Spaces:
Sleeping

Sleeping
Upload 4 files
Browse files- ap.py +57 -0
- modelrice.h5 +3 -0
- requirements.txt +2 -0
- rice-cnn.ipynb +1 -0
ap.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import streamlit as st
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import numpy as np
|
| 5 |
+
from tensorflow.keras.models import load_model
|
| 6 |
+
|
| 7 |
+
# Pirinç çeşitleri
|
| 8 |
+
rice_varieties = ['Arborio', 'Basmati', 'Ipsala', 'Jasmine', 'Karacadag']
|
| 9 |
+
|
| 10 |
+
# Modeli yükleme
|
| 11 |
+
model = load_model('modelrice.h5')
|
| 12 |
+
model.summary()
|
| 13 |
+
|
| 14 |
+
def process_img(img):
|
| 15 |
+
img = img.resize((224, 224), Image.LANCZOS) # 200x200 piksel boyutuna dönüştürme
|
| 16 |
+
img = np.array(img) / 255.0 # Normalize etme
|
| 17 |
+
img = np.expand_dims(img, axis=0) # Resme boyut ekleme
|
| 18 |
+
return img
|
| 19 |
+
|
| 20 |
+
st.title("Pirinç Çeşidi Sınıflandırması :rice:")
|
| 21 |
+
st.write(
|
| 22 |
+
"Bir pirinç resmi seçin ve modelimiz, bu resmin hangi pirinç çeşidinden olduğunu tahmin etsin. 🖼️📊\n"
|
| 23 |
+
"Upload an image and the model will predict which rice variety your image shows."
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
# Stil ayarları
|
| 27 |
+
st.markdown("""
|
| 28 |
+
<style>
|
| 29 |
+
.reportview-container {
|
| 30 |
+
background: #F0F2F6;
|
| 31 |
+
}
|
| 32 |
+
.sidebar .sidebar-content {
|
| 33 |
+
background: #E0E0E0;
|
| 34 |
+
}
|
| 35 |
+
.css-18e3th9 {
|
| 36 |
+
font-size: 1.25em;
|
| 37 |
+
color: #333;
|
| 38 |
+
}
|
| 39 |
+
</style>
|
| 40 |
+
""", unsafe_allow_html=True)
|
| 41 |
+
|
| 42 |
+
file = st.file_uploader("Resim Yükle & Bir resim seçiniz", type=['png', 'jpg', 'jpeg'])
|
| 43 |
+
|
| 44 |
+
if file is not None:
|
| 45 |
+
img = Image.open(file)
|
| 46 |
+
st.image(img, caption="Yüklenen Resim", use_column_width=True)
|
| 47 |
+
|
| 48 |
+
result = process_img(img)
|
| 49 |
+
prediction = model.predict(result)
|
| 50 |
+
prediction_class = np.argmax(prediction) # En yüksek tahmin edilen sınıf
|
| 51 |
+
|
| 52 |
+
# Sınıf isimleri
|
| 53 |
+
result_text = rice_varieties[prediction_class]
|
| 54 |
+
|
| 55 |
+
st.write(f"**Sonuç:** {result_text}")
|
| 56 |
+
else:
|
| 57 |
+
st.write("Lütfen bir resim yükleyin.")
|
modelrice.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df0693f3ab556072ac93b69e354a0032a2e9acdb309c864269e7ef5ab68d4c90
|
| 3 |
+
size 61351752
|
requirements.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tensorflow
|
| 2 |
+
streamlit
|
rice-cnn.ipynb
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"metadata":{"kernelspec":{"language":"python","display_name":"Python 3","name":"python3"},"language_info":{"name":"python","version":"3.10.13","mimetype":"text/x-python","codemirror_mode":{"name":"ipython","version":3},"pygments_lexer":"ipython3","nbconvert_exporter":"python","file_extension":".py"},"kaggle":{"accelerator":"none","dataSources":[{"sourceId":3399185,"sourceType":"datasetVersion","datasetId":2049052}],"dockerImageVersionId":30746,"isInternetEnabled":true,"language":"python","sourceType":"notebook","isGpuEnabled":false}},"nbformat_minor":4,"nbformat":4,"cells":[{"cell_type":"code","source":"import numpy as np # linear algebra\nimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\n\nimport os\nfor dirname, _, filenames in os.walk('/kaggle/input'):\n for filename in filenames:\n pass","metadata":{"_uuid":"8f2839f25d086af736a60e9eeb907d3b93b6e0e5","_cell_guid":"b1076dfc-b9ad-4769-8c92-a6c4dae69d19","execution":{"iopub.status.busy":"2024-07-31T14:21:48.155567Z","iopub.execute_input":"2024-07-31T14:21:48.156288Z","iopub.status.idle":"2024-07-31T14:23:08.330805Z","shell.execute_reply.started":"2024-07-31T14:21:48.156252Z","shell.execute_reply":"2024-07-31T14:23:08.329785Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"import os\nimport warnings\nwarnings.filterwarnings('ignore')\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:39.416567Z","iopub.execute_input":"2024-07-31T09:17:39.417045Z","iopub.status.idle":"2024-07-31T09:17:39.422992Z","shell.execute_reply.started":"2024-07-31T09:17:39.417009Z","shell.execute_reply":"2024-07-31T09:17:39.421753Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"# cat '/kaggle/input/rice-image-dataset/Rice_Image_Dataset/Rice_Citation_Request.txt'","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:40.906548Z","iopub.execute_input":"2024-07-31T09:17:40.907516Z","iopub.status.idle":"2024-07-31T09:17:40.912136Z","shell.execute_reply.started":"2024-07-31T09:17:40.907475Z","shell.execute_reply":"2024-07-31T09:17:40.910760Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"os.listdir(path)","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:41.627470Z","iopub.execute_input":"2024-07-31T09:17:41.627885Z","iopub.status.idle":"2024-07-31T09:17:41.642737Z","shell.execute_reply.started":"2024-07-31T09:17:41.627851Z","shell.execute_reply":"2024-07-31T09:17:41.641485Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"path='/kaggle/input/rice-image-dataset/Rice_Image_Dataset'","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:42.601867Z","iopub.execute_input":"2024-07-31T09:17:42.602253Z","iopub.status.idle":"2024-07-31T09:17:42.606845Z","shell.execute_reply.started":"2024-07-31T09:17:42.602222Z","shell.execute_reply":"2024-07-31T09:17:42.605761Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"def create_dataset(folders, path, max_images_per_label=1000):\n data = {'imgpath': [], 'labels': []}\n \n for folder in folders:\n folderpath = os.path.join(path, folder)\n files = os.listdir(folderpath)\n \n # Her bir klasörden sadece max_images_per_label kadar görsel alıyoruz\n selected_files = files[:max_images_per_label]\n \n for file in selected_files:\n filepath = os.path.join(folderpath, file)\n data['imgpath'].append(filepath)\n data['labels'].append(folder)\n\n dataset = pd.DataFrame(data)\n return dataset","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:43.525885Z","iopub.execute_input":"2024-07-31T09:17:43.526307Z","iopub.status.idle":"2024-07-31T09:17:43.534117Z","shell.execute_reply.started":"2024-07-31T09:17:43.526274Z","shell.execute_reply":"2024-07-31T09:17:43.532992Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":"# Ben Her piniç çeşidi için 1000 veri yeterli diye düşündüm ononu yüzündeb böyle bir işlem yaptım","metadata":{}},{"cell_type":"code","source":"folders1 = ['Arborio', 'Basmati', 'Ipsala', 'Jasmine', 'Karacadag'] \ndf=create_dataset(folders1,path)\ndf.head()","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:45.700941Z","iopub.execute_input":"2024-07-31T09:17:45.701404Z","iopub.status.idle":"2024-07-31T09:17:45.760421Z","shell.execute_reply.started":"2024-07-31T09:17:45.701369Z","shell.execute_reply":"2024-07-31T09:17:45.759159Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"import cv2\nimport matplotlib.pyplot as plt\nfor index, row in df.sample(7).iterrows():\n # Resmi yükle\n img = cv2.imread(row['imgpath'])\n \n # OpenCV resmi RGB formatına dönüştür\n img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n \n # Resmi matplotlib ile göster\n plt.figure(figsize=(6, 6))\n plt.imshow(img_rgb)\n plt.title(row['labels'])\n plt.axis('off')\n plt.show()","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:17:59.702599Z","iopub.execute_input":"2024-07-31T09:17:59.703010Z","iopub.status.idle":"2024-07-31T09:18:01.595261Z","shell.execute_reply.started":"2024-07-31T09:17:59.702980Z","shell.execute_reply":"2024-07-31T09:18:01.593874Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":"# Verilerin Görselleştirilmesi","metadata":{}},{"cell_type":"code","source":"import warnings\nwarnings.filterwarnings('ignore')\nimport matplotlib.pyplot as plt\nimport plotly.express as px\n\nsayi = df['labels'].value_counts() #hurma türe göre sayisi \n \n# Plotly ile hurma dağılımını görselleştirme\nfig=px.bar(x=sayi.index, #6 indexi var\n y=sayi.values, # sayisi \n color=sayi.index, # rekleri yine sayisina göre\n labels={'x': 'Çeşitler','y': 'Toplam Sayı'}, #label yazdırma\n title='Pirinç Çeşitleri Grafiği', #başlık \n template='plotly_dark') # arkapılan \n\nfig.show()\n\n\nfig = px.pie(names=sayi.index,\n values=sayi.values,\n title='Pirinç Dağılımı',\n labels={'names': 'Hurma',\n 'values': 'Toplam Sayı'},\n template='plotly_white')\nfig.show()","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:18:10.923743Z","iopub.execute_input":"2024-07-31T09:18:10.924671Z","iopub.status.idle":"2024-07-31T09:18:13.532763Z","shell.execute_reply.started":"2024-07-31T09:18:10.924632Z","shell.execute_reply":"2024-07-31T09:18:13.531657Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":"# Modeling ","metadata":{}},{"cell_type":"markdown","source":"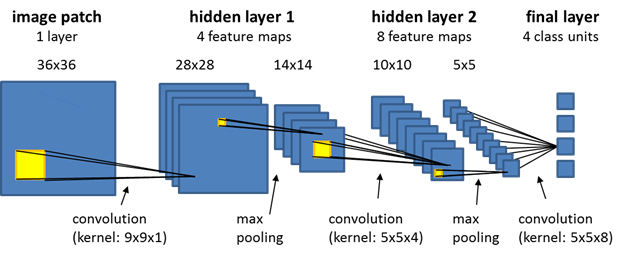","metadata":{}},{"cell_type":"code","source":"from sklearn.model_selection import train_test_split\n\n# Önce train ve geçici test (val+test) ayırma\ntrain_df, temp_df = train_test_split(df, test_size=0.2, random_state=42)\n\n# Sonra geçici test verisini (val+test) val ve test olarak ayırma\nval_df, test_df = train_test_split(temp_df, test_size=0.5, random_state=42)\n\ntrain_df.shape, val_df.shape, test_df.shape","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:18:13.534909Z","iopub.execute_input":"2024-07-31T09:18:13.535384Z","iopub.status.idle":"2024-07-31T09:18:13.548496Z","shell.execute_reply.started":"2024-07-31T09:18:13.535344Z","shell.execute_reply":"2024-07-31T09:18:13.547212Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"from tensorflow.keras.preprocessing.image import ImageDataGenerator\nseed = 42\nbatch_size = 128\nimg_size = (224, 224)\n\ngenerator = ImageDataGenerator(rescale = 1./255)\n\ntrain_data = generator.flow_from_dataframe(train_df, x_col = 'imgpath', y_col = 'labels', \n color_mode = 'rgb', class_mode = 'categorical', \n batch_size = batch_size, target_size = img_size, \n shuffle = True, seed = seed)\n\nval_data = generator.flow_from_dataframe(val_df, x_col = 'imgpath', y_col = 'labels', \n color_mode = 'rgb', class_mode = 'categorical', \n batch_size = batch_size, target_size = img_size, \n shuffle = False)\n\ntest_data = generator.flow_from_dataframe(test_df, x_col = 'imgpath', y_col = 'labels', \n color_mode = 'rgb', class_mode = 'categorical', \n batch_size = batch_size, target_size = img_size, \n shuffle = False)","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:18:19.756063Z","iopub.execute_input":"2024-07-31T09:18:19.756977Z","iopub.status.idle":"2024-07-31T09:18:25.426023Z","shell.execute_reply.started":"2024-07-31T09:18:19.756932Z","shell.execute_reply":"2024-07-31T09:18:25.424814Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"from tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense\nfrom tensorflow.keras.losses import CategoricalCrossentropy\n\nmodel = Sequential()\nmodel.add(Input(shape=(224, 224, 3)))\nmodel.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))\nmodel.add(MaxPooling2D(pool_size=(2, 2)))\nmodel.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))\nmodel.add(MaxPooling2D(pool_size=(2, 2)))\nmodel.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))\nmodel.add(MaxPooling2D(pool_size=(2, 2)))\nmodel.add(Conv2D(256, kernel_size=(3, 3), activation='relu'))\nmodel.add(MaxPooling2D(pool_size=(2, 2)))\nmodel.add(Flatten())\nmodel.add(Dense(128, activation='relu'))\n\nmodel.add(Dense(5, activation='softmax')) # 5 kategori\n\n# Modelin derlenmesi\nmodel.compile(optimizer='adam', loss=CategoricalCrossentropy(), metrics=['accuracy'])#kategorik etiketler varsa loss = 'CategoricalCrossentropy()'","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:18:25.428062Z","iopub.execute_input":"2024-07-31T09:18:25.428374Z","iopub.status.idle":"2024-07-31T09:18:26.327917Z","shell.execute_reply.started":"2024-07-31T09:18:25.428348Z","shell.execute_reply":"2024-07-31T09:18:26.326289Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"import warnings\nwarnings.filterwarnings('ignore')\nfrom tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau\n\nmodel_es = EarlyStopping(monitor = 'val_loss', mode = 'min', patience = 2, restore_best_weights = True)\nmodel_rlr = ReduceLROnPlateau(monitor = 'val_loss', factor = 0.2, patience = 1, mode = 'min')\n\nhistory = model.fit(train_data, validation_data = val_data, \n epochs = 10, callbacks = [model_es, model_rlr])","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:24:30.632052Z","iopub.execute_input":"2024-07-31T09:24:30.632779Z","iopub.status.idle":"2024-07-31T09:26:13.936510Z","shell.execute_reply.started":"2024-07-31T09:24:30.632741Z","shell.execute_reply":"2024-07-31T09:26:13.935093Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"model.save('rice_model.h5')","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:27:23.130021Z","iopub.execute_input":"2024-07-31T09:27:23.130473Z","iopub.status.idle":"2024-07-31T09:27:23.278792Z","shell.execute_reply.started":"2024-07-31T09:27:23.130439Z","shell.execute_reply":"2024-07-31T09:27:23.277770Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"# Eğitim ve Doğrulama Kaybı\nplt.plot(history.history['loss'], label='Eğitim Kaybı')\nplt.plot(history.history['val_loss'], label='Doğrulama Kaybı')\nplt.xlabel('Epoch')\nplt.ylabel('Loss')\nplt.legend()\nplt.show()\n\n# Eğitim ve Doğrulama Doğruluğu\nplt.plot(history.history['accuracy'], label='Eğitim Doğruluğu')\nplt.plot(history.history['val_accuracy'], label='Doğrulama Doğruluğu')\nplt.xlabel('Epoch')\nplt.ylabel('Accuracy')\nplt.legend()\nplt.show()","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:28:05.753844Z","iopub.execute_input":"2024-07-31T09:28:05.754917Z","iopub.status.idle":"2024-07-31T09:28:06.381174Z","shell.execute_reply.started":"2024-07-31T09:28:05.754861Z","shell.execute_reply":"2024-07-31T09:28:06.379982Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"import seaborn as sns\nfrom sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay\n\n# Model ile tahmin yapma\ny_pred = model.predict(test_data, steps=test_data.samples // test_data.batch_size + 1)\ny_pred_classes = np.argmax(y_pred, axis=1) # Tahmin edilen sınıflar\n\n# Gerçek etiketleri alma\ny_true = test_data.classes # Gerçek etiketler\n\n# Confusion Matrix hesaplama\ncm = confusion_matrix(y_true, y_pred_classes)\n\n# Confusion Matrix'i görselleştirme\nfig, ax = plt.subplots(figsize=(10, 8))\nplt.title('Confusion matrixisimiz')\ndisp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=test_data.class_indices.keys())\ndisp.plot(cmap=plt.cm.Blues, ax=ax)\nplt.show()","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:32:11.213879Z","iopub.execute_input":"2024-07-31T09:32:11.214342Z","iopub.status.idle":"2024-07-31T09:32:13.734058Z","shell.execute_reply.started":"2024-07-31T09:32:11.214306Z","shell.execute_reply":"2024-07-31T09:32:13.732834Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"class_names = list(test_data.class_indices.keys())\nreport = classification_report(y_true, y_pred_classes, target_names=class_names)\nprint(report)","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:32:55.520981Z","iopub.execute_input":"2024-07-31T09:32:55.521781Z","iopub.status.idle":"2024-07-31T09:32:55.540555Z","shell.execute_reply.started":"2024-07-31T09:32:55.521744Z","shell.execute_reply":"2024-07-31T09:32:55.539395Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"test_results = model.evaluate(test_data, verbose = 0)\n\nprint(f'Test Loss: {test_results[0]:.5f}')\nprint(f'Test Accuracy: {(test_results[1] * 100):.2f}%')","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:30:11.486081Z","iopub.execute_input":"2024-07-31T09:30:11.486534Z","iopub.status.idle":"2024-07-31T09:30:15.761744Z","shell.execute_reply.started":"2024-07-31T09:30:11.486497Z","shell.execute_reply":"2024-07-31T09:30:15.760564Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"model.summary()","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:29:57.992406Z","iopub.execute_input":"2024-07-31T09:29:57.992872Z","iopub.status.idle":"2024-07-31T09:29:58.028500Z","shell.execute_reply.started":"2024-07-31T09:29:57.992838Z","shell.execute_reply":"2024-07-31T09:29:58.027451Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"markdown","source":"****Conuç olarak CNN ile modelimiz Doğruluk olranı %95-99 arasına aldık\nve bu modeli kayıt edip mobil bir programda kullanıcağız***","metadata":{}},{"cell_type":"markdown","source":"EK olarak Daha önce Yaptığım modelden yola çıkarak aynı sonucu alabilirmiyim ? ","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:37:40.395623Z","iopub.execute_input":"2024-07-31T09:37:40.396047Z","iopub.status.idle":"2024-07-31T09:37:40.403114Z","shell.execute_reply.started":"2024-07-31T09:37:40.396016Z","shell.execute_reply":"2024-07-31T09:37:40.401805Z"}}},{"cell_type":"code","source":"from tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense\nfrom tensorflow.keras.losses import CategoricalCrossentropy\n\n\n\nimport tensorflow as tf\nfrom tensorflow.keras import layers, models\nmodel2 = models.Sequential()\n\n# Evrişimsel katmanlar(Conv) ve havuzlama(pooling) katmanları\n\nmodel2.add(Input(shape=(224, 224, 3)))\nmodel2.add(Conv2D(32, kernel_size=(3, 3), activation='relu'))\nmodel2.add(MaxPooling2D(pool_size=(2, 2)))\n\nmodel2.add(layers.Conv2D(64, (3, 3), activation='relu'))\nmodel2.add(layers.MaxPooling2D((2, 2)))\nmodel2.add(layers.Dropout(0.25))\n\nmodel2.add(layers.Conv2D(128, (3, 3), activation='relu'))\nmodel2.add(layers.MaxPooling2D((2, 2)))\nmodel2.add(layers.Dropout(0.25))\n\nmodel2.add(layers.Conv2D(128, (3, 3), activation='relu'))\nmodel2.add(layers.MaxPooling2D((2, 2)))\nmodel2.add(layers.Dropout(0.25))\n\nmodel2.add(layers.Conv2D(256, (3, 3), activation='relu'))\nmodel2.add(layers.MaxPooling2D((2, 2)))\nmodel2.add(layers.Dropout(0.25))\n\n# Düzleştirme ve tam bağlı katmanlar\nmodel2.add(layers.Flatten()) # düzleştirme\n\nmodel2.add(layers.Dense(512, activation='relu'))\nmodel2.add(layers.Dropout(0.5)) # Yüksek dropout oranı, tam bağlı katmanlarda aşırı öğrenmeyi azaltabilir\nmodel2.add(layers.Dense(5, activation='softmax')) # Çıkış katmanı: 9 sınıf için # çeşit sayımıza göre \n\nmodel2.compile(optimizer='adam',loss=CategoricalCrossentropy(),metrics=['accuracy'])\n\nimport warnings\nwarnings.filterwarnings('ignore')\nfrom tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau\n\nmodel_es = EarlyStopping(monitor = 'val_loss', mode = 'min', patience = 2, restore_best_weights = True)\nmodel_rlr = ReduceLROnPlateau(monitor = 'val_loss', factor = 0.2, patience = 1, mode = 'min')\n\nhistory2 = model2.fit(train_data, validation_data = val_data, \n epochs = 10, callbacks = [model_es, model_rlr])","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:41:45.617654Z","iopub.execute_input":"2024-07-31T09:41:45.618079Z","iopub.status.idle":"2024-07-31T09:44:22.508297Z","shell.execute_reply.started":"2024-07-31T09:41:45.618046Z","shell.execute_reply":"2024-07-31T09:44:22.507243Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"model2.save('price_model2.h5')","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:44:43.611686Z","iopub.execute_input":"2024-07-31T09:44:43.612138Z","iopub.status.idle":"2024-07-31T09:44:43.737351Z","shell.execute_reply.started":"2024-07-31T09:44:43.612102Z","shell.execute_reply":"2024-07-31T09:44:43.736418Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"import numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom sklearn.metrics import confusion_matrix, classification_report\n\n# Test veri kümesi üzerinden tahmin yapma\ntest_data = generator.flow_from_dataframe(\n dataframe=test_df,\n x_col='imgpath',\n y_col='labels',\n color_mode='rgb',\n class_mode='categorical',\n batch_size=batch_size,\n target_size=img_size,\n shuffle=False\n)\n\n# Model ile tahminler\ny_pred_probs = model2.predict(test_data)\ny_pred = np.argmax(y_pred_probs, axis=1) # En yüksek olasılığa sahip sınıfı seç\ny_true = test_data.classes # Gerçek etiketler\n\n# Confusion Matrix\ncm = confusion_matrix(y_true, y_pred)\n\n# Plot Confusion Matrix\nplt.figure(figsize=(10, 7))\nsns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=test_data.class_indices.keys(), yticklabels=test_data.class_indices.keys())\nplt.xlabel('Predicted')\nplt.ylabel('True')\nplt.title('Confusion Matrix')\nplt.show()\n\n# Classification Report\nprint(\"Classification Report:\")\nprint(classification_report(y_true, y_pred, target_names=test_data.class_indices.keys()))\n","metadata":{"execution":{"iopub.status.busy":"2024-07-31T09:44:48.630589Z","iopub.execute_input":"2024-07-31T09:44:48.631003Z","iopub.status.idle":"2024-07-31T09:44:52.011940Z","shell.execute_reply.started":"2024-07-31T09:44:48.630966Z","shell.execute_reply":"2024-07-31T09:44:52.010796Z"},"trusted":true},"execution_count":null,"outputs":[]},{"cell_type":"code","source":"","metadata":{},"execution_count":null,"outputs":[]}]}
|