Spaces:
Running

Running
Deepak Sahu
commited on
Commit
·
abf887e
1
Parent(s):
10b6366
section update
Browse files- .resources/clean_1.png +3 -0
- .resources/clean_2.png +3 -0
- README.md +37 -10
- __pycache__/z_utils.cpython-310.pyc +0 -0
- app.py +1 -1
- books_summary.csv +0 -0
- z_clean_data.ipynb +0 -0
- z_clean_data.py +1 -1
.resources/clean_1.png
ADDED

|
Git LFS Details
|
.resources/clean_2.png
ADDED
|
Git LFS Details
|
README.md
CHANGED
|
@@ -17,9 +17,19 @@ Try it out: https://huggingface.co/spaces/LunaticMaestro/book-recommender
|
|
| 17 |
|
| 18 |

|
| 19 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
## Table of Content
|
| 21 |
|
| 22 |
-
>
|
| 23 |
|
| 24 |
- [Running Inference Locally](#libraries-execution)
|
| 25 |
- [10,000 feet Approach overview](#approach)
|
|
@@ -31,6 +41,14 @@ Try it out: https://huggingface.co/spaces/LunaticMaestro/book-recommender
|
|
| 31 |
|
| 32 |
## Running Inference Locally
|
| 33 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
### Libraries
|
| 35 |
I used google colab with following libraries extra.
|
| 36 |
|
|
@@ -66,23 +84,32 @@ References:
|
|
| 66 |
|
| 67 |
## Training Steps
|
| 68 |
|
| 69 |
-
**ALL files Paths are at set as CONST in beginning of each script, to make it easier while using the paths while inferencing; hence not passing as CLI arguments**
|
| 70 |
-
|
| 71 |
### Step 1: Data Clean
|
| 72 |
|
| 73 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
|
| 75 |
-
|
| 76 |
|
| 77 |
-
|
| 78 |
|
| 79 |
-
|
| 80 |
|
| 81 |
-
|
| 82 |
|
| 83 |
-
|
| 84 |
|
| 85 |
-
|
| 86 |
|
| 87 |
```SH
|
| 88 |
python z_clean_data.py
|
|
|
|
| 17 |
|
| 18 |

|
| 19 |
|
| 20 |
+
## Foreword
|
| 21 |
+
|
| 22 |
+
- All images are my actual work please source powerpoint of them in `.resources` folder of this repo.
|
| 23 |
+
|
| 24 |
+
- Code is documentation is as per [Google's Python Style Guide](https://google.github.io/styleguide/pyguide.html)
|
| 25 |
+
|
| 26 |
+
- ALL files Paths are at set as CONST in beginning of each script, to make it easier while using the paths while inferencing & evaluation; hence not passing as CLI arguments
|
| 27 |
+
|
| 28 |
+
- prefix `z_` in filenames is just to avoid confusion (to human) of which is prebuilt module and which is custom during import.
|
| 29 |
+
|
| 30 |
## Table of Content
|
| 31 |
|
| 32 |
+
>
|
| 33 |
|
| 34 |
- [Running Inference Locally](#libraries-execution)
|
| 35 |
- [10,000 feet Approach overview](#approach)
|
|
|
|
| 41 |
|
| 42 |
## Running Inference Locally
|
| 43 |
|
| 44 |
+
### Memory Requirements
|
| 45 |
+
|
| 46 |
+
The code need <2Gb RAM to use both the following. Just CPU works fine for inferencing.
|
| 47 |
+
|
| 48 |
+
- https://huggingface.co/openai-community/gpt2 ~500 mb
|
| 49 |
+
- https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2 <500 mb
|
| 50 |
+
|
| 51 |
+
|
| 52 |
### Libraries
|
| 53 |
I used google colab with following libraries extra.
|
| 54 |
|
|
|
|
| 84 |
|
| 85 |
## Training Steps
|
| 86 |
|
|
|
|
|
|
|
| 87 |
### Step 1: Data Clean
|
| 88 |
|
| 89 |
+
What is taken care
|
| 90 |
+
- unwanted column removal (the first column of index)
|
| 91 |
+
- missing values removal (drop rows)
|
| 92 |
+
- duplicate rows removal.
|
| 93 |
+
|
| 94 |
+
What is not taken care
|
| 95 |
+
- stopword removal, stemming/lemmatization or special character removal
|
| 96 |
+
|
| 97 |
+
**because approach is to use the casual language modelling (later steps) hence makes no sense to rip apart the word meaning**
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
### Observations from `z_cleand_data.ipynb`
|
| 101 |
|
| 102 |
+
- Same title corresponds to different categories
|
| 103 |
|
| 104 |
+

|
| 105 |
|
| 106 |
+
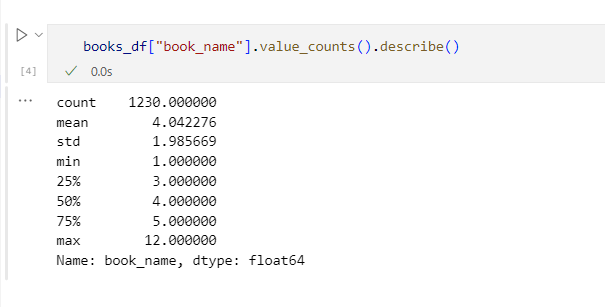
- Total 1230 unique titles.
|
| 107 |
|
| 108 |
+

|
| 109 |
|
| 110 |
+
**Action**: We are not going to remove them rows that shows same titles (& summaries) with different categories but rather create a separate file for unique titles.
|
| 111 |
|
| 112 |
+
**RUN**:
|
| 113 |
|
| 114 |
```SH
|
| 115 |
python z_clean_data.py
|
__pycache__/z_utils.cpython-310.pyc
ADDED
|
Binary file (1.22 kB). View file
|
|
|
app.py
CHANGED
|
@@ -16,7 +16,7 @@ GRADIO_TITLE = "Content Based Book Recommender"
|
|
| 16 |
GRADIO_DESCRIPTION = '''
|
| 17 |
This is a [HyDE](https://arxiv.org/abs/2212.10496) based searching mechanism that generates random summaries using your input book title and matches books which has summary similary to generated ones. The books, for search, are used from used [Kaggle Dataset: arpansri/books-summary](https://www.kaggle.com/datasets/arpansri/books-summary)
|
| 18 |
|
| 19 |
-
**Should take ~ 15s to 30s** for inferencing.
|
| 20 |
'''
|
| 21 |
|
| 22 |
# Caching mechanism for gradio
|
|
|
|
| 16 |
GRADIO_DESCRIPTION = '''
|
| 17 |
This is a [HyDE](https://arxiv.org/abs/2212.10496) based searching mechanism that generates random summaries using your input book title and matches books which has summary similary to generated ones. The books, for search, are used from used [Kaggle Dataset: arpansri/books-summary](https://www.kaggle.com/datasets/arpansri/books-summary)
|
| 18 |
|
| 19 |
+
**Should take ~ 15s to 30s** for inferencing. If taking time then then its cold starting in HF space which lasts 300s and **decreases to 15s when you have made sufficiently many ~10 to 15 call**
|
| 20 |
'''
|
| 21 |
|
| 22 |
# Caching mechanism for gradio
|
books_summary.csv
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
z_clean_data.ipynb
ADDED
|
File without changes
|
z_clean_data.py
CHANGED
|
@@ -31,7 +31,7 @@ print(f"\n\nCleaned Shape: {books_df.shape}")
|
|
| 31 |
|
| 32 |
# Saving these cleaned DF
|
| 33 |
print("Storing cleaned as (this includes same titles with diff cats: "+CLEAN_DF)
|
| 34 |
-
books_df.to_csv(
|
| 35 |
|
| 36 |
# ==== NOW to store the unique titles ====
|
| 37 |
books_df = books_df[["book_name", "summaries"]]
|
|
|
|
| 31 |
|
| 32 |
# Saving these cleaned DF
|
| 33 |
print("Storing cleaned as (this includes same titles with diff cats: "+CLEAN_DF)
|
| 34 |
+
books_df.to_csv(CLEAN_DF, index=False)
|
| 35 |
|
| 36 |
# ==== NOW to store the unique titles ====
|
| 37 |
books_df = books_df[["book_name", "summaries"]]
|