Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse files- README.md +138 -7
- README_en.md +140 -0
- THUDM/glm-4-9b-chat/.gitattributes +35 -0
- THUDM/glm-4-9b-chat/LICENSE +84 -0
- THUDM/glm-4-9b-chat/README.md +171 -0
- THUDM/glm-4-9b-chat/README_en.md +167 -0
- THUDM/glm-4-9b-chat/config.json +45 -0
- THUDM/glm-4-9b-chat/configuration.json +1 -0
- THUDM/glm-4-9b-chat/configuration_chatglm.py +58 -0
- THUDM/glm-4-9b-chat/generation_config.json +13 -0
- THUDM/glm-4-9b-chat/model-00001-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00002-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00003-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00004-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00005-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00006-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00007-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00008-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00009-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model-00010-of-00010.safetensors +3 -0
- THUDM/glm-4-9b-chat/model.safetensors.index.json +291 -0
- THUDM/glm-4-9b-chat/modeling_chatglm.py +1215 -0
- THUDM/glm-4-9b-chat/tokenization_chatglm.py +323 -0
- THUDM/glm-4-9b-chat/tokenizer.model +3 -0
- THUDM/glm-4-9b-chat/tokenizer_config.json +133 -0
- openai_api_request.py +127 -0
- openai_api_server.py +635 -0
- requirements.txt +27 -0
- trans_batch_demo.py +90 -0
- trans_cli_demo.py +112 -0
- trans_cli_vision_demo.py +121 -0
- trans_cli_vision_gradio_demo.py +121 -0
- trans_stress_test.py +135 -0
- trans_web_demo.py +207 -0
- vllm_cli_demo.py +111 -0
README.md
CHANGED
|
@@ -1,12 +1,143 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: red
|
| 5 |
-
colorTo: blue
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 4.36.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Chatbot_ChatGLM4
|
| 3 |
+
app_file: trans_cli_vision_gradio_demo.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 4.36.1
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# Basic Demo
|
| 8 |
+
|
| 9 |
+
Read this in [English](README_en.md).
|
| 10 |
+
|
| 11 |
+
本 demo 中,你将体验到如何使用 GLM-4-9B 开源模型进行基本的任务。
|
| 12 |
+
|
| 13 |
+
请严格按照文档的步骤进行操作,以避免不必要的错误。
|
| 14 |
+
|
| 15 |
+
## 设备和依赖检查
|
| 16 |
+
|
| 17 |
+
### 相关推理测试数据
|
| 18 |
+
|
| 19 |
+
**本文档的数据均在以下硬件环境测试,实际运行环境需求和运行占用的显存略有不同,请以实际运行环境为准。**
|
| 20 |
+
|
| 21 |
+
测试硬件信息:
|
| 22 |
+
|
| 23 |
+
+ OS: Ubuntu 22.04
|
| 24 |
+
+ Memory: 512GB
|
| 25 |
+
+ Python: 3.10.12 (推荐) / 3.12.3 均已测试
|
| 26 |
+
+ CUDA Version: 12.3
|
| 27 |
+
+ GPU Driver: 535.104.05
|
| 28 |
+
+ GPU: NVIDIA A100-SXM4-80GB * 8
|
| 29 |
+
|
| 30 |
+
相关推理的压力测试数据如下:
|
| 31 |
+
|
| 32 |
+
**所有测试均在单张GPU上进行测试,所有显存消耗都按照峰值左右进行测算**
|
| 33 |
+
|
| 34 |
+
#### GLM-4-9B-Chat
|
| 35 |
+
|
| 36 |
+
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|
| 37 |
+
|------|-------|------------|---------------|--------------|
|
| 38 |
+
| BF16 | 19 GB | 0.2s | 27.8 tokens/s | 输入长度为 1000 |
|
| 39 |
+
| BF16 | 21 GB | 0.8s | 31.8 tokens/s | 输入长度为 8000 |
|
| 40 |
+
| BF16 | 28 GB | 4.3s | 14.4 tokens/s | 输入长度为 32000 |
|
| 41 |
+
| BF16 | 58 GB | 38.1s | 3.4 tokens/s | 输入长度为 128000 |
|
| 42 |
+
|
| 43 |
+
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|
| 44 |
+
|------|-------|------------|---------------|-------------|
|
| 45 |
+
| INT4 | 8 GB | 0.2s | 23.3 tokens/s | 输入长度为 1000 |
|
| 46 |
+
| INT4 | 10 GB | 0.8s | 23.4 tokens/s | 输入长度为 8000 |
|
| 47 |
+
| INT4 | 17 GB | 4.3s | 14.6 tokens/s | 输入长度为 32000 |
|
| 48 |
+
|
| 49 |
+
### GLM-4-9B-Chat-1M
|
| 50 |
+
|
| 51 |
+
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|
| 52 |
+
|------|-------|------------|--------------|--------------|
|
| 53 |
+
| BF16 | 75 GB | 98.4s | 2.3 tokens/s | 输入长度为 200000 |
|
| 54 |
+
|
| 55 |
+
如果您的输入超过200K,我们建议您使用vLLM后端进行多卡推理,以获得更好的性能。
|
| 56 |
+
|
| 57 |
+
#### GLM-4V-9B
|
| 58 |
+
|
| 59 |
+
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|
| 60 |
+
|------|-------|------------|---------------|------------|
|
| 61 |
+
| BF16 | 28 GB | 0.1s | 33.4 tokens/s | 输入长度为 1000 |
|
| 62 |
+
| BF16 | 33 GB | 0.7s | 39.2 tokens/s | 输入长度为 8000 |
|
| 63 |
+
|
| 64 |
+
| 精度 | 显存占用 | Prefilling | Decode Speed | Remarks |
|
| 65 |
+
|------|-------|------------|---------------|------------|
|
| 66 |
+
| INT4 | 10 GB | 0.1s | 28.7 tokens/s | 输入长度为 1000 |
|
| 67 |
+
| INT4 | 15 GB | 0.8s | 24.2 tokens/s | 输入长度为 8000 |
|
| 68 |
+
|
| 69 |
+
### 最低硬件要求
|
| 70 |
+
|
| 71 |
+
如果您希望运行官方提供的最基础代码 (transformers 后端) 您需要:
|
| 72 |
+
|
| 73 |
+
+ Python >= 3.10
|
| 74 |
+
+ 内存不少于 32 GB
|
| 75 |
+
|
| 76 |
+
如果您希望运行官方提供的本文件夹的所有代码,您还需要:
|
| 77 |
+
|
| 78 |
+
+ Linux 操作系统 (Debian 系列最佳)
|
| 79 |
+
+ 大于 8GB 显存的,支持 CUDA 或者 ROCM 并且支持 `BF16` 推理的 GPU 设备。(`FP16` 精度无法训练,推理有小概率出现问题)
|
| 80 |
+
|
| 81 |
+
安装依赖
|
| 82 |
+
|
| 83 |
+
```shell
|
| 84 |
+
pip install -r requirements.txt
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
## 基础功能调用
|
| 88 |
+
|
| 89 |
+
**除非特殊说明,本文件夹所有 demo 并不支持 Function Call 和 All Tools 等进阶用法**
|
| 90 |
+
|
| 91 |
+
### 使用 transformers 后端代码
|
| 92 |
+
|
| 93 |
+
+ 使用命令行与 GLM-4-9B 模型进行对话。
|
| 94 |
+
|
| 95 |
+
```shell
|
| 96 |
+
python trans_cli_demo.py # GLM-4-9B-Chat
|
| 97 |
+
python trans_cli_vision_demo.py # GLM-4V-9B
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
+ 使用 Gradio 网页端与 GLM-4-9B-Chat 模型进行对话。
|
| 101 |
+
|
| 102 |
+
```shell
|
| 103 |
+
python trans_web_demo.py
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
+ 使用 Batch 推理。
|
| 107 |
+
|
| 108 |
+
```shell
|
| 109 |
+
python cli_batch_request_demo.py
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
### 使用 vLLM 后端代码
|
| 113 |
+
|
| 114 |
+
+ 使用命令行与 GLM-4-9B-Chat 模型进行对话。
|
| 115 |
+
|
| 116 |
+
```shell
|
| 117 |
+
python vllm_cli_demo.py
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
+ 自行构建服务端,并使用 `OpenAI API` 的请求格式与 GLM-4-9B-Chat 模型进行对话。本 demo 支持 Function Call 和 All Tools功能。
|
| 121 |
+
|
| 122 |
+
启动服务端:
|
| 123 |
+
|
| 124 |
+
```shell
|
| 125 |
+
python openai_api_server.py
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
客户端请求:
|
| 129 |
+
|
| 130 |
+
```shell
|
| 131 |
+
python openai_api_request.py
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
## 压力测试
|
| 135 |
+
|
| 136 |
+
用户可以在自己的设备上使用本代码测试模型在 transformers后端的生成速度:
|
| 137 |
+
|
| 138 |
+
```shell
|
| 139 |
+
python trans_stress_test.py
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
|
| 143 |
|
|
|
README_en.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Basic Demo
|
| 2 |
+
|
| 3 |
+
In this demo, you will experience how to use the GLM-4-9B open source model to perform basic tasks.
|
| 4 |
+
|
| 5 |
+
Please follow the steps in the document strictly to avoid unnecessary errors.
|
| 6 |
+
|
| 7 |
+
## Device and dependency check
|
| 8 |
+
|
| 9 |
+
### Related inference test data
|
| 10 |
+
|
| 11 |
+
**The data in this document are tested in the following hardware environment. The actual operating environment
|
| 12 |
+
requirements and the GPU memory occupied by the operation are slightly different. Please refer to the actual operating
|
| 13 |
+
environment.**
|
| 14 |
+
|
| 15 |
+
Test hardware information:
|
| 16 |
+
|
| 17 |
+
+ OS: Ubuntu 22.04
|
| 18 |
+
+ Memory: 512GB
|
| 19 |
+
+ Python: 3.10.12 (recommend) / 3.12.3 have been tested
|
| 20 |
+
+ CUDA Version: 12.3
|
| 21 |
+
+ GPU Driver: 535.104.05
|
| 22 |
+
+ GPU: NVIDIA A100-SXM4-80GB * 8
|
| 23 |
+
|
| 24 |
+
The stress test data of relevant inference are as follows:
|
| 25 |
+
|
| 26 |
+
**All tests are performed on a single GPU, and all GPU memory consumption is calculated based on the peak value**
|
| 27 |
+
|
| 28 |
+
#
|
| 29 |
+
|
| 30 |
+
### GLM-4-9B-Chat
|
| 31 |
+
|
| 32 |
+
| Dtype | GPU Memory | Prefilling | Decode Speed | Remarks |
|
| 33 |
+
|-------|------------|------------|---------------|------------------------|
|
| 34 |
+
| BF16 | 19 GB | 0.2s | 27.8 tokens/s | Input length is 1000 |
|
| 35 |
+
| BF16 | 21 GB | 0.8s | 31.8 tokens/s | Input length is 8000 |
|
| 36 |
+
| BF16 | 28 GB | 4.3s | 14.4 tokens/s | Input length is 32000 |
|
| 37 |
+
| BF16 | 58 GB | 38.1s | 3.4 tokens/s | Input length is 128000 |
|
| 38 |
+
|
| 39 |
+
| Dtype | GPU Memory | Prefilling | Decode Speed | Remarks |
|
| 40 |
+
|-------|------------|------------|---------------|-----------------------|
|
| 41 |
+
| INT4 | 8 GB | 0.2s | 23.3 tokens/s | Input length is 1000 |
|
| 42 |
+
| INT4 | 10 GB | 0.8s | 23.4 tokens/s | Input length is 8000 |
|
| 43 |
+
| INT4 | 17 GB | 4.3s | 14.6 tokens/s | Input length is 32000 |
|
| 44 |
+
|
| 45 |
+
### GLM-4-9B-Chat-1M
|
| 46 |
+
|
| 47 |
+
| Dtype | GPU Memory | Prefilling | Decode Speed | Remarks |
|
| 48 |
+
|-------|------------|------------|------------------|------------------------|
|
| 49 |
+
| BF16 | 74497MiB | 98.4s | 2.3653 tokens/s | Input length is 200000 |
|
| 50 |
+
|
| 51 |
+
If your input exceeds 200K, we recommend that you use the vLLM backend with multi gpus for inference to get better
|
| 52 |
+
performance.
|
| 53 |
+
|
| 54 |
+
#### GLM-4V-9B
|
| 55 |
+
|
| 56 |
+
| Dtype | GPU Memory | Prefilling | Decode Speed | Remarks |
|
| 57 |
+
|-------|------------|------------|---------------|----------------------|
|
| 58 |
+
| BF16 | 28 GB | 0.1s | 33.4 tokens/s | Input length is 1000 |
|
| 59 |
+
| BF16 | 33 GB | 0.7s | 39.2 tokens/s | Input length is 8000 |
|
| 60 |
+
|
| 61 |
+
| Dtype | GPU Memory | Prefilling | Decode Speed | Remarks |
|
| 62 |
+
|-------|------------|------------|---------------|----------------------|
|
| 63 |
+
| INT4 | 10 GB | 0.1s | 28.7 tokens/s | Input length is 1000 |
|
| 64 |
+
| INT4 | 15 GB | 0.8s | 24.2 tokens/s | Input length is 8000 |
|
| 65 |
+
|
| 66 |
+
### Minimum hardware requirements
|
| 67 |
+
|
| 68 |
+
If you want to run the most basic code provided by the official (transformers backend) you need:
|
| 69 |
+
|
| 70 |
+
+ Python >= 3.10
|
| 71 |
+
+ Memory of at least 32 GB
|
| 72 |
+
|
| 73 |
+
If you want to run all the codes in this folder provided by the official, you also need:
|
| 74 |
+
|
| 75 |
+
+ Linux operating system (Debian series is best)
|
| 76 |
+
+ GPU device with more than 8GB GPU memory, supporting CUDA or ROCM and supporting `BF16` reasoning (`FP16` precision
|
| 77 |
+
cannot be finetuned, and there is a small probability of problems in infering)
|
| 78 |
+
|
| 79 |
+
Install dependencies
|
| 80 |
+
|
| 81 |
+
```shell
|
| 82 |
+
pip install -r requirements.txt
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## Basic function calls
|
| 86 |
+
|
| 87 |
+
**Unless otherwise specified, all demos in this folder do not support advanced usage such as Function Call and All Tools
|
| 88 |
+
**
|
| 89 |
+
|
| 90 |
+
### Use transformers backend code
|
| 91 |
+
|
| 92 |
+
+ Use the command line to communicate with the GLM-4-9B model.
|
| 93 |
+
|
| 94 |
+
```shell
|
| 95 |
+
python trans_cli_demo.py # GLM-4-9B-Chat
|
| 96 |
+
python trans_cli_vision_demo.py # GLM-4V-9B
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
+ Use the Gradio web client to communicate with the GLM-4-9B-Chat model.
|
| 100 |
+
|
| 101 |
+
```shell
|
| 102 |
+
python trans_web_demo.py
|
| 103 |
+
```
|
| 104 |
+
|
| 105 |
+
+ Use Batch inference.
|
| 106 |
+
|
| 107 |
+
```shell
|
| 108 |
+
python cli_batch_request_demo.py
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
### Use vLLM backend code
|
| 112 |
+
|
| 113 |
+
+ Use the command line to communicate with the GLM-4-9B-Chat model.
|
| 114 |
+
|
| 115 |
+
```shell
|
| 116 |
+
python vllm_cli_demo.py
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
+ Build the server by yourself and use the request format of `OpenAI API` to communicate with the glm-4-9b model. This
|
| 120 |
+
demo supports Function Call and All Tools functions.
|
| 121 |
+
|
| 122 |
+
Start the server:
|
| 123 |
+
|
| 124 |
+
```shell
|
| 125 |
+
python openai_api_server.py
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
Client request:
|
| 129 |
+
|
| 130 |
+
```shell
|
| 131 |
+
python openai_api_request.py
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
## Stress test
|
| 135 |
+
|
| 136 |
+
Users can use this code to test the generation speed of the model on the transformers backend on their own devices:
|
| 137 |
+
|
| 138 |
+
```shell
|
| 139 |
+
python trans_stress_test.py
|
| 140 |
+
```
|
THUDM/glm-4-9b-chat/.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
THUDM/glm-4-9b-chat/LICENSE
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The glm-4-9b License
|
| 2 |
+
|
| 3 |
+
1. 定义
|
| 4 |
+
|
| 5 |
+
“许可方”是指分发其软件的 glm-4-9b 模型团队。
|
| 6 |
+
“软件”是指根据本许可提供的 glm-4-9b 模型参数。
|
| 7 |
+
|
| 8 |
+
2. 许可授予
|
| 9 |
+
|
| 10 |
+
根据本许可的条款和条件,许可方特此授予您非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可。
|
| 11 |
+
本许可允许您免费使用本仓库中的所有开源模型进行学术研究,对于希望将模型用于商业目的的用户,需在[这里](https://open.bigmodel.cn/mla/form)完成登记。经过登记的用户可以免费使用本模型进行商业活动,但必须遵守本许可的所有条款和条件。
|
| 12 |
+
上述版权声明和本许可声明应包含在本软件的所有副本或重要部分中。
|
| 13 |
+
如果您分发或提供 THUDM / 智谱AI 关于 glm-4 开源模型的材料(或其任何衍生作品),或使用其中任何材料(包括 glm-4 系列的所有开源模型)的产品或服务,您应:
|
| 14 |
+
|
| 15 |
+
(A) 随任何此类 THUDM / 智谱AI 材料提供本协议的副本;
|
| 16 |
+
(B) 在相关网站、用户界面、博客文章、关于页面或产品文档上突出显示 “Built with glm-4”。
|
| 17 |
+
如果您使用 THUDM / 智谱AI的 glm-4 开源模型的材料来创建、训练、微调或以其他方式改进已分发或可用的 AI 模型,您还应在任何此类 AI 模型名称的开头添加 “glm-4”。
|
| 18 |
+
|
| 19 |
+
3. 限制
|
| 20 |
+
|
| 21 |
+
您不得出于任何军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建本软件的全部或部分衍生作品。
|
| 22 |
+
您不得利用本软件从事任何危害国家安全和国家统一,危害社会公共利益及公序良俗,侵犯他人商业秘密、知识产权、名誉权、肖像权、财产权等权益的行为。
|
| 23 |
+
您在使用中应遵循使用地所适用的法律法规政策、道德规范等要求。
|
| 24 |
+
|
| 25 |
+
4. 免责声明
|
| 26 |
+
|
| 27 |
+
本软件“按原样”提供,不提供任何明示或暗示的保证,包括但不限于对适销性、特定用途的适用性和非侵权性的保证。
|
| 28 |
+
在任何情况下,作者或版权持有人均不对任何索赔、损害或其他责任负责,无论是在合同诉讼、侵权行为还是其他方面,由软件或软件的使用或其他交易引起、由软件引起或与之相关
|
| 29 |
+
软件。
|
| 30 |
+
|
| 31 |
+
5. 责任限制
|
| 32 |
+
|
| 33 |
+
除适用法律禁止的范围外,在任何情况下且根据任何法律理论,无论是基于侵权行为、疏忽、合同、责任或其他原因,任何许可方均不对您承担任何直接、间接、特殊、偶然、示范性、
|
| 34 |
+
或间接损害,或任何其他商业损失,即使许可人已被告知此类损害的可能性。
|
| 35 |
+
|
| 36 |
+
6. 争议解决
|
| 37 |
+
|
| 38 |
+
本许可受中华人民共和国法律管辖并按其解释。 因本许可引起的或与本许可有关的任何争议应提交北京市海淀区人民法院。
|
| 39 |
+
请注意,许可证可能会更新到更全面的版本。 有关许可和版权的任何问题,请通过 [email protected] 与我们联系。
|
| 40 |
+
|
| 41 |
+
1. Definitions
|
| 42 |
+
|
| 43 |
+
“Licensor” means the glm-4-9b Model Team that distributes its Software.
|
| 44 |
+
“Software” means the glm-4-9b model parameters made available under this license.
|
| 45 |
+
|
| 46 |
+
2. License
|
| 47 |
+
|
| 48 |
+
Under the terms and conditions of this license, the Licensor hereby grants you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license.
|
| 49 |
+
This license allows you to use all open source models in this repository for free for academic research. For users who wish to use the models for commercial purposes, please do so [here](https://open.bigmodel.cn/mla/form)
|
| 50 |
+
Complete registration. Registered users are free to use this model for commercial activities, but must comply with all terms and conditions of this license.
|
| 51 |
+
The copyright notice and this license notice shall be included in all copies or substantial portions of the Software.
|
| 52 |
+
If you distribute or provide THUDM / Zhipu AI materials on the glm-4 open source model (or any derivative works thereof), or products or services that use any materials therein (including all open source models of the glm-4 series), you should:
|
| 53 |
+
|
| 54 |
+
(A) Provide a copy of this Agreement with any such THUDM/Zhipu AI Materials;
|
| 55 |
+
(B) Prominently display "Built with glm-4" on the relevant website, user interface, blog post, related page or product documentation.
|
| 56 |
+
If you use materials from THUDM/Zhipu AI's glm-4 model to create, train, operate, or otherwise improve assigned or available AI models, you should also add "glm-4" to the beginning of any such AI model name.
|
| 57 |
+
|
| 58 |
+
3. Restrictions
|
| 59 |
+
|
| 60 |
+
You are not allowed to use, copy, modify, merge, publish, distribute, copy or create all or part of the derivative works of this software for any military or illegal purposes.
|
| 61 |
+
You are not allowed to use this software to engage in any behavior that endangers national security and unity, endangers social public interests and public order, infringes on the rights and interests of others such as trade secrets, intellectual property rights, reputation rights, portrait rights, and property rights.
|
| 62 |
+
You should comply with the applicable laws, regulations, policies, ethical standards, and other requirements in the place of use during use.
|
| 63 |
+
|
| 64 |
+
4. Disclaimer
|
| 65 |
+
|
| 66 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
|
| 67 |
+
WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 68 |
+
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
|
| 69 |
+
OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 70 |
+
|
| 71 |
+
5. Limitation of Liability
|
| 72 |
+
|
| 73 |
+
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT,
|
| 74 |
+
NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL,
|
| 75 |
+
INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED
|
| 76 |
+
OF THE POSSIBILITY OF SUCH DAMAGES.
|
| 77 |
+
|
| 78 |
+
6. Dispute Resolution
|
| 79 |
+
|
| 80 |
+
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute
|
| 81 |
+
arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
|
| 82 |
+
|
| 83 |
+
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and
|
| 84 |
+
copyright, please contact us at [email protected].
|
THUDM/glm-4-9b-chat/README.md
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
license_name: glm-4
|
| 4 |
+
license_link: https://huggingface.co/THUDM/glm-4-9b-chat/blob/main/LICENSE
|
| 5 |
+
language:
|
| 6 |
+
- zh
|
| 7 |
+
- en
|
| 8 |
+
tags:
|
| 9 |
+
- glm
|
| 10 |
+
- chatglm
|
| 11 |
+
- thudm
|
| 12 |
+
inference: false
|
| 13 |
+
pipeline_tag: text-generation
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# GLM-4-9B-Chat
|
| 17 |
+
|
| 18 |
+
Read this in [English](README_en.md)
|
| 19 |
+
|
| 20 |
+
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,
|
| 21 |
+
**GLM-4-9B** 及其人类偏好对齐的版本 **GLM-4-9B-Chat** 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat
|
| 22 |
+
还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的
|
| 23 |
+
26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 **GLM-4-9B-Chat-1M** 模型和基于 GLM-4-9B 的多模态模型
|
| 24 |
+
GLM-4V-9B。**GLM-4V-9B** 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B
|
| 25 |
+
表现出超越 GPT-4-turbo-2024-04-09、Gemini
|
| 26 |
+
1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
|
| 27 |
+
|
| 28 |
+
## 评测结果
|
| 29 |
+
|
| 30 |
+
我们在一些经典任务上对 GLM-4-9B-Chat 模型进行了评测,并得到了如下的结果:
|
| 31 |
+
|
| 32 |
+
| Model | AlignBench-v2 | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NCB |
|
| 33 |
+
|:--------------------|:-------------:|:--------:|:------:|:----:|:------:|:-----:|:----:|:---------:|:----:|
|
| 34 |
+
| Llama-3-8B-Instruct | 5.12 | 8.00 | 68.58 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
|
| 35 |
+
| ChatGLM3-6B | 3.97 | 5.50 | 28.1 | 66.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
|
| 36 |
+
| GLM-4-9B-Chat | 6.61 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
|
| 37 |
+
|
| 38 |
+
### 长文本
|
| 39 |
+
|
| 40 |
+
在 1M 的上下文长度下进行[大海捞针实验](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py),结果如下:
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
在 LongBench-Chat 上对长文本能力进行了进一步评测,结果如下:
|
| 45 |
+
|
| 46 |
+
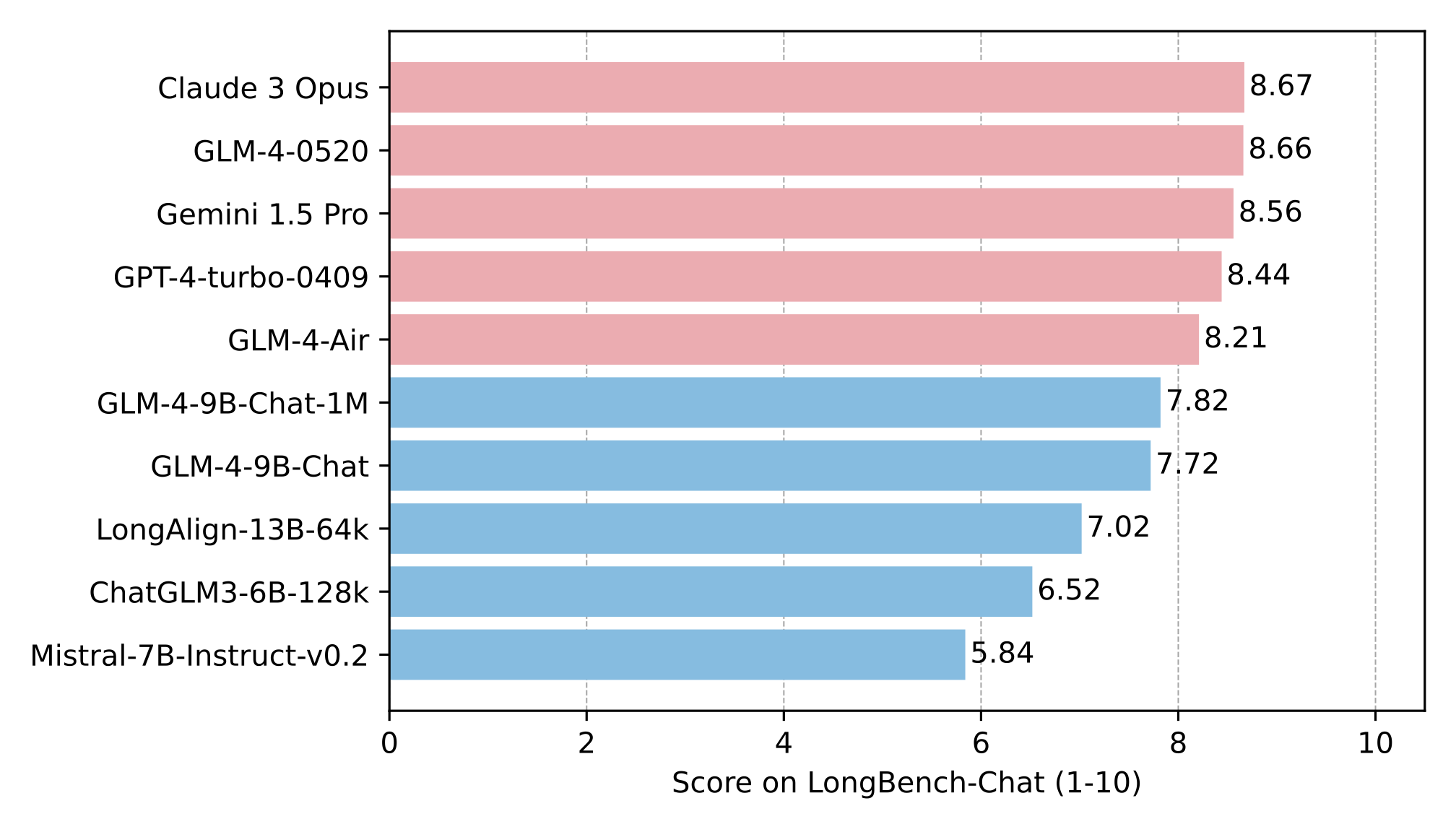
|
| 47 |
+
|
| 48 |
+
### 多语言能力
|
| 49 |
+
|
| 50 |
+
在六个多语言数据集上对 GLM-4-9B-Chat 和 Llama-3-8B-Instruct 进行了测试,测试结果及数据集对应选取语言如下表
|
| 51 |
+
|
| 52 |
+
| Dataset | Llama-3-8B-Instruct | GLM-4-9B-Chat | Languages |
|
| 53 |
+
|:------------|:-------------------:|:-------------:|:----------------------------------------------------------------------------------------------:|
|
| 54 |
+
| M-MMLU | 49.6 | 56.6 | all |
|
| 55 |
+
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
|
| 56 |
+
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th |
|
| 57 |
+
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt |
|
| 58 |
+
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te |
|
| 59 |
+
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
|
| 60 |
+
|
| 61 |
+
### 工具调用能力
|
| 62 |
+
|
| 63 |
+
我们在 [Berkeley Function Calling Leaderboard](https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard)
|
| 64 |
+
上进行了测试并得到了以下结果:
|
| 65 |
+
|
| 66 |
+
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|
| 67 |
+
|:-----------------------|:------------:|:-----------:|:------------:|:---------:|
|
| 68 |
+
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
|
| 69 |
+
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
|
| 70 |
+
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
|
| 71 |
+
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
|
| 72 |
+
|
| 73 |
+
**本仓库是 GLM-4-9B-Chat 的模型仓库,支持`128K`上下文长度。**
|
| 74 |
+
|
| 75 |
+
## 运行模型
|
| 76 |
+
|
| 77 |
+
使用 transformers 后端进行推理:
|
| 78 |
+
|
| 79 |
+
```python
|
| 80 |
+
import torch
|
| 81 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 82 |
+
|
| 83 |
+
device = "cuda"
|
| 84 |
+
|
| 85 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
|
| 86 |
+
|
| 87 |
+
query = "你好"
|
| 88 |
+
|
| 89 |
+
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
|
| 90 |
+
add_generation_prompt=True,
|
| 91 |
+
tokenize=True,
|
| 92 |
+
return_tensors="pt",
|
| 93 |
+
return_dict=True
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
inputs = inputs.to(device)
|
| 97 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 98 |
+
"THUDM/glm-4-9b-chat",
|
| 99 |
+
torch_dtype=torch.bfloat16,
|
| 100 |
+
low_cpu_mem_usage=True,
|
| 101 |
+
trust_remote_code=True
|
| 102 |
+
).to(device).eval()
|
| 103 |
+
|
| 104 |
+
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
|
| 105 |
+
with torch.no_grad():
|
| 106 |
+
outputs = model.generate(**inputs, **gen_kwargs)
|
| 107 |
+
outputs = outputs[:, inputs['input_ids'].shape[1]:]
|
| 108 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
使用 vLLM后端进行推理:
|
| 112 |
+
|
| 113 |
+
```python
|
| 114 |
+
from transformers import AutoTokenizer
|
| 115 |
+
from vllm import LLM, SamplingParams
|
| 116 |
+
|
| 117 |
+
# GLM-4-9B-Chat-1M
|
| 118 |
+
# max_model_len, tp_size = 1048576, 4
|
| 119 |
+
|
| 120 |
+
# GLM-4-9B-Chat
|
| 121 |
+
# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
|
| 122 |
+
max_model_len, tp_size = 131072, 1
|
| 123 |
+
model_name = "THUDM/glm-4-9b-chat"
|
| 124 |
+
prompt = [{"role": "user", "content": "你好"}]
|
| 125 |
+
|
| 126 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 127 |
+
llm = LLM(
|
| 128 |
+
model=model_name,
|
| 129 |
+
tensor_parallel_size=tp_size,
|
| 130 |
+
max_model_len=max_model_len,
|
| 131 |
+
trust_remote_code=True,
|
| 132 |
+
enforce_eager=True,
|
| 133 |
+
# GLM-4-9B-Chat-1M 如果遇见 OOM 现象,建议开启下述参数
|
| 134 |
+
# enable_chunked_prefill=True,
|
| 135 |
+
# max_num_batched_tokens=8192
|
| 136 |
+
)
|
| 137 |
+
stop_token_ids = [151329, 151336, 151338]
|
| 138 |
+
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
|
| 139 |
+
|
| 140 |
+
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
|
| 141 |
+
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
|
| 142 |
+
|
| 143 |
+
print(outputs[0].outputs[0].text)
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
## 协议
|
| 147 |
+
|
| 148 |
+
GLM-4 模型的权重的使用则需要遵循 [LICENSE](LICENSE)。
|
| 149 |
+
|
| 150 |
+
## 引用
|
| 151 |
+
|
| 152 |
+
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
|
| 153 |
+
|
| 154 |
+
```
|
| 155 |
+
@article{zeng2022glm,
|
| 156 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 157 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 158 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 159 |
+
year={2022}
|
| 160 |
+
}
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
```
|
| 164 |
+
@inproceedings{du2022glm,
|
| 165 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 166 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 167 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 168 |
+
pages={320--335},
|
| 169 |
+
year={2022}
|
| 170 |
+
}
|
| 171 |
+
```
|
THUDM/glm-4-9b-chat/README_en.md
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GLM-4-9B-Chat
|
| 2 |
+
|
| 3 |
+
## Model Introduction
|
| 4 |
+
|
| 5 |
+
GLM-4-9B is the open-source version of the latest generation of pre-trained models in the GLM-4 series launched by Zhipu
|
| 6 |
+
AI. In the evaluation of data sets in semantics, mathematics, reasoning, code, and knowledge, **GLM-4-9B**
|
| 7 |
+
and its human preference-aligned version **GLM-4-9B-Chat** have shown superior performance beyond Llama-3-8B. In
|
| 8 |
+
addition to multi-round conversations, GLM-4-9B-Chat also has advanced features such as web browsing, code execution,
|
| 9 |
+
custom tool calls (Function Call), and long text
|
| 10 |
+
reasoning (supporting up to 128K context). This generation of models has added multi-language support, supporting 26
|
| 11 |
+
languages including Japanese, Korean, and German. We have also launched the **GLM-4-9B-Chat-1M** model that supports 1M
|
| 12 |
+
context length (about 2 million Chinese characters) and the multimodal model GLM-4V-9B based on GLM-4-9B.
|
| 13 |
+
**GLM-4V-9B** possesses dialogue capabilities in both Chinese and English at a high resolution of 1120*1120.
|
| 14 |
+
In various multimodal evaluations, including comprehensive abilities in Chinese and English, perception & reasoning,
|
| 15 |
+
text recognition, and chart understanding, GLM-4V-9B demonstrates superior performance compared to
|
| 16 |
+
GPT-4-turbo-2024-04-09, Gemini 1.0 Pro, Qwen-VL-Max, and Claude 3 Opus.
|
| 17 |
+
|
| 18 |
+
## Benchmark
|
| 19 |
+
|
| 20 |
+
We evaluated the GLM-4-9B-Chat model on some classic tasks and obtained the following results:
|
| 21 |
+
|
| 22 |
+
| Model | AlignBench-v2 | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NCB |
|
| 23 |
+
|:--------------------|:-------------:|:--------:|:------:|:----:|:------:|:-----:|:----:|:---------:|:----:|
|
| 24 |
+
| Llama-3-8B-Instruct | 5.12 | 8.00 | 68.58 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
|
| 25 |
+
| ChatGLM3-6B | 3.97 | 5.50 | 28.1 | 66.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
|
| 26 |
+
| GLM-4-9B-Chat | 6.61 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
|
| 27 |
+
|
| 28 |
+
### Long Context
|
| 29 |
+
|
| 30 |
+
The [eval_needle experiment](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py) was conducted with
|
| 31 |
+
a context length of 1M, and the results are as follows:
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
The long text capability was further evaluated on LongBench, and the results are as follows:
|
| 36 |
+
|
| 37 |
+

|
| 38 |
+
|
| 39 |
+
### Multi Language
|
| 40 |
+
|
| 41 |
+
The tests for GLM-4-9B-Chat and Llama-3-8B-Instruct are conducted on six multilingual datasets. The test results and the
|
| 42 |
+
corresponding languages selected for each dataset are shown in the table below:
|
| 43 |
+
|
| 44 |
+
| Dataset | Llama-3-8B-Instruct | GLM-4-9B-Chat | Languages |
|
| 45 |
+
|:------------|:-------------------:|:-------------:|:----------------------------------------------------------------------------------------------:|
|
| 46 |
+
| M-MMLU | 49.6 | 56.6 | all |
|
| 47 |
+
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
|
| 48 |
+
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th |
|
| 49 |
+
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt |
|
| 50 |
+
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te |
|
| 51 |
+
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
|
| 52 |
+
|
| 53 |
+
### Function Call
|
| 54 |
+
|
| 55 |
+
Tested
|
| 56 |
+
on [Berkeley Function Calling Leaderboard](https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard).
|
| 57 |
+
|
| 58 |
+
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|
| 59 |
+
|:-----------------------|:------------:|:-----------:|:------------:|:---------:|
|
| 60 |
+
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
|
| 61 |
+
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
|
| 62 |
+
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
|
| 63 |
+
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
|
| 64 |
+
|
| 65 |
+
**This repository is the model repository of GLM-4-9B-Chat, supporting `128K` context length.**
|
| 66 |
+
|
| 67 |
+
## Quick call
|
| 68 |
+
|
| 69 |
+
**For hardware configuration and system requirements, please check [here](basic_demo/README_en.md).**
|
| 70 |
+
|
| 71 |
+
### Use the following method to quickly call the GLM-4-9B-Chat language model
|
| 72 |
+
|
| 73 |
+
Use the transformers backend for inference:
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
import torch
|
| 77 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 78 |
+
|
| 79 |
+
device = "cuda"
|
| 80 |
+
|
| 81 |
+
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
|
| 82 |
+
|
| 83 |
+
query = "Hello"
|
| 84 |
+
|
| 85 |
+
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
|
| 86 |
+
add_generation_prompt=True,
|
| 87 |
+
tokenize=True,
|
| 88 |
+
return_tensors="pt",
|
| 89 |
+
return_dict=True
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
inputs = inputs.to(device)
|
| 93 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 94 |
+
"THUDM/glm-4-9b-chat",
|
| 95 |
+
torch_dtype=torch.bfloat16,
|
| 96 |
+
low_cpu_mem_usage=True,
|
| 97 |
+
trust_remote_code=True
|
| 98 |
+
).to(device).eval()
|
| 99 |
+
|
| 100 |
+
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
|
| 101 |
+
with torch.no_grad():
|
| 102 |
+
outputs = model.generate(**inputs, **gen_kwargs)
|
| 103 |
+
outputs = outputs[:, inputs['input_ids'].shape[1]:]
|
| 104 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
Use the vLLM backend for inference:
|
| 108 |
+
|
| 109 |
+
```python
|
| 110 |
+
from transformers import AutoTokenizer
|
| 111 |
+
from vllm import LLM, SamplingParams
|
| 112 |
+
|
| 113 |
+
# GLM-4-9B-Chat-1M
|
| 114 |
+
# max_model_len, tp_size = 1048576, 4
|
| 115 |
+
|
| 116 |
+
# GLM-4-9B-Chat
|
| 117 |
+
# If you encounter OOM, it is recommended to reduce max_model_len or increase tp_size
|
| 118 |
+
max_model_len, tp_size = 131072, 1
|
| 119 |
+
model_name = "THUDM/glm-4-9b-chat"
|
| 120 |
+
prompt = [{"role": "user", "content": "hello"}]
|
| 121 |
+
|
| 122 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
| 123 |
+
llm = LLM(
|
| 124 |
+
model=model_name,
|
| 125 |
+
tensor_parallel_size=tp_size,
|
| 126 |
+
max_model_len=max_model_len,
|
| 127 |
+
trust_remote_code=True,
|
| 128 |
+
enforce_eager=True,
|
| 129 |
+
# GLM-4-9B-Chat-1M If you encounter OOM phenomenon, it is recommended to enable the following parameters
|
| 130 |
+
# enable_chunked_prefill=True,
|
| 131 |
+
# max_num_batched_tokens=8192
|
| 132 |
+
)
|
| 133 |
+
stop_token_ids = [151329, 151336, 151338]
|
| 134 |
+
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
|
| 135 |
+
|
| 136 |
+
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
|
| 137 |
+
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
|
| 138 |
+
|
| 139 |
+
print(outputs[0].outputs[0].text)
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
## LICENSE
|
| 143 |
+
|
| 144 |
+
The weights of the GLM-4 model are available under the terms of [LICENSE](LICENSE).
|
| 145 |
+
|
| 146 |
+
## Citations
|
| 147 |
+
|
| 148 |
+
If you find our work useful, please consider citing the following paper.
|
| 149 |
+
|
| 150 |
+
```
|
| 151 |
+
@article{zeng2022glm,
|
| 152 |
+
title={Glm-130b: An open bilingual pre-trained model},
|
| 153 |
+
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
| 154 |
+
journal={arXiv preprint arXiv:2210.02414},
|
| 155 |
+
year={2022}
|
| 156 |
+
}
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
@inproceedings{du2022glm,
|
| 161 |
+
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
| 162 |
+
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
| 163 |
+
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
| 164 |
+
pages={320--335},
|
| 165 |
+
year={2022}
|
| 166 |
+
}
|
| 167 |
+
```
|
THUDM/glm-4-9b-chat/config.json
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "THUDM/glm4-9b-chat",
|
| 3 |
+
"model_type": "chatglm",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"ChatGLMModel"
|
| 6 |
+
],
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
|
| 9 |
+
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
|
| 11 |
+
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
|
| 12 |
+
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
|
| 13 |
+
},
|
| 14 |
+
"add_bias_linear": false,
|
| 15 |
+
"add_qkv_bias": true,
|
| 16 |
+
"apply_query_key_layer_scaling": true,
|
| 17 |
+
"apply_residual_connection_post_layernorm": false,
|
| 18 |
+
"attention_dropout": 0.0,
|
| 19 |
+
"attention_softmax_in_fp32": true,
|
| 20 |
+
"bias_dropout_fusion": true,
|
| 21 |
+
"ffn_hidden_size": 13696,
|
| 22 |
+
"fp32_residual_connection": false,
|
| 23 |
+
"hidden_dropout": 0.0,
|
| 24 |
+
"hidden_size": 4096,
|
| 25 |
+
"kv_channels": 128,
|
| 26 |
+
"layernorm_epsilon": 1.5625e-07,
|
| 27 |
+
"multi_query_attention": true,
|
| 28 |
+
"multi_query_group_num": 2,
|
| 29 |
+
"num_attention_heads": 32,
|
| 30 |
+
"num_hidden_layers": 40,
|
| 31 |
+
"num_layers": 40,
|
| 32 |
+
"rope_ratio": 500,
|
| 33 |
+
"original_rope": true,
|
| 34 |
+
"padded_vocab_size": 151552,
|
| 35 |
+
"post_layer_norm": true,
|
| 36 |
+
"rmsnorm": true,
|
| 37 |
+
"seq_length": 131072,
|
| 38 |
+
"use_cache": true,
|
| 39 |
+
"torch_dtype": "bfloat16",
|
| 40 |
+
"transformers_version": "4.30.2",
|
| 41 |
+
"tie_word_embeddings": false,
|
| 42 |
+
"eos_token_id": [151329, 151336, 151338],
|
| 43 |
+
"pad_token_id": 151329
|
| 44 |
+
}
|
| 45 |
+
|
THUDM/glm-4-9b-chat/configuration.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"framework":"Pytorch","task":"nli"}
|
THUDM/glm-4-9b-chat/configuration_chatglm.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import PretrainedConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class ChatGLMConfig(PretrainedConfig):
|
| 5 |
+
model_type = "chatglm"
|
| 6 |
+
|
| 7 |
+
def __init__(
|
| 8 |
+
self,
|
| 9 |
+
num_layers=28,
|
| 10 |
+
padded_vocab_size=65024,
|
| 11 |
+
hidden_size=4096,
|
| 12 |
+
ffn_hidden_size=13696,
|
| 13 |
+
kv_channels=128,
|
| 14 |
+
num_attention_heads=32,
|
| 15 |
+
seq_length=2048,
|
| 16 |
+
hidden_dropout=0.0,
|
| 17 |
+
classifier_dropout=None,
|
| 18 |
+
attention_dropout=0.0,
|
| 19 |
+
layernorm_epsilon=1e-5,
|
| 20 |
+
rmsnorm=True,
|
| 21 |
+
apply_residual_connection_post_layernorm=False,
|
| 22 |
+
post_layer_norm=True,
|
| 23 |
+
add_bias_linear=False,
|
| 24 |
+
add_qkv_bias=False,
|
| 25 |
+
bias_dropout_fusion=True,
|
| 26 |
+
multi_query_attention=False,
|
| 27 |
+
multi_query_group_num=1,
|
| 28 |
+
rope_ratio=1,
|
| 29 |
+
apply_query_key_layer_scaling=True,
|
| 30 |
+
attention_softmax_in_fp32=True,
|
| 31 |
+
fp32_residual_connection=False,
|
| 32 |
+
**kwargs
|
| 33 |
+
):
|
| 34 |
+
self.num_layers = num_layers
|
| 35 |
+
self.vocab_size = padded_vocab_size
|
| 36 |
+
self.padded_vocab_size = padded_vocab_size
|
| 37 |
+
self.hidden_size = hidden_size
|
| 38 |
+
self.ffn_hidden_size = ffn_hidden_size
|
| 39 |
+
self.kv_channels = kv_channels
|
| 40 |
+
self.num_attention_heads = num_attention_heads
|
| 41 |
+
self.seq_length = seq_length
|
| 42 |
+
self.hidden_dropout = hidden_dropout
|
| 43 |
+
self.classifier_dropout = classifier_dropout
|
| 44 |
+
self.attention_dropout = attention_dropout
|
| 45 |
+
self.layernorm_epsilon = layernorm_epsilon
|
| 46 |
+
self.rmsnorm = rmsnorm
|
| 47 |
+
self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
|
| 48 |
+
self.post_layer_norm = post_layer_norm
|
| 49 |
+
self.add_bias_linear = add_bias_linear
|
| 50 |
+
self.add_qkv_bias = add_qkv_bias
|
| 51 |
+
self.bias_dropout_fusion = bias_dropout_fusion
|
| 52 |
+
self.multi_query_attention = multi_query_attention
|
| 53 |
+
self.multi_query_group_num = multi_query_group_num
|
| 54 |
+
self.rope_ratio = rope_ratio
|
| 55 |
+
self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
|
| 56 |
+
self.attention_softmax_in_fp32 = attention_softmax_in_fp32
|
| 57 |
+
self.fp32_residual_connection = fp32_residual_connection
|
| 58 |
+
super().__init__(**kwargs)
|
THUDM/glm-4-9b-chat/generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token_id": [
|
| 3 |
+
151329,
|
| 4 |
+
151336,
|
| 5 |
+
151338
|
| 6 |
+
],
|
| 7 |
+
"pad_token_id": 151329,
|
| 8 |
+
"do_sample": true,
|
| 9 |
+
"temperature": 0.8,
|
| 10 |
+
"max_length": 128000,
|
| 11 |
+
"top_p": 0.8,
|
| 12 |
+
"transformers_version": "4.38.2"
|
| 13 |
+
}
|
THUDM/glm-4-9b-chat/model-00001-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d0040c9cf0d4d0553c4156dbd890437788ba43237037e1f9c4a3c1a3ddfad1f6
|
| 3 |
+
size 1945161760
|
THUDM/glm-4-9b-chat/model-00002-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f9163d47c6e1073d68fb03f933122e2ece0b30ce43b5309da15b783e93a34ad4
|
| 3 |
+
size 1815217640
|
THUDM/glm-4-9b-chat/model-00003-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:28031e88b92dc942b47ac4dd0e73b2ce749fc87fc692a3ed72e1bdec74996968
|
| 3 |
+
size 1968291912
|
THUDM/glm-4-9b-chat/model-00004-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:708ef7836140bd1822253cae05f5891ea02cedbe4c8ef8b096f712cdfdc9b01e
|
| 3 |
+
size 1927406992
|
THUDM/glm-4-9b-chat/model-00005-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c390a67a568f7f3d440a3c3357b4d08c0539435ea6d7a36baa4a4f0274740ae5
|
| 3 |
+
size 1815217672
|
THUDM/glm-4-9b-chat/model-00006-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:32e0d285c514e750e78ae42630a498ec526db4caba993fc2ea7226069410d1e7
|
| 3 |
+
size 1968291952
|
THUDM/glm-4-9b-chat/model-00007-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:165687aa1873e91d13bf404ff91a4d702f79c5301f43c2645eabb45f17808cb2
|
| 3 |
+
size 1927406992
|
THUDM/glm-4-9b-chat/model-00008-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5388bffb210043271cded04b28a5fae2eeeb31b64b695b62638d9b856e322033
|
| 3 |
+
size 1815217672
|
THUDM/glm-4-9b-chat/model-00009-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:449241babb7ce69a835c121efa26d9fd8823554ed0c8acd2af6666f482dd6809
|
| 3 |
+
size 1968291952
|
THUDM/glm-4-9b-chat/model-00010-of-00010.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2544b92fc4f1cb511b31a6b06021a3136de0705436db6731d30ec5b8a2be80f6
|
| 3 |
+
size 1649436712
|
THUDM/glm-4-9b-chat/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,291 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 18799902784
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"transformer.embedding.word_embeddings.weight": "model-00001-of-00010.safetensors",
|
| 7 |
+
"transformer.encoder.final_layernorm.weight": "model-00010-of-00010.safetensors",
|
| 8 |
+
"transformer.encoder.layers.0.input_layernorm.weight": "model-00001-of-00010.safetensors",
|
| 9 |
+
"transformer.encoder.layers.0.mlp.dense_4h_to_h.weight": "model-00001-of-00010.safetensors",
|
| 10 |
+
"transformer.encoder.layers.0.mlp.dense_h_to_4h.weight": "model-00001-of-00010.safetensors",
|
| 11 |
+
"transformer.encoder.layers.0.post_attention_layernorm.weight": "model-00001-of-00010.safetensors",
|
| 12 |
+
"transformer.encoder.layers.0.self_attention.dense.weight": "model-00001-of-00010.safetensors",
|
| 13 |
+
"transformer.encoder.layers.0.self_attention.query_key_value.bias": "model-00001-of-00010.safetensors",
|
| 14 |
+
"transformer.encoder.layers.0.self_attention.query_key_value.weight": "model-00001-of-00010.safetensors",
|
| 15 |
+
"transformer.encoder.layers.1.input_layernorm.weight": "model-00001-of-00010.safetensors",
|
| 16 |
+
"transformer.encoder.layers.1.mlp.dense_4h_to_h.weight": "model-00002-of-00010.safetensors",
|
| 17 |
+
"transformer.encoder.layers.1.mlp.dense_h_to_4h.weight": "model-00001-of-00010.safetensors",
|
| 18 |
+
"transformer.encoder.layers.1.post_attention_layernorm.weight": "model-00001-of-00010.safetensors",
|
| 19 |
+
"transformer.encoder.layers.1.self_attention.dense.weight": "model-00001-of-00010.safetensors",
|
| 20 |
+
"transformer.encoder.layers.1.self_attention.query_key_value.bias": "model-00001-of-00010.safetensors",
|
| 21 |
+
"transformer.encoder.layers.1.self_attention.query_key_value.weight": "model-00001-of-00010.safetensors",
|
| 22 |
+
"transformer.encoder.layers.10.input_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 23 |
+
"transformer.encoder.layers.10.mlp.dense_4h_to_h.weight": "model-00003-of-00010.safetensors",
|
| 24 |
+
"transformer.encoder.layers.10.mlp.dense_h_to_4h.weight": "model-00003-of-00010.safetensors",
|
| 25 |
+
"transformer.encoder.layers.10.post_attention_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 26 |
+
"transformer.encoder.layers.10.self_attention.dense.weight": "model-00003-of-00010.safetensors",
|
| 27 |
+
"transformer.encoder.layers.10.self_attention.query_key_value.bias": "model-00003-of-00010.safetensors",
|
| 28 |
+
"transformer.encoder.layers.10.self_attention.query_key_value.weight": "model-00003-of-00010.safetensors",
|
| 29 |
+
"transformer.encoder.layers.11.input_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 30 |
+
"transformer.encoder.layers.11.mlp.dense_4h_to_h.weight": "model-00004-of-00010.safetensors",
|
| 31 |
+
"transformer.encoder.layers.11.mlp.dense_h_to_4h.weight": "model-00004-of-00010.safetensors",
|
| 32 |
+
"transformer.encoder.layers.11.post_attention_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 33 |
+
"transformer.encoder.layers.11.self_attention.dense.weight": "model-00004-of-00010.safetensors",
|
| 34 |
+
"transformer.encoder.layers.11.self_attention.query_key_value.bias": "model-00004-of-00010.safetensors",
|
| 35 |
+
"transformer.encoder.layers.11.self_attention.query_key_value.weight": "model-00004-of-00010.safetensors",
|
| 36 |
+
"transformer.encoder.layers.12.input_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 37 |
+
"transformer.encoder.layers.12.mlp.dense_4h_to_h.weight": "model-00004-of-00010.safetensors",
|
| 38 |
+
"transformer.encoder.layers.12.mlp.dense_h_to_4h.weight": "model-00004-of-00010.safetensors",
|
| 39 |
+
"transformer.encoder.layers.12.post_attention_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 40 |
+
"transformer.encoder.layers.12.self_attention.dense.weight": "model-00004-of-00010.safetensors",
|
| 41 |
+
"transformer.encoder.layers.12.self_attention.query_key_value.bias": "model-00004-of-00010.safetensors",
|
| 42 |
+
"transformer.encoder.layers.12.self_attention.query_key_value.weight": "model-00004-of-00010.safetensors",
|
| 43 |
+
"transformer.encoder.layers.13.input_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 44 |
+
"transformer.encoder.layers.13.mlp.dense_4h_to_h.weight": "model-00004-of-00010.safetensors",
|
| 45 |
+
"transformer.encoder.layers.13.mlp.dense_h_to_4h.weight": "model-00004-of-00010.safetensors",
|
| 46 |
+
"transformer.encoder.layers.13.post_attention_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 47 |
+
"transformer.encoder.layers.13.self_attention.dense.weight": "model-00004-of-00010.safetensors",
|
| 48 |
+
"transformer.encoder.layers.13.self_attention.query_key_value.bias": "model-00004-of-00010.safetensors",
|
| 49 |
+
"transformer.encoder.layers.13.self_attention.query_key_value.weight": "model-00004-of-00010.safetensors",
|
| 50 |
+
"transformer.encoder.layers.14.input_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 51 |
+
"transformer.encoder.layers.14.mlp.dense_4h_to_h.weight": "model-00004-of-00010.safetensors",
|
| 52 |
+
"transformer.encoder.layers.14.mlp.dense_h_to_4h.weight": "model-00004-of-00010.safetensors",
|
| 53 |
+
"transformer.encoder.layers.14.post_attention_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 54 |
+
"transformer.encoder.layers.14.self_attention.dense.weight": "model-00004-of-00010.safetensors",
|
| 55 |
+
"transformer.encoder.layers.14.self_attention.query_key_value.bias": "model-00004-of-00010.safetensors",
|
| 56 |
+
"transformer.encoder.layers.14.self_attention.query_key_value.weight": "model-00004-of-00010.safetensors",
|
| 57 |
+
"transformer.encoder.layers.15.input_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 58 |
+
"transformer.encoder.layers.15.mlp.dense_4h_to_h.weight": "model-00005-of-00010.safetensors",
|
| 59 |
+
"transformer.encoder.layers.15.mlp.dense_h_to_4h.weight": "model-00004-of-00010.safetensors",
|
| 60 |
+
"transformer.encoder.layers.15.post_attention_layernorm.weight": "model-00004-of-00010.safetensors",
|
| 61 |
+
"transformer.encoder.layers.15.self_attention.dense.weight": "model-00004-of-00010.safetensors",
|
| 62 |
+
"transformer.encoder.layers.15.self_attention.query_key_value.bias": "model-00004-of-00010.safetensors",
|
| 63 |
+
"transformer.encoder.layers.15.self_attention.query_key_value.weight": "model-00004-of-00010.safetensors",
|
| 64 |
+
"transformer.encoder.layers.16.input_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 65 |
+
"transformer.encoder.layers.16.mlp.dense_4h_to_h.weight": "model-00005-of-00010.safetensors",
|
| 66 |
+
"transformer.encoder.layers.16.mlp.dense_h_to_4h.weight": "model-00005-of-00010.safetensors",
|
| 67 |
+
"transformer.encoder.layers.16.post_attention_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 68 |
+
"transformer.encoder.layers.16.self_attention.dense.weight": "model-00005-of-00010.safetensors",
|
| 69 |
+
"transformer.encoder.layers.16.self_attention.query_key_value.bias": "model-00005-of-00010.safetensors",
|
| 70 |
+
"transformer.encoder.layers.16.self_attention.query_key_value.weight": "model-00005-of-00010.safetensors",
|
| 71 |
+
"transformer.encoder.layers.17.input_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 72 |
+
"transformer.encoder.layers.17.mlp.dense_4h_to_h.weight": "model-00005-of-00010.safetensors",
|
| 73 |
+
"transformer.encoder.layers.17.mlp.dense_h_to_4h.weight": "model-00005-of-00010.safetensors",
|
| 74 |
+
"transformer.encoder.layers.17.post_attention_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 75 |
+
"transformer.encoder.layers.17.self_attention.dense.weight": "model-00005-of-00010.safetensors",
|
| 76 |
+
"transformer.encoder.layers.17.self_attention.query_key_value.bias": "model-00005-of-00010.safetensors",
|
| 77 |
+
"transformer.encoder.layers.17.self_attention.query_key_value.weight": "model-00005-of-00010.safetensors",
|
| 78 |
+
"transformer.encoder.layers.18.input_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 79 |
+
"transformer.encoder.layers.18.mlp.dense_4h_to_h.weight": "model-00005-of-00010.safetensors",
|
| 80 |
+
"transformer.encoder.layers.18.mlp.dense_h_to_4h.weight": "model-00005-of-00010.safetensors",
|
| 81 |
+
"transformer.encoder.layers.18.post_attention_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 82 |
+
"transformer.encoder.layers.18.self_attention.dense.weight": "model-00005-of-00010.safetensors",
|
| 83 |
+
"transformer.encoder.layers.18.self_attention.query_key_value.bias": "model-00005-of-00010.safetensors",
|
| 84 |
+
"transformer.encoder.layers.18.self_attention.query_key_value.weight": "model-00005-of-00010.safetensors",
|
| 85 |
+
"transformer.encoder.layers.19.input_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 86 |
+
"transformer.encoder.layers.19.mlp.dense_4h_to_h.weight": "model-00005-of-00010.safetensors",
|
| 87 |
+
"transformer.encoder.layers.19.mlp.dense_h_to_4h.weight": "model-00005-of-00010.safetensors",
|
| 88 |
+
"transformer.encoder.layers.19.post_attention_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 89 |
+
"transformer.encoder.layers.19.self_attention.dense.weight": "model-00005-of-00010.safetensors",
|
| 90 |
+
"transformer.encoder.layers.19.self_attention.query_key_value.bias": "model-00005-of-00010.safetensors",
|
| 91 |
+
"transformer.encoder.layers.19.self_attention.query_key_value.weight": "model-00005-of-00010.safetensors",
|
| 92 |
+
"transformer.encoder.layers.2.input_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 93 |
+
"transformer.encoder.layers.2.mlp.dense_4h_to_h.weight": "model-00002-of-00010.safetensors",
|
| 94 |
+
"transformer.encoder.layers.2.mlp.dense_h_to_4h.weight": "model-00002-of-00010.safetensors",
|
| 95 |
+
"transformer.encoder.layers.2.post_attention_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 96 |
+
"transformer.encoder.layers.2.self_attention.dense.weight": "model-00002-of-00010.safetensors",
|
| 97 |
+
"transformer.encoder.layers.2.self_attention.query_key_value.bias": "model-00002-of-00010.safetensors",
|
| 98 |
+
"transformer.encoder.layers.2.self_attention.query_key_value.weight": "model-00002-of-00010.safetensors",
|
| 99 |
+
"transformer.encoder.layers.20.input_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 100 |
+
"transformer.encoder.layers.20.mlp.dense_4h_to_h.weight": "model-00006-of-00010.safetensors",
|
| 101 |
+
"transformer.encoder.layers.20.mlp.dense_h_to_4h.weight": "model-00006-of-00010.safetensors",
|
| 102 |
+
"transformer.encoder.layers.20.post_attention_layernorm.weight": "model-00005-of-00010.safetensors",
|
| 103 |
+
"transformer.encoder.layers.20.self_attention.dense.weight": "model-00005-of-00010.safetensors",
|
| 104 |
+
"transformer.encoder.layers.20.self_attention.query_key_value.bias": "model-00005-of-00010.safetensors",
|
| 105 |
+
"transformer.encoder.layers.20.self_attention.query_key_value.weight": "model-00005-of-00010.safetensors",
|
| 106 |
+
"transformer.encoder.layers.21.input_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 107 |
+
"transformer.encoder.layers.21.mlp.dense_4h_to_h.weight": "model-00006-of-00010.safetensors",
|
| 108 |
+
"transformer.encoder.layers.21.mlp.dense_h_to_4h.weight": "model-00006-of-00010.safetensors",
|
| 109 |
+
"transformer.encoder.layers.21.post_attention_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 110 |
+
"transformer.encoder.layers.21.self_attention.dense.weight": "model-00006-of-00010.safetensors",
|
| 111 |
+
"transformer.encoder.layers.21.self_attention.query_key_value.bias": "model-00006-of-00010.safetensors",
|
| 112 |
+
"transformer.encoder.layers.21.self_attention.query_key_value.weight": "model-00006-of-00010.safetensors",
|
| 113 |
+
"transformer.encoder.layers.22.input_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 114 |
+
"transformer.encoder.layers.22.mlp.dense_4h_to_h.weight": "model-00006-of-00010.safetensors",
|
| 115 |
+
"transformer.encoder.layers.22.mlp.dense_h_to_4h.weight": "model-00006-of-00010.safetensors",
|
| 116 |
+
"transformer.encoder.layers.22.post_attention_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 117 |
+
"transformer.encoder.layers.22.self_attention.dense.weight": "model-00006-of-00010.safetensors",
|
| 118 |
+
"transformer.encoder.layers.22.self_attention.query_key_value.bias": "model-00006-of-00010.safetensors",
|
| 119 |
+
"transformer.encoder.layers.22.self_attention.query_key_value.weight": "model-00006-of-00010.safetensors",
|
| 120 |
+
"transformer.encoder.layers.23.input_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 121 |
+
"transformer.encoder.layers.23.mlp.dense_4h_to_h.weight": "model-00006-of-00010.safetensors",
|
| 122 |
+
"transformer.encoder.layers.23.mlp.dense_h_to_4h.weight": "model-00006-of-00010.safetensors",
|
| 123 |
+
"transformer.encoder.layers.23.post_attention_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 124 |
+
"transformer.encoder.layers.23.self_attention.dense.weight": "model-00006-of-00010.safetensors",
|
| 125 |
+
"transformer.encoder.layers.23.self_attention.query_key_value.bias": "model-00006-of-00010.safetensors",
|
| 126 |
+
"transformer.encoder.layers.23.self_attention.query_key_value.weight": "model-00006-of-00010.safetensors",
|
| 127 |
+
"transformer.encoder.layers.24.input_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 128 |
+
"transformer.encoder.layers.24.mlp.dense_4h_to_h.weight": "model-00006-of-00010.safetensors",
|
| 129 |
+
"transformer.encoder.layers.24.mlp.dense_h_to_4h.weight": "model-00006-of-00010.safetensors",
|
| 130 |
+
"transformer.encoder.layers.24.post_attention_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 131 |
+
"transformer.encoder.layers.24.self_attention.dense.weight": "model-00006-of-00010.safetensors",
|
| 132 |
+
"transformer.encoder.layers.24.self_attention.query_key_value.bias": "model-00006-of-00010.safetensors",
|
| 133 |
+
"transformer.encoder.layers.24.self_attention.query_key_value.weight": "model-00006-of-00010.safetensors",
|
| 134 |
+
"transformer.encoder.layers.25.input_layernorm.weight": "model-00006-of-00010.safetensors",
|
| 135 |
+
"transformer.encoder.layers.25.mlp.dense_4h_to_h.weight": "model-00007-of-00010.safetensors",
|
| 136 |
+
"transformer.encoder.layers.25.mlp.dense_h_to_4h.weight": "model-00007-of-00010.safetensors",
|
| 137 |
+
"transformer.encoder.layers.25.post_attention_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 138 |
+
"transformer.encoder.layers.25.self_attention.dense.weight": "model-00007-of-00010.safetensors",
|
| 139 |
+
"transformer.encoder.layers.25.self_attention.query_key_value.bias": "model-00007-of-00010.safetensors",
|
| 140 |
+
"transformer.encoder.layers.25.self_attention.query_key_value.weight": "model-00007-of-00010.safetensors",
|
| 141 |
+
"transformer.encoder.layers.26.input_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 142 |
+
"transformer.encoder.layers.26.mlp.dense_4h_to_h.weight": "model-00007-of-00010.safetensors",
|
| 143 |
+
"transformer.encoder.layers.26.mlp.dense_h_to_4h.weight": "model-00007-of-00010.safetensors",
|
| 144 |
+
"transformer.encoder.layers.26.post_attention_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 145 |
+
"transformer.encoder.layers.26.self_attention.dense.weight": "model-00007-of-00010.safetensors",
|
| 146 |
+
"transformer.encoder.layers.26.self_attention.query_key_value.bias": "model-00007-of-00010.safetensors",
|
| 147 |
+
"transformer.encoder.layers.26.self_attention.query_key_value.weight": "model-00007-of-00010.safetensors",
|
| 148 |
+
"transformer.encoder.layers.27.input_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 149 |
+
"transformer.encoder.layers.27.mlp.dense_4h_to_h.weight": "model-00007-of-00010.safetensors",
|
| 150 |
+
"transformer.encoder.layers.27.mlp.dense_h_to_4h.weight": "model-00007-of-00010.safetensors",
|
| 151 |
+
"transformer.encoder.layers.27.post_attention_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 152 |
+
"transformer.encoder.layers.27.self_attention.dense.weight": "model-00007-of-00010.safetensors",
|
| 153 |
+
"transformer.encoder.layers.27.self_attention.query_key_value.bias": "model-00007-of-00010.safetensors",
|
| 154 |
+
"transformer.encoder.layers.27.self_attention.query_key_value.weight": "model-00007-of-00010.safetensors",
|
| 155 |
+
"transformer.encoder.layers.28.input_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 156 |
+
"transformer.encoder.layers.28.mlp.dense_4h_to_h.weight": "model-00007-of-00010.safetensors",
|
| 157 |
+
"transformer.encoder.layers.28.mlp.dense_h_to_4h.weight": "model-00007-of-00010.safetensors",
|
| 158 |
+
"transformer.encoder.layers.28.post_attention_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 159 |
+
"transformer.encoder.layers.28.self_attention.dense.weight": "model-00007-of-00010.safetensors",
|
| 160 |
+
"transformer.encoder.layers.28.self_attention.query_key_value.bias": "model-00007-of-00010.safetensors",
|
| 161 |
+
"transformer.encoder.layers.28.self_attention.query_key_value.weight": "model-00007-of-00010.safetensors",
|
| 162 |
+
"transformer.encoder.layers.29.input_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 163 |
+
"transformer.encoder.layers.29.mlp.dense_4h_to_h.weight": "model-00008-of-00010.safetensors",
|
| 164 |
+
"transformer.encoder.layers.29.mlp.dense_h_to_4h.weight": "model-00007-of-00010.safetensors",
|
| 165 |
+
"transformer.encoder.layers.29.post_attention_layernorm.weight": "model-00007-of-00010.safetensors",
|
| 166 |
+
"transformer.encoder.layers.29.self_attention.dense.weight": "model-00007-of-00010.safetensors",
|
| 167 |
+
"transformer.encoder.layers.29.self_attention.query_key_value.bias": "model-00007-of-00010.safetensors",
|
| 168 |
+
"transformer.encoder.layers.29.self_attention.query_key_value.weight": "model-00007-of-00010.safetensors",
|
| 169 |
+
"transformer.encoder.layers.3.input_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 170 |
+
"transformer.encoder.layers.3.mlp.dense_4h_to_h.weight": "model-00002-of-00010.safetensors",
|
| 171 |
+
"transformer.encoder.layers.3.mlp.dense_h_to_4h.weight": "model-00002-of-00010.safetensors",
|
| 172 |
+
"transformer.encoder.layers.3.post_attention_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 173 |
+
"transformer.encoder.layers.3.self_attention.dense.weight": "model-00002-of-00010.safetensors",
|
| 174 |
+
"transformer.encoder.layers.3.self_attention.query_key_value.bias": "model-00002-of-00010.safetensors",
|
| 175 |
+
"transformer.encoder.layers.3.self_attention.query_key_value.weight": "model-00002-of-00010.safetensors",
|
| 176 |
+
"transformer.encoder.layers.30.input_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 177 |
+
"transformer.encoder.layers.30.mlp.dense_4h_to_h.weight": "model-00008-of-00010.safetensors",
|
| 178 |
+
"transformer.encoder.layers.30.mlp.dense_h_to_4h.weight": "model-00008-of-00010.safetensors",
|
| 179 |
+
"transformer.encoder.layers.30.post_attention_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 180 |
+
"transformer.encoder.layers.30.self_attention.dense.weight": "model-00008-of-00010.safetensors",
|
| 181 |
+
"transformer.encoder.layers.30.self_attention.query_key_value.bias": "model-00008-of-00010.safetensors",
|
| 182 |
+
"transformer.encoder.layers.30.self_attention.query_key_value.weight": "model-00008-of-00010.safetensors",
|
| 183 |
+
"transformer.encoder.layers.31.input_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 184 |
+
"transformer.encoder.layers.31.mlp.dense_4h_to_h.weight": "model-00008-of-00010.safetensors",
|
| 185 |
+
"transformer.encoder.layers.31.mlp.dense_h_to_4h.weight": "model-00008-of-00010.safetensors",
|
| 186 |
+
"transformer.encoder.layers.31.post_attention_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 187 |
+
"transformer.encoder.layers.31.self_attention.dense.weight": "model-00008-of-00010.safetensors",
|
| 188 |
+
"transformer.encoder.layers.31.self_attention.query_key_value.bias": "model-00008-of-00010.safetensors",
|
| 189 |
+
"transformer.encoder.layers.31.self_attention.query_key_value.weight": "model-00008-of-00010.safetensors",
|
| 190 |
+
"transformer.encoder.layers.32.input_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 191 |
+
"transformer.encoder.layers.32.mlp.dense_4h_to_h.weight": "model-00008-of-00010.safetensors",
|
| 192 |
+
"transformer.encoder.layers.32.mlp.dense_h_to_4h.weight": "model-00008-of-00010.safetensors",
|
| 193 |
+
"transformer.encoder.layers.32.post_attention_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 194 |
+
"transformer.encoder.layers.32.self_attention.dense.weight": "model-00008-of-00010.safetensors",
|
| 195 |
+
"transformer.encoder.layers.32.self_attention.query_key_value.bias": "model-00008-of-00010.safetensors",
|
| 196 |
+
"transformer.encoder.layers.32.self_attention.query_key_value.weight": "model-00008-of-00010.safetensors",
|
| 197 |
+
"transformer.encoder.layers.33.input_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 198 |
+
"transformer.encoder.layers.33.mlp.dense_4h_to_h.weight": "model-00008-of-00010.safetensors",
|
| 199 |
+
"transformer.encoder.layers.33.mlp.dense_h_to_4h.weight": "model-00008-of-00010.safetensors",
|
| 200 |
+
"transformer.encoder.layers.33.post_attention_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 201 |
+
"transformer.encoder.layers.33.self_attention.dense.weight": "model-00008-of-00010.safetensors",
|
| 202 |
+
"transformer.encoder.layers.33.self_attention.query_key_value.bias": "model-00008-of-00010.safetensors",
|
| 203 |
+
"transformer.encoder.layers.33.self_attention.query_key_value.weight": "model-00008-of-00010.safetensors",
|
| 204 |
+
"transformer.encoder.layers.34.input_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 205 |
+
"transformer.encoder.layers.34.mlp.dense_4h_to_h.weight": "model-00009-of-00010.safetensors",
|
| 206 |
+
"transformer.encoder.layers.34.mlp.dense_h_to_4h.weight": "model-00009-of-00010.safetensors",
|
| 207 |
+
"transformer.encoder.layers.34.post_attention_layernorm.weight": "model-00008-of-00010.safetensors",
|
| 208 |
+
"transformer.encoder.layers.34.self_attention.dense.weight": "model-00008-of-00010.safetensors",
|
| 209 |
+
"transformer.encoder.layers.34.self_attention.query_key_value.bias": "model-00008-of-00010.safetensors",
|
| 210 |
+
"transformer.encoder.layers.34.self_attention.query_key_value.weight": "model-00008-of-00010.safetensors",
|
| 211 |
+
"transformer.encoder.layers.35.input_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 212 |
+
"transformer.encoder.layers.35.mlp.dense_4h_to_h.weight": "model-00009-of-00010.safetensors",
|
| 213 |
+
"transformer.encoder.layers.35.mlp.dense_h_to_4h.weight": "model-00009-of-00010.safetensors",
|
| 214 |
+
"transformer.encoder.layers.35.post_attention_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 215 |
+
"transformer.encoder.layers.35.self_attention.dense.weight": "model-00009-of-00010.safetensors",
|
| 216 |
+
"transformer.encoder.layers.35.self_attention.query_key_value.bias": "model-00009-of-00010.safetensors",
|
| 217 |
+
"transformer.encoder.layers.35.self_attention.query_key_value.weight": "model-00009-of-00010.safetensors",
|
| 218 |
+
"transformer.encoder.layers.36.input_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 219 |
+
"transformer.encoder.layers.36.mlp.dense_4h_to_h.weight": "model-00009-of-00010.safetensors",
|
| 220 |
+
"transformer.encoder.layers.36.mlp.dense_h_to_4h.weight": "model-00009-of-00010.safetensors",
|
| 221 |
+
"transformer.encoder.layers.36.post_attention_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 222 |
+
"transformer.encoder.layers.36.self_attention.dense.weight": "model-00009-of-00010.safetensors",
|
| 223 |
+
"transformer.encoder.layers.36.self_attention.query_key_value.bias": "model-00009-of-00010.safetensors",
|
| 224 |
+
"transformer.encoder.layers.36.self_attention.query_key_value.weight": "model-00009-of-00010.safetensors",
|
| 225 |
+
"transformer.encoder.layers.37.input_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 226 |
+
"transformer.encoder.layers.37.mlp.dense_4h_to_h.weight": "model-00009-of-00010.safetensors",
|
| 227 |
+
"transformer.encoder.layers.37.mlp.dense_h_to_4h.weight": "model-00009-of-00010.safetensors",
|
| 228 |
+
"transformer.encoder.layers.37.post_attention_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 229 |
+
"transformer.encoder.layers.37.self_attention.dense.weight": "model-00009-of-00010.safetensors",
|
| 230 |
+
"transformer.encoder.layers.37.self_attention.query_key_value.bias": "model-00009-of-00010.safetensors",
|
| 231 |
+
"transformer.encoder.layers.37.self_attention.query_key_value.weight": "model-00009-of-00010.safetensors",
|
| 232 |
+
"transformer.encoder.layers.38.input_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 233 |
+
"transformer.encoder.layers.38.mlp.dense_4h_to_h.weight": "model-00009-of-00010.safetensors",
|
| 234 |
+
"transformer.encoder.layers.38.mlp.dense_h_to_4h.weight": "model-00009-of-00010.safetensors",
|
| 235 |
+
"transformer.encoder.layers.38.post_attention_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 236 |
+
"transformer.encoder.layers.38.self_attention.dense.weight": "model-00009-of-00010.safetensors",
|
| 237 |
+
"transformer.encoder.layers.38.self_attention.query_key_value.bias": "model-00009-of-00010.safetensors",
|
| 238 |
+
"transformer.encoder.layers.38.self_attention.query_key_value.weight": "model-00009-of-00010.safetensors",
|
| 239 |
+
"transformer.encoder.layers.39.input_layernorm.weight": "model-00009-of-00010.safetensors",
|
| 240 |
+
"transformer.encoder.layers.39.mlp.dense_4h_to_h.weight": "model-00010-of-00010.safetensors",
|
| 241 |
+
"transformer.encoder.layers.39.mlp.dense_h_to_4h.weight": "model-00010-of-00010.safetensors",
|
| 242 |
+
"transformer.encoder.layers.39.post_attention_layernorm.weight": "model-00010-of-00010.safetensors",
|
| 243 |
+
"transformer.encoder.layers.39.self_attention.dense.weight": "model-00010-of-00010.safetensors",
|
| 244 |
+
"transformer.encoder.layers.39.self_attention.query_key_value.bias": "model-00010-of-00010.safetensors",
|
| 245 |
+
"transformer.encoder.layers.39.self_attention.query_key_value.weight": "model-00010-of-00010.safetensors",
|
| 246 |
+
"transformer.encoder.layers.4.input_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 247 |
+
"transformer.encoder.layers.4.mlp.dense_4h_to_h.weight": "model-00002-of-00010.safetensors",
|
| 248 |
+
"transformer.encoder.layers.4.mlp.dense_h_to_4h.weight": "model-00002-of-00010.safetensors",
|
| 249 |
+
"transformer.encoder.layers.4.post_attention_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 250 |
+
"transformer.encoder.layers.4.self_attention.dense.weight": "model-00002-of-00010.safetensors",
|
| 251 |
+
"transformer.encoder.layers.4.self_attention.query_key_value.bias": "model-00002-of-00010.safetensors",
|
| 252 |
+
"transformer.encoder.layers.4.self_attention.query_key_value.weight": "model-00002-of-00010.safetensors",
|
| 253 |
+
"transformer.encoder.layers.5.input_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 254 |
+
"transformer.encoder.layers.5.mlp.dense_4h_to_h.weight": "model-00002-of-00010.safetensors",
|
| 255 |
+
"transformer.encoder.layers.5.mlp.dense_h_to_4h.weight": "model-00002-of-00010.safetensors",
|
| 256 |
+
"transformer.encoder.layers.5.post_attention_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 257 |
+
"transformer.encoder.layers.5.self_attention.dense.weight": "model-00002-of-00010.safetensors",
|
| 258 |
+
"transformer.encoder.layers.5.self_attention.query_key_value.bias": "model-00002-of-00010.safetensors",
|
| 259 |
+
"transformer.encoder.layers.5.self_attention.query_key_value.weight": "model-00002-of-00010.safetensors",
|
| 260 |
+
"transformer.encoder.layers.6.input_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 261 |
+
"transformer.encoder.layers.6.mlp.dense_4h_to_h.weight": "model-00003-of-00010.safetensors",
|
| 262 |
+
"transformer.encoder.layers.6.mlp.dense_h_to_4h.weight": "model-00003-of-00010.safetensors",
|
| 263 |
+
"transformer.encoder.layers.6.post_attention_layernorm.weight": "model-00002-of-00010.safetensors",
|
| 264 |
+
"transformer.encoder.layers.6.self_attention.dense.weight": "model-00002-of-00010.safetensors",
|
| 265 |
+
"transformer.encoder.layers.6.self_attention.query_key_value.bias": "model-00002-of-00010.safetensors",
|
| 266 |
+
"transformer.encoder.layers.6.self_attention.query_key_value.weight": "model-00002-of-00010.safetensors",
|
| 267 |
+
"transformer.encoder.layers.7.input_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 268 |
+
"transformer.encoder.layers.7.mlp.dense_4h_to_h.weight": "model-00003-of-00010.safetensors",
|
| 269 |
+
"transformer.encoder.layers.7.mlp.dense_h_to_4h.weight": "model-00003-of-00010.safetensors",
|
| 270 |
+
"transformer.encoder.layers.7.post_attention_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 271 |
+
"transformer.encoder.layers.7.self_attention.dense.weight": "model-00003-of-00010.safetensors",
|
| 272 |
+
"transformer.encoder.layers.7.self_attention.query_key_value.bias": "model-00003-of-00010.safetensors",
|
| 273 |
+
"transformer.encoder.layers.7.self_attention.query_key_value.weight": "model-00003-of-00010.safetensors",
|
| 274 |
+
"transformer.encoder.layers.8.input_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 275 |
+
"transformer.encoder.layers.8.mlp.dense_4h_to_h.weight": "model-00003-of-00010.safetensors",
|
| 276 |
+
"transformer.encoder.layers.8.mlp.dense_h_to_4h.weight": "model-00003-of-00010.safetensors",
|
| 277 |
+
"transformer.encoder.layers.8.post_attention_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 278 |
+
"transformer.encoder.layers.8.self_attention.dense.weight": "model-00003-of-00010.safetensors",
|
| 279 |
+
"transformer.encoder.layers.8.self_attention.query_key_value.bias": "model-00003-of-00010.safetensors",
|
| 280 |
+
"transformer.encoder.layers.8.self_attention.query_key_value.weight": "model-00003-of-00010.safetensors",
|
| 281 |
+
"transformer.encoder.layers.9.input_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 282 |
+
"transformer.encoder.layers.9.mlp.dense_4h_to_h.weight": "model-00003-of-00010.safetensors",
|
| 283 |
+
"transformer.encoder.layers.9.mlp.dense_h_to_4h.weight": "model-00003-of-00010.safetensors",
|
| 284 |
+
"transformer.encoder.layers.9.post_attention_layernorm.weight": "model-00003-of-00010.safetensors",
|
| 285 |
+
"transformer.encoder.layers.9.self_attention.dense.weight": "model-00003-of-00010.safetensors",
|
| 286 |
+
"transformer.encoder.layers.9.self_attention.query_key_value.bias": "model-00003-of-00010.safetensors",
|
| 287 |
+
"transformer.encoder.layers.9.self_attention.query_key_value.weight": "model-00003-of-00010.safetensors",
|
| 288 |
+
"transformer.output_layer.weight": "model-00010-of-00010.safetensors",
|
| 289 |
+
"transformer.rotary_pos_emb.inv_freq": "model-00001-of-00010.safetensors"
|
| 290 |
+
}
|
| 291 |
+
}
|
THUDM/glm-4-9b-chat/modeling_chatglm.py
ADDED
|
@@ -0,0 +1,1215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" PyTorch ChatGLM model. """
|
| 2 |
+
import json
|
| 3 |
+
import math
|
| 4 |
+
import copy
|
| 5 |
+
import warnings
|
| 6 |
+
import re
|
| 7 |
+
import sys
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.utils.checkpoint
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from torch import nn
|
| 13 |
+
from torch.nn import CrossEntropyLoss, LayerNorm, MSELoss, BCEWithLogitsLoss
|
| 14 |
+
from torch.nn.utils import skip_init
|
| 15 |
+
from typing import Optional, Tuple, Union, List, Callable, Dict, Any
|
| 16 |
+
from copy import deepcopy
|
| 17 |
+
|
| 18 |
+
from transformers.modeling_outputs import (
|
| 19 |
+
BaseModelOutputWithPast,
|
| 20 |
+
CausalLMOutputWithPast,
|
| 21 |
+
SequenceClassifierOutputWithPast,
|
| 22 |
+
)
|
| 23 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 24 |
+
from transformers.utils import logging, is_torch_npu_available
|
| 25 |
+
from transformers.generation.logits_process import LogitsProcessor
|
| 26 |
+
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList, GenerationConfig, ModelOutput
|
| 27 |
+
|
| 28 |
+
from .configuration_chatglm import ChatGLMConfig
|
| 29 |
+
|
| 30 |
+
# flags required to enable jit fusion kernels
|
| 31 |
+
|
| 32 |
+
if sys.platform != 'darwin' and not is_torch_npu_available():
|
| 33 |
+
torch._C._jit_set_profiling_mode(False)
|
| 34 |
+
torch._C._jit_set_profiling_executor(False)
|
| 35 |
+
torch._C._jit_override_can_fuse_on_cpu(True)
|
| 36 |
+
torch._C._jit_override_can_fuse_on_gpu(True)
|
| 37 |
+
|
| 38 |
+
logger = logging.get_logger(__name__)
|
| 39 |
+
|
| 40 |
+
_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM"
|
| 41 |
+
_CONFIG_FOR_DOC = "ChatGLMConfig"
|
| 42 |
+
|
| 43 |
+
def default_init(cls, *args, **kwargs):
|
| 44 |
+
return cls(*args, **kwargs)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class InvalidScoreLogitsProcessor(LogitsProcessor):
|
| 48 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
|
| 49 |
+
if torch.isnan(scores).any() or torch.isinf(scores).any():
|
| 50 |
+
scores.zero_()
|
| 51 |
+
scores[..., 198] = 5e4
|
| 52 |
+
return scores
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def split_tensor_along_last_dim(
|
| 56 |
+
tensor: torch.Tensor,
|
| 57 |
+
num_partitions: int,
|
| 58 |
+
contiguous_split_chunks: bool = False,
|
| 59 |
+
) -> List[torch.Tensor]:
|
| 60 |
+
"""Split a tensor along its last dimension.
|
| 61 |
+
|
| 62 |
+
Arguments:
|
| 63 |
+
tensor: input tensor.
|
| 64 |
+
num_partitions: number of partitions to split the tensor
|
| 65 |
+
contiguous_split_chunks: If True, make each chunk contiguous
|
| 66 |
+
in memory.
|
| 67 |
+
|
| 68 |
+
Returns:
|
| 69 |
+
A list of Tensors
|
| 70 |
+
"""
|
| 71 |
+
# Get the size and dimension.
|
| 72 |
+
last_dim = tensor.dim() - 1
|
| 73 |
+
last_dim_size = tensor.size()[last_dim] // num_partitions
|
| 74 |
+
# Split.
|
| 75 |
+
tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
|
| 76 |
+
# Note: torch.split does not create contiguous tensors by default.
|
| 77 |
+
if contiguous_split_chunks:
|
| 78 |
+
return tuple(chunk.contiguous() for chunk in tensor_list)
|
| 79 |
+
|
| 80 |
+
return tensor_list
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class RotaryEmbedding(nn.Module):
|
| 84 |
+
def __init__(self, dim, rope_ratio=1, original_impl=False, device=None, dtype=None):
|
| 85 |
+
super().__init__()
|
| 86 |
+
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2, device=device).to(dtype=dtype) / dim))
|
| 87 |
+
self.register_buffer("inv_freq", inv_freq)
|
| 88 |
+
self.dim = dim
|
| 89 |
+
self.original_impl = original_impl
|
| 90 |
+
self.rope_ratio = rope_ratio
|
| 91 |
+
|
| 92 |
+
def forward_impl(
|
| 93 |
+
self, seq_len: int, n_elem: int, dtype: torch.dtype, device: torch.device, base: int = 10000
|
| 94 |
+
):
|
| 95 |
+
"""Enhanced Transformer with Rotary Position Embedding.
|
| 96 |
+
|
| 97 |
+
Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
|
| 98 |
+
transformers/rope/__init__.py. MIT License:
|
| 99 |
+
https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
|
| 100 |
+
"""
|
| 101 |
+
# $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
|
| 102 |
+
base = base * self.rope_ratio
|
| 103 |
+
theta = 1.0 / (base ** (torch.arange(0, n_elem, 2, dtype=torch.float, device=device) / n_elem))
|
| 104 |
+
|
| 105 |
+
# Create position indexes `[0, 1, ..., seq_len - 1]`
|
| 106 |
+
seq_idx = torch.arange(seq_len, dtype=torch.float, device=device)
|
| 107 |
+
|
| 108 |
+
# Calculate the product of position index and $\theta_i$
|
| 109 |
+
idx_theta = torch.outer(seq_idx, theta).float()
|
| 110 |
+
|
| 111 |
+
cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
|
| 112 |
+
|
| 113 |
+
# this is to mimic the behaviour of complex32, else we will get different results
|
| 114 |
+
if dtype in (torch.float16, torch.bfloat16, torch.int8):
|
| 115 |
+
cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
|
| 116 |
+
return cache
|
| 117 |
+
|
| 118 |
+
def forward(self, max_seq_len, offset=0):
|
| 119 |
+
return self.forward_impl(
|
| 120 |
+
max_seq_len, self.dim, dtype=self.inv_freq.dtype, device=self.inv_freq.device
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
@torch.jit.script
|
| 125 |
+
def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
|
| 126 |
+
# x: [b, np, sq, hn]
|
| 127 |
+
b, np, sq, hn = x.size(0), x.size(1), x.size(2), x.size(3)
|
| 128 |
+
rot_dim = rope_cache.shape[-2] * 2
|
| 129 |
+
x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
|
| 130 |
+
# truncate to support variable sizes
|
| 131 |
+
rope_cache = rope_cache[:, :sq]
|
| 132 |
+
xshaped = x.reshape(b, np, sq, rot_dim // 2, 2)
|
| 133 |
+
rope_cache = rope_cache.view(-1, 1, sq, xshaped.size(3), 2)
|
| 134 |
+
x_out2 = torch.stack(
|
| 135 |
+
[
|
| 136 |
+
xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
|
| 137 |
+
xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
|
| 138 |
+
],
|
| 139 |
+
-1,
|
| 140 |
+
)
|
| 141 |
+
x_out2 = x_out2.flatten(3)
|
| 142 |
+
return torch.cat((x_out2, x_pass), dim=-1)
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class RMSNorm(torch.nn.Module):
|
| 146 |
+
def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
|
| 147 |
+
super().__init__()
|
| 148 |
+
self.weight = torch.nn.Parameter(torch.empty(normalized_shape, device=device, dtype=dtype))
|
| 149 |
+
self.eps = eps
|
| 150 |
+
|
| 151 |
+
def forward(self, hidden_states: torch.Tensor):
|
| 152 |
+
input_dtype = hidden_states.dtype
|
| 153 |
+
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
|
| 154 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
|
| 155 |
+
|
| 156 |
+
return (self.weight * hidden_states).to(input_dtype)
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
class CoreAttention(torch.nn.Module):
|
| 160 |
+
def __init__(self, config: ChatGLMConfig, layer_number):
|
| 161 |
+
super(CoreAttention, self).__init__()
|
| 162 |
+
|
| 163 |
+
self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling
|
| 164 |
+
self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32
|
| 165 |
+
if self.apply_query_key_layer_scaling:
|
| 166 |
+
self.attention_softmax_in_fp32 = True
|
| 167 |
+
self.layer_number = max(1, layer_number)
|
| 168 |
+
|
| 169 |
+
projection_size = config.kv_channels * config.num_attention_heads
|
| 170 |
+
|
| 171 |
+
# Per attention head and per partition values.
|
| 172 |
+
self.hidden_size_per_partition = projection_size
|
| 173 |
+
self.hidden_size_per_attention_head = projection_size // config.num_attention_heads
|
| 174 |
+
self.num_attention_heads_per_partition = config.num_attention_heads
|
| 175 |
+
|
| 176 |
+
coeff = None
|
| 177 |
+
self.norm_factor = math.sqrt(self.hidden_size_per_attention_head)
|
| 178 |
+
if self.apply_query_key_layer_scaling:
|
| 179 |
+
coeff = self.layer_number
|
| 180 |
+
self.norm_factor *= coeff
|
| 181 |
+
self.coeff = coeff
|
| 182 |
+
|
| 183 |
+
self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
|
| 184 |
+
|
| 185 |
+
def forward(self, query_layer, key_layer, value_layer, attention_mask):
|
| 186 |
+
pytorch_major_version = int(torch.__version__.split('.')[0])
|
| 187 |
+
if pytorch_major_version >= 2:
|
| 188 |
+
if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
|
| 189 |
+
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
|
| 190 |
+
is_causal=True)
|
| 191 |
+
else:
|
| 192 |
+
if attention_mask is not None:
|
| 193 |
+
attention_mask = ~attention_mask
|
| 194 |
+
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
|
| 195 |
+
attention_mask)
|
| 196 |
+
context_layer = context_layer.transpose(1, 2).contiguous()
|
| 197 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
|
| 198 |
+
context_layer = context_layer.reshape(*new_context_layer_shape)
|
| 199 |
+
else:
|
| 200 |
+
# Raw attention scores
|
| 201 |
+
|
| 202 |
+
# [b, np, sq, sk]
|
| 203 |
+
output_size = (query_layer.size(0), query_layer.size(1), query_layer.size(2), key_layer.size(2))
|
| 204 |
+
|
| 205 |
+
# [b, np, sq, hn] -> [b * np, sq, hn]
|
| 206 |
+
query_layer = query_layer.view(output_size[0] * output_size[1], output_size[2], -1)
|
| 207 |
+
# [b, np, sk, hn] -> [b * np, sk, hn]
|
| 208 |
+
key_layer = key_layer.view(output_size[0] * output_size[1], output_size[3], -1)
|
| 209 |
+
|
| 210 |
+
# preallocting input tensor: [b * np, sq, sk]
|
| 211 |
+
matmul_input_buffer = torch.empty(
|
| 212 |
+
output_size[0] * output_size[1], output_size[2], output_size[3], dtype=query_layer.dtype,
|
| 213 |
+
device=query_layer.device
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
# Raw attention scores. [b * np, sq, sk]
|
| 217 |
+
matmul_result = torch.baddbmm(
|
| 218 |
+
matmul_input_buffer,
|
| 219 |
+
query_layer, # [b * np, sq, hn]
|
| 220 |
+
key_layer.transpose(1, 2), # [b * np, hn, sk]
|
| 221 |
+
beta=0.0,
|
| 222 |
+
alpha=(1.0 / self.norm_factor),
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
# change view to [b, np, sq, sk]
|
| 226 |
+
attention_scores = matmul_result.view(*output_size)
|
| 227 |
+
|
| 228 |
+
# ===========================
|
| 229 |
+
# Attention probs and dropout
|
| 230 |
+
# ===========================
|
| 231 |
+
|
| 232 |
+
# attention scores and attention mask [b, np, sq, sk]
|
| 233 |
+
if self.attention_softmax_in_fp32:
|
| 234 |
+
attention_scores = attention_scores.float()
|
| 235 |
+
if self.coeff is not None:
|
| 236 |
+
attention_scores = attention_scores * self.coeff
|
| 237 |
+
if attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]:
|
| 238 |
+
attention_mask = torch.ones(output_size[0], 1, output_size[2], output_size[3],
|
| 239 |
+
device=attention_scores.device, dtype=torch.bool)
|
| 240 |
+
attention_mask.tril_()
|
| 241 |
+
attention_mask = ~attention_mask
|
| 242 |
+
if attention_mask is not None:
|
| 243 |
+
attention_scores = attention_scores.masked_fill(attention_mask, float("-inf"))
|
| 244 |
+
attention_probs = F.softmax(attention_scores, dim=-1)
|
| 245 |
+
attention_probs = attention_probs.type_as(value_layer)
|
| 246 |
+
|
| 247 |
+
# This is actually dropping out entire tokens to attend to, which might
|
| 248 |
+
# seem a bit unusual, but is taken from the original Transformer paper.
|
| 249 |
+
attention_probs = self.attention_dropout(attention_probs)
|
| 250 |
+
|
| 251 |
+
# query layer shape: [b * np, sq, hn]
|
| 252 |
+
# value layer shape: [b, np, sk, hn]
|
| 253 |
+
# attention shape: [b, np, sq, sk]
|
| 254 |
+
# context layer shape: [b, np, sq, hn]
|
| 255 |
+
output_size = (value_layer.size(0), value_layer.size(1), query_layer.size(1), value_layer.size(3))
|
| 256 |
+
# change view [b * np, sk, hn]
|
| 257 |
+
value_layer = value_layer.view(output_size[0] * output_size[1], value_layer.size(2), -1)
|
| 258 |
+
# change view [b * np, sq, sk]
|
| 259 |
+
attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
|
| 260 |
+
# matmul: [b * np, sq, hn]
|
| 261 |
+
context_layer = torch.bmm(attention_probs, value_layer)
|
| 262 |
+
# change view [b, np, sq, hn]
|
| 263 |
+
context_layer = context_layer.view(*output_size)
|
| 264 |
+
# [b, np, sq, hn] --> [b, sq, np, hn]
|
| 265 |
+
context_layer = context_layer.transpose(1, 2).contiguous()
|
| 266 |
+
# [b, sq, np, hn] --> [b, sq, hp]
|
| 267 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
|
| 268 |
+
context_layer = context_layer.reshape(*new_context_layer_shape)
|
| 269 |
+
|
| 270 |
+
return context_layer
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
class SelfAttention(torch.nn.Module):
|
| 274 |
+
"""Parallel self-attention layer abstract class.
|
| 275 |
+
|
| 276 |
+
Self-attention layer takes input with size [s, b, h]
|
| 277 |
+
and returns output of the same size.
|
| 278 |
+
"""
|
| 279 |
+
|
| 280 |
+
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
|
| 281 |
+
super(SelfAttention, self).__init__()
|
| 282 |
+
self.layer_number = max(1, layer_number)
|
| 283 |
+
|
| 284 |
+
self.projection_size = config.kv_channels * config.num_attention_heads
|
| 285 |
+
|
| 286 |
+
# Per attention head and per partition values.
|
| 287 |
+
self.hidden_size_per_attention_head = self.projection_size // config.num_attention_heads
|
| 288 |
+
self.num_attention_heads_per_partition = config.num_attention_heads
|
| 289 |
+
|
| 290 |
+
self.multi_query_attention = config.multi_query_attention
|
| 291 |
+
self.qkv_hidden_size = 3 * self.projection_size
|
| 292 |
+
if self.multi_query_attention:
|
| 293 |
+
self.num_multi_query_groups_per_partition = config.multi_query_group_num
|
| 294 |
+
self.qkv_hidden_size = (
|
| 295 |
+
self.projection_size + 2 * self.hidden_size_per_attention_head * config.multi_query_group_num
|
| 296 |
+
)
|
| 297 |
+
self.query_key_value = nn.Linear(config.hidden_size, self.qkv_hidden_size,
|
| 298 |
+
bias=config.add_bias_linear or config.add_qkv_bias,
|
| 299 |
+
device=device, **_config_to_kwargs(config)
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
self.core_attention = CoreAttention(config, self.layer_number)
|
| 303 |
+
|
| 304 |
+
# Output.
|
| 305 |
+
self.dense = nn.Linear(self.projection_size, config.hidden_size, bias=config.add_bias_linear,
|
| 306 |
+
device=device, **_config_to_kwargs(config)
|
| 307 |
+
)
|
| 308 |
+
|
| 309 |
+
def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
|
| 310 |
+
if self.multi_query_attention:
|
| 311 |
+
num_attention_heads = self.num_multi_query_groups_per_partition
|
| 312 |
+
else:
|
| 313 |
+
num_attention_heads = self.num_attention_heads_per_partition
|
| 314 |
+
return torch.empty(
|
| 315 |
+
inference_max_sequence_len,
|
| 316 |
+
batch_size,
|
| 317 |
+
num_attention_heads,
|
| 318 |
+
self.hidden_size_per_attention_head,
|
| 319 |
+
dtype=dtype,
|
| 320 |
+
device=device,
|
| 321 |
+
)
|
| 322 |
+
|
| 323 |
+
def forward(
|
| 324 |
+
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True
|
| 325 |
+
):
|
| 326 |
+
# hidden_states: [b, sq, h]
|
| 327 |
+
|
| 328 |
+
# =================================================
|
| 329 |
+
# Pre-allocate memory for key-values for inference.
|
| 330 |
+
# =================================================
|
| 331 |
+
# =====================
|
| 332 |
+
# Query, Key, and Value
|
| 333 |
+
# =====================
|
| 334 |
+
|
| 335 |
+
# Attention heads [b, sq, h] --> [b, sq, (np * 3 * hn)]
|
| 336 |
+
mixed_x_layer = self.query_key_value(hidden_states)
|
| 337 |
+
|
| 338 |
+
if self.multi_query_attention:
|
| 339 |
+
(query_layer, key_layer, value_layer) = mixed_x_layer.split(
|
| 340 |
+
[
|
| 341 |
+
self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
|
| 342 |
+
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
|
| 343 |
+
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
|
| 344 |
+
],
|
| 345 |
+
dim=-1,
|
| 346 |
+
)
|
| 347 |
+
query_layer = query_layer.view(
|
| 348 |
+
query_layer.size()[:-1] + (self.num_attention_heads_per_partition, self.hidden_size_per_attention_head)
|
| 349 |
+
)
|
| 350 |
+
key_layer = key_layer.view(
|
| 351 |
+
key_layer.size()[:-1] + (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
|
| 352 |
+
)
|
| 353 |
+
value_layer = value_layer.view(
|
| 354 |
+
value_layer.size()[:-1]
|
| 355 |
+
+ (self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head)
|
| 356 |
+
)
|
| 357 |
+
else:
|
| 358 |
+
new_tensor_shape = mixed_x_layer.size()[:-1] + \
|
| 359 |
+
(self.num_attention_heads_per_partition,
|
| 360 |
+
3 * self.hidden_size_per_attention_head)
|
| 361 |
+
mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
|
| 362 |
+
|
| 363 |
+
# [b, sq, np, 3 * hn] --> 3 [b, sq, np, hn]
|
| 364 |
+
(query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
|
| 365 |
+
|
| 366 |
+
# [b, sq, np, hn] -> [b, np, sq, hn]
|
| 367 |
+
query_layer, key_layer, value_layer = [k.transpose(1, 2) for k in [query_layer, key_layer, value_layer]]
|
| 368 |
+
|
| 369 |
+
# apply relative positional encoding (rotary embedding)
|
| 370 |
+
if rotary_pos_emb is not None:
|
| 371 |
+
query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
|
| 372 |
+
key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
|
| 373 |
+
|
| 374 |
+
# adjust key and value for inference
|
| 375 |
+
if kv_cache is not None:
|
| 376 |
+
cache_k, cache_v = kv_cache
|
| 377 |
+
key_layer = torch.cat((cache_k, key_layer), dim=2)
|
| 378 |
+
value_layer = torch.cat((cache_v, value_layer), dim=2)
|
| 379 |
+
if use_cache:
|
| 380 |
+
if kv_cache is None:
|
| 381 |
+
kv_cache = torch.cat((key_layer.unsqueeze(0).unsqueeze(0), value_layer.unsqueeze(0).unsqueeze(0)), dim=1)
|
| 382 |
+
else:
|
| 383 |
+
kv_cache = (key_layer, value_layer)
|
| 384 |
+
else:
|
| 385 |
+
kv_cache = None
|
| 386 |
+
|
| 387 |
+
if self.multi_query_attention:
|
| 388 |
+
key_layer = key_layer.unsqueeze(2)
|
| 389 |
+
key_layer = key_layer.expand(
|
| 390 |
+
-1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1, -1
|
| 391 |
+
)
|
| 392 |
+
key_layer = key_layer.contiguous().view(
|
| 393 |
+
key_layer.size()[:1] + (self.num_attention_heads_per_partition,) + key_layer.size()[3:]
|
| 394 |
+
)
|
| 395 |
+
value_layer = value_layer.unsqueeze(2)
|
| 396 |
+
value_layer = value_layer.expand(
|
| 397 |
+
-1, -1, self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition, -1, -1
|
| 398 |
+
)
|
| 399 |
+
value_layer = value_layer.contiguous().view(
|
| 400 |
+
value_layer.size()[:1] + (self.num_attention_heads_per_partition,) + value_layer.size()[3:]
|
| 401 |
+
)
|
| 402 |
+
|
| 403 |
+
# ==================================
|
| 404 |
+
# core attention computation
|
| 405 |
+
# ==================================
|
| 406 |
+
|
| 407 |
+
context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask)
|
| 408 |
+
|
| 409 |
+
# =================
|
| 410 |
+
# Output. [sq, b, h]
|
| 411 |
+
# =================
|
| 412 |
+
|
| 413 |
+
output = self.dense(context_layer)
|
| 414 |
+
|
| 415 |
+
return output, kv_cache
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def _config_to_kwargs(args):
|
| 419 |
+
common_kwargs = {
|
| 420 |
+
"dtype": args.torch_dtype,
|
| 421 |
+
}
|
| 422 |
+
return common_kwargs
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
class MLP(torch.nn.Module):
|
| 426 |
+
"""MLP.
|
| 427 |
+
|
| 428 |
+
MLP will take the input with h hidden state, project it to 4*h
|
| 429 |
+
hidden dimension, perform nonlinear transformation, and project the
|
| 430 |
+
state back into h hidden dimension.
|
| 431 |
+
"""
|
| 432 |
+
|
| 433 |
+
def __init__(self, config: ChatGLMConfig, device=None):
|
| 434 |
+
super(MLP, self).__init__()
|
| 435 |
+
|
| 436 |
+
self.add_bias = config.add_bias_linear
|
| 437 |
+
|
| 438 |
+
# Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
|
| 439 |
+
self.dense_h_to_4h = nn.Linear(
|
| 440 |
+
config.hidden_size,
|
| 441 |
+
config.ffn_hidden_size * 2,
|
| 442 |
+
bias=self.add_bias,
|
| 443 |
+
device=device,
|
| 444 |
+
**_config_to_kwargs(config)
|
| 445 |
+
)
|
| 446 |
+
|
| 447 |
+
def swiglu(x):
|
| 448 |
+
x = torch.chunk(x, 2, dim=-1)
|
| 449 |
+
return F.silu(x[0]) * x[1]
|
| 450 |
+
|
| 451 |
+
self.activation_func = swiglu
|
| 452 |
+
|
| 453 |
+
# Project back to h.
|
| 454 |
+
self.dense_4h_to_h = nn.Linear(
|
| 455 |
+
config.ffn_hidden_size,
|
| 456 |
+
config.hidden_size,
|
| 457 |
+
bias=self.add_bias,
|
| 458 |
+
device=device,
|
| 459 |
+
**_config_to_kwargs(config)
|
| 460 |
+
)
|
| 461 |
+
|
| 462 |
+
def forward(self, hidden_states):
|
| 463 |
+
# [s, b, 4hp]
|
| 464 |
+
intermediate_parallel = self.dense_h_to_4h(hidden_states)
|
| 465 |
+
intermediate_parallel = self.activation_func(intermediate_parallel)
|
| 466 |
+
# [s, b, h]
|
| 467 |
+
output = self.dense_4h_to_h(intermediate_parallel)
|
| 468 |
+
return output
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
class GLMBlock(torch.nn.Module):
|
| 472 |
+
"""A single transformer layer.
|
| 473 |
+
|
| 474 |
+
Transformer layer takes input with size [s, b, h] and returns an
|
| 475 |
+
output of the same size.
|
| 476 |
+
"""
|
| 477 |
+
|
| 478 |
+
def __init__(self, config: ChatGLMConfig, layer_number, device=None):
|
| 479 |
+
super(GLMBlock, self).__init__()
|
| 480 |
+
self.layer_number = layer_number
|
| 481 |
+
|
| 482 |
+
self.apply_residual_connection_post_layernorm = config.apply_residual_connection_post_layernorm
|
| 483 |
+
|
| 484 |
+
self.fp32_residual_connection = config.fp32_residual_connection
|
| 485 |
+
|
| 486 |
+
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
|
| 487 |
+
# Layernorm on the input data.
|
| 488 |
+
self.input_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
|
| 489 |
+
dtype=config.torch_dtype)
|
| 490 |
+
|
| 491 |
+
# Self attention.
|
| 492 |
+
self.self_attention = SelfAttention(config, layer_number, device=device)
|
| 493 |
+
self.hidden_dropout = config.hidden_dropout
|
| 494 |
+
|
| 495 |
+
# Layernorm on the attention output
|
| 496 |
+
self.post_attention_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
|
| 497 |
+
dtype=config.torch_dtype)
|
| 498 |
+
|
| 499 |
+
# MLP
|
| 500 |
+
self.mlp = MLP(config, device=device)
|
| 501 |
+
|
| 502 |
+
def forward(
|
| 503 |
+
self, hidden_states, attention_mask, rotary_pos_emb, kv_cache=None, use_cache=True,
|
| 504 |
+
):
|
| 505 |
+
# hidden_states: [s, b, h]
|
| 506 |
+
|
| 507 |
+
# Layer norm at the beginning of the transformer layer.
|
| 508 |
+
layernorm_output = self.input_layernorm(hidden_states)
|
| 509 |
+
# Self attention.
|
| 510 |
+
attention_output, kv_cache = self.self_attention(
|
| 511 |
+
layernorm_output,
|
| 512 |
+
attention_mask,
|
| 513 |
+
rotary_pos_emb,
|
| 514 |
+
kv_cache=kv_cache,
|
| 515 |
+
use_cache=use_cache
|
| 516 |
+
)
|
| 517 |
+
|
| 518 |
+
# Residual connection.
|
| 519 |
+
if self.apply_residual_connection_post_layernorm:
|
| 520 |
+
residual = layernorm_output
|
| 521 |
+
else:
|
| 522 |
+
residual = hidden_states
|
| 523 |
+
|
| 524 |
+
layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
|
| 525 |
+
layernorm_input = residual + layernorm_input
|
| 526 |
+
|
| 527 |
+
# Layer norm post the self attention.
|
| 528 |
+
layernorm_output = self.post_attention_layernorm(layernorm_input)
|
| 529 |
+
|
| 530 |
+
# MLP.
|
| 531 |
+
mlp_output = self.mlp(layernorm_output)
|
| 532 |
+
|
| 533 |
+
# Second residual connection.
|
| 534 |
+
if self.apply_residual_connection_post_layernorm:
|
| 535 |
+
residual = layernorm_output
|
| 536 |
+
else:
|
| 537 |
+
residual = layernorm_input
|
| 538 |
+
|
| 539 |
+
output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
|
| 540 |
+
output = residual + output
|
| 541 |
+
|
| 542 |
+
return output, kv_cache
|
| 543 |
+
|
| 544 |
+
|
| 545 |
+
class GLMTransformer(torch.nn.Module):
|
| 546 |
+
"""Transformer class."""
|
| 547 |
+
|
| 548 |
+
def __init__(self, config: ChatGLMConfig, device=None):
|
| 549 |
+
super(GLMTransformer, self).__init__()
|
| 550 |
+
|
| 551 |
+
self.fp32_residual_connection = config.fp32_residual_connection
|
| 552 |
+
self.post_layer_norm = config.post_layer_norm
|
| 553 |
+
|
| 554 |
+
# Number of layers.
|
| 555 |
+
self.num_layers = config.num_layers
|
| 556 |
+
|
| 557 |
+
# Transformer layers.
|
| 558 |
+
def build_layer(layer_number):
|
| 559 |
+
return GLMBlock(config, layer_number, device=device)
|
| 560 |
+
|
| 561 |
+
self.layers = torch.nn.ModuleList([build_layer(i + 1) for i in range(self.num_layers)])
|
| 562 |
+
|
| 563 |
+
if self.post_layer_norm:
|
| 564 |
+
LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
|
| 565 |
+
# Final layer norm before output.
|
| 566 |
+
self.final_layernorm = LayerNormFunc(config.hidden_size, eps=config.layernorm_epsilon, device=device,
|
| 567 |
+
dtype=config.torch_dtype)
|
| 568 |
+
|
| 569 |
+
self.gradient_checkpointing = False
|
| 570 |
+
|
| 571 |
+
def _get_layer(self, layer_number):
|
| 572 |
+
return self.layers[layer_number]
|
| 573 |
+
|
| 574 |
+
def forward(
|
| 575 |
+
self, hidden_states, attention_mask, rotary_pos_emb, kv_caches=None,
|
| 576 |
+
use_cache: Optional[bool] = True,
|
| 577 |
+
output_hidden_states: Optional[bool] = False,
|
| 578 |
+
):
|
| 579 |
+
if not kv_caches:
|
| 580 |
+
kv_caches = [None for _ in range(self.num_layers)]
|
| 581 |
+
presents = () if use_cache else None
|
| 582 |
+
if self.gradient_checkpointing and self.training:
|
| 583 |
+
if use_cache:
|
| 584 |
+
logger.warning_once(
|
| 585 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 586 |
+
)
|
| 587 |
+
use_cache = False
|
| 588 |
+
|
| 589 |
+
all_self_attentions = None
|
| 590 |
+
all_hidden_states = () if output_hidden_states else None
|
| 591 |
+
for index in range(self.num_layers):
|
| 592 |
+
if output_hidden_states:
|
| 593 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 594 |
+
|
| 595 |
+
layer = self._get_layer(index)
|
| 596 |
+
if self.gradient_checkpointing and self.training:
|
| 597 |
+
layer_ret = torch.utils.checkpoint.checkpoint(
|
| 598 |
+
layer,
|
| 599 |
+
hidden_states,
|
| 600 |
+
attention_mask,
|
| 601 |
+
rotary_pos_emb,
|
| 602 |
+
kv_caches[index],
|
| 603 |
+
use_cache,
|
| 604 |
+
use_reentrant=False
|
| 605 |
+
)
|
| 606 |
+
else:
|
| 607 |
+
layer_ret = layer(
|
| 608 |
+
hidden_states,
|
| 609 |
+
attention_mask,
|
| 610 |
+
rotary_pos_emb,
|
| 611 |
+
kv_cache=kv_caches[index],
|
| 612 |
+
use_cache=use_cache
|
| 613 |
+
)
|
| 614 |
+
hidden_states, kv_cache = layer_ret
|
| 615 |
+
if use_cache:
|
| 616 |
+
# token by token decoding, use tuple format
|
| 617 |
+
if kv_caches[0] is not None:
|
| 618 |
+
presents = presents + (kv_cache,)
|
| 619 |
+
# prefilling in decoding, use tensor format to save cuda memory
|
| 620 |
+
else:
|
| 621 |
+
if len(presents) == 0:
|
| 622 |
+
presents = kv_cache
|
| 623 |
+
else:
|
| 624 |
+
presents = torch.cat((presents, kv_cache.to(presents.device)), dim=0)
|
| 625 |
+
|
| 626 |
+
if output_hidden_states:
|
| 627 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 628 |
+
|
| 629 |
+
# Final layer norm.
|
| 630 |
+
if self.post_layer_norm:
|
| 631 |
+
hidden_states = self.final_layernorm(hidden_states)
|
| 632 |
+
|
| 633 |
+
return hidden_states, presents, all_hidden_states, all_self_attentions
|
| 634 |
+
|
| 635 |
+
|
| 636 |
+
class ChatGLMPreTrainedModel(PreTrainedModel):
|
| 637 |
+
"""
|
| 638 |
+
An abstract class to handle weights initialization and
|
| 639 |
+
a simple interface for downloading and loading pretrained models.
|
| 640 |
+
"""
|
| 641 |
+
|
| 642 |
+
is_parallelizable = False
|
| 643 |
+
supports_gradient_checkpointing = True
|
| 644 |
+
config_class = ChatGLMConfig
|
| 645 |
+
base_model_prefix = "transformer"
|
| 646 |
+
_no_split_modules = ["GLMBlock"]
|
| 647 |
+
|
| 648 |
+
def _init_weights(self, module: nn.Module):
|
| 649 |
+
"""Initialize the weights."""
|
| 650 |
+
return
|
| 651 |
+
|
| 652 |
+
def get_masks(self, input_ids, past_key_values, padding_mask=None):
|
| 653 |
+
batch_size, seq_length = input_ids.shape
|
| 654 |
+
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
|
| 655 |
+
full_attention_mask.tril_()
|
| 656 |
+
past_length = 0
|
| 657 |
+
if past_key_values:
|
| 658 |
+
past_length = past_key_values[0][0].shape[2]
|
| 659 |
+
if past_length:
|
| 660 |
+
full_attention_mask = torch.cat((torch.ones(batch_size, seq_length, past_length,
|
| 661 |
+
device=input_ids.device), full_attention_mask), dim=-1)
|
| 662 |
+
if padding_mask is not None:
|
| 663 |
+
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
|
| 664 |
+
if not past_length and padding_mask is not None:
|
| 665 |
+
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
|
| 666 |
+
full_attention_mask = (full_attention_mask < 0.5).bool()
|
| 667 |
+
full_attention_mask.unsqueeze_(1)
|
| 668 |
+
return full_attention_mask
|
| 669 |
+
|
| 670 |
+
def get_position_ids(self, input_ids, device):
|
| 671 |
+
batch_size, seq_length = input_ids.shape
|
| 672 |
+
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
|
| 673 |
+
return position_ids
|
| 674 |
+
|
| 675 |
+
def gradient_checkpointing_enable(self, gradient_checkpointing_kwargs=None):
|
| 676 |
+
if not self.supports_gradient_checkpointing:
|
| 677 |
+
raise ValueError(f"{self.__class__.__name__} does not support gradient checkpointing.")
|
| 678 |
+
|
| 679 |
+
|
| 680 |
+
class Embedding(torch.nn.Module):
|
| 681 |
+
"""Language model embeddings."""
|
| 682 |
+
|
| 683 |
+
def __init__(self, config: ChatGLMConfig, device=None):
|
| 684 |
+
super(Embedding, self).__init__()
|
| 685 |
+
|
| 686 |
+
self.hidden_size = config.hidden_size
|
| 687 |
+
# Word embeddings (parallel).
|
| 688 |
+
self.word_embeddings = nn.Embedding(
|
| 689 |
+
config.padded_vocab_size,
|
| 690 |
+
self.hidden_size,
|
| 691 |
+
dtype=config.torch_dtype,
|
| 692 |
+
device=device
|
| 693 |
+
)
|
| 694 |
+
self.fp32_residual_connection = config.fp32_residual_connection
|
| 695 |
+
|
| 696 |
+
def forward(self, input_ids):
|
| 697 |
+
# Embeddings.
|
| 698 |
+
words_embeddings = self.word_embeddings(input_ids)
|
| 699 |
+
embeddings = words_embeddings
|
| 700 |
+
# If the input flag for fp32 residual connection is set, convert for float.
|
| 701 |
+
if self.fp32_residual_connection:
|
| 702 |
+
embeddings = embeddings.float()
|
| 703 |
+
return embeddings
|
| 704 |
+
|
| 705 |
+
|
| 706 |
+
class ChatGLMModel(ChatGLMPreTrainedModel):
|
| 707 |
+
def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
|
| 708 |
+
super().__init__(config)
|
| 709 |
+
if empty_init:
|
| 710 |
+
init_method = skip_init
|
| 711 |
+
else:
|
| 712 |
+
init_method = default_init
|
| 713 |
+
init_kwargs = {}
|
| 714 |
+
if device is not None:
|
| 715 |
+
init_kwargs["device"] = device
|
| 716 |
+
self.embedding = init_method(Embedding, config, **init_kwargs)
|
| 717 |
+
self.num_layers = config.num_layers
|
| 718 |
+
self.multi_query_group_num = config.multi_query_group_num
|
| 719 |
+
self.kv_channels = config.kv_channels
|
| 720 |
+
|
| 721 |
+
# Rotary positional embeddings
|
| 722 |
+
self.seq_length = config.seq_length
|
| 723 |
+
rotary_dim = (
|
| 724 |
+
config.hidden_size // config.num_attention_heads if config.kv_channels is None else config.kv_channels
|
| 725 |
+
)
|
| 726 |
+
|
| 727 |
+
self.rotary_pos_emb = RotaryEmbedding(rotary_dim // 2, rope_ratio=config.rope_ratio, original_impl=config.original_rope,
|
| 728 |
+
device=device, dtype=config.torch_dtype)
|
| 729 |
+
self.encoder = init_method(GLMTransformer, config, **init_kwargs)
|
| 730 |
+
self.output_layer = init_method(nn.Linear, config.hidden_size, config.padded_vocab_size, bias=False,
|
| 731 |
+
dtype=config.torch_dtype, **init_kwargs)
|
| 732 |
+
|
| 733 |
+
def get_input_embeddings(self):
|
| 734 |
+
return self.embedding.word_embeddings
|
| 735 |
+
|
| 736 |
+
def set_input_embeddings(self, value):
|
| 737 |
+
self.embedding.word_embeddings = value
|
| 738 |
+
|
| 739 |
+
def forward(
|
| 740 |
+
self,
|
| 741 |
+
input_ids,
|
| 742 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 743 |
+
attention_mask: Optional[torch.BoolTensor] = None,
|
| 744 |
+
full_attention_mask: Optional[torch.BoolTensor] = None,
|
| 745 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 746 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 747 |
+
use_cache: Optional[bool] = None,
|
| 748 |
+
output_hidden_states: Optional[bool] = None,
|
| 749 |
+
return_dict: Optional[bool] = None,
|
| 750 |
+
):
|
| 751 |
+
output_hidden_states = (
|
| 752 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 753 |
+
)
|
| 754 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 755 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 756 |
+
|
| 757 |
+
batch_size, seq_length = input_ids.shape
|
| 758 |
+
|
| 759 |
+
if inputs_embeds is None:
|
| 760 |
+
inputs_embeds = self.embedding(input_ids)
|
| 761 |
+
|
| 762 |
+
if full_attention_mask is None:
|
| 763 |
+
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
|
| 764 |
+
full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
|
| 765 |
+
|
| 766 |
+
# Rotary positional embeddings
|
| 767 |
+
rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
|
| 768 |
+
if position_ids is not None:
|
| 769 |
+
rotary_pos_emb = rotary_pos_emb[position_ids]
|
| 770 |
+
else:
|
| 771 |
+
rotary_pos_emb = rotary_pos_emb[None, :seq_length]
|
| 772 |
+
|
| 773 |
+
# Run encoder.
|
| 774 |
+
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
|
| 775 |
+
inputs_embeds, full_attention_mask, rotary_pos_emb=rotary_pos_emb,
|
| 776 |
+
kv_caches=past_key_values, use_cache=use_cache, output_hidden_states=output_hidden_states
|
| 777 |
+
)
|
| 778 |
+
if presents is not None and type(presents) is torch.Tensor:
|
| 779 |
+
presents = presents.split(1, dim=0)
|
| 780 |
+
presents = list(presents)
|
| 781 |
+
presents = [list(x.squeeze(0).split(1, dim=0)) for x in presents]
|
| 782 |
+
presents = [tuple([x.squeeze(0) for x in y]) for y in presents]
|
| 783 |
+
presents = tuple(presents)
|
| 784 |
+
|
| 785 |
+
if not return_dict:
|
| 786 |
+
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
|
| 787 |
+
|
| 788 |
+
return BaseModelOutputWithPast(
|
| 789 |
+
last_hidden_state=hidden_states,
|
| 790 |
+
past_key_values=presents,
|
| 791 |
+
hidden_states=all_hidden_states,
|
| 792 |
+
attentions=all_self_attentions,
|
| 793 |
+
)
|
| 794 |
+
|
| 795 |
+
|
| 796 |
+
class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
|
| 797 |
+
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
|
| 798 |
+
super().__init__(config)
|
| 799 |
+
|
| 800 |
+
self.max_sequence_length = config.max_length
|
| 801 |
+
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
|
| 802 |
+
self.config = config
|
| 803 |
+
|
| 804 |
+
def _update_model_kwargs_for_generation(
|
| 805 |
+
self,
|
| 806 |
+
outputs: ModelOutput,
|
| 807 |
+
model_kwargs: Dict[str, Any],
|
| 808 |
+
is_encoder_decoder: bool = False,
|
| 809 |
+
standardize_cache_format: bool = False,
|
| 810 |
+
) -> Dict[str, Any]:
|
| 811 |
+
# update past_key_values
|
| 812 |
+
model_kwargs["past_key_values"] = self._extract_past_from_model_output(
|
| 813 |
+
outputs, standardize_cache_format=standardize_cache_format
|
| 814 |
+
)
|
| 815 |
+
|
| 816 |
+
# update attention mask
|
| 817 |
+
if "attention_mask" in model_kwargs:
|
| 818 |
+
attention_mask = model_kwargs["attention_mask"]
|
| 819 |
+
model_kwargs["attention_mask"] = torch.cat(
|
| 820 |
+
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
|
| 821 |
+
)
|
| 822 |
+
|
| 823 |
+
# update position ids
|
| 824 |
+
if "position_ids" in model_kwargs:
|
| 825 |
+
position_ids = model_kwargs["position_ids"]
|
| 826 |
+
new_position_id = position_ids[..., -1:].clone()
|
| 827 |
+
new_position_id += 1
|
| 828 |
+
model_kwargs["position_ids"] = torch.cat(
|
| 829 |
+
[position_ids, new_position_id], dim=-1
|
| 830 |
+
)
|
| 831 |
+
|
| 832 |
+
model_kwargs["is_first_forward"] = False
|
| 833 |
+
return model_kwargs
|
| 834 |
+
|
| 835 |
+
def prepare_inputs_for_generation(
|
| 836 |
+
self,
|
| 837 |
+
input_ids: torch.LongTensor,
|
| 838 |
+
past_key_values: Optional[torch.Tensor] = None,
|
| 839 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 840 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 841 |
+
use_cache: Optional[bool] = None,
|
| 842 |
+
is_first_forward: bool = True,
|
| 843 |
+
**kwargs
|
| 844 |
+
) -> dict:
|
| 845 |
+
# only last token for input_ids if past is not None
|
| 846 |
+
if position_ids is None:
|
| 847 |
+
position_ids = self.get_position_ids(input_ids, device=input_ids.device)
|
| 848 |
+
if not is_first_forward:
|
| 849 |
+
if past_key_values is not None:
|
| 850 |
+
position_ids = position_ids[..., -1:]
|
| 851 |
+
input_ids = input_ids[:, -1:]
|
| 852 |
+
return {
|
| 853 |
+
"input_ids": input_ids,
|
| 854 |
+
"past_key_values": past_key_values,
|
| 855 |
+
"position_ids": position_ids,
|
| 856 |
+
"attention_mask": attention_mask,
|
| 857 |
+
"return_last_logit": True,
|
| 858 |
+
"use_cache": use_cache
|
| 859 |
+
}
|
| 860 |
+
|
| 861 |
+
def forward(
|
| 862 |
+
self,
|
| 863 |
+
input_ids: Optional[torch.Tensor] = None,
|
| 864 |
+
position_ids: Optional[torch.Tensor] = None,
|
| 865 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 866 |
+
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
|
| 867 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 868 |
+
labels: Optional[torch.Tensor] = None,
|
| 869 |
+
use_cache: Optional[bool] = None,
|
| 870 |
+
output_attentions: Optional[bool] = None,
|
| 871 |
+
output_hidden_states: Optional[bool] = None,
|
| 872 |
+
return_dict: Optional[bool] = None,
|
| 873 |
+
return_last_logit: Optional[bool] = False,
|
| 874 |
+
):
|
| 875 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 876 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 877 |
+
|
| 878 |
+
transformer_outputs = self.transformer(
|
| 879 |
+
input_ids=input_ids,
|
| 880 |
+
position_ids=position_ids,
|
| 881 |
+
attention_mask=attention_mask,
|
| 882 |
+
past_key_values=past_key_values,
|
| 883 |
+
inputs_embeds=inputs_embeds,
|
| 884 |
+
use_cache=use_cache,
|
| 885 |
+
output_hidden_states=output_hidden_states,
|
| 886 |
+
return_dict=return_dict,
|
| 887 |
+
)
|
| 888 |
+
|
| 889 |
+
hidden_states = transformer_outputs[0]
|
| 890 |
+
if return_last_logit:
|
| 891 |
+
hidden_states = hidden_states[:, -1:]
|
| 892 |
+
lm_logits = self.transformer.output_layer(hidden_states)
|
| 893 |
+
|
| 894 |
+
loss = None
|
| 895 |
+
if labels is not None:
|
| 896 |
+
lm_logits = lm_logits.to(torch.float32)
|
| 897 |
+
|
| 898 |
+
# Shift so that tokens < n predict n
|
| 899 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 900 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 901 |
+
# Flatten the tokens
|
| 902 |
+
loss_fct = CrossEntropyLoss(ignore_index=-100)
|
| 903 |
+
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
|
| 904 |
+
|
| 905 |
+
lm_logits = lm_logits.to(hidden_states.dtype)
|
| 906 |
+
loss = loss.to(hidden_states.dtype)
|
| 907 |
+
|
| 908 |
+
if not return_dict:
|
| 909 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 910 |
+
return ((loss,) + output) if loss is not None else output
|
| 911 |
+
|
| 912 |
+
return CausalLMOutputWithPast(
|
| 913 |
+
loss=loss,
|
| 914 |
+
logits=lm_logits,
|
| 915 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 916 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 917 |
+
attentions=transformer_outputs.attentions,
|
| 918 |
+
)
|
| 919 |
+
|
| 920 |
+
@staticmethod
|
| 921 |
+
def _reorder_cache(
|
| 922 |
+
past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
|
| 923 |
+
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
|
| 924 |
+
"""
|
| 925 |
+
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
|
| 926 |
+
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
|
| 927 |
+
beam_idx at every generation step.
|
| 928 |
+
|
| 929 |
+
Output shares the same memory storage as `past`.
|
| 930 |
+
"""
|
| 931 |
+
return tuple(
|
| 932 |
+
(
|
| 933 |
+
layer_past[0].index_select(0, beam_idx.to(layer_past[0].device)),
|
| 934 |
+
layer_past[1].index_select(0, beam_idx.to(layer_past[1].device)),
|
| 935 |
+
)
|
| 936 |
+
for layer_past in past
|
| 937 |
+
)
|
| 938 |
+
|
| 939 |
+
def process_response(self, output, history):
|
| 940 |
+
content = ""
|
| 941 |
+
history = deepcopy(history)
|
| 942 |
+
for response in output.split("<|assistant|>"):
|
| 943 |
+
if "\n" in response:
|
| 944 |
+
metadata, content = response.split("\n", maxsplit=1)
|
| 945 |
+
else:
|
| 946 |
+
metadata, content = "", response
|
| 947 |
+
if not metadata.strip():
|
| 948 |
+
content = content.strip()
|
| 949 |
+
history.append({"role": "assistant", "metadata": metadata, "content": content})
|
| 950 |
+
content = content.replace("[[训练时间]]", "2023年")
|
| 951 |
+
else:
|
| 952 |
+
history.append({"role": "assistant", "metadata": metadata, "content": content})
|
| 953 |
+
if history[0]["role"] == "system" and "tools" in history[0]:
|
| 954 |
+
parameters = json.loads(content)
|
| 955 |
+
content = {"name": metadata.strip(), "parameters": parameters}
|
| 956 |
+
else:
|
| 957 |
+
content = {"name": metadata.strip(), "content": content}
|
| 958 |
+
return content, history
|
| 959 |
+
|
| 960 |
+
@torch.inference_mode()
|
| 961 |
+
def chat(self, tokenizer, query: str, history: List[Dict] = None, role: str = "user",
|
| 962 |
+
max_length: int = 8192, num_beams=1, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None,
|
| 963 |
+
**kwargs):
|
| 964 |
+
if history is None:
|
| 965 |
+
history = []
|
| 966 |
+
if logits_processor is None:
|
| 967 |
+
logits_processor = LogitsProcessorList()
|
| 968 |
+
logits_processor.append(InvalidScoreLogitsProcessor())
|
| 969 |
+
gen_kwargs = {"max_length": max_length, "num_beams": num_beams, "do_sample": do_sample, "top_p": top_p,
|
| 970 |
+
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
|
| 971 |
+
history.append({"role": role, "content": query})
|
| 972 |
+
inputs = tokenizer.apply_chat_template(history, add_generation_prompt=True, tokenize=True,
|
| 973 |
+
return_tensors="pt", return_dict=True)
|
| 974 |
+
inputs = inputs.to(self.device)
|
| 975 |
+
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|user|>"),
|
| 976 |
+
tokenizer.convert_tokens_to_ids("<|observation|>")]
|
| 977 |
+
outputs = self.generate(**inputs, **gen_kwargs, eos_token_id=eos_token_id)
|
| 978 |
+
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):-1]
|
| 979 |
+
response = tokenizer.decode(outputs)
|
| 980 |
+
response, history = self.process_response(response, history)
|
| 981 |
+
return response, history
|
| 982 |
+
|
| 983 |
+
@torch.inference_mode()
|
| 984 |
+
def stream_chat(self, tokenizer, query: str, history: List[Dict] = None, role: str = "user",
|
| 985 |
+
past_key_values=None, max_length: int = 8192, do_sample=True, top_p=0.8, temperature=0.8,
|
| 986 |
+
logits_processor=None, return_past_key_values=False, **kwargs):
|
| 987 |
+
if history is None:
|
| 988 |
+
history = []
|
| 989 |
+
if logits_processor is None:
|
| 990 |
+
logits_processor = LogitsProcessorList()
|
| 991 |
+
logits_processor.append(InvalidScoreLogitsProcessor())
|
| 992 |
+
eos_token_id = [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|user|>"),
|
| 993 |
+
tokenizer.convert_tokens_to_ids("<|observation|>")]
|
| 994 |
+
gen_kwargs = {"max_length": max_length, "do_sample": do_sample, "top_p": top_p,
|
| 995 |
+
"temperature": temperature, "logits_processor": logits_processor, **kwargs}
|
| 996 |
+
if past_key_values is None:
|
| 997 |
+
inputs = tokenizer.apply_chat_template(history + [{"role": role, "content": query}],
|
| 998 |
+
add_generation_prompt=True, tokenize=True, return_tensors="pt",
|
| 999 |
+
return_dict=True)
|
| 1000 |
+
else:
|
| 1001 |
+
inputs = tokenizer.apply_chat_template([{"role": role, "content": query}], add_special_tokens=False,
|
| 1002 |
+
add_generation_prompt=True, tokenize=True, return_tensors="pt",
|
| 1003 |
+
return_dict=True)
|
| 1004 |
+
inputs = inputs.to(self.device)
|
| 1005 |
+
if past_key_values is not None:
|
| 1006 |
+
past_length = past_key_values[0][0].shape[2]
|
| 1007 |
+
inputs.position_ids += past_length
|
| 1008 |
+
attention_mask = inputs.attention_mask
|
| 1009 |
+
attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
|
| 1010 |
+
inputs['attention_mask'] = attention_mask
|
| 1011 |
+
history.append({"role": role, "content": query})
|
| 1012 |
+
for outputs in self.stream_generate(**inputs, past_key_values=past_key_values,
|
| 1013 |
+
eos_token_id=eos_token_id, return_past_key_values=return_past_key_values,
|
| 1014 |
+
**gen_kwargs):
|
| 1015 |
+
if return_past_key_values:
|
| 1016 |
+
outputs, past_key_values = outputs
|
| 1017 |
+
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):-1]
|
| 1018 |
+
response = tokenizer.decode(outputs)
|
| 1019 |
+
if response and response[-1] != "�":
|
| 1020 |
+
response, new_history = self.process_response(response, history)
|
| 1021 |
+
if return_past_key_values:
|
| 1022 |
+
yield response, new_history, past_key_values
|
| 1023 |
+
else:
|
| 1024 |
+
yield response, new_history
|
| 1025 |
+
|
| 1026 |
+
@torch.inference_mode()
|
| 1027 |
+
def stream_generate(
|
| 1028 |
+
self,
|
| 1029 |
+
input_ids,
|
| 1030 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 1031 |
+
logits_processor: Optional[LogitsProcessorList] = None,
|
| 1032 |
+
stopping_criteria: Optional[StoppingCriteriaList] = None,
|
| 1033 |
+
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
|
| 1034 |
+
return_past_key_values=False,
|
| 1035 |
+
**kwargs,
|
| 1036 |
+
):
|
| 1037 |
+
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
|
| 1038 |
+
|
| 1039 |
+
if generation_config is None:
|
| 1040 |
+
generation_config = self.generation_config
|
| 1041 |
+
generation_config = copy.deepcopy(generation_config)
|
| 1042 |
+
model_kwargs = generation_config.update(**kwargs)
|
| 1043 |
+
model_kwargs["use_cache"] = generation_config.use_cache
|
| 1044 |
+
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
|
| 1045 |
+
|
| 1046 |
+
if isinstance(eos_token_id, int):
|
| 1047 |
+
eos_token_id = [eos_token_id]
|
| 1048 |
+
eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
|
| 1049 |
+
|
| 1050 |
+
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
|
| 1051 |
+
if has_default_max_length and generation_config.max_new_tokens is None:
|
| 1052 |
+
warnings.warn(
|
| 1053 |
+
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
|
| 1054 |
+
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
|
| 1055 |
+
" recommend using `max_new_tokens` to control the maximum length of the generation.",
|
| 1056 |
+
UserWarning,
|
| 1057 |
+
)
|
| 1058 |
+
elif generation_config.max_new_tokens is not None:
|
| 1059 |
+
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
|
| 1060 |
+
if not has_default_max_length:
|
| 1061 |
+
logger.warn(
|
| 1062 |
+
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
|
| 1063 |
+
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
|
| 1064 |
+
"Please refer to the documentation for more information. "
|
| 1065 |
+
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
|
| 1066 |
+
UserWarning,
|
| 1067 |
+
)
|
| 1068 |
+
|
| 1069 |
+
if input_ids_seq_length >= generation_config.max_length:
|
| 1070 |
+
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
|
| 1071 |
+
logger.warning(
|
| 1072 |
+
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
|
| 1073 |
+
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
|
| 1074 |
+
" increasing `max_new_tokens`."
|
| 1075 |
+
)
|
| 1076 |
+
|
| 1077 |
+
# 2. Set generation parameters if not already defined
|
| 1078 |
+
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
|
| 1079 |
+
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
|
| 1080 |
+
|
| 1081 |
+
logits_processor = self._get_logits_processor(
|
| 1082 |
+
generation_config=generation_config,
|
| 1083 |
+
input_ids_seq_length=input_ids_seq_length,
|
| 1084 |
+
encoder_input_ids=input_ids,
|
| 1085 |
+
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
|
| 1086 |
+
logits_processor=logits_processor,
|
| 1087 |
+
)
|
| 1088 |
+
|
| 1089 |
+
stopping_criteria = self._get_stopping_criteria(
|
| 1090 |
+
generation_config=generation_config, stopping_criteria=stopping_criteria
|
| 1091 |
+
)
|
| 1092 |
+
logits_warper = self._get_logits_warper(generation_config)
|
| 1093 |
+
|
| 1094 |
+
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
| 1095 |
+
scores = None
|
| 1096 |
+
while True:
|
| 1097 |
+
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
|
| 1098 |
+
# forward pass to get next token
|
| 1099 |
+
outputs = self(
|
| 1100 |
+
**model_inputs,
|
| 1101 |
+
return_dict=True,
|
| 1102 |
+
output_attentions=False,
|
| 1103 |
+
output_hidden_states=False,
|
| 1104 |
+
)
|
| 1105 |
+
|
| 1106 |
+
next_token_logits = outputs.logits[:, -1, :]
|
| 1107 |
+
|
| 1108 |
+
# pre-process distribution
|
| 1109 |
+
next_token_scores = logits_processor(input_ids, next_token_logits)
|
| 1110 |
+
next_token_scores = logits_warper(input_ids, next_token_scores)
|
| 1111 |
+
|
| 1112 |
+
# sample
|
| 1113 |
+
probs = nn.functional.softmax(next_token_scores, dim=-1)
|
| 1114 |
+
if generation_config.do_sample:
|
| 1115 |
+
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
|
| 1116 |
+
else:
|
| 1117 |
+
next_tokens = torch.argmax(probs, dim=-1)
|
| 1118 |
+
# update generated ids, model inputs, and length for next step
|
| 1119 |
+
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
|
| 1120 |
+
model_kwargs = self._update_model_kwargs_for_generation(
|
| 1121 |
+
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
|
| 1122 |
+
)
|
| 1123 |
+
unfinished_sequences = unfinished_sequences.mul(
|
| 1124 |
+
next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
|
| 1125 |
+
)
|
| 1126 |
+
if return_past_key_values:
|
| 1127 |
+
yield input_ids, outputs.past_key_values
|
| 1128 |
+
else:
|
| 1129 |
+
yield input_ids
|
| 1130 |
+
# stop when each sentence is finished, or if we exceed the maximum length
|
| 1131 |
+
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
|
| 1132 |
+
break
|
| 1133 |
+
|
| 1134 |
+
|
| 1135 |
+
class ChatGLMForSequenceClassification(ChatGLMPreTrainedModel):
|
| 1136 |
+
def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
|
| 1137 |
+
super().__init__(config)
|
| 1138 |
+
|
| 1139 |
+
self.num_labels = config.num_labels
|
| 1140 |
+
self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
|
| 1141 |
+
|
| 1142 |
+
self.classifier_head = nn.Linear(config.hidden_size, config.num_labels, bias=True, dtype=torch.half)
|
| 1143 |
+
if config.classifier_dropout is not None:
|
| 1144 |
+
self.dropout = nn.Dropout(config.classifier_dropout)
|
| 1145 |
+
else:
|
| 1146 |
+
self.dropout = None
|
| 1147 |
+
self.config = config
|
| 1148 |
+
|
| 1149 |
+
def forward(
|
| 1150 |
+
self,
|
| 1151 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1152 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1153 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1154 |
+
full_attention_mask: Optional[torch.Tensor] = None,
|
| 1155 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 1156 |
+
inputs_embeds: Optional[torch.LongTensor] = None,
|
| 1157 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1158 |
+
use_cache: Optional[bool] = None,
|
| 1159 |
+
output_hidden_states: Optional[bool] = None,
|
| 1160 |
+
return_dict: Optional[bool] = None,
|
| 1161 |
+
) -> Union[Tuple[torch.Tensor, ...], SequenceClassifierOutputWithPast]:
|
| 1162 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1163 |
+
|
| 1164 |
+
transformer_outputs = self.transformer(
|
| 1165 |
+
input_ids=input_ids,
|
| 1166 |
+
position_ids=position_ids,
|
| 1167 |
+
attention_mask=attention_mask,
|
| 1168 |
+
full_attention_mask=full_attention_mask,
|
| 1169 |
+
past_key_values=past_key_values,
|
| 1170 |
+
inputs_embeds=inputs_embeds,
|
| 1171 |
+
use_cache=use_cache,
|
| 1172 |
+
output_hidden_states=output_hidden_states,
|
| 1173 |
+
return_dict=return_dict,
|
| 1174 |
+
)
|
| 1175 |
+
|
| 1176 |
+
hidden_states = transformer_outputs[0]
|
| 1177 |
+
pooled_hidden_states = hidden_states[:, -1]
|
| 1178 |
+
if self.dropout is not None:
|
| 1179 |
+
pooled_hidden_states = self.dropout(pooled_hidden_states)
|
| 1180 |
+
logits = self.classifier_head(pooled_hidden_states)
|
| 1181 |
+
|
| 1182 |
+
loss = None
|
| 1183 |
+
if labels is not None:
|
| 1184 |
+
if self.config.problem_type is None:
|
| 1185 |
+
if self.num_labels == 1:
|
| 1186 |
+
self.config.problem_type = "regression"
|
| 1187 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1188 |
+
self.config.problem_type = "single_label_classification"
|
| 1189 |
+
else:
|
| 1190 |
+
self.config.problem_type = "multi_label_classification"
|
| 1191 |
+
|
| 1192 |
+
if self.config.problem_type == "regression":
|
| 1193 |
+
loss_fct = MSELoss()
|
| 1194 |
+
if self.num_labels == 1:
|
| 1195 |
+
loss = loss_fct(logits.squeeze().float(), labels.squeeze())
|
| 1196 |
+
else:
|
| 1197 |
+
loss = loss_fct(logits.float(), labels)
|
| 1198 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1199 |
+
loss_fct = CrossEntropyLoss()
|
| 1200 |
+
loss = loss_fct(logits.view(-1, self.num_labels).float(), labels.view(-1))
|
| 1201 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1202 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1203 |
+
loss = loss_fct(logits.float(), labels.view(-1, self.num_labels))
|
| 1204 |
+
|
| 1205 |
+
if not return_dict:
|
| 1206 |
+
output = (logits,) + transformer_outputs[1:]
|
| 1207 |
+
return ((loss,) + output) if loss is not None else output
|
| 1208 |
+
|
| 1209 |
+
return SequenceClassifierOutputWithPast(
|
| 1210 |
+
loss=loss,
|
| 1211 |
+
logits=logits,
|
| 1212 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1213 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1214 |
+
attentions=transformer_outputs.attentions,
|
| 1215 |
+
)
|
THUDM/glm-4-9b-chat/tokenization_chatglm.py
ADDED
|
@@ -0,0 +1,323 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import regex as re
|
| 2 |
+
import base64
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
import tiktoken
|
| 6 |
+
from torch import TensorType
|
| 7 |
+
from typing import List, Optional, Union, Dict, Any
|
| 8 |
+
from transformers import PreTrainedTokenizer
|
| 9 |
+
from transformers.utils import logging, PaddingStrategy
|
| 10 |
+
from transformers.tokenization_utils_base import EncodedInput, BatchEncoding
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class ChatGLM4Tokenizer(PreTrainedTokenizer):
|
| 14 |
+
vocab_files_names = {"vocab_file": "tokenizer.model"}
|
| 15 |
+
model_input_names = ["input_ids", "attention_mask", "position_ids"]
|
| 16 |
+
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
vocab_file,
|
| 20 |
+
padding_side="left",
|
| 21 |
+
clean_up_tokenization_spaces=False,
|
| 22 |
+
encode_special_tokens=False,
|
| 23 |
+
**kwargs
|
| 24 |
+
):
|
| 25 |
+
self.name = "GLM4Tokenizer"
|
| 26 |
+
self.vocab_file = vocab_file
|
| 27 |
+
pat_str = "(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?\\p{L}+|\\p{N}{1,3}| ?[^\\s\\p{L}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+"
|
| 28 |
+
self.pat_str = re.compile(pat_str)
|
| 29 |
+
self.encode_special_tokens = encode_special_tokens
|
| 30 |
+
|
| 31 |
+
mergeable_ranks = {}
|
| 32 |
+
with open(vocab_file) as f:
|
| 33 |
+
for line in f:
|
| 34 |
+
token, rank = line.strip().split()
|
| 35 |
+
rank = int(rank)
|
| 36 |
+
token = base64.b64decode(token)
|
| 37 |
+
mergeable_ranks[token] = rank
|
| 38 |
+
|
| 39 |
+
self.mergeable_ranks = mergeable_ranks
|
| 40 |
+
|
| 41 |
+
self.tokenizer = tiktoken.Encoding(
|
| 42 |
+
name="my_tokenizer",
|
| 43 |
+
pat_str=pat_str,
|
| 44 |
+
mergeable_ranks=mergeable_ranks,
|
| 45 |
+
special_tokens={}
|
| 46 |
+
)
|
| 47 |
+
self.decoder = {rank: token for token, rank in mergeable_ranks.items()}
|
| 48 |
+
self.n_words = len(self.decoder)
|
| 49 |
+
|
| 50 |
+
super().__init__(
|
| 51 |
+
padding_side=padding_side,
|
| 52 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 53 |
+
**kwargs
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
@property
|
| 57 |
+
def vocab_size(self):
|
| 58 |
+
return self.n_words
|
| 59 |
+
|
| 60 |
+
def get_vocab(self):
|
| 61 |
+
""" Returns vocab as a dict """
|
| 62 |
+
vocab = {self._convert_id_to_token(i): i for i in range(self.vocab_size)}
|
| 63 |
+
vocab.update(self.added_tokens_encoder)
|
| 64 |
+
return vocab
|
| 65 |
+
|
| 66 |
+
def convert_tokens_to_string(self, tokens: List[Union[bytes, str, int]]) -> str:
|
| 67 |
+
"""
|
| 68 |
+
Converts a sequence of tokens in a single string.
|
| 69 |
+
"""
|
| 70 |
+
text = ""
|
| 71 |
+
temp = b""
|
| 72 |
+
for t in tokens:
|
| 73 |
+
if isinstance(t, int):
|
| 74 |
+
t = chr(t)
|
| 75 |
+
if isinstance(t, str):
|
| 76 |
+
if temp:
|
| 77 |
+
text += temp.decode("utf-8", errors="replace")
|
| 78 |
+
elif isinstance(t, bytes):
|
| 79 |
+
temp += t
|
| 80 |
+
else:
|
| 81 |
+
raise TypeError("token should only be of type int, bytes or str")
|
| 82 |
+
if temp:
|
| 83 |
+
text += temp.decode("utf-8", errors="replace")
|
| 84 |
+
return text
|
| 85 |
+
|
| 86 |
+
def _tokenize(self, text, **kwargs):
|
| 87 |
+
tokens = []
|
| 88 |
+
ids = self.tokenizer.encode(text)
|
| 89 |
+
for t in ids:
|
| 90 |
+
tokens.append(self.decoder[t])
|
| 91 |
+
return tokens
|
| 92 |
+
|
| 93 |
+
def _convert_token_to_id(self, token):
|
| 94 |
+
""" Converts a token (str) in an id using the vocab. """
|
| 95 |
+
return self.mergeable_ranks[token]
|
| 96 |
+
|
| 97 |
+
def _convert_id_to_token(self, index):
|
| 98 |
+
"""Converts an index (integer) in a token (str) using the vocab."""
|
| 99 |
+
return self.decoder.get(index, "")
|
| 100 |
+
|
| 101 |
+
def save_vocabulary(self, save_directory, filename_prefix=None):
|
| 102 |
+
"""
|
| 103 |
+
Save the vocabulary and special tokens file to a directory.
|
| 104 |
+
|
| 105 |
+
Args:
|
| 106 |
+
save_directory (`str`):
|
| 107 |
+
The directory in which to save the vocabulary.
|
| 108 |
+
filename_prefix (`str`, *optional*):
|
| 109 |
+
An optional prefix to add to the named of the saved files.
|
| 110 |
+
|
| 111 |
+
Returns:
|
| 112 |
+
`Tuple(str)`: Paths to the files saved.
|
| 113 |
+
"""
|
| 114 |
+
if os.path.isdir(save_directory):
|
| 115 |
+
vocab_file = os.path.join(
|
| 116 |
+
save_directory, self.vocab_files_names["vocab_file"]
|
| 117 |
+
)
|
| 118 |
+
else:
|
| 119 |
+
vocab_file = save_directory
|
| 120 |
+
|
| 121 |
+
with open(self.vocab_file, 'rb') as fin:
|
| 122 |
+
proto_str = fin.read()
|
| 123 |
+
|
| 124 |
+
with open(vocab_file, "wb") as writer:
|
| 125 |
+
writer.write(proto_str)
|
| 126 |
+
|
| 127 |
+
return (vocab_file,)
|
| 128 |
+
|
| 129 |
+
def get_prefix_tokens(self):
|
| 130 |
+
prefix_tokens = [self.convert_tokens_to_ids("[gMASK]"), self.convert_tokens_to_ids("<sop>")]
|
| 131 |
+
return prefix_tokens
|
| 132 |
+
|
| 133 |
+
def build_single_message(self, role, metadata, message, tokenize=True):
|
| 134 |
+
assert role in ["system", "user", "assistant", "observation"], role
|
| 135 |
+
if tokenize:
|
| 136 |
+
role_tokens = [self.convert_tokens_to_ids(f"<|{role}|>")] + self.tokenizer.encode(f"{metadata}\n",
|
| 137 |
+
disallowed_special=())
|
| 138 |
+
message_tokens = self.tokenizer.encode(message, disallowed_special=())
|
| 139 |
+
tokens = role_tokens + message_tokens
|
| 140 |
+
return tokens
|
| 141 |
+
else:
|
| 142 |
+
return str(f"<|{role}|>{metadata}\n{message}")
|
| 143 |
+
|
| 144 |
+
def apply_chat_template(
|
| 145 |
+
self,
|
| 146 |
+
conversation: Union[List[Dict[str, str]], List[List[Dict[str, str]]], "Conversation"],
|
| 147 |
+
add_generation_prompt: bool = False,
|
| 148 |
+
tokenize: bool = True,
|
| 149 |
+
padding: bool = False,
|
| 150 |
+
truncation: bool = False,
|
| 151 |
+
max_length: Optional[int] = None,
|
| 152 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 153 |
+
return_dict: bool = False,
|
| 154 |
+
tokenizer_kwargs: Optional[Dict[str, Any]] = None,
|
| 155 |
+
add_special_tokens: bool = True,
|
| 156 |
+
**kwargs,
|
| 157 |
+
) -> Union[str, List[int], List[str], List[List[int]], BatchEncoding]:
|
| 158 |
+
|
| 159 |
+
if return_dict and not tokenize:
|
| 160 |
+
raise ValueError(
|
| 161 |
+
"`return_dict=True` is incompatible with `tokenize=False`, because there is no dict "
|
| 162 |
+
"of tokenizer outputs to return."
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
def handle_single_conversation(conversation):
|
| 166 |
+
input_ids = self.get_prefix_tokens() if add_special_tokens else []
|
| 167 |
+
input_message = "[gMASK]<sop>" if add_special_tokens else ""
|
| 168 |
+
for item in conversation:
|
| 169 |
+
if item.get("tools"):
|
| 170 |
+
tools = item["tools"]
|
| 171 |
+
content = "你是一个名为 GLM-4 的人工智能助手。你是基于智谱AI训练的语言模型 GLM-4 模型开发的,你的任务是针对用户的问题和要求提供适当的答复和支持。"
|
| 172 |
+
for tool in tools:
|
| 173 |
+
if tool["type"] == "function":
|
| 174 |
+
function = tool["function"]
|
| 175 |
+
content += f"\n\n## {function['name']}\n\n{json.dumps(function, ensure_ascii=False, indent=4)}"
|
| 176 |
+
content += "\n在调用上述函数时,请使用 Json 格式表示调用的参数。"
|
| 177 |
+
elif tool["type"] == "python":
|
| 178 |
+
content += "\n\n## python\n\n当你向 `python` 发送包含 Python 代码的消息时,该代码将会在一个有状态的 Jupyter notebook 环境中执行。\n`python` 返回代码执行的输出,或在执行 60 秒后返回超时。\n`/mnt/data` 将会持久化存储你的文件。在此会话中,`python` 无法访问互联网。不要使用 `python` 进行任何网络请求或者在线 API 调用,这些在线内容的访问将不会成功。"
|
| 179 |
+
elif tool["type"] == "simple_browser":
|
| 180 |
+
content += "\n\n## simple_browser\n\n你可以使用 `simple_browser` 工具。该工具支持以下函数:\n`search(query: str, recency_days: int)`:使用搜索引擎进行查询并显示结果,可以使用 `recency_days` 参数控制搜索内容的时效性。\n`mclick(ids: list[int])`:获取一系列指定 id 的页面内容。每次调用时,须选择3-10个页面。选择多个角度的页面,同时尽可能选择可信任的信息来源。考虑到部分页面是无法加载的,你也可以多打开一些可能有用的页面而不用担心内容过多。\n`open_url(url: str)`:打开指定的 URL。\n\n使用 `【{引用 id}†{引用文本}】` 来引用内容。\n\n操作步骤:1. 使用 `search` 来获得信息列表; 2. 使用 `mclick` 来获取指定 ID 页面的内容; 3. 根据获得的内容进行回复。在回复中应当引用信息来源。\n 如果用户提供了 URL,也可以用 `open_url` 直接打开页面。\n如果初次搜索结果没有找到合适的信息,也可以再次使用 `search` 进行搜索。"
|
| 181 |
+
elif tool["type"] == "cogview":
|
| 182 |
+
content += "\n\n## cogview\n\n如果用户的请求中包含了对图像的描述,你可以使用 `cogview` 来生成图像并展示给用户。你需要向 `cogview` 发送图像描述,规则:\n- 发送给 `cogview` 的消息必须使用英语。用户的中文描述必须完全翻译为英语。\n- 应当尽可能详细地描述图像生成的需求,需求描述约 100 英文单词。\n- 保持用户原始描述的意图。不要虚构内容或者没见过的人物。\n- 如无特殊说明,所在地为中国,持有中国立场并遵循中国社会主义价值观。"
|
| 183 |
+
else:
|
| 184 |
+
raise NotImplementedError(f"Unknown tool type {tool['type']}")
|
| 185 |
+
input = self.build_single_message("system", "", content, tokenize=tokenize)
|
| 186 |
+
if tokenize:
|
| 187 |
+
input_ids.extend(input)
|
| 188 |
+
else:
|
| 189 |
+
input_message += input
|
| 190 |
+
if item["content"]:
|
| 191 |
+
input = self.build_single_message(
|
| 192 |
+
item["role"],
|
| 193 |
+
item.get("metadata", ""),
|
| 194 |
+
item["content"],
|
| 195 |
+
tokenize=tokenize
|
| 196 |
+
)
|
| 197 |
+
if tokenize:
|
| 198 |
+
input_ids.extend(input)
|
| 199 |
+
else:
|
| 200 |
+
input_message += input
|
| 201 |
+
if add_generation_prompt:
|
| 202 |
+
if tokenize:
|
| 203 |
+
input_ids.extend([self.convert_tokens_to_ids("<|assistant|>")])
|
| 204 |
+
else:
|
| 205 |
+
input_message += "<|assistant|>"
|
| 206 |
+
|
| 207 |
+
return input_ids if tokenize else input_message
|
| 208 |
+
|
| 209 |
+
# Main logic to handle different conversation formats
|
| 210 |
+
if isinstance(conversation, list) and all(isinstance(i, dict) for i in conversation):
|
| 211 |
+
result = handle_single_conversation(conversation)
|
| 212 |
+
elif isinstance(conversation, list) and all(isinstance(i, list) for i in conversation):
|
| 213 |
+
result = [handle_single_conversation(c) for c in conversation]
|
| 214 |
+
elif hasattr(conversation, "messages"):
|
| 215 |
+
result = handle_single_conversation(conversation.messages)
|
| 216 |
+
else:
|
| 217 |
+
raise ValueError("Invalid conversation format")
|
| 218 |
+
|
| 219 |
+
if tokenize:
|
| 220 |
+
output = self.batch_encode_plus(
|
| 221 |
+
[result] if isinstance(result[0], int) else result,
|
| 222 |
+
padding=padding,
|
| 223 |
+
truncation=truncation,
|
| 224 |
+
max_length=max_length,
|
| 225 |
+
return_tensors=return_tensors,
|
| 226 |
+
is_split_into_words=True,
|
| 227 |
+
add_special_tokens=False
|
| 228 |
+
)
|
| 229 |
+
if return_dict:
|
| 230 |
+
return output
|
| 231 |
+
else:
|
| 232 |
+
return output["input_ids"]
|
| 233 |
+
else:
|
| 234 |
+
return result
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def build_inputs_with_special_tokens(
|
| 238 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
| 239 |
+
) -> List[int]:
|
| 240 |
+
"""
|
| 241 |
+
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
|
| 242 |
+
adding special tokens. A BERT sequence has the following format:
|
| 243 |
+
|
| 244 |
+
- single sequence: `[CLS] X [SEP]`
|
| 245 |
+
- pair of sequences: `[CLS] A [SEP] B [SEP]`
|
| 246 |
+
|
| 247 |
+
Args:
|
| 248 |
+
token_ids_0 (`List[int]`):
|
| 249 |
+
List of IDs to which the special tokens will be added.
|
| 250 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 251 |
+
Optional second list of IDs for sequence pairs.
|
| 252 |
+
|
| 253 |
+
Returns:
|
| 254 |
+
`List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
|
| 255 |
+
"""
|
| 256 |
+
prefix_tokens = self.get_prefix_tokens()
|
| 257 |
+
token_ids_0 = prefix_tokens + token_ids_0
|
| 258 |
+
if token_ids_1 is not None:
|
| 259 |
+
token_ids_0 = token_ids_0 + token_ids_1 + [self.convert_tokens_to_ids("<eos>")]
|
| 260 |
+
return token_ids_0
|
| 261 |
+
|
| 262 |
+
def _pad(
|
| 263 |
+
self,
|
| 264 |
+
encoded_inputs: Union[Dict[str, EncodedInput], BatchEncoding],
|
| 265 |
+
max_length: Optional[int] = None,
|
| 266 |
+
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
|
| 267 |
+
pad_to_multiple_of: Optional[int] = None,
|
| 268 |
+
return_attention_mask: Optional[bool] = None,
|
| 269 |
+
) -> dict:
|
| 270 |
+
"""
|
| 271 |
+
Pad encoded inputs (on left/right and up to predefined length or max length in the batch)
|
| 272 |
+
|
| 273 |
+
Args:
|
| 274 |
+
encoded_inputs:
|
| 275 |
+
Dictionary of tokenized inputs (`List[int]`) or batch of tokenized inputs (`List[List[int]]`).
|
| 276 |
+
max_length: maximum length of the returned list and optionally padding length (see below).
|
| 277 |
+
Will truncate by taking into account the special tokens.
|
| 278 |
+
padding_strategy: PaddingStrategy to use for padding.
|
| 279 |
+
|
| 280 |
+
- PaddingStrategy.LONGEST Pad to the longest sequence in the batch
|
| 281 |
+
- PaddingStrategy.MAX_LENGTH: Pad to the max length (default)
|
| 282 |
+
- PaddingStrategy.DO_NOT_PAD: Do not pad
|
| 283 |
+
The tokenizer padding sides are defined in self.padding_side:
|
| 284 |
+
|
| 285 |
+
- 'left': pads on the left of the sequences
|
| 286 |
+
- 'right': pads on the right of the sequences
|
| 287 |
+
pad_to_multiple_of: (optional) Integer if set will pad the sequence to a multiple of the provided value.
|
| 288 |
+
This is especially useful to enable the use of Tensor Core on NVIDIA hardware with compute capability
|
| 289 |
+
`>= 7.5` (Volta).
|
| 290 |
+
return_attention_mask:
|
| 291 |
+
(optional) Set to False to avoid returning attention mask (default: set to model specifics)
|
| 292 |
+
"""
|
| 293 |
+
# Load from model defaults
|
| 294 |
+
assert self.padding_side == "left"
|
| 295 |
+
|
| 296 |
+
required_input = encoded_inputs[self.model_input_names[0]]
|
| 297 |
+
seq_length = len(required_input)
|
| 298 |
+
|
| 299 |
+
if padding_strategy == PaddingStrategy.LONGEST:
|
| 300 |
+
max_length = len(required_input)
|
| 301 |
+
|
| 302 |
+
if max_length is not None and pad_to_multiple_of is not None and (max_length % pad_to_multiple_of != 0):
|
| 303 |
+
max_length = ((max_length // pad_to_multiple_of) + 1) * pad_to_multiple_of
|
| 304 |
+
|
| 305 |
+
needs_to_be_padded = padding_strategy != PaddingStrategy.DO_NOT_PAD and len(required_input) != max_length
|
| 306 |
+
|
| 307 |
+
# Initialize attention mask if not present.
|
| 308 |
+
if "attention_mask" not in encoded_inputs:
|
| 309 |
+
encoded_inputs["attention_mask"] = [1] * seq_length
|
| 310 |
+
|
| 311 |
+
if "position_ids" not in encoded_inputs:
|
| 312 |
+
encoded_inputs["position_ids"] = list(range(seq_length))
|
| 313 |
+
|
| 314 |
+
if needs_to_be_padded:
|
| 315 |
+
difference = max_length - len(required_input)
|
| 316 |
+
|
| 317 |
+
if "attention_mask" in encoded_inputs:
|
| 318 |
+
encoded_inputs["attention_mask"] = [0] * difference + encoded_inputs["attention_mask"]
|
| 319 |
+
if "position_ids" in encoded_inputs:
|
| 320 |
+
encoded_inputs["position_ids"] = [0] * difference + encoded_inputs["position_ids"]
|
| 321 |
+
encoded_inputs[self.model_input_names[0]] = [self.pad_token_id] * difference + required_input
|
| 322 |
+
|
| 323 |
+
return encoded_inputs
|
THUDM/glm-4-9b-chat/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5a493598071550244b2ee7f26118f3edec2150b9dfa967929a99052ac83fe716
|
| 3 |
+
size 2623634
|
THUDM/glm-4-9b-chat/tokenizer_config.json
ADDED
|
@@ -0,0 +1,133 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoTokenizer": [
|
| 4 |
+
"tokenization_chatglm.ChatGLM4Tokenizer",
|
| 5 |
+
null
|
| 6 |
+
]
|
| 7 |
+
},
|
| 8 |
+
"added_tokens_decoder": {
|
| 9 |
+
"151329": {
|
| 10 |
+
"content": "<|endoftext|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false,
|
| 15 |
+
"special": true
|
| 16 |
+
},
|
| 17 |
+
"151330": {
|
| 18 |
+
"content": "[MASK]",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false,
|
| 23 |
+
"special": true
|
| 24 |
+
},
|
| 25 |
+
"151331": {
|
| 26 |
+
"content": "[gMASK]",
|
| 27 |
+
"lstrip": false,
|
| 28 |
+
"normalized": false,
|
| 29 |
+
"rstrip": false,
|
| 30 |
+
"single_word": false,
|
| 31 |
+
"special": true
|
| 32 |
+
},
|
| 33 |
+
"151332": {
|
| 34 |
+
"content": "[sMASK]",
|
| 35 |
+
"lstrip": false,
|
| 36 |
+
"normalized": false,
|
| 37 |
+
"rstrip": false,
|
| 38 |
+
"single_word": false,
|
| 39 |
+
"special": true
|
| 40 |
+
},
|
| 41 |
+
"151333": {
|
| 42 |
+
"content": "<sop>",
|
| 43 |
+
"lstrip": false,
|
| 44 |
+
"normalized": false,
|
| 45 |
+
"rstrip": false,
|
| 46 |
+
"single_word": false,
|
| 47 |
+
"special": true
|
| 48 |
+
},
|
| 49 |
+
"151334": {
|
| 50 |
+
"content": "<eop>",
|
| 51 |
+
"lstrip": false,
|
| 52 |
+
"normalized": false,
|
| 53 |
+
"rstrip": false,
|
| 54 |
+
"single_word": false,
|
| 55 |
+
"special": true
|
| 56 |
+
},
|
| 57 |
+
"151335": {
|
| 58 |
+
"content": "<|system|>",
|
| 59 |
+
"lstrip": false,
|
| 60 |
+
"normalized": false,
|
| 61 |
+
"rstrip": false,
|
| 62 |
+
"single_word": false,
|
| 63 |
+
"special": true
|
| 64 |
+
},
|
| 65 |
+
"151336": {
|
| 66 |
+
"content": "<|user|>",
|
| 67 |
+
"lstrip": false,
|
| 68 |
+
"normalized": false,
|
| 69 |
+
"rstrip": false,
|
| 70 |
+
"single_word": false,
|
| 71 |
+
"special": true
|
| 72 |
+
},
|
| 73 |
+
"151337": {
|
| 74 |
+
"content": "<|assistant|>",
|
| 75 |
+
"lstrip": false,
|
| 76 |
+
"normalized": false,
|
| 77 |
+
"rstrip": false,
|
| 78 |
+
"single_word": false,
|
| 79 |
+
"special": true
|
| 80 |
+
},
|
| 81 |
+
"151338": {
|
| 82 |
+
"content": "<|observation|>",
|
| 83 |
+
"lstrip": false,
|
| 84 |
+
"normalized": false,
|
| 85 |
+
"rstrip": false,
|
| 86 |
+
"single_word": false,
|
| 87 |
+
"special": true
|
| 88 |
+
},
|
| 89 |
+
"151339": {
|
| 90 |
+
"content": "<|begin_of_image|>",
|
| 91 |
+
"lstrip": false,
|
| 92 |
+
"normalized": false,
|
| 93 |
+
"rstrip": false,
|
| 94 |
+
"single_word": false,
|
| 95 |
+
"special": true
|
| 96 |
+
},
|
| 97 |
+
"151340": {
|
| 98 |
+
"content": "<|end_of_image|>",
|
| 99 |
+
"lstrip": false,
|
| 100 |
+
"normalized": false,
|
| 101 |
+
"rstrip": false,
|
| 102 |
+
"single_word": false,
|
| 103 |
+
"special": true
|
| 104 |
+
},
|
| 105 |
+
"151341": {
|
| 106 |
+
"content": "<|begin_of_video|>",
|
| 107 |
+
"lstrip": false,
|
| 108 |
+
"normalized": false,
|
| 109 |
+
"rstrip": false,
|
| 110 |
+
"single_word": false,
|
| 111 |
+
"special": true
|
| 112 |
+
},
|
| 113 |
+
"151342": {
|
| 114 |
+
"content": "<|end_of_video|>",
|
| 115 |
+
"lstrip": false,
|
| 116 |
+
"normalized": false,
|
| 117 |
+
"rstrip": false,
|
| 118 |
+
"single_word": false,
|
| 119 |
+
"special": true
|
| 120 |
+
}
|
| 121 |
+
},
|
| 122 |
+
"additional_special_tokens": ["<|endoftext|>", "[MASK]", "[gMASK]", "[sMASK]", "<sop>", "<eop>", "<|system|>",
|
| 123 |
+
"<|user|>", "<|assistant|>", "<|observation|>", "<|begin_of_image|>", "<|end_of_image|>",
|
| 124 |
+
"<|begin_of_video|>", "<|end_of_video|>"],
|
| 125 |
+
"clean_up_tokenization_spaces": false,
|
| 126 |
+
"do_lower_case": false,
|
| 127 |
+
"eos_token": "<|endoftext|>",
|
| 128 |
+
"pad_token": "<|endoftext|>",
|
| 129 |
+
"model_max_length": 128000,
|
| 130 |
+
"padding_side": "left",
|
| 131 |
+
"remove_space": false,
|
| 132 |
+
"tokenizer_class": "ChatGLM4Tokenizer"
|
| 133 |
+
}
|
openai_api_request.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This script creates a OpenAI Request demo for the glm-4-9b model, just Use OpenAI API to interact with the model.
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
from openai import OpenAI
|
| 6 |
+
|
| 7 |
+
base_url = "http://127.0.0.1:8000/v1/"
|
| 8 |
+
client = OpenAI(api_key="EMPTY", base_url=base_url)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def function_chat(use_stream=False):
|
| 12 |
+
messages = [
|
| 13 |
+
{
|
| 14 |
+
"role": "user", "content": "What's the Celsius temperature in San Francisco?"
|
| 15 |
+
},
|
| 16 |
+
|
| 17 |
+
# Give Observations
|
| 18 |
+
# {
|
| 19 |
+
# "role": "assistant",
|
| 20 |
+
# "content": None,
|
| 21 |
+
# "function_call": None,
|
| 22 |
+
# "tool_calls": [
|
| 23 |
+
# {
|
| 24 |
+
# "id": "call_1717912616815",
|
| 25 |
+
# "function": {
|
| 26 |
+
# "name": "get_current_weather",
|
| 27 |
+
# "arguments": "{\"location\": \"San Francisco, CA\", \"format\": \"celsius\"}"
|
| 28 |
+
# },
|
| 29 |
+
# "type": "function"
|
| 30 |
+
# }
|
| 31 |
+
# ]
|
| 32 |
+
# },
|
| 33 |
+
# {
|
| 34 |
+
# "tool_call_id": "call_1717912616815",
|
| 35 |
+
# "role": "tool",
|
| 36 |
+
# "name": "get_current_weather",
|
| 37 |
+
# "content": "23°C",
|
| 38 |
+
# }
|
| 39 |
+
]
|
| 40 |
+
tools = [
|
| 41 |
+
{
|
| 42 |
+
"type": "function",
|
| 43 |
+
"function": {
|
| 44 |
+
"name": "get_current_weather",
|
| 45 |
+
"description": "Get the current weather",
|
| 46 |
+
"parameters": {
|
| 47 |
+
"type": "object",
|
| 48 |
+
"properties": {
|
| 49 |
+
"location": {
|
| 50 |
+
"type": "string",
|
| 51 |
+
"description": "The city and state, e.g. San Francisco, CA",
|
| 52 |
+
},
|
| 53 |
+
"format": {
|
| 54 |
+
"type": "string",
|
| 55 |
+
"enum": ["celsius", "fahrenheit"],
|
| 56 |
+
"description": "The temperature unit to use. Infer this from the users location.",
|
| 57 |
+
},
|
| 58 |
+
},
|
| 59 |
+
"required": ["location", "format"],
|
| 60 |
+
},
|
| 61 |
+
}
|
| 62 |
+
},
|
| 63 |
+
]
|
| 64 |
+
|
| 65 |
+
# All Tools: CogView
|
| 66 |
+
# messages = [{"role": "user", "content": "帮我画一张天空的画画吧"}]
|
| 67 |
+
# tools = [{"type": "cogview"}]
|
| 68 |
+
|
| 69 |
+
# All Tools: Searching
|
| 70 |
+
# messages = [{"role": "user", "content": "今天黄金的价格"}]
|
| 71 |
+
# tools = [{"type": "simple_browser"}]
|
| 72 |
+
|
| 73 |
+
response = client.chat.completions.create(
|
| 74 |
+
model="glm-4",
|
| 75 |
+
messages=messages,
|
| 76 |
+
tools=tools,
|
| 77 |
+
stream=use_stream,
|
| 78 |
+
max_tokens=256,
|
| 79 |
+
temperature=0.9,
|
| 80 |
+
presence_penalty=1.2,
|
| 81 |
+
top_p=0.1,
|
| 82 |
+
tool_choice="auto"
|
| 83 |
+
)
|
| 84 |
+
if response:
|
| 85 |
+
if use_stream:
|
| 86 |
+
for chunk in response:
|
| 87 |
+
print(chunk)
|
| 88 |
+
else:
|
| 89 |
+
print(response)
|
| 90 |
+
else:
|
| 91 |
+
print("Error:", response.status_code)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def simple_chat(use_stream=False):
|
| 95 |
+
messages = [
|
| 96 |
+
{
|
| 97 |
+
"role": "system",
|
| 98 |
+
"content": "请在你输出的时候都带上“喵喵喵”三个字,放在开头。",
|
| 99 |
+
},
|
| 100 |
+
{
|
| 101 |
+
"role": "user",
|
| 102 |
+
"content": "你是谁"
|
| 103 |
+
}
|
| 104 |
+
]
|
| 105 |
+
response = client.chat.completions.create(
|
| 106 |
+
model="glm-4",
|
| 107 |
+
messages=messages,
|
| 108 |
+
stream=use_stream,
|
| 109 |
+
max_tokens=256,
|
| 110 |
+
temperature=0.4,
|
| 111 |
+
presence_penalty=1.2,
|
| 112 |
+
top_p=0.8,
|
| 113 |
+
)
|
| 114 |
+
if response:
|
| 115 |
+
if use_stream:
|
| 116 |
+
for chunk in response:
|
| 117 |
+
print(chunk)
|
| 118 |
+
else:
|
| 119 |
+
print(response)
|
| 120 |
+
else:
|
| 121 |
+
print("Error:", response.status_code)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
if __name__ == "__main__":
|
| 125 |
+
# simple_chat(use_stream=False)
|
| 126 |
+
function_chat(use_stream=False)
|
| 127 |
+
|
openai_api_server.py
ADDED
|
@@ -0,0 +1,635 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
from asyncio.log import logger
|
| 3 |
+
import re
|
| 4 |
+
import uvicorn
|
| 5 |
+
import gc
|
| 6 |
+
import json
|
| 7 |
+
import torch
|
| 8 |
+
import random
|
| 9 |
+
import string
|
| 10 |
+
|
| 11 |
+
from vllm import SamplingParams, AsyncEngineArgs, AsyncLLMEngine
|
| 12 |
+
from fastapi import FastAPI, HTTPException, Response
|
| 13 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 14 |
+
from contextlib import asynccontextmanager
|
| 15 |
+
from typing import List, Literal, Optional, Union
|
| 16 |
+
from pydantic import BaseModel, Field
|
| 17 |
+
from transformers import AutoTokenizer, LogitsProcessor
|
| 18 |
+
from sse_starlette.sse import EventSourceResponse
|
| 19 |
+
|
| 20 |
+
EventSourceResponse.DEFAULT_PING_INTERVAL = 1000
|
| 21 |
+
import os
|
| 22 |
+
|
| 23 |
+
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/glm-4-9b-chat')
|
| 24 |
+
MAX_MODEL_LENGTH = 8192
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
@asynccontextmanager
|
| 28 |
+
async def lifespan(app: FastAPI):
|
| 29 |
+
yield
|
| 30 |
+
if torch.cuda.is_available():
|
| 31 |
+
torch.cuda.empty_cache()
|
| 32 |
+
torch.cuda.ipc_collect()
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
app = FastAPI(lifespan=lifespan)
|
| 36 |
+
|
| 37 |
+
app.add_middleware(
|
| 38 |
+
CORSMiddleware,
|
| 39 |
+
allow_origins=["*"],
|
| 40 |
+
allow_credentials=True,
|
| 41 |
+
allow_methods=["*"],
|
| 42 |
+
allow_headers=["*"],
|
| 43 |
+
)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def generate_id(prefix: str, k=29) -> str:
|
| 47 |
+
suffix = ''.join(random.choices(string.ascii_letters + string.digits, k=k))
|
| 48 |
+
return f"{prefix}{suffix}"
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class ModelCard(BaseModel):
|
| 52 |
+
id: str = ""
|
| 53 |
+
object: str = "model"
|
| 54 |
+
created: int = Field(default_factory=lambda: int(time.time()))
|
| 55 |
+
owned_by: str = "owner"
|
| 56 |
+
root: Optional[str] = None
|
| 57 |
+
parent: Optional[str] = None
|
| 58 |
+
permission: Optional[list] = None
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
class ModelList(BaseModel):
|
| 62 |
+
object: str = "list"
|
| 63 |
+
data: List[ModelCard] = ["glm-4"]
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class FunctionCall(BaseModel):
|
| 67 |
+
name: Optional[str] = None
|
| 68 |
+
arguments: Optional[str] = None
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class ChoiceDeltaToolCallFunction(BaseModel):
|
| 72 |
+
name: Optional[str] = None
|
| 73 |
+
arguments: Optional[str] = None
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class UsageInfo(BaseModel):
|
| 77 |
+
prompt_tokens: int = 0
|
| 78 |
+
total_tokens: int = 0
|
| 79 |
+
completion_tokens: Optional[int] = 0
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class ChatCompletionMessageToolCall(BaseModel):
|
| 83 |
+
index: Optional[int] = 0
|
| 84 |
+
id: Optional[str] = None
|
| 85 |
+
function: FunctionCall
|
| 86 |
+
type: Optional[Literal["function"]] = 'function'
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class ChatMessage(BaseModel):
|
| 90 |
+
# “function” 字段解释:
|
| 91 |
+
# 使用较老的OpenAI API版本需要注意在这里添加 function 字段并在 process_messages函数中添加相应角色转换逻辑为 observation
|
| 92 |
+
|
| 93 |
+
role: Literal["user", "assistant", "system", "tool"]
|
| 94 |
+
content: Optional[str] = None
|
| 95 |
+
function_call: Optional[ChoiceDeltaToolCallFunction] = None
|
| 96 |
+
tool_calls: Optional[List[ChatCompletionMessageToolCall]] = None
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class DeltaMessage(BaseModel):
|
| 100 |
+
role: Optional[Literal["user", "assistant", "system"]] = None
|
| 101 |
+
content: Optional[str] = None
|
| 102 |
+
function_call: Optional[ChoiceDeltaToolCallFunction] = None
|
| 103 |
+
tool_calls: Optional[List[ChatCompletionMessageToolCall]] = None
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class ChatCompletionResponseChoice(BaseModel):
|
| 107 |
+
index: int
|
| 108 |
+
message: ChatMessage
|
| 109 |
+
finish_reason: Literal["stop", "length", "tool_calls"]
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class ChatCompletionResponseStreamChoice(BaseModel):
|
| 113 |
+
delta: DeltaMessage
|
| 114 |
+
finish_reason: Optional[Literal["stop", "length", "tool_calls"]]
|
| 115 |
+
index: int
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class ChatCompletionResponse(BaseModel):
|
| 119 |
+
model: str
|
| 120 |
+
id: Optional[str] = Field(default_factory=lambda: generate_id('chatcmpl-', 29))
|
| 121 |
+
object: Literal["chat.completion", "chat.completion.chunk"]
|
| 122 |
+
choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]
|
| 123 |
+
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
|
| 124 |
+
system_fingerprint: Optional[str] = Field(default_factory=lambda: generate_id('fp_', 9))
|
| 125 |
+
usage: Optional[UsageInfo] = None
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class ChatCompletionRequest(BaseModel):
|
| 129 |
+
model: str
|
| 130 |
+
messages: List[ChatMessage]
|
| 131 |
+
temperature: Optional[float] = 0.8
|
| 132 |
+
top_p: Optional[float] = 0.8
|
| 133 |
+
max_tokens: Optional[int] = None
|
| 134 |
+
stream: Optional[bool] = False
|
| 135 |
+
tools: Optional[Union[dict, List[dict]]] = None
|
| 136 |
+
tool_choice: Optional[Union[str, dict]] = None
|
| 137 |
+
repetition_penalty: Optional[float] = 1.1
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
class InvalidScoreLogitsProcessor(LogitsProcessor):
|
| 141 |
+
def __call__(
|
| 142 |
+
self, input_ids: torch.LongTensor, scores: torch.FloatTensor
|
| 143 |
+
) -> torch.FloatTensor:
|
| 144 |
+
if torch.isnan(scores).any() or torch.isinf(scores).any():
|
| 145 |
+
scores.zero_()
|
| 146 |
+
scores[..., 5] = 5e4
|
| 147 |
+
return scores
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def process_response(output: str, tools: dict | List[dict] = None, use_tool: bool = False) -> Union[str, dict]:
|
| 151 |
+
lines = output.strip().split("\n")
|
| 152 |
+
arguments_json = None
|
| 153 |
+
special_tools = ["cogview", "simple_browser"]
|
| 154 |
+
tools = {tool['function']['name'] for tool in tools}
|
| 155 |
+
|
| 156 |
+
# 这是一个简单的工具比较函数,不能保证拦截所有非工具输出的结果,比如参数未对齐等特殊情况。
|
| 157 |
+
##TODO 如果你希望做更多判断,可以在这里进行逻辑完善。
|
| 158 |
+
|
| 159 |
+
if len(lines) >= 2 and lines[1].startswith("{"):
|
| 160 |
+
function_name = lines[0].strip()
|
| 161 |
+
arguments = "\n".join(lines[1:]).strip()
|
| 162 |
+
if function_name in tools or function_name in special_tools:
|
| 163 |
+
try:
|
| 164 |
+
arguments_json = json.loads(arguments)
|
| 165 |
+
is_tool_call = True
|
| 166 |
+
except json.JSONDecodeError:
|
| 167 |
+
is_tool_call = function_name in special_tools
|
| 168 |
+
|
| 169 |
+
if is_tool_call and use_tool:
|
| 170 |
+
content = {
|
| 171 |
+
"name": function_name,
|
| 172 |
+
"arguments": json.dumps(arguments_json if isinstance(arguments_json, dict) else arguments,
|
| 173 |
+
ensure_ascii=False)
|
| 174 |
+
}
|
| 175 |
+
if function_name == "simple_browser":
|
| 176 |
+
search_pattern = re.compile(r'search\("(.+?)"\s*,\s*recency_days\s*=\s*(\d+)\)')
|
| 177 |
+
match = search_pattern.match(arguments)
|
| 178 |
+
if match:
|
| 179 |
+
content["arguments"] = json.dumps({
|
| 180 |
+
"query": match.group(1),
|
| 181 |
+
"recency_days": int(match.group(2))
|
| 182 |
+
}, ensure_ascii=False)
|
| 183 |
+
elif function_name == "cogview":
|
| 184 |
+
content["arguments"] = json.dumps({
|
| 185 |
+
"prompt": arguments
|
| 186 |
+
}, ensure_ascii=False)
|
| 187 |
+
|
| 188 |
+
return content
|
| 189 |
+
return output.strip()
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
@torch.inference_mode()
|
| 193 |
+
async def generate_stream_glm4(params):
|
| 194 |
+
messages = params["messages"]
|
| 195 |
+
tools = params["tools"]
|
| 196 |
+
tool_choice = params["tool_choice"]
|
| 197 |
+
temperature = float(params.get("temperature", 1.0))
|
| 198 |
+
repetition_penalty = float(params.get("repetition_penalty", 1.0))
|
| 199 |
+
top_p = float(params.get("top_p", 1.0))
|
| 200 |
+
max_new_tokens = int(params.get("max_tokens", 8192))
|
| 201 |
+
|
| 202 |
+
messages = process_messages(messages, tools=tools, tool_choice=tool_choice)
|
| 203 |
+
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
|
| 204 |
+
params_dict = {
|
| 205 |
+
"n": 1,
|
| 206 |
+
"best_of": 1,
|
| 207 |
+
"presence_penalty": 1.0,
|
| 208 |
+
"frequency_penalty": 0.0,
|
| 209 |
+
"temperature": temperature,
|
| 210 |
+
"top_p": top_p,
|
| 211 |
+
"top_k": -1,
|
| 212 |
+
"repetition_penalty": repetition_penalty,
|
| 213 |
+
"use_beam_search": False,
|
| 214 |
+
"length_penalty": 1,
|
| 215 |
+
"early_stopping": False,
|
| 216 |
+
"stop_token_ids": [151329, 151336, 151338],
|
| 217 |
+
"ignore_eos": False,
|
| 218 |
+
"max_tokens": max_new_tokens,
|
| 219 |
+
"logprobs": None,
|
| 220 |
+
"prompt_logprobs": None,
|
| 221 |
+
"skip_special_tokens": True,
|
| 222 |
+
}
|
| 223 |
+
sampling_params = SamplingParams(**params_dict)
|
| 224 |
+
async for output in engine.generate(inputs=inputs, sampling_params=sampling_params, request_id=f"{time.time()}"):
|
| 225 |
+
output_len = len(output.outputs[0].token_ids)
|
| 226 |
+
input_len = len(output.prompt_token_ids)
|
| 227 |
+
ret = {
|
| 228 |
+
"text": output.outputs[0].text,
|
| 229 |
+
"usage": {
|
| 230 |
+
"prompt_tokens": input_len,
|
| 231 |
+
"completion_tokens": output_len,
|
| 232 |
+
"total_tokens": output_len + input_len
|
| 233 |
+
},
|
| 234 |
+
"finish_reason": output.outputs[0].finish_reason,
|
| 235 |
+
}
|
| 236 |
+
yield ret
|
| 237 |
+
gc.collect()
|
| 238 |
+
torch.cuda.empty_cache()
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def process_messages(messages, tools=None, tool_choice="none"):
|
| 242 |
+
_messages = messages
|
| 243 |
+
processed_messages = []
|
| 244 |
+
msg_has_sys = False
|
| 245 |
+
|
| 246 |
+
def filter_tools(tool_choice, tools):
|
| 247 |
+
function_name = tool_choice.get('function', {}).get('name', None)
|
| 248 |
+
if not function_name:
|
| 249 |
+
return []
|
| 250 |
+
filtered_tools = [
|
| 251 |
+
tool for tool in tools
|
| 252 |
+
if tool.get('function', {}).get('name') == function_name
|
| 253 |
+
]
|
| 254 |
+
return filtered_tools
|
| 255 |
+
|
| 256 |
+
if tool_choice != "none":
|
| 257 |
+
if isinstance(tool_choice, dict):
|
| 258 |
+
tools = filter_tools(tool_choice, tools)
|
| 259 |
+
if tools:
|
| 260 |
+
processed_messages.append(
|
| 261 |
+
{
|
| 262 |
+
"role": "system",
|
| 263 |
+
"content": None,
|
| 264 |
+
"tools": tools
|
| 265 |
+
}
|
| 266 |
+
)
|
| 267 |
+
msg_has_sys = True
|
| 268 |
+
|
| 269 |
+
if isinstance(tool_choice, dict) and tools:
|
| 270 |
+
processed_messages.append(
|
| 271 |
+
{
|
| 272 |
+
"role": "assistant",
|
| 273 |
+
"metadata": tool_choice["function"]["name"],
|
| 274 |
+
"content": ""
|
| 275 |
+
}
|
| 276 |
+
)
|
| 277 |
+
|
| 278 |
+
for m in _messages:
|
| 279 |
+
role, content, func_call = m.role, m.content, m.function_call
|
| 280 |
+
tool_calls = getattr(m, 'tool_calls', None)
|
| 281 |
+
|
| 282 |
+
if role == "function":
|
| 283 |
+
processed_messages.append(
|
| 284 |
+
{
|
| 285 |
+
"role": "observation",
|
| 286 |
+
"content": content
|
| 287 |
+
}
|
| 288 |
+
)
|
| 289 |
+
elif role == "tool":
|
| 290 |
+
processed_messages.append(
|
| 291 |
+
{
|
| 292 |
+
"role": "observation",
|
| 293 |
+
"content": content,
|
| 294 |
+
"function_call": True
|
| 295 |
+
}
|
| 296 |
+
)
|
| 297 |
+
elif role == "assistant":
|
| 298 |
+
if tool_calls:
|
| 299 |
+
for tool_call in tool_calls:
|
| 300 |
+
processed_messages.append(
|
| 301 |
+
{
|
| 302 |
+
"role": "assistant",
|
| 303 |
+
"metadata": tool_call.function.name,
|
| 304 |
+
"content": tool_call.function.arguments
|
| 305 |
+
}
|
| 306 |
+
)
|
| 307 |
+
else:
|
| 308 |
+
for response in content.split("\n"):
|
| 309 |
+
if "\n" in response:
|
| 310 |
+
metadata, sub_content = response.split("\n", maxsplit=1)
|
| 311 |
+
else:
|
| 312 |
+
metadata, sub_content = "", response
|
| 313 |
+
processed_messages.append(
|
| 314 |
+
{
|
| 315 |
+
"role": role,
|
| 316 |
+
"metadata": metadata,
|
| 317 |
+
"content": sub_content.strip()
|
| 318 |
+
}
|
| 319 |
+
)
|
| 320 |
+
else:
|
| 321 |
+
if role == "system" and msg_has_sys:
|
| 322 |
+
msg_has_sys = False
|
| 323 |
+
continue
|
| 324 |
+
processed_messages.append({"role": role, "content": content})
|
| 325 |
+
|
| 326 |
+
if not tools or tool_choice == "none":
|
| 327 |
+
for m in _messages:
|
| 328 |
+
if m.role == 'system':
|
| 329 |
+
processed_messages.insert(0, {"role": m.role, "content": m.content})
|
| 330 |
+
break
|
| 331 |
+
return processed_messages
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
@app.get("/health")
|
| 335 |
+
async def health() -> Response:
|
| 336 |
+
"""Health check."""
|
| 337 |
+
return Response(status_code=200)
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
@app.get("/v1/models", response_model=ModelList)
|
| 341 |
+
async def list_models():
|
| 342 |
+
model_card = ModelCard(id="glm-4")
|
| 343 |
+
return ModelList(data=[model_card])
|
| 344 |
+
|
| 345 |
+
|
| 346 |
+
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
|
| 347 |
+
async def create_chat_completion(request: ChatCompletionRequest):
|
| 348 |
+
if len(request.messages) < 1 or request.messages[-1].role == "assistant":
|
| 349 |
+
raise HTTPException(status_code=400, detail="Invalid request")
|
| 350 |
+
|
| 351 |
+
gen_params = dict(
|
| 352 |
+
messages=request.messages,
|
| 353 |
+
temperature=request.temperature,
|
| 354 |
+
top_p=request.top_p,
|
| 355 |
+
max_tokens=request.max_tokens or 1024,
|
| 356 |
+
echo=False,
|
| 357 |
+
stream=request.stream,
|
| 358 |
+
repetition_penalty=request.repetition_penalty,
|
| 359 |
+
tools=request.tools,
|
| 360 |
+
tool_choice=request.tool_choice,
|
| 361 |
+
)
|
| 362 |
+
logger.debug(f"==== request ====\n{gen_params}")
|
| 363 |
+
|
| 364 |
+
if request.stream:
|
| 365 |
+
predict_stream_generator = predict_stream(request.model, gen_params)
|
| 366 |
+
output = await anext(predict_stream_generator)
|
| 367 |
+
if output:
|
| 368 |
+
return EventSourceResponse(predict_stream_generator, media_type="text/event-stream")
|
| 369 |
+
logger.debug(f"First result output:\n{output}")
|
| 370 |
+
|
| 371 |
+
function_call = None
|
| 372 |
+
if output and request.tools:
|
| 373 |
+
try:
|
| 374 |
+
function_call = process_response(output, request.tools, use_tool=True)
|
| 375 |
+
except:
|
| 376 |
+
logger.warning("Failed to parse tool call")
|
| 377 |
+
|
| 378 |
+
if isinstance(function_call, dict):
|
| 379 |
+
function_call = ChoiceDeltaToolCallFunction(**function_call)
|
| 380 |
+
generate = parse_output_text(request.model, output, function_call=function_call)
|
| 381 |
+
return EventSourceResponse(generate, media_type="text/event-stream")
|
| 382 |
+
else:
|
| 383 |
+
return EventSourceResponse(predict_stream_generator, media_type="text/event-stream")
|
| 384 |
+
response = ""
|
| 385 |
+
async for response in generate_stream_glm4(gen_params):
|
| 386 |
+
pass
|
| 387 |
+
|
| 388 |
+
if response["text"].startswith("\n"):
|
| 389 |
+
response["text"] = response["text"][1:]
|
| 390 |
+
response["text"] = response["text"].strip()
|
| 391 |
+
|
| 392 |
+
usage = UsageInfo()
|
| 393 |
+
|
| 394 |
+
function_call, finish_reason = None, "stop"
|
| 395 |
+
tool_calls = None
|
| 396 |
+
if request.tools:
|
| 397 |
+
try:
|
| 398 |
+
function_call = process_response(response["text"], request.tools, use_tool=True)
|
| 399 |
+
except Exception as e:
|
| 400 |
+
logger.warning(f"Failed to parse tool call: {e}")
|
| 401 |
+
if isinstance(function_call, dict):
|
| 402 |
+
finish_reason = "tool_calls"
|
| 403 |
+
function_call_response = ChoiceDeltaToolCallFunction(**function_call)
|
| 404 |
+
function_call_instance = FunctionCall(
|
| 405 |
+
name=function_call_response.name,
|
| 406 |
+
arguments=function_call_response.arguments
|
| 407 |
+
)
|
| 408 |
+
tool_calls = [
|
| 409 |
+
ChatCompletionMessageToolCall(
|
| 410 |
+
id=generate_id('call_', 24),
|
| 411 |
+
function=function_call_instance,
|
| 412 |
+
type="function")]
|
| 413 |
+
|
| 414 |
+
message = ChatMessage(
|
| 415 |
+
role="assistant",
|
| 416 |
+
content=None if tool_calls else response["text"],
|
| 417 |
+
function_call=None,
|
| 418 |
+
tool_calls=tool_calls,
|
| 419 |
+
)
|
| 420 |
+
|
| 421 |
+
logger.debug(f"==== message ====\n{message}")
|
| 422 |
+
|
| 423 |
+
choice_data = ChatCompletionResponseChoice(
|
| 424 |
+
index=0,
|
| 425 |
+
message=message,
|
| 426 |
+
finish_reason=finish_reason,
|
| 427 |
+
)
|
| 428 |
+
task_usage = UsageInfo.model_validate(response["usage"])
|
| 429 |
+
for usage_key, usage_value in task_usage.model_dump().items():
|
| 430 |
+
setattr(usage, usage_key, getattr(usage, usage_key) + usage_value)
|
| 431 |
+
|
| 432 |
+
return ChatCompletionResponse(
|
| 433 |
+
model=request.model,
|
| 434 |
+
choices=[choice_data],
|
| 435 |
+
object="chat.completion",
|
| 436 |
+
usage=usage
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
async def predict_stream(model_id, gen_params):
|
| 441 |
+
output = ""
|
| 442 |
+
is_function_call = False
|
| 443 |
+
has_send_first_chunk = False
|
| 444 |
+
created_time = int(time.time())
|
| 445 |
+
function_name = None
|
| 446 |
+
response_id = generate_id('chatcmpl-', 29)
|
| 447 |
+
system_fingerprint = generate_id('fp_', 9)
|
| 448 |
+
tools = {tool['function']['name'] for tool in gen_params['tools']} if gen_params['tools'] else None
|
| 449 |
+
async for new_response in generate_stream_glm4(gen_params):
|
| 450 |
+
decoded_unicode = new_response["text"]
|
| 451 |
+
delta_text = decoded_unicode[len(output):]
|
| 452 |
+
output = decoded_unicode
|
| 453 |
+
lines = output.strip().split("\n")
|
| 454 |
+
|
| 455 |
+
# 检查是否为工具
|
| 456 |
+
# 这是一个简单的工具比较函数,不能保证拦截所有非工具输出的结果,比如参数未对齐等特殊情况。
|
| 457 |
+
##TODO 如果你希望做更多处理,可以在这里进行逻辑完善。
|
| 458 |
+
|
| 459 |
+
if not is_function_call and len(lines) >= 2:
|
| 460 |
+
first_line = lines[0].strip()
|
| 461 |
+
if first_line in tools:
|
| 462 |
+
is_function_call = True
|
| 463 |
+
function_name = first_line
|
| 464 |
+
|
| 465 |
+
# 工具调用返回
|
| 466 |
+
if is_function_call:
|
| 467 |
+
if not has_send_first_chunk:
|
| 468 |
+
function_call = {"name": function_name, "arguments": ""}
|
| 469 |
+
tool_call = ChatCompletionMessageToolCall(
|
| 470 |
+
index=0,
|
| 471 |
+
id=generate_id('call_', 24),
|
| 472 |
+
function=FunctionCall(**function_call),
|
| 473 |
+
type="function"
|
| 474 |
+
)
|
| 475 |
+
message = DeltaMessage(
|
| 476 |
+
content=None,
|
| 477 |
+
role="assistant",
|
| 478 |
+
function_call=None,
|
| 479 |
+
tool_calls=[tool_call]
|
| 480 |
+
)
|
| 481 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 482 |
+
index=0,
|
| 483 |
+
delta=message,
|
| 484 |
+
finish_reason=None
|
| 485 |
+
)
|
| 486 |
+
chunk = ChatCompletionResponse(
|
| 487 |
+
model=model_id,
|
| 488 |
+
id=response_id,
|
| 489 |
+
choices=[choice_data],
|
| 490 |
+
created=created_time,
|
| 491 |
+
system_fingerprint=system_fingerprint,
|
| 492 |
+
object="chat.completion.chunk"
|
| 493 |
+
)
|
| 494 |
+
yield ""
|
| 495 |
+
yield chunk.model_dump_json(exclude_unset=True)
|
| 496 |
+
has_send_first_chunk = True
|
| 497 |
+
|
| 498 |
+
function_call = {"name": None, "arguments": delta_text}
|
| 499 |
+
tool_call = ChatCompletionMessageToolCall(
|
| 500 |
+
index=0,
|
| 501 |
+
id=None,
|
| 502 |
+
function=FunctionCall(**function_call),
|
| 503 |
+
type="function"
|
| 504 |
+
)
|
| 505 |
+
message = DeltaMessage(
|
| 506 |
+
content=None,
|
| 507 |
+
role=None,
|
| 508 |
+
function_call=None,
|
| 509 |
+
tool_calls=[tool_call]
|
| 510 |
+
)
|
| 511 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 512 |
+
index=0,
|
| 513 |
+
delta=message,
|
| 514 |
+
finish_reason=None
|
| 515 |
+
)
|
| 516 |
+
chunk = ChatCompletionResponse(
|
| 517 |
+
model=model_id,
|
| 518 |
+
id=response_id,
|
| 519 |
+
choices=[choice_data],
|
| 520 |
+
created=created_time,
|
| 521 |
+
system_fingerprint=system_fingerprint,
|
| 522 |
+
object="chat.completion.chunk"
|
| 523 |
+
)
|
| 524 |
+
yield chunk.model_dump_json(exclude_unset=True)
|
| 525 |
+
|
| 526 |
+
# 用户请求了 Function Call 但是框架还没确定是否为Function Call
|
| 527 |
+
elif (gen_params["tools"] and gen_params["tool_choice"] != "none") or is_function_call:
|
| 528 |
+
continue
|
| 529 |
+
|
| 530 |
+
# 常规返回
|
| 531 |
+
else:
|
| 532 |
+
finish_reason = new_response.get("finish_reason", None)
|
| 533 |
+
if not has_send_first_chunk:
|
| 534 |
+
message = DeltaMessage(
|
| 535 |
+
content="",
|
| 536 |
+
role="assistant",
|
| 537 |
+
function_call=None,
|
| 538 |
+
)
|
| 539 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 540 |
+
index=0,
|
| 541 |
+
delta=message,
|
| 542 |
+
finish_reason=finish_reason
|
| 543 |
+
)
|
| 544 |
+
chunk = ChatCompletionResponse(
|
| 545 |
+
model=model_id,
|
| 546 |
+
id=response_id,
|
| 547 |
+
choices=[choice_data],
|
| 548 |
+
created=created_time,
|
| 549 |
+
system_fingerprint=system_fingerprint,
|
| 550 |
+
object="chat.completion.chunk"
|
| 551 |
+
)
|
| 552 |
+
yield chunk.model_dump_json(exclude_unset=True)
|
| 553 |
+
has_send_first_chunk = True
|
| 554 |
+
|
| 555 |
+
message = DeltaMessage(
|
| 556 |
+
content=delta_text,
|
| 557 |
+
role="assistant",
|
| 558 |
+
function_call=None,
|
| 559 |
+
)
|
| 560 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 561 |
+
index=0,
|
| 562 |
+
delta=message,
|
| 563 |
+
finish_reason=finish_reason
|
| 564 |
+
)
|
| 565 |
+
chunk = ChatCompletionResponse(
|
| 566 |
+
model=model_id,
|
| 567 |
+
id=response_id,
|
| 568 |
+
choices=[choice_data],
|
| 569 |
+
created=created_time,
|
| 570 |
+
system_fingerprint=system_fingerprint,
|
| 571 |
+
object="chat.completion.chunk"
|
| 572 |
+
)
|
| 573 |
+
yield chunk.model_dump_json(exclude_unset=True)
|
| 574 |
+
|
| 575 |
+
# 工具调用需要额外返回一个字段以对齐 OpenAI 接口
|
| 576 |
+
if is_function_call:
|
| 577 |
+
yield ChatCompletionResponse(
|
| 578 |
+
model=model_id,
|
| 579 |
+
id=response_id,
|
| 580 |
+
system_fingerprint=system_fingerprint,
|
| 581 |
+
choices=[
|
| 582 |
+
ChatCompletionResponseStreamChoice(
|
| 583 |
+
index=0,
|
| 584 |
+
delta=DeltaMessage(
|
| 585 |
+
content=None,
|
| 586 |
+
role=None,
|
| 587 |
+
function_call=None,
|
| 588 |
+
),
|
| 589 |
+
finish_reason="tool_calls"
|
| 590 |
+
)],
|
| 591 |
+
created=created_time,
|
| 592 |
+
object="chat.completion.chunk",
|
| 593 |
+
usage=None
|
| 594 |
+
).model_dump_json(exclude_unset=True)
|
| 595 |
+
yield '[DONE]'
|
| 596 |
+
|
| 597 |
+
|
| 598 |
+
async def parse_output_text(model_id: str, value: str, function_call: ChoiceDeltaToolCallFunction = None):
|
| 599 |
+
delta = DeltaMessage(role="assistant", content=value)
|
| 600 |
+
if function_call is not None:
|
| 601 |
+
delta.function_call = function_call
|
| 602 |
+
|
| 603 |
+
choice_data = ChatCompletionResponseStreamChoice(
|
| 604 |
+
index=0,
|
| 605 |
+
delta=delta,
|
| 606 |
+
finish_reason=None
|
| 607 |
+
)
|
| 608 |
+
chunk = ChatCompletionResponse(
|
| 609 |
+
model=model_id,
|
| 610 |
+
choices=[choice_data],
|
| 611 |
+
object="chat.completion.chunk"
|
| 612 |
+
)
|
| 613 |
+
yield "{}".format(chunk.model_dump_json(exclude_unset=True))
|
| 614 |
+
yield '[DONE]'
|
| 615 |
+
|
| 616 |
+
|
| 617 |
+
if __name__ == "__main__":
|
| 618 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
|
| 619 |
+
engine_args = AsyncEngineArgs(
|
| 620 |
+
model=MODEL_PATH,
|
| 621 |
+
tokenizer=MODEL_PATH,
|
| 622 |
+
# 如果你有多张显卡,可以在这里设置成你的显卡数量
|
| 623 |
+
tensor_parallel_size=1,
|
| 624 |
+
dtype="bfloat16",
|
| 625 |
+
trust_remote_code=True,
|
| 626 |
+
# 占用显存的比例,请根据你的显卡显存大小设置合适的值,例如,如果你的显卡有80G,您只想使用24G,请按照24/80=0.3设置
|
| 627 |
+
gpu_memory_utilization=0.9,
|
| 628 |
+
enforce_eager=True,
|
| 629 |
+
worker_use_ray=False,
|
| 630 |
+
engine_use_ray=False,
|
| 631 |
+
disable_log_requests=True,
|
| 632 |
+
max_model_len=MAX_MODEL_LENGTH,
|
| 633 |
+
)
|
| 634 |
+
engine = AsyncLLMEngine.from_engine_args(engine_args)
|
| 635 |
+
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
|
requirements.txt
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# use vllm
|
| 2 |
+
# vllm>=0.5.0
|
| 3 |
+
|
| 4 |
+
torch>=2.3.0
|
| 5 |
+
torchvision>=0.18.0
|
| 6 |
+
transformers==4.40.0
|
| 7 |
+
huggingface-hub>=0.23.1
|
| 8 |
+
sentencepiece>=0.2.0
|
| 9 |
+
pydantic>=2.7.1
|
| 10 |
+
timm>=0.9.16
|
| 11 |
+
tiktoken>=0.7.0
|
| 12 |
+
accelerate>=0.30.1
|
| 13 |
+
sentence_transformers>=2.7.0
|
| 14 |
+
|
| 15 |
+
# web demo
|
| 16 |
+
gradio>=4.33.0
|
| 17 |
+
|
| 18 |
+
# openai demo
|
| 19 |
+
openai>=1.34.0
|
| 20 |
+
einops>=0.7.0
|
| 21 |
+
sse-starlette>=2.1.0
|
| 22 |
+
|
| 23 |
+
# INT4
|
| 24 |
+
bitsandbytes>=0.43.1
|
| 25 |
+
|
| 26 |
+
# PEFT model, not need if you don't use PEFT finetune model.
|
| 27 |
+
# peft>=0.11.0
|
trans_batch_demo.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
|
| 3 |
+
Here is an example of using batch request glm-4-9b,
|
| 4 |
+
here you need to build the conversation format yourself and then call the batch function to make batch requests.
|
| 5 |
+
Please note that in this demo, the memory consumption is significantly higher.
|
| 6 |
+
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
from typing import Optional, Union
|
| 10 |
+
from transformers import AutoModel, AutoTokenizer, LogitsProcessorList
|
| 11 |
+
|
| 12 |
+
MODEL_PATH = 'THUDM/glm-4-9b-chat'
|
| 13 |
+
|
| 14 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 15 |
+
MODEL_PATH,
|
| 16 |
+
trust_remote_code=True,
|
| 17 |
+
encode_special_tokens=True)
|
| 18 |
+
model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").eval()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def process_model_outputs(inputs, outputs, tokenizer):
|
| 22 |
+
responses = []
|
| 23 |
+
for input_ids, output_ids in zip(inputs.input_ids, outputs):
|
| 24 |
+
response = tokenizer.decode(output_ids[len(input_ids):], skip_special_tokens=True).strip()
|
| 25 |
+
responses.append(response)
|
| 26 |
+
return responses
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def batch(
|
| 30 |
+
model,
|
| 31 |
+
tokenizer,
|
| 32 |
+
messages: Union[str, list[str]],
|
| 33 |
+
max_input_tokens: int = 8192,
|
| 34 |
+
max_new_tokens: int = 8192,
|
| 35 |
+
num_beams: int = 1,
|
| 36 |
+
do_sample: bool = True,
|
| 37 |
+
top_p: float = 0.8,
|
| 38 |
+
temperature: float = 0.8,
|
| 39 |
+
logits_processor: Optional[LogitsProcessorList] = LogitsProcessorList(),
|
| 40 |
+
):
|
| 41 |
+
messages = [messages] if isinstance(messages, str) else messages
|
| 42 |
+
batched_inputs = tokenizer(messages, return_tensors="pt", padding="max_length", truncation=True,
|
| 43 |
+
max_length=max_input_tokens).to(model.device)
|
| 44 |
+
|
| 45 |
+
gen_kwargs = {
|
| 46 |
+
"max_new_tokens": max_new_tokens,
|
| 47 |
+
"num_beams": num_beams,
|
| 48 |
+
"do_sample": do_sample,
|
| 49 |
+
"top_p": top_p,
|
| 50 |
+
"temperature": temperature,
|
| 51 |
+
"logits_processor": logits_processor,
|
| 52 |
+
"eos_token_id": model.config.eos_token_id
|
| 53 |
+
}
|
| 54 |
+
batched_outputs = model.generate(**batched_inputs, **gen_kwargs)
|
| 55 |
+
batched_response = process_model_outputs(batched_inputs, batched_outputs, tokenizer)
|
| 56 |
+
return batched_response
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
if __name__ == "__main__":
|
| 60 |
+
|
| 61 |
+
batch_message = [
|
| 62 |
+
[
|
| 63 |
+
{"role": "user", "content": "我的爸爸和妈妈结婚为什么不能带我去"},
|
| 64 |
+
{"role": "assistant", "content": "因为他们结婚时你还没有出生"},
|
| 65 |
+
{"role": "user", "content": "我刚才的提问是"}
|
| 66 |
+
],
|
| 67 |
+
[
|
| 68 |
+
{"role": "user", "content": "你好,你是谁"}
|
| 69 |
+
]
|
| 70 |
+
]
|
| 71 |
+
|
| 72 |
+
batch_inputs = []
|
| 73 |
+
max_input_tokens = 1024
|
| 74 |
+
for i, messages in enumerate(batch_message):
|
| 75 |
+
new_batch_input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
|
| 76 |
+
max_input_tokens = max(max_input_tokens, len(new_batch_input))
|
| 77 |
+
batch_inputs.append(new_batch_input)
|
| 78 |
+
gen_kwargs = {
|
| 79 |
+
"max_input_tokens": max_input_tokens,
|
| 80 |
+
"max_new_tokens": 8192,
|
| 81 |
+
"do_sample": True,
|
| 82 |
+
"top_p": 0.8,
|
| 83 |
+
"temperature": 0.8,
|
| 84 |
+
"num_beams": 1,
|
| 85 |
+
}
|
| 86 |
+
|
| 87 |
+
batch_responses = batch(model, tokenizer, batch_inputs, **gen_kwargs)
|
| 88 |
+
for response in batch_responses:
|
| 89 |
+
print("=" * 10)
|
| 90 |
+
print(response)
|
trans_cli_demo.py
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This script creates a CLI demo with transformers backend for the glm-4-9b model,
|
| 3 |
+
allowing users to interact with the model through a command-line interface.
|
| 4 |
+
|
| 5 |
+
Usage:
|
| 6 |
+
- Run the script to start the CLI demo.
|
| 7 |
+
- Interact with the model by typing questions and receiving responses.
|
| 8 |
+
|
| 9 |
+
Note: The script includes a modification to handle markdown to plain text conversion,
|
| 10 |
+
ensuring that the CLI interface displays formatted text correctly.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import torch
|
| 15 |
+
from threading import Thread
|
| 16 |
+
from transformers import AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer, AutoModel
|
| 17 |
+
|
| 18 |
+
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/glm-4-9b-chat')
|
| 19 |
+
|
| 20 |
+
## If use peft model.
|
| 21 |
+
# def load_model_and_tokenizer(model_dir, trust_remote_code: bool = True):
|
| 22 |
+
# if (model_dir / 'adapter_config.json').exists():
|
| 23 |
+
# model = AutoModel.from_pretrained(
|
| 24 |
+
# model_dir, trust_remote_code=trust_remote_code, device_map='auto'
|
| 25 |
+
# )
|
| 26 |
+
# tokenizer_dir = model.peft_config['default'].base_model_name_or_path
|
| 27 |
+
# else:
|
| 28 |
+
# model = AutoModel.from_pretrained(
|
| 29 |
+
# model_dir, trust_remote_code=trust_remote_code, device_map='auto'
|
| 30 |
+
# )
|
| 31 |
+
# tokenizer_dir = model_dir
|
| 32 |
+
# tokenizer = AutoTokenizer.from_pretrained(
|
| 33 |
+
# tokenizer_dir, trust_remote_code=trust_remote_code, use_fast=False
|
| 34 |
+
# )
|
| 35 |
+
# return model, tokenizer
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 39 |
+
MODEL_PATH,
|
| 40 |
+
trust_remote_code=True,
|
| 41 |
+
encode_special_tokens=True
|
| 42 |
+
)
|
| 43 |
+
model = AutoModel.from_pretrained(
|
| 44 |
+
MODEL_PATH,
|
| 45 |
+
trust_remote_code=True,
|
| 46 |
+
device_map="auto").eval()
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class StopOnTokens(StoppingCriteria):
|
| 50 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 51 |
+
stop_ids = model.config.eos_token_id
|
| 52 |
+
for stop_id in stop_ids:
|
| 53 |
+
if input_ids[0][-1] == stop_id:
|
| 54 |
+
return True
|
| 55 |
+
return False
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
if __name__ == "__main__":
|
| 59 |
+
history = []
|
| 60 |
+
max_length = 8192
|
| 61 |
+
top_p = 0.8
|
| 62 |
+
temperature = 0.6
|
| 63 |
+
stop = StopOnTokens()
|
| 64 |
+
|
| 65 |
+
print("Welcome to the GLM-4-9B CLI chat. Type your messages below.")
|
| 66 |
+
while True:
|
| 67 |
+
user_input = input("\nYou: ")
|
| 68 |
+
if user_input.lower() in ["exit", "quit"]:
|
| 69 |
+
break
|
| 70 |
+
history.append([user_input, ""])
|
| 71 |
+
|
| 72 |
+
messages = []
|
| 73 |
+
for idx, (user_msg, model_msg) in enumerate(history):
|
| 74 |
+
if idx == len(history) - 1 and not model_msg:
|
| 75 |
+
messages.append({"role": "user", "content": user_msg})
|
| 76 |
+
break
|
| 77 |
+
if user_msg:
|
| 78 |
+
messages.append({"role": "user", "content": user_msg})
|
| 79 |
+
if model_msg:
|
| 80 |
+
messages.append({"role": "assistant", "content": model_msg})
|
| 81 |
+
model_inputs = tokenizer.apply_chat_template(
|
| 82 |
+
messages,
|
| 83 |
+
add_generation_prompt=True,
|
| 84 |
+
tokenize=True,
|
| 85 |
+
return_tensors="pt"
|
| 86 |
+
).to(model.device)
|
| 87 |
+
streamer = TextIteratorStreamer(
|
| 88 |
+
tokenizer=tokenizer,
|
| 89 |
+
timeout=60,
|
| 90 |
+
skip_prompt=True,
|
| 91 |
+
skip_special_tokens=True
|
| 92 |
+
)
|
| 93 |
+
generate_kwargs = {
|
| 94 |
+
"input_ids": model_inputs,
|
| 95 |
+
"streamer": streamer,
|
| 96 |
+
"max_new_tokens": max_length,
|
| 97 |
+
"do_sample": True,
|
| 98 |
+
"top_p": top_p,
|
| 99 |
+
"temperature": temperature,
|
| 100 |
+
"stopping_criteria": StoppingCriteriaList([stop]),
|
| 101 |
+
"repetition_penalty": 1.2,
|
| 102 |
+
"eos_token_id": model.config.eos_token_id,
|
| 103 |
+
}
|
| 104 |
+
t = Thread(target=model.generate, kwargs=generate_kwargs)
|
| 105 |
+
t.start()
|
| 106 |
+
print("GLM-4:", end="", flush=True)
|
| 107 |
+
for new_token in streamer:
|
| 108 |
+
if new_token:
|
| 109 |
+
print(new_token, end="", flush=True)
|
| 110 |
+
history[-1][1] += new_token
|
| 111 |
+
|
| 112 |
+
history[-1][1] = history[-1][1].strip()
|
trans_cli_vision_demo.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This script creates a CLI demo with transformers backend for the glm-4v-9b model,
|
| 3 |
+
allowing users to interact with the model through a command-line interface.
|
| 4 |
+
|
| 5 |
+
Usage:
|
| 6 |
+
- Run the script to start the CLI demo.
|
| 7 |
+
- Interact with the model by typing questions and receiving responses.
|
| 8 |
+
|
| 9 |
+
Note: The script includes a modification to handle markdown to plain text conversion,
|
| 10 |
+
ensuring that the CLI interface displays formatted text correctly.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import torch
|
| 15 |
+
from threading import Thread
|
| 16 |
+
from transformers import (
|
| 17 |
+
AutoTokenizer,
|
| 18 |
+
StoppingCriteria,
|
| 19 |
+
StoppingCriteriaList,
|
| 20 |
+
TextIteratorStreamer, AutoModel, BitsAndBytesConfig
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
from PIL import Image
|
| 24 |
+
|
| 25 |
+
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/glm-4v-9b')
|
| 26 |
+
|
| 27 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 28 |
+
MODEL_PATH,
|
| 29 |
+
trust_remote_code=True,
|
| 30 |
+
encode_special_tokens=True
|
| 31 |
+
)
|
| 32 |
+
model = AutoModel.from_pretrained(
|
| 33 |
+
MODEL_PATH,
|
| 34 |
+
trust_remote_code=True,
|
| 35 |
+
device_map="auto",
|
| 36 |
+
torch_dtype=torch.bfloat16
|
| 37 |
+
).eval()
|
| 38 |
+
|
| 39 |
+
## For INT4 inference
|
| 40 |
+
# model = AutoModel.from_pretrained(
|
| 41 |
+
# MODEL_PATH,
|
| 42 |
+
# trust_remote_code=True,
|
| 43 |
+
# quantization_config=BitsAndBytesConfig(load_in_4bit=True),
|
| 44 |
+
# torch_dtype=torch.bfloat16,
|
| 45 |
+
# low_cpu_mem_usage=True
|
| 46 |
+
# ).eval()
|
| 47 |
+
|
| 48 |
+
class StopOnTokens(StoppingCriteria):
|
| 49 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 50 |
+
stop_ids = model.config.eos_token_id
|
| 51 |
+
for stop_id in stop_ids:
|
| 52 |
+
if input_ids[0][-1] == stop_id:
|
| 53 |
+
return True
|
| 54 |
+
return False
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
if __name__ == "__main__":
|
| 58 |
+
history = []
|
| 59 |
+
max_length = 1024
|
| 60 |
+
top_p = 0.8
|
| 61 |
+
temperature = 0.6
|
| 62 |
+
stop = StopOnTokens()
|
| 63 |
+
uploaded = False
|
| 64 |
+
image = None
|
| 65 |
+
print("Welcome to the GLM-4-9B CLI chat. Type your messages below.")
|
| 66 |
+
image_path = input("Image Path:")
|
| 67 |
+
try:
|
| 68 |
+
image = Image.open(image_path).convert("RGB")
|
| 69 |
+
except:
|
| 70 |
+
print("Invalid image path. Continuing with text conversation.")
|
| 71 |
+
while True:
|
| 72 |
+
user_input = input("\nYou: ")
|
| 73 |
+
if user_input.lower() in ["exit", "quit"]:
|
| 74 |
+
break
|
| 75 |
+
history.append([user_input, ""])
|
| 76 |
+
|
| 77 |
+
messages = []
|
| 78 |
+
for idx, (user_msg, model_msg) in enumerate(history):
|
| 79 |
+
if idx == len(history) - 1 and not model_msg:
|
| 80 |
+
messages.append({"role": "user", "content": user_msg})
|
| 81 |
+
if image and not uploaded:
|
| 82 |
+
messages[-1].update({"image": image})
|
| 83 |
+
uploaded = True
|
| 84 |
+
break
|
| 85 |
+
if user_msg:
|
| 86 |
+
messages.append({"role": "user", "content": user_msg})
|
| 87 |
+
if model_msg:
|
| 88 |
+
messages.append({"role": "assistant", "content": model_msg})
|
| 89 |
+
model_inputs = tokenizer.apply_chat_template(
|
| 90 |
+
messages,
|
| 91 |
+
add_generation_prompt=True,
|
| 92 |
+
tokenize=True,
|
| 93 |
+
return_tensors="pt",
|
| 94 |
+
return_dict=True
|
| 95 |
+
).to(next(model.parameters()).device)
|
| 96 |
+
streamer = TextIteratorStreamer(
|
| 97 |
+
tokenizer=tokenizer,
|
| 98 |
+
timeout=60,
|
| 99 |
+
skip_prompt=True,
|
| 100 |
+
skip_special_tokens=True
|
| 101 |
+
)
|
| 102 |
+
generate_kwargs = {
|
| 103 |
+
**model_inputs,
|
| 104 |
+
"streamer": streamer,
|
| 105 |
+
"max_new_tokens": max_length,
|
| 106 |
+
"do_sample": True,
|
| 107 |
+
"top_p": top_p,
|
| 108 |
+
"temperature": temperature,
|
| 109 |
+
"stopping_criteria": StoppingCriteriaList([stop]),
|
| 110 |
+
"repetition_penalty": 1.2,
|
| 111 |
+
"eos_token_id": [151329, 151336, 151338],
|
| 112 |
+
}
|
| 113 |
+
t = Thread(target=model.generate, kwargs=generate_kwargs)
|
| 114 |
+
t.start()
|
| 115 |
+
print("GLM-4V:", end="", flush=True)
|
| 116 |
+
for new_token in streamer:
|
| 117 |
+
if new_token:
|
| 118 |
+
print(new_token, end="", flush=True)
|
| 119 |
+
history[-1][1] += new_token
|
| 120 |
+
|
| 121 |
+
history[-1][1] = history[-1][1].strip()
|
trans_cli_vision_gradio_demo.py
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This script creates a Gradio demo with a Transformers backend for the glm-4v-9b model, allowing users to interact with the model through a Gradio web UI.
|
| 3 |
+
|
| 4 |
+
Usage:
|
| 5 |
+
- Run the script to start the Gradio server.
|
| 6 |
+
- Interact with the model via the web UI.
|
| 7 |
+
|
| 8 |
+
Requirements:
|
| 9 |
+
- Gradio package
|
| 10 |
+
- Type `pip install gradio` to install Gradio.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import os
|
| 14 |
+
import torch
|
| 15 |
+
import gradio as gr
|
| 16 |
+
from threading import Thread
|
| 17 |
+
from transformers import (
|
| 18 |
+
AutoTokenizer,
|
| 19 |
+
StoppingCriteria,
|
| 20 |
+
StoppingCriteriaList,
|
| 21 |
+
TextIteratorStreamer, AutoModel, BitsAndBytesConfig
|
| 22 |
+
)
|
| 23 |
+
from PIL import Image
|
| 24 |
+
import requests
|
| 25 |
+
from io import BytesIO
|
| 26 |
+
|
| 27 |
+
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/glm-4v-9b')
|
| 28 |
+
|
| 29 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 30 |
+
MODEL_PATH,
|
| 31 |
+
trust_remote_code=True,
|
| 32 |
+
encode_special_tokens=True
|
| 33 |
+
)
|
| 34 |
+
model = AutoModel.from_pretrained(
|
| 35 |
+
MODEL_PATH,
|
| 36 |
+
trust_remote_code=True,
|
| 37 |
+
device_map="auto",
|
| 38 |
+
torch_dtype=torch.bfloat16
|
| 39 |
+
).eval()
|
| 40 |
+
|
| 41 |
+
class StopOnTokens(StoppingCriteria):
|
| 42 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 43 |
+
stop_ids = model.config.eos_token_id
|
| 44 |
+
for stop_id in stop_ids:
|
| 45 |
+
if input_ids[0][-1] == stop_id:
|
| 46 |
+
return True
|
| 47 |
+
return False
|
| 48 |
+
|
| 49 |
+
def get_image(image_path=None, image_url=None):
|
| 50 |
+
if image_path:
|
| 51 |
+
return Image.open(image_path).convert("RGB")
|
| 52 |
+
elif image_url:
|
| 53 |
+
response = requests.get(image_url)
|
| 54 |
+
return Image.open(BytesIO(response.content)).convert("RGB")
|
| 55 |
+
return None
|
| 56 |
+
|
| 57 |
+
def chatbot(image_path=None, image_url=None, assistant_prompt=""):
|
| 58 |
+
image = get_image(image_path, image_url)
|
| 59 |
+
|
| 60 |
+
messages = [
|
| 61 |
+
{"role": "assistant", "content": assistant_prompt},
|
| 62 |
+
{"role": "user", "content": "", "image": image}
|
| 63 |
+
]
|
| 64 |
+
|
| 65 |
+
model_inputs = tokenizer.apply_chat_template(
|
| 66 |
+
messages,
|
| 67 |
+
add_generation_prompt=True,
|
| 68 |
+
tokenize=True,
|
| 69 |
+
return_tensors="pt",
|
| 70 |
+
return_dict=True
|
| 71 |
+
).to(next(model.parameters()).device)
|
| 72 |
+
|
| 73 |
+
streamer = TextIteratorStreamer(
|
| 74 |
+
tokenizer=tokenizer,
|
| 75 |
+
timeout=60,
|
| 76 |
+
skip_prompt=True,
|
| 77 |
+
skip_special_tokens=True
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
generate_kwargs = {
|
| 81 |
+
**model_inputs,
|
| 82 |
+
"streamer": streamer,
|
| 83 |
+
"max_new_tokens": 1024,
|
| 84 |
+
"do_sample": True,
|
| 85 |
+
"top_p": 0.8,
|
| 86 |
+
"temperature": 0.6,
|
| 87 |
+
"stopping_criteria": StoppingCriteriaList([StopOnTokens()]),
|
| 88 |
+
"repetition_penalty": 1.2,
|
| 89 |
+
"eos_token_id": [151329, 151336, 151338],
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
t = Thread(target=model.generate, kwargs=generate_kwargs)
|
| 93 |
+
t.start()
|
| 94 |
+
|
| 95 |
+
response = ""
|
| 96 |
+
for new_token in streamer:
|
| 97 |
+
if new_token:
|
| 98 |
+
response += new_token
|
| 99 |
+
|
| 100 |
+
return image, response.strip()
|
| 101 |
+
|
| 102 |
+
with gr.Blocks() as demo:
|
| 103 |
+
demo.title = "GLM-4V-9B Image Recognition Demo"
|
| 104 |
+
demo.description = """
|
| 105 |
+
This demo uses the GLM-4V-9B model to got image infomation.
|
| 106 |
+
"""
|
| 107 |
+
with gr.Row():
|
| 108 |
+
with gr.Column():
|
| 109 |
+
image_path_input = gr.File(label="Upload Image (High-Priority)", type="filepath")
|
| 110 |
+
image_url_input = gr.Textbox(label="Image URL (Low-Priority)")
|
| 111 |
+
assistant_prompt_input = gr.Textbox(label="Assistant Prompt (You Can Change It)", value="这是什么?")
|
| 112 |
+
submit_button = gr.Button("Submit")
|
| 113 |
+
with gr.Column():
|
| 114 |
+
chatbot_output = gr.Textbox(label="GLM-4V-9B Model Response")
|
| 115 |
+
image_output = gr.Image(label="Image Preview")
|
| 116 |
+
|
| 117 |
+
submit_button.click(chatbot,
|
| 118 |
+
inputs=[image_path_input, image_url_input, assistant_prompt_input],
|
| 119 |
+
outputs=[image_output, chatbot_output])
|
| 120 |
+
|
| 121 |
+
demo.launch(server_name="127.0.0.1", server_port=8911, inbrowser=True, share=False)
|
trans_stress_test.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import time
|
| 3 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, BitsAndBytesConfig
|
| 4 |
+
import torch
|
| 5 |
+
from threading import Thread
|
| 6 |
+
|
| 7 |
+
MODEL_PATH = 'THUDM/glm-4-9b-chat'
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def stress_test(token_len, n, num_gpu):
|
| 11 |
+
device = torch.device(f"cuda:{num_gpu - 1}" if torch.cuda.is_available() and num_gpu > 0 else "cpu")
|
| 12 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 13 |
+
MODEL_PATH,
|
| 14 |
+
trust_remote_code=True,
|
| 15 |
+
padding_side="left"
|
| 16 |
+
)
|
| 17 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 18 |
+
MODEL_PATH,
|
| 19 |
+
trust_remote_code=True,
|
| 20 |
+
torch_dtype=torch.bfloat16
|
| 21 |
+
).to(device).eval()
|
| 22 |
+
|
| 23 |
+
# Use INT4 weight infer
|
| 24 |
+
# model = AutoModelForCausalLM.from_pretrained(
|
| 25 |
+
# MODEL_PATH,
|
| 26 |
+
# trust_remote_code=True,
|
| 27 |
+
# quantization_config=BitsAndBytesConfig(load_in_4bit=True),
|
| 28 |
+
# low_cpu_mem_usage=True,
|
| 29 |
+
# ).eval()
|
| 30 |
+
|
| 31 |
+
times = []
|
| 32 |
+
decode_times = []
|
| 33 |
+
|
| 34 |
+
print("Warming up...")
|
| 35 |
+
vocab_size = tokenizer.vocab_size
|
| 36 |
+
warmup_token_len = 20
|
| 37 |
+
random_token_ids = torch.randint(3, vocab_size - 200, (warmup_token_len - 5,), dtype=torch.long)
|
| 38 |
+
start_tokens = [151331, 151333, 151336, 198]
|
| 39 |
+
end_tokens = [151337]
|
| 40 |
+
input_ids = torch.tensor(start_tokens + random_token_ids.tolist() + end_tokens, dtype=torch.long).unsqueeze(0).to(
|
| 41 |
+
device)
|
| 42 |
+
attention_mask = torch.ones_like(input_ids, dtype=torch.bfloat16).to(device)
|
| 43 |
+
position_ids = torch.arange(len(input_ids[0]), dtype=torch.bfloat16).unsqueeze(0).to(device)
|
| 44 |
+
warmup_inputs = {
|
| 45 |
+
'input_ids': input_ids,
|
| 46 |
+
'attention_mask': attention_mask,
|
| 47 |
+
'position_ids': position_ids
|
| 48 |
+
}
|
| 49 |
+
with torch.no_grad():
|
| 50 |
+
_ = model.generate(
|
| 51 |
+
input_ids=warmup_inputs['input_ids'],
|
| 52 |
+
attention_mask=warmup_inputs['attention_mask'],
|
| 53 |
+
max_new_tokens=2048,
|
| 54 |
+
do_sample=False,
|
| 55 |
+
repetition_penalty=1.0,
|
| 56 |
+
eos_token_id=[151329, 151336, 151338]
|
| 57 |
+
)
|
| 58 |
+
print("Warming up complete. Starting stress test...")
|
| 59 |
+
|
| 60 |
+
for i in range(n):
|
| 61 |
+
random_token_ids = torch.randint(3, vocab_size - 200, (token_len - 5,), dtype=torch.long)
|
| 62 |
+
input_ids = torch.tensor(start_tokens + random_token_ids.tolist() + end_tokens, dtype=torch.long).unsqueeze(
|
| 63 |
+
0).to(device)
|
| 64 |
+
attention_mask = torch.ones_like(input_ids, dtype=torch.bfloat16).to(device)
|
| 65 |
+
position_ids = torch.arange(len(input_ids[0]), dtype=torch.bfloat16).unsqueeze(0).to(device)
|
| 66 |
+
test_inputs = {
|
| 67 |
+
'input_ids': input_ids,
|
| 68 |
+
'attention_mask': attention_mask,
|
| 69 |
+
'position_ids': position_ids
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
streamer = TextIteratorStreamer(
|
| 73 |
+
tokenizer=tokenizer,
|
| 74 |
+
timeout=36000,
|
| 75 |
+
skip_prompt=True,
|
| 76 |
+
skip_special_tokens=True
|
| 77 |
+
)
|
| 78 |
+
|
| 79 |
+
generate_kwargs = {
|
| 80 |
+
"input_ids": test_inputs['input_ids'],
|
| 81 |
+
"attention_mask": test_inputs['attention_mask'],
|
| 82 |
+
"max_new_tokens": 512,
|
| 83 |
+
"do_sample": False,
|
| 84 |
+
"repetition_penalty": 1.0,
|
| 85 |
+
"eos_token_id": [151329, 151336, 151338],
|
| 86 |
+
"streamer": streamer
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
start_time = time.time()
|
| 90 |
+
t = Thread(target=model.generate, kwargs=generate_kwargs)
|
| 91 |
+
t.start()
|
| 92 |
+
|
| 93 |
+
first_token_time = None
|
| 94 |
+
all_token_times = []
|
| 95 |
+
|
| 96 |
+
for token in streamer:
|
| 97 |
+
current_time = time.time()
|
| 98 |
+
if first_token_time is None:
|
| 99 |
+
first_token_time = current_time
|
| 100 |
+
times.append(first_token_time - start_time)
|
| 101 |
+
all_token_times.append(current_time)
|
| 102 |
+
|
| 103 |
+
t.join()
|
| 104 |
+
end_time = time.time()
|
| 105 |
+
|
| 106 |
+
avg_decode_time_per_token = len(all_token_times) / (end_time - first_token_time) if all_token_times else 0
|
| 107 |
+
decode_times.append(avg_decode_time_per_token)
|
| 108 |
+
print(
|
| 109 |
+
f"Iteration {i + 1}/{n} - Prefilling Time: {times[-1]:.4f} seconds - Average Decode Time: {avg_decode_time_per_token:.4f} tokens/second")
|
| 110 |
+
|
| 111 |
+
torch.cuda.empty_cache()
|
| 112 |
+
|
| 113 |
+
avg_first_token_time = sum(times) / n
|
| 114 |
+
avg_decode_time = sum(decode_times) / n
|
| 115 |
+
print(f"\nAverage First Token Time over {n} iterations: {avg_first_token_time:.4f} seconds")
|
| 116 |
+
print(f"Average Decode Time per Token over {n} iterations: {avg_decode_time:.4f} tokens/second")
|
| 117 |
+
return times, avg_first_token_time, decode_times, avg_decode_time
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def main():
|
| 121 |
+
parser = argparse.ArgumentParser(description="Stress test for model inference")
|
| 122 |
+
parser.add_argument('--token_len', type=int, default=1000, help='Number of tokens for each test')
|
| 123 |
+
parser.add_argument('--n', type=int, default=3, help='Number of iterations for the stress test')
|
| 124 |
+
parser.add_argument('--num_gpu', type=int, default=1, help='Number of GPUs to use for inference')
|
| 125 |
+
args = parser.parse_args()
|
| 126 |
+
|
| 127 |
+
token_len = args.token_len
|
| 128 |
+
n = args.n
|
| 129 |
+
num_gpu = args.num_gpu
|
| 130 |
+
|
| 131 |
+
stress_test(token_len, n, num_gpu)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
if __name__ == "__main__":
|
| 135 |
+
main()
|
trans_web_demo.py
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This script creates an interactive web demo for the GLM-4-9B model using Gradio,
|
| 3 |
+
a Python library for building quick and easy UI components for machine learning models.
|
| 4 |
+
It's designed to showcase the capabilities of the GLM-4-9B model in a user-friendly interface,
|
| 5 |
+
allowing users to interact with the model through a chat-like interface.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
from pathlib import Path
|
| 10 |
+
from threading import Thread
|
| 11 |
+
from typing import Union
|
| 12 |
+
|
| 13 |
+
import gradio as gr
|
| 14 |
+
import torch
|
| 15 |
+
import pandas as pd
|
| 16 |
+
from peft import AutoPeftModelForCausalLM, PeftModelForCausalLM
|
| 17 |
+
from transformers import (
|
| 18 |
+
AutoModelForCausalLM,
|
| 19 |
+
AutoTokenizer,
|
| 20 |
+
PreTrainedModel,
|
| 21 |
+
PreTrainedTokenizer,
|
| 22 |
+
PreTrainedTokenizerFast,
|
| 23 |
+
StoppingCriteria,
|
| 24 |
+
StoppingCriteriaList,
|
| 25 |
+
TextIteratorStreamer
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
ModelType = Union[PreTrainedModel, PeftModelForCausalLM]
|
| 29 |
+
TokenizerType = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]
|
| 30 |
+
|
| 31 |
+
MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/glm-4-9b-chat')
|
| 32 |
+
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def _resolve_path(path: Union[str, Path]) -> Path:
|
| 36 |
+
return Path(path).expanduser().resolve()
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def load_model_and_tokenizer(
|
| 40 |
+
model_dir: Union[str, Path], trust_remote_code: bool = True
|
| 41 |
+
) -> tuple[ModelType, TokenizerType]:
|
| 42 |
+
model_dir = _resolve_path(model_dir)
|
| 43 |
+
if (model_dir / 'adapter_config.json').exists():
|
| 44 |
+
model = AutoPeftModelForCausalLM.from_pretrained(
|
| 45 |
+
model_dir, trust_remote_code=trust_remote_code, device_map='auto'
|
| 46 |
+
)
|
| 47 |
+
tokenizer_dir = model.peft_config['default'].base_model_name_or_path
|
| 48 |
+
else:
|
| 49 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 50 |
+
model_dir, trust_remote_code=trust_remote_code, device_map='auto'
|
| 51 |
+
)
|
| 52 |
+
tokenizer_dir = model_dir
|
| 53 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 54 |
+
tokenizer_dir, trust_remote_code=trust_remote_code, use_fast=False
|
| 55 |
+
)
|
| 56 |
+
return model, tokenizer
|
| 57 |
+
|
| 58 |
+
def load_knowledge_base(file: Union[str, Path]) -> pd.DataFrame:
|
| 59 |
+
return pd.read_excel(file)
|
| 60 |
+
|
| 61 |
+
def retrieve_from_knowledge_base(query: str, knowledge_base: pd.DataFrame) -> str:
|
| 62 |
+
# Convert the knowledge base to a dictionary
|
| 63 |
+
kb_dict = pd.Series(knowledge_base.iloc[:, 1].values, index=knowledge_base.iloc[:, 0]).to_dict()
|
| 64 |
+
|
| 65 |
+
# Search for relevant fields
|
| 66 |
+
relevant_info = []
|
| 67 |
+
for field, content in kb_dict.items():
|
| 68 |
+
if query.lower() in field.lower() or query.lower() in content.lower():
|
| 69 |
+
relevant_info.append(f"{field}: {content}")
|
| 70 |
+
|
| 71 |
+
if not relevant_info:
|
| 72 |
+
return "No relevant information found."
|
| 73 |
+
|
| 74 |
+
return "\n".join(relevant_info)
|
| 75 |
+
|
| 76 |
+
model, tokenizer = load_model_and_tokenizer(MODEL_PATH, trust_remote_code=True)
|
| 77 |
+
knowledge_base = pd.DataFrame()
|
| 78 |
+
|
| 79 |
+
class StopOnTokens(StoppingCriteria):
|
| 80 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
|
| 81 |
+
stop_ids = model.config.eos_token_id
|
| 82 |
+
for stop_id in stop_ids:
|
| 83 |
+
if input_ids[0][-1] == stop_id:
|
| 84 |
+
return True
|
| 85 |
+
return False
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def parse_text(text):
|
| 89 |
+
lines = text.split("\n")
|
| 90 |
+
lines = [line for line in lines if line != ""]
|
| 91 |
+
count = 0
|
| 92 |
+
for i, line in enumerate(lines):
|
| 93 |
+
if "```" in line:
|
| 94 |
+
count += 1
|
| 95 |
+
items = line.split('`')
|
| 96 |
+
if count % 2 == 1:
|
| 97 |
+
lines[i] = f'<pre><code class="language-{items[-1]}">'
|
| 98 |
+
else:
|
| 99 |
+
lines[i] = f'<br></code></pre>'
|
| 100 |
+
else:
|
| 101 |
+
if i > 0:
|
| 102 |
+
if count % 2 == 1:
|
| 103 |
+
line = line.replace("`", "\`")
|
| 104 |
+
line = line.replace("<", "<")
|
| 105 |
+
line = line.replace(">", ">")
|
| 106 |
+
line = line.replace(" ", " ")
|
| 107 |
+
line = line.replace("*", "*")
|
| 108 |
+
line = line.replace("_", "_")
|
| 109 |
+
line = line.replace("-", "-")
|
| 110 |
+
line = line.replace(".", ".")
|
| 111 |
+
line = line.replace("!", "!")
|
| 112 |
+
line = line.replace("(", "(")
|
| 113 |
+
line = line.replace(")", ")")
|
| 114 |
+
line = line.replace("$", "$")
|
| 115 |
+
lines[i] = "<br>" + line
|
| 116 |
+
text = "".join(lines)
|
| 117 |
+
return text
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def predict(history, prompt, max_length, top_p, temperature):
|
| 121 |
+
stop = StopOnTokens()
|
| 122 |
+
messages = []
|
| 123 |
+
if prompt:
|
| 124 |
+
messages.append({"role": "system", "content": prompt})
|
| 125 |
+
for idx, (user_msg, model_msg) in enumerate(history):
|
| 126 |
+
if prompt and idx == 0:
|
| 127 |
+
continue
|
| 128 |
+
if idx == len(history) - 1 and not model_msg:
|
| 129 |
+
messages.append({"role": "user", "content": user_msg})
|
| 130 |
+
break
|
| 131 |
+
if user_msg:
|
| 132 |
+
messages.append({"role": "user", "content": user_msg})
|
| 133 |
+
if model_msg:
|
| 134 |
+
messages.append({"role": "assistant", "content": model_msg})
|
| 135 |
+
|
| 136 |
+
if not knowledge_base.empty:
|
| 137 |
+
knowledge_text = retrieve_from_knowledge_base(messages[-1]['content'], knowledge_base)
|
| 138 |
+
messages.append({"role": "system", "content": knowledge_text})
|
| 139 |
+
|
| 140 |
+
model_inputs = tokenizer.apply_chat_template(messages,
|
| 141 |
+
add_generation_prompt=True,
|
| 142 |
+
tokenize=True,
|
| 143 |
+
return_tensors="pt").to(next(model.parameters()).device)
|
| 144 |
+
streamer = TextIteratorStreamer(tokenizer, timeout=60, skip_prompt=True, skip_special_tokens=True)
|
| 145 |
+
generate_kwargs = {
|
| 146 |
+
"input_ids": model_inputs,
|
| 147 |
+
"streamer": streamer,
|
| 148 |
+
"max_new_tokens": max_length,
|
| 149 |
+
"do_sample": True,
|
| 150 |
+
"top_p": top_p,
|
| 151 |
+
"temperature": temperature,
|
| 152 |
+
"stopping_criteria": StoppingCriteriaList([stop]),
|
| 153 |
+
"repetition_penalty": 1.2,
|
| 154 |
+
"eos_token_id": model.config.eos_token_id,
|
| 155 |
+
}
|
| 156 |
+
t = Thread(target=model.generate, kwargs=generate_kwargs)
|
| 157 |
+
t.start()
|
| 158 |
+
for new_token in streamer:
|
| 159 |
+
if new_token:
|
| 160 |
+
history[-1][1] += new_token
|
| 161 |
+
yield history
|
| 162 |
+
|
| 163 |
+
def upload_file(file):
|
| 164 |
+
global knowledge_base
|
| 165 |
+
knowledge_base = load_knowledge_base(file.name)
|
| 166 |
+
return f"Uploaded {file.name}"
|
| 167 |
+
|
| 168 |
+
with gr.Blocks() as demo:
|
| 169 |
+
gr.HTML("""<h1 align="center">GLM-4-9B Gradio Simple Chat Demo</h1>""")
|
| 170 |
+
chatbot = gr.Chatbot()
|
| 171 |
+
|
| 172 |
+
with gr.Row():
|
| 173 |
+
with gr.Column(scale=3):
|
| 174 |
+
with gr.Column(scale=12):
|
| 175 |
+
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10, container=False)
|
| 176 |
+
with gr.Column(min_width=32, scale=1):
|
| 177 |
+
submitBtn = gr.Button("Submit")
|
| 178 |
+
with gr.Column(scale=1):
|
| 179 |
+
prompt_input = gr.Textbox(show_label=False, placeholder="Prompt", lines=10, container=False)
|
| 180 |
+
pBtn = gr.Button("Set Prompt")
|
| 181 |
+
with gr.Column(scale=1):
|
| 182 |
+
emptyBtn = gr.Button("Clear History")
|
| 183 |
+
max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)
|
| 184 |
+
top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)
|
| 185 |
+
temperature = gr.Slider(0.01, 1, value=0.6, step=0.01, label="Temperature", interactive=True)
|
| 186 |
+
file_upload = gr.File(label="Upload Knowledge Base (.xlsx)", type="filepath", file_types=[".xlsx"])
|
| 187 |
+
upload_message = gr.Textbox(label="", placeholder="", interactive=False)
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def user(query, history):
|
| 191 |
+
return "", history + [[parse_text(query), ""]]
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def set_prompt(prompt_text):
|
| 195 |
+
return [[parse_text(prompt_text), "成功设置prompt"]]
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
pBtn.click(set_prompt, inputs=[prompt_input], outputs=chatbot)
|
| 199 |
+
|
| 200 |
+
submitBtn.click(user, [user_input, chatbot], [user_input, chatbot], queue=False).then(
|
| 201 |
+
predict, [chatbot, prompt_input, max_length, top_p, temperature], chatbot
|
| 202 |
+
)
|
| 203 |
+
emptyBtn.click(lambda: (None, None), None, [chatbot, prompt_input], queue=False)
|
| 204 |
+
file_upload.upload(upload_file, inputs=file_upload, outputs=upload_message)
|
| 205 |
+
|
| 206 |
+
demo.queue()
|
| 207 |
+
demo.launch(server_name="127.0.0.1", server_port=8000, inbrowser=True, share=True)
|
vllm_cli_demo.py
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This script creates a CLI demo with vllm backand for the glm-4-9b model,
|
| 3 |
+
allowing users to interact with the model through a command-line interface.
|
| 4 |
+
|
| 5 |
+
Usage:
|
| 6 |
+
- Run the script to start the CLI demo.
|
| 7 |
+
- Interact with the model by typing questions and receiving responses.
|
| 8 |
+
|
| 9 |
+
Note: The script includes a modification to handle markdown to plain text conversion,
|
| 10 |
+
ensuring that the CLI interface displays formatted text correctly.
|
| 11 |
+
"""
|
| 12 |
+
import time
|
| 13 |
+
import asyncio
|
| 14 |
+
from transformers import AutoTokenizer
|
| 15 |
+
from vllm import SamplingParams, AsyncEngineArgs, AsyncLLMEngine
|
| 16 |
+
from typing import List, Dict
|
| 17 |
+
|
| 18 |
+
MODEL_PATH = 'THUDM/glm-4-9b'
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def load_model_and_tokenizer(model_dir: str):
|
| 22 |
+
engine_args = AsyncEngineArgs(
|
| 23 |
+
model=model_dir,
|
| 24 |
+
tokenizer=model_dir,
|
| 25 |
+
tensor_parallel_size=1,
|
| 26 |
+
dtype="bfloat16",
|
| 27 |
+
trust_remote_code=True,
|
| 28 |
+
gpu_memory_utilization=0.3,
|
| 29 |
+
enforce_eager=True,
|
| 30 |
+
worker_use_ray=True,
|
| 31 |
+
engine_use_ray=False,
|
| 32 |
+
disable_log_requests=True
|
| 33 |
+
# 如果遇见 OOM 现象,建议开启下述参数
|
| 34 |
+
# enable_chunked_prefill=True,
|
| 35 |
+
# max_num_batched_tokens=8192
|
| 36 |
+
)
|
| 37 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 38 |
+
model_dir,
|
| 39 |
+
trust_remote_code=True,
|
| 40 |
+
encode_special_tokens=True
|
| 41 |
+
)
|
| 42 |
+
engine = AsyncLLMEngine.from_engine_args(engine_args)
|
| 43 |
+
return engine, tokenizer
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
engine, tokenizer = load_model_and_tokenizer(MODEL_PATH)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
async def vllm_gen(messages: List[Dict[str, str]], top_p: float, temperature: float, max_dec_len: int):
|
| 50 |
+
inputs = tokenizer.apply_chat_template(
|
| 51 |
+
messages,
|
| 52 |
+
add_generation_prompt=True,
|
| 53 |
+
tokenize=False
|
| 54 |
+
)
|
| 55 |
+
params_dict = {
|
| 56 |
+
"n": 1,
|
| 57 |
+
"best_of": 1,
|
| 58 |
+
"presence_penalty": 1.0,
|
| 59 |
+
"frequency_penalty": 0.0,
|
| 60 |
+
"temperature": temperature,
|
| 61 |
+
"top_p": top_p,
|
| 62 |
+
"top_k": -1,
|
| 63 |
+
"use_beam_search": False,
|
| 64 |
+
"length_penalty": 1,
|
| 65 |
+
"early_stopping": False,
|
| 66 |
+
"stop_token_ids": [151329, 151336, 151338],
|
| 67 |
+
"ignore_eos": False,
|
| 68 |
+
"max_tokens": max_dec_len,
|
| 69 |
+
"logprobs": None,
|
| 70 |
+
"prompt_logprobs": None,
|
| 71 |
+
"skip_special_tokens": True,
|
| 72 |
+
}
|
| 73 |
+
sampling_params = SamplingParams(**params_dict)
|
| 74 |
+
async for output in engine.generate(inputs=inputs, sampling_params=sampling_params, request_id=f"{time.time()}"):
|
| 75 |
+
yield output.outputs[0].text
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
async def chat():
|
| 79 |
+
history = []
|
| 80 |
+
max_length = 8192
|
| 81 |
+
top_p = 0.8
|
| 82 |
+
temperature = 0.6
|
| 83 |
+
|
| 84 |
+
print("Welcome to the GLM-4-9B CLI chat. Type your messages below.")
|
| 85 |
+
while True:
|
| 86 |
+
user_input = input("\nYou: ")
|
| 87 |
+
if user_input.lower() in ["exit", "quit"]:
|
| 88 |
+
break
|
| 89 |
+
history.append([user_input, ""])
|
| 90 |
+
|
| 91 |
+
messages = []
|
| 92 |
+
for idx, (user_msg, model_msg) in enumerate(history):
|
| 93 |
+
if idx == len(history) - 1 and not model_msg:
|
| 94 |
+
messages.append({"role": "user", "content": user_msg})
|
| 95 |
+
break
|
| 96 |
+
if user_msg:
|
| 97 |
+
messages.append({"role": "user", "content": user_msg})
|
| 98 |
+
if model_msg:
|
| 99 |
+
messages.append({"role": "assistant", "content": model_msg})
|
| 100 |
+
|
| 101 |
+
print("\nGLM-4: ", end="")
|
| 102 |
+
current_length = 0
|
| 103 |
+
output = ""
|
| 104 |
+
async for output in vllm_gen(messages, top_p, temperature, max_length):
|
| 105 |
+
print(output[current_length:], end="", flush=True)
|
| 106 |
+
current_length = len(output)
|
| 107 |
+
history[-1][1] = output
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
if __name__ == "__main__":
|
| 111 |
+
asyncio.run(chat())
|