Spaces:
Running

Running
Deepak Sahu
commited on
Commit
·
e446a52
1
Parent(s):
01e2b4e
update content
Browse files- .resources/eval1.png +3 -0
- .resources/fine-tune2.png +3 -0
- README.md +33 -18
- z_embedding.py +11 -3
- z_finetune_gpt.py +5 -4
.resources/eval1.png
ADDED
|
Git LFS Details
|
.resources/fine-tune2.png
ADDED
|
Git LFS Details
|
README.md
CHANGED
|
@@ -36,9 +36,13 @@ Try it out: https://huggingface.co/spaces/LunaticMaestro/book-recommender
|
|
| 36 |
- Pipeline walkthrough in detail
|
| 37 |
|
| 38 |
*For each part of pipeline there is separate script which needs to be executed, mentioned in respective section along with output screenshots.*
|
| 39 |
-
- Training
|
| 40 |
- [Step 1: Data Clean](#step-1-data-clean)
|
|
|
|
|
|
|
| 41 |
|
|
|
|
|
|
|
| 42 |
## Running Inference Locally
|
| 43 |
|
| 44 |
### Memory Requirements
|
|
@@ -79,7 +83,7 @@ Modify app.py edit line 93 to `demo.launch(share=True)` then run following in ce
|
|
| 79 |
|
| 80 |
References:
|
| 81 |
- This is the core idea: https://arxiv.org/abs/2212.10496
|
| 82 |
-
- https://github.com/aws-samples/content-based-item-recommender
|
| 83 |
- For future, a very complex work https://github.com/HKUDS/LLMRec
|
| 84 |
|
| 85 |
## Training Steps
|
|
@@ -149,16 +153,20 @@ Output: `app_cache/summary_vectors.npy`
|
|
| 149 |
|
| 150 |
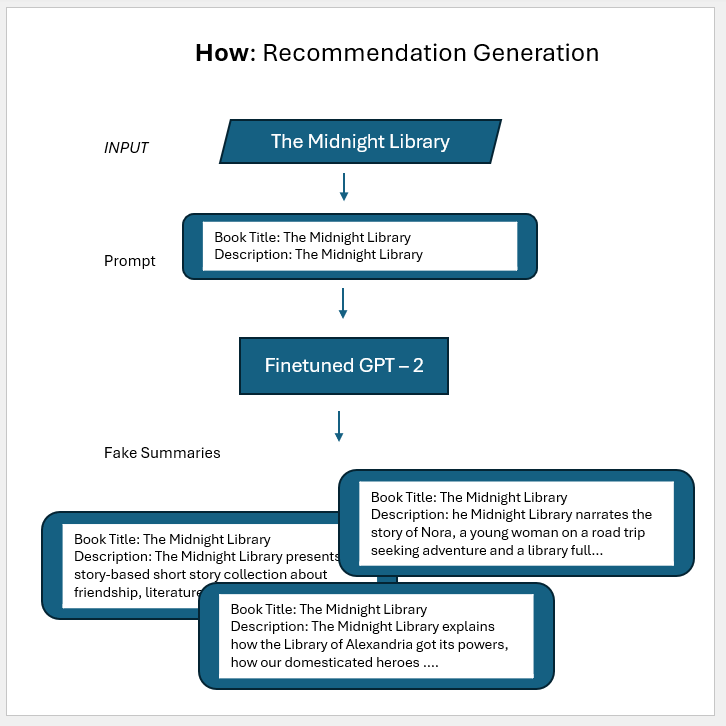
### Step 3: Fine-tune GPT-2 to Hallucinate but with some bounds.
|
| 151 |
|
| 152 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 153 |
|
| 154 |
-
Two very important reasons why to fine-tune GPT-2
|
| 155 |
1. We want it to hallucinate but withing boundaries i.e. speak words/ language that we have in books_summaries.csv NOT VERY DIFFERENT OUT OF WORLD LOGIC.
|
| 156 |
|
| 157 |
2. Prompt Tune such that we can get consistent results. (Screenshot from https://huggingface.co/openai-community/gpt2); The screenshot show the model is mildly consistent.
|
| 158 |
|
| 159 |
-

|
| 185 |
|
| 186 |
-
|
| 187 |
|
|
|
|
| 188 |
|
| 189 |
-
The loss you see is cross-entryopy loss; as ref in the fine-tuning instructions (see above reference) states : `Transformers models all have a default task-relevant loss function, so you don’t need to specify one `
|
| 190 |
|
| 191 |
-
|
| 192 |
|
| 193 |
So all we care is lower the value better is the model trained :)
|
| 194 |
|
| 195 |
-
We are NOT going to test this unit model
|
| 196 |
-
But **we are going to evaluate our HyDE approach end-2-end next to ensure sanity of the approach
|
| 197 |
|
| 198 |
## Evaluation
|
| 199 |
|
|
|
|
| 36 |
- Pipeline walkthrough in detail
|
| 37 |
|
| 38 |
*For each part of pipeline there is separate script which needs to be executed, mentioned in respective section along with output screenshots.*
|
| 39 |
+
- [Training](#training-steps)
|
| 40 |
- [Step 1: Data Clean](#step-1-data-clean)
|
| 41 |
+
- [Step 2: Generate vectors of the books summaries](#step-2-generate-vectors-of-the-books-summaries)
|
| 42 |
+
- [Step 3: Fine-tune GPT-2 to Hallucinate but with some bounds.](#step-3-fine-tune-gpt-2-to-hallucinate-but-with-some-bounds)
|
| 43 |
|
| 44 |
+
- [Evaluation](#evaluation)
|
| 45 |
+
- Inference
|
| 46 |
## Running Inference Locally
|
| 47 |
|
| 48 |
### Memory Requirements
|
|
|
|
| 83 |
|
| 84 |
References:
|
| 85 |
- This is the core idea: https://arxiv.org/abs/2212.10496
|
| 86 |
+
- Another work based on same, https://github.com/aws-samples/content-based-item-recommender
|
| 87 |
- For future, a very complex work https://github.com/HKUDS/LLMRec
|
| 88 |
|
| 89 |
## Training Steps
|
|
|
|
| 153 |
|
| 154 |
### Step 3: Fine-tune GPT-2 to Hallucinate but with some bounds.
|
| 155 |
|
| 156 |
+
**What & Why**
|
| 157 |
+
|
| 158 |
+
Hypothetical Document Extraction (HyDE) in nutshell
|
| 159 |
+
- The **Hypothetical** part of HyDE approach is all about generating random summaries,in short hallucinating. **This is why the approach will work for new book titles**
|
| 160 |
+
- The **Document Extraction** (part of HyDE) is about using these hallucinated summaries to do semantic search on database.
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
**Why to fine-tune GPT-2**
|
| 164 |
|
|
|
|
| 165 |
1. We want it to hallucinate but withing boundaries i.e. speak words/ language that we have in books_summaries.csv NOT VERY DIFFERENT OUT OF WORLD LOGIC.
|
| 166 |
|
| 167 |
2. Prompt Tune such that we can get consistent results. (Screenshot from https://huggingface.co/openai-community/gpt2); The screenshot show the model is mildly consistent.
|
| 168 |
|
| 169 |
+

|
|
|
|
|
|
|
| 170 |
|
| 171 |
Reference:
|
| 172 |
- HyDE Approach, Precise Zero-Shot Dense Retrieval without Relevance Labels https://arxiv.org/pdf/2212.10496
|
|
|
|
| 176 |
- His code base is too much, can edit it but not worth the effort.
|
| 177 |
- Fine-tuning code instructions are from https://huggingface.co/docs/transformers/en/tasks/language_modeling
|
| 178 |
|
| 179 |
+
**RUN**
|
| 180 |
|
|
|
|
| 181 |
|
| 182 |
+
If you want to
|
| 183 |
+
|
| 184 |
+
- push to HF. You must supply your token from huggingface, required to push model to HF
|
| 185 |
+
|
| 186 |
+
```SH
|
| 187 |
+
huggingface-cli login
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
- Not Push to HF, then in `z_finetune_gpt.py`:
|
| 191 |
+
|
| 192 |
+
- set line 59 ` push_to_hub` to `False`
|
| 193 |
+
- comment line 77 `trainer.push_to_hub()`
|
| 194 |
|
| 195 |
We are going to use dataset `clean_books_summary.csv` while triggering this training.
|
| 196 |
|
| 197 |
```SH
|
| 198 |
python z_finetune_gpt.py
|
| 199 |
```
|
|
|
|
| 200 |
|
| 201 |
+
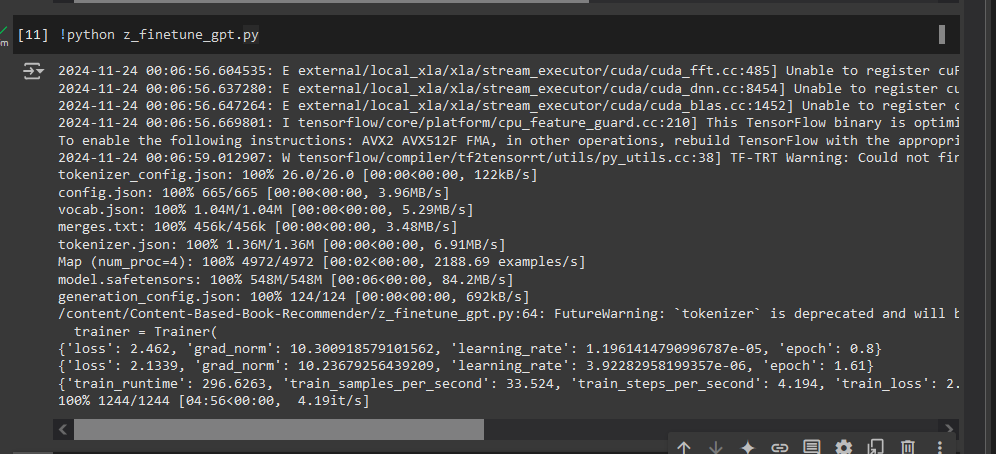
Image below just shows for 2 epochs, but the one push to my HF https://huggingface.co/LunaticMaestro/gpt2-book-summary-generator is trained for 10 epochs that lasts ~30 mins for 10 epochs with T4 GPU **reduing loss to 0.87 ~ (perplexity = 2.38)**
|
| 202 |
|
| 203 |
+

|
| 204 |
|
|
|
|
| 205 |
|
| 206 |
+
The loss you see is cross-entryopy loss; as ref in the [fine-tuning instructions](https://huggingface.co/docs/transformers/en/tasks/language_modeling) : `Transformers models all have a default task-relevant loss function, so you don’t need to specify one `
|
| 207 |
|
| 208 |
So all we care is lower the value better is the model trained :)
|
| 209 |
|
| 210 |
+
We are NOT going to test this unit model on some test dataset as the model is already proven (its GPT-2 duh!!).
|
| 211 |
+
But **we are going to evaluate our HyDE approach end-2-end next to ensure sanity of the approach** that will inherently prove the goodness of this model.
|
| 212 |
|
| 213 |
## Evaluation
|
| 214 |
|
z_embedding.py
CHANGED
|
@@ -3,15 +3,18 @@ import pandas as pd
|
|
| 3 |
import numpy as np
|
| 4 |
from z_utils import get_dataframe
|
| 5 |
from tqdm import tqdm
|
|
|
|
| 6 |
|
| 7 |
# CONST
|
| 8 |
EMB_MODEL = "all-MiniLM-L6-v2"
|
| 9 |
INP_DATASET_CSV = "unique_titles_books_summary.csv"
|
| 10 |
CACHE_SUMMARY_EMB_NPY = "app_cache/summary_vectors.npy"
|
| 11 |
|
|
|
|
| 12 |
model = None
|
| 13 |
|
| 14 |
def load_model():
|
|
|
|
| 15 |
global model
|
| 16 |
if model is None:
|
| 17 |
model = SentenceTransformer(EMB_MODEL)
|
|
@@ -53,15 +56,21 @@ def dataframe_compute_summary_vector(books_df: pd.DataFrame) -> np.ndarray:
|
|
| 53 |
|
| 54 |
return summary_vectors
|
| 55 |
|
| 56 |
-
def get_embeddings(summaries: list[str], model = None) -> np.ndarray:
|
| 57 |
'''Utils function to to take in hypothetical document(s) and return the embedding of it(s)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
'''
|
| 59 |
model = model if model else load_model()
|
| 60 |
if isinstance(summaries, str):
|
| 61 |
summaries = [summaries, ]
|
| 62 |
return model.encode(summaries)
|
| 63 |
|
| 64 |
-
|
| 65 |
def cache_create_embeddings(books_csv_path: str, output_path: str) -> None:
|
| 66 |
'''Read the books csv and generate vectors of the `summaries` columns and store in `output_path`
|
| 67 |
'''
|
|
@@ -70,7 +79,6 @@ def cache_create_embeddings(books_csv_path: str, output_path: str) -> None:
|
|
| 70 |
np.save(file=output_path, arr=vectors)
|
| 71 |
print(f"Vectors saved to {output_path}")
|
| 72 |
|
| 73 |
-
|
| 74 |
if __name__ == "__main__":
|
| 75 |
print("Generating vectors of the summaries")
|
| 76 |
cache_create_embeddings(books_csv_path=INP_DATASET_CSV, output_path=CACHE_SUMMARY_EMB_NPY)
|
|
|
|
| 3 |
import numpy as np
|
| 4 |
from z_utils import get_dataframe
|
| 5 |
from tqdm import tqdm
|
| 6 |
+
from typing import Any
|
| 7 |
|
| 8 |
# CONST
|
| 9 |
EMB_MODEL = "all-MiniLM-L6-v2"
|
| 10 |
INP_DATASET_CSV = "unique_titles_books_summary.csv"
|
| 11 |
CACHE_SUMMARY_EMB_NPY = "app_cache/summary_vectors.npy"
|
| 12 |
|
| 13 |
+
# GLOBAL VAR
|
| 14 |
model = None
|
| 15 |
|
| 16 |
def load_model():
|
| 17 |
+
'''Workaround for HF space; cross scrip loading is slow.'''
|
| 18 |
global model
|
| 19 |
if model is None:
|
| 20 |
model = SentenceTransformer(EMB_MODEL)
|
|
|
|
| 56 |
|
| 57 |
return summary_vectors
|
| 58 |
|
| 59 |
+
def get_embeddings(summaries: list[str], model: Any = None) -> np.ndarray:
|
| 60 |
'''Utils function to to take in hypothetical document(s) and return the embedding of it(s)
|
| 61 |
+
|
| 62 |
+
Args:
|
| 63 |
+
summaries: differe hypothetical summaries
|
| 64 |
+
model: The embedding model, see `app.py` to fast the HF cross-script loading.
|
| 65 |
+
|
| 66 |
+
Returns
|
| 67 |
+
list of embeddings
|
| 68 |
'''
|
| 69 |
model = model if model else load_model()
|
| 70 |
if isinstance(summaries, str):
|
| 71 |
summaries = [summaries, ]
|
| 72 |
return model.encode(summaries)
|
| 73 |
|
|
|
|
| 74 |
def cache_create_embeddings(books_csv_path: str, output_path: str) -> None:
|
| 75 |
'''Read the books csv and generate vectors of the `summaries` columns and store in `output_path`
|
| 76 |
'''
|
|
|
|
| 79 |
np.save(file=output_path, arr=vectors)
|
| 80 |
print(f"Vectors saved to {output_path}")
|
| 81 |
|
|
|
|
| 82 |
if __name__ == "__main__":
|
| 83 |
print("Generating vectors of the summaries")
|
| 84 |
cache_create_embeddings(books_csv_path=INP_DATASET_CSV, output_path=CACHE_SUMMARY_EMB_NPY)
|
z_finetune_gpt.py
CHANGED
|
@@ -1,4 +1,7 @@
|
|
| 1 |
# THIS file is meant to be used once hence not having functions just sequential code
|
|
|
|
|
|
|
|
|
|
| 2 |
import pandas as pd
|
| 3 |
from transformers import AutoTokenizer, set_seed
|
| 4 |
from transformers import DataCollatorForLanguageModeling
|
|
@@ -9,11 +12,9 @@ from z_utils import get_dataframe
|
|
| 9 |
# CONST
|
| 10 |
INP_DATASET_CSV = "clean_books_summary.csv"
|
| 11 |
BASE_CASUAL_MODEL = "openai-community/gpt2"
|
| 12 |
-
|
| 13 |
-
TRAINED_MODEL_OUTPUT_DIR = "content" # same name for HF Hub
|
| 14 |
-
|
| 15 |
set_seed(42)
|
| 16 |
-
EPOCHS = 2
|
| 17 |
LR = 2e-5
|
| 18 |
|
| 19 |
# Load dataset
|
|
|
|
| 1 |
# THIS file is meant to be used once hence not having functions just sequential code
|
| 2 |
+
# Fine-tuning code instructions are from https://huggingface.co/docs/transformers/en/tasks/language_modeling
|
| 3 |
+
|
| 4 |
+
|
| 5 |
import pandas as pd
|
| 6 |
from transformers import AutoTokenizer, set_seed
|
| 7 |
from transformers import DataCollatorForLanguageModeling
|
|
|
|
| 12 |
# CONST
|
| 13 |
INP_DATASET_CSV = "clean_books_summary.csv"
|
| 14 |
BASE_CASUAL_MODEL = "openai-community/gpt2"
|
| 15 |
+
TRAINED_MODEL_OUTPUT_DIR = "gpt2-book-summary-generator" # same name for HF Hub
|
|
|
|
|
|
|
| 16 |
set_seed(42)
|
| 17 |
+
EPOCHS = 2 # 10
|
| 18 |
LR = 2e-5
|
| 19 |
|
| 20 |
# Load dataset
|