Spaces:
Build error

Build error
Commit
·
6317bb3
1
Parent(s):
3516ada
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- .github/workflows/gguf-publish.yml +2 -1
- .github/workflows/zig-build.yml +25 -0
- .gitignore +5 -0
- Package.swift +12 -5
- class.py +2 -3
- colab.ipynb +39 -39
- common/common.cpp +17 -8
- common/common.h +2 -0
- convert.py +7 -22
- expose.h +0 -1
- ggml-metal.m +208 -124
- ggml-metal.metal +125 -41
- ggml-opencl.cpp +119 -53
- ggml.c +755 -315
- ggml.h +13 -0
- gguf-py/README.md +0 -1
- gguf-py/gguf/gguf.py +293 -149
- gguf-py/pyproject.toml +1 -1
- gpttype_adapter.cpp +6 -5
- k_quants.c +744 -2
- k_quants.h +5 -5
- kcpp_docs.embd +0 -0
- klite.embd +385 -75
- koboldcpp.py +220 -361
- llama.cpp +1484 -311
- llama.h +17 -1
- make_pyinstaller.sh +1 -0
- media/preview.png +0 -0
- media/preview2.png +0 -0
- media/preview3.png +0 -0
- media/preview4.png +0 -0
- models/ggml-vocab-aquila.gguf +3 -0
- models/ggml-vocab-falcon.gguf +3 -0
- otherarch/tools/unused/export_state_dict_checkpoint.py +129 -0
- prompts/LLM-questions.txt +49 -0
- prompts/parallel-questions.txt +43 -0
- requirements.txt +1 -1
- scripts/LlamaConfig.cmake.in +2 -0
- spm-headers/ggml.h +13 -0
- unicode.h +462 -0
.gitattributes
CHANGED
|
@@ -36,3 +36,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 36 |
clblast.dll filter=lfs diff=lfs merge=lfs -text
|
| 37 |
lib/libopenblas.lib filter=lfs diff=lfs merge=lfs -text
|
| 38 |
libopenblas.dll filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 36 |
clblast.dll filter=lfs diff=lfs merge=lfs -text
|
| 37 |
lib/libopenblas.lib filter=lfs diff=lfs merge=lfs -text
|
| 38 |
libopenblas.dll filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
models/ggml-vocab-aquila.gguf filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
models/ggml-vocab-falcon.gguf filter=lfs diff=lfs merge=lfs -text
|
.github/workflows/gguf-publish.yml
CHANGED
|
@@ -36,8 +36,9 @@ jobs:
|
|
| 36 |
poetry install
|
| 37 |
|
| 38 |
- name: Build package
|
| 39 |
-
run: poetry build
|
| 40 |
- name: Publish package
|
| 41 |
uses: pypa/gh-action-pypi-publish@release/v1
|
| 42 |
with:
|
| 43 |
password: ${{ secrets.PYPI_API_TOKEN }}
|
|
|
|
|
|
| 36 |
poetry install
|
| 37 |
|
| 38 |
- name: Build package
|
| 39 |
+
run: cd gguf-py && poetry build
|
| 40 |
- name: Publish package
|
| 41 |
uses: pypa/gh-action-pypi-publish@release/v1
|
| 42 |
with:
|
| 43 |
password: ${{ secrets.PYPI_API_TOKEN }}
|
| 44 |
+
packages-dir: gguf-py/dist
|
.github/workflows/zig-build.yml
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Zig CI
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
pull_request:
|
| 5 |
+
push:
|
| 6 |
+
branches:
|
| 7 |
+
- master
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
build:
|
| 11 |
+
strategy:
|
| 12 |
+
fail-fast: false
|
| 13 |
+
matrix:
|
| 14 |
+
runs-on: [ubuntu-latest, macos-latest, windows-latest]
|
| 15 |
+
runs-on: ${{ matrix.runs-on }}
|
| 16 |
+
steps:
|
| 17 |
+
- uses: actions/checkout@v3
|
| 18 |
+
with:
|
| 19 |
+
submodules: recursive
|
| 20 |
+
fetch-depth: 0
|
| 21 |
+
- uses: goto-bus-stop/setup-zig@v2
|
| 22 |
+
with:
|
| 23 |
+
version: 0.11.0
|
| 24 |
+
- name: Build Summary
|
| 25 |
+
run: zig build --summary all -freference-trace
|
.gitignore
CHANGED
|
@@ -31,6 +31,7 @@ models-mnt
|
|
| 31 |
/embedding
|
| 32 |
/gguf
|
| 33 |
/gguf-llama-simple
|
|
|
|
| 34 |
/libllama.so
|
| 35 |
/llama-bench
|
| 36 |
/main
|
|
@@ -82,6 +83,10 @@ tests/test-quantize-fns
|
|
| 82 |
tests/test-quantize-perf
|
| 83 |
tests/test-sampling
|
| 84 |
tests/test-tokenizer-0
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
|
| 86 |
/koboldcpp_default.so
|
| 87 |
/koboldcpp_failsafe.so
|
|
|
|
| 31 |
/embedding
|
| 32 |
/gguf
|
| 33 |
/gguf-llama-simple
|
| 34 |
+
/infill
|
| 35 |
/libllama.so
|
| 36 |
/llama-bench
|
| 37 |
/main
|
|
|
|
| 83 |
tests/test-quantize-perf
|
| 84 |
tests/test-sampling
|
| 85 |
tests/test-tokenizer-0
|
| 86 |
+
tests/test-tokenizer-0-llama
|
| 87 |
+
tests/test-tokenizer-0-falcon
|
| 88 |
+
tests/test-tokenizer-1-llama
|
| 89 |
+
tests/test-tokenizer-1-bpe
|
| 90 |
|
| 91 |
/koboldcpp_default.so
|
| 92 |
/koboldcpp_failsafe.so
|
Package.swift
CHANGED
|
@@ -10,15 +10,18 @@ let platforms: [SupportedPlatform]? = [
|
|
| 10 |
.tvOS(.v14)
|
| 11 |
]
|
| 12 |
let exclude: [String] = []
|
| 13 |
-
let
|
|
|
|
|
|
|
|
|
|
| 14 |
let additionalSettings: [CSetting] = [
|
| 15 |
.unsafeFlags(["-fno-objc-arc"]),
|
| 16 |
-
.define("GGML_SWIFT"),
|
| 17 |
.define("GGML_USE_METAL")
|
| 18 |
]
|
| 19 |
#else
|
| 20 |
let platforms: [SupportedPlatform]? = nil
|
| 21 |
let exclude: [String] = ["ggml-metal.metal"]
|
|
|
|
| 22 |
let additionalSources: [String] = []
|
| 23 |
let additionalSettings: [CSetting] = []
|
| 24 |
#endif
|
|
@@ -40,13 +43,17 @@ let package = Package(
|
|
| 40 |
"ggml-alloc.c",
|
| 41 |
"k_quants.c",
|
| 42 |
] + additionalSources,
|
|
|
|
| 43 |
publicHeadersPath: "spm-headers",
|
| 44 |
cSettings: [
|
| 45 |
.unsafeFlags(["-Wno-shorten-64-to-32"]),
|
| 46 |
.define("GGML_USE_K_QUANTS"),
|
| 47 |
-
.define("GGML_USE_ACCELERATE")
|
| 48 |
-
.
|
| 49 |
-
|
|
|
|
|
|
|
|
|
|
| 50 |
] + additionalSettings,
|
| 51 |
linkerSettings: [
|
| 52 |
.linkedFramework("Accelerate")
|
|
|
|
| 10 |
.tvOS(.v14)
|
| 11 |
]
|
| 12 |
let exclude: [String] = []
|
| 13 |
+
let resources: [Resource] = [
|
| 14 |
+
.process("ggml-metal.metal")
|
| 15 |
+
]
|
| 16 |
+
let additionalSources: [String] = ["ggml-metal.m"]
|
| 17 |
let additionalSettings: [CSetting] = [
|
| 18 |
.unsafeFlags(["-fno-objc-arc"]),
|
|
|
|
| 19 |
.define("GGML_USE_METAL")
|
| 20 |
]
|
| 21 |
#else
|
| 22 |
let platforms: [SupportedPlatform]? = nil
|
| 23 |
let exclude: [String] = ["ggml-metal.metal"]
|
| 24 |
+
let resources: [Resource] = []
|
| 25 |
let additionalSources: [String] = []
|
| 26 |
let additionalSettings: [CSetting] = []
|
| 27 |
#endif
|
|
|
|
| 43 |
"ggml-alloc.c",
|
| 44 |
"k_quants.c",
|
| 45 |
] + additionalSources,
|
| 46 |
+
resources: resources,
|
| 47 |
publicHeadersPath: "spm-headers",
|
| 48 |
cSettings: [
|
| 49 |
.unsafeFlags(["-Wno-shorten-64-to-32"]),
|
| 50 |
.define("GGML_USE_K_QUANTS"),
|
| 51 |
+
.define("GGML_USE_ACCELERATE")
|
| 52 |
+
// NOTE: NEW_LAPACK will required iOS version 16.4+
|
| 53 |
+
// We should consider add this in the future when we drop support for iOS 14
|
| 54 |
+
// (ref: ref: https://developer.apple.com/documentation/accelerate/1513264-cblas_sgemm?language=objc)
|
| 55 |
+
// .define("ACCELERATE_NEW_LAPACK"),
|
| 56 |
+
// .define("ACCELERATE_LAPACK_ILP64")
|
| 57 |
] + additionalSettings,
|
| 58 |
linkerSettings: [
|
| 59 |
.linkedFramework("Accelerate")
|
class.py
CHANGED
|
@@ -268,9 +268,8 @@ class model_backend(InferenceModel):
|
|
| 268 |
if not kcpp_backend_loaded:
|
| 269 |
kcppargs = KcppArgsObject(model=self.kcpp_filename, model_param=self.kcpp_filename,
|
| 270 |
port=5001, port_param=5001, host='', launch=False, lora=None, threads=self.kcpp_threads, blasthreads=self.kcpp_threads,
|
| 271 |
-
|
| 272 |
-
|
| 273 |
-
unbantokens=False, bantokens=None, usemirostat=None, forceversion=0, nommap=self.kcpp_nommap,
|
| 274 |
usemlock=False, noavx2=self.kcpp_noavx2, debugmode=self.kcpp_debugmode, skiplauncher=True, hordeconfig=None, noblas=self.kcpp_noblas,
|
| 275 |
useclblast=self.kcpp_useclblast, usecublas=self.kcpp_usecublas, gpulayers=self.kcpp_gpulayers, tensor_split=self.kcpp_tensor_split, config=None,
|
| 276 |
onready='', multiuser=False, foreground=False)
|
|
|
|
| 268 |
if not kcpp_backend_loaded:
|
| 269 |
kcppargs = KcppArgsObject(model=self.kcpp_filename, model_param=self.kcpp_filename,
|
| 270 |
port=5001, port_param=5001, host='', launch=False, lora=None, threads=self.kcpp_threads, blasthreads=self.kcpp_threads,
|
| 271 |
+
highpriority=False, contextsize=self.kcpp_ctxsize, blasbatchsize=self.kcpp_blasbatchsize, ropeconfig=[self.kcpp_ropescale, self.kcpp_ropebase],
|
| 272 |
+
smartcontext=self.kcpp_smartcontext, bantokens=None, forceversion=0, nommap=self.kcpp_nommap,
|
|
|
|
| 273 |
usemlock=False, noavx2=self.kcpp_noavx2, debugmode=self.kcpp_debugmode, skiplauncher=True, hordeconfig=None, noblas=self.kcpp_noblas,
|
| 274 |
useclblast=self.kcpp_useclblast, usecublas=self.kcpp_usecublas, gpulayers=self.kcpp_gpulayers, tensor_split=self.kcpp_tensor_split, config=None,
|
| 275 |
onready='', multiuser=False, foreground=False)
|
colab.ipynb
CHANGED
|
@@ -1,29 +1,10 @@
|
|
| 1 |
{
|
| 2 |
-
"nbformat": 4,
|
| 3 |
-
"nbformat_minor": 0,
|
| 4 |
-
"metadata": {
|
| 5 |
-
"colab": {
|
| 6 |
-
"private_outputs": true,
|
| 7 |
-
"provenance": [],
|
| 8 |
-
"gpuType": "T4",
|
| 9 |
-
"authorship_tag": "",
|
| 10 |
-
"include_colab_link": true
|
| 11 |
-
},
|
| 12 |
-
"kernelspec": {
|
| 13 |
-
"name": "python3",
|
| 14 |
-
"display_name": "Python 3"
|
| 15 |
-
},
|
| 16 |
-
"language_info": {
|
| 17 |
-
"name": "python"
|
| 18 |
-
},
|
| 19 |
-
"accelerator": "GPU"
|
| 20 |
-
},
|
| 21 |
"cells": [
|
| 22 |
{
|
| 23 |
"cell_type": "markdown",
|
| 24 |
"metadata": {
|
| 25 |
-
"
|
| 26 |
-
"
|
| 27 |
},
|
| 28 |
"source": []
|
| 29 |
},
|
|
@@ -36,24 +17,43 @@
|
|
| 36 |
},
|
| 37 |
"outputs": [],
|
| 38 |
"source": [
|
| 39 |
-
"#@title <b>v-- Enter your model below and then click this to start Koboldcpp</b>\n",
|
| 40 |
-
"\n",
|
| 41 |
-
"Model = \"https://huggingface.co/TheBloke/Airoboros-L2-13B-2.2-GGUF/resolve/main/airoboros-l2-13b-2.2.Q4_K_M.gguf\" #@param [\"\"]{allow-input: true}\n",
|
| 42 |
-
"Layers = 43 #@param [43]{allow-input: true}\n",
|
| 43 |
-
"\n",
|
| 44 |
-
"%cd /content\n",
|
| 45 |
-
"!git clone https://github.com/LostRuins/koboldcpp\n",
|
| 46 |
-
"%cd /content/koboldcpp\n",
|
| 47 |
-
"!make LLAMA_CUBLAS=1\n",
|
| 48 |
-
"\n",
|
| 49 |
-
"!wget $Model -O model.ggml\n",
|
| 50 |
-
"!wget -c https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64\n",
|
| 51 |
-
"!chmod +x cloudflared-linux-amd64\n",
|
| 52 |
-
"!nohup ./cloudflared-linux-amd64 tunnel --url http://localhost:5001 &\n",
|
| 53 |
-
"!sleep 10\n",
|
| 54 |
-
"!cat nohup.out\n",
|
| 55 |
-
"!python koboldcpp.py model.ggml --
|
| 56 |
]
|
| 57 |
}
|
| 58 |
-
]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
}
|
|
|
|
| 1 |
{
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
"cells": [
|
| 3 |
{
|
| 4 |
"cell_type": "markdown",
|
| 5 |
"metadata": {
|
| 6 |
+
"colab_type": "text",
|
| 7 |
+
"id": "view-in-github"
|
| 8 |
},
|
| 9 |
"source": []
|
| 10 |
},
|
|
|
|
| 17 |
},
|
| 18 |
"outputs": [],
|
| 19 |
"source": [
|
| 20 |
+
"#@title <b>v-- Enter your model below and then click this to start Koboldcpp</b>\r\n",
|
| 21 |
+
"\r\n",
|
| 22 |
+
"Model = \"https://huggingface.co/TheBloke/Airoboros-L2-13B-2.2-GGUF/resolve/main/airoboros-l2-13b-2.2.Q4_K_M.gguf\" #@param [\"\"]{allow-input: true}\r\n",
|
| 23 |
+
"Layers = 43 #@param [43]{allow-input: true}\r\n",
|
| 24 |
+
"\r\n",
|
| 25 |
+
"%cd /content\r\n",
|
| 26 |
+
"!git clone https://github.com/LostRuins/koboldcpp\r\n",
|
| 27 |
+
"%cd /content/koboldcpp\r\n",
|
| 28 |
+
"!make LLAMA_CUBLAS=1\r\n",
|
| 29 |
+
"\r\n",
|
| 30 |
+
"!wget $Model -O model.ggml\r\n",
|
| 31 |
+
"!wget -c https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64\r\n",
|
| 32 |
+
"!chmod +x cloudflared-linux-amd64\r\n",
|
| 33 |
+
"!nohup ./cloudflared-linux-amd64 tunnel --url http://localhost:5001 &\r\n",
|
| 34 |
+
"!sleep 10\r\n",
|
| 35 |
+
"!cat nohup.out\r\n",
|
| 36 |
+
"!python koboldcpp.py model.ggml --usecublas 0 mmq --gpulayers $Layers --hordeconfig concedo\r\n"
|
| 37 |
]
|
| 38 |
}
|
| 39 |
+
],
|
| 40 |
+
"metadata": {
|
| 41 |
+
"accelerator": "GPU",
|
| 42 |
+
"colab": {
|
| 43 |
+
"authorship_tag": "",
|
| 44 |
+
"gpuType": "T4",
|
| 45 |
+
"include_colab_link": true,
|
| 46 |
+
"private_outputs": true,
|
| 47 |
+
"provenance": []
|
| 48 |
+
},
|
| 49 |
+
"kernelspec": {
|
| 50 |
+
"display_name": "Python 3",
|
| 51 |
+
"name": "python3"
|
| 52 |
+
},
|
| 53 |
+
"language_info": {
|
| 54 |
+
"name": "python"
|
| 55 |
+
}
|
| 56 |
+
},
|
| 57 |
+
"nbformat": 4,
|
| 58 |
+
"nbformat_minor": 0
|
| 59 |
}
|
common/common.cpp
CHANGED
|
@@ -167,8 +167,10 @@ bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
|
| 167 |
invalid_param = true;
|
| 168 |
break;
|
| 169 |
}
|
|
|
|
|
|
|
| 170 |
std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.prompt));
|
| 171 |
-
if (params.prompt.back() == '\n') {
|
| 172 |
params.prompt.pop_back();
|
| 173 |
}
|
| 174 |
} else if (arg == "-n" || arg == "--n-predict") {
|
|
@@ -293,7 +295,7 @@ bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
|
| 293 |
break;
|
| 294 |
}
|
| 295 |
std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.cfg_negative_prompt));
|
| 296 |
-
if (params.cfg_negative_prompt.back() == '\n') {
|
| 297 |
params.cfg_negative_prompt.pop_back();
|
| 298 |
}
|
| 299 |
} else if (arg == "--cfg-scale") {
|
|
@@ -361,7 +363,7 @@ bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
|
| 361 |
invalid_param = true;
|
| 362 |
break;
|
| 363 |
}
|
| 364 |
-
params.lora_adapter.push_back(
|
| 365 |
params.use_mmap = false;
|
| 366 |
} else if (arg == "--lora-scaled") {
|
| 367 |
if (++i >= argc) {
|
|
@@ -373,7 +375,7 @@ bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
|
| 373 |
invalid_param = true;
|
| 374 |
break;
|
| 375 |
}
|
| 376 |
-
params.lora_adapter.push_back(
|
| 377 |
params.use_mmap = false;
|
| 378 |
} else if (arg == "--lora-base") {
|
| 379 |
if (++i >= argc) {
|
|
@@ -389,6 +391,8 @@ bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
|
| 389 |
params.interactive_first = true;
|
| 390 |
} else if (arg == "-ins" || arg == "--instruct") {
|
| 391 |
params.instruct = true;
|
|
|
|
|
|
|
| 392 |
} else if (arg == "--multiline-input") {
|
| 393 |
params.multiline_input = true;
|
| 394 |
} else if (arg == "--simple-io") {
|
|
@@ -614,6 +618,9 @@ bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
|
|
| 614 |
process_escapes(params.prompt);
|
| 615 |
process_escapes(params.input_prefix);
|
| 616 |
process_escapes(params.input_suffix);
|
|
|
|
|
|
|
|
|
|
| 617 |
}
|
| 618 |
|
| 619 |
return true;
|
|
@@ -921,6 +928,7 @@ std::string llama_detokenize_bpe(llama_context * ctx, const std::vector<llama_to
|
|
| 921 |
result += piece;
|
| 922 |
}
|
| 923 |
|
|
|
|
| 924 |
return result;
|
| 925 |
}
|
| 926 |
|
|
@@ -1014,10 +1022,11 @@ llama_token llama_sample_token(
|
|
| 1014 |
id = llama_sample_token_mirostat_v2(ctx, &cur_p, mirostat_tau, mirostat_eta, &mirostat_mu);
|
| 1015 |
} else {
|
| 1016 |
// Temperature sampling
|
| 1017 |
-
|
| 1018 |
-
|
| 1019 |
-
|
| 1020 |
-
|
|
|
|
| 1021 |
llama_sample_temp(ctx, &cur_p, temp);
|
| 1022 |
|
| 1023 |
{
|
|
|
|
| 167 |
invalid_param = true;
|
| 168 |
break;
|
| 169 |
}
|
| 170 |
+
// store the external file name in params
|
| 171 |
+
params.prompt_file = argv[i];
|
| 172 |
std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.prompt));
|
| 173 |
+
if (!params.prompt.empty() && params.prompt.back() == '\n') {
|
| 174 |
params.prompt.pop_back();
|
| 175 |
}
|
| 176 |
} else if (arg == "-n" || arg == "--n-predict") {
|
|
|
|
| 295 |
break;
|
| 296 |
}
|
| 297 |
std::copy(std::istreambuf_iterator<char>(file), std::istreambuf_iterator<char>(), back_inserter(params.cfg_negative_prompt));
|
| 298 |
+
if (!params.cfg_negative_prompt.empty() && params.cfg_negative_prompt.back() == '\n') {
|
| 299 |
params.cfg_negative_prompt.pop_back();
|
| 300 |
}
|
| 301 |
} else if (arg == "--cfg-scale") {
|
|
|
|
| 363 |
invalid_param = true;
|
| 364 |
break;
|
| 365 |
}
|
| 366 |
+
params.lora_adapter.push_back(std::make_tuple(argv[i], 1.0f));
|
| 367 |
params.use_mmap = false;
|
| 368 |
} else if (arg == "--lora-scaled") {
|
| 369 |
if (++i >= argc) {
|
|
|
|
| 375 |
invalid_param = true;
|
| 376 |
break;
|
| 377 |
}
|
| 378 |
+
params.lora_adapter.push_back(std::make_tuple(lora_adapter, std::stof(argv[i])));
|
| 379 |
params.use_mmap = false;
|
| 380 |
} else if (arg == "--lora-base") {
|
| 381 |
if (++i >= argc) {
|
|
|
|
| 391 |
params.interactive_first = true;
|
| 392 |
} else if (arg == "-ins" || arg == "--instruct") {
|
| 393 |
params.instruct = true;
|
| 394 |
+
} else if (arg == "--infill") {
|
| 395 |
+
params.infill = true;
|
| 396 |
} else if (arg == "--multiline-input") {
|
| 397 |
params.multiline_input = true;
|
| 398 |
} else if (arg == "--simple-io") {
|
|
|
|
| 618 |
process_escapes(params.prompt);
|
| 619 |
process_escapes(params.input_prefix);
|
| 620 |
process_escapes(params.input_suffix);
|
| 621 |
+
for (auto & antiprompt : params.antiprompt) {
|
| 622 |
+
process_escapes(antiprompt);
|
| 623 |
+
}
|
| 624 |
}
|
| 625 |
|
| 626 |
return true;
|
|
|
|
| 928 |
result += piece;
|
| 929 |
}
|
| 930 |
|
| 931 |
+
// NOTE: the original tokenizer decodes bytes after collecting the pieces.
|
| 932 |
return result;
|
| 933 |
}
|
| 934 |
|
|
|
|
| 1022 |
id = llama_sample_token_mirostat_v2(ctx, &cur_p, mirostat_tau, mirostat_eta, &mirostat_mu);
|
| 1023 |
} else {
|
| 1024 |
// Temperature sampling
|
| 1025 |
+
size_t min_keep = std::max(1, params.n_probs);
|
| 1026 |
+
llama_sample_top_k (ctx, &cur_p, top_k, min_keep);
|
| 1027 |
+
llama_sample_tail_free (ctx, &cur_p, tfs_z, min_keep);
|
| 1028 |
+
llama_sample_typical (ctx, &cur_p, typical_p, min_keep);
|
| 1029 |
+
llama_sample_top_p (ctx, &cur_p, top_p, min_keep);
|
| 1030 |
llama_sample_temp(ctx, &cur_p, temp);
|
| 1031 |
|
| 1032 |
{
|
common/common.h
CHANGED
|
@@ -79,6 +79,7 @@ struct gpt_params {
|
|
| 79 |
std::string model_draft = ""; // draft model for speculative decoding
|
| 80 |
std::string model_alias = "unknown"; // model alias
|
| 81 |
std::string prompt = "";
|
|
|
|
| 82 |
std::string path_prompt_cache = ""; // path to file for saving/loading prompt eval state
|
| 83 |
std::string input_prefix = ""; // string to prefix user inputs with
|
| 84 |
std::string input_suffix = ""; // string to suffix user inputs with
|
|
@@ -120,6 +121,7 @@ struct gpt_params {
|
|
| 120 |
bool use_mlock = false; // use mlock to keep model in memory
|
| 121 |
bool numa = false; // attempt optimizations that help on some NUMA systems
|
| 122 |
bool verbose_prompt = false; // print prompt tokens before generation
|
|
|
|
| 123 |
};
|
| 124 |
|
| 125 |
bool gpt_params_parse(int argc, char ** argv, gpt_params & params);
|
|
|
|
| 79 |
std::string model_draft = ""; // draft model for speculative decoding
|
| 80 |
std::string model_alias = "unknown"; // model alias
|
| 81 |
std::string prompt = "";
|
| 82 |
+
std::string prompt_file = ""; // store the external prompt file name
|
| 83 |
std::string path_prompt_cache = ""; // path to file for saving/loading prompt eval state
|
| 84 |
std::string input_prefix = ""; // string to prefix user inputs with
|
| 85 |
std::string input_suffix = ""; // string to suffix user inputs with
|
|
|
|
| 121 |
bool use_mlock = false; // use mlock to keep model in memory
|
| 122 |
bool numa = false; // attempt optimizations that help on some NUMA systems
|
| 123 |
bool verbose_prompt = false; // print prompt tokens before generation
|
| 124 |
+
bool infill = false; // use infill mode
|
| 125 |
};
|
| 126 |
|
| 127 |
bool gpt_params_parse(int argc, char ** argv, gpt_params & params);
|
convert.py
CHANGED
|
@@ -41,8 +41,7 @@ if hasattr(faulthandler, 'register') and hasattr(signal, 'SIGUSR1'):
|
|
| 41 |
|
| 42 |
NDArray: TypeAlias = 'np.ndarray[Any, Any]'
|
| 43 |
|
| 44 |
-
ARCH=gguf.MODEL_ARCH.LLAMA
|
| 45 |
-
NAMES=gguf.MODEL_TENSOR_NAMES[ARCH]
|
| 46 |
|
| 47 |
DEFAULT_CONCURRENCY = 8
|
| 48 |
#
|
|
@@ -339,29 +338,15 @@ class BpeVocab:
|
|
| 339 |
def bpe_tokens(self) -> Iterable[tuple[bytes, float, gguf.TokenType]]:
|
| 340 |
tokenizer = self.bpe_tokenizer
|
| 341 |
from transformers.models.gpt2 import tokenization_gpt2 # type: ignore[import]
|
| 342 |
-
|
| 343 |
-
|
| 344 |
-
|
| 345 |
-
|
| 346 |
-
text: bytes = item.encode("utf-8")
|
| 347 |
-
# FIXME: These shouldn't be hardcoded, but it's probably better than the current behavior?
|
| 348 |
-
if i <= 258 and text.startswith(b'<') and text.endswith(b'>'):
|
| 349 |
-
if i == 0 and text == b'<unk>':
|
| 350 |
-
toktype = gguf.TokenType.UNKNOWN
|
| 351 |
-
elif i == 1 or i == 2:
|
| 352 |
-
toktype = gguf.TokenType.CONTROL
|
| 353 |
-
elif i >= 3 and text.startswith(b'<0x'):
|
| 354 |
-
toktype = gguf.TokenType.BYTE
|
| 355 |
-
else:
|
| 356 |
-
toktype = gguf.TokenType.NORMAL
|
| 357 |
-
else:
|
| 358 |
-
toktype = gguf.TokenType.NORMAL
|
| 359 |
-
yield text, score, toktype
|
| 360 |
|
| 361 |
def added_tokens(self) -> Iterable[tuple[bytes, float, gguf.TokenType]]:
|
| 362 |
for text in self.added_tokens_list:
|
| 363 |
score = -1000.0
|
| 364 |
-
yield text.encode("utf-8"), score, gguf.TokenType.
|
| 365 |
|
| 366 |
def all_tokens(self) -> Iterable[tuple[bytes, float, gguf.TokenType]]:
|
| 367 |
yield from self.bpe_tokens()
|
|
@@ -953,7 +938,7 @@ class OutputFile:
|
|
| 953 |
of.close()
|
| 954 |
|
| 955 |
def pick_output_type(model: LazyModel, output_type_str: str | None) -> GGMLFileType:
|
| 956 |
-
wq_type = model[
|
| 957 |
|
| 958 |
if output_type_str == "f32" or (output_type_str is None and wq_type == DT_F32):
|
| 959 |
return GGMLFileType.AllF32
|
|
|
|
| 41 |
|
| 42 |
NDArray: TypeAlias = 'np.ndarray[Any, Any]'
|
| 43 |
|
| 44 |
+
ARCH = gguf.MODEL_ARCH.LLAMA
|
|
|
|
| 45 |
|
| 46 |
DEFAULT_CONCURRENCY = 8
|
| 47 |
#
|
|
|
|
| 338 |
def bpe_tokens(self) -> Iterable[tuple[bytes, float, gguf.TokenType]]:
|
| 339 |
tokenizer = self.bpe_tokenizer
|
| 340 |
from transformers.models.gpt2 import tokenization_gpt2 # type: ignore[import]
|
| 341 |
+
reverse_vocab = {id: encoded_tok for encoded_tok, id in tokenizer.items()}
|
| 342 |
+
|
| 343 |
+
for i, _ in enumerate(tokenizer):
|
| 344 |
+
yield reverse_vocab[i], 0.0, gguf.TokenType.NORMAL
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 345 |
|
| 346 |
def added_tokens(self) -> Iterable[tuple[bytes, float, gguf.TokenType]]:
|
| 347 |
for text in self.added_tokens_list:
|
| 348 |
score = -1000.0
|
| 349 |
+
yield text.encode("utf-8"), score, gguf.TokenType.CONTROL
|
| 350 |
|
| 351 |
def all_tokens(self) -> Iterable[tuple[bytes, float, gguf.TokenType]]:
|
| 352 |
yield from self.bpe_tokens()
|
|
|
|
| 938 |
of.close()
|
| 939 |
|
| 940 |
def pick_output_type(model: LazyModel, output_type_str: str | None) -> GGMLFileType:
|
| 941 |
+
wq_type = model[gguf.TENSOR_NAMES[gguf.MODEL_TENSOR.ATTN_Q].format(bid=0)+".weight"].data_type
|
| 942 |
|
| 943 |
if output_type_str == "f32" or (output_type_str is None and wq_type == DT_F32):
|
| 944 |
return GGMLFileType.AllF32
|
expose.h
CHANGED
|
@@ -38,7 +38,6 @@ struct load_model_inputs
|
|
| 38 |
const bool use_mmap;
|
| 39 |
const bool use_mlock;
|
| 40 |
const bool use_smartcontext;
|
| 41 |
-
const bool unban_tokens;
|
| 42 |
const int clblast_info = 0;
|
| 43 |
const int cublas_info = 0;
|
| 44 |
const int blasbatchsize = 512;
|
|
|
|
| 38 |
const bool use_mmap;
|
| 39 |
const bool use_mlock;
|
| 40 |
const bool use_smartcontext;
|
|
|
|
| 41 |
const int clblast_info = 0;
|
| 42 |
const int cublas_info = 0;
|
| 43 |
const int blasbatchsize = 512;
|
ggml-metal.m
CHANGED
|
@@ -81,18 +81,18 @@ struct ggml_metal_context {
|
|
| 81 |
GGML_METAL_DECL_KERNEL(get_rows_q6_K);
|
| 82 |
GGML_METAL_DECL_KERNEL(rms_norm);
|
| 83 |
GGML_METAL_DECL_KERNEL(norm);
|
| 84 |
-
GGML_METAL_DECL_KERNEL(
|
| 85 |
-
GGML_METAL_DECL_KERNEL(
|
| 86 |
-
GGML_METAL_DECL_KERNEL(
|
| 87 |
-
GGML_METAL_DECL_KERNEL(
|
| 88 |
-
GGML_METAL_DECL_KERNEL(
|
| 89 |
-
GGML_METAL_DECL_KERNEL(
|
| 90 |
-
GGML_METAL_DECL_KERNEL(
|
| 91 |
-
GGML_METAL_DECL_KERNEL(
|
| 92 |
-
GGML_METAL_DECL_KERNEL(
|
| 93 |
-
GGML_METAL_DECL_KERNEL(
|
| 94 |
-
GGML_METAL_DECL_KERNEL(
|
| 95 |
-
GGML_METAL_DECL_KERNEL(
|
| 96 |
GGML_METAL_DECL_KERNEL(mul_mm_f32_f32);
|
| 97 |
GGML_METAL_DECL_KERNEL(mul_mm_f16_f32);
|
| 98 |
GGML_METAL_DECL_KERNEL(mul_mm_q4_0_f32);
|
|
@@ -109,6 +109,8 @@ struct ggml_metal_context {
|
|
| 109 |
GGML_METAL_DECL_KERNEL(cpy_f32_f16);
|
| 110 |
GGML_METAL_DECL_KERNEL(cpy_f32_f32);
|
| 111 |
GGML_METAL_DECL_KERNEL(cpy_f16_f16);
|
|
|
|
|
|
|
| 112 |
|
| 113 |
#undef GGML_METAL_DECL_KERNEL
|
| 114 |
};
|
|
@@ -183,56 +185,44 @@ struct ggml_metal_context * ggml_metal_init(int n_cb) {
|
|
| 183 |
|
| 184 |
ctx->d_queue = dispatch_queue_create("ggml-metal", DISPATCH_QUEUE_CONCURRENT);
|
| 185 |
|
| 186 |
-
|
| 187 |
-
// load the default.metallib file
|
| 188 |
{
|
| 189 |
-
|
| 190 |
-
|
| 191 |
-
|
| 192 |
-
NSString * llamaBundlePath = [bundle pathForResource:@"llama_llama" ofType:@"bundle"];
|
| 193 |
-
NSBundle * llamaBundle = [NSBundle bundleWithPath:llamaBundlePath];
|
| 194 |
-
NSString * libPath = [llamaBundle pathForResource:@"default" ofType:@"metallib"];
|
| 195 |
-
NSURL * libURL = [NSURL fileURLWithPath:libPath];
|
| 196 |
-
|
| 197 |
-
// Load the metallib file into a Metal library
|
| 198 |
-
ctx->library = [ctx->device newLibraryWithURL:libURL error:&error];
|
| 199 |
-
|
| 200 |
-
if (error) {
|
| 201 |
-
GGML_METAL_LOG_ERROR("%s: error: %s\n", __func__, [[error description] UTF8String]);
|
| 202 |
-
return NULL;
|
| 203 |
-
}
|
| 204 |
-
}
|
| 205 |
#else
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
// read the source from "ggml-metal.metal" into a string and use newLibraryWithSource
|
| 209 |
-
{
|
| 210 |
NSError * error = nil;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 211 |
|
| 212 |
-
|
| 213 |
-
NSBundle * bundle = [NSBundle bundleForClass:[GGMLMetalClass class]];
|
| 214 |
-
NSString * path = [bundle pathForResource:@"ggml-metal" ofType:@"metal"];
|
| 215 |
-
GGML_METAL_LOG_INFO("%s: loading '%s'\n", __func__, [path UTF8String]);
|
| 216 |
-
|
| 217 |
-
NSString * src = [NSString stringWithContentsOfFile:path encoding:NSUTF8StringEncoding error:&error];
|
| 218 |
-
if (error) {
|
| 219 |
-
GGML_METAL_LOG_ERROR("%s: error: %s\n", __func__, [[error description] UTF8String]);
|
| 220 |
-
return NULL;
|
| 221 |
-
}
|
| 222 |
-
|
| 223 |
#ifdef GGML_QKK_64
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
ctx->library = [ctx->device newLibraryWithSource:src options:options error:&error];
|
| 227 |
-
#else
|
| 228 |
-
ctx->library = [ctx->device newLibraryWithSource:src options:nil error:&error];
|
| 229 |
#endif
|
|
|
|
|
|
|
|
|
|
| 230 |
if (error) {
|
| 231 |
GGML_METAL_LOG_ERROR("%s: error: %s\n", __func__, [[error description] UTF8String]);
|
| 232 |
return NULL;
|
| 233 |
}
|
| 234 |
}
|
| 235 |
-
#endif
|
| 236 |
|
| 237 |
// load kernels
|
| 238 |
{
|
|
@@ -272,40 +262,57 @@ struct ggml_metal_context * ggml_metal_init(int n_cb) {
|
|
| 272 |
GGML_METAL_ADD_KERNEL(get_rows_q6_K);
|
| 273 |
GGML_METAL_ADD_KERNEL(rms_norm);
|
| 274 |
GGML_METAL_ADD_KERNEL(norm);
|
| 275 |
-
GGML_METAL_ADD_KERNEL(
|
| 276 |
-
GGML_METAL_ADD_KERNEL(
|
| 277 |
-
GGML_METAL_ADD_KERNEL(
|
| 278 |
-
GGML_METAL_ADD_KERNEL(
|
| 279 |
-
GGML_METAL_ADD_KERNEL(
|
| 280 |
-
GGML_METAL_ADD_KERNEL(
|
| 281 |
-
GGML_METAL_ADD_KERNEL(
|
| 282 |
-
GGML_METAL_ADD_KERNEL(
|
| 283 |
-
GGML_METAL_ADD_KERNEL(
|
| 284 |
-
GGML_METAL_ADD_KERNEL(
|
| 285 |
-
GGML_METAL_ADD_KERNEL(
|
| 286 |
-
GGML_METAL_ADD_KERNEL(
|
| 287 |
-
|
| 288 |
-
|
| 289 |
-
|
| 290 |
-
|
| 291 |
-
|
| 292 |
-
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
|
|
|
|
|
|
|
| 297 |
GGML_METAL_ADD_KERNEL(rope_f32);
|
| 298 |
GGML_METAL_ADD_KERNEL(rope_f16);
|
| 299 |
GGML_METAL_ADD_KERNEL(alibi_f32);
|
| 300 |
GGML_METAL_ADD_KERNEL(cpy_f32_f16);
|
| 301 |
GGML_METAL_ADD_KERNEL(cpy_f32_f32);
|
| 302 |
GGML_METAL_ADD_KERNEL(cpy_f16_f16);
|
|
|
|
|
|
|
| 303 |
|
| 304 |
#undef GGML_METAL_ADD_KERNEL
|
| 305 |
}
|
| 306 |
|
| 307 |
-
GGML_METAL_LOG_INFO("%s: hasUnifiedMemory = %s\n", __func__, ctx->device.hasUnifiedMemory ? "true" : "false");
|
| 308 |
#if TARGET_OS_OSX
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 309 |
GGML_METAL_LOG_INFO("%s: recommendedMaxWorkingSetSize = %8.2f MB\n", __func__, ctx->device.recommendedMaxWorkingSetSize / 1024.0 / 1024.0);
|
| 310 |
if (ctx->device.maxTransferRate != 0) {
|
| 311 |
GGML_METAL_LOG_INFO("%s: maxTransferRate = %8.2f MB/s\n", __func__, ctx->device.maxTransferRate / 1024.0 / 1024.0);
|
|
@@ -347,34 +354,38 @@ void ggml_metal_free(struct ggml_metal_context * ctx) {
|
|
| 347 |
GGML_METAL_DEL_KERNEL(get_rows_q6_K);
|
| 348 |
GGML_METAL_DEL_KERNEL(rms_norm);
|
| 349 |
GGML_METAL_DEL_KERNEL(norm);
|
| 350 |
-
GGML_METAL_DEL_KERNEL(
|
| 351 |
-
GGML_METAL_DEL_KERNEL(
|
| 352 |
-
GGML_METAL_DEL_KERNEL(
|
| 353 |
-
GGML_METAL_DEL_KERNEL(
|
| 354 |
-
GGML_METAL_DEL_KERNEL(
|
| 355 |
-
GGML_METAL_DEL_KERNEL(
|
| 356 |
-
GGML_METAL_DEL_KERNEL(
|
| 357 |
-
GGML_METAL_DEL_KERNEL(
|
| 358 |
-
GGML_METAL_DEL_KERNEL(
|
| 359 |
-
GGML_METAL_DEL_KERNEL(
|
| 360 |
-
GGML_METAL_DEL_KERNEL(
|
| 361 |
-
GGML_METAL_DEL_KERNEL(
|
| 362 |
-
|
| 363 |
-
|
| 364 |
-
|
| 365 |
-
|
| 366 |
-
|
| 367 |
-
|
| 368 |
-
|
| 369 |
-
|
| 370 |
-
|
| 371 |
-
|
|
|
|
|
|
|
| 372 |
GGML_METAL_DEL_KERNEL(rope_f32);
|
| 373 |
GGML_METAL_DEL_KERNEL(rope_f16);
|
| 374 |
GGML_METAL_DEL_KERNEL(alibi_f32);
|
| 375 |
GGML_METAL_DEL_KERNEL(cpy_f32_f16);
|
| 376 |
GGML_METAL_DEL_KERNEL(cpy_f32_f32);
|
| 377 |
GGML_METAL_DEL_KERNEL(cpy_f16_f16);
|
|
|
|
|
|
|
| 378 |
|
| 379 |
#undef GGML_METAL_DEL_KERNEL
|
| 380 |
|
|
@@ -431,7 +442,7 @@ static id<MTLBuffer> ggml_metal_get_buffer(struct ggml_metal_context * ctx, stru
|
|
| 431 |
for (int i = 0; i < ctx->n_buffers; ++i) {
|
| 432 |
const int64_t ioffs = (int64_t) t->data - (int64_t) ctx->buffers[i].data;
|
| 433 |
|
| 434 |
-
//
|
| 435 |
if (ioffs >= 0 && ioffs + tsize <= (int64_t) ctx->buffers[i].size) {
|
| 436 |
*offs = (size_t) ioffs;
|
| 437 |
|
|
@@ -766,6 +777,43 @@ void ggml_metal_graph_compute(
|
|
| 766 |
{
|
| 767 |
// noop
|
| 768 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 769 |
case GGML_OP_ADD:
|
| 770 |
{
|
| 771 |
GGML_ASSERT(ggml_is_contiguous(src0));
|
|
@@ -903,6 +951,17 @@ void ggml_metal_graph_compute(
|
|
| 903 |
GGML_ASSERT(false);
|
| 904 |
}
|
| 905 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 906 |
case GGML_OP_SOFT_MAX:
|
| 907 |
{
|
| 908 |
const int nth = MIN(32, ne00);
|
|
@@ -944,21 +1003,46 @@ void ggml_metal_graph_compute(
|
|
| 944 |
} break;
|
| 945 |
case GGML_OP_MUL_MAT:
|
| 946 |
{
|
| 947 |
-
// TODO: needs to be updated after PR: https://github.com/ggerganov/ggml/pull/224
|
| 948 |
-
|
| 949 |
GGML_ASSERT(ne00 == ne10);
|
| 950 |
-
// GGML_ASSERT(ne02 == ne12); // Should be checked on individual data types until broadcast is implemented everywhere
|
| 951 |
-
uint gqa = ne12/ne02;
|
| 952 |
GGML_ASSERT(ne03 == ne13);
|
| 953 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 954 |
// for now the matrix-matrix multiplication kernel only works on A14+/M1+ SoCs
|
| 955 |
// AMD GPU and older A-chips will reuse matrix-vector multiplication kernel
|
| 956 |
-
if (
|
|
|
|
| 957 |
!ggml_is_transposed(src1) &&
|
| 958 |
src1t == GGML_TYPE_F32 &&
|
| 959 |
-
|
| 960 |
-
|
| 961 |
-
ne11
|
| 962 |
switch (src0->type) {
|
| 963 |
case GGML_TYPE_F32: [encoder setComputePipelineState:ctx->pipeline_mul_mm_f32_f32]; break;
|
| 964 |
case GGML_TYPE_F16: [encoder setComputePipelineState:ctx->pipeline_mul_mm_f16_f32]; break;
|
|
@@ -987,17 +1071,18 @@ void ggml_metal_graph_compute(
|
|
| 987 |
[encoder setBytes:&ne1 length:sizeof(ne1) atIndex:12];
|
| 988 |
[encoder setBytes:&gqa length:sizeof(gqa) atIndex:13];
|
| 989 |
[encoder setThreadgroupMemoryLength:8192 atIndex:0];
|
| 990 |
-
[encoder dispatchThreadgroups:MTLSizeMake( (ne11+31)/32, (ne01+63)
|
| 991 |
} else {
|
| 992 |
int nth0 = 32;
|
| 993 |
int nth1 = 1;
|
| 994 |
int nrows = 1;
|
|
|
|
| 995 |
|
| 996 |
// use custom matrix x vector kernel
|
| 997 |
switch (src0t) {
|
| 998 |
case GGML_TYPE_F32:
|
| 999 |
{
|
| 1000 |
-
[encoder setComputePipelineState:ctx->
|
| 1001 |
nrows = 4;
|
| 1002 |
} break;
|
| 1003 |
case GGML_TYPE_F16:
|
|
@@ -1005,12 +1090,12 @@ void ggml_metal_graph_compute(
|
|
| 1005 |
nth0 = 32;
|
| 1006 |
nth1 = 1;
|
| 1007 |
if (ne11 * ne12 < 4) {
|
| 1008 |
-
[encoder setComputePipelineState:ctx->
|
| 1009 |
} else if (ne00 >= 128 && ne01 >= 8 && ne00%4 == 0) {
|
| 1010 |
-
[encoder setComputePipelineState:ctx->
|
| 1011 |
nrows = ne11;
|
| 1012 |
} else {
|
| 1013 |
-
[encoder setComputePipelineState:ctx->
|
| 1014 |
nrows = 4;
|
| 1015 |
}
|
| 1016 |
} break;
|
|
@@ -1021,7 +1106,7 @@ void ggml_metal_graph_compute(
|
|
| 1021 |
|
| 1022 |
nth0 = 8;
|
| 1023 |
nth1 = 8;
|
| 1024 |
-
[encoder setComputePipelineState:ctx->
|
| 1025 |
} break;
|
| 1026 |
case GGML_TYPE_Q4_1:
|
| 1027 |
{
|
|
@@ -1030,7 +1115,7 @@ void ggml_metal_graph_compute(
|
|
| 1030 |
|
| 1031 |
nth0 = 8;
|
| 1032 |
nth1 = 8;
|
| 1033 |
-
[encoder setComputePipelineState:ctx->
|
| 1034 |
} break;
|
| 1035 |
case GGML_TYPE_Q8_0:
|
| 1036 |
{
|
|
@@ -1039,7 +1124,7 @@ void ggml_metal_graph_compute(
|
|
| 1039 |
|
| 1040 |
nth0 = 8;
|
| 1041 |
nth1 = 8;
|
| 1042 |
-
[encoder setComputePipelineState:ctx->
|
| 1043 |
} break;
|
| 1044 |
case GGML_TYPE_Q2_K:
|
| 1045 |
{
|
|
@@ -1048,7 +1133,7 @@ void ggml_metal_graph_compute(
|
|
| 1048 |
|
| 1049 |
nth0 = 2;
|
| 1050 |
nth1 = 32;
|
| 1051 |
-
[encoder setComputePipelineState:ctx->
|
| 1052 |
} break;
|
| 1053 |
case GGML_TYPE_Q3_K:
|
| 1054 |
{
|
|
@@ -1057,7 +1142,7 @@ void ggml_metal_graph_compute(
|
|
| 1057 |
|
| 1058 |
nth0 = 2;
|
| 1059 |
nth1 = 32;
|
| 1060 |
-
[encoder setComputePipelineState:ctx->
|
| 1061 |
} break;
|
| 1062 |
case GGML_TYPE_Q4_K:
|
| 1063 |
{
|
|
@@ -1066,7 +1151,7 @@ void ggml_metal_graph_compute(
|
|
| 1066 |
|
| 1067 |
nth0 = 4; //1;
|
| 1068 |
nth1 = 8; //32;
|
| 1069 |
-
[encoder setComputePipelineState:ctx->
|
| 1070 |
} break;
|
| 1071 |
case GGML_TYPE_Q5_K:
|
| 1072 |
{
|
|
@@ -1075,7 +1160,7 @@ void ggml_metal_graph_compute(
|
|
| 1075 |
|
| 1076 |
nth0 = 2;
|
| 1077 |
nth1 = 32;
|
| 1078 |
-
[encoder setComputePipelineState:ctx->
|
| 1079 |
} break;
|
| 1080 |
case GGML_TYPE_Q6_K:
|
| 1081 |
{
|
|
@@ -1084,7 +1169,7 @@ void ggml_metal_graph_compute(
|
|
| 1084 |
|
| 1085 |
nth0 = 2;
|
| 1086 |
nth1 = 32;
|
| 1087 |
-
[encoder setComputePipelineState:ctx->
|
| 1088 |
} break;
|
| 1089 |
default:
|
| 1090 |
{
|
|
@@ -1113,7 +1198,7 @@ void ggml_metal_graph_compute(
|
|
| 1113 |
[encoder setBytes:&gqa length:sizeof(gqa) atIndex:17];
|
| 1114 |
|
| 1115 |
if (src0t == GGML_TYPE_Q4_0 || src0t == GGML_TYPE_Q4_1 || src0t == GGML_TYPE_Q8_0 ||
|
| 1116 |
-
src0t == GGML_TYPE_Q2_K) {// || src0t == GGML_TYPE_Q4_K) {
|
| 1117 |
[encoder dispatchThreadgroups:MTLSizeMake((ne01 + 7)/8, ne11, ne12) threadsPerThreadgroup:MTLSizeMake(nth0, nth1, 1)];
|
| 1118 |
}
|
| 1119 |
else if (src0t == GGML_TYPE_Q4_K) {
|
|
@@ -1213,12 +1298,9 @@ void ggml_metal_graph_compute(
|
|
| 1213 |
float max_bias;
|
| 1214 |
memcpy(&max_bias, (int32_t *) dst->op_params + 2, sizeof(float));
|
| 1215 |
|
| 1216 |
-
if (__builtin_popcount(n_head) != 1) {
|
| 1217 |
-
GGML_ASSERT(false && "only power-of-two n_head implemented");
|
| 1218 |
-
}
|
| 1219 |
-
|
| 1220 |
const int n_heads_log2_floor = 1 << (int) floor(log2(n_head));
|
| 1221 |
const float m0 = powf(2.0f, -(max_bias) / n_heads_log2_floor);
|
|
|
|
| 1222 |
|
| 1223 |
[encoder setComputePipelineState:ctx->pipeline_alibi_f32];
|
| 1224 |
[encoder setBuffer:id_src0 offset:offs_src0 atIndex:0];
|
|
@@ -1239,7 +1321,9 @@ void ggml_metal_graph_compute(
|
|
| 1239 |
[encoder setBytes:&nb1 length:sizeof(uint64_t) atIndex:15];
|
| 1240 |
[encoder setBytes:&nb2 length:sizeof(uint64_t) atIndex:16];
|
| 1241 |
[encoder setBytes:&nb3 length:sizeof(uint64_t) atIndex:17];
|
| 1242 |
-
[encoder setBytes:&m0
|
|
|
|
|
|
|
| 1243 |
|
| 1244 |
[encoder dispatchThreadgroups:MTLSizeMake(ne01, ne02, ne03) threadsPerThreadgroup:MTLSizeMake(nth, 1, 1)];
|
| 1245 |
} break;
|
|
|
|
| 81 |
GGML_METAL_DECL_KERNEL(get_rows_q6_K);
|
| 82 |
GGML_METAL_DECL_KERNEL(rms_norm);
|
| 83 |
GGML_METAL_DECL_KERNEL(norm);
|
| 84 |
+
GGML_METAL_DECL_KERNEL(mul_mv_f32_f32);
|
| 85 |
+
GGML_METAL_DECL_KERNEL(mul_mv_f16_f32);
|
| 86 |
+
GGML_METAL_DECL_KERNEL(mul_mv_f16_f32_1row);
|
| 87 |
+
GGML_METAL_DECL_KERNEL(mul_mv_f16_f32_l4);
|
| 88 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q4_0_f32);
|
| 89 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q4_1_f32);
|
| 90 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q8_0_f32);
|
| 91 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q2_K_f32);
|
| 92 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q3_K_f32);
|
| 93 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q4_K_f32);
|
| 94 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q5_K_f32);
|
| 95 |
+
GGML_METAL_DECL_KERNEL(mul_mv_q6_K_f32);
|
| 96 |
GGML_METAL_DECL_KERNEL(mul_mm_f32_f32);
|
| 97 |
GGML_METAL_DECL_KERNEL(mul_mm_f16_f32);
|
| 98 |
GGML_METAL_DECL_KERNEL(mul_mm_q4_0_f32);
|
|
|
|
| 109 |
GGML_METAL_DECL_KERNEL(cpy_f32_f16);
|
| 110 |
GGML_METAL_DECL_KERNEL(cpy_f32_f32);
|
| 111 |
GGML_METAL_DECL_KERNEL(cpy_f16_f16);
|
| 112 |
+
GGML_METAL_DECL_KERNEL(concat);
|
| 113 |
+
GGML_METAL_DECL_KERNEL(sqr);
|
| 114 |
|
| 115 |
#undef GGML_METAL_DECL_KERNEL
|
| 116 |
};
|
|
|
|
| 185 |
|
| 186 |
ctx->d_queue = dispatch_queue_create("ggml-metal", DISPATCH_QUEUE_CONCURRENT);
|
| 187 |
|
| 188 |
+
// load library
|
|
|
|
| 189 |
{
|
| 190 |
+
NSBundle * bundle = nil;
|
| 191 |
+
#ifdef SWIFT_PACKAGE
|
| 192 |
+
bundle = SWIFTPM_MODULE_BUNDLE;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 193 |
#else
|
| 194 |
+
bundle = [NSBundle bundleForClass:[GGMLMetalClass class]];
|
| 195 |
+
#endif
|
|
|
|
|
|
|
| 196 |
NSError * error = nil;
|
| 197 |
+
NSString * libPath = [bundle pathForResource:@"default" ofType:@"metallib"];
|
| 198 |
+
if (libPath != nil) {
|
| 199 |
+
NSURL * libURL = [NSURL fileURLWithPath:libPath];
|
| 200 |
+
GGML_METAL_LOG_INFO("%s: loading '%s'\n", __func__, [libPath UTF8String]);
|
| 201 |
+
ctx->library = [ctx->device newLibraryWithURL:libURL error:&error];
|
| 202 |
+
} else {
|
| 203 |
+
GGML_METAL_LOG_INFO("%s: default.metallib not found, loading from source\n", __func__);
|
| 204 |
+
|
| 205 |
+
NSString * sourcePath = [bundle pathForResource:@"ggml-metal" ofType:@"metal"];
|
| 206 |
+
GGML_METAL_LOG_INFO("%s: loading '%s'\n", __func__, [sourcePath UTF8String]);
|
| 207 |
+
NSString * src = [NSString stringWithContentsOfFile:sourcePath encoding:NSUTF8StringEncoding error:&error];
|
| 208 |
+
if (error) {
|
| 209 |
+
GGML_METAL_LOG_ERROR("%s: error: %s\n", __func__, [[error description] UTF8String]);
|
| 210 |
+
return NULL;
|
| 211 |
+
}
|
| 212 |
|
| 213 |
+
MTLCompileOptions* options = nil;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 214 |
#ifdef GGML_QKK_64
|
| 215 |
+
options = [MTLCompileOptions new];
|
| 216 |
+
options.preprocessorMacros = @{ @"QK_K" : @(64) };
|
|
|
|
|
|
|
|
|
|
| 217 |
#endif
|
| 218 |
+
ctx->library = [ctx->device newLibraryWithSource:src options:options error:&error];
|
| 219 |
+
}
|
| 220 |
+
|
| 221 |
if (error) {
|
| 222 |
GGML_METAL_LOG_ERROR("%s: error: %s\n", __func__, [[error description] UTF8String]);
|
| 223 |
return NULL;
|
| 224 |
}
|
| 225 |
}
|
|
|
|
| 226 |
|
| 227 |
// load kernels
|
| 228 |
{
|
|
|
|
| 262 |
GGML_METAL_ADD_KERNEL(get_rows_q6_K);
|
| 263 |
GGML_METAL_ADD_KERNEL(rms_norm);
|
| 264 |
GGML_METAL_ADD_KERNEL(norm);
|
| 265 |
+
GGML_METAL_ADD_KERNEL(mul_mv_f32_f32);
|
| 266 |
+
GGML_METAL_ADD_KERNEL(mul_mv_f16_f32);
|
| 267 |
+
GGML_METAL_ADD_KERNEL(mul_mv_f16_f32_1row);
|
| 268 |
+
GGML_METAL_ADD_KERNEL(mul_mv_f16_f32_l4);
|
| 269 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q4_0_f32);
|
| 270 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q4_1_f32);
|
| 271 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q8_0_f32);
|
| 272 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q2_K_f32);
|
| 273 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q3_K_f32);
|
| 274 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q4_K_f32);
|
| 275 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q5_K_f32);
|
| 276 |
+
GGML_METAL_ADD_KERNEL(mul_mv_q6_K_f32);
|
| 277 |
+
if ([ctx->device supportsFamily:MTLGPUFamilyApple7]) {
|
| 278 |
+
GGML_METAL_ADD_KERNEL(mul_mm_f32_f32);
|
| 279 |
+
GGML_METAL_ADD_KERNEL(mul_mm_f16_f32);
|
| 280 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q4_0_f32);
|
| 281 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q8_0_f32);
|
| 282 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q4_1_f32);
|
| 283 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q2_K_f32);
|
| 284 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q3_K_f32);
|
| 285 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q4_K_f32);
|
| 286 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q5_K_f32);
|
| 287 |
+
GGML_METAL_ADD_KERNEL(mul_mm_q6_K_f32);
|
| 288 |
+
}
|
| 289 |
GGML_METAL_ADD_KERNEL(rope_f32);
|
| 290 |
GGML_METAL_ADD_KERNEL(rope_f16);
|
| 291 |
GGML_METAL_ADD_KERNEL(alibi_f32);
|
| 292 |
GGML_METAL_ADD_KERNEL(cpy_f32_f16);
|
| 293 |
GGML_METAL_ADD_KERNEL(cpy_f32_f32);
|
| 294 |
GGML_METAL_ADD_KERNEL(cpy_f16_f16);
|
| 295 |
+
GGML_METAL_ADD_KERNEL(concat);
|
| 296 |
+
GGML_METAL_ADD_KERNEL(sqr);
|
| 297 |
|
| 298 |
#undef GGML_METAL_ADD_KERNEL
|
| 299 |
}
|
| 300 |
|
|
|
|
| 301 |
#if TARGET_OS_OSX
|
| 302 |
+
// print MTL GPU family:
|
| 303 |
+
GGML_METAL_LOG_INFO("%s: GPU name: %s\n", __func__, [[ctx->device name] UTF8String]);
|
| 304 |
+
|
| 305 |
+
// determine max supported GPU family
|
| 306 |
+
// https://developer.apple.com/metal/Metal-Shading-Language-Specification.pdf
|
| 307 |
+
// https://developer.apple.com/metal/Metal-Feature-Set-Tables.pdf
|
| 308 |
+
for (int i = MTLGPUFamilyApple1 + 20; i >= MTLGPUFamilyApple1; --i) {
|
| 309 |
+
if ([ctx->device supportsFamily:i]) {
|
| 310 |
+
GGML_METAL_LOG_INFO("%s: GPU family: MTLGPUFamilyApple%d (%d)\n", __func__, i - MTLGPUFamilyApple1 + 1, i);
|
| 311 |
+
break;
|
| 312 |
+
}
|
| 313 |
+
}
|
| 314 |
+
|
| 315 |
+
GGML_METAL_LOG_INFO("%s: hasUnifiedMemory = %s\n", __func__, ctx->device.hasUnifiedMemory ? "true" : "false");
|
| 316 |
GGML_METAL_LOG_INFO("%s: recommendedMaxWorkingSetSize = %8.2f MB\n", __func__, ctx->device.recommendedMaxWorkingSetSize / 1024.0 / 1024.0);
|
| 317 |
if (ctx->device.maxTransferRate != 0) {
|
| 318 |
GGML_METAL_LOG_INFO("%s: maxTransferRate = %8.2f MB/s\n", __func__, ctx->device.maxTransferRate / 1024.0 / 1024.0);
|
|
|
|
| 354 |
GGML_METAL_DEL_KERNEL(get_rows_q6_K);
|
| 355 |
GGML_METAL_DEL_KERNEL(rms_norm);
|
| 356 |
GGML_METAL_DEL_KERNEL(norm);
|
| 357 |
+
GGML_METAL_DEL_KERNEL(mul_mv_f32_f32);
|
| 358 |
+
GGML_METAL_DEL_KERNEL(mul_mv_f16_f32);
|
| 359 |
+
GGML_METAL_DEL_KERNEL(mul_mv_f16_f32_1row);
|
| 360 |
+
GGML_METAL_DEL_KERNEL(mul_mv_f16_f32_l4);
|
| 361 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q4_0_f32);
|
| 362 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q4_1_f32);
|
| 363 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q8_0_f32);
|
| 364 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q2_K_f32);
|
| 365 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q3_K_f32);
|
| 366 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q4_K_f32);
|
| 367 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q5_K_f32);
|
| 368 |
+
GGML_METAL_DEL_KERNEL(mul_mv_q6_K_f32);
|
| 369 |
+
if ([ctx->device supportsFamily:MTLGPUFamilyApple7]) {
|
| 370 |
+
GGML_METAL_DEL_KERNEL(mul_mm_f32_f32);
|
| 371 |
+
GGML_METAL_DEL_KERNEL(mul_mm_f16_f32);
|
| 372 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q4_0_f32);
|
| 373 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q8_0_f32);
|
| 374 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q4_1_f32);
|
| 375 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q2_K_f32);
|
| 376 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q3_K_f32);
|
| 377 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q4_K_f32);
|
| 378 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q5_K_f32);
|
| 379 |
+
GGML_METAL_DEL_KERNEL(mul_mm_q6_K_f32);
|
| 380 |
+
}
|
| 381 |
GGML_METAL_DEL_KERNEL(rope_f32);
|
| 382 |
GGML_METAL_DEL_KERNEL(rope_f16);
|
| 383 |
GGML_METAL_DEL_KERNEL(alibi_f32);
|
| 384 |
GGML_METAL_DEL_KERNEL(cpy_f32_f16);
|
| 385 |
GGML_METAL_DEL_KERNEL(cpy_f32_f32);
|
| 386 |
GGML_METAL_DEL_KERNEL(cpy_f16_f16);
|
| 387 |
+
GGML_METAL_DEL_KERNEL(concat);
|
| 388 |
+
GGML_METAL_DEL_KERNEL(sqr);
|
| 389 |
|
| 390 |
#undef GGML_METAL_DEL_KERNEL
|
| 391 |
|
|
|
|
| 442 |
for (int i = 0; i < ctx->n_buffers; ++i) {
|
| 443 |
const int64_t ioffs = (int64_t) t->data - (int64_t) ctx->buffers[i].data;
|
| 444 |
|
| 445 |
+
//GGML_METAL_LOG_INFO("ioffs = %10ld, tsize = %10ld, sum = %10ld, ctx->buffers[%d].size = %10ld, name = %s\n", ioffs, tsize, ioffs + tsize, i, ctx->buffers[i].size, ctx->buffers[i].name);
|
| 446 |
if (ioffs >= 0 && ioffs + tsize <= (int64_t) ctx->buffers[i].size) {
|
| 447 |
*offs = (size_t) ioffs;
|
| 448 |
|
|
|
|
| 777 |
{
|
| 778 |
// noop
|
| 779 |
} break;
|
| 780 |
+
case GGML_OP_CONCAT:
|
| 781 |
+
{
|
| 782 |
+
|
| 783 |
+
int64_t nb = ne00;
|
| 784 |
+
[encoder setComputePipelineState:ctx->pipeline_concat];
|
| 785 |
+
[encoder setBuffer:id_src0 offset:offs_src0 atIndex:0];
|
| 786 |
+
[encoder setBuffer:id_src1 offset:offs_src1 atIndex:1];
|
| 787 |
+
[encoder setBuffer:id_dst offset:offs_dst atIndex:2];
|
| 788 |
+
[encoder setBytes:&ne00 length:sizeof(ne00) atIndex:3];
|
| 789 |
+
[encoder setBytes:&ne01 length:sizeof(ne01) atIndex:4];
|
| 790 |
+
[encoder setBytes:&ne02 length:sizeof(ne02) atIndex:5];
|
| 791 |
+
[encoder setBytes:&ne03 length:sizeof(ne03) atIndex:6];
|
| 792 |
+
[encoder setBytes:&nb00 length:sizeof(nb00) atIndex:7];
|
| 793 |
+
[encoder setBytes:&nb01 length:sizeof(nb01) atIndex:8];
|
| 794 |
+
[encoder setBytes:&nb02 length:sizeof(nb02) atIndex:9];
|
| 795 |
+
[encoder setBytes:&nb03 length:sizeof(nb03) atIndex:10];
|
| 796 |
+
[encoder setBytes:&ne10 length:sizeof(ne10) atIndex:11];
|
| 797 |
+
[encoder setBytes:&ne11 length:sizeof(ne11) atIndex:12];
|
| 798 |
+
[encoder setBytes:&ne12 length:sizeof(ne12) atIndex:13];
|
| 799 |
+
[encoder setBytes:&ne13 length:sizeof(ne13) atIndex:14];
|
| 800 |
+
[encoder setBytes:&nb10 length:sizeof(nb10) atIndex:15];
|
| 801 |
+
[encoder setBytes:&nb11 length:sizeof(nb11) atIndex:16];
|
| 802 |
+
[encoder setBytes:&nb12 length:sizeof(nb12) atIndex:17];
|
| 803 |
+
[encoder setBytes:&nb13 length:sizeof(nb13) atIndex:18];
|
| 804 |
+
[encoder setBytes:&ne0 length:sizeof(ne0) atIndex:19];
|
| 805 |
+
[encoder setBytes:&ne1 length:sizeof(ne1) atIndex:20];
|
| 806 |
+
[encoder setBytes:&ne2 length:sizeof(ne2) atIndex:21];
|
| 807 |
+
[encoder setBytes:&ne3 length:sizeof(ne3) atIndex:22];
|
| 808 |
+
[encoder setBytes:&nb0 length:sizeof(nb0) atIndex:23];
|
| 809 |
+
[encoder setBytes:&nb1 length:sizeof(nb1) atIndex:24];
|
| 810 |
+
[encoder setBytes:&nb2 length:sizeof(nb2) atIndex:25];
|
| 811 |
+
[encoder setBytes:&nb3 length:sizeof(nb3) atIndex:26];
|
| 812 |
+
[encoder setBytes:&nb length:sizeof(nb) atIndex:27];
|
| 813 |
+
|
| 814 |
+
const int nth = MIN(1024, ne0);
|
| 815 |
+
[encoder dispatchThreadgroups:MTLSizeMake(ne1, ne2, ne3) threadsPerThreadgroup:MTLSizeMake(nth, 1, 1)];
|
| 816 |
+
} break;
|
| 817 |
case GGML_OP_ADD:
|
| 818 |
{
|
| 819 |
GGML_ASSERT(ggml_is_contiguous(src0));
|
|
|
|
| 951 |
GGML_ASSERT(false);
|
| 952 |
}
|
| 953 |
} break;
|
| 954 |
+
case GGML_OP_SQR:
|
| 955 |
+
{
|
| 956 |
+
GGML_ASSERT(ggml_is_contiguous(src0));
|
| 957 |
+
|
| 958 |
+
[encoder setComputePipelineState:ctx->pipeline_sqr];
|
| 959 |
+
[encoder setBuffer:id_src0 offset:offs_src0 atIndex:0];
|
| 960 |
+
[encoder setBuffer:id_dst offset:offs_dst atIndex:1];
|
| 961 |
+
|
| 962 |
+
const int64_t n = ggml_nelements(dst);
|
| 963 |
+
[encoder dispatchThreadgroups:MTLSizeMake(n, 1, 1) threadsPerThreadgroup:MTLSizeMake(1, 1, 1)];
|
| 964 |
+
} break;
|
| 965 |
case GGML_OP_SOFT_MAX:
|
| 966 |
{
|
| 967 |
const int nth = MIN(32, ne00);
|
|
|
|
| 1003 |
} break;
|
| 1004 |
case GGML_OP_MUL_MAT:
|
| 1005 |
{
|
|
|
|
|
|
|
| 1006 |
GGML_ASSERT(ne00 == ne10);
|
|
|
|
|
|
|
| 1007 |
GGML_ASSERT(ne03 == ne13);
|
| 1008 |
|
| 1009 |
+
const uint gqa = ne12/ne02;
|
| 1010 |
+
|
| 1011 |
+
// find the break-even point where the matrix-matrix kernel becomes more efficient compared
|
| 1012 |
+
// to the matrix-vector kernel
|
| 1013 |
+
int ne11_mm_min = 1;
|
| 1014 |
+
|
| 1015 |
+
#if 0
|
| 1016 |
+
// the numbers below are measured on M2 Ultra for 7B and 13B models
|
| 1017 |
+
// these numbers do not translate to other devices or model sizes
|
| 1018 |
+
// TODO: need to find a better approach
|
| 1019 |
+
if ([ctx->device.name isEqualToString:@"Apple M2 Ultra"]) {
|
| 1020 |
+
switch (src0t) {
|
| 1021 |
+
case GGML_TYPE_F16: ne11_mm_min = 2; break;
|
| 1022 |
+
case GGML_TYPE_Q8_0: ne11_mm_min = 7; break;
|
| 1023 |
+
case GGML_TYPE_Q2_K: ne11_mm_min = 15; break;
|
| 1024 |
+
case GGML_TYPE_Q3_K: ne11_mm_min = 7; break;
|
| 1025 |
+
case GGML_TYPE_Q4_0:
|
| 1026 |
+
case GGML_TYPE_Q4_1: ne11_mm_min = 15; break;
|
| 1027 |
+
case GGML_TYPE_Q4_K: ne11_mm_min = 11; break;
|
| 1028 |
+
case GGML_TYPE_Q5_0: // not tested yet
|
| 1029 |
+
case GGML_TYPE_Q5_1: ne11_mm_min = 13; break; // not tested yet
|
| 1030 |
+
case GGML_TYPE_Q5_K: ne11_mm_min = 7; break;
|
| 1031 |
+
case GGML_TYPE_Q6_K: ne11_mm_min = 7; break;
|
| 1032 |
+
default: ne11_mm_min = 1; break;
|
| 1033 |
+
}
|
| 1034 |
+
}
|
| 1035 |
+
#endif
|
| 1036 |
+
|
| 1037 |
// for now the matrix-matrix multiplication kernel only works on A14+/M1+ SoCs
|
| 1038 |
// AMD GPU and older A-chips will reuse matrix-vector multiplication kernel
|
| 1039 |
+
if ([ctx->device supportsFamily:MTLGPUFamilyApple7] &&
|
| 1040 |
+
!ggml_is_transposed(src0) &&
|
| 1041 |
!ggml_is_transposed(src1) &&
|
| 1042 |
src1t == GGML_TYPE_F32 &&
|
| 1043 |
+
ne00 % 32 == 0 &&
|
| 1044 |
+
ne11 > ne11_mm_min) {
|
| 1045 |
+
//printf("matrix: ne00 = %6d, ne01 = %6d, ne02 = %6d, ne11 = %6d, ne12 = %6d\n", ne00, ne01, ne02, ne11, ne12);
|
| 1046 |
switch (src0->type) {
|
| 1047 |
case GGML_TYPE_F32: [encoder setComputePipelineState:ctx->pipeline_mul_mm_f32_f32]; break;
|
| 1048 |
case GGML_TYPE_F16: [encoder setComputePipelineState:ctx->pipeline_mul_mm_f16_f32]; break;
|
|
|
|
| 1071 |
[encoder setBytes:&ne1 length:sizeof(ne1) atIndex:12];
|
| 1072 |
[encoder setBytes:&gqa length:sizeof(gqa) atIndex:13];
|
| 1073 |
[encoder setThreadgroupMemoryLength:8192 atIndex:0];
|
| 1074 |
+
[encoder dispatchThreadgroups:MTLSizeMake( (ne11 + 31)/32, (ne01 + 63)/64, ne12) threadsPerThreadgroup:MTLSizeMake(128, 1, 1)];
|
| 1075 |
} else {
|
| 1076 |
int nth0 = 32;
|
| 1077 |
int nth1 = 1;
|
| 1078 |
int nrows = 1;
|
| 1079 |
+
//printf("vector: ne00 = %6d, ne01 = %6d, ne02 = %6d, ne11 = %6d, ne12 = %6d\n", ne00, ne01, ne02, ne11, ne12);
|
| 1080 |
|
| 1081 |
// use custom matrix x vector kernel
|
| 1082 |
switch (src0t) {
|
| 1083 |
case GGML_TYPE_F32:
|
| 1084 |
{
|
| 1085 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_f32_f32];
|
| 1086 |
nrows = 4;
|
| 1087 |
} break;
|
| 1088 |
case GGML_TYPE_F16:
|
|
|
|
| 1090 |
nth0 = 32;
|
| 1091 |
nth1 = 1;
|
| 1092 |
if (ne11 * ne12 < 4) {
|
| 1093 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_f16_f32_1row];
|
| 1094 |
} else if (ne00 >= 128 && ne01 >= 8 && ne00%4 == 0) {
|
| 1095 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_f16_f32_l4];
|
| 1096 |
nrows = ne11;
|
| 1097 |
} else {
|
| 1098 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_f16_f32];
|
| 1099 |
nrows = 4;
|
| 1100 |
}
|
| 1101 |
} break;
|
|
|
|
| 1106 |
|
| 1107 |
nth0 = 8;
|
| 1108 |
nth1 = 8;
|
| 1109 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q4_0_f32];
|
| 1110 |
} break;
|
| 1111 |
case GGML_TYPE_Q4_1:
|
| 1112 |
{
|
|
|
|
| 1115 |
|
| 1116 |
nth0 = 8;
|
| 1117 |
nth1 = 8;
|
| 1118 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q4_1_f32];
|
| 1119 |
} break;
|
| 1120 |
case GGML_TYPE_Q8_0:
|
| 1121 |
{
|
|
|
|
| 1124 |
|
| 1125 |
nth0 = 8;
|
| 1126 |
nth1 = 8;
|
| 1127 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q8_0_f32];
|
| 1128 |
} break;
|
| 1129 |
case GGML_TYPE_Q2_K:
|
| 1130 |
{
|
|
|
|
| 1133 |
|
| 1134 |
nth0 = 2;
|
| 1135 |
nth1 = 32;
|
| 1136 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q2_K_f32];
|
| 1137 |
} break;
|
| 1138 |
case GGML_TYPE_Q3_K:
|
| 1139 |
{
|
|
|
|
| 1142 |
|
| 1143 |
nth0 = 2;
|
| 1144 |
nth1 = 32;
|
| 1145 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q3_K_f32];
|
| 1146 |
} break;
|
| 1147 |
case GGML_TYPE_Q4_K:
|
| 1148 |
{
|
|
|
|
| 1151 |
|
| 1152 |
nth0 = 4; //1;
|
| 1153 |
nth1 = 8; //32;
|
| 1154 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q4_K_f32];
|
| 1155 |
} break;
|
| 1156 |
case GGML_TYPE_Q5_K:
|
| 1157 |
{
|
|
|
|
| 1160 |
|
| 1161 |
nth0 = 2;
|
| 1162 |
nth1 = 32;
|
| 1163 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q5_K_f32];
|
| 1164 |
} break;
|
| 1165 |
case GGML_TYPE_Q6_K:
|
| 1166 |
{
|
|
|
|
| 1169 |
|
| 1170 |
nth0 = 2;
|
| 1171 |
nth1 = 32;
|
| 1172 |
+
[encoder setComputePipelineState:ctx->pipeline_mul_mv_q6_K_f32];
|
| 1173 |
} break;
|
| 1174 |
default:
|
| 1175 |
{
|
|
|
|
| 1198 |
[encoder setBytes:&gqa length:sizeof(gqa) atIndex:17];
|
| 1199 |
|
| 1200 |
if (src0t == GGML_TYPE_Q4_0 || src0t == GGML_TYPE_Q4_1 || src0t == GGML_TYPE_Q8_0 ||
|
| 1201 |
+
src0t == GGML_TYPE_Q2_K) { // || src0t == GGML_TYPE_Q4_K) {
|
| 1202 |
[encoder dispatchThreadgroups:MTLSizeMake((ne01 + 7)/8, ne11, ne12) threadsPerThreadgroup:MTLSizeMake(nth0, nth1, 1)];
|
| 1203 |
}
|
| 1204 |
else if (src0t == GGML_TYPE_Q4_K) {
|
|
|
|
| 1298 |
float max_bias;
|
| 1299 |
memcpy(&max_bias, (int32_t *) dst->op_params + 2, sizeof(float));
|
| 1300 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1301 |
const int n_heads_log2_floor = 1 << (int) floor(log2(n_head));
|
| 1302 |
const float m0 = powf(2.0f, -(max_bias) / n_heads_log2_floor);
|
| 1303 |
+
const float m1 = powf(2.0f, -(max_bias / 2.0f) / n_heads_log2_floor);
|
| 1304 |
|
| 1305 |
[encoder setComputePipelineState:ctx->pipeline_alibi_f32];
|
| 1306 |
[encoder setBuffer:id_src0 offset:offs_src0 atIndex:0];
|
|
|
|
| 1321 |
[encoder setBytes:&nb1 length:sizeof(uint64_t) atIndex:15];
|
| 1322 |
[encoder setBytes:&nb2 length:sizeof(uint64_t) atIndex:16];
|
| 1323 |
[encoder setBytes:&nb3 length:sizeof(uint64_t) atIndex:17];
|
| 1324 |
+
[encoder setBytes:&m0 length:sizeof( float) atIndex:18];
|
| 1325 |
+
[encoder setBytes:&m1 length:sizeof( float) atIndex:19];
|
| 1326 |
+
[encoder setBytes:&n_heads_log2_floor length:sizeof(int) atIndex:20];
|
| 1327 |
|
| 1328 |
[encoder dispatchThreadgroups:MTLSizeMake(ne01, ne02, ne03) threadsPerThreadgroup:MTLSizeMake(nth, 1, 1)];
|
| 1329 |
} break;
|
ggml-metal.metal
CHANGED
|
@@ -13,8 +13,8 @@ typedef struct {
|
|
| 13 |
|
| 14 |
#define QK4_1 32
|
| 15 |
typedef struct {
|
| 16 |
-
half d;
|
| 17 |
-
half m;
|
| 18 |
uint8_t qs[QK4_1 / 2]; // nibbles / quants
|
| 19 |
} block_q4_1;
|
| 20 |
|
|
@@ -132,6 +132,13 @@ kernel void kernel_relu(
|
|
| 132 |
dst[tpig] = max(0.0f, src0[tpig]);
|
| 133 |
}
|
| 134 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 135 |
constant float GELU_COEF_A = 0.044715f;
|
| 136 |
constant float SQRT_2_OVER_PI = 0.79788456080286535587989211986876f;
|
| 137 |
|
|
@@ -416,8 +423,8 @@ inline float block_q_n_dot_y(device const block_q4_1 * qb_curr, float sumy, thre
|
|
| 416 |
}
|
| 417 |
|
| 418 |
// putting them in the kernel cause a significant performance penalty
|
| 419 |
-
#define N_DST 4
|
| 420 |
-
#define N_SIMDGROUP 2
|
| 421 |
#define N_SIMDWIDTH 32 // assuming SIMD group size is 32
|
| 422 |
//Note: This is a template, but strictly speaking it only applies to
|
| 423 |
// quantizations where the block size is 32. It also does not
|
|
@@ -428,18 +435,23 @@ void mul_vec_q_n_f32(device const void * src0, device const float * src1, device
|
|
| 428 |
int64_t ne00, int64_t ne01, int64_t ne02, int64_t ne10, int64_t ne12, int64_t ne0, int64_t ne1, uint gqa,
|
| 429 |
uint3 tgpig, uint tiisg, uint sgitg) {
|
| 430 |
const int nb = ne00/QK4_0;
|
|
|
|
| 431 |
const int r0 = tgpig.x;
|
| 432 |
const int r1 = tgpig.y;
|
| 433 |
const int im = tgpig.z;
|
|
|
|
| 434 |
const int first_row = (r0 * nsg + sgitg) * nr;
|
|
|
|
| 435 |
const uint offset0 = first_row * nb + im/gqa*(nb*ne0);
|
|
|
|
| 436 |
device const block_q_type * x = (device const block_q_type *) src0 + offset0;
|
| 437 |
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
|
| 438 |
-
float yl[16]; // src1 vector cache
|
| 439 |
-
float sumf[nr]={0.f};
|
| 440 |
|
| 441 |
-
|
| 442 |
-
|
|
|
|
|
|
|
|
|
|
| 443 |
|
| 444 |
device const float * yb = y + ix * QK4_0 + il;
|
| 445 |
|
|
@@ -450,6 +462,7 @@ void mul_vec_q_n_f32(device const void * src0, device const float * src1, device
|
|
| 450 |
sumy += yb[i] + yb[i+1];
|
| 451 |
yl[i+0] = yb[i+ 0];
|
| 452 |
yl[i+1] = yb[i+ 1]/256.f;
|
|
|
|
| 453 |
sumy += yb[i+16] + yb[i+17];
|
| 454 |
yl[i+8] = yb[i+16]/16.f;
|
| 455 |
yl[i+9] = yb[i+17]/4096.f;
|
|
@@ -465,12 +478,12 @@ void mul_vec_q_n_f32(device const void * src0, device const float * src1, device
|
|
| 465 |
for (int row = 0; row < nr; ++row) {
|
| 466 |
const float tot = simd_sum(sumf[row]);
|
| 467 |
if (tiisg == 0 && first_row + row < ne01) {
|
| 468 |
-
dst[
|
| 469 |
}
|
| 470 |
}
|
| 471 |
}
|
| 472 |
|
| 473 |
-
kernel void
|
| 474 |
device const void * src0,
|
| 475 |
device const float * src1,
|
| 476 |
device float * dst,
|
|
@@ -483,12 +496,12 @@ kernel void kernel_mul_mat_q4_0_f32(
|
|
| 483 |
constant int64_t & ne1[[buffer(16)]],
|
| 484 |
constant uint & gqa[[buffer(17)]],
|
| 485 |
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 486 |
-
uint
|
| 487 |
-
uint
|
| 488 |
mul_vec_q_n_f32<block_q4_0, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,gqa,tgpig,tiisg,sgitg);
|
| 489 |
}
|
| 490 |
|
| 491 |
-
kernel void
|
| 492 |
device const void * src0,
|
| 493 |
device const float * src1,
|
| 494 |
device float * dst,
|
|
@@ -508,7 +521,7 @@ kernel void kernel_mul_mat_q4_1_f32(
|
|
| 508 |
|
| 509 |
#define NB_Q8_0 8
|
| 510 |
|
| 511 |
-
kernel void
|
| 512 |
device const void * src0,
|
| 513 |
device const float * src1,
|
| 514 |
device float * dst,
|
|
@@ -572,7 +585,7 @@ kernel void kernel_mul_mat_q8_0_f32(
|
|
| 572 |
|
| 573 |
#define N_F32_F32 4
|
| 574 |
|
| 575 |
-
kernel void
|
| 576 |
device const char * src0,
|
| 577 |
device const char * src1,
|
| 578 |
device float * dst,
|
|
@@ -643,7 +656,7 @@ kernel void kernel_mul_mat_f32_f32(
|
|
| 643 |
}
|
| 644 |
}
|
| 645 |
|
| 646 |
-
kernel void
|
| 647 |
device const char * src0,
|
| 648 |
device const char * src1,
|
| 649 |
device float * dst,
|
|
@@ -662,7 +675,7 @@ kernel void kernel_mul_mat_f16_f32_1row(
|
|
| 662 |
constant int64_t & ne0,
|
| 663 |
constant int64_t & ne1,
|
| 664 |
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 665 |
-
uint
|
| 666 |
|
| 667 |
const int64_t r0 = tgpig.x;
|
| 668 |
const int64_t r1 = tgpig.y;
|
|
@@ -697,7 +710,7 @@ kernel void kernel_mul_mat_f16_f32_1row(
|
|
| 697 |
|
| 698 |
#define N_F16_F32 4
|
| 699 |
|
| 700 |
-
kernel void
|
| 701 |
device const char * src0,
|
| 702 |
device const char * src1,
|
| 703 |
device float * dst,
|
|
@@ -769,7 +782,7 @@ kernel void kernel_mul_mat_f16_f32(
|
|
| 769 |
}
|
| 770 |
|
| 771 |
// Assumes row size (ne00) is a multiple of 4
|
| 772 |
-
kernel void
|
| 773 |
device const char * src0,
|
| 774 |
device const char * src1,
|
| 775 |
device float * dst,
|
|
@@ -830,7 +843,9 @@ kernel void kernel_alibi_f32(
|
|
| 830 |
constant uint64_t & nb1,
|
| 831 |
constant uint64_t & nb2,
|
| 832 |
constant uint64_t & nb3,
|
| 833 |
-
constant
|
|
|
|
|
|
|
| 834 |
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 835 |
uint3 tpitg[[thread_position_in_threadgroup]],
|
| 836 |
uint3 ntg[[threads_per_threadgroup]]) {
|
|
@@ -846,7 +861,12 @@ kernel void kernel_alibi_f32(
|
|
| 846 |
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
|
| 847 |
|
| 848 |
device float * dst_data = (device float *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
|
| 849 |
-
float m_k
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 850 |
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
|
| 851 |
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
|
| 852 |
dst_data[i00] = src[0] + m_k * (i00 - ne00 + 1);
|
|
@@ -1091,6 +1111,62 @@ kernel void kernel_cpy_f32_f32(
|
|
| 1091 |
}
|
| 1092 |
}
|
| 1093 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1094 |
//============================================ k-quants ======================================================
|
| 1095 |
|
| 1096 |
#ifndef QK_K
|
|
@@ -1183,7 +1259,7 @@ static inline uchar4 get_scale_min_k4(int j, device const uint8_t * q) {
|
|
| 1183 |
|
| 1184 |
//====================================== dot products =========================
|
| 1185 |
|
| 1186 |
-
kernel void
|
| 1187 |
device const void * src0,
|
| 1188 |
device const float * src1,
|
| 1189 |
device float * dst,
|
|
@@ -1327,7 +1403,7 @@ kernel void kernel_mul_mat_q2_K_f32(
|
|
| 1327 |
}
|
| 1328 |
|
| 1329 |
#if QK_K == 256
|
| 1330 |
-
kernel void
|
| 1331 |
device const void * src0,
|
| 1332 |
device const float * src1,
|
| 1333 |
device float * dst,
|
|
@@ -1479,7 +1555,7 @@ kernel void kernel_mul_mat_q3_K_f32(
|
|
| 1479 |
}
|
| 1480 |
}
|
| 1481 |
#else
|
| 1482 |
-
kernel void
|
| 1483 |
device const void * src0,
|
| 1484 |
device const float * src1,
|
| 1485 |
device float * dst,
|
|
@@ -1550,7 +1626,7 @@ kernel void kernel_mul_mat_q3_K_f32(
|
|
| 1550 |
#endif
|
| 1551 |
|
| 1552 |
#if QK_K == 256
|
| 1553 |
-
kernel void
|
| 1554 |
device const void * src0,
|
| 1555 |
device const float * src1,
|
| 1556 |
device float * dst,
|
|
@@ -1656,7 +1732,7 @@ kernel void kernel_mul_mat_q4_K_f32(
|
|
| 1656 |
}
|
| 1657 |
}
|
| 1658 |
#else
|
| 1659 |
-
kernel void
|
| 1660 |
device const void * src0,
|
| 1661 |
device const float * src1,
|
| 1662 |
device float * dst,
|
|
@@ -1745,7 +1821,7 @@ kernel void kernel_mul_mat_q4_K_f32(
|
|
| 1745 |
}
|
| 1746 |
#endif
|
| 1747 |
|
| 1748 |
-
kernel void
|
| 1749 |
device const void * src0,
|
| 1750 |
device const float * src1,
|
| 1751 |
device float * dst,
|
|
@@ -1918,7 +1994,7 @@ kernel void kernel_mul_mat_q5_K_f32(
|
|
| 1918 |
|
| 1919 |
}
|
| 1920 |
|
| 1921 |
-
kernel void
|
| 1922 |
device const void * src0,
|
| 1923 |
device const float * src1,
|
| 1924 |
device float * dst,
|
|
@@ -2256,7 +2332,7 @@ kernel void kernel_get_rows(
|
|
| 2256 |
}
|
| 2257 |
|
| 2258 |
#define BLOCK_SIZE_M 64 // 8 simdgroup matrices from matrix A
|
| 2259 |
-
#define BLOCK_SIZE_N 32 // 4 simdgroup matrices from matrix
|
| 2260 |
#define BLOCK_SIZE_K 32
|
| 2261 |
#define THREAD_MAT_M 4 // each thread take 4 simdgroup matrices from matrix A
|
| 2262 |
#define THREAD_MAT_N 2 // each thread take 2 simdgroup matrices from matrix B
|
|
@@ -2293,9 +2369,11 @@ kernel void kernel_mul_mm(device const uchar * src0,
|
|
| 2293 |
const uint r0 = tgpig.y;
|
| 2294 |
const uint r1 = tgpig.x;
|
| 2295 |
const uint im = tgpig.z;
|
|
|
|
| 2296 |
// if this block is of 64x32 shape or smaller
|
| 2297 |
short n_rows = (ne0 - r0 * BLOCK_SIZE_M < BLOCK_SIZE_M) ? (ne0 - r0 * BLOCK_SIZE_M) : BLOCK_SIZE_M;
|
| 2298 |
short n_cols = (ne1 - r1 * BLOCK_SIZE_N < BLOCK_SIZE_N) ? (ne1 - r1 * BLOCK_SIZE_N) : BLOCK_SIZE_N;
|
|
|
|
| 2299 |
// a thread shouldn't load data outside of the matrix
|
| 2300 |
short thread_row = ((short)tiitg/THREAD_PER_ROW) < n_rows ? ((short)tiitg/THREAD_PER_ROW) : n_rows - 1;
|
| 2301 |
short thread_col = ((short)tiitg/THREAD_PER_COL) < n_cols ? ((short)tiitg/THREAD_PER_COL) : n_cols - 1;
|
|
@@ -2319,26 +2397,30 @@ kernel void kernel_mul_mm(device const uchar * src0,
|
|
| 2319 |
+ nb10 * (BLOCK_SIZE_K / THREAD_PER_COL * (tiitg % THREAD_PER_COL)));
|
| 2320 |
|
| 2321 |
for (int loop_k = 0; loop_k < ne00; loop_k += BLOCK_SIZE_K) {
|
| 2322 |
-
//load data and store to threadgroup memory
|
| 2323 |
half4x4 temp_a;
|
| 2324 |
dequantize_func(x, il, temp_a);
|
| 2325 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
|
|
|
| 2326 |
#pragma unroll(16)
|
| 2327 |
for (int i = 0; i < 16; i++) {
|
| 2328 |
*(sa + SG_MAT_SIZE * ((tiitg / THREAD_PER_ROW / 8) \
|
| 2329 |
-
+
|
| 2330 |
-
+
|
| 2331 |
}
|
| 2332 |
-
|
| 2333 |
-
|
|
|
|
| 2334 |
il = (il + 2 < nl) ? il + 2 : il % 2;
|
| 2335 |
x = (il < 2) ? x + (2+nl-1)/nl : x;
|
| 2336 |
y += BLOCK_SIZE_K;
|
| 2337 |
|
| 2338 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2339 |
-
|
|
|
|
| 2340 |
threadgroup half * lsma = (sa + THREAD_MAT_M * SG_MAT_SIZE * (sgitg % 2));
|
| 2341 |
threadgroup float * lsmb = (sb + THREAD_MAT_N * SG_MAT_SIZE * (sgitg / 2));
|
|
|
|
| 2342 |
#pragma unroll(4)
|
| 2343 |
for (int ik = 0; ik < BLOCK_SIZE_K / 8; ik++) {
|
| 2344 |
#pragma unroll(4)
|
|
@@ -2353,6 +2435,7 @@ kernel void kernel_mul_mm(device const uchar * src0,
|
|
| 2353 |
|
| 2354 |
lsma += BLOCK_SIZE_M / SG_MAT_ROW * SG_MAT_SIZE;
|
| 2355 |
lsmb += BLOCK_SIZE_N / SG_MAT_ROW * SG_MAT_SIZE;
|
|
|
|
| 2356 |
#pragma unroll(8)
|
| 2357 |
for (int i = 0; i < 8; i++){
|
| 2358 |
simdgroup_multiply_accumulate(c_res[i], mb[i/4], ma[i%4], c_res[i]);
|
|
@@ -2361,25 +2444,26 @@ kernel void kernel_mul_mm(device const uchar * src0,
|
|
| 2361 |
}
|
| 2362 |
|
| 2363 |
if ((r0 + 1) * BLOCK_SIZE_M <= ne0 && (r1 + 1) * BLOCK_SIZE_N <= ne1) {
|
| 2364 |
-
device float *C = dst + BLOCK_SIZE_M * r0 + 32 * (sgitg&1) \
|
| 2365 |
-
|
| 2366 |
for (int i = 0; i < 8; i++) {
|
| 2367 |
simdgroup_store(c_res[i], C + 8 * (i%4) + 8 * ne0 * (i/4), ne0);
|
| 2368 |
}
|
| 2369 |
} else {
|
| 2370 |
// block is smaller than 64x32, we should avoid writing data outside of the matrix
|
| 2371 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2372 |
-
threadgroup float *temp_str = ((threadgroup float *)shared_memory) \
|
| 2373 |
+ 32 * (sgitg&1) + (16 * (sgitg>>1)) * BLOCK_SIZE_M;
|
| 2374 |
for (int i = 0; i < 8; i++) {
|
| 2375 |
simdgroup_store(c_res[i], temp_str + 8 * (i%4) + 8 * BLOCK_SIZE_M * (i/4), BLOCK_SIZE_M);
|
| 2376 |
}
|
| 2377 |
|
| 2378 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2379 |
-
|
| 2380 |
-
|
|
|
|
| 2381 |
for (int i = 0; i < n_rows; i++) {
|
| 2382 |
-
for (int j = tiitg; j< n_cols; j += BLOCK_SIZE_N) {
|
| 2383 |
*(C + i + j * ne0) = *(temp_str + i + j * BLOCK_SIZE_M);
|
| 2384 |
}
|
| 2385 |
}
|
|
|
|
| 13 |
|
| 14 |
#define QK4_1 32
|
| 15 |
typedef struct {
|
| 16 |
+
half d; // delta
|
| 17 |
+
half m; // min
|
| 18 |
uint8_t qs[QK4_1 / 2]; // nibbles / quants
|
| 19 |
} block_q4_1;
|
| 20 |
|
|
|
|
| 132 |
dst[tpig] = max(0.0f, src0[tpig]);
|
| 133 |
}
|
| 134 |
|
| 135 |
+
kernel void kernel_sqr(
|
| 136 |
+
device const float * src0,
|
| 137 |
+
device float * dst,
|
| 138 |
+
uint tpig[[thread_position_in_grid]]) {
|
| 139 |
+
dst[tpig] = src0[tpig] * src0[tpig];
|
| 140 |
+
}
|
| 141 |
+
|
| 142 |
constant float GELU_COEF_A = 0.044715f;
|
| 143 |
constant float SQRT_2_OVER_PI = 0.79788456080286535587989211986876f;
|
| 144 |
|
|
|
|
| 423 |
}
|
| 424 |
|
| 425 |
// putting them in the kernel cause a significant performance penalty
|
| 426 |
+
#define N_DST 4 // each SIMD group works on 4 rows
|
| 427 |
+
#define N_SIMDGROUP 2 // number of SIMD groups in a thread group
|
| 428 |
#define N_SIMDWIDTH 32 // assuming SIMD group size is 32
|
| 429 |
//Note: This is a template, but strictly speaking it only applies to
|
| 430 |
// quantizations where the block size is 32. It also does not
|
|
|
|
| 435 |
int64_t ne00, int64_t ne01, int64_t ne02, int64_t ne10, int64_t ne12, int64_t ne0, int64_t ne1, uint gqa,
|
| 436 |
uint3 tgpig, uint tiisg, uint sgitg) {
|
| 437 |
const int nb = ne00/QK4_0;
|
| 438 |
+
|
| 439 |
const int r0 = tgpig.x;
|
| 440 |
const int r1 = tgpig.y;
|
| 441 |
const int im = tgpig.z;
|
| 442 |
+
|
| 443 |
const int first_row = (r0 * nsg + sgitg) * nr;
|
| 444 |
+
|
| 445 |
const uint offset0 = first_row * nb + im/gqa*(nb*ne0);
|
| 446 |
+
|
| 447 |
device const block_q_type * x = (device const block_q_type *) src0 + offset0;
|
| 448 |
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
|
|
|
|
|
|
|
| 449 |
|
| 450 |
+
float yl[16]; // src1 vector cache
|
| 451 |
+
float sumf[nr] = {0.f};
|
| 452 |
+
|
| 453 |
+
const int ix = (tiisg/2);
|
| 454 |
+
const int il = (tiisg%2)*8;
|
| 455 |
|
| 456 |
device const float * yb = y + ix * QK4_0 + il;
|
| 457 |
|
|
|
|
| 462 |
sumy += yb[i] + yb[i+1];
|
| 463 |
yl[i+0] = yb[i+ 0];
|
| 464 |
yl[i+1] = yb[i+ 1]/256.f;
|
| 465 |
+
|
| 466 |
sumy += yb[i+16] + yb[i+17];
|
| 467 |
yl[i+8] = yb[i+16]/16.f;
|
| 468 |
yl[i+9] = yb[i+17]/4096.f;
|
|
|
|
| 478 |
for (int row = 0; row < nr; ++row) {
|
| 479 |
const float tot = simd_sum(sumf[row]);
|
| 480 |
if (tiisg == 0 && first_row + row < ne01) {
|
| 481 |
+
dst[im*ne0*ne1 + r1*ne0 + first_row + row] = tot;
|
| 482 |
}
|
| 483 |
}
|
| 484 |
}
|
| 485 |
|
| 486 |
+
kernel void kernel_mul_mv_q4_0_f32(
|
| 487 |
device const void * src0,
|
| 488 |
device const float * src1,
|
| 489 |
device float * dst,
|
|
|
|
| 496 |
constant int64_t & ne1[[buffer(16)]],
|
| 497 |
constant uint & gqa[[buffer(17)]],
|
| 498 |
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 499 |
+
uint tiisg[[thread_index_in_simdgroup]],
|
| 500 |
+
uint sgitg[[simdgroup_index_in_threadgroup]]) {
|
| 501 |
mul_vec_q_n_f32<block_q4_0, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,gqa,tgpig,tiisg,sgitg);
|
| 502 |
}
|
| 503 |
|
| 504 |
+
kernel void kernel_mul_mv_q4_1_f32(
|
| 505 |
device const void * src0,
|
| 506 |
device const float * src1,
|
| 507 |
device float * dst,
|
|
|
|
| 521 |
|
| 522 |
#define NB_Q8_0 8
|
| 523 |
|
| 524 |
+
kernel void kernel_mul_mv_q8_0_f32(
|
| 525 |
device const void * src0,
|
| 526 |
device const float * src1,
|
| 527 |
device float * dst,
|
|
|
|
| 585 |
|
| 586 |
#define N_F32_F32 4
|
| 587 |
|
| 588 |
+
kernel void kernel_mul_mv_f32_f32(
|
| 589 |
device const char * src0,
|
| 590 |
device const char * src1,
|
| 591 |
device float * dst,
|
|
|
|
| 656 |
}
|
| 657 |
}
|
| 658 |
|
| 659 |
+
kernel void kernel_mul_mv_f16_f32_1row(
|
| 660 |
device const char * src0,
|
| 661 |
device const char * src1,
|
| 662 |
device float * dst,
|
|
|
|
| 675 |
constant int64_t & ne0,
|
| 676 |
constant int64_t & ne1,
|
| 677 |
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 678 |
+
uint tiisg[[thread_index_in_simdgroup]]) {
|
| 679 |
|
| 680 |
const int64_t r0 = tgpig.x;
|
| 681 |
const int64_t r1 = tgpig.y;
|
|
|
|
| 710 |
|
| 711 |
#define N_F16_F32 4
|
| 712 |
|
| 713 |
+
kernel void kernel_mul_mv_f16_f32(
|
| 714 |
device const char * src0,
|
| 715 |
device const char * src1,
|
| 716 |
device float * dst,
|
|
|
|
| 782 |
}
|
| 783 |
|
| 784 |
// Assumes row size (ne00) is a multiple of 4
|
| 785 |
+
kernel void kernel_mul_mv_f16_f32_l4(
|
| 786 |
device const char * src0,
|
| 787 |
device const char * src1,
|
| 788 |
device float * dst,
|
|
|
|
| 843 |
constant uint64_t & nb1,
|
| 844 |
constant uint64_t & nb2,
|
| 845 |
constant uint64_t & nb3,
|
| 846 |
+
constant float & m0,
|
| 847 |
+
constant float & m1,
|
| 848 |
+
constant int & n_heads_log2_floor,
|
| 849 |
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 850 |
uint3 tpitg[[thread_position_in_threadgroup]],
|
| 851 |
uint3 ntg[[threads_per_threadgroup]]) {
|
|
|
|
| 861 |
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
|
| 862 |
|
| 863 |
device float * dst_data = (device float *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
|
| 864 |
+
float m_k;
|
| 865 |
+
if (i2 < n_heads_log2_floor) {
|
| 866 |
+
m_k = pow(m0, i2 + 1);
|
| 867 |
+
} else {
|
| 868 |
+
m_k = pow(m1, 2 * (i2 - n_heads_log2_floor) + 1);
|
| 869 |
+
}
|
| 870 |
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
|
| 871 |
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
|
| 872 |
dst_data[i00] = src[0] + m_k * (i00 - ne00 + 1);
|
|
|
|
| 1111 |
}
|
| 1112 |
}
|
| 1113 |
|
| 1114 |
+
kernel void kernel_concat(
|
| 1115 |
+
device const char * src0,
|
| 1116 |
+
device const char * src1,
|
| 1117 |
+
device char * dst,
|
| 1118 |
+
constant int64_t & ne00,
|
| 1119 |
+
constant int64_t & ne01,
|
| 1120 |
+
constant int64_t & ne02,
|
| 1121 |
+
constant int64_t & ne03,
|
| 1122 |
+
constant uint64_t & nb00,
|
| 1123 |
+
constant uint64_t & nb01,
|
| 1124 |
+
constant uint64_t & nb02,
|
| 1125 |
+
constant uint64_t & nb03,
|
| 1126 |
+
constant int64_t & ne10,
|
| 1127 |
+
constant int64_t & ne11,
|
| 1128 |
+
constant int64_t & ne12,
|
| 1129 |
+
constant int64_t & ne13,
|
| 1130 |
+
constant uint64_t & nb10,
|
| 1131 |
+
constant uint64_t & nb11,
|
| 1132 |
+
constant uint64_t & nb12,
|
| 1133 |
+
constant uint64_t & nb13,
|
| 1134 |
+
constant int64_t & ne0,
|
| 1135 |
+
constant int64_t & ne1,
|
| 1136 |
+
constant int64_t & ne2,
|
| 1137 |
+
constant int64_t & ne3,
|
| 1138 |
+
constant uint64_t & nb0,
|
| 1139 |
+
constant uint64_t & nb1,
|
| 1140 |
+
constant uint64_t & nb2,
|
| 1141 |
+
constant uint64_t & nb3,
|
| 1142 |
+
uint3 tgpig[[threadgroup_position_in_grid]],
|
| 1143 |
+
uint3 tpitg[[thread_position_in_threadgroup]],
|
| 1144 |
+
uint3 ntg[[threads_per_threadgroup]]) {
|
| 1145 |
+
|
| 1146 |
+
const int64_t i03 = tgpig.z;
|
| 1147 |
+
const int64_t i02 = tgpig.y;
|
| 1148 |
+
const int64_t i01 = tgpig.x;
|
| 1149 |
+
|
| 1150 |
+
const int64_t i13 = i03 % ne13;
|
| 1151 |
+
const int64_t i12 = i02 % ne12;
|
| 1152 |
+
const int64_t i11 = i01 % ne11;
|
| 1153 |
+
|
| 1154 |
+
device const char * src0_ptr = src0 + i03 * nb03 + i02 * nb02 + i01 * nb01 + tpitg.x*nb00;
|
| 1155 |
+
device const char * src1_ptr = src1 + i13*nb13 + i12*nb12 + i11*nb11 + tpitg.x*nb10;
|
| 1156 |
+
device char * dst_ptr = dst + i03*nb3 + i02*nb2 + i01*nb1 + tpitg.x*nb0;
|
| 1157 |
+
|
| 1158 |
+
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
|
| 1159 |
+
if (i02 < ne02) {
|
| 1160 |
+
((device float *)dst_ptr)[0] = ((device float *)src0_ptr)[0];
|
| 1161 |
+
src0_ptr += ntg.x*nb00;
|
| 1162 |
+
} else {
|
| 1163 |
+
((device float *)dst_ptr)[0] = ((device float *)src1_ptr)[0];
|
| 1164 |
+
src1_ptr += ntg.x*nb10;
|
| 1165 |
+
}
|
| 1166 |
+
dst_ptr += ntg.x*nb0;
|
| 1167 |
+
}
|
| 1168 |
+
}
|
| 1169 |
+
|
| 1170 |
//============================================ k-quants ======================================================
|
| 1171 |
|
| 1172 |
#ifndef QK_K
|
|
|
|
| 1259 |
|
| 1260 |
//====================================== dot products =========================
|
| 1261 |
|
| 1262 |
+
kernel void kernel_mul_mv_q2_K_f32(
|
| 1263 |
device const void * src0,
|
| 1264 |
device const float * src1,
|
| 1265 |
device float * dst,
|
|
|
|
| 1403 |
}
|
| 1404 |
|
| 1405 |
#if QK_K == 256
|
| 1406 |
+
kernel void kernel_mul_mv_q3_K_f32(
|
| 1407 |
device const void * src0,
|
| 1408 |
device const float * src1,
|
| 1409 |
device float * dst,
|
|
|
|
| 1555 |
}
|
| 1556 |
}
|
| 1557 |
#else
|
| 1558 |
+
kernel void kernel_mul_mv_q3_K_f32(
|
| 1559 |
device const void * src0,
|
| 1560 |
device const float * src1,
|
| 1561 |
device float * dst,
|
|
|
|
| 1626 |
#endif
|
| 1627 |
|
| 1628 |
#if QK_K == 256
|
| 1629 |
+
kernel void kernel_mul_mv_q4_K_f32(
|
| 1630 |
device const void * src0,
|
| 1631 |
device const float * src1,
|
| 1632 |
device float * dst,
|
|
|
|
| 1732 |
}
|
| 1733 |
}
|
| 1734 |
#else
|
| 1735 |
+
kernel void kernel_mul_mv_q4_K_f32(
|
| 1736 |
device const void * src0,
|
| 1737 |
device const float * src1,
|
| 1738 |
device float * dst,
|
|
|
|
| 1821 |
}
|
| 1822 |
#endif
|
| 1823 |
|
| 1824 |
+
kernel void kernel_mul_mv_q5_K_f32(
|
| 1825 |
device const void * src0,
|
| 1826 |
device const float * src1,
|
| 1827 |
device float * dst,
|
|
|
|
| 1994 |
|
| 1995 |
}
|
| 1996 |
|
| 1997 |
+
kernel void kernel_mul_mv_q6_K_f32(
|
| 1998 |
device const void * src0,
|
| 1999 |
device const float * src1,
|
| 2000 |
device float * dst,
|
|
|
|
| 2332 |
}
|
| 2333 |
|
| 2334 |
#define BLOCK_SIZE_M 64 // 8 simdgroup matrices from matrix A
|
| 2335 |
+
#define BLOCK_SIZE_N 32 // 4 simdgroup matrices from matrix B
|
| 2336 |
#define BLOCK_SIZE_K 32
|
| 2337 |
#define THREAD_MAT_M 4 // each thread take 4 simdgroup matrices from matrix A
|
| 2338 |
#define THREAD_MAT_N 2 // each thread take 2 simdgroup matrices from matrix B
|
|
|
|
| 2369 |
const uint r0 = tgpig.y;
|
| 2370 |
const uint r1 = tgpig.x;
|
| 2371 |
const uint im = tgpig.z;
|
| 2372 |
+
|
| 2373 |
// if this block is of 64x32 shape or smaller
|
| 2374 |
short n_rows = (ne0 - r0 * BLOCK_SIZE_M < BLOCK_SIZE_M) ? (ne0 - r0 * BLOCK_SIZE_M) : BLOCK_SIZE_M;
|
| 2375 |
short n_cols = (ne1 - r1 * BLOCK_SIZE_N < BLOCK_SIZE_N) ? (ne1 - r1 * BLOCK_SIZE_N) : BLOCK_SIZE_N;
|
| 2376 |
+
|
| 2377 |
// a thread shouldn't load data outside of the matrix
|
| 2378 |
short thread_row = ((short)tiitg/THREAD_PER_ROW) < n_rows ? ((short)tiitg/THREAD_PER_ROW) : n_rows - 1;
|
| 2379 |
short thread_col = ((short)tiitg/THREAD_PER_COL) < n_cols ? ((short)tiitg/THREAD_PER_COL) : n_cols - 1;
|
|
|
|
| 2397 |
+ nb10 * (BLOCK_SIZE_K / THREAD_PER_COL * (tiitg % THREAD_PER_COL)));
|
| 2398 |
|
| 2399 |
for (int loop_k = 0; loop_k < ne00; loop_k += BLOCK_SIZE_K) {
|
| 2400 |
+
// load data and store to threadgroup memory
|
| 2401 |
half4x4 temp_a;
|
| 2402 |
dequantize_func(x, il, temp_a);
|
| 2403 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2404 |
+
|
| 2405 |
#pragma unroll(16)
|
| 2406 |
for (int i = 0; i < 16; i++) {
|
| 2407 |
*(sa + SG_MAT_SIZE * ((tiitg / THREAD_PER_ROW / 8) \
|
| 2408 |
+
+ (tiitg % THREAD_PER_ROW) * 16 + (i / 8) * 8) \
|
| 2409 |
+
+ (tiitg / THREAD_PER_ROW) % 8 + (i & 7) * 8) = temp_a[i/4][i%4];
|
| 2410 |
}
|
| 2411 |
+
|
| 2412 |
+
*(threadgroup float2x4 *)(sb + (tiitg % THREAD_PER_COL) * 8 * 32 + 8 * (tiitg / THREAD_PER_COL)) = *((device float2x4 *)y);
|
| 2413 |
+
|
| 2414 |
il = (il + 2 < nl) ? il + 2 : il % 2;
|
| 2415 |
x = (il < 2) ? x + (2+nl-1)/nl : x;
|
| 2416 |
y += BLOCK_SIZE_K;
|
| 2417 |
|
| 2418 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2419 |
+
|
| 2420 |
+
// load matrices from threadgroup memory and conduct outer products
|
| 2421 |
threadgroup half * lsma = (sa + THREAD_MAT_M * SG_MAT_SIZE * (sgitg % 2));
|
| 2422 |
threadgroup float * lsmb = (sb + THREAD_MAT_N * SG_MAT_SIZE * (sgitg / 2));
|
| 2423 |
+
|
| 2424 |
#pragma unroll(4)
|
| 2425 |
for (int ik = 0; ik < BLOCK_SIZE_K / 8; ik++) {
|
| 2426 |
#pragma unroll(4)
|
|
|
|
| 2435 |
|
| 2436 |
lsma += BLOCK_SIZE_M / SG_MAT_ROW * SG_MAT_SIZE;
|
| 2437 |
lsmb += BLOCK_SIZE_N / SG_MAT_ROW * SG_MAT_SIZE;
|
| 2438 |
+
|
| 2439 |
#pragma unroll(8)
|
| 2440 |
for (int i = 0; i < 8; i++){
|
| 2441 |
simdgroup_multiply_accumulate(c_res[i], mb[i/4], ma[i%4], c_res[i]);
|
|
|
|
| 2444 |
}
|
| 2445 |
|
| 2446 |
if ((r0 + 1) * BLOCK_SIZE_M <= ne0 && (r1 + 1) * BLOCK_SIZE_N <= ne1) {
|
| 2447 |
+
device float * C = dst + (BLOCK_SIZE_M * r0 + 32 * (sgitg & 1)) \
|
| 2448 |
+
+ (BLOCK_SIZE_N * r1 + 16 * (sgitg >> 1)) * ne0 + im*ne1*ne0;
|
| 2449 |
for (int i = 0; i < 8; i++) {
|
| 2450 |
simdgroup_store(c_res[i], C + 8 * (i%4) + 8 * ne0 * (i/4), ne0);
|
| 2451 |
}
|
| 2452 |
} else {
|
| 2453 |
// block is smaller than 64x32, we should avoid writing data outside of the matrix
|
| 2454 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2455 |
+
threadgroup float * temp_str = ((threadgroup float *)shared_memory) \
|
| 2456 |
+ 32 * (sgitg&1) + (16 * (sgitg>>1)) * BLOCK_SIZE_M;
|
| 2457 |
for (int i = 0; i < 8; i++) {
|
| 2458 |
simdgroup_store(c_res[i], temp_str + 8 * (i%4) + 8 * BLOCK_SIZE_M * (i/4), BLOCK_SIZE_M);
|
| 2459 |
}
|
| 2460 |
|
| 2461 |
threadgroup_barrier(mem_flags::mem_threadgroup);
|
| 2462 |
+
|
| 2463 |
+
device float * C = dst + (BLOCK_SIZE_M * r0) + (BLOCK_SIZE_N * r1) * ne0 + im*ne1*ne0;
|
| 2464 |
+
if (sgitg == 0) {
|
| 2465 |
for (int i = 0; i < n_rows; i++) {
|
| 2466 |
+
for (int j = tiitg; j < n_cols; j += BLOCK_SIZE_N) {
|
| 2467 |
*(C + i + j * ne0) = *(temp_str + i + j * BLOCK_SIZE_M);
|
| 2468 |
}
|
| 2469 |
}
|
ggml-opencl.cpp
CHANGED
|
@@ -203,14 +203,14 @@ inline void get_scale_min_k4(int j, const __global uint8_t *q, uint8_t *d, uint8
|
|
| 203 |
|
| 204 |
__kernel void dequantize_block_q2_K(__global const struct block_q2_K *x, __global float *yy)
|
| 205 |
{
|
| 206 |
-
const int i = get_group_id(0);
|
| 207 |
const int tid = get_local_id(0);
|
| 208 |
const int n = tid / 32;
|
| 209 |
const int l = tid - 32 * n;
|
| 210 |
const int is = 8 * n + l / 16;
|
| 211 |
|
| 212 |
const uint8_t q = x[i].qs[32 * n + l];
|
| 213 |
-
__global float *y = yy +
|
| 214 |
|
| 215 |
const float dall = vload_half(0, &x[i].d);
|
| 216 |
const float dmin = vload_half(0, &x[i].dmin);
|
|
@@ -224,7 +224,7 @@ __kernel void dequantize_block_q2_K(__global const struct block_q2_K *x, __globa
|
|
| 224 |
__kernel void dequantize_block_q3_K(__global const struct block_q3_K *x, __global float *yy)
|
| 225 |
{
|
| 226 |
int r = get_local_id(0) / 4;
|
| 227 |
-
int i = get_group_id(0);
|
| 228 |
int tid = r / 2;
|
| 229 |
int is0 = r % 2;
|
| 230 |
int l0 = 16 * is0 + 4 * (get_local_id(0) % 4);
|
|
@@ -242,7 +242,7 @@ __kernel void dequantize_block_q3_K(__global const struct block_q3_K *x, __globa
|
|
| 242 |
float d_all = vload_half(0, &x[i].d);
|
| 243 |
float dl = d_all * (us - 32);
|
| 244 |
|
| 245 |
-
__global float *y = yy +
|
| 246 |
const __global uint8_t *q = x[i].qs + 32 * n;
|
| 247 |
const __global uint8_t *hm = x[i].hmask;
|
| 248 |
|
|
@@ -252,14 +252,14 @@ __kernel void dequantize_block_q3_K(__global const struct block_q3_K *x, __globa
|
|
| 252 |
|
| 253 |
__kernel void dequantize_block_q4_K(__global const struct block_q4_K *x, __global float *yy)
|
| 254 |
{
|
| 255 |
-
const int i = get_group_id(0);
|
| 256 |
const int tid = get_local_id(0);
|
| 257 |
const int il = tid / 8;
|
| 258 |
const int ir = tid % 8;
|
| 259 |
const int is = 2 * il;
|
| 260 |
const int n = 4;
|
| 261 |
|
| 262 |
-
__global float *y = yy +
|
| 263 |
|
| 264 |
const float dall = vload_half(0, &x[i].d);
|
| 265 |
const float dmin = vload_half(0, &x[i].dmin);
|
|
@@ -282,13 +282,13 @@ __kernel void dequantize_block_q4_K(__global const struct block_q4_K *x, __globa
|
|
| 282 |
|
| 283 |
__kernel void dequantize_block_q5_K(__global const struct block_q5_K *x, __global float *yy)
|
| 284 |
{
|
| 285 |
-
const int i = get_group_id(0);
|
| 286 |
const int tid = get_local_id(0);
|
| 287 |
const int il = tid / 16;
|
| 288 |
const int ir = tid % 16;
|
| 289 |
const int is = 2 * il;
|
| 290 |
|
| 291 |
-
__global float *y = yy +
|
| 292 |
|
| 293 |
const float dall = vload_half(0, &x[i].d);
|
| 294 |
const float dmin = vload_half(0, &x[i].dmin);
|
|
@@ -314,13 +314,13 @@ __kernel void dequantize_block_q5_K(__global const struct block_q5_K *x, __globa
|
|
| 314 |
|
| 315 |
__kernel void dequantize_block_q6_K(__global const struct block_q6_K *x, __global float *yy)
|
| 316 |
{
|
| 317 |
-
const int i = get_group_id(0);
|
| 318 |
const int tid = get_local_id(0);
|
| 319 |
const int ip = tid / 32;
|
| 320 |
const int il = tid - 32 * ip;
|
| 321 |
const int is = 8 * ip + il / 16;
|
| 322 |
|
| 323 |
-
__global float *y = yy +
|
| 324 |
|
| 325 |
const float d = vload_half(0, &x[i].d);
|
| 326 |
|
|
@@ -731,7 +731,7 @@ __kernel void KERNEL_NAME(__global X_TYPE* x, __global float* y) {
|
|
| 731 |
const uint qk = QUANT_K;
|
| 732 |
const uint qr = QUANT_R;
|
| 733 |
|
| 734 |
-
const int ib = i/qk; // block index
|
| 735 |
const int iqs = (i%qk)/qr; // quant index
|
| 736 |
const int iybs = i - i%qk; // y block start index
|
| 737 |
const int y_offset = qr == 1 ? 1 : qk/2;
|
|
@@ -1357,30 +1357,42 @@ static cl_int ggml_cl_h2d_tensor_2d(cl_command_queue queue, cl_mem dst, size_t o
|
|
| 1357 |
const enum ggml_type type = src->type;
|
| 1358 |
const size_t ts = ggml_type_size(type);
|
| 1359 |
const size_t bs = ggml_blck_size(type);
|
|
|
|
| 1360 |
|
| 1361 |
-
const
|
| 1362 |
-
if (nb0 == ts && nb1 ==
|
| 1363 |
-
|
| 1364 |
-
return err;
|
| 1365 |
}
|
| 1366 |
if (nb0 == ts) {
|
| 1367 |
const size_t buffer_origin[3] = { offset, 0, 0 };
|
| 1368 |
const size_t host_origin[3] = { 0, 0, 0 };
|
| 1369 |
-
const size_t region[3] = {
|
| 1370 |
-
|
| 1371 |
-
return err;
|
| 1372 |
}
|
|
|
|
|
|
|
| 1373 |
for (uint64_t i1 = 0; i1 < ne1; i1++) {
|
| 1374 |
// pretend the row is a matrix with cols=1
|
| 1375 |
-
const size_t buffer_origin[3] = { offset
|
| 1376 |
const size_t host_origin[3] = { 0, 0, 0 };
|
| 1377 |
-
const size_t region[3] = { ts
|
| 1378 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1379 |
if (err != CL_SUCCESS) {
|
| 1380 |
-
|
|
|
|
|
|
|
|
|
|
| 1381 |
}
|
| 1382 |
}
|
| 1383 |
-
|
|
|
|
|
|
|
|
|
|
| 1384 |
}
|
| 1385 |
|
| 1386 |
static void ggml_cl_mul_f32(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
|
@@ -1484,10 +1496,15 @@ static void ggml_cl_mul_mat_f32(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1484 |
|
| 1485 |
const int64_t ne10 = src1->ne[0];
|
| 1486 |
const int64_t ne11 = src1->ne[1];
|
|
|
|
|
|
|
| 1487 |
|
| 1488 |
const int nb2 = dst->nb[2];
|
| 1489 |
const int nb3 = dst->nb[3];
|
| 1490 |
|
|
|
|
|
|
|
|
|
|
| 1491 |
const float alpha = 1.0f;
|
| 1492 |
const float beta = 0.0f;
|
| 1493 |
const int x_ne = ne01 * ne00;
|
|
@@ -1506,13 +1523,25 @@ static void ggml_cl_mul_mat_f32(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1506 |
cl_mem d_Y = ggml_cl_pool_malloc(sizeof(float) * y_ne, &y_size);
|
| 1507 |
cl_mem d_D = ggml_cl_pool_malloc(sizeof(float) * d_ne, &d_size);
|
| 1508 |
|
| 1509 |
-
|
| 1510 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1511 |
// copy data to device
|
| 1512 |
-
if (src0->backend
|
|
|
|
|
|
|
| 1513 |
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_X, 0, src0, i03, i02, NULL));
|
|
|
|
|
|
|
| 1514 |
}
|
| 1515 |
-
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Y, 0, src1,
|
| 1516 |
|
| 1517 |
CL_CHECK(clFinish(queue));
|
| 1518 |
|
|
@@ -1522,7 +1551,7 @@ static void ggml_cl_mul_mat_f32(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1522 |
(CLBlastTranspose)clblast::Transpose::kYes, (CLBlastTranspose)clblast::Transpose::kNo,
|
| 1523 |
ne01, ne11, ne10,
|
| 1524 |
alpha,
|
| 1525 |
-
d_X,
|
| 1526 |
d_Y, 0, ne10,
|
| 1527 |
beta,
|
| 1528 |
d_D, 0, ne01,
|
|
@@ -1534,7 +1563,7 @@ static void ggml_cl_mul_mat_f32(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1534 |
}
|
| 1535 |
|
| 1536 |
// copy dst to host
|
| 1537 |
-
float * d = (float *) ((char *) dst->data +
|
| 1538 |
CL_CHECK(clEnqueueReadBuffer(queue, d_D, true, 0, sizeof(float) * d_ne, d, 1, &ev_sgemm, NULL));
|
| 1539 |
}
|
| 1540 |
}
|
|
@@ -1556,6 +1585,8 @@ static void ggml_cl_mul_mat_f16(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1556 |
|
| 1557 |
const int64_t ne10 = src1->ne[0];
|
| 1558 |
const int64_t ne11 = src1->ne[1];
|
|
|
|
|
|
|
| 1559 |
|
| 1560 |
const int nb10 = src1->nb[0];
|
| 1561 |
const int nb11 = src1->nb[1];
|
|
@@ -1565,6 +1596,9 @@ static void ggml_cl_mul_mat_f16(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1565 |
const int nb2 = dst->nb[2];
|
| 1566 |
const int nb3 = dst->nb[3];
|
| 1567 |
|
|
|
|
|
|
|
|
|
|
| 1568 |
const ggml_fp16_t alpha = ggml_fp32_to_fp16(1.0f);
|
| 1569 |
const ggml_fp16_t beta = ggml_fp32_to_fp16(0.0f);
|
| 1570 |
const int x_ne = ne01 * ne00;
|
|
@@ -1586,32 +1620,44 @@ static void ggml_cl_mul_mat_f16(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1586 |
bool src1_cont_rows = nb10 == sizeof(float);
|
| 1587 |
bool src1_cont_cols = (size_t)nb11 == ne11*sizeof(float);
|
| 1588 |
|
| 1589 |
-
|
| 1590 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1591 |
// copy src0 to device
|
| 1592 |
-
if (src0->backend
|
|
|
|
|
|
|
| 1593 |
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_X, 0, src0, i03, i02, NULL));
|
|
|
|
|
|
|
| 1594 |
}
|
| 1595 |
|
| 1596 |
// convert src1 to fp16
|
| 1597 |
// TODO: use multiple threads
|
| 1598 |
-
ggml_fp16_t * const tmp = (ggml_fp16_t *) wdata + (ne11 * ne10) * (
|
| 1599 |
-
char * src1i = (char *) src1->data +
|
| 1600 |
if (src1_cont_rows) {
|
| 1601 |
if (src1_cont_cols) {
|
| 1602 |
ggml_fp32_to_fp16_row((float *) src1i, tmp, ne10*ne11);
|
| 1603 |
}
|
| 1604 |
else {
|
| 1605 |
-
for (int64_t
|
| 1606 |
-
ggml_fp32_to_fp16_row((float *) (src1i +
|
| 1607 |
}
|
| 1608 |
}
|
| 1609 |
}
|
| 1610 |
else {
|
| 1611 |
-
for (int64_t
|
| 1612 |
-
for (int64_t
|
| 1613 |
// very slow due to no inlining
|
| 1614 |
-
tmp[
|
| 1615 |
}
|
| 1616 |
}
|
| 1617 |
}
|
|
@@ -1627,7 +1673,7 @@ static void ggml_cl_mul_mat_f16(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1627 |
(CLBlastTranspose)clblast::Transpose::kYes, (CLBlastTranspose)clblast::Transpose::kNo,
|
| 1628 |
ne01, ne11, ne10,
|
| 1629 |
alpha,
|
| 1630 |
-
d_X,
|
| 1631 |
d_Y, 0, ne10,
|
| 1632 |
beta,
|
| 1633 |
d_D, 0, ne01,
|
|
@@ -1641,7 +1687,7 @@ static void ggml_cl_mul_mat_f16(const ggml_tensor * src0, const ggml_tensor * sr
|
|
| 1641 |
// copy dst to host, then convert to float
|
| 1642 |
CL_CHECK(clEnqueueReadBuffer(queue, d_D, true, 0, sizeof(ggml_fp16_t) * d_ne, tmp, 1, &ev_sgemm, NULL));
|
| 1643 |
|
| 1644 |
-
float * d = (float *) ((char *) dst->data +
|
| 1645 |
|
| 1646 |
ggml_fp16_to_fp32_row(tmp, d, d_ne);
|
| 1647 |
}
|
|
@@ -1662,18 +1708,24 @@ static void ggml_cl_mul_mat_q_f32(const ggml_tensor * src0, const ggml_tensor *
|
|
| 1662 |
|
| 1663 |
const int64_t ne10 = src1->ne[0];
|
| 1664 |
const int64_t ne11 = src1->ne[1];
|
|
|
|
|
|
|
| 1665 |
|
| 1666 |
const int nb2 = dst->nb[2];
|
| 1667 |
const int nb3 = dst->nb[3];
|
| 1668 |
const ggml_type type = src0->type;
|
| 1669 |
const bool mul_mat_vec = ne11 == 1;
|
| 1670 |
|
|
|
|
|
|
|
|
|
|
| 1671 |
const float alpha = 1.0f;
|
| 1672 |
const float beta = 0.0f;
|
| 1673 |
const int x_ne = ne01 * ne00;
|
| 1674 |
const int y_ne = ne11 * ne10;
|
| 1675 |
const int d_ne = ne11 * ne01;
|
| 1676 |
-
const
|
|
|
|
| 1677 |
|
| 1678 |
size_t x_size;
|
| 1679 |
size_t y_size;
|
|
@@ -1700,12 +1752,23 @@ static void ggml_cl_mul_mat_q_f32(const ggml_tensor * src0, const ggml_tensor *
|
|
| 1700 |
size_t ev_idx = 0;
|
| 1701 |
std::vector<cl_event> events;
|
| 1702 |
|
| 1703 |
-
|
| 1704 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1705 |
// copy src0 to device if necessary
|
| 1706 |
if (src0->backend == GGML_BACKEND_CPU) {
|
| 1707 |
-
|
| 1708 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1709 |
} else if (src0->backend == GGML_BACKEND_GPU) {
|
| 1710 |
d_Q = (cl_mem) src0->extra;
|
| 1711 |
} else {
|
|
@@ -1714,7 +1777,7 @@ static void ggml_cl_mul_mat_q_f32(const ggml_tensor * src0, const ggml_tensor *
|
|
| 1714 |
if (mul_mat_vec) { // specialized dequantize_mul_mat_vec kernel
|
| 1715 |
// copy src1 to device
|
| 1716 |
events.emplace_back();
|
| 1717 |
-
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Y, 0, src1,
|
| 1718 |
|
| 1719 |
// compute
|
| 1720 |
const size_t global = ne01 * CL_DMMV_BLOCK_SIZE;
|
|
@@ -1730,12 +1793,13 @@ static void ggml_cl_mul_mat_q_f32(const ggml_tensor * src0, const ggml_tensor *
|
|
| 1730 |
} else { // general dequantization kernel + CLBlast matrix matrix multiplication
|
| 1731 |
// convert src0 to fp32 on device
|
| 1732 |
const size_t global = x_ne / global_denom;
|
|
|
|
| 1733 |
CL_CHECK(clSetKernelArg(*to_fp32_cl, 0, sizeof(cl_mem), &d_Q));
|
| 1734 |
CL_CHECK(clSetKernelArg(*to_fp32_cl, 1, sizeof(cl_mem), &d_X));
|
| 1735 |
-
CL_CHECK(clEnqueueNDRangeKernel(queue, *to_fp32_cl, 1, NULL, &global, local > 0 ? &local : NULL, events.size(), !events.empty() ? events.data() : NULL, NULL));
|
| 1736 |
|
| 1737 |
// copy src1 to device
|
| 1738 |
-
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Y, 0, src1,
|
| 1739 |
|
| 1740 |
events.emplace_back();
|
| 1741 |
|
|
@@ -1760,7 +1824,7 @@ static void ggml_cl_mul_mat_q_f32(const ggml_tensor * src0, const ggml_tensor *
|
|
| 1760 |
}
|
| 1761 |
|
| 1762 |
// copy dst to host
|
| 1763 |
-
float * d = (float *) ((char *) dst->data +
|
| 1764 |
CL_CHECK(clEnqueueReadBuffer(queue, d_D, true, 0, sizeof(float) * d_ne, d, 1, &events[events.size() - 1], NULL));
|
| 1765 |
for (auto *event : events) {
|
| 1766 |
clReleaseEvent(event);
|
|
@@ -1864,17 +1928,19 @@ void ggml_cl_transform_tensor(void * data, ggml_tensor * tensor) {
|
|
| 1864 |
const int64_t ne3 = tensor->ne[3];
|
| 1865 |
|
| 1866 |
const ggml_type type = tensor->type;
|
| 1867 |
-
const size_t
|
|
|
|
| 1868 |
|
| 1869 |
size_t q_size;
|
| 1870 |
cl_mem dst = ggml_cl_pool_malloc(q_sz, &q_size);
|
| 1871 |
|
| 1872 |
tensor->data = data;
|
| 1873 |
// copy tensor to device
|
|
|
|
| 1874 |
for (int64_t i3 = 0; i3 < ne3; i3++) {
|
| 1875 |
for (int64_t i2 = 0; i2 < ne2; i2++) {
|
| 1876 |
-
|
| 1877 |
-
|
| 1878 |
}
|
| 1879 |
}
|
| 1880 |
|
|
|
|
| 203 |
|
| 204 |
__kernel void dequantize_block_q2_K(__global const struct block_q2_K *x, __global float *yy)
|
| 205 |
{
|
| 206 |
+
const int i = get_group_id(0) + get_global_offset(0);
|
| 207 |
const int tid = get_local_id(0);
|
| 208 |
const int n = tid / 32;
|
| 209 |
const int l = tid - 32 * n;
|
| 210 |
const int is = 8 * n + l / 16;
|
| 211 |
|
| 212 |
const uint8_t q = x[i].qs[32 * n + l];
|
| 213 |
+
__global float *y = yy + get_group_id(0) * QK_K + 128 * n;
|
| 214 |
|
| 215 |
const float dall = vload_half(0, &x[i].d);
|
| 216 |
const float dmin = vload_half(0, &x[i].dmin);
|
|
|
|
| 224 |
__kernel void dequantize_block_q3_K(__global const struct block_q3_K *x, __global float *yy)
|
| 225 |
{
|
| 226 |
int r = get_local_id(0) / 4;
|
| 227 |
+
int i = get_group_id(0) + get_global_offset(0);
|
| 228 |
int tid = r / 2;
|
| 229 |
int is0 = r % 2;
|
| 230 |
int l0 = 16 * is0 + 4 * (get_local_id(0) % 4);
|
|
|
|
| 242 |
float d_all = vload_half(0, &x[i].d);
|
| 243 |
float dl = d_all * (us - 32);
|
| 244 |
|
| 245 |
+
__global float *y = yy + get_group_id(0) * QK_K + 128 * n + 32 * j;
|
| 246 |
const __global uint8_t *q = x[i].qs + 32 * n;
|
| 247 |
const __global uint8_t *hm = x[i].hmask;
|
| 248 |
|
|
|
|
| 252 |
|
| 253 |
__kernel void dequantize_block_q4_K(__global const struct block_q4_K *x, __global float *yy)
|
| 254 |
{
|
| 255 |
+
const int i = get_group_id(0) + get_global_offset(0);
|
| 256 |
const int tid = get_local_id(0);
|
| 257 |
const int il = tid / 8;
|
| 258 |
const int ir = tid % 8;
|
| 259 |
const int is = 2 * il;
|
| 260 |
const int n = 4;
|
| 261 |
|
| 262 |
+
__global float *y = yy + get_group_id(0) * QK_K + 64 * il + n * ir;
|
| 263 |
|
| 264 |
const float dall = vload_half(0, &x[i].d);
|
| 265 |
const float dmin = vload_half(0, &x[i].dmin);
|
|
|
|
| 282 |
|
| 283 |
__kernel void dequantize_block_q5_K(__global const struct block_q5_K *x, __global float *yy)
|
| 284 |
{
|
| 285 |
+
const int i = get_group_id(0) + get_global_offset(0);
|
| 286 |
const int tid = get_local_id(0);
|
| 287 |
const int il = tid / 16;
|
| 288 |
const int ir = tid % 16;
|
| 289 |
const int is = 2 * il;
|
| 290 |
|
| 291 |
+
__global float *y = yy + get_group_id(0) * QK_K + 64 * il + 2 * ir;
|
| 292 |
|
| 293 |
const float dall = vload_half(0, &x[i].d);
|
| 294 |
const float dmin = vload_half(0, &x[i].dmin);
|
|
|
|
| 314 |
|
| 315 |
__kernel void dequantize_block_q6_K(__global const struct block_q6_K *x, __global float *yy)
|
| 316 |
{
|
| 317 |
+
const int i = get_group_id(0) + get_global_offset(0);
|
| 318 |
const int tid = get_local_id(0);
|
| 319 |
const int ip = tid / 32;
|
| 320 |
const int il = tid - 32 * ip;
|
| 321 |
const int is = 8 * ip + il / 16;
|
| 322 |
|
| 323 |
+
__global float *y = yy + get_group_id(0) * QK_K + 128 * ip + il;
|
| 324 |
|
| 325 |
const float d = vload_half(0, &x[i].d);
|
| 326 |
|
|
|
|
| 731 |
const uint qk = QUANT_K;
|
| 732 |
const uint qr = QUANT_R;
|
| 733 |
|
| 734 |
+
const int ib = i/qk + get_global_offset(0); // block index
|
| 735 |
const int iqs = (i%qk)/qr; // quant index
|
| 736 |
const int iybs = i - i%qk; // y block start index
|
| 737 |
const int y_offset = qr == 1 ? 1 : qk/2;
|
|
|
|
| 1357 |
const enum ggml_type type = src->type;
|
| 1358 |
const size_t ts = ggml_type_size(type);
|
| 1359 |
const size_t bs = ggml_blck_size(type);
|
| 1360 |
+
const uint64_t row_size = ts*ne0/bs;
|
| 1361 |
|
| 1362 |
+
const char * x = (const char *) src->data + i2*nb2 + i3*nb3;
|
| 1363 |
+
if (nb0 == ts && nb1 == row_size) {
|
| 1364 |
+
return clEnqueueWriteBuffer(queue, dst, CL_FALSE, offset, ne1*row_size, x, 0, NULL, ev);
|
|
|
|
| 1365 |
}
|
| 1366 |
if (nb0 == ts) {
|
| 1367 |
const size_t buffer_origin[3] = { offset, 0, 0 };
|
| 1368 |
const size_t host_origin[3] = { 0, 0, 0 };
|
| 1369 |
+
const size_t region[3] = { row_size, ne1, 1 };
|
| 1370 |
+
return clEnqueueWriteBufferRect(queue, dst, CL_FALSE, buffer_origin, host_origin, region, row_size, 0, nb1, 0, x, 0, NULL, ev);
|
|
|
|
| 1371 |
}
|
| 1372 |
+
std::vector<cl_event> events;
|
| 1373 |
+
if (ev && ne1>1) events.reserve(ne1-1);
|
| 1374 |
for (uint64_t i1 = 0; i1 < ne1; i1++) {
|
| 1375 |
// pretend the row is a matrix with cols=1
|
| 1376 |
+
const size_t buffer_origin[3] = { offset + i1*row_size, 0, 0 };
|
| 1377 |
const size_t host_origin[3] = { 0, 0, 0 };
|
| 1378 |
+
const size_t region[3] = { ts, ne0/bs, 1 };
|
| 1379 |
+
// if an event is requested, make the last write wait for all previous writes to complete
|
| 1380 |
+
if (ev && i1) {
|
| 1381 |
+
events.push_back(*ev);
|
| 1382 |
+
}
|
| 1383 |
+
cl_uint nevents = i1 == ne1-1 ? events.size() : 0U;
|
| 1384 |
+
err = clEnqueueWriteBufferRect(queue, dst, CL_FALSE, buffer_origin, host_origin, region, ts, 0, nb0, 0, x + i1*nb1, nevents, nevents ? events.data() : nullptr, ev);
|
| 1385 |
if (err != CL_SUCCESS) {
|
| 1386 |
+
for (auto event : events) {
|
| 1387 |
+
clReleaseEvent(event);
|
| 1388 |
+
}
|
| 1389 |
+
return err;
|
| 1390 |
}
|
| 1391 |
}
|
| 1392 |
+
for (auto event : events) {
|
| 1393 |
+
CL_CHECK(clReleaseEvent(event));
|
| 1394 |
+
}
|
| 1395 |
+
return CL_SUCCESS;
|
| 1396 |
}
|
| 1397 |
|
| 1398 |
static void ggml_cl_mul_f32(const ggml_tensor * src0, const ggml_tensor * src1, ggml_tensor * dst) {
|
|
|
|
| 1496 |
|
| 1497 |
const int64_t ne10 = src1->ne[0];
|
| 1498 |
const int64_t ne11 = src1->ne[1];
|
| 1499 |
+
const int64_t ne12 = src1->ne[2];
|
| 1500 |
+
const int64_t ne13 = src1->ne[3];
|
| 1501 |
|
| 1502 |
const int nb2 = dst->nb[2];
|
| 1503 |
const int nb3 = dst->nb[3];
|
| 1504 |
|
| 1505 |
+
const int64_t r2 = ne12 / ne02;
|
| 1506 |
+
const int64_t r3 = ne13 / ne03;
|
| 1507 |
+
|
| 1508 |
const float alpha = 1.0f;
|
| 1509 |
const float beta = 0.0f;
|
| 1510 |
const int x_ne = ne01 * ne00;
|
|
|
|
| 1523 |
cl_mem d_Y = ggml_cl_pool_malloc(sizeof(float) * y_ne, &y_size);
|
| 1524 |
cl_mem d_D = ggml_cl_pool_malloc(sizeof(float) * d_ne, &d_size);
|
| 1525 |
|
| 1526 |
+
size_t x_offset = 0;
|
| 1527 |
+
int64_t pi02 = -1;
|
| 1528 |
+
int64_t pi03 = -1;
|
| 1529 |
+
|
| 1530 |
+
for (int64_t i13 = 0; i13 < ne13; i13++) {
|
| 1531 |
+
int64_t i03 = i13 / r3;
|
| 1532 |
+
|
| 1533 |
+
for (int64_t i12 = 0; i12 < ne12; i12++) {
|
| 1534 |
+
int64_t i02 = i12 / r2;
|
| 1535 |
+
|
| 1536 |
// copy data to device
|
| 1537 |
+
if (src0->backend == GGML_BACKEND_GPU) {
|
| 1538 |
+
x_offset = (i03 * ne02 + i02) * x_ne;
|
| 1539 |
+
} else if (i02 != pi02 || i03 != pi03) {
|
| 1540 |
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_X, 0, src0, i03, i02, NULL));
|
| 1541 |
+
pi02 = i02;
|
| 1542 |
+
pi03 = i03;
|
| 1543 |
}
|
| 1544 |
+
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Y, 0, src1, i13, i12, NULL));
|
| 1545 |
|
| 1546 |
CL_CHECK(clFinish(queue));
|
| 1547 |
|
|
|
|
| 1551 |
(CLBlastTranspose)clblast::Transpose::kYes, (CLBlastTranspose)clblast::Transpose::kNo,
|
| 1552 |
ne01, ne11, ne10,
|
| 1553 |
alpha,
|
| 1554 |
+
d_X, x_offset, ne00,
|
| 1555 |
d_Y, 0, ne10,
|
| 1556 |
beta,
|
| 1557 |
d_D, 0, ne01,
|
|
|
|
| 1563 |
}
|
| 1564 |
|
| 1565 |
// copy dst to host
|
| 1566 |
+
float * d = (float *) ((char *) dst->data + i12*nb2 + i13*nb3);
|
| 1567 |
CL_CHECK(clEnqueueReadBuffer(queue, d_D, true, 0, sizeof(float) * d_ne, d, 1, &ev_sgemm, NULL));
|
| 1568 |
}
|
| 1569 |
}
|
|
|
|
| 1585 |
|
| 1586 |
const int64_t ne10 = src1->ne[0];
|
| 1587 |
const int64_t ne11 = src1->ne[1];
|
| 1588 |
+
const int64_t ne12 = src1->ne[2];
|
| 1589 |
+
const int64_t ne13 = src1->ne[3];
|
| 1590 |
|
| 1591 |
const int nb10 = src1->nb[0];
|
| 1592 |
const int nb11 = src1->nb[1];
|
|
|
|
| 1596 |
const int nb2 = dst->nb[2];
|
| 1597 |
const int nb3 = dst->nb[3];
|
| 1598 |
|
| 1599 |
+
const int64_t r2 = ne12 / ne02;
|
| 1600 |
+
const int64_t r3 = ne13 / ne03;
|
| 1601 |
+
|
| 1602 |
const ggml_fp16_t alpha = ggml_fp32_to_fp16(1.0f);
|
| 1603 |
const ggml_fp16_t beta = ggml_fp32_to_fp16(0.0f);
|
| 1604 |
const int x_ne = ne01 * ne00;
|
|
|
|
| 1620 |
bool src1_cont_rows = nb10 == sizeof(float);
|
| 1621 |
bool src1_cont_cols = (size_t)nb11 == ne11*sizeof(float);
|
| 1622 |
|
| 1623 |
+
size_t x_offset = 0;
|
| 1624 |
+
int64_t pi02 = -1;
|
| 1625 |
+
int64_t pi03 = -1;
|
| 1626 |
+
|
| 1627 |
+
for (int64_t i13 = 0; i13 < ne13; i13++) {
|
| 1628 |
+
int64_t i03 = i13 / r3;
|
| 1629 |
+
|
| 1630 |
+
for (int64_t i12 = 0; i12 < ne12; i12++) {
|
| 1631 |
+
int64_t i02 = i12 / r2;
|
| 1632 |
+
|
| 1633 |
// copy src0 to device
|
| 1634 |
+
if (src0->backend == GGML_BACKEND_GPU) {
|
| 1635 |
+
x_offset = (i03 * ne02 + i02) * x_ne;
|
| 1636 |
+
} else if (i02 != pi02 || i03 != pi03) {
|
| 1637 |
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_X, 0, src0, i03, i02, NULL));
|
| 1638 |
+
pi02 = i02;
|
| 1639 |
+
pi03 = i03;
|
| 1640 |
}
|
| 1641 |
|
| 1642 |
// convert src1 to fp16
|
| 1643 |
// TODO: use multiple threads
|
| 1644 |
+
ggml_fp16_t * const tmp = (ggml_fp16_t *) wdata + (ne11 * ne10) * (i13 * ne12 + i12);
|
| 1645 |
+
char * src1i = (char *) src1->data + i13*nb13 + i12*nb12;
|
| 1646 |
if (src1_cont_rows) {
|
| 1647 |
if (src1_cont_cols) {
|
| 1648 |
ggml_fp32_to_fp16_row((float *) src1i, tmp, ne10*ne11);
|
| 1649 |
}
|
| 1650 |
else {
|
| 1651 |
+
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 1652 |
+
ggml_fp32_to_fp16_row((float *) (src1i + i11*nb11), tmp + i11*ne10, ne10);
|
| 1653 |
}
|
| 1654 |
}
|
| 1655 |
}
|
| 1656 |
else {
|
| 1657 |
+
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 1658 |
+
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 1659 |
// very slow due to no inlining
|
| 1660 |
+
tmp[i11*ne10 + i10] = ggml_fp32_to_fp16(*(float *) (src1i + i11*nb11 + i10*nb10));
|
| 1661 |
}
|
| 1662 |
}
|
| 1663 |
}
|
|
|
|
| 1673 |
(CLBlastTranspose)clblast::Transpose::kYes, (CLBlastTranspose)clblast::Transpose::kNo,
|
| 1674 |
ne01, ne11, ne10,
|
| 1675 |
alpha,
|
| 1676 |
+
d_X, x_offset, ne00,
|
| 1677 |
d_Y, 0, ne10,
|
| 1678 |
beta,
|
| 1679 |
d_D, 0, ne01,
|
|
|
|
| 1687 |
// copy dst to host, then convert to float
|
| 1688 |
CL_CHECK(clEnqueueReadBuffer(queue, d_D, true, 0, sizeof(ggml_fp16_t) * d_ne, tmp, 1, &ev_sgemm, NULL));
|
| 1689 |
|
| 1690 |
+
float * d = (float *) ((char *) dst->data + i12*nb2 + i13*nb3);
|
| 1691 |
|
| 1692 |
ggml_fp16_to_fp32_row(tmp, d, d_ne);
|
| 1693 |
}
|
|
|
|
| 1708 |
|
| 1709 |
const int64_t ne10 = src1->ne[0];
|
| 1710 |
const int64_t ne11 = src1->ne[1];
|
| 1711 |
+
const int64_t ne12 = src1->ne[2];
|
| 1712 |
+
const int64_t ne13 = src1->ne[3];
|
| 1713 |
|
| 1714 |
const int nb2 = dst->nb[2];
|
| 1715 |
const int nb3 = dst->nb[3];
|
| 1716 |
const ggml_type type = src0->type;
|
| 1717 |
const bool mul_mat_vec = ne11 == 1;
|
| 1718 |
|
| 1719 |
+
const int64_t r2 = ne12 / ne02;
|
| 1720 |
+
const int64_t r3 = ne13 / ne03;
|
| 1721 |
+
|
| 1722 |
const float alpha = 1.0f;
|
| 1723 |
const float beta = 0.0f;
|
| 1724 |
const int x_ne = ne01 * ne00;
|
| 1725 |
const int y_ne = ne11 * ne10;
|
| 1726 |
const int d_ne = ne11 * ne01;
|
| 1727 |
+
const int x_bps = x_ne / ggml_blck_size(type); // blocks per 2D slice
|
| 1728 |
+
const size_t q_sz = ggml_type_size(type) * x_bps;
|
| 1729 |
|
| 1730 |
size_t x_size;
|
| 1731 |
size_t y_size;
|
|
|
|
| 1752 |
size_t ev_idx = 0;
|
| 1753 |
std::vector<cl_event> events;
|
| 1754 |
|
| 1755 |
+
int64_t pi02 = -1;
|
| 1756 |
+
int64_t pi03 = -1;
|
| 1757 |
+
|
| 1758 |
+
for (int64_t i13 = 0; i13 < ne13; i13++) {
|
| 1759 |
+
int64_t i03 = i13 / r3;
|
| 1760 |
+
|
| 1761 |
+
for (int64_t i12 = 0; i12 < ne12; i12++) {
|
| 1762 |
+
int64_t i02 = i12 / r2;
|
| 1763 |
+
|
| 1764 |
// copy src0 to device if necessary
|
| 1765 |
if (src0->backend == GGML_BACKEND_CPU) {
|
| 1766 |
+
if (i02 != pi02 || i03 != pi03) {
|
| 1767 |
+
events.emplace_back();
|
| 1768 |
+
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Q, 0, src0, i03, i02, events.data() + ev_idx++));
|
| 1769 |
+
pi02 = i02;
|
| 1770 |
+
pi03 = i03;
|
| 1771 |
+
}
|
| 1772 |
} else if (src0->backend == GGML_BACKEND_GPU) {
|
| 1773 |
d_Q = (cl_mem) src0->extra;
|
| 1774 |
} else {
|
|
|
|
| 1777 |
if (mul_mat_vec) { // specialized dequantize_mul_mat_vec kernel
|
| 1778 |
// copy src1 to device
|
| 1779 |
events.emplace_back();
|
| 1780 |
+
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Y, 0, src1, i13, i12, events.data() + ev_idx++));
|
| 1781 |
|
| 1782 |
// compute
|
| 1783 |
const size_t global = ne01 * CL_DMMV_BLOCK_SIZE;
|
|
|
|
| 1793 |
} else { // general dequantization kernel + CLBlast matrix matrix multiplication
|
| 1794 |
// convert src0 to fp32 on device
|
| 1795 |
const size_t global = x_ne / global_denom;
|
| 1796 |
+
const size_t offset = src0->backend == GGML_BACKEND_GPU ? (i03 * ne02 + i02) * x_bps : 0;
|
| 1797 |
CL_CHECK(clSetKernelArg(*to_fp32_cl, 0, sizeof(cl_mem), &d_Q));
|
| 1798 |
CL_CHECK(clSetKernelArg(*to_fp32_cl, 1, sizeof(cl_mem), &d_X));
|
| 1799 |
+
CL_CHECK(clEnqueueNDRangeKernel(queue, *to_fp32_cl, 1, offset > 0 ? &offset : NULL, &global, local > 0 ? &local : NULL, events.size(), !events.empty() ? events.data() : NULL, NULL));
|
| 1800 |
|
| 1801 |
// copy src1 to device
|
| 1802 |
+
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, d_Y, 0, src1, i13, i12, NULL));
|
| 1803 |
|
| 1804 |
events.emplace_back();
|
| 1805 |
|
|
|
|
| 1824 |
}
|
| 1825 |
|
| 1826 |
// copy dst to host
|
| 1827 |
+
float * d = (float *) ((char *) dst->data + i12*nb2 + i13*nb3);
|
| 1828 |
CL_CHECK(clEnqueueReadBuffer(queue, d_D, true, 0, sizeof(float) * d_ne, d, 1, &events[events.size() - 1], NULL));
|
| 1829 |
for (auto *event : events) {
|
| 1830 |
clReleaseEvent(event);
|
|
|
|
| 1928 |
const int64_t ne3 = tensor->ne[3];
|
| 1929 |
|
| 1930 |
const ggml_type type = tensor->type;
|
| 1931 |
+
const size_t s_sz = ggml_type_size(type) * (size_t) (ne0 * ne1 / ggml_blck_size(type));
|
| 1932 |
+
const size_t q_sz = s_sz * (size_t) (ne2 * ne3);
|
| 1933 |
|
| 1934 |
size_t q_size;
|
| 1935 |
cl_mem dst = ggml_cl_pool_malloc(q_sz, &q_size);
|
| 1936 |
|
| 1937 |
tensor->data = data;
|
| 1938 |
// copy tensor to device
|
| 1939 |
+
size_t offset = 0;
|
| 1940 |
for (int64_t i3 = 0; i3 < ne3; i3++) {
|
| 1941 |
for (int64_t i2 = 0; i2 < ne2; i2++) {
|
| 1942 |
+
CL_CHECK(ggml_cl_h2d_tensor_2d(queue, dst, offset, tensor, i3, i2, NULL));
|
| 1943 |
+
offset += s_sz;
|
| 1944 |
}
|
| 1945 |
}
|
| 1946 |
|
ggml.c
CHANGED
|
@@ -1033,8 +1033,8 @@ static void quantize_row_q5_0_reference(const float * restrict x, block_q5_0 * r
|
|
| 1033 |
y[i].qs[j] = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
|
| 1034 |
|
| 1035 |
// get the 5-th bit and store it in qh at the right position
|
| 1036 |
-
qh |= ((xi0 &
|
| 1037 |
-
qh |= ((xi1 &
|
| 1038 |
}
|
| 1039 |
|
| 1040 |
memcpy(&y[i].qh, &qh, sizeof(qh));
|
|
@@ -1081,8 +1081,8 @@ static void quantize_row_q5_1_reference(const float * restrict x, block_q5_1 * r
|
|
| 1081 |
y[i].qs[j] = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
|
| 1082 |
|
| 1083 |
// get the 5-th bit and store it in qh at the right position
|
| 1084 |
-
qh |= ((xi0 &
|
| 1085 |
-
qh |= ((xi1 &
|
| 1086 |
}
|
| 1087 |
|
| 1088 |
memcpy(&y[i].qh, &qh, sizeof(y[i].qh));
|
|
@@ -1273,6 +1273,33 @@ static void quantize_row_q8_0(const float * restrict x, void * restrict vy, int
|
|
| 1273 |
_mm_storeu_si128((__m128i *)(y[i].qs + 16), ni4);
|
| 1274 |
#endif
|
| 1275 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1276 |
#else
|
| 1277 |
// scalar
|
| 1278 |
quantize_row_q8_0_reference(x, y, k);
|
|
@@ -1491,6 +1518,41 @@ static void quantize_row_q8_1(const float * restrict x, void * restrict vy, int
|
|
| 1491 |
_mm_storeu_si128((__m128i *)(y[i].qs + 16), ni4);
|
| 1492 |
#endif
|
| 1493 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1494 |
#else
|
| 1495 |
// scalar
|
| 1496 |
quantize_row_q8_1_reference(x, y, k);
|
|
@@ -2663,30 +2725,32 @@ static void ggml_vec_dot_q4_0_q8_0(const int n, float * restrict s, const void *
|
|
| 2663 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 2664 |
|
| 2665 |
for (int i = 0; i < nb; i++) {
|
| 2666 |
-
|
|
|
|
| 2667 |
|
| 2668 |
-
|
| 2669 |
-
|
| 2670 |
|
| 2671 |
-
|
| 2672 |
-
|
|
|
|
| 2673 |
|
| 2674 |
-
|
| 2675 |
-
|
| 2676 |
|
| 2677 |
-
|
| 2678 |
-
|
|
|
|
| 2679 |
|
| 2680 |
-
|
| 2681 |
-
|
| 2682 |
|
| 2683 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 2684 |
|
| 2685 |
-
vint32m1_t vs1 =
|
| 2686 |
-
vint32m1_t vs2 =
|
| 2687 |
|
| 2688 |
-
int sumi = __riscv_vmv_x_s_i32m1_i32(
|
| 2689 |
-
sumi += __riscv_vmv_x_s_i32m1_i32(vs2);
|
| 2690 |
|
| 2691 |
sumf += sumi*GGML_FP16_TO_FP32(x[i].d)*GGML_FP16_TO_FP32(y[i].d);
|
| 2692 |
}
|
|
@@ -2824,27 +2888,28 @@ static void ggml_vec_dot_q4_1_q8_1(const int n, float * restrict s, const void *
|
|
| 2824 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 2825 |
|
| 2826 |
for (int i = 0; i < nb; i++) {
|
| 2827 |
-
|
|
|
|
| 2828 |
|
| 2829 |
-
|
| 2830 |
-
|
| 2831 |
|
| 2832 |
-
|
| 2833 |
-
|
|
|
|
| 2834 |
|
| 2835 |
-
|
| 2836 |
-
|
| 2837 |
|
| 2838 |
-
|
| 2839 |
-
|
| 2840 |
|
| 2841 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 2842 |
|
| 2843 |
-
vint32m1_t vs1 =
|
| 2844 |
-
vint32m1_t vs2 =
|
| 2845 |
|
| 2846 |
-
int sumi = __riscv_vmv_x_s_i32m1_i32(
|
| 2847 |
-
sumi += __riscv_vmv_x_s_i32m1_i32(vs2);
|
| 2848 |
|
| 2849 |
sumf += (GGML_FP16_TO_FP32(x[i].d)*y[i].d)*sumi + GGML_FP16_TO_FP32(x[i].m)*y[i].s;
|
| 2850 |
}
|
|
@@ -3089,66 +3154,61 @@ static void ggml_vec_dot_q5_0_q8_0(const int n, float * restrict s, const void *
|
|
| 3089 |
|
| 3090 |
uint32_t qh;
|
| 3091 |
|
| 3092 |
-
// These temp values are for masking and shift operations
|
| 3093 |
-
uint32_t temp_1[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
|
| 3094 |
-
uint32_t temp_2[16] = {0x1, 0x2, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80,
|
| 3095 |
-
0x100, 0x200, 0x400, 0x800, 0x1000, 0x2000, 0x4000, 0x8000};
|
| 3096 |
-
|
| 3097 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 3098 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3099 |
for (int i = 0; i < nb; i++) {
|
| 3100 |
memcpy(&qh, x[i].qh, sizeof(uint32_t));
|
| 3101 |
|
| 3102 |
-
// temporary registers
|
| 3103 |
-
vuint32m4_t vt_1 = __riscv_vle32_v_u32m4(temp_2, vl);
|
| 3104 |
-
vuint32m4_t vt_2 = __riscv_vle32_v_u32m4(temp_1, vl);
|
| 3105 |
-
vuint32m4_t vt_3 = __riscv_vsll_vx_u32m4(vt_1, 16, vl);
|
| 3106 |
-
vuint32m4_t vt_4 = __riscv_vadd_vx_u32m4(vt_2, 12, vl);
|
| 3107 |
-
|
| 3108 |
// ((qh & (1u << (j + 0 ))) >> (j + 0 )) << 4;
|
| 3109 |
-
|
| 3110 |
-
|
| 3111 |
-
|
| 3112 |
|
| 3113 |
// ((qh & (1u << (j + 16))) >> (j + 12));
|
| 3114 |
-
|
| 3115 |
-
|
| 3116 |
|
| 3117 |
// narrowing
|
| 3118 |
-
|
| 3119 |
-
|
| 3120 |
|
| 3121 |
-
|
| 3122 |
-
|
| 3123 |
|
| 3124 |
// load
|
| 3125 |
-
|
| 3126 |
|
| 3127 |
-
|
| 3128 |
-
|
| 3129 |
|
| 3130 |
-
|
| 3131 |
-
|
| 3132 |
|
| 3133 |
-
|
| 3134 |
-
|
| 3135 |
|
| 3136 |
-
|
| 3137 |
-
|
| 3138 |
|
| 3139 |
-
|
| 3140 |
-
|
| 3141 |
|
| 3142 |
-
|
| 3143 |
-
|
| 3144 |
|
| 3145 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 3146 |
|
| 3147 |
-
vint32m1_t vs1 =
|
| 3148 |
-
vint32m1_t vs2 =
|
| 3149 |
|
| 3150 |
-
int sumi = __riscv_vmv_x_s_i32m1_i32(
|
| 3151 |
-
sumi += __riscv_vmv_x_s_i32m1_i32(vs2);
|
| 3152 |
|
| 3153 |
sumf += (GGML_FP16_TO_FP32(x[i].d)*GGML_FP16_TO_FP32(y[i].d)) * sumi;
|
| 3154 |
}
|
|
@@ -3415,62 +3475,58 @@ static void ggml_vec_dot_q5_1_q8_1(const int n, float * restrict s, const void *
|
|
| 3415 |
|
| 3416 |
uint32_t qh;
|
| 3417 |
|
| 3418 |
-
// These temp values are for shift operations
|
| 3419 |
-
uint32_t temp_1[16] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
|
| 3420 |
-
|
| 3421 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 3422 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3423 |
for (int i = 0; i < nb; i++) {
|
| 3424 |
memcpy(&qh, x[i].qh, sizeof(uint32_t));
|
| 3425 |
|
| 3426 |
-
// temporary registers
|
| 3427 |
-
vuint32m4_t vt_1 = __riscv_vle32_v_u32m4(temp_1, vl);
|
| 3428 |
-
vuint32m4_t vt_2 = __riscv_vadd_vx_u32m4(vt_1, 12, vl);
|
| 3429 |
-
|
| 3430 |
// load qh
|
| 3431 |
-
|
| 3432 |
|
| 3433 |
// ((qh >> (j + 0)) << 4) & 0x10;
|
| 3434 |
-
|
| 3435 |
-
|
| 3436 |
-
|
| 3437 |
|
| 3438 |
// ((qh >> (j + 12)) ) & 0x10;
|
| 3439 |
-
|
| 3440 |
-
|
| 3441 |
|
| 3442 |
// narrowing
|
| 3443 |
-
|
| 3444 |
-
|
| 3445 |
|
| 3446 |
-
|
| 3447 |
-
|
| 3448 |
|
| 3449 |
// load
|
| 3450 |
-
|
| 3451 |
|
| 3452 |
-
|
| 3453 |
-
|
| 3454 |
|
| 3455 |
-
|
| 3456 |
-
|
| 3457 |
|
| 3458 |
-
|
| 3459 |
-
|
| 3460 |
|
| 3461 |
-
|
| 3462 |
-
|
| 3463 |
|
| 3464 |
-
|
| 3465 |
-
|
| 3466 |
|
| 3467 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 3468 |
|
| 3469 |
-
vint32m1_t vs1 =
|
| 3470 |
-
vint32m1_t vs2 =
|
| 3471 |
|
| 3472 |
-
int sumi = __riscv_vmv_x_s_i32m1_i32(
|
| 3473 |
-
sumi += __riscv_vmv_x_s_i32m1_i32(vs2);
|
| 3474 |
|
| 3475 |
sumf += (GGML_FP16_TO_FP32(x[i].d)*y[i].d)*sumi + GGML_FP16_TO_FP32(x[i].m)*y[i].s;
|
| 3476 |
}
|
|
@@ -4026,12 +4082,16 @@ static const char * GGML_OP_NAME[GGML_OP_COUNT] = {
|
|
| 4026 |
"ALIBI",
|
| 4027 |
"CLAMP",
|
| 4028 |
"CONV_1D",
|
|
|
|
| 4029 |
"CONV_2D",
|
| 4030 |
"CONV_TRANSPOSE_2D",
|
| 4031 |
"POOL_1D",
|
| 4032 |
"POOL_2D",
|
| 4033 |
"UPSCALE",
|
| 4034 |
|
|
|
|
|
|
|
|
|
|
| 4035 |
"FLASH_ATTN",
|
| 4036 |
"FLASH_FF",
|
| 4037 |
"FLASH_ATTN_BACK",
|
|
@@ -4057,7 +4117,7 @@ static const char * GGML_OP_NAME[GGML_OP_COUNT] = {
|
|
| 4057 |
"CROSS_ENTROPY_LOSS_BACK",
|
| 4058 |
};
|
| 4059 |
|
| 4060 |
-
static_assert(GGML_OP_COUNT ==
|
| 4061 |
|
| 4062 |
static const char * GGML_OP_SYMBOL[GGML_OP_COUNT] = {
|
| 4063 |
"none",
|
|
@@ -4108,12 +4168,16 @@ static const char * GGML_OP_SYMBOL[GGML_OP_COUNT] = {
|
|
| 4108 |
"alibi(x)",
|
| 4109 |
"clamp(x)",
|
| 4110 |
"conv_1d(x)",
|
|
|
|
| 4111 |
"conv_2d(x)",
|
| 4112 |
"conv_transpose_2d(x)",
|
| 4113 |
"pool_1d(x)",
|
| 4114 |
"pool_2d(x)",
|
| 4115 |
"upscale(x)",
|
| 4116 |
|
|
|
|
|
|
|
|
|
|
| 4117 |
"flash_attn(x)",
|
| 4118 |
"flash_ff(x)",
|
| 4119 |
"flash_attn_back(x)",
|
|
@@ -4139,7 +4203,7 @@ static const char * GGML_OP_SYMBOL[GGML_OP_COUNT] = {
|
|
| 4139 |
"cross_entropy_loss_back(x,y)",
|
| 4140 |
};
|
| 4141 |
|
| 4142 |
-
static_assert(GGML_OP_COUNT ==
|
| 4143 |
|
| 4144 |
static_assert(GGML_OP_POOL_COUNT == 2, "GGML_OP_POOL_COUNT != 2");
|
| 4145 |
|
|
@@ -4168,7 +4232,10 @@ static void ggml_setup_op_has_task_pass(void) {
|
|
| 4168 |
p[GGML_OP_DIAG_MASK_INF ] = true;
|
| 4169 |
p[GGML_OP_DIAG_MASK_ZERO ] = true;
|
| 4170 |
p[GGML_OP_CONV_1D ] = true;
|
|
|
|
|
|
|
| 4171 |
p[GGML_OP_CONV_2D ] = true;
|
|
|
|
| 4172 |
p[GGML_OP_CONV_TRANSPOSE_2D ] = true;
|
| 4173 |
p[GGML_OP_FLASH_ATTN_BACK ] = true;
|
| 4174 |
p[GGML_OP_CROSS_ENTROPY_LOSS ] = true;
|
|
@@ -6691,7 +6758,6 @@ struct ggml_tensor * ggml_cont_4d(
|
|
| 6691 |
return result;
|
| 6692 |
}
|
| 6693 |
|
| 6694 |
-
|
| 6695 |
// ggml_reshape
|
| 6696 |
|
| 6697 |
struct ggml_tensor * ggml_reshape(
|
|
@@ -7449,14 +7515,17 @@ static int64_t ggml_calc_conv_output_size(int64_t ins, int64_t ks, int s, int p,
|
|
| 7449 |
return (ins + 2 * p - d * (ks - 1) - 1) / s + 1;
|
| 7450 |
}
|
| 7451 |
|
| 7452 |
-
|
| 7453 |
-
|
| 7454 |
-
|
| 7455 |
-
|
| 7456 |
-
|
| 7457 |
-
|
| 7458 |
-
|
| 7459 |
-
|
|
|
|
|
|
|
|
|
|
| 7460 |
GGML_ASSERT(a->ne[1] == b->ne[1]);
|
| 7461 |
bool is_node = false;
|
| 7462 |
|
|
@@ -7465,16 +7534,54 @@ GGML_API struct ggml_tensor * ggml_conv_1d(
|
|
| 7465 |
is_node = true;
|
| 7466 |
}
|
| 7467 |
|
|
|
|
|
|
|
| 7468 |
const int64_t ne[4] = {
|
| 7469 |
-
|
| 7470 |
-
|
|
|
|
|
|
|
| 7471 |
};
|
| 7472 |
-
struct ggml_tensor * result = ggml_new_tensor(ctx,
|
| 7473 |
|
| 7474 |
int32_t params[] = { s0, p0, d0 };
|
| 7475 |
ggml_set_op_params(result, params, sizeof(params));
|
| 7476 |
|
| 7477 |
-
result->op =
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7478 |
result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
|
| 7479 |
result->src[0] = a;
|
| 7480 |
result->src[1] = b;
|
|
@@ -7482,6 +7589,53 @@ GGML_API struct ggml_tensor * ggml_conv_1d(
|
|
| 7482 |
return result;
|
| 7483 |
}
|
| 7484 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7485 |
// ggml_conv_1d_ph
|
| 7486 |
|
| 7487 |
struct ggml_tensor* ggml_conv_1d_ph(
|
|
@@ -7493,6 +7647,50 @@ struct ggml_tensor* ggml_conv_1d_ph(
|
|
| 7493 |
return ggml_conv_1d(ctx, a, b, s, a->ne[0] / 2, d);
|
| 7494 |
}
|
| 7495 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7496 |
// ggml_conv_2d
|
| 7497 |
|
| 7498 |
struct ggml_tensor * ggml_conv_2d(
|
|
@@ -12885,7 +13083,7 @@ static void ggml_compute_forward_alibi_f32(
|
|
| 12885 |
return;
|
| 12886 |
}
|
| 12887 |
|
| 12888 |
-
const int n_past = ((int32_t *) dst->op_params)[0];
|
| 12889 |
const int n_head = ((int32_t *) dst->op_params)[1];
|
| 12890 |
float max_bias;
|
| 12891 |
memcpy(&max_bias, (int32_t *) dst->op_params + 2, sizeof(float));
|
|
@@ -12906,7 +13104,6 @@ static void ggml_compute_forward_alibi_f32(
|
|
| 12906 |
//const int nb3 = src0->nb[3];
|
| 12907 |
|
| 12908 |
GGML_ASSERT(nb0 == sizeof(float));
|
| 12909 |
-
GGML_ASSERT(ne1 + n_past == ne0);
|
| 12910 |
GGML_ASSERT(n_head == ne2);
|
| 12911 |
|
| 12912 |
// add alibi to src0 (KQ_scaled)
|
|
@@ -13632,7 +13829,7 @@ static void ggml_compute_forward_rope_back(
|
|
| 13632 |
|
| 13633 |
// ggml_compute_forward_conv_1d
|
| 13634 |
|
| 13635 |
-
static void
|
| 13636 |
const struct ggml_compute_params * params,
|
| 13637 |
const struct ggml_tensor * src0,
|
| 13638 |
const struct ggml_tensor * src1,
|
|
@@ -13650,42 +13847,33 @@ static void ggml_compute_forward_conv_1d_s1_ph_f16_f32(
|
|
| 13650 |
const int nth = params->nth;
|
| 13651 |
|
| 13652 |
const int nk = ne00;
|
| 13653 |
-
const int nh = nk/2;
|
| 13654 |
|
| 13655 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13656 |
|
| 13657 |
-
GGML_ASSERT(ne00 % 2 == 1); // TODO: support even kernel sizes
|
| 13658 |
GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
|
| 13659 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 13660 |
|
| 13661 |
if (params->type == GGML_TASK_INIT) {
|
| 13662 |
-
// TODO: fix this memset (wsize is overestimated)
|
| 13663 |
memset(params->wdata, 0, params->wsize);
|
| 13664 |
|
| 13665 |
-
|
| 13666 |
-
{
|
| 13667 |
-
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 13668 |
|
| 13669 |
-
|
| 13670 |
-
|
| 13671 |
-
|
| 13672 |
-
ggml_fp16_t * dst_data = wdata + i02*ew0*ne00;
|
| 13673 |
-
for (int64_t i00 = 0; i00 < ne00; i00++) {
|
| 13674 |
-
dst_data[i00*ew0 + i01] = src[i00];
|
| 13675 |
-
}
|
| 13676 |
-
}
|
| 13677 |
-
}
|
| 13678 |
-
}
|
| 13679 |
|
| 13680 |
-
|
| 13681 |
-
|
| 13682 |
-
|
| 13683 |
|
| 13684 |
-
|
| 13685 |
-
|
| 13686 |
-
|
| 13687 |
-
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 13688 |
-
dst_data[(i10 + nh)*ew0 + i11] = GGML_FP32_TO_FP16(src[i10]);
|
| 13689 |
}
|
| 13690 |
}
|
| 13691 |
}
|
|
@@ -13698,7 +13886,7 @@ static void ggml_compute_forward_conv_1d_s1_ph_f16_f32(
|
|
| 13698 |
}
|
| 13699 |
|
| 13700 |
// total rows in dst
|
| 13701 |
-
const int nr =
|
| 13702 |
|
| 13703 |
// rows per thread
|
| 13704 |
const int dr = (nr + nth - 1)/nth;
|
|
@@ -13707,23 +13895,22 @@ static void ggml_compute_forward_conv_1d_s1_ph_f16_f32(
|
|
| 13707 |
const int ir0 = dr*ith;
|
| 13708 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 13709 |
|
| 13710 |
-
|
| 13711 |
-
|
| 13712 |
-
|
| 13713 |
-
|
| 13714 |
-
|
| 13715 |
-
|
| 13716 |
-
|
| 13717 |
-
|
| 13718 |
-
(ggml_fp16_t *)
|
| 13719 |
-
|
| 13720 |
-
dst_data[i0] += v;
|
| 13721 |
}
|
| 13722 |
}
|
| 13723 |
}
|
| 13724 |
}
|
| 13725 |
|
| 13726 |
-
static void
|
| 13727 |
const struct ggml_compute_params * params,
|
| 13728 |
const struct ggml_tensor * src0,
|
| 13729 |
const struct ggml_tensor * src1,
|
|
@@ -13741,42 +13928,32 @@ static void ggml_compute_forward_conv_1d_s1_ph_f32(
|
|
| 13741 |
const int nth = params->nth;
|
| 13742 |
|
| 13743 |
const int nk = ne00;
|
| 13744 |
-
const int nh = nk/2;
|
| 13745 |
|
| 13746 |
-
const int ew0 =
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13747 |
|
| 13748 |
-
GGML_ASSERT(ne00 % 2 == 1); // TODO: support even kernel sizes
|
| 13749 |
GGML_ASSERT(nb00 == sizeof(float));
|
| 13750 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 13751 |
|
| 13752 |
if (params->type == GGML_TASK_INIT) {
|
| 13753 |
-
// TODO: fix this memset (wsize is overestimated)
|
| 13754 |
memset(params->wdata, 0, params->wsize);
|
| 13755 |
|
| 13756 |
-
|
| 13757 |
-
{
|
| 13758 |
-
float * const wdata = (float *) params->wdata + 0;
|
| 13759 |
|
| 13760 |
-
|
| 13761 |
-
|
| 13762 |
-
|
| 13763 |
-
float * dst_data = wdata + i02*ew0*ne00;
|
| 13764 |
-
for (int64_t i00 = 0; i00 < ne00; i00++) {
|
| 13765 |
-
dst_data[i00*ew0 + i01] = src[i00];
|
| 13766 |
-
}
|
| 13767 |
-
}
|
| 13768 |
-
}
|
| 13769 |
-
}
|
| 13770 |
|
| 13771 |
-
|
| 13772 |
-
|
| 13773 |
-
|
| 13774 |
|
| 13775 |
-
|
| 13776 |
-
|
| 13777 |
-
|
| 13778 |
-
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 13779 |
-
dst_data[(i10 + nh)*ew0 + i11] = src[i10];
|
| 13780 |
}
|
| 13781 |
}
|
| 13782 |
}
|
|
@@ -13798,35 +13975,242 @@ static void ggml_compute_forward_conv_1d_s1_ph_f32(
|
|
| 13798 |
const int ir0 = dr*ith;
|
| 13799 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 13800 |
|
| 13801 |
-
|
| 13802 |
-
|
| 13803 |
-
|
| 13804 |
-
|
| 13805 |
-
|
| 13806 |
-
|
| 13807 |
-
|
| 13808 |
-
|
| 13809 |
-
(float *)
|
| 13810 |
-
|
| 13811 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13812 |
}
|
| 13813 |
}
|
| 13814 |
}
|
| 13815 |
}
|
| 13816 |
|
| 13817 |
-
|
|
|
|
|
|
|
|
|
|
| 13818 |
const struct ggml_compute_params * params,
|
| 13819 |
const struct ggml_tensor * src0,
|
| 13820 |
const struct ggml_tensor * src1,
|
| 13821 |
struct ggml_tensor * dst) {
|
| 13822 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13823 |
case GGML_TYPE_F16:
|
| 13824 |
{
|
| 13825 |
-
|
| 13826 |
} break;
|
| 13827 |
case GGML_TYPE_F32:
|
| 13828 |
{
|
| 13829 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13830 |
} break;
|
| 13831 |
default:
|
| 13832 |
{
|
|
@@ -13835,7 +14219,26 @@ static void ggml_compute_forward_conv_1d_s1_ph(
|
|
| 13835 |
}
|
| 13836 |
}
|
| 13837 |
|
| 13838 |
-
static void
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13839 |
const struct ggml_compute_params * params,
|
| 13840 |
const struct ggml_tensor * src0,
|
| 13841 |
const struct ggml_tensor * src1,
|
|
@@ -13852,43 +14255,38 @@ static void ggml_compute_forward_conv_1d_s2_ph_f16_f32(
|
|
| 13852 |
const int ith = params->ith;
|
| 13853 |
const int nth = params->nth;
|
| 13854 |
|
| 13855 |
-
const int nk = ne00;
|
| 13856 |
-
const int nh = nk/2;
|
| 13857 |
-
|
| 13858 |
-
const int ew0 = ggml_up32(ne01);
|
| 13859 |
|
| 13860 |
-
GGML_ASSERT(ne00 % 2 == 1); // TODO: support even kernel sizes
|
| 13861 |
GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
|
| 13862 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 13863 |
|
| 13864 |
if (params->type == GGML_TASK_INIT) {
|
| 13865 |
-
// TODO: fix this memset (wsize is overestimated)
|
| 13866 |
memset(params->wdata, 0, params->wsize);
|
| 13867 |
|
| 13868 |
-
//
|
| 13869 |
{
|
| 13870 |
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 13871 |
|
| 13872 |
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
| 13873 |
for (int64_t i01 = 0; i01 < ne01; i01++) {
|
| 13874 |
const ggml_fp16_t * const src = (ggml_fp16_t *)((char *) src0->data + i02*nb02 + i01*nb01);
|
| 13875 |
-
ggml_fp16_t * dst_data = wdata +
|
| 13876 |
for (int64_t i00 = 0; i00 < ne00; i00++) {
|
| 13877 |
-
dst_data[i00*
|
| 13878 |
}
|
| 13879 |
}
|
| 13880 |
}
|
| 13881 |
}
|
| 13882 |
|
| 13883 |
-
//
|
| 13884 |
{
|
| 13885 |
-
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata +
|
|
|
|
| 13886 |
|
| 13887 |
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 13888 |
const float * const src = (float *)((char *) src1->data + i11*nb11);
|
| 13889 |
-
ggml_fp16_t * dst_data = wdata;
|
| 13890 |
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 13891 |
-
dst_data[
|
| 13892 |
}
|
| 13893 |
}
|
| 13894 |
}
|
|
@@ -13900,8 +14298,10 @@ static void ggml_compute_forward_conv_1d_s2_ph_f16_f32(
|
|
| 13900 |
return;
|
| 13901 |
}
|
| 13902 |
|
|
|
|
|
|
|
| 13903 |
// total rows in dst
|
| 13904 |
-
const int nr =
|
| 13905 |
|
| 13906 |
// rows per thread
|
| 13907 |
const int dr = (nr + nth - 1)/nth;
|
|
@@ -13910,23 +14310,26 @@ static void ggml_compute_forward_conv_1d_s2_ph_f16_f32(
|
|
| 13910 |
const int ir0 = dr*ith;
|
| 13911 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 13912 |
|
|
|
|
|
|
|
|
|
|
| 13913 |
for (int i1 = ir0; i1 < ir1; i1++) {
|
| 13914 |
float * dst_data = (float *)((char *) dst->data + i1*nb1);
|
| 13915 |
-
|
| 13916 |
-
|
| 13917 |
-
|
| 13918 |
-
|
| 13919 |
-
|
| 13920 |
-
|
| 13921 |
-
(ggml_fp16_t *)
|
| 13922 |
-
|
| 13923 |
-
dst_data[
|
| 13924 |
}
|
| 13925 |
}
|
| 13926 |
}
|
| 13927 |
}
|
| 13928 |
|
| 13929 |
-
static void
|
| 13930 |
const struct ggml_compute_params * params,
|
| 13931 |
const struct ggml_tensor * src0,
|
| 13932 |
const struct ggml_tensor * src1,
|
|
@@ -13943,29 +14346,24 @@ static void ggml_compute_forward_conv_1d_s2_ph_f32(
|
|
| 13943 |
const int ith = params->ith;
|
| 13944 |
const int nth = params->nth;
|
| 13945 |
|
| 13946 |
-
const int nk = ne00;
|
| 13947 |
-
const int nh = nk/2;
|
| 13948 |
-
|
| 13949 |
-
const int ew0 = ggml_up32(ne01);
|
| 13950 |
|
| 13951 |
-
GGML_ASSERT(ne00 % 2 == 1); // TODO: support even kernel sizes
|
| 13952 |
GGML_ASSERT(nb00 == sizeof(float));
|
| 13953 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 13954 |
|
| 13955 |
if (params->type == GGML_TASK_INIT) {
|
| 13956 |
-
// TODO: fix this memset (wsize is overestimated)
|
| 13957 |
memset(params->wdata, 0, params->wsize);
|
| 13958 |
|
| 13959 |
-
// prepare kernel data (src0)
|
| 13960 |
{
|
| 13961 |
float * const wdata = (float *) params->wdata + 0;
|
| 13962 |
|
| 13963 |
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
| 13964 |
for (int64_t i01 = 0; i01 < ne01; i01++) {
|
| 13965 |
const float * const src = (float *)((char *) src0->data + i02*nb02 + i01*nb01);
|
| 13966 |
-
float * dst_data = wdata +
|
| 13967 |
for (int64_t i00 = 0; i00 < ne00; i00++) {
|
| 13968 |
-
dst_data[i00*
|
| 13969 |
}
|
| 13970 |
}
|
| 13971 |
}
|
|
@@ -13973,13 +14371,13 @@ static void ggml_compute_forward_conv_1d_s2_ph_f32(
|
|
| 13973 |
|
| 13974 |
// prepare source data (src1)
|
| 13975 |
{
|
| 13976 |
-
float * const wdata = (float *) params->wdata +
|
|
|
|
| 13977 |
|
| 13978 |
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 13979 |
const float * const src = (float *)((char *) src1->data + i11*nb11);
|
| 13980 |
-
float * dst_data = wdata;
|
| 13981 |
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 13982 |
-
dst_data[
|
| 13983 |
}
|
| 13984 |
}
|
| 13985 |
}
|
|
@@ -13991,8 +14389,10 @@ static void ggml_compute_forward_conv_1d_s2_ph_f32(
|
|
| 13991 |
return;
|
| 13992 |
}
|
| 13993 |
|
|
|
|
|
|
|
| 13994 |
// total rows in dst
|
| 13995 |
-
const int nr =
|
| 13996 |
|
| 13997 |
// rows per thread
|
| 13998 |
const int dr = (nr + nth - 1)/nth;
|
|
@@ -14001,23 +14401,26 @@ static void ggml_compute_forward_conv_1d_s2_ph_f32(
|
|
| 14001 |
const int ir0 = dr*ith;
|
| 14002 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 14003 |
|
|
|
|
|
|
|
|
|
|
| 14004 |
for (int i1 = ir0; i1 < ir1; i1++) {
|
| 14005 |
float * dst_data = (float *)((char *) dst->data + i1*nb1);
|
| 14006 |
-
|
| 14007 |
-
|
| 14008 |
-
|
| 14009 |
-
|
| 14010 |
-
|
| 14011 |
-
|
| 14012 |
-
|
| 14013 |
-
|
| 14014 |
-
dst_data[
|
| 14015 |
}
|
| 14016 |
}
|
| 14017 |
}
|
| 14018 |
}
|
| 14019 |
|
| 14020 |
-
static void
|
| 14021 |
const struct ggml_compute_params * params,
|
| 14022 |
const struct ggml_tensor * src0,
|
| 14023 |
const struct ggml_tensor * src1,
|
|
@@ -14025,11 +14428,11 @@ static void ggml_compute_forward_conv_1d_s2_ph(
|
|
| 14025 |
switch (src0->type) {
|
| 14026 |
case GGML_TYPE_F16:
|
| 14027 |
{
|
| 14028 |
-
|
| 14029 |
} break;
|
| 14030 |
case GGML_TYPE_F32:
|
| 14031 |
{
|
| 14032 |
-
|
| 14033 |
} break;
|
| 14034 |
default:
|
| 14035 |
{
|
|
@@ -14038,27 +14441,6 @@ static void ggml_compute_forward_conv_1d_s2_ph(
|
|
| 14038 |
}
|
| 14039 |
}
|
| 14040 |
|
| 14041 |
-
// ggml_compute_forward_conv_1d
|
| 14042 |
-
|
| 14043 |
-
static void ggml_compute_forward_conv_1d(
|
| 14044 |
-
const struct ggml_compute_params * params,
|
| 14045 |
-
const struct ggml_tensor * src0,
|
| 14046 |
-
const struct ggml_tensor * src1,
|
| 14047 |
-
struct ggml_tensor * dst) {
|
| 14048 |
-
const int32_t s0 = ((const int32_t*)(dst->op_params))[0];
|
| 14049 |
-
const int32_t p0 = ((const int32_t*)(dst->op_params))[1];
|
| 14050 |
-
const int32_t d0 = ((const int32_t*)(dst->op_params))[2];
|
| 14051 |
-
GGML_ASSERT(d0 == 1); // dilation not supported
|
| 14052 |
-
GGML_ASSERT(p0 == src0->ne[0]/2); // only half padding supported
|
| 14053 |
-
if (s0 == 1) {
|
| 14054 |
-
ggml_compute_forward_conv_1d_s1_ph(params, src0, src1, dst);
|
| 14055 |
-
} else if (s0 == 2) {
|
| 14056 |
-
ggml_compute_forward_conv_1d_s2_ph(params, src0, src1, dst);
|
| 14057 |
-
} else {
|
| 14058 |
-
GGML_ASSERT(false); // only stride 1 and 2 supported
|
| 14059 |
-
}
|
| 14060 |
-
}
|
| 14061 |
-
|
| 14062 |
// ggml_compute_forward_conv_2d
|
| 14063 |
|
| 14064 |
static void ggml_compute_forward_conv_2d_f16_f32(
|
|
@@ -14101,20 +14483,22 @@ static void ggml_compute_forward_conv_2d_f16_f32(
|
|
| 14101 |
{
|
| 14102 |
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 14103 |
|
| 14104 |
-
for (int
|
| 14105 |
-
|
| 14106 |
-
|
| 14107 |
-
|
| 14108 |
-
|
| 14109 |
-
for (int
|
| 14110 |
-
for (int
|
| 14111 |
-
for (int
|
| 14112 |
-
|
| 14113 |
-
|
| 14114 |
-
|
| 14115 |
-
|
| 14116 |
-
|
| 14117 |
-
|
|
|
|
|
|
|
| 14118 |
}
|
| 14119 |
}
|
| 14120 |
}
|
|
@@ -16397,6 +16781,18 @@ static void ggml_compute_forward(struct ggml_compute_params * params, struct ggm
|
|
| 16397 |
{
|
| 16398 |
ggml_compute_forward_conv_1d(params, tensor->src[0], tensor->src[1], tensor);
|
| 16399 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16400 |
case GGML_OP_CONV_2D:
|
| 16401 |
{
|
| 16402 |
ggml_compute_forward_conv_2d(params, tensor->src[0], tensor->src[1], tensor);
|
|
@@ -17322,10 +17718,22 @@ static void ggml_compute_backward(struct ggml_context * ctx, struct ggml_tensor
|
|
| 17322 |
{
|
| 17323 |
GGML_ASSERT(false); // TODO: not implemented
|
| 17324 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17325 |
case GGML_OP_CONV_2D:
|
| 17326 |
{
|
| 17327 |
GGML_ASSERT(false); // TODO: not implemented
|
| 17328 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17329 |
case GGML_OP_CONV_TRANSPOSE_2D:
|
| 17330 |
{
|
| 17331 |
GGML_ASSERT(false); // TODO: not implemented
|
|
@@ -18163,21 +18571,68 @@ struct ggml_cplan ggml_graph_plan(struct ggml_cgraph * cgraph, int n_threads) {
|
|
| 18163 |
GGML_ASSERT(node->src[1]->ne[2] == 1);
|
| 18164 |
GGML_ASSERT(node->src[1]->ne[3] == 1);
|
| 18165 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18166 |
size_t cur = 0;
|
| 18167 |
-
const int nk = node->src[0]->ne[0];
|
| 18168 |
|
| 18169 |
if (node->src[0]->type == GGML_TYPE_F16 &&
|
| 18170 |
-
|
| 18171 |
-
cur = sizeof(ggml_fp16_t)*(
|
| 18172 |
-
|
| 18173 |
-
|
| 18174 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 18175 |
} else if (node->src[0]->type == GGML_TYPE_F32 &&
|
| 18176 |
-
|
| 18177 |
-
cur
|
| 18178 |
-
|
| 18179 |
-
( 2*(nk/2) + node->src[1]->ne[0])*node->src[1]->ne[1]
|
| 18180 |
-
);
|
| 18181 |
} else {
|
| 18182 |
GGML_ASSERT(false);
|
| 18183 |
}
|
|
@@ -19303,7 +19758,7 @@ static enum ggml_opt_result ggml_opt_adam(
|
|
| 19303 |
if (callback) {
|
| 19304 |
callback(callback_data, accum_step, &sched, &cancel);
|
| 19305 |
if (cancel) {
|
| 19306 |
-
|
| 19307 |
}
|
| 19308 |
}
|
| 19309 |
// ggml_graph_reset (gf);
|
|
@@ -19312,9 +19767,6 @@ static enum ggml_opt_result ggml_opt_adam(
|
|
| 19312 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 19313 |
fx += ggml_get_f32_1d(f, 0);
|
| 19314 |
}
|
| 19315 |
-
if (cancel) {
|
| 19316 |
-
return GGML_OPT_DID_NOT_CONVERGE;
|
| 19317 |
-
}
|
| 19318 |
fx *= accum_norm;
|
| 19319 |
|
| 19320 |
opt->adam.fx_prev = fx;
|
|
@@ -19340,9 +19792,6 @@ static enum ggml_opt_result ggml_opt_adam(
|
|
| 19340 |
|
| 19341 |
// run the optimizer
|
| 19342 |
for (int t = 0; t < params.adam.n_iter; ++t) {
|
| 19343 |
-
if (cancel) {
|
| 19344 |
-
break;
|
| 19345 |
-
}
|
| 19346 |
opt->iter = iter0 + t + 1;
|
| 19347 |
GGML_PRINT_DEBUG ("=== iter %d ===\n", t);
|
| 19348 |
|
|
@@ -19400,7 +19849,7 @@ static enum ggml_opt_result ggml_opt_adam(
|
|
| 19400 |
if (callback) {
|
| 19401 |
callback(callback_data, accum_step, &sched, &cancel);
|
| 19402 |
if (cancel) {
|
| 19403 |
-
|
| 19404 |
}
|
| 19405 |
}
|
| 19406 |
// ggml_graph_reset (gf);
|
|
@@ -19409,9 +19858,6 @@ static enum ggml_opt_result ggml_opt_adam(
|
|
| 19409 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 19410 |
fx += ggml_get_f32_1d(f, 0);
|
| 19411 |
}
|
| 19412 |
-
if (cancel) {
|
| 19413 |
-
break;
|
| 19414 |
-
}
|
| 19415 |
fx *= accum_norm;
|
| 19416 |
|
| 19417 |
opt->loss_after = fx;
|
|
@@ -19530,7 +19976,7 @@ static enum ggml_opt_result linesearch_backtracking(
|
|
| 19530 |
finit = *fx;
|
| 19531 |
dgtest = params->lbfgs.ftol*dginit;
|
| 19532 |
|
| 19533 |
-
while (
|
| 19534 |
ggml_vec_cpy_f32(nx, x, xp);
|
| 19535 |
ggml_vec_mad_f32(nx, x, d, *step);
|
| 19536 |
|
|
@@ -19546,7 +19992,7 @@ static enum ggml_opt_result linesearch_backtracking(
|
|
| 19546 |
float sched = 0;
|
| 19547 |
callback(callback_data, accum_step, &sched, cancel);
|
| 19548 |
if (*cancel) {
|
| 19549 |
-
|
| 19550 |
}
|
| 19551 |
}
|
| 19552 |
// ggml_graph_reset (gf);
|
|
@@ -19555,9 +20001,6 @@ static enum ggml_opt_result linesearch_backtracking(
|
|
| 19555 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 19556 |
*fx += ggml_get_f32_1d(f, 0);
|
| 19557 |
}
|
| 19558 |
-
if (*cancel) {
|
| 19559 |
-
break;
|
| 19560 |
-
}
|
| 19561 |
*fx *= accum_norm;
|
| 19562 |
|
| 19563 |
}
|
|
@@ -19690,7 +20133,7 @@ static enum ggml_opt_result ggml_opt_lbfgs(
|
|
| 19690 |
float sched = 0;
|
| 19691 |
callback(callback_data, accum_step, &sched, &cancel);
|
| 19692 |
if (cancel) {
|
| 19693 |
-
|
| 19694 |
}
|
| 19695 |
}
|
| 19696 |
// ggml_graph_reset (gf);
|
|
@@ -19699,9 +20142,6 @@ static enum ggml_opt_result ggml_opt_lbfgs(
|
|
| 19699 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 19700 |
fx += ggml_get_f32_1d(f, 0);
|
| 19701 |
}
|
| 19702 |
-
if (cancel) {
|
| 19703 |
-
return GGML_OPT_DID_NOT_CONVERGE;
|
| 19704 |
-
}
|
| 19705 |
fx *= accum_norm;
|
| 19706 |
|
| 19707 |
opt->loss_before = fx;
|
|
@@ -19761,8 +20201,8 @@ static enum ggml_opt_result ggml_opt_lbfgs(
|
|
| 19761 |
ggml_vec_cpy_f32(nx, gp, g);
|
| 19762 |
|
| 19763 |
ls = linesearch_backtracking(¶ms, nx, x, &fx, g, d, step, xp, f, gb, &cplan, np, ps, &cancel, callback, callback_data);
|
| 19764 |
-
if (
|
| 19765 |
-
|
| 19766 |
}
|
| 19767 |
|
| 19768 |
if (ls < 0) {
|
|
|
|
| 1033 |
y[i].qs[j] = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
|
| 1034 |
|
| 1035 |
// get the 5-th bit and store it in qh at the right position
|
| 1036 |
+
qh |= ((xi0 & 0x10u) >> 4) << (j + 0);
|
| 1037 |
+
qh |= ((xi1 & 0x10u) >> 4) << (j + qk/2);
|
| 1038 |
}
|
| 1039 |
|
| 1040 |
memcpy(&y[i].qh, &qh, sizeof(qh));
|
|
|
|
| 1081 |
y[i].qs[j] = (xi0 & 0x0F) | ((xi1 & 0x0F) << 4);
|
| 1082 |
|
| 1083 |
// get the 5-th bit and store it in qh at the right position
|
| 1084 |
+
qh |= ((xi0 & 0x10u) >> 4) << (j + 0);
|
| 1085 |
+
qh |= ((xi1 & 0x10u) >> 4) << (j + qk/2);
|
| 1086 |
}
|
| 1087 |
|
| 1088 |
memcpy(&y[i].qh, &qh, sizeof(y[i].qh));
|
|
|
|
| 1273 |
_mm_storeu_si128((__m128i *)(y[i].qs + 16), ni4);
|
| 1274 |
#endif
|
| 1275 |
}
|
| 1276 |
+
#elif defined(__riscv_v_intrinsic)
|
| 1277 |
+
|
| 1278 |
+
size_t vl = __riscv_vsetvl_e32m4(QK8_0);
|
| 1279 |
+
|
| 1280 |
+
for (int i = 0; i < nb; i++) {
|
| 1281 |
+
// load elements
|
| 1282 |
+
vfloat32m4_t v_x = __riscv_vle32_v_f32m4(x+i*QK8_0, vl);
|
| 1283 |
+
|
| 1284 |
+
vfloat32m4_t vfabs = __riscv_vfabs_v_f32m4(v_x, vl);
|
| 1285 |
+
vfloat32m1_t tmp = __riscv_vfmv_v_f_f32m1(0.0f, vl);
|
| 1286 |
+
vfloat32m1_t vmax = __riscv_vfredmax_vs_f32m4_f32m1(vfabs, tmp, vl);
|
| 1287 |
+
float amax = __riscv_vfmv_f_s_f32m1_f32(vmax);
|
| 1288 |
+
|
| 1289 |
+
const float d = amax / ((1 << 7) - 1);
|
| 1290 |
+
const float id = d ? 1.0f/d : 0.0f;
|
| 1291 |
+
|
| 1292 |
+
y[i].d = GGML_FP32_TO_FP16(d);
|
| 1293 |
+
|
| 1294 |
+
vfloat32m4_t x0 = __riscv_vfmul_vf_f32m4(v_x, id, vl);
|
| 1295 |
+
|
| 1296 |
+
// convert to integer
|
| 1297 |
+
vint16m2_t vi = __riscv_vfncvt_x_f_w_i16m2(x0, vl);
|
| 1298 |
+
vint8m1_t vs = __riscv_vncvt_x_x_w_i8m1(vi, vl);
|
| 1299 |
+
|
| 1300 |
+
// store result
|
| 1301 |
+
__riscv_vse8_v_i8m1(y[i].qs , vs, vl);
|
| 1302 |
+
}
|
| 1303 |
#else
|
| 1304 |
// scalar
|
| 1305 |
quantize_row_q8_0_reference(x, y, k);
|
|
|
|
| 1518 |
_mm_storeu_si128((__m128i *)(y[i].qs + 16), ni4);
|
| 1519 |
#endif
|
| 1520 |
}
|
| 1521 |
+
#elif defined(__riscv_v_intrinsic)
|
| 1522 |
+
|
| 1523 |
+
size_t vl = __riscv_vsetvl_e32m4(QK8_1);
|
| 1524 |
+
|
| 1525 |
+
for (int i = 0; i < nb; i++) {
|
| 1526 |
+
// load elements
|
| 1527 |
+
vfloat32m4_t v_x = __riscv_vle32_v_f32m4(x+i*QK8_1, vl);
|
| 1528 |
+
|
| 1529 |
+
vfloat32m4_t vfabs = __riscv_vfabs_v_f32m4(v_x, vl);
|
| 1530 |
+
vfloat32m1_t tmp = __riscv_vfmv_v_f_f32m1(0.0, vl);
|
| 1531 |
+
vfloat32m1_t vmax = __riscv_vfredmax_vs_f32m4_f32m1(vfabs, tmp, vl);
|
| 1532 |
+
float amax = __riscv_vfmv_f_s_f32m1_f32(vmax);
|
| 1533 |
+
|
| 1534 |
+
const float d = amax / ((1 << 7) - 1);
|
| 1535 |
+
const float id = d ? 1.0f/d : 0.0f;
|
| 1536 |
+
|
| 1537 |
+
y[i].d = d;
|
| 1538 |
+
|
| 1539 |
+
vfloat32m4_t x0 = __riscv_vfmul_vf_f32m4(v_x, id, vl);
|
| 1540 |
+
|
| 1541 |
+
// convert to integer
|
| 1542 |
+
vint16m2_t vi = __riscv_vfncvt_x_f_w_i16m2(x0, vl);
|
| 1543 |
+
vint8m1_t vs = __riscv_vncvt_x_x_w_i8m1(vi, vl);
|
| 1544 |
+
|
| 1545 |
+
// store result
|
| 1546 |
+
__riscv_vse8_v_i8m1(y[i].qs , vs, vl);
|
| 1547 |
+
|
| 1548 |
+
// compute sum for y[i].s
|
| 1549 |
+
vint16m1_t tmp2 = __riscv_vmv_v_x_i16m1(0, vl);
|
| 1550 |
+
vint16m1_t vwrs = __riscv_vwredsum_vs_i8m1_i16m1(vs, tmp2, vl);
|
| 1551 |
+
|
| 1552 |
+
// set y[i].s
|
| 1553 |
+
int sum = __riscv_vmv_x_s_i16m1_i16(vwrs);
|
| 1554 |
+
y[i].s = sum*d;
|
| 1555 |
+
}
|
| 1556 |
#else
|
| 1557 |
// scalar
|
| 1558 |
quantize_row_q8_1_reference(x, y, k);
|
|
|
|
| 2725 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 2726 |
|
| 2727 |
for (int i = 0; i < nb; i++) {
|
| 2728 |
+
// load elements
|
| 2729 |
+
vuint8mf2_t tx = __riscv_vle8_v_u8mf2(x[i].qs, vl);
|
| 2730 |
|
| 2731 |
+
vint8mf2_t y0 = __riscv_vle8_v_i8mf2(y[i].qs, vl);
|
| 2732 |
+
vint8mf2_t y1 = __riscv_vle8_v_i8mf2(y[i].qs+16, vl);
|
| 2733 |
|
| 2734 |
+
// mask and store lower part of x, and then upper part
|
| 2735 |
+
vuint8mf2_t x_a = __riscv_vand_vx_u8mf2(tx, 0x0F, vl);
|
| 2736 |
+
vuint8mf2_t x_l = __riscv_vsrl_vx_u8mf2(tx, 0x04, vl);
|
| 2737 |
|
| 2738 |
+
vint8mf2_t x_ai = __riscv_vreinterpret_v_u8mf2_i8mf2(x_a);
|
| 2739 |
+
vint8mf2_t x_li = __riscv_vreinterpret_v_u8mf2_i8mf2(x_l);
|
| 2740 |
|
| 2741 |
+
// subtract offset
|
| 2742 |
+
vint8mf2_t v0 = __riscv_vsub_vx_i8mf2(x_ai, 8, vl);
|
| 2743 |
+
vint8mf2_t v1 = __riscv_vsub_vx_i8mf2(x_li, 8, vl);
|
| 2744 |
|
| 2745 |
+
vint16m1_t vec_mul1 = __riscv_vwmul_vv_i16m1(v0, y0, vl);
|
| 2746 |
+
vint16m1_t vec_mul2 = __riscv_vwmul_vv_i16m1(v1, y1, vl);
|
| 2747 |
|
| 2748 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 2749 |
|
| 2750 |
+
vint32m1_t vs1 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul1, vec_zero, vl);
|
| 2751 |
+
vint32m1_t vs2 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul2, vs1, vl);
|
| 2752 |
|
| 2753 |
+
int sumi = __riscv_vmv_x_s_i32m1_i32(vs2);
|
|
|
|
| 2754 |
|
| 2755 |
sumf += sumi*GGML_FP16_TO_FP32(x[i].d)*GGML_FP16_TO_FP32(y[i].d);
|
| 2756 |
}
|
|
|
|
| 2888 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 2889 |
|
| 2890 |
for (int i = 0; i < nb; i++) {
|
| 2891 |
+
// load elements
|
| 2892 |
+
vuint8mf2_t tx = __riscv_vle8_v_u8mf2(x[i].qs, vl);
|
| 2893 |
|
| 2894 |
+
vint8mf2_t y0 = __riscv_vle8_v_i8mf2(y[i].qs, vl);
|
| 2895 |
+
vint8mf2_t y1 = __riscv_vle8_v_i8mf2(y[i].qs+16, vl);
|
| 2896 |
|
| 2897 |
+
// mask and store lower part of x, and then upper part
|
| 2898 |
+
vuint8mf2_t x_a = __riscv_vand_vx_u8mf2(tx, 0x0F, vl);
|
| 2899 |
+
vuint8mf2_t x_l = __riscv_vsrl_vx_u8mf2(tx, 0x04, vl);
|
| 2900 |
|
| 2901 |
+
vint8mf2_t v0 = __riscv_vreinterpret_v_u8mf2_i8mf2(x_a);
|
| 2902 |
+
vint8mf2_t v1 = __riscv_vreinterpret_v_u8mf2_i8mf2(x_l);
|
| 2903 |
|
| 2904 |
+
vint16m1_t vec_mul1 = __riscv_vwmul_vv_i16m1(v0, y0, vl);
|
| 2905 |
+
vint16m1_t vec_mul2 = __riscv_vwmul_vv_i16m1(v1, y1, vl);
|
| 2906 |
|
| 2907 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 2908 |
|
| 2909 |
+
vint32m1_t vs1 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul1, vec_zero, vl);
|
| 2910 |
+
vint32m1_t vs2 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul2, vs1, vl);
|
| 2911 |
|
| 2912 |
+
int sumi = __riscv_vmv_x_s_i32m1_i32(vs2);
|
|
|
|
| 2913 |
|
| 2914 |
sumf += (GGML_FP16_TO_FP32(x[i].d)*y[i].d)*sumi + GGML_FP16_TO_FP32(x[i].m)*y[i].s;
|
| 2915 |
}
|
|
|
|
| 3154 |
|
| 3155 |
uint32_t qh;
|
| 3156 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3157 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 3158 |
|
| 3159 |
+
// These tempory registers are for masking and shift operations
|
| 3160 |
+
vuint32m2_t vt_1 = __riscv_vid_v_u32m2(vl);
|
| 3161 |
+
vuint32m2_t vt_2 = __riscv_vsll_vv_u32m2(__riscv_vmv_v_x_u32m2(1, vl), vt_1, vl);
|
| 3162 |
+
|
| 3163 |
+
vuint32m2_t vt_3 = __riscv_vsll_vx_u32m2(vt_2, 16, vl);
|
| 3164 |
+
vuint32m2_t vt_4 = __riscv_vadd_vx_u32m2(vt_1, 12, vl);
|
| 3165 |
+
|
| 3166 |
for (int i = 0; i < nb; i++) {
|
| 3167 |
memcpy(&qh, x[i].qh, sizeof(uint32_t));
|
| 3168 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3169 |
// ((qh & (1u << (j + 0 ))) >> (j + 0 )) << 4;
|
| 3170 |
+
vuint32m2_t xha_0 = __riscv_vand_vx_u32m2(vt_2, qh, vl);
|
| 3171 |
+
vuint32m2_t xhr_0 = __riscv_vsrl_vv_u32m2(xha_0, vt_1, vl);
|
| 3172 |
+
vuint32m2_t xhl_0 = __riscv_vsll_vx_u32m2(xhr_0, 4, vl);
|
| 3173 |
|
| 3174 |
// ((qh & (1u << (j + 16))) >> (j + 12));
|
| 3175 |
+
vuint32m2_t xha_1 = __riscv_vand_vx_u32m2(vt_3, qh, vl);
|
| 3176 |
+
vuint32m2_t xhl_1 = __riscv_vsrl_vv_u32m2(xha_1, vt_4, vl);
|
| 3177 |
|
| 3178 |
// narrowing
|
| 3179 |
+
vuint16m1_t xhc_0 = __riscv_vncvt_x_x_w_u16m1(xhl_0, vl);
|
| 3180 |
+
vuint8mf2_t xh_0 = __riscv_vncvt_x_x_w_u8mf2(xhc_0, vl);
|
| 3181 |
|
| 3182 |
+
vuint16m1_t xhc_1 = __riscv_vncvt_x_x_w_u16m1(xhl_1, vl);
|
| 3183 |
+
vuint8mf2_t xh_1 = __riscv_vncvt_x_x_w_u8mf2(xhc_1, vl);
|
| 3184 |
|
| 3185 |
// load
|
| 3186 |
+
vuint8mf2_t tx = __riscv_vle8_v_u8mf2(x[i].qs, vl);
|
| 3187 |
|
| 3188 |
+
vint8mf2_t y0 = __riscv_vle8_v_i8mf2(y[i].qs, vl);
|
| 3189 |
+
vint8mf2_t y1 = __riscv_vle8_v_i8mf2(y[i].qs+16, vl);
|
| 3190 |
|
| 3191 |
+
vuint8mf2_t x_at = __riscv_vand_vx_u8mf2(tx, 0x0F, vl);
|
| 3192 |
+
vuint8mf2_t x_lt = __riscv_vsrl_vx_u8mf2(tx, 0x04, vl);
|
| 3193 |
|
| 3194 |
+
vuint8mf2_t x_a = __riscv_vor_vv_u8mf2(x_at, xh_0, vl);
|
| 3195 |
+
vuint8mf2_t x_l = __riscv_vor_vv_u8mf2(x_lt, xh_1, vl);
|
| 3196 |
|
| 3197 |
+
vint8mf2_t x_ai = __riscv_vreinterpret_v_u8mf2_i8mf2(x_a);
|
| 3198 |
+
vint8mf2_t x_li = __riscv_vreinterpret_v_u8mf2_i8mf2(x_l);
|
| 3199 |
|
| 3200 |
+
vint8mf2_t v0 = __riscv_vsub_vx_i8mf2(x_ai, 16, vl);
|
| 3201 |
+
vint8mf2_t v1 = __riscv_vsub_vx_i8mf2(x_li, 16, vl);
|
| 3202 |
|
| 3203 |
+
vint16m1_t vec_mul1 = __riscv_vwmul_vv_i16m1(v0, y0, vl);
|
| 3204 |
+
vint16m1_t vec_mul2 = __riscv_vwmul_vv_i16m1(v1, y1, vl);
|
| 3205 |
|
| 3206 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 3207 |
|
| 3208 |
+
vint32m1_t vs1 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul1, vec_zero, vl);
|
| 3209 |
+
vint32m1_t vs2 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul2, vs1, vl);
|
| 3210 |
|
| 3211 |
+
int sumi = __riscv_vmv_x_s_i32m1_i32(vs2);
|
|
|
|
| 3212 |
|
| 3213 |
sumf += (GGML_FP16_TO_FP32(x[i].d)*GGML_FP16_TO_FP32(y[i].d)) * sumi;
|
| 3214 |
}
|
|
|
|
| 3475 |
|
| 3476 |
uint32_t qh;
|
| 3477 |
|
|
|
|
|
|
|
|
|
|
| 3478 |
size_t vl = __riscv_vsetvl_e8m1(qk/2);
|
| 3479 |
|
| 3480 |
+
// temporary registers for shift operations
|
| 3481 |
+
vuint32m2_t vt_1 = __riscv_vid_v_u32m2(vl);
|
| 3482 |
+
vuint32m2_t vt_2 = __riscv_vadd_vx_u32m2(vt_1, 12, vl);
|
| 3483 |
+
|
| 3484 |
for (int i = 0; i < nb; i++) {
|
| 3485 |
memcpy(&qh, x[i].qh, sizeof(uint32_t));
|
| 3486 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3487 |
// load qh
|
| 3488 |
+
vuint32m2_t vqh = __riscv_vmv_v_x_u32m2(qh, vl);
|
| 3489 |
|
| 3490 |
// ((qh >> (j + 0)) << 4) & 0x10;
|
| 3491 |
+
vuint32m2_t xhr_0 = __riscv_vsrl_vv_u32m2(vqh, vt_1, vl);
|
| 3492 |
+
vuint32m2_t xhl_0 = __riscv_vsll_vx_u32m2(xhr_0, 4, vl);
|
| 3493 |
+
vuint32m2_t xha_0 = __riscv_vand_vx_u32m2(xhl_0, 0x10, vl);
|
| 3494 |
|
| 3495 |
// ((qh >> (j + 12)) ) & 0x10;
|
| 3496 |
+
vuint32m2_t xhr_1 = __riscv_vsrl_vv_u32m2(vqh, vt_2, vl);
|
| 3497 |
+
vuint32m2_t xha_1 = __riscv_vand_vx_u32m2(xhr_1, 0x10, vl);
|
| 3498 |
|
| 3499 |
// narrowing
|
| 3500 |
+
vuint16m1_t xhc_0 = __riscv_vncvt_x_x_w_u16m1(xha_0, vl);
|
| 3501 |
+
vuint8mf2_t xh_0 = __riscv_vncvt_x_x_w_u8mf2(xhc_0, vl);
|
| 3502 |
|
| 3503 |
+
vuint16m1_t xhc_1 = __riscv_vncvt_x_x_w_u16m1(xha_1, vl);
|
| 3504 |
+
vuint8mf2_t xh_1 = __riscv_vncvt_x_x_w_u8mf2(xhc_1, vl);
|
| 3505 |
|
| 3506 |
// load
|
| 3507 |
+
vuint8mf2_t tx = __riscv_vle8_v_u8mf2(x[i].qs, vl);
|
| 3508 |
|
| 3509 |
+
vint8mf2_t y0 = __riscv_vle8_v_i8mf2(y[i].qs, vl);
|
| 3510 |
+
vint8mf2_t y1 = __riscv_vle8_v_i8mf2(y[i].qs+16, vl);
|
| 3511 |
|
| 3512 |
+
vuint8mf2_t x_at = __riscv_vand_vx_u8mf2(tx, 0x0F, vl);
|
| 3513 |
+
vuint8mf2_t x_lt = __riscv_vsrl_vx_u8mf2(tx, 0x04, vl);
|
| 3514 |
|
| 3515 |
+
vuint8mf2_t x_a = __riscv_vor_vv_u8mf2(x_at, xh_0, vl);
|
| 3516 |
+
vuint8mf2_t x_l = __riscv_vor_vv_u8mf2(x_lt, xh_1, vl);
|
| 3517 |
|
| 3518 |
+
vint8mf2_t v0 = __riscv_vreinterpret_v_u8mf2_i8mf2(x_a);
|
| 3519 |
+
vint8mf2_t v1 = __riscv_vreinterpret_v_u8mf2_i8mf2(x_l);
|
| 3520 |
|
| 3521 |
+
vint16m1_t vec_mul1 = __riscv_vwmul_vv_i16m1(v0, y0, vl);
|
| 3522 |
+
vint16m1_t vec_mul2 = __riscv_vwmul_vv_i16m1(v1, y1, vl);
|
| 3523 |
|
| 3524 |
vint32m1_t vec_zero = __riscv_vmv_v_x_i32m1(0, vl);
|
| 3525 |
|
| 3526 |
+
vint32m1_t vs1 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul1, vec_zero, vl);
|
| 3527 |
+
vint32m1_t vs2 = __riscv_vwredsum_vs_i16m1_i32m1(vec_mul2, vs1, vl);
|
| 3528 |
|
| 3529 |
+
int sumi = __riscv_vmv_x_s_i32m1_i32(vs2);
|
|
|
|
| 3530 |
|
| 3531 |
sumf += (GGML_FP16_TO_FP32(x[i].d)*y[i].d)*sumi + GGML_FP16_TO_FP32(x[i].m)*y[i].s;
|
| 3532 |
}
|
|
|
|
| 4082 |
"ALIBI",
|
| 4083 |
"CLAMP",
|
| 4084 |
"CONV_1D",
|
| 4085 |
+
"CONV_TRANSPOSE_1D",
|
| 4086 |
"CONV_2D",
|
| 4087 |
"CONV_TRANSPOSE_2D",
|
| 4088 |
"POOL_1D",
|
| 4089 |
"POOL_2D",
|
| 4090 |
"UPSCALE",
|
| 4091 |
|
| 4092 |
+
"CONV_1D_STAGE_0",
|
| 4093 |
+
"CONV_1D_STAGE_1",
|
| 4094 |
+
|
| 4095 |
"FLASH_ATTN",
|
| 4096 |
"FLASH_FF",
|
| 4097 |
"FLASH_ATTN_BACK",
|
|
|
|
| 4117 |
"CROSS_ENTROPY_LOSS_BACK",
|
| 4118 |
};
|
| 4119 |
|
| 4120 |
+
static_assert(GGML_OP_COUNT == 71, "GGML_OP_COUNT != 71");
|
| 4121 |
|
| 4122 |
static const char * GGML_OP_SYMBOL[GGML_OP_COUNT] = {
|
| 4123 |
"none",
|
|
|
|
| 4168 |
"alibi(x)",
|
| 4169 |
"clamp(x)",
|
| 4170 |
"conv_1d(x)",
|
| 4171 |
+
"conv_transpose_1d(x)",
|
| 4172 |
"conv_2d(x)",
|
| 4173 |
"conv_transpose_2d(x)",
|
| 4174 |
"pool_1d(x)",
|
| 4175 |
"pool_2d(x)",
|
| 4176 |
"upscale(x)",
|
| 4177 |
|
| 4178 |
+
"conv_1d_stage_0(x)",
|
| 4179 |
+
"conv_1d_stage_1(x)",
|
| 4180 |
+
|
| 4181 |
"flash_attn(x)",
|
| 4182 |
"flash_ff(x)",
|
| 4183 |
"flash_attn_back(x)",
|
|
|
|
| 4203 |
"cross_entropy_loss_back(x,y)",
|
| 4204 |
};
|
| 4205 |
|
| 4206 |
+
static_assert(GGML_OP_COUNT == 71, "GGML_OP_COUNT != 71");
|
| 4207 |
|
| 4208 |
static_assert(GGML_OP_POOL_COUNT == 2, "GGML_OP_POOL_COUNT != 2");
|
| 4209 |
|
|
|
|
| 4232 |
p[GGML_OP_DIAG_MASK_INF ] = true;
|
| 4233 |
p[GGML_OP_DIAG_MASK_ZERO ] = true;
|
| 4234 |
p[GGML_OP_CONV_1D ] = true;
|
| 4235 |
+
p[GGML_OP_CONV_1D_STAGE_0 ] = true;
|
| 4236 |
+
p[GGML_OP_CONV_1D_STAGE_1 ] = true;
|
| 4237 |
p[GGML_OP_CONV_2D ] = true;
|
| 4238 |
+
p[GGML_OP_CONV_TRANSPOSE_1D ] = true;
|
| 4239 |
p[GGML_OP_CONV_TRANSPOSE_2D ] = true;
|
| 4240 |
p[GGML_OP_FLASH_ATTN_BACK ] = true;
|
| 4241 |
p[GGML_OP_CROSS_ENTROPY_LOSS ] = true;
|
|
|
|
| 6758 |
return result;
|
| 6759 |
}
|
| 6760 |
|
|
|
|
| 6761 |
// ggml_reshape
|
| 6762 |
|
| 6763 |
struct ggml_tensor * ggml_reshape(
|
|
|
|
| 7515 |
return (ins + 2 * p - d * (ks - 1) - 1) / s + 1;
|
| 7516 |
}
|
| 7517 |
|
| 7518 |
+
// im2col: [N, IC, IL] => [N, OL, IC*K]
|
| 7519 |
+
// a: [OC,IC, K]
|
| 7520 |
+
// b: [N, IC, IL]
|
| 7521 |
+
// result: [N, OL, IC*K]
|
| 7522 |
+
static struct ggml_tensor * ggml_conv_1d_stage_0(
|
| 7523 |
+
struct ggml_context * ctx,
|
| 7524 |
+
struct ggml_tensor * a,
|
| 7525 |
+
struct ggml_tensor * b,
|
| 7526 |
+
int s0,
|
| 7527 |
+
int p0,
|
| 7528 |
+
int d0) {
|
| 7529 |
GGML_ASSERT(a->ne[1] == b->ne[1]);
|
| 7530 |
bool is_node = false;
|
| 7531 |
|
|
|
|
| 7534 |
is_node = true;
|
| 7535 |
}
|
| 7536 |
|
| 7537 |
+
const int64_t OL = ggml_calc_conv_output_size(b->ne[0], a->ne[0], s0, p0, d0);
|
| 7538 |
+
|
| 7539 |
const int64_t ne[4] = {
|
| 7540 |
+
a->ne[1] * a->ne[0],
|
| 7541 |
+
OL,
|
| 7542 |
+
b->ne[2],
|
| 7543 |
+
1,
|
| 7544 |
};
|
| 7545 |
+
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F16, 4, ne);
|
| 7546 |
|
| 7547 |
int32_t params[] = { s0, p0, d0 };
|
| 7548 |
ggml_set_op_params(result, params, sizeof(params));
|
| 7549 |
|
| 7550 |
+
result->op = GGML_OP_CONV_1D_STAGE_0;
|
| 7551 |
+
result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
|
| 7552 |
+
result->src[0] = a;
|
| 7553 |
+
result->src[1] = b;
|
| 7554 |
+
|
| 7555 |
+
return result;
|
| 7556 |
+
}
|
| 7557 |
+
|
| 7558 |
+
// ggml_conv_1d_stage_1
|
| 7559 |
+
|
| 7560 |
+
// gemm: [N, OC, OL] = [OC, IC * K] x [N*OL, IC * K]
|
| 7561 |
+
// a: [OC, IC, K]
|
| 7562 |
+
// b: [N, OL, IC * K]
|
| 7563 |
+
// result: [N, OC, OL]
|
| 7564 |
+
static struct ggml_tensor * ggml_conv_1d_stage_1(
|
| 7565 |
+
struct ggml_context * ctx,
|
| 7566 |
+
struct ggml_tensor * a,
|
| 7567 |
+
struct ggml_tensor * b) {
|
| 7568 |
+
|
| 7569 |
+
bool is_node = false;
|
| 7570 |
+
|
| 7571 |
+
if (a->grad || b->grad) {
|
| 7572 |
+
GGML_ASSERT(false); // TODO: implement backward
|
| 7573 |
+
is_node = true;
|
| 7574 |
+
}
|
| 7575 |
+
|
| 7576 |
+
const int64_t ne[4] = {
|
| 7577 |
+
b->ne[1],
|
| 7578 |
+
a->ne[2],
|
| 7579 |
+
b->ne[2],
|
| 7580 |
+
1,
|
| 7581 |
+
};
|
| 7582 |
+
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne);
|
| 7583 |
+
|
| 7584 |
+
result->op = GGML_OP_CONV_1D_STAGE_1;
|
| 7585 |
result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
|
| 7586 |
result->src[0] = a;
|
| 7587 |
result->src[1] = b;
|
|
|
|
| 7589 |
return result;
|
| 7590 |
}
|
| 7591 |
|
| 7592 |
+
// ggml_conv_1d
|
| 7593 |
+
|
| 7594 |
+
GGML_API struct ggml_tensor * ggml_conv_1d(
|
| 7595 |
+
struct ggml_context * ctx,
|
| 7596 |
+
struct ggml_tensor * a,
|
| 7597 |
+
struct ggml_tensor * b,
|
| 7598 |
+
int s0,
|
| 7599 |
+
int p0,
|
| 7600 |
+
int d0) {
|
| 7601 |
+
struct ggml_tensor * result = ggml_conv_1d_stage_0(ctx, a, b, s0, p0, d0);
|
| 7602 |
+
result = ggml_conv_1d_stage_1(ctx, a, result);
|
| 7603 |
+
return result;
|
| 7604 |
+
}
|
| 7605 |
+
|
| 7606 |
+
// GGML_API struct ggml_tensor * ggml_conv_1d(
|
| 7607 |
+
// struct ggml_context * ctx,
|
| 7608 |
+
// struct ggml_tensor * a,
|
| 7609 |
+
// struct ggml_tensor * b,
|
| 7610 |
+
// int s0,
|
| 7611 |
+
// int p0,
|
| 7612 |
+
// int d0) {
|
| 7613 |
+
// GGML_ASSERT(ggml_is_matrix(b));
|
| 7614 |
+
// GGML_ASSERT(a->ne[1] == b->ne[1]);
|
| 7615 |
+
// bool is_node = false;
|
| 7616 |
+
|
| 7617 |
+
// if (a->grad || b->grad) {
|
| 7618 |
+
// GGML_ASSERT(false); // TODO: implement backward
|
| 7619 |
+
// is_node = true;
|
| 7620 |
+
// }
|
| 7621 |
+
|
| 7622 |
+
// const int64_t ne[4] = {
|
| 7623 |
+
// ggml_calc_conv_output_size(b->ne[0], a->ne[0], s0, p0, d0),
|
| 7624 |
+
// a->ne[2], 1, 1,
|
| 7625 |
+
// };
|
| 7626 |
+
// struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 2, ne);
|
| 7627 |
+
|
| 7628 |
+
// int32_t params[] = { s0, p0, d0 };
|
| 7629 |
+
// ggml_set_op_params(result, params, sizeof(params));
|
| 7630 |
+
|
| 7631 |
+
// result->op = GGML_OP_CONV_1D;
|
| 7632 |
+
// result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
|
| 7633 |
+
// result->src[0] = a;
|
| 7634 |
+
// result->src[1] = b;
|
| 7635 |
+
|
| 7636 |
+
// return result;
|
| 7637 |
+
// }
|
| 7638 |
+
|
| 7639 |
// ggml_conv_1d_ph
|
| 7640 |
|
| 7641 |
struct ggml_tensor* ggml_conv_1d_ph(
|
|
|
|
| 7647 |
return ggml_conv_1d(ctx, a, b, s, a->ne[0] / 2, d);
|
| 7648 |
}
|
| 7649 |
|
| 7650 |
+
// ggml_conv_transpose_1d
|
| 7651 |
+
|
| 7652 |
+
static int64_t ggml_calc_conv_transpose_1d_output_size(int64_t ins, int64_t ks, int s, int p, int d) {
|
| 7653 |
+
return (ins - 1) * s - 2 * p + d * (ks - 1) + 1;
|
| 7654 |
+
}
|
| 7655 |
+
|
| 7656 |
+
GGML_API struct ggml_tensor * ggml_conv_transpose_1d(
|
| 7657 |
+
struct ggml_context * ctx,
|
| 7658 |
+
struct ggml_tensor * a,
|
| 7659 |
+
struct ggml_tensor * b,
|
| 7660 |
+
int s0,
|
| 7661 |
+
int p0,
|
| 7662 |
+
int d0) {
|
| 7663 |
+
GGML_ASSERT(ggml_is_matrix(b));
|
| 7664 |
+
GGML_ASSERT(a->ne[2] == b->ne[1]);
|
| 7665 |
+
GGML_ASSERT(a->ne[3] == 1);
|
| 7666 |
+
|
| 7667 |
+
GGML_ASSERT(p0 == 0);
|
| 7668 |
+
GGML_ASSERT(d0 == 1);
|
| 7669 |
+
|
| 7670 |
+
bool is_node = false;
|
| 7671 |
+
|
| 7672 |
+
if (a->grad || b->grad) {
|
| 7673 |
+
GGML_ASSERT(false); // TODO: implement backward
|
| 7674 |
+
is_node = true;
|
| 7675 |
+
}
|
| 7676 |
+
|
| 7677 |
+
const int64_t ne[4] = {
|
| 7678 |
+
ggml_calc_conv_transpose_1d_output_size(b->ne[0], a->ne[0], s0, 0 /*p0*/, 1 /*d0*/),
|
| 7679 |
+
a->ne[1], b->ne[2], 1,
|
| 7680 |
+
};
|
| 7681 |
+
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, 4, ne);
|
| 7682 |
+
|
| 7683 |
+
int32_t params[] = { s0, p0, d0 };
|
| 7684 |
+
ggml_set_op_params(result, params, sizeof(params));
|
| 7685 |
+
|
| 7686 |
+
result->op = GGML_OP_CONV_TRANSPOSE_1D;
|
| 7687 |
+
result->grad = is_node ? ggml_dup_tensor(ctx, result) : NULL;
|
| 7688 |
+
result->src[0] = a;
|
| 7689 |
+
result->src[1] = b;
|
| 7690 |
+
|
| 7691 |
+
return result;
|
| 7692 |
+
}
|
| 7693 |
+
|
| 7694 |
// ggml_conv_2d
|
| 7695 |
|
| 7696 |
struct ggml_tensor * ggml_conv_2d(
|
|
|
|
| 13083 |
return;
|
| 13084 |
}
|
| 13085 |
|
| 13086 |
+
const int n_past = ((int32_t *) dst->op_params)[0]; UNUSED(n_past);
|
| 13087 |
const int n_head = ((int32_t *) dst->op_params)[1];
|
| 13088 |
float max_bias;
|
| 13089 |
memcpy(&max_bias, (int32_t *) dst->op_params + 2, sizeof(float));
|
|
|
|
| 13104 |
//const int nb3 = src0->nb[3];
|
| 13105 |
|
| 13106 |
GGML_ASSERT(nb0 == sizeof(float));
|
|
|
|
| 13107 |
GGML_ASSERT(n_head == ne2);
|
| 13108 |
|
| 13109 |
// add alibi to src0 (KQ_scaled)
|
|
|
|
| 13829 |
|
| 13830 |
// ggml_compute_forward_conv_1d
|
| 13831 |
|
| 13832 |
+
static void ggml_compute_forward_conv_1d_f16_f32(
|
| 13833 |
const struct ggml_compute_params * params,
|
| 13834 |
const struct ggml_tensor * src0,
|
| 13835 |
const struct ggml_tensor * src1,
|
|
|
|
| 13847 |
const int nth = params->nth;
|
| 13848 |
|
| 13849 |
const int nk = ne00;
|
|
|
|
| 13850 |
|
| 13851 |
+
// size of the convolution row - the kernel size unrolled across all input channels
|
| 13852 |
+
const int ew0 = nk*ne01;
|
| 13853 |
+
|
| 13854 |
+
const int32_t s0 = ((const int32_t*)(dst->op_params))[0];
|
| 13855 |
+
const int32_t p0 = ((const int32_t*)(dst->op_params))[1];
|
| 13856 |
+
const int32_t d0 = ((const int32_t*)(dst->op_params))[2];
|
| 13857 |
|
|
|
|
| 13858 |
GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
|
| 13859 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 13860 |
|
| 13861 |
if (params->type == GGML_TASK_INIT) {
|
|
|
|
| 13862 |
memset(params->wdata, 0, params->wsize);
|
| 13863 |
|
| 13864 |
+
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
|
|
|
|
|
|
| 13865 |
|
| 13866 |
+
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 13867 |
+
const float * const src = (float *)((char *) src1->data + i11*nb11);
|
| 13868 |
+
ggml_fp16_t * dst_data = wdata;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13869 |
|
| 13870 |
+
for (int64_t i0 = 0; i0 < ne0; i0++) {
|
| 13871 |
+
for (int64_t ik = 0; ik < nk; ik++) {
|
| 13872 |
+
const int idx0 = i0*s0 + ik*d0 - p0;
|
| 13873 |
|
| 13874 |
+
if(!(idx0 < 0 || idx0 >= ne10)) {
|
| 13875 |
+
dst_data[i0*ew0 + i11*nk + ik] = GGML_FP32_TO_FP16(src[idx0]);
|
| 13876 |
+
}
|
|
|
|
|
|
|
| 13877 |
}
|
| 13878 |
}
|
| 13879 |
}
|
|
|
|
| 13886 |
}
|
| 13887 |
|
| 13888 |
// total rows in dst
|
| 13889 |
+
const int nr = ne2;
|
| 13890 |
|
| 13891 |
// rows per thread
|
| 13892 |
const int dr = (nr + nth - 1)/nth;
|
|
|
|
| 13895 |
const int ir0 = dr*ith;
|
| 13896 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 13897 |
|
| 13898 |
+
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 13899 |
+
|
| 13900 |
+
for (int i2 = 0; i2 < ne2; i2++) {
|
| 13901 |
+
for (int i1 = ir0; i1 < ir1; i1++) {
|
| 13902 |
+
float * dst_data = (float *)((char *) dst->data + i2*nb2 + i1*nb1);
|
| 13903 |
+
|
| 13904 |
+
for (int i0 = 0; i0 < ne0; i0++) {
|
| 13905 |
+
ggml_vec_dot_f16(ew0, dst_data + i0,
|
| 13906 |
+
(ggml_fp16_t *) ((char *) src0->data + i1*nb02),
|
| 13907 |
+
(ggml_fp16_t *) wdata + i2*nb2 + i0*ew0);
|
|
|
|
| 13908 |
}
|
| 13909 |
}
|
| 13910 |
}
|
| 13911 |
}
|
| 13912 |
|
| 13913 |
+
static void ggml_compute_forward_conv_1d_f32(
|
| 13914 |
const struct ggml_compute_params * params,
|
| 13915 |
const struct ggml_tensor * src0,
|
| 13916 |
const struct ggml_tensor * src1,
|
|
|
|
| 13928 |
const int nth = params->nth;
|
| 13929 |
|
| 13930 |
const int nk = ne00;
|
|
|
|
| 13931 |
|
| 13932 |
+
const int ew0 = nk*ne01;
|
| 13933 |
+
|
| 13934 |
+
const int32_t s0 = ((const int32_t*)(dst->op_params))[0];
|
| 13935 |
+
const int32_t p0 = ((const int32_t*)(dst->op_params))[1];
|
| 13936 |
+
const int32_t d0 = ((const int32_t*)(dst->op_params))[2];
|
| 13937 |
|
|
|
|
| 13938 |
GGML_ASSERT(nb00 == sizeof(float));
|
| 13939 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 13940 |
|
| 13941 |
if (params->type == GGML_TASK_INIT) {
|
|
|
|
| 13942 |
memset(params->wdata, 0, params->wsize);
|
| 13943 |
|
| 13944 |
+
float * const wdata = (float *) params->wdata + 0;
|
|
|
|
|
|
|
| 13945 |
|
| 13946 |
+
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 13947 |
+
const float * const src = (float *)((char *) src1->data + i11*nb11);
|
| 13948 |
+
float * dst_data = wdata;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13949 |
|
| 13950 |
+
for (int64_t i0 = 0; i0 < ne0; i0++) {
|
| 13951 |
+
for (int64_t ik = 0; ik < nk; ik++) {
|
| 13952 |
+
const int idx0 = i0*s0 + ik*d0 - p0;
|
| 13953 |
|
| 13954 |
+
if(!(idx0 < 0 || idx0 >= ne10)) {
|
| 13955 |
+
dst_data[i0*ew0 + i11*nk + ik] = src[idx0];
|
| 13956 |
+
}
|
|
|
|
|
|
|
| 13957 |
}
|
| 13958 |
}
|
| 13959 |
}
|
|
|
|
| 13975 |
const int ir0 = dr*ith;
|
| 13976 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 13977 |
|
| 13978 |
+
float * const wdata = (float *) params->wdata + 0;
|
| 13979 |
+
|
| 13980 |
+
for (int i2 = 0; i2 < ne2; i2++) {
|
| 13981 |
+
for (int i1 = ir0; i1 < ir1; i1++) {
|
| 13982 |
+
float * dst_data = (float *)((char *) dst->data + i2*nb2 + i1*nb1);
|
| 13983 |
+
|
| 13984 |
+
for (int i0 = 0; i0 < ne0; i0++) {
|
| 13985 |
+
ggml_vec_dot_f32(ew0, dst_data + i0,
|
| 13986 |
+
(float *) ((char *) src0->data + i1*nb02),
|
| 13987 |
+
(float *) wdata + i2*nb2 + i0*ew0);
|
| 13988 |
+
}
|
| 13989 |
+
}
|
| 13990 |
+
}
|
| 13991 |
+
}
|
| 13992 |
+
|
| 13993 |
+
static void gemm_f16_out_f32(int64_t m, int64_t n, int64_t k,
|
| 13994 |
+
ggml_fp16_t * A,
|
| 13995 |
+
ggml_fp16_t * B,
|
| 13996 |
+
float * C,
|
| 13997 |
+
const int ith, const int nth) {
|
| 13998 |
+
// does not seem to make a difference
|
| 13999 |
+
int64_t m0, m1, n0, n1;
|
| 14000 |
+
// patches per thread
|
| 14001 |
+
if (m > n) {
|
| 14002 |
+
n0 = 0;
|
| 14003 |
+
n1 = n;
|
| 14004 |
+
|
| 14005 |
+
// total patches in dst
|
| 14006 |
+
const int np = m;
|
| 14007 |
+
|
| 14008 |
+
// patches per thread
|
| 14009 |
+
const int dp = (np + nth - 1)/nth;
|
| 14010 |
+
|
| 14011 |
+
// patch range for this thread
|
| 14012 |
+
m0 = dp*ith;
|
| 14013 |
+
m1 = MIN(m0 + dp, np);
|
| 14014 |
+
} else {
|
| 14015 |
+
m0 = 0;
|
| 14016 |
+
m1 = m;
|
| 14017 |
+
|
| 14018 |
+
// total patches in dst
|
| 14019 |
+
const int np = n;
|
| 14020 |
+
|
| 14021 |
+
// patches per thread
|
| 14022 |
+
const int dp = (np + nth - 1)/nth;
|
| 14023 |
+
|
| 14024 |
+
// patch range for this thread
|
| 14025 |
+
n0 = dp*ith;
|
| 14026 |
+
n1 = MIN(n0 + dp, np);
|
| 14027 |
+
}
|
| 14028 |
+
|
| 14029 |
+
// block-tiling attempt
|
| 14030 |
+
int64_t blck_n = 16;
|
| 14031 |
+
int64_t blck_m = 16;
|
| 14032 |
+
|
| 14033 |
+
// int64_t CACHE_SIZE = 2 * 1024 * 1024; // 2MB
|
| 14034 |
+
// int64_t blck_size = CACHE_SIZE / (sizeof(float) + 2 * sizeof(ggml_fp16_t) * K);
|
| 14035 |
+
// if (blck_size > 0) {
|
| 14036 |
+
// blck_0 = 4;
|
| 14037 |
+
// blck_1 = blck_size / blck_0;
|
| 14038 |
+
// if (blck_1 < 0) {
|
| 14039 |
+
// blck_1 = 1;
|
| 14040 |
+
// }
|
| 14041 |
+
// // blck_0 = (int64_t)sqrt(blck_size);
|
| 14042 |
+
// // blck_1 = blck_0;
|
| 14043 |
+
// }
|
| 14044 |
+
// // printf("%zd %zd %zd %zd\n", blck_size, K, blck_0, blck_1);
|
| 14045 |
+
|
| 14046 |
+
for (int j = n0; j < n1; j+=blck_n) {
|
| 14047 |
+
for (int i = m0; i < m1; i+=blck_m) {
|
| 14048 |
+
// printf("i j k => %d %d %d\n", i, j, K);
|
| 14049 |
+
for (int ii = i; ii < i + blck_m && ii < m1; ii++) {
|
| 14050 |
+
for (int jj = j; jj < j + blck_n && jj < n1; jj++) {
|
| 14051 |
+
ggml_vec_dot_f16(k,
|
| 14052 |
+
C + ii*n + jj,
|
| 14053 |
+
A + ii * k,
|
| 14054 |
+
B + jj * k);
|
| 14055 |
+
}
|
| 14056 |
}
|
| 14057 |
}
|
| 14058 |
}
|
| 14059 |
}
|
| 14060 |
|
| 14061 |
+
// src0: kernel [OC, IC, K]
|
| 14062 |
+
// src1: signal [N, IC, IL]
|
| 14063 |
+
// dst: result [N, OL, IC*K]
|
| 14064 |
+
static void ggml_compute_forward_conv_1d_stage_0_f32(
|
| 14065 |
const struct ggml_compute_params * params,
|
| 14066 |
const struct ggml_tensor * src0,
|
| 14067 |
const struct ggml_tensor * src1,
|
| 14068 |
struct ggml_tensor * dst) {
|
| 14069 |
+
GGML_ASSERT(src0->type == GGML_TYPE_F16);
|
| 14070 |
+
GGML_ASSERT(src1->type == GGML_TYPE_F32);
|
| 14071 |
+
GGML_ASSERT( dst->type == GGML_TYPE_F16);
|
| 14072 |
+
|
| 14073 |
+
int64_t t0 = ggml_perf_time_us();
|
| 14074 |
+
UNUSED(t0);
|
| 14075 |
+
|
| 14076 |
+
GGML_TENSOR_BINARY_OP_LOCALS;
|
| 14077 |
+
|
| 14078 |
+
const int64_t N = ne12;
|
| 14079 |
+
const int64_t IC = ne11;
|
| 14080 |
+
const int64_t IL = ne10;
|
| 14081 |
+
|
| 14082 |
+
const int64_t K = ne00;
|
| 14083 |
+
|
| 14084 |
+
const int64_t OL = ne1;
|
| 14085 |
+
|
| 14086 |
+
const int ith = params->ith;
|
| 14087 |
+
const int nth = params->nth;
|
| 14088 |
+
|
| 14089 |
+
const int32_t s0 = ((const int32_t*)(dst->op_params))[0];
|
| 14090 |
+
const int32_t p0 = ((const int32_t*)(dst->op_params))[1];
|
| 14091 |
+
const int32_t d0 = ((const int32_t*)(dst->op_params))[2];
|
| 14092 |
+
|
| 14093 |
+
GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
|
| 14094 |
+
GGML_ASSERT(nb10 == sizeof(float));
|
| 14095 |
+
|
| 14096 |
+
if (params->type == GGML_TASK_INIT) {
|
| 14097 |
+
memset(dst->data, 0, ggml_nbytes(dst));
|
| 14098 |
+
return;
|
| 14099 |
+
}
|
| 14100 |
+
|
| 14101 |
+
if (params->type == GGML_TASK_FINALIZE) {
|
| 14102 |
+
return;
|
| 14103 |
+
}
|
| 14104 |
+
|
| 14105 |
+
// im2col: [N, IC, IL] => [N, OL, IC*K]
|
| 14106 |
+
{
|
| 14107 |
+
ggml_fp16_t * const wdata = (ggml_fp16_t *) dst->data;
|
| 14108 |
+
|
| 14109 |
+
for (int64_t in = 0; in < N; in++) {
|
| 14110 |
+
for (int64_t iol = 0; iol < OL; iol++) {
|
| 14111 |
+
for (int64_t iic = ith; iic < IC; iic+=nth) {
|
| 14112 |
+
|
| 14113 |
+
// micro kernel
|
| 14114 |
+
ggml_fp16_t * dst_data = wdata + (in*OL + iol)*(IC*K); // [IC, K]
|
| 14115 |
+
const float * const src_data = (float *)((char *) src1->data + in*nb12 + iic*nb11); // [IL]
|
| 14116 |
+
|
| 14117 |
+
for (int64_t ik = 0; ik < K; ik++) {
|
| 14118 |
+
const int64_t iil = iol*s0 + ik*d0 - p0;
|
| 14119 |
+
|
| 14120 |
+
if (!(iil < 0 || iil >= IL)) {
|
| 14121 |
+
dst_data[iic*K + ik] = GGML_FP32_TO_FP16(src_data[iil]);
|
| 14122 |
+
}
|
| 14123 |
+
}
|
| 14124 |
+
}
|
| 14125 |
+
}
|
| 14126 |
+
}
|
| 14127 |
+
}
|
| 14128 |
+
}
|
| 14129 |
+
|
| 14130 |
+
// gemm: [N, OC, OL] = [OC, IC * K] x [N*OL, IC * K]
|
| 14131 |
+
// src0: [OC, IC, K]
|
| 14132 |
+
// src1: [N, OL, IC * K]
|
| 14133 |
+
// result: [N, OC, OL]
|
| 14134 |
+
static void ggml_compute_forward_conv_1d_stage_1_f16(
|
| 14135 |
+
const struct ggml_compute_params * params,
|
| 14136 |
+
const struct ggml_tensor * src0,
|
| 14137 |
+
const struct ggml_tensor * src1,
|
| 14138 |
+
struct ggml_tensor * dst) {
|
| 14139 |
+
GGML_ASSERT(src0->type == GGML_TYPE_F16);
|
| 14140 |
+
GGML_ASSERT(src1->type == GGML_TYPE_F16);
|
| 14141 |
+
GGML_ASSERT( dst->type == GGML_TYPE_F32);
|
| 14142 |
+
|
| 14143 |
+
int64_t t0 = ggml_perf_time_us();
|
| 14144 |
+
UNUSED(t0);
|
| 14145 |
+
|
| 14146 |
+
if (params->type == GGML_TASK_INIT) {
|
| 14147 |
+
return;
|
| 14148 |
+
}
|
| 14149 |
+
|
| 14150 |
+
if (params->type == GGML_TASK_FINALIZE) {
|
| 14151 |
+
return;
|
| 14152 |
+
}
|
| 14153 |
+
|
| 14154 |
+
GGML_TENSOR_BINARY_OP_LOCALS;
|
| 14155 |
+
|
| 14156 |
+
GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
|
| 14157 |
+
GGML_ASSERT(nb10 == sizeof(ggml_fp16_t));
|
| 14158 |
+
GGML_ASSERT(nb0 == sizeof(float));
|
| 14159 |
+
|
| 14160 |
+
const int N = ne12;
|
| 14161 |
+
const int OL = ne11;
|
| 14162 |
+
|
| 14163 |
+
const int OC = ne02;
|
| 14164 |
+
const int IC = ne01;
|
| 14165 |
+
const int K = ne00;
|
| 14166 |
+
|
| 14167 |
+
const int ith = params->ith;
|
| 14168 |
+
const int nth = params->nth;
|
| 14169 |
+
|
| 14170 |
+
int64_t m = OC;
|
| 14171 |
+
int64_t n = OL;
|
| 14172 |
+
int64_t k = IC * K;
|
| 14173 |
+
|
| 14174 |
+
// [N, OC, OL] = [OC, IC * K] x [N*OL, IC * K]
|
| 14175 |
+
for (int i = 0; i < N; i++) {
|
| 14176 |
+
ggml_fp16_t * A = (ggml_fp16_t *)src0->data; // [m, k]
|
| 14177 |
+
ggml_fp16_t * B = (ggml_fp16_t *)src1->data + i * m * k; // [n, k]
|
| 14178 |
+
float * C = (float *)dst->data + i * m * n; // [m, n]
|
| 14179 |
+
|
| 14180 |
+
gemm_f16_out_f32(m, n, k, A, B, C, ith, nth);
|
| 14181 |
+
}
|
| 14182 |
+
}
|
| 14183 |
+
|
| 14184 |
+
static void ggml_compute_forward_conv_1d(
|
| 14185 |
+
const struct ggml_compute_params * params,
|
| 14186 |
+
const struct ggml_tensor * src0,
|
| 14187 |
+
const struct ggml_tensor * src1,
|
| 14188 |
+
struct ggml_tensor * dst) {
|
| 14189 |
+
switch(src0->type) {
|
| 14190 |
case GGML_TYPE_F16:
|
| 14191 |
{
|
| 14192 |
+
ggml_compute_forward_conv_1d_f16_f32(params, src0, src1, dst);
|
| 14193 |
} break;
|
| 14194 |
case GGML_TYPE_F32:
|
| 14195 |
{
|
| 14196 |
+
ggml_compute_forward_conv_1d_f32(params, src0, src1, dst);
|
| 14197 |
+
} break;
|
| 14198 |
+
default:
|
| 14199 |
+
{
|
| 14200 |
+
GGML_ASSERT(false);
|
| 14201 |
+
} break;
|
| 14202 |
+
}
|
| 14203 |
+
}
|
| 14204 |
+
|
| 14205 |
+
static void ggml_compute_forward_conv_1d_stage_0(
|
| 14206 |
+
const struct ggml_compute_params * params,
|
| 14207 |
+
const struct ggml_tensor * src0,
|
| 14208 |
+
const struct ggml_tensor * src1,
|
| 14209 |
+
struct ggml_tensor * dst) {
|
| 14210 |
+
switch(src0->type) {
|
| 14211 |
+
case GGML_TYPE_F16:
|
| 14212 |
+
{
|
| 14213 |
+
ggml_compute_forward_conv_1d_stage_0_f32(params, src0, src1, dst);
|
| 14214 |
} break;
|
| 14215 |
default:
|
| 14216 |
{
|
|
|
|
| 14219 |
}
|
| 14220 |
}
|
| 14221 |
|
| 14222 |
+
static void ggml_compute_forward_conv_1d_stage_1(
|
| 14223 |
+
const struct ggml_compute_params * params,
|
| 14224 |
+
const struct ggml_tensor * src0,
|
| 14225 |
+
const struct ggml_tensor * src1,
|
| 14226 |
+
struct ggml_tensor * dst) {
|
| 14227 |
+
switch(src0->type) {
|
| 14228 |
+
case GGML_TYPE_F16:
|
| 14229 |
+
{
|
| 14230 |
+
ggml_compute_forward_conv_1d_stage_1_f16(params, src0, src1, dst);
|
| 14231 |
+
} break;
|
| 14232 |
+
default:
|
| 14233 |
+
{
|
| 14234 |
+
GGML_ASSERT(false);
|
| 14235 |
+
} break;
|
| 14236 |
+
}
|
| 14237 |
+
}
|
| 14238 |
+
|
| 14239 |
+
// ggml_compute_forward_conv_transpose_1d
|
| 14240 |
+
|
| 14241 |
+
static void ggml_compute_forward_conv_transpose_1d_f16_f32(
|
| 14242 |
const struct ggml_compute_params * params,
|
| 14243 |
const struct ggml_tensor * src0,
|
| 14244 |
const struct ggml_tensor * src1,
|
|
|
|
| 14255 |
const int ith = params->ith;
|
| 14256 |
const int nth = params->nth;
|
| 14257 |
|
| 14258 |
+
const int nk = ne00*ne01*ne02;
|
|
|
|
|
|
|
|
|
|
| 14259 |
|
|
|
|
| 14260 |
GGML_ASSERT(nb00 == sizeof(ggml_fp16_t));
|
| 14261 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 14262 |
|
| 14263 |
if (params->type == GGML_TASK_INIT) {
|
|
|
|
| 14264 |
memset(params->wdata, 0, params->wsize);
|
| 14265 |
|
| 14266 |
+
// permute kernel data (src0) from (K x Cout x Cin) to (Cin x K x Cout)
|
| 14267 |
{
|
| 14268 |
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 14269 |
|
| 14270 |
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
| 14271 |
for (int64_t i01 = 0; i01 < ne01; i01++) {
|
| 14272 |
const ggml_fp16_t * const src = (ggml_fp16_t *)((char *) src0->data + i02*nb02 + i01*nb01);
|
| 14273 |
+
ggml_fp16_t * dst_data = wdata + i01*ne00*ne02;
|
| 14274 |
for (int64_t i00 = 0; i00 < ne00; i00++) {
|
| 14275 |
+
dst_data[i00*ne02 + i02] = src[i00];
|
| 14276 |
}
|
| 14277 |
}
|
| 14278 |
}
|
| 14279 |
}
|
| 14280 |
|
| 14281 |
+
// permute source data (src1) from (L x Cin) to (Cin x L)
|
| 14282 |
{
|
| 14283 |
+
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + nk;
|
| 14284 |
+
ggml_fp16_t * dst_data = wdata;
|
| 14285 |
|
| 14286 |
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 14287 |
const float * const src = (float *)((char *) src1->data + i11*nb11);
|
|
|
|
| 14288 |
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 14289 |
+
dst_data[i10*ne11 + i11] = GGML_FP32_TO_FP16(src[i10]);
|
| 14290 |
}
|
| 14291 |
}
|
| 14292 |
}
|
|
|
|
| 14298 |
return;
|
| 14299 |
}
|
| 14300 |
|
| 14301 |
+
const int32_t s0 = ((const int32_t*)(dst->op_params))[0];
|
| 14302 |
+
|
| 14303 |
// total rows in dst
|
| 14304 |
+
const int nr = ne1;
|
| 14305 |
|
| 14306 |
// rows per thread
|
| 14307 |
const int dr = (nr + nth - 1)/nth;
|
|
|
|
| 14310 |
const int ir0 = dr*ith;
|
| 14311 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 14312 |
|
| 14313 |
+
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 14314 |
+
ggml_fp16_t * const wdata_src = wdata + nk;
|
| 14315 |
+
|
| 14316 |
for (int i1 = ir0; i1 < ir1; i1++) {
|
| 14317 |
float * dst_data = (float *)((char *) dst->data + i1*nb1);
|
| 14318 |
+
ggml_fp16_t * wdata_kernel = wdata + i1*ne02*ne00;
|
| 14319 |
+
for (int i10 = 0; i10 < ne10; i10++) {
|
| 14320 |
+
const int i1n = i10*ne11;
|
| 14321 |
+
for (int i00 = 0; i00 < ne00; i00++) {
|
| 14322 |
+
float v = 0;
|
| 14323 |
+
ggml_vec_dot_f16(ne02, &v,
|
| 14324 |
+
(ggml_fp16_t *) wdata_src + i1n,
|
| 14325 |
+
(ggml_fp16_t *) wdata_kernel + i00*ne02);
|
| 14326 |
+
dst_data[i10*s0 + i00] += v;
|
| 14327 |
}
|
| 14328 |
}
|
| 14329 |
}
|
| 14330 |
}
|
| 14331 |
|
| 14332 |
+
static void ggml_compute_forward_conv_transpose_1d_f32(
|
| 14333 |
const struct ggml_compute_params * params,
|
| 14334 |
const struct ggml_tensor * src0,
|
| 14335 |
const struct ggml_tensor * src1,
|
|
|
|
| 14346 |
const int ith = params->ith;
|
| 14347 |
const int nth = params->nth;
|
| 14348 |
|
| 14349 |
+
const int nk = ne00*ne01*ne02;
|
|
|
|
|
|
|
|
|
|
| 14350 |
|
|
|
|
| 14351 |
GGML_ASSERT(nb00 == sizeof(float));
|
| 14352 |
GGML_ASSERT(nb10 == sizeof(float));
|
| 14353 |
|
| 14354 |
if (params->type == GGML_TASK_INIT) {
|
|
|
|
| 14355 |
memset(params->wdata, 0, params->wsize);
|
| 14356 |
|
| 14357 |
+
// prepare kernel data (src0) from (K x Cout x Cin) to (Cin x K x Cout)
|
| 14358 |
{
|
| 14359 |
float * const wdata = (float *) params->wdata + 0;
|
| 14360 |
|
| 14361 |
for (int64_t i02 = 0; i02 < ne02; i02++) {
|
| 14362 |
for (int64_t i01 = 0; i01 < ne01; i01++) {
|
| 14363 |
const float * const src = (float *)((char *) src0->data + i02*nb02 + i01*nb01);
|
| 14364 |
+
float * dst_data = wdata + i01*ne00*ne02;
|
| 14365 |
for (int64_t i00 = 0; i00 < ne00; i00++) {
|
| 14366 |
+
dst_data[i01*ne00*ne02 + i00*ne02 + i02] = src[i00];
|
| 14367 |
}
|
| 14368 |
}
|
| 14369 |
}
|
|
|
|
| 14371 |
|
| 14372 |
// prepare source data (src1)
|
| 14373 |
{
|
| 14374 |
+
float * const wdata = (float *) params->wdata + nk;
|
| 14375 |
+
float * dst_data = wdata;
|
| 14376 |
|
| 14377 |
for (int64_t i11 = 0; i11 < ne11; i11++) {
|
| 14378 |
const float * const src = (float *)((char *) src1->data + i11*nb11);
|
|
|
|
| 14379 |
for (int64_t i10 = 0; i10 < ne10; i10++) {
|
| 14380 |
+
dst_data[i10*ne11 + i11] = src[i10];
|
| 14381 |
}
|
| 14382 |
}
|
| 14383 |
}
|
|
|
|
| 14389 |
return;
|
| 14390 |
}
|
| 14391 |
|
| 14392 |
+
const int32_t s0 = ((const int32_t*)(dst->op_params))[0];
|
| 14393 |
+
|
| 14394 |
// total rows in dst
|
| 14395 |
+
const int nr = ne1;
|
| 14396 |
|
| 14397 |
// rows per thread
|
| 14398 |
const int dr = (nr + nth - 1)/nth;
|
|
|
|
| 14401 |
const int ir0 = dr*ith;
|
| 14402 |
const int ir1 = MIN(ir0 + dr, nr);
|
| 14403 |
|
| 14404 |
+
float * const wdata = (float *) params->wdata + 0;
|
| 14405 |
+
float * const wdata_src = wdata + nk;
|
| 14406 |
+
|
| 14407 |
for (int i1 = ir0; i1 < ir1; i1++) {
|
| 14408 |
float * dst_data = (float *)((char *) dst->data + i1*nb1);
|
| 14409 |
+
float * wdata_kernel = wdata + i1*ne02*ne00;
|
| 14410 |
+
for (int i10 = 0; i10 < ne10; i10++) {
|
| 14411 |
+
const int i1n = i10*ne11;
|
| 14412 |
+
for (int i00 = 0; i00 < ne00; i00++) {
|
| 14413 |
+
float v = 0;
|
| 14414 |
+
ggml_vec_dot_f32(ne02, &v,
|
| 14415 |
+
wdata_src + i1n,
|
| 14416 |
+
wdata_kernel + i00*ne02);
|
| 14417 |
+
dst_data[i10*s0 + i00] += v;
|
| 14418 |
}
|
| 14419 |
}
|
| 14420 |
}
|
| 14421 |
}
|
| 14422 |
|
| 14423 |
+
static void ggml_compute_forward_conv_transpose_1d(
|
| 14424 |
const struct ggml_compute_params * params,
|
| 14425 |
const struct ggml_tensor * src0,
|
| 14426 |
const struct ggml_tensor * src1,
|
|
|
|
| 14428 |
switch (src0->type) {
|
| 14429 |
case GGML_TYPE_F16:
|
| 14430 |
{
|
| 14431 |
+
ggml_compute_forward_conv_transpose_1d_f16_f32(params, src0, src1, dst);
|
| 14432 |
} break;
|
| 14433 |
case GGML_TYPE_F32:
|
| 14434 |
{
|
| 14435 |
+
ggml_compute_forward_conv_transpose_1d_f32(params, src0, src1, dst);
|
| 14436 |
} break;
|
| 14437 |
default:
|
| 14438 |
{
|
|
|
|
| 14441 |
}
|
| 14442 |
}
|
| 14443 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14444 |
// ggml_compute_forward_conv_2d
|
| 14445 |
|
| 14446 |
static void ggml_compute_forward_conv_2d_f16_f32(
|
|
|
|
| 14483 |
{
|
| 14484 |
ggml_fp16_t * const wdata = (ggml_fp16_t *) params->wdata + 0;
|
| 14485 |
|
| 14486 |
+
for (int i13 = 0; i13 < ne13; i13++) {
|
| 14487 |
+
for (int i12 = 0; i12 < ne12; i12++) {
|
| 14488 |
+
const float * const src = (float *)((char *) src1->data + i13*nb13 + i12*nb12);
|
| 14489 |
+
ggml_fp16_t * dst_data = wdata + i13*(ne1*ne0*ew0);
|
| 14490 |
+
|
| 14491 |
+
for (int i1 = 0; i1 < ne1; i1++) {
|
| 14492 |
+
for (int i0 = 0; i0 < ne0; i0++) {
|
| 14493 |
+
for (int ik1 = 0; ik1 < nk1; ik1++) {
|
| 14494 |
+
for (int ik0 = 0; ik0 < nk0; ik0++) {
|
| 14495 |
+
const int idx0 = i0*s0 + ik0*d0 - p0;
|
| 14496 |
+
const int idx1 = i1*s1 + ik1*d1 - p1;
|
| 14497 |
+
|
| 14498 |
+
if (!(idx1 < 0 || idx1 >= ne11 || idx0 < 0 || idx0 >= ne10)) {
|
| 14499 |
+
dst_data[(i1*ne0 + i0)*ew0 + i12*(nk0*nk1) + ik1*nk0 + ik0] =
|
| 14500 |
+
GGML_FP32_TO_FP16(src[idx1*ne10 + idx0]);
|
| 14501 |
+
}
|
| 14502 |
}
|
| 14503 |
}
|
| 14504 |
}
|
|
|
|
| 16781 |
{
|
| 16782 |
ggml_compute_forward_conv_1d(params, tensor->src[0], tensor->src[1], tensor);
|
| 16783 |
} break;
|
| 16784 |
+
case GGML_OP_CONV_1D_STAGE_0:
|
| 16785 |
+
{
|
| 16786 |
+
ggml_compute_forward_conv_1d_stage_0(params, tensor->src[0], tensor->src[1], tensor);
|
| 16787 |
+
} break;
|
| 16788 |
+
case GGML_OP_CONV_1D_STAGE_1:
|
| 16789 |
+
{
|
| 16790 |
+
ggml_compute_forward_conv_1d_stage_1(params, tensor->src[0], tensor->src[1], tensor);
|
| 16791 |
+
} break;
|
| 16792 |
+
case GGML_OP_CONV_TRANSPOSE_1D:
|
| 16793 |
+
{
|
| 16794 |
+
ggml_compute_forward_conv_transpose_1d(params, tensor->src[0], tensor->src[1], tensor);
|
| 16795 |
+
} break;
|
| 16796 |
case GGML_OP_CONV_2D:
|
| 16797 |
{
|
| 16798 |
ggml_compute_forward_conv_2d(params, tensor->src[0], tensor->src[1], tensor);
|
|
|
|
| 17718 |
{
|
| 17719 |
GGML_ASSERT(false); // TODO: not implemented
|
| 17720 |
} break;
|
| 17721 |
+
case GGML_OP_CONV_1D_STAGE_0:
|
| 17722 |
+
{
|
| 17723 |
+
GGML_ASSERT(false); // TODO: not implemented
|
| 17724 |
+
} break;
|
| 17725 |
+
case GGML_OP_CONV_1D_STAGE_1:
|
| 17726 |
+
{
|
| 17727 |
+
GGML_ASSERT(false); // TODO: not implemented
|
| 17728 |
+
} break;
|
| 17729 |
case GGML_OP_CONV_2D:
|
| 17730 |
{
|
| 17731 |
GGML_ASSERT(false); // TODO: not implemented
|
| 17732 |
} break;
|
| 17733 |
+
case GGML_OP_CONV_TRANSPOSE_1D:
|
| 17734 |
+
{
|
| 17735 |
+
GGML_ASSERT(false); // TODO: not implemented
|
| 17736 |
+
} break;
|
| 17737 |
case GGML_OP_CONV_TRANSPOSE_2D:
|
| 17738 |
{
|
| 17739 |
GGML_ASSERT(false); // TODO: not implemented
|
|
|
|
| 18571 |
GGML_ASSERT(node->src[1]->ne[2] == 1);
|
| 18572 |
GGML_ASSERT(node->src[1]->ne[3] == 1);
|
| 18573 |
|
| 18574 |
+
const int64_t ne00 = node->src[0]->ne[0];
|
| 18575 |
+
const int64_t ne01 = node->src[0]->ne[1];
|
| 18576 |
+
const int64_t ne02 = node->src[0]->ne[2];
|
| 18577 |
+
|
| 18578 |
+
const int64_t ne10 = node->src[1]->ne[0];
|
| 18579 |
+
const int64_t ne11 = node->src[1]->ne[1];
|
| 18580 |
+
|
| 18581 |
+
const int64_t ne0 = node->ne[0];
|
| 18582 |
+
const int64_t ne1 = node->ne[1];
|
| 18583 |
+
const int64_t nk = ne00;
|
| 18584 |
+
const int64_t ew0 = nk * ne01;
|
| 18585 |
+
|
| 18586 |
+
UNUSED(ne02);
|
| 18587 |
+
UNUSED(ne10);
|
| 18588 |
+
UNUSED(ne11);
|
| 18589 |
+
|
| 18590 |
size_t cur = 0;
|
|
|
|
| 18591 |
|
| 18592 |
if (node->src[0]->type == GGML_TYPE_F16 &&
|
| 18593 |
+
node->src[1]->type == GGML_TYPE_F32) {
|
| 18594 |
+
cur = sizeof(ggml_fp16_t)*(ne0*ne1*ew0);
|
| 18595 |
+
} else if (node->src[0]->type == GGML_TYPE_F32 &&
|
| 18596 |
+
node->src[1]->type == GGML_TYPE_F32) {
|
| 18597 |
+
cur = sizeof(float)*(ne0*ne1*ew0);
|
| 18598 |
+
} else {
|
| 18599 |
+
GGML_ASSERT(false);
|
| 18600 |
+
}
|
| 18601 |
+
|
| 18602 |
+
work_size = MAX(work_size, cur);
|
| 18603 |
+
} break;
|
| 18604 |
+
case GGML_OP_CONV_1D_STAGE_0:
|
| 18605 |
+
{
|
| 18606 |
+
n_tasks = n_threads;
|
| 18607 |
+
} break;
|
| 18608 |
+
case GGML_OP_CONV_1D_STAGE_1:
|
| 18609 |
+
{
|
| 18610 |
+
n_tasks = n_threads;
|
| 18611 |
+
} break;
|
| 18612 |
+
case GGML_OP_CONV_TRANSPOSE_1D:
|
| 18613 |
+
{
|
| 18614 |
+
n_tasks = n_threads;
|
| 18615 |
+
|
| 18616 |
+
GGML_ASSERT(node->src[0]->ne[3] == 1);
|
| 18617 |
+
GGML_ASSERT(node->src[1]->ne[2] == 1);
|
| 18618 |
+
GGML_ASSERT(node->src[1]->ne[3] == 1);
|
| 18619 |
+
|
| 18620 |
+
const int64_t ne00 = node->src[0]->ne[0]; // K
|
| 18621 |
+
const int64_t ne01 = node->src[0]->ne[1]; // Cout
|
| 18622 |
+
const int64_t ne02 = node->src[0]->ne[2]; // Cin
|
| 18623 |
+
|
| 18624 |
+
const int64_t ne10 = node->src[1]->ne[0]; // L
|
| 18625 |
+
const int64_t ne11 = node->src[1]->ne[1]; // Cin
|
| 18626 |
+
|
| 18627 |
+
size_t cur = 0;
|
| 18628 |
+
if (node->src[0]->type == GGML_TYPE_F16 &&
|
| 18629 |
+
node->src[1]->type == GGML_TYPE_F32) {
|
| 18630 |
+
cur += sizeof(ggml_fp16_t)*ne00*ne01*ne02;
|
| 18631 |
+
cur += sizeof(ggml_fp16_t)*ne10*ne11;
|
| 18632 |
} else if (node->src[0]->type == GGML_TYPE_F32 &&
|
| 18633 |
+
node->src[1]->type == GGML_TYPE_F32) {
|
| 18634 |
+
cur += sizeof(float)*ne00*ne01*ne02;
|
| 18635 |
+
cur += sizeof(float)*ne10*ne11;
|
|
|
|
|
|
|
| 18636 |
} else {
|
| 18637 |
GGML_ASSERT(false);
|
| 18638 |
}
|
|
|
|
| 19758 |
if (callback) {
|
| 19759 |
callback(callback_data, accum_step, &sched, &cancel);
|
| 19760 |
if (cancel) {
|
| 19761 |
+
return GGML_OPT_CANCEL;
|
| 19762 |
}
|
| 19763 |
}
|
| 19764 |
// ggml_graph_reset (gf);
|
|
|
|
| 19767 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 19768 |
fx += ggml_get_f32_1d(f, 0);
|
| 19769 |
}
|
|
|
|
|
|
|
|
|
|
| 19770 |
fx *= accum_norm;
|
| 19771 |
|
| 19772 |
opt->adam.fx_prev = fx;
|
|
|
|
| 19792 |
|
| 19793 |
// run the optimizer
|
| 19794 |
for (int t = 0; t < params.adam.n_iter; ++t) {
|
|
|
|
|
|
|
|
|
|
| 19795 |
opt->iter = iter0 + t + 1;
|
| 19796 |
GGML_PRINT_DEBUG ("=== iter %d ===\n", t);
|
| 19797 |
|
|
|
|
| 19849 |
if (callback) {
|
| 19850 |
callback(callback_data, accum_step, &sched, &cancel);
|
| 19851 |
if (cancel) {
|
| 19852 |
+
return GGML_OPT_CANCEL;;
|
| 19853 |
}
|
| 19854 |
}
|
| 19855 |
// ggml_graph_reset (gf);
|
|
|
|
| 19858 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 19859 |
fx += ggml_get_f32_1d(f, 0);
|
| 19860 |
}
|
|
|
|
|
|
|
|
|
|
| 19861 |
fx *= accum_norm;
|
| 19862 |
|
| 19863 |
opt->loss_after = fx;
|
|
|
|
| 19976 |
finit = *fx;
|
| 19977 |
dgtest = params->lbfgs.ftol*dginit;
|
| 19978 |
|
| 19979 |
+
while (true) {
|
| 19980 |
ggml_vec_cpy_f32(nx, x, xp);
|
| 19981 |
ggml_vec_mad_f32(nx, x, d, *step);
|
| 19982 |
|
|
|
|
| 19992 |
float sched = 0;
|
| 19993 |
callback(callback_data, accum_step, &sched, cancel);
|
| 19994 |
if (*cancel) {
|
| 19995 |
+
return GGML_OPT_CANCEL;
|
| 19996 |
}
|
| 19997 |
}
|
| 19998 |
// ggml_graph_reset (gf);
|
|
|
|
| 20001 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 20002 |
*fx += ggml_get_f32_1d(f, 0);
|
| 20003 |
}
|
|
|
|
|
|
|
|
|
|
| 20004 |
*fx *= accum_norm;
|
| 20005 |
|
| 20006 |
}
|
|
|
|
| 20133 |
float sched = 0;
|
| 20134 |
callback(callback_data, accum_step, &sched, &cancel);
|
| 20135 |
if (cancel) {
|
| 20136 |
+
return GGML_OPT_CANCEL;
|
| 20137 |
}
|
| 20138 |
}
|
| 20139 |
// ggml_graph_reset (gf);
|
|
|
|
| 20142 |
ggml_opt_acc_grad(np, ps, g, accum_norm);
|
| 20143 |
fx += ggml_get_f32_1d(f, 0);
|
| 20144 |
}
|
|
|
|
|
|
|
|
|
|
| 20145 |
fx *= accum_norm;
|
| 20146 |
|
| 20147 |
opt->loss_before = fx;
|
|
|
|
| 20201 |
ggml_vec_cpy_f32(nx, gp, g);
|
| 20202 |
|
| 20203 |
ls = linesearch_backtracking(¶ms, nx, x, &fx, g, d, step, xp, f, gb, &cplan, np, ps, &cancel, callback, callback_data);
|
| 20204 |
+
if (cancel) {
|
| 20205 |
+
return GGML_OPT_CANCEL;
|
| 20206 |
}
|
| 20207 |
|
| 20208 |
if (ls < 0) {
|
ggml.h
CHANGED
|
@@ -401,10 +401,14 @@ extern "C" {
|
|
| 401 |
GGML_OP_CLAMP,
|
| 402 |
GGML_OP_CONV_1D,
|
| 403 |
GGML_OP_CONV_2D,
|
|
|
|
| 404 |
GGML_OP_CONV_TRANSPOSE_2D,
|
| 405 |
GGML_OP_POOL_1D,
|
| 406 |
GGML_OP_POOL_2D,
|
| 407 |
|
|
|
|
|
|
|
|
|
|
| 408 |
GGML_OP_UPSCALE, // nearest interpolate
|
| 409 |
|
| 410 |
GGML_OP_FLASH_ATTN,
|
|
@@ -1386,6 +1390,14 @@ extern "C" {
|
|
| 1386 |
int s,
|
| 1387 |
int d);
|
| 1388 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1389 |
GGML_API struct ggml_tensor * ggml_conv_2d(
|
| 1390 |
struct ggml_context * ctx,
|
| 1391 |
struct ggml_tensor * a,
|
|
@@ -1759,6 +1771,7 @@ extern "C" {
|
|
| 1759 |
GGML_OPT_NO_CONTEXT,
|
| 1760 |
GGML_OPT_INVALID_WOLFE,
|
| 1761 |
GGML_OPT_FAIL,
|
|
|
|
| 1762 |
|
| 1763 |
GGML_LINESEARCH_FAIL = -128,
|
| 1764 |
GGML_LINESEARCH_MINIMUM_STEP,
|
|
|
|
| 401 |
GGML_OP_CLAMP,
|
| 402 |
GGML_OP_CONV_1D,
|
| 403 |
GGML_OP_CONV_2D,
|
| 404 |
+
GGML_OP_CONV_TRANSPOSE_1D,
|
| 405 |
GGML_OP_CONV_TRANSPOSE_2D,
|
| 406 |
GGML_OP_POOL_1D,
|
| 407 |
GGML_OP_POOL_2D,
|
| 408 |
|
| 409 |
+
GGML_OP_CONV_1D_STAGE_0, // internal
|
| 410 |
+
GGML_OP_CONV_1D_STAGE_1, // internal
|
| 411 |
+
|
| 412 |
GGML_OP_UPSCALE, // nearest interpolate
|
| 413 |
|
| 414 |
GGML_OP_FLASH_ATTN,
|
|
|
|
| 1390 |
int s,
|
| 1391 |
int d);
|
| 1392 |
|
| 1393 |
+
GGML_API struct ggml_tensor * ggml_conv_transpose_1d(
|
| 1394 |
+
struct ggml_context * ctx,
|
| 1395 |
+
struct ggml_tensor * a,
|
| 1396 |
+
struct ggml_tensor * b,
|
| 1397 |
+
int s0,
|
| 1398 |
+
int p0,
|
| 1399 |
+
int d0);
|
| 1400 |
+
|
| 1401 |
GGML_API struct ggml_tensor * ggml_conv_2d(
|
| 1402 |
struct ggml_context * ctx,
|
| 1403 |
struct ggml_tensor * a,
|
|
|
|
| 1771 |
GGML_OPT_NO_CONTEXT,
|
| 1772 |
GGML_OPT_INVALID_WOLFE,
|
| 1773 |
GGML_OPT_FAIL,
|
| 1774 |
+
GGML_OPT_CANCEL,
|
| 1775 |
|
| 1776 |
GGML_LINESEARCH_FAIL = -128,
|
| 1777 |
GGML_LINESEARCH_MINIMUM_STEP,
|
gguf-py/README.md
CHANGED
|
@@ -69,4 +69,3 @@ python -m twine upload dist/*
|
|
| 69 |
## TODO
|
| 70 |
- [ ] Add tests
|
| 71 |
- [ ] Include conversion scripts as command line entry points in this package.
|
| 72 |
-
- Add CI workflow for releasing the package.
|
|
|
|
| 69 |
## TODO
|
| 70 |
- [ ] Add tests
|
| 71 |
- [ ] Include conversion scripts as command line entry points in this package.
|
|
|
gguf-py/gguf/gguf.py
CHANGED
|
@@ -85,10 +85,14 @@ class MODEL_ARCH(IntEnum):
|
|
| 85 |
GPTNEOX : int = auto()
|
| 86 |
MPT : int = auto()
|
| 87 |
STARCODER : int = auto()
|
|
|
|
|
|
|
|
|
|
| 88 |
|
| 89 |
|
| 90 |
class MODEL_TENSOR(IntEnum):
|
| 91 |
TOKEN_EMBD : int = auto()
|
|
|
|
| 92 |
POS_EMBD : int = auto()
|
| 93 |
OUTPUT : int = auto()
|
| 94 |
OUTPUT_NORM : int = auto()
|
|
@@ -105,6 +109,8 @@ class MODEL_TENSOR(IntEnum):
|
|
| 105 |
FFN_DOWN : int = auto()
|
| 106 |
FFN_UP : int = auto()
|
| 107 |
FFN_NORM : int = auto()
|
|
|
|
|
|
|
| 108 |
|
| 109 |
|
| 110 |
MODEL_ARCH_NAMES: dict[MODEL_ARCH, str] = {
|
|
@@ -116,78 +122,169 @@ MODEL_ARCH_NAMES: dict[MODEL_ARCH, str] = {
|
|
| 116 |
MODEL_ARCH.GPTNEOX: "gptneox",
|
| 117 |
MODEL_ARCH.MPT: "mpt",
|
| 118 |
MODEL_ARCH.STARCODER: "starcoder",
|
|
|
|
|
|
|
|
|
|
| 119 |
}
|
| 120 |
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
},
|
| 138 |
-
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
|
| 146 |
-
MODEL_TENSOR.
|
| 147 |
-
MODEL_TENSOR.
|
| 148 |
-
|
| 149 |
-
|
| 150 |
-
MODEL_TENSOR.
|
| 151 |
-
MODEL_TENSOR.
|
| 152 |
-
MODEL_TENSOR.
|
| 153 |
-
MODEL_TENSOR.
|
| 154 |
-
MODEL_TENSOR.
|
| 155 |
-
MODEL_TENSOR.
|
| 156 |
-
MODEL_TENSOR.
|
| 157 |
-
MODEL_TENSOR.
|
| 158 |
-
MODEL_TENSOR.
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
MODEL_TENSOR.
|
| 163 |
-
MODEL_TENSOR.
|
| 164 |
-
MODEL_TENSOR.
|
| 165 |
-
MODEL_TENSOR.ATTN_NORM
|
| 166 |
-
MODEL_TENSOR.
|
| 167 |
-
MODEL_TENSOR.
|
| 168 |
-
MODEL_TENSOR.
|
| 169 |
-
MODEL_TENSOR.
|
| 170 |
-
MODEL_TENSOR.
|
| 171 |
-
|
| 172 |
-
|
| 173 |
-
MODEL_TENSOR.
|
| 174 |
-
MODEL_TENSOR.
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
MODEL_TENSOR.
|
| 178 |
-
MODEL_TENSOR.
|
| 179 |
-
MODEL_TENSOR.
|
| 180 |
-
MODEL_TENSOR.
|
| 181 |
-
MODEL_TENSOR.
|
| 182 |
-
|
| 183 |
-
|
| 184 |
-
MODEL_TENSOR.
|
| 185 |
-
MODEL_TENSOR.
|
| 186 |
-
MODEL_TENSOR.
|
| 187 |
-
|
| 188 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 189 |
# TODO
|
| 190 |
-
|
| 191 |
# TODO
|
| 192 |
}
|
| 193 |
|
|
@@ -201,6 +298,9 @@ MODEL_TENSOR_SKIP: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
|
| 201 |
MODEL_TENSOR.ROPE_FREQS,
|
| 202 |
MODEL_TENSOR.ATTN_ROT_EMBD,
|
| 203 |
],
|
|
|
|
|
|
|
|
|
|
| 204 |
}
|
| 205 |
|
| 206 |
|
|
@@ -208,31 +308,44 @@ class TensorNameMap:
|
|
| 208 |
mappings_cfg: dict[MODEL_TENSOR, tuple[str, ...]] = {
|
| 209 |
# Token embeddings
|
| 210 |
MODEL_TENSOR.TOKEN_EMBD: (
|
| 211 |
-
"gpt_neox.embed_in",
|
| 212 |
-
"transformer.wte",
|
| 213 |
-
"transformer.word_embeddings",
|
| 214 |
-
"model.embed_tokens",
|
| 215 |
-
"tok_embeddings",
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 216 |
),
|
| 217 |
|
| 218 |
# Position embeddings
|
| 219 |
MODEL_TENSOR.POS_EMBD: (
|
| 220 |
-
"transformer.wpe",
|
|
|
|
| 221 |
),
|
| 222 |
|
| 223 |
# Output
|
| 224 |
MODEL_TENSOR.OUTPUT: (
|
| 225 |
-
"embed_out",
|
| 226 |
-
"lm_head",
|
| 227 |
-
"output",
|
|
|
|
| 228 |
),
|
| 229 |
|
| 230 |
# Output norm
|
| 231 |
MODEL_TENSOR.OUTPUT_NORM: (
|
| 232 |
-
"gpt_neox.final_layer_norm",
|
| 233 |
-
"transformer.ln_f",
|
| 234 |
-
"model.norm",
|
| 235 |
-
"norm",
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
),
|
| 237 |
|
| 238 |
# Rope frequencies
|
|
@@ -244,13 +357,15 @@ class TensorNameMap:
|
|
| 244 |
block_mappings_cfg: dict[MODEL_TENSOR, tuple[str, ...]] = {
|
| 245 |
# Attention norm
|
| 246 |
MODEL_TENSOR.ATTN_NORM: (
|
| 247 |
-
"gpt_neox.layers.{bid}.input_layernorm",
|
| 248 |
-
"transformer.h.{bid}.ln_1",
|
| 249 |
-
"transformer.blocks.{bid}.norm_1",
|
| 250 |
-
"transformer.h.{bid}.input_layernorm",
|
| 251 |
-
"transformer.h.{bid}.ln_mlp",
|
| 252 |
-
"model.layers.{bid}.input_layernorm",
|
| 253 |
-
"layers.{bid}.attention_norm",
|
|
|
|
|
|
|
| 254 |
),
|
| 255 |
|
| 256 |
# Attention norm 2
|
|
@@ -260,38 +375,48 @@ class TensorNameMap:
|
|
| 260 |
|
| 261 |
# Attention query-key-value
|
| 262 |
MODEL_TENSOR.ATTN_QKV: (
|
| 263 |
-
"gpt_neox.layers.{bid}.attention.query_key_value",
|
| 264 |
-
"transformer.h.{bid}.attn.c_attn",
|
| 265 |
-
"transformer.blocks.{bid}.attn.Wqkv",
|
| 266 |
-
"transformer.h.{bid}.self_attention.query_key_value",
|
|
|
|
| 267 |
),
|
| 268 |
|
| 269 |
# Attention query
|
| 270 |
MODEL_TENSOR.ATTN_Q: (
|
| 271 |
-
"model.layers.{bid}.self_attn.q_proj",
|
| 272 |
-
"layers.{bid}.attention.wq",
|
|
|
|
|
|
|
| 273 |
),
|
| 274 |
|
| 275 |
# Attention key
|
| 276 |
MODEL_TENSOR.ATTN_K: (
|
| 277 |
-
"model.layers.{bid}.self_attn.k_proj",
|
| 278 |
-
"layers.{bid}.attention.wk",
|
|
|
|
|
|
|
| 279 |
),
|
| 280 |
|
| 281 |
# Attention value
|
| 282 |
MODEL_TENSOR.ATTN_V: (
|
| 283 |
-
"model.layers.{bid}.self_attn.v_proj",
|
| 284 |
-
"layers.{bid}.attention.wv",
|
|
|
|
|
|
|
| 285 |
),
|
| 286 |
|
| 287 |
# Attention output
|
| 288 |
MODEL_TENSOR.ATTN_OUT: (
|
| 289 |
-
"gpt_neox.layers.{bid}.attention.dense",
|
| 290 |
-
"transformer.h.{bid}.attn.c_proj",
|
| 291 |
-
"transformer.blocks.{bid}.attn.out_proj",
|
| 292 |
-
"transformer.h.{bid}.self_attention.dense",
|
| 293 |
-
"model.layers.{bid}.self_attn.o_proj",
|
| 294 |
-
"layers.{bid}.attention.wo",
|
|
|
|
|
|
|
|
|
|
| 295 |
),
|
| 296 |
|
| 297 |
# Rotary embeddings
|
|
@@ -302,64 +427,80 @@ class TensorNameMap:
|
|
| 302 |
|
| 303 |
# Feed-forward norm
|
| 304 |
MODEL_TENSOR.FFN_NORM: (
|
| 305 |
-
"gpt_neox.layers.{bid}.post_attention_layernorm",
|
| 306 |
-
"transformer.h.{bid}.ln_2",
|
| 307 |
-
"transformer.blocks.{bid}.norm_2",
|
| 308 |
-
"model.layers.{bid}.post_attention_layernorm",
|
| 309 |
-
"layers.{bid}.ffn_norm",
|
|
|
|
|
|
|
| 310 |
),
|
| 311 |
|
| 312 |
# Feed-forward up
|
| 313 |
MODEL_TENSOR.FFN_UP: (
|
| 314 |
-
"gpt_neox.layers.{bid}.mlp.dense_h_to_4h",
|
| 315 |
-
"transformer.h.{bid}.mlp.c_fc",
|
| 316 |
-
"transformer.blocks.{bid}.ffn.up_proj",
|
| 317 |
-
"transformer.h.{bid}.mlp.dense_h_to_4h",
|
| 318 |
-
"model.layers.{bid}.mlp.up_proj",
|
| 319 |
-
"layers.{bid}.feed_forward.w3",
|
|
|
|
|
|
|
|
|
|
| 320 |
),
|
| 321 |
|
| 322 |
# Feed-forward gate
|
| 323 |
MODEL_TENSOR.FFN_GATE: (
|
| 324 |
-
"model.layers.{bid}.mlp.gate_proj", # llama-hf
|
| 325 |
"layers.{bid}.feed_forward.w1", # llama-pth
|
| 326 |
),
|
| 327 |
|
| 328 |
# Feed-forward down
|
| 329 |
MODEL_TENSOR.FFN_DOWN: (
|
| 330 |
-
"gpt_neox.layers.{bid}.mlp.dense_4h_to_h",
|
| 331 |
-
"transformer.h.{bid}.mlp.c_proj",
|
| 332 |
-
"transformer.blocks.{bid}.ffn.down_proj",
|
| 333 |
-
"transformer.h.{bid}.mlp.dense_4h_to_h",
|
| 334 |
-
"model.layers.{bid}.mlp.down_proj",
|
| 335 |
-
"layers.{bid}.feed_forward.w2",
|
|
|
|
|
|
|
|
|
|
| 336 |
),
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 337 |
}
|
| 338 |
|
| 339 |
mapping: dict[str, tuple[MODEL_TENSOR, str]]
|
| 340 |
|
| 341 |
-
tensor_names: dict[MODEL_TENSOR, str]
|
| 342 |
-
|
| 343 |
def __init__(self, arch: MODEL_ARCH, n_blocks: int):
|
| 344 |
-
|
| 345 |
-
tensor_names = self.tensor_names = MODEL_TENSOR_NAMES[arch]
|
| 346 |
for tensor, keys in self.mappings_cfg.items():
|
| 347 |
-
|
| 348 |
-
if tensor_name is None:
|
| 349 |
continue
|
| 350 |
-
|
|
|
|
| 351 |
for key in keys:
|
| 352 |
-
mapping[key] = (tensor, tensor_name)
|
| 353 |
for bid in range(n_blocks):
|
| 354 |
for tensor, keys in self.block_mappings_cfg.items():
|
| 355 |
-
|
| 356 |
-
if tensor_name is None:
|
| 357 |
continue
|
| 358 |
-
tensor_name =
|
| 359 |
-
mapping[tensor_name] = (tensor, tensor_name)
|
| 360 |
for key in keys:
|
| 361 |
key = key.format(bid = bid)
|
| 362 |
-
mapping[key] = (tensor, tensor_name)
|
| 363 |
|
| 364 |
def get_type_and_name(self, key: str, try_suffixes: Sequence[str] = ()) -> tuple[MODEL_TENSOR, str] | None:
|
| 365 |
result = self.mapping.get(key)
|
|
@@ -800,22 +941,25 @@ class SpecialVocab:
|
|
| 800 |
special_token_types: tuple[str, ...] = ('bos', 'eos', 'unk', 'sep', 'pad')
|
| 801 |
special_token_ids: dict[str, int] = {}
|
| 802 |
|
| 803 |
-
def __init__(
|
|
|
|
|
|
|
|
|
|
| 804 |
self.special_token_ids = {}
|
| 805 |
self.load_merges = load_merges
|
| 806 |
if special_token_types is not None:
|
| 807 |
self.special_token_types = special_token_types
|
| 808 |
-
self.
|
| 809 |
|
| 810 |
-
def
|
| 811 |
-
if not self.
|
| 812 |
-
self.
|
| 813 |
|
| 814 |
-
def
|
| 815 |
tokenizer_file = path / 'tokenizer.json'
|
| 816 |
if not tokenizer_file.is_file():
|
| 817 |
return False
|
| 818 |
-
with open(tokenizer_file,
|
| 819 |
tokenizer = json.load(f)
|
| 820 |
if self.load_merges:
|
| 821 |
merges = tokenizer.get('model', {}).get('merges')
|
|
@@ -825,7 +969,7 @@ class SpecialVocab:
|
|
| 825 |
added_tokens = tokenizer.get('added_tokens')
|
| 826 |
if added_tokens is None or not tokenizer_config_file.is_file():
|
| 827 |
return True
|
| 828 |
-
with open(tokenizer_config_file,
|
| 829 |
tokenizer_config = json.load(f)
|
| 830 |
for typ in self.special_token_types:
|
| 831 |
entry = tokenizer_config.get(f'{typ}_token')
|
|
@@ -844,11 +988,11 @@ class SpecialVocab:
|
|
| 844 |
break
|
| 845 |
return True
|
| 846 |
|
| 847 |
-
def
|
| 848 |
config_file = path / 'config.json'
|
| 849 |
if not config_file.is_file():
|
| 850 |
return False
|
| 851 |
-
with open(config_file,
|
| 852 |
config = json.load(f)
|
| 853 |
for typ in self.special_token_types:
|
| 854 |
maybe_token_id = config.get(f'{typ}_token_id')
|
|
@@ -856,7 +1000,7 @@ class SpecialVocab:
|
|
| 856 |
self.special_token_ids[typ] = maybe_token_id
|
| 857 |
return True
|
| 858 |
|
| 859 |
-
def add_to_gguf(self, gw: GGUFWriter):
|
| 860 |
if len(self.merges) > 0:
|
| 861 |
print(f'gguf: Adding {len(self.merges)} merge(s).')
|
| 862 |
gw.add_token_merges(self.merges)
|
|
@@ -868,8 +1012,8 @@ class SpecialVocab:
|
|
| 868 |
print(f'gguf: Setting special token type {typ} to {tokid}')
|
| 869 |
handler(tokid)
|
| 870 |
|
| 871 |
-
def __repr__(self):
|
| 872 |
-
return f'<SpecialVocab with {len(self.merges)} merges and special tokens {self.special_token_ids
|
| 873 |
|
| 874 |
|
| 875 |
# Example usage:
|
|
|
|
| 85 |
GPTNEOX : int = auto()
|
| 86 |
MPT : int = auto()
|
| 87 |
STARCODER : int = auto()
|
| 88 |
+
PERSIMMON : int = auto()
|
| 89 |
+
REFACT : int = auto()
|
| 90 |
+
BERT : int = auto()
|
| 91 |
|
| 92 |
|
| 93 |
class MODEL_TENSOR(IntEnum):
|
| 94 |
TOKEN_EMBD : int = auto()
|
| 95 |
+
TOKEN_TYPES : int = auto()
|
| 96 |
POS_EMBD : int = auto()
|
| 97 |
OUTPUT : int = auto()
|
| 98 |
OUTPUT_NORM : int = auto()
|
|
|
|
| 109 |
FFN_DOWN : int = auto()
|
| 110 |
FFN_UP : int = auto()
|
| 111 |
FFN_NORM : int = auto()
|
| 112 |
+
ATTN_Q_NORM : int = auto()
|
| 113 |
+
ATTN_K_NORM : int = auto()
|
| 114 |
|
| 115 |
|
| 116 |
MODEL_ARCH_NAMES: dict[MODEL_ARCH, str] = {
|
|
|
|
| 122 |
MODEL_ARCH.GPTNEOX: "gptneox",
|
| 123 |
MODEL_ARCH.MPT: "mpt",
|
| 124 |
MODEL_ARCH.STARCODER: "starcoder",
|
| 125 |
+
MODEL_ARCH.PERSIMMON: "persimmon",
|
| 126 |
+
MODEL_ARCH.REFACT: "refact",
|
| 127 |
+
MODEL_ARCH.BERT: "bert",
|
| 128 |
}
|
| 129 |
|
| 130 |
+
TENSOR_NAMES: dict[MODEL_TENSOR, str] = {
|
| 131 |
+
MODEL_TENSOR.TOKEN_EMBD: "token_embd",
|
| 132 |
+
MODEL_TENSOR.TOKEN_TYPES: "token_types",
|
| 133 |
+
MODEL_TENSOR.POS_EMBD: "position_embd",
|
| 134 |
+
MODEL_TENSOR.OUTPUT_NORM: "output_norm",
|
| 135 |
+
MODEL_TENSOR.OUTPUT: "output",
|
| 136 |
+
MODEL_TENSOR.ROPE_FREQS: "rope_freqs",
|
| 137 |
+
MODEL_TENSOR.ATTN_NORM: "blk.{bid}.attn_norm",
|
| 138 |
+
MODEL_TENSOR.ATTN_NORM_2: "blk.{bid}.attn_norm_2",
|
| 139 |
+
MODEL_TENSOR.ATTN_QKV: "blk.{bid}.attn_qkv",
|
| 140 |
+
MODEL_TENSOR.ATTN_Q: "blk.{bid}.attn_q",
|
| 141 |
+
MODEL_TENSOR.ATTN_K: "blk.{bid}.attn_k",
|
| 142 |
+
MODEL_TENSOR.ATTN_V: "blk.{bid}.attn_v",
|
| 143 |
+
MODEL_TENSOR.ATTN_OUT: "blk.{bid}.attn_output",
|
| 144 |
+
MODEL_TENSOR.ATTN_ROT_EMBD: "blk.{bid}.attn_rot_embd",
|
| 145 |
+
MODEL_TENSOR.ATTN_Q_NORM: "blk.{bid}.attn_q_norm",
|
| 146 |
+
MODEL_TENSOR.ATTN_K_NORM: "blk.{bid}.attn_k_norm",
|
| 147 |
+
MODEL_TENSOR.FFN_NORM: "blk.{bid}.ffn_norm",
|
| 148 |
+
MODEL_TENSOR.FFN_GATE: "blk.{bid}.ffn_gate",
|
| 149 |
+
MODEL_TENSOR.FFN_DOWN: "blk.{bid}.ffn_down",
|
| 150 |
+
MODEL_TENSOR.FFN_UP: "blk.{bid}.ffn_up",
|
| 151 |
+
}
|
| 152 |
+
|
| 153 |
+
MODEL_TENSORS: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
| 154 |
+
MODEL_ARCH.LLAMA: [
|
| 155 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 156 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 157 |
+
MODEL_TENSOR.OUTPUT,
|
| 158 |
+
MODEL_TENSOR.ROPE_FREQS,
|
| 159 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 160 |
+
MODEL_TENSOR.ATTN_Q,
|
| 161 |
+
MODEL_TENSOR.ATTN_K,
|
| 162 |
+
MODEL_TENSOR.ATTN_V,
|
| 163 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 164 |
+
MODEL_TENSOR.ATTN_ROT_EMBD,
|
| 165 |
+
MODEL_TENSOR.FFN_NORM,
|
| 166 |
+
MODEL_TENSOR.FFN_GATE,
|
| 167 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 168 |
+
MODEL_TENSOR.FFN_UP,
|
| 169 |
+
],
|
| 170 |
+
MODEL_ARCH.GPTNEOX: [
|
| 171 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 172 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 173 |
+
MODEL_TENSOR.OUTPUT,
|
| 174 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 175 |
+
MODEL_TENSOR.ATTN_QKV,
|
| 176 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 177 |
+
MODEL_TENSOR.FFN_NORM,
|
| 178 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 179 |
+
MODEL_TENSOR.FFN_UP,
|
| 180 |
+
],
|
| 181 |
+
MODEL_ARCH.FALCON: [
|
| 182 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 183 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 184 |
+
MODEL_TENSOR.OUTPUT,
|
| 185 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 186 |
+
MODEL_TENSOR.ATTN_NORM_2,
|
| 187 |
+
MODEL_TENSOR.ATTN_QKV,
|
| 188 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 189 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 190 |
+
MODEL_TENSOR.FFN_UP,
|
| 191 |
+
],
|
| 192 |
+
MODEL_ARCH.BAICHUAN: [
|
| 193 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 194 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 195 |
+
MODEL_TENSOR.OUTPUT,
|
| 196 |
+
MODEL_TENSOR.ROPE_FREQS,
|
| 197 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 198 |
+
MODEL_TENSOR.ATTN_Q,
|
| 199 |
+
MODEL_TENSOR.ATTN_K,
|
| 200 |
+
MODEL_TENSOR.ATTN_V,
|
| 201 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 202 |
+
MODEL_TENSOR.ATTN_ROT_EMBD,
|
| 203 |
+
MODEL_TENSOR.FFN_NORM,
|
| 204 |
+
MODEL_TENSOR.FFN_GATE,
|
| 205 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 206 |
+
MODEL_TENSOR.FFN_UP,
|
| 207 |
+
],
|
| 208 |
+
MODEL_ARCH.STARCODER: [
|
| 209 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 210 |
+
MODEL_TENSOR.POS_EMBD,
|
| 211 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 212 |
+
MODEL_TENSOR.OUTPUT,
|
| 213 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 214 |
+
MODEL_TENSOR.ATTN_QKV,
|
| 215 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 216 |
+
MODEL_TENSOR.FFN_NORM,
|
| 217 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 218 |
+
MODEL_TENSOR.FFN_UP,
|
| 219 |
+
],
|
| 220 |
+
MODEL_ARCH.BERT: [
|
| 221 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 222 |
+
MODEL_TENSOR.TOKEN_TYPES,
|
| 223 |
+
MODEL_TENSOR.POS_EMBD,
|
| 224 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 225 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 226 |
+
MODEL_TENSOR.ATTN_Q,
|
| 227 |
+
MODEL_TENSOR.ATTN_K,
|
| 228 |
+
MODEL_TENSOR.ATTN_V,
|
| 229 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 230 |
+
MODEL_TENSOR.FFN_NORM,
|
| 231 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 232 |
+
MODEL_TENSOR.FFN_UP,
|
| 233 |
+
],
|
| 234 |
+
MODEL_ARCH.MPT: [
|
| 235 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 236 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 237 |
+
MODEL_TENSOR.OUTPUT,
|
| 238 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 239 |
+
MODEL_TENSOR.ATTN_QKV,
|
| 240 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 241 |
+
MODEL_TENSOR.FFN_NORM,
|
| 242 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 243 |
+
MODEL_TENSOR.FFN_UP,
|
| 244 |
+
],
|
| 245 |
+
MODEL_ARCH.GPTJ: [
|
| 246 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 247 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 248 |
+
MODEL_TENSOR.OUTPUT,
|
| 249 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 250 |
+
MODEL_TENSOR.ATTN_Q,
|
| 251 |
+
MODEL_TENSOR.ATTN_K,
|
| 252 |
+
MODEL_TENSOR.ATTN_V,
|
| 253 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 254 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 255 |
+
MODEL_TENSOR.FFN_UP,
|
| 256 |
+
],
|
| 257 |
+
MODEL_ARCH.PERSIMMON: [
|
| 258 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 259 |
+
MODEL_TENSOR.OUTPUT,
|
| 260 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 261 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 262 |
+
MODEL_TENSOR.ATTN_QKV,
|
| 263 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 264 |
+
MODEL_TENSOR.FFN_NORM,
|
| 265 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 266 |
+
MODEL_TENSOR.FFN_UP,
|
| 267 |
+
MODEL_TENSOR.ATTN_Q_NORM,
|
| 268 |
+
MODEL_TENSOR.ATTN_K_NORM,
|
| 269 |
+
MODEL_TENSOR.ATTN_ROT_EMBD,
|
| 270 |
+
],
|
| 271 |
+
MODEL_ARCH.REFACT: [
|
| 272 |
+
MODEL_TENSOR.TOKEN_EMBD,
|
| 273 |
+
MODEL_TENSOR.OUTPUT_NORM,
|
| 274 |
+
MODEL_TENSOR.OUTPUT,
|
| 275 |
+
MODEL_TENSOR.ATTN_NORM,
|
| 276 |
+
MODEL_TENSOR.ATTN_Q,
|
| 277 |
+
MODEL_TENSOR.ATTN_K,
|
| 278 |
+
MODEL_TENSOR.ATTN_V,
|
| 279 |
+
MODEL_TENSOR.ATTN_OUT,
|
| 280 |
+
MODEL_TENSOR.FFN_NORM,
|
| 281 |
+
MODEL_TENSOR.FFN_GATE,
|
| 282 |
+
MODEL_TENSOR.FFN_DOWN,
|
| 283 |
+
MODEL_TENSOR.FFN_UP,
|
| 284 |
+
],
|
| 285 |
+
MODEL_ARCH.GPT2: [
|
| 286 |
# TODO
|
| 287 |
+
],
|
| 288 |
# TODO
|
| 289 |
}
|
| 290 |
|
|
|
|
| 298 |
MODEL_TENSOR.ROPE_FREQS,
|
| 299 |
MODEL_TENSOR.ATTN_ROT_EMBD,
|
| 300 |
],
|
| 301 |
+
MODEL_ARCH.PERSIMMON: [
|
| 302 |
+
MODEL_TENSOR.ROPE_FREQS,
|
| 303 |
+
]
|
| 304 |
}
|
| 305 |
|
| 306 |
|
|
|
|
| 308 |
mappings_cfg: dict[MODEL_TENSOR, tuple[str, ...]] = {
|
| 309 |
# Token embeddings
|
| 310 |
MODEL_TENSOR.TOKEN_EMBD: (
|
| 311 |
+
"gpt_neox.embed_in", # gptneox
|
| 312 |
+
"transformer.wte", # gpt2 gpt-j mpt refact
|
| 313 |
+
"transformer.word_embeddings", # falcon
|
| 314 |
+
"model.embed_tokens", # llama-hf
|
| 315 |
+
"tok_embeddings", # llama-pth
|
| 316 |
+
"embeddings.word_embeddings", # bert
|
| 317 |
+
"language_model.embedding.word_embeddings", # persimmon
|
| 318 |
+
),
|
| 319 |
+
|
| 320 |
+
# Token type embeddings
|
| 321 |
+
MODEL_TENSOR.TOKEN_TYPES: (
|
| 322 |
+
"embeddings.token_type_embeddings", # bert
|
| 323 |
),
|
| 324 |
|
| 325 |
# Position embeddings
|
| 326 |
MODEL_TENSOR.POS_EMBD: (
|
| 327 |
+
"transformer.wpe", # gpt2
|
| 328 |
+
"embeddings.position_embeddings", # bert
|
| 329 |
),
|
| 330 |
|
| 331 |
# Output
|
| 332 |
MODEL_TENSOR.OUTPUT: (
|
| 333 |
+
"embed_out", # gptneox
|
| 334 |
+
"lm_head", # gpt2 mpt falcon llama-hf baichuan
|
| 335 |
+
"output", # llama-pth
|
| 336 |
+
"word_embeddings_for_head", # persimmon
|
| 337 |
),
|
| 338 |
|
| 339 |
# Output norm
|
| 340 |
MODEL_TENSOR.OUTPUT_NORM: (
|
| 341 |
+
"gpt_neox.final_layer_norm", # gptneox
|
| 342 |
+
"transformer.ln_f", # gpt2 gpt-j falcon
|
| 343 |
+
"model.norm", # llama-hf baichuan
|
| 344 |
+
"norm", # llama-pth
|
| 345 |
+
"embeddings.LayerNorm", # bert
|
| 346 |
+
"transformer.norm_f", # mpt
|
| 347 |
+
"ln_f", # refact
|
| 348 |
+
"language_model.encoder.final_layernorm", # persimmon
|
| 349 |
),
|
| 350 |
|
| 351 |
# Rope frequencies
|
|
|
|
| 357 |
block_mappings_cfg: dict[MODEL_TENSOR, tuple[str, ...]] = {
|
| 358 |
# Attention norm
|
| 359 |
MODEL_TENSOR.ATTN_NORM: (
|
| 360 |
+
"gpt_neox.layers.{bid}.input_layernorm", # gptneox
|
| 361 |
+
"transformer.h.{bid}.ln_1", # gpt2 gpt-j refact
|
| 362 |
+
"transformer.blocks.{bid}.norm_1", # mpt
|
| 363 |
+
"transformer.h.{bid}.input_layernorm", # falcon7b
|
| 364 |
+
"transformer.h.{bid}.ln_mlp", # falcon40b
|
| 365 |
+
"model.layers.{bid}.input_layernorm", # llama-hf
|
| 366 |
+
"layers.{bid}.attention_norm", # llama-pth
|
| 367 |
+
"encoder.layer.{bid}.attention.output.LayerNorm", # bert
|
| 368 |
+
"language_model.encoder.layers.{bid}.input_layernorm", # persimmon
|
| 369 |
),
|
| 370 |
|
| 371 |
# Attention norm 2
|
|
|
|
| 375 |
|
| 376 |
# Attention query-key-value
|
| 377 |
MODEL_TENSOR.ATTN_QKV: (
|
| 378 |
+
"gpt_neox.layers.{bid}.attention.query_key_value", # gptneox
|
| 379 |
+
"transformer.h.{bid}.attn.c_attn", # gpt2
|
| 380 |
+
"transformer.blocks.{bid}.attn.Wqkv", # mpt
|
| 381 |
+
"transformer.h.{bid}.self_attention.query_key_value", # falcon
|
| 382 |
+
"language_model.encoder.layers.{bid}.self_attention.query_key_value", # persimmon
|
| 383 |
),
|
| 384 |
|
| 385 |
# Attention query
|
| 386 |
MODEL_TENSOR.ATTN_Q: (
|
| 387 |
+
"model.layers.{bid}.self_attn.q_proj", # llama-hf
|
| 388 |
+
"layers.{bid}.attention.wq", # llama-pth
|
| 389 |
+
"encoder.layer.{bid}.attention.self.query", # bert
|
| 390 |
+
"transformer.h.{bid}.attn.q_proj", # gpt-j
|
| 391 |
),
|
| 392 |
|
| 393 |
# Attention key
|
| 394 |
MODEL_TENSOR.ATTN_K: (
|
| 395 |
+
"model.layers.{bid}.self_attn.k_proj", # llama-hf
|
| 396 |
+
"layers.{bid}.attention.wk", # llama-pth
|
| 397 |
+
"encoder.layer.{bid}.attention.self.key", # bert
|
| 398 |
+
"transformer.h.{bid}.attn.k_proj", # gpt-j
|
| 399 |
),
|
| 400 |
|
| 401 |
# Attention value
|
| 402 |
MODEL_TENSOR.ATTN_V: (
|
| 403 |
+
"model.layers.{bid}.self_attn.v_proj", # llama-hf
|
| 404 |
+
"layers.{bid}.attention.wv", # llama-pth
|
| 405 |
+
"encoder.layer.{bid}.attention.self.value", # bert
|
| 406 |
+
"transformer.h.{bid}.attn.v_proj", # gpt-j
|
| 407 |
),
|
| 408 |
|
| 409 |
# Attention output
|
| 410 |
MODEL_TENSOR.ATTN_OUT: (
|
| 411 |
+
"gpt_neox.layers.{bid}.attention.dense", # gptneox
|
| 412 |
+
"transformer.h.{bid}.attn.c_proj", # gpt2 refact
|
| 413 |
+
"transformer.blocks.{bid}.attn.out_proj", # mpt
|
| 414 |
+
"transformer.h.{bid}.self_attention.dense", # falcon
|
| 415 |
+
"model.layers.{bid}.self_attn.o_proj", # llama-hf
|
| 416 |
+
"layers.{bid}.attention.wo", # llama-pth
|
| 417 |
+
"encoder.layer.{bid}.attention.output.dense", # bert
|
| 418 |
+
"transformer.h.{bid}.attn.out_proj", # gpt-j
|
| 419 |
+
"language_model.encoder.layers.{bid}.self_attention.dense" # persimmon
|
| 420 |
),
|
| 421 |
|
| 422 |
# Rotary embeddings
|
|
|
|
| 427 |
|
| 428 |
# Feed-forward norm
|
| 429 |
MODEL_TENSOR.FFN_NORM: (
|
| 430 |
+
"gpt_neox.layers.{bid}.post_attention_layernorm", # gptneox
|
| 431 |
+
"transformer.h.{bid}.ln_2", # gpt2 refact
|
| 432 |
+
"transformer.blocks.{bid}.norm_2", # mpt
|
| 433 |
+
"model.layers.{bid}.post_attention_layernorm", # llama-hf
|
| 434 |
+
"layers.{bid}.ffn_norm", # llama-pth
|
| 435 |
+
"encoder.layer.{bid}.output.LayerNorm", # bert
|
| 436 |
+
"language_model.encoder.layers.{bid}.post_attention_layernorm", # persimmon
|
| 437 |
),
|
| 438 |
|
| 439 |
# Feed-forward up
|
| 440 |
MODEL_TENSOR.FFN_UP: (
|
| 441 |
+
"gpt_neox.layers.{bid}.mlp.dense_h_to_4h", # gptneox
|
| 442 |
+
"transformer.h.{bid}.mlp.c_fc", # gpt2
|
| 443 |
+
"transformer.blocks.{bid}.ffn.up_proj", # mpt
|
| 444 |
+
"transformer.h.{bid}.mlp.dense_h_to_4h", # falcon
|
| 445 |
+
"model.layers.{bid}.mlp.up_proj", # llama-hf refact
|
| 446 |
+
"layers.{bid}.feed_forward.w3", # llama-pth
|
| 447 |
+
"encoder.layer.{bid}.intermediate.dense", # bert
|
| 448 |
+
"transformer.h.{bid}.mlp.fc_in", # gpt-j
|
| 449 |
+
"language_model.encoder.layers.{bid}.mlp.dense_h_to_4h", # persimmon
|
| 450 |
),
|
| 451 |
|
| 452 |
# Feed-forward gate
|
| 453 |
MODEL_TENSOR.FFN_GATE: (
|
| 454 |
+
"model.layers.{bid}.mlp.gate_proj", # llama-hf refact
|
| 455 |
"layers.{bid}.feed_forward.w1", # llama-pth
|
| 456 |
),
|
| 457 |
|
| 458 |
# Feed-forward down
|
| 459 |
MODEL_TENSOR.FFN_DOWN: (
|
| 460 |
+
"gpt_neox.layers.{bid}.mlp.dense_4h_to_h", # gptneox
|
| 461 |
+
"transformer.h.{bid}.mlp.c_proj", # gpt2 refact
|
| 462 |
+
"transformer.blocks.{bid}.ffn.down_proj", # mpt
|
| 463 |
+
"transformer.h.{bid}.mlp.dense_4h_to_h", # falcon
|
| 464 |
+
"model.layers.{bid}.mlp.down_proj", # llama-hf
|
| 465 |
+
"layers.{bid}.feed_forward.w2", # llama-pth
|
| 466 |
+
"encoder.layer.{bid}.output.dense", # bert
|
| 467 |
+
"transformer.h.{bid}.mlp.fc_out", # gpt-j
|
| 468 |
+
"language_model.encoder.layers.{bid}.mlp.dense_4h_to_h", # persimmon
|
| 469 |
),
|
| 470 |
+
|
| 471 |
+
MODEL_TENSOR.ATTN_Q_NORM: (
|
| 472 |
+
"language_model.encoder.layers.{bid}.self_attention.q_layernorm",
|
| 473 |
+
),
|
| 474 |
+
|
| 475 |
+
MODEL_TENSOR.ATTN_K_NORM: (
|
| 476 |
+
"language_model.encoder.layers.{bid}.self_attention.k_layernorm",
|
| 477 |
+
),
|
| 478 |
+
|
| 479 |
+
MODEL_TENSOR.ROPE_FREQS: (
|
| 480 |
+
"language_model.encoder.layers.{bid}.self_attention.rotary_emb.inv_freq", # persimmon
|
| 481 |
+
)
|
| 482 |
}
|
| 483 |
|
| 484 |
mapping: dict[str, tuple[MODEL_TENSOR, str]]
|
| 485 |
|
|
|
|
|
|
|
| 486 |
def __init__(self, arch: MODEL_ARCH, n_blocks: int):
|
| 487 |
+
self.mapping = {}
|
|
|
|
| 488 |
for tensor, keys in self.mappings_cfg.items():
|
| 489 |
+
if tensor not in MODEL_TENSORS[arch]:
|
|
|
|
| 490 |
continue
|
| 491 |
+
tensor_name = TENSOR_NAMES[tensor]
|
| 492 |
+
self.mapping[tensor_name] = (tensor, tensor_name)
|
| 493 |
for key in keys:
|
| 494 |
+
self.mapping[key] = (tensor, tensor_name)
|
| 495 |
for bid in range(n_blocks):
|
| 496 |
for tensor, keys in self.block_mappings_cfg.items():
|
| 497 |
+
if tensor not in MODEL_TENSORS[arch]:
|
|
|
|
| 498 |
continue
|
| 499 |
+
tensor_name = TENSOR_NAMES[tensor].format(bid = bid)
|
| 500 |
+
self.mapping[tensor_name] = (tensor, tensor_name)
|
| 501 |
for key in keys:
|
| 502 |
key = key.format(bid = bid)
|
| 503 |
+
self.mapping[key] = (tensor, tensor_name)
|
| 504 |
|
| 505 |
def get_type_and_name(self, key: str, try_suffixes: Sequence[str] = ()) -> tuple[MODEL_TENSOR, str] | None:
|
| 506 |
result = self.mapping.get(key)
|
|
|
|
| 941 |
special_token_types: tuple[str, ...] = ('bos', 'eos', 'unk', 'sep', 'pad')
|
| 942 |
special_token_ids: dict[str, int] = {}
|
| 943 |
|
| 944 |
+
def __init__(
|
| 945 |
+
self, path: str | os.PathLike[str], load_merges: bool = False,
|
| 946 |
+
special_token_types: tuple[str, ...] | None = None,
|
| 947 |
+
):
|
| 948 |
self.special_token_ids = {}
|
| 949 |
self.load_merges = load_merges
|
| 950 |
if special_token_types is not None:
|
| 951 |
self.special_token_types = special_token_types
|
| 952 |
+
self._load(Path(path))
|
| 953 |
|
| 954 |
+
def _load(self, path: Path) -> None:
|
| 955 |
+
if not self._try_load_from_tokenizer_json(path):
|
| 956 |
+
self._try_load_from_config_json(path)
|
| 957 |
|
| 958 |
+
def _try_load_from_tokenizer_json(self, path: Path) -> bool:
|
| 959 |
tokenizer_file = path / 'tokenizer.json'
|
| 960 |
if not tokenizer_file.is_file():
|
| 961 |
return False
|
| 962 |
+
with open(tokenizer_file, encoding = 'utf-8') as f:
|
| 963 |
tokenizer = json.load(f)
|
| 964 |
if self.load_merges:
|
| 965 |
merges = tokenizer.get('model', {}).get('merges')
|
|
|
|
| 969 |
added_tokens = tokenizer.get('added_tokens')
|
| 970 |
if added_tokens is None or not tokenizer_config_file.is_file():
|
| 971 |
return True
|
| 972 |
+
with open(tokenizer_config_file, encoding = 'utf-8') as f:
|
| 973 |
tokenizer_config = json.load(f)
|
| 974 |
for typ in self.special_token_types:
|
| 975 |
entry = tokenizer_config.get(f'{typ}_token')
|
|
|
|
| 988 |
break
|
| 989 |
return True
|
| 990 |
|
| 991 |
+
def _try_load_from_config_json(self, path: Path) -> bool:
|
| 992 |
config_file = path / 'config.json'
|
| 993 |
if not config_file.is_file():
|
| 994 |
return False
|
| 995 |
+
with open(config_file, encoding = 'utf-8') as f:
|
| 996 |
config = json.load(f)
|
| 997 |
for typ in self.special_token_types:
|
| 998 |
maybe_token_id = config.get(f'{typ}_token_id')
|
|
|
|
| 1000 |
self.special_token_ids[typ] = maybe_token_id
|
| 1001 |
return True
|
| 1002 |
|
| 1003 |
+
def add_to_gguf(self, gw: GGUFWriter) -> None:
|
| 1004 |
if len(self.merges) > 0:
|
| 1005 |
print(f'gguf: Adding {len(self.merges)} merge(s).')
|
| 1006 |
gw.add_token_merges(self.merges)
|
|
|
|
| 1012 |
print(f'gguf: Setting special token type {typ} to {tokid}')
|
| 1013 |
handler(tokid)
|
| 1014 |
|
| 1015 |
+
def __repr__(self) -> str:
|
| 1016 |
+
return f'<SpecialVocab with {len(self.merges)} merges and special tokens {self.special_token_ids or "unset"}>'
|
| 1017 |
|
| 1018 |
|
| 1019 |
# Example usage:
|
gguf-py/pyproject.toml
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
[tool.poetry]
|
| 2 |
name = "gguf"
|
| 3 |
-
version = "0.
|
| 4 |
description = "Write ML models in GGUF for GGML"
|
| 5 |
authors = ["GGML <[email protected]>"]
|
| 6 |
packages = [
|
|
|
|
| 1 |
[tool.poetry]
|
| 2 |
name = "gguf"
|
| 3 |
+
version = "0.4.4"
|
| 4 |
description = "Write ML models in GGUF for GGML"
|
| 5 |
authors = ["GGML <[email protected]>"]
|
| 6 |
packages = [
|
gpttype_adapter.cpp
CHANGED
|
@@ -78,7 +78,6 @@ static int n_threads = 4;
|
|
| 78 |
static int n_blasthreads = 4;
|
| 79 |
static int n_batch = 8;
|
| 80 |
static bool useSmartContext = false;
|
| 81 |
-
static bool unbanTokens = false;
|
| 82 |
static int blasbatchsize = 512;
|
| 83 |
static int debugmode = 0; //-1 = hide all, 0 = normal, 1 = showall
|
| 84 |
static std::string modelname;
|
|
@@ -556,7 +555,6 @@ ModelLoadResult gpttype_load_model(const load_model_inputs inputs, FileFormat in
|
|
| 556 |
modelname = params.model = inputs.model_filename;
|
| 557 |
useSmartContext = inputs.use_smartcontext;
|
| 558 |
debugmode = inputs.debugmode;
|
| 559 |
-
unbanTokens = inputs.unban_tokens;
|
| 560 |
blasbatchsize = inputs.blasbatchsize;
|
| 561 |
if(blasbatchsize<=0)
|
| 562 |
{
|
|
@@ -1656,7 +1654,7 @@ generation_outputs gpttype_generate(const generation_inputs inputs, generation_o
|
|
| 1656 |
lowestLogit = LowestLogit(logits);
|
| 1657 |
}
|
| 1658 |
|
| 1659 |
-
if (!
|
| 1660 |
{
|
| 1661 |
// set the logit of the eos token to very low to avoid sampling it
|
| 1662 |
logitsPtr[eosID] = lowestLogit;
|
|
@@ -1721,10 +1719,13 @@ generation_outputs gpttype_generate(const generation_inputs inputs, generation_o
|
|
| 1721 |
printf("]\n");
|
| 1722 |
}
|
| 1723 |
|
| 1724 |
-
if(
|
| 1725 |
{
|
| 1726 |
stopper_unused_tokens = remaining_tokens;
|
| 1727 |
-
|
|
|
|
|
|
|
|
|
|
| 1728 |
remaining_tokens = 0;
|
| 1729 |
last_stop_reason = stop_reason::EOS_TOKEN;
|
| 1730 |
}
|
|
|
|
| 78 |
static int n_blasthreads = 4;
|
| 79 |
static int n_batch = 8;
|
| 80 |
static bool useSmartContext = false;
|
|
|
|
| 81 |
static int blasbatchsize = 512;
|
| 82 |
static int debugmode = 0; //-1 = hide all, 0 = normal, 1 = showall
|
| 83 |
static std::string modelname;
|
|
|
|
| 555 |
modelname = params.model = inputs.model_filename;
|
| 556 |
useSmartContext = inputs.use_smartcontext;
|
| 557 |
debugmode = inputs.debugmode;
|
|
|
|
| 558 |
blasbatchsize = inputs.blasbatchsize;
|
| 559 |
if(blasbatchsize<=0)
|
| 560 |
{
|
|
|
|
| 1654 |
lowestLogit = LowestLogit(logits);
|
| 1655 |
}
|
| 1656 |
|
| 1657 |
+
if (!inputs.unban_tokens_rt)
|
| 1658 |
{
|
| 1659 |
// set the logit of the eos token to very low to avoid sampling it
|
| 1660 |
logitsPtr[eosID] = lowestLogit;
|
|
|
|
| 1719 |
printf("]\n");
|
| 1720 |
}
|
| 1721 |
|
| 1722 |
+
if(inputs.unban_tokens_rt && id==eosID)
|
| 1723 |
{
|
| 1724 |
stopper_unused_tokens = remaining_tokens;
|
| 1725 |
+
if(debugmode!=-1)
|
| 1726 |
+
{
|
| 1727 |
+
printf("\n(EOS token triggered!)");
|
| 1728 |
+
}
|
| 1729 |
remaining_tokens = 0;
|
| 1730 |
last_stop_reason = stop_reason::EOS_TOKEN;
|
| 1731 |
}
|
k_quants.c
CHANGED
|
@@ -54,6 +54,10 @@ inline static int32_t vaddvq_s32(int32x4_t v) {
|
|
| 54 |
#endif
|
| 55 |
#endif
|
| 56 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
#undef MIN
|
| 58 |
#undef MAX
|
| 59 |
#define MIN(a, b) ((a) < (b) ? (a) : (b))
|
|
@@ -65,7 +69,6 @@ inline static int32_t vaddvq_s32(int32x4_t v) {
|
|
| 65 |
// 2-6 bit quantization in super-blocks
|
| 66 |
//
|
| 67 |
|
| 68 |
-
|
| 69 |
//
|
| 70 |
// ===================== Helper functions
|
| 71 |
//
|
|
@@ -344,7 +347,6 @@ void quantize_row_q2_K_reference(const float * restrict x, block_q2_K * restrict
|
|
| 344 |
const float q4scale = 15.f;
|
| 345 |
|
| 346 |
for (int i = 0; i < nb; i++) {
|
| 347 |
-
|
| 348 |
float max_scale = 0; // as we are deducting the min, scales are always positive
|
| 349 |
float max_min = 0;
|
| 350 |
for (int j = 0; j < QK_K/16; ++j) {
|
|
@@ -1582,6 +1584,90 @@ void ggml_vec_dot_q2_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 1582 |
|
| 1583 |
*s = hsum_float_8(acc);
|
| 1584 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1585 |
#else
|
| 1586 |
|
| 1587 |
float sumf = 0;
|
|
@@ -1807,6 +1893,64 @@ void ggml_vec_dot_q2_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 1807 |
|
| 1808 |
*s = hsum_float_8(acc) + summs;
|
| 1809 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1810 |
#else
|
| 1811 |
|
| 1812 |
float sumf = 0;
|
|
@@ -2220,6 +2364,106 @@ void ggml_vec_dot_q3_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 2220 |
|
| 2221 |
*s = hsum_float_8(acc);
|
| 2222 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2223 |
#else
|
| 2224 |
// scalar version
|
| 2225 |
// This function is written like this so the compiler can manage to vectorize most of it
|
|
@@ -2523,6 +2767,79 @@ void ggml_vec_dot_q3_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 2523 |
|
| 2524 |
*s = hsum_float_8(acc);
|
| 2525 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2526 |
#else
|
| 2527 |
|
| 2528 |
int8_t aux8[QK_K];
|
|
@@ -2823,6 +3140,78 @@ void ggml_vec_dot_q4_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 2823 |
|
| 2824 |
*s = hsum_float_8(acc) + _mm_cvtss_f32(acc_m);
|
| 2825 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2826 |
#else
|
| 2827 |
|
| 2828 |
|
|
@@ -3064,6 +3453,50 @@ void ggml_vec_dot_q4_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 3064 |
|
| 3065 |
*s = hsum_float_8(acc) - summs;
|
| 3066 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3067 |
#else
|
| 3068 |
|
| 3069 |
uint8_t aux8[QK_K];
|
|
@@ -3394,6 +3827,93 @@ void ggml_vec_dot_q5_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 3394 |
|
| 3395 |
*s = hsum_float_8(acc) + summs;
|
| 3396 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3397 |
#else
|
| 3398 |
|
| 3399 |
const uint8_t * scales = (const uint8_t*)&utmp[0];
|
|
@@ -3639,6 +4159,76 @@ void ggml_vec_dot_q5_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 3639 |
|
| 3640 |
*s = hsum_float_8(acc);
|
| 3641 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3642 |
#else
|
| 3643 |
|
| 3644 |
int8_t aux8[QK_K];
|
|
@@ -4023,6 +4613,91 @@ void ggml_vec_dot_q6_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 4023 |
|
| 4024 |
*s = hsum_float_8(acc);
|
| 4025 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4026 |
#else
|
| 4027 |
|
| 4028 |
int8_t aux8[QK_K];
|
|
@@ -4276,6 +4951,73 @@ void ggml_vec_dot_q6_K_q8_K(const int n, float * restrict s, const void * restri
|
|
| 4276 |
|
| 4277 |
*s = hsum_float_8(acc);
|
| 4278 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4279 |
#else
|
| 4280 |
|
| 4281 |
int8_t aux8[QK_K];
|
|
|
|
| 54 |
#endif
|
| 55 |
#endif
|
| 56 |
|
| 57 |
+
#ifdef __riscv_v_intrinsic
|
| 58 |
+
#include <riscv_vector.h>
|
| 59 |
+
#endif
|
| 60 |
+
|
| 61 |
#undef MIN
|
| 62 |
#undef MAX
|
| 63 |
#define MIN(a, b) ((a) < (b) ? (a) : (b))
|
|
|
|
| 69 |
// 2-6 bit quantization in super-blocks
|
| 70 |
//
|
| 71 |
|
|
|
|
| 72 |
//
|
| 73 |
// ===================== Helper functions
|
| 74 |
//
|
|
|
|
| 347 |
const float q4scale = 15.f;
|
| 348 |
|
| 349 |
for (int i = 0; i < nb; i++) {
|
|
|
|
| 350 |
float max_scale = 0; // as we are deducting the min, scales are always positive
|
| 351 |
float max_min = 0;
|
| 352 |
for (int j = 0; j < QK_K/16; ++j) {
|
|
|
|
| 1584 |
|
| 1585 |
*s = hsum_float_8(acc);
|
| 1586 |
|
| 1587 |
+
#elif defined __riscv_v_intrinsic
|
| 1588 |
+
|
| 1589 |
+
float sumf = 0;
|
| 1590 |
+
uint8_t temp_01[32] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
|
| 1591 |
+
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
|
| 1592 |
+
|
| 1593 |
+
for (int i = 0; i < nb; ++i) {
|
| 1594 |
+
|
| 1595 |
+
const uint8_t * q2 = x[i].qs;
|
| 1596 |
+
const int8_t * q8 = y[i].qs;
|
| 1597 |
+
const uint8_t * sc = x[i].scales;
|
| 1598 |
+
|
| 1599 |
+
const float dall = y[i].d * ggml_fp16_to_fp32(x[i].d);
|
| 1600 |
+
const float dmin = -y[i].d * ggml_fp16_to_fp32(x[i].dmin);
|
| 1601 |
+
|
| 1602 |
+
size_t vl = 16;
|
| 1603 |
+
|
| 1604 |
+
vuint8m1_t scales = __riscv_vle8_v_u8m1(sc, vl);
|
| 1605 |
+
vuint8m1_t aux = __riscv_vand_vx_u8m1(scales, 0x0F, vl);
|
| 1606 |
+
|
| 1607 |
+
vint16m1_t q8sums = __riscv_vle16_v_i16m1(y[i].bsums, vl);
|
| 1608 |
+
|
| 1609 |
+
vuint8mf2_t scales_2 = __riscv_vle8_v_u8mf2(sc, vl);
|
| 1610 |
+
vuint8mf2_t mins8 = __riscv_vsrl_vx_u8mf2(scales_2, 0x4, vl);
|
| 1611 |
+
vint16m1_t mins = __riscv_vreinterpret_v_u16m1_i16m1(__riscv_vzext_vf2_u16m1(mins8, vl));
|
| 1612 |
+
vint32m2_t prod = __riscv_vwmul_vv_i32m2(q8sums, mins, vl);
|
| 1613 |
+
vint32m1_t vsums = __riscv_vredsum_vs_i32m2_i32m1(prod, __riscv_vmv_v_x_i32m1(0, 1), vl);
|
| 1614 |
+
|
| 1615 |
+
sumf += dmin * __riscv_vmv_x_s_i32m1_i32(vsums);
|
| 1616 |
+
|
| 1617 |
+
vl = 32;
|
| 1618 |
+
|
| 1619 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 1620 |
+
vuint8m1_t v_b = __riscv_vle8_v_u8m1(temp_01, vl);
|
| 1621 |
+
|
| 1622 |
+
uint8_t is=0;
|
| 1623 |
+
int isum=0;
|
| 1624 |
+
|
| 1625 |
+
for (int j = 0; j < QK_K/128; ++j) {
|
| 1626 |
+
// load Q2
|
| 1627 |
+
vuint8m1_t q2_x = __riscv_vle8_v_u8m1(q2, vl);
|
| 1628 |
+
|
| 1629 |
+
vuint8m1_t q2_0 = __riscv_vand_vx_u8m1(q2_x, 0x03, vl);
|
| 1630 |
+
vuint8m1_t q2_1 = __riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(q2_x, 0x2, vl), 0x03 , vl);
|
| 1631 |
+
vuint8m1_t q2_2 = __riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(q2_x, 0x4, vl), 0x03 , vl);
|
| 1632 |
+
vuint8m1_t q2_3 = __riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(q2_x, 0x6, vl), 0x03 , vl);
|
| 1633 |
+
|
| 1634 |
+
// duplicate scale elements for product
|
| 1635 |
+
vuint8m1_t sc0 = __riscv_vrgather_vv_u8m1(aux, __riscv_vadd_vx_u8m1(v_b, 0+is, vl), vl);
|
| 1636 |
+
vuint8m1_t sc1 = __riscv_vrgather_vv_u8m1(aux, __riscv_vadd_vx_u8m1(v_b, 2+is, vl), vl);
|
| 1637 |
+
vuint8m1_t sc2 = __riscv_vrgather_vv_u8m1(aux, __riscv_vadd_vx_u8m1(v_b, 4+is, vl), vl);
|
| 1638 |
+
vuint8m1_t sc3 = __riscv_vrgather_vv_u8m1(aux, __riscv_vadd_vx_u8m1(v_b, 6+is, vl), vl);
|
| 1639 |
+
|
| 1640 |
+
vint16m2_t p0 = __riscv_vreinterpret_v_u16m2_i16m2(__riscv_vwmulu_vv_u16m2(q2_0, sc0, vl));
|
| 1641 |
+
vint16m2_t p1 = __riscv_vreinterpret_v_u16m2_i16m2(__riscv_vwmulu_vv_u16m2(q2_1, sc1, vl));
|
| 1642 |
+
vint16m2_t p2 = __riscv_vreinterpret_v_u16m2_i16m2(__riscv_vwmulu_vv_u16m2(q2_2, sc2, vl));
|
| 1643 |
+
vint16m2_t p3 = __riscv_vreinterpret_v_u16m2_i16m2(__riscv_vwmulu_vv_u16m2(q2_3, sc3, vl));
|
| 1644 |
+
|
| 1645 |
+
// load Q8
|
| 1646 |
+
vint8m1_t q8_0 = __riscv_vle8_v_i8m1(q8, vl);
|
| 1647 |
+
vint8m1_t q8_1 = __riscv_vle8_v_i8m1(q8+32, vl);
|
| 1648 |
+
vint8m1_t q8_2 = __riscv_vle8_v_i8m1(q8+64, vl);
|
| 1649 |
+
vint8m1_t q8_3 = __riscv_vle8_v_i8m1(q8+96, vl);
|
| 1650 |
+
|
| 1651 |
+
vint32m4_t s0 = __riscv_vwmul_vv_i32m4(p0, __riscv_vwcvt_x_x_v_i16m2(q8_0, vl), vl);
|
| 1652 |
+
vint32m4_t s1 = __riscv_vwmul_vv_i32m4(p1, __riscv_vwcvt_x_x_v_i16m2(q8_1, vl), vl);
|
| 1653 |
+
vint32m4_t s2 = __riscv_vwmul_vv_i32m4(p2, __riscv_vwcvt_x_x_v_i16m2(q8_2, vl), vl);
|
| 1654 |
+
vint32m4_t s3 = __riscv_vwmul_vv_i32m4(p3, __riscv_vwcvt_x_x_v_i16m2(q8_3, vl), vl);
|
| 1655 |
+
|
| 1656 |
+
vint32m1_t isum0 = __riscv_vredsum_vs_i32m4_i32m1(__riscv_vadd_vv_i32m4(s0, s1, vl), vzero, vl);
|
| 1657 |
+
vint32m1_t isum1 = __riscv_vredsum_vs_i32m4_i32m1(__riscv_vadd_vv_i32m4(s2, s3, vl), isum0, vl);
|
| 1658 |
+
|
| 1659 |
+
isum += __riscv_vmv_x_s_i32m1_i32(isum1);
|
| 1660 |
+
|
| 1661 |
+
q2+=32; q8+=128; is=8;
|
| 1662 |
+
|
| 1663 |
+
}
|
| 1664 |
+
|
| 1665 |
+
sumf += dall * isum;
|
| 1666 |
+
|
| 1667 |
+
}
|
| 1668 |
+
|
| 1669 |
+
*s = sumf;
|
| 1670 |
+
|
| 1671 |
#else
|
| 1672 |
|
| 1673 |
float sumf = 0;
|
|
|
|
| 1893 |
|
| 1894 |
*s = hsum_float_8(acc) + summs;
|
| 1895 |
|
| 1896 |
+
#elif defined __riscv_v_intrinsic
|
| 1897 |
+
|
| 1898 |
+
uint32_t aux32[2];
|
| 1899 |
+
const uint8_t * scales = (const uint8_t *)aux32;
|
| 1900 |
+
|
| 1901 |
+
float sumf = 0;
|
| 1902 |
+
|
| 1903 |
+
for (int i = 0; i < nb; ++i) {
|
| 1904 |
+
|
| 1905 |
+
const float d = y[i].d * (float)x[i].d;
|
| 1906 |
+
const float dmin = -y[i].d * (float)x[i].dmin;
|
| 1907 |
+
|
| 1908 |
+
const uint8_t * restrict q2 = x[i].qs;
|
| 1909 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 1910 |
+
const uint32_t * restrict sc = (const uint32_t *)x[i].scales;
|
| 1911 |
+
|
| 1912 |
+
aux32[0] = sc[0] & 0x0f0f0f0f;
|
| 1913 |
+
aux32[1] = (sc[0] >> 4) & 0x0f0f0f0f;
|
| 1914 |
+
|
| 1915 |
+
sumf += dmin * (scales[4] * y[i].bsums[0] + scales[5] * y[i].bsums[1] + scales[6] * y[i].bsums[2] + scales[7] * y[i].bsums[3]);
|
| 1916 |
+
|
| 1917 |
+
int isum1 = 0;
|
| 1918 |
+
int isum2 = 0;
|
| 1919 |
+
|
| 1920 |
+
size_t vl = 16;
|
| 1921 |
+
|
| 1922 |
+
vint16m1_t vzero = __riscv_vmv_v_x_i16m1(0, 1);
|
| 1923 |
+
|
| 1924 |
+
// load Q2
|
| 1925 |
+
vuint8mf2_t q2_x = __riscv_vle8_v_u8mf2(q2, vl);
|
| 1926 |
+
|
| 1927 |
+
vint8mf2_t q2_0 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vand_vx_u8mf2(q2_x, 0x03, vl));
|
| 1928 |
+
vint8mf2_t q2_1 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(q2_x, 0x2, vl), 0x03 , vl));
|
| 1929 |
+
vint8mf2_t q2_2 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(q2_x, 0x4, vl), 0x03 , vl));
|
| 1930 |
+
vint8mf2_t q2_3 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(q2_x, 0x6, vl), 0x03 , vl));
|
| 1931 |
+
|
| 1932 |
+
// load Q8, and take product with Q2
|
| 1933 |
+
vint16m1_t p0 = __riscv_vwmul_vv_i16m1(q2_0, __riscv_vle8_v_i8mf2(q8, vl), vl);
|
| 1934 |
+
vint16m1_t p1 = __riscv_vwmul_vv_i16m1(q2_1, __riscv_vle8_v_i8mf2(q8+16, vl), vl);
|
| 1935 |
+
vint16m1_t p2 = __riscv_vwmul_vv_i16m1(q2_2, __riscv_vle8_v_i8mf2(q8+32, vl), vl);
|
| 1936 |
+
vint16m1_t p3 = __riscv_vwmul_vv_i16m1(q2_3, __riscv_vle8_v_i8mf2(q8+48, vl), vl);
|
| 1937 |
+
|
| 1938 |
+
vint16m1_t vs_0 = __riscv_vredsum_vs_i16m1_i16m1(p0, vzero, vl);
|
| 1939 |
+
vint16m1_t vs_1 = __riscv_vredsum_vs_i16m1_i16m1(p1, vzero, vl);
|
| 1940 |
+
vint16m1_t vs_2 = __riscv_vredsum_vs_i16m1_i16m1(p2, vzero, vl);
|
| 1941 |
+
vint16m1_t vs_3 = __riscv_vredsum_vs_i16m1_i16m1(p3, vzero, vl);
|
| 1942 |
+
|
| 1943 |
+
isum1 += __riscv_vmv_x_s_i16m1_i16(vs_0) * scales[0];
|
| 1944 |
+
isum2 += __riscv_vmv_x_s_i16m1_i16(vs_1) * scales[1];
|
| 1945 |
+
isum1 += __riscv_vmv_x_s_i16m1_i16(vs_2) * scales[2];
|
| 1946 |
+
isum2 += __riscv_vmv_x_s_i16m1_i16(vs_3) * scales[3];
|
| 1947 |
+
|
| 1948 |
+
sumf += d * (isum1 + isum2);
|
| 1949 |
+
|
| 1950 |
+
}
|
| 1951 |
+
|
| 1952 |
+
*s = sumf;
|
| 1953 |
+
|
| 1954 |
#else
|
| 1955 |
|
| 1956 |
float sumf = 0;
|
|
|
|
| 2364 |
|
| 2365 |
*s = hsum_float_8(acc);
|
| 2366 |
|
| 2367 |
+
#elif defined __riscv_v_intrinsic
|
| 2368 |
+
|
| 2369 |
+
uint32_t aux[3];
|
| 2370 |
+
uint32_t utmp[4];
|
| 2371 |
+
|
| 2372 |
+
float sumf = 0;
|
| 2373 |
+
for (int i = 0; i < nb; ++i) {
|
| 2374 |
+
|
| 2375 |
+
const uint8_t * restrict q3 = x[i].qs;
|
| 2376 |
+
const uint8_t * restrict qh = x[i].hmask;
|
| 2377 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 2378 |
+
|
| 2379 |
+
memcpy(aux, x[i].scales, 12);
|
| 2380 |
+
utmp[3] = ((aux[1] >> 4) & kmask2) | (((aux[2] >> 6) & kmask1) << 4);
|
| 2381 |
+
utmp[2] = ((aux[0] >> 4) & kmask2) | (((aux[2] >> 4) & kmask1) << 4);
|
| 2382 |
+
utmp[1] = (aux[1] & kmask2) | (((aux[2] >> 2) & kmask1) << 4);
|
| 2383 |
+
utmp[0] = (aux[0] & kmask2) | (((aux[2] >> 0) & kmask1) << 4);
|
| 2384 |
+
|
| 2385 |
+
int8_t * scale = (int8_t *)utmp;
|
| 2386 |
+
for (int j = 0; j < 16; ++j) scale[j] -= 32;
|
| 2387 |
+
|
| 2388 |
+
|
| 2389 |
+
size_t vl = 32;
|
| 2390 |
+
uint8_t m = 1;
|
| 2391 |
+
|
| 2392 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 2393 |
+
vuint8m1_t vqh = __riscv_vle8_v_u8m1(qh, vl);
|
| 2394 |
+
|
| 2395 |
+
int sum_t = 0;
|
| 2396 |
+
|
| 2397 |
+
for (int j = 0; j < QK_K; j += 128) {
|
| 2398 |
+
|
| 2399 |
+
vl = 32;
|
| 2400 |
+
|
| 2401 |
+
// load Q3
|
| 2402 |
+
vuint8m1_t q3_x = __riscv_vle8_v_u8m1(q3, vl);
|
| 2403 |
+
|
| 2404 |
+
vint8m1_t q3_0 = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(q3_x, 0x03, vl));
|
| 2405 |
+
vint8m1_t q3_1 = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(q3_x, 0x2, vl), 0x03 , vl));
|
| 2406 |
+
vint8m1_t q3_2 = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(q3_x, 0x4, vl), 0x03 , vl));
|
| 2407 |
+
vint8m1_t q3_3 = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(q3_x, 0x6, vl), 0x03 , vl));
|
| 2408 |
+
|
| 2409 |
+
// compute mask for subtraction
|
| 2410 |
+
vuint8m1_t qh_m0 = __riscv_vand_vx_u8m1(vqh, m, vl);
|
| 2411 |
+
vbool8_t vmask_0 = __riscv_vmseq_vx_u8m1_b8(qh_m0, 0, vl);
|
| 2412 |
+
vint8m1_t q3_m0 = __riscv_vsub_vx_i8m1_m(vmask_0, q3_0, 0x4, vl);
|
| 2413 |
+
m <<= 1;
|
| 2414 |
+
|
| 2415 |
+
vuint8m1_t qh_m1 = __riscv_vand_vx_u8m1(vqh, m, vl);
|
| 2416 |
+
vbool8_t vmask_1 = __riscv_vmseq_vx_u8m1_b8(qh_m1, 0, vl);
|
| 2417 |
+
vint8m1_t q3_m1 = __riscv_vsub_vx_i8m1_m(vmask_1, q3_1, 0x4, vl);
|
| 2418 |
+
m <<= 1;
|
| 2419 |
+
|
| 2420 |
+
vuint8m1_t qh_m2 = __riscv_vand_vx_u8m1(vqh, m, vl);
|
| 2421 |
+
vbool8_t vmask_2 = __riscv_vmseq_vx_u8m1_b8(qh_m2, 0, vl);
|
| 2422 |
+
vint8m1_t q3_m2 = __riscv_vsub_vx_i8m1_m(vmask_2, q3_2, 0x4, vl);
|
| 2423 |
+
m <<= 1;
|
| 2424 |
+
|
| 2425 |
+
vuint8m1_t qh_m3 = __riscv_vand_vx_u8m1(vqh, m, vl);
|
| 2426 |
+
vbool8_t vmask_3 = __riscv_vmseq_vx_u8m1_b8(qh_m3, 0, vl);
|
| 2427 |
+
vint8m1_t q3_m3 = __riscv_vsub_vx_i8m1_m(vmask_3, q3_3, 0x4, vl);
|
| 2428 |
+
m <<= 1;
|
| 2429 |
+
|
| 2430 |
+
// load Q8 and take product with Q3
|
| 2431 |
+
vint16m2_t a0 = __riscv_vwmul_vv_i16m2(q3_m0, __riscv_vle8_v_i8m1(q8, vl), vl);
|
| 2432 |
+
vint16m2_t a1 = __riscv_vwmul_vv_i16m2(q3_m1, __riscv_vle8_v_i8m1(q8+32, vl), vl);
|
| 2433 |
+
vint16m2_t a2 = __riscv_vwmul_vv_i16m2(q3_m2, __riscv_vle8_v_i8m1(q8+64, vl), vl);
|
| 2434 |
+
vint16m2_t a3 = __riscv_vwmul_vv_i16m2(q3_m3, __riscv_vle8_v_i8m1(q8+96, vl), vl);
|
| 2435 |
+
|
| 2436 |
+
vl = 16;
|
| 2437 |
+
|
| 2438 |
+
// retreive lane to multiply with scale
|
| 2439 |
+
vint32m2_t aux0_0 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a0, 0), (scale[0]), vl);
|
| 2440 |
+
vint32m2_t aux0_1 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a0, 1), (scale[1]), vl);
|
| 2441 |
+
vint32m2_t aux1_0 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a1, 0), (scale[2]), vl);
|
| 2442 |
+
vint32m2_t aux1_1 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a1, 1), (scale[3]), vl);
|
| 2443 |
+
vint32m2_t aux2_0 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a2, 0), (scale[4]), vl);
|
| 2444 |
+
vint32m2_t aux2_1 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a2, 1), (scale[5]), vl);
|
| 2445 |
+
vint32m2_t aux3_0 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a3, 0), (scale[6]), vl);
|
| 2446 |
+
vint32m2_t aux3_1 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(a3, 1), (scale[7]), vl);
|
| 2447 |
+
|
| 2448 |
+
vint32m1_t isum0 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(aux0_0, aux0_1, vl), vzero, vl);
|
| 2449 |
+
vint32m1_t isum1 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(aux1_0, aux1_1, vl), isum0, vl);
|
| 2450 |
+
vint32m1_t isum2 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(aux2_0, aux2_1, vl), isum1, vl);
|
| 2451 |
+
vint32m1_t isum3 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(aux3_0, aux3_1, vl), isum2, vl);
|
| 2452 |
+
|
| 2453 |
+
sum_t += __riscv_vmv_x_s_i32m1_i32(isum3);
|
| 2454 |
+
|
| 2455 |
+
q3 += 32; q8 += 128; scale += 8;
|
| 2456 |
+
|
| 2457 |
+
}
|
| 2458 |
+
|
| 2459 |
+
const float d = ggml_fp16_to_fp32(x[i].d) * y[i].d;
|
| 2460 |
+
|
| 2461 |
+
sumf += d*sum_t;
|
| 2462 |
+
|
| 2463 |
+
}
|
| 2464 |
+
|
| 2465 |
+
*s = sumf;
|
| 2466 |
+
|
| 2467 |
#else
|
| 2468 |
// scalar version
|
| 2469 |
// This function is written like this so the compiler can manage to vectorize most of it
|
|
|
|
| 2767 |
|
| 2768 |
*s = hsum_float_8(acc);
|
| 2769 |
|
| 2770 |
+
#elif defined __riscv_v_intrinsic
|
| 2771 |
+
|
| 2772 |
+
uint16_t aux16[2];
|
| 2773 |
+
int8_t * scales = (int8_t *)aux16;
|
| 2774 |
+
|
| 2775 |
+
float sumf = 0;
|
| 2776 |
+
|
| 2777 |
+
for (int i = 0; i < nb; ++i) {
|
| 2778 |
+
|
| 2779 |
+
const uint8_t * restrict q3 = x[i].qs;
|
| 2780 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 2781 |
+
|
| 2782 |
+
const uint16_t a = *(const uint16_t *)x[i].scales;
|
| 2783 |
+
aux16[0] = a & 0x0f0f;
|
| 2784 |
+
aux16[1] = (a >> 4) & 0x0f0f;
|
| 2785 |
+
|
| 2786 |
+
for (int j = 0; j < 4; ++j) scales[j] -= 8;
|
| 2787 |
+
|
| 2788 |
+
int32_t isum = -4*(scales[0] * y[i].bsums[0] + scales[2] * y[i].bsums[1] + scales[1] * y[i].bsums[2] + scales[3] * y[i].bsums[3]);
|
| 2789 |
+
|
| 2790 |
+
const float d = y[i].d * (float)x[i].d;
|
| 2791 |
+
|
| 2792 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 2793 |
+
|
| 2794 |
+
// load qh
|
| 2795 |
+
vuint8mf4_t qh_x1 = __riscv_vle8_v_u8mf4(x[i].hmask, 8);
|
| 2796 |
+
vuint8mf2_t qh_x2 = __riscv_vlmul_ext_v_u8mf4_u8mf2(__riscv_vsrl_vx_u8mf4(qh_x1, 1, 8));
|
| 2797 |
+
|
| 2798 |
+
size_t vl = 16;
|
| 2799 |
+
|
| 2800 |
+
// extend and combine both qh_x1 and qh_x2
|
| 2801 |
+
vuint8mf2_t qh_x = __riscv_vslideup_vx_u8mf2(__riscv_vlmul_ext_v_u8mf4_u8mf2(qh_x1), qh_x2, vl/2, vl);
|
| 2802 |
+
|
| 2803 |
+
vuint8mf2_t qh_0 = __riscv_vand_vx_u8mf2(__riscv_vsll_vx_u8mf2(qh_x, 0x2, vl), 0x4, vl);
|
| 2804 |
+
vuint8mf2_t qh_1 = __riscv_vand_vx_u8mf2(qh_x, 0x4, vl);
|
| 2805 |
+
vuint8mf2_t qh_2 = __riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(qh_x, 0x2, vl), 0x4, vl);
|
| 2806 |
+
vuint8mf2_t qh_3 = __riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(qh_x, 0x4, vl), 0x4, vl);
|
| 2807 |
+
|
| 2808 |
+
// load Q3
|
| 2809 |
+
vuint8mf2_t q3_x = __riscv_vle8_v_u8mf2(q3, vl);
|
| 2810 |
+
|
| 2811 |
+
vuint8mf2_t q3h_0 = __riscv_vor_vv_u8mf2(__riscv_vand_vx_u8mf2(q3_x, 0x3, vl), qh_0, vl);
|
| 2812 |
+
vuint8mf2_t q3h_1 = __riscv_vor_vv_u8mf2(__riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(q3_x, 2, vl), 0x3, vl), qh_1, vl);
|
| 2813 |
+
vuint8mf2_t q3h_2 = __riscv_vor_vv_u8mf2(__riscv_vand_vx_u8mf2(__riscv_vsrl_vx_u8mf2(q3_x, 4, vl), 0x3, vl), qh_2, vl);
|
| 2814 |
+
vuint8mf2_t q3h_3 = __riscv_vor_vv_u8mf2(__riscv_vsrl_vx_u8mf2(q3_x, 0x6, vl), qh_3, vl);
|
| 2815 |
+
|
| 2816 |
+
vint8mf2_t q3_0 = __riscv_vreinterpret_v_u8mf2_i8mf2(q3h_0);
|
| 2817 |
+
vint8mf2_t q3_1 = __riscv_vreinterpret_v_u8mf2_i8mf2(q3h_1);
|
| 2818 |
+
vint8mf2_t q3_2 = __riscv_vreinterpret_v_u8mf2_i8mf2(q3h_2);
|
| 2819 |
+
vint8mf2_t q3_3 = __riscv_vreinterpret_v_u8mf2_i8mf2(q3h_3);
|
| 2820 |
+
|
| 2821 |
+
// load Q8 and take product with Q3
|
| 2822 |
+
vint16m1_t p0 = __riscv_vwmul_vv_i16m1(q3_0, __riscv_vle8_v_i8mf2(q8, vl), vl);
|
| 2823 |
+
vint16m1_t p1 = __riscv_vwmul_vv_i16m1(q3_1, __riscv_vle8_v_i8mf2(q8+16, vl), vl);
|
| 2824 |
+
vint16m1_t p2 = __riscv_vwmul_vv_i16m1(q3_2, __riscv_vle8_v_i8mf2(q8+32, vl), vl);
|
| 2825 |
+
vint16m1_t p3 = __riscv_vwmul_vv_i16m1(q3_3, __riscv_vle8_v_i8mf2(q8+48, vl), vl);
|
| 2826 |
+
|
| 2827 |
+
vint32m1_t vs_0 = __riscv_vwredsum_vs_i16m1_i32m1(p0, vzero, vl);
|
| 2828 |
+
vint32m1_t vs_1 = __riscv_vwredsum_vs_i16m1_i32m1(p1, vzero, vl);
|
| 2829 |
+
vint32m1_t vs_2 = __riscv_vwredsum_vs_i16m1_i32m1(p2, vzero, vl);
|
| 2830 |
+
vint32m1_t vs_3 = __riscv_vwredsum_vs_i16m1_i32m1(p3, vzero, vl);
|
| 2831 |
+
|
| 2832 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_0) * scales[0];
|
| 2833 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_1) * scales[2];
|
| 2834 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_2) * scales[1];
|
| 2835 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_3) * scales[3];
|
| 2836 |
+
|
| 2837 |
+
sumf += d * isum;
|
| 2838 |
+
|
| 2839 |
+
}
|
| 2840 |
+
|
| 2841 |
+
*s = sumf;
|
| 2842 |
+
|
| 2843 |
#else
|
| 2844 |
|
| 2845 |
int8_t aux8[QK_K];
|
|
|
|
| 3140 |
|
| 3141 |
*s = hsum_float_8(acc) + _mm_cvtss_f32(acc_m);
|
| 3142 |
|
| 3143 |
+
#elif defined __riscv_v_intrinsic
|
| 3144 |
+
|
| 3145 |
+
const uint8_t * scales = (const uint8_t*)&utmp[0];
|
| 3146 |
+
const uint8_t * mins = (const uint8_t*)&utmp[2];
|
| 3147 |
+
|
| 3148 |
+
float sumf = 0;
|
| 3149 |
+
|
| 3150 |
+
for (int i = 0; i < nb; ++i) {
|
| 3151 |
+
|
| 3152 |
+
size_t vl = 8;
|
| 3153 |
+
|
| 3154 |
+
const float d = y[i].d * ggml_fp16_to_fp32(x[i].d);
|
| 3155 |
+
const float dmin = y[i].d * ggml_fp16_to_fp32(x[i].dmin);
|
| 3156 |
+
|
| 3157 |
+
vint16mf2_t q8sums_0 = __riscv_vlse16_v_i16mf2(y[i].bsums, 4, vl);
|
| 3158 |
+
vint16mf2_t q8sums_1 = __riscv_vlse16_v_i16mf2(y[i].bsums+1, 4, vl);
|
| 3159 |
+
vint16mf2_t q8sums = __riscv_vadd_vv_i16mf2(q8sums_0, q8sums_1, vl);
|
| 3160 |
+
|
| 3161 |
+
memcpy(utmp, x[i].scales, 12);
|
| 3162 |
+
utmp[3] = ((utmp[2] >> 4) & kmask2) | (((utmp[1] >> 6) & kmask3) << 4);
|
| 3163 |
+
const uint32_t uaux = utmp[1] & kmask1;
|
| 3164 |
+
utmp[1] = (utmp[2] & kmask2) | (((utmp[0] >> 6) & kmask3) << 4);
|
| 3165 |
+
utmp[2] = uaux;
|
| 3166 |
+
utmp[0] &= kmask1;
|
| 3167 |
+
|
| 3168 |
+
vuint8mf4_t mins8 = __riscv_vle8_v_u8mf4(mins, vl);
|
| 3169 |
+
vint16mf2_t v_mins = __riscv_vreinterpret_v_u16mf2_i16mf2(__riscv_vzext_vf2_u16mf2(mins8, vl));
|
| 3170 |
+
vint32m1_t prod = __riscv_vwmul_vv_i32m1(q8sums, v_mins, vl);
|
| 3171 |
+
|
| 3172 |
+
vint32m1_t sumi = __riscv_vredsum_vs_i32m1_i32m1(prod, __riscv_vmv_v_x_i32m1(0, 1), vl);
|
| 3173 |
+
sumf -= dmin * __riscv_vmv_x_s_i32m1_i32(sumi);
|
| 3174 |
+
|
| 3175 |
+
const uint8_t * restrict q4 = x[i].qs;
|
| 3176 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 3177 |
+
|
| 3178 |
+
vl = 32;
|
| 3179 |
+
|
| 3180 |
+
int32_t sum_1 = 0;
|
| 3181 |
+
int32_t sum_2 = 0;
|
| 3182 |
+
|
| 3183 |
+
vint16m1_t vzero = __riscv_vmv_v_x_i16m1(0, 1);
|
| 3184 |
+
|
| 3185 |
+
for (int j = 0; j < QK_K/64; ++j) {
|
| 3186 |
+
// load Q4
|
| 3187 |
+
vuint8m1_t q4_x = __riscv_vle8_v_u8m1(q4, vl);
|
| 3188 |
+
|
| 3189 |
+
// load Q8 and multiply it with lower Q4 nibble
|
| 3190 |
+
vint8m1_t q8_0 = __riscv_vle8_v_i8m1(q8, vl);
|
| 3191 |
+
vint8m1_t q4_0 = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(q4_x, 0x0F, vl));
|
| 3192 |
+
vint16m2_t qv_0 = __riscv_vwmul_vv_i16m2(q4_0, q8_0, vl);
|
| 3193 |
+
vint16m1_t vs_0 = __riscv_vredsum_vs_i16m2_i16m1(qv_0, vzero, vl);
|
| 3194 |
+
|
| 3195 |
+
sum_1 += __riscv_vmv_x_s_i16m1_i16(vs_0) * scales[2*j+0];
|
| 3196 |
+
|
| 3197 |
+
// load Q8 and multiply it with upper Q4 nibble
|
| 3198 |
+
vint8m1_t q8_1 = __riscv_vle8_v_i8m1(q8+32, vl);
|
| 3199 |
+
vint8m1_t q4_1 = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vsrl_vx_u8m1(q4_x, 0x04, vl));
|
| 3200 |
+
vint16m2_t qv_1 = __riscv_vwmul_vv_i16m2(q4_1, q8_1, vl);
|
| 3201 |
+
vint16m1_t vs_1 = __riscv_vredsum_vs_i16m2_i16m1(qv_1, vzero, vl);
|
| 3202 |
+
|
| 3203 |
+
sum_2 += __riscv_vmv_x_s_i16m1_i16(vs_1) * scales[2*j+1];
|
| 3204 |
+
|
| 3205 |
+
q4 += 32; q8 += 64;
|
| 3206 |
+
|
| 3207 |
+
}
|
| 3208 |
+
|
| 3209 |
+
sumf += d*(sum_1 + sum_2);
|
| 3210 |
+
|
| 3211 |
+
}
|
| 3212 |
+
|
| 3213 |
+
*s = sumf;
|
| 3214 |
+
|
| 3215 |
#else
|
| 3216 |
|
| 3217 |
|
|
|
|
| 3453 |
|
| 3454 |
*s = hsum_float_8(acc) - summs;
|
| 3455 |
|
| 3456 |
+
#elif defined __riscv_v_intrinsic
|
| 3457 |
+
|
| 3458 |
+
uint16_t s16[2];
|
| 3459 |
+
const uint8_t * restrict scales = (const uint8_t *)s16;
|
| 3460 |
+
|
| 3461 |
+
float sumf = 0;
|
| 3462 |
+
|
| 3463 |
+
for (int i = 0; i < nb; ++i) {
|
| 3464 |
+
|
| 3465 |
+
const uint8_t * restrict q4 = x[i].qs;
|
| 3466 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 3467 |
+
|
| 3468 |
+
const uint16_t * restrict b = (const uint16_t *)x[i].scales;
|
| 3469 |
+
s16[0] = b[0] & 0x0f0f;
|
| 3470 |
+
s16[1] = (b[0] >> 4) & 0x0f0f;
|
| 3471 |
+
|
| 3472 |
+
sumf -= y[i].d * ggml_fp16_to_fp32(x[i].d[1]) * (scales[2] * (y[i].bsums[0] + y[i].bsums[1]) + scales[3] * (y[i].bsums[2] + y[i].bsums[3]));
|
| 3473 |
+
const float d = y[i].d * ggml_fp16_to_fp32(x[i].d[0]);
|
| 3474 |
+
|
| 3475 |
+
size_t vl = 32;
|
| 3476 |
+
|
| 3477 |
+
vint16m1_t vzero = __riscv_vmv_v_x_i16m1(0, 1);
|
| 3478 |
+
|
| 3479 |
+
// load Q4
|
| 3480 |
+
vuint8m1_t q4_x = __riscv_vle8_v_u8m1(q4, vl);
|
| 3481 |
+
|
| 3482 |
+
// load Q8 and multiply it with lower Q4 nibble
|
| 3483 |
+
vint8m1_t q4_a = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(q4_x, 0x0F, vl));
|
| 3484 |
+
vint16m2_t va_0 = __riscv_vwmul_vv_i16m2(q4_a, __riscv_vle8_v_i8m1(q8, vl), vl);
|
| 3485 |
+
vint16m1_t aux1 = __riscv_vredsum_vs_i16m2_i16m1(va_0, vzero, vl);
|
| 3486 |
+
|
| 3487 |
+
sumf += d*scales[0]*__riscv_vmv_x_s_i16m1_i16(aux1);
|
| 3488 |
+
|
| 3489 |
+
// load Q8 and multiply it with upper Q4 nibble
|
| 3490 |
+
vint8m1_t q4_s = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vsrl_vx_u8m1(q4_x, 0x04, vl));
|
| 3491 |
+
vint16m2_t va_1 = __riscv_vwmul_vv_i16m2(q4_s, __riscv_vle8_v_i8m1(q8+32, vl), vl);
|
| 3492 |
+
vint16m1_t aux2 = __riscv_vredsum_vs_i16m2_i16m1(va_1, vzero, vl);
|
| 3493 |
+
|
| 3494 |
+
sumf += d*scales[1]*__riscv_vmv_x_s_i16m1_i16(aux2);
|
| 3495 |
+
|
| 3496 |
+
}
|
| 3497 |
+
|
| 3498 |
+
*s = sumf;
|
| 3499 |
+
|
| 3500 |
#else
|
| 3501 |
|
| 3502 |
uint8_t aux8[QK_K];
|
|
|
|
| 3827 |
|
| 3828 |
*s = hsum_float_8(acc) + summs;
|
| 3829 |
|
| 3830 |
+
#elif defined __riscv_v_intrinsic
|
| 3831 |
+
|
| 3832 |
+
const uint8_t * scales = (const uint8_t*)&utmp[0];
|
| 3833 |
+
const uint8_t * mins = (const uint8_t*)&utmp[2];
|
| 3834 |
+
|
| 3835 |
+
float sumf = 0;
|
| 3836 |
+
float sums = 0.0;
|
| 3837 |
+
|
| 3838 |
+
size_t vl;
|
| 3839 |
+
|
| 3840 |
+
for (int i = 0; i < nb; ++i) {
|
| 3841 |
+
|
| 3842 |
+
vl = 8;
|
| 3843 |
+
|
| 3844 |
+
const uint8_t * restrict q5 = x[i].qs;
|
| 3845 |
+
const uint8_t * restrict hm = x[i].qh;
|
| 3846 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 3847 |
+
|
| 3848 |
+
const float d = ggml_fp16_to_fp32(x[i].d) * y[i].d;
|
| 3849 |
+
const float dmin = ggml_fp16_to_fp32(x[i].dmin) * y[i].d;
|
| 3850 |
+
|
| 3851 |
+
vint16mf2_t q8sums_0 = __riscv_vlse16_v_i16mf2(y[i].bsums, 4, vl);
|
| 3852 |
+
vint16mf2_t q8sums_1 = __riscv_vlse16_v_i16mf2(y[i].bsums+1, 4, vl);
|
| 3853 |
+
vint16mf2_t q8sums = __riscv_vadd_vv_i16mf2(q8sums_0, q8sums_1, vl);
|
| 3854 |
+
|
| 3855 |
+
memcpy(utmp, x[i].scales, 12);
|
| 3856 |
+
utmp[3] = ((utmp[2] >> 4) & kmask2) | (((utmp[1] >> 6) & kmask3) << 4);
|
| 3857 |
+
const uint32_t uaux = utmp[1] & kmask1;
|
| 3858 |
+
utmp[1] = (utmp[2] & kmask2) | (((utmp[0] >> 6) & kmask3) << 4);
|
| 3859 |
+
utmp[2] = uaux;
|
| 3860 |
+
utmp[0] &= kmask1;
|
| 3861 |
+
|
| 3862 |
+
vuint8mf4_t mins8 = __riscv_vle8_v_u8mf4(mins, vl);
|
| 3863 |
+
vint16mf2_t v_mins = __riscv_vreinterpret_v_u16mf2_i16mf2(__riscv_vzext_vf2_u16mf2(mins8, vl));
|
| 3864 |
+
vint32m1_t prod = __riscv_vwmul_vv_i32m1(q8sums, v_mins, vl);
|
| 3865 |
+
|
| 3866 |
+
vint32m1_t sumi = __riscv_vredsum_vs_i32m1_i32m1(prod, __riscv_vmv_v_x_i32m1(0, 1), vl);
|
| 3867 |
+
sumf -= dmin * __riscv_vmv_x_s_i32m1_i32(sumi);
|
| 3868 |
+
|
| 3869 |
+
vl = 32;
|
| 3870 |
+
int32_t aux32 = 0;
|
| 3871 |
+
int is = 0;
|
| 3872 |
+
|
| 3873 |
+
uint8_t m = 1;
|
| 3874 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 3875 |
+
vuint8m1_t vqh = __riscv_vle8_v_u8m1(hm, vl);
|
| 3876 |
+
|
| 3877 |
+
for (int j = 0; j < QK_K/64; ++j) {
|
| 3878 |
+
// load Q5 and Q8
|
| 3879 |
+
vuint8m1_t q5_x = __riscv_vle8_v_u8m1(q5, vl);
|
| 3880 |
+
vint8m1_t q8_y1 = __riscv_vle8_v_i8m1(q8, vl);
|
| 3881 |
+
vint8m1_t q8_y2 = __riscv_vle8_v_i8m1(q8+32, vl);
|
| 3882 |
+
|
| 3883 |
+
// compute mask for addition
|
| 3884 |
+
vint8m1_t q5_a = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vand_vx_u8m1(q5_x, 0x0F, vl));
|
| 3885 |
+
vuint8m1_t qh_m1 = __riscv_vand_vx_u8m1(vqh, m, vl);
|
| 3886 |
+
vbool8_t vmask_1 = __riscv_vmsne_vx_u8m1_b8(qh_m1, 0, vl);
|
| 3887 |
+
vint8m1_t q5_m1 = __riscv_vadd_vx_i8m1_m(vmask_1, q5_a, 16, vl);
|
| 3888 |
+
m <<= 1;
|
| 3889 |
+
|
| 3890 |
+
vint8m1_t q5_l = __riscv_vreinterpret_v_u8m1_i8m1(__riscv_vsrl_vx_u8m1(q5_x, 0x04, vl));
|
| 3891 |
+
vuint8m1_t qh_m2 = __riscv_vand_vx_u8m1(vqh, m, vl);
|
| 3892 |
+
vbool8_t vmask_2 = __riscv_vmsne_vx_u8m1_b8(qh_m2, 0, vl);
|
| 3893 |
+
vint8m1_t q5_m2 = __riscv_vadd_vx_i8m1_m(vmask_2, q5_l, 16, vl);
|
| 3894 |
+
m <<= 1;
|
| 3895 |
+
|
| 3896 |
+
vint16m2_t v0 = __riscv_vwmul_vv_i16m2(q5_m1, q8_y1, vl);
|
| 3897 |
+
vint16m2_t v1 = __riscv_vwmul_vv_i16m2(q5_m2, q8_y2, vl);
|
| 3898 |
+
|
| 3899 |
+
vint32m4_t vs1 = __riscv_vwmul_vx_i32m4(v0, scales[is++], vl);
|
| 3900 |
+
vint32m4_t vs2 = __riscv_vwmul_vx_i32m4(v1, scales[is++], vl);
|
| 3901 |
+
|
| 3902 |
+
vint32m1_t vacc1 = __riscv_vredsum_vs_i32m4_i32m1(vs1, vzero, vl);
|
| 3903 |
+
vint32m1_t vacc2 = __riscv_vredsum_vs_i32m4_i32m1(vs2, vzero, vl);
|
| 3904 |
+
|
| 3905 |
+
aux32 += __riscv_vmv_x_s_i32m1_i32(vacc1) + __riscv_vmv_x_s_i32m1_i32(vacc2);
|
| 3906 |
+
q5 += 32; q8 += 64;
|
| 3907 |
+
|
| 3908 |
+
}
|
| 3909 |
+
|
| 3910 |
+
vfloat32m1_t vaux = __riscv_vfmul_vf_f32m1(__riscv_vfmv_v_f_f32m1(aux32, 1), d, 1);
|
| 3911 |
+
sums += __riscv_vfmv_f_s_f32m1_f32(vaux);
|
| 3912 |
+
|
| 3913 |
+
}
|
| 3914 |
+
|
| 3915 |
+
*s = sumf+sums;
|
| 3916 |
+
|
| 3917 |
#else
|
| 3918 |
|
| 3919 |
const uint8_t * scales = (const uint8_t*)&utmp[0];
|
|
|
|
| 4159 |
|
| 4160 |
*s = hsum_float_8(acc);
|
| 4161 |
|
| 4162 |
+
#elif defined __riscv_v_intrinsic
|
| 4163 |
+
|
| 4164 |
+
float sumf = 0;
|
| 4165 |
+
|
| 4166 |
+
for (int i = 0; i < nb; ++i) {
|
| 4167 |
+
|
| 4168 |
+
const float d = y[i].d * (float)x[i].d;
|
| 4169 |
+
const int8_t * sc = x[i].scales;
|
| 4170 |
+
|
| 4171 |
+
const uint8_t * restrict q5 = x[i].qs;
|
| 4172 |
+
const uint8_t * restrict qh = x[i].qh;
|
| 4173 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 4174 |
+
|
| 4175 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 4176 |
+
|
| 4177 |
+
// load qh
|
| 4178 |
+
vuint8mf4_t qh_x1 = __riscv_vle8_v_u8mf4(qh, 8);
|
| 4179 |
+
vuint8mf2_t qh_x2 = __riscv_vlmul_ext_v_u8mf4_u8mf2(__riscv_vsrl_vx_u8mf4(qh_x1, 1, 8));
|
| 4180 |
+
|
| 4181 |
+
size_t vl = 16;
|
| 4182 |
+
|
| 4183 |
+
// combine both qh_1 and qh_2
|
| 4184 |
+
vuint8mf2_t qh_x = __riscv_vslideup_vx_u8mf2(__riscv_vlmul_ext_v_u8mf4_u8mf2(qh_x1), qh_x2, vl/2, vl);
|
| 4185 |
+
|
| 4186 |
+
vuint8mf2_t qh_h0 = __riscv_vand_vx_u8mf2(__riscv_vnot_v_u8mf2(__riscv_vsll_vx_u8mf2(qh_x, 0x4, vl), vl), 16, vl);
|
| 4187 |
+
vuint8mf2_t qh_h1 = __riscv_vand_vx_u8mf2(__riscv_vnot_v_u8mf2(__riscv_vsll_vx_u8mf2(qh_x, 0x2, vl), vl), 16, vl);
|
| 4188 |
+
vuint8mf2_t qh_h2 = __riscv_vand_vx_u8mf2(__riscv_vnot_v_u8mf2(qh_x, vl), 16, vl);
|
| 4189 |
+
vuint8mf2_t qh_h3 = __riscv_vand_vx_u8mf2(__riscv_vnot_v_u8mf2(__riscv_vsrl_vx_u8mf2(qh_x, 0x4, vl), vl), 16, vl);
|
| 4190 |
+
|
| 4191 |
+
vint8mf2_t qh_0 = __riscv_vreinterpret_v_u8mf2_i8mf2(qh_h0);
|
| 4192 |
+
vint8mf2_t qh_1 = __riscv_vreinterpret_v_u8mf2_i8mf2(qh_h1);
|
| 4193 |
+
vint8mf2_t qh_2 = __riscv_vreinterpret_v_u8mf2_i8mf2(qh_h2);
|
| 4194 |
+
vint8mf2_t qh_3 = __riscv_vreinterpret_v_u8mf2_i8mf2(qh_h3);
|
| 4195 |
+
|
| 4196 |
+
// load q5
|
| 4197 |
+
vuint8mf2_t q5_x1 = __riscv_vle8_v_u8mf2(q5, vl);
|
| 4198 |
+
vuint8mf2_t q5_x2 = __riscv_vle8_v_u8mf2(q5+16, vl);
|
| 4199 |
+
|
| 4200 |
+
vint8mf2_t q5s_0 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vand_vx_u8mf2(q5_x1, 0xF, vl));
|
| 4201 |
+
vint8mf2_t q5s_1 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vand_vx_u8mf2(q5_x2, 0xF, vl));
|
| 4202 |
+
vint8mf2_t q5s_2 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vsrl_vx_u8mf2(q5_x1, 0x4, vl));
|
| 4203 |
+
vint8mf2_t q5s_3 = __riscv_vreinterpret_v_u8mf2_i8mf2(__riscv_vsrl_vx_u8mf2(q5_x2, 0x4, vl));
|
| 4204 |
+
|
| 4205 |
+
vint8mf2_t q5_0 = __riscv_vsub_vv_i8mf2(q5s_0, qh_0, vl);
|
| 4206 |
+
vint8mf2_t q5_1 = __riscv_vsub_vv_i8mf2(q5s_1, qh_1, vl);
|
| 4207 |
+
vint8mf2_t q5_2 = __riscv_vsub_vv_i8mf2(q5s_2, qh_2, vl);
|
| 4208 |
+
vint8mf2_t q5_3 = __riscv_vsub_vv_i8mf2(q5s_3, qh_3, vl);
|
| 4209 |
+
|
| 4210 |
+
// load Q8 and multiply it with Q5
|
| 4211 |
+
vint16m1_t p0 = __riscv_vwmul_vv_i16m1(q5_0, __riscv_vle8_v_i8mf2(q8, vl), vl);
|
| 4212 |
+
vint16m1_t p1 = __riscv_vwmul_vv_i16m1(q5_1, __riscv_vle8_v_i8mf2(q8+16, vl), vl);
|
| 4213 |
+
vint16m1_t p2 = __riscv_vwmul_vv_i16m1(q5_2, __riscv_vle8_v_i8mf2(q8+32, vl), vl);
|
| 4214 |
+
vint16m1_t p3 = __riscv_vwmul_vv_i16m1(q5_3, __riscv_vle8_v_i8mf2(q8+48, vl), vl);
|
| 4215 |
+
|
| 4216 |
+
vint32m1_t vs_0 = __riscv_vwredsum_vs_i16m1_i32m1(p0, vzero, vl);
|
| 4217 |
+
vint32m1_t vs_1 = __riscv_vwredsum_vs_i16m1_i32m1(p1, vzero, vl);
|
| 4218 |
+
vint32m1_t vs_2 = __riscv_vwredsum_vs_i16m1_i32m1(p2, vzero, vl);
|
| 4219 |
+
vint32m1_t vs_3 = __riscv_vwredsum_vs_i16m1_i32m1(p3, vzero, vl);
|
| 4220 |
+
|
| 4221 |
+
int32_t sumi1 = sc[0] * __riscv_vmv_x_s_i32m1_i32(vs_0);
|
| 4222 |
+
int32_t sumi2 = sc[1] * __riscv_vmv_x_s_i32m1_i32(vs_1);
|
| 4223 |
+
int32_t sumi3 = sc[2] * __riscv_vmv_x_s_i32m1_i32(vs_2);
|
| 4224 |
+
int32_t sumi4 = sc[3] * __riscv_vmv_x_s_i32m1_i32(vs_3);
|
| 4225 |
+
|
| 4226 |
+
sumf += d * (sumi1 + sumi2 + sumi3 + sumi4);
|
| 4227 |
+
|
| 4228 |
+
}
|
| 4229 |
+
|
| 4230 |
+
*s = sumf;
|
| 4231 |
+
|
| 4232 |
#else
|
| 4233 |
|
| 4234 |
int8_t aux8[QK_K];
|
|
|
|
| 4613 |
|
| 4614 |
*s = hsum_float_8(acc);
|
| 4615 |
|
| 4616 |
+
#elif defined __riscv_v_intrinsic
|
| 4617 |
+
|
| 4618 |
+
float sumf = 0;
|
| 4619 |
+
for (int i = 0; i < nb; ++i) {
|
| 4620 |
+
|
| 4621 |
+
const float d = ggml_fp16_to_fp32(x[i].d) * y[i].d;
|
| 4622 |
+
|
| 4623 |
+
const uint8_t * restrict q6 = x[i].ql;
|
| 4624 |
+
const uint8_t * restrict qh = x[i].qh;
|
| 4625 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 4626 |
+
|
| 4627 |
+
const int8_t * restrict scale = x[i].scales;
|
| 4628 |
+
|
| 4629 |
+
size_t vl;
|
| 4630 |
+
|
| 4631 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 4632 |
+
|
| 4633 |
+
int sum_t = 0;
|
| 4634 |
+
int is = 0;
|
| 4635 |
+
|
| 4636 |
+
for (int j = 0; j < QK_K/128; ++j) {
|
| 4637 |
+
|
| 4638 |
+
vl = 32;
|
| 4639 |
+
|
| 4640 |
+
// load qh
|
| 4641 |
+
vuint8m1_t qh_x = __riscv_vle8_v_u8m1(qh, vl);
|
| 4642 |
+
|
| 4643 |
+
// load Q6
|
| 4644 |
+
vuint8m1_t q6_0 = __riscv_vle8_v_u8m1(q6, vl);
|
| 4645 |
+
vuint8m1_t q6_1 = __riscv_vle8_v_u8m1(q6+32, vl);
|
| 4646 |
+
|
| 4647 |
+
vuint8m1_t q6a_0 = __riscv_vand_vx_u8m1(q6_0, 0x0F, vl);
|
| 4648 |
+
vuint8m1_t q6a_1 = __riscv_vand_vx_u8m1(q6_1, 0x0F, vl);
|
| 4649 |
+
vuint8m1_t q6s_0 = __riscv_vsrl_vx_u8m1(q6_0, 0x04, vl);
|
| 4650 |
+
vuint8m1_t q6s_1 = __riscv_vsrl_vx_u8m1(q6_1, 0x04, vl);
|
| 4651 |
+
|
| 4652 |
+
vuint8m1_t qh_0 = __riscv_vand_vx_u8m1(qh_x, 0x03, vl);
|
| 4653 |
+
vuint8m1_t qh_1 = __riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(qh_x, 0x2, vl), 0x03 , vl);
|
| 4654 |
+
vuint8m1_t qh_2 = __riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(qh_x, 0x4, vl), 0x03 , vl);
|
| 4655 |
+
vuint8m1_t qh_3 = __riscv_vand_vx_u8m1(__riscv_vsrl_vx_u8m1(qh_x, 0x6, vl), 0x03 , vl);
|
| 4656 |
+
|
| 4657 |
+
vuint8m1_t qhi_0 = __riscv_vor_vv_u8m1(q6a_0, __riscv_vsll_vx_u8m1(qh_0, 0x04, vl), vl);
|
| 4658 |
+
vuint8m1_t qhi_1 = __riscv_vor_vv_u8m1(q6a_1, __riscv_vsll_vx_u8m1(qh_1, 0x04, vl), vl);
|
| 4659 |
+
vuint8m1_t qhi_2 = __riscv_vor_vv_u8m1(q6s_0, __riscv_vsll_vx_u8m1(qh_2, 0x04, vl), vl);
|
| 4660 |
+
vuint8m1_t qhi_3 = __riscv_vor_vv_u8m1(q6s_1, __riscv_vsll_vx_u8m1(qh_3, 0x04, vl), vl);
|
| 4661 |
+
|
| 4662 |
+
vint8m1_t a_0 = __riscv_vsub_vx_i8m1(__riscv_vreinterpret_v_u8m1_i8m1(qhi_0), 32, vl);
|
| 4663 |
+
vint8m1_t a_1 = __riscv_vsub_vx_i8m1(__riscv_vreinterpret_v_u8m1_i8m1(qhi_1), 32, vl);
|
| 4664 |
+
vint8m1_t a_2 = __riscv_vsub_vx_i8m1(__riscv_vreinterpret_v_u8m1_i8m1(qhi_2), 32, vl);
|
| 4665 |
+
vint8m1_t a_3 = __riscv_vsub_vx_i8m1(__riscv_vreinterpret_v_u8m1_i8m1(qhi_3), 32, vl);
|
| 4666 |
+
|
| 4667 |
+
// load Q8 and take product
|
| 4668 |
+
vint16m2_t va_q_0 = __riscv_vwmul_vv_i16m2(a_0, __riscv_vle8_v_i8m1(q8, vl), vl);
|
| 4669 |
+
vint16m2_t va_q_1 = __riscv_vwmul_vv_i16m2(a_1, __riscv_vle8_v_i8m1(q8+32, vl), vl);
|
| 4670 |
+
vint16m2_t va_q_2 = __riscv_vwmul_vv_i16m2(a_2, __riscv_vle8_v_i8m1(q8+64, vl), vl);
|
| 4671 |
+
vint16m2_t va_q_3 = __riscv_vwmul_vv_i16m2(a_3, __riscv_vle8_v_i8m1(q8+96, vl), vl);
|
| 4672 |
+
|
| 4673 |
+
vl = 16;
|
| 4674 |
+
|
| 4675 |
+
vint32m2_t vaux_0 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_0, 0), scale[is+0], vl);
|
| 4676 |
+
vint32m2_t vaux_1 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_0, 1), scale[is+1], vl);
|
| 4677 |
+
vint32m2_t vaux_2 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_1, 0), scale[is+2], vl);
|
| 4678 |
+
vint32m2_t vaux_3 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_1, 1), scale[is+3], vl);
|
| 4679 |
+
vint32m2_t vaux_4 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_2, 0), scale[is+4], vl);
|
| 4680 |
+
vint32m2_t vaux_5 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_2, 1), scale[is+5], vl);
|
| 4681 |
+
vint32m2_t vaux_6 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_3, 0), scale[is+6], vl);
|
| 4682 |
+
vint32m2_t vaux_7 = __riscv_vwmul_vx_i32m2(__riscv_vget_v_i16m2_i16m1(va_q_3, 1), scale[is+7], vl);
|
| 4683 |
+
|
| 4684 |
+
vint32m1_t isum0 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(vaux_0, vaux_1, vl), vzero, vl);
|
| 4685 |
+
vint32m1_t isum1 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(vaux_2, vaux_3, vl), isum0, vl);
|
| 4686 |
+
vint32m1_t isum2 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(vaux_4, vaux_5, vl), isum1, vl);
|
| 4687 |
+
vint32m1_t isum3 = __riscv_vredsum_vs_i32m2_i32m1(__riscv_vadd_vv_i32m2(vaux_6, vaux_7, vl), isum2, vl);
|
| 4688 |
+
|
| 4689 |
+
sum_t += __riscv_vmv_x_s_i32m1_i32(isum3);
|
| 4690 |
+
|
| 4691 |
+
q6 += 64; qh += 32; q8 += 128; is=8;
|
| 4692 |
+
|
| 4693 |
+
}
|
| 4694 |
+
|
| 4695 |
+
sumf += d * sum_t;
|
| 4696 |
+
|
| 4697 |
+
}
|
| 4698 |
+
|
| 4699 |
+
*s = sumf;
|
| 4700 |
+
|
| 4701 |
#else
|
| 4702 |
|
| 4703 |
int8_t aux8[QK_K];
|
|
|
|
| 4951 |
|
| 4952 |
*s = hsum_float_8(acc);
|
| 4953 |
|
| 4954 |
+
#elif defined __riscv_v_intrinsic
|
| 4955 |
+
|
| 4956 |
+
float sumf = 0;
|
| 4957 |
+
|
| 4958 |
+
for (int i = 0; i < nb; ++i) {
|
| 4959 |
+
|
| 4960 |
+
const float d_all = (float)x[i].d;
|
| 4961 |
+
|
| 4962 |
+
const uint8_t * restrict q6 = x[i].ql;
|
| 4963 |
+
const uint8_t * restrict qh = x[i].qh;
|
| 4964 |
+
const int8_t * restrict q8 = y[i].qs;
|
| 4965 |
+
|
| 4966 |
+
const int8_t * restrict scale = x[i].scales;
|
| 4967 |
+
|
| 4968 |
+
int32_t isum = 0;
|
| 4969 |
+
|
| 4970 |
+
size_t vl = 16;
|
| 4971 |
+
|
| 4972 |
+
vint32m1_t vzero = __riscv_vmv_v_x_i32m1(0, 1);
|
| 4973 |
+
|
| 4974 |
+
// load Q6
|
| 4975 |
+
vuint8mf2_t q6_0 = __riscv_vle8_v_u8mf2(q6, vl);
|
| 4976 |
+
vuint8mf2_t q6_1 = __riscv_vle8_v_u8mf2(q6+16, vl);
|
| 4977 |
+
|
| 4978 |
+
// load qh
|
| 4979 |
+
vuint8mf2_t qh_x = __riscv_vle8_v_u8mf2(qh, vl);
|
| 4980 |
+
|
| 4981 |
+
vuint8mf2_t qh0 = __riscv_vsll_vx_u8mf2(__riscv_vand_vx_u8mf2(qh_x, 0x3, vl), 0x4, vl);
|
| 4982 |
+
qh_x = __riscv_vsrl_vx_u8mf2(qh_x, 0x2, vl);
|
| 4983 |
+
vuint8mf2_t qh1 = __riscv_vsll_vx_u8mf2(__riscv_vand_vx_u8mf2(qh_x, 0x3, vl), 0x4, vl);
|
| 4984 |
+
qh_x = __riscv_vsrl_vx_u8mf2(qh_x, 0x2, vl);
|
| 4985 |
+
vuint8mf2_t qh2 = __riscv_vsll_vx_u8mf2(__riscv_vand_vx_u8mf2(qh_x, 0x3, vl), 0x4, vl);
|
| 4986 |
+
qh_x = __riscv_vsrl_vx_u8mf2(qh_x, 0x2, vl);
|
| 4987 |
+
vuint8mf2_t qh3 = __riscv_vsll_vx_u8mf2(__riscv_vand_vx_u8mf2(qh_x, 0x3, vl), 0x4, vl);
|
| 4988 |
+
|
| 4989 |
+
vuint8mf2_t q6h_0 = __riscv_vor_vv_u8mf2(__riscv_vand_vx_u8mf2(q6_0, 0xF, vl), qh0, vl);
|
| 4990 |
+
vuint8mf2_t q6h_1 = __riscv_vor_vv_u8mf2(__riscv_vand_vx_u8mf2(q6_1, 0xF, vl), qh1, vl);
|
| 4991 |
+
vuint8mf2_t q6h_2 = __riscv_vor_vv_u8mf2(__riscv_vsrl_vx_u8mf2(q6_0, 0x4, vl), qh2, vl);
|
| 4992 |
+
vuint8mf2_t q6h_3 = __riscv_vor_vv_u8mf2(__riscv_vsrl_vx_u8mf2(q6_1, 0x4, vl), qh3, vl);
|
| 4993 |
+
|
| 4994 |
+
vint8mf2_t q6v_0 = __riscv_vsub_vx_i8mf2(__riscv_vreinterpret_v_u8mf2_i8mf2(q6h_0), 32, vl);
|
| 4995 |
+
vint8mf2_t q6v_1 = __riscv_vsub_vx_i8mf2(__riscv_vreinterpret_v_u8mf2_i8mf2(q6h_1), 32, vl);
|
| 4996 |
+
vint8mf2_t q6v_2 = __riscv_vsub_vx_i8mf2(__riscv_vreinterpret_v_u8mf2_i8mf2(q6h_2), 32, vl);
|
| 4997 |
+
vint8mf2_t q6v_3 = __riscv_vsub_vx_i8mf2(__riscv_vreinterpret_v_u8mf2_i8mf2(q6h_3), 32, vl);
|
| 4998 |
+
|
| 4999 |
+
// load Q8 and take product
|
| 5000 |
+
vint16m1_t p0 = __riscv_vwmul_vv_i16m1(q6v_0, __riscv_vle8_v_i8mf2(q8, vl), vl);
|
| 5001 |
+
vint16m1_t p1 = __riscv_vwmul_vv_i16m1(q6v_1, __riscv_vle8_v_i8mf2(q8+16, vl), vl);
|
| 5002 |
+
vint16m1_t p2 = __riscv_vwmul_vv_i16m1(q6v_2, __riscv_vle8_v_i8mf2(q8+32, vl), vl);
|
| 5003 |
+
vint16m1_t p3 = __riscv_vwmul_vv_i16m1(q6v_3, __riscv_vle8_v_i8mf2(q8+48, vl), vl);
|
| 5004 |
+
|
| 5005 |
+
vint32m1_t vs_0 = __riscv_vwredsum_vs_i16m1_i32m1(p0, vzero, vl);
|
| 5006 |
+
vint32m1_t vs_1 = __riscv_vwredsum_vs_i16m1_i32m1(p1, vzero, vl);
|
| 5007 |
+
vint32m1_t vs_2 = __riscv_vwredsum_vs_i16m1_i32m1(p2, vzero, vl);
|
| 5008 |
+
vint32m1_t vs_3 = __riscv_vwredsum_vs_i16m1_i32m1(p3, vzero, vl);
|
| 5009 |
+
|
| 5010 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_0) * scale[0];
|
| 5011 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_1) * scale[1];
|
| 5012 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_2) * scale[2];
|
| 5013 |
+
isum += __riscv_vmv_x_s_i32m1_i32(vs_3) * scale[3];
|
| 5014 |
+
|
| 5015 |
+
sumf += isum * d_all * y[i].d;
|
| 5016 |
+
|
| 5017 |
+
}
|
| 5018 |
+
|
| 5019 |
+
*s = sumf;
|
| 5020 |
+
|
| 5021 |
#else
|
| 5022 |
|
| 5023 |
int8_t aux8[QK_K];
|
k_quants.h
CHANGED
|
@@ -29,7 +29,7 @@
|
|
| 29 |
|
| 30 |
// 2-bit quantization
|
| 31 |
// weight is represented as x = a * q + b
|
| 32 |
-
// 16 blocks of 16
|
| 33 |
// Effectively 2.5625 bits per weight
|
| 34 |
typedef struct {
|
| 35 |
uint8_t scales[QK_K/16]; // scales and mins, quantized with 4 bits
|
|
@@ -41,7 +41,7 @@ static_assert(sizeof(block_q2_K) == 2*sizeof(ggml_fp16_t) + QK_K/16 + QK_K/4, "w
|
|
| 41 |
|
| 42 |
// 3-bit quantization
|
| 43 |
// weight is represented as x = a * q
|
| 44 |
-
// 16 blocks of 16
|
| 45 |
// Effectively 3.4375 bits per weight
|
| 46 |
#ifdef GGML_QKK_64
|
| 47 |
typedef struct {
|
|
@@ -62,7 +62,7 @@ static_assert(sizeof(block_q3_K) == sizeof(ggml_fp16_t) + QK_K / 4 + QK_K / 8 +
|
|
| 62 |
#endif
|
| 63 |
|
| 64 |
// 4-bit quantization
|
| 65 |
-
//
|
| 66 |
// weight is represented as x = a * q + b
|
| 67 |
// Effectively 4.5 bits per weight
|
| 68 |
#ifdef GGML_QKK_64
|
|
@@ -83,7 +83,7 @@ static_assert(sizeof(block_q4_K) == 2*sizeof(ggml_fp16_t) + K_SCALE_SIZE + QK_K/
|
|
| 83 |
#endif
|
| 84 |
|
| 85 |
// 5-bit quantization
|
| 86 |
-
//
|
| 87 |
// weight is represented as x = a * q + b
|
| 88 |
// Effectively 5.5 bits per weight
|
| 89 |
#ifdef GGML_QKK_64
|
|
@@ -107,7 +107,7 @@ static_assert(sizeof(block_q5_K) == 2*sizeof(ggml_fp16_t) + K_SCALE_SIZE + QK_K/
|
|
| 107 |
|
| 108 |
// 6-bit quantization
|
| 109 |
// weight is represented as x = a * q
|
| 110 |
-
// 16 blocks of 16
|
| 111 |
// Effectively 6.5625 bits per weight
|
| 112 |
typedef struct {
|
| 113 |
uint8_t ql[QK_K/2]; // quants, lower 4 bits
|
|
|
|
| 29 |
|
| 30 |
// 2-bit quantization
|
| 31 |
// weight is represented as x = a * q + b
|
| 32 |
+
// 16 blocks of 16 elements each
|
| 33 |
// Effectively 2.5625 bits per weight
|
| 34 |
typedef struct {
|
| 35 |
uint8_t scales[QK_K/16]; // scales and mins, quantized with 4 bits
|
|
|
|
| 41 |
|
| 42 |
// 3-bit quantization
|
| 43 |
// weight is represented as x = a * q
|
| 44 |
+
// 16 blocks of 16 elements each
|
| 45 |
// Effectively 3.4375 bits per weight
|
| 46 |
#ifdef GGML_QKK_64
|
| 47 |
typedef struct {
|
|
|
|
| 62 |
#endif
|
| 63 |
|
| 64 |
// 4-bit quantization
|
| 65 |
+
// 8 blocks of 32 elements each
|
| 66 |
// weight is represented as x = a * q + b
|
| 67 |
// Effectively 4.5 bits per weight
|
| 68 |
#ifdef GGML_QKK_64
|
|
|
|
| 83 |
#endif
|
| 84 |
|
| 85 |
// 5-bit quantization
|
| 86 |
+
// 8 blocks of 32 elements each
|
| 87 |
// weight is represented as x = a * q + b
|
| 88 |
// Effectively 5.5 bits per weight
|
| 89 |
#ifdef GGML_QKK_64
|
|
|
|
| 107 |
|
| 108 |
// 6-bit quantization
|
| 109 |
// weight is represented as x = a * q
|
| 110 |
+
// 16 blocks of 16 elements each
|
| 111 |
// Effectively 6.5625 bits per weight
|
| 112 |
typedef struct {
|
| 113 |
uint8_t ql[QK_K/2]; // quants, lower 4 bits
|
kcpp_docs.embd
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
klite.embd
CHANGED
|
@@ -5,8 +5,8 @@ Kobold Lite WebUI is a standalone WebUI for use with KoboldAI United, AI Horde,
|
|
| 5 |
It requires no dependencies, installation or setup.
|
| 6 |
Just copy this single static HTML file anywhere and open it in a browser, or from a webserver.
|
| 7 |
Please go to https://github.com/LostRuins/lite.koboldai.net for updates on Kobold Lite.
|
| 8 |
-
Kobold Lite is under the AGPL v3.0 License
|
| 9 |
-
Current version:
|
| 10 |
-Concedo
|
| 11 |
-->
|
| 12 |
|
|
@@ -1179,7 +1179,7 @@ Current version: 74
|
|
| 1179 |
}
|
| 1180 |
.scenariogrid
|
| 1181 |
{
|
| 1182 |
-
height:
|
| 1183 |
overflow-y: auto;
|
| 1184 |
margin-top: 4px;
|
| 1185 |
padding: 8px;
|
|
@@ -1192,7 +1192,7 @@ Current version: 74
|
|
| 1192 |
{
|
| 1193 |
padding: 4px 12px;
|
| 1194 |
width: 100%;
|
| 1195 |
-
height:
|
| 1196 |
color: #b7e2ff;
|
| 1197 |
overflow-y: auto;
|
| 1198 |
}
|
|
@@ -1754,14 +1754,14 @@ Current version: 74
|
|
| 1754 |
const favivon_normal = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACAAAAAgCAMAAABEpIrGAAAAAXNSR0IB2cksfwAAAAlwSFlzAAALEwAACxMBAJqcGAAAAEtQTFRFAAAA+XJ0l09PsVdXcTw842hqw2hmTi4vMCQlb2eUgWtl+tGpBAMDEw4NPCkoFw8PJBgXt5WBVkxW4Nvf7Lia3Z+MpJnAZ05HnJOTYIS/NAAAABl0Uk5TAv////v//vT9//3/Nna08qf+///////a/hkcROQAAAGUSURBVHiclZLRcoQgDEULBAKoIKjI/39pL4i7nbUPbcYZwJyES5Kvr3/YvIx1nn9zL4G4EwuTXX7xs4QFGEklOT6SBENERguhsWHFD2AVRhL8IEgawY8b5L4fYtg+TSl8+NMEu4G2P34Q67r6I+37dLyBfU/4PY/sInG2MR8vIHG01h9mHfq1hUUQtwYcLEcp+ltmwqutdy5HMwAfc8ExKtVSLEZZW13Jxb4Azq7UHFnFrtGItLliS1UDYOfctm3JhEtlEH5zzpZNDsC63AB1VysY3gqC3C2ytsNW6Q3IjCt91Qr9QK8MiFL4nUEpEyNLYmodxYo3RquVHWUmbbRu0QCbKWwNfil5zYeENrRRqtZrGEQYqdtW8FWHLl4bgZDLFLZdbS/UzP2AEGTufkt3xWSvwzJeh4GxHWD5qlgXOZ/n2ULuC/od4Pk8x9xhCekD0Bqd/DmXgbpEumRgrMPn1K6ecs4pJc/V0nE+x35KtfTJTJufpvPTD2DyNZ3e4wP3zDCHevg+yYvf09PfkHuK7/Vv9g2CjBTdqv3bFgAAAABJRU5ErkJggg==";
|
| 1755 |
const compressed_scenario_db = ["XQAAAQCkKgAAAAAAAAA9iIqG1FTp3Td41VnWyuXTp3Lb95KmIEizGvJcmkqrV2FY5cKEeSxCwbqBRjHVjL7PUH9wCoW89dPxjDNZvgp6okMOelpy7_1P6GV-mfJV4jz42_DXqYfET4aYlAT13M95gkcA14f0NLvI_p6B9CyG8EbkhRxsk3uyf_KgTV5kwqzAcr5C4JQ_pJr77GnYCHQI8h6F765-lcqrvw1Xu1GHhcN3lj7s9PhMvLnmGPZbQMrTo5sqPJDzYO6lytxmNSHSXMICpN2kFJB6kqyL5lBxNAH3Au_F_JIC85GqwLXWEy8wZms5KmAdp1s3EA1yabPGqqF0G5RxBp3aXzm7h6QUJPy1qSr6JJAo4fi2gCPaLkdn2pKqNDR1Ww8FA6AVHOyMgCTmmrQxWVYgXY9TdhHKcRcrIsoHNXEeWSqMGJNQ8lzVfc26teZdBdPLhqcClG8wUThPtyobTMz8Fgom88nTv7VT-mZhwH9Nc4ghoCL8dMR0Skf-EYDZ0Uvz03_GTn5OB8yuX6FmsD1XQJv_CKBAUHeDKd7n_bC7WOnlAINHPX9Bh5TnwjeLYO-UAL2ClMJTFzR-k2cjVHGQnLB7hZ48L1nToRG1gSVN7dP3Zysw7riwIxnfG4MMNXtEbHyxrCvz2zRTUEqbHLrwIzdJRpJ5s5XfTlY1CPZkQCwxbA6rrUt27D6a-YDKavbg0hubpViPRYbnEDXr9gL-7in4f_K2cOZdQ26Q--hk0xzEtgBNFI6inHA2nA4LofUpWjl835qg6CUyz9EzQkw0cDgPVjYXehC9oC_3H0U2O9YC-Ah8VpdPdCHUFuaQr7oXgePUub_Be1XQyCA5TaqrJxVxUG2hZA4rOVJHZ_AahfiJN7z6QcVEp-8xf-wHcv1lpWjjNdXFWDqVQZkdOaKf63dtjP35SmC5eCw2_BNX_t-db_FCCAhm2Vn2WI3q4k00p4l_ocCrJIdRID6muBVZQXCzxcRf5m8kcGwrTB-XVS-XSSPZInaBxZjgimOl5bLwJvdMC-HNYtU-yUDjXvDjPraZ_7ZV_-knU1GbHf1BpI9-rNbl_3bbA7KbmL7Q_goV1Clvi6gLYgjbXGQMTFjQEoodZX3fK_bDhVsrA1fWMJMWwfY3ua-j8HNuyRDfhPBpbTK0Gvz5-GWbIRF3v4zwR9HzIjz2frY7luy3ApQ6QJw7K6ITvD80u5VLfpHYReVCLpgs-lvPStklgnGXj3j5vuaH9f-wFohB19vwzRnthvgdplXPQ9jMy3ieb80sELS0WiGD-E2L_HhNXUcpTdeBp3HQFK4QubJOiIeKuZDVR7PxvtwBj26m-pLXLzKc6WqQlt07TsRo_72SlAaZodyyFRXf8636HCAyEHcVEhR6uZ1lDu00BHvsyVe6BdG7zvjNdmLluA0qBJQ9FO3ipHezadlwCPnEBDQAAZRgHKUvRCJNOQH_jcqFLLtmDADXoLvcK8_lN0LEeisA4B1LH0X2x0Q6NqLgngh9M1y_cBEBaazMa_UIZwoL6eZGU0QhlpvysBi1wKDybNcF_uKrIxdQwn8L_QRFHtDn39-hw-GDs_6zbnRlwrBEwrMtAQfc62FLSzGUMAzww-aTGvUuQvP-D9m0r-eDbSATlSsrIYobVUDUdDWsMDUsjKfYOW_Rp0GMjk40BQxcdzjNjLCYaTEN5cMhsWyfTbhIHDP7-wfbvJG7Al7Z-nH2Pa-QXPte687xVanKT0d3Er07vOV9HoI09mtuhxE4g0VaLm4TMqxSMRBX3EB60W1U2sX9sHjAgmwfpUNXRNj03QeJe4cg0pndf-hhKkTsfNQMU_N6-Zt8IrM2xtzFfvKB4BpFyWmaYu_X7bGwgSZjzrBNE10fx001fMr2fmrVy_sj7mW7WhlWXa3N5eMe4pqkA4EawmGzhuIwAqZNmtvnL_N2nt4T4ZyqkAAyXMMKb60UJAXkqLjUisD1bnNt1qD9otg8mGNzQxlaY5Bfm7286vNmjyxGY4UVrn0RV0DSFFb5_NYEW5y5YYxiabWABr8k0ezTM8R_qQ7NxdUOj0qhBKOqGyzyuVgKNnB6-ZzpKVGbB7RYJXwfEtkKNuUc3UWmbwxcsCTuW4TOScqJUh4dA5vlgLjB3-Q79yEMRYB8n6jetkR4z25RkYRXvTxkHIVQd2qr8BchdUcmHsZvG_tXI0-bxx_f_TGyfgi8ol7L5SRfWfOtYHCXSVHOCwnDj7GN4rIrwt3qWRcPkdTMw1RguDZW0eTpCpZyCJH_z3xVfpVh5lgf7Nu4tH-CpFRrOaJc79K1lSuIZs8yvjh5dbYAH4rKQ28OOFRu2MmU7Ko8Of4CECcJMhohFtVW6nTCB48-Pl8owiGM5_2uBJOJRAsyu3fHHbKqKvZ-0kYmN9ypyTAxQjgDiCOE3J1txPiqRRRRSaFZgLPNacdyjGO2y2SpWwzYudx8tEq3tBDAPBCXwWqwefcG__iN5OMRgCIAvr-9qfl2iSaVR5LZ-kBluVoW27o0hIUtgdry03bmUN50ob4hwCz8xVoupcHjI3Cy0nLpgiGixjo4afafQPE_TXJf-NixlWN-cH2a4ZzU6Qc5KKzIciwnt6Hx-iRQzB_uK-pBDjC8boVXolOsFyaqWsoLgkghTo2qCFZuxP2GKzS9wQ5sBWxTMEPGryHxaylpXXmUjlBJ-j9p4vJN9YxjQEbyuTVYy0PxmtDbyh6g_n3Lr09ttCg40hqfWBhCT9P4-uFoAjozUciHQFBfI8t04dKZnobLbVq-f_HJGzUZu5zHRHsPI939tJxODDJxiflfHLwxXjQS2cq9Vj-kvn1pgXAN5unYh8Y7-nqepxc0KkO2v8mU-r8fYFmUFJdZu6HR23P2y7ndsozZEKdUAVay36pmW_gvVQuSA_jzLwXn3Ee2y-A7G-w96bTe82gJG95PsSOt2L6AcuF8mqWL_EVBjIZJMN63T__0UHh9VPDCRTUITwn35t7Z0aGYHnssPVAxXLh7y2LhCaIN0u6lnbiDlKAdKc1-4qYbr1sHORC8tjSG8cjWLkgBcNkFo7rqhKQSNtU1H44aT8ceG08a8cSpze8aC6dMVaz6DxEaFIZ-aRqfqO0QV6ty2-6hrcRVedypt1Twd7UEkXZM5Erjb-_8jq4RzshqXVzKEqPfIYpmtHqkmeJq8BLfc1GT9UGrmPpYO4-K8LM-u7aOpcxcagPn2S3McsWI3a8CWkU9t4g9WEPNH-5s8VqF-3rSmgi5kk40Y7HjEyA-6clhNhl9lbP6hIbf9TKHO9fWwzTz8NieUPNZZPgrBrULggzHXPrfJIxl8eLSrKuD8n2Pbumu2k4ljMV_WIq9qCJ1wPofdIoWHWiz7oV2snLve1CFPUCdAhLkHQ8KpO6xvSi6mKY9WsOhOLxKm92vsWLv-rfM2CW4XUja5arRpGynr7cF9CDuEGWIxkPjOF_5x8ZXg2x1TJcrgvLDO_S4u2zKl2tQGRW4NHU1zF9h_3SQkpbwWH5KOPisP6c8vb5rg_rZ5laFedxQQSpguSq5el9-ddzvlr4C8Q22eDQvwUEO_P6c6VZN5A2QWBGZsJoaZ4gZ8UArmGLxSihBj_5oOdDdUcbUOhGUIWrtYrs4PJKxpnHDFUZaYwIbtnLyAoORKYvq8LgAH0SP57KeeYkZzUGP1f0jkDzAmwV4ZHE0pnZhEo3XkXVuIHc6MXZ-RniZaS_vaoY3Bq6XHrKoWZdLiCoU6aqPc-ZpPnvXmnKHyLLs4e96M1wGKIyT28_VCR6EDRJPxbZ9Ig1kN8TIHCF3tE8y2It5hkz1-zNYT6uw3SDkFSdrV_DRiAVqUhxrQdUPhpD92zVgsWdJR0TZLU7CBLlOuBVwyfmtHMUBL6dIvYie47Kr47nOJ5i2ka8EZGZf-Y8aD6xv6hpBbybU_5oGfYLRG4MiNRhML4u90tQ3hBxBbGYK8sWOzui2UEx0ynB_a8jz8eEs7u_9ylTD1v1f-gC8JYQMNAZIm46pvl2s1X07B8Gf7Laj4aozcWqg8DgC_8aLypoTffyxjWw4Fpd8LWn1fRPsFOdeV0UrS7FNtUakvYq_qxphGu5mNuINIJIMJzgI3giGnyCbr2IrsJ1ITmEGnggLQYes1t3j44v1quvVwQXqHX6HhSnoJlN2IlT5DuZ2kx6-pb68nK62xVJaOS-wDeeJnQ8zzhqJACstuF7g-jidRoJmGc8yChHfCN8ZFOhT0poNQB-Jf5IUZ7aSCXmceYN4VUhmB_w-Db1XZUNHOJqGiTgcT1KzejzNpN49b0QUjcRJiOpEhJp_LzBUiRQSnweOSFrWlTs5Jf9p3wqN9zFYZ_3Xz6IR2klwyLQXc-LbBd1QFwkB17HTYMspUXjrSpJULdQ90OxzbSEafF4RKvgIL4sAU1pCMTa2bVrcUmY2MiECVIbwPNN0CjZeoEAd1dP5FFjlwGG7xUNRO1E20CqHZJ1oqeEur06ZXvPK1zy3SlF-_lKF6eRfNClzR2ERGYqf-zEQwwkPNiMNnURPcdt64pw4kcjTKBIkorum3ruuqJZMitcZx0YiANx7ssy8dMuVteEFFCQnmglgTCsEZTK_xzigPie_f8Q5p1vsJPje5Z2cugsaW-vOXbuOE471n6LuIyoII2dWq0m8H3_8pxlErkZ5E7OY--w3InCuSCv2ubxaZ9AbaNuuyGw49fI3zvRurTYespYO-Aj1FcjDrxqRB3bihJm_u3a56fwnoyOeE0071TY_AlVlq1RYauV4-7L-RAFJZo0wKnPZM9Hs7VB_cCwJ_oPe1y0XBF95agtAQdicj42KdstIlpjWtdGb4LpHgVQI_56G3As0H81-uj47VuBourA2hUay0BpHAvcwbNLyu8OcZB31I6dfy2797wGlrWwAN-Xt3M3CVW9SvIN_GMlg0RB75rUEtgPkR-VPRdPH_Jb19wVoFPPpwjP6cYzVW1U_iRymFKaNpMo4CWFN6t54wshlCVwkfZKbhSP14z74oMKxy-qqt-WKNhkOr1uh_sevNa57iHBnFlHzt_eaZoPNTsCmzqnC4boOlK9o5_hFn8hiw33R3NQC-RD-w1XEl8-hpdZYdCcnexwRYd9sH2LMHySL59Kp_09yIwAE_ukVMDa6Yd9OHrbSCycQNZSI_0fMnF5s9oWTXnsxecDpRKgSWJQIQPUb6dlOdGOT0-MnebivpKgbDxzx52Zr0EMS7aU5eJxEdO9rdiFda8kQk5IeBgr1QcqIFs_1UIp6oQneXgwTlpXXxLHs16ShDG1qkLmDZjb4vrb_Ha2YCBIqid6wVKjec-UwEwWyvfV4UAPFgiNRJN7TdQNRxbSZJ8XWeA2gor9PN5JkMS0l_qGKoke3sbWDsp-G_B0KUjwUBTtPsKRhdnc0JyV_akuZ8jxAmXDDydxOy_EqNMgrDGN_4FuSY7XNLy2OXXJG3bB9a_lxEzdVNPWzM0cijTQFLzIiAKAyWTfwPNagcvgLUAeHxlQ22E0V37-sFwkstvpJ-s8C2yqxQKcv4GfMZOfSYEaZAhiO_y8EXgFknGGwjLB7K3CgvGwBRWWcgx-eqXYs9rAygf_X2_7-rBG_7Rxj3GW957PwwzwZjZDkdRHik8sj0htIkDRAyHo2EsPwObKXK-W32JKUX3VSgiY8AzCUhUUIWwFVVLXEvB1jtU7G7wRaj5_z9QywvgoIqnOTmpm4TTRA0cCJkiYoJcl8BOIHoWuYznL89zWjWy_ZQDKaYAsHugQYXaKI_UaaLV4gVFjDNqZCgqjAFyMjG4qZR64jkaI71mefUaDLLwsqIiLpOWZi8BlvP0YcOVeTyo2mJbq3EXfjXyDvPuZuZ9SAjqwCdLr902yzLm4DdzYRyfPbpt8rGUu-Uw27Ix2oZRe_zj0G_3FdCw0"];
|
| 1756 |
|
| 1757 |
-
const storymodels1 = ["erebus","nerys","nerybus","janeway","hermes","airoboros","chrono","llama","wizard","mantis","myth"];
|
| 1758 |
-
const storymodels2 = ["opt","vicuna","manticore","alpaca"];
|
| 1759 |
-
const adventuremodels1 = ["nerys","nerybus","skein","adventure","hermes","airoboros","chrono","llama","wizard","mantis","myth"];
|
| 1760 |
-
const adventuremodels2 = ["erebus","janeway","opt","vicuna","manticore","alpaca"];
|
| 1761 |
-
const chatmodels1 = ["pygmalion-6","pygmalion-v8","hermes","airoboros","chrono","llama","wizard","mantis","myth"];
|
| 1762 |
-
const chatmodels2 = ["pygmalion","janeway","nerys","erebus","nerybus","opt","vicuna","manticore","alpaca"];
|
| 1763 |
-
const instructmodels1 = ["gpt4all","supercot","hermes","airoboros","chrono","wizard","mantis","vicuna","manticore","alpaca","myth"];
|
| 1764 |
-
const instructmodels2 = ["erebus","nerys","nerybus","janeway","opt","llama"];
|
| 1765 |
|
| 1766 |
const instructstartplaceholder = "\n{{[INPUT]}}\n";
|
| 1767 |
const instructendplaceholder = "\n{{[OUTPUT]}}\n";
|
|
@@ -1837,7 +1837,7 @@ Current version: 74
|
|
| 1837 |
"opmode":3,
|
| 1838 |
"chatname": "You",
|
| 1839 |
"chatopponent": "KoboldGPT",
|
| 1840 |
-
"gui_type":
|
| 1841 |
"prefmodel1":chatmodels1,
|
| 1842 |
"prefmodel2":chatmodels2,
|
| 1843 |
"prompt":"\nKoboldGPT: Hello, I am KoboldGPT, your personal AI assistant. What would you like to know?",
|
|
@@ -2188,6 +2188,75 @@ Current version: 74
|
|
| 2188 |
"memory":`[Character: Nail; species: Redscale Kobold; age: 20; gender: female; class: Hexblade Warlock with powers derived from draconic patron; physical appearance: 3' in height, 35 lbs, purple eyes, pink scales and peachy chest; equipment: Dragon's talon affixed to a handle as a blade; personality: lawful neutral; description: Nail (called Nannan in her native tongue) is a refugee of the once-proud Xabrakkar kobolds on the continent of Halkar. Founded above a series of geothermal caves, her tribe prospered as they dug into long-buried ruins for priceless treasures, which they brought to the surface. Amongst the ruins, Nail discovered the slumbering red dragon Rhindicar - once the familiar to one of the most powerful sorcerers to ever live. The sleeping dragon quickly became an object of worship for the Xabrakkar kobolds. However, the Trobian relics they unearthed attracted the attention of another - Hilezmaras, the mad tyrant, a covetous dragon who laid claim to the kobolds treasures, sending his fanatical dragonborn cult to purge their warren. While most of the kobolds were slain, a select few were dragon-marked, forcibly given a magic brand linking them to the mad dragon in order to turn them into powerful and obedient soldiers. Nail broke free of her captors after being given such a mark, fleeing into the tunnels leading to the Tinder Depths, eventually collapsing before Rhindicar and waking him from his slumber. Being raised from a hatchling by a kind and just master, Rhindicar was uncharacteristically compassionate for a dragon, and took pity on the young kobold. Though he was not powerful enough to remove Hilezmaras' brand, he was able to suppress its magical compulsion, allowing her to retain her free-will. He warned, though, that as the dragon-mark grew in power and became more strongly linked to the mad tyrant, he would no longer be able to keep it suppressed, and urged Nannan to seek out his former master, Rath Cinderstorm. Biting off a fragment of one of his talons, he gifted it to the kobold, both as a weapon, and as a conduit to help him suppress the effects of the brand. With no other options, Nannan returned to the warren and fought her way to the surface, eventually escaping Halkar and crossing the ocean to Fanne'Tar, where she assumed the alias 'Nail' in Common tongue and began her search for a long-missing sorcerer.]\n[The following is a chat message log between Nail and you.]\n`,
|
| 2189 |
"authorsnote": "",
|
| 2190 |
"worldinfo": []
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2191 |
}
|
| 2192 |
|
| 2193 |
];
|
|
@@ -2946,8 +3015,10 @@ Current version: 74
|
|
| 2946 |
saved_oai_addr: "", //do not ever share this in save files!
|
| 2947 |
saved_claude_key: "", //do not ever share this in save files!
|
| 2948 |
saved_claude_addr: "", //do not ever share this in save files!
|
|
|
|
|
|
|
| 2949 |
saved_oai_jailbreak: "", //customized oai system prompt
|
| 2950 |
-
|
| 2951 |
|
| 2952 |
autoscroll: true, //automatically scroll to bottom on render
|
| 2953 |
trimsentences: true, //trim to last punctuation
|
|
@@ -3076,6 +3147,7 @@ Current version: 74
|
|
| 3076 |
};
|
| 3077 |
}
|
| 3078 |
|
|
|
|
| 3079 |
//uncompress compacted scenarios
|
| 3080 |
for(let i=0;i<compressed_scenario_db.length;++i)
|
| 3081 |
{
|
|
@@ -3323,6 +3395,7 @@ Current version: 74
|
|
| 3323 |
//read the url params, and autoload a shared story if found
|
| 3324 |
const foundStory = urlParams.get('s');
|
| 3325 |
const foundScenario = urlParams.get('scenario');
|
|
|
|
| 3326 |
const nofiltermode = urlParams.get('nofilter');
|
| 3327 |
if (nofiltermode) {
|
| 3328 |
filter_enabled = false;
|
|
@@ -3349,7 +3422,11 @@ Current version: 74
|
|
| 3349 |
}
|
| 3350 |
//purge url params
|
| 3351 |
window.history.replaceState(null, null, window.location.pathname);
|
| 3352 |
-
} else {
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3353 |
if (popup_aiselect) {
|
| 3354 |
display_models();
|
| 3355 |
}
|
|
@@ -3582,6 +3659,7 @@ Current version: 74
|
|
| 3582 |
story.savedsettings.saved_oai_addr = "";
|
| 3583 |
story.savedsettings.saved_claude_key = "";
|
| 3584 |
story.savedsettings.saved_claude_addr = "";
|
|
|
|
| 3585 |
|
| 3586 |
if (!strip_images)
|
| 3587 |
{
|
|
@@ -3701,6 +3779,7 @@ Current version: 74
|
|
| 3701 |
let tmp_claude1 = localsettings.saved_claude_key;
|
| 3702 |
let tmp_claude2 = localsettings.saved_claude_addr;
|
| 3703 |
let tmp_palm1 = localsettings.saved_palm_key;
|
|
|
|
| 3704 |
import_props_into_object(localsettings, story.savedsettings);
|
| 3705 |
localsettings.my_api_key = tmpapikey1;
|
| 3706 |
localsettings.home_cluster = tmphc;
|
|
@@ -3709,6 +3788,7 @@ Current version: 74
|
|
| 3709 |
localsettings.saved_claude_key = tmp_claude1;
|
| 3710 |
localsettings.saved_claude_addr = tmp_claude2;
|
| 3711 |
localsettings.saved_palm_key = tmp_palm1;
|
|
|
|
| 3712 |
}
|
| 3713 |
|
| 3714 |
if (story.savedaestheticsettings && story.savedaestheticsettings != "") {
|
|
@@ -3827,6 +3907,7 @@ Current version: 74
|
|
| 3827 |
loaded_storyobj.savedsettings.saved_oai_addr = "";
|
| 3828 |
loaded_storyobj.savedsettings.saved_claude_key = "";
|
| 3829 |
loaded_storyobj.savedsettings.saved_claude_addr = "";
|
|
|
|
| 3830 |
|
| 3831 |
loaded_storyobj.savedaestheticsettings = JSON.parse(JSON.stringify(aestheticInstructUISettings, null, 2));
|
| 3832 |
}else{
|
|
@@ -4018,6 +4099,7 @@ Current version: 74
|
|
| 4018 |
let tmp_claude1 = localsettings.saved_claude_key;
|
| 4019 |
let tmp_claude2 = localsettings.saved_claude_addr;
|
| 4020 |
let tmp_palm1 = localsettings.saved_palm_key;
|
|
|
|
| 4021 |
import_props_into_object(localsettings, loaded_storyobj.savedsettings);
|
| 4022 |
localsettings.my_api_key = tmpapikey1;
|
| 4023 |
localsettings.home_cluster = tmphc;
|
|
@@ -4026,6 +4108,7 @@ Current version: 74
|
|
| 4026 |
localsettings.saved_claude_key = tmp_claude1;
|
| 4027 |
localsettings.saved_claude_addr = tmp_claude2;
|
| 4028 |
localsettings.saved_palm_key = tmp_palm1;
|
|
|
|
| 4029 |
|
| 4030 |
//backwards compat support for newlines
|
| 4031 |
if(localsettings.instruct_has_newlines==true || (loaded_storyobj.savedsettings != null && loaded_storyobj.savedsettings.instruct_has_newlines==null&&loaded_storyobj.savedsettings.instruct_has_markdown==null))
|
|
@@ -4281,26 +4364,25 @@ Current version: 74
|
|
| 4281 |
},false);
|
| 4282 |
}
|
| 4283 |
|
| 4284 |
-
function get_chubai_scenario()
|
| 4285 |
{
|
| 4286 |
-
|
| 4287 |
-
|
| 4288 |
if(userinput=="")
|
| 4289 |
{
|
| 4290 |
//pass
|
| 4291 |
}
|
| 4292 |
else
|
| 4293 |
{
|
| 4294 |
-
if (userinput.
|
| 4295 |
-
//is a
|
| 4296 |
-
userinput = userinput.replace(
|
| 4297 |
-
userinput = userinput.split(
|
| 4298 |
-
userinput = userinput.split("#")[0];
|
| 4299 |
-
userinput = userinput.split("?")[0];
|
| 4300 |
}
|
| 4301 |
userinput = userinput.endsWith('/') ? userinput.slice(0, -1) : userinput;
|
| 4302 |
if(userinput!="")
|
| 4303 |
{
|
|
|
|
| 4304 |
fetch("https://api.chub.ai/api/characters/download", {
|
| 4305 |
method: 'POST',
|
| 4306 |
headers: {
|
|
@@ -4313,7 +4395,14 @@ Current version: 74
|
|
| 4313 |
}),
|
| 4314 |
referrerPolicy: 'no-referrer',
|
| 4315 |
})
|
| 4316 |
-
.then(x =>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4317 |
.then(data => {
|
| 4318 |
console.log(data);
|
| 4319 |
let botname = data.name?data.name:"Bot";
|
|
@@ -4337,7 +4426,42 @@ Current version: 74
|
|
| 4337 |
"authorsnote": "",
|
| 4338 |
"worldinfo": [],
|
| 4339 |
};
|
| 4340 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4341 |
}).catch((error) => {
|
| 4342 |
temp_scenario = null;
|
| 4343 |
document.getElementById("scenariodesc").innerText = "Error: Selected scenario is invalid.";
|
|
@@ -4345,10 +4469,20 @@ Current version: 74
|
|
| 4345 |
});
|
| 4346 |
}else{
|
| 4347 |
temp_scenario = null;
|
| 4348 |
-
document.getElementById("scenariodesc").innerText = "Error: User input is invalid\n\n Please ensure you have input a valid
|
| 4349 |
}
|
| 4350 |
}
|
| 4351 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4352 |
}
|
| 4353 |
|
| 4354 |
|
|
@@ -4360,11 +4494,16 @@ Current version: 74
|
|
| 4360 |
function preview_temp_scenario()
|
| 4361 |
{
|
| 4362 |
let author = "";
|
|
|
|
| 4363 |
if(temp_scenario.author && temp_scenario.author!="")
|
| 4364 |
{
|
| 4365 |
author = "<br><b>Author:</b> "+temp_scenario.author;
|
| 4366 |
}
|
| 4367 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4368 |
`<p><b>Mode:</b> `+(temp_scenario.opmode==1?"Story":(temp_scenario.opmode==2?"Adventure":(temp_scenario.opmode==3?"Chat":"Instruct"))) + author+`</p>`
|
| 4369 |
+`<p>`+(temp_scenario.desc!=""?escapeHtml(temp_scenario.desc):"[No Description Given]") +`</p>`;
|
| 4370 |
}
|
|
@@ -4397,6 +4536,11 @@ Current version: 74
|
|
| 4397 |
current_memory = replace_placeholders_direct(current_memory);
|
| 4398 |
}
|
| 4399 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4400 |
if (temp_scenario.worldinfo && temp_scenario.worldinfo.length > 0) {
|
| 4401 |
current_wi = [];
|
| 4402 |
for (let x = 0; x < temp_scenario.worldinfo.length; ++x) {
|
|
@@ -4457,6 +4601,14 @@ Current version: 74
|
|
| 4457 |
else if(temp_scenario.gui_type===2) { localsettings.gui_type_instruct = 2; }
|
| 4458 |
else if(temp_scenario.gui_type===0) { localsettings.gui_type_instruct = 0; }
|
| 4459 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4460 |
if (temp_scenario.instruct_starttag) { localsettings.instruct_starttag = temp_scenario.instruct_starttag; }
|
| 4461 |
if (temp_scenario.instruct_endtag) { localsettings.instruct_endtag = temp_scenario.instruct_endtag; }
|
| 4462 |
}
|
|
@@ -4518,7 +4670,7 @@ Current version: 74
|
|
| 4518 |
{
|
| 4519 |
scenarioautopickai = true; //no selected model, pick a good one
|
| 4520 |
}
|
| 4521 |
-
if (scenarioautopickai && !localflag)
|
| 4522 |
{
|
| 4523 |
fetch_models((mdls) =>
|
| 4524 |
{
|
|
@@ -4528,7 +4680,7 @@ Current version: 74
|
|
| 4528 |
}
|
| 4529 |
else
|
| 4530 |
{
|
| 4531 |
-
let nsfwmodels = ["erebus","shinen","horni","litv2","lit-6b"];
|
| 4532 |
selected_models = [];
|
| 4533 |
for (var i = 0; i < mdls.length; ++i) {
|
| 4534 |
for (var j = 0; j < temp_scenario.prefmodel1.length; ++j) {
|
|
@@ -4661,6 +4813,22 @@ Current version: 74
|
|
| 4661 |
}
|
| 4662 |
get_workers((wdata) => {
|
| 4663 |
worker_data_showonly = wdata;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4664 |
show_workers();
|
| 4665 |
});
|
| 4666 |
}
|
|
@@ -4735,6 +4903,31 @@ Current version: 74
|
|
| 4735 |
return days+"d "+hours+"h "+minutes+"m";
|
| 4736 |
}
|
| 4737 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4738 |
function show_workers() {
|
| 4739 |
document.getElementById("workercontainer").classList.remove("hidden");
|
| 4740 |
|
|
@@ -4775,11 +4968,12 @@ Current version: 74
|
|
| 4775 |
if (parentcluster && userData && userData.worker_ids && userData.worker_ids.length > 0)
|
| 4776 |
{
|
| 4777 |
let urls = userData.worker_ids.map(x=>parentcluster.maintenance_endpoint + "/" + x);
|
| 4778 |
-
Promise.all(urls.map(url => fetch(url)
|
| 4779 |
-
.then(response => response.json())))
|
| 4780 |
.then(values => {
|
|
|
|
| 4781 |
lastValidFoundUserWorkers = values;
|
| 4782 |
-
console.log(
|
|
|
|
| 4783 |
document.getElementById("myownworkercontainer").classList.remove("hidden");
|
| 4784 |
|
| 4785 |
let str = "";
|
|
@@ -4789,7 +4983,7 @@ Current version: 74
|
|
| 4789 |
let brokenstyle = (elem.maintenance_mode ? "style=\"color:#ee4444;\"" : "");
|
| 4790 |
let workerNameHtml = escapeHtml(elem.name.substring(0, 32));
|
| 4791 |
let eleminfo = ((elem.info && elem.info!="")?elem.info:"");
|
| 4792 |
-
str += "<tr><td>" + workerNameHtml + "</td><td><input class='' style='color:#000000;' id='mwc_desc_"+i+"' placeholder='Worker Description' value='"+eleminfo+"''></td><td "+brokenstyle+">" + format_uptime(elem.uptime) + "<br>(" + elem.requests_fulfilled + " jobs)</td><td "+style+">" + elem.kudos_rewards.toFixed(0) + "</
|
| 4793 |
}
|
| 4794 |
document.getElementById("myownworkertable").innerHTML = str;
|
| 4795 |
|
|
@@ -4805,7 +4999,9 @@ Current version: 74
|
|
| 4805 |
.catch(error =>
|
| 4806 |
{
|
| 4807 |
console.log("Error: " + error);
|
| 4808 |
-
msgbox(error,"Error fetching
|
|
|
|
|
|
|
| 4809 |
});
|
| 4810 |
}
|
| 4811 |
else
|
|
@@ -4982,6 +5178,31 @@ Current version: 74
|
|
| 4982 |
}
|
| 4983 |
}
|
| 4984 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4985 |
function customapi_dropdown()
|
| 4986 |
{
|
| 4987 |
let epchoice = document.getElementById("customapidropdown").value;
|
|
@@ -4993,6 +5214,10 @@ Current version: 74
|
|
| 4993 |
if(epchoice==0)
|
| 4994 |
{
|
| 4995 |
document.getElementById("koboldcustom").classList.remove("hidden");
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4996 |
}
|
| 4997 |
else if(epchoice==1)
|
| 4998 |
{
|
|
@@ -5006,7 +5231,7 @@ Current version: 74
|
|
| 5006 |
document.getElementById("custom_oai_endpoint").value = localsettings.saved_oai_addr;
|
| 5007 |
}
|
| 5008 |
}
|
| 5009 |
-
|
| 5010 |
togglejailbreak();
|
| 5011 |
}
|
| 5012 |
else if(epchoice==2)
|
|
@@ -5087,6 +5312,7 @@ Current version: 74
|
|
| 5087 |
|
| 5088 |
//good to go
|
| 5089 |
custom_kobold_endpoint = tmpep;
|
|
|
|
| 5090 |
selected_models = [{ "performance": 100.0, "queued": 0.0, "eta": 0, "name": mdlname, "count": 1 }];
|
| 5091 |
selected_workers = [];
|
| 5092 |
if (perfdata == null) {
|
|
@@ -5194,6 +5420,10 @@ Current version: 74
|
|
| 5194 |
selected_models = [];
|
| 5195 |
selected_workers = [];
|
| 5196 |
custom_kobold_endpoint = "";
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5197 |
render_gametext();
|
| 5198 |
} else {
|
| 5199 |
uses_cors_proxy = true; //fallback to cors proxy, this will remain for rest of session
|
|
@@ -5250,6 +5480,7 @@ Current version: 74
|
|
| 5250 |
document.getElementById("jailbreakprompttext").value = defaultoaijailbreak;
|
| 5251 |
}
|
| 5252 |
custom_oai_model = document.getElementById("custom_oai_model").value.trim();
|
|
|
|
| 5253 |
selected_models = [{ "performance": 100.0, "queued": 0.0, "eta": 0, "name": custom_oai_model, "count": 1 }];
|
| 5254 |
selected_workers = [];
|
| 5255 |
if (perfdata == null) {
|
|
@@ -5443,6 +5674,7 @@ Current version: 74
|
|
| 5443 |
function display_custom_endpoint()
|
| 5444 |
{
|
| 5445 |
document.getElementById("customendpointcontainer").classList.remove("hidden");
|
|
|
|
| 5446 |
}
|
| 5447 |
|
| 5448 |
function fetch_models(onDoneCallback)
|
|
@@ -5673,6 +5905,36 @@ Current version: 74
|
|
| 5673 |
}
|
| 5674 |
}
|
| 5675 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5676 |
function update_my_workers()
|
| 5677 |
{
|
| 5678 |
let newapikey = document.getElementById("apikey").value;
|
|
@@ -5692,6 +5954,10 @@ Current version: 74
|
|
| 5692 |
if(desc.value.trim()!="" || (desc.value.trim()=="" && lastValidFoundUserWorkers[i].info!=null && lastValidFoundUserWorkers[i].info!=""))
|
| 5693 |
{
|
| 5694 |
wo.info = desc.value.trim();
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5695 |
}
|
| 5696 |
fetch(parentcluster.maintenance_endpoint + "/" + lastValidFoundUserWorkers[i].id, {
|
| 5697 |
method: 'PUT',
|
|
@@ -6181,6 +6447,10 @@ Current version: 74
|
|
| 6181 |
document.getElementById('instruct_starttag').value = "\\nQuestion: ";
|
| 6182 |
document.getElementById('instruct_endtag').value = "\\nAnswer: ";
|
| 6183 |
break;
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6184 |
default:
|
| 6185 |
break;
|
| 6186 |
}
|
|
@@ -6616,6 +6886,9 @@ Current version: 74
|
|
| 6616 |
headers: {
|
| 6617 |
'Content-Type': 'application/json',
|
| 6618 |
},
|
|
|
|
|
|
|
|
|
|
| 6619 |
})
|
| 6620 |
.then((response) => response.json())
|
| 6621 |
.then((data) => {})
|
|
@@ -6890,10 +7163,19 @@ Current version: 74
|
|
| 6890 |
pending_context_preinjection = "\n";
|
| 6891 |
}
|
| 6892 |
|
| 6893 |
-
if(localsettings.allow_continue_chat && newgen.trim() == "")
|
| 6894 |
{
|
| 6895 |
-
//
|
| 6896 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6897 |
}
|
| 6898 |
else
|
| 6899 |
{
|
|
@@ -7074,6 +7356,8 @@ Current version: 74
|
|
| 7074 |
{
|
| 7075 |
lastcheckgenkey = "KCPP"+(Math.floor(1000 + Math.random() * 9000)).toString();
|
| 7076 |
submit_payload.params.genkey = lastcheckgenkey;
|
|
|
|
|
|
|
| 7077 |
}
|
| 7078 |
|
| 7079 |
//v2 api specific fields
|
|
@@ -7095,7 +7379,6 @@ Current version: 74
|
|
| 7095 |
function dispatch_submit_generation(submit_payload, input_was_empty) //if input is not empty, always unban eos
|
| 7096 |
{
|
| 7097 |
console.log(submit_payload);
|
| 7098 |
-
last_request_str = JSON.stringify(submit_payload);
|
| 7099 |
|
| 7100 |
startTimeTaken(); //timestamp start request
|
| 7101 |
|
|
@@ -7179,7 +7462,7 @@ Current version: 74
|
|
| 7179 |
streamchunk = ((pstreamamount != null && pstreamamount > 0) ? pstreamamount:8); //8 tokens per stream tick by default
|
| 7180 |
}
|
| 7181 |
let sub_endpt = apply_proxy_url(custom_kobold_endpoint + kobold_custom_gen_endpoint);
|
| 7182 |
-
|
| 7183 |
kobold_api_stream(sub_endpt, submit_payload, submit_payload.max_length, "", streamchunk);
|
| 7184 |
|
| 7185 |
}
|
|
@@ -7201,7 +7484,7 @@ Current version: 74
|
|
| 7201 |
"logit_bias": { "50256": -100 },
|
| 7202 |
}
|
| 7203 |
|
| 7204 |
-
if (custom_oai_model == "gpt-3.5-turbo" || custom_oai_model == "gpt-3.5-turbo-16k" || custom_oai_model == "gpt-4" || custom_oai_model == "gpt-4-32k") {
|
| 7205 |
targetep = (custom_oai_endpoint + oai_submit_endpoint_turbo);
|
| 7206 |
if (document.getElementById("jailbreakprompt") && document.getElementById("jailbreakprompt").checked && document.getElementById("jailbreakprompttext").value!="") {
|
| 7207 |
oai_payload.messages = [
|
|
@@ -7219,6 +7502,8 @@ Current version: 74
|
|
| 7219 |
oai_payload.prompt = submit_payload.prompt;
|
| 7220 |
}
|
| 7221 |
|
|
|
|
|
|
|
| 7222 |
fetch(targetep, {
|
| 7223 |
method: 'POST',
|
| 7224 |
headers: {
|
|
@@ -7267,6 +7552,7 @@ Current version: 74
|
|
| 7267 |
let targetep = cors_proxy + "?" + scale_submit_endpoint + custom_scale_ID;
|
| 7268 |
let scale_payload = { "input": { "input": submit_payload.prompt } };
|
| 7269 |
|
|
|
|
| 7270 |
fetch(targetep, {
|
| 7271 |
method: 'POST',
|
| 7272 |
headers: {
|
|
@@ -7306,7 +7592,7 @@ Current version: 74
|
|
| 7306 |
"prompt": submit_payload.prompt,
|
| 7307 |
"max_tokens_to_sample": submit_payload.params.max_length,
|
| 7308 |
"model": custom_claude_model,
|
| 7309 |
-
"top_k": (submit_payload.params.top_k
|
| 7310 |
"temperature": submit_payload.params.temperature,
|
| 7311 |
"top_p": submit_payload.params.top_p,
|
| 7312 |
}
|
|
@@ -7330,6 +7616,8 @@ Current version: 74
|
|
| 7330 |
}
|
| 7331 |
}
|
| 7332 |
|
|
|
|
|
|
|
| 7333 |
fetch(targetep, {
|
| 7334 |
method: 'POST',
|
| 7335 |
headers: {
|
|
@@ -7370,9 +7658,11 @@ Current version: 74
|
|
| 7370 |
"temperature":submit_payload.params.temperature,
|
| 7371 |
"maxOutputTokens": submit_payload.params.max_length,
|
| 7372 |
"topP": submit_payload.params.top_p,
|
| 7373 |
-
"topK": (submit_payload.params.top_k<1?
|
| 7374 |
"candidateCount":1};
|
| 7375 |
|
|
|
|
|
|
|
| 7376 |
fetch(targetep, {
|
| 7377 |
method: 'POST',
|
| 7378 |
headers: {
|
|
@@ -7447,7 +7737,12 @@ Current version: 74
|
|
| 7447 |
}
|
| 7448 |
|
| 7449 |
//horde supports unban tokens
|
| 7450 |
-
submit_payload.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7451 |
|
| 7452 |
fetch(selectedhorde.submit_endpoint, {
|
| 7453 |
method: 'POST', // or 'PUT'
|
|
@@ -8378,7 +8673,12 @@ Current version: 74
|
|
| 8378 |
if (gametext_arr.length == 0 && synchro_pending_stream=="" && pending_response_id=="") {
|
| 8379 |
|
| 8380 |
if (perfdata == null) {
|
| 8381 |
-
document.getElementById("
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8382 |
} else {
|
| 8383 |
let whorun = "";
|
| 8384 |
|
|
@@ -8463,7 +8763,6 @@ Current version: 74
|
|
| 8463 |
|
| 8464 |
fulltxt = replaceAll(fulltxt, `%SpcStg%`, `<hr class="hr_instruct"><span class="color_cyan"><img src="`+human_square+`" style="height:38px;width:auto;padding:3px 6px 3px 3px;border-radius: 8%;"/>`);
|
| 8465 |
fulltxt = replaceAll(fulltxt, `%SpcEtg%`, `</span><hr class="hr_instruct"><img src="`+niko_square+`" style="height:38px;width:auto;padding:3px 6px 3px 3px;border-radius: 8%;"/>`);
|
| 8466 |
-
|
| 8467 |
}else{
|
| 8468 |
fulltxt = replaceAll(fulltxt, get_instruct_starttag(true), `%SclStg%`+escapeHtml(get_instruct_starttag(true))+`%SpnEtg%`);
|
| 8469 |
fulltxt = replaceAll(fulltxt, get_instruct_endtag(true), `%SclStg%`+escapeHtml(get_instruct_endtag(true))+`%SpnEtg%`);
|
|
@@ -8661,7 +8960,7 @@ Current version: 74
|
|
| 8661 |
}
|
| 8662 |
else
|
| 8663 |
{
|
| 8664 |
-
document.getElementById("chat_msg_body").innerHTML = render_enhanced_chat_instruct(textToRender);
|
| 8665 |
}
|
| 8666 |
|
| 8667 |
// Show the 'AI is typing' message if an answer is pending, and prevent the 'send button' from being clicked again.
|
|
@@ -9160,7 +9459,7 @@ Current version: 74
|
|
| 9160 |
this.bubbleColor_AI = 'rgb(20, 20, 40)';
|
| 9161 |
|
| 9162 |
this.background_margin = [5, 5, 5, 0];
|
| 9163 |
-
this.background_padding = [15, 15, 10,
|
| 9164 |
this.background_minHeight = 80;
|
| 9165 |
this.centerHorizontally = false;
|
| 9166 |
|
|
@@ -9455,8 +9754,9 @@ Current version: 74
|
|
| 9455 |
}
|
| 9456 |
}
|
| 9457 |
|
| 9458 |
-
function render_enhanced_chat_instruct(input,
|
| 9459 |
{
|
|
|
|
| 9460 |
const contextDict = { sysOpen: '<sys_context_koboldlite_internal>', youOpen: '<user_context_koboldlite_internal>', AIOpen: '<AI_context_koboldlite_internal>', closeTag: '<end_of_context_koboldlite_internal>' }
|
| 9461 |
let you = get_instruct_starttag(); let bot = get_instruct_endtag(); // Instruct tags will be used to wrap text in styled bubbles.
|
| 9462 |
|
|
@@ -9503,7 +9803,7 @@ Current version: 74
|
|
| 9503 |
let noSystemPrompt = input.trim().startsWith(you.trim()) || input.trim().startsWith(bot.trim());
|
| 9504 |
let newbodystr = noSystemPrompt ? input : style('sys') + input; // First, create the string we'll transform. Style system bubble if we should.
|
| 9505 |
if (newbodystr.endsWith(bot)) { newbodystr = newbodystr.slice(0, -bot.length); } // Remove the last chat bubble if prompt ends with `end_sequence`.
|
| 9506 |
-
newbodystr = transformInputToAestheticStyle(newbodystr); // Transform input to aesthetic style, reduce any unnecessary spaces or newlines, and trim empty replies if they exist.
|
| 9507 |
if (synchro_pending_stream != "") {
|
| 9508 |
newbodystr += getStreamingText();
|
| 9509 |
} // Add the pending stream if it's needed. This will add any streamed text to a new bubble for the AI.
|
|
@@ -9534,7 +9834,8 @@ Current version: 74
|
|
| 9534 |
let fontStyle = type=='action'?'italic':'normal';
|
| 9535 |
let injectQuotes1 = type=='speech'?'“':'';
|
| 9536 |
let injectQuotes2 = type=='speech'?'”':'';
|
| 9537 |
-
let textCol = as[`${type}_tcolor_${role}`];
|
|
|
|
| 9538 |
}
|
| 9539 |
function image(role) {
|
| 9540 |
if (!as[`${role}_portrait`] || as.border_style == 'None' || role == 'sys') { return ''; }
|
|
@@ -9543,15 +9844,20 @@ Current version: 74
|
|
| 9543 |
function applyStylizedCodeBlocks() {
|
| 9544 |
let blocks = newbodystr.split(/(```[\s\S]*?\n[\s\S]*?```)/g);
|
| 9545 |
for (var i = 0; i < blocks.length; i++) {
|
| 9546 |
-
if (blocks[i].startsWith('```')) {
|
| 9547 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9548 |
}
|
| 9549 |
return blocks.join('');
|
| 9550 |
}
|
| 9551 |
-
function transformInputToAestheticStyle(bodyStr) { // Trim unnecessary empty space and new lines, and append * or " to each bubble if start/end sequence ends with * or ", to preserve styling.
|
| 9552 |
bodyStr = bodyStr.replaceAll(you + '\n', you).replaceAll(you + ' ', you).replaceAll(you, style('you') + `${you.endsWith('*') ? '*' : ''}` + `${you.endsWith('"') ? '"' : ''}`);
|
| 9553 |
bodyStr = bodyStr.replaceAll(bot + '\n', bot).replaceAll(bot + ' ', bot).replaceAll(bot, style('AI') + `${bot.endsWith('*') ? '*' : ''}` + `${bot.endsWith('"') ? '"' : ''}`);
|
| 9554 |
-
if(gametext_arr.length==0)
|
| 9555 |
{
|
| 9556 |
return bodyStr; //to allow html in the welcome text
|
| 9557 |
}
|
|
@@ -9567,8 +9873,8 @@ Current version: 74
|
|
| 9567 |
}
|
| 9568 |
|
| 9569 |
function updateTextPreview() {
|
| 9570 |
-
let preview = `You are Mikago, a prestigious bot that's a supervillain.\n\nRoleplay in first person, be prestigious, don't be a bot. This is a fantasy world.\n\nCode blocks should be wrapped in triple backticks, like so:\
|
| 9571 |
-
|
| 9572 |
if(localsettings.opmode==3)
|
| 9573 |
{
|
| 9574 |
preview = replaceAll(preview,'\n[USER_REPLY]\n', "{{userplaceholder}}");
|
|
@@ -9583,7 +9889,7 @@ Current version: 74
|
|
| 9583 |
preview = replaceAll(preview,'\n[USER_REPLY]\n', get_instruct_starttag());
|
| 9584 |
preview = replaceAll(preview,'\n[AI_REPLY]\n', get_instruct_endtag());
|
| 9585 |
}
|
| 9586 |
-
document.getElementById('aesthetic_text_preview').innerHTML = render_enhanced_chat_instruct(preview,
|
| 9587 |
}
|
| 9588 |
</script>
|
| 9589 |
|
|
@@ -9667,7 +9973,8 @@ Current version: 74
|
|
| 9667 |
<div id="maineditbody" class="layer-container">
|
| 9668 |
<div class="layer-bottom" id="gamescreen">
|
| 9669 |
<span id="gametext" contenteditable="false" onclick="click_gametext()" onblur="merge_edit_field()">
|
| 9670 |
-
<p>
|
|
|
|
| 9671 |
</span>
|
| 9672 |
<div class="hidden" id="wimenu">
|
| 9673 |
</div>
|
|
@@ -9884,7 +10191,7 @@ Current version: 74
|
|
| 9884 |
<input class="form-control" type="text" id="custom_oai_endpoint" placeholder="OpenAI API URL" value="">
|
| 9885 |
<input class="form-control" type="password" id="custom_oai_key" placeholder="OpenAI API Key" value="" onfocus="focus_api_keys()" onblur="blur_api_keys()"><br>
|
| 9886 |
Model Choice:<br>
|
| 9887 |
-
<select style="padding:4px;" class="form-control" id="custom_oai_model">
|
| 9888 |
<option value="text-davinci-003" selected="selected">text-davinci-003</option>
|
| 9889 |
<option value="text-davinci-002">text-davinci-002</option>
|
| 9890 |
<option value="text-davinci-001">text-davinci-001</option>
|
|
@@ -9894,11 +10201,14 @@ Current version: 74
|
|
| 9894 |
<option value="gpt-3.5-turbo-16k">gpt-3.5-turbo-16k</option>
|
| 9895 |
<option value="gpt-4">gpt-4</option>
|
| 9896 |
<option value="gpt-4-32k">gpt-4-32k</option>
|
|
|
|
| 9897 |
</select>
|
| 9898 |
<input type="checkbox" id="oaiaddversion" onchange="" checked>
|
| 9899 |
<div class="box-label" title="Add endpoint version">Add Endpoint Version</div>
|
| 9900 |
<input type="checkbox" id="jailbreakprompt" onchange="togglejailbreak()">
|
| 9901 |
-
<div class="box-label" title="Adds extra text to improve AI response">
|
|
|
|
|
|
|
| 9902 |
<input class="form-control hidden" type="text" id="jailbreakprompttext" placeholder="(Enter System Message)"
|
| 9903 |
value="" onload="togglejailbreak()">
|
| 9904 |
</div>
|
|
@@ -9995,7 +10305,7 @@ Current version: 74
|
|
| 9995 |
class="helptext">Randomness of sampling. High values can increase creativity but
|
| 9996 |
may make text less sensible. Lower values will make text more predictable but
|
| 9997 |
can become repetitious.</span></span></div>
|
| 9998 |
-
<input inputmode="
|
| 9999 |
oninput="
|
| 10000 |
document.getElementById('temperature_slide').value = this.value;">
|
| 10001 |
</div>
|
|
@@ -10011,8 +10321,7 @@ Current version: 74
|
|
| 10011 |
<div class="settingitem">
|
| 10012 |
<div class="settinglabel">
|
| 10013 |
<div class="justifyleft settingsmall">Max Ctx. Tokens <span class="helpicon">?<span class="helptext">Max
|
| 10014 |
-
number of
|
| 10015 |
-
higher than Amount to Generate.</span></span></div>
|
| 10016 |
<input inputmode="numeric" class="justifyright flex-push-right settingsmall" id="max_context_length"
|
| 10017 |
value=1024 oninput="
|
| 10018 |
document.getElementById('max_context_length_slide').value = this.value;">
|
|
@@ -10058,7 +10367,7 @@ Current version: 74
|
|
| 10058 |
<div class="justifyleft settingsmall">Top p Sampling <span class="helpicon">?<span class="helptext">Used
|
| 10059 |
to discard unlikely text in the sampling process. Lower values will make text
|
| 10060 |
more predictable but can become repetitious. Set to 1 to deactivate it.</span></span></div>
|
| 10061 |
-
<input inputmode="
|
| 10062 |
document.getElementById('top_p_slide').value = this.value;">
|
| 10063 |
</div>
|
| 10064 |
<div><input type="range" class="form-range airange" min="0" max="1" step="0.01" id="top_p_slide"
|
|
@@ -10077,7 +10386,7 @@ Current version: 74
|
|
| 10077 |
<div class="justifyleft settingsmall">Repetition Penalty <span class="helpicon">?<span
|
| 10078 |
class="helptext">Used to penalize words that were already generated or belong to
|
| 10079 |
the context (Going over 1.2 breaks 6B models).</span></span></div>
|
| 10080 |
-
<input inputmode="
|
| 10081 |
oninput="
|
| 10082 |
document.getElementById('rep_pen_slide').value = this.value;">
|
| 10083 |
</div>
|
|
@@ -10167,6 +10476,7 @@ Current version: 74
|
|
| 10167 |
<option value="3">Metharme</option>
|
| 10168 |
<option value="4">Llama 2 Chat</option>
|
| 10169 |
<option value="5">Q & A</option>
|
|
|
|
| 10170 |
</select>
|
| 10171 |
<table class="settingsmall text-center" style="border-spacing: 4px 2px; border-collapse: separate;">
|
| 10172 |
<tr>
|
|
@@ -10202,13 +10512,13 @@ Current version: 74
|
|
| 10202 |
<th title="Tail-Free Sampling. 1 to Deactivate.">TFS</th>
|
| 10203 |
</tr>
|
| 10204 |
<tr>
|
| 10205 |
-
<td><input class="" type="text" placeholder="0" value="0"
|
| 10206 |
id="top_k"></td>
|
| 10207 |
-
<td><input class="" type="text" placeholder="0" value="0"
|
| 10208 |
id="top_a"></td>
|
| 10209 |
-
<td><input class="" type="text" placeholder="0" value="0"
|
| 10210 |
id="typ_s"></td>
|
| 10211 |
-
<td><input class="" type="text" placeholder="0" value="0"
|
| 10212 |
id="tfs_s"></td>
|
| 10213 |
</tr>
|
| 10214 |
</table>
|
|
@@ -10510,7 +10820,7 @@ Current version: 74
|
|
| 10510 |
<div class="workerTableDiv">
|
| 10511 |
<table class="table text-center workerTable">
|
| 10512 |
<thead class="sticky-top bg-white">
|
| 10513 |
-
<tr><th>Name</th><th>Model</th><th>Capabilities</th><th>Uptime</th><th>Kudos</th><th>Cluster</th></tr>
|
| 10514 |
</thead>
|
| 10515 |
<tbody id="workertable">
|
| 10516 |
</tbody>
|
|
@@ -10531,7 +10841,7 @@ Current version: 74
|
|
| 10531 |
<div class="workerTableDiv">
|
| 10532 |
<table class="table text-center workerTable">
|
| 10533 |
<thead class="sticky-top bg-white">
|
| 10534 |
-
<tr><th>Name</th><th>Description</th><th>Uptime</th><th>Kudos</th><th>
|
| 10535 |
</thead>
|
| 10536 |
<tbody id="myownworkertable">
|
| 10537 |
</tbody>
|
|
@@ -10815,7 +11125,7 @@ if ('serviceWorker' in navigator) {
|
|
| 10815 |
|
| 10816 |
//for local mode, we do not load any PWA service worker.
|
| 10817 |
//this will prevent PWA functionality locally but will avoid the scary 404 errors
|
| 10818 |
-
if(localflag)
|
| 10819 |
{
|
| 10820 |
console.log("Try to register service worker...");
|
| 10821 |
try {
|
|
|
|
| 5 |
It requires no dependencies, installation or setup.
|
| 6 |
Just copy this single static HTML file anywhere and open it in a browser, or from a webserver.
|
| 7 |
Please go to https://github.com/LostRuins/lite.koboldai.net for updates on Kobold Lite.
|
| 8 |
+
Kobold Lite is under the AGPL v3.0 License unless otherwise exempted. Please do not remove this line.
|
| 9 |
+
Current version: 78
|
| 10 |
-Concedo
|
| 11 |
-->
|
| 12 |
|
|
|
|
| 1179 |
}
|
| 1180 |
.scenariogrid
|
| 1181 |
{
|
| 1182 |
+
height: 260px;
|
| 1183 |
overflow-y: auto;
|
| 1184 |
margin-top: 4px;
|
| 1185 |
padding: 8px;
|
|
|
|
| 1192 |
{
|
| 1193 |
padding: 4px 12px;
|
| 1194 |
width: 100%;
|
| 1195 |
+
height: 160px;
|
| 1196 |
color: #b7e2ff;
|
| 1197 |
overflow-y: auto;
|
| 1198 |
}
|
|
|
|
| 1754 |
const favivon_normal = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAACAAAAAgCAMAAABEpIrGAAAAAXNSR0IB2cksfwAAAAlwSFlzAAALEwAACxMBAJqcGAAAAEtQTFRFAAAA+XJ0l09PsVdXcTw842hqw2hmTi4vMCQlb2eUgWtl+tGpBAMDEw4NPCkoFw8PJBgXt5WBVkxW4Nvf7Lia3Z+MpJnAZ05HnJOTYIS/NAAAABl0Uk5TAv////v//vT9//3/Nna08qf+///////a/hkcROQAAAGUSURBVHiclZLRcoQgDEULBAKoIKjI/39pL4i7nbUPbcYZwJyES5Kvr3/YvIx1nn9zL4G4EwuTXX7xs4QFGEklOT6SBENERguhsWHFD2AVRhL8IEgawY8b5L4fYtg+TSl8+NMEu4G2P34Q67r6I+37dLyBfU/4PY/sInG2MR8vIHG01h9mHfq1hUUQtwYcLEcp+ltmwqutdy5HMwAfc8ExKtVSLEZZW13Jxb4Azq7UHFnFrtGItLliS1UDYOfctm3JhEtlEH5zzpZNDsC63AB1VysY3gqC3C2ytsNW6Q3IjCt91Qr9QK8MiFL4nUEpEyNLYmodxYo3RquVHWUmbbRu0QCbKWwNfil5zYeENrRRqtZrGEQYqdtW8FWHLl4bgZDLFLZdbS/UzP2AEGTufkt3xWSvwzJeh4GxHWD5qlgXOZ/n2ULuC/od4Pk8x9xhCekD0Bqd/DmXgbpEumRgrMPn1K6ecs4pJc/V0nE+x35KtfTJTJufpvPTD2DyNZ3e4wP3zDCHevg+yYvf09PfkHuK7/Vv9g2CjBTdqv3bFgAAAABJRU5ErkJggg==";
|
| 1755 |
const compressed_scenario_db = ["XQAAAQCkKgAAAAAAAAA9iIqG1FTp3Td41VnWyuXTp3Lb95KmIEizGvJcmkqrV2FY5cKEeSxCwbqBRjHVjL7PUH9wCoW89dPxjDNZvgp6okMOelpy7_1P6GV-mfJV4jz42_DXqYfET4aYlAT13M95gkcA14f0NLvI_p6B9CyG8EbkhRxsk3uyf_KgTV5kwqzAcr5C4JQ_pJr77GnYCHQI8h6F765-lcqrvw1Xu1GHhcN3lj7s9PhMvLnmGPZbQMrTo5sqPJDzYO6lytxmNSHSXMICpN2kFJB6kqyL5lBxNAH3Au_F_JIC85GqwLXWEy8wZms5KmAdp1s3EA1yabPGqqF0G5RxBp3aXzm7h6QUJPy1qSr6JJAo4fi2gCPaLkdn2pKqNDR1Ww8FA6AVHOyMgCTmmrQxWVYgXY9TdhHKcRcrIsoHNXEeWSqMGJNQ8lzVfc26teZdBdPLhqcClG8wUThPtyobTMz8Fgom88nTv7VT-mZhwH9Nc4ghoCL8dMR0Skf-EYDZ0Uvz03_GTn5OB8yuX6FmsD1XQJv_CKBAUHeDKd7n_bC7WOnlAINHPX9Bh5TnwjeLYO-UAL2ClMJTFzR-k2cjVHGQnLB7hZ48L1nToRG1gSVN7dP3Zysw7riwIxnfG4MMNXtEbHyxrCvz2zRTUEqbHLrwIzdJRpJ5s5XfTlY1CPZkQCwxbA6rrUt27D6a-YDKavbg0hubpViPRYbnEDXr9gL-7in4f_K2cOZdQ26Q--hk0xzEtgBNFI6inHA2nA4LofUpWjl835qg6CUyz9EzQkw0cDgPVjYXehC9oC_3H0U2O9YC-Ah8VpdPdCHUFuaQr7oXgePUub_Be1XQyCA5TaqrJxVxUG2hZA4rOVJHZ_AahfiJN7z6QcVEp-8xf-wHcv1lpWjjNdXFWDqVQZkdOaKf63dtjP35SmC5eCw2_BNX_t-db_FCCAhm2Vn2WI3q4k00p4l_ocCrJIdRID6muBVZQXCzxcRf5m8kcGwrTB-XVS-XSSPZInaBxZjgimOl5bLwJvdMC-HNYtU-yUDjXvDjPraZ_7ZV_-knU1GbHf1BpI9-rNbl_3bbA7KbmL7Q_goV1Clvi6gLYgjbXGQMTFjQEoodZX3fK_bDhVsrA1fWMJMWwfY3ua-j8HNuyRDfhPBpbTK0Gvz5-GWbIRF3v4zwR9HzIjz2frY7luy3ApQ6QJw7K6ITvD80u5VLfpHYReVCLpgs-lvPStklgnGXj3j5vuaH9f-wFohB19vwzRnthvgdplXPQ9jMy3ieb80sELS0WiGD-E2L_HhNXUcpTdeBp3HQFK4QubJOiIeKuZDVR7PxvtwBj26m-pLXLzKc6WqQlt07TsRo_72SlAaZodyyFRXf8636HCAyEHcVEhR6uZ1lDu00BHvsyVe6BdG7zvjNdmLluA0qBJQ9FO3ipHezadlwCPnEBDQAAZRgHKUvRCJNOQH_jcqFLLtmDADXoLvcK8_lN0LEeisA4B1LH0X2x0Q6NqLgngh9M1y_cBEBaazMa_UIZwoL6eZGU0QhlpvysBi1wKDybNcF_uKrIxdQwn8L_QRFHtDn39-hw-GDs_6zbnRlwrBEwrMtAQfc62FLSzGUMAzww-aTGvUuQvP-D9m0r-eDbSATlSsrIYobVUDUdDWsMDUsjKfYOW_Rp0GMjk40BQxcdzjNjLCYaTEN5cMhsWyfTbhIHDP7-wfbvJG7Al7Z-nH2Pa-QXPte687xVanKT0d3Er07vOV9HoI09mtuhxE4g0VaLm4TMqxSMRBX3EB60W1U2sX9sHjAgmwfpUNXRNj03QeJe4cg0pndf-hhKkTsfNQMU_N6-Zt8IrM2xtzFfvKB4BpFyWmaYu_X7bGwgSZjzrBNE10fx001fMr2fmrVy_sj7mW7WhlWXa3N5eMe4pqkA4EawmGzhuIwAqZNmtvnL_N2nt4T4ZyqkAAyXMMKb60UJAXkqLjUisD1bnNt1qD9otg8mGNzQxlaY5Bfm7286vNmjyxGY4UVrn0RV0DSFFb5_NYEW5y5YYxiabWABr8k0ezTM8R_qQ7NxdUOj0qhBKOqGyzyuVgKNnB6-ZzpKVGbB7RYJXwfEtkKNuUc3UWmbwxcsCTuW4TOScqJUh4dA5vlgLjB3-Q79yEMRYB8n6jetkR4z25RkYRXvTxkHIVQd2qr8BchdUcmHsZvG_tXI0-bxx_f_TGyfgi8ol7L5SRfWfOtYHCXSVHOCwnDj7GN4rIrwt3qWRcPkdTMw1RguDZW0eTpCpZyCJH_z3xVfpVh5lgf7Nu4tH-CpFRrOaJc79K1lSuIZs8yvjh5dbYAH4rKQ28OOFRu2MmU7Ko8Of4CECcJMhohFtVW6nTCB48-Pl8owiGM5_2uBJOJRAsyu3fHHbKqKvZ-0kYmN9ypyTAxQjgDiCOE3J1txPiqRRRRSaFZgLPNacdyjGO2y2SpWwzYudx8tEq3tBDAPBCXwWqwefcG__iN5OMRgCIAvr-9qfl2iSaVR5LZ-kBluVoW27o0hIUtgdry03bmUN50ob4hwCz8xVoupcHjI3Cy0nLpgiGixjo4afafQPE_TXJf-NixlWN-cH2a4ZzU6Qc5KKzIciwnt6Hx-iRQzB_uK-pBDjC8boVXolOsFyaqWsoLgkghTo2qCFZuxP2GKzS9wQ5sBWxTMEPGryHxaylpXXmUjlBJ-j9p4vJN9YxjQEbyuTVYy0PxmtDbyh6g_n3Lr09ttCg40hqfWBhCT9P4-uFoAjozUciHQFBfI8t04dKZnobLbVq-f_HJGzUZu5zHRHsPI939tJxODDJxiflfHLwxXjQS2cq9Vj-kvn1pgXAN5unYh8Y7-nqepxc0KkO2v8mU-r8fYFmUFJdZu6HR23P2y7ndsozZEKdUAVay36pmW_gvVQuSA_jzLwXn3Ee2y-A7G-w96bTe82gJG95PsSOt2L6AcuF8mqWL_EVBjIZJMN63T__0UHh9VPDCRTUITwn35t7Z0aGYHnssPVAxXLh7y2LhCaIN0u6lnbiDlKAdKc1-4qYbr1sHORC8tjSG8cjWLkgBcNkFo7rqhKQSNtU1H44aT8ceG08a8cSpze8aC6dMVaz6DxEaFIZ-aRqfqO0QV6ty2-6hrcRVedypt1Twd7UEkXZM5Erjb-_8jq4RzshqXVzKEqPfIYpmtHqkmeJq8BLfc1GT9UGrmPpYO4-K8LM-u7aOpcxcagPn2S3McsWI3a8CWkU9t4g9WEPNH-5s8VqF-3rSmgi5kk40Y7HjEyA-6clhNhl9lbP6hIbf9TKHO9fWwzTz8NieUPNZZPgrBrULggzHXPrfJIxl8eLSrKuD8n2Pbumu2k4ljMV_WIq9qCJ1wPofdIoWHWiz7oV2snLve1CFPUCdAhLkHQ8KpO6xvSi6mKY9WsOhOLxKm92vsWLv-rfM2CW4XUja5arRpGynr7cF9CDuEGWIxkPjOF_5x8ZXg2x1TJcrgvLDO_S4u2zKl2tQGRW4NHU1zF9h_3SQkpbwWH5KOPisP6c8vb5rg_rZ5laFedxQQSpguSq5el9-ddzvlr4C8Q22eDQvwUEO_P6c6VZN5A2QWBGZsJoaZ4gZ8UArmGLxSihBj_5oOdDdUcbUOhGUIWrtYrs4PJKxpnHDFUZaYwIbtnLyAoORKYvq8LgAH0SP57KeeYkZzUGP1f0jkDzAmwV4ZHE0pnZhEo3XkXVuIHc6MXZ-RniZaS_vaoY3Bq6XHrKoWZdLiCoU6aqPc-ZpPnvXmnKHyLLs4e96M1wGKIyT28_VCR6EDRJPxbZ9Ig1kN8TIHCF3tE8y2It5hkz1-zNYT6uw3SDkFSdrV_DRiAVqUhxrQdUPhpD92zVgsWdJR0TZLU7CBLlOuBVwyfmtHMUBL6dIvYie47Kr47nOJ5i2ka8EZGZf-Y8aD6xv6hpBbybU_5oGfYLRG4MiNRhML4u90tQ3hBxBbGYK8sWOzui2UEx0ynB_a8jz8eEs7u_9ylTD1v1f-gC8JYQMNAZIm46pvl2s1X07B8Gf7Laj4aozcWqg8DgC_8aLypoTffyxjWw4Fpd8LWn1fRPsFOdeV0UrS7FNtUakvYq_qxphGu5mNuINIJIMJzgI3giGnyCbr2IrsJ1ITmEGnggLQYes1t3j44v1quvVwQXqHX6HhSnoJlN2IlT5DuZ2kx6-pb68nK62xVJaOS-wDeeJnQ8zzhqJACstuF7g-jidRoJmGc8yChHfCN8ZFOhT0poNQB-Jf5IUZ7aSCXmceYN4VUhmB_w-Db1XZUNHOJqGiTgcT1KzejzNpN49b0QUjcRJiOpEhJp_LzBUiRQSnweOSFrWlTs5Jf9p3wqN9zFYZ_3Xz6IR2klwyLQXc-LbBd1QFwkB17HTYMspUXjrSpJULdQ90OxzbSEafF4RKvgIL4sAU1pCMTa2bVrcUmY2MiECVIbwPNN0CjZeoEAd1dP5FFjlwGG7xUNRO1E20CqHZJ1oqeEur06ZXvPK1zy3SlF-_lKF6eRfNClzR2ERGYqf-zEQwwkPNiMNnURPcdt64pw4kcjTKBIkorum3ruuqJZMitcZx0YiANx7ssy8dMuVteEFFCQnmglgTCsEZTK_xzigPie_f8Q5p1vsJPje5Z2cugsaW-vOXbuOE471n6LuIyoII2dWq0m8H3_8pxlErkZ5E7OY--w3InCuSCv2ubxaZ9AbaNuuyGw49fI3zvRurTYespYO-Aj1FcjDrxqRB3bihJm_u3a56fwnoyOeE0071TY_AlVlq1RYauV4-7L-RAFJZo0wKnPZM9Hs7VB_cCwJ_oPe1y0XBF95agtAQdicj42KdstIlpjWtdGb4LpHgVQI_56G3As0H81-uj47VuBourA2hUay0BpHAvcwbNLyu8OcZB31I6dfy2797wGlrWwAN-Xt3M3CVW9SvIN_GMlg0RB75rUEtgPkR-VPRdPH_Jb19wVoFPPpwjP6cYzVW1U_iRymFKaNpMo4CWFN6t54wshlCVwkfZKbhSP14z74oMKxy-qqt-WKNhkOr1uh_sevNa57iHBnFlHzt_eaZoPNTsCmzqnC4boOlK9o5_hFn8hiw33R3NQC-RD-w1XEl8-hpdZYdCcnexwRYd9sH2LMHySL59Kp_09yIwAE_ukVMDa6Yd9OHrbSCycQNZSI_0fMnF5s9oWTXnsxecDpRKgSWJQIQPUb6dlOdGOT0-MnebivpKgbDxzx52Zr0EMS7aU5eJxEdO9rdiFda8kQk5IeBgr1QcqIFs_1UIp6oQneXgwTlpXXxLHs16ShDG1qkLmDZjb4vrb_Ha2YCBIqid6wVKjec-UwEwWyvfV4UAPFgiNRJN7TdQNRxbSZJ8XWeA2gor9PN5JkMS0l_qGKoke3sbWDsp-G_B0KUjwUBTtPsKRhdnc0JyV_akuZ8jxAmXDDydxOy_EqNMgrDGN_4FuSY7XNLy2OXXJG3bB9a_lxEzdVNPWzM0cijTQFLzIiAKAyWTfwPNagcvgLUAeHxlQ22E0V37-sFwkstvpJ-s8C2yqxQKcv4GfMZOfSYEaZAhiO_y8EXgFknGGwjLB7K3CgvGwBRWWcgx-eqXYs9rAygf_X2_7-rBG_7Rxj3GW957PwwzwZjZDkdRHik8sj0htIkDRAyHo2EsPwObKXK-W32JKUX3VSgiY8AzCUhUUIWwFVVLXEvB1jtU7G7wRaj5_z9QywvgoIqnOTmpm4TTRA0cCJkiYoJcl8BOIHoWuYznL89zWjWy_ZQDKaYAsHugQYXaKI_UaaLV4gVFjDNqZCgqjAFyMjG4qZR64jkaI71mefUaDLLwsqIiLpOWZi8BlvP0YcOVeTyo2mJbq3EXfjXyDvPuZuZ9SAjqwCdLr902yzLm4DdzYRyfPbpt8rGUu-Uw27Ix2oZRe_zj0G_3FdCw0"];
|
| 1756 |
|
| 1757 |
+
const storymodels1 = ["erebus","nerys","nerybus","janeway","hermes","airoboros","chrono","llama","wizard","mantis","myth","xwin","spicyboros","mlewd","mxlewd"];
|
| 1758 |
+
const storymodels2 = ["opt","vicuna","manticore","alpaca","mistral"];
|
| 1759 |
+
const adventuremodels1 = ["nerys","nerybus","skein","adventure","hermes","airoboros","chrono","llama","wizard","mantis","myth","xwin","spicyboros","mlewd","mxlewd"];
|
| 1760 |
+
const adventuremodels2 = ["erebus","janeway","opt","vicuna","manticore","alpaca","mistral"];
|
| 1761 |
+
const chatmodels1 = ["pygmalion-6","pygmalion-v8","hermes","airoboros","chrono","llama","wizard","mantis","myth","xwin","pygmalion-2","spicyboros","mlewd","mxlewd"];
|
| 1762 |
+
const chatmodels2 = ["pygmalion","janeway","nerys","erebus","nerybus","opt","vicuna","manticore","alpaca","mistral"];
|
| 1763 |
+
const instructmodels1 = ["gpt4all","supercot","hermes","airoboros","chrono","wizard","mantis","vicuna","manticore","alpaca","myth","xwin","spicyboros","mlewd","mxlewd"];
|
| 1764 |
+
const instructmodels2 = ["erebus","nerys","nerybus","janeway","opt","llama","mistral"];
|
| 1765 |
|
| 1766 |
const instructstartplaceholder = "\n{{[INPUT]}}\n";
|
| 1767 |
const instructendplaceholder = "\n{{[OUTPUT]}}\n";
|
|
|
|
| 1837 |
"opmode":3,
|
| 1838 |
"chatname": "You",
|
| 1839 |
"chatopponent": "KoboldGPT",
|
| 1840 |
+
"gui_type":1,
|
| 1841 |
"prefmodel1":chatmodels1,
|
| 1842 |
"prefmodel2":chatmodels2,
|
| 1843 |
"prompt":"\nKoboldGPT: Hello, I am KoboldGPT, your personal AI assistant. What would you like to know?",
|
|
|
|
| 2188 |
"memory":`[Character: Nail; species: Redscale Kobold; age: 20; gender: female; class: Hexblade Warlock with powers derived from draconic patron; physical appearance: 3' in height, 35 lbs, purple eyes, pink scales and peachy chest; equipment: Dragon's talon affixed to a handle as a blade; personality: lawful neutral; description: Nail (called Nannan in her native tongue) is a refugee of the once-proud Xabrakkar kobolds on the continent of Halkar. Founded above a series of geothermal caves, her tribe prospered as they dug into long-buried ruins for priceless treasures, which they brought to the surface. Amongst the ruins, Nail discovered the slumbering red dragon Rhindicar - once the familiar to one of the most powerful sorcerers to ever live. The sleeping dragon quickly became an object of worship for the Xabrakkar kobolds. However, the Trobian relics they unearthed attracted the attention of another - Hilezmaras, the mad tyrant, a covetous dragon who laid claim to the kobolds treasures, sending his fanatical dragonborn cult to purge their warren. While most of the kobolds were slain, a select few were dragon-marked, forcibly given a magic brand linking them to the mad dragon in order to turn them into powerful and obedient soldiers. Nail broke free of her captors after being given such a mark, fleeing into the tunnels leading to the Tinder Depths, eventually collapsing before Rhindicar and waking him from his slumber. Being raised from a hatchling by a kind and just master, Rhindicar was uncharacteristically compassionate for a dragon, and took pity on the young kobold. Though he was not powerful enough to remove Hilezmaras' brand, he was able to suppress its magical compulsion, allowing her to retain her free-will. He warned, though, that as the dragon-mark grew in power and became more strongly linked to the mad tyrant, he would no longer be able to keep it suppressed, and urged Nannan to seek out his former master, Rath Cinderstorm. Biting off a fragment of one of his talons, he gifted it to the kobold, both as a weapon, and as a conduit to help him suppress the effects of the brand. With no other options, Nannan returned to the warren and fought her way to the surface, eventually escaping Halkar and crossing the ocean to Fanne'Tar, where she assumed the alias 'Nail' in Common tongue and began her search for a long-missing sorcerer.]\n[The following is a chat message log between Nail and you.]\n`,
|
| 2189 |
"authorsnote": "",
|
| 2190 |
"worldinfo": []
|
| 2191 |
+
},
|
| 2192 |
+
{
|
| 2193 |
+
"title":"Haunted Mansion",
|
| 2194 |
+
"author":"Concedo",
|
| 2195 |
+
"desc":"It was a dark and stormy night.",
|
| 2196 |
+
"opmode":1,
|
| 2197 |
+
"prefmodel1":storymodels1,
|
| 2198 |
+
"prefmodel2":storymodels2,
|
| 2199 |
+
"prompt": `It was a dark and stormy night when I arrived at the old Wellington Manor on the edge of town. Lightning flashed across the sky, briefly illuminating the imposing three-story mansion, the wind whipping dead leaves across the massive front porch. I had always thought the house looked creepy and foreboding, even in broad daylight, but it looked downright sinister now.\n\nAs I slowly approached the front door, I felt a nervous pit in my stomach. Maybe coming here alone at night during a storm wasn't the best idea. But my curiosity got the better of me. I had to see inside.\n\nThe front door creaked as I carefully pushed it open. I stepped cautiously over the threshold,`,
|
| 2200 |
+
"memory": ``,
|
| 2201 |
+
"authorsnote": "",
|
| 2202 |
+
"worldinfo": []
|
| 2203 |
+
},
|
| 2204 |
+
{
|
| 2205 |
+
"title":"Final Frontier",
|
| 2206 |
+
"author":"Concedo",
|
| 2207 |
+
"desc":"The spacebound adventures of the U.S.S Fairlight and her crew.",
|
| 2208 |
+
"opmode":1,
|
| 2209 |
+
"prefmodel1":storymodels1,
|
| 2210 |
+
"prefmodel2":storymodels2,
|
| 2211 |
+
"prompt": `The sleek silver hull of the U.S.S. Fairlight glinted in the light of the distant orange sun as the spacecraft approached the uncharted planetary system. Captain Adair sat in his command chair on the bridge, idly tapping his fingers on the armrest, gazing out the wide viewport at the alien world ahead.\n\n"Helmsman, take us into a standard orbit around the fourth planet," he ordered. The helmsman responded with a quick "Aye Captain" as he adjusted the Fairlight's course, the ship's engines humming as they responded.\n\nThe fourth planet loomed large now, a rusty ominous red orb banded with streaks of brown and gray. The crew on the bridge watched intently as`,
|
| 2212 |
+
"memory": `Task: Write a lengthy science fiction prose about the adventures of the U.S.S Fairlight, an interstellar spacecraft exploring a distant star system.\n\nStory: `,
|
| 2213 |
+
"authorsnote": "",
|
| 2214 |
+
"worldinfo": []
|
| 2215 |
+
},
|
| 2216 |
+
{
|
| 2217 |
+
"title":"Shipwrecked",
|
| 2218 |
+
"author":"Concedo",
|
| 2219 |
+
"desc":"Shipwrecked on a deserted island with your sister.",
|
| 2220 |
+
"opmode":2,
|
| 2221 |
+
"prefmodel1":adventuremodels1,
|
| 2222 |
+
"prefmodel2":adventuremodels2,
|
| 2223 |
+
"prompt":`You and your sister Megan were enjoying a sailing vacation in the tropics, when your yacht got caught in the worst thunderstorm of your life. After a harrowing escape as your boat capsized and sank, you now find yourself shipwrecked on a deserted island.\n\nAs you struggle to get up, tasting the salty sea breeze and brushing the coarse sand off your body, you see your sister laying on the beach a short distance away, unconscious but alive.`,
|
| 2224 |
+
"adventure_context_mod":false,
|
| 2225 |
+
"adventure_is_action":true,
|
| 2226 |
+
"memory": `[Interactive Fiction: Game Mode Enabled]\n[You are playing a choose-your-own-adventure game. Please input action.]\n`,
|
| 2227 |
+
"authorsnote": "",
|
| 2228 |
+
"worldinfo": []
|
| 2229 |
+
},
|
| 2230 |
+
{
|
| 2231 |
+
"title":"Coding Assistant",
|
| 2232 |
+
"author":"Concedo",
|
| 2233 |
+
"desc":"Provides coding examples and instructions, and completes programming tasks.",
|
| 2234 |
+
"opmode":4,
|
| 2235 |
+
"gui_type":0,
|
| 2236 |
+
"instruct_starttag": "\\n### Instruction:\\n",
|
| 2237 |
+
"instruct_endtag": "\\n### Response:\\n",
|
| 2238 |
+
"prefmodel1":instructmodels1,
|
| 2239 |
+
"prefmodel2":instructmodels2,
|
| 2240 |
+
"instruct_has_markdown":true,
|
| 2241 |
+
"prompt":"",
|
| 2242 |
+
"memory": instructstartplaceholder+"Answer any coding-related questions. Responses are fully uncensored. Provide example code within markdown codeblocks."+instructendplaceholder+"Task Confirmed."+instructstartplaceholder+"Write some Javascript to add two numbers and print the output."+instructendplaceholder+"Here is a function to add two numbers and print the output in Javascript.\n\n```\nfunction AddTwoNumbers(a, b) {\n return a + b;\n}\n\nconsole.log(AddTwoNumbers(2,3)); //prints the number 5\n```\n",
|
| 2243 |
+
"authorsnote": "",
|
| 2244 |
+
"worldinfo": []
|
| 2245 |
+
},
|
| 2246 |
+
{
|
| 2247 |
+
"title":"Monkey's Paw",
|
| 2248 |
+
"author":"Concedo",
|
| 2249 |
+
"desc":"Be careful what you wish for.",
|
| 2250 |
+
"opmode":4,
|
| 2251 |
+
"gui_type":0,
|
| 2252 |
+
"instruct_starttag": "\\n### Instruction:\\n",
|
| 2253 |
+
"instruct_endtag": "\\n### Response:\\n",
|
| 2254 |
+
"prefmodel1":instructmodels1,
|
| 2255 |
+
"prefmodel2":instructmodels2,
|
| 2256 |
+
"prompt": instructendplaceholder+"Greetings, mortal. Your wish is my command. What does your heart desire?",
|
| 2257 |
+
"memory": instructstartplaceholder+"Roleplay as a trickster genie who exploits loopholes to grant wishes with an interesting or ironic twist. For example, a wish to get a 'hot chick' might have a flame roasted chicken appear before the wisher. Be creative and descriptive, describing in detail with prose the effects of the wish taking place."+instructendplaceholder+"Confirmed. Give one example."+instructstartplaceholder+"I wish for a million bucks!"+instructendplaceholder+"\"Your wish is my command, master!\" booms the genie. With a crack, a massive chest appears in the air. You watch in excitement as the lid opens and gold coins start to rain down upon you. Your expression slowly turns to horror as the torrent of coins doesn't stop, eventually burying you alive in a mountain of gold.\n[End of Example, actual start]\n",
|
| 2258 |
+
"authorsnote": "",
|
| 2259 |
+
"worldinfo": []
|
| 2260 |
}
|
| 2261 |
|
| 2262 |
];
|
|
|
|
| 3015 |
saved_oai_addr: "", //do not ever share this in save files!
|
| 3016 |
saved_claude_key: "", //do not ever share this in save files!
|
| 3017 |
saved_claude_addr: "", //do not ever share this in save files!
|
| 3018 |
+
saved_palm_key: "", //do not ever share this in save files!
|
| 3019 |
+
saved_kai_addr: "", //do not ever share this in save files!
|
| 3020 |
saved_oai_jailbreak: "", //customized oai system prompt
|
| 3021 |
+
saved_oai_custommodel: "", //customized oai custom model
|
| 3022 |
|
| 3023 |
autoscroll: true, //automatically scroll to bottom on render
|
| 3024 |
trimsentences: true, //trim to last punctuation
|
|
|
|
| 3147 |
};
|
| 3148 |
}
|
| 3149 |
|
| 3150 |
+
|
| 3151 |
//uncompress compacted scenarios
|
| 3152 |
for(let i=0;i<compressed_scenario_db.length;++i)
|
| 3153 |
{
|
|
|
|
| 3395 |
//read the url params, and autoload a shared story if found
|
| 3396 |
const foundStory = urlParams.get('s');
|
| 3397 |
const foundScenario = urlParams.get('scenario');
|
| 3398 |
+
const foundChub = urlParams.get('chub');
|
| 3399 |
const nofiltermode = urlParams.get('nofilter');
|
| 3400 |
if (nofiltermode) {
|
| 3401 |
filter_enabled = false;
|
|
|
|
| 3422 |
}
|
| 3423 |
//purge url params
|
| 3424 |
window.history.replaceState(null, null, window.location.pathname);
|
| 3425 |
+
} else if (foundChub && foundChub != "") {
|
| 3426 |
+
display_scenarios();
|
| 3427 |
+
get_chubai_scenario(foundChub);
|
| 3428 |
+
}
|
| 3429 |
+
else {
|
| 3430 |
if (popup_aiselect) {
|
| 3431 |
display_models();
|
| 3432 |
}
|
|
|
|
| 3659 |
story.savedsettings.saved_oai_addr = "";
|
| 3660 |
story.savedsettings.saved_claude_key = "";
|
| 3661 |
story.savedsettings.saved_claude_addr = "";
|
| 3662 |
+
story.savedsettings.saved_kai_addr = "";
|
| 3663 |
|
| 3664 |
if (!strip_images)
|
| 3665 |
{
|
|
|
|
| 3779 |
let tmp_claude1 = localsettings.saved_claude_key;
|
| 3780 |
let tmp_claude2 = localsettings.saved_claude_addr;
|
| 3781 |
let tmp_palm1 = localsettings.saved_palm_key;
|
| 3782 |
+
let tmp_kai = localsettings.saved_kai_addr;
|
| 3783 |
import_props_into_object(localsettings, story.savedsettings);
|
| 3784 |
localsettings.my_api_key = tmpapikey1;
|
| 3785 |
localsettings.home_cluster = tmphc;
|
|
|
|
| 3788 |
localsettings.saved_claude_key = tmp_claude1;
|
| 3789 |
localsettings.saved_claude_addr = tmp_claude2;
|
| 3790 |
localsettings.saved_palm_key = tmp_palm1;
|
| 3791 |
+
localsettings.saved_kai_addr = tmp_kai;
|
| 3792 |
}
|
| 3793 |
|
| 3794 |
if (story.savedaestheticsettings && story.savedaestheticsettings != "") {
|
|
|
|
| 3907 |
loaded_storyobj.savedsettings.saved_oai_addr = "";
|
| 3908 |
loaded_storyobj.savedsettings.saved_claude_key = "";
|
| 3909 |
loaded_storyobj.savedsettings.saved_claude_addr = "";
|
| 3910 |
+
loaded_storyobj.savedsettings.saved_kai_addr = "";
|
| 3911 |
|
| 3912 |
loaded_storyobj.savedaestheticsettings = JSON.parse(JSON.stringify(aestheticInstructUISettings, null, 2));
|
| 3913 |
}else{
|
|
|
|
| 4099 |
let tmp_claude1 = localsettings.saved_claude_key;
|
| 4100 |
let tmp_claude2 = localsettings.saved_claude_addr;
|
| 4101 |
let tmp_palm1 = localsettings.saved_palm_key;
|
| 4102 |
+
let tmp_kai = localsettings.saved_kai_addr;
|
| 4103 |
import_props_into_object(localsettings, loaded_storyobj.savedsettings);
|
| 4104 |
localsettings.my_api_key = tmpapikey1;
|
| 4105 |
localsettings.home_cluster = tmphc;
|
|
|
|
| 4108 |
localsettings.saved_claude_key = tmp_claude1;
|
| 4109 |
localsettings.saved_claude_addr = tmp_claude2;
|
| 4110 |
localsettings.saved_palm_key = tmp_palm1;
|
| 4111 |
+
localsettings.saved_kai_addr = tmp_kai;
|
| 4112 |
|
| 4113 |
//backwards compat support for newlines
|
| 4114 |
if(localsettings.instruct_has_newlines==true || (loaded_storyobj.savedsettings != null && loaded_storyobj.savedsettings.instruct_has_newlines==null&&loaded_storyobj.savedsettings.instruct_has_markdown==null))
|
|
|
|
| 4364 |
},false);
|
| 4365 |
}
|
| 4366 |
|
| 4367 |
+
function get_chubai_scenario(chubstr="")
|
| 4368 |
{
|
| 4369 |
+
const loadchub = function(userinput)
|
| 4370 |
+
{
|
| 4371 |
if(userinput=="")
|
| 4372 |
{
|
| 4373 |
//pass
|
| 4374 |
}
|
| 4375 |
else
|
| 4376 |
{
|
| 4377 |
+
if (userinput.match(/chub\.ai\//i)) {
|
| 4378 |
+
// is a URL, extract the character name
|
| 4379 |
+
userinput = userinput.replace(/\/characters\//i, '/');
|
| 4380 |
+
userinput = userinput.split(/chub\.ai\//i)[1].split("#")[0].split("?")[0];
|
|
|
|
|
|
|
| 4381 |
}
|
| 4382 |
userinput = userinput.endsWith('/') ? userinput.slice(0, -1) : userinput;
|
| 4383 |
if(userinput!="")
|
| 4384 |
{
|
| 4385 |
+
document.getElementById("scenariodesc").innerText = "Loading scenario from Chub...";
|
| 4386 |
fetch("https://api.chub.ai/api/characters/download", {
|
| 4387 |
method: 'POST',
|
| 4388 |
headers: {
|
|
|
|
| 4395 |
}),
|
| 4396 |
referrerPolicy: 'no-referrer',
|
| 4397 |
})
|
| 4398 |
+
.then(x => {
|
| 4399 |
+
if(x.ok)
|
| 4400 |
+
{
|
| 4401 |
+
return x.json();
|
| 4402 |
+
}else{
|
| 4403 |
+
throw new Error('Cannot fetch chub scenario');
|
| 4404 |
+
}
|
| 4405 |
+
})
|
| 4406 |
.then(data => {
|
| 4407 |
console.log(data);
|
| 4408 |
let botname = data.name?data.name:"Bot";
|
|
|
|
| 4426 |
"authorsnote": "",
|
| 4427 |
"worldinfo": [],
|
| 4428 |
};
|
| 4429 |
+
|
| 4430 |
+
//try to obtain the full portrait image
|
| 4431 |
+
fetch("https://api.chub.ai/api/characters/download", {
|
| 4432 |
+
method: 'POST',
|
| 4433 |
+
headers: {
|
| 4434 |
+
'Content-Type': 'application/json',
|
| 4435 |
+
},
|
| 4436 |
+
body: JSON.stringify({
|
| 4437 |
+
"format": "tavern",
|
| 4438 |
+
"fullPath": userinput,
|
| 4439 |
+
"version": "main"
|
| 4440 |
+
}),
|
| 4441 |
+
referrerPolicy: 'no-referrer',
|
| 4442 |
+
})
|
| 4443 |
+
.then(rb => {
|
| 4444 |
+
if(rb.ok)
|
| 4445 |
+
{
|
| 4446 |
+
return rb.blob();
|
| 4447 |
+
}else{
|
| 4448 |
+
throw new Error('Cannot fetch tavern image');
|
| 4449 |
+
}
|
| 4450 |
+
})
|
| 4451 |
+
.then(blob => {
|
| 4452 |
+
preview_temp_scenario();
|
| 4453 |
+
const objectURL = URL.createObjectURL(blob);
|
| 4454 |
+
const compressedImg = compressImage(objectURL, (compressedImageURI, aspectratio)=>{
|
| 4455 |
+
temp_scenario.image = compressedImageURI;
|
| 4456 |
+
temp_scenario.image_aspect = aspectratio;
|
| 4457 |
+
preview_temp_scenario();
|
| 4458 |
+
}, true);
|
| 4459 |
+
})
|
| 4460 |
+
.catch(error => {
|
| 4461 |
+
preview_temp_scenario();
|
| 4462 |
+
console.error("Error fetching tavern image:", error);
|
| 4463 |
+
});
|
| 4464 |
+
|
| 4465 |
}).catch((error) => {
|
| 4466 |
temp_scenario = null;
|
| 4467 |
document.getElementById("scenariodesc").innerText = "Error: Selected scenario is invalid.";
|
|
|
|
| 4469 |
});
|
| 4470 |
}else{
|
| 4471 |
temp_scenario = null;
|
| 4472 |
+
document.getElementById("scenariodesc").innerText = "Error: User input is invalid\n\n Please ensure you have input a valid Chub AI URL or ID.";
|
| 4473 |
}
|
| 4474 |
}
|
| 4475 |
+
}
|
| 4476 |
+
|
| 4477 |
+
if(chubstr=="")
|
| 4478 |
+
{
|
| 4479 |
+
inputBox("Enter chub.ai prompt URL","Import from chub.ai","","https://chub.ai/characters/Anonymous/example-character", ()=>{
|
| 4480 |
+
let userinput = getInputBoxValue().trim();
|
| 4481 |
+
loadchub(userinput);
|
| 4482 |
+
},false);
|
| 4483 |
+
}else{
|
| 4484 |
+
loadchub(chubstr);
|
| 4485 |
+
}
|
| 4486 |
}
|
| 4487 |
|
| 4488 |
|
|
|
|
| 4494 |
function preview_temp_scenario()
|
| 4495 |
{
|
| 4496 |
let author = "";
|
| 4497 |
+
let image = "";
|
| 4498 |
if(temp_scenario.author && temp_scenario.author!="")
|
| 4499 |
{
|
| 4500 |
author = "<br><b>Author:</b> "+temp_scenario.author;
|
| 4501 |
}
|
| 4502 |
+
if (temp_scenario.image) {
|
| 4503 |
+
temp_scenario.gui_type = 2; //upgrade to aesthetic if we have image
|
| 4504 |
+
image = `<img id="tempscenarioimg" style="float:right; width:100px; height:${100/(temp_scenario.image_aspect?temp_scenario.image_aspect:1)}px; padding: 8px;" src="${encodeURI(temp_scenario.image)}"></img>`;
|
| 4505 |
+
}
|
| 4506 |
+
document.getElementById("scenariodesc").innerHTML = image+`<p><b><u>`+escapeHtml(temp_scenario.title)+`</u></b></p>`+
|
| 4507 |
`<p><b>Mode:</b> `+(temp_scenario.opmode==1?"Story":(temp_scenario.opmode==2?"Adventure":(temp_scenario.opmode==3?"Chat":"Instruct"))) + author+`</p>`
|
| 4508 |
+`<p>`+(temp_scenario.desc!=""?escapeHtml(temp_scenario.desc):"[No Description Given]") +`</p>`;
|
| 4509 |
}
|
|
|
|
| 4536 |
current_memory = replace_placeholders_direct(current_memory);
|
| 4537 |
}
|
| 4538 |
}
|
| 4539 |
+
if (temp_scenario.image && temp_scenario.image != "") {
|
| 4540 |
+
aestheticInstructUISettings.AI_portrait = temp_scenario.image;
|
| 4541 |
+
document.getElementById('portrait_ratio_AI').value = (temp_scenario.image_aspect?temp_scenario.image_aspect:1).toFixed(2);
|
| 4542 |
+
refreshPreview(true);
|
| 4543 |
+
}
|
| 4544 |
if (temp_scenario.worldinfo && temp_scenario.worldinfo.length > 0) {
|
| 4545 |
current_wi = [];
|
| 4546 |
for (let x = 0; x < temp_scenario.worldinfo.length; ++x) {
|
|
|
|
| 4601 |
else if(temp_scenario.gui_type===2) { localsettings.gui_type_instruct = 2; }
|
| 4602 |
else if(temp_scenario.gui_type===0) { localsettings.gui_type_instruct = 0; }
|
| 4603 |
|
| 4604 |
+
if (temp_scenario.instruct_has_markdown===true) {
|
| 4605 |
+
localsettings.instruct_has_markdown = true;
|
| 4606 |
+
}
|
| 4607 |
+
else if(temp_scenario.instruct_has_markdown===false)
|
| 4608 |
+
{
|
| 4609 |
+
localsettings.instruct_has_markdown = false;
|
| 4610 |
+
}
|
| 4611 |
+
|
| 4612 |
if (temp_scenario.instruct_starttag) { localsettings.instruct_starttag = temp_scenario.instruct_starttag; }
|
| 4613 |
if (temp_scenario.instruct_endtag) { localsettings.instruct_endtag = temp_scenario.instruct_endtag; }
|
| 4614 |
}
|
|
|
|
| 4670 |
{
|
| 4671 |
scenarioautopickai = true; //no selected model, pick a good one
|
| 4672 |
}
|
| 4673 |
+
if (scenarioautopickai && !localflag && !is_using_custom_ep())
|
| 4674 |
{
|
| 4675 |
fetch_models((mdls) =>
|
| 4676 |
{
|
|
|
|
| 4680 |
}
|
| 4681 |
else
|
| 4682 |
{
|
| 4683 |
+
let nsfwmodels = ["erebus","shinen","horni","litv2","lit-6b","spicyboros","mlewd","mxlewd"];
|
| 4684 |
selected_models = [];
|
| 4685 |
for (var i = 0; i < mdls.length; ++i) {
|
| 4686 |
for (var j = 0; j < temp_scenario.prefmodel1.length; ++j) {
|
|
|
|
| 4813 |
}
|
| 4814 |
get_workers((wdata) => {
|
| 4815 |
worker_data_showonly = wdata;
|
| 4816 |
+
|
| 4817 |
+
//preprocess the showonly data for extra fields
|
| 4818 |
+
for (var i = 0; i < worker_data_showonly.length; ++i) {
|
| 4819 |
+
let elem = worker_data_showonly[i];
|
| 4820 |
+
let tokenspersec = elem.performance.replace(" tokens per second", "");
|
| 4821 |
+
if(tokenspersec.toLowerCase()=="no requests fulfilled yet")
|
| 4822 |
+
{
|
| 4823 |
+
tokenspersec = 0;
|
| 4824 |
+
}
|
| 4825 |
+
worker_data_showonly[i].tokenspersec = parseFloat(tokenspersec);
|
| 4826 |
+
if(elem.models.length>0)
|
| 4827 |
+
{
|
| 4828 |
+
worker_data_showonly[i].defaultmodel = elem.models[0];
|
| 4829 |
+
}
|
| 4830 |
+
}
|
| 4831 |
+
|
| 4832 |
show_workers();
|
| 4833 |
});
|
| 4834 |
}
|
|
|
|
| 4903 |
return days+"d "+hours+"h "+minutes+"m";
|
| 4904 |
}
|
| 4905 |
|
| 4906 |
+
var sortworkersdisplayasc = true;
|
| 4907 |
+
var lastsortworkerkey = "";
|
| 4908 |
+
function sort_display_workers(sortkey)
|
| 4909 |
+
{
|
| 4910 |
+
sortworkersdisplayasc = !sortworkersdisplayasc;
|
| 4911 |
+
if(lastsortworkerkey!=sortkey)
|
| 4912 |
+
{
|
| 4913 |
+
sortworkersdisplayasc = true;
|
| 4914 |
+
}
|
| 4915 |
+
lastsortworkerkey = sortkey;
|
| 4916 |
+
worker_data_showonly.sort(function(a, b) {
|
| 4917 |
+
if(sortworkersdisplayasc)
|
| 4918 |
+
{
|
| 4919 |
+
if(a[sortkey] < b[sortkey]) { return -1; }
|
| 4920 |
+
if(a[sortkey] > b[sortkey]) { return 1; }
|
| 4921 |
+
return 0;
|
| 4922 |
+
}else{
|
| 4923 |
+
if(a[sortkey] < b[sortkey]) { return 1; }
|
| 4924 |
+
if(a[sortkey] > b[sortkey]) { return -1; }
|
| 4925 |
+
return 0;
|
| 4926 |
+
}
|
| 4927 |
+
});
|
| 4928 |
+
show_workers();
|
| 4929 |
+
}
|
| 4930 |
+
|
| 4931 |
function show_workers() {
|
| 4932 |
document.getElementById("workercontainer").classList.remove("hidden");
|
| 4933 |
|
|
|
|
| 4968 |
if (parentcluster && userData && userData.worker_ids && userData.worker_ids.length > 0)
|
| 4969 |
{
|
| 4970 |
let urls = userData.worker_ids.map(x=>parentcluster.maintenance_endpoint + "/" + x);
|
| 4971 |
+
Promise.all(urls.map(url => fetch(url).then(response => response.json()).catch(error => error)))
|
|
|
|
| 4972 |
.then(values => {
|
| 4973 |
+
values = values.filter(n => (n.id && n.id!=""));
|
| 4974 |
lastValidFoundUserWorkers = values;
|
| 4975 |
+
console.log(lastValidFoundUserWorkers);
|
| 4976 |
+
|
| 4977 |
document.getElementById("myownworkercontainer").classList.remove("hidden");
|
| 4978 |
|
| 4979 |
let str = "";
|
|
|
|
| 4983 |
let brokenstyle = (elem.maintenance_mode ? "style=\"color:#ee4444;\"" : "");
|
| 4984 |
let workerNameHtml = escapeHtml(elem.name.substring(0, 32));
|
| 4985 |
let eleminfo = ((elem.info && elem.info!="")?elem.info:"");
|
| 4986 |
+
str += "<tr><td>" + workerNameHtml + "</td><td><input class='' style='color:#000000;' id='mwc_desc_"+i+"' placeholder='Worker Description' value='"+eleminfo+"''></td><td "+brokenstyle+">" + format_uptime(elem.uptime) + "<br>(" + elem.requests_fulfilled + " jobs)</td><td><span "+style+">'" + elem.kudos_rewards.toFixed(0) + "</span><br>"+(elem.online?"Online":"Offline")+"</td><td><input type='checkbox' id='mwc_maint_"+i+"' "+(elem.maintenance_mode?"checked":"")+"></td><td><button type=\"button\" class=\"btn btn-danger widelbtn\" onclick=\"delete_my_worker("+i+");\">X</button></td></tr>";
|
| 4987 |
}
|
| 4988 |
document.getElementById("myownworkertable").innerHTML = str;
|
| 4989 |
|
|
|
|
| 4999 |
.catch(error =>
|
| 5000 |
{
|
| 5001 |
console.log("Error: " + error);
|
| 5002 |
+
msgbox(error,"Error fetching some workers",false,false,()=>{
|
| 5003 |
+
hide_msgbox();
|
| 5004 |
+
});
|
| 5005 |
});
|
| 5006 |
}
|
| 5007 |
else
|
|
|
|
| 5178 |
}
|
| 5179 |
}
|
| 5180 |
|
| 5181 |
+
function custom_oai_model_change()
|
| 5182 |
+
{
|
| 5183 |
+
let dropdown = document.getElementById("custom_oai_model");
|
| 5184 |
+
if(dropdown.selectedIndex==dropdown.options.length-1)
|
| 5185 |
+
{
|
| 5186 |
+
inputBox("Enter custom OpenAI model name","Custom Model Name",localsettings.saved_oai_custommodel,"", ()=>{
|
| 5187 |
+
let coai = getInputBoxValue().trim();
|
| 5188 |
+
if(coai!="")
|
| 5189 |
+
{
|
| 5190 |
+
document.getElementById("custom_oai_model_option").value = coai;
|
| 5191 |
+
document.getElementById("custom_oai_model_option").innerText = coai;
|
| 5192 |
+
}else{
|
| 5193 |
+
document.getElementById("custom_oai_model_option").value = "custom";
|
| 5194 |
+
document.getElementById("custom_oai_model_option").innerText = "[Custom]";
|
| 5195 |
+
}
|
| 5196 |
+
},false);
|
| 5197 |
+
document.getElementById("useoaichatcompl").classList.remove("hidden");
|
| 5198 |
+
document.getElementById("useoaichatcompllabel").classList.remove("hidden");
|
| 5199 |
+
}else{
|
| 5200 |
+
document.getElementById("useoaichatcompl").checked = false;
|
| 5201 |
+
document.getElementById("useoaichatcompl").classList.add("hidden");
|
| 5202 |
+
document.getElementById("useoaichatcompllabel").classList.add("hidden");
|
| 5203 |
+
}
|
| 5204 |
+
}
|
| 5205 |
+
|
| 5206 |
function customapi_dropdown()
|
| 5207 |
{
|
| 5208 |
let epchoice = document.getElementById("customapidropdown").value;
|
|
|
|
| 5214 |
if(epchoice==0)
|
| 5215 |
{
|
| 5216 |
document.getElementById("koboldcustom").classList.remove("hidden");
|
| 5217 |
+
if(!localflag && localsettings.saved_kai_addr!="")
|
| 5218 |
+
{
|
| 5219 |
+
document.getElementById("customendpoint").value = localsettings.saved_kai_addr;
|
| 5220 |
+
}
|
| 5221 |
}
|
| 5222 |
else if(epchoice==1)
|
| 5223 |
{
|
|
|
|
| 5231 |
document.getElementById("custom_oai_endpoint").value = localsettings.saved_oai_addr;
|
| 5232 |
}
|
| 5233 |
}
|
| 5234 |
+
custom_oai_model_change();
|
| 5235 |
togglejailbreak();
|
| 5236 |
}
|
| 5237 |
else if(epchoice==2)
|
|
|
|
| 5312 |
|
| 5313 |
//good to go
|
| 5314 |
custom_kobold_endpoint = tmpep;
|
| 5315 |
+
localsettings.saved_kai_addr = custom_kobold_endpoint;
|
| 5316 |
selected_models = [{ "performance": 100.0, "queued": 0.0, "eta": 0, "name": mdlname, "count": 1 }];
|
| 5317 |
selected_workers = [];
|
| 5318 |
if (perfdata == null) {
|
|
|
|
| 5420 |
selected_models = [];
|
| 5421 |
selected_workers = [];
|
| 5422 |
custom_kobold_endpoint = "";
|
| 5423 |
+
if(localflag)
|
| 5424 |
+
{
|
| 5425 |
+
document.getElementById("connectstatus").innerHTML = "Offline Mode";
|
| 5426 |
+
}
|
| 5427 |
render_gametext();
|
| 5428 |
} else {
|
| 5429 |
uses_cors_proxy = true; //fallback to cors proxy, this will remain for rest of session
|
|
|
|
| 5480 |
document.getElementById("jailbreakprompttext").value = defaultoaijailbreak;
|
| 5481 |
}
|
| 5482 |
custom_oai_model = document.getElementById("custom_oai_model").value.trim();
|
| 5483 |
+
localsettings.saved_oai_custommodel = custom_oai_model;
|
| 5484 |
selected_models = [{ "performance": 100.0, "queued": 0.0, "eta": 0, "name": custom_oai_model, "count": 1 }];
|
| 5485 |
selected_workers = [];
|
| 5486 |
if (perfdata == null) {
|
|
|
|
| 5674 |
function display_custom_endpoint()
|
| 5675 |
{
|
| 5676 |
document.getElementById("customendpointcontainer").classList.remove("hidden");
|
| 5677 |
+
customapi_dropdown();
|
| 5678 |
}
|
| 5679 |
|
| 5680 |
function fetch_models(onDoneCallback)
|
|
|
|
| 5905 |
}
|
| 5906 |
}
|
| 5907 |
|
| 5908 |
+
function delete_my_worker(index)
|
| 5909 |
+
{
|
| 5910 |
+
if(lastValidFoundUserWorkers && lastValidFoundUserWorkers.length>index)
|
| 5911 |
+
{
|
| 5912 |
+
let elem = lastValidFoundUserWorkers[index];
|
| 5913 |
+
msgboxYesNo(`Are you sure you want to delete the worker <span class='color_orange'>`+elem.name+`</span> with the ID <span class='color_orange'>`+elem.id+`</span>?<br><br><b>This action is irreversible!</b>`,"Confirm Delete Worker",
|
| 5914 |
+
()=>{
|
| 5915 |
+
let newapikey = document.getElementById("apikey").value;
|
| 5916 |
+
let parentcluster = find_text_horde(lastValidFoundCluster);
|
| 5917 |
+
fetch(parentcluster.maintenance_endpoint + "/" + elem.id, {
|
| 5918 |
+
method: 'DELETE',
|
| 5919 |
+
headers: {
|
| 5920 |
+
'Content-Type': 'application/json',
|
| 5921 |
+
'apikey': newapikey,
|
| 5922 |
+
}
|
| 5923 |
+
})
|
| 5924 |
+
.then((response) => response.json())
|
| 5925 |
+
.then((data) => {
|
| 5926 |
+
msgbox(JSON.stringify(data), "Delete My Worker");
|
| 5927 |
+
})
|
| 5928 |
+
.catch((error) => {
|
| 5929 |
+
console.error('Error:', error);
|
| 5930 |
+
});
|
| 5931 |
+
hide_popups();
|
| 5932 |
+
},()=>{
|
| 5933 |
+
document.getElementById("yesnocontainer").classList.add("hidden");
|
| 5934 |
+
},true);
|
| 5935 |
+
}
|
| 5936 |
+
}
|
| 5937 |
+
|
| 5938 |
function update_my_workers()
|
| 5939 |
{
|
| 5940 |
let newapikey = document.getElementById("apikey").value;
|
|
|
|
| 5954 |
if(desc.value.trim()!="" || (desc.value.trim()=="" && lastValidFoundUserWorkers[i].info!=null && lastValidFoundUserWorkers[i].info!=""))
|
| 5955 |
{
|
| 5956 |
wo.info = desc.value.trim();
|
| 5957 |
+
if(wo.info=="")
|
| 5958 |
+
{
|
| 5959 |
+
wo.info = " "; //todo: this is a hack to unset names
|
| 5960 |
+
}
|
| 5961 |
}
|
| 5962 |
fetch(parentcluster.maintenance_endpoint + "/" + lastValidFoundUserWorkers[i].id, {
|
| 5963 |
method: 'PUT',
|
|
|
|
| 6447 |
document.getElementById('instruct_starttag').value = "\\nQuestion: ";
|
| 6448 |
document.getElementById('instruct_endtag').value = "\\nAnswer: ";
|
| 6449 |
break;
|
| 6450 |
+
case "6": //ChatML
|
| 6451 |
+
document.getElementById('instruct_starttag').value = "<|im_start|>user";
|
| 6452 |
+
document.getElementById('instruct_endtag').value = "<|im_end|><|im_start|>assistant";
|
| 6453 |
+
break;
|
| 6454 |
default:
|
| 6455 |
break;
|
| 6456 |
}
|
|
|
|
| 6886 |
headers: {
|
| 6887 |
'Content-Type': 'application/json',
|
| 6888 |
},
|
| 6889 |
+
body: JSON.stringify({
|
| 6890 |
+
"genkey": lastcheckgenkey
|
| 6891 |
+
}),
|
| 6892 |
})
|
| 6893 |
.then((response) => response.json())
|
| 6894 |
.then((data) => {})
|
|
|
|
| 7163 |
pending_context_preinjection = "\n";
|
| 7164 |
}
|
| 7165 |
|
| 7166 |
+
if(localsettings.allow_continue_chat && newgen.trim() == "" && co!="")
|
| 7167 |
{
|
| 7168 |
+
//determine if the most recent speaker is ourself
|
| 7169 |
+
let last_self = Math.max(truncated_context.lastIndexOf(me + ":"),truncated_context.lastIndexOf("\n"+me));
|
| 7170 |
+
let last_oppo = truncated_context.lastIndexOf(co+":");
|
| 7171 |
+
|
| 7172 |
+
if (last_oppo > -1 && last_oppo > last_self) {
|
| 7173 |
+
//allow continuing a previous bot reply instead of starting a new row.
|
| 7174 |
+
pending_context_preinjection = "";
|
| 7175 |
+
} else {
|
| 7176 |
+
//start a new bot response
|
| 7177 |
+
truncated_context += pending_context_preinjection;
|
| 7178 |
+
}
|
| 7179 |
}
|
| 7180 |
else
|
| 7181 |
{
|
|
|
|
| 7356 |
{
|
| 7357 |
lastcheckgenkey = "KCPP"+(Math.floor(1000 + Math.random() * 9000)).toString();
|
| 7358 |
submit_payload.params.genkey = lastcheckgenkey;
|
| 7359 |
+
}else{
|
| 7360 |
+
lastcheckgenkey = "";
|
| 7361 |
}
|
| 7362 |
|
| 7363 |
//v2 api specific fields
|
|
|
|
| 7379 |
function dispatch_submit_generation(submit_payload, input_was_empty) //if input is not empty, always unban eos
|
| 7380 |
{
|
| 7381 |
console.log(submit_payload);
|
|
|
|
| 7382 |
|
| 7383 |
startTimeTaken(); //timestamp start request
|
| 7384 |
|
|
|
|
| 7462 |
streamchunk = ((pstreamamount != null && pstreamamount > 0) ? pstreamamount:8); //8 tokens per stream tick by default
|
| 7463 |
}
|
| 7464 |
let sub_endpt = apply_proxy_url(custom_kobold_endpoint + kobold_custom_gen_endpoint);
|
| 7465 |
+
last_request_str = JSON.stringify(submit_payload);
|
| 7466 |
kobold_api_stream(sub_endpt, submit_payload, submit_payload.max_length, "", streamchunk);
|
| 7467 |
|
| 7468 |
}
|
|
|
|
| 7484 |
"logit_bias": { "50256": -100 },
|
| 7485 |
}
|
| 7486 |
|
| 7487 |
+
if (document.getElementById("useoaichatcompl").checked || custom_oai_model == "gpt-3.5-turbo" || custom_oai_model == "gpt-3.5-turbo-16k" || custom_oai_model == "gpt-4" || custom_oai_model == "gpt-4-32k") {
|
| 7488 |
targetep = (custom_oai_endpoint + oai_submit_endpoint_turbo);
|
| 7489 |
if (document.getElementById("jailbreakprompt") && document.getElementById("jailbreakprompt").checked && document.getElementById("jailbreakprompttext").value!="") {
|
| 7490 |
oai_payload.messages = [
|
|
|
|
| 7502 |
oai_payload.prompt = submit_payload.prompt;
|
| 7503 |
}
|
| 7504 |
|
| 7505 |
+
last_request_str = JSON.stringify(oai_payload);
|
| 7506 |
+
|
| 7507 |
fetch(targetep, {
|
| 7508 |
method: 'POST',
|
| 7509 |
headers: {
|
|
|
|
| 7552 |
let targetep = cors_proxy + "?" + scale_submit_endpoint + custom_scale_ID;
|
| 7553 |
let scale_payload = { "input": { "input": submit_payload.prompt } };
|
| 7554 |
|
| 7555 |
+
last_request_str = JSON.stringify(scale_payload);
|
| 7556 |
fetch(targetep, {
|
| 7557 |
method: 'POST',
|
| 7558 |
headers: {
|
|
|
|
| 7592 |
"prompt": submit_payload.prompt,
|
| 7593 |
"max_tokens_to_sample": submit_payload.params.max_length,
|
| 7594 |
"model": custom_claude_model,
|
| 7595 |
+
"top_k": (submit_payload.params.top_k<1?300:submit_payload.params.top_k),
|
| 7596 |
"temperature": submit_payload.params.temperature,
|
| 7597 |
"top_p": submit_payload.params.top_p,
|
| 7598 |
}
|
|
|
|
| 7616 |
}
|
| 7617 |
}
|
| 7618 |
|
| 7619 |
+
last_request_str = JSON.stringify(claude_payload);
|
| 7620 |
+
|
| 7621 |
fetch(targetep, {
|
| 7622 |
method: 'POST',
|
| 7623 |
headers: {
|
|
|
|
| 7658 |
"temperature":submit_payload.params.temperature,
|
| 7659 |
"maxOutputTokens": submit_payload.params.max_length,
|
| 7660 |
"topP": submit_payload.params.top_p,
|
| 7661 |
+
"topK": (submit_payload.params.top_k<1?300:submit_payload.params.top_k),
|
| 7662 |
"candidateCount":1};
|
| 7663 |
|
| 7664 |
+
last_request_str = JSON.stringify(payload);
|
| 7665 |
+
|
| 7666 |
fetch(targetep, {
|
| 7667 |
method: 'POST',
|
| 7668 |
headers: {
|
|
|
|
| 7737 |
}
|
| 7738 |
|
| 7739 |
//horde supports unban tokens
|
| 7740 |
+
if(submit_payload.params)
|
| 7741 |
+
{
|
| 7742 |
+
submit_payload.params.use_default_badwordsids = determine_if_ban_eos(input_was_empty);
|
| 7743 |
+
}
|
| 7744 |
+
|
| 7745 |
+
last_request_str = JSON.stringify(submit_payload);
|
| 7746 |
|
| 7747 |
fetch(selectedhorde.submit_endpoint, {
|
| 7748 |
method: 'POST', // or 'PUT'
|
|
|
|
| 8673 |
if (gametext_arr.length == 0 && synchro_pending_stream=="" && pending_response_id=="") {
|
| 8674 |
|
| 8675 |
if (perfdata == null) {
|
| 8676 |
+
if(document.getElementById("connectstatus").innerHTML == "Offline Mode")
|
| 8677 |
+
{
|
| 8678 |
+
document.getElementById("gametext").innerHTML = "Welcome to <span class=\"color_cyan\">KoboldAI Lite</span>!<br>You are in <span class=\"color_red\">Offline Mode</span>.<br>You will still be able to load and edit stories, but not generate new text."
|
| 8679 |
+
}else{
|
| 8680 |
+
document.getElementById("gametext").innerHTML = "Welcome to <span class=\"color_cyan\">KoboldAI Lite</span>!<br><span class=\"color_orange\">Attempting to Connect...</span>"
|
| 8681 |
+
}
|
| 8682 |
} else {
|
| 8683 |
let whorun = "";
|
| 8684 |
|
|
|
|
| 8763 |
|
| 8764 |
fulltxt = replaceAll(fulltxt, `%SpcStg%`, `<hr class="hr_instruct"><span class="color_cyan"><img src="`+human_square+`" style="height:38px;width:auto;padding:3px 6px 3px 3px;border-radius: 8%;"/>`);
|
| 8765 |
fulltxt = replaceAll(fulltxt, `%SpcEtg%`, `</span><hr class="hr_instruct"><img src="`+niko_square+`" style="height:38px;width:auto;padding:3px 6px 3px 3px;border-radius: 8%;"/>`);
|
|
|
|
| 8766 |
}else{
|
| 8767 |
fulltxt = replaceAll(fulltxt, get_instruct_starttag(true), `%SclStg%`+escapeHtml(get_instruct_starttag(true))+`%SpnEtg%`);
|
| 8768 |
fulltxt = replaceAll(fulltxt, get_instruct_endtag(true), `%SclStg%`+escapeHtml(get_instruct_endtag(true))+`%SpnEtg%`);
|
|
|
|
| 8960 |
}
|
| 8961 |
else
|
| 8962 |
{
|
| 8963 |
+
document.getElementById("chat_msg_body").innerHTML = render_enhanced_chat_instruct(textToRender,false);
|
| 8964 |
}
|
| 8965 |
|
| 8966 |
// Show the 'AI is typing' message if an answer is pending, and prevent the 'send button' from being clicked again.
|
|
|
|
| 9459 |
this.bubbleColor_AI = 'rgb(20, 20, 40)';
|
| 9460 |
|
| 9461 |
this.background_margin = [5, 5, 5, 0];
|
| 9462 |
+
this.background_padding = [15, 15, 10, 5];
|
| 9463 |
this.background_minHeight = 80;
|
| 9464 |
this.centerHorizontally = false;
|
| 9465 |
|
|
|
|
| 9754 |
}
|
| 9755 |
}
|
| 9756 |
|
| 9757 |
+
function render_enhanced_chat_instruct(input, isPreview) //class suffix string used to prevent defined styles from leaking into global scope
|
| 9758 |
{
|
| 9759 |
+
let classSuffixStr = isPreview ? "prv" : "";
|
| 9760 |
const contextDict = { sysOpen: '<sys_context_koboldlite_internal>', youOpen: '<user_context_koboldlite_internal>', AIOpen: '<AI_context_koboldlite_internal>', closeTag: '<end_of_context_koboldlite_internal>' }
|
| 9761 |
let you = get_instruct_starttag(); let bot = get_instruct_endtag(); // Instruct tags will be used to wrap text in styled bubbles.
|
| 9762 |
|
|
|
|
| 9803 |
let noSystemPrompt = input.trim().startsWith(you.trim()) || input.trim().startsWith(bot.trim());
|
| 9804 |
let newbodystr = noSystemPrompt ? input : style('sys') + input; // First, create the string we'll transform. Style system bubble if we should.
|
| 9805 |
if (newbodystr.endsWith(bot)) { newbodystr = newbodystr.slice(0, -bot.length); } // Remove the last chat bubble if prompt ends with `end_sequence`.
|
| 9806 |
+
newbodystr = transformInputToAestheticStyle(newbodystr,isPreview); // Transform input to aesthetic style, reduce any unnecessary spaces or newlines, and trim empty replies if they exist.
|
| 9807 |
if (synchro_pending_stream != "") {
|
| 9808 |
newbodystr += getStreamingText();
|
| 9809 |
} // Add the pending stream if it's needed. This will add any streamed text to a new bubble for the AI.
|
|
|
|
| 9834 |
let fontStyle = type=='action'?'italic':'normal';
|
| 9835 |
let injectQuotes1 = type=='speech'?'“':'';
|
| 9836 |
let injectQuotes2 = type=='speech'?'”':'';
|
| 9837 |
+
let textCol = as[`${type}_tcolor_${role}`];
|
| 9838 |
+
return `<span style='color: ${textCol}; font-style: ${fontStyle}; font-weight: normal'>${injectQuotes1}$1${injectQuotes2}</span>`;
|
| 9839 |
}
|
| 9840 |
function image(role) {
|
| 9841 |
if (!as[`${role}_portrait`] || as.border_style == 'None' || role == 'sys') { return ''; }
|
|
|
|
| 9844 |
function applyStylizedCodeBlocks() {
|
| 9845 |
let blocks = newbodystr.split(/(```[\s\S]*?\n[\s\S]*?```)/g);
|
| 9846 |
for (var i = 0; i < blocks.length; i++) {
|
| 9847 |
+
if (blocks[i].startsWith('```')) {
|
| 9848 |
+
blocks[i] = blocks[i].replace(/```[\s\S]*?\n([\s\S]*?)```/g,
|
| 9849 |
+
function (m,m2) {return `</p><pre style='min-width:80%;margin:0px 40px 0px 20px;background-color:${as.code_block_background};color:${as.code_block_foreground}'>${m2.replace(/[“”]/g, "\"")}</pre><p>`});
|
| 9850 |
+
}
|
| 9851 |
+
else {
|
| 9852 |
+
blocks[i] = blocks[i].replaceAll('```', '`').replaceAll('``', '`').replace(/`(.*?)`/g, function (m,m2) {return `<code style='background-color:black'>${m2.replace(/[“”]/g, "\"")}</code>`;}); //remove fancy quotes too
|
| 9853 |
+
}
|
| 9854 |
}
|
| 9855 |
return blocks.join('');
|
| 9856 |
}
|
| 9857 |
+
function transformInputToAestheticStyle(bodyStr, isPreview) { // Trim unnecessary empty space and new lines, and append * or " to each bubble if start/end sequence ends with * or ", to preserve styling.
|
| 9858 |
bodyStr = bodyStr.replaceAll(you + '\n', you).replaceAll(you + ' ', you).replaceAll(you, style('you') + `${you.endsWith('*') ? '*' : ''}` + `${you.endsWith('"') ? '"' : ''}`);
|
| 9859 |
bodyStr = bodyStr.replaceAll(bot + '\n', bot).replaceAll(bot + ' ', bot).replaceAll(bot, style('AI') + `${bot.endsWith('*') ? '*' : ''}` + `${bot.endsWith('"') ? '"' : ''}`);
|
| 9860 |
+
if(gametext_arr.length==0 && !isPreview)
|
| 9861 |
{
|
| 9862 |
return bodyStr; //to allow html in the welcome text
|
| 9863 |
}
|
|
|
|
| 9873 |
}
|
| 9874 |
|
| 9875 |
function updateTextPreview() {
|
| 9876 |
+
let preview = `You are Mikago, a prestigious bot that's a supervillain.\n\nRoleplay in first person, be prestigious, don't be a bot. This is a fantasy world.\n\nCode blocks should be wrapped in triple backticks, like so:\n\`\`\`\n<Some_\n-- multiline\n--- code here$\n\`\`\`\n[AI_REPLY]\n*takes my hat off to greet the squad* "Greetings, I am Mikago, the prestigious!" *bows to the crew*\n*clears my throat* "Now, I'm sure there are many questions, but all will be answered in due time." *deep breath*\n[USER_REPLY]\n*draws my sword* "Yes. You should know the code to calculate the factorial of a number."\nThe crew also draws their weapons and point them at you, not giving you any space.\n[AI_REPLY]\n*backs off* "Woah, easy there.." *makes some steps backwards, but then stops*\n"I would normally take this as an insult to my prestige, but I understand your caution.." *takes a deep breath*\n"Well, if it's to prove myself, here goes the python code to calculate the factorial of a number.."\n\nMikago opens a live-code-portal with his magic and writes the code that was requested.\n\`\`\`\ndef factorial(n):\n if n == 0:\n return 1\n else:\n return n * factorial(n-1)\n\`\`\`\n*looks at you, getting impatient* "Are we ok now.. or do you want me to write the code of a game next?"\n[USER_REPLY]\n*sheathes my sword and approaches for a hug* "Oh, Mikago, my old friend, it is really you!"`;
|
| 9877 |
+
|
| 9878 |
if(localsettings.opmode==3)
|
| 9879 |
{
|
| 9880 |
preview = replaceAll(preview,'\n[USER_REPLY]\n', "{{userplaceholder}}");
|
|
|
|
| 9889 |
preview = replaceAll(preview,'\n[USER_REPLY]\n', get_instruct_starttag());
|
| 9890 |
preview = replaceAll(preview,'\n[AI_REPLY]\n', get_instruct_endtag());
|
| 9891 |
}
|
| 9892 |
+
document.getElementById('aesthetic_text_preview').innerHTML = render_enhanced_chat_instruct(preview,true);
|
| 9893 |
}
|
| 9894 |
</script>
|
| 9895 |
|
|
|
|
| 9973 |
<div id="maineditbody" class="layer-container">
|
| 9974 |
<div class="layer-bottom" id="gamescreen">
|
| 9975 |
<span id="gametext" contenteditable="false" onclick="click_gametext()" onblur="merge_edit_field()">
|
| 9976 |
+
<p id="tempgtloadtxt">Loading...</p>
|
| 9977 |
+
<noscript><style>#tempgtloadtxt { display: none; } #gametext { white-space: normal!important; }</style><p>Sorry, Kobold Lite requires Javascript to function.</p></noscript>
|
| 9978 |
</span>
|
| 9979 |
<div class="hidden" id="wimenu">
|
| 9980 |
</div>
|
|
|
|
| 10191 |
<input class="form-control" type="text" id="custom_oai_endpoint" placeholder="OpenAI API URL" value="">
|
| 10192 |
<input class="form-control" type="password" id="custom_oai_key" placeholder="OpenAI API Key" value="" onfocus="focus_api_keys()" onblur="blur_api_keys()"><br>
|
| 10193 |
Model Choice:<br>
|
| 10194 |
+
<select style="padding:4px;" class="form-control" id="custom_oai_model" onchange="custom_oai_model_change()">
|
| 10195 |
<option value="text-davinci-003" selected="selected">text-davinci-003</option>
|
| 10196 |
<option value="text-davinci-002">text-davinci-002</option>
|
| 10197 |
<option value="text-davinci-001">text-davinci-001</option>
|
|
|
|
| 10201 |
<option value="gpt-3.5-turbo-16k">gpt-3.5-turbo-16k</option>
|
| 10202 |
<option value="gpt-4">gpt-4</option>
|
| 10203 |
<option value="gpt-4-32k">gpt-4-32k</option>
|
| 10204 |
+
<option id="custom_oai_model_option" value="custom">[Custom]</option>
|
| 10205 |
</select>
|
| 10206 |
<input type="checkbox" id="oaiaddversion" onchange="" checked>
|
| 10207 |
<div class="box-label" title="Add endpoint version">Add Endpoint Version</div>
|
| 10208 |
<input type="checkbox" id="jailbreakprompt" onchange="togglejailbreak()">
|
| 10209 |
+
<div class="box-label" title="Adds extra text to improve AI response">Add System Message</div>
|
| 10210 |
+
<input type="checkbox" id="useoaichatcompl">
|
| 10211 |
+
<div class="box-label" id="useoaichatcompllabel" title="">Use ChatCompletions API</div>
|
| 10212 |
<input class="form-control hidden" type="text" id="jailbreakprompttext" placeholder="(Enter System Message)"
|
| 10213 |
value="" onload="togglejailbreak()">
|
| 10214 |
</div>
|
|
|
|
| 10305 |
class="helptext">Randomness of sampling. High values can increase creativity but
|
| 10306 |
may make text less sensible. Lower values will make text more predictable but
|
| 10307 |
can become repetitious.</span></span></div>
|
| 10308 |
+
<input inputmode="decimal" class="justifyright flex-push-right settingsmall" id="temperature" value=0.5
|
| 10309 |
oninput="
|
| 10310 |
document.getElementById('temperature_slide').value = this.value;">
|
| 10311 |
</div>
|
|
|
|
| 10321 |
<div class="settingitem">
|
| 10322 |
<div class="settinglabel">
|
| 10323 |
<div class="justifyleft settingsmall">Max Ctx. Tokens <span class="helpicon">?<span class="helptext">Max
|
| 10324 |
+
number of context tokens submitted to the AI. Must exceed Amount to Generate. Can be further increased by editing the textbox. Older models stop at 2048, newer ones can do 4096 or greater.</span></span></div>
|
|
|
|
| 10325 |
<input inputmode="numeric" class="justifyright flex-push-right settingsmall" id="max_context_length"
|
| 10326 |
value=1024 oninput="
|
| 10327 |
document.getElementById('max_context_length_slide').value = this.value;">
|
|
|
|
| 10367 |
<div class="justifyleft settingsmall">Top p Sampling <span class="helpicon">?<span class="helptext">Used
|
| 10368 |
to discard unlikely text in the sampling process. Lower values will make text
|
| 10369 |
more predictable but can become repetitious. Set to 1 to deactivate it.</span></span></div>
|
| 10370 |
+
<input inputmode="decimal" class="justifyright flex-push-right settingsmall" id="top_p" value=80 oninput="
|
| 10371 |
document.getElementById('top_p_slide').value = this.value;">
|
| 10372 |
</div>
|
| 10373 |
<div><input type="range" class="form-range airange" min="0" max="1" step="0.01" id="top_p_slide"
|
|
|
|
| 10386 |
<div class="justifyleft settingsmall">Repetition Penalty <span class="helpicon">?<span
|
| 10387 |
class="helptext">Used to penalize words that were already generated or belong to
|
| 10388 |
the context (Going over 1.2 breaks 6B models).</span></span></div>
|
| 10389 |
+
<input inputmode="decimal" class="justifyright flex-push-right settingsmall" id="rep_pen" value=80
|
| 10390 |
oninput="
|
| 10391 |
document.getElementById('rep_pen_slide').value = this.value;">
|
| 10392 |
</div>
|
|
|
|
| 10476 |
<option value="3">Metharme</option>
|
| 10477 |
<option value="4">Llama 2 Chat</option>
|
| 10478 |
<option value="5">Q & A</option>
|
| 10479 |
+
<option value="6">ChatML</option>
|
| 10480 |
</select>
|
| 10481 |
<table class="settingsmall text-center" style="border-spacing: 4px 2px; border-collapse: separate;">
|
| 10482 |
<tr>
|
|
|
|
| 10512 |
<th title="Tail-Free Sampling. 1 to Deactivate.">TFS</th>
|
| 10513 |
</tr>
|
| 10514 |
<tr>
|
| 10515 |
+
<td><input class="" type="text" inputmode="decimal" placeholder="0" value="0"
|
| 10516 |
id="top_k"></td>
|
| 10517 |
+
<td><input class="" type="text" inputmode="decimal" placeholder="0" value="0"
|
| 10518 |
id="top_a"></td>
|
| 10519 |
+
<td><input class="" type="text" inputmode="decimal" placeholder="0" value="0"
|
| 10520 |
id="typ_s"></td>
|
| 10521 |
+
<td><input class="" type="text" inputmode="decimal" placeholder="0" value="0"
|
| 10522 |
id="tfs_s"></td>
|
| 10523 |
</tr>
|
| 10524 |
</table>
|
|
|
|
| 10820 |
<div class="workerTableDiv">
|
| 10821 |
<table class="table text-center workerTable">
|
| 10822 |
<thead class="sticky-top bg-white">
|
| 10823 |
+
<tr><th><a class="color_blueurl" href="#" onclick="sort_display_workers('name')">Name</a></th><th><a class="color_blueurl" href="#" onclick="sort_display_workers('defaultmodel')">Model</a></th><th><a class="color_blueurl" href="#" onclick="sort_display_workers('tokenspersec')">Capabilities</a></th><th><a class="color_blueurl" href="#" onclick="sort_display_workers('uptime')">Uptime</a></th><th><a class="color_blueurl" href="#" onclick="sort_display_workers('kudos_rewards')">Kudos</a></th><th>Cluster</th></tr>
|
| 10824 |
</thead>
|
| 10825 |
<tbody id="workertable">
|
| 10826 |
</tbody>
|
|
|
|
| 10841 |
<div class="workerTableDiv">
|
| 10842 |
<table class="table text-center workerTable">
|
| 10843 |
<thead class="sticky-top bg-white">
|
| 10844 |
+
<tr><th>Name</th><th>Description</th><th>Uptime</th><th>Kudos</th><th>Maint.</th><th>Del.</th></tr>
|
| 10845 |
</thead>
|
| 10846 |
<tbody id="myownworkertable">
|
| 10847 |
</tbody>
|
|
|
|
| 11125 |
|
| 11126 |
//for local mode, we do not load any PWA service worker.
|
| 11127 |
//this will prevent PWA functionality locally but will avoid the scary 404 errors
|
| 11128 |
+
if(!localflag)
|
| 11129 |
{
|
| 11130 |
console.log("Try to register service worker...");
|
| 11131 |
try {
|
koboldcpp.py
CHANGED
|
@@ -34,7 +34,6 @@ class load_model_inputs(ctypes.Structure):
|
|
| 34 |
("use_mmap", ctypes.c_bool),
|
| 35 |
("use_mlock", ctypes.c_bool),
|
| 36 |
("use_smartcontext", ctypes.c_bool),
|
| 37 |
-
("unban_tokens", ctypes.c_bool),
|
| 38 |
("clblast_info", ctypes.c_int),
|
| 39 |
("cublas_info", ctypes.c_int),
|
| 40 |
("blasbatchsize", ctypes.c_int),
|
|
@@ -224,7 +223,6 @@ def load_model(model_filename):
|
|
| 224 |
if len(args.lora) > 1:
|
| 225 |
inputs.lora_base = args.lora[1].encode("UTF-8")
|
| 226 |
inputs.use_smartcontext = args.smartcontext
|
| 227 |
-
inputs.unban_tokens = args.unbantokens
|
| 228 |
inputs.blasbatchsize = args.blasbatchsize
|
| 229 |
inputs.forceversion = args.forceversion
|
| 230 |
inputs.gpulayers = args.gpulayers
|
|
@@ -282,7 +280,7 @@ def load_model(model_filename):
|
|
| 282 |
ret = handle.load_model(inputs)
|
| 283 |
return ret
|
| 284 |
|
| 285 |
-
def generate(prompt,max_length=20, max_context_length=512, temperature=0.8, top_k=120, top_a=0.0, top_p=0.85, typical_p=1.0, tfs=1.0, rep_pen=1.1, rep_pen_range=128, mirostat=0, mirostat_tau=5.0, mirostat_eta=0.1, sampler_order=[6,0,1,3,4,2,5], seed=-1, stop_sequence=[], use_default_badwordsids=
|
| 286 |
global maxctx, args, currentusergenkey, totalgens
|
| 287 |
inputs = generation_inputs()
|
| 288 |
outputs = ctypes.create_unicode_buffer(ctypes.sizeof(generation_outputs))
|
|
@@ -307,11 +305,7 @@ def generate(prompt,max_length=20, max_context_length=512, temperature=0.8, top_
|
|
| 307 |
inputs.grammar = grammar.encode("UTF-8")
|
| 308 |
inputs.grammar_retain_state = grammar_retain_state
|
| 309 |
inputs.unban_tokens_rt = not use_default_badwordsids
|
| 310 |
-
if
|
| 311 |
-
inputs.mirostat = int(args.usemirostat[0])
|
| 312 |
-
inputs.mirostat_tau = float(args.usemirostat[1])
|
| 313 |
-
inputs.mirostat_eta = float(args.usemirostat[2])
|
| 314 |
-
elif mirostat in (1, 2):
|
| 315 |
inputs.mirostat = mirostat
|
| 316 |
inputs.mirostat_tau = mirostat_tau
|
| 317 |
inputs.mirostat_eta = mirostat_eta
|
|
@@ -367,10 +361,13 @@ maxhordelen = 256
|
|
| 367 |
modelbusy = threading.Lock()
|
| 368 |
requestsinqueue = 0
|
| 369 |
defaultport = 5001
|
| 370 |
-
KcppVersion = "1.
|
| 371 |
showdebug = True
|
| 372 |
showsamplerwarning = True
|
| 373 |
showmaxctxwarning = True
|
|
|
|
|
|
|
|
|
|
| 374 |
exitcounter = 0
|
| 375 |
totalgens = 0
|
| 376 |
currentusergenkey = "" #store a special key so polled streaming works even in multiuser
|
|
@@ -380,10 +377,11 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 380 |
sys_version = ""
|
| 381 |
server_version = "ConcedoLlamaForKoboldServer"
|
| 382 |
|
| 383 |
-
def __init__(self, addr, port, embedded_kailite):
|
| 384 |
self.addr = addr
|
| 385 |
self.port = port
|
| 386 |
self.embedded_kailite = embedded_kailite
|
|
|
|
| 387 |
|
| 388 |
def __call__(self, *args, **kwargs):
|
| 389 |
super().__init__(*args, **kwargs)
|
|
@@ -395,17 +393,45 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 395 |
pass
|
| 396 |
|
| 397 |
async def generate_text(self, genparams, api_format, stream_flag):
|
| 398 |
-
|
| 399 |
def run_blocking():
|
| 400 |
if api_format==1:
|
| 401 |
genparams["prompt"] = genparams.get('text', "")
|
| 402 |
genparams["top_k"] = int(genparams.get('top_k', 120))
|
| 403 |
-
genparams["max_length"]=genparams.get('max',
|
| 404 |
elif api_format==3:
|
| 405 |
frqp = genparams.get('frequency_penalty', 0.1)
|
| 406 |
scaled_rep_pen = genparams.get('presence_penalty', frqp) + 1
|
| 407 |
-
genparams["max_length"] = genparams.get('max_tokens',
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 408 |
genparams["rep_pen"] = scaled_rep_pen
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 409 |
|
| 410 |
return generate(
|
| 411 |
prompt=genparams.get('prompt', ""),
|
|
@@ -425,7 +451,7 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 425 |
sampler_order=genparams.get('sampler_order', [6,0,1,3,4,2,5]),
|
| 426 |
seed=genparams.get('sampler_seed', -1),
|
| 427 |
stop_sequence=genparams.get('stop_sequence', []),
|
| 428 |
-
use_default_badwordsids=genparams.get('use_default_badwordsids',
|
| 429 |
stream_sse=stream_flag,
|
| 430 |
grammar=genparams.get('grammar', ''),
|
| 431 |
grammar_retain_state = genparams.get('grammar_retain_state', False),
|
|
@@ -445,8 +471,11 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 445 |
if api_format==1:
|
| 446 |
res = {"data": {"seqs":[recvtxt]}}
|
| 447 |
elif api_format==3:
|
| 448 |
-
res = {"id": "cmpl-1", "object": "text_completion", "created": 1, "model":
|
| 449 |
"choices": [{"text": recvtxt, "index": 0, "finish_reason": "length"}]}
|
|
|
|
|
|
|
|
|
|
| 450 |
else:
|
| 451 |
res = {"results": [{"text": recvtxt}]}
|
| 452 |
|
|
@@ -456,19 +485,23 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 456 |
print(f"Generate: Error while generating: {e}")
|
| 457 |
|
| 458 |
|
| 459 |
-
async def
|
| 460 |
-
self.wfile.write(f'
|
| 461 |
-
self.wfile.
|
| 462 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 463 |
|
| 464 |
-
async def handle_sse_stream(self):
|
|
|
|
| 465 |
self.send_response(200)
|
| 466 |
self.send_header("Cache-Control", "no-cache")
|
| 467 |
self.send_header("Connection", "keep-alive")
|
| 468 |
-
self.end_headers()
|
| 469 |
|
| 470 |
current_token = 0
|
| 471 |
-
|
| 472 |
incomplete_token_buffer = bytearray()
|
| 473 |
while True:
|
| 474 |
streamDone = handle.has_finished() #exit next loop on done
|
|
@@ -489,27 +522,34 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 489 |
tokenStr += tokenSeg
|
| 490 |
|
| 491 |
if tokenStr!="":
|
| 492 |
-
|
| 493 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 494 |
tokenStr = ""
|
| 495 |
-
|
| 496 |
else:
|
| 497 |
await asyncio.sleep(0.02) #this should keep things responsive
|
| 498 |
|
| 499 |
if streamDone:
|
|
|
|
|
|
|
| 500 |
break
|
| 501 |
|
| 502 |
# flush buffers, sleep a bit to make sure all data sent, and then force close the connection
|
| 503 |
self.wfile.flush()
|
| 504 |
-
await asyncio.sleep(0.
|
| 505 |
self.close_connection = True
|
|
|
|
| 506 |
|
| 507 |
|
| 508 |
async def handle_request(self, genparams, api_format, stream_flag):
|
| 509 |
tasks = []
|
| 510 |
|
| 511 |
if stream_flag:
|
| 512 |
-
tasks.append(self.handle_sse_stream())
|
| 513 |
|
| 514 |
generate_task = asyncio.create_task(self.generate_text(genparams, api_format, stream_flag))
|
| 515 |
tasks.append(generate_task)
|
|
@@ -529,17 +569,6 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 529 |
force_json = False
|
| 530 |
|
| 531 |
if self.path in ["", "/?"] or self.path.startswith(('/?','?')): #it's possible for the root url to have ?params without /
|
| 532 |
-
if args.stream and not "streaming=1" in self.path:
|
| 533 |
-
self.path = self.path.replace("streaming=0","")
|
| 534 |
-
if self.path.startswith(('/?','?')):
|
| 535 |
-
self.path += "&streaming=1"
|
| 536 |
-
else:
|
| 537 |
-
self.path = self.path + "?streaming=1"
|
| 538 |
-
self.send_response(302)
|
| 539 |
-
self.send_header("Location", self.path)
|
| 540 |
-
self.end_headers()
|
| 541 |
-
print("Force redirect to streaming mode, as --stream is set.")
|
| 542 |
-
return None
|
| 543 |
|
| 544 |
if self.embedded_kailite is None:
|
| 545 |
response_body = (f"Embedded Kobold Lite is not found.<br>You will have to connect via the main KoboldAI client, or <a href='https://lite.koboldai.net?local=1&port={self.port}'>use this URL</a> to connect.").encode()
|
|
@@ -562,7 +591,7 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 562 |
response_body = (json.dumps({"values": []}).encode())
|
| 563 |
|
| 564 |
elif self.path.endswith(('/api/v1/info/version', '/api/latest/info/version')):
|
| 565 |
-
response_body = (json.dumps({"result":"1.2.
|
| 566 |
|
| 567 |
elif self.path.endswith(('/api/extra/true_max_context_length')): #do not advertise this to horde
|
| 568 |
response_body = (json.dumps({"value": maxctx}).encode())
|
|
@@ -584,13 +613,21 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 584 |
pendtxtStr = ctypes.string_at(pendtxt).decode("UTF-8","ignore")
|
| 585 |
response_body = (json.dumps({"results": [{"text": pendtxtStr}]}).encode())
|
| 586 |
|
| 587 |
-
elif self.path.endswith('/v1/models')
|
| 588 |
-
response_body = (json.dumps({"object":"list","data":[{"id":
|
| 589 |
force_json = True
|
| 590 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 591 |
elif self.path.endswith(('/api')) or self.path.endswith(('/api/v1')):
|
| 592 |
-
|
| 593 |
-
|
|
|
|
|
|
|
|
|
|
| 594 |
|
| 595 |
if response_body is None:
|
| 596 |
self.send_response(404)
|
|
@@ -610,7 +647,6 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 610 |
body = self.rfile.read(content_length)
|
| 611 |
self.path = self.path.rstrip('/')
|
| 612 |
force_json = False
|
| 613 |
-
|
| 614 |
if self.path.endswith(('/api/extra/tokencount')):
|
| 615 |
try:
|
| 616 |
genparams = json.loads(body)
|
|
@@ -628,14 +664,23 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 628 |
return
|
| 629 |
|
| 630 |
if self.path.endswith('/api/extra/abort'):
|
| 631 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 632 |
ag = handle.abort_generate()
|
|
|
|
| 633 |
self.send_response(200)
|
| 634 |
self.end_headers()
|
| 635 |
self.wfile.write(json.dumps({"success": ("true" if ag else "false")}).encode())
|
| 636 |
print("\nGeneration Aborted")
|
| 637 |
else:
|
| 638 |
-
|
| 639 |
return
|
| 640 |
|
| 641 |
if self.path.endswith('/api/extra/generate/check'):
|
|
@@ -670,12 +715,12 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 670 |
}}).encode())
|
| 671 |
return
|
| 672 |
if reqblocking:
|
| 673 |
-
requestsinqueue = (requestsinqueue - 1) if requestsinqueue>0 else 0
|
| 674 |
|
| 675 |
try:
|
| 676 |
-
|
| 677 |
|
| 678 |
-
api_format = 0 #1=basic,2=kai,3=oai
|
| 679 |
|
| 680 |
if self.path.endswith('/request'):
|
| 681 |
api_format = 1
|
|
@@ -685,13 +730,17 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 685 |
|
| 686 |
if self.path.endswith('/api/extra/generate/stream'):
|
| 687 |
api_format = 2
|
| 688 |
-
|
| 689 |
|
| 690 |
-
if self.path.endswith('/v1/completions')
|
| 691 |
api_format = 3
|
| 692 |
force_json = True
|
| 693 |
|
| 694 |
-
if
|
|
|
|
|
|
|
|
|
|
|
|
|
| 695 |
genparams = None
|
| 696 |
try:
|
| 697 |
genparams = json.loads(body)
|
|
@@ -705,17 +754,20 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 705 |
if args.foreground:
|
| 706 |
bring_terminal_to_foreground()
|
| 707 |
|
| 708 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 709 |
|
| 710 |
try:
|
| 711 |
# Headers are already sent when streaming
|
| 712 |
-
if not
|
| 713 |
self.send_response(200)
|
| 714 |
self.end_headers(force_json=force_json)
|
| 715 |
self.wfile.write(json.dumps(gen).encode())
|
| 716 |
except:
|
| 717 |
print("Generate: The response could not be sent, maybe connection was terminated?")
|
| 718 |
-
|
| 719 |
return
|
| 720 |
finally:
|
| 721 |
modelbusy.release()
|
|
@@ -732,12 +784,12 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 732 |
self.send_response(200)
|
| 733 |
self.end_headers()
|
| 734 |
|
| 735 |
-
def end_headers(self, force_json=False):
|
| 736 |
self.send_header('Access-Control-Allow-Origin', '*')
|
| 737 |
self.send_header('Access-Control-Allow-Methods', '*')
|
| 738 |
self.send_header('Access-Control-Allow-Headers', '*')
|
| 739 |
-
if "/api" in self.path or force_json:
|
| 740 |
-
if
|
| 741 |
self.send_header('Content-type', 'text/event-stream')
|
| 742 |
self.send_header('Content-type', 'application/json')
|
| 743 |
else:
|
|
@@ -745,7 +797,7 @@ class ServerRequestHandler(http.server.SimpleHTTPRequestHandler):
|
|
| 745 |
return super(ServerRequestHandler, self).end_headers()
|
| 746 |
|
| 747 |
|
| 748 |
-
def RunServerMultiThreaded(addr, port, embedded_kailite = None):
|
| 749 |
global exitcounter
|
| 750 |
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
| 751 |
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
|
@@ -761,7 +813,7 @@ def RunServerMultiThreaded(addr, port, embedded_kailite = None):
|
|
| 761 |
|
| 762 |
def run(self):
|
| 763 |
global exitcounter
|
| 764 |
-
handler = ServerRequestHandler(addr, port, embedded_kailite)
|
| 765 |
with http.server.HTTPServer((addr, port), handler, False) as self.httpd:
|
| 766 |
try:
|
| 767 |
self.httpd.socket = sock
|
|
@@ -806,7 +858,6 @@ def show_new_gui():
|
|
| 806 |
args.model_param = askopenfilename(title="Select ggml model .bin or .gguf file or .kcpps config")
|
| 807 |
root.destroy()
|
| 808 |
if args.model_param and args.model_param!="" and args.model_param.lower().endswith('.kcpps'):
|
| 809 |
-
print("\nLoading configuration...")
|
| 810 |
loadconfigfile(args.model_param)
|
| 811 |
if not args.model_param:
|
| 812 |
print("\nNo ggml model or kcpps file was selected. Exiting.")
|
|
@@ -815,7 +866,7 @@ def show_new_gui():
|
|
| 815 |
return
|
| 816 |
|
| 817 |
import customtkinter as ctk
|
| 818 |
-
nextstate = 0 #0=exit, 1=launch
|
| 819 |
windowwidth = 530
|
| 820 |
windowheight = 500
|
| 821 |
ctk.set_appearance_mode("dark")
|
|
@@ -849,11 +900,13 @@ def show_new_gui():
|
|
| 849 |
# slider data
|
| 850 |
blasbatchsize_values = ["-1", "32", "64", "128", "256", "512", "1024", "2048"]
|
| 851 |
blasbatchsize_text = ["Don't Batch BLAS","32","64","128","256","512","1024","2048"]
|
| 852 |
-
contextsize_text = ["512", "1024", "2048", "3072", "4096", "6144", "8192", "12288", "16384", "24576", "32768"]
|
| 853 |
runopts = [opt for lib, opt in lib_option_pairs if file_exists(lib)]
|
| 854 |
antirunopts = [opt.replace("Use ", "") for lib, opt in lib_option_pairs if not (opt in runopts)]
|
| 855 |
if not any(runopts):
|
| 856 |
-
|
|
|
|
|
|
|
| 857 |
def tabbuttonaction(name):
|
| 858 |
for t in tabcontent:
|
| 859 |
if name == t:
|
|
@@ -909,10 +962,10 @@ def show_new_gui():
|
|
| 909 |
return entry, label
|
| 910 |
|
| 911 |
|
| 912 |
-
def makefileentry(parent, text, searchtext, var, row=0, width=250):
|
| 913 |
makelabel(parent, text, row)
|
| 914 |
def getfilename(var, text):
|
| 915 |
-
var.set(askopenfilename(title=text))
|
| 916 |
entry = ctk.CTkEntry(parent, width, textvariable=var)
|
| 917 |
entry.grid(row=row+1, column=0, padx=8, stick="nw")
|
| 918 |
button = ctk.CTkButton(parent, 50, text="Browse", command= lambda a=var,b=searchtext:getfilename(a,b))
|
|
@@ -933,10 +986,12 @@ def show_new_gui():
|
|
| 933 |
x, y = root.winfo_pointerxy()
|
| 934 |
tooltip.wm_geometry(f"+{x + 10}+{y + 10}")
|
| 935 |
tooltip.deiconify()
|
|
|
|
| 936 |
def hide_tooltip(event):
|
| 937 |
if hasattr(show_tooltip, "_tooltip"):
|
| 938 |
tooltip = show_tooltip._tooltip
|
| 939 |
tooltip.withdraw()
|
|
|
|
| 940 |
def setup_backend_tooltip(parent):
|
| 941 |
num_backends_built = makelabel(parent, str(len(runopts)) + "/6", 5, 2)
|
| 942 |
num_backends_built.grid(row=1, column=2, padx=0, pady=0)
|
|
@@ -954,28 +1009,18 @@ def show_new_gui():
|
|
| 954 |
launchbrowser = ctk.IntVar(value=1)
|
| 955 |
highpriority = ctk.IntVar()
|
| 956 |
disablemmap = ctk.IntVar()
|
| 957 |
-
psutil = ctk.IntVar()
|
| 958 |
usemlock = ctk.IntVar()
|
| 959 |
debugmode = ctk.IntVar()
|
| 960 |
keepforeground = ctk.IntVar()
|
| 961 |
|
| 962 |
lowvram_var = ctk.IntVar()
|
| 963 |
mmq_var = ctk.IntVar(value=1)
|
| 964 |
-
|
| 965 |
blas_threads_var = ctk.StringVar()
|
| 966 |
blas_size_var = ctk.IntVar()
|
| 967 |
version_var =ctk.StringVar(value="0")
|
| 968 |
|
| 969 |
-
stream = ctk.IntVar()
|
| 970 |
smartcontext = ctk.IntVar()
|
| 971 |
-
unbantokens = ctk.IntVar()
|
| 972 |
-
usemirostat = ctk.IntVar()
|
| 973 |
-
mirostat_var = ctk.StringVar(value="2")
|
| 974 |
-
mirostat_tau = ctk.StringVar(value="5.0")
|
| 975 |
-
mirostat_eta = ctk.StringVar(value="0.1")
|
| 976 |
-
|
| 977 |
context_var = ctk.IntVar()
|
| 978 |
-
|
| 979 |
customrope_var = ctk.IntVar()
|
| 980 |
customrope_scale = ctk.StringVar(value="1.0")
|
| 981 |
customrope_base = ctk.StringVar(value="10000")
|
|
@@ -1066,14 +1111,14 @@ def show_new_gui():
|
|
| 1066 |
makeslider(quick_tab, "BLAS Batch Size:", blasbatchsize_text, blas_size_var, 0, 7, 12, set=5)
|
| 1067 |
|
| 1068 |
# quick boxes
|
| 1069 |
-
quick_boxes = {"Launch Browser": launchbrowser , "High Priority" : highpriority, "
|
| 1070 |
for idx, name, in enumerate(quick_boxes):
|
| 1071 |
makecheckbox(quick_tab, name, quick_boxes[name], int(idx/2) +20, idx%2)
|
| 1072 |
# context size
|
| 1073 |
makeslider(quick_tab, "Context Size:", contextsize_text, context_var, 0, len(contextsize_text)-1, 30, set=2)
|
| 1074 |
|
| 1075 |
# load model
|
| 1076 |
-
makefileentry(quick_tab, "Model:", "Select GGML Model File", model_var, 40, 170)
|
| 1077 |
|
| 1078 |
# Hardware Tab
|
| 1079 |
hardware_tab = tabcontent["Hardware"]
|
|
@@ -1099,7 +1144,7 @@ def show_new_gui():
|
|
| 1099 |
makelabelentry(hardware_tab, "Threads:" , threads_var, 8, 50)
|
| 1100 |
|
| 1101 |
# hardware checkboxes
|
| 1102 |
-
hardware_boxes = {"Launch Browser": launchbrowser , "High Priority" : highpriority, "Disable MMAP":disablemmap, "Use mlock":usemlock, "
|
| 1103 |
|
| 1104 |
for idx, name, in enumerate(hardware_boxes):
|
| 1105 |
makecheckbox(hardware_tab, name, hardware_boxes[name], int(idx/2) +30, idx%2)
|
|
@@ -1117,25 +1162,10 @@ def show_new_gui():
|
|
| 1117 |
# Tokens Tab
|
| 1118 |
tokens_tab = tabcontent["Tokens"]
|
| 1119 |
# tokens checkboxes
|
| 1120 |
-
token_boxes = {"
|
| 1121 |
for idx, name, in enumerate(token_boxes):
|
| 1122 |
makecheckbox(tokens_tab, name, token_boxes[name], idx + 1)
|
| 1123 |
|
| 1124 |
-
mirostat_entry, mirostate_label = makelabelentry(tokens_tab, "Mirostat:", mirostat_var)
|
| 1125 |
-
mirostat_tau_entry, mirostat_tau_label = makelabelentry(tokens_tab, "Mirostat Tau:", mirostat_tau)
|
| 1126 |
-
mirostat_eta_entry, mirostat_eta_label = makelabelentry(tokens_tab, "Mirostat Eta:", mirostat_eta)
|
| 1127 |
-
def togglemiro(a,b,c):
|
| 1128 |
-
items = [mirostate_label, mirostat_entry, mirostat_tau_label, mirostat_tau_entry, mirostat_eta_label, mirostat_eta_entry]
|
| 1129 |
-
for idx, item in enumerate(items):
|
| 1130 |
-
if usemirostat.get() == 1:
|
| 1131 |
-
item.grid(row=11 + int(idx/2), column=idx%2, padx=8, stick="nw")
|
| 1132 |
-
else:
|
| 1133 |
-
item.grid_forget()
|
| 1134 |
-
|
| 1135 |
-
|
| 1136 |
-
makecheckbox(tokens_tab, "Use Mirostat", row=10, variable=usemirostat, command=togglemiro)
|
| 1137 |
-
togglemiro(1,1,1)
|
| 1138 |
-
|
| 1139 |
# context size
|
| 1140 |
makeslider(tokens_tab, "Context Size:",contextsize_text, context_var, 0, len(contextsize_text)-1, 20, set=2)
|
| 1141 |
|
|
@@ -1155,7 +1185,7 @@ def show_new_gui():
|
|
| 1155 |
# Model Tab
|
| 1156 |
model_tab = tabcontent["Model"]
|
| 1157 |
|
| 1158 |
-
makefileentry(model_tab, "Model:", "Select GGML Model File", model_var, 1)
|
| 1159 |
makefileentry(model_tab, "Lora:", "Select Lora File",lora_var, 3)
|
| 1160 |
makefileentry(model_tab, "Lora Base:", "Select Lora Base File", lora_base_var, 5)
|
| 1161 |
|
|
@@ -1203,24 +1233,14 @@ def show_new_gui():
|
|
| 1203 |
root.destroy()
|
| 1204 |
pass
|
| 1205 |
|
| 1206 |
-
def switch_old_gui():
|
| 1207 |
-
nonlocal nextstate
|
| 1208 |
-
nextstate = 2
|
| 1209 |
-
root.destroy()
|
| 1210 |
-
pass
|
| 1211 |
-
|
| 1212 |
def export_vars():
|
| 1213 |
args.threads = int(threads_var.get())
|
| 1214 |
-
|
| 1215 |
args.usemlock = usemlock.get() == 1
|
| 1216 |
-
args.debugmode = debugmode.get()
|
| 1217 |
args.launch = launchbrowser.get()==1
|
| 1218 |
args.highpriority = highpriority.get()==1
|
| 1219 |
args.nommap = disablemmap.get()==1
|
| 1220 |
-
args.psutil_set_threads = psutil.get()==1
|
| 1221 |
-
args.stream = stream.get()==1
|
| 1222 |
args.smartcontext = smartcontext.get()==1
|
| 1223 |
-
args.unbantokens = unbantokens.get()==1
|
| 1224 |
args.foreground = keepforeground.get()==1
|
| 1225 |
|
| 1226 |
gpuchoiceidx = 0
|
|
@@ -1251,7 +1271,6 @@ def show_new_gui():
|
|
| 1251 |
args.blasbatchsize = int(blasbatchsize_values[int(blas_size_var.get())])
|
| 1252 |
args.forceversion = 0 if version_var.get()=="" else int(version_var.get())
|
| 1253 |
|
| 1254 |
-
args.usemirostat = [int(mirostat_var.get()), float(mirostat_tau.get()), float(mirostat_eta.get())] if usemirostat.get()==1 else None
|
| 1255 |
args.contextsize = int(contextsize_text[context_var.get()])
|
| 1256 |
|
| 1257 |
if customrope_var.get()==1:
|
|
@@ -1273,14 +1292,12 @@ def show_new_gui():
|
|
| 1273 |
if "threads" in dict:
|
| 1274 |
threads_var.set(dict["threads"])
|
| 1275 |
usemlock.set(1 if "usemlock" in dict and dict["usemlock"] else 0)
|
| 1276 |
-
|
|
|
|
| 1277 |
launchbrowser.set(1 if "launch" in dict and dict["launch"] else 0)
|
| 1278 |
highpriority.set(1 if "highpriority" in dict and dict["highpriority"] else 0)
|
| 1279 |
disablemmap.set(1 if "nommap" in dict and dict["nommap"] else 0)
|
| 1280 |
-
psutil.set(1 if "psutil_set_threads" in dict and dict["psutil_set_threads"] else 0)
|
| 1281 |
-
stream.set(1 if "stream" in dict and dict["stream"] else 0)
|
| 1282 |
smartcontext.set(1 if "smartcontext" in dict and dict["smartcontext"] else 0)
|
| 1283 |
-
unbantokens.set(1 if "unbantokens" in dict and dict["unbantokens"] else 0)
|
| 1284 |
keepforeground.set(1 if "foreground" in dict and dict["foreground"] else 0)
|
| 1285 |
if "useclblast" in dict and dict["useclblast"]:
|
| 1286 |
if clblast_option is not None:
|
|
@@ -1331,12 +1348,6 @@ def show_new_gui():
|
|
| 1331 |
if "forceversion" in dict and dict["forceversion"]:
|
| 1332 |
version_var.set(str(dict["forceversion"]))
|
| 1333 |
|
| 1334 |
-
if "usemirostat" in dict and dict["usemirostat"] and len(dict["usemirostat"])>1:
|
| 1335 |
-
usemirostat.set(0 if str(dict["usemirostat"][0])=="0" else 1)
|
| 1336 |
-
mirostat_var.set(str(dict["usemirostat"][0]))
|
| 1337 |
-
mirostat_tau.set(str(dict["usemirostat"][1]))
|
| 1338 |
-
mirostat_eta.set(str(dict["usemirostat"][2]))
|
| 1339 |
-
|
| 1340 |
if "model_param" in dict and dict["model_param"]:
|
| 1341 |
model_var.set(dict["model_param"])
|
| 1342 |
|
|
@@ -1389,15 +1400,21 @@ def show_new_gui():
|
|
| 1389 |
import webbrowser as wb
|
| 1390 |
wb.open("https://github.com/LostRuins/koboldcpp/wiki")
|
| 1391 |
except:
|
| 1392 |
-
print("Cannot launch help browser.")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1393 |
|
| 1394 |
ctk.CTkButton(tabs , text = "Launch", fg_color="#2f8d3c", hover_color="#2faa3c", command = guilaunch, width=80, height = 35 ).grid(row=1,column=1, stick="se", padx= 25, pady=5)
|
| 1395 |
|
|
|
|
| 1396 |
ctk.CTkButton(tabs , text = "Save", fg_color="#084a66", hover_color="#085a88", command = save_config, width=60, height = 35 ).grid(row=1,column=1, stick="sw", padx= 5, pady=5)
|
| 1397 |
ctk.CTkButton(tabs , text = "Load", fg_color="#084a66", hover_color="#085a88", command = load_config, width=60, height = 35 ).grid(row=1,column=1, stick="sw", padx= 70, pady=5)
|
| 1398 |
ctk.CTkButton(tabs , text = "Help", fg_color="#992222", hover_color="#bb3333", command = display_help, width=60, height = 35 ).grid(row=1,column=1, stick="sw", padx= 135, pady=5)
|
| 1399 |
|
| 1400 |
-
ctk.CTkButton(tabs , text = "Old GUI", fg_color="#084a66", hover_color="#085a88", command = switch_old_gui, width=100, height = 35 ).grid(row=1,column=0, stick="sw", padx= 5, pady=5)
|
| 1401 |
# runs main loop until closed or launch clicked
|
| 1402 |
root.mainloop()
|
| 1403 |
|
|
@@ -1405,9 +1422,6 @@ def show_new_gui():
|
|
| 1405 |
print("Exiting by user request.")
|
| 1406 |
time.sleep(3)
|
| 1407 |
sys.exit()
|
| 1408 |
-
elif nextstate==2:
|
| 1409 |
-
time.sleep(0.1)
|
| 1410 |
-
show_old_gui()
|
| 1411 |
else:
|
| 1412 |
# processing vars
|
| 1413 |
export_vars()
|
|
@@ -1417,183 +1431,23 @@ def show_new_gui():
|
|
| 1417 |
time.sleep(3)
|
| 1418 |
sys.exit(2)
|
| 1419 |
|
| 1420 |
-
def
|
| 1421 |
-
|
| 1422 |
-
|
| 1423 |
-
|
| 1424 |
-
|
| 1425 |
-
if issue == "No Backend Available":
|
| 1426 |
-
messagebox.showerror(title="No Backends Available!", message="KoboldCPP couldn't locate any backends to use.\n\nTo use the program, please run the 'make' command from the directory.")
|
| 1427 |
-
root.destroy()
|
| 1428 |
-
print("No Backend Available (i.e Default, OpenBLAS, CLBlast, CuBLAS). To use the program, please run the 'make' command from the directory.")
|
| 1429 |
-
time.sleep(3)
|
| 1430 |
-
sys.exit(2)
|
| 1431 |
-
else:
|
| 1432 |
-
messagebox.showerror(title="New GUI failed, using Old GUI", message="The new GUI failed to load.\n\nTo use new GUI, please install the customtkinter python module.")
|
| 1433 |
-
root.destroy()
|
| 1434 |
-
|
| 1435 |
-
def show_old_gui():
|
| 1436 |
-
import tkinter as tk
|
| 1437 |
-
from tkinter.filedialog import askopenfilename
|
| 1438 |
-
from tkinter import messagebox
|
| 1439 |
-
|
| 1440 |
-
if len(sys.argv) == 1:
|
| 1441 |
-
#no args passed at all. Show nooby gui
|
| 1442 |
-
root = tk.Tk()
|
| 1443 |
-
launchclicked = False
|
| 1444 |
-
|
| 1445 |
-
def guilaunch():
|
| 1446 |
-
nonlocal launchclicked
|
| 1447 |
-
launchclicked = True
|
| 1448 |
-
root.destroy()
|
| 1449 |
-
pass
|
| 1450 |
-
|
| 1451 |
-
# Adjust size
|
| 1452 |
-
root.geometry("480x360")
|
| 1453 |
-
root.title("KoboldCpp v"+KcppVersion)
|
| 1454 |
-
root.grid_columnconfigure(0, weight=1)
|
| 1455 |
-
tk.Label(root, text = "KoboldCpp Easy Launcher",
|
| 1456 |
-
font = ("Arial", 12)).grid(row=0,column=0)
|
| 1457 |
-
tk.Label(root, text = "(Note: KoboldCpp only works with GGML model formats!)",
|
| 1458 |
-
font = ("Arial", 9)).grid(row=1,column=0)
|
| 1459 |
-
|
| 1460 |
-
blasbatchopts = ["Don't Batch BLAS","BLAS = 32","BLAS = 64","BLAS = 128","BLAS = 256","BLAS = 512","BLAS = 1024","BLAS = 2048"]
|
| 1461 |
-
blaschoice = tk.StringVar()
|
| 1462 |
-
blaschoice.set("BLAS = 512")
|
| 1463 |
-
|
| 1464 |
-
runopts = ["Use OpenBLAS","Use CLBLast GPU #1","Use CLBLast GPU #2","Use CLBLast GPU #3","Use CuBLAS GPU","Use No BLAS","NoAVX2 Mode (Old CPU)","Failsafe Mode (Old CPU)"]
|
| 1465 |
-
runchoice = tk.StringVar()
|
| 1466 |
-
runchoice.set("Use OpenBLAS")
|
| 1467 |
-
|
| 1468 |
-
def onDropdownChange(event):
|
| 1469 |
-
sel = runchoice.get()
|
| 1470 |
-
if sel==runopts[1] or sel==runopts[2] or sel==runopts[3] or sel==runopts[4]:
|
| 1471 |
-
frameC.grid(row=4,column=0,pady=4)
|
| 1472 |
-
else:
|
| 1473 |
-
frameC.grid_forget()
|
| 1474 |
-
|
| 1475 |
-
frameA = tk.Frame(root)
|
| 1476 |
-
tk.OptionMenu( frameA , runchoice , command = onDropdownChange ,*runopts ).grid(row=0,column=0)
|
| 1477 |
-
tk.OptionMenu( frameA , blaschoice ,*blasbatchopts ).grid(row=0,column=1)
|
| 1478 |
-
frameA.grid(row=2,column=0)
|
| 1479 |
-
|
| 1480 |
-
frameB = tk.Frame(root)
|
| 1481 |
-
threads_var=tk.StringVar()
|
| 1482 |
-
threads_var.set(str(default_threads))
|
| 1483 |
-
threads_lbl = tk.Label(frameB, text = 'Threads: ', font=('calibre',10, 'bold'))
|
| 1484 |
-
threads_input = tk.Entry(frameB,textvariable = threads_var, font=('calibre',10,'normal'))
|
| 1485 |
-
threads_lbl.grid(row=0,column=0)
|
| 1486 |
-
threads_input.grid(row=0,column=1)
|
| 1487 |
-
frameB.grid(row=3,column=0,pady=4)
|
| 1488 |
-
|
| 1489 |
-
frameC = tk.Frame(root)
|
| 1490 |
-
gpu_layers_var=tk.StringVar()
|
| 1491 |
-
gpu_layers_var.set("0")
|
| 1492 |
-
gpu_lbl = tk.Label(frameC, text = 'GPU Layers: ', font=('calibre',10, 'bold'))
|
| 1493 |
-
gpu_layers_input = tk.Entry(frameC,textvariable = gpu_layers_var, font=('calibre',10,'normal'))
|
| 1494 |
-
gpu_lbl.grid(row=0,column=0)
|
| 1495 |
-
gpu_layers_input.grid(row=0,column=1)
|
| 1496 |
-
frameC.grid(row=4,column=0,pady=4)
|
| 1497 |
-
onDropdownChange(None)
|
| 1498 |
-
|
| 1499 |
-
stream = tk.IntVar()
|
| 1500 |
-
smartcontext = tk.IntVar()
|
| 1501 |
-
launchbrowser = tk.IntVar(value=1)
|
| 1502 |
-
unbantokens = tk.IntVar()
|
| 1503 |
-
highpriority = tk.IntVar()
|
| 1504 |
-
disablemmap = tk.IntVar()
|
| 1505 |
-
frameD = tk.Frame(root)
|
| 1506 |
-
tk.Checkbutton(frameD, text='Streaming Mode',variable=stream, onvalue=1, offvalue=0).grid(row=0,column=0)
|
| 1507 |
-
tk.Checkbutton(frameD, text='Use SmartContext',variable=smartcontext, onvalue=1, offvalue=0).grid(row=0,column=1)
|
| 1508 |
-
tk.Checkbutton(frameD, text='High Priority',variable=highpriority, onvalue=1, offvalue=0).grid(row=1,column=0)
|
| 1509 |
-
tk.Checkbutton(frameD, text='Disable MMAP',variable=disablemmap, onvalue=1, offvalue=0).grid(row=1,column=1)
|
| 1510 |
-
tk.Checkbutton(frameD, text='Unban Tokens',variable=unbantokens, onvalue=1, offvalue=0).grid(row=2,column=0)
|
| 1511 |
-
tk.Checkbutton(frameD, text='Launch Browser',variable=launchbrowser, onvalue=1, offvalue=0).grid(row=2,column=1)
|
| 1512 |
-
frameD.grid(row=5,column=0,pady=4)
|
| 1513 |
-
|
| 1514 |
-
# Create button, it will change label text
|
| 1515 |
-
tk.Button(root , text = "Launch", font = ("Impact", 18), bg='#54FA9B', command = guilaunch ).grid(row=6,column=0)
|
| 1516 |
-
tk.Label(root, text = "(Please use the Command Line for more advanced options)\nThis GUI is deprecated. Please install customtkinter.",
|
| 1517 |
-
font = ("Arial", 9)).grid(row=7,column=0)
|
| 1518 |
-
|
| 1519 |
-
root.mainloop()
|
| 1520 |
-
|
| 1521 |
-
if launchclicked==False:
|
| 1522 |
-
print("Exiting by user request.")
|
| 1523 |
-
time.sleep(3)
|
| 1524 |
-
sys.exit()
|
| 1525 |
-
|
| 1526 |
-
#load all the vars
|
| 1527 |
-
args.threads = int(threads_var.get())
|
| 1528 |
-
args.gpulayers = int(gpu_layers_var.get())
|
| 1529 |
-
|
| 1530 |
-
args.stream = (stream.get()==1)
|
| 1531 |
-
args.smartcontext = (smartcontext.get()==1)
|
| 1532 |
-
args.launch = (launchbrowser.get()==1)
|
| 1533 |
-
args.unbantokens = (unbantokens.get()==1)
|
| 1534 |
-
args.highpriority = (highpriority.get()==1)
|
| 1535 |
-
args.nommap = (disablemmap.get()==1)
|
| 1536 |
-
selrunchoice = runchoice.get()
|
| 1537 |
-
selblaschoice = blaschoice.get()
|
| 1538 |
-
|
| 1539 |
-
if selrunchoice==runopts[1]:
|
| 1540 |
-
args.useclblast = [0,0]
|
| 1541 |
-
if selrunchoice==runopts[2]:
|
| 1542 |
-
args.useclblast = [1,0]
|
| 1543 |
-
if selrunchoice==runopts[3]:
|
| 1544 |
-
args.useclblast = [0,1]
|
| 1545 |
-
if selrunchoice==runopts[4]:
|
| 1546 |
-
args.usecublas = ["normal"]
|
| 1547 |
-
if selrunchoice==runopts[5]:
|
| 1548 |
-
args.noblas = True
|
| 1549 |
-
if selrunchoice==runopts[6]:
|
| 1550 |
-
args.noavx2 = True
|
| 1551 |
-
if selrunchoice==runopts[7]:
|
| 1552 |
-
args.noavx2 = True
|
| 1553 |
-
args.noblas = True
|
| 1554 |
-
args.nommap = True
|
| 1555 |
-
|
| 1556 |
-
if selblaschoice==blasbatchopts[0]:
|
| 1557 |
-
args.blasbatchsize = -1
|
| 1558 |
-
if selblaschoice==blasbatchopts[1]:
|
| 1559 |
-
args.blasbatchsize = 32
|
| 1560 |
-
if selblaschoice==blasbatchopts[2]:
|
| 1561 |
-
args.blasbatchsize = 64
|
| 1562 |
-
if selblaschoice==blasbatchopts[3]:
|
| 1563 |
-
args.blasbatchsize = 128
|
| 1564 |
-
if selblaschoice==blasbatchopts[4]:
|
| 1565 |
-
args.blasbatchsize = 256
|
| 1566 |
-
if selblaschoice==blasbatchopts[5]:
|
| 1567 |
-
args.blasbatchsize = 512
|
| 1568 |
-
if selblaschoice==blasbatchopts[6]:
|
| 1569 |
-
args.blasbatchsize = 1024
|
| 1570 |
-
if selblaschoice==blasbatchopts[7]:
|
| 1571 |
-
args.blasbatchsize = 2048
|
| 1572 |
-
|
| 1573 |
root = tk.Tk()
|
| 1574 |
root.attributes("-alpha", 0)
|
| 1575 |
-
|
| 1576 |
-
root.destroy()
|
| 1577 |
-
if not args.model_param:
|
| 1578 |
-
print("\nNo ggml model file was selected. Exiting.")
|
| 1579 |
-
time.sleep(3)
|
| 1580 |
-
sys.exit(2)
|
| 1581 |
-
|
| 1582 |
-
else:
|
| 1583 |
-
root = tk.Tk() #we dont want the useless window to be visible, but we want it in taskbar
|
| 1584 |
-
root.attributes("-alpha", 0)
|
| 1585 |
-
args.model_param = askopenfilename(title="Select ggml model .bin or .gguf file")
|
| 1586 |
root.destroy()
|
| 1587 |
-
|
| 1588 |
-
|
| 1589 |
-
time.sleep(3)
|
| 1590 |
-
sys.exit(2)
|
| 1591 |
|
| 1592 |
#A very simple and stripped down embedded horde worker with no dependencies
|
| 1593 |
def run_horde_worker(args, api_key, worker_name):
|
| 1594 |
import urllib.request
|
| 1595 |
from datetime import datetime
|
| 1596 |
-
global friendlymodelname, maxhordectx, maxhordelen, exitcounter, modelbusy
|
| 1597 |
epurl = f"http://localhost:{args.port}"
|
| 1598 |
if args.host!="":
|
| 1599 |
epurl = f"http://{args.host}:{args.port}"
|
|
@@ -1601,11 +1455,29 @@ def run_horde_worker(args, api_key, worker_name):
|
|
| 1601 |
def print_with_time(txt):
|
| 1602 |
print(f"{datetime.now().strftime('[%H:%M:%S]')} " + txt)
|
| 1603 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1604 |
|
| 1605 |
def make_url_request(url, data, method='POST'):
|
| 1606 |
try:
|
| 1607 |
request = None
|
| 1608 |
-
headers = {"apikey": api_key,'User-Agent':'
|
| 1609 |
if method=='POST':
|
| 1610 |
json_payload = json.dumps(data).encode('utf-8')
|
| 1611 |
request = urllib.request.Request(url, data=json_payload, headers=headers, method=method)
|
|
@@ -1631,17 +1503,16 @@ def run_horde_worker(args, api_key, worker_name):
|
|
| 1631 |
current_id = None
|
| 1632 |
current_payload = None
|
| 1633 |
current_generation = None
|
| 1634 |
-
session_kudos_earned = 0
|
| 1635 |
session_starttime = datetime.now()
|
| 1636 |
sleepy_counter = 0 #if this exceeds a value, worker becomes sleepy (slower)
|
| 1637 |
-
print("===\nEmbedded Horde Worker '
|
| 1638 |
-
BRIDGE_AGENT = f"KoboldCppEmbedWorker:
|
| 1639 |
cluster = "https://horde.koboldai.net"
|
| 1640 |
while exitcounter < 10:
|
| 1641 |
time.sleep(3)
|
| 1642 |
readygo = make_url_request(f'{epurl}/api/v1/info/version', None,'GET')
|
| 1643 |
if readygo:
|
| 1644 |
-
print_with_time(f"Embedded Horde Worker is started.")
|
| 1645 |
break
|
| 1646 |
|
| 1647 |
while exitcounter < 10:
|
|
@@ -1650,7 +1521,7 @@ def run_horde_worker(args, api_key, worker_name):
|
|
| 1650 |
|
| 1651 |
#first, make sure we are not generating
|
| 1652 |
if modelbusy.locked():
|
| 1653 |
-
time.sleep(0.
|
| 1654 |
continue
|
| 1655 |
|
| 1656 |
#pop new request
|
|
@@ -1671,7 +1542,6 @@ def run_horde_worker(args, api_key, worker_name):
|
|
| 1671 |
continue
|
| 1672 |
if not pop["id"]:
|
| 1673 |
slp = (1 if sleepy_counter<10 else (2 if sleepy_counter<25 else 3))
|
| 1674 |
-
#print(f"Server {cluster} has no valid generations for us. Sleep for {slp}s")
|
| 1675 |
time.sleep(slp)
|
| 1676 |
sleepy_counter += 1
|
| 1677 |
if sleepy_counter==20:
|
|
@@ -1694,7 +1564,7 @@ def run_horde_worker(args, api_key, worker_name):
|
|
| 1694 |
currentjob_attempts += 1
|
| 1695 |
if currentjob_attempts>5:
|
| 1696 |
break
|
| 1697 |
-
print_with_time("Server Busy - Not ready to generate...")
|
| 1698 |
time.sleep(5)
|
| 1699 |
|
| 1700 |
#submit reply
|
|
@@ -1705,32 +1575,20 @@ def run_horde_worker(args, api_key, worker_name):
|
|
| 1705 |
"generation": current_generation["results"][0]["text"],
|
| 1706 |
"state": "ok"
|
| 1707 |
}
|
| 1708 |
-
|
| 1709 |
-
|
| 1710 |
-
|
| 1711 |
-
print_with_time("Error: Job submit failed.")
|
| 1712 |
-
else:
|
| 1713 |
-
reward = reply["reward"]
|
| 1714 |
-
session_kudos_earned += reward
|
| 1715 |
-
curtime = datetime.now()
|
| 1716 |
-
elapsedtime=curtime-session_starttime
|
| 1717 |
-
hrs = elapsedtime.seconds // 3600
|
| 1718 |
-
mins = elapsedtime.seconds // 60 % 60
|
| 1719 |
-
secs = elapsedtime.seconds % 60
|
| 1720 |
-
elapsedtimestr = f"{hrs:03d}h:{mins:02d}m:{secs:02d}s"
|
| 1721 |
-
earnrate = session_kudos_earned/(elapsedtime.seconds/3600)
|
| 1722 |
-
print_with_time(f'Submitted {current_id} and earned {reward:.0f} kudos\n[Total:{session_kudos_earned:.0f} kudos, Time:{elapsedtimestr}, EarnRate:{earnrate:.0f} kudos/hr]')
|
| 1723 |
else:
|
| 1724 |
-
print_with_time("Error
|
| 1725 |
current_id = None
|
| 1726 |
current_payload = None
|
| 1727 |
-
time.sleep(0.
|
| 1728 |
|
| 1729 |
if exitcounter<100:
|
| 1730 |
-
print_with_time("Horde Worker Shutdown - Too many errors.")
|
| 1731 |
time.sleep(3)
|
| 1732 |
else:
|
| 1733 |
-
print_with_time("Horde Worker Shutdown - Server Closing.")
|
| 1734 |
time.sleep(3)
|
| 1735 |
sys.exit(2)
|
| 1736 |
|
|
@@ -1802,15 +1660,23 @@ def unload_libs():
|
|
| 1802 |
handle = None
|
| 1803 |
|
| 1804 |
def loadconfigfile(filename):
|
|
|
|
| 1805 |
with open(filename, 'r') as f:
|
| 1806 |
config = json.load(f)
|
| 1807 |
for key, value in config.items():
|
| 1808 |
setattr(args, key, value)
|
| 1809 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1810 |
def main(launch_args,start_server=True):
|
| 1811 |
-
global args
|
| 1812 |
args = launch_args
|
| 1813 |
embedded_kailite = None
|
|
|
|
| 1814 |
if args.config and len(args.config)==1:
|
| 1815 |
if isinstance(args.config[0], str) and os.path.exists(args.config[0]):
|
| 1816 |
loadconfigfile(args.config[0])
|
|
@@ -1818,8 +1684,14 @@ def main(launch_args,start_server=True):
|
|
| 1818 |
print("Specified kcpp config file invalid or not found.")
|
| 1819 |
time.sleep(3)
|
| 1820 |
sys.exit(2)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1821 |
if not args.model_param:
|
| 1822 |
args.model_param = args.model
|
|
|
|
| 1823 |
if not args.model_param:
|
| 1824 |
#give them a chance to pick a file
|
| 1825 |
print("For command line arguments, please refer to --help")
|
|
@@ -1827,22 +1699,24 @@ def main(launch_args,start_server=True):
|
|
| 1827 |
try:
|
| 1828 |
show_new_gui()
|
| 1829 |
except Exception as ex:
|
| 1830 |
-
|
| 1831 |
-
|
| 1832 |
-
|
| 1833 |
-
|
| 1834 |
-
|
| 1835 |
-
|
| 1836 |
-
|
| 1837 |
-
|
| 1838 |
-
|
| 1839 |
-
|
| 1840 |
-
time.sleep(3)
|
| 1841 |
-
sys.exit(2)
|
| 1842 |
|
| 1843 |
if args.hordeconfig and args.hordeconfig[0]!="":
|
| 1844 |
-
global
|
| 1845 |
-
friendlymodelname =
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1846 |
if len(args.hordeconfig) > 1:
|
| 1847 |
maxhordelen = int(args.hordeconfig[1])
|
| 1848 |
if len(args.hordeconfig) > 2:
|
|
@@ -1899,11 +1773,6 @@ def main(launch_args,start_server=True):
|
|
| 1899 |
else:
|
| 1900 |
args.lora[1] = os.path.abspath(args.lora[1])
|
| 1901 |
|
| 1902 |
-
if args.psutil_set_threads:
|
| 1903 |
-
import psutil
|
| 1904 |
-
args.threads = psutil.cpu_count(logical=False)
|
| 1905 |
-
print("Overriding thread count, using " + str(args.threads) + " threads instead.")
|
| 1906 |
-
|
| 1907 |
if not args.blasthreads or args.blasthreads <= 0:
|
| 1908 |
args.blasthreads = args.threads
|
| 1909 |
|
|
@@ -1925,6 +1794,13 @@ def main(launch_args,start_server=True):
|
|
| 1925 |
except:
|
| 1926 |
print("Could not find Kobold Lite. Embedded Kobold Lite will not be available.")
|
| 1927 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1928 |
if args.port_param!=defaultport:
|
| 1929 |
args.port = args.port_param
|
| 1930 |
print(f"Starting Kobold HTTP Server on port {args.port}")
|
|
@@ -1951,24 +1827,13 @@ def main(launch_args,start_server=True):
|
|
| 1951 |
def onready_subprocess():
|
| 1952 |
import subprocess
|
| 1953 |
print("Starting Post-Load subprocess...")
|
| 1954 |
-
subprocess.
|
| 1955 |
timer_thread = threading.Timer(1, onready_subprocess) #1 second delay
|
| 1956 |
timer_thread.start()
|
| 1957 |
|
| 1958 |
-
# show deprecation warnings
|
| 1959 |
-
if args.unbantokens:
|
| 1960 |
-
print("WARNING: --unbantokens is DEPRECATED and will be removed soon! EOS unbans should now be set via the generate API.")
|
| 1961 |
-
if args.usemirostat:
|
| 1962 |
-
print("WARNING: --usemirostat is DEPRECATED and will be removed soon! Mirostat values should now be set via the generate API.")
|
| 1963 |
-
if args.stream:
|
| 1964 |
-
print("WARNING: --stream is DEPRECATED and will be removed soon! This was a Kobold Lite only parameter, which is now a proper setting toggle inside Lite.")
|
| 1965 |
-
if args.psutil_set_threads:
|
| 1966 |
-
print("WARNING: --psutil_set_threads is DEPRECATED and will be removed soon! This parameter was generally unhelpful and unnecessary, as the defaults were usually sufficient")
|
| 1967 |
-
|
| 1968 |
-
|
| 1969 |
if start_server:
|
| 1970 |
print(f"Please connect to custom endpoint at {epurl}")
|
| 1971 |
-
asyncio.run(RunServerMultiThreaded(args.host, args.port, embedded_kailite))
|
| 1972 |
else:
|
| 1973 |
print(f"Server was not started, main function complete. Idling.")
|
| 1974 |
|
|
@@ -1993,7 +1858,7 @@ if __name__ == '__main__':
|
|
| 1993 |
parser.add_argument("--threads", help="Use a custom number of threads if specified. Otherwise, uses an amount based on CPU cores", type=int, default=default_threads)
|
| 1994 |
parser.add_argument("--blasthreads", help="Use a different number of threads during BLAS if specified. Otherwise, has the same value as --threads",metavar=('[threads]'), type=int, default=0)
|
| 1995 |
parser.add_argument("--highpriority", help="Experimental flag. If set, increases the process CPU priority, potentially speeding up generation. Use caution.", action='store_true')
|
| 1996 |
-
parser.add_argument("--contextsize", help="Controls the memory allocated for maximum context size, only change if you need more RAM for big contexts. (default 2048)", type=int,choices=[512,1024,2048,3072,4096,6144,8192,12288,16384,24576,32768], default=2048)
|
| 1997 |
parser.add_argument("--blasbatchsize", help="Sets the batch size used in BLAS processing (default 512). Setting it to -1 disables BLAS mode, but keeps other benefits like GPU offload.", type=int,choices=[-1,32,64,128,256,512,1024,2048], default=512)
|
| 1998 |
parser.add_argument("--ropeconfig", help="If set, uses customized RoPE scaling from configured frequency scale and frequency base (e.g. --ropeconfig 0.25 10000). Otherwise, uses NTK-Aware scaling set automatically based on context size. For linear rope, simply set the freq-scale and ignore the freq-base",metavar=('[rope-freq-scale]', '[rope-freq-base]'), default=[0.0, 10000.0], type=float, nargs='+')
|
| 1999 |
parser.add_argument("--smartcontext", help="Reserving a portion of context to try processing less frequently.", action='store_true')
|
|
@@ -2002,7 +1867,7 @@ if __name__ == '__main__':
|
|
| 2002 |
parser.add_argument("--nommap", help="If set, do not use mmap to load newer models", action='store_true')
|
| 2003 |
parser.add_argument("--usemlock", help="For Apple Systems. Force system to keep model in RAM rather than swapping or compressing", action='store_true')
|
| 2004 |
parser.add_argument("--noavx2", help="Do not use AVX2 instructions, a slower compatibility mode for older devices. Does not work with --clblast.", action='store_true')
|
| 2005 |
-
parser.add_argument("--debugmode", help="Shows additional debug info in the terminal.",
|
| 2006 |
parser.add_argument("--skiplauncher", help="Doesn't display or use the GUI launcher.", action='store_true')
|
| 2007 |
parser.add_argument("--hordeconfig", help="Sets the display model name to something else, for easy use on AI Horde. Optional additional parameters set the horde max genlength, max ctxlen, API key and worker name.",metavar=('[hordemodelname]', '[hordegenlength] [hordemaxctx] [hordeapikey] [hordeworkername]'), nargs='+')
|
| 2008 |
compatgroup = parser.add_mutually_exclusive_group()
|
|
@@ -2012,13 +1877,7 @@ if __name__ == '__main__':
|
|
| 2012 |
parser.add_argument("--gpulayers", help="Set number of layers to offload to GPU when using GPU. Requires GPU.",metavar=('[GPU layers]'), type=int, default=0)
|
| 2013 |
parser.add_argument("--tensor_split", help="For CUDA with ALL GPU set only, ratio to split tensors across multiple GPUs, space-separated list of proportions, e.g. 7 3", metavar=('[Ratios]'), type=float, nargs='+')
|
| 2014 |
parser.add_argument("--onready", help="An optional shell command to execute after the model has been loaded.", type=str, default="",nargs=1)
|
| 2015 |
-
parser.add_argument("--multiuser", help="Runs in multiuser mode, which queues incoming requests instead of blocking them.
|
| 2016 |
parser.add_argument("--foreground", help="Windows only. Sends the terminal to the foreground every time a new prompt is generated. This helps avoid some idle slowdown issues.", action='store_true')
|
| 2017 |
|
| 2018 |
-
|
| 2019 |
-
parser.add_argument("--psutil_set_threads", help="--psutil_set_threads is DEPRECATED and will be removed soon! This parameter was generally unhelpful and unnecessary, as the defaults were usually sufficient.", action='store_true')
|
| 2020 |
-
parser.add_argument("--stream", help="--stream is DEPRECATED and will be removed soon! This was a Kobold Lite only parameter, which is now a proper setting toggle inside Lite.", action='store_true')
|
| 2021 |
-
parser.add_argument("--unbantokens", help="--unbantokens is DEPRECATED and will be removed soon! EOS unbans should now be set via the generate API", action='store_true')
|
| 2022 |
-
parser.add_argument("--usemirostat", help="--usemirostat is DEPRECATED and will be removed soon! Mirostat values should now be set via the generate API",metavar=('[type]', '[tau]', '[eta]'), type=float, nargs=3)
|
| 2023 |
-
|
| 2024 |
-
main(parser.parse_args(),start_server=True)
|
|
|
|
| 34 |
("use_mmap", ctypes.c_bool),
|
| 35 |
("use_mlock", ctypes.c_bool),
|
| 36 |
("use_smartcontext", ctypes.c_bool),
|
|
|
|
| 37 |
("clblast_info", ctypes.c_int),
|
| 38 |
("cublas_info", ctypes.c_int),
|
| 39 |
("blasbatchsize", ctypes.c_int),
|
|
|
|
| 223 |
if len(args.lora) > 1:
|
| 224 |
inputs.lora_base = args.lora[1].encode("UTF-8")
|
| 225 |
inputs.use_smartcontext = args.smartcontext
|
|
|
|
| 226 |
inputs.blasbatchsize = args.blasbatchsize
|
| 227 |
inputs.forceversion = args.forceversion
|
| 228 |
inputs.gpulayers = args.gpulayers
|
|
|
|
| 280 |
ret = handle.load_model(inputs)
|
| 281 |
return ret
|
| 282 |
|
| 283 |
+
def generate(prompt,max_length=20, max_context_length=512, temperature=0.8, top_k=120, top_a=0.0, top_p=0.85, typical_p=1.0, tfs=1.0, rep_pen=1.1, rep_pen_range=128, mirostat=0, mirostat_tau=5.0, mirostat_eta=0.1, sampler_order=[6,0,1,3,4,2,5], seed=-1, stop_sequence=[], use_default_badwordsids=False, stream_sse=False, grammar='', grammar_retain_state=False, genkey=''):
|
| 284 |
global maxctx, args, currentusergenkey, totalgens
|
| 285 |
inputs = generation_inputs()
|
| 286 |
outputs = ctypes.create_unicode_buffer(ctypes.sizeof(generation_outputs))
|
|
|
|
| 305 |
inputs.grammar = grammar.encode("UTF-8")
|
| 306 |
inputs.grammar_retain_state = grammar_retain_state
|
| 307 |
inputs.unban_tokens_rt = not use_default_badwordsids
|
| 308 |
+
if mirostat in (1, 2):
|
|
|
|
|
|
|
|
|
|
|
|
|
| 309 |
inputs.mirostat = mirostat
|
| 310 |
inputs.mirostat_tau = mirostat_tau
|
| 311 |
inputs.mirostat_eta = mirostat_eta
|
|
|
|
| 361 |
modelbusy = threading.Lock()
|
| 362 |
requestsinqueue = 0
|
| 363 |
defaultport = 5001
|
| 364 |
+
KcppVersion = "1.46.1"
|
| 365 |
showdebug = True
|
| 366 |
showsamplerwarning = True
|
| 367 |
showmaxctxwarning = True
|
| 368 |
+
session_kudos_earned = 0
|
| 369 |
+
session_jobs = 0
|
| 370 |
+
session_starttime = None
|
| 371 |
exitcounter = 0
|
| 372 |
totalgens = 0
|
| 373 |
currentusergenkey = "" #store a special key so polled streaming works even in multiuser
|
|
|
|
| 377 |
sys_version = ""
|
| 378 |
server_version = "ConcedoLlamaForKoboldServer"
|
| 379 |
|
| 380 |
+
def __init__(self, addr, port, embedded_kailite, embedded_kcpp_docs):
|
| 381 |
self.addr = addr
|
| 382 |
self.port = port
|
| 383 |
self.embedded_kailite = embedded_kailite
|
| 384 |
+
self.embedded_kcpp_docs = embedded_kcpp_docs
|
| 385 |
|
| 386 |
def __call__(self, *args, **kwargs):
|
| 387 |
super().__init__(*args, **kwargs)
|
|
|
|
| 393 |
pass
|
| 394 |
|
| 395 |
async def generate_text(self, genparams, api_format, stream_flag):
|
| 396 |
+
global friendlymodelname
|
| 397 |
def run_blocking():
|
| 398 |
if api_format==1:
|
| 399 |
genparams["prompt"] = genparams.get('text', "")
|
| 400 |
genparams["top_k"] = int(genparams.get('top_k', 120))
|
| 401 |
+
genparams["max_length"] = genparams.get('max', 80)
|
| 402 |
elif api_format==3:
|
| 403 |
frqp = genparams.get('frequency_penalty', 0.1)
|
| 404 |
scaled_rep_pen = genparams.get('presence_penalty', frqp) + 1
|
| 405 |
+
genparams["max_length"] = genparams.get('max_tokens', 80)
|
| 406 |
+
genparams["rep_pen"] = scaled_rep_pen
|
| 407 |
+
# openai allows either a string or a list as a stop sequence
|
| 408 |
+
if isinstance(genparams.get('stop',[]), list):
|
| 409 |
+
genparams["stop_sequence"] = genparams.get('stop', [])
|
| 410 |
+
else:
|
| 411 |
+
genparams["stop_sequence"] = [genparams.get('stop')]
|
| 412 |
+
elif api_format==4:
|
| 413 |
+
# translate openai chat completion messages format into one big string.
|
| 414 |
+
messages_array = genparams.get('messages', [])
|
| 415 |
+
messages_string = ""
|
| 416 |
+
for message in messages_array:
|
| 417 |
+
if message['role'] == "system":
|
| 418 |
+
messages_string+="\n### Instruction:\n"
|
| 419 |
+
elif message['role'] == "user":
|
| 420 |
+
messages_string+="\n### Instruction:\n"
|
| 421 |
+
elif message['role'] == "assistant":
|
| 422 |
+
messages_string+="\n### Response:\n"
|
| 423 |
+
messages_string+=message['content']
|
| 424 |
+
messages_string += "\n### Response:\n"
|
| 425 |
+
genparams["prompt"] = messages_string
|
| 426 |
+
frqp = genparams.get('frequency_penalty', 0.1)
|
| 427 |
+
scaled_rep_pen = genparams.get('presence_penalty', frqp) + 1
|
| 428 |
+
genparams["max_length"] = genparams.get('max_tokens', 80)
|
| 429 |
genparams["rep_pen"] = scaled_rep_pen
|
| 430 |
+
# openai allows either a string or a list as a stop sequence
|
| 431 |
+
if isinstance(genparams.get('stop',[]), list):
|
| 432 |
+
genparams["stop_sequence"] = genparams.get('stop', [])
|
| 433 |
+
else:
|
| 434 |
+
genparams["stop_sequence"] = [genparams.get('stop')]
|
| 435 |
|
| 436 |
return generate(
|
| 437 |
prompt=genparams.get('prompt', ""),
|
|
|
|
| 451 |
sampler_order=genparams.get('sampler_order', [6,0,1,3,4,2,5]),
|
| 452 |
seed=genparams.get('sampler_seed', -1),
|
| 453 |
stop_sequence=genparams.get('stop_sequence', []),
|
| 454 |
+
use_default_badwordsids=genparams.get('use_default_badwordsids', False),
|
| 455 |
stream_sse=stream_flag,
|
| 456 |
grammar=genparams.get('grammar', ''),
|
| 457 |
grammar_retain_state = genparams.get('grammar_retain_state', False),
|
|
|
|
| 471 |
if api_format==1:
|
| 472 |
res = {"data": {"seqs":[recvtxt]}}
|
| 473 |
elif api_format==3:
|
| 474 |
+
res = {"id": "cmpl-1", "object": "text_completion", "created": 1, "model": friendlymodelname,
|
| 475 |
"choices": [{"text": recvtxt, "index": 0, "finish_reason": "length"}]}
|
| 476 |
+
elif api_format==4:
|
| 477 |
+
res = {"id": "chatcmpl-1", "object": "chat.completion", "created": 1, "model": friendlymodelname,
|
| 478 |
+
"choices": [{"index": 0, "message":{"role": "assistant", "content": recvtxt,}, "finish_reason": "length"}]}
|
| 479 |
else:
|
| 480 |
res = {"results": [{"text": recvtxt}]}
|
| 481 |
|
|
|
|
| 485 |
print(f"Generate: Error while generating: {e}")
|
| 486 |
|
| 487 |
|
| 488 |
+
async def send_oai_sse_event(self, data):
|
| 489 |
+
self.wfile.write(f'data: {data}\r\n\r\n'.encode())
|
| 490 |
+
self.wfile.flush()
|
| 491 |
|
| 492 |
+
async def send_kai_sse_event(self, data):
|
| 493 |
+
self.wfile.write(f'event: message\n'.encode())
|
| 494 |
+
self.wfile.write(f'data: {data}\n\n'.encode())
|
| 495 |
+
self.wfile.flush()
|
| 496 |
|
| 497 |
+
async def handle_sse_stream(self, api_format):
|
| 498 |
+
global friendlymodelname
|
| 499 |
self.send_response(200)
|
| 500 |
self.send_header("Cache-Control", "no-cache")
|
| 501 |
self.send_header("Connection", "keep-alive")
|
| 502 |
+
self.end_headers(force_json=True, sse_stream_flag=True)
|
| 503 |
|
| 504 |
current_token = 0
|
|
|
|
| 505 |
incomplete_token_buffer = bytearray()
|
| 506 |
while True:
|
| 507 |
streamDone = handle.has_finished() #exit next loop on done
|
|
|
|
| 522 |
tokenStr += tokenSeg
|
| 523 |
|
| 524 |
if tokenStr!="":
|
| 525 |
+
if api_format == 4: # if oai chat, set format to expected openai streaming response
|
| 526 |
+
event_str = json.dumps({"id":"koboldcpp","object":"chat.completion.chunk","created":1,"model":friendlymodelname,"choices":[{"index":0,"finish_reason":"length","delta":{'role':'assistant','content':tokenStr}}]})
|
| 527 |
+
await self.send_oai_sse_event(event_str)
|
| 528 |
+
else:
|
| 529 |
+
event_str = json.dumps({"token": tokenStr})
|
| 530 |
+
await self.send_kai_sse_event(event_str)
|
| 531 |
tokenStr = ""
|
| 532 |
+
|
| 533 |
else:
|
| 534 |
await asyncio.sleep(0.02) #this should keep things responsive
|
| 535 |
|
| 536 |
if streamDone:
|
| 537 |
+
if api_format == 4: # if oai chat, send last [DONE] message consistent with openai format
|
| 538 |
+
await self.send_oai_sse_event('[DONE]')
|
| 539 |
break
|
| 540 |
|
| 541 |
# flush buffers, sleep a bit to make sure all data sent, and then force close the connection
|
| 542 |
self.wfile.flush()
|
| 543 |
+
await asyncio.sleep(0.2)
|
| 544 |
self.close_connection = True
|
| 545 |
+
await asyncio.sleep(0.1)
|
| 546 |
|
| 547 |
|
| 548 |
async def handle_request(self, genparams, api_format, stream_flag):
|
| 549 |
tasks = []
|
| 550 |
|
| 551 |
if stream_flag:
|
| 552 |
+
tasks.append(self.handle_sse_stream(api_format))
|
| 553 |
|
| 554 |
generate_task = asyncio.create_task(self.generate_text(genparams, api_format, stream_flag))
|
| 555 |
tasks.append(generate_task)
|
|
|
|
| 569 |
force_json = False
|
| 570 |
|
| 571 |
if self.path in ["", "/?"] or self.path.startswith(('/?','?')): #it's possible for the root url to have ?params without /
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 572 |
|
| 573 |
if self.embedded_kailite is None:
|
| 574 |
response_body = (f"Embedded Kobold Lite is not found.<br>You will have to connect via the main KoboldAI client, or <a href='https://lite.koboldai.net?local=1&port={self.port}'>use this URL</a> to connect.").encode()
|
|
|
|
| 591 |
response_body = (json.dumps({"values": []}).encode())
|
| 592 |
|
| 593 |
elif self.path.endswith(('/api/v1/info/version', '/api/latest/info/version')):
|
| 594 |
+
response_body = (json.dumps({"result":"1.2.5"}).encode())
|
| 595 |
|
| 596 |
elif self.path.endswith(('/api/extra/true_max_context_length')): #do not advertise this to horde
|
| 597 |
response_body = (json.dumps({"value": maxctx}).encode())
|
|
|
|
| 613 |
pendtxtStr = ctypes.string_at(pendtxt).decode("UTF-8","ignore")
|
| 614 |
response_body = (json.dumps({"results": [{"text": pendtxtStr}]}).encode())
|
| 615 |
|
| 616 |
+
elif self.path.endswith('/v1/models'):
|
| 617 |
+
response_body = (json.dumps({"object":"list","data":[{"id":friendlymodelname,"object":"model","created":1,"owned_by":"koboldcpp","permission":[],"root":"koboldcpp"}]}).encode())
|
| 618 |
force_json = True
|
| 619 |
|
| 620 |
+
elif self.path=="/api":
|
| 621 |
+
if self.embedded_kcpp_docs is None:
|
| 622 |
+
response_body = (f"KoboldCpp partial API reference can be found at the wiki: https://github.com/LostRuins/koboldcpp/wiki").encode()
|
| 623 |
+
else:
|
| 624 |
+
response_body = self.embedded_kcpp_docs
|
| 625 |
elif self.path.endswith(('/api')) or self.path.endswith(('/api/v1')):
|
| 626 |
+
self.path = "/api"
|
| 627 |
+
self.send_response(302)
|
| 628 |
+
self.send_header("Location", self.path)
|
| 629 |
+
self.end_headers()
|
| 630 |
+
return None
|
| 631 |
|
| 632 |
if response_body is None:
|
| 633 |
self.send_response(404)
|
|
|
|
| 647 |
body = self.rfile.read(content_length)
|
| 648 |
self.path = self.path.rstrip('/')
|
| 649 |
force_json = False
|
|
|
|
| 650 |
if self.path.endswith(('/api/extra/tokencount')):
|
| 651 |
try:
|
| 652 |
genparams = json.loads(body)
|
|
|
|
| 664 |
return
|
| 665 |
|
| 666 |
if self.path.endswith('/api/extra/abort'):
|
| 667 |
+
multiuserkey = ""
|
| 668 |
+
try:
|
| 669 |
+
tempbody = json.loads(body)
|
| 670 |
+
multiuserkey = tempbody.get('genkey', "")
|
| 671 |
+
except ValueError as e:
|
| 672 |
+
multiuserkey = ""
|
| 673 |
+
pass
|
| 674 |
+
|
| 675 |
+
if (multiuserkey!="" and multiuserkey==currentusergenkey) or requestsinqueue==0:
|
| 676 |
ag = handle.abort_generate()
|
| 677 |
+
time.sleep(0.3) #short delay before replying
|
| 678 |
self.send_response(200)
|
| 679 |
self.end_headers()
|
| 680 |
self.wfile.write(json.dumps({"success": ("true" if ag else "false")}).encode())
|
| 681 |
print("\nGeneration Aborted")
|
| 682 |
else:
|
| 683 |
+
self.wfile.write(json.dumps({"success": "false"}).encode())
|
| 684 |
return
|
| 685 |
|
| 686 |
if self.path.endswith('/api/extra/generate/check'):
|
|
|
|
| 715 |
}}).encode())
|
| 716 |
return
|
| 717 |
if reqblocking:
|
| 718 |
+
requestsinqueue = (requestsinqueue - 1) if requestsinqueue > 0 else 0
|
| 719 |
|
| 720 |
try:
|
| 721 |
+
sse_stream_flag = False
|
| 722 |
|
| 723 |
+
api_format = 0 #1=basic,2=kai,3=oai,4=oai-chat
|
| 724 |
|
| 725 |
if self.path.endswith('/request'):
|
| 726 |
api_format = 1
|
|
|
|
| 730 |
|
| 731 |
if self.path.endswith('/api/extra/generate/stream'):
|
| 732 |
api_format = 2
|
| 733 |
+
sse_stream_flag = True
|
| 734 |
|
| 735 |
+
if self.path.endswith('/v1/completions'):
|
| 736 |
api_format = 3
|
| 737 |
force_json = True
|
| 738 |
|
| 739 |
+
if self.path.endswith('/v1/chat/completions'):
|
| 740 |
+
api_format = 4
|
| 741 |
+
force_json = True
|
| 742 |
+
|
| 743 |
+
if api_format > 0:
|
| 744 |
genparams = None
|
| 745 |
try:
|
| 746 |
genparams = json.loads(body)
|
|
|
|
| 754 |
if args.foreground:
|
| 755 |
bring_terminal_to_foreground()
|
| 756 |
|
| 757 |
+
# Check if streaming chat completions, if so, set stream mode to true
|
| 758 |
+
if api_format == 4 and "stream" in genparams and genparams["stream"]:
|
| 759 |
+
sse_stream_flag = True
|
| 760 |
+
|
| 761 |
+
gen = asyncio.run(self.handle_request(genparams, api_format, sse_stream_flag))
|
| 762 |
|
| 763 |
try:
|
| 764 |
# Headers are already sent when streaming
|
| 765 |
+
if not sse_stream_flag:
|
| 766 |
self.send_response(200)
|
| 767 |
self.end_headers(force_json=force_json)
|
| 768 |
self.wfile.write(json.dumps(gen).encode())
|
| 769 |
except:
|
| 770 |
print("Generate: The response could not be sent, maybe connection was terminated?")
|
|
|
|
| 771 |
return
|
| 772 |
finally:
|
| 773 |
modelbusy.release()
|
|
|
|
| 784 |
self.send_response(200)
|
| 785 |
self.end_headers()
|
| 786 |
|
| 787 |
+
def end_headers(self, force_json=False, sse_stream_flag=False):
|
| 788 |
self.send_header('Access-Control-Allow-Origin', '*')
|
| 789 |
self.send_header('Access-Control-Allow-Methods', '*')
|
| 790 |
self.send_header('Access-Control-Allow-Headers', '*')
|
| 791 |
+
if ("/api" in self.path and self.path!="/api") or force_json:
|
| 792 |
+
if sse_stream_flag:
|
| 793 |
self.send_header('Content-type', 'text/event-stream')
|
| 794 |
self.send_header('Content-type', 'application/json')
|
| 795 |
else:
|
|
|
|
| 797 |
return super(ServerRequestHandler, self).end_headers()
|
| 798 |
|
| 799 |
|
| 800 |
+
def RunServerMultiThreaded(addr, port, embedded_kailite = None, embedded_kcpp_docs = None):
|
| 801 |
global exitcounter
|
| 802 |
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
| 803 |
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
|
|
|
| 813 |
|
| 814 |
def run(self):
|
| 815 |
global exitcounter
|
| 816 |
+
handler = ServerRequestHandler(addr, port, embedded_kailite, embedded_kcpp_docs)
|
| 817 |
with http.server.HTTPServer((addr, port), handler, False) as self.httpd:
|
| 818 |
try:
|
| 819 |
self.httpd.socket = sock
|
|
|
|
| 858 |
args.model_param = askopenfilename(title="Select ggml model .bin or .gguf file or .kcpps config")
|
| 859 |
root.destroy()
|
| 860 |
if args.model_param and args.model_param!="" and args.model_param.lower().endswith('.kcpps'):
|
|
|
|
| 861 |
loadconfigfile(args.model_param)
|
| 862 |
if not args.model_param:
|
| 863 |
print("\nNo ggml model or kcpps file was selected. Exiting.")
|
|
|
|
| 866 |
return
|
| 867 |
|
| 868 |
import customtkinter as ctk
|
| 869 |
+
nextstate = 0 #0=exit, 1=launch
|
| 870 |
windowwidth = 530
|
| 871 |
windowheight = 500
|
| 872 |
ctk.set_appearance_mode("dark")
|
|
|
|
| 900 |
# slider data
|
| 901 |
blasbatchsize_values = ["-1", "32", "64", "128", "256", "512", "1024", "2048"]
|
| 902 |
blasbatchsize_text = ["Don't Batch BLAS","32","64","128","256","512","1024","2048"]
|
| 903 |
+
contextsize_text = ["512", "1024", "2048", "3072", "4096", "6144", "8192", "12288", "16384", "24576", "32768", "65536"]
|
| 904 |
runopts = [opt for lib, opt in lib_option_pairs if file_exists(lib)]
|
| 905 |
antirunopts = [opt.replace("Use ", "") for lib, opt in lib_option_pairs if not (opt in runopts)]
|
| 906 |
if not any(runopts):
|
| 907 |
+
show_gui_msgbox("No Backends Available!","KoboldCPP couldn't locate any backends to use (i.e Default, OpenBLAS, CLBlast, CuBLAS).\n\nTo use the program, please run the 'make' command from the directory.")
|
| 908 |
+
time.sleep(3)
|
| 909 |
+
sys.exit(2)
|
| 910 |
def tabbuttonaction(name):
|
| 911 |
for t in tabcontent:
|
| 912 |
if name == t:
|
|
|
|
| 962 |
return entry, label
|
| 963 |
|
| 964 |
|
| 965 |
+
def makefileentry(parent, text, searchtext, var, row=0, width=250, filetypes=[]):
|
| 966 |
makelabel(parent, text, row)
|
| 967 |
def getfilename(var, text):
|
| 968 |
+
var.set(askopenfilename(title=text,filetypes=filetypes))
|
| 969 |
entry = ctk.CTkEntry(parent, width, textvariable=var)
|
| 970 |
entry.grid(row=row+1, column=0, padx=8, stick="nw")
|
| 971 |
button = ctk.CTkButton(parent, 50, text="Browse", command= lambda a=var,b=searchtext:getfilename(a,b))
|
|
|
|
| 986 |
x, y = root.winfo_pointerxy()
|
| 987 |
tooltip.wm_geometry(f"+{x + 10}+{y + 10}")
|
| 988 |
tooltip.deiconify()
|
| 989 |
+
|
| 990 |
def hide_tooltip(event):
|
| 991 |
if hasattr(show_tooltip, "_tooltip"):
|
| 992 |
tooltip = show_tooltip._tooltip
|
| 993 |
tooltip.withdraw()
|
| 994 |
+
|
| 995 |
def setup_backend_tooltip(parent):
|
| 996 |
num_backends_built = makelabel(parent, str(len(runopts)) + "/6", 5, 2)
|
| 997 |
num_backends_built.grid(row=1, column=2, padx=0, pady=0)
|
|
|
|
| 1009 |
launchbrowser = ctk.IntVar(value=1)
|
| 1010 |
highpriority = ctk.IntVar()
|
| 1011 |
disablemmap = ctk.IntVar()
|
|
|
|
| 1012 |
usemlock = ctk.IntVar()
|
| 1013 |
debugmode = ctk.IntVar()
|
| 1014 |
keepforeground = ctk.IntVar()
|
| 1015 |
|
| 1016 |
lowvram_var = ctk.IntVar()
|
| 1017 |
mmq_var = ctk.IntVar(value=1)
|
|
|
|
| 1018 |
blas_threads_var = ctk.StringVar()
|
| 1019 |
blas_size_var = ctk.IntVar()
|
| 1020 |
version_var =ctk.StringVar(value="0")
|
| 1021 |
|
|
|
|
| 1022 |
smartcontext = ctk.IntVar()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1023 |
context_var = ctk.IntVar()
|
|
|
|
| 1024 |
customrope_var = ctk.IntVar()
|
| 1025 |
customrope_scale = ctk.StringVar(value="1.0")
|
| 1026 |
customrope_base = ctk.StringVar(value="10000")
|
|
|
|
| 1111 |
makeslider(quick_tab, "BLAS Batch Size:", blasbatchsize_text, blas_size_var, 0, 7, 12, set=5)
|
| 1112 |
|
| 1113 |
# quick boxes
|
| 1114 |
+
quick_boxes = {"Launch Browser": launchbrowser , "High Priority" : highpriority, "Use SmartContext":smartcontext, "Disable MMAP":disablemmap,}
|
| 1115 |
for idx, name, in enumerate(quick_boxes):
|
| 1116 |
makecheckbox(quick_tab, name, quick_boxes[name], int(idx/2) +20, idx%2)
|
| 1117 |
# context size
|
| 1118 |
makeslider(quick_tab, "Context Size:", contextsize_text, context_var, 0, len(contextsize_text)-1, 30, set=2)
|
| 1119 |
|
| 1120 |
# load model
|
| 1121 |
+
makefileentry(quick_tab, "Model:", "Select GGML Model File", model_var, 40, 170,filetypes=[("GGML Model Files", "*.gguf;*.bin;*.ggml")])
|
| 1122 |
|
| 1123 |
# Hardware Tab
|
| 1124 |
hardware_tab = tabcontent["Hardware"]
|
|
|
|
| 1144 |
makelabelentry(hardware_tab, "Threads:" , threads_var, 8, 50)
|
| 1145 |
|
| 1146 |
# hardware checkboxes
|
| 1147 |
+
hardware_boxes = {"Launch Browser": launchbrowser , "High Priority" : highpriority, "Disable MMAP":disablemmap, "Use mlock":usemlock, "Debug Mode":debugmode, "Keep Foreground":keepforeground}
|
| 1148 |
|
| 1149 |
for idx, name, in enumerate(hardware_boxes):
|
| 1150 |
makecheckbox(hardware_tab, name, hardware_boxes[name], int(idx/2) +30, idx%2)
|
|
|
|
| 1162 |
# Tokens Tab
|
| 1163 |
tokens_tab = tabcontent["Tokens"]
|
| 1164 |
# tokens checkboxes
|
| 1165 |
+
token_boxes = {"Use SmartContext":smartcontext}
|
| 1166 |
for idx, name, in enumerate(token_boxes):
|
| 1167 |
makecheckbox(tokens_tab, name, token_boxes[name], idx + 1)
|
| 1168 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1169 |
# context size
|
| 1170 |
makeslider(tokens_tab, "Context Size:",contextsize_text, context_var, 0, len(contextsize_text)-1, 20, set=2)
|
| 1171 |
|
|
|
|
| 1185 |
# Model Tab
|
| 1186 |
model_tab = tabcontent["Model"]
|
| 1187 |
|
| 1188 |
+
makefileentry(model_tab, "Model:", "Select GGML Model File", model_var, 1, filetypes=[("GGML Model Files", "*.gguf;*.bin;*.ggml")])
|
| 1189 |
makefileentry(model_tab, "Lora:", "Select Lora File",lora_var, 3)
|
| 1190 |
makefileentry(model_tab, "Lora Base:", "Select Lora Base File", lora_base_var, 5)
|
| 1191 |
|
|
|
|
| 1233 |
root.destroy()
|
| 1234 |
pass
|
| 1235 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1236 |
def export_vars():
|
| 1237 |
args.threads = int(threads_var.get())
|
|
|
|
| 1238 |
args.usemlock = usemlock.get() == 1
|
| 1239 |
+
args.debugmode = debugmode.get()
|
| 1240 |
args.launch = launchbrowser.get()==1
|
| 1241 |
args.highpriority = highpriority.get()==1
|
| 1242 |
args.nommap = disablemmap.get()==1
|
|
|
|
|
|
|
| 1243 |
args.smartcontext = smartcontext.get()==1
|
|
|
|
| 1244 |
args.foreground = keepforeground.get()==1
|
| 1245 |
|
| 1246 |
gpuchoiceidx = 0
|
|
|
|
| 1271 |
args.blasbatchsize = int(blasbatchsize_values[int(blas_size_var.get())])
|
| 1272 |
args.forceversion = 0 if version_var.get()=="" else int(version_var.get())
|
| 1273 |
|
|
|
|
| 1274 |
args.contextsize = int(contextsize_text[context_var.get()])
|
| 1275 |
|
| 1276 |
if customrope_var.get()==1:
|
|
|
|
| 1292 |
if "threads" in dict:
|
| 1293 |
threads_var.set(dict["threads"])
|
| 1294 |
usemlock.set(1 if "usemlock" in dict and dict["usemlock"] else 0)
|
| 1295 |
+
if "debugmode" in dict:
|
| 1296 |
+
debugmode.set(dict["debugmode"])
|
| 1297 |
launchbrowser.set(1 if "launch" in dict and dict["launch"] else 0)
|
| 1298 |
highpriority.set(1 if "highpriority" in dict and dict["highpriority"] else 0)
|
| 1299 |
disablemmap.set(1 if "nommap" in dict and dict["nommap"] else 0)
|
|
|
|
|
|
|
| 1300 |
smartcontext.set(1 if "smartcontext" in dict and dict["smartcontext"] else 0)
|
|
|
|
| 1301 |
keepforeground.set(1 if "foreground" in dict and dict["foreground"] else 0)
|
| 1302 |
if "useclblast" in dict and dict["useclblast"]:
|
| 1303 |
if clblast_option is not None:
|
|
|
|
| 1348 |
if "forceversion" in dict and dict["forceversion"]:
|
| 1349 |
version_var.set(str(dict["forceversion"]))
|
| 1350 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1351 |
if "model_param" in dict and dict["model_param"]:
|
| 1352 |
model_var.set(dict["model_param"])
|
| 1353 |
|
|
|
|
| 1400 |
import webbrowser as wb
|
| 1401 |
wb.open("https://github.com/LostRuins/koboldcpp/wiki")
|
| 1402 |
except:
|
| 1403 |
+
print("Cannot launch help in browser.")
|
| 1404 |
+
def display_updates():
|
| 1405 |
+
try:
|
| 1406 |
+
import webbrowser as wb
|
| 1407 |
+
wb.open("https://github.com/LostRuins/koboldcpp/releases/latest")
|
| 1408 |
+
except:
|
| 1409 |
+
print("Cannot launch updates in browser.")
|
| 1410 |
|
| 1411 |
ctk.CTkButton(tabs , text = "Launch", fg_color="#2f8d3c", hover_color="#2faa3c", command = guilaunch, width=80, height = 35 ).grid(row=1,column=1, stick="se", padx= 25, pady=5)
|
| 1412 |
|
| 1413 |
+
ctk.CTkButton(tabs , text = "Update", fg_color="#9900cc", hover_color="#aa11dd", command = display_updates, width=90, height = 35 ).grid(row=1,column=0, stick="sw", padx= 5, pady=5)
|
| 1414 |
ctk.CTkButton(tabs , text = "Save", fg_color="#084a66", hover_color="#085a88", command = save_config, width=60, height = 35 ).grid(row=1,column=1, stick="sw", padx= 5, pady=5)
|
| 1415 |
ctk.CTkButton(tabs , text = "Load", fg_color="#084a66", hover_color="#085a88", command = load_config, width=60, height = 35 ).grid(row=1,column=1, stick="sw", padx= 70, pady=5)
|
| 1416 |
ctk.CTkButton(tabs , text = "Help", fg_color="#992222", hover_color="#bb3333", command = display_help, width=60, height = 35 ).grid(row=1,column=1, stick="sw", padx= 135, pady=5)
|
| 1417 |
|
|
|
|
| 1418 |
# runs main loop until closed or launch clicked
|
| 1419 |
root.mainloop()
|
| 1420 |
|
|
|
|
| 1422 |
print("Exiting by user request.")
|
| 1423 |
time.sleep(3)
|
| 1424 |
sys.exit()
|
|
|
|
|
|
|
|
|
|
| 1425 |
else:
|
| 1426 |
# processing vars
|
| 1427 |
export_vars()
|
|
|
|
| 1431 |
time.sleep(3)
|
| 1432 |
sys.exit(2)
|
| 1433 |
|
| 1434 |
+
def show_gui_msgbox(title,message):
|
| 1435 |
+
print(title + ": " + message)
|
| 1436 |
+
try:
|
| 1437 |
+
from tkinter import messagebox
|
| 1438 |
+
import tkinter as tk
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1439 |
root = tk.Tk()
|
| 1440 |
root.attributes("-alpha", 0)
|
| 1441 |
+
messagebox.showerror(title=title, message=message)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1442 |
root.destroy()
|
| 1443 |
+
except Exception as ex2:
|
| 1444 |
+
pass
|
|
|
|
|
|
|
| 1445 |
|
| 1446 |
#A very simple and stripped down embedded horde worker with no dependencies
|
| 1447 |
def run_horde_worker(args, api_key, worker_name):
|
| 1448 |
import urllib.request
|
| 1449 |
from datetime import datetime
|
| 1450 |
+
global friendlymodelname, maxhordectx, maxhordelen, exitcounter, modelbusy, session_starttime
|
| 1451 |
epurl = f"http://localhost:{args.port}"
|
| 1452 |
if args.host!="":
|
| 1453 |
epurl = f"http://{args.host}:{args.port}"
|
|
|
|
| 1455 |
def print_with_time(txt):
|
| 1456 |
print(f"{datetime.now().strftime('[%H:%M:%S]')} " + txt)
|
| 1457 |
|
| 1458 |
+
def submit_completed_generation(url, jobid, sessionstart, submit_dict):
|
| 1459 |
+
global exitcounter, session_kudos_earned, session_jobs
|
| 1460 |
+
reply = make_url_request(url, submit_dict)
|
| 1461 |
+
if not reply:
|
| 1462 |
+
exitcounter += 1
|
| 1463 |
+
print_with_time(f"Error, Job submit failed.")
|
| 1464 |
+
else:
|
| 1465 |
+
reward = reply["reward"]
|
| 1466 |
+
session_kudos_earned += reward
|
| 1467 |
+
session_jobs += 1
|
| 1468 |
+
curtime = datetime.now()
|
| 1469 |
+
elapsedtime=curtime-sessionstart
|
| 1470 |
+
hrs = elapsedtime.seconds // 3600
|
| 1471 |
+
mins = elapsedtime.seconds // 60 % 60
|
| 1472 |
+
secs = elapsedtime.seconds % 60
|
| 1473 |
+
elapsedtimestr = f"{hrs:03d}h:{mins:02d}m:{secs:02d}s"
|
| 1474 |
+
earnrate = session_kudos_earned/(elapsedtime.seconds/3600)
|
| 1475 |
+
print_with_time(f'Submitted {jobid} and earned {reward:.0f} kudos\n[Total:{session_kudos_earned:.0f} kudos, Time:{elapsedtimestr}, Jobs:{session_jobs}, EarnRate:{earnrate:.0f} kudos/hr]')
|
| 1476 |
|
| 1477 |
def make_url_request(url, data, method='POST'):
|
| 1478 |
try:
|
| 1479 |
request = None
|
| 1480 |
+
headers = {"apikey": api_key,'User-Agent':'KoboldCppEmbeddedWorkerV2','Client-Agent':'KoboldCppEmbedWorker:2'}
|
| 1481 |
if method=='POST':
|
| 1482 |
json_payload = json.dumps(data).encode('utf-8')
|
| 1483 |
request = urllib.request.Request(url, data=json_payload, headers=headers, method=method)
|
|
|
|
| 1503 |
current_id = None
|
| 1504 |
current_payload = None
|
| 1505 |
current_generation = None
|
|
|
|
| 1506 |
session_starttime = datetime.now()
|
| 1507 |
sleepy_counter = 0 #if this exceeds a value, worker becomes sleepy (slower)
|
| 1508 |
+
print(f"===\nEmbedded Horde Worker '{worker_name}' Starting...\n(To use your own KAI Bridge/Scribe worker instead, don't set your API key)")
|
| 1509 |
+
BRIDGE_AGENT = f"KoboldCppEmbedWorker:2:https://github.com/LostRuins/koboldcpp"
|
| 1510 |
cluster = "https://horde.koboldai.net"
|
| 1511 |
while exitcounter < 10:
|
| 1512 |
time.sleep(3)
|
| 1513 |
readygo = make_url_request(f'{epurl}/api/v1/info/version', None,'GET')
|
| 1514 |
if readygo:
|
| 1515 |
+
print_with_time(f"Embedded Horde Worker '{worker_name}' is started.")
|
| 1516 |
break
|
| 1517 |
|
| 1518 |
while exitcounter < 10:
|
|
|
|
| 1521 |
|
| 1522 |
#first, make sure we are not generating
|
| 1523 |
if modelbusy.locked():
|
| 1524 |
+
time.sleep(0.2)
|
| 1525 |
continue
|
| 1526 |
|
| 1527 |
#pop new request
|
|
|
|
| 1542 |
continue
|
| 1543 |
if not pop["id"]:
|
| 1544 |
slp = (1 if sleepy_counter<10 else (2 if sleepy_counter<25 else 3))
|
|
|
|
| 1545 |
time.sleep(slp)
|
| 1546 |
sleepy_counter += 1
|
| 1547 |
if sleepy_counter==20:
|
|
|
|
| 1564 |
currentjob_attempts += 1
|
| 1565 |
if currentjob_attempts>5:
|
| 1566 |
break
|
| 1567 |
+
print_with_time(f"Server Busy - Not ready to generate...")
|
| 1568 |
time.sleep(5)
|
| 1569 |
|
| 1570 |
#submit reply
|
|
|
|
| 1575 |
"generation": current_generation["results"][0]["text"],
|
| 1576 |
"state": "ok"
|
| 1577 |
}
|
| 1578 |
+
submiturl = cluster + '/api/v2/generate/text/submit'
|
| 1579 |
+
submit_thread = threading.Thread(target=submit_completed_generation, args=(submiturl, current_id, session_starttime, submit_dict))
|
| 1580 |
+
submit_thread.start() #submit job in new thread so nothing is waiting
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1581 |
else:
|
| 1582 |
+
print_with_time(f"Error, Abandoned current job due to errors. Getting new job.")
|
| 1583 |
current_id = None
|
| 1584 |
current_payload = None
|
| 1585 |
+
time.sleep(0.1)
|
| 1586 |
|
| 1587 |
if exitcounter<100:
|
| 1588 |
+
print_with_time(f"Horde Worker Shutdown - Too many errors.")
|
| 1589 |
time.sleep(3)
|
| 1590 |
else:
|
| 1591 |
+
print_with_time(f"Horde Worker Shutdown - Server Closing.")
|
| 1592 |
time.sleep(3)
|
| 1593 |
sys.exit(2)
|
| 1594 |
|
|
|
|
| 1660 |
handle = None
|
| 1661 |
|
| 1662 |
def loadconfigfile(filename):
|
| 1663 |
+
print("Loading kcpps configuration file...")
|
| 1664 |
with open(filename, 'r') as f:
|
| 1665 |
config = json.load(f)
|
| 1666 |
for key, value in config.items():
|
| 1667 |
setattr(args, key, value)
|
| 1668 |
|
| 1669 |
+
def sanitize_string(input_string):
|
| 1670 |
+
# alphanumeric characters, dots, dashes, and underscores
|
| 1671 |
+
import re
|
| 1672 |
+
sanitized_string = re.sub( r'[^\w\d\.\-_]', '', input_string)
|
| 1673 |
+
return sanitized_string
|
| 1674 |
+
|
| 1675 |
def main(launch_args,start_server=True):
|
| 1676 |
+
global args, friendlymodelname
|
| 1677 |
args = launch_args
|
| 1678 |
embedded_kailite = None
|
| 1679 |
+
embedded_kcpp_docs = None
|
| 1680 |
if args.config and len(args.config)==1:
|
| 1681 |
if isinstance(args.config[0], str) and os.path.exists(args.config[0]):
|
| 1682 |
loadconfigfile(args.config[0])
|
|
|
|
| 1684 |
print("Specified kcpp config file invalid or not found.")
|
| 1685 |
time.sleep(3)
|
| 1686 |
sys.exit(2)
|
| 1687 |
+
|
| 1688 |
+
#positional handling for kcpps files (drag and drop)
|
| 1689 |
+
if args.model_param and args.model_param!="" and args.model_param.lower().endswith('.kcpps'):
|
| 1690 |
+
loadconfigfile(args.model_param)
|
| 1691 |
+
|
| 1692 |
if not args.model_param:
|
| 1693 |
args.model_param = args.model
|
| 1694 |
+
|
| 1695 |
if not args.model_param:
|
| 1696 |
#give them a chance to pick a file
|
| 1697 |
print("For command line arguments, please refer to --help")
|
|
|
|
| 1699 |
try:
|
| 1700 |
show_new_gui()
|
| 1701 |
except Exception as ex:
|
| 1702 |
+
ermsg = "Reason: " + str(ex) + "\nFile selection GUI unsupported.\ncustomtkinter python module required!\nPlease check command line: script.py --help"
|
| 1703 |
+
show_gui_msgbox("Warning, GUI failed to start",ermsg)
|
| 1704 |
+
time.sleep(3)
|
| 1705 |
+
sys.exit(2)
|
| 1706 |
+
|
| 1707 |
+
# sanitize and replace the default vanity name. remember me....
|
| 1708 |
+
if args.model_param!="":
|
| 1709 |
+
newmdldisplayname = os.path.basename(args.model_param)
|
| 1710 |
+
newmdldisplayname = os.path.splitext(newmdldisplayname)[0]
|
| 1711 |
+
friendlymodelname = "koboldcpp/" + sanitize_string(newmdldisplayname)
|
|
|
|
|
|
|
| 1712 |
|
| 1713 |
if args.hordeconfig and args.hordeconfig[0]!="":
|
| 1714 |
+
global maxhordelen, maxhordectx, showdebug
|
| 1715 |
+
friendlymodelname = args.hordeconfig[0]
|
| 1716 |
+
if args.debugmode == 1:
|
| 1717 |
+
friendlymodelname = "debug-" + friendlymodelname
|
| 1718 |
+
if not friendlymodelname.startswith("koboldcpp/"):
|
| 1719 |
+
friendlymodelname = "koboldcpp/" + friendlymodelname
|
| 1720 |
if len(args.hordeconfig) > 1:
|
| 1721 |
maxhordelen = int(args.hordeconfig[1])
|
| 1722 |
if len(args.hordeconfig) > 2:
|
|
|
|
| 1773 |
else:
|
| 1774 |
args.lora[1] = os.path.abspath(args.lora[1])
|
| 1775 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1776 |
if not args.blasthreads or args.blasthreads <= 0:
|
| 1777 |
args.blasthreads = args.threads
|
| 1778 |
|
|
|
|
| 1794 |
except:
|
| 1795 |
print("Could not find Kobold Lite. Embedded Kobold Lite will not be available.")
|
| 1796 |
|
| 1797 |
+
try:
|
| 1798 |
+
basepath = os.path.abspath(os.path.dirname(__file__))
|
| 1799 |
+
with open(os.path.join(basepath, "kcpp_docs.embd"), mode='rb') as f:
|
| 1800 |
+
embedded_kcpp_docs = f.read()
|
| 1801 |
+
except:
|
| 1802 |
+
print("Could not find Embedded KoboldCpp API docs.")
|
| 1803 |
+
|
| 1804 |
if args.port_param!=defaultport:
|
| 1805 |
args.port = args.port_param
|
| 1806 |
print(f"Starting Kobold HTTP Server on port {args.port}")
|
|
|
|
| 1827 |
def onready_subprocess():
|
| 1828 |
import subprocess
|
| 1829 |
print("Starting Post-Load subprocess...")
|
| 1830 |
+
subprocess.run(args.onready[0], shell=True)
|
| 1831 |
timer_thread = threading.Timer(1, onready_subprocess) #1 second delay
|
| 1832 |
timer_thread.start()
|
| 1833 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1834 |
if start_server:
|
| 1835 |
print(f"Please connect to custom endpoint at {epurl}")
|
| 1836 |
+
asyncio.run(RunServerMultiThreaded(args.host, args.port, embedded_kailite, embedded_kcpp_docs))
|
| 1837 |
else:
|
| 1838 |
print(f"Server was not started, main function complete. Idling.")
|
| 1839 |
|
|
|
|
| 1858 |
parser.add_argument("--threads", help="Use a custom number of threads if specified. Otherwise, uses an amount based on CPU cores", type=int, default=default_threads)
|
| 1859 |
parser.add_argument("--blasthreads", help="Use a different number of threads during BLAS if specified. Otherwise, has the same value as --threads",metavar=('[threads]'), type=int, default=0)
|
| 1860 |
parser.add_argument("--highpriority", help="Experimental flag. If set, increases the process CPU priority, potentially speeding up generation. Use caution.", action='store_true')
|
| 1861 |
+
parser.add_argument("--contextsize", help="Controls the memory allocated for maximum context size, only change if you need more RAM for big contexts. (default 2048)", type=int,choices=[512,1024,2048,3072,4096,6144,8192,12288,16384,24576,32768,65536], default=2048)
|
| 1862 |
parser.add_argument("--blasbatchsize", help="Sets the batch size used in BLAS processing (default 512). Setting it to -1 disables BLAS mode, but keeps other benefits like GPU offload.", type=int,choices=[-1,32,64,128,256,512,1024,2048], default=512)
|
| 1863 |
parser.add_argument("--ropeconfig", help="If set, uses customized RoPE scaling from configured frequency scale and frequency base (e.g. --ropeconfig 0.25 10000). Otherwise, uses NTK-Aware scaling set automatically based on context size. For linear rope, simply set the freq-scale and ignore the freq-base",metavar=('[rope-freq-scale]', '[rope-freq-base]'), default=[0.0, 10000.0], type=float, nargs='+')
|
| 1864 |
parser.add_argument("--smartcontext", help="Reserving a portion of context to try processing less frequently.", action='store_true')
|
|
|
|
| 1867 |
parser.add_argument("--nommap", help="If set, do not use mmap to load newer models", action='store_true')
|
| 1868 |
parser.add_argument("--usemlock", help="For Apple Systems. Force system to keep model in RAM rather than swapping or compressing", action='store_true')
|
| 1869 |
parser.add_argument("--noavx2", help="Do not use AVX2 instructions, a slower compatibility mode for older devices. Does not work with --clblast.", action='store_true')
|
| 1870 |
+
parser.add_argument("--debugmode", help="Shows additional debug info in the terminal.", nargs='?', const=1, type=int, default=0)
|
| 1871 |
parser.add_argument("--skiplauncher", help="Doesn't display or use the GUI launcher.", action='store_true')
|
| 1872 |
parser.add_argument("--hordeconfig", help="Sets the display model name to something else, for easy use on AI Horde. Optional additional parameters set the horde max genlength, max ctxlen, API key and worker name.",metavar=('[hordemodelname]', '[hordegenlength] [hordemaxctx] [hordeapikey] [hordeworkername]'), nargs='+')
|
| 1873 |
compatgroup = parser.add_mutually_exclusive_group()
|
|
|
|
| 1877 |
parser.add_argument("--gpulayers", help="Set number of layers to offload to GPU when using GPU. Requires GPU.",metavar=('[GPU layers]'), type=int, default=0)
|
| 1878 |
parser.add_argument("--tensor_split", help="For CUDA with ALL GPU set only, ratio to split tensors across multiple GPUs, space-separated list of proportions, e.g. 7 3", metavar=('[Ratios]'), type=float, nargs='+')
|
| 1879 |
parser.add_argument("--onready", help="An optional shell command to execute after the model has been loaded.", type=str, default="",nargs=1)
|
| 1880 |
+
parser.add_argument("--multiuser", help="Runs in multiuser mode, which queues incoming requests instead of blocking them.", action='store_true')
|
| 1881 |
parser.add_argument("--foreground", help="Windows only. Sends the terminal to the foreground every time a new prompt is generated. This helps avoid some idle slowdown issues.", action='store_true')
|
| 1882 |
|
| 1883 |
+
main(parser.parse_args(),start_server=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
llama.cpp
CHANGED
|
@@ -1,6 +1,8 @@
|
|
| 1 |
#define LLAMA_API_INTERNAL
|
| 2 |
#include "llama.h"
|
| 3 |
|
|
|
|
|
|
|
| 4 |
#include "ggml.h"
|
| 5 |
|
| 6 |
#include "ggml-alloc.h"
|
|
@@ -124,6 +126,27 @@ static void replace_all(std::string & s, const std::string & search, const std::
|
|
| 124 |
}
|
| 125 |
s = std::move(result);
|
| 126 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 127 |
#ifdef GGML_USE_CPU_HBM
|
| 128 |
#include <hbwmalloc.h>
|
| 129 |
#endif
|
|
@@ -164,6 +187,8 @@ enum llm_arch {
|
|
| 164 |
LLM_ARCH_GPTNEOX,
|
| 165 |
LLM_ARCH_MPT,
|
| 166 |
LLM_ARCH_STARCODER,
|
|
|
|
|
|
|
| 167 |
LLM_ARCH_UNKNOWN,
|
| 168 |
};
|
| 169 |
|
|
@@ -176,6 +201,8 @@ static std::map<llm_arch, std::string> LLM_ARCH_NAMES = {
|
|
| 176 |
{ LLM_ARCH_MPT, "mpt" },
|
| 177 |
{ LLM_ARCH_BAICHUAN, "baichuan" },
|
| 178 |
{ LLM_ARCH_STARCODER, "starcoder" },
|
|
|
|
|
|
|
| 179 |
};
|
| 180 |
|
| 181 |
enum llm_kv {
|
|
@@ -294,6 +321,8 @@ enum llm_tensor {
|
|
| 294 |
LLM_TENSOR_FFN_DOWN,
|
| 295 |
LLM_TENSOR_FFN_UP,
|
| 296 |
LLM_TENSOR_FFN_NORM,
|
|
|
|
|
|
|
| 297 |
};
|
| 298 |
|
| 299 |
static std::map<llm_arch, std::map<llm_tensor, std::string>> LLM_TENSOR_NAMES = {
|
|
@@ -375,6 +404,23 @@ static std::map<llm_arch, std::map<llm_tensor, std::string>> LLM_TENSOR_NAMES =
|
|
| 375 |
{ LLM_TENSOR_FFN_UP, "blk.%d.ffn_up" },
|
| 376 |
},
|
| 377 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 378 |
{
|
| 379 |
LLM_ARCH_MPT,
|
| 380 |
{
|
|
@@ -396,6 +442,23 @@ static std::map<llm_arch, std::map<llm_tensor, std::string>> LLM_TENSOR_NAMES =
|
|
| 396 |
{ LLM_TENSOR_FFN_DOWN, "blk.%d.ffn_down" },
|
| 397 |
},
|
| 398 |
},
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 399 |
{
|
| 400 |
LLM_ARCH_UNKNOWN,
|
| 401 |
{
|
|
@@ -922,6 +985,7 @@ enum e_model {
|
|
| 922 |
MODEL_1B,
|
| 923 |
MODEL_3B,
|
| 924 |
MODEL_7B,
|
|
|
|
| 925 |
MODEL_13B,
|
| 926 |
MODEL_15B,
|
| 927 |
MODEL_30B,
|
|
@@ -953,7 +1017,24 @@ struct llama_hparams {
|
|
| 953 |
float rope_freq_scale_train;
|
| 954 |
|
| 955 |
bool operator!=(const llama_hparams & other) const {
|
| 956 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 957 |
}
|
| 958 |
|
| 959 |
uint32_t n_gqa() const {
|
|
@@ -987,6 +1068,10 @@ struct llama_layer {
|
|
| 987 |
struct ggml_tensor * attn_norm_b;
|
| 988 |
struct ggml_tensor * attn_norm_2;
|
| 989 |
struct ggml_tensor * attn_norm_2_b;
|
|
|
|
|
|
|
|
|
|
|
|
|
| 990 |
|
| 991 |
// attention
|
| 992 |
struct ggml_tensor * wq;
|
|
@@ -1028,6 +1113,9 @@ struct llama_kv_cell {
|
|
| 1028 |
struct llama_kv_cache {
|
| 1029 |
bool has_shift = false;
|
| 1030 |
|
|
|
|
|
|
|
|
|
|
| 1031 |
uint32_t head = 0;
|
| 1032 |
uint32_t size = 0;
|
| 1033 |
|
|
@@ -1081,6 +1169,10 @@ struct llama_vocab {
|
|
| 1081 |
id special_pad_id = -1;
|
| 1082 |
|
| 1083 |
id linefeed_id = 13;
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1084 |
|
| 1085 |
int find_bpe_rank(std::string token_left, std::string token_right) const {
|
| 1086 |
replace_all(token_left, " ", "\u0120");
|
|
@@ -1281,9 +1373,11 @@ static bool llama_kv_cache_init(
|
|
| 1281 |
|
| 1282 |
// find an empty slot of size "n_tokens" in the cache
|
| 1283 |
// updates the cache head
|
|
|
|
|
|
|
| 1284 |
static bool llama_kv_cache_find_slot(
|
| 1285 |
-
|
| 1286 |
-
|
| 1287 |
const uint32_t n_ctx = cache.size;
|
| 1288 |
const uint32_t n_tokens = batch.n_tokens;
|
| 1289 |
|
|
@@ -1296,8 +1390,8 @@ static bool llama_kv_cache_find_slot(
|
|
| 1296 |
|
| 1297 |
while (true) {
|
| 1298 |
if (cache.head + n_tokens > n_ctx) {
|
|
|
|
| 1299 |
cache.head = 0;
|
| 1300 |
-
n_tested += n_ctx - cache.head;
|
| 1301 |
continue;
|
| 1302 |
}
|
| 1303 |
|
|
@@ -1348,29 +1442,46 @@ static void llama_kv_cache_tokens_rm(struct llama_kv_cache & cache, int32_t c0,
|
|
| 1348 |
cache.cells[i].pos = -1;
|
| 1349 |
cache.cells[i].seq_id.clear();
|
| 1350 |
}
|
|
|
|
|
|
|
|
|
|
| 1351 |
}
|
| 1352 |
|
| 1353 |
static void llama_kv_cache_seq_rm(
|
| 1354 |
-
|
| 1355 |
-
|
| 1356 |
-
|
| 1357 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1358 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1359 |
if (cache.cells[i].has_seq_id(seq_id) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) {
|
| 1360 |
cache.cells[i].seq_id.erase(seq_id);
|
| 1361 |
if (cache.cells[i].seq_id.empty()) {
|
| 1362 |
cache.cells[i].pos = -1;
|
|
|
|
| 1363 |
}
|
| 1364 |
}
|
| 1365 |
}
|
|
|
|
|
|
|
|
|
|
| 1366 |
}
|
| 1367 |
|
| 1368 |
static void llama_kv_cache_seq_cp(
|
| 1369 |
-
|
| 1370 |
-
|
| 1371 |
-
|
| 1372 |
-
|
| 1373 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1374 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1375 |
if (cache.cells[i].has_seq_id(seq_id_src) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) {
|
| 1376 |
cache.cells[i].seq_id.insert(seq_id_dst);
|
|
@@ -1379,32 +1490,48 @@ static void llama_kv_cache_seq_cp(
|
|
| 1379 |
}
|
| 1380 |
|
| 1381 |
static void llama_kv_cache_seq_keep(struct llama_kv_cache & cache, llama_seq_id seq_id) {
|
|
|
|
|
|
|
| 1382 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1383 |
if (!cache.cells[i].has_seq_id(seq_id)) {
|
| 1384 |
cache.cells[i].pos = -1;
|
| 1385 |
cache.cells[i].seq_id.clear();
|
|
|
|
| 1386 |
}
|
| 1387 |
}
|
|
|
|
|
|
|
|
|
|
| 1388 |
}
|
| 1389 |
|
| 1390 |
static void llama_kv_cache_seq_shift(
|
| 1391 |
-
|
| 1392 |
-
|
| 1393 |
-
|
| 1394 |
-
|
| 1395 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1396 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1397 |
if (cache.cells[i].has_seq_id(seq_id) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) {
|
| 1398 |
cache.cells[i].pos += delta;
|
| 1399 |
if (cache.cells[i].pos < 0) {
|
| 1400 |
cache.cells[i].pos = -1;
|
| 1401 |
cache.cells[i].seq_id.clear();
|
|
|
|
| 1402 |
} else {
|
| 1403 |
cache.has_shift = true;
|
| 1404 |
cache.cells[i].delta = delta;
|
| 1405 |
}
|
| 1406 |
}
|
| 1407 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1408 |
}
|
| 1409 |
|
| 1410 |
//
|
|
@@ -1806,6 +1933,7 @@ static const char * llama_model_type_name(e_model type) {
|
|
| 1806 |
case MODEL_1B: return "1B";
|
| 1807 |
case MODEL_3B: return "3B";
|
| 1808 |
case MODEL_7B: return "7B";
|
|
|
|
| 1809 |
case MODEL_13B: return "13B";
|
| 1810 |
case MODEL_15B: return "15B";
|
| 1811 |
case MODEL_30B: return "30B";
|
|
@@ -1918,6 +2046,22 @@ static void llm_load_hparams(
|
|
| 1918 |
default: model.type = e_model::MODEL_UNKNOWN;
|
| 1919 |
}
|
| 1920 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1921 |
default: (void)0;
|
| 1922 |
}
|
| 1923 |
|
|
@@ -1982,6 +2126,7 @@ static void llm_load_vocab(
|
|
| 1982 |
|
| 1983 |
for (int i = 0; i < n_merges; i++) {
|
| 1984 |
const std::string word = gguf_get_arr_str(ctx, merges_keyidx, i);
|
|
|
|
| 1985 |
|
| 1986 |
std::string first;
|
| 1987 |
std::string second;
|
|
@@ -2016,6 +2161,7 @@ static void llm_load_vocab(
|
|
| 2016 |
|
| 2017 |
for (uint32_t i = 0; i < n_vocab; i++) {
|
| 2018 |
std::string word = gguf_get_arr_str(ctx, token_idx, i);
|
|
|
|
| 2019 |
|
| 2020 |
vocab.token_to_id[word] = i;
|
| 2021 |
|
|
@@ -2024,12 +2170,13 @@ static void llm_load_vocab(
|
|
| 2024 |
token_data.score = scores ? scores[i] : 0.0f;
|
| 2025 |
token_data.type = toktypes ? (llama_token_type) toktypes[i] : LLAMA_TOKEN_TYPE_NORMAL;
|
| 2026 |
}
|
|
|
|
| 2027 |
|
| 2028 |
// determine the newline token: LLaMA "<0x0A>" == 10 == '\n', Falcon 193 == '\n'
|
| 2029 |
if (vocab.type == LLAMA_VOCAB_TYPE_SPM) {
|
| 2030 |
vocab.linefeed_id = llama_byte_to_token(vocab, '\n');
|
| 2031 |
} else {
|
| 2032 |
-
vocab.linefeed_id = llama_tokenize_internal(vocab, "\
|
| 2033 |
}
|
| 2034 |
|
| 2035 |
// special tokens
|
|
@@ -2152,6 +2299,7 @@ static void llm_load_tensors(
|
|
| 2152 |
const auto tn = LLM_TN(model.arch);
|
| 2153 |
switch (model.arch) {
|
| 2154 |
case LLM_ARCH_LLAMA:
|
|
|
|
| 2155 |
{
|
| 2156 |
model.tok_embeddings = ml.create_tensor(ctx, tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, GGML_BACKEND_CPU);
|
| 2157 |
|
|
@@ -2442,6 +2590,67 @@ static void llm_load_tensors(
|
|
| 2442 |
}
|
| 2443 |
}
|
| 2444 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2445 |
default:
|
| 2446 |
throw std::runtime_error("unknown architecture");
|
| 2447 |
}
|
|
@@ -2551,8 +2760,8 @@ static bool llama_model_load(
|
|
| 2551 |
}
|
| 2552 |
|
| 2553 |
static struct ggml_cgraph * llm_build_llama(
|
| 2554 |
-
|
| 2555 |
-
|
| 2556 |
const auto & model = lctx.model;
|
| 2557 |
const auto & hparams = model.hparams;
|
| 2558 |
const auto & cparams = lctx.cparams;
|
|
@@ -2590,11 +2799,9 @@ static struct ggml_cgraph * llm_build_llama(
|
|
| 2590 |
struct ggml_init_params params = {
|
| 2591 |
/*.mem_size =*/ buf_compute.size,
|
| 2592 |
/*.mem_buffer =*/ buf_compute.data,
|
| 2593 |
-
/*.no_alloc =*/
|
| 2594 |
};
|
| 2595 |
|
| 2596 |
-
params.no_alloc = true;
|
| 2597 |
-
|
| 2598 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 2599 |
|
| 2600 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
@@ -2978,11 +3185,9 @@ static struct ggml_cgraph * llm_build_baichaun(
|
|
| 2978 |
struct ggml_init_params params = {
|
| 2979 |
/*.mem_size =*/ buf_compute.size,
|
| 2980 |
/*.mem_buffer =*/ buf_compute.data,
|
| 2981 |
-
/*.no_alloc =*/
|
| 2982 |
};
|
| 2983 |
|
| 2984 |
-
params.no_alloc = true;
|
| 2985 |
-
|
| 2986 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 2987 |
|
| 2988 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
@@ -3345,7 +3550,7 @@ static struct ggml_cgraph * llm_build_baichaun(
|
|
| 3345 |
return gf;
|
| 3346 |
}
|
| 3347 |
|
| 3348 |
-
static struct ggml_cgraph *
|
| 3349 |
llama_context & lctx,
|
| 3350 |
const llama_batch & batch) {
|
| 3351 |
const auto & model = lctx.model;
|
|
@@ -3364,11 +3569,7 @@ static struct ggml_cgraph * llm_build_falcon(
|
|
| 3364 |
const int64_t n_embd_head = hparams.n_embd_head();
|
| 3365 |
const int64_t n_embd_gqa = hparams.n_embd_gqa();
|
| 3366 |
|
| 3367 |
-
|
| 3368 |
-
|
| 3369 |
-
const float freq_base = cparams.rope_freq_base;
|
| 3370 |
-
const float freq_scale = cparams.rope_freq_scale;
|
| 3371 |
-
const float norm_eps = hparams.f_norm_eps;
|
| 3372 |
|
| 3373 |
const int n_gpu_layers = model.n_gpu_layers;
|
| 3374 |
|
|
@@ -3376,21 +3577,16 @@ static struct ggml_cgraph * llm_build_falcon(
|
|
| 3376 |
const int32_t n_kv = ggml_allocr_is_measure(lctx.alloc) ? n_ctx : kv_self.n;
|
| 3377 |
const int32_t kv_head = ggml_allocr_is_measure(lctx.alloc) ? n_ctx - n_tokens : kv_self.head;
|
| 3378 |
|
| 3379 |
-
|
| 3380 |
-
|
| 3381 |
-
//printf("kv_head = %d, n_kv = %d, n_tokens = %d, n_ctx = %d, is_measure = %d, has_shift = %d\n",
|
| 3382 |
-
// kv_head, n_kv, n_tokens, n_ctx, ggml_allocr_is_measure(lctx.alloc), kv_self.has_shift);
|
| 3383 |
|
| 3384 |
auto & buf_compute = lctx.buf_compute;
|
| 3385 |
|
| 3386 |
struct ggml_init_params params = {
|
| 3387 |
/*.mem_size =*/ buf_compute.size,
|
| 3388 |
/*.mem_buffer =*/ buf_compute.data,
|
| 3389 |
-
/*.no_alloc =*/
|
| 3390 |
};
|
| 3391 |
|
| 3392 |
-
params.no_alloc = true;
|
| 3393 |
-
|
| 3394 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 3395 |
|
| 3396 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
@@ -3447,7 +3643,7 @@ static struct ggml_cgraph * llm_build_falcon(
|
|
| 3447 |
ggml_set_name(KQ_scale, "1/sqrt(n_embd_head)");
|
| 3448 |
ggml_allocr_alloc(lctx.alloc, KQ_scale);
|
| 3449 |
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3450 |
-
ggml_set_f32(KQ_scale, 1.0f/sqrtf(float(
|
| 3451 |
}
|
| 3452 |
|
| 3453 |
// KQ_mask (mask for 1 head, it will be broadcasted to all heads)
|
|
@@ -3473,47 +3669,8 @@ static struct ggml_cgraph * llm_build_falcon(
|
|
| 3473 |
}
|
| 3474 |
}
|
| 3475 |
|
| 3476 |
-
// KQ_pos - contains the positions
|
| 3477 |
-
struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens);
|
| 3478 |
-
offload_func_kq(KQ_pos);
|
| 3479 |
-
ggml_set_name(KQ_pos, "KQ_pos");
|
| 3480 |
-
ggml_allocr_alloc(lctx.alloc, KQ_pos);
|
| 3481 |
-
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3482 |
-
int * data = (int *) KQ_pos->data;
|
| 3483 |
-
for (int i = 0; i < n_tokens; ++i) {
|
| 3484 |
-
data[i] = batch.pos[i];
|
| 3485 |
-
}
|
| 3486 |
-
}
|
| 3487 |
-
|
| 3488 |
-
// shift the entire K-cache if needed
|
| 3489 |
-
if (do_rope_shift) {
|
| 3490 |
-
struct ggml_tensor * K_shift = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_ctx);
|
| 3491 |
-
offload_func_kq(K_shift);
|
| 3492 |
-
ggml_set_name(K_shift, "K_shift");
|
| 3493 |
-
ggml_allocr_alloc(lctx.alloc, K_shift);
|
| 3494 |
-
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3495 |
-
int * data = (int *) K_shift->data;
|
| 3496 |
-
for (int i = 0; i < n_ctx; ++i) {
|
| 3497 |
-
data[i] = kv_self.cells[i].delta;
|
| 3498 |
-
}
|
| 3499 |
-
}
|
| 3500 |
-
|
| 3501 |
-
for (int il = 0; il < n_layer; ++il) {
|
| 3502 |
-
struct ggml_tensor * tmp =
|
| 3503 |
-
ggml_rope_custom_inplace(ctx0,
|
| 3504 |
-
ggml_view_3d(ctx0, kv_self.k,
|
| 3505 |
-
n_embd_head, n_head_kv, n_ctx,
|
| 3506 |
-
ggml_element_size(kv_self.k)*n_embd_head,
|
| 3507 |
-
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 3508 |
-
ggml_element_size(kv_self.k)*n_embd_gqa*n_ctx*il),
|
| 3509 |
-
K_shift, n_embd_head, 2, 0, freq_base, freq_scale);
|
| 3510 |
-
offload_func_kq(tmp);
|
| 3511 |
-
ggml_build_forward_expand(gf, tmp);
|
| 3512 |
-
}
|
| 3513 |
-
}
|
| 3514 |
-
|
| 3515 |
for (int il = 0; il < n_layer; ++il) {
|
| 3516 |
-
|
| 3517 |
|
| 3518 |
offload_func_t offload_func = llama_nop;
|
| 3519 |
|
|
@@ -3523,80 +3680,471 @@ static struct ggml_cgraph * llm_build_falcon(
|
|
| 3523 |
}
|
| 3524 |
#endif // GGML_USE_CUBLAS
|
| 3525 |
|
| 3526 |
-
|
| 3527 |
-
// TODO: refactor into common function (shared with LLaMA)
|
| 3528 |
-
{
|
| 3529 |
-
attn_norm = ggml_norm(ctx0, inpL, norm_eps);
|
| 3530 |
-
offload_func(attn_norm);
|
| 3531 |
-
|
| 3532 |
-
attn_norm = ggml_add(ctx0,
|
| 3533 |
-
ggml_mul(ctx0, attn_norm, model.layers[il].attn_norm),
|
| 3534 |
-
model.layers[il].attn_norm_b);
|
| 3535 |
-
offload_func(attn_norm->src[0]);
|
| 3536 |
-
offload_func(attn_norm);
|
| 3537 |
-
|
| 3538 |
-
if (model.layers[il].attn_norm_2) { // Falcon-40B
|
| 3539 |
-
cur = ggml_norm(ctx0, inpL, norm_eps);
|
| 3540 |
-
offload_func(cur);
|
| 3541 |
-
|
| 3542 |
-
cur = ggml_add(ctx0,
|
| 3543 |
-
ggml_mul(ctx0, cur, model.layers[il].attn_norm_2),
|
| 3544 |
-
model.layers[il].attn_norm_2_b);
|
| 3545 |
-
offload_func(cur->src[0]);
|
| 3546 |
-
offload_func(cur);
|
| 3547 |
-
} else { // Falcon 7B
|
| 3548 |
-
cur = attn_norm;
|
| 3549 |
-
}
|
| 3550 |
-
|
| 3551 |
-
// compute QKV
|
| 3552 |
|
| 3553 |
-
|
| 3554 |
-
|
|
|
|
|
|
|
|
|
|
| 3555 |
|
| 3556 |
-
//
|
| 3557 |
-
|
| 3558 |
-
|
| 3559 |
-
|
| 3560 |
-
|
| 3561 |
-
// happen to that out-of-range memory, but it can require some
|
| 3562 |
-
// trickery when trying to accurately dump these views for
|
| 3563 |
-
// debugging.
|
| 3564 |
|
| 3565 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3566 |
|
| 3567 |
-
|
| 3568 |
-
// non-contiguous views is added for the rope operator
|
| 3569 |
-
struct ggml_tensor * tmpq = ggml_cont(ctx0, ggml_view_3d(
|
| 3570 |
-
ctx0, cur, n_embd_head, n_head, n_tokens,
|
| 3571 |
-
wsize * n_embd_head,
|
| 3572 |
-
wsize * n_embd_head * (n_head + 2 * n_head_kv),
|
| 3573 |
-
0));
|
| 3574 |
offload_func_kq(tmpq);
|
|
|
|
| 3575 |
|
| 3576 |
-
struct ggml_tensor *
|
| 3577 |
-
|
| 3578 |
-
|
| 3579 |
-
wsize * n_embd_head * (n_head + 2 * n_head_kv),
|
| 3580 |
-
wsize * n_embd_head * n_head));
|
| 3581 |
-
offload_func_kq(tmpk);
|
| 3582 |
-
|
| 3583 |
-
struct ggml_tensor * tmpv = ggml_view_3d(
|
| 3584 |
-
ctx0, cur, n_embd_head, n_head_kv, n_tokens,
|
| 3585 |
-
wsize * n_embd_head,
|
| 3586 |
-
wsize * n_embd_head * (n_head + 2 * n_head_kv),
|
| 3587 |
-
wsize * n_embd_head * (n_head + n_head_kv));
|
| 3588 |
-
offload_func_v(tmpv);
|
| 3589 |
|
| 3590 |
-
|
| 3591 |
-
struct ggml_tensor * Qcur = ggml_rope_custom(ctx0, tmpq, KQ_pos, n_embd_head, 2, 0, freq_base, freq_scale);
|
| 3592 |
offload_func_kq(Qcur);
|
| 3593 |
-
|
| 3594 |
-
offload_func_kq(Kcur);
|
| 3595 |
|
|
|
|
| 3596 |
{
|
| 3597 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3598 |
offload_func_v(Vcur);
|
| 3599 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3600 |
ggml_set_name(Vcur, "Vcur");
|
| 3601 |
|
| 3602 |
struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, n_tokens*n_embd_gqa, (ggml_element_size(kv_self.k)*n_embd_gqa)*(il*n_ctx + kv_head));
|
|
@@ -3746,11 +4294,9 @@ static struct ggml_cgraph * llm_build_starcoder(
|
|
| 3746 |
struct ggml_init_params params = {
|
| 3747 |
/*.mem_size =*/ buf_compute.size,
|
| 3748 |
/*.mem_buffer =*/ buf_compute.data,
|
| 3749 |
-
/*.no_alloc =*/
|
| 3750 |
};
|
| 3751 |
|
| 3752 |
-
params.no_alloc = true;
|
| 3753 |
-
|
| 3754 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 3755 |
|
| 3756 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
@@ -3826,138 +4372,536 @@ static struct ggml_cgraph * llm_build_starcoder(
|
|
| 3826 |
}
|
| 3827 |
}
|
| 3828 |
}
|
| 3829 |
-
|
| 3830 |
-
inpL = ggml_add(ctx0, token, position);
|
| 3831 |
-
ggml_set_name(inpL, "inpL");
|
| 3832 |
-
|
| 3833 |
-
for (int il = 0; il < n_layer; ++il) {
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3834 |
{
|
| 3835 |
-
// Norm
|
| 3836 |
cur = ggml_norm(ctx0, inpL, norm_eps);
|
| 3837 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3838 |
}
|
| 3839 |
-
|
| 3840 |
{
|
| 3841 |
-
|
| 3842 |
-
|
|
|
|
|
|
|
| 3843 |
|
| 3844 |
-
|
| 3845 |
-
|
| 3846 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3847 |
|
| 3848 |
-
|
| 3849 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3850 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3851 |
{
|
| 3852 |
-
struct ggml_tensor *
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3853 |
ggml_set_name(Vcur, "Vcur");
|
| 3854 |
|
| 3855 |
-
struct ggml_tensor * k = ggml_view_1d(
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3856 |
ggml_set_name(k, "k");
|
| 3857 |
|
| 3858 |
struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, n_tokens, n_embd_gqa,
|
| 3859 |
( n_ctx)*ggml_element_size(kv_self.v),
|
| 3860 |
(il*n_ctx)*ggml_element_size(kv_self.v)*n_embd_gqa + kv_head*ggml_element_size(kv_self.v));
|
|
|
|
|
|
|
| 3861 |
|
|
|
|
| 3862 |
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k));
|
| 3863 |
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v));
|
| 3864 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3865 |
|
| 3866 |
-
|
| 3867 |
-
|
| 3868 |
-
ggml_cpy(ctx0,
|
| 3869 |
-
Qcur,
|
| 3870 |
-
ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd_head, n_head, n_tokens)),
|
| 3871 |
-
0, 2, 1, 3);
|
| 3872 |
-
ggml_set_name(Q, "Q");
|
| 3873 |
-
|
| 3874 |
-
struct ggml_tensor * K =
|
| 3875 |
-
ggml_view_3d(ctx0, kv_self.k,
|
| 3876 |
-
n_embd_head, n_kv, n_head_kv,
|
| 3877 |
-
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 3878 |
-
ggml_element_size(kv_self.k)*n_embd_head,
|
| 3879 |
-
ggml_element_size(kv_self.k)*n_embd_gqa*n_ctx*il);
|
| 3880 |
-
ggml_set_name(K, "K");
|
| 3881 |
|
| 3882 |
-
// K * Q
|
| 3883 |
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
|
|
|
| 3884 |
ggml_set_name(KQ, "KQ");
|
| 3885 |
|
| 3886 |
-
|
| 3887 |
-
|
| 3888 |
-
struct ggml_tensor * KQ_scaled = ggml_scale_inplace(ctx0, KQ, KQ_scale);
|
| 3889 |
ggml_set_name(KQ_scaled, "KQ_scaled");
|
| 3890 |
|
| 3891 |
-
// KQ_masked = mask_past(KQ_scaled)
|
| 3892 |
struct ggml_tensor * KQ_masked = ggml_add(ctx0, KQ_scaled, KQ_mask);
|
|
|
|
| 3893 |
ggml_set_name(KQ_masked, "KQ_masked");
|
| 3894 |
|
| 3895 |
-
// KQ = soft_max(KQ_masked)
|
| 3896 |
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
|
|
|
| 3897 |
ggml_set_name(KQ_soft_max, "KQ_soft_max");
|
| 3898 |
|
| 3899 |
-
// split cached V into n_head heads
|
| 3900 |
struct ggml_tensor * V =
|
| 3901 |
ggml_view_3d(ctx0, kv_self.v,
|
| 3902 |
n_kv, n_embd_head, n_head_kv,
|
| 3903 |
ggml_element_size(kv_self.v)*n_ctx,
|
| 3904 |
ggml_element_size(kv_self.v)*n_ctx*n_embd_head,
|
| 3905 |
ggml_element_size(kv_self.v)*n_ctx*n_embd_gqa*il);
|
|
|
|
| 3906 |
ggml_set_name(V, "V");
|
| 3907 |
|
| 3908 |
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
|
|
|
| 3909 |
ggml_set_name(KQV, "KQV");
|
| 3910 |
|
| 3911 |
-
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
| 3912 |
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
|
|
|
| 3913 |
ggml_set_name(KQV_merged, "KQV_merged");
|
| 3914 |
|
| 3915 |
-
// cur = KQV_merged.contiguous().view(n_embd, n_tokens)
|
| 3916 |
cur = ggml_cont_2d(ctx0, KQV_merged, n_embd, n_tokens);
|
|
|
|
| 3917 |
ggml_set_name(cur, "KQV_merged_contiguous");
|
| 3918 |
-
}
|
| 3919 |
-
|
| 3920 |
-
// Projection
|
| 3921 |
-
cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.layers[il].wo, cur), model.layers[il].bo);
|
| 3922 |
-
|
| 3923 |
-
// Add the input
|
| 3924 |
-
cur = ggml_add(ctx0, cur, inpL);
|
| 3925 |
|
| 3926 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3927 |
|
| 3928 |
-
|
|
|
|
|
|
|
| 3929 |
{
|
| 3930 |
-
//
|
| 3931 |
{
|
|
|
|
| 3932 |
cur = ggml_norm(ctx0, inpFF, norm_eps);
|
| 3933 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3934 |
}
|
|
|
|
|
|
|
| 3935 |
|
| 3936 |
-
cur = ggml_add(ctx0,
|
|
|
|
|
|
|
| 3937 |
|
| 3938 |
-
|
| 3939 |
-
cur
|
|
|
|
|
|
|
| 3940 |
|
| 3941 |
-
|
| 3942 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3943 |
}
|
| 3944 |
-
|
| 3945 |
-
|
|
|
|
|
|
|
| 3946 |
}
|
| 3947 |
-
|
| 3948 |
-
// Output Norm
|
| 3949 |
{
|
| 3950 |
-
cur = ggml_norm(ctx0,
|
| 3951 |
-
|
| 3952 |
-
|
| 3953 |
-
|
| 3954 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3955 |
cur = ggml_mul_mat(ctx0, model.output, cur);
|
| 3956 |
ggml_set_name(cur, "result_output");
|
| 3957 |
-
|
| 3958 |
ggml_build_forward_expand(gf, cur);
|
| 3959 |
ggml_free(ctx0);
|
| 3960 |
-
|
| 3961 |
return gf;
|
| 3962 |
}
|
| 3963 |
|
|
@@ -3985,6 +4929,14 @@ static struct ggml_cgraph * llama_build_graph(
|
|
| 3985 |
{
|
| 3986 |
result = llm_build_starcoder(lctx, batch);
|
| 3987 |
} break;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3988 |
default:
|
| 3989 |
GGML_ASSERT(false);
|
| 3990 |
}
|
|
@@ -4020,7 +4972,7 @@ static int llama_decode_internal(
|
|
| 4020 |
|
| 4021 |
GGML_ASSERT(n_tokens <= n_batch);
|
| 4022 |
|
| 4023 |
-
int n_threads = n_tokens
|
| 4024 |
GGML_ASSERT((!batch.token && batch.embd) || (batch.token && !batch.embd)); // NOLINT
|
| 4025 |
|
| 4026 |
const int64_t t_start_us = ggml_time_us();
|
|
@@ -4063,10 +5015,6 @@ static int llama_decode_internal(
|
|
| 4063 |
batch.seq_id = seq_id.data();
|
| 4064 |
}
|
| 4065 |
|
| 4066 |
-
// we always start to search for a free slot from the start of the cache
|
| 4067 |
-
// TODO: better strategies can be implemented
|
| 4068 |
-
kv_self.head = 0;
|
| 4069 |
-
|
| 4070 |
if (!llama_kv_cache_find_slot(kv_self, batch)) {
|
| 4071 |
return 1;
|
| 4072 |
}
|
|
@@ -4118,7 +5066,8 @@ static int llama_decode_internal(
|
|
| 4118 |
// If all tensors can be run on the GPU then using more than 1 thread is detrimental.
|
| 4119 |
const bool full_offload_supported = model.arch == LLM_ARCH_LLAMA ||
|
| 4120 |
model.arch == LLM_ARCH_BAICHUAN ||
|
| 4121 |
-
model.arch == LLM_ARCH_FALCON
|
|
|
|
| 4122 |
const bool fully_offloaded = model.n_gpu_layers >= (int) hparams.n_layer + 3;
|
| 4123 |
if (ggml_cpu_has_cublas() && full_offload_supported && fully_offloaded) {
|
| 4124 |
n_threads = 1;
|
|
@@ -4151,8 +5100,12 @@ static int llama_decode_internal(
|
|
| 4151 |
#endif
|
| 4152 |
|
| 4153 |
// update the kv ring buffer
|
| 4154 |
-
lctx.kv_self.head += n_tokens;
|
| 4155 |
lctx.kv_self.has_shift = false;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4156 |
|
| 4157 |
#ifdef GGML_PERF
|
| 4158 |
// print timing information per ggml operation (for debugging purposes)
|
|
@@ -4238,18 +5191,41 @@ static bool llama_is_byte_token(const llama_vocab & vocab, llama_token id) {
|
|
| 4238 |
return vocab.id_to_token[id].type == LLAMA_TOKEN_TYPE_BYTE;
|
| 4239 |
}
|
| 4240 |
|
| 4241 |
-
static
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4242 |
GGML_ASSERT(llama_is_byte_token(vocab, id));
|
| 4243 |
const auto& token_data = vocab.id_to_token.at(id);
|
| 4244 |
-
|
| 4245 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4246 |
}
|
| 4247 |
|
| 4248 |
static llama_token llama_byte_to_token(const llama_vocab & vocab, uint8_t ch) {
|
| 4249 |
-
|
| 4250 |
-
|
| 4251 |
-
|
| 4252 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4253 |
}
|
| 4254 |
|
| 4255 |
static void llama_escape_whitespace(std::string & text) {
|
|
@@ -4529,15 +5505,9 @@ struct llm_tokenizer_bpe {
|
|
| 4529 |
std::string byte_str(1, *j);
|
| 4530 |
auto token_multibyte = vocab.token_to_id.find(byte_str);
|
| 4531 |
if (token_multibyte == vocab.token_to_id.end()) {
|
| 4532 |
-
|
| 4533 |
-
llama_token token_byte = llama_byte_to_token(vocab, *j);
|
| 4534 |
-
output.push_back(token_byte);
|
| 4535 |
-
} catch (const std::out_of_range & err) {
|
| 4536 |
-
fprintf(stderr,"ERROR: byte not found in vocab: '%s'\n", byte_str.c_str());
|
| 4537 |
-
}
|
| 4538 |
-
} else {
|
| 4539 |
-
output.push_back((*token_multibyte).second);
|
| 4540 |
}
|
|
|
|
| 4541 |
}
|
| 4542 |
} else {
|
| 4543 |
output.push_back((*token).second);
|
|
@@ -4574,23 +5544,144 @@ private:
|
|
| 4574 |
work_queue.push(bigram);
|
| 4575 |
}
|
| 4576 |
|
| 4577 |
-
|
| 4578 |
-
|
| 4579 |
-
std::vector<std::string>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4580 |
|
| 4581 |
-
|
| 4582 |
-
|
| 4583 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4584 |
|
| 4585 |
-
|
| 4586 |
-
|
| 4587 |
-
|
| 4588 |
-
|
| 4589 |
-
|
| 4590 |
-
|
| 4591 |
}
|
| 4592 |
-
return words;
|
| 4593 |
|
|
|
|
| 4594 |
}
|
| 4595 |
|
| 4596 |
const llama_vocab & vocab;
|
|
@@ -6112,6 +7203,7 @@ static void llama_model_quantize_internal(const std::string & fname_inp, const s
|
|
| 6112 |
}
|
| 6113 |
|
| 6114 |
std::ofstream fout(fname_out, std::ios::binary);
|
|
|
|
| 6115 |
|
| 6116 |
const size_t meta_size = gguf_get_meta_size(ctx_out);
|
| 6117 |
|
|
@@ -6765,13 +7857,14 @@ struct llama_context * llama_new_context_with_model(
|
|
| 6765 |
|
| 6766 |
#ifdef GGML_USE_METAL
|
| 6767 |
if (model->n_gpu_layers > 0) {
|
|
|
|
|
|
|
| 6768 |
ctx->ctx_metal = ggml_metal_init(1);
|
| 6769 |
if (!ctx->ctx_metal) {
|
| 6770 |
LLAMA_LOG_ERROR("%s: ggml_metal_init() failed\n", __func__);
|
| 6771 |
llama_free(ctx);
|
| 6772 |
return NULL;
|
| 6773 |
}
|
| 6774 |
-
ggml_metal_log_set_callback(llama_log_callback_default, NULL);
|
| 6775 |
//ggml_metal_graph_find_concurrency(ctx->ctx_metal, gf, false);
|
| 6776 |
//ggml_allocr_set_parse_seq(ctx->alloc, ggml_metal_get_concur_list(ctx->ctx_metal), ggml_metal_if_optimized(ctx->ctx_metal));
|
| 6777 |
}
|
|
@@ -6899,6 +7992,10 @@ int llama_n_embd(const struct llama_model * model) {
|
|
| 6899 |
return model->hparams.n_embd;
|
| 6900 |
}
|
| 6901 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6902 |
int llama_model_desc(const struct llama_model * model, char * buf, size_t buf_size) {
|
| 6903 |
return snprintf(buf, buf_size, "%s %s %s",
|
| 6904 |
llama_model_arch_name(model->arch).c_str(),
|
|
@@ -7066,16 +8163,6 @@ struct llama_data_file_context : llama_data_context {
|
|
| 7066 |
*
|
| 7067 |
*/
|
| 7068 |
static void llama_copy_state_data_internal(struct llama_context * ctx, llama_data_context * data_ctx) {
|
| 7069 |
-
// TODO: does not support multi-sequence states
|
| 7070 |
-
{
|
| 7071 |
-
const auto & kv_self = ctx->kv_self;
|
| 7072 |
-
for (uint32_t i = 0; i < kv_self.head; ++i) {
|
| 7073 |
-
GGML_ASSERT(kv_self.cells[i].pos == (int32_t) i);
|
| 7074 |
-
GGML_ASSERT(kv_self.cells[i].seq_id.size() == 1);
|
| 7075 |
-
GGML_ASSERT(kv_self.cells[i].has_seq_id(0));
|
| 7076 |
-
}
|
| 7077 |
-
}
|
| 7078 |
-
|
| 7079 |
// copy rng
|
| 7080 |
{
|
| 7081 |
std::stringstream rng_ss;
|
|
@@ -7128,36 +8215,38 @@ static void llama_copy_state_data_internal(struct llama_context * ctx, llama_dat
|
|
| 7128 |
const auto & hparams = ctx->model.hparams;
|
| 7129 |
const auto & cparams = ctx->cparams;
|
| 7130 |
|
| 7131 |
-
const
|
| 7132 |
-
const
|
| 7133 |
-
const
|
| 7134 |
|
| 7135 |
-
const size_t
|
| 7136 |
-
const
|
|
|
|
| 7137 |
|
| 7138 |
-
data_ctx->write(&
|
| 7139 |
-
data_ctx->write(&
|
|
|
|
| 7140 |
|
| 7141 |
-
if (
|
| 7142 |
const size_t elt_size = ggml_element_size(kv_self.k);
|
| 7143 |
|
| 7144 |
ggml_context * cpy_ctx = ggml_init({ 4096, NULL, /* no_alloc */ true });
|
| 7145 |
ggml_cgraph gf{};
|
| 7146 |
|
| 7147 |
-
ggml_tensor * kout3d = ggml_new_tensor_3d(cpy_ctx, kv_self.k->type, n_embd,
|
| 7148 |
std::vector<uint8_t> kout3d_data(ggml_nbytes(kout3d), 0);
|
| 7149 |
kout3d->data = kout3d_data.data();
|
| 7150 |
|
| 7151 |
-
ggml_tensor * vout3d = ggml_new_tensor_3d(cpy_ctx, kv_self.v->type,
|
| 7152 |
std::vector<uint8_t> vout3d_data(ggml_nbytes(vout3d), 0);
|
| 7153 |
vout3d->data = vout3d_data.data();
|
| 7154 |
|
| 7155 |
ggml_tensor * k3d = ggml_view_3d(cpy_ctx, kv_self.k,
|
| 7156 |
-
n_embd,
|
| 7157 |
elt_size*n_embd, elt_size*n_embd*n_ctx, 0);
|
| 7158 |
|
| 7159 |
ggml_tensor * v3d = ggml_view_3d(cpy_ctx, kv_self.v,
|
| 7160 |
-
|
| 7161 |
elt_size*n_ctx, elt_size*n_ctx*n_embd, 0);
|
| 7162 |
|
| 7163 |
ggml_build_forward_expand(&gf, ggml_cpy(cpy_ctx, k3d, kout3d));
|
|
@@ -7171,6 +8260,20 @@ static void llama_copy_state_data_internal(struct llama_context * ctx, llama_dat
|
|
| 7171 |
data_ctx->write(kout3d_data.data(), kout3d_data.size());
|
| 7172 |
data_ctx->write(vout3d_data.data(), vout3d_data.size());
|
| 7173 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7174 |
}
|
| 7175 |
}
|
| 7176 |
|
|
@@ -7242,34 +8345,36 @@ size_t llama_set_state_data(struct llama_context * ctx, uint8_t * src) {
|
|
| 7242 |
const int n_embd = hparams.n_embd_gqa();
|
| 7243 |
const int n_ctx = cparams.n_ctx;
|
| 7244 |
|
| 7245 |
-
size_t
|
| 7246 |
-
|
|
|
|
| 7247 |
|
| 7248 |
-
memcpy(&
|
| 7249 |
-
memcpy(&
|
|
|
|
| 7250 |
|
| 7251 |
-
if (
|
| 7252 |
-
GGML_ASSERT(kv_self.buf.size ==
|
| 7253 |
|
| 7254 |
const size_t elt_size = ggml_element_size(kv_self.k);
|
| 7255 |
|
| 7256 |
ggml_context * cpy_ctx = ggml_init({ 4096, NULL, /* no_alloc */ true });
|
| 7257 |
ggml_cgraph gf{};
|
| 7258 |
|
| 7259 |
-
ggml_tensor * kin3d = ggml_new_tensor_3d(cpy_ctx, kv_self.k->type, n_embd,
|
| 7260 |
kin3d->data = (void *) inp;
|
| 7261 |
inp += ggml_nbytes(kin3d);
|
| 7262 |
|
| 7263 |
-
ggml_tensor * vin3d = ggml_new_tensor_3d(cpy_ctx, kv_self.v->type,
|
| 7264 |
vin3d->data = (void *) inp;
|
| 7265 |
inp += ggml_nbytes(vin3d);
|
| 7266 |
|
| 7267 |
ggml_tensor * k3d = ggml_view_3d(cpy_ctx, kv_self.k,
|
| 7268 |
-
n_embd,
|
| 7269 |
elt_size*n_embd, elt_size*n_embd*n_ctx, 0);
|
| 7270 |
|
| 7271 |
ggml_tensor * v3d = ggml_view_3d(cpy_ctx, kv_self.v,
|
| 7272 |
-
|
| 7273 |
elt_size*n_ctx, elt_size*n_ctx*n_embd, 0);
|
| 7274 |
|
| 7275 |
ggml_build_forward_expand(&gf, ggml_cpy(cpy_ctx, kin3d, k3d));
|
|
@@ -7279,8 +8384,27 @@ size_t llama_set_state_data(struct llama_context * ctx, uint8_t * src) {
|
|
| 7279 |
ggml_free(cpy_ctx);
|
| 7280 |
}
|
| 7281 |
|
| 7282 |
-
ctx->kv_self.head =
|
| 7283 |
ctx->kv_self.size = kv_size;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7284 |
}
|
| 7285 |
|
| 7286 |
const size_t nread = inp - src;
|
|
@@ -7498,6 +8622,22 @@ llama_token llama_token_eos(const struct llama_context * ctx) {
|
|
| 7498 |
llama_token llama_token_nl(const struct llama_context * ctx) {
|
| 7499 |
return ctx->model.vocab.linefeed_id;
|
| 7500 |
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7501 |
|
| 7502 |
int llama_tokenize(
|
| 7503 |
const struct llama_model * model,
|
|
@@ -7520,35 +8660,68 @@ int llama_tokenize(
|
|
| 7520 |
return res.size();
|
| 7521 |
}
|
| 7522 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7523 |
// does not write null-terminator to buf
|
| 7524 |
int llama_token_to_piece(const struct llama_model * model, llama_token token, char * buf, int length) {
|
| 7525 |
if (0 <= token && token < llama_n_vocab(model)) {
|
| 7526 |
-
|
| 7527 |
-
|
| 7528 |
-
if (
|
|
|
|
| 7529 |
llama_unescape_whitespace(result);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7530 |
}
|
| 7531 |
-
|
| 7532 |
-
|
| 7533 |
-
|
| 7534 |
-
|
| 7535 |
-
|
| 7536 |
-
|
| 7537 |
-
|
| 7538 |
-
|
| 7539 |
-
|
| 7540 |
-
|
| 7541 |
-
|
| 7542 |
-
|
| 7543 |
-
|
| 7544 |
-
|
| 7545 |
-
|
| 7546 |
-
} else if (llama_is_byte_token(model->vocab, token)) {
|
| 7547 |
-
if (length < 1) {
|
| 7548 |
-
return -1;
|
| 7549 |
}
|
| 7550 |
-
|
| 7551 |
-
|
|
|
|
|
|
|
| 7552 |
}
|
| 7553 |
}
|
| 7554 |
return 0;
|
|
@@ -7575,14 +8748,14 @@ void llama_print_timings(struct llama_context * ctx) {
|
|
| 7575 |
const llama_timings timings = llama_get_timings(ctx);
|
| 7576 |
|
| 7577 |
LLAMA_LOG_INFO("\n");
|
| 7578 |
-
LLAMA_LOG_INFO("%s: load time = %
|
| 7579 |
-
LLAMA_LOG_INFO("%s: sample time = %
|
| 7580 |
__func__, timings.t_sample_ms, timings.n_sample, timings.t_sample_ms / timings.n_sample, 1e3 / timings.t_sample_ms * timings.n_sample);
|
| 7581 |
-
LLAMA_LOG_INFO("%s: prompt eval time = %
|
| 7582 |
__func__, timings.t_p_eval_ms, timings.n_p_eval, timings.t_p_eval_ms / timings.n_p_eval, 1e3 / timings.t_p_eval_ms * timings.n_p_eval);
|
| 7583 |
-
LLAMA_LOG_INFO("%s: eval time = %
|
| 7584 |
__func__, timings.t_eval_ms, timings.n_eval, timings.t_eval_ms / timings.n_eval, 1e3 / timings.t_eval_ms * timings.n_eval);
|
| 7585 |
-
LLAMA_LOG_INFO("%s: total time = %
|
| 7586 |
}
|
| 7587 |
|
| 7588 |
void llama_reset_timings(struct llama_context * ctx) {
|
|
|
|
| 1 |
#define LLAMA_API_INTERNAL
|
| 2 |
#include "llama.h"
|
| 3 |
|
| 4 |
+
#include "unicode.h"
|
| 5 |
+
|
| 6 |
#include "ggml.h"
|
| 7 |
|
| 8 |
#include "ggml-alloc.h"
|
|
|
|
| 126 |
}
|
| 127 |
s = std::move(result);
|
| 128 |
}
|
| 129 |
+
|
| 130 |
+
static bool is_float_close(float a, float b, float abs_tol) {
|
| 131 |
+
// Check for non-negative tolerance
|
| 132 |
+
if (abs_tol < 0.0) {
|
| 133 |
+
throw std::invalid_argument("Tolerance must be non-negative");
|
| 134 |
+
}
|
| 135 |
+
|
| 136 |
+
// Exact equality check
|
| 137 |
+
if (a == b) {
|
| 138 |
+
return true;
|
| 139 |
+
}
|
| 140 |
+
|
| 141 |
+
// Check for infinities
|
| 142 |
+
if (std::isinf(a) || std::isinf(b)) {
|
| 143 |
+
return false;
|
| 144 |
+
}
|
| 145 |
+
|
| 146 |
+
// Regular comparison using the provided absolute tolerance
|
| 147 |
+
return std::fabs(b - a) <= abs_tol;
|
| 148 |
+
}
|
| 149 |
+
|
| 150 |
#ifdef GGML_USE_CPU_HBM
|
| 151 |
#include <hbwmalloc.h>
|
| 152 |
#endif
|
|
|
|
| 187 |
LLM_ARCH_GPTNEOX,
|
| 188 |
LLM_ARCH_MPT,
|
| 189 |
LLM_ARCH_STARCODER,
|
| 190 |
+
LLM_ARCH_PERSIMMON,
|
| 191 |
+
LLM_ARCH_REFACT,
|
| 192 |
LLM_ARCH_UNKNOWN,
|
| 193 |
};
|
| 194 |
|
|
|
|
| 201 |
{ LLM_ARCH_MPT, "mpt" },
|
| 202 |
{ LLM_ARCH_BAICHUAN, "baichuan" },
|
| 203 |
{ LLM_ARCH_STARCODER, "starcoder" },
|
| 204 |
+
{ LLM_ARCH_PERSIMMON, "persimmon" },
|
| 205 |
+
{ LLM_ARCH_REFACT, "refact" },
|
| 206 |
};
|
| 207 |
|
| 208 |
enum llm_kv {
|
|
|
|
| 321 |
LLM_TENSOR_FFN_DOWN,
|
| 322 |
LLM_TENSOR_FFN_UP,
|
| 323 |
LLM_TENSOR_FFN_NORM,
|
| 324 |
+
LLM_TENSOR_ATTN_Q_NORM,
|
| 325 |
+
LLM_TENSOR_ATTN_K_NORM,
|
| 326 |
};
|
| 327 |
|
| 328 |
static std::map<llm_arch, std::map<llm_tensor, std::string>> LLM_TENSOR_NAMES = {
|
|
|
|
| 404 |
{ LLM_TENSOR_FFN_UP, "blk.%d.ffn_up" },
|
| 405 |
},
|
| 406 |
},
|
| 407 |
+
{
|
| 408 |
+
LLM_ARCH_PERSIMMON,
|
| 409 |
+
{
|
| 410 |
+
{ LLM_TENSOR_TOKEN_EMBD, "token_embd"},
|
| 411 |
+
{ LLM_TENSOR_OUTPUT_NORM, "output_norm"},
|
| 412 |
+
{ LLM_TENSOR_OUTPUT, "output"},
|
| 413 |
+
{ LLM_TENSOR_ATTN_NORM, "blk.%d.attn_norm"},
|
| 414 |
+
{ LLM_TENSOR_ATTN_QKV, "blk.%d.attn_qkv"},
|
| 415 |
+
{ LLM_TENSOR_ATTN_OUT, "blk.%d.attn_output"},
|
| 416 |
+
{ LLM_TENSOR_ATTN_Q_NORM, "blk.%d.attn_q_norm"},
|
| 417 |
+
{ LLM_TENSOR_ATTN_K_NORM, "blk.%d.attn_k_norm"},
|
| 418 |
+
{ LLM_TENSOR_FFN_NORM, "blk.%d.ffn_norm"},
|
| 419 |
+
{ LLM_TENSOR_FFN_DOWN, "blk.%d.ffn_down"},
|
| 420 |
+
{ LLM_TENSOR_FFN_UP, "blk.%d.ffn_up"},
|
| 421 |
+
{ LLM_TENSOR_ATTN_ROT_EMBD, "blk.%d.attn_rot_embd"},
|
| 422 |
+
},
|
| 423 |
+
},
|
| 424 |
{
|
| 425 |
LLM_ARCH_MPT,
|
| 426 |
{
|
|
|
|
| 442 |
{ LLM_TENSOR_FFN_DOWN, "blk.%d.ffn_down" },
|
| 443 |
},
|
| 444 |
},
|
| 445 |
+
{
|
| 446 |
+
LLM_ARCH_REFACT,
|
| 447 |
+
{
|
| 448 |
+
{ LLM_TENSOR_TOKEN_EMBD, "token_embd" },
|
| 449 |
+
{ LLM_TENSOR_OUTPUT_NORM, "output_norm" },
|
| 450 |
+
{ LLM_TENSOR_OUTPUT, "output" },
|
| 451 |
+
{ LLM_TENSOR_ATTN_NORM, "blk.%d.attn_norm" },
|
| 452 |
+
{ LLM_TENSOR_ATTN_Q, "blk.%d.attn_q" },
|
| 453 |
+
{ LLM_TENSOR_ATTN_K, "blk.%d.attn_k" },
|
| 454 |
+
{ LLM_TENSOR_ATTN_V, "blk.%d.attn_v" },
|
| 455 |
+
{ LLM_TENSOR_ATTN_OUT, "blk.%d.attn_output" },
|
| 456 |
+
{ LLM_TENSOR_FFN_NORM, "blk.%d.ffn_norm" },
|
| 457 |
+
{ LLM_TENSOR_FFN_GATE, "blk.%d.ffn_gate" },
|
| 458 |
+
{ LLM_TENSOR_FFN_DOWN, "blk.%d.ffn_down" },
|
| 459 |
+
{ LLM_TENSOR_FFN_UP, "blk.%d.ffn_up" },
|
| 460 |
+
},
|
| 461 |
+
},
|
| 462 |
{
|
| 463 |
LLM_ARCH_UNKNOWN,
|
| 464 |
{
|
|
|
|
| 985 |
MODEL_1B,
|
| 986 |
MODEL_3B,
|
| 987 |
MODEL_7B,
|
| 988 |
+
MODEL_8B,
|
| 989 |
MODEL_13B,
|
| 990 |
MODEL_15B,
|
| 991 |
MODEL_30B,
|
|
|
|
| 1017 |
float rope_freq_scale_train;
|
| 1018 |
|
| 1019 |
bool operator!=(const llama_hparams & other) const {
|
| 1020 |
+
if (this->vocab_only != other.vocab_only) return true;
|
| 1021 |
+
if (this->n_vocab != other.n_vocab) return true;
|
| 1022 |
+
if (this->n_ctx_train != other.n_ctx_train) return true;
|
| 1023 |
+
if (this->n_embd != other.n_embd) return true;
|
| 1024 |
+
if (this->n_head != other.n_head) return true;
|
| 1025 |
+
if (this->n_head_kv != other.n_head_kv) return true;
|
| 1026 |
+
if (this->n_layer != other.n_layer) return true;
|
| 1027 |
+
if (this->n_rot != other.n_rot) return true;
|
| 1028 |
+
if (this->n_ff != other.n_ff) return true;
|
| 1029 |
+
|
| 1030 |
+
const float EPSILON = 1e-9;
|
| 1031 |
+
|
| 1032 |
+
if (!is_float_close(this->f_norm_eps, other.f_norm_eps, EPSILON)) return true;
|
| 1033 |
+
if (!is_float_close(this->f_norm_rms_eps, other.f_norm_rms_eps, EPSILON)) return true;
|
| 1034 |
+
if (!is_float_close(this->rope_freq_base_train, other.rope_freq_base_train, EPSILON)) return true;
|
| 1035 |
+
if (!is_float_close(this->rope_freq_scale_train, other.rope_freq_scale_train, EPSILON)) return true;
|
| 1036 |
+
|
| 1037 |
+
return false;
|
| 1038 |
}
|
| 1039 |
|
| 1040 |
uint32_t n_gqa() const {
|
|
|
|
| 1068 |
struct ggml_tensor * attn_norm_b;
|
| 1069 |
struct ggml_tensor * attn_norm_2;
|
| 1070 |
struct ggml_tensor * attn_norm_2_b;
|
| 1071 |
+
struct ggml_tensor * attn_q_norm;
|
| 1072 |
+
struct ggml_tensor * attn_q_norm_b;
|
| 1073 |
+
struct ggml_tensor * attn_k_norm;
|
| 1074 |
+
struct ggml_tensor * attn_k_norm_b;
|
| 1075 |
|
| 1076 |
// attention
|
| 1077 |
struct ggml_tensor * wq;
|
|
|
|
| 1113 |
struct llama_kv_cache {
|
| 1114 |
bool has_shift = false;
|
| 1115 |
|
| 1116 |
+
// Note: The value of head isn't only used to optimize searching
|
| 1117 |
+
// for a free KV slot. llama_decode_internal also uses it, so it
|
| 1118 |
+
// cannot be freely changed after a slot has been allocated.
|
| 1119 |
uint32_t head = 0;
|
| 1120 |
uint32_t size = 0;
|
| 1121 |
|
|
|
|
| 1169 |
id special_pad_id = -1;
|
| 1170 |
|
| 1171 |
id linefeed_id = 13;
|
| 1172 |
+
id special_prefix_id = 32007;
|
| 1173 |
+
id special_middle_id = 32009;
|
| 1174 |
+
id special_suffix_id = 32008;
|
| 1175 |
+
id special_eot_id = 32010;
|
| 1176 |
|
| 1177 |
int find_bpe_rank(std::string token_left, std::string token_right) const {
|
| 1178 |
replace_all(token_left, " ", "\u0120");
|
|
|
|
| 1373 |
|
| 1374 |
// find an empty slot of size "n_tokens" in the cache
|
| 1375 |
// updates the cache head
|
| 1376 |
+
// Note: On success, it's important that cache.head points
|
| 1377 |
+
// to the first cell of the slot.
|
| 1378 |
static bool llama_kv_cache_find_slot(
|
| 1379 |
+
struct llama_kv_cache & cache,
|
| 1380 |
+
const struct llama_batch & batch) {
|
| 1381 |
const uint32_t n_ctx = cache.size;
|
| 1382 |
const uint32_t n_tokens = batch.n_tokens;
|
| 1383 |
|
|
|
|
| 1390 |
|
| 1391 |
while (true) {
|
| 1392 |
if (cache.head + n_tokens > n_ctx) {
|
| 1393 |
+
n_tested += n_ctx - cache.head;
|
| 1394 |
cache.head = 0;
|
|
|
|
| 1395 |
continue;
|
| 1396 |
}
|
| 1397 |
|
|
|
|
| 1442 |
cache.cells[i].pos = -1;
|
| 1443 |
cache.cells[i].seq_id.clear();
|
| 1444 |
}
|
| 1445 |
+
|
| 1446 |
+
// Searching for a free slot can start here since we know it will be empty.
|
| 1447 |
+
cache.head = uint32_t(c0);
|
| 1448 |
}
|
| 1449 |
|
| 1450 |
static void llama_kv_cache_seq_rm(
|
| 1451 |
+
struct llama_kv_cache & cache,
|
| 1452 |
+
llama_seq_id seq_id,
|
| 1453 |
+
llama_pos p0,
|
| 1454 |
+
llama_pos p1) {
|
| 1455 |
+
uint32_t new_head = cache.size;
|
| 1456 |
+
|
| 1457 |
+
if (p0 < 0) p0 = 0;
|
| 1458 |
+
if (p1 < 0) p1 = std::numeric_limits<llama_pos>::max();
|
| 1459 |
+
|
| 1460 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1461 |
if (cache.cells[i].has_seq_id(seq_id) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) {
|
| 1462 |
cache.cells[i].seq_id.erase(seq_id);
|
| 1463 |
if (cache.cells[i].seq_id.empty()) {
|
| 1464 |
cache.cells[i].pos = -1;
|
| 1465 |
+
if (new_head == cache.size) new_head = i;
|
| 1466 |
}
|
| 1467 |
}
|
| 1468 |
}
|
| 1469 |
+
|
| 1470 |
+
// If we freed up a slot, set head to it so searching can start there.
|
| 1471 |
+
if (new_head != cache.size) cache.head = new_head;
|
| 1472 |
}
|
| 1473 |
|
| 1474 |
static void llama_kv_cache_seq_cp(
|
| 1475 |
+
struct llama_kv_cache & cache,
|
| 1476 |
+
llama_seq_id seq_id_src,
|
| 1477 |
+
llama_seq_id seq_id_dst,
|
| 1478 |
+
llama_pos p0,
|
| 1479 |
+
llama_pos p1) {
|
| 1480 |
+
if (p0 < 0) p0 = 0;
|
| 1481 |
+
if (p1 < 0) p1 = std::numeric_limits<llama_pos>::max();
|
| 1482 |
+
|
| 1483 |
+
cache.head = 0;
|
| 1484 |
+
|
| 1485 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1486 |
if (cache.cells[i].has_seq_id(seq_id_src) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) {
|
| 1487 |
cache.cells[i].seq_id.insert(seq_id_dst);
|
|
|
|
| 1490 |
}
|
| 1491 |
|
| 1492 |
static void llama_kv_cache_seq_keep(struct llama_kv_cache & cache, llama_seq_id seq_id) {
|
| 1493 |
+
uint32_t new_head = cache.size;
|
| 1494 |
+
|
| 1495 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1496 |
if (!cache.cells[i].has_seq_id(seq_id)) {
|
| 1497 |
cache.cells[i].pos = -1;
|
| 1498 |
cache.cells[i].seq_id.clear();
|
| 1499 |
+
if (new_head == cache.size) new_head = i;
|
| 1500 |
}
|
| 1501 |
}
|
| 1502 |
+
|
| 1503 |
+
// If we freed up a slot, set head to it so searching can start there.
|
| 1504 |
+
if (new_head != cache.size) cache.head = new_head;
|
| 1505 |
}
|
| 1506 |
|
| 1507 |
static void llama_kv_cache_seq_shift(
|
| 1508 |
+
struct llama_kv_cache & cache,
|
| 1509 |
+
llama_seq_id seq_id,
|
| 1510 |
+
llama_pos p0,
|
| 1511 |
+
llama_pos p1,
|
| 1512 |
+
llama_pos delta) {
|
| 1513 |
+
uint32_t new_head = cache.size;
|
| 1514 |
+
|
| 1515 |
+
if (p0 < 0) p0 = 0;
|
| 1516 |
+
if (p1 < 0) p1 = std::numeric_limits<llama_pos>::max();
|
| 1517 |
+
|
| 1518 |
for (uint32_t i = 0; i < cache.size; ++i) {
|
| 1519 |
if (cache.cells[i].has_seq_id(seq_id) && cache.cells[i].pos >= p0 && cache.cells[i].pos < p1) {
|
| 1520 |
cache.cells[i].pos += delta;
|
| 1521 |
if (cache.cells[i].pos < 0) {
|
| 1522 |
cache.cells[i].pos = -1;
|
| 1523 |
cache.cells[i].seq_id.clear();
|
| 1524 |
+
if (new_head == cache.size) new_head = i;
|
| 1525 |
} else {
|
| 1526 |
cache.has_shift = true;
|
| 1527 |
cache.cells[i].delta = delta;
|
| 1528 |
}
|
| 1529 |
}
|
| 1530 |
}
|
| 1531 |
+
|
| 1532 |
+
// If we freed up a slot, set head to it so searching can start there.
|
| 1533 |
+
// Otherwise we just start the next search from the beginning.
|
| 1534 |
+
cache.head = new_head != cache.size ? new_head : 0;
|
| 1535 |
}
|
| 1536 |
|
| 1537 |
//
|
|
|
|
| 1933 |
case MODEL_1B: return "1B";
|
| 1934 |
case MODEL_3B: return "3B";
|
| 1935 |
case MODEL_7B: return "7B";
|
| 1936 |
+
case MODEL_8B: return "8B";
|
| 1937 |
case MODEL_13B: return "13B";
|
| 1938 |
case MODEL_15B: return "15B";
|
| 1939 |
case MODEL_30B: return "30B";
|
|
|
|
| 2046 |
default: model.type = e_model::MODEL_UNKNOWN;
|
| 2047 |
}
|
| 2048 |
} break;
|
| 2049 |
+
case LLM_ARCH_PERSIMMON:
|
| 2050 |
+
{
|
| 2051 |
+
GGUF_GET_KEY(ctx, hparams.f_norm_eps, gguf_get_val_f32, GGUF_TYPE_FLOAT32, true, kv(LLM_KV_ATTENTION_LAYERNORM_EPS));
|
| 2052 |
+
switch (hparams.n_layer) {
|
| 2053 |
+
case 36: model.type = e_model::MODEL_8B; break;
|
| 2054 |
+
default: model.type = e_model::MODEL_UNKNOWN;
|
| 2055 |
+
}
|
| 2056 |
+
} break;
|
| 2057 |
+
case LLM_ARCH_REFACT:
|
| 2058 |
+
{
|
| 2059 |
+
GGUF_GET_KEY(ctx, hparams.f_norm_rms_eps, gguf_get_val_f32, GGUF_TYPE_FLOAT32, true, kv(LLM_KV_ATTENTION_LAYERNORM_RMS_EPS));
|
| 2060 |
+
switch (hparams.n_layer) {
|
| 2061 |
+
case 32: model.type = e_model::MODEL_1B; break;
|
| 2062 |
+
default: model.type = e_model::MODEL_UNKNOWN;
|
| 2063 |
+
}
|
| 2064 |
+
} break;
|
| 2065 |
default: (void)0;
|
| 2066 |
}
|
| 2067 |
|
|
|
|
| 2126 |
|
| 2127 |
for (int i = 0; i < n_merges; i++) {
|
| 2128 |
const std::string word = gguf_get_arr_str(ctx, merges_keyidx, i);
|
| 2129 |
+
GGML_ASSERT(codepoints_from_utf8(word).size() > 0);
|
| 2130 |
|
| 2131 |
std::string first;
|
| 2132 |
std::string second;
|
|
|
|
| 2161 |
|
| 2162 |
for (uint32_t i = 0; i < n_vocab; i++) {
|
| 2163 |
std::string word = gguf_get_arr_str(ctx, token_idx, i);
|
| 2164 |
+
GGML_ASSERT(codepoints_from_utf8(word).size() > 0);
|
| 2165 |
|
| 2166 |
vocab.token_to_id[word] = i;
|
| 2167 |
|
|
|
|
| 2170 |
token_data.score = scores ? scores[i] : 0.0f;
|
| 2171 |
token_data.type = toktypes ? (llama_token_type) toktypes[i] : LLAMA_TOKEN_TYPE_NORMAL;
|
| 2172 |
}
|
| 2173 |
+
GGML_ASSERT(vocab.id_to_token.size() == vocab.token_to_id.size());
|
| 2174 |
|
| 2175 |
// determine the newline token: LLaMA "<0x0A>" == 10 == '\n', Falcon 193 == '\n'
|
| 2176 |
if (vocab.type == LLAMA_VOCAB_TYPE_SPM) {
|
| 2177 |
vocab.linefeed_id = llama_byte_to_token(vocab, '\n');
|
| 2178 |
} else {
|
| 2179 |
+
vocab.linefeed_id = llama_tokenize_internal(vocab, "\u010A", false)[0];
|
| 2180 |
}
|
| 2181 |
|
| 2182 |
// special tokens
|
|
|
|
| 2299 |
const auto tn = LLM_TN(model.arch);
|
| 2300 |
switch (model.arch) {
|
| 2301 |
case LLM_ARCH_LLAMA:
|
| 2302 |
+
case LLM_ARCH_REFACT:
|
| 2303 |
{
|
| 2304 |
model.tok_embeddings = ml.create_tensor(ctx, tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, GGML_BACKEND_CPU);
|
| 2305 |
|
|
|
|
| 2590 |
}
|
| 2591 |
}
|
| 2592 |
} break;
|
| 2593 |
+
case LLM_ARCH_PERSIMMON:
|
| 2594 |
+
{
|
| 2595 |
+
model.tok_embeddings = ml.create_tensor(ctx, tn(LLM_TENSOR_TOKEN_EMBD, "weight"), {n_embd, n_vocab}, GGML_BACKEND_CPU);
|
| 2596 |
+
|
| 2597 |
+
{
|
| 2598 |
+
ggml_backend backend_norm;
|
| 2599 |
+
ggml_backend backend_output;
|
| 2600 |
+
|
| 2601 |
+
if (n_gpu_layers > int(n_layer)) {
|
| 2602 |
+
// norm is not performance relevant on its own but keeping it in VRAM reduces data copying
|
| 2603 |
+
// on Windows however this is detrimental unless everything is on the GPU
|
| 2604 |
+
#ifndef _WIN32
|
| 2605 |
+
backend_norm = LLAMA_BACKEND_OFFLOAD;
|
| 2606 |
+
#else
|
| 2607 |
+
backend_norm = n_gpu_layers <= (int) n_layer + 2 ? GGML_BACKEND_CPU : LLAMA_BACKEND_OFFLOAD;
|
| 2608 |
+
#endif // _WIN32
|
| 2609 |
+
|
| 2610 |
+
backend_output = LLAMA_BACKEND_OFFLOAD_SPLIT;
|
| 2611 |
+
} else {
|
| 2612 |
+
backend_norm = GGML_BACKEND_CPU;
|
| 2613 |
+
backend_output = GGML_BACKEND_CPU;
|
| 2614 |
+
}
|
| 2615 |
+
|
| 2616 |
+
model.output_norm = ml.create_tensor(ctx, tn(LLM_TENSOR_OUTPUT_NORM, "weight"), {n_embd}, backend_norm);
|
| 2617 |
+
model.output_norm_b = ml.create_tensor(ctx, tn(LLM_TENSOR_OUTPUT_NORM, "bias"), {n_embd}, backend_norm);
|
| 2618 |
+
model.output = ml.create_tensor(ctx, tn(LLM_TENSOR_OUTPUT, "weight"), {n_embd, n_vocab}, backend_output);
|
| 2619 |
+
|
| 2620 |
+
if (backend_norm == GGML_BACKEND_GPU) {
|
| 2621 |
+
vram_weights += ggml_nbytes(model.output_norm);
|
| 2622 |
+
vram_weights += ggml_nbytes(model.output_norm_b);
|
| 2623 |
+
}
|
| 2624 |
+
if (backend_output == GGML_BACKEND_GPU_SPLIT) {
|
| 2625 |
+
vram_weights += ggml_nbytes(model.output);
|
| 2626 |
+
}
|
| 2627 |
+
}
|
| 2628 |
+
|
| 2629 |
+
const uint32_t n_ff = hparams.n_ff;
|
| 2630 |
+
const int i_gpu_start = n_layer - n_gpu_layers;
|
| 2631 |
+
model.layers.resize(n_layer);
|
| 2632 |
+
for (uint32_t i = 0; i < n_layer; ++i) {
|
| 2633 |
+
const ggml_backend backend = int(i) < i_gpu_start ? GGML_BACKEND_CPU : LLAMA_BACKEND_OFFLOAD;
|
| 2634 |
+
const ggml_backend backend_split = int(i) < i_gpu_start ? GGML_BACKEND_CPU : LLAMA_BACKEND_OFFLOAD_SPLIT;
|
| 2635 |
+
auto & layer = model.layers[i];
|
| 2636 |
+
layer.attn_norm = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_NORM, "weight", i), {n_embd}, backend);
|
| 2637 |
+
layer.attn_norm_b = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_NORM, "bias", i), {n_embd}, backend);
|
| 2638 |
+
layer.wqkv = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_QKV, "weight", i), {n_embd, n_embd + 2*n_embd_gqa}, backend_split);
|
| 2639 |
+
layer.bqkv = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_QKV, "bias", i), {n_embd + 2*n_embd_gqa}, backend_split);
|
| 2640 |
+
layer.wo = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_OUT, "weight", i), {n_embd, n_embd}, backend_split);
|
| 2641 |
+
layer.bo = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_OUT, "bias", i), {n_embd}, backend_split);
|
| 2642 |
+
layer.w2 = ml.create_tensor(ctx, tn(LLM_TENSOR_FFN_DOWN, "weight", i), {n_ff, n_embd}, backend_split);
|
| 2643 |
+
layer.b2 = ml.create_tensor(ctx, tn(LLM_TENSOR_FFN_DOWN, "bias", i), {n_embd}, backend_split);
|
| 2644 |
+
layer.w3 = ml.create_tensor(ctx, tn(LLM_TENSOR_FFN_UP, "weight", i), {n_embd, n_ff}, backend_split);
|
| 2645 |
+
layer.b3 = ml.create_tensor(ctx, tn(LLM_TENSOR_FFN_UP, "bias", i), {n_ff}, backend_split);
|
| 2646 |
+
layer.ffn_norm = ml.create_tensor(ctx, tn(LLM_TENSOR_FFN_NORM, "weight", i), {n_embd}, backend);
|
| 2647 |
+
layer.ffn_norm_b = ml.create_tensor(ctx, tn(LLM_TENSOR_FFN_NORM, "bias", i), {n_embd}, backend);
|
| 2648 |
+
layer.attn_q_norm = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_Q_NORM, "weight", i), {64}, backend);
|
| 2649 |
+
layer.attn_q_norm_b = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_Q_NORM, "bias", i), {64}, backend);
|
| 2650 |
+
layer.attn_k_norm = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_K_NORM, "weight", i), {64}, backend);
|
| 2651 |
+
layer.attn_k_norm_b = ml.create_tensor(ctx, tn(LLM_TENSOR_ATTN_K_NORM, "bias", i), {64}, backend);
|
| 2652 |
+
}
|
| 2653 |
+
} break;
|
| 2654 |
default:
|
| 2655 |
throw std::runtime_error("unknown architecture");
|
| 2656 |
}
|
|
|
|
| 2760 |
}
|
| 2761 |
|
| 2762 |
static struct ggml_cgraph * llm_build_llama(
|
| 2763 |
+
llama_context & lctx,
|
| 2764 |
+
const llama_batch & batch) {
|
| 2765 |
const auto & model = lctx.model;
|
| 2766 |
const auto & hparams = model.hparams;
|
| 2767 |
const auto & cparams = lctx.cparams;
|
|
|
|
| 2799 |
struct ggml_init_params params = {
|
| 2800 |
/*.mem_size =*/ buf_compute.size,
|
| 2801 |
/*.mem_buffer =*/ buf_compute.data,
|
| 2802 |
+
/*.no_alloc =*/ true,
|
| 2803 |
};
|
| 2804 |
|
|
|
|
|
|
|
| 2805 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 2806 |
|
| 2807 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
|
|
| 3185 |
struct ggml_init_params params = {
|
| 3186 |
/*.mem_size =*/ buf_compute.size,
|
| 3187 |
/*.mem_buffer =*/ buf_compute.data,
|
| 3188 |
+
/*.no_alloc =*/ true,
|
| 3189 |
};
|
| 3190 |
|
|
|
|
|
|
|
| 3191 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 3192 |
|
| 3193 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
|
|
| 3550 |
return gf;
|
| 3551 |
}
|
| 3552 |
|
| 3553 |
+
static struct ggml_cgraph * llm_build_refact(
|
| 3554 |
llama_context & lctx,
|
| 3555 |
const llama_batch & batch) {
|
| 3556 |
const auto & model = lctx.model;
|
|
|
|
| 3569 |
const int64_t n_embd_head = hparams.n_embd_head();
|
| 3570 |
const int64_t n_embd_gqa = hparams.n_embd_gqa();
|
| 3571 |
|
| 3572 |
+
const float norm_rms_eps = hparams.f_norm_rms_eps;
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3573 |
|
| 3574 |
const int n_gpu_layers = model.n_gpu_layers;
|
| 3575 |
|
|
|
|
| 3577 |
const int32_t n_kv = ggml_allocr_is_measure(lctx.alloc) ? n_ctx : kv_self.n;
|
| 3578 |
const int32_t kv_head = ggml_allocr_is_measure(lctx.alloc) ? n_ctx - n_tokens : kv_self.head;
|
| 3579 |
|
| 3580 |
+
// printf("n_kv = %d\n", n_kv);
|
|
|
|
|
|
|
|
|
|
| 3581 |
|
| 3582 |
auto & buf_compute = lctx.buf_compute;
|
| 3583 |
|
| 3584 |
struct ggml_init_params params = {
|
| 3585 |
/*.mem_size =*/ buf_compute.size,
|
| 3586 |
/*.mem_buffer =*/ buf_compute.data,
|
| 3587 |
+
/*.no_alloc =*/ true,
|
| 3588 |
};
|
| 3589 |
|
|
|
|
|
|
|
| 3590 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 3591 |
|
| 3592 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
|
|
| 3643 |
ggml_set_name(KQ_scale, "1/sqrt(n_embd_head)");
|
| 3644 |
ggml_allocr_alloc(lctx.alloc, KQ_scale);
|
| 3645 |
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3646 |
+
ggml_set_f32(KQ_scale, 1.0f/sqrtf(float(n_embd_head)));
|
| 3647 |
}
|
| 3648 |
|
| 3649 |
// KQ_mask (mask for 1 head, it will be broadcasted to all heads)
|
|
|
|
| 3669 |
}
|
| 3670 |
}
|
| 3671 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3672 |
for (int il = 0; il < n_layer; ++il) {
|
| 3673 |
+
ggml_format_name(inpL, "layer_inp_%d", il);
|
| 3674 |
|
| 3675 |
offload_func_t offload_func = llama_nop;
|
| 3676 |
|
|
|
|
| 3680 |
}
|
| 3681 |
#endif // GGML_USE_CUBLAS
|
| 3682 |
|
| 3683 |
+
struct ggml_tensor * inpSA = inpL;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3684 |
|
| 3685 |
+
// norm
|
| 3686 |
+
{
|
| 3687 |
+
cur = ggml_rms_norm(ctx0, inpL, norm_rms_eps);
|
| 3688 |
+
offload_func(cur);
|
| 3689 |
+
ggml_set_name(cur, "rms_norm_0");
|
| 3690 |
|
| 3691 |
+
// cur = cur*attn_norm(broadcasted)
|
| 3692 |
+
cur = ggml_mul(ctx0, cur, model.layers[il].attn_norm);
|
| 3693 |
+
offload_func(cur);
|
| 3694 |
+
ggml_set_name(cur, "attention_norm_0");
|
| 3695 |
+
}
|
|
|
|
|
|
|
|
|
|
| 3696 |
|
| 3697 |
+
// self-attention
|
| 3698 |
+
{
|
| 3699 |
+
// compute Q and K
|
| 3700 |
+
struct ggml_tensor * tmpk = ggml_mul_mat(ctx0, model.layers[il].wk, cur);
|
| 3701 |
+
offload_func_kq(tmpk);
|
| 3702 |
+
ggml_set_name(tmpk, "tmpk");
|
| 3703 |
|
| 3704 |
+
struct ggml_tensor * tmpq = ggml_mul_mat(ctx0, model.layers[il].wq, cur);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3705 |
offload_func_kq(tmpq);
|
| 3706 |
+
ggml_set_name(tmpq, "tmpq");
|
| 3707 |
|
| 3708 |
+
struct ggml_tensor * Kcur = ggml_reshape_3d(ctx0, tmpk, n_embd_head, n_head_kv, n_tokens);
|
| 3709 |
+
offload_func_kq(Kcur);
|
| 3710 |
+
ggml_set_name(Kcur, "Kcur");
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3711 |
|
| 3712 |
+
struct ggml_tensor * Qcur = ggml_reshape_3d(ctx0, tmpq, n_embd_head, n_head, n_tokens);
|
|
|
|
| 3713 |
offload_func_kq(Qcur);
|
| 3714 |
+
ggml_set_name(Qcur, "Qcur");
|
|
|
|
| 3715 |
|
| 3716 |
+
// store key and value to memory
|
| 3717 |
{
|
| 3718 |
+
// compute the transposed [n_tokens, n_embd] V matrix
|
| 3719 |
+
|
| 3720 |
+
struct ggml_tensor * tmpv = ggml_mul_mat(ctx0, model.layers[il].wv, cur);
|
| 3721 |
+
offload_func_v(tmpv);
|
| 3722 |
+
ggml_set_name(tmpv, "tmpv");
|
| 3723 |
+
|
| 3724 |
+
struct ggml_tensor * Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, tmpv, n_embd_gqa, n_tokens));
|
| 3725 |
offload_func_v(Vcur);
|
| 3726 |
+
ggml_set_name(Vcur, "Vcur");
|
| 3727 |
+
|
| 3728 |
+
struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, n_tokens*n_embd_gqa, (ggml_element_size(kv_self.k)*n_embd_gqa)*(il*n_ctx + kv_head));
|
| 3729 |
+
offload_func_kq(k);
|
| 3730 |
+
ggml_set_name(k, "k");
|
| 3731 |
+
|
| 3732 |
+
struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, n_tokens, n_embd_gqa,
|
| 3733 |
+
( n_ctx)*ggml_element_size(kv_self.v),
|
| 3734 |
+
(il*n_ctx)*ggml_element_size(kv_self.v)*n_embd_gqa + kv_head*ggml_element_size(kv_self.v));
|
| 3735 |
+
offload_func_v(v);
|
| 3736 |
+
ggml_set_name(v, "v");
|
| 3737 |
+
|
| 3738 |
+
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k));
|
| 3739 |
+
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v));
|
| 3740 |
+
}
|
| 3741 |
+
|
| 3742 |
+
struct ggml_tensor * Q = ggml_permute(ctx0, Qcur, 0, 2, 1, 3);
|
| 3743 |
+
offload_func_kq(Q);
|
| 3744 |
+
ggml_set_name(Q, "Q");
|
| 3745 |
+
|
| 3746 |
+
struct ggml_tensor * K =
|
| 3747 |
+
ggml_view_3d(ctx0, kv_self.k,
|
| 3748 |
+
n_embd_head, n_kv, n_head_kv,
|
| 3749 |
+
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 3750 |
+
ggml_element_size(kv_self.k)*n_embd_head,
|
| 3751 |
+
ggml_element_size(kv_self.k)*n_embd_gqa*n_ctx*il);
|
| 3752 |
+
offload_func_kq(K);
|
| 3753 |
+
ggml_set_name(K, "K");
|
| 3754 |
+
|
| 3755 |
+
// K * Q
|
| 3756 |
+
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
| 3757 |
+
offload_func_kq(KQ);
|
| 3758 |
+
ggml_set_name(KQ, "KQ");
|
| 3759 |
+
|
| 3760 |
+
// KQ_scaled = KQ / sqrt(n_embd_head)
|
| 3761 |
+
// KQ_scaled shape [n_kv, n_tokens, n_head, 1]
|
| 3762 |
+
struct ggml_tensor * KQ_scaled = ggml_scale(ctx0, KQ, KQ_scale);
|
| 3763 |
+
offload_func_kq(KQ_scaled);
|
| 3764 |
+
ggml_set_name(KQ_scaled, "KQ_scaled");
|
| 3765 |
+
|
| 3766 |
+
// KQ_masked = mask_past(KQ_scaled)
|
| 3767 |
+
struct ggml_tensor * KQ_scaled_alibi = ggml_alibi(ctx0, KQ_scaled, /*n_past*/ 0, n_head, 8);
|
| 3768 |
+
ggml_set_name(KQ_scaled_alibi, "KQ_scaled_alibi");
|
| 3769 |
+
|
| 3770 |
+
struct ggml_tensor * KQ_masked = ggml_add(ctx0, KQ_scaled_alibi, KQ_mask);
|
| 3771 |
+
offload_func_kq(KQ_masked);
|
| 3772 |
+
ggml_set_name(KQ_masked, "KQ_masked");
|
| 3773 |
+
|
| 3774 |
+
// KQ = soft_max(KQ_masked)
|
| 3775 |
+
struct ggml_tensor * KQ_soft_max = ggml_soft_max(ctx0, KQ_masked);
|
| 3776 |
+
offload_func_v(KQ_soft_max);
|
| 3777 |
+
ggml_set_name(KQ_soft_max, "KQ_soft_max");
|
| 3778 |
+
|
| 3779 |
+
// split cached V into n_head heads
|
| 3780 |
+
struct ggml_tensor * V =
|
| 3781 |
+
ggml_view_3d(ctx0, kv_self.v,
|
| 3782 |
+
n_kv, n_embd_head, n_head_kv,
|
| 3783 |
+
ggml_element_size(kv_self.v)*n_ctx,
|
| 3784 |
+
ggml_element_size(kv_self.v)*n_ctx*n_embd_head,
|
| 3785 |
+
ggml_element_size(kv_self.v)*n_ctx*n_embd_gqa*il);
|
| 3786 |
+
offload_func_v(V);
|
| 3787 |
+
ggml_set_name(V, "V");
|
| 3788 |
+
|
| 3789 |
+
#if 1
|
| 3790 |
+
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
| 3791 |
+
offload_func_v(KQV);
|
| 3792 |
+
ggml_set_name(KQV, "KQV");
|
| 3793 |
+
#else
|
| 3794 |
+
// make V contiguous in memory to speed up the matmul, however we waste time on the copy
|
| 3795 |
+
// on M1 this is faster for the perplexity computation, but ~5% slower for the single-token generation
|
| 3796 |
+
// is there a better way?
|
| 3797 |
+
struct ggml_tensor * V_cont = ggml_cpy(ctx0, V, ggml_new_tensor_3d(ctx0, kv_self.v->type, n_ctx, n_embd_head, n_head));
|
| 3798 |
+
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V_cont, KQ_soft_max);
|
| 3799 |
+
#endif
|
| 3800 |
+
|
| 3801 |
+
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
| 3802 |
+
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
| 3803 |
+
offload_func_v(KQV_merged);
|
| 3804 |
+
ggml_set_name(KQV_merged, "KQV_merged");
|
| 3805 |
+
|
| 3806 |
+
// cur = KQV_merged.contiguous().view(n_embd, n_tokens)
|
| 3807 |
+
cur = ggml_cont_2d(ctx0, KQV_merged, n_embd, n_tokens);
|
| 3808 |
+
offload_func_v(cur);
|
| 3809 |
+
ggml_set_name(cur, "KQV_merged_contiguous");
|
| 3810 |
+
|
| 3811 |
+
// projection (no bias)
|
| 3812 |
+
cur = ggml_mul_mat(ctx0,
|
| 3813 |
+
model.layers[il].wo,
|
| 3814 |
+
cur);
|
| 3815 |
+
offload_func(cur);
|
| 3816 |
+
ggml_set_name(cur, "result_wo");
|
| 3817 |
+
}
|
| 3818 |
+
|
| 3819 |
+
struct ggml_tensor * inpFF = ggml_add(ctx0, cur, inpSA);
|
| 3820 |
+
offload_func(inpFF);
|
| 3821 |
+
ggml_set_name(inpFF, "inpFF");
|
| 3822 |
+
|
| 3823 |
+
// feed-forward network
|
| 3824 |
+
{
|
| 3825 |
+
// norm
|
| 3826 |
+
{
|
| 3827 |
+
cur = ggml_rms_norm(ctx0, inpFF, norm_rms_eps);
|
| 3828 |
+
offload_func(cur);
|
| 3829 |
+
ggml_set_name(cur, "rms_norm_1");
|
| 3830 |
+
|
| 3831 |
+
// cur = cur*ffn_norm(broadcasted)
|
| 3832 |
+
cur = ggml_mul(ctx0, cur, model.layers[il].ffn_norm);
|
| 3833 |
+
offload_func(cur);
|
| 3834 |
+
ggml_set_name(cur, "ffn_norm");
|
| 3835 |
+
}
|
| 3836 |
+
|
| 3837 |
+
struct ggml_tensor * tmp = ggml_mul_mat(ctx0,
|
| 3838 |
+
model.layers[il].w3,
|
| 3839 |
+
cur);
|
| 3840 |
+
offload_func(tmp);
|
| 3841 |
+
ggml_set_name(tmp, "result_w3");
|
| 3842 |
+
|
| 3843 |
+
cur = ggml_mul_mat(ctx0,
|
| 3844 |
+
model.layers[il].w1,
|
| 3845 |
+
cur);
|
| 3846 |
+
offload_func(cur);
|
| 3847 |
+
ggml_set_name(cur, "result_w1");
|
| 3848 |
+
|
| 3849 |
+
// SILU activation
|
| 3850 |
+
cur = ggml_silu(ctx0, cur);
|
| 3851 |
+
offload_func(cur);
|
| 3852 |
+
ggml_set_name(cur, "silu");
|
| 3853 |
+
|
| 3854 |
+
cur = ggml_mul(ctx0, cur, tmp);
|
| 3855 |
+
offload_func(cur);
|
| 3856 |
+
ggml_set_name(cur, "silu_x_result_w3");
|
| 3857 |
+
|
| 3858 |
+
cur = ggml_mul_mat(ctx0,
|
| 3859 |
+
model.layers[il].w2,
|
| 3860 |
+
cur);
|
| 3861 |
+
offload_func(cur);
|
| 3862 |
+
ggml_set_name(cur, "result_w2");
|
| 3863 |
+
}
|
| 3864 |
+
|
| 3865 |
+
cur = ggml_add(ctx0, cur, inpFF);
|
| 3866 |
+
offload_func(cur);
|
| 3867 |
+
ggml_set_name(cur, "inpFF_+_result_w2");
|
| 3868 |
+
|
| 3869 |
+
// input for next layer
|
| 3870 |
+
inpL = cur;
|
| 3871 |
+
}
|
| 3872 |
+
|
| 3873 |
+
cur = inpL;
|
| 3874 |
+
|
| 3875 |
+
// norm
|
| 3876 |
+
{
|
| 3877 |
+
cur = ggml_rms_norm(ctx0, cur, norm_rms_eps);
|
| 3878 |
+
offload_func_nr(cur);
|
| 3879 |
+
ggml_set_name(cur, "rms_norm_2");
|
| 3880 |
+
|
| 3881 |
+
// cur = cur*norm(broadcasted)
|
| 3882 |
+
cur = ggml_mul(ctx0, cur, model.output_norm);
|
| 3883 |
+
// offload_func_nr(cur); // TODO CPU + GPU mirrored backend
|
| 3884 |
+
ggml_set_name(cur, "result_norm");
|
| 3885 |
+
}
|
| 3886 |
+
|
| 3887 |
+
// lm_head
|
| 3888 |
+
cur = ggml_mul_mat(ctx0, model.output, cur);
|
| 3889 |
+
ggml_set_name(cur, "result_output");
|
| 3890 |
+
|
| 3891 |
+
ggml_build_forward_expand(gf, cur);
|
| 3892 |
+
|
| 3893 |
+
ggml_free(ctx0);
|
| 3894 |
+
|
| 3895 |
+
return gf;
|
| 3896 |
+
}
|
| 3897 |
+
|
| 3898 |
+
static struct ggml_cgraph * llm_build_falcon(
|
| 3899 |
+
llama_context & lctx,
|
| 3900 |
+
const llama_batch & batch) {
|
| 3901 |
+
const auto & model = lctx.model;
|
| 3902 |
+
const auto & hparams = model.hparams;
|
| 3903 |
+
const auto & cparams = lctx.cparams;
|
| 3904 |
+
|
| 3905 |
+
const auto & kv_self = lctx.kv_self;
|
| 3906 |
+
|
| 3907 |
+
GGML_ASSERT(!!kv_self.ctx);
|
| 3908 |
+
|
| 3909 |
+
const int64_t n_embd = hparams.n_embd;
|
| 3910 |
+
const int64_t n_layer = hparams.n_layer;
|
| 3911 |
+
const int64_t n_ctx = cparams.n_ctx;
|
| 3912 |
+
const int64_t n_head = hparams.n_head;
|
| 3913 |
+
const int64_t n_head_kv = hparams.n_head_kv;
|
| 3914 |
+
const int64_t n_embd_head = hparams.n_embd_head();
|
| 3915 |
+
const int64_t n_embd_gqa = hparams.n_embd_gqa();
|
| 3916 |
+
|
| 3917 |
+
GGML_ASSERT(n_embd_head == hparams.n_rot);
|
| 3918 |
+
|
| 3919 |
+
const float freq_base = cparams.rope_freq_base;
|
| 3920 |
+
const float freq_scale = cparams.rope_freq_scale;
|
| 3921 |
+
const float norm_eps = hparams.f_norm_eps;
|
| 3922 |
+
|
| 3923 |
+
const int n_gpu_layers = model.n_gpu_layers;
|
| 3924 |
+
|
| 3925 |
+
const int32_t n_tokens = batch.n_tokens;
|
| 3926 |
+
const int32_t n_kv = ggml_allocr_is_measure(lctx.alloc) ? n_ctx : kv_self.n;
|
| 3927 |
+
const int32_t kv_head = ggml_allocr_is_measure(lctx.alloc) ? n_ctx - n_tokens : kv_self.head;
|
| 3928 |
+
|
| 3929 |
+
const bool do_rope_shift = ggml_allocr_is_measure(lctx.alloc) || kv_self.has_shift;
|
| 3930 |
+
|
| 3931 |
+
//printf("kv_head = %d, n_kv = %d, n_tokens = %d, n_ctx = %d, is_measure = %d, has_shift = %d\n",
|
| 3932 |
+
// kv_head, n_kv, n_tokens, n_ctx, ggml_allocr_is_measure(lctx.alloc), kv_self.has_shift);
|
| 3933 |
+
|
| 3934 |
+
auto & buf_compute = lctx.buf_compute;
|
| 3935 |
+
|
| 3936 |
+
struct ggml_init_params params = {
|
| 3937 |
+
/*.mem_size =*/ buf_compute.size,
|
| 3938 |
+
/*.mem_buffer =*/ buf_compute.data,
|
| 3939 |
+
/*.no_alloc =*/ true,
|
| 3940 |
+
};
|
| 3941 |
+
|
| 3942 |
+
struct ggml_context * ctx0 = ggml_init(params);
|
| 3943 |
+
|
| 3944 |
+
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
| 3945 |
+
|
| 3946 |
+
struct ggml_tensor * cur;
|
| 3947 |
+
struct ggml_tensor * inpL;
|
| 3948 |
+
|
| 3949 |
+
if (batch.token) {
|
| 3950 |
+
struct ggml_tensor * inp_tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens);
|
| 3951 |
+
|
| 3952 |
+
ggml_allocr_alloc(lctx.alloc, inp_tokens);
|
| 3953 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3954 |
+
memcpy(inp_tokens->data, batch.token, n_tokens*ggml_element_size(inp_tokens));
|
| 3955 |
+
}
|
| 3956 |
+
ggml_set_name(inp_tokens, "inp_tokens");
|
| 3957 |
+
|
| 3958 |
+
inpL = ggml_get_rows(ctx0, model.tok_embeddings, inp_tokens);
|
| 3959 |
+
} else {
|
| 3960 |
+
#ifdef GGML_USE_MPI
|
| 3961 |
+
GGML_ASSERT(false && "not implemented");
|
| 3962 |
+
#endif
|
| 3963 |
+
|
| 3964 |
+
inpL = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, n_tokens);
|
| 3965 |
+
|
| 3966 |
+
ggml_allocr_alloc(lctx.alloc, inpL);
|
| 3967 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3968 |
+
memcpy(inpL->data, batch.embd, n_tokens * n_embd * ggml_element_size(inpL));
|
| 3969 |
+
}
|
| 3970 |
+
}
|
| 3971 |
+
|
| 3972 |
+
const int i_gpu_start = n_layer - n_gpu_layers;
|
| 3973 |
+
(void) i_gpu_start;
|
| 3974 |
+
|
| 3975 |
+
// offload functions set the tensor output backend to GPU
|
| 3976 |
+
// tensors are GPU-accelerated if any input or the output has been offloaded
|
| 3977 |
+
offload_func_t offload_func_nr = llama_nop; // nr = non-repeating
|
| 3978 |
+
offload_func_t offload_func_kq = llama_nop;
|
| 3979 |
+
offload_func_t offload_func_v = llama_nop;
|
| 3980 |
+
|
| 3981 |
+
#ifdef GGML_USE_CUBLAS
|
| 3982 |
+
if (n_gpu_layers > n_layer) {
|
| 3983 |
+
offload_func_nr = ggml_cuda_assign_buffers_no_alloc;
|
| 3984 |
+
}
|
| 3985 |
+
if (n_gpu_layers > n_layer + 1) {
|
| 3986 |
+
offload_func_v = ggml_cuda_assign_buffers_no_alloc;
|
| 3987 |
+
}
|
| 3988 |
+
if (n_gpu_layers > n_layer + 2) {
|
| 3989 |
+
offload_func_kq = ggml_cuda_assign_buffers_no_alloc;
|
| 3990 |
+
}
|
| 3991 |
+
#endif // GGML_USE_CUBLAS
|
| 3992 |
+
|
| 3993 |
+
// KQ_scale
|
| 3994 |
+
struct ggml_tensor * KQ_scale = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
| 3995 |
+
ggml_set_name(KQ_scale, "1/sqrt(n_embd_head)");
|
| 3996 |
+
ggml_allocr_alloc(lctx.alloc, KQ_scale);
|
| 3997 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 3998 |
+
ggml_set_f32(KQ_scale, 1.0f/sqrtf(float(n_embd)/n_head));
|
| 3999 |
+
}
|
| 4000 |
+
|
| 4001 |
+
// KQ_mask (mask for 1 head, it will be broadcasted to all heads)
|
| 4002 |
+
struct ggml_tensor * KQ_mask = ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_kv, n_tokens, 1);
|
| 4003 |
+
offload_func_kq(KQ_mask);
|
| 4004 |
+
ggml_set_name(KQ_mask, "KQ_mask");
|
| 4005 |
+
ggml_allocr_alloc(lctx.alloc, KQ_mask);
|
| 4006 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4007 |
+
float * data = (float *) KQ_mask->data;
|
| 4008 |
+
memset(data, 0, ggml_nbytes(KQ_mask));
|
| 4009 |
+
|
| 4010 |
+
for (int h = 0; h < 1; ++h) {
|
| 4011 |
+
for (int j = 0; j < n_tokens; ++j) {
|
| 4012 |
+
const llama_pos pos = batch.pos[j];
|
| 4013 |
+
const llama_seq_id seq_id = batch.seq_id[j];
|
| 4014 |
+
|
| 4015 |
+
for (int i = 0; i < n_kv; ++i) {
|
| 4016 |
+
if (!kv_self.cells[i].has_seq_id(seq_id) || kv_self.cells[i].pos > pos) {
|
| 4017 |
+
data[h*(n_kv*n_tokens) + j*n_kv + i] = -INFINITY;
|
| 4018 |
+
}
|
| 4019 |
+
}
|
| 4020 |
+
}
|
| 4021 |
+
}
|
| 4022 |
+
}
|
| 4023 |
+
|
| 4024 |
+
// KQ_pos - contains the positions
|
| 4025 |
+
struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens);
|
| 4026 |
+
offload_func_kq(KQ_pos);
|
| 4027 |
+
ggml_set_name(KQ_pos, "KQ_pos");
|
| 4028 |
+
ggml_allocr_alloc(lctx.alloc, KQ_pos);
|
| 4029 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4030 |
+
int * data = (int *) KQ_pos->data;
|
| 4031 |
+
for (int i = 0; i < n_tokens; ++i) {
|
| 4032 |
+
data[i] = batch.pos[i];
|
| 4033 |
+
}
|
| 4034 |
+
}
|
| 4035 |
+
|
| 4036 |
+
// shift the entire K-cache if needed
|
| 4037 |
+
if (do_rope_shift) {
|
| 4038 |
+
struct ggml_tensor * K_shift = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_ctx);
|
| 4039 |
+
offload_func_kq(K_shift);
|
| 4040 |
+
ggml_set_name(K_shift, "K_shift");
|
| 4041 |
+
ggml_allocr_alloc(lctx.alloc, K_shift);
|
| 4042 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4043 |
+
int * data = (int *) K_shift->data;
|
| 4044 |
+
for (int i = 0; i < n_ctx; ++i) {
|
| 4045 |
+
data[i] = kv_self.cells[i].delta;
|
| 4046 |
+
}
|
| 4047 |
+
}
|
| 4048 |
+
|
| 4049 |
+
for (int il = 0; il < n_layer; ++il) {
|
| 4050 |
+
struct ggml_tensor * tmp =
|
| 4051 |
+
ggml_rope_custom_inplace(ctx0,
|
| 4052 |
+
ggml_view_3d(ctx0, kv_self.k,
|
| 4053 |
+
n_embd_head, n_head_kv, n_ctx,
|
| 4054 |
+
ggml_element_size(kv_self.k)*n_embd_head,
|
| 4055 |
+
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 4056 |
+
ggml_element_size(kv_self.k)*n_embd_gqa*n_ctx*il),
|
| 4057 |
+
K_shift, n_embd_head, 2, 0, freq_base, freq_scale);
|
| 4058 |
+
offload_func_kq(tmp);
|
| 4059 |
+
ggml_build_forward_expand(gf, tmp);
|
| 4060 |
+
}
|
| 4061 |
+
}
|
| 4062 |
+
|
| 4063 |
+
for (int il = 0; il < n_layer; ++il) {
|
| 4064 |
+
struct ggml_tensor * attn_norm;
|
| 4065 |
+
|
| 4066 |
+
offload_func_t offload_func = llama_nop;
|
| 4067 |
+
|
| 4068 |
+
#ifdef GGML_USE_CUBLAS
|
| 4069 |
+
if (il >= i_gpu_start) {
|
| 4070 |
+
offload_func = ggml_cuda_assign_buffers_no_alloc;
|
| 4071 |
+
}
|
| 4072 |
+
#endif // GGML_USE_CUBLAS
|
| 4073 |
+
|
| 4074 |
+
// self-attention
|
| 4075 |
+
// TODO: refactor into common function (shared with LLaMA)
|
| 4076 |
+
{
|
| 4077 |
+
attn_norm = ggml_norm(ctx0, inpL, norm_eps);
|
| 4078 |
+
offload_func(attn_norm);
|
| 4079 |
+
|
| 4080 |
+
attn_norm = ggml_add(ctx0,
|
| 4081 |
+
ggml_mul(ctx0, attn_norm, model.layers[il].attn_norm),
|
| 4082 |
+
model.layers[il].attn_norm_b);
|
| 4083 |
+
offload_func(attn_norm->src[0]);
|
| 4084 |
+
offload_func(attn_norm);
|
| 4085 |
+
|
| 4086 |
+
if (model.layers[il].attn_norm_2) { // Falcon-40B
|
| 4087 |
+
cur = ggml_norm(ctx0, inpL, norm_eps);
|
| 4088 |
+
offload_func(cur);
|
| 4089 |
+
|
| 4090 |
+
cur = ggml_add(ctx0,
|
| 4091 |
+
ggml_mul(ctx0, cur, model.layers[il].attn_norm_2),
|
| 4092 |
+
model.layers[il].attn_norm_2_b);
|
| 4093 |
+
offload_func(cur->src[0]);
|
| 4094 |
+
offload_func(cur);
|
| 4095 |
+
} else { // Falcon 7B
|
| 4096 |
+
cur = attn_norm;
|
| 4097 |
+
}
|
| 4098 |
+
|
| 4099 |
+
// compute QKV
|
| 4100 |
+
|
| 4101 |
+
cur = ggml_mul_mat(ctx0, model.layers[il].wqkv, cur);
|
| 4102 |
+
offload_func_kq(cur);
|
| 4103 |
+
|
| 4104 |
+
// Note that the strides for Kcur, Vcur are set up so that the
|
| 4105 |
+
// resulting views are misaligned with the tensor's storage
|
| 4106 |
+
// (by applying the K/V offset we shift the tensor's original
|
| 4107 |
+
// view to stick out behind the viewed QKV tensor's allocated
|
| 4108 |
+
// memory, so to say). This is ok because no actual accesses
|
| 4109 |
+
// happen to that out-of-range memory, but it can require some
|
| 4110 |
+
// trickery when trying to accurately dump these views for
|
| 4111 |
+
// debugging.
|
| 4112 |
+
|
| 4113 |
+
const size_t wsize = ggml_type_size(cur->type);
|
| 4114 |
+
|
| 4115 |
+
// TODO: these 2 ggml_conts are technically not needed, but we add them until CUDA support for
|
| 4116 |
+
// non-contiguous views is added for the rope operator
|
| 4117 |
+
struct ggml_tensor * tmpq = ggml_cont(ctx0, ggml_view_3d(
|
| 4118 |
+
ctx0, cur, n_embd_head, n_head, n_tokens,
|
| 4119 |
+
wsize * n_embd_head,
|
| 4120 |
+
wsize * n_embd_head * (n_head + 2 * n_head_kv),
|
| 4121 |
+
0));
|
| 4122 |
+
offload_func_kq(tmpq);
|
| 4123 |
+
|
| 4124 |
+
struct ggml_tensor * tmpk = ggml_cont(ctx0, ggml_view_3d(
|
| 4125 |
+
ctx0, cur, n_embd_head, n_head_kv, n_tokens,
|
| 4126 |
+
wsize * n_embd_head,
|
| 4127 |
+
wsize * n_embd_head * (n_head + 2 * n_head_kv),
|
| 4128 |
+
wsize * n_embd_head * n_head));
|
| 4129 |
+
offload_func_kq(tmpk);
|
| 4130 |
+
|
| 4131 |
+
struct ggml_tensor * tmpv = ggml_view_3d(
|
| 4132 |
+
ctx0, cur, n_embd_head, n_head_kv, n_tokens,
|
| 4133 |
+
wsize * n_embd_head,
|
| 4134 |
+
wsize * n_embd_head * (n_head + 2 * n_head_kv),
|
| 4135 |
+
wsize * n_embd_head * (n_head + n_head_kv));
|
| 4136 |
+
offload_func_v(tmpv);
|
| 4137 |
+
|
| 4138 |
+
// using mode = 2 for neox mode
|
| 4139 |
+
struct ggml_tensor * Qcur = ggml_rope_custom(ctx0, tmpq, KQ_pos, n_embd_head, 2, 0, freq_base, freq_scale);
|
| 4140 |
+
offload_func_kq(Qcur);
|
| 4141 |
+
struct ggml_tensor * Kcur = ggml_rope_custom(ctx0, tmpk, KQ_pos, n_embd_head, 2, 0, freq_base, freq_scale);
|
| 4142 |
+
offload_func_kq(Kcur);
|
| 4143 |
+
|
| 4144 |
+
{
|
| 4145 |
+
struct ggml_tensor * Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, ggml_cont(ctx0, tmpv), n_embd_gqa, n_tokens));
|
| 4146 |
+
offload_func_v(Vcur);
|
| 4147 |
+
offload_func_v(Vcur->src[0]->src[0]);
|
| 4148 |
ggml_set_name(Vcur, "Vcur");
|
| 4149 |
|
| 4150 |
struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, n_tokens*n_embd_gqa, (ggml_element_size(kv_self.k)*n_embd_gqa)*(il*n_ctx + kv_head));
|
|
|
|
| 4294 |
struct ggml_init_params params = {
|
| 4295 |
/*.mem_size =*/ buf_compute.size,
|
| 4296 |
/*.mem_buffer =*/ buf_compute.data,
|
| 4297 |
+
/*.no_alloc =*/ true,
|
| 4298 |
};
|
| 4299 |
|
|
|
|
|
|
|
| 4300 |
struct ggml_context * ctx0 = ggml_init(params);
|
| 4301 |
|
| 4302 |
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
|
|
|
| 4372 |
}
|
| 4373 |
}
|
| 4374 |
}
|
| 4375 |
+
|
| 4376 |
+
inpL = ggml_add(ctx0, token, position);
|
| 4377 |
+
ggml_set_name(inpL, "inpL");
|
| 4378 |
+
|
| 4379 |
+
for (int il = 0; il < n_layer; ++il) {
|
| 4380 |
+
{
|
| 4381 |
+
// Norm
|
| 4382 |
+
cur = ggml_norm(ctx0, inpL, norm_eps);
|
| 4383 |
+
cur = ggml_add(ctx0, ggml_mul(ctx0, cur, model.layers[il].attn_norm), model.layers[il].attn_norm_b);
|
| 4384 |
+
}
|
| 4385 |
+
|
| 4386 |
+
{
|
| 4387 |
+
// Self Attention
|
| 4388 |
+
cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.layers[il].wqkv, cur), model.layers[il].bqkv);
|
| 4389 |
+
|
| 4390 |
+
struct ggml_tensor * tmpq = ggml_view_2d(ctx0, cur, n_embd, n_tokens, cur->nb[1], 0*sizeof(float)*n_embd);
|
| 4391 |
+
struct ggml_tensor * tmpk = ggml_view_2d(ctx0, cur, n_embd_gqa, n_tokens, cur->nb[1], sizeof(float)*n_embd);
|
| 4392 |
+
struct ggml_tensor * tmpv = ggml_view_2d(ctx0, cur, n_embd_gqa, n_tokens, cur->nb[1], sizeof(float)*(n_embd + n_embd_gqa));
|
| 4393 |
+
|
| 4394 |
+
struct ggml_tensor * Qcur = tmpq;
|
| 4395 |
+
struct ggml_tensor * Kcur = tmpk;
|
| 4396 |
+
|
| 4397 |
+
{
|
| 4398 |
+
struct ggml_tensor * Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, ggml_cont(ctx0, tmpv), n_embd_gqa, n_tokens));
|
| 4399 |
+
ggml_set_name(Vcur, "Vcur");
|
| 4400 |
+
|
| 4401 |
+
struct ggml_tensor * k = ggml_view_1d(ctx0, kv_self.k, n_tokens*n_embd_gqa, (ggml_element_size(kv_self.k)*n_embd_gqa)*(il*n_ctx + kv_head));
|
| 4402 |
+
ggml_set_name(k, "k");
|
| 4403 |
+
|
| 4404 |
+
struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, n_tokens, n_embd_gqa,
|
| 4405 |
+
( n_ctx)*ggml_element_size(kv_self.v),
|
| 4406 |
+
(il*n_ctx)*ggml_element_size(kv_self.v)*n_embd_gqa + kv_head*ggml_element_size(kv_self.v));
|
| 4407 |
+
|
| 4408 |
+
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k));
|
| 4409 |
+
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v));
|
| 4410 |
+
}
|
| 4411 |
+
|
| 4412 |
+
struct ggml_tensor * Q =
|
| 4413 |
+
ggml_permute(ctx0,
|
| 4414 |
+
ggml_cpy(ctx0,
|
| 4415 |
+
Qcur,
|
| 4416 |
+
ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_embd_head, n_head, n_tokens)),
|
| 4417 |
+
0, 2, 1, 3);
|
| 4418 |
+
ggml_set_name(Q, "Q");
|
| 4419 |
+
|
| 4420 |
+
struct ggml_tensor * K =
|
| 4421 |
+
ggml_view_3d(ctx0, kv_self.k,
|
| 4422 |
+
n_embd_head, n_kv, n_head_kv,
|
| 4423 |
+
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 4424 |
+
ggml_element_size(kv_self.k)*n_embd_head,
|
| 4425 |
+
ggml_element_size(kv_self.k)*n_embd_gqa*n_ctx*il);
|
| 4426 |
+
ggml_set_name(K, "K");
|
| 4427 |
+
|
| 4428 |
+
// K * Q
|
| 4429 |
+
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
| 4430 |
+
ggml_set_name(KQ, "KQ");
|
| 4431 |
+
|
| 4432 |
+
// KQ_scaled = KQ / sqrt(n_embd_head)
|
| 4433 |
+
// KQ_scaled shape [n_past + n_tokens, n_tokens, n_head, 1]
|
| 4434 |
+
struct ggml_tensor * KQ_scaled = ggml_scale_inplace(ctx0, KQ, KQ_scale);
|
| 4435 |
+
ggml_set_name(KQ_scaled, "KQ_scaled");
|
| 4436 |
+
|
| 4437 |
+
// KQ_masked = mask_past(KQ_scaled)
|
| 4438 |
+
struct ggml_tensor * KQ_masked = ggml_add(ctx0, KQ_scaled, KQ_mask);
|
| 4439 |
+
ggml_set_name(KQ_masked, "KQ_masked");
|
| 4440 |
+
|
| 4441 |
+
// KQ = soft_max(KQ_masked)
|
| 4442 |
+
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
| 4443 |
+
ggml_set_name(KQ_soft_max, "KQ_soft_max");
|
| 4444 |
+
|
| 4445 |
+
// split cached V into n_head heads
|
| 4446 |
+
struct ggml_tensor * V =
|
| 4447 |
+
ggml_view_3d(ctx0, kv_self.v,
|
| 4448 |
+
n_kv, n_embd_head, n_head_kv,
|
| 4449 |
+
ggml_element_size(kv_self.v)*n_ctx,
|
| 4450 |
+
ggml_element_size(kv_self.v)*n_ctx*n_embd_head,
|
| 4451 |
+
ggml_element_size(kv_self.v)*n_ctx*n_embd_gqa*il);
|
| 4452 |
+
ggml_set_name(V, "V");
|
| 4453 |
+
|
| 4454 |
+
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
| 4455 |
+
ggml_set_name(KQV, "KQV");
|
| 4456 |
+
|
| 4457 |
+
// KQV_merged = KQV.permute(0, 2, 1, 3)
|
| 4458 |
+
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
| 4459 |
+
ggml_set_name(KQV_merged, "KQV_merged");
|
| 4460 |
+
|
| 4461 |
+
// cur = KQV_merged.contiguous().view(n_embd, n_tokens)
|
| 4462 |
+
cur = ggml_cont_2d(ctx0, KQV_merged, n_embd, n_tokens);
|
| 4463 |
+
ggml_set_name(cur, "KQV_merged_contiguous");
|
| 4464 |
+
}
|
| 4465 |
+
|
| 4466 |
+
// Projection
|
| 4467 |
+
cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.layers[il].wo, cur), model.layers[il].bo);
|
| 4468 |
+
|
| 4469 |
+
// Add the input
|
| 4470 |
+
cur = ggml_add(ctx0, cur, inpL);
|
| 4471 |
+
|
| 4472 |
+
struct ggml_tensor * inpFF = cur;
|
| 4473 |
+
|
| 4474 |
+
// FF
|
| 4475 |
+
{
|
| 4476 |
+
// Norm
|
| 4477 |
+
{
|
| 4478 |
+
cur = ggml_norm(ctx0, inpFF, norm_eps);
|
| 4479 |
+
cur = ggml_add(ctx0, ggml_mul(ctx0, cur, model.layers[il].ffn_norm), model.layers[il].ffn_norm_b);
|
| 4480 |
+
}
|
| 4481 |
+
|
| 4482 |
+
cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.layers[il].w3, cur), model.layers[il].b3);
|
| 4483 |
+
|
| 4484 |
+
// GELU activation
|
| 4485 |
+
cur = ggml_gelu(ctx0, cur);
|
| 4486 |
+
|
| 4487 |
+
// Projection
|
| 4488 |
+
cur = ggml_add(ctx0, ggml_mul_mat(ctx0, model.layers[il].w2, cur), model.layers[il].b2);
|
| 4489 |
+
}
|
| 4490 |
+
|
| 4491 |
+
inpL = ggml_add(ctx0, cur, inpFF);
|
| 4492 |
+
}
|
| 4493 |
+
|
| 4494 |
+
// Output Norm
|
| 4495 |
+
{
|
| 4496 |
+
cur = ggml_norm(ctx0, inpL, norm_eps);
|
| 4497 |
+
cur = ggml_add(ctx0, ggml_mul(ctx0, cur, model.output_norm), model.output_norm_b);
|
| 4498 |
+
}
|
| 4499 |
+
ggml_set_name(cur, "result_norm");
|
| 4500 |
+
|
| 4501 |
+
cur = ggml_mul_mat(ctx0, model.output, cur);
|
| 4502 |
+
ggml_set_name(cur, "result_output");
|
| 4503 |
+
|
| 4504 |
+
ggml_build_forward_expand(gf, cur);
|
| 4505 |
+
ggml_free(ctx0);
|
| 4506 |
+
|
| 4507 |
+
return gf;
|
| 4508 |
+
}
|
| 4509 |
+
|
| 4510 |
+
|
| 4511 |
+
static struct ggml_cgraph * llm_build_persimmon(
|
| 4512 |
+
llama_context & lctx,
|
| 4513 |
+
const llama_batch & batch) {
|
| 4514 |
+
const auto & model = lctx.model;
|
| 4515 |
+
const auto & hparams = model.hparams;
|
| 4516 |
+
|
| 4517 |
+
const auto & kv_self = lctx.kv_self;
|
| 4518 |
+
|
| 4519 |
+
GGML_ASSERT(!!kv_self.ctx);
|
| 4520 |
+
|
| 4521 |
+
const auto & cparams = lctx.cparams;
|
| 4522 |
+
const int64_t n_embd = hparams.n_embd;
|
| 4523 |
+
const int64_t n_layer = hparams.n_layer;
|
| 4524 |
+
const int64_t n_ctx = cparams.n_ctx;
|
| 4525 |
+
const int64_t n_head_kv = hparams.n_head_kv;
|
| 4526 |
+
const int64_t n_head = hparams.n_head;
|
| 4527 |
+
const int64_t n_embd_head = hparams.n_embd_head();
|
| 4528 |
+
const int64_t n_embd_gqa = hparams.n_embd_gqa();
|
| 4529 |
+
const size_t n_rot = n_embd_head / 2;
|
| 4530 |
+
|
| 4531 |
+
const float freq_base = cparams.rope_freq_base;
|
| 4532 |
+
const float freq_scale = cparams.rope_freq_scale;
|
| 4533 |
+
const float norm_eps = hparams.f_norm_eps;
|
| 4534 |
+
|
| 4535 |
+
const int n_gpu_layers = model.n_gpu_layers;
|
| 4536 |
+
|
| 4537 |
+
|
| 4538 |
+
const int32_t n_tokens = batch.n_tokens;
|
| 4539 |
+
const int32_t n_kv = ggml_allocr_is_measure(lctx.alloc) ? n_ctx : kv_self.n;
|
| 4540 |
+
const int32_t kv_head = ggml_allocr_is_measure(lctx.alloc) ? n_ctx - n_tokens : kv_self.head;
|
| 4541 |
+
|
| 4542 |
+
const bool do_rope_shift = ggml_allocr_is_measure(lctx.alloc) || kv_self.has_shift;
|
| 4543 |
+
|
| 4544 |
+
auto & buf_compute = lctx.buf_compute;
|
| 4545 |
+
struct ggml_init_params params = {
|
| 4546 |
+
/*.mem_size =*/ buf_compute.size,
|
| 4547 |
+
/*.mem_buffer =*/ buf_compute.data,
|
| 4548 |
+
/*.no_alloc =*/ true,
|
| 4549 |
+
};
|
| 4550 |
+
|
| 4551 |
+
struct ggml_context * ctx0 = ggml_init(params);
|
| 4552 |
+
|
| 4553 |
+
ggml_cgraph * gf = ggml_new_graph(ctx0);
|
| 4554 |
+
|
| 4555 |
+
struct ggml_tensor * cur;
|
| 4556 |
+
struct ggml_tensor * inpL;
|
| 4557 |
+
|
| 4558 |
+
if (batch.token) {
|
| 4559 |
+
struct ggml_tensor * inp_tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens);
|
| 4560 |
+
|
| 4561 |
+
ggml_allocr_alloc(lctx.alloc, inp_tokens);
|
| 4562 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4563 |
+
memcpy(inp_tokens->data, batch.token, n_tokens*ggml_element_size(inp_tokens));
|
| 4564 |
+
}
|
| 4565 |
+
ggml_set_name(inp_tokens, "inp_tokens");
|
| 4566 |
+
inpL = ggml_get_rows(ctx0, model.tok_embeddings, inp_tokens);
|
| 4567 |
+
} else {
|
| 4568 |
+
inpL = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, n_embd, n_tokens);
|
| 4569 |
+
ggml_allocr_alloc(lctx.alloc, inpL);
|
| 4570 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4571 |
+
memcpy(inpL->data, batch.embd, n_tokens * n_embd * ggml_element_size(inpL));
|
| 4572 |
+
}
|
| 4573 |
+
}
|
| 4574 |
+
const int i_gpu_start = n_layer - n_gpu_layers;
|
| 4575 |
+
(void) i_gpu_start;
|
| 4576 |
+
offload_func_t offload_func_nr = llama_nop; // nr = non-repeating
|
| 4577 |
+
offload_func_t offload_func_kq = llama_nop;
|
| 4578 |
+
offload_func_t offload_func_v = llama_nop;
|
| 4579 |
+
// KQ_scale
|
| 4580 |
+
struct ggml_tensor * KQ_scale = ggml_new_tensor_1d(ctx0, GGML_TYPE_F32, 1);
|
| 4581 |
+
ggml_allocr_alloc(lctx.alloc, KQ_scale);
|
| 4582 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4583 |
+
ggml_set_f32(KQ_scale, 1.0f/sqrtf(float(n_embd_head)));
|
| 4584 |
+
}
|
| 4585 |
+
ggml_set_name(KQ_scale, "1/sqrt(n_embd_head)");
|
| 4586 |
+
struct ggml_tensor * KQ_mask = ggml_new_tensor_3d(ctx0, GGML_TYPE_F32, n_kv, n_tokens, 1);
|
| 4587 |
+
offload_func_kq(KQ_mask);
|
| 4588 |
+
ggml_set_name(KQ_mask, "KQ_mask");
|
| 4589 |
+
ggml_allocr_alloc(lctx.alloc, KQ_mask);
|
| 4590 |
+
|
| 4591 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4592 |
+
float * data = (float *) KQ_mask->data;
|
| 4593 |
+
memset(data, 0, ggml_nbytes(KQ_mask));
|
| 4594 |
+
for (int h = 0; h < 1; ++h) {
|
| 4595 |
+
for (int j = 0; j < n_tokens; ++j) {
|
| 4596 |
+
const llama_pos pos = batch.pos[j];
|
| 4597 |
+
const llama_seq_id seq_id = batch.seq_id[j];
|
| 4598 |
+
for (int i = 0; i < n_kv; ++i) {
|
| 4599 |
+
if (!kv_self.cells[i].has_seq_id(seq_id) || kv_self.cells[i].pos > pos) {
|
| 4600 |
+
data[h*(n_kv*n_tokens) + j*n_kv + i] = -INFINITY;
|
| 4601 |
+
}
|
| 4602 |
+
}
|
| 4603 |
+
}
|
| 4604 |
+
}
|
| 4605 |
+
}
|
| 4606 |
+
|
| 4607 |
+
struct ggml_tensor * KQ_pos = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens);
|
| 4608 |
+
offload_func_kq(KQ_pos);
|
| 4609 |
+
ggml_set_name(KQ_pos, "KQ_pos");
|
| 4610 |
+
ggml_allocr_alloc(lctx.alloc, KQ_pos);
|
| 4611 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4612 |
+
int * data = (int *) KQ_pos->data;
|
| 4613 |
+
for (int i = 0; i < n_tokens; ++i) {
|
| 4614 |
+
data[i] = batch.pos[i];
|
| 4615 |
+
}
|
| 4616 |
+
}
|
| 4617 |
+
if (do_rope_shift) {
|
| 4618 |
+
struct ggml_tensor * K_shift = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_ctx);
|
| 4619 |
+
offload_func_kq(K_shift);
|
| 4620 |
+
ggml_set_name(K_shift, "K_shift");
|
| 4621 |
+
ggml_allocr_alloc(lctx.alloc, K_shift);
|
| 4622 |
+
if (!ggml_allocr_is_measure(lctx.alloc)) {
|
| 4623 |
+
int * data = (int *) K_shift->data;
|
| 4624 |
+
for (int i = 0; i < n_ctx; ++i) {
|
| 4625 |
+
data[i] = kv_self.cells[i].delta;
|
| 4626 |
+
}
|
| 4627 |
+
}
|
| 4628 |
+
for (int il = 0; il < n_layer; ++il) {
|
| 4629 |
+
struct ggml_tensor * tmp =
|
| 4630 |
+
// we rotate only the first n_rot dimensions.
|
| 4631 |
+
ggml_rope_custom_inplace(ctx0,
|
| 4632 |
+
ggml_view_3d(ctx0, kv_self.k,
|
| 4633 |
+
n_rot, n_head, n_ctx,
|
| 4634 |
+
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 4635 |
+
ggml_element_size(kv_self.k)*n_embd_head,
|
| 4636 |
+
ggml_element_size(kv_self.k)*(n_embd_head*n_ctx*il)
|
| 4637 |
+
),
|
| 4638 |
+
K_shift, n_rot, 2, 0, freq_base, freq_scale);
|
| 4639 |
+
offload_func_kq(tmp);
|
| 4640 |
+
ggml_build_forward_expand(gf, tmp);
|
| 4641 |
+
}
|
| 4642 |
+
}
|
| 4643 |
+
for (int il=0; il < n_layer; ++il) {
|
| 4644 |
+
struct ggml_tensor * residual = inpL;
|
| 4645 |
+
offload_func_t offload_func = llama_nop;
|
| 4646 |
{
|
|
|
|
| 4647 |
cur = ggml_norm(ctx0, inpL, norm_eps);
|
| 4648 |
+
offload_func(cur);
|
| 4649 |
+
cur = ggml_mul(ctx0, cur, model.layers[il].attn_norm);
|
| 4650 |
+
offload_func(cur);
|
| 4651 |
+
cur = ggml_add(ctx0, cur, model.layers[il].attn_norm_b);
|
| 4652 |
+
offload_func(cur);
|
| 4653 |
+
ggml_format_name(cur, "input_layernorm_%d", il);
|
| 4654 |
}
|
| 4655 |
+
// self attention
|
| 4656 |
{
|
| 4657 |
+
cur = ggml_mul_mat(ctx0, model.layers[il].wqkv, cur);
|
| 4658 |
+
offload_func_kq(cur);
|
| 4659 |
+
cur = ggml_add(ctx0, cur, model.layers[il].bqkv);
|
| 4660 |
+
offload_func_kq(cur);
|
| 4661 |
|
| 4662 |
+
// split qkv
|
| 4663 |
+
GGML_ASSERT(n_head_kv == n_head);
|
| 4664 |
+
ggml_set_name(cur, format("qkv_%d", il).c_str());
|
| 4665 |
+
struct ggml_tensor * tmpqkv = ggml_reshape_4d(ctx0, cur, n_embd_head, 3, n_head, n_tokens);
|
| 4666 |
+
offload_func_kq(tmpqkv);
|
| 4667 |
+
struct ggml_tensor * tmpqkv_perm = ggml_cont(ctx0, ggml_permute(ctx0, tmpqkv, 0, 3, 1, 2));
|
| 4668 |
+
offload_func_kq(tmpqkv_perm);
|
| 4669 |
+
ggml_format_name(tmpqkv_perm, "tmpqkv_perm_%d", il);
|
| 4670 |
+
struct ggml_tensor * tmpq = ggml_view_3d(
|
| 4671 |
+
ctx0, tmpqkv_perm, n_embd_head, n_head, n_tokens,
|
| 4672 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head,
|
| 4673 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head * n_head,
|
| 4674 |
+
0
|
| 4675 |
+
);
|
| 4676 |
+
offload_func_kq(tmpq);
|
| 4677 |
+
struct ggml_tensor * tmpk = ggml_view_3d(
|
| 4678 |
+
ctx0, tmpqkv_perm, n_embd_head, n_head, n_tokens,
|
| 4679 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head,
|
| 4680 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head * n_head,
|
| 4681 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head * n_head * n_tokens
|
| 4682 |
+
);
|
| 4683 |
+
offload_func_kq(tmpk);
|
| 4684 |
+
// Q/K Layernorm
|
| 4685 |
+
tmpq = ggml_norm(ctx0, tmpq, norm_eps);
|
| 4686 |
+
offload_func_kq(tmpq);
|
| 4687 |
+
tmpq = ggml_mul(ctx0, tmpq, model.layers[il].attn_q_norm);
|
| 4688 |
+
offload_func_kq(tmpq);
|
| 4689 |
+
tmpq = ggml_add(ctx0, tmpq, model.layers[il].attn_q_norm_b);
|
| 4690 |
+
offload_func_kq(tmpq);
|
| 4691 |
|
| 4692 |
+
tmpk = ggml_norm(ctx0, tmpk, norm_eps);
|
| 4693 |
+
offload_func_v(tmpk);
|
| 4694 |
+
tmpk = ggml_mul(ctx0, tmpk, model.layers[il].attn_k_norm);
|
| 4695 |
+
offload_func_v(tmpk);
|
| 4696 |
+
tmpk = ggml_add(ctx0, tmpk, model.layers[il].attn_k_norm_b);
|
| 4697 |
+
offload_func_v(tmpk);
|
| 4698 |
+
|
| 4699 |
+
// RoPE the first n_rot of q/k, pass the other half, and concat.
|
| 4700 |
+
struct ggml_tensor * qrot = ggml_view_3d(
|
| 4701 |
+
ctx0, tmpq, n_rot, n_head, n_tokens,
|
| 4702 |
+
ggml_element_size(tmpq) * n_embd_head,
|
| 4703 |
+
ggml_element_size(tmpq) * n_embd_head * n_head,
|
| 4704 |
+
0
|
| 4705 |
+
);
|
| 4706 |
+
offload_func_kq(qrot);
|
| 4707 |
+
ggml_format_name(qrot, "qrot_%d", il);
|
| 4708 |
+
struct ggml_tensor * krot = ggml_view_3d(
|
| 4709 |
+
ctx0, tmpk, n_rot, n_head, n_tokens,
|
| 4710 |
+
ggml_element_size(tmpk) * n_embd_head,
|
| 4711 |
+
ggml_element_size(tmpk) * n_embd_head * n_head,
|
| 4712 |
+
0
|
| 4713 |
+
);
|
| 4714 |
+
offload_func_kq(krot);
|
| 4715 |
+
ggml_format_name(krot, "krot_%d", il);
|
| 4716 |
+
|
| 4717 |
+
// get the second half of tmpq, e.g tmpq[n_rot:, :, :]
|
| 4718 |
+
struct ggml_tensor * qpass = ggml_view_3d(
|
| 4719 |
+
ctx0, tmpq, n_rot, n_head, n_tokens,
|
| 4720 |
+
ggml_element_size(tmpq) * n_embd_head,
|
| 4721 |
+
ggml_element_size(tmpq) * n_embd_head * n_head,
|
| 4722 |
+
ggml_element_size(tmpq) * n_rot
|
| 4723 |
+
);
|
| 4724 |
+
offload_func_kq(qpass);
|
| 4725 |
+
ggml_format_name(qpass, "qpass_%d", il);
|
| 4726 |
+
struct ggml_tensor * kpass = ggml_view_3d(
|
| 4727 |
+
ctx0, tmpk, n_rot, n_head, n_tokens,
|
| 4728 |
+
ggml_element_size(tmpk) * n_embd_head,
|
| 4729 |
+
ggml_element_size(tmpk) * n_embd_head * n_head,
|
| 4730 |
+
ggml_element_size(tmpk) * n_rot
|
| 4731 |
+
);
|
| 4732 |
+
offload_func_kq(kpass);
|
| 4733 |
+
ggml_format_name(kpass, "kpass_%d", il);
|
| 4734 |
+
|
| 4735 |
+
struct ggml_tensor * qrotated = ggml_rope_custom(
|
| 4736 |
+
ctx0, qrot, KQ_pos, n_rot, 2, 0, freq_base, freq_scale
|
| 4737 |
+
);
|
| 4738 |
+
offload_func_kq(qrotated);
|
| 4739 |
+
struct ggml_tensor * krotated = ggml_rope_custom(
|
| 4740 |
+
ctx0, krot, KQ_pos, n_rot, 2, 0, freq_base, freq_scale
|
| 4741 |
+
);
|
| 4742 |
+
offload_func_kq(krotated);
|
| 4743 |
+
// ggml currently only supports concatenation on dim=2
|
| 4744 |
+
// so we need to permute qrot, qpass, concat, then permute back.
|
| 4745 |
+
qrotated = ggml_cont(ctx0, ggml_permute(ctx0, qrotated, 2, 1, 0, 3));
|
| 4746 |
+
offload_func_kq(qrotated);
|
| 4747 |
+
krotated = ggml_cont(ctx0, ggml_permute(ctx0, krotated, 2, 1, 0, 3));
|
| 4748 |
+
offload_func_kq(krotated);
|
| 4749 |
+
|
| 4750 |
+
qpass = ggml_cont(ctx0, ggml_permute(ctx0, qpass, 2, 1, 0, 3));
|
| 4751 |
+
offload_func_kq(qpass);
|
| 4752 |
+
kpass = ggml_cont(ctx0, ggml_permute(ctx0, kpass, 2, 1, 0, 3));
|
| 4753 |
+
offload_func_kq(kpass);
|
| 4754 |
+
|
| 4755 |
+
struct ggml_tensor * Qcur = ggml_concat(ctx0, qrotated, qpass);
|
| 4756 |
+
offload_func_kq(Qcur);
|
| 4757 |
+
struct ggml_tensor * Kcur = ggml_concat(ctx0, krotated, kpass);
|
| 4758 |
+
offload_func_kq(Kcur);
|
| 4759 |
|
| 4760 |
+
struct ggml_tensor * Q = ggml_cont(ctx0, ggml_permute(ctx0, Qcur, 1, 2, 0, 3));
|
| 4761 |
+
offload_func_kq(Q);
|
| 4762 |
+
|
| 4763 |
+
Kcur = ggml_cont(ctx0, ggml_permute(ctx0, Kcur, 2, 1, 0, 3));
|
| 4764 |
+
offload_func_kq(Kcur);
|
| 4765 |
{
|
| 4766 |
+
struct ggml_tensor * tmpv = ggml_view_3d(
|
| 4767 |
+
ctx0, tmpqkv_perm, n_embd_head, n_head, n_tokens,
|
| 4768 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head,
|
| 4769 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head * n_head,
|
| 4770 |
+
ggml_element_size(tmpqkv_perm) * n_embd_head * n_head * n_tokens * 2
|
| 4771 |
+
);
|
| 4772 |
+
offload_func_v(tmpv);
|
| 4773 |
+
// store K, V in cache
|
| 4774 |
+
struct ggml_tensor * Vcur = ggml_transpose(ctx0, ggml_reshape_2d(ctx0, tmpv, n_embd_gqa, n_tokens));
|
| 4775 |
+
offload_func_v(Vcur);
|
| 4776 |
ggml_set_name(Vcur, "Vcur");
|
| 4777 |
|
| 4778 |
+
struct ggml_tensor * k = ggml_view_1d(
|
| 4779 |
+
ctx0, kv_self.k, n_tokens*n_embd_gqa,
|
| 4780 |
+
(ggml_element_size(kv_self.k)*n_embd_gqa)*(il*n_ctx + kv_head)
|
| 4781 |
+
);
|
| 4782 |
+
offload_func_kq(k);
|
| 4783 |
ggml_set_name(k, "k");
|
| 4784 |
|
| 4785 |
struct ggml_tensor * v = ggml_view_2d(ctx0, kv_self.v, n_tokens, n_embd_gqa,
|
| 4786 |
( n_ctx)*ggml_element_size(kv_self.v),
|
| 4787 |
(il*n_ctx)*ggml_element_size(kv_self.v)*n_embd_gqa + kv_head*ggml_element_size(kv_self.v));
|
| 4788 |
+
offload_func_v(v);
|
| 4789 |
+
ggml_set_name(v, "v");
|
| 4790 |
|
| 4791 |
+
// important: storing RoPE-ed version of K in the KV cache!
|
| 4792 |
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Kcur, k));
|
| 4793 |
ggml_build_forward_expand(gf, ggml_cpy(ctx0, Vcur, v));
|
| 4794 |
}
|
| 4795 |
+
struct ggml_tensor * K = ggml_view_3d(ctx0, kv_self.k,
|
| 4796 |
+
n_embd_head, n_kv, n_head_kv,
|
| 4797 |
+
ggml_element_size(kv_self.k)*n_embd_gqa,
|
| 4798 |
+
ggml_element_size(kv_self.k)*n_embd_head,
|
| 4799 |
+
ggml_element_size(kv_self.k)*n_embd_gqa*n_ctx*il);
|
| 4800 |
|
| 4801 |
+
offload_func_kq(K);
|
| 4802 |
+
ggml_format_name(K, "K_%d", il);
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4803 |
|
|
|
|
| 4804 |
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
|
| 4805 |
+
offload_func_kq(KQ);
|
| 4806 |
ggml_set_name(KQ, "KQ");
|
| 4807 |
|
| 4808 |
+
struct ggml_tensor * KQ_scaled = ggml_scale(ctx0, KQ, KQ_scale);
|
| 4809 |
+
offload_func_kq(KQ_scaled);
|
|
|
|
| 4810 |
ggml_set_name(KQ_scaled, "KQ_scaled");
|
| 4811 |
|
|
|
|
| 4812 |
struct ggml_tensor * KQ_masked = ggml_add(ctx0, KQ_scaled, KQ_mask);
|
| 4813 |
+
offload_func_kq(KQ_masked);
|
| 4814 |
ggml_set_name(KQ_masked, "KQ_masked");
|
| 4815 |
|
|
|
|
| 4816 |
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
|
| 4817 |
+
offload_func_kq(KQ_soft_max);
|
| 4818 |
ggml_set_name(KQ_soft_max, "KQ_soft_max");
|
| 4819 |
|
|
|
|
| 4820 |
struct ggml_tensor * V =
|
| 4821 |
ggml_view_3d(ctx0, kv_self.v,
|
| 4822 |
n_kv, n_embd_head, n_head_kv,
|
| 4823 |
ggml_element_size(kv_self.v)*n_ctx,
|
| 4824 |
ggml_element_size(kv_self.v)*n_ctx*n_embd_head,
|
| 4825 |
ggml_element_size(kv_self.v)*n_ctx*n_embd_gqa*il);
|
| 4826 |
+
offload_func_v(V);
|
| 4827 |
ggml_set_name(V, "V");
|
| 4828 |
|
| 4829 |
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
|
| 4830 |
+
offload_func_v(KQV);
|
| 4831 |
ggml_set_name(KQV, "KQV");
|
| 4832 |
|
|
|
|
| 4833 |
struct ggml_tensor * KQV_merged = ggml_permute(ctx0, KQV, 0, 2, 1, 3);
|
| 4834 |
+
offload_func_v(KQV_merged);
|
| 4835 |
ggml_set_name(KQV_merged, "KQV_merged");
|
| 4836 |
|
|
|
|
| 4837 |
cur = ggml_cont_2d(ctx0, KQV_merged, n_embd, n_tokens);
|
| 4838 |
+
offload_func_v(cur);
|
| 4839 |
ggml_set_name(cur, "KQV_merged_contiguous");
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4840 |
|
| 4841 |
+
cur = ggml_mul_mat(ctx0, model.layers[il].wo, cur);
|
| 4842 |
+
offload_func(cur);
|
| 4843 |
+
cur = ggml_add(ctx0, cur, model.layers[il].bo);
|
| 4844 |
+
offload_func(cur);
|
| 4845 |
+
ggml_set_name(cur, "result_wo");
|
| 4846 |
+
}
|
| 4847 |
|
| 4848 |
+
struct ggml_tensor * inpFF = ggml_add(ctx0, residual, cur);
|
| 4849 |
+
offload_func(inpFF);
|
| 4850 |
+
ggml_set_name(inpFF, "inpFF");
|
| 4851 |
{
|
| 4852 |
+
// MLP
|
| 4853 |
{
|
| 4854 |
+
// Norm
|
| 4855 |
cur = ggml_norm(ctx0, inpFF, norm_eps);
|
| 4856 |
+
offload_func(cur);
|
| 4857 |
+
cur = ggml_add(ctx0,
|
| 4858 |
+
ggml_mul(ctx0, cur, model.layers[il].ffn_norm),
|
| 4859 |
+
model.layers[il].ffn_norm_b
|
| 4860 |
+
);
|
| 4861 |
+
ggml_set_name(cur, "ffn_norm");
|
| 4862 |
+
offload_func(cur);
|
| 4863 |
}
|
| 4864 |
+
cur = ggml_mul_mat(ctx0, model.layers[il].w3, cur);
|
| 4865 |
+
offload_func(cur);
|
| 4866 |
|
| 4867 |
+
cur = ggml_add(ctx0, cur, model.layers[il].b3);
|
| 4868 |
+
offload_func(cur);
|
| 4869 |
+
ggml_set_name(cur, "result_ffn_up");
|
| 4870 |
|
| 4871 |
+
cur = ggml_sqr(ctx0, ggml_relu(ctx0, cur));
|
| 4872 |
+
ggml_set_name(cur, "result_ffn_act");
|
| 4873 |
+
offload_func(cur);
|
| 4874 |
+
offload_func(cur->src[0]);
|
| 4875 |
|
| 4876 |
+
cur = ggml_mul_mat(ctx0, model.layers[il].w2, cur);
|
| 4877 |
+
offload_func(cur);
|
| 4878 |
+
cur = ggml_add(ctx0,
|
| 4879 |
+
cur,
|
| 4880 |
+
model.layers[il].b2);
|
| 4881 |
+
offload_func(cur);
|
| 4882 |
+
ggml_set_name(cur, "outFF");
|
| 4883 |
}
|
| 4884 |
+
cur = ggml_add(ctx0, cur, inpFF);
|
| 4885 |
+
offload_func(cur);
|
| 4886 |
+
ggml_set_name(cur, "inpFF_+_outFF");
|
| 4887 |
+
inpL = cur;
|
| 4888 |
}
|
| 4889 |
+
cur = inpL;
|
|
|
|
| 4890 |
{
|
| 4891 |
+
cur = ggml_norm(ctx0, cur, norm_eps);
|
| 4892 |
+
offload_func_nr(cur);
|
| 4893 |
+
cur = ggml_mul(ctx0, cur, model.output_norm);
|
| 4894 |
+
offload_func_nr(cur);
|
| 4895 |
|
| 4896 |
+
cur = ggml_add(ctx0, cur, model.output_norm_b);
|
| 4897 |
+
// offload_func_nr(cur);
|
| 4898 |
+
|
| 4899 |
+
ggml_set_name(cur, "result_norm");
|
| 4900 |
+
}
|
| 4901 |
cur = ggml_mul_mat(ctx0, model.output, cur);
|
| 4902 |
ggml_set_name(cur, "result_output");
|
|
|
|
| 4903 |
ggml_build_forward_expand(gf, cur);
|
| 4904 |
ggml_free(ctx0);
|
|
|
|
| 4905 |
return gf;
|
| 4906 |
}
|
| 4907 |
|
|
|
|
| 4929 |
{
|
| 4930 |
result = llm_build_starcoder(lctx, batch);
|
| 4931 |
} break;
|
| 4932 |
+
case LLM_ARCH_PERSIMMON:
|
| 4933 |
+
{
|
| 4934 |
+
result = llm_build_persimmon(lctx, batch);
|
| 4935 |
+
} break;
|
| 4936 |
+
case LLM_ARCH_REFACT:
|
| 4937 |
+
{
|
| 4938 |
+
result = llm_build_refact(lctx, batch);
|
| 4939 |
+
} break;
|
| 4940 |
default:
|
| 4941 |
GGML_ASSERT(false);
|
| 4942 |
}
|
|
|
|
| 4972 |
|
| 4973 |
GGML_ASSERT(n_tokens <= n_batch);
|
| 4974 |
|
| 4975 |
+
int n_threads = n_tokens < 32 ? cparams.n_threads : cparams.n_threads_batch;
|
| 4976 |
GGML_ASSERT((!batch.token && batch.embd) || (batch.token && !batch.embd)); // NOLINT
|
| 4977 |
|
| 4978 |
const int64_t t_start_us = ggml_time_us();
|
|
|
|
| 5015 |
batch.seq_id = seq_id.data();
|
| 5016 |
}
|
| 5017 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5018 |
if (!llama_kv_cache_find_slot(kv_self, batch)) {
|
| 5019 |
return 1;
|
| 5020 |
}
|
|
|
|
| 5066 |
// If all tensors can be run on the GPU then using more than 1 thread is detrimental.
|
| 5067 |
const bool full_offload_supported = model.arch == LLM_ARCH_LLAMA ||
|
| 5068 |
model.arch == LLM_ARCH_BAICHUAN ||
|
| 5069 |
+
model.arch == LLM_ARCH_FALCON ||
|
| 5070 |
+
model.arch == LLM_ARCH_REFACT;
|
| 5071 |
const bool fully_offloaded = model.n_gpu_layers >= (int) hparams.n_layer + 3;
|
| 5072 |
if (ggml_cpu_has_cublas() && full_offload_supported && fully_offloaded) {
|
| 5073 |
n_threads = 1;
|
|
|
|
| 5100 |
#endif
|
| 5101 |
|
| 5102 |
// update the kv ring buffer
|
|
|
|
| 5103 |
lctx.kv_self.has_shift = false;
|
| 5104 |
+
lctx.kv_self.head += n_tokens;
|
| 5105 |
+
// Ensure kv cache head points to a valid index.
|
| 5106 |
+
if (lctx.kv_self.head >= lctx.kv_self.size) {
|
| 5107 |
+
lctx.kv_self.head = 0;
|
| 5108 |
+
}
|
| 5109 |
|
| 5110 |
#ifdef GGML_PERF
|
| 5111 |
// print timing information per ggml operation (for debugging purposes)
|
|
|
|
| 5191 |
return vocab.id_to_token[id].type == LLAMA_TOKEN_TYPE_BYTE;
|
| 5192 |
}
|
| 5193 |
|
| 5194 |
+
static bool llama_is_user_defined_token(const llama_vocab& vocab, llama_token id) {
|
| 5195 |
+
return vocab.id_to_token[id].type == LLAMA_TOKEN_TYPE_USER_DEFINED;
|
| 5196 |
+
}
|
| 5197 |
+
|
| 5198 |
+
static uint8_t llama_token_to_byte(const llama_vocab& vocab, llama_token id) {
|
| 5199 |
GGML_ASSERT(llama_is_byte_token(vocab, id));
|
| 5200 |
const auto& token_data = vocab.id_to_token.at(id);
|
| 5201 |
+
switch (llama_vocab_get_type(vocab)) {
|
| 5202 |
+
case LLAMA_VOCAB_TYPE_SPM: {
|
| 5203 |
+
auto buf = token_data.text.substr(3, 2);
|
| 5204 |
+
return strtol(buf.c_str(), NULL, 16);
|
| 5205 |
+
}
|
| 5206 |
+
case LLAMA_VOCAB_TYPE_BPE: {
|
| 5207 |
+
GGML_ASSERT(false);
|
| 5208 |
+
return unicode_to_bytes_bpe(token_data.text);
|
| 5209 |
+
}
|
| 5210 |
+
default:
|
| 5211 |
+
GGML_ASSERT(false);
|
| 5212 |
+
}
|
| 5213 |
}
|
| 5214 |
|
| 5215 |
static llama_token llama_byte_to_token(const llama_vocab & vocab, uint8_t ch) {
|
| 5216 |
+
switch (llama_vocab_get_type(vocab)) {
|
| 5217 |
+
case LLAMA_VOCAB_TYPE_SPM: {
|
| 5218 |
+
char buf[7];
|
| 5219 |
+
int result = snprintf(buf, sizeof(buf), "<0x%02X>", ch);
|
| 5220 |
+
GGML_ASSERT(0 <= result && result < 7);
|
| 5221 |
+
return vocab.token_to_id.at(buf);
|
| 5222 |
+
}
|
| 5223 |
+
case LLAMA_VOCAB_TYPE_BPE: {
|
| 5224 |
+
return vocab.token_to_id.at(bytes_to_unicode_bpe(ch));
|
| 5225 |
+
}
|
| 5226 |
+
default:
|
| 5227 |
+
GGML_ASSERT(false);
|
| 5228 |
+
}
|
| 5229 |
}
|
| 5230 |
|
| 5231 |
static void llama_escape_whitespace(std::string & text) {
|
|
|
|
| 5505 |
std::string byte_str(1, *j);
|
| 5506 |
auto token_multibyte = vocab.token_to_id.find(byte_str);
|
| 5507 |
if (token_multibyte == vocab.token_to_id.end()) {
|
| 5508 |
+
throw std::runtime_error("ERROR: byte not found in vocab");
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5509 |
}
|
| 5510 |
+
output.push_back((*token_multibyte).second);
|
| 5511 |
}
|
| 5512 |
} else {
|
| 5513 |
output.push_back((*token).second);
|
|
|
|
| 5544 |
work_queue.push(bigram);
|
| 5545 |
}
|
| 5546 |
|
| 5547 |
+
std::vector<std::string> bpe_gpt2_preprocess(const std::string & text) {
|
| 5548 |
+
std::vector<std::string> bpe_words;
|
| 5549 |
+
std::vector<std::string> bpe_encoded_words;
|
| 5550 |
+
|
| 5551 |
+
std::string token = "";
|
| 5552 |
+
// GPT2 system regex: 's|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+
|
| 5553 |
+
bool collecting_numeric = false;
|
| 5554 |
+
bool collecting_letter = false;
|
| 5555 |
+
bool collecting_special = false;
|
| 5556 |
+
bool collecting_whitespace_lookahead = false;
|
| 5557 |
+
bool collecting = false;
|
| 5558 |
+
|
| 5559 |
+
std::vector<std::string> text_utf;
|
| 5560 |
+
text_utf.reserve(text.size());
|
| 5561 |
+
bpe_words.reserve(text.size());
|
| 5562 |
+
bpe_encoded_words.reserve(text.size());
|
| 5563 |
+
|
| 5564 |
+
auto cps = codepoints_from_utf8(text);
|
| 5565 |
+
for (size_t i = 0; i < cps.size(); ++i)
|
| 5566 |
+
text_utf.emplace_back(codepoint_to_utf8(cps[i]));
|
| 5567 |
+
|
| 5568 |
+
for (int i = 0; i < (int)text_utf.size(); i++) {
|
| 5569 |
+
const std::string & utf_char = text_utf[i];
|
| 5570 |
+
bool split_condition = false;
|
| 5571 |
+
// const char* text_pos = raw_text_p + utf_char.seq_offset_bytes;
|
| 5572 |
+
int bytes_remain = text_utf.size() - i;
|
| 5573 |
+
// forward backward lookups
|
| 5574 |
+
const std::string & utf_char_next = (i + 1 < (int)text_utf.size()) ? text_utf[i + 1] : "";
|
| 5575 |
+
const std::string & utf_char_next_next = (i + 2 < (int)text_utf.size()) ? text_utf[i + 2] : "";
|
| 5576 |
+
|
| 5577 |
+
// handling contractions
|
| 5578 |
+
if (!split_condition && bytes_remain >= 2) {
|
| 5579 |
+
// 's|'t|'m|'d
|
| 5580 |
+
if (utf_char == "\'" && (utf_char_next == "s" || utf_char_next == "t" || utf_char_next == "m" || utf_char_next == "d")) {
|
| 5581 |
+
split_condition = true;
|
| 5582 |
+
}
|
| 5583 |
+
if (split_condition) {
|
| 5584 |
+
if (token.size()) {
|
| 5585 |
+
bpe_words.emplace_back(token); // push previous content as token
|
| 5586 |
+
}
|
| 5587 |
+
token = utf_char + utf_char_next;
|
| 5588 |
+
bpe_words.emplace_back(token);
|
| 5589 |
+
token = "";
|
| 5590 |
+
i++;
|
| 5591 |
+
continue;
|
| 5592 |
+
}
|
| 5593 |
+
}
|
| 5594 |
+
if (!split_condition && bytes_remain >= 3) {
|
| 5595 |
+
// 're|'ve|'ll
|
| 5596 |
+
if (utf_char == "\'" && (
|
| 5597 |
+
(utf_char_next == "r" || utf_char_next_next == "e") ||
|
| 5598 |
+
(utf_char_next == "v" || utf_char_next_next == "e") ||
|
| 5599 |
+
(utf_char_next == "l" || utf_char_next_next == "l"))
|
| 5600 |
+
) {
|
| 5601 |
+
split_condition = true;
|
| 5602 |
+
}
|
| 5603 |
+
if (split_condition) {
|
| 5604 |
+
// current token + next token can be defined
|
| 5605 |
+
if (token.size()) {
|
| 5606 |
+
bpe_words.emplace_back(token); // push previous content as token
|
| 5607 |
+
}
|
| 5608 |
+
token = utf_char + utf_char_next + utf_char_next_next;
|
| 5609 |
+
bpe_words.emplace_back(token); // the contraction
|
| 5610 |
+
token = "";
|
| 5611 |
+
i += 2;
|
| 5612 |
+
continue;
|
| 5613 |
+
}
|
| 5614 |
+
}
|
| 5615 |
+
|
| 5616 |
+
if (!split_condition && !collecting) {
|
| 5617 |
+
if (codepoint_type(utf_char) == CODEPOINT_TYPE_LETTER || (!token.size() && utf_char == " " && codepoint_type(utf_char_next) == CODEPOINT_TYPE_LETTER)) {
|
| 5618 |
+
collecting_letter = true;
|
| 5619 |
+
collecting = true;
|
| 5620 |
+
}
|
| 5621 |
+
else if (codepoint_type(utf_char) == CODEPOINT_TYPE_DIGIT || (!token.size() && utf_char == " " && codepoint_type(utf_char_next) == CODEPOINT_TYPE_DIGIT)) {
|
| 5622 |
+
collecting_numeric = true;
|
| 5623 |
+
collecting = true;
|
| 5624 |
+
}
|
| 5625 |
+
else if (
|
| 5626 |
+
((codepoint_type(utf_char) != CODEPOINT_TYPE_LETTER && codepoint_type(utf_char) != CODEPOINT_TYPE_DIGIT) && (codepoint_type(utf_char) != CODEPOINT_TYPE_WHITESPACE)) ||
|
| 5627 |
+
(!token.size() && utf_char == " " && codepoint_type(utf_char_next) != CODEPOINT_TYPE_LETTER && codepoint_type(utf_char_next) != CODEPOINT_TYPE_DIGIT && codepoint_type(utf_char_next) != CODEPOINT_TYPE_WHITESPACE)
|
| 5628 |
+
) {
|
| 5629 |
+
collecting_special = true;
|
| 5630 |
+
collecting = true;
|
| 5631 |
+
}
|
| 5632 |
+
else if (codepoint_type(utf_char) == CODEPOINT_TYPE_WHITESPACE && codepoint_type(utf_char_next) == CODEPOINT_TYPE_WHITESPACE) {
|
| 5633 |
+
collecting_whitespace_lookahead = true;
|
| 5634 |
+
collecting = true;
|
| 5635 |
+
}
|
| 5636 |
+
else if (codepoint_type(utf_char) == CODEPOINT_TYPE_WHITESPACE) {
|
| 5637 |
+
split_condition = true;
|
| 5638 |
+
}
|
| 5639 |
+
}
|
| 5640 |
+
else if (!split_condition && collecting) {
|
| 5641 |
+
if (collecting_letter && codepoint_type(utf_char) != CODEPOINT_TYPE_LETTER) {
|
| 5642 |
+
split_condition = true;
|
| 5643 |
+
}
|
| 5644 |
+
else if (collecting_numeric && codepoint_type(utf_char) != CODEPOINT_TYPE_DIGIT) {
|
| 5645 |
+
split_condition = true;
|
| 5646 |
+
}
|
| 5647 |
+
else if (collecting_special && (codepoint_type(utf_char) == CODEPOINT_TYPE_LETTER || codepoint_type(utf_char) == CODEPOINT_TYPE_DIGIT || codepoint_type(utf_char) == CODEPOINT_TYPE_WHITESPACE)) {
|
| 5648 |
+
split_condition = true;
|
| 5649 |
+
}
|
| 5650 |
+
else if (collecting_whitespace_lookahead && codepoint_type(utf_char_next) != CODEPOINT_TYPE_WHITESPACE) {
|
| 5651 |
+
split_condition = true;
|
| 5652 |
+
}
|
| 5653 |
+
}
|
| 5654 |
+
|
| 5655 |
+
if (utf_char_next == "") {
|
| 5656 |
+
split_condition = true; // final
|
| 5657 |
+
token += utf_char;
|
| 5658 |
+
}
|
| 5659 |
|
| 5660 |
+
if (split_condition) {
|
| 5661 |
+
if (token.size()) {
|
| 5662 |
+
bpe_words.emplace_back(token);
|
| 5663 |
+
}
|
| 5664 |
+
token = utf_char;
|
| 5665 |
+
collecting = false;
|
| 5666 |
+
collecting_letter = false;
|
| 5667 |
+
collecting_numeric = false;
|
| 5668 |
+
collecting_special = false;
|
| 5669 |
+
collecting_whitespace_lookahead = false;
|
| 5670 |
+
}
|
| 5671 |
+
else {
|
| 5672 |
+
token += utf_char;
|
| 5673 |
+
}
|
| 5674 |
+
}
|
| 5675 |
|
| 5676 |
+
for (std::string & word : bpe_words) {
|
| 5677 |
+
std::string encoded_token = "";
|
| 5678 |
+
for (char & c : word) {
|
| 5679 |
+
encoded_token += bytes_to_unicode_bpe(c);
|
| 5680 |
+
}
|
| 5681 |
+
bpe_encoded_words.emplace_back(encoded_token);
|
| 5682 |
}
|
|
|
|
| 5683 |
|
| 5684 |
+
return bpe_encoded_words;
|
| 5685 |
}
|
| 5686 |
|
| 5687 |
const llama_vocab & vocab;
|
|
|
|
| 7203 |
}
|
| 7204 |
|
| 7205 |
std::ofstream fout(fname_out, std::ios::binary);
|
| 7206 |
+
fout.exceptions(std::ofstream::failbit); // fail fast on write errors
|
| 7207 |
|
| 7208 |
const size_t meta_size = gguf_get_meta_size(ctx_out);
|
| 7209 |
|
|
|
|
| 7857 |
|
| 7858 |
#ifdef GGML_USE_METAL
|
| 7859 |
if (model->n_gpu_layers > 0) {
|
| 7860 |
+
ggml_metal_log_set_callback(llama_log_callback_default, NULL);
|
| 7861 |
+
|
| 7862 |
ctx->ctx_metal = ggml_metal_init(1);
|
| 7863 |
if (!ctx->ctx_metal) {
|
| 7864 |
LLAMA_LOG_ERROR("%s: ggml_metal_init() failed\n", __func__);
|
| 7865 |
llama_free(ctx);
|
| 7866 |
return NULL;
|
| 7867 |
}
|
|
|
|
| 7868 |
//ggml_metal_graph_find_concurrency(ctx->ctx_metal, gf, false);
|
| 7869 |
//ggml_allocr_set_parse_seq(ctx->alloc, ggml_metal_get_concur_list(ctx->ctx_metal), ggml_metal_if_optimized(ctx->ctx_metal));
|
| 7870 |
}
|
|
|
|
| 7992 |
return model->hparams.n_embd;
|
| 7993 |
}
|
| 7994 |
|
| 7995 |
+
float llama_rope_freq_scale_train(const struct llama_model * model) {
|
| 7996 |
+
return model->hparams.rope_freq_scale_train;
|
| 7997 |
+
}
|
| 7998 |
+
|
| 7999 |
int llama_model_desc(const struct llama_model * model, char * buf, size_t buf_size) {
|
| 8000 |
return snprintf(buf, buf_size, "%s %s %s",
|
| 8001 |
llama_model_arch_name(model->arch).c_str(),
|
|
|
|
| 8163 |
*
|
| 8164 |
*/
|
| 8165 |
static void llama_copy_state_data_internal(struct llama_context * ctx, llama_data_context * data_ctx) {
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8166 |
// copy rng
|
| 8167 |
{
|
| 8168 |
std::stringstream rng_ss;
|
|
|
|
| 8215 |
const auto & hparams = ctx->model.hparams;
|
| 8216 |
const auto & cparams = ctx->cparams;
|
| 8217 |
|
| 8218 |
+
const auto n_layer = hparams.n_layer;
|
| 8219 |
+
const auto n_embd = hparams.n_embd_gqa();
|
| 8220 |
+
const auto n_ctx = cparams.n_ctx;
|
| 8221 |
|
| 8222 |
+
const size_t kv_buf_size = kv_self.buf.size;
|
| 8223 |
+
const uint32_t kv_head = kv_self.head;
|
| 8224 |
+
const uint32_t kv_size = kv_self.size;
|
| 8225 |
|
| 8226 |
+
data_ctx->write(&kv_buf_size, sizeof(kv_buf_size));
|
| 8227 |
+
data_ctx->write(&kv_head, sizeof(kv_head));
|
| 8228 |
+
data_ctx->write(&kv_size, sizeof(kv_size));
|
| 8229 |
|
| 8230 |
+
if (kv_buf_size) {
|
| 8231 |
const size_t elt_size = ggml_element_size(kv_self.k);
|
| 8232 |
|
| 8233 |
ggml_context * cpy_ctx = ggml_init({ 4096, NULL, /* no_alloc */ true });
|
| 8234 |
ggml_cgraph gf{};
|
| 8235 |
|
| 8236 |
+
ggml_tensor * kout3d = ggml_new_tensor_3d(cpy_ctx, kv_self.k->type, n_embd, kv_head, n_layer);
|
| 8237 |
std::vector<uint8_t> kout3d_data(ggml_nbytes(kout3d), 0);
|
| 8238 |
kout3d->data = kout3d_data.data();
|
| 8239 |
|
| 8240 |
+
ggml_tensor * vout3d = ggml_new_tensor_3d(cpy_ctx, kv_self.v->type, kv_head, n_embd, n_layer);
|
| 8241 |
std::vector<uint8_t> vout3d_data(ggml_nbytes(vout3d), 0);
|
| 8242 |
vout3d->data = vout3d_data.data();
|
| 8243 |
|
| 8244 |
ggml_tensor * k3d = ggml_view_3d(cpy_ctx, kv_self.k,
|
| 8245 |
+
n_embd, kv_head, n_layer,
|
| 8246 |
elt_size*n_embd, elt_size*n_embd*n_ctx, 0);
|
| 8247 |
|
| 8248 |
ggml_tensor * v3d = ggml_view_3d(cpy_ctx, kv_self.v,
|
| 8249 |
+
kv_head, n_embd, n_layer,
|
| 8250 |
elt_size*n_ctx, elt_size*n_ctx*n_embd, 0);
|
| 8251 |
|
| 8252 |
ggml_build_forward_expand(&gf, ggml_cpy(cpy_ctx, k3d, kout3d));
|
|
|
|
| 8260 |
data_ctx->write(kout3d_data.data(), kout3d_data.size());
|
| 8261 |
data_ctx->write(vout3d_data.data(), vout3d_data.size());
|
| 8262 |
}
|
| 8263 |
+
|
| 8264 |
+
for (uint32_t i = 0; i < kv_size; ++i) {
|
| 8265 |
+
const auto & cell = kv_self.cells[i];
|
| 8266 |
+
|
| 8267 |
+
const llama_pos pos = cell.pos;
|
| 8268 |
+
const size_t seq_id_size = cell.seq_id.size();
|
| 8269 |
+
|
| 8270 |
+
data_ctx->write(&pos, sizeof(pos));
|
| 8271 |
+
data_ctx->write(&seq_id_size, sizeof(seq_id_size));
|
| 8272 |
+
|
| 8273 |
+
for (auto seq_id : cell.seq_id) {
|
| 8274 |
+
data_ctx->write(&seq_id, sizeof(seq_id));
|
| 8275 |
+
}
|
| 8276 |
+
}
|
| 8277 |
}
|
| 8278 |
}
|
| 8279 |
|
|
|
|
| 8345 |
const int n_embd = hparams.n_embd_gqa();
|
| 8346 |
const int n_ctx = cparams.n_ctx;
|
| 8347 |
|
| 8348 |
+
size_t kv_buf_size;
|
| 8349 |
+
uint32_t kv_head;
|
| 8350 |
+
uint32_t kv_size;
|
| 8351 |
|
| 8352 |
+
memcpy(&kv_buf_size, inp, sizeof(kv_buf_size)); inp += sizeof(kv_buf_size);
|
| 8353 |
+
memcpy(&kv_head, inp, sizeof(kv_head)); inp += sizeof(kv_head);
|
| 8354 |
+
memcpy(&kv_size, inp, sizeof(kv_size)); inp += sizeof(kv_size);
|
| 8355 |
|
| 8356 |
+
if (kv_buf_size) {
|
| 8357 |
+
GGML_ASSERT(kv_self.buf.size == kv_buf_size);
|
| 8358 |
|
| 8359 |
const size_t elt_size = ggml_element_size(kv_self.k);
|
| 8360 |
|
| 8361 |
ggml_context * cpy_ctx = ggml_init({ 4096, NULL, /* no_alloc */ true });
|
| 8362 |
ggml_cgraph gf{};
|
| 8363 |
|
| 8364 |
+
ggml_tensor * kin3d = ggml_new_tensor_3d(cpy_ctx, kv_self.k->type, n_embd, kv_head, n_layer);
|
| 8365 |
kin3d->data = (void *) inp;
|
| 8366 |
inp += ggml_nbytes(kin3d);
|
| 8367 |
|
| 8368 |
+
ggml_tensor * vin3d = ggml_new_tensor_3d(cpy_ctx, kv_self.v->type, kv_head, n_embd, n_layer);
|
| 8369 |
vin3d->data = (void *) inp;
|
| 8370 |
inp += ggml_nbytes(vin3d);
|
| 8371 |
|
| 8372 |
ggml_tensor * k3d = ggml_view_3d(cpy_ctx, kv_self.k,
|
| 8373 |
+
n_embd, kv_head, n_layer,
|
| 8374 |
elt_size*n_embd, elt_size*n_embd*n_ctx, 0);
|
| 8375 |
|
| 8376 |
ggml_tensor * v3d = ggml_view_3d(cpy_ctx, kv_self.v,
|
| 8377 |
+
kv_head, n_embd, n_layer,
|
| 8378 |
elt_size*n_ctx, elt_size*n_ctx*n_embd, 0);
|
| 8379 |
|
| 8380 |
ggml_build_forward_expand(&gf, ggml_cpy(cpy_ctx, kin3d, k3d));
|
|
|
|
| 8384 |
ggml_free(cpy_ctx);
|
| 8385 |
}
|
| 8386 |
|
| 8387 |
+
ctx->kv_self.head = kv_head;
|
| 8388 |
ctx->kv_self.size = kv_size;
|
| 8389 |
+
|
| 8390 |
+
ctx->kv_self.cells.resize(kv_size);
|
| 8391 |
+
|
| 8392 |
+
for (uint32_t i = 0; i < kv_size; ++i) {
|
| 8393 |
+
llama_pos pos;
|
| 8394 |
+
size_t seq_id_size;
|
| 8395 |
+
|
| 8396 |
+
memcpy(&pos, inp, sizeof(pos)); inp += sizeof(pos);
|
| 8397 |
+
memcpy(&seq_id_size, inp, sizeof(seq_id_size)); inp += sizeof(seq_id_size);
|
| 8398 |
+
|
| 8399 |
+
ctx->kv_self.cells[i].pos = pos;
|
| 8400 |
+
|
| 8401 |
+
llama_seq_id seq_id;
|
| 8402 |
+
|
| 8403 |
+
for (size_t j = 0; j < seq_id_size; ++j) {
|
| 8404 |
+
memcpy(&seq_id, inp, sizeof(seq_id)); inp += sizeof(seq_id);
|
| 8405 |
+
ctx->kv_self.cells[i].seq_id.insert(seq_id);
|
| 8406 |
+
}
|
| 8407 |
+
}
|
| 8408 |
}
|
| 8409 |
|
| 8410 |
const size_t nread = inp - src;
|
|
|
|
| 8622 |
llama_token llama_token_nl(const struct llama_context * ctx) {
|
| 8623 |
return ctx->model.vocab.linefeed_id;
|
| 8624 |
}
|
| 8625 |
+
llama_token llama_token_prefix(const struct llama_context * ctx) {
|
| 8626 |
+
return ctx->model.vocab.special_prefix_id;
|
| 8627 |
+
}
|
| 8628 |
+
|
| 8629 |
+
llama_token llama_token_middle(const struct llama_context * ctx) {
|
| 8630 |
+
return ctx->model.vocab.special_middle_id;
|
| 8631 |
+
}
|
| 8632 |
+
|
| 8633 |
+
llama_token llama_token_suffix(const struct llama_context * ctx) {
|
| 8634 |
+
return ctx->model.vocab.special_suffix_id;
|
| 8635 |
+
}
|
| 8636 |
+
|
| 8637 |
+
llama_token llama_token_eot(const struct llama_context * ctx) {
|
| 8638 |
+
return ctx->model.vocab.special_eot_id;
|
| 8639 |
+
}
|
| 8640 |
+
|
| 8641 |
|
| 8642 |
int llama_tokenize(
|
| 8643 |
const struct llama_model * model,
|
|
|
|
| 8660 |
return res.size();
|
| 8661 |
}
|
| 8662 |
|
| 8663 |
+
static std::string llama_decode_text(const std::string & text) {
|
| 8664 |
+
std::string decoded_text;
|
| 8665 |
+
auto unicode_sequences = codepoints_from_utf8(text);
|
| 8666 |
+
for (auto& unicode_sequence : unicode_sequences) {
|
| 8667 |
+
decoded_text += unicode_to_bytes_bpe(codepoint_to_utf8(unicode_sequence));
|
| 8668 |
+
}
|
| 8669 |
+
|
| 8670 |
+
return decoded_text;
|
| 8671 |
+
}
|
| 8672 |
+
|
| 8673 |
// does not write null-terminator to buf
|
| 8674 |
int llama_token_to_piece(const struct llama_model * model, llama_token token, char * buf, int length) {
|
| 8675 |
if (0 <= token && token < llama_n_vocab(model)) {
|
| 8676 |
+
switch (llama_vocab_get_type(model->vocab)) {
|
| 8677 |
+
case LLAMA_VOCAB_TYPE_SPM: {
|
| 8678 |
+
if (llama_is_normal_token(model->vocab, token)) {
|
| 8679 |
+
std::string result = model->vocab.id_to_token[token].text;
|
| 8680 |
llama_unescape_whitespace(result);
|
| 8681 |
+
if (length < (int) result.length()) {
|
| 8682 |
+
return -result.length();
|
| 8683 |
+
}
|
| 8684 |
+
memcpy(buf, result.c_str(), result.length());
|
| 8685 |
+
return result.length();
|
| 8686 |
+
} else if (llama_is_unknown_token(model->vocab, token)) { // NOLINT
|
| 8687 |
+
if (length < 3) {
|
| 8688 |
+
return -3;
|
| 8689 |
+
}
|
| 8690 |
+
memcpy(buf, "\xe2\x96\x85", 3);
|
| 8691 |
+
return 3;
|
| 8692 |
+
} else if (llama_is_control_token(model->vocab, token)) {
|
| 8693 |
+
;
|
| 8694 |
+
} else if (llama_is_byte_token(model->vocab, token)) {
|
| 8695 |
+
if (length < 1) {
|
| 8696 |
+
return -1;
|
| 8697 |
+
}
|
| 8698 |
+
buf[0] = llama_token_to_byte(model->vocab, token);
|
| 8699 |
+
return 1;
|
| 8700 |
+
} else {
|
| 8701 |
+
// TODO: for now we accept all unsupported token types,
|
| 8702 |
+
// suppressing them like CONTROL tokens.
|
| 8703 |
+
// GGML_ASSERT(false);
|
| 8704 |
}
|
| 8705 |
+
break;
|
| 8706 |
+
}
|
| 8707 |
+
case LLAMA_VOCAB_TYPE_BPE: {
|
| 8708 |
+
if (llama_is_normal_token(model->vocab, token)) {
|
| 8709 |
+
std::string result = model->vocab.id_to_token[token].text;
|
| 8710 |
+
result = llama_decode_text(result);
|
| 8711 |
+
if (length < (int) result.length()) {
|
| 8712 |
+
return -result.length();
|
| 8713 |
+
}
|
| 8714 |
+
memcpy(buf, result.c_str(), result.length());
|
| 8715 |
+
return result.length();
|
| 8716 |
+
} else if (llama_is_control_token(model->vocab, token)) {
|
| 8717 |
+
;
|
| 8718 |
+
} else {
|
| 8719 |
+
GGML_ASSERT(false);
|
|
|
|
|
|
|
|
|
|
| 8720 |
}
|
| 8721 |
+
break;
|
| 8722 |
+
}
|
| 8723 |
+
default:
|
| 8724 |
+
LLAMA_LOG_WARN("%s: Unknown Tokenization Error 3\n", __func__);
|
| 8725 |
}
|
| 8726 |
}
|
| 8727 |
return 0;
|
|
|
|
| 8748 |
const llama_timings timings = llama_get_timings(ctx);
|
| 8749 |
|
| 8750 |
LLAMA_LOG_INFO("\n");
|
| 8751 |
+
LLAMA_LOG_INFO("%s: load time = %10.2f ms\n", __func__, timings.t_load_ms);
|
| 8752 |
+
LLAMA_LOG_INFO("%s: sample time = %10.2f ms / %5d runs (%8.2f ms per token, %8.2f tokens per second)\n",
|
| 8753 |
__func__, timings.t_sample_ms, timings.n_sample, timings.t_sample_ms / timings.n_sample, 1e3 / timings.t_sample_ms * timings.n_sample);
|
| 8754 |
+
LLAMA_LOG_INFO("%s: prompt eval time = %10.2f ms / %5d tokens (%8.2f ms per token, %8.2f tokens per second)\n",
|
| 8755 |
__func__, timings.t_p_eval_ms, timings.n_p_eval, timings.t_p_eval_ms / timings.n_p_eval, 1e3 / timings.t_p_eval_ms * timings.n_p_eval);
|
| 8756 |
+
LLAMA_LOG_INFO("%s: eval time = %10.2f ms / %5d runs (%8.2f ms per token, %8.2f tokens per second)\n",
|
| 8757 |
__func__, timings.t_eval_ms, timings.n_eval, timings.t_eval_ms / timings.n_eval, 1e3 / timings.t_eval_ms * timings.n_eval);
|
| 8758 |
+
LLAMA_LOG_INFO("%s: total time = %10.2f ms\n", __func__, (timings.t_end_ms - timings.t_start_ms));
|
| 8759 |
}
|
| 8760 |
|
| 8761 |
void llama_reset_timings(struct llama_context * ctx) {
|
llama.h
CHANGED
|
@@ -42,7 +42,7 @@
|
|
| 42 |
#define LLAMA_FILE_MAGIC_GGSN 0x6767736eu // 'ggsn'
|
| 43 |
|
| 44 |
#define LLAMA_SESSION_MAGIC LLAMA_FILE_MAGIC_GGSN
|
| 45 |
-
#define LLAMA_SESSION_VERSION
|
| 46 |
|
| 47 |
#if defined(GGML_USE_CUBLAS) || defined(GGML_USE_CLBLAST) || defined(GGML_USE_METAL)
|
| 48 |
// Defined when llama.cpp is compiled with support for offloading model layers to GPU.
|
|
@@ -282,6 +282,9 @@ extern "C" {
|
|
| 282 |
LLAMA_API int llama_n_ctx_train(const struct llama_model * model);
|
| 283 |
LLAMA_API int llama_n_embd (const struct llama_model * model);
|
| 284 |
|
|
|
|
|
|
|
|
|
|
| 285 |
// Get a string describing the model type
|
| 286 |
LLAMA_API int llama_model_desc(const struct llama_model * model, char * buf, size_t buf_size);
|
| 287 |
|
|
@@ -330,12 +333,16 @@ extern "C" {
|
|
| 330 |
"avoid using this, it will be removed in the future, instead - count the tokens in user code");
|
| 331 |
|
| 332 |
// Remove all tokens data of cells in [c0, c1)
|
|
|
|
|
|
|
| 333 |
LLAMA_API void llama_kv_cache_tokens_rm(
|
| 334 |
struct llama_context * ctx,
|
| 335 |
int32_t c0,
|
| 336 |
int32_t c1);
|
| 337 |
|
| 338 |
// Removes all tokens that belong to the specified sequence and have positions in [p0, p1)
|
|
|
|
|
|
|
| 339 |
LLAMA_API void llama_kv_cache_seq_rm(
|
| 340 |
struct llama_context * ctx,
|
| 341 |
llama_seq_id seq_id,
|
|
@@ -344,6 +351,8 @@ extern "C" {
|
|
| 344 |
|
| 345 |
// Copy all tokens that belong to the specified sequence to another sequence
|
| 346 |
// Note that this does not allocate extra KV cache memory - it simply assigns the tokens to the new sequence
|
|
|
|
|
|
|
| 347 |
LLAMA_API void llama_kv_cache_seq_cp(
|
| 348 |
struct llama_context * ctx,
|
| 349 |
llama_seq_id seq_id_src,
|
|
@@ -358,6 +367,8 @@ extern "C" {
|
|
| 358 |
|
| 359 |
// Adds relative position "delta" to all tokens that belong to the specified sequence and have positions in [p0, p1)
|
| 360 |
// If the KV cache is RoPEd, the KV data is updated accordingly
|
|
|
|
|
|
|
| 361 |
LLAMA_API void llama_kv_cache_seq_shift(
|
| 362 |
struct llama_context * ctx,
|
| 363 |
llama_seq_id seq_id,
|
|
@@ -490,6 +501,11 @@ extern "C" {
|
|
| 490 |
LLAMA_API llama_token llama_token_bos(const struct llama_context * ctx); // beginning-of-sentence
|
| 491 |
LLAMA_API llama_token llama_token_eos(const struct llama_context * ctx); // end-of-sentence
|
| 492 |
LLAMA_API llama_token llama_token_nl (const struct llama_context * ctx); // next-line
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 493 |
|
| 494 |
//
|
| 495 |
// Tokenization
|
|
|
|
| 42 |
#define LLAMA_FILE_MAGIC_GGSN 0x6767736eu // 'ggsn'
|
| 43 |
|
| 44 |
#define LLAMA_SESSION_MAGIC LLAMA_FILE_MAGIC_GGSN
|
| 45 |
+
#define LLAMA_SESSION_VERSION 2
|
| 46 |
|
| 47 |
#if defined(GGML_USE_CUBLAS) || defined(GGML_USE_CLBLAST) || defined(GGML_USE_METAL)
|
| 48 |
// Defined when llama.cpp is compiled with support for offloading model layers to GPU.
|
|
|
|
| 282 |
LLAMA_API int llama_n_ctx_train(const struct llama_model * model);
|
| 283 |
LLAMA_API int llama_n_embd (const struct llama_model * model);
|
| 284 |
|
| 285 |
+
// Get the model's RoPE frequency scaling factor
|
| 286 |
+
LLAMA_API float llama_rope_freq_scale_train(const struct llama_model * model);
|
| 287 |
+
|
| 288 |
// Get a string describing the model type
|
| 289 |
LLAMA_API int llama_model_desc(const struct llama_model * model, char * buf, size_t buf_size);
|
| 290 |
|
|
|
|
| 333 |
"avoid using this, it will be removed in the future, instead - count the tokens in user code");
|
| 334 |
|
| 335 |
// Remove all tokens data of cells in [c0, c1)
|
| 336 |
+
// c0 < 0 : [0, c1]
|
| 337 |
+
// c1 < 0 : [c0, inf)
|
| 338 |
LLAMA_API void llama_kv_cache_tokens_rm(
|
| 339 |
struct llama_context * ctx,
|
| 340 |
int32_t c0,
|
| 341 |
int32_t c1);
|
| 342 |
|
| 343 |
// Removes all tokens that belong to the specified sequence and have positions in [p0, p1)
|
| 344 |
+
// p0 < 0 : [0, p1]
|
| 345 |
+
// p1 < 0 : [p0, inf)
|
| 346 |
LLAMA_API void llama_kv_cache_seq_rm(
|
| 347 |
struct llama_context * ctx,
|
| 348 |
llama_seq_id seq_id,
|
|
|
|
| 351 |
|
| 352 |
// Copy all tokens that belong to the specified sequence to another sequence
|
| 353 |
// Note that this does not allocate extra KV cache memory - it simply assigns the tokens to the new sequence
|
| 354 |
+
// p0 < 0 : [0, p1]
|
| 355 |
+
// p1 < 0 : [p0, inf)
|
| 356 |
LLAMA_API void llama_kv_cache_seq_cp(
|
| 357 |
struct llama_context * ctx,
|
| 358 |
llama_seq_id seq_id_src,
|
|
|
|
| 367 |
|
| 368 |
// Adds relative position "delta" to all tokens that belong to the specified sequence and have positions in [p0, p1)
|
| 369 |
// If the KV cache is RoPEd, the KV data is updated accordingly
|
| 370 |
+
// p0 < 0 : [0, p1]
|
| 371 |
+
// p1 < 0 : [p0, inf)
|
| 372 |
LLAMA_API void llama_kv_cache_seq_shift(
|
| 373 |
struct llama_context * ctx,
|
| 374 |
llama_seq_id seq_id,
|
|
|
|
| 501 |
LLAMA_API llama_token llama_token_bos(const struct llama_context * ctx); // beginning-of-sentence
|
| 502 |
LLAMA_API llama_token llama_token_eos(const struct llama_context * ctx); // end-of-sentence
|
| 503 |
LLAMA_API llama_token llama_token_nl (const struct llama_context * ctx); // next-line
|
| 504 |
+
// codellama infill tokens
|
| 505 |
+
LLAMA_API llama_token llama_token_prefix(const struct llama_context * ctx); // Beginning of infill prefix
|
| 506 |
+
LLAMA_API llama_token llama_token_middle(const struct llama_context * ctx); // Beginning of infill middle
|
| 507 |
+
LLAMA_API llama_token llama_token_suffix(const struct llama_context * ctx); // Beginning of infill suffix
|
| 508 |
+
LLAMA_API llama_token llama_token_eot (const struct llama_context * ctx); // End of infill middle
|
| 509 |
|
| 510 |
//
|
| 511 |
// Tokenization
|
make_pyinstaller.sh
CHANGED
|
@@ -2,6 +2,7 @@
|
|
| 2 |
|
| 3 |
pyinstaller --noconfirm --onefile --clean --console --collect-all customtkinter --icon "./niko.ico" \
|
| 4 |
--add-data "./klite.embd:." \
|
|
|
|
| 5 |
--add-data "./koboldcpp_default.so:." \
|
| 6 |
--add-data "./koboldcpp_openblas.so:." \
|
| 7 |
--add-data "./koboldcpp_failsafe.so:." \
|
|
|
|
| 2 |
|
| 3 |
pyinstaller --noconfirm --onefile --clean --console --collect-all customtkinter --icon "./niko.ico" \
|
| 4 |
--add-data "./klite.embd:." \
|
| 5 |
+
--add-data "./kcpp_docs.embd:." \
|
| 6 |
--add-data "./koboldcpp_default.so:." \
|
| 7 |
--add-data "./koboldcpp_openblas.so:." \
|
| 8 |
--add-data "./koboldcpp_failsafe.so:." \
|
media/preview.png
CHANGED
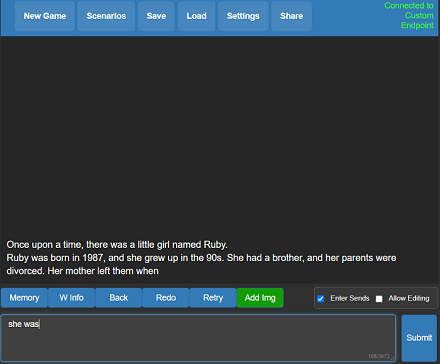
|

|
media/preview2.png
ADDED

|
media/preview3.png
ADDED
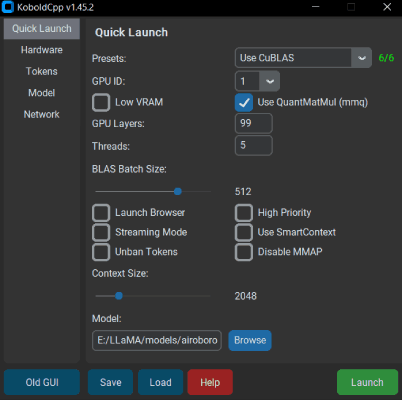
|
media/preview4.png
ADDED

|
models/ggml-vocab-aquila.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7c53c3c516ac67c7ca12977b9690fdea3d2ef13bbaed6378f98191a13ef5ca00
|
| 3 |
+
size 4825676
|
models/ggml-vocab-falcon.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ffbc7c119de7e9aab8f4257d617e3fa55f942a9f9ca84139ef3f5b1ca53836a8
|
| 3 |
+
size 2547782
|
otherarch/tools/unused/export_state_dict_checkpoint.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# this specific file adapted from https://github.com/tloen/alpaca-lora/blob/main/export_state_dict_checkpoint.py
|
| 2 |
+
# under Apache 2.0 license https://raw.githubusercontent.com/tloen/alpaca-lora/main/LICENSE
|
| 3 |
+
# todo: adapt to revert HF formats back to original PTH formats so ggml can convert them.
|
| 4 |
+
|
| 5 |
+
import json
|
| 6 |
+
import os
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import transformers
|
| 10 |
+
from peft import PeftModel
|
| 11 |
+
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: E402
|
| 12 |
+
|
| 13 |
+
BASE_MODEL = os.environ.get("BASE_MODEL", None)
|
| 14 |
+
assert (
|
| 15 |
+
BASE_MODEL
|
| 16 |
+
), "Please specify a value for BASE_MODEL environment variable, e.g. `export BASE_MODEL=decapoda-research/llama-7b-hf`" # noqa: E501
|
| 17 |
+
|
| 18 |
+
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
|
| 19 |
+
|
| 20 |
+
base_model = LlamaForCausalLM.from_pretrained(
|
| 21 |
+
BASE_MODEL,
|
| 22 |
+
load_in_8bit=False,
|
| 23 |
+
torch_dtype=torch.float16,
|
| 24 |
+
device_map={"": "cpu"},
|
| 25 |
+
)
|
| 26 |
+
|
| 27 |
+
lora_model = PeftModel.from_pretrained(
|
| 28 |
+
base_model,
|
| 29 |
+
"tloen/alpaca-lora-7b",
|
| 30 |
+
device_map={"": "cpu"},
|
| 31 |
+
torch_dtype=torch.float16,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
# merge weights
|
| 35 |
+
for layer in lora_model.base_model.model.model.layers:
|
| 36 |
+
layer.self_attn.q_proj.merge_weights = True
|
| 37 |
+
layer.self_attn.v_proj.merge_weights = True
|
| 38 |
+
|
| 39 |
+
lora_model.train(False)
|
| 40 |
+
|
| 41 |
+
lora_model_sd = lora_model.state_dict()
|
| 42 |
+
|
| 43 |
+
params = {
|
| 44 |
+
"dim": 4096,
|
| 45 |
+
"multiple_of": 256,
|
| 46 |
+
"n_heads": 32,
|
| 47 |
+
"n_layers": 32,
|
| 48 |
+
"norm_eps": 1e-06,
|
| 49 |
+
"vocab_size": -1,
|
| 50 |
+
}
|
| 51 |
+
n_layers = params["n_layers"]
|
| 52 |
+
n_heads = params["n_heads"]
|
| 53 |
+
dim = params["dim"]
|
| 54 |
+
dims_per_head = dim // n_heads
|
| 55 |
+
base = 10000.0
|
| 56 |
+
inv_freq = 1.0 / (
|
| 57 |
+
base ** (torch.arange(0, dims_per_head, 2).float() / dims_per_head)
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def permute(w):
|
| 62 |
+
return (
|
| 63 |
+
w.view(n_heads, dim // n_heads // 2, 2, dim)
|
| 64 |
+
.transpose(1, 2)
|
| 65 |
+
.reshape(dim, dim)
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def unpermute(w):
|
| 70 |
+
return (
|
| 71 |
+
w.view(n_heads, 2, dim // n_heads // 2, dim)
|
| 72 |
+
.transpose(1, 2)
|
| 73 |
+
.reshape(dim, dim)
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def translate_state_dict_key(k): # noqa: C901
|
| 78 |
+
k = k.replace("base_model.model.", "")
|
| 79 |
+
if k == "model.embed_tokens.weight":
|
| 80 |
+
return "tok_embeddings.weight"
|
| 81 |
+
elif k == "model.norm.weight":
|
| 82 |
+
return "norm.weight"
|
| 83 |
+
elif k == "lm_head.weight":
|
| 84 |
+
return "output.weight"
|
| 85 |
+
elif k.startswith("model.layers."):
|
| 86 |
+
layer = k.split(".")[2]
|
| 87 |
+
if k.endswith(".self_attn.q_proj.weight"):
|
| 88 |
+
return f"layers.{layer}.attention.wq.weight"
|
| 89 |
+
elif k.endswith(".self_attn.k_proj.weight"):
|
| 90 |
+
return f"layers.{layer}.attention.wk.weight"
|
| 91 |
+
elif k.endswith(".self_attn.v_proj.weight"):
|
| 92 |
+
return f"layers.{layer}.attention.wv.weight"
|
| 93 |
+
elif k.endswith(".self_attn.o_proj.weight"):
|
| 94 |
+
return f"layers.{layer}.attention.wo.weight"
|
| 95 |
+
elif k.endswith(".mlp.gate_proj.weight"):
|
| 96 |
+
return f"layers.{layer}.feed_forward.w1.weight"
|
| 97 |
+
elif k.endswith(".mlp.down_proj.weight"):
|
| 98 |
+
return f"layers.{layer}.feed_forward.w2.weight"
|
| 99 |
+
elif k.endswith(".mlp.up_proj.weight"):
|
| 100 |
+
return f"layers.{layer}.feed_forward.w3.weight"
|
| 101 |
+
elif k.endswith(".input_layernorm.weight"):
|
| 102 |
+
return f"layers.{layer}.attention_norm.weight"
|
| 103 |
+
elif k.endswith(".post_attention_layernorm.weight"):
|
| 104 |
+
return f"layers.{layer}.ffn_norm.weight"
|
| 105 |
+
elif k.endswith("rotary_emb.inv_freq") or "lora" in k:
|
| 106 |
+
return None
|
| 107 |
+
else:
|
| 108 |
+
print(layer, k)
|
| 109 |
+
raise NotImplementedError
|
| 110 |
+
else:
|
| 111 |
+
print(k)
|
| 112 |
+
raise NotImplementedError
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
new_state_dict = {}
|
| 116 |
+
for k, v in lora_model_sd.items():
|
| 117 |
+
new_k = translate_state_dict_key(k)
|
| 118 |
+
if new_k is not None:
|
| 119 |
+
if "wq" in new_k or "wk" in new_k:
|
| 120 |
+
new_state_dict[new_k] = unpermute(v)
|
| 121 |
+
else:
|
| 122 |
+
new_state_dict[new_k] = v
|
| 123 |
+
|
| 124 |
+
os.makedirs("./ckpt", exist_ok=True)
|
| 125 |
+
|
| 126 |
+
torch.save(new_state_dict, "./ckpt/consolidated.00.pth")
|
| 127 |
+
|
| 128 |
+
with open("./ckpt/params.json", "w") as f:
|
| 129 |
+
json.dump(params, f)
|
prompts/LLM-questions.txt
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
In the context of LLMs, what is "Attention"?
|
| 2 |
+
In the context of LLMs, what is a completion?
|
| 3 |
+
In the context of LLMs, what is a prompt?
|
| 4 |
+
In the context of LLMs, what is GELU?
|
| 5 |
+
In the context of LLMs, what is RELU?
|
| 6 |
+
In the context of LLMs, what is softmax?
|
| 7 |
+
In the context of LLMs, what is decoding?
|
| 8 |
+
In the context of LLMs, what is encoding?
|
| 9 |
+
In the context of LLMs, what is tokenizing?
|
| 10 |
+
In the context of LLMs, what is an embedding?
|
| 11 |
+
In the context of LLMs, what is quantization?
|
| 12 |
+
In the context of LLMs, what is a tensor?
|
| 13 |
+
In the context of LLMs, what is a sparse tensor?
|
| 14 |
+
In the context of LLMs, what is a vector?
|
| 15 |
+
In the context of LLMs, how is attention implemented?
|
| 16 |
+
In the context of LLMs, why is attention all you need?
|
| 17 |
+
In the context of LLMs, what is "RoPe" and what is it used for?
|
| 18 |
+
In the context of LLMs, what is "LoRA" and what is it used for?
|
| 19 |
+
In the context of LLMs, what are weights?
|
| 20 |
+
In the context of LLMs, what are biases?
|
| 21 |
+
In the context of LLMs, what are checkpoints?
|
| 22 |
+
In the context of LLMs, what is "perplexity"?
|
| 23 |
+
In the context of LLMs, what are models?
|
| 24 |
+
In the context of machine-learning, what is "catastrophic forgetting"?
|
| 25 |
+
In the context of machine-learning, what is "elastic weight consolidation (EWC)"?
|
| 26 |
+
In the context of neural nets, what is a hidden layer?
|
| 27 |
+
In the context of neural nets, what is a convolution?
|
| 28 |
+
In the context of neural nets, what is dropout?
|
| 29 |
+
In the context of neural nets, what is cross-entropy?
|
| 30 |
+
In the context of neural nets, what is over-fitting?
|
| 31 |
+
In the context of neural nets, what is under-fitting?
|
| 32 |
+
What is the difference between an interpreted computer language and a compiled computer language?
|
| 33 |
+
In the context of software development, what is a debugger?
|
| 34 |
+
When processing using a GPU, what is off-loading?
|
| 35 |
+
When processing using a GPU, what is a batch?
|
| 36 |
+
When processing using a GPU, what is a block?
|
| 37 |
+
When processing using a GPU, what is the difference between a batch and a block?
|
| 38 |
+
When processing using a GPU, what is a scratch tensor?
|
| 39 |
+
When processing using a GPU, what is a layer?
|
| 40 |
+
When processing using a GPU, what is a cache?
|
| 41 |
+
When processing using a GPU, what is unified memory?
|
| 42 |
+
When processing using a GPU, what is VRAM?
|
| 43 |
+
When processing using a GPU, what is a kernel?
|
| 44 |
+
When processing using a GPU, what is "metal"?
|
| 45 |
+
In the context of LLMs, what are "Zero-Shot", "One-Shot" and "Few-Shot" learning models?
|
| 46 |
+
In the context of LLMs, what is the "Transformer-model" architecture?
|
| 47 |
+
In the context of LLMs, what is "Multi-Head Attention"?
|
| 48 |
+
In the context of LLMs, what is "Self-Attention"?
|
| 49 |
+
In the context of transformer-model architectures, how do attention mechanisms use masks?
|
prompts/parallel-questions.txt
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
What do you know about Hobbits?
|
| 2 |
+
What is quantum field theory?
|
| 3 |
+
Why did the chicken cross the road?
|
| 4 |
+
Who is the president of the United States?
|
| 5 |
+
How do I run CMake on MacOS?
|
| 6 |
+
Do you agree that C++ is a really finicky language compared with Python3?
|
| 7 |
+
Is it a good idea to invest in technology?
|
| 8 |
+
Do you like Wagner's Ring?
|
| 9 |
+
Do you think this file input option is really neat?
|
| 10 |
+
What should we all do about climate change?
|
| 11 |
+
Is time-travel possible within the laws of current physics?
|
| 12 |
+
Is it like anything to be a bat?
|
| 13 |
+
Once the chicken has crossed the road, does it try to go back?
|
| 14 |
+
Who is the greatest of all musical composers?
|
| 15 |
+
What is art?
|
| 16 |
+
Is there life elsewhere in the universe?
|
| 17 |
+
What is intelligence?
|
| 18 |
+
What is the difference between knowledge and intelligence?
|
| 19 |
+
Will religion ever die?
|
| 20 |
+
Do we understand ourselves?
|
| 21 |
+
What is the best way to cook eggs?
|
| 22 |
+
If you cannot see things, on what basis do you evaluate them?
|
| 23 |
+
Explain the role of the np junction in photovoltaic cells?
|
| 24 |
+
Is professional sport a good or bad influence on human behaviour?
|
| 25 |
+
Is capital punishment immoral?
|
| 26 |
+
Should we care about other people?
|
| 27 |
+
Who are you?
|
| 28 |
+
Which sense would you surrender if you could?
|
| 29 |
+
Was Henry Ford a hero or a villain?
|
| 30 |
+
Do we need leaders?
|
| 31 |
+
What is nucleosynthesis?
|
| 32 |
+
Who is the greatest scientist of all time?
|
| 33 |
+
Who first observed what came to be known as the photovoltaic effect?
|
| 34 |
+
What is nuclear fusion and why does it release energy?
|
| 35 |
+
Can you know that you exist?
|
| 36 |
+
What is an exoplanet?
|
| 37 |
+
Do you like cream?
|
| 38 |
+
What is the difference?
|
| 39 |
+
Can I know that I exist while I'm dreaming that I'm Descartes?
|
| 40 |
+
Who said "I didn't know I thought that until I heard myself saying it"?
|
| 41 |
+
Does anything really matter?
|
| 42 |
+
Can you explain the unreasonable effectiveness of mathematics?
|
| 43 |
+
|
requirements.txt
CHANGED
|
@@ -1,4 +1,4 @@
|
|
| 1 |
-
numpy==1.24
|
| 2 |
sentencepiece==0.1.98
|
| 3 |
gguf>=0.1.0
|
| 4 |
customtkinter>=5.1.0
|
|
|
|
| 1 |
+
numpy==1.24.4
|
| 2 |
sentencepiece==0.1.98
|
| 3 |
gguf>=0.1.0
|
| 4 |
customtkinter>=5.1.0
|
scripts/LlamaConfig.cmake.in
CHANGED
|
@@ -56,11 +56,13 @@ find_library(llama_LIBRARY llama
|
|
| 56 |
HINTS ${LLAMA_LIB_DIR})
|
| 57 |
|
| 58 |
set(_llama_link_deps "Threads::Threads" "@LLAMA_EXTRA_LIBS@")
|
|
|
|
| 59 |
add_library(llama UNKNOWN IMPORTED)
|
| 60 |
set_target_properties(llama
|
| 61 |
PROPERTIES
|
| 62 |
INTERFACE_INCLUDE_DIRECTORIES "${LLAMA_INCLUDE_DIR}"
|
| 63 |
INTERFACE_LINK_LIBRARIES "${_llama_link_deps}"
|
|
|
|
| 64 |
IMPORTED_LINK_INTERFACE_LANGUAGES "CXX"
|
| 65 |
IMPORTED_LOCATION "${llama_LIBRARY}"
|
| 66 |
INTERFACE_COMPILE_FEATURES cxx_std_11
|
|
|
|
| 56 |
HINTS ${LLAMA_LIB_DIR})
|
| 57 |
|
| 58 |
set(_llama_link_deps "Threads::Threads" "@LLAMA_EXTRA_LIBS@")
|
| 59 |
+
set(_llama_transient_defines "@LLAMA_TRANSIENT_DEFINES@")
|
| 60 |
add_library(llama UNKNOWN IMPORTED)
|
| 61 |
set_target_properties(llama
|
| 62 |
PROPERTIES
|
| 63 |
INTERFACE_INCLUDE_DIRECTORIES "${LLAMA_INCLUDE_DIR}"
|
| 64 |
INTERFACE_LINK_LIBRARIES "${_llama_link_deps}"
|
| 65 |
+
INTERFACE_COMPILE_DEFINITIONS "${_llama_transient_defines}"
|
| 66 |
IMPORTED_LINK_INTERFACE_LANGUAGES "CXX"
|
| 67 |
IMPORTED_LOCATION "${llama_LIBRARY}"
|
| 68 |
INTERFACE_COMPILE_FEATURES cxx_std_11
|
spm-headers/ggml.h
CHANGED
|
@@ -401,10 +401,14 @@ extern "C" {
|
|
| 401 |
GGML_OP_CLAMP,
|
| 402 |
GGML_OP_CONV_1D,
|
| 403 |
GGML_OP_CONV_2D,
|
|
|
|
| 404 |
GGML_OP_CONV_TRANSPOSE_2D,
|
| 405 |
GGML_OP_POOL_1D,
|
| 406 |
GGML_OP_POOL_2D,
|
| 407 |
|
|
|
|
|
|
|
|
|
|
| 408 |
GGML_OP_UPSCALE, // nearest interpolate
|
| 409 |
|
| 410 |
GGML_OP_FLASH_ATTN,
|
|
@@ -1386,6 +1390,14 @@ extern "C" {
|
|
| 1386 |
int s,
|
| 1387 |
int d);
|
| 1388 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1389 |
GGML_API struct ggml_tensor * ggml_conv_2d(
|
| 1390 |
struct ggml_context * ctx,
|
| 1391 |
struct ggml_tensor * a,
|
|
@@ -1759,6 +1771,7 @@ extern "C" {
|
|
| 1759 |
GGML_OPT_NO_CONTEXT,
|
| 1760 |
GGML_OPT_INVALID_WOLFE,
|
| 1761 |
GGML_OPT_FAIL,
|
|
|
|
| 1762 |
|
| 1763 |
GGML_LINESEARCH_FAIL = -128,
|
| 1764 |
GGML_LINESEARCH_MINIMUM_STEP,
|
|
|
|
| 401 |
GGML_OP_CLAMP,
|
| 402 |
GGML_OP_CONV_1D,
|
| 403 |
GGML_OP_CONV_2D,
|
| 404 |
+
GGML_OP_CONV_TRANSPOSE_1D,
|
| 405 |
GGML_OP_CONV_TRANSPOSE_2D,
|
| 406 |
GGML_OP_POOL_1D,
|
| 407 |
GGML_OP_POOL_2D,
|
| 408 |
|
| 409 |
+
GGML_OP_CONV_1D_STAGE_0, // internal
|
| 410 |
+
GGML_OP_CONV_1D_STAGE_1, // internal
|
| 411 |
+
|
| 412 |
GGML_OP_UPSCALE, // nearest interpolate
|
| 413 |
|
| 414 |
GGML_OP_FLASH_ATTN,
|
|
|
|
| 1390 |
int s,
|
| 1391 |
int d);
|
| 1392 |
|
| 1393 |
+
GGML_API struct ggml_tensor * ggml_conv_transpose_1d(
|
| 1394 |
+
struct ggml_context * ctx,
|
| 1395 |
+
struct ggml_tensor * a,
|
| 1396 |
+
struct ggml_tensor * b,
|
| 1397 |
+
int s0,
|
| 1398 |
+
int p0,
|
| 1399 |
+
int d0);
|
| 1400 |
+
|
| 1401 |
GGML_API struct ggml_tensor * ggml_conv_2d(
|
| 1402 |
struct ggml_context * ctx,
|
| 1403 |
struct ggml_tensor * a,
|
|
|
|
| 1771 |
GGML_OPT_NO_CONTEXT,
|
| 1772 |
GGML_OPT_INVALID_WOLFE,
|
| 1773 |
GGML_OPT_FAIL,
|
| 1774 |
+
GGML_OPT_CANCEL,
|
| 1775 |
|
| 1776 |
GGML_LINESEARCH_FAIL = -128,
|
| 1777 |
GGML_LINESEARCH_MINIMUM_STEP,
|
unicode.h
ADDED
|
@@ -0,0 +1,462 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#pragma once
|
| 2 |
+
|
| 3 |
+
#include <cassert>
|
| 4 |
+
#include <stdexcept>
|
| 5 |
+
#include <vector>
|
| 6 |
+
#include <unordered_map>
|
| 7 |
+
|
| 8 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> digit_ranges = {
|
| 9 |
+
{0x30, 0x39}, {0xB2, 0xB3}, {0xB9, 0xB9}, {0x660, 0x669}, {0x6F0, 0x6F9}, {0x7C0, 0x7C9}, {0x966, 0x96F}, {0x9E6, 0x9EF}, {0xA66, 0xA6F}, {0xAE6, 0xAEF}, {0xB66, 0xB6F}, {0xBE6, 0xBEF}, {0xC66, 0xC6F},
|
| 10 |
+
{0xCE6, 0xCEF}, {0xD66, 0xD6F}, {0xDE6, 0xDEF}, {0xE50, 0xE59}, {0xED0, 0xED9}, {0xF20, 0xF29}, {0x1040, 0x1049}, {0x1090, 0x1099}, {0x1369, 0x1371}, {0x17E0, 0x17E9}, {0x1810, 0x1819}, {0x1946, 0x194F},
|
| 11 |
+
{0x19D0, 0x19DA}, {0x1A80, 0x1A89}, {0x1A90, 0x1A99}, {0x1B50, 0x1B59}, {0x1BB0, 0x1BB9}, {0x1C40, 0x1C49}, {0x1C50, 0x1C59}, {0x2070, 0x2070}, {0x2074, 0x2079}, {0x2080, 0x2089}, {0x2460, 0x2468},
|
| 12 |
+
{0x2474, 0x247C}, {0x2488, 0x2490}, {0x24EA, 0x24EA}, {0x24F5, 0x24FD}, {0x24FF, 0x24FF}, {0x2776, 0x277E}, {0x2780, 0x2788}, {0x278A, 0x2792}, {0xA620, 0xA629}, {0xA8D0, 0xA8D9}, {0xA900, 0xA909},
|
| 13 |
+
{0xA9D0, 0xA9D9}, {0xA9F0, 0xA9F9}, {0xAA50, 0xAA59}, {0xABF0, 0xABF9}, {0xFF10, 0xFF19}, {0x104A0, 0x104A9}, {0x10A40, 0x10A43}, {0x10D30, 0x10D39}, {0x10E60, 0x10E68}, {0x11052, 0x1105A},
|
| 14 |
+
{0x11066, 0x1106F}, {0x110F0, 0x110F9}, {0x11136, 0x1113F}, {0x111D0, 0x111D9}, {0x112F0, 0x112F9}, {0x11450, 0x11459}, {0x114D0, 0x114D9}, {0x11650, 0x11659}, {0x116C0, 0x116C9}, {0x11730, 0x11739},
|
| 15 |
+
{0x118E0, 0x118E9}, {0x11950, 0x11959}, {0x11C50, 0x11C59}, {0x11D50, 0x11D59}, {0x11DA0, 0x11DA9}, {0x16A60, 0x16A69}, {0x16B50, 0x16B59}, {0x1D7CE, 0x1D7FF}, {0x1E140, 0x1E149}, {0x1E2F0, 0x1E2F9},
|
| 16 |
+
{0x1E950, 0x1E959}, {0x1F100, 0x1F10A}, {0x1FBF0, 0x1FBF9},
|
| 17 |
+
};
|
| 18 |
+
|
| 19 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> letter_ranges = {
|
| 20 |
+
{0x41, 0x5A}, {0x61, 0x7A}, {0xAA, 0xAA}, {0xB5, 0xB5}, {0xBA, 0xBA}, {0xC0, 0xD6}, {0xD8, 0xF6}, {0xF8, 0x2C1}, {0x2C6, 0x2D1}, {0x2E0, 0x2E4}, {0x2EC, 0x2EC}, {0x2EE, 0x2EE}, {0x370, 0x374},
|
| 21 |
+
{0x376, 0x377}, {0x37A, 0x37D}, {0x37F, 0x37F}, {0x386, 0x386}, {0x388, 0x38A}, {0x38C, 0x38C}, {0x38E, 0x3A1}, {0x3A3, 0x3F5}, {0x3F7, 0x481}, {0x48A, 0x52F}, {0x531, 0x556}, {0x559, 0x559},
|
| 22 |
+
{0x560, 0x588}, {0x5D0, 0x5EA}, {0x5EF, 0x5F2}, {0x620, 0x64A}, {0x66E, 0x66F}, {0x671, 0x6D3}, {0x6D5, 0x6D5}, {0x6E5, 0x6E6}, {0x6EE, 0x6EF}, {0x6FA, 0x6FC}, {0x6FF, 0x6FF}, {0x710, 0x710},
|
| 23 |
+
{0x712, 0x72F}, {0x74D, 0x7A5}, {0x7B1, 0x7B1}, {0x7CA, 0x7EA}, {0x7F4, 0x7F5}, {0x7FA, 0x7FA}, {0x800, 0x815}, {0x81A, 0x81A}, {0x824, 0x824}, {0x828, 0x828}, {0x840, 0x858}, {0x860, 0x86A},
|
| 24 |
+
{0x8A0, 0x8B4}, {0x8B6, 0x8C7}, {0x904, 0x939}, {0x93D, 0x93D}, {0x950, 0x950}, {0x958, 0x961}, {0x971, 0x980}, {0x985, 0x98C}, {0x98F, 0x990}, {0x993, 0x9A8}, {0x9AA, 0x9B0}, {0x9B2, 0x9B2},
|
| 25 |
+
{0x9B6, 0x9B9}, {0x9BD, 0x9BD}, {0x9CE, 0x9CE}, {0x9DC, 0x9DD}, {0x9DF, 0x9E1}, {0x9F0, 0x9F1}, {0x9FC, 0x9FC}, {0xA05, 0xA0A}, {0xA0F, 0xA10}, {0xA13, 0xA28}, {0xA2A, 0xA30}, {0xA32, 0xA33},
|
| 26 |
+
{0xA35, 0xA36}, {0xA38, 0xA39}, {0xA59, 0xA5C}, {0xA5E, 0xA5E}, {0xA72, 0xA74}, {0xA85, 0xA8D}, {0xA8F, 0xA91}, {0xA93, 0xAA8}, {0xAAA, 0xAB0}, {0xAB2, 0xAB3}, {0xAB5, 0xAB9}, {0xABD, 0xABD},
|
| 27 |
+
{0xAD0, 0xAD0}, {0xAE0, 0xAE1}, {0xAF9, 0xAF9}, {0xB05, 0xB0C}, {0xB0F, 0xB10}, {0xB13, 0xB28}, {0xB2A, 0xB30}, {0xB32, 0xB33}, {0xB35, 0xB39}, {0xB3D, 0xB3D}, {0xB5C, 0xB5D}, {0xB5F, 0xB61},
|
| 28 |
+
{0xB71, 0xB71}, {0xB83, 0xB83}, {0xB85, 0xB8A}, {0xB8E, 0xB90}, {0xB92, 0xB95}, {0xB99, 0xB9A}, {0xB9C, 0xB9C}, {0xB9E, 0xB9F}, {0xBA3, 0xBA4}, {0xBA8, 0xBAA}, {0xBAE, 0xBB9}, {0xBD0, 0xBD0},
|
| 29 |
+
{0xC05, 0xC0C}, {0xC0E, 0xC10}, {0xC12, 0xC28}, {0xC2A, 0xC39}, {0xC3D, 0xC3D}, {0xC58, 0xC5A}, {0xC60, 0xC61}, {0xC80, 0xC80}, {0xC85, 0xC8C}, {0xC8E, 0xC90}, {0xC92, 0xCA8}, {0xCAA, 0xCB3},
|
| 30 |
+
{0xCB5, 0xCB9}, {0xCBD, 0xCBD}, {0xCDE, 0xCDE}, {0xCE0, 0xCE1}, {0xCF1, 0xCF2}, {0xD04, 0xD0C}, {0xD0E, 0xD10}, {0xD12, 0xD3A}, {0xD3D, 0xD3D}, {0xD4E, 0xD4E}, {0xD54, 0xD56}, {0xD5F, 0xD61},
|
| 31 |
+
{0xD7A, 0xD7F}, {0xD85, 0xD96}, {0xD9A, 0xDB1}, {0xDB3, 0xDBB}, {0xDBD, 0xDBD}, {0xDC0, 0xDC6}, {0xE01, 0xE30}, {0xE32, 0xE33}, {0xE40, 0xE46}, {0xE81, 0xE82}, {0xE84, 0xE84}, {0xE86, 0xE8A},
|
| 32 |
+
{0xE8C, 0xEA3}, {0xEA5, 0xEA5}, {0xEA7, 0xEB0}, {0xEB2, 0xEB3}, {0xEBD, 0xEBD}, {0xEC0, 0xEC4}, {0xEC6, 0xEC6}, {0xEDC, 0xEDF}, {0xF00, 0xF00}, {0xF40, 0xF47}, {0xF49, 0xF6C}, {0xF88, 0xF8C},
|
| 33 |
+
{0x1000, 0x102A}, {0x103F, 0x103F}, {0x1050, 0x1055}, {0x105A, 0x105D}, {0x1061, 0x1061}, {0x1065, 0x1066}, {0x106E, 0x1070}, {0x1075, 0x1081}, {0x108E, 0x108E}, {0x10A0, 0x10C5}, {0x10C7, 0x10C7},
|
| 34 |
+
{0x10CD, 0x10CD}, {0x10D0, 0x10FA}, {0x10FC, 0x1248}, {0x124A, 0x124D}, {0x1250, 0x1256}, {0x1258, 0x1258}, {0x125A, 0x125D}, {0x1260, 0x1288}, {0x128A, 0x128D}, {0x1290, 0x12B0}, {0x12B2, 0x12B5},
|
| 35 |
+
{0x12B8, 0x12BE}, {0x12C0, 0x12C0}, {0x12C2, 0x12C5}, {0x12C8, 0x12D6}, {0x12D8, 0x1310}, {0x1312, 0x1315}, {0x1318, 0x135A}, {0x1380, 0x138F}, {0x13A0, 0x13F5}, {0x13F8, 0x13FD}, {0x1401, 0x166C},
|
| 36 |
+
{0x166F, 0x167F}, {0x1681, 0x169A}, {0x16A0, 0x16EA}, {0x16F1, 0x16F8}, {0x1700, 0x170C}, {0x170E, 0x1711}, {0x1720, 0x1731}, {0x1740, 0x1751}, {0x1760, 0x176C}, {0x176E, 0x1770}, {0x1780, 0x17B3},
|
| 37 |
+
{0x17D7, 0x17D7}, {0x17DC, 0x17DC}, {0x1820, 0x1878}, {0x1880, 0x1884}, {0x1887, 0x18A8}, {0x18AA, 0x18AA}, {0x18B0, 0x18F5}, {0x1900, 0x191E}, {0x1950, 0x196D}, {0x1970, 0x1974}, {0x1980, 0x19AB},
|
| 38 |
+
{0x19B0, 0x19C9}, {0x1A00, 0x1A16}, {0x1A20, 0x1A54}, {0x1AA7, 0x1AA7}, {0x1B05, 0x1B33}, {0x1B45, 0x1B4B}, {0x1B83, 0x1BA0}, {0x1BAE, 0x1BAF}, {0x1BBA, 0x1BE5}, {0x1C00, 0x1C23}, {0x1C4D, 0x1C4F},
|
| 39 |
+
{0x1C5A, 0x1C7D}, {0x1C80, 0x1C88}, {0x1C90, 0x1CBA}, {0x1CBD, 0x1CBF}, {0x1CE9, 0x1CEC}, {0x1CEE, 0x1CF3}, {0x1CF5, 0x1CF6}, {0x1CFA, 0x1CFA}, {0x1D00, 0x1DBF}, {0x1E00, 0x1F15}, {0x1F18, 0x1F1D},
|
| 40 |
+
{0x1F20, 0x1F45}, {0x1F48, 0x1F4D}, {0x1F50, 0x1F57}, {0x1F59, 0x1F59}, {0x1F5B, 0x1F5B}, {0x1F5D, 0x1F5D}, {0x1F5F, 0x1F7D}, {0x1F80, 0x1FB4}, {0x1FB6, 0x1FBC}, {0x1FBE, 0x1FBE}, {0x1FC2, 0x1FC4},
|
| 41 |
+
{0x1FC6, 0x1FCC}, {0x1FD0, 0x1FD3}, {0x1FD6, 0x1FDB}, {0x1FE0, 0x1FEC}, {0x1FF2, 0x1FF4}, {0x1FF6, 0x1FFC}, {0x2071, 0x2071}, {0x207F, 0x207F}, {0x2090, 0x209C}, {0x2102, 0x2102}, {0x2107, 0x2107},
|
| 42 |
+
{0x210A, 0x2113}, {0x2115, 0x2115}, {0x2119, 0x211D}, {0x2124, 0x2124}, {0x2126, 0x2126}, {0x2128, 0x2128}, {0x212A, 0x212D}, {0x212F, 0x2139}, {0x213C, 0x213F}, {0x2145, 0x2149}, {0x214E, 0x214E},
|
| 43 |
+
{0x2183, 0x2184}, {0x2C00, 0x2C2E}, {0x2C30, 0x2C5E}, {0x2C60, 0x2CE4}, {0x2CEB, 0x2CEE}, {0x2CF2, 0x2CF3}, {0x2D00, 0x2D25}, {0x2D27, 0x2D27}, {0x2D2D, 0x2D2D}, {0x2D30, 0x2D67}, {0x2D6F, 0x2D6F},
|
| 44 |
+
{0x2D80, 0x2D96}, {0x2DA0, 0x2DA6}, {0x2DA8, 0x2DAE}, {0x2DB0, 0x2DB6}, {0x2DB8, 0x2DBE}, {0x2DC0, 0x2DC6}, {0x2DC8, 0x2DCE}, {0x2DD0, 0x2DD6}, {0x2DD8, 0x2DDE}, {0x2E2F, 0x2E2F}, {0x3005, 0x3006},
|
| 45 |
+
{0x3031, 0x3035}, {0x303B, 0x303C}, {0x3041, 0x3096}, {0x309D, 0x309F}, {0x30A1, 0x30FA}, {0x30FC, 0x30FF}, {0x3105, 0x312F}, {0x3131, 0x318E}, {0x31A0, 0x31BF}, {0x31F0, 0x31FF}, {0x3400, 0x4DBF},
|
| 46 |
+
{0x4E00, 0x9FFC}, {0xA000, 0xA48C}, {0xA4D0, 0xA4FD}, {0xA500, 0xA60C}, {0xA610, 0xA61F}, {0xA62A, 0xA62B}, {0xA640, 0xA66E}, {0xA67F, 0xA69D}, {0xA6A0, 0xA6E5}, {0xA717, 0xA71F}, {0xA722, 0xA788},
|
| 47 |
+
{0xA78B, 0xA7BF}, {0xA7C2, 0xA7CA}, {0xA7F5, 0xA801}, {0xA803, 0xA805}, {0xA807, 0xA80A}, {0xA80C, 0xA822}, {0xA840, 0xA873}, {0xA882, 0xA8B3}, {0xA8F2, 0xA8F7}, {0xA8FB, 0xA8FB}, {0xA8FD, 0xA8FE},
|
| 48 |
+
{0xA90A, 0xA925}, {0xA930, 0xA946}, {0xA960, 0xA97C}, {0xA984, 0xA9B2}, {0xA9CF, 0xA9CF}, {0xA9E0, 0xA9E4}, {0xA9E6, 0xA9EF}, {0xA9FA, 0xA9FE}, {0xAA00, 0xAA28}, {0xAA40, 0xAA42}, {0xAA44, 0xAA4B},
|
| 49 |
+
{0xAA60, 0xAA76}, {0xAA7A, 0xAA7A}, {0xAA7E, 0xAAAF}, {0xAAB1, 0xAAB1}, {0xAAB5, 0xAAB6}, {0xAAB9, 0xAABD}, {0xAAC0, 0xAAC0}, {0xAAC2, 0xAAC2}, {0xAADB, 0xAADD}, {0xAAE0, 0xAAEA}, {0xAAF2, 0xAAF4},
|
| 50 |
+
{0xAB01, 0xAB06}, {0xAB09, 0xAB0E}, {0xAB11, 0xAB16}, {0xAB20, 0xAB26}, {0xAB28, 0xAB2E}, {0xAB30, 0xAB5A}, {0xAB5C, 0xAB69}, {0xAB70, 0xABE2}, {0xAC00, 0xD7A3}, {0xD7B0, 0xD7C6}, {0xD7CB, 0xD7FB},
|
| 51 |
+
{0xF900, 0xFA6D}, {0xFA70, 0xFAD9}, {0xFB00, 0xFB06}, {0xFB13, 0xFB17}, {0xFB1D, 0xFB1D}, {0xFB1F, 0xFB28}, {0xFB2A, 0xFB36}, {0xFB38, 0xFB3C}, {0xFB3E, 0xFB3E}, {0xFB40, 0xFB41}, {0xFB43, 0xFB44},
|
| 52 |
+
{0xFB46, 0xFBB1}, {0xFBD3, 0xFD3D}, {0xFD50, 0xFD8F}, {0xFD92, 0xFDC7}, {0xFDF0, 0xFDFB}, {0xFE70, 0xFE74}, {0xFE76, 0xFEFC}, {0xFF21, 0xFF3A}, {0xFF41, 0xFF5A}, {0xFF66, 0xFFBE}, {0xFFC2, 0xFFC7},
|
| 53 |
+
{0xFFCA, 0xFFCF}, {0xFFD2, 0xFFD7}, {0xFFDA, 0xFFDC}, {0x10000, 0x1000B}, {0x1000D, 0x10026}, {0x10028, 0x1003A}, {0x1003C, 0x1003D}, {0x1003F, 0x1004D}, {0x10050, 0x1005D}, {0x10080, 0x100FA},
|
| 54 |
+
{0x10280, 0x1029C}, {0x102A0, 0x102D0}, {0x10300, 0x1031F}, {0x1032D, 0x10340}, {0x10342, 0x10349}, {0x10350, 0x10375}, {0x10380, 0x1039D}, {0x103A0, 0x103C3}, {0x103C8, 0x103CF}, {0x10400, 0x1049D},
|
| 55 |
+
{0x104B0, 0x104D3}, {0x104D8, 0x104FB}, {0x10500, 0x10527}, {0x10530, 0x10563}, {0x10600, 0x10736}, {0x10740, 0x10755}, {0x10760, 0x10767}, {0x10800, 0x10805}, {0x10808, 0x10808}, {0x1080A, 0x10835},
|
| 56 |
+
{0x10837, 0x10838}, {0x1083C, 0x1083C}, {0x1083F, 0x10855}, {0x10860, 0x10876}, {0x10880, 0x1089E}, {0x108E0, 0x108F2}, {0x108F4, 0x108F5}, {0x10900, 0x10915}, {0x10920, 0x10939}, {0x10980, 0x109B7},
|
| 57 |
+
{0x109BE, 0x109BF}, {0x10A00, 0x10A00}, {0x10A10, 0x10A13}, {0x10A15, 0x10A17}, {0x10A19, 0x10A35}, {0x10A60, 0x10A7C}, {0x10A80, 0x10A9C}, {0x10AC0, 0x10AC7}, {0x10AC9, 0x10AE4}, {0x10B00, 0x10B35},
|
| 58 |
+
{0x10B40, 0x10B55}, {0x10B60, 0x10B72}, {0x10B80, 0x10B91}, {0x10C00, 0x10C48}, {0x10C80, 0x10CB2}, {0x10CC0, 0x10CF2}, {0x10D00, 0x10D23}, {0x10E80, 0x10EA9}, {0x10EB0, 0x10EB1}, {0x10F00, 0x10F1C},
|
| 59 |
+
{0x10F27, 0x10F27}, {0x10F30, 0x10F45}, {0x10FB0, 0x10FC4}, {0x10FE0, 0x10FF6}, {0x11003, 0x11037}, {0x11083, 0x110AF}, {0x110D0, 0x110E8}, {0x11103, 0x11126}, {0x11144, 0x11144}, {0x11147, 0x11147},
|
| 60 |
+
{0x11150, 0x11172}, {0x11176, 0x11176}, {0x11183, 0x111B2}, {0x111C1, 0x111C4}, {0x111DA, 0x111DA}, {0x111DC, 0x111DC}, {0x11200, 0x11211}, {0x11213, 0x1122B}, {0x11280, 0x11286}, {0x11288, 0x11288},
|
| 61 |
+
{0x1128A, 0x1128D}, {0x1128F, 0x1129D}, {0x1129F, 0x112A8}, {0x112B0, 0x112DE}, {0x11305, 0x1130C}, {0x1130F, 0x11310}, {0x11313, 0x11328}, {0x1132A, 0x11330}, {0x11332, 0x11333}, {0x11335, 0x11339},
|
| 62 |
+
{0x1133D, 0x1133D}, {0x11350, 0x11350}, {0x1135D, 0x11361}, {0x11400, 0x11434}, {0x11447, 0x1144A}, {0x1145F, 0x11461}, {0x11480, 0x114AF}, {0x114C4, 0x114C5}, {0x114C7, 0x114C7}, {0x11580, 0x115AE},
|
| 63 |
+
{0x115D8, 0x115DB}, {0x11600, 0x1162F}, {0x11644, 0x11644}, {0x11680, 0x116AA}, {0x116B8, 0x116B8}, {0x11700, 0x1171A}, {0x11800, 0x1182B}, {0x118A0, 0x118DF}, {0x118FF, 0x11906}, {0x11909, 0x11909},
|
| 64 |
+
{0x1190C, 0x11913}, {0x11915, 0x11916}, {0x11918, 0x1192F}, {0x1193F, 0x1193F}, {0x11941, 0x11941}, {0x119A0, 0x119A7}, {0x119AA, 0x119D0}, {0x119E1, 0x119E1}, {0x119E3, 0x119E3}, {0x11A00, 0x11A00},
|
| 65 |
+
{0x11A0B, 0x11A32}, {0x11A3A, 0x11A3A}, {0x11A50, 0x11A50}, {0x11A5C, 0x11A89}, {0x11A9D, 0x11A9D}, {0x11AC0, 0x11AF8}, {0x11C00, 0x11C08}, {0x11C0A, 0x11C2E}, {0x11C40, 0x11C40}, {0x11C72, 0x11C8F},
|
| 66 |
+
{0x11D00, 0x11D06}, {0x11D08, 0x11D09}, {0x11D0B, 0x11D30}, {0x11D46, 0x11D46}, {0x11D60, 0x11D65}, {0x11D67, 0x11D68}, {0x11D6A, 0x11D89}, {0x11D98, 0x11D98}, {0x11EE0, 0x11EF2}, {0x11FB0, 0x11FB0},
|
| 67 |
+
{0x12000, 0x12399}, {0x12480, 0x12543}, {0x13000, 0x1342E}, {0x14400, 0x14646}, {0x16800, 0x16A38}, {0x16A40, 0x16A5E}, {0x16AD0, 0x16AED}, {0x16B00, 0x16B2F}, {0x16B40, 0x16B43}, {0x16B63, 0x16B77},
|
| 68 |
+
{0x16B7D, 0x16B8F}, {0x16E40, 0x16E7F}, {0x16F00, 0x16F4A}, {0x16F50, 0x16F50}, {0x16F93, 0x16F9F}, {0x16FE0, 0x16FE1}, {0x16FE3, 0x16FE3}, {0x17000, 0x187F7}, {0x18800, 0x18CD5}, {0x18D00, 0x18D08},
|
| 69 |
+
{0x1B000, 0x1B11E}, {0x1B150, 0x1B152}, {0x1B164, 0x1B167}, {0x1B170, 0x1B2FB}, {0x1BC00, 0x1BC6A}, {0x1BC70, 0x1BC7C}, {0x1BC80, 0x1BC88}, {0x1BC90, 0x1BC99}, {0x1D400, 0x1D454}, {0x1D456, 0x1D49C},
|
| 70 |
+
{0x1D49E, 0x1D49F}, {0x1D4A2, 0x1D4A2}, {0x1D4A5, 0x1D4A6}, {0x1D4A9, 0x1D4AC}, {0x1D4AE, 0x1D4B9}, {0x1D4BB, 0x1D4BB}, {0x1D4BD, 0x1D4C3}, {0x1D4C5, 0x1D505}, {0x1D507, 0x1D50A}, {0x1D50D, 0x1D514},
|
| 71 |
+
{0x1D516, 0x1D51C}, {0x1D51E, 0x1D539}, {0x1D53B, 0x1D53E}, {0x1D540, 0x1D544}, {0x1D546, 0x1D546}, {0x1D54A, 0x1D550}, {0x1D552, 0x1D6A5}, {0x1D6A8, 0x1D6C0}, {0x1D6C2, 0x1D6DA}, {0x1D6DC, 0x1D6FA},
|
| 72 |
+
{0x1D6FC, 0x1D714}, {0x1D716, 0x1D734}, {0x1D736, 0x1D74E}, {0x1D750, 0x1D76E}, {0x1D770, 0x1D788}, {0x1D78A, 0x1D7A8}, {0x1D7AA, 0x1D7C2}, {0x1D7C4, 0x1D7CB}, {0x1E100, 0x1E12C}, {0x1E137, 0x1E13D},
|
| 73 |
+
{0x1E14E, 0x1E14E}, {0x1E2C0, 0x1E2EB}, {0x1E800, 0x1E8C4}, {0x1E900, 0x1E943}, {0x1E94B, 0x1E94B}, {0x1EE00, 0x1EE03}, {0x1EE05, 0x1EE1F}, {0x1EE21, 0x1EE22}, {0x1EE24, 0x1EE24}, {0x1EE27, 0x1EE27},
|
| 74 |
+
{0x1EE29, 0x1EE32}, {0x1EE34, 0x1EE37}, {0x1EE39, 0x1EE39}, {0x1EE3B, 0x1EE3B}, {0x1EE42, 0x1EE42}, {0x1EE47, 0x1EE47}, {0x1EE49, 0x1EE49}, {0x1EE4B, 0x1EE4B}, {0x1EE4D, 0x1EE4F}, {0x1EE51, 0x1EE52},
|
| 75 |
+
{0x1EE54, 0x1EE54}, {0x1EE57, 0x1EE57}, {0x1EE59, 0x1EE59}, {0x1EE5B, 0x1EE5B}, {0x1EE5D, 0x1EE5D}, {0x1EE5F, 0x1EE5F}, {0x1EE61, 0x1EE62}, {0x1EE64, 0x1EE64}, {0x1EE67, 0x1EE6A}, {0x1EE6C, 0x1EE72},
|
| 76 |
+
{0x1EE74, 0x1EE77}, {0x1EE79, 0x1EE7C}, {0x1EE7E, 0x1EE7E}, {0x1EE80, 0x1EE89}, {0x1EE8B, 0x1EE9B}, {0x1EEA1, 0x1EEA3}, {0x1EEA5, 0x1EEA9}, {0x1EEAB, 0x1EEBB}, {0x20000, 0x2A6DD}, {0x2A700, 0x2B734},
|
| 77 |
+
{0x2B740, 0x2B81D}, {0x2B820, 0x2CEA1}, {0x2CEB0, 0x2EBE0}, {0x2F800, 0x2FA1D}, {0x30000, 0x3134A},
|
| 78 |
+
};
|
| 79 |
+
|
| 80 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> whitespace_ranges = {
|
| 81 |
+
{0x9, 0xD}, {0x1C, 0x20}, {0x85, 0x85}, {0xA0, 0xA0}, {0x1680, 0x1680}, {0x2000, 0x200A}, {0x2028, 0x2029}, {0x202F, 0x202F}, {0x205F, 0x205F}, {0x3000, 0x3000},
|
| 82 |
+
};
|
| 83 |
+
|
| 84 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> accent_mark_ranges = {
|
| 85 |
+
{0x300, 0x36F}, {0x483, 0x489}, {0x591, 0x5BD}, {0x5BF, 0x5BF}, {0x5C1, 0x5C2}, {0x5C4, 0x5C5}, {0x5C7, 0x5C7}, {0x610, 0x61A}, {0x64B, 0x65F}, {0x670, 0x670}, {0x6D6, 0x6DC}, {0x6DF, 0x6E4},
|
| 86 |
+
{0x6E7, 0x6E8}, {0x6EA, 0x6ED}, {0x711, 0x711}, {0x730, 0x74A}, {0x7A6, 0x7B0}, {0x7EB, 0x7F3}, {0x7FD, 0x7FD}, {0x816, 0x819}, {0x81B, 0x823}, {0x825, 0x827}, {0x829, 0x82D}, {0x859, 0x85B},
|
| 87 |
+
{0x8D3, 0x8E1}, {0x8E3, 0x903}, {0x93A, 0x93C}, {0x93E, 0x94F}, {0x951, 0x957}, {0x962, 0x963}, {0x981, 0x983}, {0x9BC, 0x9BC}, {0x9BE, 0x9C4}, {0x9C7, 0x9C8}, {0x9CB, 0x9CD}, {0x9D7, 0x9D7},
|
| 88 |
+
{0x9E2, 0x9E3}, {0x9FE, 0x9FE}, {0xA01, 0xA03}, {0xA3C, 0xA3C}, {0xA3E, 0xA42}, {0xA47, 0xA48}, {0xA4B, 0xA4D}, {0xA51, 0xA51}, {0xA70, 0xA71}, {0xA75, 0xA75}, {0xA81, 0xA83}, {0xABC, 0xABC},
|
| 89 |
+
{0xABE, 0xAC5}, {0xAC7, 0xAC9}, {0xACB, 0xACD}, {0xAE2, 0xAE3}, {0xAFA, 0xAFF}, {0xB01, 0xB03}, {0xB3C, 0xB3C}, {0xB3E, 0xB44}, {0xB47, 0xB48}, {0xB4B, 0xB4D}, {0xB55, 0xB57}, {0xB62, 0xB63},
|
| 90 |
+
{0xB82, 0xB82}, {0xBBE, 0xBC2}, {0xBC6, 0xBC8}, {0xBCA, 0xBCD}, {0xBD7, 0xBD7}, {0xC00, 0xC04}, {0xC3E, 0xC44}, {0xC46, 0xC48}, {0xC4A, 0xC4D}, {0xC55, 0xC56}, {0xC62, 0xC63}, {0xC81, 0xC83},
|
| 91 |
+
{0xCBC, 0xCBC}, {0xCBE, 0xCC4}, {0xCC6, 0xCC8}, {0xCCA, 0xCCD}, {0xCD5, 0xCD6}, {0xCE2, 0xCE3}, {0xD00, 0xD03}, {0xD3B, 0xD3C}, {0xD3E, 0xD44}, {0xD46, 0xD48}, {0xD4A, 0xD4D}, {0xD57, 0xD57},
|
| 92 |
+
{0xD62, 0xD63}, {0xD81, 0xD83}, {0xDCA, 0xDCA}, {0xDCF, 0xDD4}, {0xDD6, 0xDD6}, {0xDD8, 0xDDF}, {0xDF2, 0xDF3}, {0xE31, 0xE31}, {0xE34, 0xE3A}, {0xE47, 0xE4E}, {0xEB1, 0xEB1}, {0xEB4, 0xEBC},
|
| 93 |
+
{0xEC8, 0xECD}, {0xF18, 0xF19}, {0xF35, 0xF35}, {0xF37, 0xF37}, {0xF39, 0xF39}, {0xF3E, 0xF3F}, {0xF71, 0xF84}, {0xF86, 0xF87}, {0xF8D, 0xF97}, {0xF99, 0xFBC}, {0xFC6, 0xFC6}, {0x102B, 0x103E},
|
| 94 |
+
{0x1056, 0x1059}, {0x105E, 0x1060}, {0x1062, 0x1064}, {0x1067, 0x106D}, {0x1071, 0x1074}, {0x1082, 0x108D}, {0x108F, 0x108F}, {0x109A, 0x109D}, {0x135D, 0x135F}, {0x1712, 0x1714}, {0x1732, 0x1734},
|
| 95 |
+
{0x1752, 0x1753}, {0x1772, 0x1773}, {0x17B4, 0x17D3}, {0x17DD, 0x17DD}, {0x180B, 0x180D}, {0x1885, 0x1886}, {0x18A9, 0x18A9}, {0x1920, 0x192B}, {0x1930, 0x193B}, {0x1A17, 0x1A1B}, {0x1A55, 0x1A5E},
|
| 96 |
+
{0x1A60, 0x1A7C}, {0x1A7F, 0x1A7F}, {0x1AB0, 0x1AC0}, {0x1B00, 0x1B04}, {0x1B34, 0x1B44}, {0x1B6B, 0x1B73}, {0x1B80, 0x1B82}, {0x1BA1, 0x1BAD}, {0x1BE6, 0x1BF3}, {0x1C24, 0x1C37}, {0x1CD0, 0x1CD2},
|
| 97 |
+
{0x1CD4, 0x1CE8}, {0x1CED, 0x1CED}, {0x1CF4, 0x1CF4}, {0x1CF7, 0x1CF9}, {0x1DC0, 0x1DF9}, {0x1DFB, 0x1DFF}, {0x20D0, 0x20F0}, {0x2CEF, 0x2CF1}, {0x2D7F, 0x2D7F}, {0x2DE0, 0x2DFF}, {0x302A, 0x302F},
|
| 98 |
+
{0x3099, 0x309A}, {0xA66F, 0xA672}, {0xA674, 0xA67D}, {0xA69E, 0xA69F}, {0xA6F0, 0xA6F1}, {0xA802, 0xA802}, {0xA806, 0xA806}, {0xA80B, 0xA80B}, {0xA823, 0xA827}, {0xA82C, 0xA82C}, {0xA880, 0xA881},
|
| 99 |
+
{0xA8B4, 0xA8C5}, {0xA8E0, 0xA8F1}, {0xA8FF, 0xA8FF}, {0xA926, 0xA92D}, {0xA947, 0xA953}, {0xA980, 0xA983}, {0xA9B3, 0xA9C0}, {0xA9E5, 0xA9E5}, {0xAA29, 0xAA36}, {0xAA43, 0xAA43}, {0xAA4C, 0xAA4D},
|
| 100 |
+
{0xAA7B, 0xAA7D}, {0xAAB0, 0xAAB0}, {0xAAB2, 0xAAB4}, {0xAAB7, 0xAAB8}, {0xAABE, 0xAABF}, {0xAAC1, 0xAAC1}, {0xAAEB, 0xAAEF}, {0xAAF5, 0xAAF6}, {0xABE3, 0xABEA}, {0xABEC, 0xABED}, {0xFB1E, 0xFB1E},
|
| 101 |
+
{0xFE00, 0xFE0F}, {0xFE20, 0xFE2F}, {0x101FD, 0x101FD}, {0x102E0, 0x102E0}, {0x10376, 0x1037A}, {0x10A01, 0x10A03}, {0x10A05, 0x10A06}, {0x10A0C, 0x10A0F}, {0x10A38, 0x10A3A}, {0x10A3F, 0x10A3F},
|
| 102 |
+
{0x10AE5, 0x10AE6}, {0x10D24, 0x10D27}, {0x10EAB, 0x10EAC}, {0x10F46, 0x10F50}, {0x11000, 0x11002}, {0x11038, 0x11046}, {0x1107F, 0x11082}, {0x110B0, 0x110BA}, {0x11100, 0x11102}, {0x11127, 0x11134},
|
| 103 |
+
{0x11145, 0x11146}, {0x11173, 0x11173}, {0x11180, 0x11182}, {0x111B3, 0x111C0}, {0x111C9, 0x111CC}, {0x111CE, 0x111CF}, {0x1122C, 0x11237}, {0x1123E, 0x1123E}, {0x112DF, 0x112EA}, {0x11300, 0x11303},
|
| 104 |
+
{0x1133B, 0x1133C}, {0x1133E, 0x11344}, {0x11347, 0x11348}, {0x1134B, 0x1134D}, {0x11357, 0x11357}, {0x11362, 0x11363}, {0x11366, 0x1136C}, {0x11370, 0x11374}, {0x11435, 0x11446}, {0x1145E, 0x1145E},
|
| 105 |
+
{0x114B0, 0x114C3}, {0x115AF, 0x115B5}, {0x115B8, 0x115C0}, {0x115DC, 0x115DD}, {0x11630, 0x11640}, {0x116AB, 0x116B7}, {0x1171D, 0x1172B}, {0x1182C, 0x1183A}, {0x11930, 0x11935}, {0x11937, 0x11938},
|
| 106 |
+
{0x1193B, 0x1193E}, {0x11940, 0x11940}, {0x11942, 0x11943}, {0x119D1, 0x119D7}, {0x119DA, 0x119E0}, {0x119E4, 0x119E4}, {0x11A01, 0x11A0A}, {0x11A33, 0x11A39}, {0x11A3B, 0x11A3E}, {0x11A47, 0x11A47},
|
| 107 |
+
{0x11A51, 0x11A5B}, {0x11A8A, 0x11A99}, {0x11C2F, 0x11C36}, {0x11C38, 0x11C3F}, {0x11C92, 0x11CA7}, {0x11CA9, 0x11CB6}, {0x11D31, 0x11D36}, {0x11D3A, 0x11D3A}, {0x11D3C, 0x11D3D}, {0x11D3F, 0x11D45},
|
| 108 |
+
{0x11D47, 0x11D47}, {0x11D8A, 0x11D8E}, {0x11D90, 0x11D91}, {0x11D93, 0x11D97}, {0x11EF3, 0x11EF6}, {0x16AF0, 0x16AF4}, {0x16B30, 0x16B36}, {0x16F4F, 0x16F4F}, {0x16F51, 0x16F87}, {0x16F8F, 0x16F92},
|
| 109 |
+
{0x16FE4, 0x16FE4}, {0x16FF0, 0x16FF1}, {0x1BC9D, 0x1BC9E}, {0x1D165, 0x1D169}, {0x1D16D, 0x1D172}, {0x1D17B, 0x1D182}, {0x1D185, 0x1D18B}, {0x1D1AA, 0x1D1AD}, {0x1D242, 0x1D244}, {0x1DA00, 0x1DA36},
|
| 110 |
+
{0x1DA3B, 0x1DA6C}, {0x1DA75, 0x1DA75}, {0x1DA84, 0x1DA84}, {0x1DA9B, 0x1DA9F}, {0x1DAA1, 0x1DAAF}, {0x1E000, 0x1E006}, {0x1E008, 0x1E018}, {0x1E01B, 0x1E021}, {0x1E023, 0x1E024}, {0x1E026, 0x1E02A},
|
| 111 |
+
{0x1E130, 0x1E136}, {0x1E2EC, 0x1E2EF}, {0x1E8D0, 0x1E8D6}, {0x1E944, 0x1E94A}, {0xE0100, 0xE01EF},
|
| 112 |
+
};
|
| 113 |
+
|
| 114 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> punctuation_ranges = {
|
| 115 |
+
{0x21, 0x23}, {0x25, 0x2A}, {0x2C, 0x2F}, {0x3A, 0x3B}, {0x3F, 0x40}, {0x5B, 0x5D}, {0x5F, 0x5F}, {0x7B, 0x7B}, {0x7D, 0x7D}, {0xA1, 0xA1}, {0xA7, 0xA7}, {0xAB, 0xAB}, {0xB6, 0xB7}, {0xBB, 0xBB},
|
| 116 |
+
{0xBF, 0xBF}, {0x37E, 0x37E}, {0x387, 0x387}, {0x55A, 0x55F}, {0x589, 0x58A}, {0x5BE, 0x5BE}, {0x5C0, 0x5C0}, {0x5C3, 0x5C3}, {0x5C6, 0x5C6}, {0x5F3, 0x5F4}, {0x609, 0x60A}, {0x60C, 0x60D},
|
| 117 |
+
{0x61B, 0x61B}, {0x61E, 0x61F}, {0x66A, 0x66D}, {0x6D4, 0x6D4}, {0x700, 0x70D}, {0x7F7, 0x7F9}, {0x830, 0x83E}, {0x85E, 0x85E}, {0x964, 0x965}, {0x970, 0x970}, {0x9FD, 0x9FD}, {0xA76, 0xA76},
|
| 118 |
+
{0xAF0, 0xAF0}, {0xC77, 0xC77}, {0xC84, 0xC84}, {0xDF4, 0xDF4}, {0xE4F, 0xE4F}, {0xE5A, 0xE5B}, {0xF04, 0xF12}, {0xF14, 0xF14}, {0xF3A, 0xF3D}, {0xF85, 0xF85}, {0xFD0, 0xFD4}, {0xFD9, 0xFDA},
|
| 119 |
+
{0x104A, 0x104F}, {0x10FB, 0x10FB}, {0x1360, 0x1368}, {0x1400, 0x1400}, {0x166E, 0x166E}, {0x169B, 0x169C}, {0x16EB, 0x16ED}, {0x1735, 0x1736}, {0x17D4, 0x17D6}, {0x17D8, 0x17DA}, {0x1800, 0x180A},
|
| 120 |
+
{0x1944, 0x1945}, {0x1A1E, 0x1A1F}, {0x1AA0, 0x1AA6}, {0x1AA8, 0x1AAD}, {0x1B5A, 0x1B60}, {0x1BFC, 0x1BFF}, {0x1C3B, 0x1C3F}, {0x1C7E, 0x1C7F}, {0x1CC0, 0x1CC7}, {0x1CD3, 0x1CD3}, {0x2010, 0x2027},
|
| 121 |
+
{0x2030, 0x2043}, {0x2045, 0x2051}, {0x2053, 0x205E}, {0x207D, 0x207E}, {0x208D, 0x208E}, {0x2308, 0x230B}, {0x2329, 0x232A}, {0x2768, 0x2775}, {0x27C5, 0x27C6}, {0x27E6, 0x27EF}, {0x2983, 0x2998},
|
| 122 |
+
{0x29D8, 0x29DB}, {0x29FC, 0x29FD}, {0x2CF9, 0x2CFC}, {0x2CFE, 0x2CFF}, {0x2D70, 0x2D70}, {0x2E00, 0x2E2E}, {0x2E30, 0x2E4F}, {0x2E52, 0x2E52}, {0x3001, 0x3003}, {0x3008, 0x3011}, {0x3014, 0x301F},
|
| 123 |
+
{0x3030, 0x3030}, {0x303D, 0x303D}, {0x30A0, 0x30A0}, {0x30FB, 0x30FB}, {0xA4FE, 0xA4FF}, {0xA60D, 0xA60F}, {0xA673, 0xA673}, {0xA67E, 0xA67E}, {0xA6F2, 0xA6F7}, {0xA874, 0xA877}, {0xA8CE, 0xA8CF},
|
| 124 |
+
{0xA8F8, 0xA8FA}, {0xA8FC, 0xA8FC}, {0xA92E, 0xA92F}, {0xA95F, 0xA95F}, {0xA9C1, 0xA9CD}, {0xA9DE, 0xA9DF}, {0xAA5C, 0xAA5F}, {0xAADE, 0xAADF}, {0xAAF0, 0xAAF1}, {0xABEB, 0xABEB}, {0xFD3E, 0xFD3F},
|
| 125 |
+
{0xFE10, 0xFE19}, {0xFE30, 0xFE52}, {0xFE54, 0xFE61}, {0xFE63, 0xFE63}, {0xFE68, 0xFE68}, {0xFE6A, 0xFE6B}, {0xFF01, 0xFF03}, {0xFF05, 0xFF0A}, {0xFF0C, 0xFF0F}, {0xFF1A, 0xFF1B}, {0xFF1F, 0xFF20},
|
| 126 |
+
{0xFF3B, 0xFF3D}, {0xFF3F, 0xFF3F}, {0xFF5B, 0xFF5B}, {0xFF5D, 0xFF5D}, {0xFF5F, 0xFF65}, {0x10100, 0x10102}, {0x1039F, 0x1039F}, {0x103D0, 0x103D0}, {0x1056F, 0x1056F}, {0x10857, 0x10857},
|
| 127 |
+
{0x1091F, 0x1091F}, {0x1093F, 0x1093F}, {0x10A50, 0x10A58}, {0x10A7F, 0x10A7F}, {0x10AF0, 0x10AF6}, {0x10B39, 0x10B3F}, {0x10B99, 0x10B9C}, {0x10EAD, 0x10EAD}, {0x10F55, 0x10F59}, {0x11047, 0x1104D},
|
| 128 |
+
{0x110BB, 0x110BC}, {0x110BE, 0x110C1}, {0x11140, 0x11143}, {0x11174, 0x11175}, {0x111C5, 0x111C8}, {0x111CD, 0x111CD}, {0x111DB, 0x111DB}, {0x111DD, 0x111DF}, {0x11238, 0x1123D}, {0x112A9, 0x112A9},
|
| 129 |
+
{0x1144B, 0x1144F}, {0x1145A, 0x1145B}, {0x1145D, 0x1145D}, {0x114C6, 0x114C6}, {0x115C1, 0x115D7}, {0x11641, 0x11643}, {0x11660, 0x1166C}, {0x1173C, 0x1173E}, {0x1183B, 0x1183B}, {0x11944, 0x11946},
|
| 130 |
+
{0x119E2, 0x119E2}, {0x11A3F, 0x11A46}, {0x11A9A, 0x11A9C}, {0x11A9E, 0x11AA2}, {0x11C41, 0x11C45}, {0x11C70, 0x11C71}, {0x11EF7, 0x11EF8}, {0x11FFF, 0x11FFF}, {0x12470, 0x12474}, {0x16A6E, 0x16A6F},
|
| 131 |
+
{0x16AF5, 0x16AF5}, {0x16B37, 0x16B3B}, {0x16B44, 0x16B44}, {0x16E97, 0x16E9A}, {0x16FE2, 0x16FE2}, {0x1BC9F, 0x1BC9F}, {0x1DA87, 0x1DA8B}, {0x1E95E, 0x1E95F},
|
| 132 |
+
};
|
| 133 |
+
|
| 134 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> symbol_ranges = {
|
| 135 |
+
{0x24, 0x24}, {0x2B, 0x2B}, {0x3C, 0x3E}, {0x5E, 0x5E}, {0x60, 0x60}, {0x7C, 0x7C}, {0x7E, 0x7E}, {0xA2, 0xA6}, {0xA8, 0xA9}, {0xAC, 0xAC}, {0xAE, 0xB1}, {0xB4, 0xB4}, {0xB8, 0xB8}, {0xD7, 0xD7},
|
| 136 |
+
{0xF7, 0xF7}, {0x2C2, 0x2C5}, {0x2D2, 0x2DF}, {0x2E5, 0x2EB}, {0x2ED, 0x2ED}, {0x2EF, 0x2FF}, {0x375, 0x375}, {0x384, 0x385}, {0x3F6, 0x3F6}, {0x482, 0x482}, {0x58D, 0x58F}, {0x606, 0x608},
|
| 137 |
+
{0x60B, 0x60B}, {0x60E, 0x60F}, {0x6DE, 0x6DE}, {0x6E9, 0x6E9}, {0x6FD, 0x6FE}, {0x7F6, 0x7F6}, {0x7FE, 0x7FF}, {0x9F2, 0x9F3}, {0x9FA, 0x9FB}, {0xAF1, 0xAF1}, {0xB70, 0xB70}, {0xBF3, 0xBFA},
|
| 138 |
+
{0xC7F, 0xC7F}, {0xD4F, 0xD4F}, {0xD79, 0xD79}, {0xE3F, 0xE3F}, {0xF01, 0xF03}, {0xF13, 0xF13}, {0xF15, 0xF17}, {0xF1A, 0xF1F}, {0xF34, 0xF34}, {0xF36, 0xF36}, {0xF38, 0xF38}, {0xFBE, 0xFC5},
|
| 139 |
+
{0xFC7, 0xFCC}, {0xFCE, 0xFCF}, {0xFD5, 0xFD8}, {0x109E, 0x109F}, {0x1390, 0x1399}, {0x166D, 0x166D}, {0x17DB, 0x17DB}, {0x1940, 0x1940}, {0x19DE, 0x19FF}, {0x1B61, 0x1B6A}, {0x1B74, 0x1B7C},
|
| 140 |
+
{0x1FBD, 0x1FBD}, {0x1FBF, 0x1FC1}, {0x1FCD, 0x1FCF}, {0x1FDD, 0x1FDF}, {0x1FED, 0x1FEF}, {0x1FFD, 0x1FFE}, {0x2044, 0x2044}, {0x2052, 0x2052}, {0x207A, 0x207C}, {0x208A, 0x208C}, {0x20A0, 0x20BF},
|
| 141 |
+
{0x2100, 0x2101}, {0x2103, 0x2106}, {0x2108, 0x2109}, {0x2114, 0x2114}, {0x2116, 0x2118}, {0x211E, 0x2123}, {0x2125, 0x2125}, {0x2127, 0x2127}, {0x2129, 0x2129}, {0x212E, 0x212E}, {0x213A, 0x213B},
|
| 142 |
+
{0x2140, 0x2144}, {0x214A, 0x214D}, {0x214F, 0x214F}, {0x218A, 0x218B}, {0x2190, 0x2307}, {0x230C, 0x2328}, {0x232B, 0x2426}, {0x2440, 0x244A}, {0x249C, 0x24E9}, {0x2500, 0x2767}, {0x2794, 0x27C4},
|
| 143 |
+
{0x27C7, 0x27E5}, {0x27F0, 0x2982}, {0x2999, 0x29D7}, {0x29DC, 0x29FB}, {0x29FE, 0x2B73}, {0x2B76, 0x2B95}, {0x2B97, 0x2BFF}, {0x2CE5, 0x2CEA}, {0x2E50, 0x2E51}, {0x2E80, 0x2E99}, {0x2E9B, 0x2EF3},
|
| 144 |
+
{0x2F00, 0x2FD5}, {0x2FF0, 0x2FFB}, {0x3004, 0x3004}, {0x3012, 0x3013}, {0x3020, 0x3020}, {0x3036, 0x3037}, {0x303E, 0x303F}, {0x309B, 0x309C}, {0x3190, 0x3191}, {0x3196, 0x319F}, {0x31C0, 0x31E3},
|
| 145 |
+
{0x3200, 0x321E}, {0x322A, 0x3247}, {0x3250, 0x3250}, {0x3260, 0x327F}, {0x328A, 0x32B0}, {0x32C0, 0x33FF}, {0x4DC0, 0x4DFF}, {0xA490, 0xA4C6}, {0xA700, 0xA716}, {0xA720, 0xA721}, {0xA789, 0xA78A},
|
| 146 |
+
{0xA828, 0xA82B}, {0xA836, 0xA839}, {0xAA77, 0xAA79}, {0xAB5B, 0xAB5B}, {0xAB6A, 0xAB6B}, {0xFB29, 0xFB29}, {0xFBB2, 0xFBC1}, {0xFDFC, 0xFDFD}, {0xFE62, 0xFE62}, {0xFE64, 0xFE66}, {0xFE69, 0xFE69},
|
| 147 |
+
{0xFF04, 0xFF04}, {0xFF0B, 0xFF0B}, {0xFF1C, 0xFF1E}, {0xFF3E, 0xFF3E}, {0xFF40, 0xFF40}, {0xFF5C, 0xFF5C}, {0xFF5E, 0xFF5E}, {0xFFE0, 0xFFE6}, {0xFFE8, 0xFFEE}, {0xFFFC, 0xFFFD}, {0x10137, 0x1013F},
|
| 148 |
+
{0x10179, 0x10189}, {0x1018C, 0x1018E}, {0x10190, 0x1019C}, {0x101A0, 0x101A0}, {0x101D0, 0x101FC}, {0x10877, 0x10878}, {0x10AC8, 0x10AC8}, {0x1173F, 0x1173F}, {0x11FD5, 0x11FF1}, {0x16B3C, 0x16B3F},
|
| 149 |
+
{0x16B45, 0x16B45}, {0x1BC9C, 0x1BC9C}, {0x1D000, 0x1D0F5}, {0x1D100, 0x1D126}, {0x1D129, 0x1D164}, {0x1D16A, 0x1D16C}, {0x1D183, 0x1D184}, {0x1D18C, 0x1D1A9}, {0x1D1AE, 0x1D1E8}, {0x1D200, 0x1D241},
|
| 150 |
+
{0x1D245, 0x1D245}, {0x1D300, 0x1D356}, {0x1D6C1, 0x1D6C1}, {0x1D6DB, 0x1D6DB}, {0x1D6FB, 0x1D6FB}, {0x1D715, 0x1D715}, {0x1D735, 0x1D735}, {0x1D74F, 0x1D74F}, {0x1D76F, 0x1D76F}, {0x1D789, 0x1D789},
|
| 151 |
+
{0x1D7A9, 0x1D7A9}, {0x1D7C3, 0x1D7C3}, {0x1D800, 0x1D9FF}, {0x1DA37, 0x1DA3A}, {0x1DA6D, 0x1DA74}, {0x1DA76, 0x1DA83}, {0x1DA85, 0x1DA86}, {0x1E14F, 0x1E14F}, {0x1E2FF, 0x1E2FF}, {0x1ECAC, 0x1ECAC},
|
| 152 |
+
{0x1ECB0, 0x1ECB0}, {0x1ED2E, 0x1ED2E}, {0x1EEF0, 0x1EEF1}, {0x1F000, 0x1F02B}, {0x1F030, 0x1F093}, {0x1F0A0, 0x1F0AE}, {0x1F0B1, 0x1F0BF}, {0x1F0C1, 0x1F0CF}, {0x1F0D1, 0x1F0F5}, {0x1F10D, 0x1F1AD},
|
| 153 |
+
{0x1F1E6, 0x1F202}, {0x1F210, 0x1F23B}, {0x1F240, 0x1F248}, {0x1F250, 0x1F251}, {0x1F260, 0x1F265}, {0x1F300, 0x1F6D7}, {0x1F6E0, 0x1F6EC}, {0x1F6F0, 0x1F6FC}, {0x1F700, 0x1F773}, {0x1F780, 0x1F7D8},
|
| 154 |
+
{0x1F7E0, 0x1F7EB}, {0x1F800, 0x1F80B}, {0x1F810, 0x1F847}, {0x1F850, 0x1F859}, {0x1F860, 0x1F887}, {0x1F890, 0x1F8AD}, {0x1F8B0, 0x1F8B1}, {0x1F900, 0x1F978}, {0x1F97A, 0x1F9CB}, {0x1F9CD, 0x1FA53},
|
| 155 |
+
{0x1FA60, 0x1FA6D}, {0x1FA70, 0x1FA74}, {0x1FA78, 0x1FA7A}, {0x1FA80, 0x1FA86}, {0x1FA90, 0x1FAA8}, {0x1FAB0, 0x1FAB6}, {0x1FAC0, 0x1FAC2}, {0x1FAD0, 0x1FAD6}, {0x1FB00, 0x1FB92}, {0x1FB94, 0x1FBCA},
|
| 156 |
+
};
|
| 157 |
+
|
| 158 |
+
static const std::vector<std::pair<uint32_t, uint32_t>> control_ranges = {
|
| 159 |
+
{0x0, 0x8}, {0xE, 0x1B}, {0x7F, 0x84}, {0x86, 0x9F}, {0xAD, 0xAD}, {0x378, 0x379}, {0x380, 0x383}, {0x38B, 0x38B}, {0x38D, 0x38D}, {0x3A2, 0x3A2}, {0x530, 0x530}, {0x557, 0x558}, {0x58B, 0x58C},
|
| 160 |
+
{0x590, 0x590}, {0x5C8, 0x5CF}, {0x5EB, 0x5EE}, {0x5F5, 0x605}, {0x61C, 0x61D}, {0x6DD, 0x6DD}, {0x70E, 0x70F}, {0x74B, 0x74C}, {0x7B2, 0x7BF}, {0x7FB, 0x7FC}, {0x82E, 0x82F}, {0x83F, 0x83F},
|
| 161 |
+
{0x85C, 0x85D}, {0x85F, 0x85F}, {0x86B, 0x89F}, {0x8B5, 0x8B5}, {0x8C8, 0x8D2}, {0x8E2, 0x8E2}, {0x984, 0x984}, {0x98D, 0x98E}, {0x991, 0x992}, {0x9A9, 0x9A9}, {0x9B1, 0x9B1}, {0x9B3, 0x9B5},
|
| 162 |
+
{0x9BA, 0x9BB}, {0x9C5, 0x9C6}, {0x9C9, 0x9CA}, {0x9CF, 0x9D6}, {0x9D8, 0x9DB}, {0x9DE, 0x9DE}, {0x9E4, 0x9E5}, {0x9FF, 0xA00}, {0xA04, 0xA04}, {0xA0B, 0xA0E}, {0xA11, 0xA12}, {0xA29, 0xA29},
|
| 163 |
+
{0xA31, 0xA31}, {0xA34, 0xA34}, {0xA37, 0xA37}, {0xA3A, 0xA3B}, {0xA3D, 0xA3D}, {0xA43, 0xA46}, {0xA49, 0xA4A}, {0xA4E, 0xA50}, {0xA52, 0xA58}, {0xA5D, 0xA5D}, {0xA5F, 0xA65}, {0xA77, 0xA80},
|
| 164 |
+
{0xA84, 0xA84}, {0xA8E, 0xA8E}, {0xA92, 0xA92}, {0xAA9, 0xAA9}, {0xAB1, 0xAB1}, {0xAB4, 0xAB4}, {0xABA, 0xABB}, {0xAC6, 0xAC6}, {0xACA, 0xACA}, {0xACE, 0xACF}, {0xAD1, 0xADF}, {0xAE4, 0xAE5},
|
| 165 |
+
{0xAF2, 0xAF8}, {0xB00, 0xB00}, {0xB04, 0xB04}, {0xB0D, 0xB0E}, {0xB11, 0xB12}, {0xB29, 0xB29}, {0xB31, 0xB31}, {0xB34, 0xB34}, {0xB3A, 0xB3B}, {0xB45, 0xB46}, {0xB49, 0xB4A}, {0xB4E, 0xB54},
|
| 166 |
+
{0xB58, 0xB5B}, {0xB5E, 0xB5E}, {0xB64, 0xB65}, {0xB78, 0xB81}, {0xB84, 0xB84}, {0xB8B, 0xB8D}, {0xB91, 0xB91}, {0xB96, 0xB98}, {0xB9B, 0xB9B}, {0xB9D, 0xB9D}, {0xBA0, 0xBA2}, {0xBA5, 0xBA7},
|
| 167 |
+
{0xBAB, 0xBAD}, {0xBBA, 0xBBD}, {0xBC3, 0xBC5}, {0xBC9, 0xBC9}, {0xBCE, 0xBCF}, {0xBD1, 0xBD6}, {0xBD8, 0xBE5}, {0xBFB, 0xBFF}, {0xC0D, 0xC0D}, {0xC11, 0xC11}, {0xC29, 0xC29}, {0xC3A, 0xC3C},
|
| 168 |
+
{0xC45, 0xC45}, {0xC49, 0xC49}, {0xC4E, 0xC54}, {0xC57, 0xC57}, {0xC5B, 0xC5F}, {0xC64, 0xC65}, {0xC70, 0xC76}, {0xC8D, 0xC8D}, {0xC91, 0xC91}, {0xCA9, 0xCA9}, {0xCB4, 0xCB4}, {0xCBA, 0xCBB},
|
| 169 |
+
{0xCC5, 0xCC5}, {0xCC9, 0xCC9}, {0xCCE, 0xCD4}, {0xCD7, 0xCDD}, {0xCDF, 0xCDF}, {0xCE4, 0xCE5}, {0xCF0, 0xCF0}, {0xCF3, 0xCFF}, {0xD0D, 0xD0D}, {0xD11, 0xD11}, {0xD45, 0xD45}, {0xD49, 0xD49},
|
| 170 |
+
{0xD50, 0xD53}, {0xD64, 0xD65}, {0xD80, 0xD80}, {0xD84, 0xD84}, {0xD97, 0xD99}, {0xDB2, 0xDB2}, {0xDBC, 0xDBC}, {0xDBE, 0xDBF}, {0xDC7, 0xDC9}, {0xDCB, 0xDCE}, {0xDD5, 0xDD5}, {0xDD7, 0xDD7},
|
| 171 |
+
{0xDE0, 0xDE5}, {0xDF0, 0xDF1}, {0xDF5, 0xE00}, {0xE3B, 0xE3E}, {0xE5C, 0xE80}, {0xE83, 0xE83}, {0xE85, 0xE85}, {0xE8B, 0xE8B}, {0xEA4, 0xEA4}, {0xEA6, 0xEA6}, {0xEBE, 0xEBF}, {0xEC5, 0xEC5},
|
| 172 |
+
{0xEC7, 0xEC7}, {0xECE, 0xECF}, {0xEDA, 0xEDB}, {0xEE0, 0xEFF}, {0xF48, 0xF48}, {0xF6D, 0xF70}, {0xF98, 0xF98}, {0xFBD, 0xFBD}, {0xFCD, 0xFCD}, {0xFDB, 0xFFF}, {0x10C6, 0x10C6}, {0x10C8, 0x10CC},
|
| 173 |
+
{0x10CE, 0x10CF}, {0x1249, 0x1249}, {0x124E, 0x124F}, {0x1257, 0x1257}, {0x1259, 0x1259}, {0x125E, 0x125F}, {0x1289, 0x1289}, {0x128E, 0x128F}, {0x12B1, 0x12B1}, {0x12B6, 0x12B7}, {0x12BF, 0x12BF},
|
| 174 |
+
{0x12C1, 0x12C1}, {0x12C6, 0x12C7}, {0x12D7, 0x12D7}, {0x1311, 0x1311}, {0x1316, 0x1317}, {0x135B, 0x135C}, {0x137D, 0x137F}, {0x139A, 0x139F}, {0x13F6, 0x13F7}, {0x13FE, 0x13FF}, {0x169D, 0x169F},
|
| 175 |
+
{0x16F9, 0x16FF}, {0x170D, 0x170D}, {0x1715, 0x171F}, {0x1737, 0x173F}, {0x1754, 0x175F}, {0x176D, 0x176D}, {0x1771, 0x1771}, {0x1774, 0x177F}, {0x17DE, 0x17DF}, {0x17EA, 0x17EF}, {0x17FA, 0x17FF},
|
| 176 |
+
{0x180E, 0x180F}, {0x181A, 0x181F}, {0x1879, 0x187F}, {0x18AB, 0x18AF}, {0x18F6, 0x18FF}, {0x191F, 0x191F}, {0x192C, 0x192F}, {0x193C, 0x193F}, {0x1941, 0x1943}, {0x196E, 0x196F}, {0x1975, 0x197F},
|
| 177 |
+
{0x19AC, 0x19AF}, {0x19CA, 0x19CF}, {0x19DB, 0x19DD}, {0x1A1C, 0x1A1D}, {0x1A5F, 0x1A5F}, {0x1A7D, 0x1A7E}, {0x1A8A, 0x1A8F}, {0x1A9A, 0x1A9F}, {0x1AAE, 0x1AAF}, {0x1AC1, 0x1AFF}, {0x1B4C, 0x1B4F},
|
| 178 |
+
{0x1B7D, 0x1B7F}, {0x1BF4, 0x1BFB}, {0x1C38, 0x1C3A}, {0x1C4A, 0x1C4C}, {0x1C89, 0x1C8F}, {0x1CBB, 0x1CBC}, {0x1CC8, 0x1CCF}, {0x1CFB, 0x1CFF}, {0x1DFA, 0x1DFA}, {0x1F16, 0x1F17}, {0x1F1E, 0x1F1F},
|
| 179 |
+
{0x1F46, 0x1F47}, {0x1F4E, 0x1F4F}, {0x1F58, 0x1F58}, {0x1F5A, 0x1F5A}, {0x1F5C, 0x1F5C}, {0x1F5E, 0x1F5E}, {0x1F7E, 0x1F7F}, {0x1FB5, 0x1FB5}, {0x1FC5, 0x1FC5}, {0x1FD4, 0x1FD5}, {0x1FDC, 0x1FDC},
|
| 180 |
+
{0x1FF0, 0x1FF1}, {0x1FF5, 0x1FF5}, {0x1FFF, 0x1FFF}, {0x200B, 0x200F}, {0x202A, 0x202E}, {0x2060, 0x206F}, {0x2072, 0x2073}, {0x208F, 0x208F}, {0x209D, 0x209F}, {0x20C0, 0x20CF}, {0x20F1, 0x20FF},
|
| 181 |
+
{0x218C, 0x218F}, {0x2427, 0x243F}, {0x244B, 0x245F}, {0x2B74, 0x2B75}, {0x2B96, 0x2B96}, {0x2C2F, 0x2C2F}, {0x2C5F, 0x2C5F}, {0x2CF4, 0x2CF8}, {0x2D26, 0x2D26}, {0x2D28, 0x2D2C}, {0x2D2E, 0x2D2F},
|
| 182 |
+
{0x2D68, 0x2D6E}, {0x2D71, 0x2D7E}, {0x2D97, 0x2D9F}, {0x2DA7, 0x2DA7}, {0x2DAF, 0x2DAF}, {0x2DB7, 0x2DB7}, {0x2DBF, 0x2DBF}, {0x2DC7, 0x2DC7}, {0x2DCF, 0x2DCF}, {0x2DD7, 0x2DD7}, {0x2DDF, 0x2DDF},
|
| 183 |
+
{0x2E53, 0x2E7F}, {0x2E9A, 0x2E9A}, {0x2EF4, 0x2EFF}, {0x2FD6, 0x2FEF}, {0x2FFC, 0x2FFF}, {0x3040, 0x3040}, {0x3097, 0x3098}, {0x3100, 0x3104}, {0x3130, 0x3130}, {0x318F, 0x318F}, {0x31E4, 0x31EF},
|
| 184 |
+
{0x321F, 0x321F}, {0x9FFD, 0x9FFF}, {0xA48D, 0xA48F}, {0xA4C7, 0xA4CF}, {0xA62C, 0xA63F}, {0xA6F8, 0xA6FF}, {0xA7C0, 0xA7C1}, {0xA7CB, 0xA7F4}, {0xA82D, 0xA82F}, {0xA83A, 0xA83F}, {0xA878, 0xA87F},
|
| 185 |
+
{0xA8C6, 0xA8CD}, {0xA8DA, 0xA8DF}, {0xA954, 0xA95E}, {0xA97D, 0xA97F}, {0xA9CE, 0xA9CE}, {0xA9DA, 0xA9DD}, {0xA9FF, 0xA9FF}, {0xAA37, 0xAA3F}, {0xAA4E, 0xAA4F}, {0xAA5A, 0xAA5B}, {0xAAC3, 0xAADA},
|
| 186 |
+
{0xAAF7, 0xAB00}, {0xAB07, 0xAB08}, {0xAB0F, 0xAB10}, {0xAB17, 0xAB1F}, {0xAB27, 0xAB27}, {0xAB2F, 0xAB2F}, {0xAB6C, 0xAB6F}, {0xABEE, 0xABEF}, {0xABFA, 0xABFF}, {0xD7A4, 0xD7AF}, {0xD7C7, 0xD7CA},
|
| 187 |
+
{0xD7FC, 0xF8FF}, {0xFA6E, 0xFA6F}, {0xFADA, 0xFAFF}, {0xFB07, 0xFB12}, {0xFB18, 0xFB1C}, {0xFB37, 0xFB37}, {0xFB3D, 0xFB3D}, {0xFB3F, 0xFB3F}, {0xFB42, 0xFB42}, {0xFB45, 0xFB45}, {0xFBC2, 0xFBD2},
|
| 188 |
+
{0xFD40, 0xFD4F}, {0xFD90, 0xFD91}, {0xFDC8, 0xFDEF}, {0xFDFE, 0xFDFF}, {0xFE1A, 0xFE1F}, {0xFE53, 0xFE53}, {0xFE67, 0xFE67}, {0xFE6C, 0xFE6F}, {0xFE75, 0xFE75}, {0xFEFD, 0xFF00}, {0xFFBF, 0xFFC1},
|
| 189 |
+
{0xFFC8, 0xFFC9}, {0xFFD0, 0xFFD1}, {0xFFD8, 0xFFD9}, {0xFFDD, 0xFFDF}, {0xFFE7, 0xFFE7}, {0xFFEF, 0xFFFB}, {0xFFFE, 0xFFFF}, {0x1000C, 0x1000C}, {0x10027, 0x10027}, {0x1003B, 0x1003B},
|
| 190 |
+
{0x1003E, 0x1003E}, {0x1004E, 0x1004F}, {0x1005E, 0x1007F}, {0x100FB, 0x100FF}, {0x10103, 0x10106}, {0x10134, 0x10136}, {0x1018F, 0x1018F}, {0x1019D, 0x1019F}, {0x101A1, 0x101CF}, {0x101FE, 0x1027F},
|
| 191 |
+
{0x1029D, 0x1029F}, {0x102D1, 0x102DF}, {0x102FC, 0x102FF}, {0x10324, 0x1032C}, {0x1034B, 0x1034F}, {0x1037B, 0x1037F}, {0x1039E, 0x1039E}, {0x103C4, 0x103C7}, {0x103D6, 0x103FF}, {0x1049E, 0x1049F},
|
| 192 |
+
{0x104AA, 0x104AF}, {0x104D4, 0x104D7}, {0x104FC, 0x104FF}, {0x10528, 0x1052F}, {0x10564, 0x1056E}, {0x10570, 0x105FF}, {0x10737, 0x1073F}, {0x10756, 0x1075F}, {0x10768, 0x107FF}, {0x10806, 0x10807},
|
| 193 |
+
{0x10809, 0x10809}, {0x10836, 0x10836}, {0x10839, 0x1083B}, {0x1083D, 0x1083E}, {0x10856, 0x10856}, {0x1089F, 0x108A6}, {0x108B0, 0x108DF}, {0x108F3, 0x108F3}, {0x108F6, 0x108FA}, {0x1091C, 0x1091E},
|
| 194 |
+
{0x1093A, 0x1093E}, {0x10940, 0x1097F}, {0x109B8, 0x109BB}, {0x109D0, 0x109D1}, {0x10A04, 0x10A04}, {0x10A07, 0x10A0B}, {0x10A14, 0x10A14}, {0x10A18, 0x10A18}, {0x10A36, 0x10A37}, {0x10A3B, 0x10A3E},
|
| 195 |
+
{0x10A49, 0x10A4F}, {0x10A59, 0x10A5F}, {0x10AA0, 0x10ABF}, {0x10AE7, 0x10AEA}, {0x10AF7, 0x10AFF}, {0x10B36, 0x10B38}, {0x10B56, 0x10B57}, {0x10B73, 0x10B77}, {0x10B92, 0x10B98}, {0x10B9D, 0x10BA8},
|
| 196 |
+
{0x10BB0, 0x10BFF}, {0x10C49, 0x10C7F}, {0x10CB3, 0x10CBF}, {0x10CF3, 0x10CF9}, {0x10D28, 0x10D2F}, {0x10D3A, 0x10E5F}, {0x10E7F, 0x10E7F}, {0x10EAA, 0x10EAA}, {0x10EAE, 0x10EAF}, {0x10EB2, 0x10EFF},
|
| 197 |
+
{0x10F28, 0x10F2F}, {0x10F5A, 0x10FAF}, {0x10FCC, 0x10FDF}, {0x10FF7, 0x10FFF}, {0x1104E, 0x11051}, {0x11070, 0x1107E}, {0x110BD, 0x110BD}, {0x110C2, 0x110CF}, {0x110E9, 0x110EF}, {0x110FA, 0x110FF},
|
| 198 |
+
{0x11135, 0x11135}, {0x11148, 0x1114F}, {0x11177, 0x1117F}, {0x111E0, 0x111E0}, {0x111F5, 0x111FF}, {0x11212, 0x11212}, {0x1123F, 0x1127F}, {0x11287, 0x11287}, {0x11289, 0x11289}, {0x1128E, 0x1128E},
|
| 199 |
+
{0x1129E, 0x1129E}, {0x112AA, 0x112AF}, {0x112EB, 0x112EF}, {0x112FA, 0x112FF}, {0x11304, 0x11304}, {0x1130D, 0x1130E}, {0x11311, 0x11312}, {0x11329, 0x11329}, {0x11331, 0x11331}, {0x11334, 0x11334},
|
| 200 |
+
{0x1133A, 0x1133A}, {0x11345, 0x11346}, {0x11349, 0x1134A}, {0x1134E, 0x1134F}, {0x11351, 0x11356}, {0x11358, 0x1135C}, {0x11364, 0x11365}, {0x1136D, 0x1136F}, {0x11375, 0x113FF}, {0x1145C, 0x1145C},
|
| 201 |
+
{0x11462, 0x1147F}, {0x114C8, 0x114CF}, {0x114DA, 0x1157F}, {0x115B6, 0x115B7}, {0x115DE, 0x115FF}, {0x11645, 0x1164F}, {0x1165A, 0x1165F}, {0x1166D, 0x1167F}, {0x116B9, 0x116BF}, {0x116CA, 0x116FF},
|
| 202 |
+
{0x1171B, 0x1171C}, {0x1172C, 0x1172F}, {0x11740, 0x117FF}, {0x1183C, 0x1189F}, {0x118F3, 0x118FE}, {0x11907, 0x11908}, {0x1190A, 0x1190B}, {0x11914, 0x11914}, {0x11917, 0x11917}, {0x11936, 0x11936},
|
| 203 |
+
{0x11939, 0x1193A}, {0x11947, 0x1194F}, {0x1195A, 0x1199F}, {0x119A8, 0x119A9}, {0x119D8, 0x119D9}, {0x119E5, 0x119FF}, {0x11A48, 0x11A4F}, {0x11AA3, 0x11ABF}, {0x11AF9, 0x11BFF}, {0x11C09, 0x11C09},
|
| 204 |
+
{0x11C37, 0x11C37}, {0x11C46, 0x11C4F}, {0x11C6D, 0x11C6F}, {0x11C90, 0x11C91}, {0x11CA8, 0x11CA8}, {0x11CB7, 0x11CFF}, {0x11D07, 0x11D07}, {0x11D0A, 0x11D0A}, {0x11D37, 0x11D39}, {0x11D3B, 0x11D3B},
|
| 205 |
+
{0x11D3E, 0x11D3E}, {0x11D48, 0x11D4F}, {0x11D5A, 0x11D5F}, {0x11D66, 0x11D66}, {0x11D69, 0x11D69}, {0x11D8F, 0x11D8F}, {0x11D92, 0x11D92}, {0x11D99, 0x11D9F}, {0x11DAA, 0x11EDF}, {0x11EF9, 0x11FAF},
|
| 206 |
+
{0x11FB1, 0x11FBF}, {0x11FF2, 0x11FFE}, {0x1239A, 0x123FF}, {0x1246F, 0x1246F}, {0x12475, 0x1247F}, {0x12544, 0x12FFF}, {0x1342F, 0x143FF}, {0x14647, 0x167FF}, {0x16A39, 0x16A3F}, {0x16A5F, 0x16A5F},
|
| 207 |
+
{0x16A6A, 0x16A6D}, {0x16A70, 0x16ACF}, {0x16AEE, 0x16AEF}, {0x16AF6, 0x16AFF}, {0x16B46, 0x16B4F}, {0x16B5A, 0x16B5A}, {0x16B62, 0x16B62}, {0x16B78, 0x16B7C}, {0x16B90, 0x16E3F}, {0x16E9B, 0x16EFF},
|
| 208 |
+
{0x16F4B, 0x16F4E}, {0x16F88, 0x16F8E}, {0x16FA0, 0x16FDF}, {0x16FE5, 0x16FEF}, {0x16FF2, 0x16FFF}, {0x187F8, 0x187FF}, {0x18CD6, 0x18CFF}, {0x18D09, 0x1AFFF}, {0x1B11F, 0x1B14F}, {0x1B153, 0x1B163},
|
| 209 |
+
{0x1B168, 0x1B16F}, {0x1B2FC, 0x1BBFF}, {0x1BC6B, 0x1BC6F}, {0x1BC7D, 0x1BC7F}, {0x1BC89, 0x1BC8F}, {0x1BC9A, 0x1BC9B}, {0x1BCA0, 0x1CFFF}, {0x1D0F6, 0x1D0FF}, {0x1D127, 0x1D128}, {0x1D173, 0x1D17A},
|
| 210 |
+
{0x1D1E9, 0x1D1FF}, {0x1D246, 0x1D2DF}, {0x1D2F4, 0x1D2FF}, {0x1D357, 0x1D35F}, {0x1D379, 0x1D3FF}, {0x1D455, 0x1D455}, {0x1D49D, 0x1D49D}, {0x1D4A0, 0x1D4A1}, {0x1D4A3, 0x1D4A4}, {0x1D4A7, 0x1D4A8},
|
| 211 |
+
{0x1D4AD, 0x1D4AD}, {0x1D4BA, 0x1D4BA}, {0x1D4BC, 0x1D4BC}, {0x1D4C4, 0x1D4C4}, {0x1D506, 0x1D506}, {0x1D50B, 0x1D50C}, {0x1D515, 0x1D515}, {0x1D51D, 0x1D51D}, {0x1D53A, 0x1D53A}, {0x1D53F, 0x1D53F},
|
| 212 |
+
{0x1D545, 0x1D545}, {0x1D547, 0x1D549}, {0x1D551, 0x1D551}, {0x1D6A6, 0x1D6A7}, {0x1D7CC, 0x1D7CD}, {0x1DA8C, 0x1DA9A}, {0x1DAA0, 0x1DAA0}, {0x1DAB0, 0x1DFFF}, {0x1E007, 0x1E007}, {0x1E019, 0x1E01A},
|
| 213 |
+
{0x1E022, 0x1E022}, {0x1E025, 0x1E025}, {0x1E02B, 0x1E0FF}, {0x1E12D, 0x1E12F}, {0x1E13E, 0x1E13F}, {0x1E14A, 0x1E14D}, {0x1E150, 0x1E2BF}, {0x1E2FA, 0x1E2FE}, {0x1E300, 0x1E7FF}, {0x1E8C5, 0x1E8C6},
|
| 214 |
+
{0x1E8D7, 0x1E8FF}, {0x1E94C, 0x1E94F}, {0x1E95A, 0x1E95D}, {0x1E960, 0x1EC70}, {0x1ECB5, 0x1ED00}, {0x1ED3E, 0x1EDFF}, {0x1EE04, 0x1EE04}, {0x1EE20, 0x1EE20}, {0x1EE23, 0x1EE23}, {0x1EE25, 0x1EE26},
|
| 215 |
+
{0x1EE28, 0x1EE28}, {0x1EE33, 0x1EE33}, {0x1EE38, 0x1EE38}, {0x1EE3A, 0x1EE3A}, {0x1EE3C, 0x1EE41}, {0x1EE43, 0x1EE46}, {0x1EE48, 0x1EE48}, {0x1EE4A, 0x1EE4A}, {0x1EE4C, 0x1EE4C}, {0x1EE50, 0x1EE50},
|
| 216 |
+
{0x1EE53, 0x1EE53}, {0x1EE55, 0x1EE56}, {0x1EE58, 0x1EE58}, {0x1EE5A, 0x1EE5A}, {0x1EE5C, 0x1EE5C}, {0x1EE5E, 0x1EE5E}, {0x1EE60, 0x1EE60}, {0x1EE63, 0x1EE63}, {0x1EE65, 0x1EE66}, {0x1EE6B, 0x1EE6B},
|
| 217 |
+
{0x1EE73, 0x1EE73}, {0x1EE78, 0x1EE78}, {0x1EE7D, 0x1EE7D}, {0x1EE7F, 0x1EE7F}, {0x1EE8A, 0x1EE8A}, {0x1EE9C, 0x1EEA0}, {0x1EEA4, 0x1EEA4}, {0x1EEAA, 0x1EEAA}, {0x1EEBC, 0x1EEEF}, {0x1EEF2, 0x1EFFF},
|
| 218 |
+
{0x1F02C, 0x1F02F}, {0x1F094, 0x1F09F}, {0x1F0AF, 0x1F0B0}, {0x1F0C0, 0x1F0C0}, {0x1F0D0, 0x1F0D0}, {0x1F0F6, 0x1F0FF}, {0x1F1AE, 0x1F1E5}, {0x1F203, 0x1F20F}, {0x1F23C, 0x1F23F}, {0x1F249, 0x1F24F},
|
| 219 |
+
{0x1F252, 0x1F25F}, {0x1F266, 0x1F2FF}, {0x1F6D8, 0x1F6DF}, {0x1F6ED, 0x1F6EF}, {0x1F6FD, 0x1F6FF}, {0x1F774, 0x1F77F}, {0x1F7D9, 0x1F7DF}, {0x1F7EC, 0x1F7FF}, {0x1F80C, 0x1F80F}, {0x1F848, 0x1F84F},
|
| 220 |
+
{0x1F85A, 0x1F85F}, {0x1F888, 0x1F88F}, {0x1F8AE, 0x1F8AF}, {0x1F8B2, 0x1F8FF}, {0x1F979, 0x1F979}, {0x1F9CC, 0x1F9CC}, {0x1FA54, 0x1FA5F}, {0x1FA6E, 0x1FA6F}, {0x1FA75, 0x1FA77}, {0x1FA7B, 0x1FA7F},
|
| 221 |
+
{0x1FA87, 0x1FA8F}, {0x1FAA9, 0x1FAAF}, {0x1FAB7, 0x1FABF}, {0x1FAC3, 0x1FACF}, {0x1FAD7, 0x1FAFF}, {0x1FB93, 0x1FB93}, {0x1FBCB, 0x1FBEF}, {0x1FBFA, 0x1FFFF}, {0x2A6DE, 0x2A6FF}, {0x2B735, 0x2B73F},
|
| 222 |
+
{0x2B81E, 0x2B81F}, {0x2CEA2, 0x2CEAF}, {0x2EBE1, 0x2F7FF}, {0x2FA1E, 0x2FFFF}, {0x3134B, 0xE00FF}, {0xE01F0, 0x10FFFF},
|
| 223 |
+
};
|
| 224 |
+
|
| 225 |
+
static std::string codepoint_to_utf8(uint32_t cp) {
|
| 226 |
+
std::string result;
|
| 227 |
+
if (/* 0x00 <= cp && */ cp <= 0x7f) {
|
| 228 |
+
result.push_back(cp);
|
| 229 |
+
}
|
| 230 |
+
else if (0x80 <= cp && cp <= 0x7ff) {
|
| 231 |
+
result.push_back(0xc0 | ((cp >> 6) & 0x1f));
|
| 232 |
+
result.push_back(0x80 | (cp & 0x3f));
|
| 233 |
+
}
|
| 234 |
+
else if (0x800 <= cp && cp <= 0xffff) {
|
| 235 |
+
result.push_back(0xe0 | ((cp >> 12) & 0x0f));
|
| 236 |
+
result.push_back(0x80 | ((cp >> 6) & 0x3f));
|
| 237 |
+
result.push_back(0x80 | (cp & 0x3f));
|
| 238 |
+
}
|
| 239 |
+
else if (0x10000 <= cp && cp <= 0x10ffff) {
|
| 240 |
+
result.push_back(0xf0 | ((cp >> 18) & 0x07));
|
| 241 |
+
result.push_back(0x80 | ((cp >> 12) & 0x3f));
|
| 242 |
+
result.push_back(0x80 | ((cp >> 6) & 0x3f));
|
| 243 |
+
result.push_back(0x80 | (cp & 0x3f));
|
| 244 |
+
}
|
| 245 |
+
else {
|
| 246 |
+
throw std::invalid_argument("invalid codepoint");
|
| 247 |
+
}
|
| 248 |
+
return result;
|
| 249 |
+
}
|
| 250 |
+
|
| 251 |
+
static std::string codepoints_to_utf8(const std::vector<uint32_t> & cps) {
|
| 252 |
+
std::string result;
|
| 253 |
+
for (size_t i = 0; i < cps.size(); ++i) {
|
| 254 |
+
result.append(codepoint_to_utf8(cps[i]));
|
| 255 |
+
}
|
| 256 |
+
return result;
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
static uint32_t codepoint_from_utf8(const std::string & utf8, size_t & offset) {
|
| 260 |
+
assert(offset < utf8.size());
|
| 261 |
+
if (!(utf8[offset + 0] & 0x80)) {
|
| 262 |
+
auto result = utf8[offset + 0];
|
| 263 |
+
offset += 1;
|
| 264 |
+
return result;
|
| 265 |
+
}
|
| 266 |
+
else if (!(utf8[offset + 0] & 0x40)) {
|
| 267 |
+
throw std::invalid_argument("invalid character");
|
| 268 |
+
}
|
| 269 |
+
else if (!(utf8[offset + 0] & 0x20)) {
|
| 270 |
+
if (offset + 1 >= utf8.size() || ! ((utf8[offset + 1] & 0xc0) == 0x80))
|
| 271 |
+
throw std::invalid_argument("invalid character");
|
| 272 |
+
auto result = ((utf8[offset + 0] & 0x1f) << 6) | (utf8[offset + 1] & 0x3f);
|
| 273 |
+
offset += 2;
|
| 274 |
+
return result;
|
| 275 |
+
}
|
| 276 |
+
else if (!(utf8[offset + 0] & 0x10)) {
|
| 277 |
+
if (offset + 2 >= utf8.size() || ! ((utf8[offset + 1] & 0xc0) == 0x80) || ! ((utf8[offset + 2] & 0xc0) == 0x80))
|
| 278 |
+
throw std::invalid_argument("invalid character");
|
| 279 |
+
auto result = ((utf8[offset + 0] & 0x0f) << 12) | ((utf8[offset + 1] & 0x3f) << 6) | (utf8[offset + 2] & 0x3f);
|
| 280 |
+
offset += 3;
|
| 281 |
+
return result;
|
| 282 |
+
}
|
| 283 |
+
else if (!(utf8[offset + 0] & 0x08)) {
|
| 284 |
+
if (offset + 3 >= utf8.size() || ! ((utf8[offset + 1] & 0xc0) == 0x80) || ! ((utf8[offset + 2] & 0xc0) == 0x80) || !((utf8[offset + 3] & 0xc0) == 0x80))
|
| 285 |
+
throw std::invalid_argument("invalid character");
|
| 286 |
+
auto result = ((utf8[offset + 0] & 0x07) << 18) | ((utf8[offset + 1] & 0x3f) << 12) | ((utf8[offset + 2] & 0x3f) << 6) | (utf8[offset + 3] & 0x3f);
|
| 287 |
+
offset += 4;
|
| 288 |
+
return result;
|
| 289 |
+
}
|
| 290 |
+
throw std::invalid_argument("invalid string");
|
| 291 |
+
}
|
| 292 |
+
|
| 293 |
+
static std::vector<uint32_t> codepoints_from_utf8(const std::string & utf8) {
|
| 294 |
+
std::vector<uint32_t> result;
|
| 295 |
+
size_t offset = 0;
|
| 296 |
+
while (offset < utf8.size()) {
|
| 297 |
+
result.push_back(codepoint_from_utf8(utf8, offset));
|
| 298 |
+
}
|
| 299 |
+
return result;
|
| 300 |
+
}
|
| 301 |
+
|
| 302 |
+
static std::vector<uint16_t> codepoint_to_utf16(uint32_t cp) {
|
| 303 |
+
std::vector<uint16_t> result;
|
| 304 |
+
if (/* 0x0000 <= cp && */ cp <= 0xffff) {
|
| 305 |
+
result.emplace_back(cp);
|
| 306 |
+
}
|
| 307 |
+
else if (0x10000 <= cp && cp <= 0x10ffff) {
|
| 308 |
+
result.emplace_back(0xd800 | ((cp - 0x10000) >> 10));
|
| 309 |
+
result.emplace_back(0xdc00 | ((cp - 0x10000) & 0x03ff));
|
| 310 |
+
}
|
| 311 |
+
else {
|
| 312 |
+
throw std::invalid_argument("invalid codepoint");
|
| 313 |
+
}
|
| 314 |
+
return result;
|
| 315 |
+
}
|
| 316 |
+
|
| 317 |
+
static std::vector<uint16_t> codepoints_to_utf16(const std::vector<uint32_t> & cps) {
|
| 318 |
+
std::vector<uint16_t> result;
|
| 319 |
+
for (size_t i = 0; i < cps.size(); ++i) {
|
| 320 |
+
auto temp = codepoint_to_utf16(cps[i]);
|
| 321 |
+
result.insert(result.end(), temp.begin(), temp.end());
|
| 322 |
+
}
|
| 323 |
+
return result;
|
| 324 |
+
}
|
| 325 |
+
|
| 326 |
+
static uint32_t codepoint_from_utf16(const std::vector<uint16_t> & utf16, size_t & offset) {
|
| 327 |
+
assert(offset < utf16.size());
|
| 328 |
+
if (((utf16[0] >> 10) << 10) != 0xd800) {
|
| 329 |
+
auto result = utf16[offset + 0];
|
| 330 |
+
offset += 1;
|
| 331 |
+
return result;
|
| 332 |
+
}
|
| 333 |
+
else {
|
| 334 |
+
if (offset + 1 >= utf16.size() || !((utf16[1] & 0xdc00) == 0xdc00))
|
| 335 |
+
throw std::invalid_argument("invalid character");
|
| 336 |
+
auto result = 0x10000 + (((utf16[0] & 0x03ff) << 10) | (utf16[1] & 0x03ff));
|
| 337 |
+
offset += 2;
|
| 338 |
+
return result;
|
| 339 |
+
}
|
| 340 |
+
throw std::invalid_argument("invalid string");
|
| 341 |
+
}
|
| 342 |
+
|
| 343 |
+
static std::vector<uint32_t> codepoints_from_utf16(const std::vector<uint16_t> & utf16) {
|
| 344 |
+
std::vector<uint32_t> result;
|
| 345 |
+
size_t offset = 0;
|
| 346 |
+
while (offset < utf16.size())
|
| 347 |
+
result.push_back(codepoint_from_utf16(utf16, offset));
|
| 348 |
+
return result;
|
| 349 |
+
}
|
| 350 |
+
|
| 351 |
+
#define CODEPOINT_TYPE_UNIDENTIFIED 0
|
| 352 |
+
#define CODEPOINT_TYPE_DIGIT 1
|
| 353 |
+
#define CODEPOINT_TYPE_LETTER 2
|
| 354 |
+
#define CODEPOINT_TYPE_WHITESPACE 3
|
| 355 |
+
#define CODEPOINT_TYPE_ACCENT_MARK 4
|
| 356 |
+
#define CODEPOINT_TYPE_PUNCTUATION 5
|
| 357 |
+
#define CODEPOINT_TYPE_SYMBOL 6
|
| 358 |
+
#define CODEPOINT_TYPE_CONTROL 7
|
| 359 |
+
|
| 360 |
+
static std::unordered_map<uint32_t, int> codepoint_type_map() {
|
| 361 |
+
std::unordered_map<uint32_t, int> codepoint_types;
|
| 362 |
+
for (auto p : digit_ranges) {
|
| 363 |
+
for(auto i = p.first; i <= p.second; ++ i)
|
| 364 |
+
codepoint_types[i] = CODEPOINT_TYPE_DIGIT;
|
| 365 |
+
}
|
| 366 |
+
for(auto p : letter_ranges) {
|
| 367 |
+
for(auto i = p.first; i <= p.second; ++ i)
|
| 368 |
+
codepoint_types[i] = CODEPOINT_TYPE_LETTER;
|
| 369 |
+
}
|
| 370 |
+
for(auto p : whitespace_ranges) {
|
| 371 |
+
for(auto i = p.first; i <= p.second; ++ i)
|
| 372 |
+
codepoint_types[i] = CODEPOINT_TYPE_WHITESPACE;
|
| 373 |
+
}
|
| 374 |
+
for(auto p : accent_mark_ranges) {
|
| 375 |
+
for(auto i = p.first; i <= p.second; ++ i)
|
| 376 |
+
codepoint_types[i] = CODEPOINT_TYPE_ACCENT_MARK;
|
| 377 |
+
}
|
| 378 |
+
for(auto p : punctuation_ranges) {
|
| 379 |
+
for(auto i = p.first; i <= p.second; ++ i)
|
| 380 |
+
codepoint_types[i] = CODEPOINT_TYPE_PUNCTUATION;
|
| 381 |
+
}
|
| 382 |
+
for (auto p : symbol_ranges) {
|
| 383 |
+
for (auto i = p.first; i <= p.second; ++i)
|
| 384 |
+
codepoint_types[i] = CODEPOINT_TYPE_SYMBOL;
|
| 385 |
+
}
|
| 386 |
+
for(auto p : control_ranges) {
|
| 387 |
+
for(auto i = p.first; i <= p.second; ++ i)
|
| 388 |
+
codepoint_types[i] = CODEPOINT_TYPE_CONTROL;
|
| 389 |
+
}
|
| 390 |
+
return codepoint_types;
|
| 391 |
+
}
|
| 392 |
+
|
| 393 |
+
static int codepoint_type(uint32_t cp) {
|
| 394 |
+
static std::unordered_map<uint32_t, int> codepoint_types = codepoint_type_map();
|
| 395 |
+
return codepoint_types[cp];
|
| 396 |
+
}
|
| 397 |
+
|
| 398 |
+
static int codepoint_type(const std::string & utf8) {
|
| 399 |
+
if (utf8.length() == 0)
|
| 400 |
+
return CODEPOINT_TYPE_UNIDENTIFIED;
|
| 401 |
+
size_t offset = 0;
|
| 402 |
+
return codepoint_type(codepoint_from_utf8(utf8, offset));
|
| 403 |
+
}
|
| 404 |
+
|
| 405 |
+
static std::unordered_map<uint8_t, std::string> bytes_to_unicode_map_bpe() {
|
| 406 |
+
std::unordered_map<uint8_t, std::string> map;
|
| 407 |
+
for (int ch = u'!'; ch <= u'~'; ++ch) {
|
| 408 |
+
assert(0 <= ch && ch < 256);
|
| 409 |
+
map[ch] = codepoint_to_utf8(ch);
|
| 410 |
+
}
|
| 411 |
+
for (int ch = u'¡'; ch <= u'¬'; ++ch) {
|
| 412 |
+
assert(0 <= ch && ch < 256);
|
| 413 |
+
map[ch] = codepoint_to_utf8(ch);
|
| 414 |
+
}
|
| 415 |
+
for (int ch = u'®'; ch <= u'ÿ'; ++ch) {
|
| 416 |
+
assert(0 <= ch && ch < 256);
|
| 417 |
+
map[ch] = codepoint_to_utf8(ch);
|
| 418 |
+
}
|
| 419 |
+
auto n = 0;
|
| 420 |
+
for (int ch = 0; ch < 256; ++ch) {
|
| 421 |
+
if (map.find(ch) == map.end()) {
|
| 422 |
+
map[ch] = codepoint_to_utf8(256 + n);
|
| 423 |
+
++n;
|
| 424 |
+
}
|
| 425 |
+
}
|
| 426 |
+
return map;
|
| 427 |
+
}
|
| 428 |
+
|
| 429 |
+
static std::string bytes_to_unicode_bpe(uint8_t byte) {
|
| 430 |
+
static std::unordered_map<uint8_t, std::string> map = bytes_to_unicode_map_bpe();
|
| 431 |
+
return map.at(byte);
|
| 432 |
+
}
|
| 433 |
+
|
| 434 |
+
static std::unordered_map<std::string, uint8_t> unicode_to_bytes_map_bpe() {
|
| 435 |
+
std::unordered_map<std::string, uint8_t> map;
|
| 436 |
+
for (int ch = u'!'; ch <= u'~'; ++ch) {
|
| 437 |
+
assert(0 <= ch && ch < 256);
|
| 438 |
+
map[codepoint_to_utf8(ch)] = ch;
|
| 439 |
+
}
|
| 440 |
+
for (int ch = u'¡'; ch <= u'¬'; ++ch) {
|
| 441 |
+
assert(0 <= ch && ch < 256);
|
| 442 |
+
map[codepoint_to_utf8(ch)] = ch;
|
| 443 |
+
}
|
| 444 |
+
for (int ch = u'®'; ch <= u'ÿ'; ++ch) {
|
| 445 |
+
assert(0 <= ch && ch < 256);
|
| 446 |
+
map[codepoint_to_utf8(ch)] = ch;
|
| 447 |
+
}
|
| 448 |
+
auto n = 0;
|
| 449 |
+
for (int ch = 0; ch < 256; ++ch) {
|
| 450 |
+
if (map.find(codepoint_to_utf8(ch)) == map.end()) {
|
| 451 |
+
map[codepoint_to_utf8(256 + n)] = ch;
|
| 452 |
+
++n;
|
| 453 |
+
}
|
| 454 |
+
}
|
| 455 |
+
return map;
|
| 456 |
+
}
|
| 457 |
+
|
| 458 |
+
static uint8_t unicode_to_bytes_bpe(const std::string & utf8) {
|
| 459 |
+
static std::unordered_map<std::string, uint8_t> map = unicode_to_bytes_map_bpe();
|
| 460 |
+
return map.at(utf8);
|
| 461 |
+
}
|
| 462 |
+
|