Spaces:
Sleeping

Sleeping
Deepak Sahu
commited on
Commit
·
2c1ff7f
1
Parent(s):
ac2255b
training; app
Browse files- .devcontainer/devcontainer.json +16 -0
- .gitattributes +1 -0
- .vscode/launch.json +16 -0
- README.md +17 -2
- app.py +53 -0
- model/evaluate.png +0 -0
- model/label.json +20 -0
- model/loss.png +0 -0
- model/lowercase_evaluate.png +0 -0
- model/lowercase_loss.png +0 -0
- model/rnn.pth +3 -0
- z_dataops.py +103 -0
- z_inference.py +30 -0
- z_modelops.py +155 -0
.devcontainer/devcontainer.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name": "NLP Pytorch",
|
| 3 |
+
|
| 4 |
+
"image": "76e5e98ec29501e94739cafb6daa580774619fa92b6c4d71efade219a23b4b22"
|
| 5 |
+
,
|
| 6 |
+
"customizations": {
|
| 7 |
+
"vscode": {
|
| 8 |
+
"extensions": [
|
| 9 |
+
"ms-toolsai.jupyter",
|
| 10 |
+
"ms-python.python",
|
| 11 |
+
"ms-python.vscode-pylance",
|
| 12 |
+
"ms-python.debugpy"
|
| 13 |
+
]
|
| 14 |
+
}
|
| 15 |
+
}
|
| 16 |
+
}
|
.gitattributes
CHANGED
|
@@ -35,3 +35,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
data/ filter=lfs diff=lfs merge=lfs -text
|
| 37 |
*.txt filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
data/ filter=lfs diff=lfs merge=lfs -text
|
| 37 |
*.txt filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
.pth filter=lfs diff=lfs merge=lfs -text
|
.vscode/launch.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
// Use IntelliSense to learn about possible attributes.
|
| 3 |
+
// Hover to view descriptions of existing attributes.
|
| 4 |
+
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
|
| 5 |
+
"version": "0.2.0",
|
| 6 |
+
"configurations": [
|
| 7 |
+
|
| 8 |
+
{
|
| 9 |
+
"name": "Python Debugger: Current File",
|
| 10 |
+
"type": "debugpy",
|
| 11 |
+
"request": "launch",
|
| 12 |
+
"program": "${file}",
|
| 13 |
+
"console": "integratedTerminal"
|
| 14 |
+
}
|
| 15 |
+
]
|
| 16 |
+
}
|
README.md
CHANGED
|
@@ -10,7 +10,7 @@ pinned: false
|
|
| 10 |
short_description: I guess you might speak <Language>
|
| 11 |
---
|
| 12 |
|
| 13 |
-
|
| 14 |
|
| 15 |
|
| 16 |
## Data Source
|
|
@@ -23,4 +23,19 @@ Last Accessed: 30th Dec 2024
|
|
| 23 |
The code is partially inspired by https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
|
| 24 |
|
| 25 |
**Changes I Introduced**
|
| 26 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
short_description: I guess you might speak <Language>
|
| 11 |
---
|
| 12 |
|
| 13 |
+
# Language Guesser based on Name
|
| 14 |
|
| 15 |
|
| 16 |
## Data Source
|
|
|
|
| 23 |
The code is partially inspired by https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
|
| 24 |
|
| 25 |
**Changes I Introduced**
|
| 26 |
+
- NamesDataset is separated from transformation, useful for transformation during inference
|
| 27 |
+
- target is made integer instead of one-hot encoding;
|
| 28 |
+
- changed the loss from combination of LogSoftmax + NLLoss to CrossEntropy (EXACTLY THE SAME STUFF); which further required removing the softmax layer from the architecture.
|
| 29 |
+
- DataLoader is added
|
| 30 |
+
- Input made batch first > Corresponding RNN is also made batch first.
|
| 31 |
+
|
| 32 |
+
## Evaluation
|
| 33 |
+
Although the code is mostly replicated. However, I changed the dataloader to use apply lowercase transformation to data, and it confused the model.
|
| 34 |
+
|
| 35 |
+
- Confusion matrix with **with lowercase** transformation
|
| 36 |
+

|
| 37 |
+

|
| 38 |
+
|
| 39 |
+
- Confusion matrix **without lowercase** transformation
|
| 40 |
+

|
| 41 |
+

|
app.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
GRADIO_TITLE = "Langues Guesser based on Name"
|
| 2 |
+
GRADIO_DESCRIPTION = '''
|
| 3 |
+
This is a self-learning project which replicates the [pytorch tutorial](https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html) with modifications.
|
| 4 |
+
Kindly see [my GitHub: you may speak](https://github.com/LunaticMaestro/-NLP-_you_may_speak) readme to checkout the modifications.
|
| 5 |
+
|
| 6 |
+
Model Trained for names on following languages: ['Korean 🇰🇷', 'Portuguese 🇵🇹', 'Dutch 🇳🇱', 'Italian 🇮🇹', 'German 🇩🇪', 'Scottish 🏴\U000e0067\U000e0062\U000e0073\U000e0063\U000e0074\U000e007f', 'Vietnamese 🇻🇳', 'French 🇫🇷', 'English 🇬🇧', 'Arabic 🇲🇦', 'Irish 🇮🇪', 'Chinese 🇨🇳', 'Japanese 🇯🇵', 'Russian 🇷🇺', 'Polish 🇵🇱', 'Czech 🇨🇿', 'Spanish 🇪🇸', 'Greek 🇬🇷']
|
| 7 |
+
|
| 8 |
+
'''
|
| 9 |
+
|
| 10 |
+
import gradio as gr
|
| 11 |
+
from z_modelops import NameToLanguages
|
| 12 |
+
from z_inference import setup_inference, infer_lang
|
| 13 |
+
|
| 14 |
+
model, labels = setup_inference()
|
| 15 |
+
|
| 16 |
+
def get_langauge(name):
|
| 17 |
+
langugages = infer_lang(name, model, labels)
|
| 18 |
+
|
| 19 |
+
language_flags = {
|
| 20 |
+
"Korean": "\U0001F1F0\U0001F1F7", # South Korea
|
| 21 |
+
"Portuguese": "\U0001F1F5\U0001F1F9", # Portugal
|
| 22 |
+
"Dutch": "\U0001F1F3\U0001F1F1", # Netherlands
|
| 23 |
+
"Italian": "\U0001F1EE\U0001F1F9", # Italy
|
| 24 |
+
"German": "\U0001F1E9\U0001F1EA", # Germany
|
| 25 |
+
"Scottish": "\U0001F3F4\U000E0067\U000E0062\U000E0073\U000E0063\U000E0074\U000E007F", # Scotland (flag sequence)
|
| 26 |
+
"Vietnamese": "\U0001F1FB\U0001F1F3", # Vietnam
|
| 27 |
+
"French": "\U0001F1EB\U0001F1F7", # France
|
| 28 |
+
"English": "\U0001F1EC\U0001F1E7", # England (flag sequence)
|
| 29 |
+
"Arabic": "\U0001F1F2\U0001F1E6", # UAE (commonly associated with Arabic)
|
| 30 |
+
"Irish": "\U0001F1EE\U0001F1EA", # Ireland
|
| 31 |
+
"Chinese": "\U0001F1E8\U0001F1F3", # China
|
| 32 |
+
"Japanese": "\U0001F1EF\U0001F1F5", # Japan
|
| 33 |
+
"Russian": "\U0001F1F7\U0001F1FA", # Russia
|
| 34 |
+
"Polish": "\U0001F1F5\U0001F1F1", # Poland
|
| 35 |
+
"Czech": "\U0001F1E8\U0001F1FF", # Czech Republic
|
| 36 |
+
"Spanish": "\U0001F1EA\U0001F1F8", # Spain
|
| 37 |
+
"Greek": "\U0001F1EC\U0001F1F7" # Greece
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
return '\n'.join([lang + " " + language_flags[lang] for lang in langugages])
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
input_textbox = gr.Textbox(label="Your Name", placeholder="Naifeh", max_lines=1)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
demo = gr.Interface(
|
| 47 |
+
fn=get_langauge,
|
| 48 |
+
inputs=input_textbox ,
|
| 49 |
+
outputs=gr.Label(label="You may speak"),
|
| 50 |
+
title=GRADIO_TITLE,
|
| 51 |
+
description=GRADIO_DESCRIPTION
|
| 52 |
+
)
|
| 53 |
+
demo.launch(debug=True)
|
model/evaluate.png
ADDED
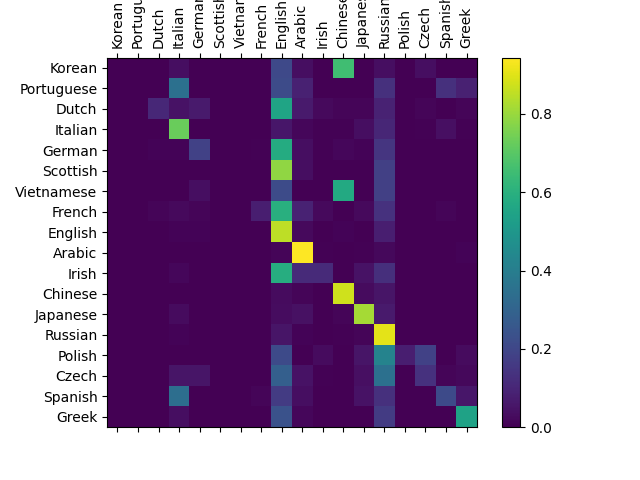
|
model/label.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"0": "Korean",
|
| 3 |
+
"1": "Portuguese",
|
| 4 |
+
"2": "Dutch",
|
| 5 |
+
"3": "Italian",
|
| 6 |
+
"4": "German",
|
| 7 |
+
"5": "Scottish",
|
| 8 |
+
"6": "Vietnamese",
|
| 9 |
+
"7": "French",
|
| 10 |
+
"8": "English",
|
| 11 |
+
"9": "Arabic",
|
| 12 |
+
"10": "Irish",
|
| 13 |
+
"11": "Chinese",
|
| 14 |
+
"12": "Japanese",
|
| 15 |
+
"13": "Russian",
|
| 16 |
+
"14": "Polish",
|
| 17 |
+
"15": "Czech",
|
| 18 |
+
"16": "Spanish",
|
| 19 |
+
"17": "Greek"
|
| 20 |
+
}
|
model/loss.png
ADDED
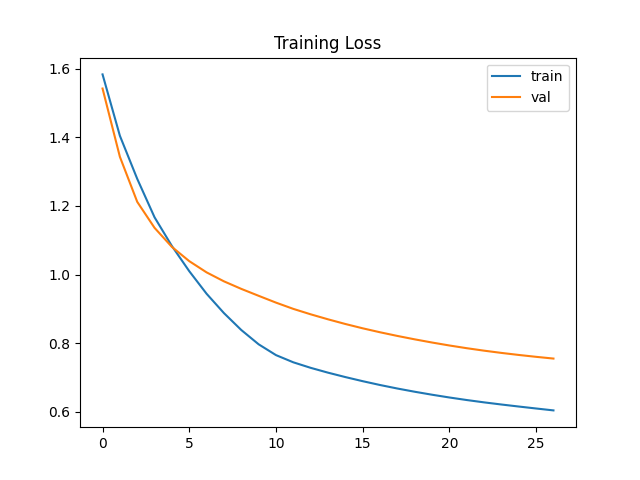
|
model/lowercase_evaluate.png
ADDED
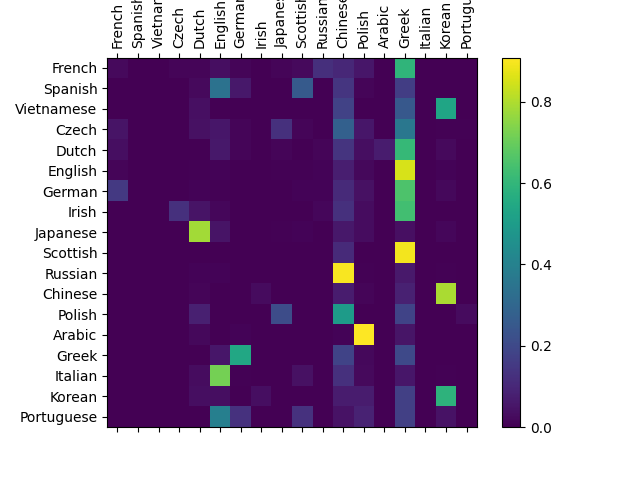
|
model/lowercase_loss.png
ADDED
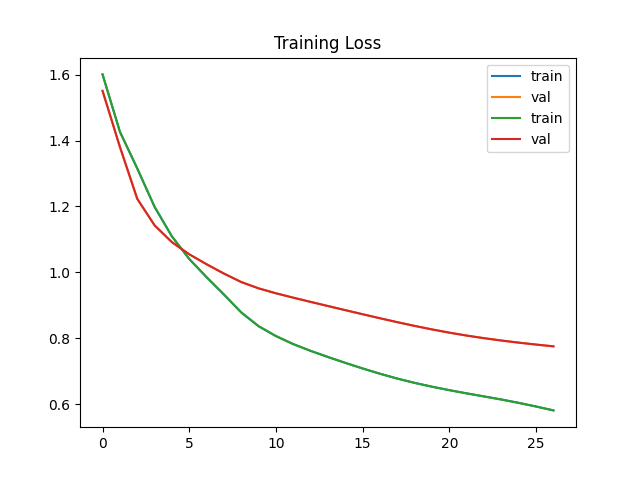
|
model/rnn.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f401906eced2fa8d49e39126687542cb871b1b7112d34123f993139074e68b9f
|
| 3 |
+
size 106016
|
z_dataops.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from typing import List
|
| 3 |
+
import torch
|
| 4 |
+
import unicodedata
|
| 5 |
+
from torch.utils.data import DataLoader, Dataset
|
| 6 |
+
from torchvision.transforms import transforms, Lambda
|
| 7 |
+
import glob
|
| 8 |
+
import os
|
| 9 |
+
import string
|
| 10 |
+
|
| 11 |
+
### Dataset
|
| 12 |
+
class NamesDataset(Dataset):
|
| 13 |
+
'''Loads names from different languages. Store the names in runtime and DOES NOT do lazy loading.
|
| 14 |
+
'''
|
| 15 |
+
def __init__(self, data_dir: str="data/names", transform=None):
|
| 16 |
+
super().__init__()
|
| 17 |
+
# track object variables
|
| 18 |
+
self.data_dir = data_dir
|
| 19 |
+
self.transform = transform
|
| 20 |
+
# generated variables
|
| 21 |
+
self.names = []
|
| 22 |
+
self.labels = []
|
| 23 |
+
self.classes_to_idx: dict = []
|
| 24 |
+
self.idx_to_classes: dict = []
|
| 25 |
+
|
| 26 |
+
# locate all languages names file .txt
|
| 27 |
+
self.read_data_files()
|
| 28 |
+
self.set_classes()
|
| 29 |
+
|
| 30 |
+
def read_data_files(self):
|
| 31 |
+
'''locates files with .txt pattern and reads them, output stored in self.names, labels'''
|
| 32 |
+
files: List[str] = glob.glob(os.path.join(self.data_dir, "*.txt"))
|
| 33 |
+
for file in files:
|
| 34 |
+
language: str = os.path.splitext(os.path.basename(file))[0]
|
| 35 |
+
# Read File contents
|
| 36 |
+
with open(file, "r") as f:
|
| 37 |
+
contents = f.read()
|
| 38 |
+
names = contents.split("\n")
|
| 39 |
+
# Store data
|
| 40 |
+
self.names.extend(names)
|
| 41 |
+
self.labels.extend([language for _ in range(len(names))])
|
| 42 |
+
return None
|
| 43 |
+
|
| 44 |
+
def __len__(self):
|
| 45 |
+
return len(self.labels)
|
| 46 |
+
|
| 47 |
+
def __getitem__(self, index):
|
| 48 |
+
name = self.names[index]
|
| 49 |
+
label = self.labels[index]
|
| 50 |
+
|
| 51 |
+
if self.transform:
|
| 52 |
+
name = self.transform(name)
|
| 53 |
+
|
| 54 |
+
# label: torch.Tensor = torch.zeros((len(self.classes_to_idx)), dtype=torch.float).scatter_(dim=0, index=torch.tensor(self.classes_to_idx.get(label)), value=1)
|
| 55 |
+
label = torch.tensor([self.classes_to_idx.get(label)])
|
| 56 |
+
|
| 57 |
+
return name.unsqueeze(0), label
|
| 58 |
+
|
| 59 |
+
def set_classes(self, cache_location:str = "model/label.json"):
|
| 60 |
+
'''takes the unique labels and store in self.classes'''
|
| 61 |
+
# first saves the labels to file so it can be used during inferencing
|
| 62 |
+
unique_labels = list(set(self.labels))
|
| 63 |
+
|
| 64 |
+
self.classes_to_idx = dict([(label, i) for i, label in enumerate(unique_labels)])
|
| 65 |
+
self.idx_to_classes = {value: key for key, value in self.classes_to_idx.items()}
|
| 66 |
+
|
| 67 |
+
with open(cache_location, "w") as file:
|
| 68 |
+
json.dump(self.idx_to_classes, file, indent=4)
|
| 69 |
+
|
| 70 |
+
### Transformations
|
| 71 |
+
## **Why**: So that they can be applied separately during inference
|
| 72 |
+
|
| 73 |
+
def _allowed_characters(s: str):
|
| 74 |
+
allowed_characters = string.ascii_letters
|
| 75 |
+
return ''.join([char if allowed_characters.find(char) >= 0 else '' for char in s])
|
| 76 |
+
|
| 77 |
+
def _unicode_to_ascii(s:str):
|
| 78 |
+
'''Converts Unicode to ASCII to normalize ACCENTS'''
|
| 79 |
+
# CODE from https://stackoverflow.com/a/518232/2809427
|
| 80 |
+
return ''.join(c for c in unicodedata.normalize('NFD', s) if unicodedata.category(c) != 'Mn')
|
| 81 |
+
|
| 82 |
+
def _string_to_Tensor(name: str):
|
| 83 |
+
'''Converts to dimensionality (chars, LowerCaseAscii)'''
|
| 84 |
+
name_lower = name
|
| 85 |
+
name_tensor = torch.zeros((len(name_lower), len(string.ascii_letters))).scatter_(dim=1, index= torch.tensor(list(map(string.ascii_letters.index, name_lower))).unsqueeze(1), value=1)
|
| 86 |
+
return name_tensor
|
| 87 |
+
|
| 88 |
+
transform = transforms.Compose([
|
| 89 |
+
_unicode_to_ascii,
|
| 90 |
+
_allowed_characters,
|
| 91 |
+
_string_to_Tensor,
|
| 92 |
+
])
|
| 93 |
+
|
| 94 |
+
def proxy_collate_batch(batch: List)-> List[torch.Tensor]:
|
| 95 |
+
'''Although we are not padding the sequence we created this proxy function to avoid stacking the jagged array.'''
|
| 96 |
+
batch = [(x, y) for x, y in batch if x.shape[1] > 1]
|
| 97 |
+
return batch
|
| 98 |
+
|
| 99 |
+
if __name__ == "__main__":
|
| 100 |
+
ds = NamesDataset(transform=transform)
|
| 101 |
+
train_dataset = DataLoader(ds, batch_size=64, shuffle=True, collate_fn=proxy_collate_batch)
|
| 102 |
+
batch = next(iter(train_dataset))
|
| 103 |
+
print(batch[0][0].shape, batch[0][1].shape) # (1, x, 26), # (1)
|
z_inference.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from z_modelops import NameToLanguages, load_labels
|
| 3 |
+
from z_dataops import transform
|
| 4 |
+
import json
|
| 5 |
+
from torch import nn
|
| 6 |
+
|
| 7 |
+
def load_model(location="model/rnn.pth"):
|
| 8 |
+
'''loads the model, together with arch'''
|
| 9 |
+
model = torch.load(location, weights_only=False)
|
| 10 |
+
return model
|
| 11 |
+
|
| 12 |
+
def infer_lang(name:str, model, label:dict, k=3)-> str:
|
| 13 |
+
name_tensor = transform(name)
|
| 14 |
+
with torch.no_grad():
|
| 15 |
+
logits = model(name_tensor.unsqueeze(0))
|
| 16 |
+
y_pred = nn.Softmax(dim=1)(logits)
|
| 17 |
+
top_k_idx = y_pred.sort(descending=True, dim=1).indices.numpy()[0][:k]
|
| 18 |
+
return [label[str(idx)] for idx in top_k_idx]
|
| 19 |
+
|
| 20 |
+
def setup_inference():
|
| 21 |
+
# load model
|
| 22 |
+
model = load_model()
|
| 23 |
+
# call the model with inputs
|
| 24 |
+
labels = load_labels()
|
| 25 |
+
return model, labels
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
if __name__=="__main__":
|
| 29 |
+
model, labels = setup_inference()
|
| 30 |
+
|
z_modelops.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import numpy as np
|
| 3 |
+
from torch import nn
|
| 4 |
+
import torch
|
| 5 |
+
from torch.utils.data import random_split, DataLoader
|
| 6 |
+
from z_dataops import NamesDataset, transform, proxy_collate_batch
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
import matplotlib.ticker as ticker
|
| 9 |
+
import string
|
| 10 |
+
|
| 11 |
+
class NameToLanguages(nn.Module):
|
| 12 |
+
def __init__(self, feature_size=26, n_classes=18):
|
| 13 |
+
super().__init__()
|
| 14 |
+
|
| 15 |
+
# create simple architecture
|
| 16 |
+
self.net_rnn = nn.RNN(input_size=feature_size, hidden_size=128, batch_first=True)
|
| 17 |
+
self.net_linear = nn.Linear(in_features=128, out_features=n_classes)
|
| 18 |
+
|
| 19 |
+
def forward(self, x):
|
| 20 |
+
rnn_out, last_ts = self.net_rnn(x)
|
| 21 |
+
output = self.net_linear(last_ts[0])
|
| 22 |
+
return output
|
| 23 |
+
|
| 24 |
+
def training(model: nn.Module, train_batch: list, optimizer, loss_fn):
|
| 25 |
+
model.train()
|
| 26 |
+
batch_loss = 0
|
| 27 |
+
|
| 28 |
+
for x, y in train_batch:
|
| 29 |
+
# predict
|
| 30 |
+
y_pred = model(x)
|
| 31 |
+
# compute loss
|
| 32 |
+
curr_loss = loss_fn(y_pred, y)
|
| 33 |
+
batch_loss += curr_loss
|
| 34 |
+
|
| 35 |
+
# reset grad
|
| 36 |
+
optimizer.zero_grad()
|
| 37 |
+
# calculate grad
|
| 38 |
+
batch_loss.backward()
|
| 39 |
+
# nn.utils.clip_grad_norm_(model.parameters(), 3)
|
| 40 |
+
# step
|
| 41 |
+
optimizer.step()
|
| 42 |
+
|
| 43 |
+
return batch_loss.item() / len(train_batch)
|
| 44 |
+
|
| 45 |
+
def validation(model, dl: DataLoader, loss_fn):
|
| 46 |
+
model.eval()
|
| 47 |
+
batch_loss = 0
|
| 48 |
+
with torch.no_grad():
|
| 49 |
+
for item in dl:
|
| 50 |
+
for x, y in item:
|
| 51 |
+
# predict
|
| 52 |
+
y_pred = model(x)
|
| 53 |
+
# loss
|
| 54 |
+
curr_loss = loss_fn(y_pred, y)
|
| 55 |
+
batch_loss += curr_loss
|
| 56 |
+
return batch_loss.item() / len(dl)
|
| 57 |
+
|
| 58 |
+
def plot_losses(loss_label, title, save_location="model/loss.png"):
|
| 59 |
+
for k, v in loss_label.items():
|
| 60 |
+
plt.plot(v, label=k)
|
| 61 |
+
plt.legend()
|
| 62 |
+
plt.title(title)
|
| 63 |
+
plt.savefig(save_location)
|
| 64 |
+
|
| 65 |
+
def load_labels(input_file="model/label.json"):
|
| 66 |
+
# Read the dictionary from the file
|
| 67 |
+
with open(input_file, 'r') as file:
|
| 68 |
+
dictionary = json.load(file)
|
| 69 |
+
return dictionary
|
| 70 |
+
|
| 71 |
+
def evaluate(rnn, validation_dl, classes):
|
| 72 |
+
# CODE AS IS FROM: https://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html#evaluating-the-results
|
| 73 |
+
confusion = torch.zeros(len(classes), len(classes))
|
| 74 |
+
|
| 75 |
+
rnn.eval() #set to eval mode
|
| 76 |
+
with torch.no_grad(): # do not record the gradients during eval phase
|
| 77 |
+
for item in validation_dl:
|
| 78 |
+
for text_tensor, label in item:
|
| 79 |
+
output = rnn(text_tensor)
|
| 80 |
+
#
|
| 81 |
+
_, idx = output.topk(1)
|
| 82 |
+
guess, guess_i = classes[str(idx.item())], idx.item()
|
| 83 |
+
label_i = label.item()
|
| 84 |
+
confusion[label_i][guess_i] += 1
|
| 85 |
+
|
| 86 |
+
# Normalize by dividing every row by its sum
|
| 87 |
+
for i in range(len(classes)):
|
| 88 |
+
denom = confusion[i].sum()
|
| 89 |
+
if denom > 0:
|
| 90 |
+
confusion[i] = confusion[i] / denom
|
| 91 |
+
|
| 92 |
+
# Set up plot
|
| 93 |
+
fig = plt.figure()
|
| 94 |
+
ax = fig.add_subplot(111)
|
| 95 |
+
cax = ax.matshow(confusion.cpu().numpy()) #numpy uses cpu here so we need to use a cpu version
|
| 96 |
+
fig.colorbar(cax)
|
| 97 |
+
|
| 98 |
+
tag = [classes[str(i)] for i in range(len(classes))]
|
| 99 |
+
# Set up axes
|
| 100 |
+
ax.set_xticks(np.arange(len(classes)), labels=tag, rotation=90)
|
| 101 |
+
ax.set_yticks(np.arange(len(classes)), labels=tag)
|
| 102 |
+
|
| 103 |
+
# Force label at every tick
|
| 104 |
+
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
|
| 105 |
+
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
|
| 106 |
+
|
| 107 |
+
# sphinx_gallery_thumbnail_number = 2
|
| 108 |
+
plt.savefig("model/evaluate.png")
|
| 109 |
+
|
| 110 |
+
def load_labels(input_file="model/label.json"):
|
| 111 |
+
# Read the dictionary from the file
|
| 112 |
+
with open(input_file, 'r') as file:
|
| 113 |
+
dictionary = json.load(file)
|
| 114 |
+
return dictionary
|
| 115 |
+
|
| 116 |
+
if __name__=="__main__":
|
| 117 |
+
model = NameToLanguages(feature_size=len(string.ascii_letters))
|
| 118 |
+
|
| 119 |
+
# #Sanity Check Model
|
| 120 |
+
# x = torch.randn((1, 7, 26)) # (batch, word_length, one-hot-ascii-char)
|
| 121 |
+
# model.eval()
|
| 122 |
+
# with torch.no_grad():
|
| 123 |
+
# out = model(x)
|
| 124 |
+
# print(out.shape)
|
| 125 |
+
|
| 126 |
+
# #Optimziers, Loss
|
| 127 |
+
optimizer = torch.optim.SGD(params=model.parameters(), lr=1e-3)
|
| 128 |
+
loss_fn = nn.CrossEntropyLoss()
|
| 129 |
+
n_epoch = 27
|
| 130 |
+
|
| 131 |
+
# #Training Loop
|
| 132 |
+
ds = NamesDataset(transform=transform)
|
| 133 |
+
train_ds, val_ds = random_split(ds, [0.7, 0.3], generator=torch.Generator().manual_seed(31))
|
| 134 |
+
train_dl = DataLoader(dataset=train_ds, batch_size=64, collate_fn=proxy_collate_batch)
|
| 135 |
+
val_dl = DataLoader(dataset=val_ds, collate_fn=proxy_collate_batch)
|
| 136 |
+
# #Trackers
|
| 137 |
+
train_losses, val_losses = [], []
|
| 138 |
+
|
| 139 |
+
for epoch in range(n_epoch):
|
| 140 |
+
for batch in train_dl:
|
| 141 |
+
train_loss = training(model, batch, optimizer, loss_fn)
|
| 142 |
+
# report val loss
|
| 143 |
+
|
| 144 |
+
train_losses.append(train_loss)
|
| 145 |
+
val_loss = validation(model, val_dl, loss_fn)
|
| 146 |
+
val_losses.append(val_loss)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
print(f"Epoch {epoch}: Train_loss: {train_losses[-1]}, Val_loss: {val_loss}")
|
| 150 |
+
plot_losses({"train": train_losses, "val": val_losses}, "Training Loss")
|
| 151 |
+
torch.save(model, "model/rnn.pth")
|
| 152 |
+
|
| 153 |
+
classes = load_labels()
|
| 154 |
+
evaluate(model, val_dl, classes)
|
| 155 |
+
|