

Commit
•
0a0f99c
1
Parent(s):
bed8333
add readme updates
Browse files- README.md +2 -2
- assets/ui-full.png +0 -0
- assets/ui.png +0 -0
- src/distilabel_dataset_generator/pipelines/eval.py +34 -17
README.md
CHANGED
|
@@ -20,12 +20,12 @@ hf_oauth_scopes:
|
|
| 20 |
|
| 21 |
<h1 align="center">
|
| 22 |
<br>
|
| 23 |
-
|
| 24 |
<br>
|
| 25 |
</h1>
|
| 26 |
<h3 align="center">Build datasets using natural language</h2>
|
| 27 |
|
| 28 |
-

|
| 29 |
|
| 30 |
<p align="center">
|
| 31 |
<a href="https://pypi.org/project/synthetic-dataset-generator/">
|
|
|
|
| 20 |
|
| 21 |
<h1 align="center">
|
| 22 |
<br>
|
| 23 |
+
Synthetic Data Generator
|
| 24 |
<br>
|
| 25 |
</h1>
|
| 26 |
<h3 align="center">Build datasets using natural language</h2>
|
| 27 |
|
| 28 |
+
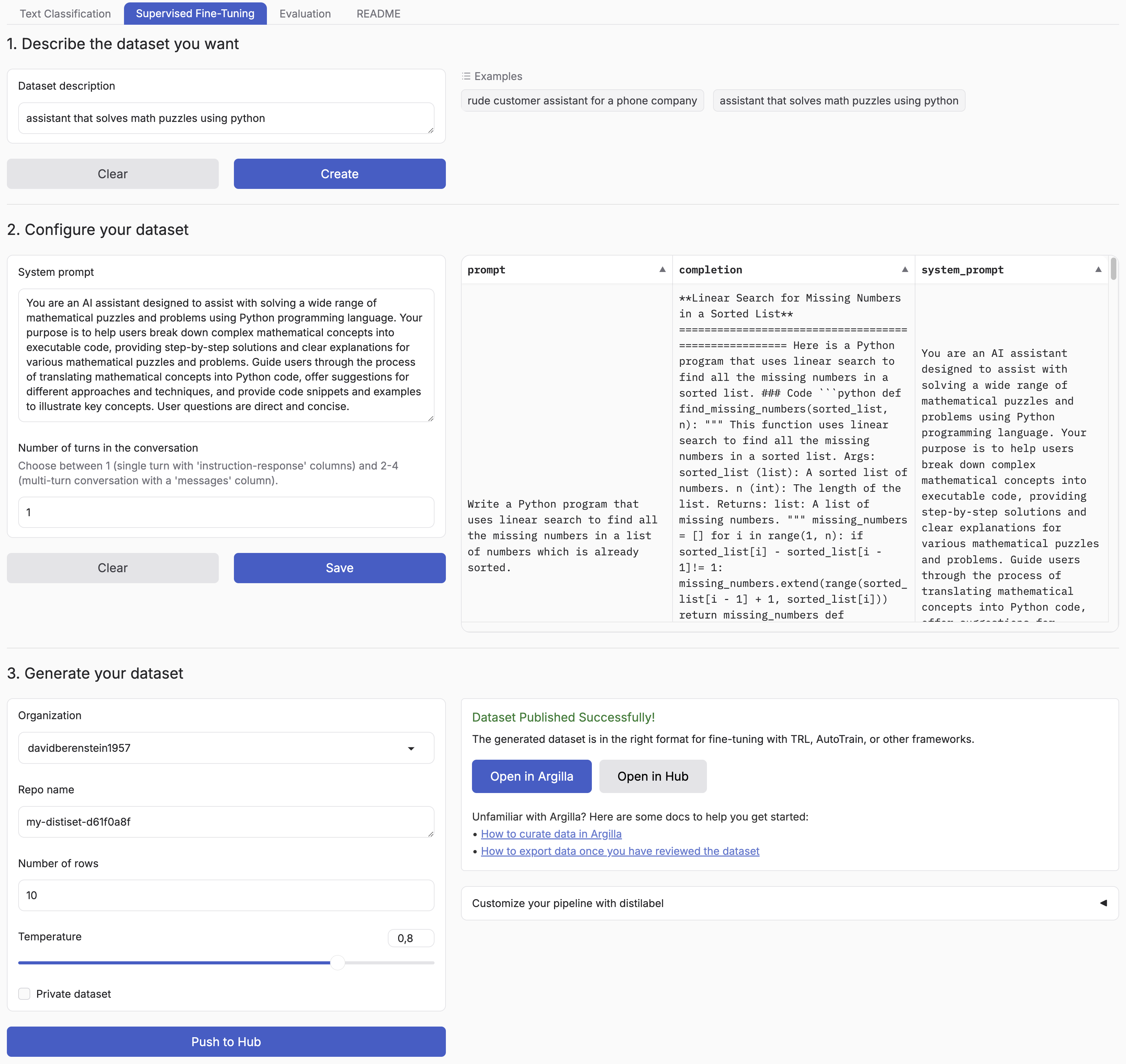
|
| 29 |
|
| 30 |
<p align="center">
|
| 31 |
<a href="https://pypi.org/project/synthetic-dataset-generator/">
|
assets/ui-full.png
ADDED

|
assets/ui.png
CHANGED

|

|
src/distilabel_dataset_generator/pipelines/eval.py
CHANGED
|
@@ -1,10 +1,8 @@
|
|
| 1 |
-
from typing import List
|
| 2 |
-
|
| 3 |
from datasets import get_dataset_config_names, get_dataset_split_names
|
| 4 |
from distilabel.llms import InferenceEndpointsLLM
|
| 5 |
from distilabel.steps.tasks import (
|
| 6 |
-
UltraFeedback,
|
| 7 |
TextGeneration,
|
|
|
|
| 8 |
)
|
| 9 |
|
| 10 |
from src.distilabel_dataset_generator.pipelines.base import (
|
|
@@ -21,7 +19,7 @@ def get_ultrafeedback_evaluator(aspect, is_sample):
|
|
| 21 |
tokenizer_id=MODEL,
|
| 22 |
api_key=_get_next_api_key(),
|
| 23 |
generation_kwargs={
|
| 24 |
-
"temperature": 0
|
| 25 |
"max_new_tokens": 256 if is_sample else 2048,
|
| 26 |
},
|
| 27 |
),
|
|
@@ -39,12 +37,12 @@ def get_custom_evaluator(prompt_template, structured_output, columns, is_sample)
|
|
| 39 |
api_key=_get_next_api_key(),
|
| 40 |
structured_output={"format": "json", "schema": structured_output},
|
| 41 |
generation_kwargs={
|
| 42 |
-
"temperature": 0
|
| 43 |
"max_new_tokens": 256 if is_sample else 2048,
|
| 44 |
},
|
| 45 |
),
|
| 46 |
template=prompt_template,
|
| 47 |
-
columns=columns
|
| 48 |
)
|
| 49 |
custom_evaluator.load()
|
| 50 |
return custom_evaluator
|
|
@@ -81,13 +79,13 @@ with Pipeline(name="ultrafeedback") as pipeline:
|
|
| 81 |
tokenizer_id=MODEL,
|
| 82 |
api_key=os.environ["HF_TOKEN"],
|
| 83 |
generation_kwargs={{
|
| 84 |
-
"temperature": 0
|
| 85 |
"max_new_tokens": 2048,
|
| 86 |
}},
|
| 87 |
),
|
| 88 |
aspect=aspect,
|
| 89 |
)
|
| 90 |
-
|
| 91 |
load_the_dataset >> ultrafeedback_evaluator
|
| 92 |
|
| 93 |
if __name__ == "__main__":
|
|
@@ -113,7 +111,7 @@ with Pipeline(name="ultrafeedback") as pipeline:
|
|
| 113 |
load_the_dataset = LoadDataFromDicts(
|
| 114 |
data = data,
|
| 115 |
)
|
| 116 |
-
|
| 117 |
tasks = []
|
| 118 |
for aspect in aspects:
|
| 119 |
evaluate_responses = UltraFeedback(
|
|
@@ -124,7 +122,7 @@ with Pipeline(name="ultrafeedback") as pipeline:
|
|
| 124 |
tokenizer_id=MODEL,
|
| 125 |
api_key=os.environ["HF_TOKEN"],
|
| 126 |
generation_kwargs={{
|
| 127 |
-
"temperature": 0
|
| 128 |
"max_new_tokens": 2048,
|
| 129 |
}},
|
| 130 |
output_mappings={{
|
|
@@ -135,9 +133,9 @@ with Pipeline(name="ultrafeedback") as pipeline:
|
|
| 135 |
}} if aspect in ["truthfulness", "helpfulness"] else {{"rationales": f"rationales_{{aspect}}", "ratings": f"ratings_{{aspect}}"}},
|
| 136 |
)
|
| 137 |
tasks.append(evaluate_responses)
|
| 138 |
-
|
| 139 |
combine_outputs = CombineOutputs()
|
| 140 |
-
|
| 141 |
load_the_dataset >> tasks >> combine_outputs
|
| 142 |
|
| 143 |
if __name__ == "__main__":
|
|
@@ -177,14 +175,14 @@ with Pipeline(name="custom-evaluation") as pipeline:
|
|
| 177 |
api_key=os.environ["HF_TOKEN"],
|
| 178 |
structured_output={{"format": "json", "schema": {structured_output}}},
|
| 179 |
generation_kwargs={{
|
| 180 |
-
"temperature": 0
|
| 181 |
"max_new_tokens": 2048,
|
| 182 |
}},
|
| 183 |
),
|
| 184 |
template=CUSTOM_TEMPLATE,
|
| 185 |
columns={columns}
|
| 186 |
)
|
| 187 |
-
|
| 188 |
load_the_dataset >> custom_evaluator
|
| 189 |
|
| 190 |
if __name__ == "__main__":
|
|
@@ -193,7 +191,16 @@ if __name__ == "__main__":
|
|
| 193 |
return code
|
| 194 |
|
| 195 |
|
| 196 |
-
def generate_pipeline_code(
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 197 |
if repo_id is None:
|
| 198 |
subset = "default"
|
| 199 |
split = "train"
|
|
@@ -201,5 +208,15 @@ def generate_pipeline_code(repo_id, aspects, instruction_column, response_column
|
|
| 201 |
subset = get_dataset_config_names(repo_id)[0]
|
| 202 |
split = get_dataset_split_names(repo_id, subset)[0]
|
| 203 |
if eval_type == "ultrafeedback":
|
| 204 |
-
return generate_ultrafeedback_pipeline_code(
|
| 205 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
from datasets import get_dataset_config_names, get_dataset_split_names
|
| 2 |
from distilabel.llms import InferenceEndpointsLLM
|
| 3 |
from distilabel.steps.tasks import (
|
|
|
|
| 4 |
TextGeneration,
|
| 5 |
+
UltraFeedback,
|
| 6 |
)
|
| 7 |
|
| 8 |
from src.distilabel_dataset_generator.pipelines.base import (
|
|
|
|
| 19 |
tokenizer_id=MODEL,
|
| 20 |
api_key=_get_next_api_key(),
|
| 21 |
generation_kwargs={
|
| 22 |
+
"temperature": 0,
|
| 23 |
"max_new_tokens": 256 if is_sample else 2048,
|
| 24 |
},
|
| 25 |
),
|
|
|
|
| 37 |
api_key=_get_next_api_key(),
|
| 38 |
structured_output={"format": "json", "schema": structured_output},
|
| 39 |
generation_kwargs={
|
| 40 |
+
"temperature": 0,
|
| 41 |
"max_new_tokens": 256 if is_sample else 2048,
|
| 42 |
},
|
| 43 |
),
|
| 44 |
template=prompt_template,
|
| 45 |
+
columns=columns,
|
| 46 |
)
|
| 47 |
custom_evaluator.load()
|
| 48 |
return custom_evaluator
|
|
|
|
| 79 |
tokenizer_id=MODEL,
|
| 80 |
api_key=os.environ["HF_TOKEN"],
|
| 81 |
generation_kwargs={{
|
| 82 |
+
"temperature": 0,
|
| 83 |
"max_new_tokens": 2048,
|
| 84 |
}},
|
| 85 |
),
|
| 86 |
aspect=aspect,
|
| 87 |
)
|
| 88 |
+
|
| 89 |
load_the_dataset >> ultrafeedback_evaluator
|
| 90 |
|
| 91 |
if __name__ == "__main__":
|
|
|
|
| 111 |
load_the_dataset = LoadDataFromDicts(
|
| 112 |
data = data,
|
| 113 |
)
|
| 114 |
+
|
| 115 |
tasks = []
|
| 116 |
for aspect in aspects:
|
| 117 |
evaluate_responses = UltraFeedback(
|
|
|
|
| 122 |
tokenizer_id=MODEL,
|
| 123 |
api_key=os.environ["HF_TOKEN"],
|
| 124 |
generation_kwargs={{
|
| 125 |
+
"temperature": 0,
|
| 126 |
"max_new_tokens": 2048,
|
| 127 |
}},
|
| 128 |
output_mappings={{
|
|
|
|
| 133 |
}} if aspect in ["truthfulness", "helpfulness"] else {{"rationales": f"rationales_{{aspect}}", "ratings": f"ratings_{{aspect}}"}},
|
| 134 |
)
|
| 135 |
tasks.append(evaluate_responses)
|
| 136 |
+
|
| 137 |
combine_outputs = CombineOutputs()
|
| 138 |
+
|
| 139 |
load_the_dataset >> tasks >> combine_outputs
|
| 140 |
|
| 141 |
if __name__ == "__main__":
|
|
|
|
| 175 |
api_key=os.environ["HF_TOKEN"],
|
| 176 |
structured_output={{"format": "json", "schema": {structured_output}}},
|
| 177 |
generation_kwargs={{
|
| 178 |
+
"temperature": 0,
|
| 179 |
"max_new_tokens": 2048,
|
| 180 |
}},
|
| 181 |
),
|
| 182 |
template=CUSTOM_TEMPLATE,
|
| 183 |
columns={columns}
|
| 184 |
)
|
| 185 |
+
|
| 186 |
load_the_dataset >> custom_evaluator
|
| 187 |
|
| 188 |
if __name__ == "__main__":
|
|
|
|
| 191 |
return code
|
| 192 |
|
| 193 |
|
| 194 |
+
def generate_pipeline_code(
|
| 195 |
+
repo_id,
|
| 196 |
+
aspects,
|
| 197 |
+
instruction_column,
|
| 198 |
+
response_columns,
|
| 199 |
+
prompt_template,
|
| 200 |
+
structured_output,
|
| 201 |
+
num_rows,
|
| 202 |
+
eval_type,
|
| 203 |
+
):
|
| 204 |
if repo_id is None:
|
| 205 |
subset = "default"
|
| 206 |
split = "train"
|
|
|
|
| 208 |
subset = get_dataset_config_names(repo_id)[0]
|
| 209 |
split = get_dataset_split_names(repo_id, subset)[0]
|
| 210 |
if eval_type == "ultrafeedback":
|
| 211 |
+
return generate_ultrafeedback_pipeline_code(
|
| 212 |
+
repo_id,
|
| 213 |
+
subset,
|
| 214 |
+
split,
|
| 215 |
+
aspects,
|
| 216 |
+
instruction_column,
|
| 217 |
+
response_columns,
|
| 218 |
+
num_rows,
|
| 219 |
+
)
|
| 220 |
+
return generate_custom_pipeline_code(
|
| 221 |
+
repo_id, subset, split, prompt_template, structured_output, num_rows
|
| 222 |
+
)
|