Spaces:
Running
on
Zero

Running
on
Zero
玙珲
commited on
Commit
·
e47dfe1
1
Parent(s):
c5415fe
1st commit
Browse files- .gitattributes +3 -0
- app.py +259 -0
- examples/ovis2_figure0.png +3 -0
- examples/ovis2_figure1.png +3 -0
- examples/ovis2_math0.jpg +3 -0
- examples/ovis2_math1.jpg +3 -0
- examples/ovis2_multi0.jpg +3 -0
- requirements.txt +5 -0
- resource/logo.svg +5 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
examples/ovis2_figure1.png filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import subprocess
|
| 2 |
+
subprocess.run('pip install flash-attn==2.7.0.post2 --no-build-isolation', env={'FLASH_ATTENTION_SKIP_CUDA_BUILD': "TRUE"}, shell=True)
|
| 3 |
+
|
| 4 |
+
import spaces
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
import argparse
|
| 8 |
+
import os
|
| 9 |
+
import re
|
| 10 |
+
from typing import List, Optional, Tuple
|
| 11 |
+
|
| 12 |
+
import gradio as gr
|
| 13 |
+
import PIL.Image
|
| 14 |
+
import torch
|
| 15 |
+
import numpy as np
|
| 16 |
+
from moviepy.editor import VideoFileClip
|
| 17 |
+
from transformers import AutoModelForCausalLM
|
| 18 |
+
|
| 19 |
+
# --- Global Model Variable ---
|
| 20 |
+
# model = None
|
| 21 |
+
# This should point to the directory containing your SVG file.
|
| 22 |
+
CUR_DIR = os.path.dirname(os.path.abspath(__file__))
|
| 23 |
+
|
| 24 |
+
# --- Helper Functions ---
|
| 25 |
+
|
| 26 |
+
def load_video_frames(video_path: Optional[str], n_frames: int = 8) -> Optional[List[PIL.Image.Image]]:
|
| 27 |
+
"""Extracts a specified number of frames from a video file."""
|
| 28 |
+
if not video_path:
|
| 29 |
+
return None
|
| 30 |
+
try:
|
| 31 |
+
with VideoFileClip(video_path) as clip:
|
| 32 |
+
total_frames = int(clip.fps * clip.duration)
|
| 33 |
+
if total_frames <= 0: return None
|
| 34 |
+
num_to_extract = min(n_frames, total_frames)
|
| 35 |
+
indices = np.linspace(0, total_frames - 1, num_to_extract, dtype=int)
|
| 36 |
+
frames = [PIL.Image.fromarray(clip.get_frame(index / clip.fps)) for index in indices]
|
| 37 |
+
return frames
|
| 38 |
+
except Exception as e:
|
| 39 |
+
print(f"Error processing video {video_path}: {e}")
|
| 40 |
+
return None
|
| 41 |
+
|
| 42 |
+
def parse_model_output(response_text: str, enable_thinking: bool) -> str:
|
| 43 |
+
"""Formats the model output, separating 'thinking' and 'response' parts if enabled."""
|
| 44 |
+
if enable_thinking:
|
| 45 |
+
think_match = re.search(r"<think>(.*?)</think>", response_text, re.DOTALL)
|
| 46 |
+
if think_match:
|
| 47 |
+
thinking_content = think_match.group(1).strip()
|
| 48 |
+
response_content = re.sub(r"<think>.*?</think>", "", response_text, flags=re.DOTALL).strip()
|
| 49 |
+
return f"**Thinking:**\n```\n{thinking_content}\n```\n\n**Response:**\n{response_content}"
|
| 50 |
+
else:
|
| 51 |
+
return response_text
|
| 52 |
+
else:
|
| 53 |
+
return response_text
|
| 54 |
+
|
| 55 |
+
# --- Core Inference Logic ---
|
| 56 |
+
@spaces.GPU
|
| 57 |
+
def run_inference(
|
| 58 |
+
image_input: Optional[PIL.Image.Image],
|
| 59 |
+
video_input: Optional[str],
|
| 60 |
+
prompt: str,
|
| 61 |
+
do_sample: bool,
|
| 62 |
+
max_new_tokens: int,
|
| 63 |
+
enable_thinking: bool,
|
| 64 |
+
) -> List[List[str]]:
|
| 65 |
+
"""Runs a single turn of inference and formats the output for a gr.Chatbot."""
|
| 66 |
+
if (not image_input and not video_input and not prompt) or not prompt:
|
| 67 |
+
gr.Warning("A text prompt is required for generation.")
|
| 68 |
+
return []
|
| 69 |
+
|
| 70 |
+
content = []
|
| 71 |
+
if image_input:
|
| 72 |
+
content.append({"type": "image", "image": image_input})
|
| 73 |
+
if video_input:
|
| 74 |
+
frames = load_video_frames(video_input)
|
| 75 |
+
if frames: content.append({"type": "video", "video": frames})
|
| 76 |
+
else:
|
| 77 |
+
gr.Warning("Failed to process the video file.")
|
| 78 |
+
return [[prompt, "Error: Could not process the video file."]]
|
| 79 |
+
|
| 80 |
+
content.append({"type": "text", "text": prompt})
|
| 81 |
+
|
| 82 |
+
messages = [{"role": "user", "content": content}]
|
| 83 |
+
|
| 84 |
+
try:
|
| 85 |
+
if video_input:
|
| 86 |
+
input_ids, pixel_values, grid_thws = model.preprocess_inputs(messages=messages, add_generation_prompt=True, enable_thinking=enable_thinking, max_pixels=896*896)
|
| 87 |
+
else:
|
| 88 |
+
input_ids, pixel_values, grid_thws = model.preprocess_inputs(messages=messages, add_generation_prompt=True, enable_thinking=enable_thinking)
|
| 89 |
+
except Exception as e:
|
| 90 |
+
return [[prompt, f"Error during input preprocessing: {e}"]]
|
| 91 |
+
|
| 92 |
+
input_ids = input_ids.to(model.device)
|
| 93 |
+
if pixel_values is not None:
|
| 94 |
+
pixel_values = pixel_values.to(model.device, dtype=torch.bfloat16)
|
| 95 |
+
if grid_thws is not None:
|
| 96 |
+
grid_thws = grid_thws.to(model.device)
|
| 97 |
+
|
| 98 |
+
gen_kwargs = {
|
| 99 |
+
"max_new_tokens": max_new_tokens, "do_sample": do_sample,
|
| 100 |
+
"eos_token_id": model.text_tokenizer.eos_token_id, "pad_token_id": model.text_tokenizer.pad_token_id
|
| 101 |
+
}
|
| 102 |
+
|
| 103 |
+
with torch.inference_mode():
|
| 104 |
+
try:
|
| 105 |
+
outputs = model.generate(inputs=input_ids, pixel_values=pixel_values, grid_thws=grid_thws, **gen_kwargs)
|
| 106 |
+
except Exception as e:
|
| 107 |
+
return [[prompt, f"Error during model generation: {e}"]]
|
| 108 |
+
|
| 109 |
+
response_text = model.text_tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 110 |
+
formatted_response = parse_model_output(response_text, enable_thinking)
|
| 111 |
+
|
| 112 |
+
return [[prompt, formatted_response]]
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# --- UI Helper Functions ---
|
| 116 |
+
def toggle_media_input(choice: str) -> Tuple:
|
| 117 |
+
"""Switches visibility between Image/Video inputs and their corresponding examples."""
|
| 118 |
+
if choice == "Image":
|
| 119 |
+
return gr.update(visible=True, value=None), gr.update(visible=False, value=None), gr.update(visible=True), gr.update(visible=False)
|
| 120 |
+
else: # Video
|
| 121 |
+
return gr.update(visible=False, value=None), gr.update(visible=True, value=None), gr.update(visible=False), gr.update(visible=True)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
# --- Build Gradio Application ---
|
| 125 |
+
# @spaces.GPU
|
| 126 |
+
def build_demo(model_path: str):
|
| 127 |
+
"""Builds the Gradio user interface for the model."""
|
| 128 |
+
global model
|
| 129 |
+
device = f"cuda"
|
| 130 |
+
print(f"Loading model {model_path} onto device {device}...")
|
| 131 |
+
|
| 132 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 133 |
+
model_path, torch_dtype=torch.bfloat16, trust_remote_code=True
|
| 134 |
+
).to(device).eval()
|
| 135 |
+
|
| 136 |
+
print("Model loaded successfully.")
|
| 137 |
+
|
| 138 |
+
model_name_display = model_path.split('/')[-1]
|
| 139 |
+
|
| 140 |
+
# --- Logo & Header ---
|
| 141 |
+
logo_html = ""
|
| 142 |
+
logo_svg_path = os.path.join(CUR_DIR, "resource", "logo.svg")
|
| 143 |
+
if os.path.exists(logo_svg_path):
|
| 144 |
+
with open(logo_svg_path, "r", encoding="utf-8") as svg_file:
|
| 145 |
+
svg_content = svg_file.read()
|
| 146 |
+
font_size = "2.5em"
|
| 147 |
+
svg_content_styled = re.sub(r'(<svg[^>]*)(>)', rf'\1 height="{font_size}" style="vertical-align: middle; display: inline-block;"\2', svg_content)
|
| 148 |
+
logo_html = f'<span style="display: inline-block; vertical-align: middle;">{svg_content_styled}</span>'
|
| 149 |
+
else:
|
| 150 |
+
# Fallback if SVG is not found
|
| 151 |
+
logo_html = '<span style="font-weight: bold; font-size: 2.5em; display: inline-block; vertical-align: middle;">Ovis</span>'
|
| 152 |
+
print(f"Warning: Logo file not found at {logo_svg_path}. Using text fallback.")
|
| 153 |
+
|
| 154 |
+
html_header = f"""
|
| 155 |
+
<p align="center" style="font-size: 2.5em; line-height: 1;">
|
| 156 |
+
{logo_html}
|
| 157 |
+
<span style="display: inline-block; vertical-align: middle;">{model_name_display}</span>
|
| 158 |
+
</p>
|
| 159 |
+
<center><font size=3><b>Ovis</b> has been open-sourced on <a href='https://huggingface.co/{model_path}'>😊 Huggingface</a> and <a href='https://github.com/AIDC-AI/Ovis'>🌟 GitHub</a>. If you find Ovis useful, a like❤️ or a star🌟 would be appreciated.</font></center>
|
| 160 |
+
"""
|
| 161 |
+
|
| 162 |
+
with gr.Blocks(theme=gr.themes.Ocean()) as demo:
|
| 163 |
+
gr.HTML(html_header)
|
| 164 |
+
gr.Markdown(f"This interface is served by a single model. Each submission starts a new, independent conversation.")
|
| 165 |
+
|
| 166 |
+
with gr.Row():
|
| 167 |
+
# --- Left Column (Media Inputs, Settings, Prompt & Actions) ---
|
| 168 |
+
with gr.Column(scale=4):
|
| 169 |
+
input_type_radio = gr.Radio(choices=["Image"], value="Image", label="Select Input Type")
|
| 170 |
+
image_input = gr.Image(label="Image Input", type="pil", visible=True)
|
| 171 |
+
video_input = gr.Video(label="Video Input", visible=False)
|
| 172 |
+
|
| 173 |
+
with gr.Accordion("Generation Settings", open=True):
|
| 174 |
+
do_sample = gr.Checkbox(label="Enable Sampling (Do Sample)", value=False)
|
| 175 |
+
max_new_tokens = gr.Slider(minimum=32, maximum=4096, value=1024, step=32, label="Max New Tokens")
|
| 176 |
+
enable_thinking = gr.Checkbox(label="Enable Deep Thinking", value=True)
|
| 177 |
+
|
| 178 |
+
prompt_input = gr.Textbox(label="Prompt", placeholder="Enter your text here and press ENTER", lines=3)
|
| 179 |
+
with gr.Row():
|
| 180 |
+
generate_btn = gr.Button("Send", variant="primary")
|
| 181 |
+
clear_btn = gr.Button("Clear", variant="secondary")
|
| 182 |
+
|
| 183 |
+
with gr.Column(visible=True) as image_examples_col:
|
| 184 |
+
gr.Examples(
|
| 185 |
+
examples=[
|
| 186 |
+
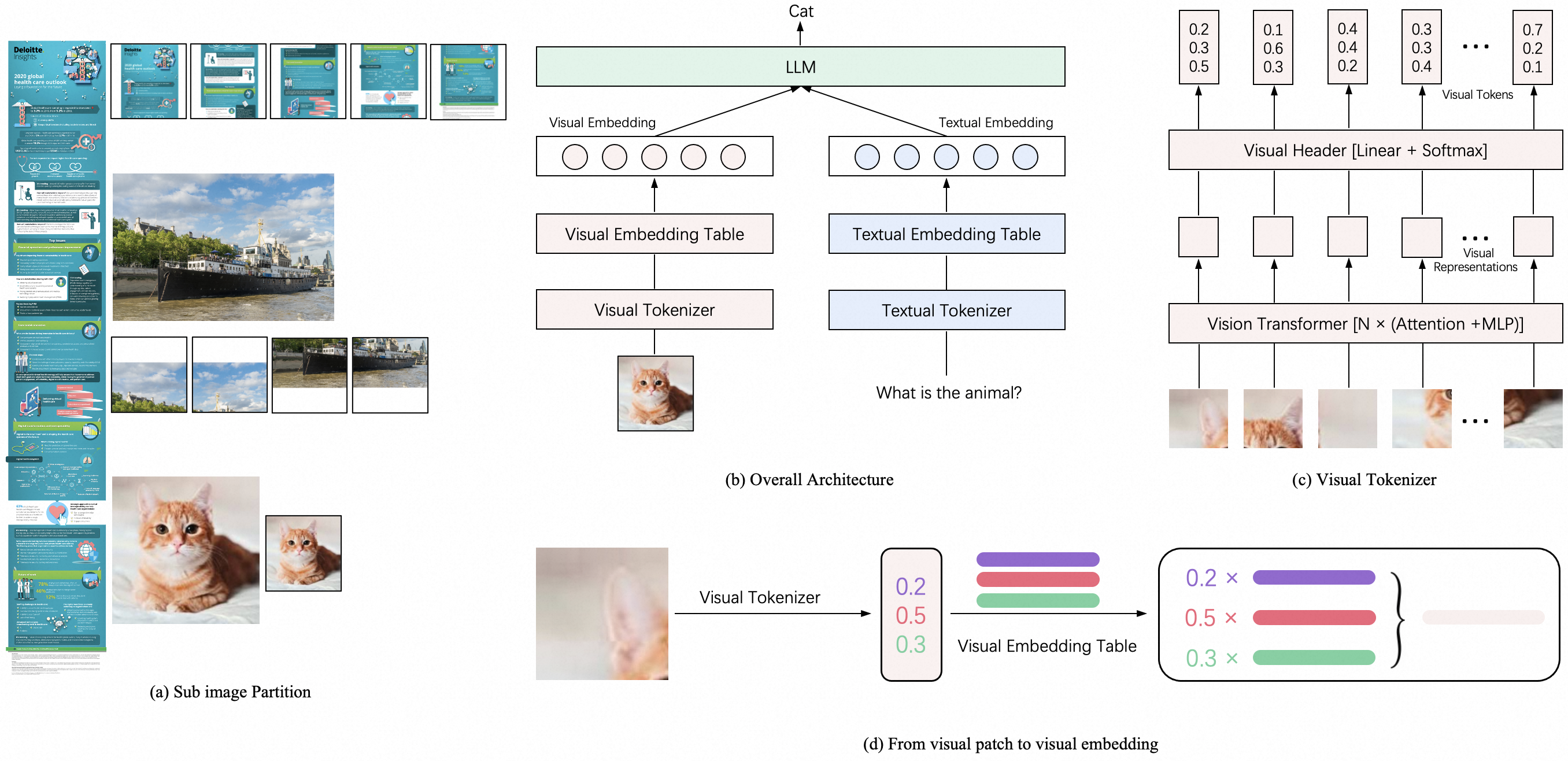
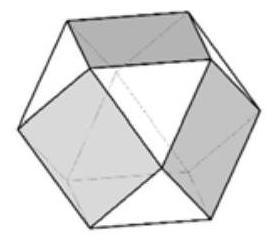
[os.path.join(CUR_DIR, "examples", "ovis2_math0.jpg"), "Each face of the polyhedron shown is either a triangle or a square. Each square borders 4 triangles, and each triangle borders 3 squares. The polyhedron has 6 squares. How many triangles does it have?\n\nProvide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."],
|
| 187 |
+
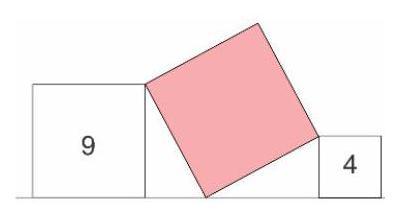
[os.path.join(CUR_DIR, "examples", "ovis2_math1.jpg"), "A large square touches another two squares, as shown in the picture. The numbers inside the smaller squares indicate their areas. What is the area of the largest square?\n\nProvide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."],
|
| 188 |
+
[os.path.join(CUR_DIR, "examples", "ovis2_figure0.png"), "Explain this model."],
|
| 189 |
+
[os.path.join(CUR_DIR, "examples", "ovis2_figure1.png"), "Organize the notes about GRPO in the figure."],
|
| 190 |
+
[os.path.join(CUR_DIR, "examples", "ovis2_multi0.jpg"), "Posso avere un frappuccino e un caffè americano di taglia M? Quanto costa in totale?"],
|
| 191 |
+
],
|
| 192 |
+
inputs=[image_input, prompt_input]
|
| 193 |
+
)
|
| 194 |
+
# with gr.Column(visible=False) as video_examples_col:
|
| 195 |
+
# gr.Examples(examples=[[os.path.join(CUR_DIR, "examples", "video_demo_1.mp4"), "Describe the video."]],
|
| 196 |
+
# inputs=[video_input, prompt_input])
|
| 197 |
+
|
| 198 |
+
# --- Right Column (Chat Display) ---
|
| 199 |
+
with gr.Column(scale=6):
|
| 200 |
+
chatbot = gr.Chatbot(label="Ovis", height=750, show_copy_button=True, layout="panel")
|
| 201 |
+
|
| 202 |
+
# --- Event Handlers ---
|
| 203 |
+
input_type_radio.change(
|
| 204 |
+
fn=toggle_media_input,
|
| 205 |
+
inputs=input_type_radio,
|
| 206 |
+
outputs=[image_input, video_input, image_examples_col]
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
run_inputs = [image_input, video_input, prompt_input, do_sample, max_new_tokens, enable_thinking]
|
| 210 |
+
|
| 211 |
+
generate_btn.click(fn=run_inference, inputs=run_inputs, outputs=chatbot)
|
| 212 |
+
prompt_input.submit(fn=run_inference, inputs=run_inputs, outputs=chatbot)
|
| 213 |
+
|
| 214 |
+
clear_btn.click(
|
| 215 |
+
fn=lambda: ([], None, None, "", "Image", False, 1024, True),
|
| 216 |
+
outputs=[chatbot, image_input, video_input, prompt_input, input_type_radio, do_sample, max_new_tokens, enable_thinking]
|
| 217 |
+
).then(
|
| 218 |
+
fn=toggle_media_input,
|
| 219 |
+
inputs=input_type_radio,
|
| 220 |
+
outputs=[image_input, video_input, image_examples_col]
|
| 221 |
+
)
|
| 222 |
+
return demo
|
| 223 |
+
|
| 224 |
+
# --- Main Execution Block ---
|
| 225 |
+
# def parse_args():
|
| 226 |
+
# parser = argparse.ArgumentParser(description="Gradio interface for a single Multimodal Large Language Model.")
|
| 227 |
+
# parser.add_argument("--model-path", type=str, default='AIDC-AI/Ovis2.5-2B', help="Path to the model checkpoint on Hugging Face Hub or local directory.")
|
| 228 |
+
# parser.add_argument("--gpu", type=int, default=0, help="GPU index to run the model on.")
|
| 229 |
+
# parser.add_argument("--port", type=int, default=7860, help="Port to run the Gradio server on.")
|
| 230 |
+
# parser.add_argument("--server-name", type=str, default="0.0.0.0", help="Server name for the Gradio app.")
|
| 231 |
+
# return parser.parse_args()
|
| 232 |
+
|
| 233 |
+
# if __name__ == "__main__":
|
| 234 |
+
# if not os.path.exists("examples"): os.makedirs("examples")
|
| 235 |
+
# if not os.path.exists("resource"): os.makedirs("resource")
|
| 236 |
+
# print("Note: For the logo to display correctly, place 'logo.svg' inside the 'resource' directory.")
|
| 237 |
+
|
| 238 |
+
# example_files = [
|
| 239 |
+
# "ovis2_math0.jpg",
|
| 240 |
+
# "ovis2_math1.jpg",
|
| 241 |
+
# "ovis2_figure0.png",
|
| 242 |
+
# "ovis2_figure1.png",
|
| 243 |
+
# "ovis2_multi0.jpg",
|
| 244 |
+
# "video_demo_1.mp4",
|
| 245 |
+
# ]
|
| 246 |
+
# for fname in example_files:
|
| 247 |
+
# fpath = os.path.join("examples", fname)
|
| 248 |
+
# if not os.path.exists(fpath):
|
| 249 |
+
# if fname.endswith(".mp4"):
|
| 250 |
+
# os.system(f'ffmpeg -y -f lavfi -i "smptebars=size=128x72:rate=10" -t 3 -pix_fmt yuv420p "{fpath}" >/dev/null 2>&1')
|
| 251 |
+
# else:
|
| 252 |
+
# PIL.Image.new('RGB', (224, 224), color = 'grey').save(fpath)
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
model_path = 'AIDC-AI/Ovis2.5-2B'
|
| 256 |
+
demo = build_demo(model_path=model_path)
|
| 257 |
+
# print(f"Launching Gradio app on http://{args.server_name}:{args.port}")
|
| 258 |
+
# demo.queue().launch(server_name=args.server_name, server_port=args.port, share=False, ssl_verify=False)
|
| 259 |
+
demo.launch()
|
examples/ovis2_figure0.png
ADDED
|
Git LFS Details
|
examples/ovis2_figure1.png
ADDED

|
Git LFS Details
|
examples/ovis2_math0.jpg
ADDED
|
Git LFS Details
|
examples/ovis2_math1.jpg
ADDED
|
Git LFS Details
|
examples/ovis2_multi0.jpg
ADDED

|
Git LFS Details
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.4.0
|
| 2 |
+
transformers==4.51.3
|
| 3 |
+
numpy==1.25.0
|
| 4 |
+
pillow==10.3.0
|
| 5 |
+
moviepy==1.0.3
|
resource/logo.svg
ADDED
|
|