
+
torch.nn.functional.interpolate(
|
| 240 |
+
img[None].cpu(), size=(h, w), mode='bicubic').transpose(
|
| 241 |
+
0, 1),
|
| 242 |
+
torch.zeros(3, F - 1, h, w)
|
| 243 |
+
],
|
| 244 |
+
dim=1).to(self.device)
|
| 245 |
+
])[0]
|
| 246 |
+
y = torch.concat([msk, y])
|
| 247 |
+
|
| 248 |
+
@contextmanager
|
| 249 |
+
def noop_no_sync():
|
| 250 |
+
yield
|
| 251 |
+
|
| 252 |
+
no_sync = getattr(self.model, 'no_sync', noop_no_sync)
|
| 253 |
+
|
| 254 |
+
# evaluation mode
|
| 255 |
+
with amp.autocast(dtype=self.param_dtype), torch.no_grad(), no_sync():
|
| 256 |
+
|
| 257 |
+
if sample_solver == 'unipc':
|
| 258 |
+
sample_scheduler = FlowUniPCMultistepScheduler(
|
| 259 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 260 |
+
shift=1,
|
| 261 |
+
use_dynamic_shifting=False)
|
| 262 |
+
sample_scheduler.set_timesteps(
|
| 263 |
+
sampling_steps, device=self.device, shift=shift)
|
| 264 |
+
timesteps = sample_scheduler.timesteps
|
| 265 |
+
elif sample_solver == 'dpm++':
|
| 266 |
+
sample_scheduler = FlowDPMSolverMultistepScheduler(
|
| 267 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 268 |
+
shift=1,
|
| 269 |
+
use_dynamic_shifting=False)
|
| 270 |
+
sampling_sigmas = get_sampling_sigmas(sampling_steps, shift)
|
| 271 |
+
timesteps, _ = retrieve_timesteps(
|
| 272 |
+
sample_scheduler,
|
| 273 |
+
device=self.device,
|
| 274 |
+
sigmas=sampling_sigmas)
|
| 275 |
+
else:
|
| 276 |
+
raise NotImplementedError("Unsupported solver.")
|
| 277 |
+
|
| 278 |
+
# sample videos
|
| 279 |
+
latent = noise
|
| 280 |
+
|
| 281 |
+
arg_c = {
|
| 282 |
+
'context': [context[0]],
|
| 283 |
+
'clip_fea': clip_context,
|
| 284 |
+
'seq_len': max_seq_len,
|
| 285 |
+
'y': [y],
|
| 286 |
+
}
|
| 287 |
+
|
| 288 |
+
arg_null = {
|
| 289 |
+
'context': context_null,
|
| 290 |
+
'clip_fea': clip_context,
|
| 291 |
+
'seq_len': max_seq_len,
|
| 292 |
+
'y': [y],
|
| 293 |
+
}
|
| 294 |
+
|
| 295 |
+
if offload_model:
|
| 296 |
+
torch.cuda.empty_cache()
|
| 297 |
+
|
| 298 |
+
self.model.to(self.device)
|
| 299 |
+
for _, t in enumerate(tqdm(timesteps)):
|
| 300 |
+
latent_model_input = [latent.to(self.device)]
|
| 301 |
+
timestep = [t]
|
| 302 |
+
|
| 303 |
+
timestep = torch.stack(timestep).to(self.device)
|
| 304 |
+
|
| 305 |
+
noise_pred_cond = self.model(
|
| 306 |
+
latent_model_input, t=timestep, **arg_c)[0].to(
|
| 307 |
+
torch.device('cpu') if offload_model else self.device)
|
| 308 |
+
if offload_model:
|
| 309 |
+
torch.cuda.empty_cache()
|
| 310 |
+
noise_pred_uncond = self.model(
|
| 311 |
+
latent_model_input, t=timestep, **arg_null)[0].to(
|
| 312 |
+
torch.device('cpu') if offload_model else self.device)
|
| 313 |
+
if offload_model:
|
| 314 |
+
torch.cuda.empty_cache()
|
| 315 |
+
noise_pred = noise_pred_uncond + guide_scale * (
|
| 316 |
+
noise_pred_cond - noise_pred_uncond)
|
| 317 |
+
|
| 318 |
+
latent = latent.to(
|
| 319 |
+
torch.device('cpu') if offload_model else self.device)
|
| 320 |
+
|
| 321 |
+
temp_x0 = sample_scheduler.step(
|
| 322 |
+
noise_pred.unsqueeze(0),
|
| 323 |
+
t,
|
| 324 |
+
latent.unsqueeze(0),
|
| 325 |
+
return_dict=False,
|
| 326 |
+
generator=seed_g)[0]
|
| 327 |
+
latent = temp_x0.squeeze(0)
|
| 328 |
+
|
| 329 |
+
x0 = [latent.to(self.device)]
|
| 330 |
+
del latent_model_input, timestep
|
| 331 |
+
|
| 332 |
+
if offload_model:
|
| 333 |
+
self.model.cpu()
|
| 334 |
+
torch.cuda.empty_cache()
|
| 335 |
+
|
| 336 |
+
if self.rank == 0:
|
| 337 |
+
videos = self.vae.decode(x0)
|
| 338 |
+
|
| 339 |
+
del noise, latent
|
| 340 |
+
del sample_scheduler
|
| 341 |
+
if offload_model:
|
| 342 |
+
gc.collect()
|
| 343 |
+
torch.cuda.synchronize()
|
| 344 |
+
if dist.is_initialized():
|
| 345 |
+
dist.barrier()
|
| 346 |
+
|
| 347 |
+
return videos[0] if self.rank == 0 else None
|
wan/modules/__init__.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .attention import flash_attention
|
| 2 |
+
from .model import WanModel
|
| 3 |
+
from .t5 import T5Decoder, T5Encoder, T5EncoderModel, T5Model
|
| 4 |
+
from .tokenizers import HuggingfaceTokenizer
|
| 5 |
+
from .vace_model import VaceWanModel
|
| 6 |
+
from .vae import WanVAE
|
| 7 |
+
|
| 8 |
+
__all__ = [
|
| 9 |
+
'WanVAE',
|
| 10 |
+
'WanModel',
|
| 11 |
+
'VaceWanModel',
|
| 12 |
+
'T5Model',
|
| 13 |
+
'T5Encoder',
|
| 14 |
+
'T5Decoder',
|
| 15 |
+
'T5EncoderModel',
|
| 16 |
+
'HuggingfaceTokenizer',
|
| 17 |
+
'flash_attention',
|
| 18 |
+
]
|
wan/modules/attention.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
try:
|
| 5 |
+
import flash_attn_interface
|
| 6 |
+
FLASH_ATTN_3_AVAILABLE = True
|
| 7 |
+
except ModuleNotFoundError:
|
| 8 |
+
FLASH_ATTN_3_AVAILABLE = False
|
| 9 |
+
|
| 10 |
+
try:
|
| 11 |
+
import flash_attn
|
| 12 |
+
FLASH_ATTN_2_AVAILABLE = True
|
| 13 |
+
except ModuleNotFoundError:
|
| 14 |
+
FLASH_ATTN_2_AVAILABLE = False
|
| 15 |
+
|
| 16 |
+
import warnings
|
| 17 |
+
|
| 18 |
+
__all__ = [
|
| 19 |
+
'flash_attention',
|
| 20 |
+
'attention',
|
| 21 |
+
]
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def flash_attention(
|
| 25 |
+
q,
|
| 26 |
+
k,
|
| 27 |
+
v,
|
| 28 |
+
q_lens=None,
|
| 29 |
+
k_lens=None,
|
| 30 |
+
dropout_p=0.,
|
| 31 |
+
softmax_scale=None,
|
| 32 |
+
q_scale=None,
|
| 33 |
+
causal=False,
|
| 34 |
+
window_size=(-1, -1),
|
| 35 |
+
deterministic=False,
|
| 36 |
+
dtype=torch.bfloat16,
|
| 37 |
+
version=None,
|
| 38 |
+
):
|
| 39 |
+
"""
|
| 40 |
+
q: [B, Lq, Nq, C1].
|
| 41 |
+
k: [B, Lk, Nk, C1].
|
| 42 |
+
v: [B, Lk, Nk, C2]. Nq must be divisible by Nk.
|
| 43 |
+
q_lens: [B].
|
| 44 |
+
k_lens: [B].
|
| 45 |
+
dropout_p: float. Dropout probability.
|
| 46 |
+
softmax_scale: float. The scaling of QK^T before applying softmax.
|
| 47 |
+
causal: bool. Whether to apply causal attention mask.
|
| 48 |
+
window_size: (left right). If not (-1, -1), apply sliding window local attention.
|
| 49 |
+
deterministic: bool. If True, slightly slower and uses more memory.
|
| 50 |
+
dtype: torch.dtype. Apply when dtype of q/k/v is not float16/bfloat16.
|
| 51 |
+
"""
|
| 52 |
+
half_dtypes = (torch.float16, torch.bfloat16)
|
| 53 |
+
assert dtype in half_dtypes
|
| 54 |
+
assert q.device.type == 'cuda' and q.size(-1) <= 256
|
| 55 |
+
|
| 56 |
+
# params
|
| 57 |
+
b, lq, lk, out_dtype = q.size(0), q.size(1), k.size(1), q.dtype
|
| 58 |
+
|
| 59 |
+
def half(x):
|
| 60 |
+
return x if x.dtype in half_dtypes else x.to(dtype)
|
| 61 |
+
|
| 62 |
+
# preprocess query
|
| 63 |
+
if q_lens is None:
|
| 64 |
+
q = half(q.flatten(0, 1))
|
| 65 |
+
q_lens = torch.tensor(
|
| 66 |
+
[lq] * b, dtype=torch.int32).to(
|
| 67 |
+
device=q.device, non_blocking=True)
|
| 68 |
+
else:
|
| 69 |
+
q = half(torch.cat([u[:v] for u, v in zip(q, q_lens)]))
|
| 70 |
+
|
| 71 |
+
# preprocess key, value
|
| 72 |
+
if k_lens is None:
|
| 73 |
+
k = half(k.flatten(0, 1))
|
| 74 |
+
v = half(v.flatten(0, 1))
|
| 75 |
+
k_lens = torch.tensor(
|
| 76 |
+
[lk] * b, dtype=torch.int32).to(
|
| 77 |
+
device=k.device, non_blocking=True)
|
| 78 |
+
else:
|
| 79 |
+
k = half(torch.cat([u[:v] for u, v in zip(k, k_lens)]))
|
| 80 |
+
v = half(torch.cat([u[:v] for u, v in zip(v, k_lens)]))
|
| 81 |
+
|
| 82 |
+
q = q.to(v.dtype)
|
| 83 |
+
k = k.to(v.dtype)
|
| 84 |
+
|
| 85 |
+
if q_scale is not None:
|
| 86 |
+
q = q * q_scale
|
| 87 |
+
|
| 88 |
+
if version is not None and version == 3 and not FLASH_ATTN_3_AVAILABLE:
|
| 89 |
+
warnings.warn(
|
| 90 |
+
'Flash attention 3 is not available, use flash attention 2 instead.'
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# apply attention
|
| 94 |
+
if (version is None or version == 3) and FLASH_ATTN_3_AVAILABLE:
|
| 95 |
+
# Note: dropout_p, window_size are not supported in FA3 now.
|
| 96 |
+
x = flash_attn_interface.flash_attn_varlen_func(
|
| 97 |
+
q=q,
|
| 98 |
+
k=k,
|
| 99 |
+
v=v,
|
| 100 |
+
cu_seqlens_q=torch.cat([q_lens.new_zeros([1]), q_lens]).cumsum(
|
| 101 |
+
0, dtype=torch.int32).to(q.device, non_blocking=True),
|
| 102 |
+
cu_seqlens_k=torch.cat([k_lens.new_zeros([1]), k_lens]).cumsum(
|
| 103 |
+
0, dtype=torch.int32).to(q.device, non_blocking=True),
|
| 104 |
+
seqused_q=None,
|
| 105 |
+
seqused_k=None,
|
| 106 |
+
max_seqlen_q=lq,
|
| 107 |
+
max_seqlen_k=lk,
|
| 108 |
+
softmax_scale=softmax_scale,
|
| 109 |
+
causal=causal,
|
| 110 |
+
deterministic=deterministic)[0].unflatten(0, (b, lq))
|
| 111 |
+
else:
|
| 112 |
+
assert FLASH_ATTN_2_AVAILABLE
|
| 113 |
+
x = flash_attn.flash_attn_varlen_func(
|
| 114 |
+
q=q,
|
| 115 |
+
k=k,
|
| 116 |
+
v=v,
|
| 117 |
+
cu_seqlens_q=torch.cat([q_lens.new_zeros([1]), q_lens]).cumsum(
|
| 118 |
+
0, dtype=torch.int32).to(q.device, non_blocking=True),
|
| 119 |
+
cu_seqlens_k=torch.cat([k_lens.new_zeros([1]), k_lens]).cumsum(
|
| 120 |
+
0, dtype=torch.int32).to(q.device, non_blocking=True),
|
| 121 |
+
max_seqlen_q=lq,
|
| 122 |
+
max_seqlen_k=lk,
|
| 123 |
+
dropout_p=dropout_p,
|
| 124 |
+
softmax_scale=softmax_scale,
|
| 125 |
+
causal=causal,
|
| 126 |
+
window_size=window_size,
|
| 127 |
+
deterministic=deterministic).unflatten(0, (b, lq))
|
| 128 |
+
|
| 129 |
+
# output
|
| 130 |
+
return x.type(out_dtype)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def attention(
|
| 134 |
+
q,
|
| 135 |
+
k,
|
| 136 |
+
v,
|
| 137 |
+
q_lens=None,
|
| 138 |
+
k_lens=None,
|
| 139 |
+
dropout_p=0.,
|
| 140 |
+
softmax_scale=None,
|
| 141 |
+
q_scale=None,
|
| 142 |
+
causal=False,
|
| 143 |
+
window_size=(-1, -1),
|
| 144 |
+
deterministic=False,
|
| 145 |
+
dtype=torch.bfloat16,
|
| 146 |
+
fa_version=None,
|
| 147 |
+
):
|
| 148 |
+
if FLASH_ATTN_2_AVAILABLE or FLASH_ATTN_3_AVAILABLE:
|
| 149 |
+
return flash_attention(
|
| 150 |
+
q=q,
|
| 151 |
+
k=k,
|
| 152 |
+
v=v,
|
| 153 |
+
q_lens=q_lens,
|
| 154 |
+
k_lens=k_lens,
|
| 155 |
+
dropout_p=dropout_p,
|
| 156 |
+
softmax_scale=softmax_scale,
|
| 157 |
+
q_scale=q_scale,
|
| 158 |
+
causal=causal,
|
| 159 |
+
window_size=window_size,
|
| 160 |
+
deterministic=deterministic,
|
| 161 |
+
dtype=dtype,
|
| 162 |
+
version=fa_version,
|
| 163 |
+
)
|
| 164 |
+
else:
|
| 165 |
+
if q_lens is not None or k_lens is not None:
|
| 166 |
+
warnings.warn(
|
| 167 |
+
'Padding mask is disabled when using scaled_dot_product_attention. It can have a significant impact on performance.'
|
| 168 |
+
)
|
| 169 |
+
attn_mask = None
|
| 170 |
+
|
| 171 |
+
q = q.transpose(1, 2).to(dtype)
|
| 172 |
+
k = k.transpose(1, 2).to(dtype)
|
| 173 |
+
v = v.transpose(1, 2).to(dtype)
|
| 174 |
+
|
| 175 |
+
out = torch.nn.functional.scaled_dot_product_attention(
|
| 176 |
+
q, k, v, attn_mask=attn_mask, is_causal=causal, dropout_p=dropout_p)
|
| 177 |
+
|
| 178 |
+
out = out.transpose(1, 2).contiguous()
|
| 179 |
+
return out
|
wan/modules/clip.py
ADDED
|
@@ -0,0 +1,542 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from ``https://github.com/openai/CLIP'' and ``https://github.com/mlfoundations/open_clip''
|
| 2 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 3 |
+
import logging
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
import torchvision.transforms as T
|
| 10 |
+
|
| 11 |
+
from .attention import flash_attention
|
| 12 |
+
from .tokenizers import HuggingfaceTokenizer
|
| 13 |
+
from .xlm_roberta import XLMRoberta
|
| 14 |
+
|
| 15 |
+
__all__ = [
|
| 16 |
+
'XLMRobertaCLIP',
|
| 17 |
+
'clip_xlm_roberta_vit_h_14',
|
| 18 |
+
'CLIPModel',
|
| 19 |
+
]
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def pos_interpolate(pos, seq_len):
|
| 23 |
+
if pos.size(1) == seq_len:
|
| 24 |
+
return pos
|
| 25 |
+
else:
|
| 26 |
+
src_grid = int(math.sqrt(pos.size(1)))
|
| 27 |
+
tar_grid = int(math.sqrt(seq_len))
|
| 28 |
+
n = pos.size(1) - src_grid * src_grid
|
| 29 |
+
return torch.cat([
|
| 30 |
+
pos[:, :n],
|
| 31 |
+
F.interpolate(
|
| 32 |
+
pos[:, n:].float().reshape(1, src_grid, src_grid, -1).permute(
|
| 33 |
+
0, 3, 1, 2),
|
| 34 |
+
size=(tar_grid, tar_grid),
|
| 35 |
+
mode='bicubic',
|
| 36 |
+
align_corners=False).flatten(2).transpose(1, 2)
|
| 37 |
+
],
|
| 38 |
+
dim=1)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class QuickGELU(nn.Module):
|
| 42 |
+
|
| 43 |
+
def forward(self, x):
|
| 44 |
+
return x * torch.sigmoid(1.702 * x)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class LayerNorm(nn.LayerNorm):
|
| 48 |
+
|
| 49 |
+
def forward(self, x):
|
| 50 |
+
return super().forward(x.float()).type_as(x)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class SelfAttention(nn.Module):
|
| 54 |
+
|
| 55 |
+
def __init__(self,
|
| 56 |
+
dim,
|
| 57 |
+
num_heads,
|
| 58 |
+
causal=False,
|
| 59 |
+
attn_dropout=0.0,
|
| 60 |
+
proj_dropout=0.0):
|
| 61 |
+
assert dim % num_heads == 0
|
| 62 |
+
super().__init__()
|
| 63 |
+
self.dim = dim
|
| 64 |
+
self.num_heads = num_heads
|
| 65 |
+
self.head_dim = dim // num_heads
|
| 66 |
+
self.causal = causal
|
| 67 |
+
self.attn_dropout = attn_dropout
|
| 68 |
+
self.proj_dropout = proj_dropout
|
| 69 |
+
|
| 70 |
+
# layers
|
| 71 |
+
self.to_qkv = nn.Linear(dim, dim * 3)
|
| 72 |
+
self.proj = nn.Linear(dim, dim)
|
| 73 |
+
|
| 74 |
+
def forward(self, x):
|
| 75 |
+
"""
|
| 76 |
+
x: [B, L, C].
|
| 77 |
+
"""
|
| 78 |
+
b, s, c, n, d = *x.size(), self.num_heads, self.head_dim
|
| 79 |
+
|
| 80 |
+
# compute query, key, value
|
| 81 |
+
q, k, v = self.to_qkv(x).view(b, s, 3, n, d).unbind(2)
|
| 82 |
+
|
| 83 |
+
# compute attention
|
| 84 |
+
p = self.attn_dropout if self.training else 0.0
|
| 85 |
+
x = flash_attention(q, k, v, dropout_p=p, causal=self.causal, version=2)
|
| 86 |
+
x = x.reshape(b, s, c)
|
| 87 |
+
|
| 88 |
+
# output
|
| 89 |
+
x = self.proj(x)
|
| 90 |
+
x = F.dropout(x, self.proj_dropout, self.training)
|
| 91 |
+
return x
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class SwiGLU(nn.Module):
|
| 95 |
+
|
| 96 |
+
def __init__(self, dim, mid_dim):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.dim = dim
|
| 99 |
+
self.mid_dim = mid_dim
|
| 100 |
+
|
| 101 |
+
# layers
|
| 102 |
+
self.fc1 = nn.Linear(dim, mid_dim)
|
| 103 |
+
self.fc2 = nn.Linear(dim, mid_dim)
|
| 104 |
+
self.fc3 = nn.Linear(mid_dim, dim)
|
| 105 |
+
|
| 106 |
+
def forward(self, x):
|
| 107 |
+
x = F.silu(self.fc1(x)) * self.fc2(x)
|
| 108 |
+
x = self.fc3(x)
|
| 109 |
+
return x
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class AttentionBlock(nn.Module):
|
| 113 |
+
|
| 114 |
+
def __init__(self,
|
| 115 |
+
dim,
|
| 116 |
+
mlp_ratio,
|
| 117 |
+
num_heads,
|
| 118 |
+
post_norm=False,
|
| 119 |
+
causal=False,
|
| 120 |
+
activation='quick_gelu',
|
| 121 |
+
attn_dropout=0.0,
|
| 122 |
+
proj_dropout=0.0,
|
| 123 |
+
norm_eps=1e-5):
|
| 124 |
+
assert activation in ['quick_gelu', 'gelu', 'swi_glu']
|
| 125 |
+
super().__init__()
|
| 126 |
+
self.dim = dim
|
| 127 |
+
self.mlp_ratio = mlp_ratio
|
| 128 |
+
self.num_heads = num_heads
|
| 129 |
+
self.post_norm = post_norm
|
| 130 |
+
self.causal = causal
|
| 131 |
+
self.norm_eps = norm_eps
|
| 132 |
+
|
| 133 |
+
# layers
|
| 134 |
+
self.norm1 = LayerNorm(dim, eps=norm_eps)
|
| 135 |
+
self.attn = SelfAttention(dim, num_heads, causal, attn_dropout,
|
| 136 |
+
proj_dropout)
|
| 137 |
+
self.norm2 = LayerNorm(dim, eps=norm_eps)
|
| 138 |
+
if activation == 'swi_glu':
|
| 139 |
+
self.mlp = SwiGLU(dim, int(dim * mlp_ratio))
|
| 140 |
+
else:
|
| 141 |
+
self.mlp = nn.Sequential(
|
| 142 |
+
nn.Linear(dim, int(dim * mlp_ratio)),
|
| 143 |
+
QuickGELU() if activation == 'quick_gelu' else nn.GELU(),
|
| 144 |
+
nn.Linear(int(dim * mlp_ratio), dim), nn.Dropout(proj_dropout))
|
| 145 |
+
|
| 146 |
+
def forward(self, x):
|
| 147 |
+
if self.post_norm:
|
| 148 |
+
x = x + self.norm1(self.attn(x))
|
| 149 |
+
x = x + self.norm2(self.mlp(x))
|
| 150 |
+
else:
|
| 151 |
+
x = x + self.attn(self.norm1(x))
|
| 152 |
+
x = x + self.mlp(self.norm2(x))
|
| 153 |
+
return x
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
class AttentionPool(nn.Module):
|
| 157 |
+
|
| 158 |
+
def __init__(self,
|
| 159 |
+
dim,
|
| 160 |
+
mlp_ratio,
|
| 161 |
+
num_heads,
|
| 162 |
+
activation='gelu',
|
| 163 |
+
proj_dropout=0.0,
|
| 164 |
+
norm_eps=1e-5):
|
| 165 |
+
assert dim % num_heads == 0
|
| 166 |
+
super().__init__()
|
| 167 |
+
self.dim = dim
|
| 168 |
+
self.mlp_ratio = mlp_ratio
|
| 169 |
+
self.num_heads = num_heads
|
| 170 |
+
self.head_dim = dim // num_heads
|
| 171 |
+
self.proj_dropout = proj_dropout
|
| 172 |
+
self.norm_eps = norm_eps
|
| 173 |
+
|
| 174 |
+
# layers
|
| 175 |
+
gain = 1.0 / math.sqrt(dim)
|
| 176 |
+
self.cls_embedding = nn.Parameter(gain * torch.randn(1, 1, dim))
|
| 177 |
+
self.to_q = nn.Linear(dim, dim)
|
| 178 |
+
self.to_kv = nn.Linear(dim, dim * 2)
|
| 179 |
+
self.proj = nn.Linear(dim, dim)
|
| 180 |
+
self.norm = LayerNorm(dim, eps=norm_eps)
|
| 181 |
+
self.mlp = nn.Sequential(
|
| 182 |
+
nn.Linear(dim, int(dim * mlp_ratio)),
|
| 183 |
+
QuickGELU() if activation == 'quick_gelu' else nn.GELU(),
|
| 184 |
+
nn.Linear(int(dim * mlp_ratio), dim), nn.Dropout(proj_dropout))
|
| 185 |
+
|
| 186 |
+
def forward(self, x):
|
| 187 |
+
"""
|
| 188 |
+
x: [B, L, C].
|
| 189 |
+
"""
|
| 190 |
+
b, s, c, n, d = *x.size(), self.num_heads, self.head_dim
|
| 191 |
+
|
| 192 |
+
# compute query, key, value
|
| 193 |
+
q = self.to_q(self.cls_embedding).view(1, 1, n, d).expand(b, -1, -1, -1)
|
| 194 |
+
k, v = self.to_kv(x).view(b, s, 2, n, d).unbind(2)
|
| 195 |
+
|
| 196 |
+
# compute attention
|
| 197 |
+
x = flash_attention(q, k, v, version=2)
|
| 198 |
+
x = x.reshape(b, 1, c)
|
| 199 |
+
|
| 200 |
+
# output
|
| 201 |
+
x = self.proj(x)
|
| 202 |
+
x = F.dropout(x, self.proj_dropout, self.training)
|
| 203 |
+
|
| 204 |
+
# mlp
|
| 205 |
+
x = x + self.mlp(self.norm(x))
|
| 206 |
+
return x[:, 0]
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
class VisionTransformer(nn.Module):
|
| 210 |
+
|
| 211 |
+
def __init__(self,
|
| 212 |
+
image_size=224,
|
| 213 |
+
patch_size=16,
|
| 214 |
+
dim=768,
|
| 215 |
+
mlp_ratio=4,
|
| 216 |
+
out_dim=512,
|
| 217 |
+
num_heads=12,
|
| 218 |
+
num_layers=12,
|
| 219 |
+
pool_type='token',
|
| 220 |
+
pre_norm=True,
|
| 221 |
+
post_norm=False,
|
| 222 |
+
activation='quick_gelu',
|
| 223 |
+
attn_dropout=0.0,
|
| 224 |
+
proj_dropout=0.0,
|
| 225 |
+
embedding_dropout=0.0,
|
| 226 |
+
norm_eps=1e-5):
|
| 227 |
+
if image_size % patch_size != 0:
|
| 228 |
+
print(
|
| 229 |
+
'[WARNING] image_size is not divisible by patch_size',
|
| 230 |
+
flush=True)
|
| 231 |
+
assert pool_type in ('token', 'token_fc', 'attn_pool')
|
| 232 |
+
out_dim = out_dim or dim
|
| 233 |
+
super().__init__()
|
| 234 |
+
self.image_size = image_size
|
| 235 |
+
self.patch_size = patch_size
|
| 236 |
+
self.num_patches = (image_size // patch_size)**2
|
| 237 |
+
self.dim = dim
|
| 238 |
+
self.mlp_ratio = mlp_ratio
|
| 239 |
+
self.out_dim = out_dim
|
| 240 |
+
self.num_heads = num_heads
|
| 241 |
+
self.num_layers = num_layers
|
| 242 |
+
self.pool_type = pool_type
|
| 243 |
+
self.post_norm = post_norm
|
| 244 |
+
self.norm_eps = norm_eps
|
| 245 |
+
|
| 246 |
+
# embeddings
|
| 247 |
+
gain = 1.0 / math.sqrt(dim)
|
| 248 |
+
self.patch_embedding = nn.Conv2d(
|
| 249 |
+
3,
|
| 250 |
+
dim,
|
| 251 |
+
kernel_size=patch_size,
|
| 252 |
+
stride=patch_size,
|
| 253 |
+
bias=not pre_norm)
|
| 254 |
+
if pool_type in ('token', 'token_fc'):
|
| 255 |
+
self.cls_embedding = nn.Parameter(gain * torch.randn(1, 1, dim))
|
| 256 |
+
self.pos_embedding = nn.Parameter(gain * torch.randn(
|
| 257 |
+
1, self.num_patches +
|
| 258 |
+
(1 if pool_type in ('token', 'token_fc') else 0), dim))
|
| 259 |
+
self.dropout = nn.Dropout(embedding_dropout)
|
| 260 |
+
|
| 261 |
+
# transformer
|
| 262 |
+
self.pre_norm = LayerNorm(dim, eps=norm_eps) if pre_norm else None
|
| 263 |
+
self.transformer = nn.Sequential(*[
|
| 264 |
+
AttentionBlock(dim, mlp_ratio, num_heads, post_norm, False,
|
| 265 |
+
activation, attn_dropout, proj_dropout, norm_eps)
|
| 266 |
+
for _ in range(num_layers)
|
| 267 |
+
])
|
| 268 |
+
self.post_norm = LayerNorm(dim, eps=norm_eps)
|
| 269 |
+
|
| 270 |
+
# head
|
| 271 |
+
if pool_type == 'token':
|
| 272 |
+
self.head = nn.Parameter(gain * torch.randn(dim, out_dim))
|
| 273 |
+
elif pool_type == 'token_fc':
|
| 274 |
+
self.head = nn.Linear(dim, out_dim)
|
| 275 |
+
elif pool_type == 'attn_pool':
|
| 276 |
+
self.head = AttentionPool(dim, mlp_ratio, num_heads, activation,
|
| 277 |
+
proj_dropout, norm_eps)
|
| 278 |
+
|
| 279 |
+
def forward(self, x, interpolation=False, use_31_block=False):
|
| 280 |
+
b = x.size(0)
|
| 281 |
+
|
| 282 |
+
# embeddings
|
| 283 |
+
x = self.patch_embedding(x).flatten(2).permute(0, 2, 1)
|
| 284 |
+
if self.pool_type in ('token', 'token_fc'):
|
| 285 |
+
x = torch.cat([self.cls_embedding.expand(b, -1, -1), x], dim=1)
|
| 286 |
+
if interpolation:
|
| 287 |
+
e = pos_interpolate(self.pos_embedding, x.size(1))
|
| 288 |
+
else:
|
| 289 |
+
e = self.pos_embedding
|
| 290 |
+
x = self.dropout(x + e)
|
| 291 |
+
if self.pre_norm is not None:
|
| 292 |
+
x = self.pre_norm(x)
|
| 293 |
+
|
| 294 |
+
# transformer
|
| 295 |
+
if use_31_block:
|
| 296 |
+
x = self.transformer[:-1](x)
|
| 297 |
+
return x
|
| 298 |
+
else:
|
| 299 |
+
x = self.transformer(x)
|
| 300 |
+
return x
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
class XLMRobertaWithHead(XLMRoberta):
|
| 304 |
+
|
| 305 |
+
def __init__(self, **kwargs):
|
| 306 |
+
self.out_dim = kwargs.pop('out_dim')
|
| 307 |
+
super().__init__(**kwargs)
|
| 308 |
+
|
| 309 |
+
# head
|
| 310 |
+
mid_dim = (self.dim + self.out_dim) // 2
|
| 311 |
+
self.head = nn.Sequential(
|
| 312 |
+
nn.Linear(self.dim, mid_dim, bias=False), nn.GELU(),
|
| 313 |
+
nn.Linear(mid_dim, self.out_dim, bias=False))
|
| 314 |
+
|
| 315 |
+
def forward(self, ids):
|
| 316 |
+
# xlm-roberta
|
| 317 |
+
x = super().forward(ids)
|
| 318 |
+
|
| 319 |
+
# average pooling
|
| 320 |
+
mask = ids.ne(self.pad_id).unsqueeze(-1).to(x)
|
| 321 |
+
x = (x * mask).sum(dim=1) / mask.sum(dim=1)
|
| 322 |
+
|
| 323 |
+
# head
|
| 324 |
+
x = self.head(x)
|
| 325 |
+
return x
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
class XLMRobertaCLIP(nn.Module):
|
| 329 |
+
|
| 330 |
+
def __init__(self,
|
| 331 |
+
embed_dim=1024,
|
| 332 |
+
image_size=224,
|
| 333 |
+
patch_size=14,
|
| 334 |
+
vision_dim=1280,
|
| 335 |
+
vision_mlp_ratio=4,
|
| 336 |
+
vision_heads=16,
|
| 337 |
+
vision_layers=32,
|
| 338 |
+
vision_pool='token',
|
| 339 |
+
vision_pre_norm=True,
|
| 340 |
+
vision_post_norm=False,
|
| 341 |
+
activation='gelu',
|
| 342 |
+
vocab_size=250002,
|
| 343 |
+
max_text_len=514,
|
| 344 |
+
type_size=1,
|
| 345 |
+
pad_id=1,
|
| 346 |
+
text_dim=1024,
|
| 347 |
+
text_heads=16,
|
| 348 |
+
text_layers=24,
|
| 349 |
+
text_post_norm=True,
|
| 350 |
+
text_dropout=0.1,
|
| 351 |
+
attn_dropout=0.0,
|
| 352 |
+
proj_dropout=0.0,
|
| 353 |
+
embedding_dropout=0.0,
|
| 354 |
+
norm_eps=1e-5):
|
| 355 |
+
super().__init__()
|
| 356 |
+
self.embed_dim = embed_dim
|
| 357 |
+
self.image_size = image_size
|
| 358 |
+
self.patch_size = patch_size
|
| 359 |
+
self.vision_dim = vision_dim
|
| 360 |
+
self.vision_mlp_ratio = vision_mlp_ratio
|
| 361 |
+
self.vision_heads = vision_heads
|
| 362 |
+
self.vision_layers = vision_layers
|
| 363 |
+
self.vision_pre_norm = vision_pre_norm
|
| 364 |
+
self.vision_post_norm = vision_post_norm
|
| 365 |
+
self.activation = activation
|
| 366 |
+
self.vocab_size = vocab_size
|
| 367 |
+
self.max_text_len = max_text_len
|
| 368 |
+
self.type_size = type_size
|
| 369 |
+
self.pad_id = pad_id
|
| 370 |
+
self.text_dim = text_dim
|
| 371 |
+
self.text_heads = text_heads
|
| 372 |
+
self.text_layers = text_layers
|
| 373 |
+
self.text_post_norm = text_post_norm
|
| 374 |
+
self.norm_eps = norm_eps
|
| 375 |
+
|
| 376 |
+
# models
|
| 377 |
+
self.visual = VisionTransformer(
|
| 378 |
+
image_size=image_size,
|
| 379 |
+
patch_size=patch_size,
|
| 380 |
+
dim=vision_dim,
|
| 381 |
+
mlp_ratio=vision_mlp_ratio,
|
| 382 |
+
out_dim=embed_dim,
|
| 383 |
+
num_heads=vision_heads,
|
| 384 |
+
num_layers=vision_layers,
|
| 385 |
+
pool_type=vision_pool,
|
| 386 |
+
pre_norm=vision_pre_norm,
|
| 387 |
+
post_norm=vision_post_norm,
|
| 388 |
+
activation=activation,
|
| 389 |
+
attn_dropout=attn_dropout,
|
| 390 |
+
proj_dropout=proj_dropout,
|
| 391 |
+
embedding_dropout=embedding_dropout,
|
| 392 |
+
norm_eps=norm_eps)
|
| 393 |
+
self.textual = XLMRobertaWithHead(
|
| 394 |
+
vocab_size=vocab_size,
|
| 395 |
+
max_seq_len=max_text_len,
|
| 396 |
+
type_size=type_size,
|
| 397 |
+
pad_id=pad_id,
|
| 398 |
+
dim=text_dim,
|
| 399 |
+
out_dim=embed_dim,
|
| 400 |
+
num_heads=text_heads,
|
| 401 |
+
num_layers=text_layers,
|
| 402 |
+
post_norm=text_post_norm,
|
| 403 |
+
dropout=text_dropout)
|
| 404 |
+
self.log_scale = nn.Parameter(math.log(1 / 0.07) * torch.ones([]))
|
| 405 |
+
|
| 406 |
+
def forward(self, imgs, txt_ids):
|
| 407 |
+
"""
|
| 408 |
+
imgs: [B, 3, H, W] of torch.float32.
|
| 409 |
+
- mean: [0.48145466, 0.4578275, 0.40821073]
|
| 410 |
+
- std: [0.26862954, 0.26130258, 0.27577711]
|
| 411 |
+
txt_ids: [B, L] of torch.long.
|
| 412 |
+
Encoded by data.CLIPTokenizer.
|
| 413 |
+
"""
|
| 414 |
+
xi = self.visual(imgs)
|
| 415 |
+
xt = self.textual(txt_ids)
|
| 416 |
+
return xi, xt
|
| 417 |
+
|
| 418 |
+
def param_groups(self):
|
| 419 |
+
groups = [{
|
| 420 |
+
'params': [
|
| 421 |
+
p for n, p in self.named_parameters()
|
| 422 |
+
if 'norm' in n or n.endswith('bias')
|
| 423 |
+
],
|
| 424 |
+
'weight_decay': 0.0
|
| 425 |
+
}, {
|
| 426 |
+
'params': [
|
| 427 |
+
p for n, p in self.named_parameters()
|
| 428 |
+
if not ('norm' in n or n.endswith('bias'))
|
| 429 |
+
]
|
| 430 |
+
}]
|
| 431 |
+
return groups
|
| 432 |
+
|
| 433 |
+
|
| 434 |
+
def _clip(pretrained=False,
|
| 435 |
+
pretrained_name=None,
|
| 436 |
+
model_cls=XLMRobertaCLIP,
|
| 437 |
+
return_transforms=False,
|
| 438 |
+
return_tokenizer=False,
|
| 439 |
+
tokenizer_padding='eos',
|
| 440 |
+
dtype=torch.float32,
|
| 441 |
+
device='cpu',
|
| 442 |
+
**kwargs):
|
| 443 |
+
# init a model on device
|
| 444 |
+
with torch.device(device):
|
| 445 |
+
model = model_cls(**kwargs)
|
| 446 |
+
|
| 447 |
+
# set device
|
| 448 |
+
model = model.to(dtype=dtype, device=device)
|
| 449 |
+
output = (model,)
|
| 450 |
+
|
| 451 |
+
# init transforms
|
| 452 |
+
if return_transforms:
|
| 453 |
+
# mean and std
|
| 454 |
+
if 'siglip' in pretrained_name.lower():
|
| 455 |
+
mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]
|
| 456 |
+
else:
|
| 457 |
+
mean = [0.48145466, 0.4578275, 0.40821073]
|
| 458 |
+
std = [0.26862954, 0.26130258, 0.27577711]
|
| 459 |
+
|
| 460 |
+
# transforms
|
| 461 |
+
transforms = T.Compose([
|
| 462 |
+
T.Resize((model.image_size, model.image_size),
|
| 463 |
+
interpolation=T.InterpolationMode.BICUBIC),
|
| 464 |
+
T.ToTensor(),
|
| 465 |
+
T.Normalize(mean=mean, std=std)
|
| 466 |
+
])
|
| 467 |
+
output += (transforms,)
|
| 468 |
+
return output[0] if len(output) == 1 else output
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
def clip_xlm_roberta_vit_h_14(
|
| 472 |
+
pretrained=False,
|
| 473 |
+
pretrained_name='open-clip-xlm-roberta-large-vit-huge-14',
|
| 474 |
+
**kwargs):
|
| 475 |
+
cfg = dict(
|
| 476 |
+
embed_dim=1024,
|
| 477 |
+
image_size=224,
|
| 478 |
+
patch_size=14,
|
| 479 |
+
vision_dim=1280,
|
| 480 |
+
vision_mlp_ratio=4,
|
| 481 |
+
vision_heads=16,
|
| 482 |
+
vision_layers=32,
|
| 483 |
+
vision_pool='token',
|
| 484 |
+
activation='gelu',
|
| 485 |
+
vocab_size=250002,
|
| 486 |
+
max_text_len=514,
|
| 487 |
+
type_size=1,
|
| 488 |
+
pad_id=1,
|
| 489 |
+
text_dim=1024,
|
| 490 |
+
text_heads=16,
|
| 491 |
+
text_layers=24,
|
| 492 |
+
text_post_norm=True,
|
| 493 |
+
text_dropout=0.1,
|
| 494 |
+
attn_dropout=0.0,
|
| 495 |
+
proj_dropout=0.0,
|
| 496 |
+
embedding_dropout=0.0)
|
| 497 |
+
cfg.update(**kwargs)
|
| 498 |
+
return _clip(pretrained, pretrained_name, XLMRobertaCLIP, **cfg)
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
class CLIPModel:
|
| 502 |
+
|
| 503 |
+
def __init__(self, dtype, device, checkpoint_path, tokenizer_path):
|
| 504 |
+
self.dtype = dtype
|
| 505 |
+
self.device = device
|
| 506 |
+
self.checkpoint_path = checkpoint_path
|
| 507 |
+
self.tokenizer_path = tokenizer_path
|
| 508 |
+
|
| 509 |
+
# init model
|
| 510 |
+
self.model, self.transforms = clip_xlm_roberta_vit_h_14(
|
| 511 |
+
pretrained=False,
|
| 512 |
+
return_transforms=True,
|
| 513 |
+
return_tokenizer=False,
|
| 514 |
+
dtype=dtype,
|
| 515 |
+
device=device)
|
| 516 |
+
self.model = self.model.eval().requires_grad_(False)
|
| 517 |
+
logging.info(f'loading {checkpoint_path}')
|
| 518 |
+
self.model.load_state_dict(
|
| 519 |
+
torch.load(checkpoint_path, map_location='cpu'))
|
| 520 |
+
|
| 521 |
+
# init tokenizer
|
| 522 |
+
self.tokenizer = HuggingfaceTokenizer(
|
| 523 |
+
name=tokenizer_path,
|
| 524 |
+
seq_len=self.model.max_text_len - 2,
|
| 525 |
+
clean='whitespace')
|
| 526 |
+
|
| 527 |
+
def visual(self, videos):
|
| 528 |
+
# preprocess
|
| 529 |
+
size = (self.model.image_size,) * 2
|
| 530 |
+
videos = torch.cat([
|
| 531 |
+
F.interpolate(
|
| 532 |
+
u.transpose(0, 1),
|
| 533 |
+
size=size,
|
| 534 |
+
mode='bicubic',
|
| 535 |
+
align_corners=False) for u in videos
|
| 536 |
+
])
|
| 537 |
+
videos = self.transforms.transforms[-1](videos.mul_(0.5).add_(0.5))
|
| 538 |
+
|
| 539 |
+
# forward
|
| 540 |
+
with torch.cuda.amp.autocast(dtype=self.dtype):
|
| 541 |
+
out = self.model.visual(videos, use_31_block=True)
|
| 542 |
+
return out
|
wan/modules/model.py
ADDED
|
@@ -0,0 +1,630 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import math
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.cuda.amp as amp
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
| 8 |
+
from diffusers.models.modeling_utils import ModelMixin
|
| 9 |
+
|
| 10 |
+
from .attention import flash_attention
|
| 11 |
+
|
| 12 |
+
__all__ = ['WanModel']
|
| 13 |
+
|
| 14 |
+
T5_CONTEXT_TOKEN_NUMBER = 512
|
| 15 |
+
FIRST_LAST_FRAME_CONTEXT_TOKEN_NUMBER = 257 * 2
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def sinusoidal_embedding_1d(dim, position):
|
| 19 |
+
# preprocess
|
| 20 |
+
assert dim % 2 == 0
|
| 21 |
+
half = dim // 2
|
| 22 |
+
position = position.type(torch.float64)
|
| 23 |
+
|
| 24 |
+
# calculation
|
| 25 |
+
sinusoid = torch.outer(
|
| 26 |
+
position, torch.pow(10000, -torch.arange(half).to(position).div(half)))
|
| 27 |
+
x = torch.cat([torch.cos(sinusoid), torch.sin(sinusoid)], dim=1)
|
| 28 |
+
return x
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
@amp.autocast(enabled=False)
|
| 32 |
+
def rope_params(max_seq_len, dim, theta=10000):
|
| 33 |
+
assert dim % 2 == 0
|
| 34 |
+
freqs = torch.outer(
|
| 35 |
+
torch.arange(max_seq_len),
|
| 36 |
+
1.0 / torch.pow(theta,
|
| 37 |
+
torch.arange(0, dim, 2).to(torch.float64).div(dim)))
|
| 38 |
+
freqs = torch.polar(torch.ones_like(freqs), freqs)
|
| 39 |
+
return freqs
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
@amp.autocast(enabled=False)
|
| 43 |
+
def rope_apply(x, grid_sizes, freqs):
|
| 44 |
+
n, c = x.size(2), x.size(3) // 2
|
| 45 |
+
|
| 46 |
+
# split freqs
|
| 47 |
+
freqs = freqs.split([c - 2 * (c // 3), c // 3, c // 3], dim=1)
|
| 48 |
+
|
| 49 |
+
# loop over samples
|
| 50 |
+
output = []
|
| 51 |
+
for i, (f, h, w) in enumerate(grid_sizes.tolist()):
|
| 52 |
+
seq_len = f * h * w
|
| 53 |
+
|
| 54 |
+
# precompute multipliers
|
| 55 |
+
x_i = torch.view_as_complex(x[i, :seq_len].to(torch.float64).reshape(
|
| 56 |
+
seq_len, n, -1, 2))
|
| 57 |
+
freqs_i = torch.cat([
|
| 58 |
+
freqs[0][:f].view(f, 1, 1, -1).expand(f, h, w, -1),
|
| 59 |
+
freqs[1][:h].view(1, h, 1, -1).expand(f, h, w, -1),
|
| 60 |
+
freqs[2][:w].view(1, 1, w, -1).expand(f, h, w, -1)
|
| 61 |
+
],
|
| 62 |
+
dim=-1).reshape(seq_len, 1, -1)
|
| 63 |
+
|
| 64 |
+
# apply rotary embedding
|
| 65 |
+
x_i = torch.view_as_real(x_i * freqs_i).flatten(2)
|
| 66 |
+
x_i = torch.cat([x_i, x[i, seq_len:]])
|
| 67 |
+
|
| 68 |
+
# append to collection
|
| 69 |
+
output.append(x_i)
|
| 70 |
+
return torch.stack(output).float()
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class WanRMSNorm(nn.Module):
|
| 74 |
+
|
| 75 |
+
def __init__(self, dim, eps=1e-5):
|
| 76 |
+
super().__init__()
|
| 77 |
+
self.dim = dim
|
| 78 |
+
self.eps = eps
|
| 79 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 80 |
+
|
| 81 |
+
def forward(self, x):
|
| 82 |
+
r"""
|
| 83 |
+
Args:
|
| 84 |
+
x(Tensor): Shape [B, L, C]
|
| 85 |
+
"""
|
| 86 |
+
return self._norm(x.float()).type_as(x) * self.weight
|
| 87 |
+
|
| 88 |
+
def _norm(self, x):
|
| 89 |
+
return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class WanLayerNorm(nn.LayerNorm):
|
| 93 |
+
|
| 94 |
+
def __init__(self, dim, eps=1e-6, elementwise_affine=False):
|
| 95 |
+
super().__init__(dim, elementwise_affine=elementwise_affine, eps=eps)
|
| 96 |
+
|
| 97 |
+
def forward(self, x):
|
| 98 |
+
r"""
|
| 99 |
+
Args:
|
| 100 |
+
x(Tensor): Shape [B, L, C]
|
| 101 |
+
"""
|
| 102 |
+
return super().forward(x.float()).type_as(x)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class WanSelfAttention(nn.Module):
|
| 106 |
+
|
| 107 |
+
def __init__(self,
|
| 108 |
+
dim,
|
| 109 |
+
num_heads,
|
| 110 |
+
window_size=(-1, -1),
|
| 111 |
+
qk_norm=True,
|
| 112 |
+
eps=1e-6):
|
| 113 |
+
assert dim % num_heads == 0
|
| 114 |
+
super().__init__()
|
| 115 |
+
self.dim = dim
|
| 116 |
+
self.num_heads = num_heads
|
| 117 |
+
self.head_dim = dim // num_heads
|
| 118 |
+
self.window_size = window_size
|
| 119 |
+
self.qk_norm = qk_norm
|
| 120 |
+
self.eps = eps
|
| 121 |
+
|
| 122 |
+
# layers
|
| 123 |
+
self.q = nn.Linear(dim, dim)
|
| 124 |
+
self.k = nn.Linear(dim, dim)
|
| 125 |
+
self.v = nn.Linear(dim, dim)
|
| 126 |
+
self.o = nn.Linear(dim, dim)
|
| 127 |
+
self.norm_q = WanRMSNorm(dim, eps=eps) if qk_norm else nn.Identity()
|
| 128 |
+
self.norm_k = WanRMSNorm(dim, eps=eps) if qk_norm else nn.Identity()
|
| 129 |
+
|
| 130 |
+
def forward(self, x, seq_lens, grid_sizes, freqs):
|
| 131 |
+
r"""
|
| 132 |
+
Args:
|
| 133 |
+
x(Tensor): Shape [B, L, num_heads, C / num_heads]
|
| 134 |
+
seq_lens(Tensor): Shape [B]
|
| 135 |
+
grid_sizes(Tensor): Shape [B, 3], the second dimension contains (F, H, W)
|
| 136 |
+
freqs(Tensor): Rope freqs, shape [1024, C / num_heads / 2]
|
| 137 |
+
"""
|
| 138 |
+
b, s, n, d = *x.shape[:2], self.num_heads, self.head_dim
|
| 139 |
+
|
| 140 |
+
# query, key, value function
|
| 141 |
+
def qkv_fn(x):
|
| 142 |
+
q = self.norm_q(self.q(x)).view(b, s, n, d)
|
| 143 |
+
k = self.norm_k(self.k(x)).view(b, s, n, d)
|
| 144 |
+
v = self.v(x).view(b, s, n, d)
|
| 145 |
+
return q, k, v
|
| 146 |
+
|
| 147 |
+
q, k, v = qkv_fn(x)
|
| 148 |
+
|
| 149 |
+
x = flash_attention(
|
| 150 |
+
q=rope_apply(q, grid_sizes, freqs),
|
| 151 |
+
k=rope_apply(k, grid_sizes, freqs),
|
| 152 |
+
v=v,
|
| 153 |
+
k_lens=seq_lens,
|
| 154 |
+
window_size=self.window_size)
|
| 155 |
+
|
| 156 |
+
# output
|
| 157 |
+
x = x.flatten(2)
|
| 158 |
+
x = self.o(x)
|
| 159 |
+
return x
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class WanT2VCrossAttention(WanSelfAttention):
|
| 163 |
+
|
| 164 |
+
def forward(self, x, context, context_lens):
|
| 165 |
+
r"""
|
| 166 |
+
Args:
|
| 167 |
+
x(Tensor): Shape [B, L1, C]
|
| 168 |
+
context(Tensor): Shape [B, L2, C]
|
| 169 |
+
context_lens(Tensor): Shape [B]
|
| 170 |
+
"""
|
| 171 |
+
b, n, d = x.size(0), self.num_heads, self.head_dim
|
| 172 |
+
|
| 173 |
+
# compute query, key, value
|
| 174 |
+
q = self.norm_q(self.q(x)).view(b, -1, n, d)
|
| 175 |
+
k = self.norm_k(self.k(context)).view(b, -1, n, d)
|
| 176 |
+
v = self.v(context).view(b, -1, n, d)
|
| 177 |
+
|
| 178 |
+
# compute attention
|
| 179 |
+
x = flash_attention(q, k, v, k_lens=context_lens)
|
| 180 |
+
|
| 181 |
+
# output
|
| 182 |
+
x = x.flatten(2)
|
| 183 |
+
x = self.o(x)
|
| 184 |
+
return x
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class WanI2VCrossAttention(WanSelfAttention):
|
| 188 |
+
|
| 189 |
+
def __init__(self,
|
| 190 |
+
dim,
|
| 191 |
+
num_heads,
|
| 192 |
+
window_size=(-1, -1),
|
| 193 |
+
qk_norm=True,
|
| 194 |
+
eps=1e-6):
|
| 195 |
+
super().__init__(dim, num_heads, window_size, qk_norm, eps)
|
| 196 |
+
|
| 197 |
+
self.k_img = nn.Linear(dim, dim)
|
| 198 |
+
self.v_img = nn.Linear(dim, dim)
|
| 199 |
+
# self.alpha = nn.Parameter(torch.zeros((1, )))
|
| 200 |
+
self.norm_k_img = WanRMSNorm(dim, eps=eps) if qk_norm else nn.Identity()
|
| 201 |
+
|
| 202 |
+
def forward(self, x, context, context_lens):
|
| 203 |
+
r"""
|
| 204 |
+
Args:
|
| 205 |
+
x(Tensor): Shape [B, L1, C]
|
| 206 |
+
context(Tensor): Shape [B, L2, C]
|
| 207 |
+
context_lens(Tensor): Shape [B]
|
| 208 |
+
"""
|
| 209 |
+
image_context_length = context.shape[1] - T5_CONTEXT_TOKEN_NUMBER
|
| 210 |
+
context_img = context[:, :image_context_length]
|
| 211 |
+
context = context[:, image_context_length:]
|
| 212 |
+
b, n, d = x.size(0), self.num_heads, self.head_dim
|
| 213 |
+
|
| 214 |
+
# compute query, key, value
|
| 215 |
+
q = self.norm_q(self.q(x)).view(b, -1, n, d)
|
| 216 |
+
k = self.norm_k(self.k(context)).view(b, -1, n, d)
|
| 217 |
+
v = self.v(context).view(b, -1, n, d)
|
| 218 |
+
k_img = self.norm_k_img(self.k_img(context_img)).view(b, -1, n, d)
|
| 219 |
+
v_img = self.v_img(context_img).view(b, -1, n, d)
|
| 220 |
+
img_x = flash_attention(q, k_img, v_img, k_lens=None)
|
| 221 |
+
# compute attention
|
| 222 |
+
x = flash_attention(q, k, v, k_lens=context_lens)
|
| 223 |
+
|
| 224 |
+
# output
|
| 225 |
+
x = x.flatten(2)
|
| 226 |
+
img_x = img_x.flatten(2)
|
| 227 |
+
x = x + img_x
|
| 228 |
+
x = self.o(x)
|
| 229 |
+
return x
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
WAN_CROSSATTENTION_CLASSES = {
|
| 233 |
+
't2v_cross_attn': WanT2VCrossAttention,
|
| 234 |
+
'i2v_cross_attn': WanI2VCrossAttention,
|
| 235 |
+
}
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
class WanAttentionBlock(nn.Module):
|
| 239 |
+
|
| 240 |
+
def __init__(self,
|
| 241 |
+
cross_attn_type,
|
| 242 |
+
dim,
|
| 243 |
+
ffn_dim,
|
| 244 |
+
num_heads,
|
| 245 |
+
window_size=(-1, -1),
|
| 246 |
+
qk_norm=True,
|
| 247 |
+
cross_attn_norm=False,
|
| 248 |
+
eps=1e-6):
|
| 249 |
+
super().__init__()
|
| 250 |
+
self.dim = dim
|
| 251 |
+
self.ffn_dim = ffn_dim
|
| 252 |
+
self.num_heads = num_heads
|
| 253 |
+
self.window_size = window_size
|
| 254 |
+
self.qk_norm = qk_norm
|
| 255 |
+
self.cross_attn_norm = cross_attn_norm
|
| 256 |
+
self.eps = eps
|
| 257 |
+
|
| 258 |
+
# layers
|
| 259 |
+
self.norm1 = WanLayerNorm(dim, eps)
|
| 260 |
+
self.self_attn = WanSelfAttention(dim, num_heads, window_size, qk_norm,
|
| 261 |
+
eps)
|
| 262 |
+
self.norm3 = WanLayerNorm(
|
| 263 |
+
dim, eps,
|
| 264 |
+
elementwise_affine=True) if cross_attn_norm else nn.Identity()
|
| 265 |
+
self.cross_attn = WAN_CROSSATTENTION_CLASSES[cross_attn_type](dim,
|
| 266 |
+
num_heads,
|
| 267 |
+
(-1, -1),
|
| 268 |
+
qk_norm,
|
| 269 |
+
eps)
|
| 270 |
+
self.norm2 = WanLayerNorm(dim, eps)
|
| 271 |
+
self.ffn = nn.Sequential(
|
| 272 |
+
nn.Linear(dim, ffn_dim), nn.GELU(approximate='tanh'),
|
| 273 |
+
nn.Linear(ffn_dim, dim))
|
| 274 |
+
|
| 275 |
+
# modulation
|
| 276 |
+
self.modulation = nn.Parameter(torch.randn(1, 6, dim) / dim ** 0.5)
|
| 277 |
+
|
| 278 |
+
def forward(
|
| 279 |
+
self,
|
| 280 |
+
x,
|
| 281 |
+
e,
|
| 282 |
+
seq_lens,
|
| 283 |
+
grid_sizes,
|
| 284 |
+
freqs,
|
| 285 |
+
context,
|
| 286 |
+
context_lens,
|
| 287 |
+
):
|
| 288 |
+
r"""
|
| 289 |
+
Args:
|
| 290 |
+
x(Tensor): Shape [B, L, C]
|
| 291 |
+
e(Tensor): Shape [B, 6, C]
|
| 292 |
+
seq_lens(Tensor): Shape [B], length of each sequence in batch
|
| 293 |
+
grid_sizes(Tensor): Shape [B, 3], the second dimension contains (F, H, W)
|
| 294 |
+
freqs(Tensor): Rope freqs, shape [1024, C / num_heads / 2]
|
| 295 |
+
"""
|
| 296 |
+
assert e.dtype == torch.float32
|
| 297 |
+
with amp.autocast(dtype=torch.float32):
|
| 298 |
+
e = (self.modulation + e).chunk(6, dim=1)
|
| 299 |
+
assert e[0].dtype == torch.float32
|
| 300 |
+
|
| 301 |
+
# self-attention
|
| 302 |
+
y = self.self_attn(
|
| 303 |
+
self.norm1(x).float() * (1 + e[1]) + e[0], seq_lens, grid_sizes,
|
| 304 |
+
freqs)
|
| 305 |
+
with amp.autocast(dtype=torch.float32):
|
| 306 |
+
x = x + y * e[2]
|
| 307 |
+
|
| 308 |
+
# cross-attention & ffn function
|
| 309 |
+
def cross_attn_ffn(x, context, context_lens, e):
|
| 310 |
+
x = x + self.cross_attn(self.norm3(x), context, context_lens)
|
| 311 |
+
y = self.ffn(self.norm2(x).float() * (1 + e[4]) + e[3])
|
| 312 |
+
with amp.autocast(dtype=torch.float32):
|
| 313 |
+
x = x + y * e[5]
|
| 314 |
+
return x
|
| 315 |
+
|
| 316 |
+
x = cross_attn_ffn(x, context, context_lens, e)
|
| 317 |
+
return x
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
class Head(nn.Module):
|
| 321 |
+
|
| 322 |
+
def __init__(self, dim, out_dim, patch_size, eps=1e-6):
|
| 323 |
+
super().__init__()
|
| 324 |
+
self.dim = dim
|
| 325 |
+
self.out_dim = out_dim
|
| 326 |
+
self.patch_size = patch_size
|
| 327 |
+
self.eps = eps
|
| 328 |
+
|
| 329 |
+
# layers
|
| 330 |
+
out_dim = math.prod(patch_size) * out_dim
|
| 331 |
+
self.norm = WanLayerNorm(dim, eps)
|
| 332 |
+
self.head = nn.Linear(dim, out_dim)
|
| 333 |
+
|
| 334 |
+
# modulation
|
| 335 |
+
self.modulation = nn.Parameter(torch.randn(1, 2, dim) / dim ** 0.5)
|
| 336 |
+
|
| 337 |
+
def forward(self, x, e):
|
| 338 |
+
r"""
|
| 339 |
+
Args:
|
| 340 |
+
x(Tensor): Shape [B, L1, C]
|
| 341 |
+
e(Tensor): Shape [B, C]
|
| 342 |
+
"""
|
| 343 |
+
assert e.dtype == torch.float32
|
| 344 |
+
with amp.autocast(dtype=torch.float32):
|
| 345 |
+
e = (self.modulation + e.unsqueeze(1)).chunk(2, dim=1)
|
| 346 |
+
x = (self.head(self.norm(x) * (1 + e[1]) + e[0]))
|
| 347 |
+
return x
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
class MLPProj(torch.nn.Module):
|
| 351 |
+
|
| 352 |
+
def __init__(self, in_dim, out_dim, flf_pos_emb=False):
|
| 353 |
+
super().__init__()
|
| 354 |
+
|
| 355 |
+
self.proj = torch.nn.Sequential(
|
| 356 |
+
torch.nn.LayerNorm(in_dim), torch.nn.Linear(in_dim, in_dim),
|
| 357 |
+
torch.nn.GELU(), torch.nn.Linear(in_dim, out_dim),
|
| 358 |
+
torch.nn.LayerNorm(out_dim))
|
| 359 |
+
if flf_pos_emb: # NOTE: we only use this for `flf2v`
|
| 360 |
+
self.emb_pos = nn.Parameter(torch.zeros(1, FIRST_LAST_FRAME_CONTEXT_TOKEN_NUMBER, 1280))
|
| 361 |
+
|
| 362 |
+
def forward(self, image_embeds):
|
| 363 |
+
if hasattr(self, 'emb_pos'):
|
| 364 |
+
bs, n, d = image_embeds.shape
|
| 365 |
+
image_embeds = image_embeds.view(-1, 2 * n, d)
|
| 366 |
+
image_embeds = image_embeds + self.emb_pos
|
| 367 |
+
clip_extra_context_tokens = self.proj(image_embeds)
|
| 368 |
+
return clip_extra_context_tokens
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
class WanModel(ModelMixin, ConfigMixin):
|
| 372 |
+
r"""
|
| 373 |
+
Wan diffusion backbone supporting both text-to-video and image-to-video.
|
| 374 |
+
"""
|
| 375 |
+
|
| 376 |
+
ignore_for_config = [
|
| 377 |
+
'patch_size', 'cross_attn_norm', 'qk_norm', 'text_dim', 'window_size'
|
| 378 |
+
]
|
| 379 |
+
_no_split_modules = ['WanAttentionBlock']
|
| 380 |
+
|
| 381 |
+
@register_to_config
|
| 382 |
+
def __init__(self,
|
| 383 |
+
model_type='t2v',
|
| 384 |
+
patch_size=(1, 2, 2),
|
| 385 |
+
text_len=512,
|
| 386 |
+
in_dim=16,
|
| 387 |
+
dim=2048,
|
| 388 |
+
ffn_dim=8192,
|
| 389 |
+
freq_dim=256,
|
| 390 |
+
text_dim=4096,
|
| 391 |
+
out_dim=16,
|
| 392 |
+
num_heads=16,
|
| 393 |
+
num_layers=32,
|
| 394 |
+
window_size=(-1, -1),
|
| 395 |
+
qk_norm=True,
|
| 396 |
+
cross_attn_norm=True,
|
| 397 |
+
eps=1e-6):
|
| 398 |
+
r"""
|
| 399 |
+
Initialize the diffusion model backbone.
|
| 400 |
+
|
| 401 |
+
Args:
|
| 402 |
+
model_type (`str`, *optional*, defaults to 't2v'):
|
| 403 |
+
Model variant - 't2v' (text-to-video) or 'i2v' (image-to-video) or 'flf2v' (first-last-frame-to-video) or 'vace'
|
| 404 |
+
patch_size (`tuple`, *optional*, defaults to (1, 2, 2)):
|
| 405 |
+
3D patch dimensions for video embedding (t_patch, h_patch, w_patch)
|
| 406 |
+
text_len (`int`, *optional*, defaults to 512):
|
| 407 |
+
Fixed length for text embeddings
|
| 408 |
+
in_dim (`int`, *optional*, defaults to 16):
|
| 409 |
+
Input video channels (C_in)
|
| 410 |
+
dim (`int`, *optional*, defaults to 2048):
|
| 411 |
+
Hidden dimension of the transformer
|
| 412 |
+
ffn_dim (`int`, *optional*, defaults to 8192):
|
| 413 |
+
Intermediate dimension in feed-forward network
|
| 414 |
+
freq_dim (`int`, *optional*, defaults to 256):
|
| 415 |
+
Dimension for sinusoidal time embeddings
|
| 416 |
+
text_dim (`int`, *optional*, defaults to 4096):
|
| 417 |
+
Input dimension for text embeddings
|
| 418 |
+
out_dim (`int`, *optional*, defaults to 16):
|
| 419 |
+
Output video channels (C_out)
|
| 420 |
+
num_heads (`int`, *optional*, defaults to 16):
|
| 421 |
+
Number of attention heads
|
| 422 |
+
num_layers (`int`, *optional*, defaults to 32):
|
| 423 |
+
Number of transformer blocks
|
| 424 |
+
window_size (`tuple`, *optional*, defaults to (-1, -1)):
|
| 425 |
+
Window size for local attention (-1 indicates global attention)
|
| 426 |
+
qk_norm (`bool`, *optional*, defaults to True):
|
| 427 |
+
Enable query/key normalization
|
| 428 |
+
cross_attn_norm (`bool`, *optional*, defaults to False):
|
| 429 |
+
Enable cross-attention normalization
|
| 430 |
+
eps (`float`, *optional*, defaults to 1e-6):
|
| 431 |
+
Epsilon value for normalization layers
|
| 432 |
+
"""
|
| 433 |
+
|
| 434 |
+
super().__init__()
|
| 435 |
+
|
| 436 |
+
assert model_type in ['t2v', 'i2v', 'flf2v', 'vace']
|
| 437 |
+
self.model_type = model_type
|
| 438 |
+
|
| 439 |
+
self.patch_size = patch_size
|
| 440 |
+
self.text_len = text_len
|
| 441 |
+
self.in_dim = in_dim
|
| 442 |
+
self.dim = dim
|
| 443 |
+
self.ffn_dim = ffn_dim
|
| 444 |
+
self.freq_dim = freq_dim
|
| 445 |
+
self.text_dim = text_dim
|
| 446 |
+
self.out_dim = out_dim
|
| 447 |
+
self.num_heads = num_heads
|
| 448 |
+
self.num_layers = num_layers
|
| 449 |
+
self.window_size = window_size
|
| 450 |
+
self.qk_norm = qk_norm
|
| 451 |
+
self.cross_attn_norm = cross_attn_norm
|
| 452 |
+
self.eps = eps
|
| 453 |
+
|
| 454 |
+
# embeddings
|
| 455 |
+
self.patch_embedding = nn.Conv3d(
|
| 456 |
+
in_dim, dim, kernel_size=patch_size, stride=patch_size)
|
| 457 |
+
self.text_embedding = nn.Sequential(
|
| 458 |
+
nn.Linear(text_dim, dim), nn.GELU(approximate='tanh'),
|
| 459 |
+
nn.Linear(dim, dim))
|
| 460 |
+
|
| 461 |
+
self.time_embedding = nn.Sequential(
|
| 462 |
+
nn.Linear(freq_dim, dim), nn.SiLU(), nn.Linear(dim, dim))
|
| 463 |
+
self.time_projection = nn.Sequential(nn.SiLU(), nn.Linear(dim, dim * 6))
|
| 464 |
+
|
| 465 |
+
# blocks
|
| 466 |
+
cross_attn_type = 't2v_cross_attn' if model_type == 't2v' else 'i2v_cross_attn'
|
| 467 |
+
self.blocks = nn.ModuleList([
|
| 468 |
+
WanAttentionBlock(cross_attn_type, dim, ffn_dim, num_heads,
|
| 469 |
+
window_size, qk_norm, cross_attn_norm, eps)
|
| 470 |
+
for _ in range(num_layers)
|
| 471 |
+
])
|
| 472 |
+
|
| 473 |
+
# head
|
| 474 |
+
self.head = Head(dim, out_dim, patch_size, eps)
|
| 475 |
+
|
| 476 |
+
# buffers (don't use register_buffer otherwise dtype will be changed in to())
|
| 477 |
+
assert (dim % num_heads) == 0 and (dim // num_heads) % 2 == 0
|
| 478 |
+
d = dim // num_heads
|
| 479 |
+
self.freqs = torch.cat([
|
| 480 |
+
rope_params(1024, d - 4 * (d // 6)),
|
| 481 |
+
rope_params(1024, 2 * (d // 6)),
|
| 482 |
+
rope_params(1024, 2 * (d // 6))
|
| 483 |
+
],
|
| 484 |
+
dim=1)
|
| 485 |
+
|
| 486 |
+
if model_type == 'i2v' or model_type == 'flf2v':
|
| 487 |
+
self.img_emb = MLPProj(1280, dim, flf_pos_emb=model_type == 'flf2v')
|
| 488 |
+
|
| 489 |
+
# initialize weights
|
| 490 |
+
self.init_weights()
|
| 491 |
+
|
| 492 |
+
def forward(
|
| 493 |
+
self,
|
| 494 |
+
x,
|
| 495 |
+
t,
|
| 496 |
+
context,
|
| 497 |
+
seq_len,
|
| 498 |
+
clip_fea=None,
|
| 499 |
+
y=None,
|
| 500 |
+
):
|
| 501 |
+
r"""
|
| 502 |
+
Forward pass through the diffusion model
|
| 503 |
+
|
| 504 |
+
Args:
|
| 505 |
+
x (List[Tensor]):
|
| 506 |
+
List of input video tensors, each with shape [C_in, F, H, W]
|
| 507 |
+
t (Tensor):
|
| 508 |
+
Diffusion timesteps tensor of shape [B]
|
| 509 |
+
context (List[Tensor]):
|
| 510 |
+
List of text embeddings each with shape [L, C]
|
| 511 |
+
seq_len (`int`):
|
| 512 |
+
Maximum sequence length for positional encoding
|
| 513 |
+
clip_fea (Tensor, *optional*):
|
| 514 |
+
CLIP image features for image-to-video mode or first-last-frame-to-video mode
|
| 515 |
+
y (List[Tensor], *optional*):
|
| 516 |
+
Conditional video inputs for image-to-video mode, same shape as x
|
| 517 |
+
|
| 518 |
+
Returns:
|
| 519 |
+
List[Tensor]:
|
| 520 |
+
List of denoised video tensors with original input shapes [C_out, F, H / 8, W / 8]
|
| 521 |
+
"""
|
| 522 |
+
if self.model_type == 'i2v' or self.model_type == 'flf2v':
|
| 523 |
+
assert clip_fea is not None and y is not None
|
| 524 |
+
# params
|
| 525 |
+
device = self.patch_embedding.weight.device
|
| 526 |
+
if self.freqs.device != device:
|
| 527 |
+
self.freqs = self.freqs.to(device)
|
| 528 |
+
|
| 529 |
+
if y is not None:
|
| 530 |
+
x = [torch.cat([u, v], dim=0) for u, v in zip(x, y)]
|
| 531 |
+
|
| 532 |
+
# embeddings
|
| 533 |
+
x = [self.patch_embedding(u.unsqueeze(0)) for u in x]
|
| 534 |
+
grid_sizes = torch.stack(
|
| 535 |
+
[torch.tensor(u.shape[2:], dtype=torch.long) for u in x])
|
| 536 |
+
x = [u.flatten(2).transpose(1, 2) for u in x]
|
| 537 |
+
seq_lens = torch.tensor([u.size(1) for u in x], dtype=torch.long)
|
| 538 |
+
assert seq_lens.max() <= seq_len
|
| 539 |
+
x = torch.cat([
|
| 540 |
+
torch.cat([u, u.new_zeros(1, seq_len - u.size(1), u.size(2))],
|
| 541 |
+
dim=1) for u in x
|
| 542 |
+
])
|
| 543 |
+
|
| 544 |
+
# time embeddings
|
| 545 |
+
with amp.autocast(dtype=torch.float32):
|
| 546 |
+
e = self.time_embedding(
|
| 547 |
+
sinusoidal_embedding_1d(self.freq_dim, t).float())
|
| 548 |
+
e0 = self.time_projection(e).unflatten(1, (6, self.dim))
|
| 549 |
+
assert e.dtype == torch.float32 and e0.dtype == torch.float32
|
| 550 |
+
|
| 551 |
+
# context
|
| 552 |
+
context_lens = None
|
| 553 |
+
context = self.text_embedding(
|
| 554 |
+
torch.stack([
|
| 555 |
+
torch.cat(
|
| 556 |
+
[u, u.new_zeros(self.text_len - u.size(0), u.size(1))])
|
| 557 |
+
for u in context
|
| 558 |
+
]))
|
| 559 |
+
|
| 560 |
+
if clip_fea is not None:
|
| 561 |
+
context_clip = self.img_emb(clip_fea) # bs x 257 (x2) x dim
|
| 562 |
+
context = torch.concat([context_clip, context], dim=1)
|
| 563 |
+
|
| 564 |
+
# arguments
|
| 565 |
+
kwargs = dict(
|
| 566 |
+
e=e0,
|
| 567 |
+
seq_lens=seq_lens,
|
| 568 |
+
grid_sizes=grid_sizes,
|
| 569 |
+
freqs=self.freqs,
|
| 570 |
+
context=context,
|
| 571 |
+
context_lens=context_lens)
|
| 572 |
+
|
| 573 |
+
for block in self.blocks:
|
| 574 |
+
x = block(x, **kwargs)
|
| 575 |
+
|
| 576 |
+
# head
|
| 577 |
+
x = self.head(x, e)
|
| 578 |
+
|
| 579 |
+
# unpatchify
|
| 580 |
+
x = self.unpatchify(x, grid_sizes)
|
| 581 |
+
return [u.float() for u in x]
|
| 582 |
+
|
| 583 |
+
def unpatchify(self, x, grid_sizes):
|
| 584 |
+
r"""
|
| 585 |
+
Reconstruct video tensors from patch embeddings.
|
| 586 |
+
|
| 587 |
+
Args:
|
| 588 |
+
x (List[Tensor]):
|
| 589 |
+
List of patchified features, each with shape [L, C_out * prod(patch_size)]
|
| 590 |
+
grid_sizes (Tensor):
|
| 591 |
+
Original spatial-temporal grid dimensions before patching,
|
| 592 |
+
shape [B, 3] (3 dimensions correspond to F_patches, H_patches, W_patches)
|
| 593 |
+
|
| 594 |
+
Returns:
|
| 595 |
+
List[Tensor]:
|
| 596 |
+
Reconstructed video tensors with shape [C_out, F, H / 8, W / 8]
|
| 597 |
+
"""
|
| 598 |
+
|
| 599 |
+
c = self.out_dim
|
| 600 |
+
out = []
|
| 601 |
+
for u, v in zip(x, grid_sizes.tolist()):
|
| 602 |
+
u = u[:math.prod(v)].view(*v, *self.patch_size, c)
|
| 603 |
+
u = torch.einsum('fhwpqrc->cfphqwr', u)
|
| 604 |
+
u = u.reshape(c, *[i * j for i, j in zip(v, self.patch_size)])
|
| 605 |
+
out.append(u)
|
| 606 |
+
return out
|
| 607 |
+
|
| 608 |
+
def init_weights(self):
|
| 609 |
+
r"""
|
| 610 |
+
Initialize model parameters using Xavier initialization.
|
| 611 |
+
"""
|
| 612 |
+
|
| 613 |
+
# basic init
|
| 614 |
+
for m in self.modules():
|
| 615 |
+
if isinstance(m, nn.Linear):
|
| 616 |
+
nn.init.xavier_uniform_(m.weight)
|
| 617 |
+
if m.bias is not None:
|
| 618 |
+
nn.init.zeros_(m.bias)
|
| 619 |
+
|
| 620 |
+
# init embeddings
|
| 621 |
+
nn.init.xavier_uniform_(self.patch_embedding.weight.flatten(1))
|
| 622 |
+
for m in self.text_embedding.modules():
|
| 623 |
+
if isinstance(m, nn.Linear):
|
| 624 |
+
nn.init.normal_(m.weight, std=.02)
|
| 625 |
+
for m in self.time_embedding.modules():
|
| 626 |
+
if isinstance(m, nn.Linear):
|
| 627 |
+
nn.init.normal_(m.weight, std=.02)
|
| 628 |
+
|
| 629 |
+
# init output layer
|
| 630 |
+
nn.init.zeros_(self.head.head.weight)
|
wan/modules/t5.py
ADDED
|
@@ -0,0 +1,513 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from transformers.models.t5.modeling_t5
|
| 2 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 3 |
+
import logging
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
from .tokenizers import HuggingfaceTokenizer
|
| 11 |
+
|
| 12 |
+
__all__ = [
|
| 13 |
+
'T5Model',
|
| 14 |
+
'T5Encoder',
|
| 15 |
+
'T5Decoder',
|
| 16 |
+
'T5EncoderModel',
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def fp16_clamp(x):
|
| 21 |
+
if x.dtype == torch.float16 and torch.isinf(x).any():
|
| 22 |
+
clamp = torch.finfo(x.dtype).max - 1000
|
| 23 |
+
x = torch.clamp(x, min=-clamp, max=clamp)
|
| 24 |
+
return x
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def init_weights(m):
|
| 28 |
+
if isinstance(m, T5LayerNorm):
|
| 29 |
+
nn.init.ones_(m.weight)
|
| 30 |
+
elif isinstance(m, T5Model):
|
| 31 |
+
nn.init.normal_(m.token_embedding.weight, std=1.0)
|
| 32 |
+
elif isinstance(m, T5FeedForward):
|
| 33 |
+
nn.init.normal_(m.gate[0].weight, std=m.dim**-0.5)
|
| 34 |
+
nn.init.normal_(m.fc1.weight, std=m.dim**-0.5)
|
| 35 |
+
nn.init.normal_(m.fc2.weight, std=m.dim_ffn**-0.5)
|
| 36 |
+
elif isinstance(m, T5Attention):
|
| 37 |
+
nn.init.normal_(m.q.weight, std=(m.dim * m.dim_attn)**-0.5)
|
| 38 |
+
nn.init.normal_(m.k.weight, std=m.dim**-0.5)
|
| 39 |
+
nn.init.normal_(m.v.weight, std=m.dim**-0.5)
|
| 40 |
+
nn.init.normal_(m.o.weight, std=(m.num_heads * m.dim_attn)**-0.5)
|
| 41 |
+
elif isinstance(m, T5RelativeEmbedding):
|
| 42 |
+
nn.init.normal_(
|
| 43 |
+
m.embedding.weight, std=(2 * m.num_buckets * m.num_heads)**-0.5)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class GELU(nn.Module):
|
| 47 |
+
|
| 48 |
+
def forward(self, x):
|
| 49 |
+
return 0.5 * x * (1.0 + torch.tanh(
|
| 50 |
+
math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0))))
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class T5LayerNorm(nn.Module):
|
| 54 |
+
|
| 55 |
+
def __init__(self, dim, eps=1e-6):
|
| 56 |
+
super(T5LayerNorm, self).__init__()
|
| 57 |
+
self.dim = dim
|
| 58 |
+
self.eps = eps
|
| 59 |
+
self.weight = nn.Parameter(torch.ones(dim))
|
| 60 |
+
|
| 61 |
+
def forward(self, x):
|
| 62 |
+
x = x * torch.rsqrt(x.float().pow(2).mean(dim=-1, keepdim=True) +
|
| 63 |
+
self.eps)
|
| 64 |
+
if self.weight.dtype in [torch.float16, torch.bfloat16]:
|
| 65 |
+
x = x.type_as(self.weight)
|
| 66 |
+
return self.weight * x
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class T5Attention(nn.Module):
|
| 70 |
+
|
| 71 |
+
def __init__(self, dim, dim_attn, num_heads, dropout=0.1):
|
| 72 |
+
assert dim_attn % num_heads == 0
|
| 73 |
+
super(T5Attention, self).__init__()
|
| 74 |
+
self.dim = dim
|
| 75 |
+
self.dim_attn = dim_attn
|
| 76 |
+
self.num_heads = num_heads
|
| 77 |
+
self.head_dim = dim_attn // num_heads
|
| 78 |
+
|
| 79 |
+
# layers
|
| 80 |
+
self.q = nn.Linear(dim, dim_attn, bias=False)
|
| 81 |
+
self.k = nn.Linear(dim, dim_attn, bias=False)
|
| 82 |
+
self.v = nn.Linear(dim, dim_attn, bias=False)
|
| 83 |
+
self.o = nn.Linear(dim_attn, dim, bias=False)
|
| 84 |
+
self.dropout = nn.Dropout(dropout)
|
| 85 |
+
|
| 86 |
+
def forward(self, x, context=None, mask=None, pos_bias=None):
|
| 87 |
+
"""
|
| 88 |
+
x: [B, L1, C].
|
| 89 |
+
context: [B, L2, C] or None.
|
| 90 |
+
mask: [B, L2] or [B, L1, L2] or None.
|
| 91 |
+
"""
|
| 92 |
+
# check inputs
|
| 93 |
+
context = x if context is None else context
|
| 94 |
+
b, n, c = x.size(0), self.num_heads, self.head_dim
|
| 95 |
+
|
| 96 |
+
# compute query, key, value
|
| 97 |
+
q = self.q(x).view(b, -1, n, c)
|
| 98 |
+
k = self.k(context).view(b, -1, n, c)
|
| 99 |
+
v = self.v(context).view(b, -1, n, c)
|
| 100 |
+
|
| 101 |
+
# attention bias
|
| 102 |
+
attn_bias = x.new_zeros(b, n, q.size(1), k.size(1))
|
| 103 |
+
if pos_bias is not None:
|
| 104 |
+
attn_bias += pos_bias
|
| 105 |
+
if mask is not None:
|
| 106 |
+
assert mask.ndim in [2, 3]
|
| 107 |
+
mask = mask.view(b, 1, 1,
|
| 108 |
+
-1) if mask.ndim == 2 else mask.unsqueeze(1)
|
| 109 |
+
attn_bias.masked_fill_(mask == 0, torch.finfo(x.dtype).min)
|
| 110 |
+
|
| 111 |
+
# compute attention (T5 does not use scaling)
|
| 112 |
+
attn = torch.einsum('binc,bjnc->bnij', q, k) + attn_bias
|
| 113 |
+
attn = F.softmax(attn.float(), dim=-1).type_as(attn)
|
| 114 |
+
x = torch.einsum('bnij,bjnc->binc', attn, v)
|
| 115 |
+
|
| 116 |
+
# output
|
| 117 |
+
x = x.reshape(b, -1, n * c)
|
| 118 |
+
x = self.o(x)
|
| 119 |
+
x = self.dropout(x)
|
| 120 |
+
return x
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class T5FeedForward(nn.Module):
|
| 124 |
+
|
| 125 |
+
def __init__(self, dim, dim_ffn, dropout=0.1):
|
| 126 |
+
super(T5FeedForward, self).__init__()
|
| 127 |
+
self.dim = dim
|
| 128 |
+
self.dim_ffn = dim_ffn
|
| 129 |
+
|
| 130 |
+
# layers
|
| 131 |
+
self.gate = nn.Sequential(nn.Linear(dim, dim_ffn, bias=False), GELU())
|
| 132 |
+
self.fc1 = nn.Linear(dim, dim_ffn, bias=False)
|
| 133 |
+
self.fc2 = nn.Linear(dim_ffn, dim, bias=False)
|
| 134 |
+
self.dropout = nn.Dropout(dropout)
|
| 135 |
+
|
| 136 |
+
def forward(self, x):
|
| 137 |
+
x = self.fc1(x) * self.gate(x)
|
| 138 |
+
x = self.dropout(x)
|
| 139 |
+
x = self.fc2(x)
|
| 140 |
+
x = self.dropout(x)
|
| 141 |
+
return x
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class T5SelfAttention(nn.Module):
|
| 145 |
+
|
| 146 |
+
def __init__(self,
|
| 147 |
+
dim,
|
| 148 |
+
dim_attn,
|
| 149 |
+
dim_ffn,
|
| 150 |
+
num_heads,
|
| 151 |
+
num_buckets,
|
| 152 |
+
shared_pos=True,
|
| 153 |
+
dropout=0.1):
|
| 154 |
+
super(T5SelfAttention, self).__init__()
|
| 155 |
+
self.dim = dim
|
| 156 |
+
self.dim_attn = dim_attn
|
| 157 |
+
self.dim_ffn = dim_ffn
|
| 158 |
+
self.num_heads = num_heads
|
| 159 |
+
self.num_buckets = num_buckets
|
| 160 |
+
self.shared_pos = shared_pos
|
| 161 |
+
|
| 162 |
+
# layers
|
| 163 |
+
self.norm1 = T5LayerNorm(dim)
|
| 164 |
+
self.attn = T5Attention(dim, dim_attn, num_heads, dropout)
|
| 165 |
+
self.norm2 = T5LayerNorm(dim)
|
| 166 |
+
self.ffn = T5FeedForward(dim, dim_ffn, dropout)
|
| 167 |
+
self.pos_embedding = None if shared_pos else T5RelativeEmbedding(
|
| 168 |
+
num_buckets, num_heads, bidirectional=True)
|
| 169 |
+
|
| 170 |
+
def forward(self, x, mask=None, pos_bias=None):
|
| 171 |
+
e = pos_bias if self.shared_pos else self.pos_embedding(
|
| 172 |
+
x.size(1), x.size(1))
|
| 173 |
+
x = fp16_clamp(x + self.attn(self.norm1(x), mask=mask, pos_bias=e))
|
| 174 |
+
x = fp16_clamp(x + self.ffn(self.norm2(x)))
|
| 175 |
+
return x
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class T5CrossAttention(nn.Module):
|
| 179 |
+
|
| 180 |
+
def __init__(self,
|
| 181 |
+
dim,
|
| 182 |
+
dim_attn,
|
| 183 |
+
dim_ffn,
|
| 184 |
+
num_heads,
|
| 185 |
+
num_buckets,
|
| 186 |
+
shared_pos=True,
|
| 187 |
+
dropout=0.1):
|
| 188 |
+
super(T5CrossAttention, self).__init__()
|
| 189 |
+
self.dim = dim
|
| 190 |
+
self.dim_attn = dim_attn
|
| 191 |
+
self.dim_ffn = dim_ffn
|
| 192 |
+
self.num_heads = num_heads
|
| 193 |
+
self.num_buckets = num_buckets
|
| 194 |
+
self.shared_pos = shared_pos
|
| 195 |
+
|
| 196 |
+
# layers
|
| 197 |
+
self.norm1 = T5LayerNorm(dim)
|
| 198 |
+
self.self_attn = T5Attention(dim, dim_attn, num_heads, dropout)
|
| 199 |
+
self.norm2 = T5LayerNorm(dim)
|
| 200 |
+
self.cross_attn = T5Attention(dim, dim_attn, num_heads, dropout)
|
| 201 |
+
self.norm3 = T5LayerNorm(dim)
|
| 202 |
+
self.ffn = T5FeedForward(dim, dim_ffn, dropout)
|
| 203 |
+
self.pos_embedding = None if shared_pos else T5RelativeEmbedding(
|
| 204 |
+
num_buckets, num_heads, bidirectional=False)
|
| 205 |
+
|
| 206 |
+
def forward(self,
|
| 207 |
+
x,
|
| 208 |
+
mask=None,
|
| 209 |
+
encoder_states=None,
|
| 210 |
+
encoder_mask=None,
|
| 211 |
+
pos_bias=None):
|
| 212 |
+
e = pos_bias if self.shared_pos else self.pos_embedding(
|
| 213 |
+
x.size(1), x.size(1))
|
| 214 |
+
x = fp16_clamp(x + self.self_attn(self.norm1(x), mask=mask, pos_bias=e))
|
| 215 |
+
x = fp16_clamp(x + self.cross_attn(
|
| 216 |
+
self.norm2(x), context=encoder_states, mask=encoder_mask))
|
| 217 |
+
x = fp16_clamp(x + self.ffn(self.norm3(x)))
|
| 218 |
+
return x
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class T5RelativeEmbedding(nn.Module):
|
| 222 |
+
|
| 223 |
+
def __init__(self, num_buckets, num_heads, bidirectional, max_dist=128):
|
| 224 |
+
super(T5RelativeEmbedding, self).__init__()
|
| 225 |
+
self.num_buckets = num_buckets
|
| 226 |
+
self.num_heads = num_heads
|
| 227 |
+
self.bidirectional = bidirectional
|
| 228 |
+
self.max_dist = max_dist
|
| 229 |
+
|
| 230 |
+
# layers
|
| 231 |
+
self.embedding = nn.Embedding(num_buckets, num_heads)
|
| 232 |
+
|
| 233 |
+
def forward(self, lq, lk):
|
| 234 |
+
device = self.embedding.weight.device
|
| 235 |
+
# rel_pos = torch.arange(lk).unsqueeze(0).to(device) - \
|
| 236 |
+
# torch.arange(lq).unsqueeze(1).to(device)
|
| 237 |
+
rel_pos = torch.arange(lk, device=device).unsqueeze(0) - \
|
| 238 |
+
torch.arange(lq, device=device).unsqueeze(1)
|
| 239 |
+
rel_pos = self._relative_position_bucket(rel_pos)
|
| 240 |
+
rel_pos_embeds = self.embedding(rel_pos)
|
| 241 |
+
rel_pos_embeds = rel_pos_embeds.permute(2, 0, 1).unsqueeze(
|
| 242 |
+
0) # [1, N, Lq, Lk]
|
| 243 |
+
return rel_pos_embeds.contiguous()
|
| 244 |
+
|
| 245 |
+
def _relative_position_bucket(self, rel_pos):
|
| 246 |
+
# preprocess
|
| 247 |
+
if self.bidirectional:
|
| 248 |
+
num_buckets = self.num_buckets // 2
|
| 249 |
+
rel_buckets = (rel_pos > 0).long() * num_buckets
|
| 250 |
+
rel_pos = torch.abs(rel_pos)
|
| 251 |
+
else:
|
| 252 |
+
num_buckets = self.num_buckets
|
| 253 |
+
rel_buckets = 0
|
| 254 |
+
rel_pos = -torch.min(rel_pos, torch.zeros_like(rel_pos))
|
| 255 |
+
|
| 256 |
+
# embeddings for small and large positions
|
| 257 |
+
max_exact = num_buckets // 2
|
| 258 |
+
rel_pos_large = max_exact + (torch.log(rel_pos.float() / max_exact) /
|
| 259 |
+
math.log(self.max_dist / max_exact) *
|
| 260 |
+
(num_buckets - max_exact)).long()
|
| 261 |
+
rel_pos_large = torch.min(
|
| 262 |
+
rel_pos_large, torch.full_like(rel_pos_large, num_buckets - 1))
|
| 263 |
+
rel_buckets += torch.where(rel_pos < max_exact, rel_pos, rel_pos_large)
|
| 264 |
+
return rel_buckets
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
class T5Encoder(nn.Module):
|
| 268 |
+
|
| 269 |
+
def __init__(self,
|
| 270 |
+
vocab,
|
| 271 |
+
dim,
|
| 272 |
+
dim_attn,
|
| 273 |
+
dim_ffn,
|
| 274 |
+
num_heads,
|
| 275 |
+
num_layers,
|
| 276 |
+
num_buckets,
|
| 277 |
+
shared_pos=True,
|
| 278 |
+
dropout=0.1):
|
| 279 |
+
super(T5Encoder, self).__init__()
|
| 280 |
+
self.dim = dim
|
| 281 |
+
self.dim_attn = dim_attn
|
| 282 |
+
self.dim_ffn = dim_ffn
|
| 283 |
+
self.num_heads = num_heads
|
| 284 |
+
self.num_layers = num_layers
|
| 285 |
+
self.num_buckets = num_buckets
|
| 286 |
+
self.shared_pos = shared_pos
|
| 287 |
+
|
| 288 |
+
# layers
|
| 289 |
+
self.token_embedding = vocab if isinstance(vocab, nn.Embedding) \
|
| 290 |
+
else nn.Embedding(vocab, dim)
|
| 291 |
+
self.pos_embedding = T5RelativeEmbedding(
|
| 292 |
+
num_buckets, num_heads, bidirectional=True) if shared_pos else None
|
| 293 |
+
self.dropout = nn.Dropout(dropout)
|
| 294 |
+
self.blocks = nn.ModuleList([
|
| 295 |
+
T5SelfAttention(dim, dim_attn, dim_ffn, num_heads, num_buckets,
|
| 296 |
+
shared_pos, dropout) for _ in range(num_layers)
|
| 297 |
+
])
|
| 298 |
+
self.norm = T5LayerNorm(dim)
|
| 299 |
+
|
| 300 |
+
# initialize weights
|
| 301 |
+
self.apply(init_weights)
|
| 302 |
+
|
| 303 |
+
def forward(self, ids, mask=None):
|
| 304 |
+
x = self.token_embedding(ids)
|
| 305 |
+
x = self.dropout(x)
|
| 306 |
+
e = self.pos_embedding(x.size(1),
|
| 307 |
+
x.size(1)) if self.shared_pos else None
|
| 308 |
+
for block in self.blocks:
|
| 309 |
+
x = block(x, mask, pos_bias=e)
|
| 310 |
+
x = self.norm(x)
|
| 311 |
+
x = self.dropout(x)
|
| 312 |
+
return x
|
| 313 |
+
|
| 314 |
+
|
| 315 |
+
class T5Decoder(nn.Module):
|
| 316 |
+
|
| 317 |
+
def __init__(self,
|
| 318 |
+
vocab,
|
| 319 |
+
dim,
|
| 320 |
+
dim_attn,
|
| 321 |
+
dim_ffn,
|
| 322 |
+
num_heads,
|
| 323 |
+
num_layers,
|
| 324 |
+
num_buckets,
|
| 325 |
+
shared_pos=True,
|
| 326 |
+
dropout=0.1):
|
| 327 |
+
super(T5Decoder, self).__init__()
|
| 328 |
+
self.dim = dim
|
| 329 |
+
self.dim_attn = dim_attn
|
| 330 |
+
self.dim_ffn = dim_ffn
|
| 331 |
+
self.num_heads = num_heads
|
| 332 |
+
self.num_layers = num_layers
|
| 333 |
+
self.num_buckets = num_buckets
|
| 334 |
+
self.shared_pos = shared_pos
|
| 335 |
+
|
| 336 |
+
# layers
|
| 337 |
+
self.token_embedding = vocab if isinstance(vocab, nn.Embedding) \
|
| 338 |
+
else nn.Embedding(vocab, dim)
|
| 339 |
+
self.pos_embedding = T5RelativeEmbedding(
|
| 340 |
+
num_buckets, num_heads, bidirectional=False) if shared_pos else None
|
| 341 |
+
self.dropout = nn.Dropout(dropout)
|
| 342 |
+
self.blocks = nn.ModuleList([
|
| 343 |
+
T5CrossAttention(dim, dim_attn, dim_ffn, num_heads, num_buckets,
|
| 344 |
+
shared_pos, dropout) for _ in range(num_layers)
|
| 345 |
+
])
|
| 346 |
+
self.norm = T5LayerNorm(dim)
|
| 347 |
+
|
| 348 |
+
# initialize weights
|
| 349 |
+
self.apply(init_weights)
|
| 350 |
+
|
| 351 |
+
def forward(self, ids, mask=None, encoder_states=None, encoder_mask=None):
|
| 352 |
+
b, s = ids.size()
|
| 353 |
+
|
| 354 |
+
# causal mask
|
| 355 |
+
if mask is None:
|
| 356 |
+
mask = torch.tril(torch.ones(1, s, s).to(ids.device))
|
| 357 |
+
elif mask.ndim == 2:
|
| 358 |
+
mask = torch.tril(mask.unsqueeze(1).expand(-1, s, -1))
|
| 359 |
+
|
| 360 |
+
# layers
|
| 361 |
+
x = self.token_embedding(ids)
|
| 362 |
+
x = self.dropout(x)
|
| 363 |
+
e = self.pos_embedding(x.size(1),
|
| 364 |
+
x.size(1)) if self.shared_pos else None
|
| 365 |
+
for block in self.blocks:
|
| 366 |
+
x = block(x, mask, encoder_states, encoder_mask, pos_bias=e)
|
| 367 |
+
x = self.norm(x)
|
| 368 |
+
x = self.dropout(x)
|
| 369 |
+
return x
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
class T5Model(nn.Module):
|
| 373 |
+
|
| 374 |
+
def __init__(self,
|
| 375 |
+
vocab_size,
|
| 376 |
+
dim,
|
| 377 |
+
dim_attn,
|
| 378 |
+
dim_ffn,
|
| 379 |
+
num_heads,
|
| 380 |
+
encoder_layers,
|
| 381 |
+
decoder_layers,
|
| 382 |
+
num_buckets,
|
| 383 |
+
shared_pos=True,
|
| 384 |
+
dropout=0.1):
|
| 385 |
+
super(T5Model, self).__init__()
|
| 386 |
+
self.vocab_size = vocab_size
|
| 387 |
+
self.dim = dim
|
| 388 |
+
self.dim_attn = dim_attn
|
| 389 |
+
self.dim_ffn = dim_ffn
|
| 390 |
+
self.num_heads = num_heads
|
| 391 |
+
self.encoder_layers = encoder_layers
|
| 392 |
+
self.decoder_layers = decoder_layers
|
| 393 |
+
self.num_buckets = num_buckets
|
| 394 |
+
|
| 395 |
+
# layers
|
| 396 |
+
self.token_embedding = nn.Embedding(vocab_size, dim)
|
| 397 |
+
self.encoder = T5Encoder(self.token_embedding, dim, dim_attn, dim_ffn,
|
| 398 |
+
num_heads, encoder_layers, num_buckets,
|
| 399 |
+
shared_pos, dropout)
|
| 400 |
+
self.decoder = T5Decoder(self.token_embedding, dim, dim_attn, dim_ffn,
|
| 401 |
+
num_heads, decoder_layers, num_buckets,
|
| 402 |
+
shared_pos, dropout)
|
| 403 |
+
self.head = nn.Linear(dim, vocab_size, bias=False)
|
| 404 |
+
|
| 405 |
+
# initialize weights
|
| 406 |
+
self.apply(init_weights)
|
| 407 |
+
|
| 408 |
+
def forward(self, encoder_ids, encoder_mask, decoder_ids, decoder_mask):
|
| 409 |
+
x = self.encoder(encoder_ids, encoder_mask)
|
| 410 |
+
x = self.decoder(decoder_ids, decoder_mask, x, encoder_mask)
|
| 411 |
+
x = self.head(x)
|
| 412 |
+
return x
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
def _t5(name,
|
| 416 |
+
encoder_only=False,
|
| 417 |
+
decoder_only=False,
|
| 418 |
+
return_tokenizer=False,
|
| 419 |
+
tokenizer_kwargs={},
|
| 420 |
+
dtype=torch.float32,
|
| 421 |
+
device='cpu',
|
| 422 |
+
**kwargs):
|
| 423 |
+
# sanity check
|
| 424 |
+
assert not (encoder_only and decoder_only)
|
| 425 |
+
|
| 426 |
+
# params
|
| 427 |
+
if encoder_only:
|
| 428 |
+
model_cls = T5Encoder
|
| 429 |
+
kwargs['vocab'] = kwargs.pop('vocab_size')
|
| 430 |
+
kwargs['num_layers'] = kwargs.pop('encoder_layers')
|
| 431 |
+
_ = kwargs.pop('decoder_layers')
|
| 432 |
+
elif decoder_only:
|
| 433 |
+
model_cls = T5Decoder
|
| 434 |
+
kwargs['vocab'] = kwargs.pop('vocab_size')
|
| 435 |
+
kwargs['num_layers'] = kwargs.pop('decoder_layers')
|
| 436 |
+
_ = kwargs.pop('encoder_layers')
|
| 437 |
+
else:
|
| 438 |
+
model_cls = T5Model
|
| 439 |
+
|
| 440 |
+
# init model
|
| 441 |
+
with torch.device(device):
|
| 442 |
+
model = model_cls(**kwargs)
|
| 443 |
+
|
| 444 |
+
# set device
|
| 445 |
+
model = model.to(dtype=dtype, device=device)
|
| 446 |
+
|
| 447 |
+
# init tokenizer
|
| 448 |
+
if return_tokenizer:
|
| 449 |
+
from .tokenizers import HuggingfaceTokenizer
|
| 450 |
+
tokenizer = HuggingfaceTokenizer(f'google/{name}', **tokenizer_kwargs)
|
| 451 |
+
return model, tokenizer
|
| 452 |
+
else:
|
| 453 |
+
return model
|
| 454 |
+
|
| 455 |
+
|
| 456 |
+
def umt5_xxl(**kwargs):
|
| 457 |
+
cfg = dict(
|
| 458 |
+
vocab_size=256384,
|
| 459 |
+
dim=4096,
|
| 460 |
+
dim_attn=4096,
|
| 461 |
+
dim_ffn=10240,
|
| 462 |
+
num_heads=64,
|
| 463 |
+
encoder_layers=24,
|
| 464 |
+
decoder_layers=24,
|
| 465 |
+
num_buckets=32,
|
| 466 |
+
shared_pos=False,
|
| 467 |
+
dropout=0.1)
|
| 468 |
+
cfg.update(**kwargs)
|
| 469 |
+
return _t5('umt5-xxl', **cfg)
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
class T5EncoderModel:
|
| 473 |
+
|
| 474 |
+
def __init__(
|
| 475 |
+
self,
|
| 476 |
+
text_len,
|
| 477 |
+
dtype=torch.bfloat16,
|
| 478 |
+
device=torch.cuda.current_device(),
|
| 479 |
+
checkpoint_path=None,
|
| 480 |
+
tokenizer_path=None,
|
| 481 |
+
shard_fn=None,
|
| 482 |
+
):
|
| 483 |
+
self.text_len = text_len
|
| 484 |
+
self.dtype = dtype
|
| 485 |
+
self.device = device
|
| 486 |
+
self.checkpoint_path = checkpoint_path
|
| 487 |
+
self.tokenizer_path = tokenizer_path
|
| 488 |
+
|
| 489 |
+
# init model
|
| 490 |
+
model = umt5_xxl(
|
| 491 |
+
encoder_only=True,
|
| 492 |
+
return_tokenizer=False,
|
| 493 |
+
dtype=dtype,
|
| 494 |
+
device=device).eval().requires_grad_(False)
|
| 495 |
+
logging.info(f'loading {checkpoint_path}')
|
| 496 |
+
model.load_state_dict(torch.load(checkpoint_path, map_location='cpu'))
|
| 497 |
+
self.model = model
|
| 498 |
+
if shard_fn is not None:
|
| 499 |
+
self.model = shard_fn(self.model, sync_module_states=False)
|
| 500 |
+
else:
|
| 501 |
+
self.model.to(self.device)
|
| 502 |
+
# init tokenizer
|
| 503 |
+
self.tokenizer = HuggingfaceTokenizer(
|
| 504 |
+
name=tokenizer_path, seq_len=text_len, clean='whitespace')
|
| 505 |
+
|
| 506 |
+
def __call__(self, texts, device):
|
| 507 |
+
ids, mask = self.tokenizer(
|
| 508 |
+
texts, return_mask=True, add_special_tokens=True)
|
| 509 |
+
ids = ids.to(device)
|
| 510 |
+
mask = mask.to(device)
|
| 511 |
+
seq_lens = mask.gt(0).sum(dim=1).long()
|
| 512 |
+
context = self.model(ids, mask)
|
| 513 |
+
return [u[:v] for u, v in zip(context, seq_lens)]
|
wan/modules/tokenizers.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import html
|
| 3 |
+
import string
|
| 4 |
+
|
| 5 |
+
import ftfy
|
| 6 |
+
import regex as re
|
| 7 |
+
from transformers import AutoTokenizer
|
| 8 |
+
|
| 9 |
+
__all__ = ['HuggingfaceTokenizer']
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def basic_clean(text):
|
| 13 |
+
text = ftfy.fix_text(text)
|
| 14 |
+
text = html.unescape(html.unescape(text))
|
| 15 |
+
return text.strip()
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def whitespace_clean(text):
|
| 19 |
+
text = re.sub(r'\s+', ' ', text)
|
| 20 |
+
text = text.strip()
|
| 21 |
+
return text
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def canonicalize(text, keep_punctuation_exact_string=None):
|
| 25 |
+
text = text.replace('_', ' ')
|
| 26 |
+
if keep_punctuation_exact_string:
|
| 27 |
+
text = keep_punctuation_exact_string.join(
|
| 28 |
+
part.translate(str.maketrans('', '', string.punctuation))
|
| 29 |
+
for part in text.split(keep_punctuation_exact_string))
|
| 30 |
+
else:
|
| 31 |
+
text = text.translate(str.maketrans('', '', string.punctuation))
|
| 32 |
+
text = text.lower()
|
| 33 |
+
text = re.sub(r'\s+', ' ', text)
|
| 34 |
+
return text.strip()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class HuggingfaceTokenizer:
|
| 38 |
+
|
| 39 |
+
def __init__(self, name, seq_len=None, clean=None, **kwargs):
|
| 40 |
+
assert clean in (None, 'whitespace', 'lower', 'canonicalize')
|
| 41 |
+
self.name = name
|
| 42 |
+
self.seq_len = seq_len
|
| 43 |
+
self.clean = clean
|
| 44 |
+
|
| 45 |
+
# init tokenizer
|
| 46 |
+
self.tokenizer = AutoTokenizer.from_pretrained(name, **kwargs)
|
| 47 |
+
self.vocab_size = self.tokenizer.vocab_size
|
| 48 |
+
|
| 49 |
+
def __call__(self, sequence, **kwargs):
|
| 50 |
+
return_mask = kwargs.pop('return_mask', False)
|
| 51 |
+
|
| 52 |
+
# arguments
|
| 53 |
+
_kwargs = {'return_tensors': 'pt'}
|
| 54 |
+
if self.seq_len is not None:
|
| 55 |
+
_kwargs.update({
|
| 56 |
+
'padding': 'max_length',
|
| 57 |
+
'truncation': True,
|
| 58 |
+
'max_length': self.seq_len
|
| 59 |
+
})
|
| 60 |
+
_kwargs.update(**kwargs)
|
| 61 |
+
|
| 62 |
+
# tokenization
|
| 63 |
+
if isinstance(sequence, str):
|
| 64 |
+
sequence = [sequence]
|
| 65 |
+
if self.clean:
|
| 66 |
+
sequence = [self._clean(u) for u in sequence]
|
| 67 |
+
ids = self.tokenizer(sequence, **_kwargs)
|
| 68 |
+
|
| 69 |
+
# output
|
| 70 |
+
if return_mask:
|
| 71 |
+
return ids.input_ids, ids.attention_mask
|
| 72 |
+
else:
|
| 73 |
+
return ids.input_ids
|
| 74 |
+
|
| 75 |
+
def _clean(self, text):
|
| 76 |
+
if self.clean == 'whitespace':
|
| 77 |
+
text = whitespace_clean(basic_clean(text))
|
| 78 |
+
elif self.clean == 'lower':
|
| 79 |
+
text = whitespace_clean(basic_clean(text)).lower()
|
| 80 |
+
elif self.clean == 'canonicalize':
|
| 81 |
+
text = canonicalize(basic_clean(text))
|
| 82 |
+
return text
|
wan/modules/vace_model.py
ADDED
|
@@ -0,0 +1,233 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import torch
|
| 3 |
+
import torch.cuda.amp as amp
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from diffusers.configuration_utils import register_to_config
|
| 6 |
+
from .model import WanModel, WanAttentionBlock, sinusoidal_embedding_1d
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class VaceWanAttentionBlock(WanAttentionBlock):
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
cross_attn_type,
|
| 13 |
+
dim,
|
| 14 |
+
ffn_dim,
|
| 15 |
+
num_heads,
|
| 16 |
+
window_size=(-1, -1),
|
| 17 |
+
qk_norm=True,
|
| 18 |
+
cross_attn_norm=False,
|
| 19 |
+
eps=1e-6,
|
| 20 |
+
block_id=0
|
| 21 |
+
):
|
| 22 |
+
super().__init__(cross_attn_type, dim, ffn_dim, num_heads, window_size, qk_norm, cross_attn_norm, eps)
|
| 23 |
+
self.block_id = block_id
|
| 24 |
+
if block_id == 0:
|
| 25 |
+
self.before_proj = nn.Linear(self.dim, self.dim)
|
| 26 |
+
nn.init.zeros_(self.before_proj.weight)
|
| 27 |
+
nn.init.zeros_(self.before_proj.bias)
|
| 28 |
+
self.after_proj = nn.Linear(self.dim, self.dim)
|
| 29 |
+
nn.init.zeros_(self.after_proj.weight)
|
| 30 |
+
nn.init.zeros_(self.after_proj.bias)
|
| 31 |
+
|
| 32 |
+
def forward(self, c, x, **kwargs):
|
| 33 |
+
if self.block_id == 0:
|
| 34 |
+
c = self.before_proj(c) + x
|
| 35 |
+
|
| 36 |
+
c = super().forward(c, **kwargs)
|
| 37 |
+
c_skip = self.after_proj(c)
|
| 38 |
+
return c, c_skip
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class BaseWanAttentionBlock(WanAttentionBlock):
|
| 42 |
+
def __init__(
|
| 43 |
+
self,
|
| 44 |
+
cross_attn_type,
|
| 45 |
+
dim,
|
| 46 |
+
ffn_dim,
|
| 47 |
+
num_heads,
|
| 48 |
+
window_size=(-1, -1),
|
| 49 |
+
qk_norm=True,
|
| 50 |
+
cross_attn_norm=False,
|
| 51 |
+
eps=1e-6,
|
| 52 |
+
block_id=None
|
| 53 |
+
):
|
| 54 |
+
super().__init__(cross_attn_type, dim, ffn_dim, num_heads, window_size, qk_norm, cross_attn_norm, eps)
|
| 55 |
+
self.block_id = block_id
|
| 56 |
+
|
| 57 |
+
def forward(self, x, hints, context_scale=1.0, **kwargs):
|
| 58 |
+
x = super().forward(x, **kwargs)
|
| 59 |
+
if self.block_id is not None:
|
| 60 |
+
x = x + hints[self.block_id] * context_scale
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class VaceWanModel(WanModel):
|
| 65 |
+
@register_to_config
|
| 66 |
+
def __init__(self,
|
| 67 |
+
vace_layers=None,
|
| 68 |
+
vace_in_dim=None,
|
| 69 |
+
model_type='vace',
|
| 70 |
+
patch_size=(1, 2, 2),
|
| 71 |
+
text_len=512,
|
| 72 |
+
in_dim=16,
|
| 73 |
+
dim=2048,
|
| 74 |
+
ffn_dim=8192,
|
| 75 |
+
freq_dim=256,
|
| 76 |
+
text_dim=4096,
|
| 77 |
+
out_dim=16,
|
| 78 |
+
num_heads=16,
|
| 79 |
+
num_layers=32,
|
| 80 |
+
window_size=(-1, -1),
|
| 81 |
+
qk_norm=True,
|
| 82 |
+
cross_attn_norm=True,
|
| 83 |
+
eps=1e-6):
|
| 84 |
+
super().__init__(model_type, patch_size, text_len, in_dim, dim, ffn_dim, freq_dim, text_dim, out_dim,
|
| 85 |
+
num_heads, num_layers, window_size, qk_norm, cross_attn_norm, eps)
|
| 86 |
+
|
| 87 |
+
self.vace_layers = [i for i in range(0, self.num_layers, 2)] if vace_layers is None else vace_layers
|
| 88 |
+
self.vace_in_dim = self.in_dim if vace_in_dim is None else vace_in_dim
|
| 89 |
+
|
| 90 |
+
assert 0 in self.vace_layers
|
| 91 |
+
self.vace_layers_mapping = {i: n for n, i in enumerate(self.vace_layers)}
|
| 92 |
+
|
| 93 |
+
# blocks
|
| 94 |
+
self.blocks = nn.ModuleList([
|
| 95 |
+
BaseWanAttentionBlock('t2v_cross_attn', self.dim, self.ffn_dim, self.num_heads, self.window_size, self.qk_norm,
|
| 96 |
+
self.cross_attn_norm, self.eps,
|
| 97 |
+
block_id=self.vace_layers_mapping[i] if i in self.vace_layers else None)
|
| 98 |
+
for i in range(self.num_layers)
|
| 99 |
+
])
|
| 100 |
+
|
| 101 |
+
# vace blocks
|
| 102 |
+
self.vace_blocks = nn.ModuleList([
|
| 103 |
+
VaceWanAttentionBlock('t2v_cross_attn', self.dim, self.ffn_dim, self.num_heads, self.window_size, self.qk_norm,
|
| 104 |
+
self.cross_attn_norm, self.eps, block_id=i)
|
| 105 |
+
for i in self.vace_layers
|
| 106 |
+
])
|
| 107 |
+
|
| 108 |
+
# vace patch embeddings
|
| 109 |
+
self.vace_patch_embedding = nn.Conv3d(
|
| 110 |
+
self.vace_in_dim, self.dim, kernel_size=self.patch_size, stride=self.patch_size
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
def forward_vace(
|
| 114 |
+
self,
|
| 115 |
+
x,
|
| 116 |
+
vace_context,
|
| 117 |
+
seq_len,
|
| 118 |
+
kwargs
|
| 119 |
+
):
|
| 120 |
+
# embeddings
|
| 121 |
+
c = [self.vace_patch_embedding(u.unsqueeze(0)) for u in vace_context]
|
| 122 |
+
c = [u.flatten(2).transpose(1, 2) for u in c]
|
| 123 |
+
c = torch.cat([
|
| 124 |
+
torch.cat([u, u.new_zeros(1, seq_len - u.size(1), u.size(2))],
|
| 125 |
+
dim=1) for u in c
|
| 126 |
+
])
|
| 127 |
+
|
| 128 |
+
# arguments
|
| 129 |
+
new_kwargs = dict(x=x)
|
| 130 |
+
new_kwargs.update(kwargs)
|
| 131 |
+
|
| 132 |
+
hints = []
|
| 133 |
+
for block in self.vace_blocks:
|
| 134 |
+
c, c_skip = block(c, **new_kwargs)
|
| 135 |
+
hints.append(c_skip)
|
| 136 |
+
return hints
|
| 137 |
+
|
| 138 |
+
def forward(
|
| 139 |
+
self,
|
| 140 |
+
x,
|
| 141 |
+
t,
|
| 142 |
+
vace_context,
|
| 143 |
+
context,
|
| 144 |
+
seq_len,
|
| 145 |
+
vace_context_scale=1.0,
|
| 146 |
+
clip_fea=None,
|
| 147 |
+
y=None,
|
| 148 |
+
):
|
| 149 |
+
r"""
|
| 150 |
+
Forward pass through the diffusion model
|
| 151 |
+
|
| 152 |
+
Args:
|
| 153 |
+
x (List[Tensor]):
|
| 154 |
+
List of input video tensors, each with shape [C_in, F, H, W]
|
| 155 |
+
t (Tensor):
|
| 156 |
+
Diffusion timesteps tensor of shape [B]
|
| 157 |
+
context (List[Tensor]):
|
| 158 |
+
List of text embeddings each with shape [L, C]
|
| 159 |
+
seq_len (`int`):
|
| 160 |
+
Maximum sequence length for positional encoding
|
| 161 |
+
clip_fea (Tensor, *optional*):
|
| 162 |
+
CLIP image features for image-to-video mode
|
| 163 |
+
y (List[Tensor], *optional*):
|
| 164 |
+
Conditional video inputs for image-to-video mode, same shape as x
|
| 165 |
+
|
| 166 |
+
Returns:
|
| 167 |
+
List[Tensor]:
|
| 168 |
+
List of denoised video tensors with original input shapes [C_out, F, H / 8, W / 8]
|
| 169 |
+
"""
|
| 170 |
+
# if self.model_type == 'i2v':
|
| 171 |
+
# assert clip_fea is not None and y is not None
|
| 172 |
+
# params
|
| 173 |
+
device = self.patch_embedding.weight.device
|
| 174 |
+
if self.freqs.device != device:
|
| 175 |
+
self.freqs = self.freqs.to(device)
|
| 176 |
+
|
| 177 |
+
# if y is not None:
|
| 178 |
+
# x = [torch.cat([u, v], dim=0) for u, v in zip(x, y)]
|
| 179 |
+
|
| 180 |
+
# embeddings
|
| 181 |
+
x = [self.patch_embedding(u.unsqueeze(0)) for u in x]
|
| 182 |
+
grid_sizes = torch.stack(
|
| 183 |
+
[torch.tensor(u.shape[2:], dtype=torch.long) for u in x])
|
| 184 |
+
x = [u.flatten(2).transpose(1, 2) for u in x]
|
| 185 |
+
seq_lens = torch.tensor([u.size(1) for u in x], dtype=torch.long)
|
| 186 |
+
assert seq_lens.max() <= seq_len
|
| 187 |
+
x = torch.cat([
|
| 188 |
+
torch.cat([u, u.new_zeros(1, seq_len - u.size(1), u.size(2))],
|
| 189 |
+
dim=1) for u in x
|
| 190 |
+
])
|
| 191 |
+
|
| 192 |
+
# time embeddings
|
| 193 |
+
with amp.autocast(dtype=torch.float32):
|
| 194 |
+
e = self.time_embedding(
|
| 195 |
+
sinusoidal_embedding_1d(self.freq_dim, t).float())
|
| 196 |
+
e0 = self.time_projection(e).unflatten(1, (6, self.dim))
|
| 197 |
+
assert e.dtype == torch.float32 and e0.dtype == torch.float32
|
| 198 |
+
|
| 199 |
+
# context
|
| 200 |
+
context_lens = None
|
| 201 |
+
context = self.text_embedding(
|
| 202 |
+
torch.stack([
|
| 203 |
+
torch.cat(
|
| 204 |
+
[u, u.new_zeros(self.text_len - u.size(0), u.size(1))])
|
| 205 |
+
for u in context
|
| 206 |
+
]))
|
| 207 |
+
|
| 208 |
+
# if clip_fea is not None:
|
| 209 |
+
# context_clip = self.img_emb(clip_fea) # bs x 257 x dim
|
| 210 |
+
# context = torch.concat([context_clip, context], dim=1)
|
| 211 |
+
|
| 212 |
+
# arguments
|
| 213 |
+
kwargs = dict(
|
| 214 |
+
e=e0,
|
| 215 |
+
seq_lens=seq_lens,
|
| 216 |
+
grid_sizes=grid_sizes,
|
| 217 |
+
freqs=self.freqs,
|
| 218 |
+
context=context,
|
| 219 |
+
context_lens=context_lens)
|
| 220 |
+
|
| 221 |
+
hints = self.forward_vace(x, vace_context, seq_len, kwargs)
|
| 222 |
+
kwargs['hints'] = hints
|
| 223 |
+
kwargs['context_scale'] = vace_context_scale
|
| 224 |
+
|
| 225 |
+
for block in self.blocks:
|
| 226 |
+
x = block(x, **kwargs)
|
| 227 |
+
|
| 228 |
+
# head
|
| 229 |
+
x = self.head(x, e)
|
| 230 |
+
|
| 231 |
+
# unpatchify
|
| 232 |
+
x = self.unpatchify(x, grid_sizes)
|
| 233 |
+
return [u.float() for u in x]
|
wan/modules/vae.py
ADDED
|
@@ -0,0 +1,663 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.cuda.amp as amp
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
|
| 10 |
+
__all__ = [
|
| 11 |
+
'WanVAE',
|
| 12 |
+
]
|
| 13 |
+
|
| 14 |
+
CACHE_T = 2
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class CausalConv3d(nn.Conv3d):
|
| 18 |
+
"""
|
| 19 |
+
Causal 3d convolusion.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
def __init__(self, *args, **kwargs):
|
| 23 |
+
super().__init__(*args, **kwargs)
|
| 24 |
+
self._padding = (self.padding[2], self.padding[2], self.padding[1],
|
| 25 |
+
self.padding[1], 2 * self.padding[0], 0)
|
| 26 |
+
self.padding = (0, 0, 0)
|
| 27 |
+
|
| 28 |
+
def forward(self, x, cache_x=None):
|
| 29 |
+
padding = list(self._padding)
|
| 30 |
+
if cache_x is not None and self._padding[4] > 0:
|
| 31 |
+
cache_x = cache_x.to(x.device)
|
| 32 |
+
x = torch.cat([cache_x, x], dim=2)
|
| 33 |
+
padding[4] -= cache_x.shape[2]
|
| 34 |
+
x = F.pad(x, padding)
|
| 35 |
+
|
| 36 |
+
return super().forward(x)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class RMS_norm(nn.Module):
|
| 40 |
+
|
| 41 |
+
def __init__(self, dim, channel_first=True, images=True, bias=False):
|
| 42 |
+
super().__init__()
|
| 43 |
+
broadcastable_dims = (1, 1, 1) if not images else (1, 1)
|
| 44 |
+
shape = (dim, *broadcastable_dims) if channel_first else (dim,)
|
| 45 |
+
|
| 46 |
+
self.channel_first = channel_first
|
| 47 |
+
self.scale = dim**0.5
|
| 48 |
+
self.gamma = nn.Parameter(torch.ones(shape))
|
| 49 |
+
self.bias = nn.Parameter(torch.zeros(shape)) if bias else 0.
|
| 50 |
+
|
| 51 |
+
def forward(self, x):
|
| 52 |
+
return F.normalize(
|
| 53 |
+
x, dim=(1 if self.channel_first else
|
| 54 |
+
-1)) * self.scale * self.gamma + self.bias
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class Upsample(nn.Upsample):
|
| 58 |
+
|
| 59 |
+
def forward(self, x):
|
| 60 |
+
"""
|
| 61 |
+
Fix bfloat16 support for nearest neighbor interpolation.
|
| 62 |
+
"""
|
| 63 |
+
return super().forward(x.float()).type_as(x)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class Resample(nn.Module):
|
| 67 |
+
|
| 68 |
+
def __init__(self, dim, mode):
|
| 69 |
+
assert mode in ('none', 'upsample2d', 'upsample3d', 'downsample2d',
|
| 70 |
+
'downsample3d')
|
| 71 |
+
super().__init__()
|
| 72 |
+
self.dim = dim
|
| 73 |
+
self.mode = mode
|
| 74 |
+
|
| 75 |
+
# layers
|
| 76 |
+
if mode == 'upsample2d':
|
| 77 |
+
self.resample = nn.Sequential(
|
| 78 |
+
Upsample(scale_factor=(2., 2.), mode='nearest-exact'),
|
| 79 |
+
nn.Conv2d(dim, dim // 2, 3, padding=1))
|
| 80 |
+
elif mode == 'upsample3d':
|
| 81 |
+
self.resample = nn.Sequential(
|
| 82 |
+
Upsample(scale_factor=(2., 2.), mode='nearest-exact'),
|
| 83 |
+
nn.Conv2d(dim, dim // 2, 3, padding=1))
|
| 84 |
+
self.time_conv = CausalConv3d(
|
| 85 |
+
dim, dim * 2, (3, 1, 1), padding=(1, 0, 0))
|
| 86 |
+
|
| 87 |
+
elif mode == 'downsample2d':
|
| 88 |
+
self.resample = nn.Sequential(
|
| 89 |
+
nn.ZeroPad2d((0, 1, 0, 1)),
|
| 90 |
+
nn.Conv2d(dim, dim, 3, stride=(2, 2)))
|
| 91 |
+
elif mode == 'downsample3d':
|
| 92 |
+
self.resample = nn.Sequential(
|
| 93 |
+
nn.ZeroPad2d((0, 1, 0, 1)),
|
| 94 |
+
nn.Conv2d(dim, dim, 3, stride=(2, 2)))
|
| 95 |
+
self.time_conv = CausalConv3d(
|
| 96 |
+
dim, dim, (3, 1, 1), stride=(2, 1, 1), padding=(0, 0, 0))
|
| 97 |
+
|
| 98 |
+
else:
|
| 99 |
+
self.resample = nn.Identity()
|
| 100 |
+
|
| 101 |
+
def forward(self, x, feat_cache=None, feat_idx=[0]):
|
| 102 |
+
b, c, t, h, w = x.size()
|
| 103 |
+
if self.mode == 'upsample3d':
|
| 104 |
+
if feat_cache is not None:
|
| 105 |
+
idx = feat_idx[0]
|
| 106 |
+
if feat_cache[idx] is None:
|
| 107 |
+
feat_cache[idx] = 'Rep'
|
| 108 |
+
feat_idx[0] += 1
|
| 109 |
+
else:
|
| 110 |
+
|
| 111 |
+
cache_x = x[:, :, -CACHE_T:, :, :].clone()
|
| 112 |
+
if cache_x.shape[2] < 2 and feat_cache[
|
| 113 |
+
idx] is not None and feat_cache[idx] != 'Rep':
|
| 114 |
+
# cache last frame of last two chunk
|
| 115 |
+
cache_x = torch.cat([
|
| 116 |
+
feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
|
| 117 |
+
cache_x.device), cache_x
|
| 118 |
+
],
|
| 119 |
+
dim=2)
|
| 120 |
+
if cache_x.shape[2] < 2 and feat_cache[
|
| 121 |
+
idx] is not None and feat_cache[idx] == 'Rep':
|
| 122 |
+
cache_x = torch.cat([
|
| 123 |
+
torch.zeros_like(cache_x).to(cache_x.device),
|
| 124 |
+
cache_x
|
| 125 |
+
],
|
| 126 |
+
dim=2)
|
| 127 |
+
if feat_cache[idx] == 'Rep':
|
| 128 |
+
x = self.time_conv(x)
|
| 129 |
+
else:
|
| 130 |
+
x = self.time_conv(x, feat_cache[idx])
|
| 131 |
+
feat_cache[idx] = cache_x
|
| 132 |
+
feat_idx[0] += 1
|
| 133 |
+
|
| 134 |
+
x = x.reshape(b, 2, c, t, h, w)
|
| 135 |
+
x = torch.stack((x[:, 0, :, :, :, :], x[:, 1, :, :, :, :]),
|
| 136 |
+
3)
|
| 137 |
+
x = x.reshape(b, c, t * 2, h, w)
|
| 138 |
+
t = x.shape[2]
|
| 139 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 140 |
+
x = self.resample(x)
|
| 141 |
+
x = rearrange(x, '(b t) c h w -> b c t h w', t=t)
|
| 142 |
+
|
| 143 |
+
if self.mode == 'downsample3d':
|
| 144 |
+
if feat_cache is not None:
|
| 145 |
+
idx = feat_idx[0]
|
| 146 |
+
if feat_cache[idx] is None:
|
| 147 |
+
feat_cache[idx] = x.clone()
|
| 148 |
+
feat_idx[0] += 1
|
| 149 |
+
else:
|
| 150 |
+
|
| 151 |
+
cache_x = x[:, :, -1:, :, :].clone()
|
| 152 |
+
# if cache_x.shape[2] < 2 and feat_cache[idx] is not None and feat_cache[idx]!='Rep':
|
| 153 |
+
# # cache last frame of last two chunk
|
| 154 |
+
# cache_x = torch.cat([feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(cache_x.device), cache_x], dim=2)
|
| 155 |
+
|
| 156 |
+
x = self.time_conv(
|
| 157 |
+
torch.cat([feat_cache[idx][:, :, -1:, :, :], x], 2))
|
| 158 |
+
feat_cache[idx] = cache_x
|
| 159 |
+
feat_idx[0] += 1
|
| 160 |
+
return x
|
| 161 |
+
|
| 162 |
+
def init_weight(self, conv):
|
| 163 |
+
conv_weight = conv.weight
|
| 164 |
+
nn.init.zeros_(conv_weight)
|
| 165 |
+
c1, c2, t, h, w = conv_weight.size()
|
| 166 |
+
one_matrix = torch.eye(c1, c2)
|
| 167 |
+
init_matrix = one_matrix
|
| 168 |
+
nn.init.zeros_(conv_weight)
|
| 169 |
+
#conv_weight.data[:,:,-1,1,1] = init_matrix * 0.5
|
| 170 |
+
conv_weight.data[:, :, 1, 0, 0] = init_matrix #* 0.5
|
| 171 |
+
conv.weight.data.copy_(conv_weight)
|
| 172 |
+
nn.init.zeros_(conv.bias.data)
|
| 173 |
+
|
| 174 |
+
def init_weight2(self, conv):
|
| 175 |
+
conv_weight = conv.weight.data
|
| 176 |
+
nn.init.zeros_(conv_weight)
|
| 177 |
+
c1, c2, t, h, w = conv_weight.size()
|
| 178 |
+
init_matrix = torch.eye(c1 // 2, c2)
|
| 179 |
+
#init_matrix = repeat(init_matrix, 'o ... -> (o 2) ...').permute(1,0,2).contiguous().reshape(c1,c2)
|
| 180 |
+
conv_weight[:c1 // 2, :, -1, 0, 0] = init_matrix
|
| 181 |
+
conv_weight[c1 // 2:, :, -1, 0, 0] = init_matrix
|
| 182 |
+
conv.weight.data.copy_(conv_weight)
|
| 183 |
+
nn.init.zeros_(conv.bias.data)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
class ResidualBlock(nn.Module):
|
| 187 |
+
|
| 188 |
+
def __init__(self, in_dim, out_dim, dropout=0.0):
|
| 189 |
+
super().__init__()
|
| 190 |
+
self.in_dim = in_dim
|
| 191 |
+
self.out_dim = out_dim
|
| 192 |
+
|
| 193 |
+
# layers
|
| 194 |
+
self.residual = nn.Sequential(
|
| 195 |
+
RMS_norm(in_dim, images=False), nn.SiLU(),
|
| 196 |
+
CausalConv3d(in_dim, out_dim, 3, padding=1),
|
| 197 |
+
RMS_norm(out_dim, images=False), nn.SiLU(), nn.Dropout(dropout),
|
| 198 |
+
CausalConv3d(out_dim, out_dim, 3, padding=1))
|
| 199 |
+
self.shortcut = CausalConv3d(in_dim, out_dim, 1) \
|
| 200 |
+
if in_dim != out_dim else nn.Identity()
|
| 201 |
+
|
| 202 |
+
def forward(self, x, feat_cache=None, feat_idx=[0]):
|
| 203 |
+
h = self.shortcut(x)
|
| 204 |
+
for layer in self.residual:
|
| 205 |
+
if isinstance(layer, CausalConv3d) and feat_cache is not None:
|
| 206 |
+
idx = feat_idx[0]
|
| 207 |
+
cache_x = x[:, :, -CACHE_T:, :, :].clone()
|
| 208 |
+
if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
|
| 209 |
+
# cache last frame of last two chunk
|
| 210 |
+
cache_x = torch.cat([
|
| 211 |
+
feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
|
| 212 |
+
cache_x.device), cache_x
|
| 213 |
+
],
|
| 214 |
+
dim=2)
|
| 215 |
+
x = layer(x, feat_cache[idx])
|
| 216 |
+
feat_cache[idx] = cache_x
|
| 217 |
+
feat_idx[0] += 1
|
| 218 |
+
else:
|
| 219 |
+
x = layer(x)
|
| 220 |
+
return x + h
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
class AttentionBlock(nn.Module):
|
| 224 |
+
"""
|
| 225 |
+
Causal self-attention with a single head.
|
| 226 |
+
"""
|
| 227 |
+
|
| 228 |
+
def __init__(self, dim):
|
| 229 |
+
super().__init__()
|
| 230 |
+
self.dim = dim
|
| 231 |
+
|
| 232 |
+
# layers
|
| 233 |
+
self.norm = RMS_norm(dim)
|
| 234 |
+
self.to_qkv = nn.Conv2d(dim, dim * 3, 1)
|
| 235 |
+
self.proj = nn.Conv2d(dim, dim, 1)
|
| 236 |
+
|
| 237 |
+
# zero out the last layer params
|
| 238 |
+
nn.init.zeros_(self.proj.weight)
|
| 239 |
+
|
| 240 |
+
def forward(self, x):
|
| 241 |
+
identity = x
|
| 242 |
+
b, c, t, h, w = x.size()
|
| 243 |
+
x = rearrange(x, 'b c t h w -> (b t) c h w')
|
| 244 |
+
x = self.norm(x)
|
| 245 |
+
# compute query, key, value
|
| 246 |
+
q, k, v = self.to_qkv(x).reshape(b * t, 1, c * 3,
|
| 247 |
+
-1).permute(0, 1, 3,
|
| 248 |
+
2).contiguous().chunk(
|
| 249 |
+
3, dim=-1)
|
| 250 |
+
|
| 251 |
+
# apply attention
|
| 252 |
+
x = F.scaled_dot_product_attention(
|
| 253 |
+
q,
|
| 254 |
+
k,
|
| 255 |
+
v,
|
| 256 |
+
)
|
| 257 |
+
x = x.squeeze(1).permute(0, 2, 1).reshape(b * t, c, h, w)
|
| 258 |
+
|
| 259 |
+
# output
|
| 260 |
+
x = self.proj(x)
|
| 261 |
+
x = rearrange(x, '(b t) c h w-> b c t h w', t=t)
|
| 262 |
+
return x + identity
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
class Encoder3d(nn.Module):
|
| 266 |
+
|
| 267 |
+
def __init__(self,
|
| 268 |
+
dim=128,
|
| 269 |
+
z_dim=4,
|
| 270 |
+
dim_mult=[1, 2, 4, 4],
|
| 271 |
+
num_res_blocks=2,
|
| 272 |
+
attn_scales=[],
|
| 273 |
+
temperal_downsample=[True, True, False],
|
| 274 |
+
dropout=0.0):
|
| 275 |
+
super().__init__()
|
| 276 |
+
self.dim = dim
|
| 277 |
+
self.z_dim = z_dim
|
| 278 |
+
self.dim_mult = dim_mult
|
| 279 |
+
self.num_res_blocks = num_res_blocks
|
| 280 |
+
self.attn_scales = attn_scales
|
| 281 |
+
self.temperal_downsample = temperal_downsample
|
| 282 |
+
|
| 283 |
+
# dimensions
|
| 284 |
+
dims = [dim * u for u in [1] + dim_mult]
|
| 285 |
+
scale = 1.0
|
| 286 |
+
|
| 287 |
+
# init block
|
| 288 |
+
self.conv1 = CausalConv3d(3, dims[0], 3, padding=1)
|
| 289 |
+
|
| 290 |
+
# downsample blocks
|
| 291 |
+
downsamples = []
|
| 292 |
+
for i, (in_dim, out_dim) in enumerate(zip(dims[:-1], dims[1:])):
|
| 293 |
+
# residual (+attention) blocks
|
| 294 |
+
for _ in range(num_res_blocks):
|
| 295 |
+
downsamples.append(ResidualBlock(in_dim, out_dim, dropout))
|
| 296 |
+
if scale in attn_scales:
|
| 297 |
+
downsamples.append(AttentionBlock(out_dim))
|
| 298 |
+
in_dim = out_dim
|
| 299 |
+
|
| 300 |
+
# downsample block
|
| 301 |
+
if i != len(dim_mult) - 1:
|
| 302 |
+
mode = 'downsample3d' if temperal_downsample[
|
| 303 |
+
i] else 'downsample2d'
|
| 304 |
+
downsamples.append(Resample(out_dim, mode=mode))
|
| 305 |
+
scale /= 2.0
|
| 306 |
+
self.downsamples = nn.Sequential(*downsamples)
|
| 307 |
+
|
| 308 |
+
# middle blocks
|
| 309 |
+
self.middle = nn.Sequential(
|
| 310 |
+
ResidualBlock(out_dim, out_dim, dropout), AttentionBlock(out_dim),
|
| 311 |
+
ResidualBlock(out_dim, out_dim, dropout))
|
| 312 |
+
|
| 313 |
+
# output blocks
|
| 314 |
+
self.head = nn.Sequential(
|
| 315 |
+
RMS_norm(out_dim, images=False), nn.SiLU(),
|
| 316 |
+
CausalConv3d(out_dim, z_dim, 3, padding=1))
|
| 317 |
+
|
| 318 |
+
def forward(self, x, feat_cache=None, feat_idx=[0]):
|
| 319 |
+
if feat_cache is not None:
|
| 320 |
+
idx = feat_idx[0]
|
| 321 |
+
cache_x = x[:, :, -CACHE_T:, :, :].clone()
|
| 322 |
+
if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
|
| 323 |
+
# cache last frame of last two chunk
|
| 324 |
+
cache_x = torch.cat([
|
| 325 |
+
feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
|
| 326 |
+
cache_x.device), cache_x
|
| 327 |
+
],
|
| 328 |
+
dim=2)
|
| 329 |
+
x = self.conv1(x, feat_cache[idx])
|
| 330 |
+
feat_cache[idx] = cache_x
|
| 331 |
+
feat_idx[0] += 1
|
| 332 |
+
else:
|
| 333 |
+
x = self.conv1(x)
|
| 334 |
+
|
| 335 |
+
## downsamples
|
| 336 |
+
for layer in self.downsamples:
|
| 337 |
+
if feat_cache is not None:
|
| 338 |
+
x = layer(x, feat_cache, feat_idx)
|
| 339 |
+
else:
|
| 340 |
+
x = layer(x)
|
| 341 |
+
|
| 342 |
+
## middle
|
| 343 |
+
for layer in self.middle:
|
| 344 |
+
if isinstance(layer, ResidualBlock) and feat_cache is not None:
|
| 345 |
+
x = layer(x, feat_cache, feat_idx)
|
| 346 |
+
else:
|
| 347 |
+
x = layer(x)
|
| 348 |
+
|
| 349 |
+
## head
|
| 350 |
+
for layer in self.head:
|
| 351 |
+
if isinstance(layer, CausalConv3d) and feat_cache is not None:
|
| 352 |
+
idx = feat_idx[0]
|
| 353 |
+
cache_x = x[:, :, -CACHE_T:, :, :].clone()
|
| 354 |
+
if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
|
| 355 |
+
# cache last frame of last two chunk
|
| 356 |
+
cache_x = torch.cat([
|
| 357 |
+
feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
|
| 358 |
+
cache_x.device), cache_x
|
| 359 |
+
],
|
| 360 |
+
dim=2)
|
| 361 |
+
x = layer(x, feat_cache[idx])
|
| 362 |
+
feat_cache[idx] = cache_x
|
| 363 |
+
feat_idx[0] += 1
|
| 364 |
+
else:
|
| 365 |
+
x = layer(x)
|
| 366 |
+
return x
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class Decoder3d(nn.Module):
|
| 370 |
+
|
| 371 |
+
def __init__(self,
|
| 372 |
+
dim=128,
|
| 373 |
+
z_dim=4,
|
| 374 |
+
dim_mult=[1, 2, 4, 4],
|
| 375 |
+
num_res_blocks=2,
|
| 376 |
+
attn_scales=[],
|
| 377 |
+
temperal_upsample=[False, True, True],
|
| 378 |
+
dropout=0.0):
|
| 379 |
+
super().__init__()
|
| 380 |
+
self.dim = dim
|
| 381 |
+
self.z_dim = z_dim
|
| 382 |
+
self.dim_mult = dim_mult
|
| 383 |
+
self.num_res_blocks = num_res_blocks
|
| 384 |
+
self.attn_scales = attn_scales
|
| 385 |
+
self.temperal_upsample = temperal_upsample
|
| 386 |
+
|
| 387 |
+
# dimensions
|
| 388 |
+
dims = [dim * u for u in [dim_mult[-1]] + dim_mult[::-1]]
|
| 389 |
+
scale = 1.0 / 2**(len(dim_mult) - 2)
|
| 390 |
+
|
| 391 |
+
# init block
|
| 392 |
+
self.conv1 = CausalConv3d(z_dim, dims[0], 3, padding=1)
|
| 393 |
+
|
| 394 |
+
# middle blocks
|
| 395 |
+
self.middle = nn.Sequential(
|
| 396 |
+
ResidualBlock(dims[0], dims[0], dropout), AttentionBlock(dims[0]),
|
| 397 |
+
ResidualBlock(dims[0], dims[0], dropout))
|
| 398 |
+
|
| 399 |
+
# upsample blocks
|
| 400 |
+
upsamples = []
|
| 401 |
+
for i, (in_dim, out_dim) in enumerate(zip(dims[:-1], dims[1:])):
|
| 402 |
+
# residual (+attention) blocks
|
| 403 |
+
if i == 1 or i == 2 or i == 3:
|
| 404 |
+
in_dim = in_dim // 2
|
| 405 |
+
for _ in range(num_res_blocks + 1):
|
| 406 |
+
upsamples.append(ResidualBlock(in_dim, out_dim, dropout))
|
| 407 |
+
if scale in attn_scales:
|
| 408 |
+
upsamples.append(AttentionBlock(out_dim))
|
| 409 |
+
in_dim = out_dim
|
| 410 |
+
|
| 411 |
+
# upsample block
|
| 412 |
+
if i != len(dim_mult) - 1:
|
| 413 |
+
mode = 'upsample3d' if temperal_upsample[i] else 'upsample2d'
|
| 414 |
+
upsamples.append(Resample(out_dim, mode=mode))
|
| 415 |
+
scale *= 2.0
|
| 416 |
+
self.upsamples = nn.Sequential(*upsamples)
|
| 417 |
+
|
| 418 |
+
# output blocks
|
| 419 |
+
self.head = nn.Sequential(
|
| 420 |
+
RMS_norm(out_dim, images=False), nn.SiLU(),
|
| 421 |
+
CausalConv3d(out_dim, 3, 3, padding=1))
|
| 422 |
+
|
| 423 |
+
def forward(self, x, feat_cache=None, feat_idx=[0]):
|
| 424 |
+
## conv1
|
| 425 |
+
if feat_cache is not None:
|
| 426 |
+
idx = feat_idx[0]
|
| 427 |
+
cache_x = x[:, :, -CACHE_T:, :, :].clone()
|
| 428 |
+
if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
|
| 429 |
+
# cache last frame of last two chunk
|
| 430 |
+
cache_x = torch.cat([
|
| 431 |
+
feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
|
| 432 |
+
cache_x.device), cache_x
|
| 433 |
+
],
|
| 434 |
+
dim=2)
|
| 435 |
+
x = self.conv1(x, feat_cache[idx])
|
| 436 |
+
feat_cache[idx] = cache_x
|
| 437 |
+
feat_idx[0] += 1
|
| 438 |
+
else:
|
| 439 |
+
x = self.conv1(x)
|
| 440 |
+
|
| 441 |
+
## middle
|
| 442 |
+
for layer in self.middle:
|
| 443 |
+
if isinstance(layer, ResidualBlock) and feat_cache is not None:
|
| 444 |
+
x = layer(x, feat_cache, feat_idx)
|
| 445 |
+
else:
|
| 446 |
+
x = layer(x)
|
| 447 |
+
|
| 448 |
+
## upsamples
|
| 449 |
+
for layer in self.upsamples:
|
| 450 |
+
if feat_cache is not None:
|
| 451 |
+
x = layer(x, feat_cache, feat_idx)
|
| 452 |
+
else:
|
| 453 |
+
x = layer(x)
|
| 454 |
+
|
| 455 |
+
## head
|
| 456 |
+
for layer in self.head:
|
| 457 |
+
if isinstance(layer, CausalConv3d) and feat_cache is not None:
|
| 458 |
+
idx = feat_idx[0]
|
| 459 |
+
cache_x = x[:, :, -CACHE_T:, :, :].clone()
|
| 460 |
+
if cache_x.shape[2] < 2 and feat_cache[idx] is not None:
|
| 461 |
+
# cache last frame of last two chunk
|
| 462 |
+
cache_x = torch.cat([
|
| 463 |
+
feat_cache[idx][:, :, -1, :, :].unsqueeze(2).to(
|
| 464 |
+
cache_x.device), cache_x
|
| 465 |
+
],
|
| 466 |
+
dim=2)
|
| 467 |
+
x = layer(x, feat_cache[idx])
|
| 468 |
+
feat_cache[idx] = cache_x
|
| 469 |
+
feat_idx[0] += 1
|
| 470 |
+
else:
|
| 471 |
+
x = layer(x)
|
| 472 |
+
return x
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
def count_conv3d(model):
|
| 476 |
+
count = 0
|
| 477 |
+
for m in model.modules():
|
| 478 |
+
if isinstance(m, CausalConv3d):
|
| 479 |
+
count += 1
|
| 480 |
+
return count
|
| 481 |
+
|
| 482 |
+
|
| 483 |
+
class WanVAE_(nn.Module):
|
| 484 |
+
|
| 485 |
+
def __init__(self,
|
| 486 |
+
dim=128,
|
| 487 |
+
z_dim=4,
|
| 488 |
+
dim_mult=[1, 2, 4, 4],
|
| 489 |
+
num_res_blocks=2,
|
| 490 |
+
attn_scales=[],
|
| 491 |
+
temperal_downsample=[True, True, False],
|
| 492 |
+
dropout=0.0):
|
| 493 |
+
super().__init__()
|
| 494 |
+
self.dim = dim
|
| 495 |
+
self.z_dim = z_dim
|
| 496 |
+
self.dim_mult = dim_mult
|
| 497 |
+
self.num_res_blocks = num_res_blocks
|
| 498 |
+
self.attn_scales = attn_scales
|
| 499 |
+
self.temperal_downsample = temperal_downsample
|
| 500 |
+
self.temperal_upsample = temperal_downsample[::-1]
|
| 501 |
+
|
| 502 |
+
# modules
|
| 503 |
+
self.encoder = Encoder3d(dim, z_dim * 2, dim_mult, num_res_blocks,
|
| 504 |
+
attn_scales, self.temperal_downsample, dropout)
|
| 505 |
+
self.conv1 = CausalConv3d(z_dim * 2, z_dim * 2, 1)
|
| 506 |
+
self.conv2 = CausalConv3d(z_dim, z_dim, 1)
|
| 507 |
+
self.decoder = Decoder3d(dim, z_dim, dim_mult, num_res_blocks,
|
| 508 |
+
attn_scales, self.temperal_upsample, dropout)
|
| 509 |
+
|
| 510 |
+
def forward(self, x):
|
| 511 |
+
mu, log_var = self.encode(x)
|
| 512 |
+
z = self.reparameterize(mu, log_var)
|
| 513 |
+
x_recon = self.decode(z)
|
| 514 |
+
return x_recon, mu, log_var
|
| 515 |
+
|
| 516 |
+
def encode(self, x, scale):
|
| 517 |
+
self.clear_cache()
|
| 518 |
+
## cache
|
| 519 |
+
t = x.shape[2]
|
| 520 |
+
iter_ = 1 + (t - 1) // 4
|
| 521 |
+
## 对encode输入的x,按时间拆分为1、4、4、4....
|
| 522 |
+
for i in range(iter_):
|
| 523 |
+
self._enc_conv_idx = [0]
|
| 524 |
+
if i == 0:
|
| 525 |
+
out = self.encoder(
|
| 526 |
+
x[:, :, :1, :, :],
|
| 527 |
+
feat_cache=self._enc_feat_map,
|
| 528 |
+
feat_idx=self._enc_conv_idx)
|
| 529 |
+
else:
|
| 530 |
+
out_ = self.encoder(
|
| 531 |
+
x[:, :, 1 + 4 * (i - 1):1 + 4 * i, :, :],
|
| 532 |
+
feat_cache=self._enc_feat_map,
|
| 533 |
+
feat_idx=self._enc_conv_idx)
|
| 534 |
+
out = torch.cat([out, out_], 2)
|
| 535 |
+
mu, log_var = self.conv1(out).chunk(2, dim=1)
|
| 536 |
+
if isinstance(scale[0], torch.Tensor):
|
| 537 |
+
mu = (mu - scale[0].view(1, self.z_dim, 1, 1, 1)) * scale[1].view(
|
| 538 |
+
1, self.z_dim, 1, 1, 1)
|
| 539 |
+
else:
|
| 540 |
+
mu = (mu - scale[0]) * scale[1]
|
| 541 |
+
self.clear_cache()
|
| 542 |
+
return mu
|
| 543 |
+
|
| 544 |
+
def decode(self, z, scale):
|
| 545 |
+
self.clear_cache()
|
| 546 |
+
# z: [b,c,t,h,w]
|
| 547 |
+
if isinstance(scale[0], torch.Tensor):
|
| 548 |
+
z = z / scale[1].view(1, self.z_dim, 1, 1, 1) + scale[0].view(
|
| 549 |
+
1, self.z_dim, 1, 1, 1)
|
| 550 |
+
else:
|
| 551 |
+
z = z / scale[1] + scale[0]
|
| 552 |
+
iter_ = z.shape[2]
|
| 553 |
+
x = self.conv2(z)
|
| 554 |
+
for i in range(iter_):
|
| 555 |
+
self._conv_idx = [0]
|
| 556 |
+
if i == 0:
|
| 557 |
+
out = self.decoder(
|
| 558 |
+
x[:, :, i:i + 1, :, :],
|
| 559 |
+
feat_cache=self._feat_map,
|
| 560 |
+
feat_idx=self._conv_idx)
|
| 561 |
+
else:
|
| 562 |
+
out_ = self.decoder(
|
| 563 |
+
x[:, :, i:i + 1, :, :],
|
| 564 |
+
feat_cache=self._feat_map,
|
| 565 |
+
feat_idx=self._conv_idx)
|
| 566 |
+
out = torch.cat([out, out_], 2)
|
| 567 |
+
self.clear_cache()
|
| 568 |
+
return out
|
| 569 |
+
|
| 570 |
+
def reparameterize(self, mu, log_var):
|
| 571 |
+
std = torch.exp(0.5 * log_var)
|
| 572 |
+
eps = torch.randn_like(std)
|
| 573 |
+
return eps * std + mu
|
| 574 |
+
|
| 575 |
+
def sample(self, imgs, deterministic=False):
|
| 576 |
+
mu, log_var = self.encode(imgs)
|
| 577 |
+
if deterministic:
|
| 578 |
+
return mu
|
| 579 |
+
std = torch.exp(0.5 * log_var.clamp(-30.0, 20.0))
|
| 580 |
+
return mu + std * torch.randn_like(std)
|
| 581 |
+
|
| 582 |
+
def clear_cache(self):
|
| 583 |
+
self._conv_num = count_conv3d(self.decoder)
|
| 584 |
+
self._conv_idx = [0]
|
| 585 |
+
self._feat_map = [None] * self._conv_num
|
| 586 |
+
#cache encode
|
| 587 |
+
self._enc_conv_num = count_conv3d(self.encoder)
|
| 588 |
+
self._enc_conv_idx = [0]
|
| 589 |
+
self._enc_feat_map = [None] * self._enc_conv_num
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
def _video_vae(pretrained_path=None, z_dim=None, device='cpu', **kwargs):
|
| 593 |
+
"""
|
| 594 |
+
Autoencoder3d adapted from Stable Diffusion 1.x, 2.x and XL.
|
| 595 |
+
"""
|
| 596 |
+
# params
|
| 597 |
+
cfg = dict(
|
| 598 |
+
dim=96,
|
| 599 |
+
z_dim=z_dim,
|
| 600 |
+
dim_mult=[1, 2, 4, 4],
|
| 601 |
+
num_res_blocks=2,
|
| 602 |
+
attn_scales=[],
|
| 603 |
+
temperal_downsample=[False, True, True],
|
| 604 |
+
dropout=0.0)
|
| 605 |
+
cfg.update(**kwargs)
|
| 606 |
+
|
| 607 |
+
# init model
|
| 608 |
+
with torch.device('meta'):
|
| 609 |
+
model = WanVAE_(**cfg)
|
| 610 |
+
|
| 611 |
+
# load checkpoint
|
| 612 |
+
logging.info(f'loading {pretrained_path}')
|
| 613 |
+
model.load_state_dict(
|
| 614 |
+
torch.load(pretrained_path, map_location=device), assign=True)
|
| 615 |
+
|
| 616 |
+
return model
|
| 617 |
+
|
| 618 |
+
|
| 619 |
+
class WanVAE:
|
| 620 |
+
|
| 621 |
+
def __init__(self,
|
| 622 |
+
z_dim=16,
|
| 623 |
+
vae_pth='cache/vae_step_411000.pth',
|
| 624 |
+
dtype=torch.float,
|
| 625 |
+
device="cuda"):
|
| 626 |
+
self.dtype = dtype
|
| 627 |
+
self.device = device
|
| 628 |
+
|
| 629 |
+
mean = [
|
| 630 |
+
-0.7571, -0.7089, -0.9113, 0.1075, -0.1745, 0.9653, -0.1517, 1.5508,
|
| 631 |
+
0.4134, -0.0715, 0.5517, -0.3632, -0.1922, -0.9497, 0.2503, -0.2921
|
| 632 |
+
]
|
| 633 |
+
std = [
|
| 634 |
+
2.8184, 1.4541, 2.3275, 2.6558, 1.2196, 1.7708, 2.6052, 2.0743,
|
| 635 |
+
3.2687, 2.1526, 2.8652, 1.5579, 1.6382, 1.1253, 2.8251, 1.9160
|
| 636 |
+
]
|
| 637 |
+
self.mean = torch.tensor(mean, dtype=dtype, device=device)
|
| 638 |
+
self.std = torch.tensor(std, dtype=dtype, device=device)
|
| 639 |
+
self.scale = [self.mean, 1.0 / self.std]
|
| 640 |
+
|
| 641 |
+
# init model
|
| 642 |
+
self.model = _video_vae(
|
| 643 |
+
pretrained_path=vae_pth,
|
| 644 |
+
z_dim=z_dim,
|
| 645 |
+
).eval().requires_grad_(False).to(device)
|
| 646 |
+
|
| 647 |
+
def encode(self, videos):
|
| 648 |
+
"""
|
| 649 |
+
videos: A list of videos each with shape [C, T, H, W].
|
| 650 |
+
"""
|
| 651 |
+
with amp.autocast(dtype=self.dtype):
|
| 652 |
+
return [
|
| 653 |
+
self.model.encode(u.unsqueeze(0), self.scale).float().squeeze(0)
|
| 654 |
+
for u in videos
|
| 655 |
+
]
|
| 656 |
+
|
| 657 |
+
def decode(self, zs):
|
| 658 |
+
with amp.autocast(dtype=self.dtype):
|
| 659 |
+
return [
|
| 660 |
+
self.model.decode(u.unsqueeze(0),
|
| 661 |
+
self.scale).float().clamp_(-1, 1).squeeze(0)
|
| 662 |
+
for u in zs
|
| 663 |
+
]
|
wan/modules/xlm_roberta.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from transformers.models.xlm_roberta.modeling_xlm_roberta
|
| 2 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
__all__ = ['XLMRoberta', 'xlm_roberta_large']
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class SelfAttention(nn.Module):
|
| 11 |
+
|
| 12 |
+
def __init__(self, dim, num_heads, dropout=0.1, eps=1e-5):
|
| 13 |
+
assert dim % num_heads == 0
|
| 14 |
+
super().__init__()
|
| 15 |
+
self.dim = dim
|
| 16 |
+
self.num_heads = num_heads
|
| 17 |
+
self.head_dim = dim // num_heads
|
| 18 |
+
self.eps = eps
|
| 19 |
+
|
| 20 |
+
# layers
|
| 21 |
+
self.q = nn.Linear(dim, dim)
|
| 22 |
+
self.k = nn.Linear(dim, dim)
|
| 23 |
+
self.v = nn.Linear(dim, dim)
|
| 24 |
+
self.o = nn.Linear(dim, dim)
|
| 25 |
+
self.dropout = nn.Dropout(dropout)
|
| 26 |
+
|
| 27 |
+
def forward(self, x, mask):
|
| 28 |
+
"""
|
| 29 |
+
x: [B, L, C].
|
| 30 |
+
"""
|
| 31 |
+
b, s, c, n, d = *x.size(), self.num_heads, self.head_dim
|
| 32 |
+
|
| 33 |
+
# compute query, key, value
|
| 34 |
+
q = self.q(x).reshape(b, s, n, d).permute(0, 2, 1, 3)
|
| 35 |
+
k = self.k(x).reshape(b, s, n, d).permute(0, 2, 1, 3)
|
| 36 |
+
v = self.v(x).reshape(b, s, n, d).permute(0, 2, 1, 3)
|
| 37 |
+
|
| 38 |
+
# compute attention
|
| 39 |
+
p = self.dropout.p if self.training else 0.0
|
| 40 |
+
x = F.scaled_dot_product_attention(q, k, v, mask, p)
|
| 41 |
+
x = x.permute(0, 2, 1, 3).reshape(b, s, c)
|
| 42 |
+
|
| 43 |
+
# output
|
| 44 |
+
x = self.o(x)
|
| 45 |
+
x = self.dropout(x)
|
| 46 |
+
return x
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class AttentionBlock(nn.Module):
|
| 50 |
+
|
| 51 |
+
def __init__(self, dim, num_heads, post_norm, dropout=0.1, eps=1e-5):
|
| 52 |
+
super().__init__()
|
| 53 |
+
self.dim = dim
|
| 54 |
+
self.num_heads = num_heads
|
| 55 |
+
self.post_norm = post_norm
|
| 56 |
+
self.eps = eps
|
| 57 |
+
|
| 58 |
+
# layers
|
| 59 |
+
self.attn = SelfAttention(dim, num_heads, dropout, eps)
|
| 60 |
+
self.norm1 = nn.LayerNorm(dim, eps=eps)
|
| 61 |
+
self.ffn = nn.Sequential(
|
| 62 |
+
nn.Linear(dim, dim * 4), nn.GELU(), nn.Linear(dim * 4, dim),
|
| 63 |
+
nn.Dropout(dropout))
|
| 64 |
+
self.norm2 = nn.LayerNorm(dim, eps=eps)
|
| 65 |
+
|
| 66 |
+
def forward(self, x, mask):
|
| 67 |
+
if self.post_norm:
|
| 68 |
+
x = self.norm1(x + self.attn(x, mask))
|
| 69 |
+
x = self.norm2(x + self.ffn(x))
|
| 70 |
+
else:
|
| 71 |
+
x = x + self.attn(self.norm1(x), mask)
|
| 72 |
+
x = x + self.ffn(self.norm2(x))
|
| 73 |
+
return x
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class XLMRoberta(nn.Module):
|
| 77 |
+
"""
|
| 78 |
+
XLMRobertaModel with no pooler and no LM head.
|
| 79 |
+
"""
|
| 80 |
+
|
| 81 |
+
def __init__(self,
|
| 82 |
+
vocab_size=250002,
|
| 83 |
+
max_seq_len=514,
|
| 84 |
+
type_size=1,
|
| 85 |
+
pad_id=1,
|
| 86 |
+
dim=1024,
|
| 87 |
+
num_heads=16,
|
| 88 |
+
num_layers=24,
|
| 89 |
+
post_norm=True,
|
| 90 |
+
dropout=0.1,
|
| 91 |
+
eps=1e-5):
|
| 92 |
+
super().__init__()
|
| 93 |
+
self.vocab_size = vocab_size
|
| 94 |
+
self.max_seq_len = max_seq_len
|
| 95 |
+
self.type_size = type_size
|
| 96 |
+
self.pad_id = pad_id
|
| 97 |
+
self.dim = dim
|
| 98 |
+
self.num_heads = num_heads
|
| 99 |
+
self.num_layers = num_layers
|
| 100 |
+
self.post_norm = post_norm
|
| 101 |
+
self.eps = eps
|
| 102 |
+
|
| 103 |
+
# embeddings
|
| 104 |
+
self.token_embedding = nn.Embedding(vocab_size, dim, padding_idx=pad_id)
|
| 105 |
+
self.type_embedding = nn.Embedding(type_size, dim)
|
| 106 |
+
self.pos_embedding = nn.Embedding(max_seq_len, dim, padding_idx=pad_id)
|
| 107 |
+
self.dropout = nn.Dropout(dropout)
|
| 108 |
+
|
| 109 |
+
# blocks
|
| 110 |
+
self.blocks = nn.ModuleList([
|
| 111 |
+
AttentionBlock(dim, num_heads, post_norm, dropout, eps)
|
| 112 |
+
for _ in range(num_layers)
|
| 113 |
+
])
|
| 114 |
+
|
| 115 |
+
# norm layer
|
| 116 |
+
self.norm = nn.LayerNorm(dim, eps=eps)
|
| 117 |
+
|
| 118 |
+
def forward(self, ids):
|
| 119 |
+
"""
|
| 120 |
+
ids: [B, L] of torch.LongTensor.
|
| 121 |
+
"""
|
| 122 |
+
b, s = ids.shape
|
| 123 |
+
mask = ids.ne(self.pad_id).long()
|
| 124 |
+
|
| 125 |
+
# embeddings
|
| 126 |
+
x = self.token_embedding(ids) + \
|
| 127 |
+
self.type_embedding(torch.zeros_like(ids)) + \
|
| 128 |
+
self.pos_embedding(self.pad_id + torch.cumsum(mask, dim=1) * mask)
|
| 129 |
+
if self.post_norm:
|
| 130 |
+
x = self.norm(x)
|
| 131 |
+
x = self.dropout(x)
|
| 132 |
+
|
| 133 |
+
# blocks
|
| 134 |
+
mask = torch.where(
|
| 135 |
+
mask.view(b, 1, 1, s).gt(0), 0.0,
|
| 136 |
+
torch.finfo(x.dtype).min)
|
| 137 |
+
for block in self.blocks:
|
| 138 |
+
x = block(x, mask)
|
| 139 |
+
|
| 140 |
+
# output
|
| 141 |
+
if not self.post_norm:
|
| 142 |
+
x = self.norm(x)
|
| 143 |
+
return x
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def xlm_roberta_large(pretrained=False,
|
| 147 |
+
return_tokenizer=False,
|
| 148 |
+
device='cpu',
|
| 149 |
+
**kwargs):
|
| 150 |
+
"""
|
| 151 |
+
XLMRobertaLarge adapted from Huggingface.
|
| 152 |
+
"""
|
| 153 |
+
# params
|
| 154 |
+
cfg = dict(
|
| 155 |
+
vocab_size=250002,
|
| 156 |
+
max_seq_len=514,
|
| 157 |
+
type_size=1,
|
| 158 |
+
pad_id=1,
|
| 159 |
+
dim=1024,
|
| 160 |
+
num_heads=16,
|
| 161 |
+
num_layers=24,
|
| 162 |
+
post_norm=True,
|
| 163 |
+
dropout=0.1,
|
| 164 |
+
eps=1e-5)
|
| 165 |
+
cfg.update(**kwargs)
|
| 166 |
+
|
| 167 |
+
# init a model on device
|
| 168 |
+
with torch.device(device):
|
| 169 |
+
model = XLMRoberta(**cfg)
|
| 170 |
+
return model
|
wan/text2video.py
ADDED
|
@@ -0,0 +1,267 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024-2025 The Alibaba Wan Team Authors. All rights reserved.
|
| 2 |
+
import gc
|
| 3 |
+
import logging
|
| 4 |
+
import math
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
import sys
|
| 8 |
+
import types
|
| 9 |
+
from contextlib import contextmanager
|
| 10 |
+
from functools import partial
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import torch.cuda.amp as amp
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
|
| 17 |
+
from .distributed.fsdp import shard_model
|
| 18 |
+
from .modules.model import WanModel
|
| 19 |
+
from .modules.t5 import T5EncoderModel
|
| 20 |
+
from .modules.vae import WanVAE
|
| 21 |
+
from .utils.fm_solvers import (FlowDPMSolverMultistepScheduler,
|
| 22 |
+
get_sampling_sigmas, retrieve_timesteps)
|
| 23 |
+
from .utils.fm_solvers_unipc import FlowUniPCMultistepScheduler
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class WanT2V:
|
| 27 |
+
|
| 28 |
+
def __init__(
|
| 29 |
+
self,
|
| 30 |
+
config,
|
| 31 |
+
checkpoint_dir,
|
| 32 |
+
device_id=0,
|
| 33 |
+
rank=0,
|
| 34 |
+
t5_fsdp=False,
|
| 35 |
+
dit_fsdp=False,
|
| 36 |
+
use_usp=False,
|
| 37 |
+
t5_cpu=False,
|
| 38 |
+
):
|
| 39 |
+
r"""
|
| 40 |
+
Initializes the Wan text-to-video generation model components.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
config (EasyDict):
|
| 44 |
+
Object containing model parameters initialized from config.py
|
| 45 |
+
checkpoint_dir (`str`):
|
| 46 |
+
Path to directory containing model checkpoints
|
| 47 |
+
device_id (`int`, *optional*, defaults to 0):
|
| 48 |
+
Id of target GPU device
|
| 49 |
+
rank (`int`, *optional*, defaults to 0):
|
| 50 |
+
Process rank for distributed training
|
| 51 |
+
t5_fsdp (`bool`, *optional*, defaults to False):
|
| 52 |
+
Enable FSDP sharding for T5 model
|
| 53 |
+
dit_fsdp (`bool`, *optional*, defaults to False):
|
| 54 |
+
Enable FSDP sharding for DiT model
|
| 55 |
+
use_usp (`bool`, *optional*, defaults to False):
|
| 56 |
+
Enable distribution strategy of USP.
|
| 57 |
+
t5_cpu (`bool`, *optional*, defaults to False):
|
| 58 |
+
Whether to place T5 model on CPU. Only works without t5_fsdp.
|
| 59 |
+
"""
|
| 60 |
+
self.device = torch.device(f"cuda:{device_id}")
|
| 61 |
+
self.config = config
|
| 62 |
+
self.rank = rank
|
| 63 |
+
self.t5_cpu = t5_cpu
|
| 64 |
+
|
| 65 |
+
self.num_train_timesteps = config.num_train_timesteps
|
| 66 |
+
self.param_dtype = config.param_dtype
|
| 67 |
+
|
| 68 |
+
shard_fn = partial(shard_model, device_id=device_id)
|
| 69 |
+
self.text_encoder = T5EncoderModel(
|
| 70 |
+
text_len=config.text_len,
|
| 71 |
+
dtype=config.t5_dtype,
|
| 72 |
+
device=torch.device('cpu'),
|
| 73 |
+
checkpoint_path=os.path.join(checkpoint_dir, config.t5_checkpoint),
|
| 74 |
+
tokenizer_path=os.path.join(checkpoint_dir, config.t5_tokenizer),
|
| 75 |
+
shard_fn=shard_fn if t5_fsdp else None)
|
| 76 |
+
|
| 77 |
+
self.vae_stride = config.vae_stride
|
| 78 |
+
self.patch_size = config.patch_size
|
| 79 |
+
self.vae = WanVAE(
|
| 80 |
+
vae_pth=os.path.join(checkpoint_dir, config.vae_checkpoint),
|
| 81 |
+
device=self.device)
|
| 82 |
+
|
| 83 |
+
logging.info(f"Creating WanModel from {checkpoint_dir}")
|
| 84 |
+
self.model = WanModel.from_pretrained(checkpoint_dir)
|
| 85 |
+
self.model.eval().requires_grad_(False)
|
| 86 |
+
|
| 87 |
+
if use_usp:
|
| 88 |
+
from xfuser.core.distributed import \
|
| 89 |
+
get_sequence_parallel_world_size
|
| 90 |
+
|
| 91 |
+
from .distributed.xdit_context_parallel import (usp_attn_forward,
|
| 92 |
+
usp_dit_forward)
|
| 93 |
+
for block in self.model.blocks:
|
| 94 |
+
block.self_attn.forward = types.MethodType(
|
| 95 |
+
usp_attn_forward, block.self_attn)
|
| 96 |
+
self.model.forward = types.MethodType(usp_dit_forward, self.model)
|
| 97 |
+
self.sp_size = get_sequence_parallel_world_size()
|
| 98 |
+
else:
|
| 99 |
+
self.sp_size = 1
|
| 100 |
+
|
| 101 |
+
if dist.is_initialized():
|
| 102 |
+
dist.barrier()
|
| 103 |
+
if dit_fsdp:
|
| 104 |
+
self.model = shard_fn(self.model)
|
| 105 |
+
else:
|
| 106 |
+
self.model.to(self.device)
|
| 107 |
+
|
| 108 |
+
self.sample_neg_prompt = config.sample_neg_prompt
|
| 109 |
+
|
| 110 |
+
def generate(self,
|
| 111 |
+
input_prompt,
|
| 112 |
+
size=(1280, 720),
|
| 113 |
+
frame_num=81,
|
| 114 |
+
shift=5.0,
|
| 115 |
+
sample_solver='unipc',
|
| 116 |
+
sampling_steps=50,
|
| 117 |
+
guide_scale=5.0,
|
| 118 |
+
n_prompt="",
|
| 119 |
+
seed=-1,
|
| 120 |
+
offload_model=True):
|
| 121 |
+
r"""
|
| 122 |
+
Generates video frames from text prompt using diffusion process.
|
| 123 |
+
|
| 124 |
+
Args:
|
| 125 |
+
input_prompt (`str`):
|
| 126 |
+
Text prompt for content generation
|
| 127 |
+
size (tupele[`int`], *optional*, defaults to (1280,720)):
|
| 128 |
+
Controls video resolution, (width,height).
|
| 129 |
+
frame_num (`int`, *optional*, defaults to 81):
|
| 130 |
+
How many frames to sample from a video. The number should be 4n+1
|
| 131 |
+
shift (`float`, *optional*, defaults to 5.0):
|
| 132 |
+
Noise schedule shift parameter. Affects temporal dynamics
|
| 133 |
+
sample_solver (`str`, *optional*, defaults to 'unipc'):
|
| 134 |
+
Solver used to sample the video.
|
| 135 |
+
sampling_steps (`int`, *optional*, defaults to 40):
|
| 136 |
+
Number of diffusion sampling steps. Higher values improve quality but slow generation
|
| 137 |
+
guide_scale (`float`, *optional*, defaults 5.0):
|
| 138 |
+
Classifier-free guidance scale. Controls prompt adherence vs. creativity
|
| 139 |
+
n_prompt (`str`, *optional*, defaults to ""):
|
| 140 |
+
Negative prompt for content exclusion. If not given, use `config.sample_neg_prompt`
|
| 141 |
+
seed (`int`, *optional*, defaults to -1):
|
| 142 |
+
Random seed for noise generation. If -1, use random seed.
|
| 143 |
+
offload_model (`bool`, *optional*, defaults to True):
|
| 144 |
+
If True, offloads models to CPU during generation to save VRAM
|
| 145 |
+
|
| 146 |
+
Returns:
|
| 147 |
+
torch.Tensor:
|
| 148 |
+
Generated video frames tensor. Dimensions: (C, N H, W) where:
|
| 149 |
+
- C: Color channels (3 for RGB)
|
| 150 |
+
- N: Number of frames (81)
|
| 151 |
+
- H: Frame height (from size)
|
| 152 |
+
- W: Frame width from size)
|
| 153 |
+
"""
|
| 154 |
+
# preprocess
|
| 155 |
+
F = frame_num
|
| 156 |
+
target_shape = (self.vae.model.z_dim, (F - 1) // self.vae_stride[0] + 1,
|
| 157 |
+
size[1] // self.vae_stride[1],
|
| 158 |
+
size[0] // self.vae_stride[2])
|
| 159 |
+
|
| 160 |
+
seq_len = math.ceil((target_shape[2] * target_shape[3]) /
|
| 161 |
+
(self.patch_size[1] * self.patch_size[2]) *
|
| 162 |
+
target_shape[1] / self.sp_size) * self.sp_size
|
| 163 |
+
|
| 164 |
+
if n_prompt == "":
|
| 165 |
+
n_prompt = self.sample_neg_prompt
|
| 166 |
+
seed = seed if seed >= 0 else random.randint(0, sys.maxsize)
|
| 167 |
+
seed_g = torch.Generator(device=self.device)
|
| 168 |
+
seed_g.manual_seed(seed)
|
| 169 |
+
|
| 170 |
+
if not self.t5_cpu:
|
| 171 |
+
self.text_encoder.model.to(self.device)
|
| 172 |
+
context = self.text_encoder([input_prompt], self.device)
|
| 173 |
+
context_null = self.text_encoder([n_prompt], self.device)
|
| 174 |
+
if offload_model:
|
| 175 |
+
self.text_encoder.model.cpu()
|
| 176 |
+
else:
|
| 177 |
+
context = self.text_encoder([input_prompt], torch.device('cpu'))
|
| 178 |
+
context_null = self.text_encoder([n_prompt], torch.device('cpu'))
|
| 179 |
+
context = [t.to(self.device) for t in context]
|
| 180 |
+
context_null = [t.to(self.device) for t in context_null]
|
| 181 |
+
|
| 182 |
+
noise = [
|
| 183 |
+
torch.randn(
|
| 184 |
+
target_shape[0],
|
| 185 |
+
target_shape[1],
|
| 186 |
+
target_shape[2],
|
| 187 |
+
target_shape[3],
|
| 188 |
+
dtype=torch.float32,
|
| 189 |
+
device=self.device,
|
| 190 |
+
generator=seed_g)
|
| 191 |
+
]
|
| 192 |
+
|
| 193 |
+
@contextmanager
|
| 194 |
+
def noop_no_sync():
|
| 195 |
+
yield
|
| 196 |
+
|
| 197 |
+
no_sync = getattr(self.model, 'no_sync', noop_no_sync)
|
| 198 |
+
|
| 199 |
+
# evaluation mode
|
| 200 |
+
with amp.autocast(dtype=self.param_dtype), torch.no_grad(), no_sync():
|
| 201 |
+
|
| 202 |
+
if sample_solver == 'unipc':
|
| 203 |
+
sample_scheduler = FlowUniPCMultistepScheduler(
|
| 204 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 205 |
+
shift=1,
|
| 206 |
+
use_dynamic_shifting=False)
|
| 207 |
+
sample_scheduler.set_timesteps(
|
| 208 |
+
sampling_steps, device=self.device, shift=shift)
|
| 209 |
+
timesteps = sample_scheduler.timesteps
|
| 210 |
+
elif sample_solver == 'dpm++':
|
| 211 |
+
sample_scheduler = FlowDPMSolverMultistepScheduler(
|
| 212 |
+
num_train_timesteps=self.num_train_timesteps,
|
| 213 |
+
shift=1,
|
| 214 |
+
use_dynamic_shifting=False)
|
| 215 |
+
sampling_sigmas = get_sampling_sigmas(sampling_steps, shift)
|
| 216 |
+
timesteps, _ = retrieve_timesteps(
|
| 217 |
+
sample_scheduler,
|
| 218 |
+
device=self.device,
|
| 219 |
+
sigmas=sampling_sigmas)
|
| 220 |
+
else:
|
| 221 |
+
raise NotImplementedError("Unsupported solver.")
|
| 222 |
+
|
| 223 |
+
# sample videos
|
| 224 |
+
latents = noise
|
| 225 |
+
|
| 226 |
+
arg_c = {'context': context, 'seq_len': seq_len}
|
| 227 |
+
arg_null = {'context': context_null, 'seq_len': seq_len}
|
| 228 |
+
|
| 229 |
+
for _, t in enumerate(tqdm(timesteps)):
|
| 230 |
+
latent_model_input = latents
|
| 231 |
+
timestep = [t]
|
| 232 |
+
|
| 233 |
+
timestep = torch.stack(timestep)
|
| 234 |
+
|
| 235 |
+
self.model.to(self.device)
|
| 236 |
+
noise_pred_cond = self.model(
|
| 237 |
+
latent_model_input, t=timestep, **arg_c)[0]
|
| 238 |
+
noise_pred_uncond = self.model(
|
| 239 |
+
latent_model_input, t=timestep, **arg_null)[0]
|
| 240 |
+
|
| 241 |
+
noise_pred = noise_pred_uncond + guide_scale * (
|
| 242 |
+
noise_pred_cond - noise_pred_uncond)
|
| 243 |
+
|
| 244 |
+
temp_x0 = sample_scheduler.step(
|
| 245 |
+
noise_pred.unsqueeze(0),
|
| 246 |
+
t,
|
| 247 |
+
latents[0].unsqueeze(0),
|
| 248 |
+
return_dict=False,
|
| 249 |
+
generator=seed_g)[0]
|
| 250 |
+
latents = [temp_x0.squeeze(0)]
|
| 251 |
+
|
| 252 |
+
x0 = latents
|
| 253 |
+
if offload_model:
|
| 254 |
+
self.model.cpu()
|
| 255 |
+
torch.cuda.empty_cache()
|
| 256 |
+
if self.rank == 0:
|
| 257 |
+
videos = self.vae.decode(x0)
|
| 258 |
+
|
| 259 |
+
del noise, latents
|
| 260 |
+
del sample_scheduler
|
| 261 |
+
if offload_model:
|
| 262 |
+
gc.collect()
|
| 263 |
+
torch.cuda.synchronize()
|
| 264 |
+
if dist.is_initialized():
|
| 265 |
+
dist.barrier()
|
| 266 |
+
|
| 267 |
+
return videos[0] if self.rank == 0 else None
|
wan/utils/__init__.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .fm_solvers import (FlowDPMSolverMultistepScheduler, get_sampling_sigmas,
|
| 2 |
+
retrieve_timesteps)
|
| 3 |
+
from .fm_solvers_unipc import FlowUniPCMultistepScheduler
|
| 4 |
+
from .vace_processor import VaceVideoProcessor
|
| 5 |
+
|
| 6 |
+
__all__ = [
|
| 7 |
+
'HuggingfaceTokenizer', 'get_sampling_sigmas', 'retrieve_timesteps',
|
| 8 |
+
'FlowDPMSolverMultistepScheduler', 'FlowUniPCMultistepScheduler',
|
| 9 |
+
'VaceVideoProcessor'
|
| 10 |
+
]
|