
Sarthak
commited on
Commit
·
ecfceb8
1
Parent(s):
7bb46ce
initial commit
Browse files- .gitattributes +4 -35
- .gitignore +14 -0
- .python-version +1 -0
- LICENSE +201 -0
- MTEB_evaluate.py +350 -0
- README.md +3 -3
- config.json +13 -0
- distill.py +116 -0
- evaluate.py +422 -0
- evaluation/memory_comparison.png +3 -0
- evaluation/similarity_matrix.png +3 -0
- evaluation/size_comparison.png +3 -0
- evaluation/speed_comparison.png +3 -0
- model.safetensors +3 -0
- modules.json +14 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/AmazonCounterfactualClassification.json +179 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/Banking77Classification.json +73 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/CQADupstackProgrammersRetrieval.json +158 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/STSBenchmark.json +26 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/SprintDuplicateQuestions.json +58 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/StackExchangeClustering.json +47 -0
- mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/model_meta.json +1 -0
- mteb_results/mteb_parsed_results.json +3 -0
- mteb_results/mteb_raw_results.json +7 -0
- mteb_results/mteb_report.txt +21 -0
- mteb_results/mteb_summary.json +20 -0
- pipeline.skops +3 -0
- pyproject.toml +101 -0
- tokenizer.json +3 -0
- train_code_classification.py +365 -0
- uv.lock +0 -0
.gitattributes
CHANGED
|
@@ -1,37 +1,6 @@
|
|
| 1 |
-
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
-
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
-
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
-
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
-
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
-
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
-
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
-
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
-
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
-
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
-
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
-
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
-
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 37 |
*.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
model.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.png filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
evaluation/** filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.skops* filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Python-generated files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[oc]
|
| 4 |
+
build/
|
| 5 |
+
dist/
|
| 6 |
+
wheels/
|
| 7 |
+
*.egg-info
|
| 8 |
+
|
| 9 |
+
# Virtual environments
|
| 10 |
+
.venv
|
| 11 |
+
|
| 12 |
+
# Cache
|
| 13 |
+
.ruff_cache
|
| 14 |
+
.mypy_cache
|
.python-version
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
3.12
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
MTEB_evaluate.py
ADDED
|
@@ -0,0 +1,350 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
"""
|
| 3 |
+
MTEB Evaluation Script for Distilled Model - Code-Focused Tasks.
|
| 4 |
+
|
| 5 |
+
This script evaluates the distilled gte-Qwen2-7B-instruct model using MTEB
|
| 6 |
+
(Massive Text Embedding Benchmark) with a focus on tasks relevant for code:
|
| 7 |
+
|
| 8 |
+
- Classification: Tests ability to distinguish between different categories (e.g., programming languages)
|
| 9 |
+
- Clustering: Tests ability to group similar code by functionality
|
| 10 |
+
- STS: Tests semantic similarity understanding between code snippets
|
| 11 |
+
- Retrieval: Tests code search and duplicate detection capabilities
|
| 12 |
+
|
| 13 |
+
Features:
|
| 14 |
+
- Incremental evaluation: Skips tasks that already have results in mteb_results/
|
| 15 |
+
- Combines existing and new results automatically
|
| 16 |
+
- Saves results in multiple formats for analysis
|
| 17 |
+
|
| 18 |
+
Usage:
|
| 19 |
+
python MTEB_evaluate.py
|
| 20 |
+
|
| 21 |
+
Configuration:
|
| 22 |
+
- Set EVAL_ALL_TASKS = False to use only CODE_SPECIFIC_TASKS
|
| 23 |
+
- Modify CODE_SPECIFIC_TASKS for granular task selection
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
import json
|
| 27 |
+
import logging
|
| 28 |
+
import sys
|
| 29 |
+
import time
|
| 30 |
+
from pathlib import Path
|
| 31 |
+
|
| 32 |
+
import mteb
|
| 33 |
+
from model2vec import StaticModel
|
| 34 |
+
from mteb import ModelMeta
|
| 35 |
+
|
| 36 |
+
from evaluation import (
|
| 37 |
+
CustomMTEB,
|
| 38 |
+
get_tasks,
|
| 39 |
+
make_leaderboard,
|
| 40 |
+
parse_mteb_results,
|
| 41 |
+
summarize_results,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
# =============================================================================
|
| 45 |
+
# CONFIGURATION CONSTANTS
|
| 46 |
+
# =============================================================================
|
| 47 |
+
|
| 48 |
+
# Model Configuration
|
| 49 |
+
MODEL_PATH = "." # Path to the distilled model directory
|
| 50 |
+
MODEL_NAME = "gte-Qwen2-7B-instruct-M2V-Distilled" # Name for the model in results
|
| 51 |
+
|
| 52 |
+
# Evaluation Configuration
|
| 53 |
+
OUTPUT_DIR = "mteb_results" # Directory to save evaluation results
|
| 54 |
+
|
| 55 |
+
EVAL_ALL_TASKS = True
|
| 56 |
+
|
| 57 |
+
# Specific tasks most relevant for code evaluation (focused selection)
|
| 58 |
+
CODE_SPECIFIC_TASKS = [
|
| 59 |
+
# Classification - Programming language/category classification
|
| 60 |
+
"Banking77Classification", # Fine-grained classification (77 classes)
|
| 61 |
+
# Clustering - Code grouping by functionality
|
| 62 |
+
"StackExchangeClustering.v2", # Technical Q&A clustering (most relevant)
|
| 63 |
+
# STS - Code similarity understanding
|
| 64 |
+
"STSBenchmark", # Standard semantic similarity benchmark
|
| 65 |
+
# Retrieval - Code search capabilities
|
| 66 |
+
"CQADupstackProgrammersRetrieval", # Programming Q&A retrieval
|
| 67 |
+
# PairClassification - Duplicate/similar code detection
|
| 68 |
+
"SprintDuplicateQuestions", # Duplicate question detection
|
| 69 |
+
]
|
| 70 |
+
|
| 71 |
+
# Evaluation settings
|
| 72 |
+
EVAL_SPLITS = ["test"] # Dataset splits to evaluate on
|
| 73 |
+
VERBOSITY = 2 # MTEB verbosity level
|
| 74 |
+
|
| 75 |
+
# =============================================================================
|
| 76 |
+
|
| 77 |
+
# Configure logging
|
| 78 |
+
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 79 |
+
logger = logging.getLogger(__name__)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def check_existing_results(output_path: Path, tasks: list) -> list:
|
| 83 |
+
"""Check for existing task results and filter out completed tasks."""
|
| 84 |
+
remaining_tasks = []
|
| 85 |
+
completed_tasks = []
|
| 86 |
+
|
| 87 |
+
for task in tasks:
|
| 88 |
+
task_name = task.metadata.name
|
| 89 |
+
# MTEB saves results as {model_name}__{task_name}.json
|
| 90 |
+
result_file = output_path / MODEL_NAME / f"{task_name}.json"
|
| 91 |
+
|
| 92 |
+
if result_file.exists():
|
| 93 |
+
completed_tasks.append(task_name)
|
| 94 |
+
logger.info(f"Skipping {task_name} - results already exist")
|
| 95 |
+
else:
|
| 96 |
+
remaining_tasks.append(task)
|
| 97 |
+
|
| 98 |
+
if completed_tasks:
|
| 99 |
+
logger.info(f"Found existing results for {len(completed_tasks)} tasks: {completed_tasks}")
|
| 100 |
+
|
| 101 |
+
return remaining_tasks
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def load_existing_parsed_results(output_path: Path) -> dict:
|
| 105 |
+
"""Load existing parsed results if they exist."""
|
| 106 |
+
parsed_results_file = output_path / "mteb_parsed_results.json"
|
| 107 |
+
if parsed_results_file.exists():
|
| 108 |
+
try:
|
| 109 |
+
with parsed_results_file.open("r") as f:
|
| 110 |
+
return json.load(f)
|
| 111 |
+
except (json.JSONDecodeError, OSError) as e:
|
| 112 |
+
logger.warning(f"Could not load existing parsed results: {e}")
|
| 113 |
+
return {}
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def load_and_display_existing_results(output_path: Path) -> None:
|
| 117 |
+
"""Load and display existing MTEB results."""
|
| 118 |
+
summary_file = output_path / "mteb_summary.json"
|
| 119 |
+
if summary_file.exists():
|
| 120 |
+
with summary_file.open("r") as f:
|
| 121 |
+
summary = json.load(f)
|
| 122 |
+
|
| 123 |
+
logger.info("=" * 80)
|
| 124 |
+
logger.info("EXISTING MTEB EVALUATION RESULTS:")
|
| 125 |
+
logger.info("=" * 80)
|
| 126 |
+
|
| 127 |
+
stats = summary.get("summary_stats")
|
| 128 |
+
if stats:
|
| 129 |
+
logger.info(f"Total Datasets: {stats.get('total_datasets', 'N/A')}")
|
| 130 |
+
logger.info(f"Average Score: {stats.get('average_score', 0):.4f}")
|
| 131 |
+
logger.info(f"Median Score: {stats.get('median_score', 0):.4f}")
|
| 132 |
+
|
| 133 |
+
logger.info("=" * 80)
|
| 134 |
+
else:
|
| 135 |
+
logger.info("No existing summary found. Individual task results may still exist.")
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def run_mteb_evaluation() -> None:
|
| 139 |
+
"""Run MTEB evaluation using the evaluation package."""
|
| 140 |
+
output_path = Path(OUTPUT_DIR)
|
| 141 |
+
output_path.mkdir(parents=True, exist_ok=True)
|
| 142 |
+
|
| 143 |
+
logger.info(f"Loading model from {MODEL_PATH}")
|
| 144 |
+
model = StaticModel.from_pretrained(MODEL_PATH)
|
| 145 |
+
logger.info("Model loaded successfully")
|
| 146 |
+
|
| 147 |
+
# Set up model metadata for MTEB
|
| 148 |
+
model.mteb_model_meta = ModelMeta( # type: ignore[attr-defined]
|
| 149 |
+
name=MODEL_NAME, revision="distilled", release_date=None, languages=["eng"]
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
# Get specific code-relevant tasks (focused selection)
|
| 153 |
+
logger.info("Getting focused code-relevant MTEB tasks")
|
| 154 |
+
logger.info(f"Selected specific tasks: {CODE_SPECIFIC_TASKS}")
|
| 155 |
+
|
| 156 |
+
if EVAL_ALL_TASKS:
|
| 157 |
+
all_tasks = get_tasks()
|
| 158 |
+
else:
|
| 159 |
+
all_tasks = [mteb.get_task(task_name, languages=["eng"]) for task_name in CODE_SPECIFIC_TASKS]
|
| 160 |
+
|
| 161 |
+
logger.info(f"Found {len(all_tasks)} total tasks")
|
| 162 |
+
|
| 163 |
+
# Check for existing results and filter out completed tasks
|
| 164 |
+
tasks = check_existing_results(output_path, all_tasks)
|
| 165 |
+
logger.info(f"Will evaluate {len(tasks)} remaining tasks")
|
| 166 |
+
|
| 167 |
+
if not tasks:
|
| 168 |
+
logger.info("No new tasks to evaluate - all tasks already completed!")
|
| 169 |
+
|
| 170 |
+
# Load and display existing results
|
| 171 |
+
logger.info("Loading existing results...")
|
| 172 |
+
try:
|
| 173 |
+
load_and_display_existing_results(output_path)
|
| 174 |
+
except (json.JSONDecodeError, OSError, KeyError) as e:
|
| 175 |
+
logger.warning(f"Could not load existing results: {e}")
|
| 176 |
+
return
|
| 177 |
+
|
| 178 |
+
# Define the CustomMTEB object with the specified tasks
|
| 179 |
+
evaluation = CustomMTEB(tasks=tasks)
|
| 180 |
+
|
| 181 |
+
# Run the evaluation
|
| 182 |
+
logger.info("Starting MTEB evaluation...")
|
| 183 |
+
start_time = time.time()
|
| 184 |
+
|
| 185 |
+
results = evaluation.run(model, eval_splits=EVAL_SPLITS, output_folder=str(output_path), verbosity=VERBOSITY)
|
| 186 |
+
|
| 187 |
+
end_time = time.time()
|
| 188 |
+
evaluation_time = end_time - start_time
|
| 189 |
+
logger.info(f"Evaluation completed in {evaluation_time:.2f} seconds")
|
| 190 |
+
|
| 191 |
+
# Parse the results and summarize them
|
| 192 |
+
logger.info("Parsing and summarizing results...")
|
| 193 |
+
parsed_results = parse_mteb_results(mteb_results=results, model_name=MODEL_NAME)
|
| 194 |
+
|
| 195 |
+
# Load existing results if any and combine them
|
| 196 |
+
existing_results = load_existing_parsed_results(output_path)
|
| 197 |
+
if existing_results:
|
| 198 |
+
logger.info("Combining with existing results...")
|
| 199 |
+
# Convert to dict for merging
|
| 200 |
+
parsed_dict = dict(parsed_results) if hasattr(parsed_results, "items") else {}
|
| 201 |
+
# Simple merge - existing results take precedence to avoid overwriting
|
| 202 |
+
for key, value in existing_results.items():
|
| 203 |
+
if key not in parsed_dict:
|
| 204 |
+
parsed_dict[key] = value
|
| 205 |
+
parsed_results = parsed_dict
|
| 206 |
+
|
| 207 |
+
task_scores = summarize_results(parsed_results)
|
| 208 |
+
|
| 209 |
+
# Save results in different formats
|
| 210 |
+
save_results(output_path, results, parsed_results, task_scores, evaluation_time)
|
| 211 |
+
|
| 212 |
+
# Print the results in a leaderboard format
|
| 213 |
+
logger.info("MTEB Evaluation Results:")
|
| 214 |
+
logger.info("=" * 80)
|
| 215 |
+
leaderboard = make_leaderboard(task_scores) # type: ignore[arg-type]
|
| 216 |
+
logger.info(leaderboard.to_string(index=False))
|
| 217 |
+
logger.info("=" * 80)
|
| 218 |
+
|
| 219 |
+
logger.info(f"Evaluation completed successfully. Results saved to {OUTPUT_DIR}")
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def save_results(
|
| 223 |
+
output_path: Path, raw_results: list, parsed_results: dict, task_scores: dict, evaluation_time: float
|
| 224 |
+
) -> None:
|
| 225 |
+
"""Save evaluation results in multiple formats."""
|
| 226 |
+
# Save raw results
|
| 227 |
+
raw_results_file = output_path / "mteb_raw_results.json"
|
| 228 |
+
with raw_results_file.open("w") as f:
|
| 229 |
+
json.dump(raw_results, f, indent=2, default=str)
|
| 230 |
+
logger.info(f"Raw results saved to {raw_results_file}")
|
| 231 |
+
|
| 232 |
+
# Save parsed results
|
| 233 |
+
parsed_results_file = output_path / "mteb_parsed_results.json"
|
| 234 |
+
with parsed_results_file.open("w") as f:
|
| 235 |
+
json.dump(parsed_results, f, indent=2, default=str)
|
| 236 |
+
logger.info(f"Parsed results saved to {parsed_results_file}")
|
| 237 |
+
|
| 238 |
+
# Generate summary statistics
|
| 239 |
+
summary_stats = generate_summary_stats(task_scores)
|
| 240 |
+
|
| 241 |
+
# Save task scores summary
|
| 242 |
+
summary = {
|
| 243 |
+
"model_name": MODEL_NAME,
|
| 244 |
+
"evaluation_time_seconds": evaluation_time,
|
| 245 |
+
"task_scores": task_scores,
|
| 246 |
+
"summary_stats": summary_stats,
|
| 247 |
+
}
|
| 248 |
+
|
| 249 |
+
summary_file = output_path / "mteb_summary.json"
|
| 250 |
+
with summary_file.open("w") as f:
|
| 251 |
+
json.dump(summary, f, indent=2, default=str)
|
| 252 |
+
logger.info(f"Summary saved to {summary_file}")
|
| 253 |
+
|
| 254 |
+
# Save human-readable report
|
| 255 |
+
report_file = output_path / "mteb_report.txt"
|
| 256 |
+
generate_report(output_path, task_scores, summary_stats, evaluation_time)
|
| 257 |
+
logger.info(f"Report saved to {report_file}")
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def generate_summary_stats(task_scores: dict) -> dict:
|
| 261 |
+
"""Generate summary statistics from task scores."""
|
| 262 |
+
if not task_scores:
|
| 263 |
+
return {}
|
| 264 |
+
|
| 265 |
+
# Extract all individual dataset scores
|
| 266 |
+
all_scores = []
|
| 267 |
+
for model_data in task_scores.values():
|
| 268 |
+
if isinstance(model_data, dict) and "dataset_scores" in model_data:
|
| 269 |
+
dataset_scores = model_data["dataset_scores"]
|
| 270 |
+
if isinstance(dataset_scores, dict):
|
| 271 |
+
all_scores.extend(
|
| 272 |
+
[
|
| 273 |
+
float(score)
|
| 274 |
+
for score in dataset_scores.values()
|
| 275 |
+
if isinstance(score, int | float) and str(score).lower() != "nan"
|
| 276 |
+
]
|
| 277 |
+
)
|
| 278 |
+
|
| 279 |
+
if not all_scores:
|
| 280 |
+
return {}
|
| 281 |
+
|
| 282 |
+
import numpy as np
|
| 283 |
+
|
| 284 |
+
return {
|
| 285 |
+
"total_datasets": len(all_scores),
|
| 286 |
+
"average_score": float(np.mean(all_scores)),
|
| 287 |
+
"median_score": float(np.median(all_scores)),
|
| 288 |
+
"std_dev": float(np.std(all_scores)),
|
| 289 |
+
"min_score": float(np.min(all_scores)),
|
| 290 |
+
"max_score": float(np.max(all_scores)),
|
| 291 |
+
}
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
def generate_report(output_path: Path, task_scores: dict, summary_stats: dict, evaluation_time: float) -> None:
|
| 295 |
+
"""Generate human-readable evaluation report."""
|
| 296 |
+
report_file = output_path / "mteb_report.txt"
|
| 297 |
+
|
| 298 |
+
with report_file.open("w") as f:
|
| 299 |
+
f.write("=" * 80 + "\n")
|
| 300 |
+
f.write("MTEB Evaluation Report\n")
|
| 301 |
+
f.write("=" * 80 + "\n\n")
|
| 302 |
+
f.write(f"Model: {MODEL_NAME}\n")
|
| 303 |
+
f.write(f"Model Path: {MODEL_PATH}\n")
|
| 304 |
+
f.write(f"Evaluation Time: {evaluation_time:.2f} seconds\n")
|
| 305 |
+
|
| 306 |
+
# Write summary stats
|
| 307 |
+
if summary_stats:
|
| 308 |
+
f.write(f"Total Datasets: {summary_stats['total_datasets']}\n\n")
|
| 309 |
+
f.write("Summary Statistics:\n")
|
| 310 |
+
f.write(f" Average Score: {summary_stats['average_score']:.4f}\n")
|
| 311 |
+
f.write(f" Median Score: {summary_stats['median_score']:.4f}\n")
|
| 312 |
+
f.write(f" Standard Deviation: {summary_stats['std_dev']:.4f}\n")
|
| 313 |
+
f.write(f" Score Range: {summary_stats['min_score']:.4f} - {summary_stats['max_score']:.4f}\n\n")
|
| 314 |
+
else:
|
| 315 |
+
f.write("Summary Statistics: No valid results found\n\n")
|
| 316 |
+
|
| 317 |
+
# Write leaderboard
|
| 318 |
+
f.write("Detailed Results:\n")
|
| 319 |
+
f.write("-" * 50 + "\n")
|
| 320 |
+
if task_scores:
|
| 321 |
+
leaderboard = make_leaderboard(task_scores) # type: ignore[arg-type]
|
| 322 |
+
f.write(leaderboard.to_string(index=False))
|
| 323 |
+
else:
|
| 324 |
+
f.write("No results available\n")
|
| 325 |
+
|
| 326 |
+
f.write("\n\n" + "=" * 80 + "\n")
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
def main() -> None:
|
| 330 |
+
"""Main evaluation function."""
|
| 331 |
+
logger.info(f"Starting MTEB evaluation for {MODEL_NAME}")
|
| 332 |
+
logger.info(f"Model path: {MODEL_PATH}")
|
| 333 |
+
logger.info(f"Output directory: {OUTPUT_DIR}")
|
| 334 |
+
logger.info("Running focused MTEB evaluation on code-relevant tasks:")
|
| 335 |
+
logger.info(" - Classification: Programming language classification")
|
| 336 |
+
logger.info(" - Clustering: Code clustering by functionality")
|
| 337 |
+
logger.info(" - STS: Semantic similarity between code snippets")
|
| 338 |
+
logger.info(" - Retrieval: Code search and retrieval")
|
| 339 |
+
|
| 340 |
+
try:
|
| 341 |
+
run_mteb_evaluation()
|
| 342 |
+
logger.info("Evaluation pipeline completed successfully!")
|
| 343 |
+
|
| 344 |
+
except Exception:
|
| 345 |
+
logger.exception("Evaluation failed")
|
| 346 |
+
sys.exit(1)
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
if __name__ == "__main__":
|
| 350 |
+
main()
|
README.md
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
---
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_type": "model2vec",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"StaticModel"
|
| 5 |
+
],
|
| 6 |
+
"tokenizer_name": "Alibaba-NLP/gte-Qwen2-7B-instruct",
|
| 7 |
+
"apply_pca": 256,
|
| 8 |
+
"apply_zipf": null,
|
| 9 |
+
"sif_coefficient": 0.0001,
|
| 10 |
+
"hidden_dim": 256,
|
| 11 |
+
"seq_length": 1000000,
|
| 12 |
+
"normalize": true
|
| 13 |
+
}
|
distill.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
"""
|
| 3 |
+
Script to distill Alibaba-NLP/gte-Qwen2-7B-instruct using Model2Vec.
|
| 4 |
+
|
| 5 |
+
This script performs the following operations:
|
| 6 |
+
1. Downloads the Alibaba-NLP/gte-Qwen2-7B-instruct model
|
| 7 |
+
2. Distills it using Model2Vec to create a smaller, faster static model
|
| 8 |
+
3. Saves the distilled model for further use
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
import logging
|
| 12 |
+
import shutil
|
| 13 |
+
import time
|
| 14 |
+
from pathlib import Path
|
| 15 |
+
|
| 16 |
+
from model2vec.distill import distill
|
| 17 |
+
|
| 18 |
+
# =============================================================================
|
| 19 |
+
# CONFIGURATION CONSTANTS
|
| 20 |
+
# =============================================================================
|
| 21 |
+
|
| 22 |
+
# Model Configuration
|
| 23 |
+
MODEL_NAME = "Alibaba-NLP/gte-Qwen2-7B-instruct" # Model name or path for the source model
|
| 24 |
+
OUTPUT_DIR = "." # Directory to save the distilled model (current directory)
|
| 25 |
+
PCA_DIMS = 256 # Dimensions for PCA reduction (smaller = faster but less accurate)
|
| 26 |
+
|
| 27 |
+
# Hub Configuration
|
| 28 |
+
SAVE_TO_HUB = False # Whether to push the model to HuggingFace Hub
|
| 29 |
+
HUB_MODEL_ID = None # Model ID for HuggingFace Hub (if saving to hub)
|
| 30 |
+
|
| 31 |
+
# Generation Configuration
|
| 32 |
+
SKIP_README = True # Skip generating the README file
|
| 33 |
+
|
| 34 |
+
# =============================================================================
|
| 35 |
+
|
| 36 |
+
# Configure logging
|
| 37 |
+
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 38 |
+
logger = logging.getLogger(__name__)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main() -> None:
|
| 42 |
+
"""Run the distillation process for Alibaba-NLP/gte-Qwen2-7B-instruct."""
|
| 43 |
+
# Create output directory if it doesn't exist
|
| 44 |
+
output_dir = Path(OUTPUT_DIR)
|
| 45 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 46 |
+
|
| 47 |
+
logger.info(f"Starting distillation of {MODEL_NAME}")
|
| 48 |
+
logger.info(f"Distilled model will be saved to {output_dir}")
|
| 49 |
+
logger.info(f"Using PCA dimensions: {PCA_DIMS}")
|
| 50 |
+
logger.info(f"Skipping README generation: {SKIP_README}")
|
| 51 |
+
|
| 52 |
+
# Record start time for benchmarking
|
| 53 |
+
start_time = time.time()
|
| 54 |
+
|
| 55 |
+
# Run the distillation
|
| 56 |
+
try:
|
| 57 |
+
logger.info("Starting Model2Vec distillation...")
|
| 58 |
+
m2v_model = distill(
|
| 59 |
+
model_name=MODEL_NAME,
|
| 60 |
+
pca_dims=PCA_DIMS,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
distill_time = time.time() - start_time
|
| 64 |
+
logger.info(f"Distillation completed in {distill_time:.2f} seconds")
|
| 65 |
+
|
| 66 |
+
# Save the distilled model
|
| 67 |
+
m2v_model.save_pretrained(OUTPUT_DIR)
|
| 68 |
+
logger.info(f"Model saved to {OUTPUT_DIR}")
|
| 69 |
+
|
| 70 |
+
# Remove README.md if it was created and we want to skip it
|
| 71 |
+
if SKIP_README and (output_dir / "README.md").exists():
|
| 72 |
+
(output_dir / "README.md").unlink()
|
| 73 |
+
logger.info("Removed auto-generated README.md")
|
| 74 |
+
|
| 75 |
+
# Get model size information
|
| 76 |
+
model_size_mb = sum(
|
| 77 |
+
f.stat().st_size for f in output_dir.glob("**/*") if f.is_file() and f.name != "README.md"
|
| 78 |
+
) / (1024 * 1024)
|
| 79 |
+
logger.info(f"Distilled model size: {model_size_mb:.2f} MB")
|
| 80 |
+
|
| 81 |
+
# Push to hub if requested
|
| 82 |
+
if SAVE_TO_HUB:
|
| 83 |
+
if HUB_MODEL_ID:
|
| 84 |
+
logger.info(f"Pushing model to HuggingFace Hub as {HUB_MODEL_ID}")
|
| 85 |
+
|
| 86 |
+
# Create a temporary README for Hub upload if needed
|
| 87 |
+
readme_path = output_dir / "README.md"
|
| 88 |
+
had_readme = readme_path.exists()
|
| 89 |
+
|
| 90 |
+
if SKIP_README and had_readme:
|
| 91 |
+
# Backup the README
|
| 92 |
+
shutil.move(readme_path, output_dir / "README.md.bak")
|
| 93 |
+
|
| 94 |
+
# Push to Hub
|
| 95 |
+
m2v_model.push_to_hub(HUB_MODEL_ID)
|
| 96 |
+
|
| 97 |
+
# Restore state
|
| 98 |
+
if SKIP_README:
|
| 99 |
+
if had_readme:
|
| 100 |
+
# Restore the backup
|
| 101 |
+
shutil.move(output_dir / "README.md.bak", readme_path)
|
| 102 |
+
elif (output_dir / "README.md").exists():
|
| 103 |
+
# Remove README created during push_to_hub
|
| 104 |
+
(output_dir / "README.md").unlink()
|
| 105 |
+
else:
|
| 106 |
+
logger.error("HUB_MODEL_ID must be specified when SAVE_TO_HUB is True")
|
| 107 |
+
|
| 108 |
+
logger.info("Distillation process completed successfully!")
|
| 109 |
+
|
| 110 |
+
except Exception:
|
| 111 |
+
logger.exception("Error during distillation")
|
| 112 |
+
raise
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
if __name__ == "__main__":
|
| 116 |
+
main()
|
evaluate.py
ADDED
|
@@ -0,0 +1,422 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
"""
|
| 3 |
+
Script to evaluate the performance of the distilled Qodo-Embed model.
|
| 4 |
+
|
| 5 |
+
This script performs the following:
|
| 6 |
+
1. Loads both the original Qodo-Embed-1-1.5B model and the distilled version
|
| 7 |
+
2. Compares them on:
|
| 8 |
+
- Embedding similarity
|
| 9 |
+
- Inference speed
|
| 10 |
+
- Memory usage
|
| 11 |
+
3. Outputs a comprehensive evaluation report
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
import gc
|
| 16 |
+
import logging
|
| 17 |
+
import os
|
| 18 |
+
import time
|
| 19 |
+
from pathlib import Path
|
| 20 |
+
from typing import Any, cast
|
| 21 |
+
|
| 22 |
+
import matplotlib.pyplot as plt
|
| 23 |
+
import numpy as np
|
| 24 |
+
import psutil # type: ignore [import]
|
| 25 |
+
import torch
|
| 26 |
+
from model2vec import StaticModel
|
| 27 |
+
from sentence_transformers import SentenceTransformer
|
| 28 |
+
from sklearn.metrics.pairwise import cosine_similarity # type: ignore [import]
|
| 29 |
+
|
| 30 |
+
# For transformer models
|
| 31 |
+
from transformers import AutoModel, AutoTokenizer
|
| 32 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 33 |
+
|
| 34 |
+
# =============================================================================
|
| 35 |
+
# CONFIGURATION CONSTANTS
|
| 36 |
+
# =============================================================================
|
| 37 |
+
|
| 38 |
+
# Model Configuration
|
| 39 |
+
ORIGINAL_MODEL = "Alibaba-NLP/gte-Qwen2-7B-instruct" # Original model name or path
|
| 40 |
+
DISTILLED_MODEL = "." # Path to the distilled model (current directory)
|
| 41 |
+
OUTPUT_DIR = "evaluation" # Directory to save evaluation results
|
| 42 |
+
|
| 43 |
+
# =============================================================================
|
| 44 |
+
|
| 45 |
+
# Constants
|
| 46 |
+
BYTES_PER_KB = 1024.0
|
| 47 |
+
TEXT_TRUNCATE_LENGTH = 20
|
| 48 |
+
|
| 49 |
+
# Configure logging
|
| 50 |
+
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 51 |
+
logger = logging.getLogger(__name__)
|
| 52 |
+
|
| 53 |
+
# Sample texts for evaluation
|
| 54 |
+
SAMPLE_TEXTS = [
|
| 55 |
+
"def process_data_stream(source_iterator):",
|
| 56 |
+
"implement binary search tree",
|
| 57 |
+
"how to handle memory efficient data streaming",
|
| 58 |
+
"""class LazyLoader:
|
| 59 |
+
def __init__(self, source):
|
| 60 |
+
self.generator = iter(source)
|
| 61 |
+
self._cache = []""",
|
| 62 |
+
"""def dfs_traversal(root):
|
| 63 |
+
if not root:
|
| 64 |
+
return []
|
| 65 |
+
visited = []
|
| 66 |
+
stack = [root]
|
| 67 |
+
while stack:
|
| 68 |
+
node = stack.pop()
|
| 69 |
+
visited.append(node.val)
|
| 70 |
+
if node.right:
|
| 71 |
+
stack.append(node.right)
|
| 72 |
+
if node.left:
|
| 73 |
+
stack.append(node.left)
|
| 74 |
+
return visited""",
|
| 75 |
+
]
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def load_models(
|
| 79 |
+
original_model_name: str, distilled_model_path: str
|
| 80 |
+
) -> tuple[tuple[SentenceTransformer | PreTrainedModel, str], StaticModel]:
|
| 81 |
+
"""Load both the original and distilled models."""
|
| 82 |
+
logger.info(f"Loading original model: {original_model_name}")
|
| 83 |
+
|
| 84 |
+
try:
|
| 85 |
+
# Try to load as a sentence transformer first
|
| 86 |
+
original_model = SentenceTransformer(original_model_name)
|
| 87 |
+
model_type = "sentence_transformer"
|
| 88 |
+
except (ValueError, OSError, ImportError) as e:
|
| 89 |
+
# If that fails, try loading as a Hugging Face transformer
|
| 90 |
+
logger.info(f"Failed to load as SentenceTransformer: {e}")
|
| 91 |
+
AutoTokenizer.from_pretrained(original_model_name)
|
| 92 |
+
original_model = AutoModel.from_pretrained(original_model_name)
|
| 93 |
+
model_type = "huggingface"
|
| 94 |
+
|
| 95 |
+
logger.info(f"Loading distilled model from: {distilled_model_path}")
|
| 96 |
+
distilled_model = StaticModel.from_pretrained(distilled_model_path)
|
| 97 |
+
|
| 98 |
+
return (original_model, model_type), distilled_model
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def measure_memory_usage(model: SentenceTransformer | PreTrainedModel | StaticModel) -> float:
|
| 102 |
+
"""Measure memory usage of a model in MB."""
|
| 103 |
+
gc.collect()
|
| 104 |
+
torch.cuda.empty_cache() if torch.cuda.is_available() else None
|
| 105 |
+
|
| 106 |
+
process = psutil.Process(os.getpid())
|
| 107 |
+
memory_before = process.memory_info().rss / (1024 * 1024) # MB
|
| 108 |
+
|
| 109 |
+
# Force model to allocate memory if it hasn't already
|
| 110 |
+
if isinstance(model, StaticModel | SentenceTransformer):
|
| 111 |
+
_ = model.encode(["Test"])
|
| 112 |
+
else:
|
| 113 |
+
# For HF models, we need to handle differently
|
| 114 |
+
pass
|
| 115 |
+
|
| 116 |
+
gc.collect()
|
| 117 |
+
torch.cuda.empty_cache() if torch.cuda.is_available() else None
|
| 118 |
+
|
| 119 |
+
process = psutil.Process(os.getpid())
|
| 120 |
+
memory_after = process.memory_info().rss / (1024 * 1024) # MB
|
| 121 |
+
|
| 122 |
+
return memory_after - memory_before
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def compute_embeddings(
|
| 126 |
+
original_model: SentenceTransformer | PreTrainedModel,
|
| 127 |
+
original_model_type: str,
|
| 128 |
+
distilled_model: StaticModel,
|
| 129 |
+
texts: list[str],
|
| 130 |
+
original_model_name: str = "unknown",
|
| 131 |
+
) -> tuple[np.ndarray, np.ndarray]:
|
| 132 |
+
"""Compute embeddings using both models."""
|
| 133 |
+
# Original model embeddings
|
| 134 |
+
if original_model_type == "sentence_transformer":
|
| 135 |
+
# Type narrowing: we know it's a SentenceTransformer here
|
| 136 |
+
sentence_model = cast("SentenceTransformer", original_model)
|
| 137 |
+
original_embeddings = sentence_model.encode(texts)
|
| 138 |
+
else:
|
| 139 |
+
# Type narrowing: we know it's a PreTrainedModel here
|
| 140 |
+
auto_model = original_model # AutoModel.from_pretrained returns a PreTrainedModel instance
|
| 141 |
+
|
| 142 |
+
# For HF models, we need more custom code
|
| 143 |
+
# Simple mean pooling function for HF models
|
| 144 |
+
def mean_pooling(model_output: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
|
| 145 |
+
token_embeddings = model_output
|
| 146 |
+
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
| 147 |
+
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(
|
| 148 |
+
input_mask_expanded.sum(1), min=1e-9
|
| 149 |
+
)
|
| 150 |
+
|
| 151 |
+
# Get model name for tokenizer
|
| 152 |
+
model_name = getattr(auto_model.config, "name_or_path", original_model_name)
|
| 153 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 154 |
+
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
|
| 155 |
+
|
| 156 |
+
with torch.no_grad():
|
| 157 |
+
model_output = auto_model(**encoded_input)
|
| 158 |
+
original_embeddings = mean_pooling(model_output.last_hidden_state, encoded_input["attention_mask"]).numpy()
|
| 159 |
+
|
| 160 |
+
# Distilled model embeddings
|
| 161 |
+
distilled_embeddings = distilled_model.encode(texts)
|
| 162 |
+
|
| 163 |
+
return original_embeddings, distilled_embeddings
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def measure_inference_speed(
|
| 167 |
+
model: SentenceTransformer | PreTrainedModel | StaticModel, model_type: str, texts: list[str], n_runs: int = 5
|
| 168 |
+
) -> float:
|
| 169 |
+
"""Measure inference speed in texts/second."""
|
| 170 |
+
# Warmup
|
| 171 |
+
if model_type in {"sentence_transformer", "static_model"}:
|
| 172 |
+
# Type narrowing: we know it has encode method here
|
| 173 |
+
encode_model = cast("SentenceTransformer | StaticModel", model)
|
| 174 |
+
_ = encode_model.encode(texts[:1])
|
| 175 |
+
else:
|
| 176 |
+
# Type narrowing: we know it's a PreTrainedModel here
|
| 177 |
+
auto_model = cast("PreTrainedModel", model)
|
| 178 |
+
# Warmup for HF models
|
| 179 |
+
model_name = getattr(auto_model.config, "name_or_path", "unknown")
|
| 180 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 181 |
+
encoded_input = tokenizer(texts[:1], padding=True, truncation=True, return_tensors="pt")
|
| 182 |
+
with torch.no_grad():
|
| 183 |
+
_ = auto_model(**encoded_input)
|
| 184 |
+
|
| 185 |
+
# Measure speed
|
| 186 |
+
start_time = time.time()
|
| 187 |
+
|
| 188 |
+
if model_type in {"sentence_transformer", "static_model"}:
|
| 189 |
+
# Type narrowing: we know it has encode method here
|
| 190 |
+
encode_model = cast("SentenceTransformer | StaticModel", model)
|
| 191 |
+
for _ in range(n_runs):
|
| 192 |
+
_ = encode_model.encode(texts)
|
| 193 |
+
else:
|
| 194 |
+
# Type narrowing: we know it's a PreTrainedModel here
|
| 195 |
+
auto_model = cast("PreTrainedModel", model)
|
| 196 |
+
# For HF models
|
| 197 |
+
model_name = getattr(auto_model.config, "name_or_path", "unknown")
|
| 198 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 199 |
+
for _ in range(n_runs):
|
| 200 |
+
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
|
| 201 |
+
with torch.no_grad():
|
| 202 |
+
_ = auto_model(**encoded_input)
|
| 203 |
+
|
| 204 |
+
total_time = time.time() - start_time
|
| 205 |
+
return (len(texts) * n_runs) / total_time
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def compute_cosine_similarity(embeddings1: np.ndarray, embeddings2: np.ndarray) -> np.ndarray:
|
| 209 |
+
"""Compute cosine similarity between embeddings, handling different dimensions.
|
| 210 |
+
|
| 211 |
+
For embeddings with different dimensions, we compute similarity by comparing
|
| 212 |
+
how they rank the same texts (semantically equivalent).
|
| 213 |
+
"""
|
| 214 |
+
# Ensure embeddings1 and embeddings2 are 2D arrays with shapes (n_samples, n_features)
|
| 215 |
+
if embeddings1.ndim == 1:
|
| 216 |
+
embeddings1 = embeddings1.reshape(1, -1)
|
| 217 |
+
if embeddings2.ndim == 1:
|
| 218 |
+
embeddings2 = embeddings2.reshape(1, -1)
|
| 219 |
+
|
| 220 |
+
# Check and transpose if needed to ensure samples are in rows
|
| 221 |
+
if embeddings2.shape[0] != len(SAMPLE_TEXTS) and embeddings2.shape[1] == len(SAMPLE_TEXTS):
|
| 222 |
+
embeddings2 = embeddings2.T
|
| 223 |
+
|
| 224 |
+
logger.info(f"Embeddings shapes: original={embeddings1.shape}, distilled={embeddings2.shape}")
|
| 225 |
+
|
| 226 |
+
# If dimensions differ, we compute similarity matrix based on how each model ranks text pairs
|
| 227 |
+
# This is a form of semantic similarity evaluation rather than direct vector comparison
|
| 228 |
+
similarity_matrix = np.zeros((len(SAMPLE_TEXTS), len(SAMPLE_TEXTS)))
|
| 229 |
+
|
| 230 |
+
# Compute similarity matrices within each embedding space
|
| 231 |
+
sim1 = cosine_similarity(embeddings1)
|
| 232 |
+
sim2 = cosine_similarity(embeddings2)
|
| 233 |
+
|
| 234 |
+
# The similarity between samples i and j is the correlation between how they rank other samples
|
| 235 |
+
for i in range(len(SAMPLE_TEXTS)):
|
| 236 |
+
for j in range(len(SAMPLE_TEXTS)):
|
| 237 |
+
# For diagonal elements (same sample), use a direct measure of how similar
|
| 238 |
+
# the two models rank that sample against all others
|
| 239 |
+
if i == j:
|
| 240 |
+
# Pearson correlation between the rankings (excluding self-comparison)
|
| 241 |
+
rankings1 = np.delete(sim1[i], i)
|
| 242 |
+
rankings2 = np.delete(sim2[i], i)
|
| 243 |
+
# Higher correlation means the models agree on the semantic similarity
|
| 244 |
+
similarity_matrix[i, j] = np.corrcoef(rankings1, rankings2)[0, 1]
|
| 245 |
+
else:
|
| 246 |
+
# For off-diagonal elements, compare how similarly both models relate samples i and j
|
| 247 |
+
similarity_matrix[i, j] = 1 - abs(sim1[i, j] - sim2[i, j])
|
| 248 |
+
|
| 249 |
+
return similarity_matrix
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def format_size(size_bytes: float) -> str:
|
| 253 |
+
"""Format size in bytes to human-readable format."""
|
| 254 |
+
for unit in ["B", "KB", "MB", "GB"]:
|
| 255 |
+
if size_bytes < BYTES_PER_KB:
|
| 256 |
+
return f"{size_bytes:.2f} {unit}"
|
| 257 |
+
size_bytes /= BYTES_PER_KB
|
| 258 |
+
return f"{size_bytes:.2f} TB"
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def plot_comparison(results: dict[str, Any], output_dir: str) -> None:
|
| 262 |
+
"""Generate comparison plots and save them."""
|
| 263 |
+
output_path = Path(output_dir)
|
| 264 |
+
output_path.mkdir(exist_ok=True, parents=True)
|
| 265 |
+
|
| 266 |
+
# Speed comparison
|
| 267 |
+
plt.figure(figsize=(10, 6))
|
| 268 |
+
models = ["Original", "Distilled"]
|
| 269 |
+
speeds = [results["original_speed"], results["distilled_speed"]]
|
| 270 |
+
plt.bar(models, speeds, color=["#1f77b4", "#ff7f0e"])
|
| 271 |
+
plt.ylabel("Texts per second")
|
| 272 |
+
plt.title("Inference Speed Comparison")
|
| 273 |
+
plt.savefig(output_path / "speed_comparison.png", dpi=300, bbox_inches="tight")
|
| 274 |
+
|
| 275 |
+
# Memory comparison
|
| 276 |
+
plt.figure(figsize=(10, 6))
|
| 277 |
+
memories = [results["original_memory"], results["distilled_memory"]]
|
| 278 |
+
plt.bar(models, memories, color=["#1f77b4", "#ff7f0e"])
|
| 279 |
+
plt.ylabel("Memory Usage (MB)")
|
| 280 |
+
plt.title("Memory Usage Comparison")
|
| 281 |
+
plt.savefig(output_path / "memory_comparison.png", dpi=300, bbox_inches="tight")
|
| 282 |
+
|
| 283 |
+
# Size comparison
|
| 284 |
+
plt.figure(figsize=(10, 6))
|
| 285 |
+
sizes = [results["original_size"], results["distilled_size"]]
|
| 286 |
+
plt.bar(models, sizes, color=["#1f77b4", "#ff7f0e"])
|
| 287 |
+
plt.ylabel("Model Size (MB)")
|
| 288 |
+
plt.title("Model Size Comparison")
|
| 289 |
+
plt.savefig(output_path / "size_comparison.png", dpi=300, bbox_inches="tight")
|
| 290 |
+
|
| 291 |
+
# Similarity matrix heatmap
|
| 292 |
+
plt.figure(figsize=(8, 6))
|
| 293 |
+
plt.imshow(results["similarity_matrix"], cmap="viridis", interpolation="nearest")
|
| 294 |
+
plt.colorbar(label="Cosine Similarity")
|
| 295 |
+
plt.title("Embedding Similarity Between Original and Distilled Models")
|
| 296 |
+
plt.xticks([])
|
| 297 |
+
plt.yticks(
|
| 298 |
+
range(len(SAMPLE_TEXTS)),
|
| 299 |
+
[t[:TEXT_TRUNCATE_LENGTH] + "..." if len(t) > TEXT_TRUNCATE_LENGTH else t for t in SAMPLE_TEXTS],
|
| 300 |
+
)
|
| 301 |
+
plt.savefig(output_path / "similarity_matrix.png", dpi=300, bbox_inches="tight")
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
def evaluate_models(original_model_name: str, distilled_model_path: str, output_dir: str) -> dict[str, Any]:
|
| 305 |
+
"""Evaluate the original and distilled models."""
|
| 306 |
+
# Load models
|
| 307 |
+
(original_model, original_model_type), distilled_model = load_models(original_model_name, distilled_model_path)
|
| 308 |
+
|
| 309 |
+
# Measure model sizes
|
| 310 |
+
if isinstance(original_model, SentenceTransformer):
|
| 311 |
+
# For SentenceTransformer, get parameters from all modules
|
| 312 |
+
total_params = 0
|
| 313 |
+
for module in original_model.modules():
|
| 314 |
+
if hasattr(module, "parameters"):
|
| 315 |
+
for param in module.parameters():
|
| 316 |
+
total_params += param.numel()
|
| 317 |
+
original_model_size = total_params * 4 / (1024 * 1024) # MB (assuming float32)
|
| 318 |
+
else:
|
| 319 |
+
# For PreTrainedModel
|
| 320 |
+
auto_model = original_model # AutoModel.from_pretrained returns a PreTrainedModel instance
|
| 321 |
+
original_model_size = sum(p.numel() * 4 for p in auto_model.parameters()) / (
|
| 322 |
+
1024 * 1024
|
| 323 |
+
) # MB (assuming float32)
|
| 324 |
+
|
| 325 |
+
# Calculate distilled model size - only count actual model files
|
| 326 |
+
model_files = ["model.safetensors", "config.json", "modules.json", "tokenizer.json"]
|
| 327 |
+
distilled_model_size = 0.0
|
| 328 |
+
for file_name in model_files:
|
| 329 |
+
file_path = Path(distilled_model_path) / file_name
|
| 330 |
+
if file_path.exists():
|
| 331 |
+
distilled_model_size += file_path.stat().st_size
|
| 332 |
+
distilled_model_size = distilled_model_size / (1024 * 1024) # Convert to MB
|
| 333 |
+
|
| 334 |
+
# Measure memory usage
|
| 335 |
+
original_memory = measure_memory_usage(original_model)
|
| 336 |
+
distilled_memory = measure_memory_usage(distilled_model)
|
| 337 |
+
|
| 338 |
+
# Compute embeddings
|
| 339 |
+
original_embeddings, distilled_embeddings = compute_embeddings(
|
| 340 |
+
original_model, original_model_type, distilled_model, SAMPLE_TEXTS, original_model_name
|
| 341 |
+
)
|
| 342 |
+
|
| 343 |
+
# Compute similarity between embeddings
|
| 344 |
+
similarity_matrix = compute_cosine_similarity(original_embeddings, distilled_embeddings)
|
| 345 |
+
similarity_diagonal = np.diag(similarity_matrix)
|
| 346 |
+
avg_similarity = np.mean(similarity_diagonal)
|
| 347 |
+
|
| 348 |
+
# Measure inference speed
|
| 349 |
+
original_speed = measure_inference_speed(original_model, original_model_type, SAMPLE_TEXTS, n_runs=5)
|
| 350 |
+
distilled_speed = measure_inference_speed(distilled_model, "static_model", SAMPLE_TEXTS, n_runs=5)
|
| 351 |
+
|
| 352 |
+
# Collect results
|
| 353 |
+
results = {
|
| 354 |
+
"original_size": original_model_size,
|
| 355 |
+
"distilled_size": distilled_model_size,
|
| 356 |
+
"original_memory": original_memory,
|
| 357 |
+
"distilled_memory": distilled_memory,
|
| 358 |
+
"similarity_matrix": similarity_matrix,
|
| 359 |
+
"avg_similarity": avg_similarity,
|
| 360 |
+
"original_speed": original_speed,
|
| 361 |
+
"distilled_speed": distilled_speed,
|
| 362 |
+
"speed_improvement": distilled_speed / original_speed if original_speed > 0 else float("inf"),
|
| 363 |
+
"size_reduction": original_model_size / distilled_model_size if distilled_model_size > 0 else float("inf"),
|
| 364 |
+
"memory_reduction": original_memory / distilled_memory if distilled_memory > 0 else float("inf"),
|
| 365 |
+
}
|
| 366 |
+
|
| 367 |
+
# Generate plots
|
| 368 |
+
plot_comparison(results, output_dir)
|
| 369 |
+
|
| 370 |
+
# Print results
|
| 371 |
+
separator = "=" * 50
|
| 372 |
+
logger.info("\n%s", separator)
|
| 373 |
+
logger.info("Model Evaluation Results")
|
| 374 |
+
logger.info("%s", separator)
|
| 375 |
+
logger.info(f"Original Model Size: {results['original_size']:.2f} MB")
|
| 376 |
+
logger.info(f"Distilled Model Size: {results['distilled_size']:.2f} MB")
|
| 377 |
+
logger.info(f"Size Reduction Factor: {results['size_reduction']:.2f}x")
|
| 378 |
+
logger.info("\n")
|
| 379 |
+
logger.info(f"Original Model Memory: {results['original_memory']:.2f} MB")
|
| 380 |
+
logger.info(f"Distilled Model Memory: {results['distilled_memory']:.2f} MB")
|
| 381 |
+
logger.info(f"Memory Reduction Factor: {results['memory_reduction']:.2f}x")
|
| 382 |
+
logger.info("\n")
|
| 383 |
+
logger.info(f"Original Model Speed: {results['original_speed']:.2f} texts/second")
|
| 384 |
+
logger.info(f"Distilled Model Speed: {results['distilled_speed']:.2f} texts/second")
|
| 385 |
+
logger.info(f"Speed Improvement Factor: {results['speed_improvement']:.2f}x")
|
| 386 |
+
logger.info("\n")
|
| 387 |
+
logger.info(f"Average Embedding Similarity: {results['avg_similarity']:.4f}")
|
| 388 |
+
logger.info("%s", separator)
|
| 389 |
+
|
| 390 |
+
return results
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
def main() -> None:
|
| 394 |
+
"""Run the evaluation process."""
|
| 395 |
+
parser = argparse.ArgumentParser(description="Evaluate the distilled model against the original")
|
| 396 |
+
parser.add_argument("--original_model", default=ORIGINAL_MODEL, help="Original model name or path")
|
| 397 |
+
parser.add_argument("--distilled_model", default=DISTILLED_MODEL, help="Path to the distilled model")
|
| 398 |
+
parser.add_argument("--output_dir", default=OUTPUT_DIR, help="Directory to save evaluation results")
|
| 399 |
+
|
| 400 |
+
args = parser.parse_args()
|
| 401 |
+
|
| 402 |
+
# Validate configuration
|
| 403 |
+
if not args.distilled_model:
|
| 404 |
+
logger.error("Distilled model path must be provided")
|
| 405 |
+
logger.error("Use --distilled_model to specify the path or set DISTILLED_MODEL constant")
|
| 406 |
+
return
|
| 407 |
+
|
| 408 |
+
# Create output directory
|
| 409 |
+
output_dir = Path(args.output_dir)
|
| 410 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 411 |
+
|
| 412 |
+
# Run evaluation
|
| 413 |
+
try:
|
| 414 |
+
evaluate_models(args.original_model, args.distilled_model, args.output_dir)
|
| 415 |
+
logger.info(f"Evaluation completed. Results saved to {args.output_dir}")
|
| 416 |
+
except Exception:
|
| 417 |
+
logger.exception("Error during evaluation")
|
| 418 |
+
raise
|
| 419 |
+
|
| 420 |
+
|
| 421 |
+
if __name__ == "__main__":
|
| 422 |
+
main()
|
evaluation/memory_comparison.png
ADDED
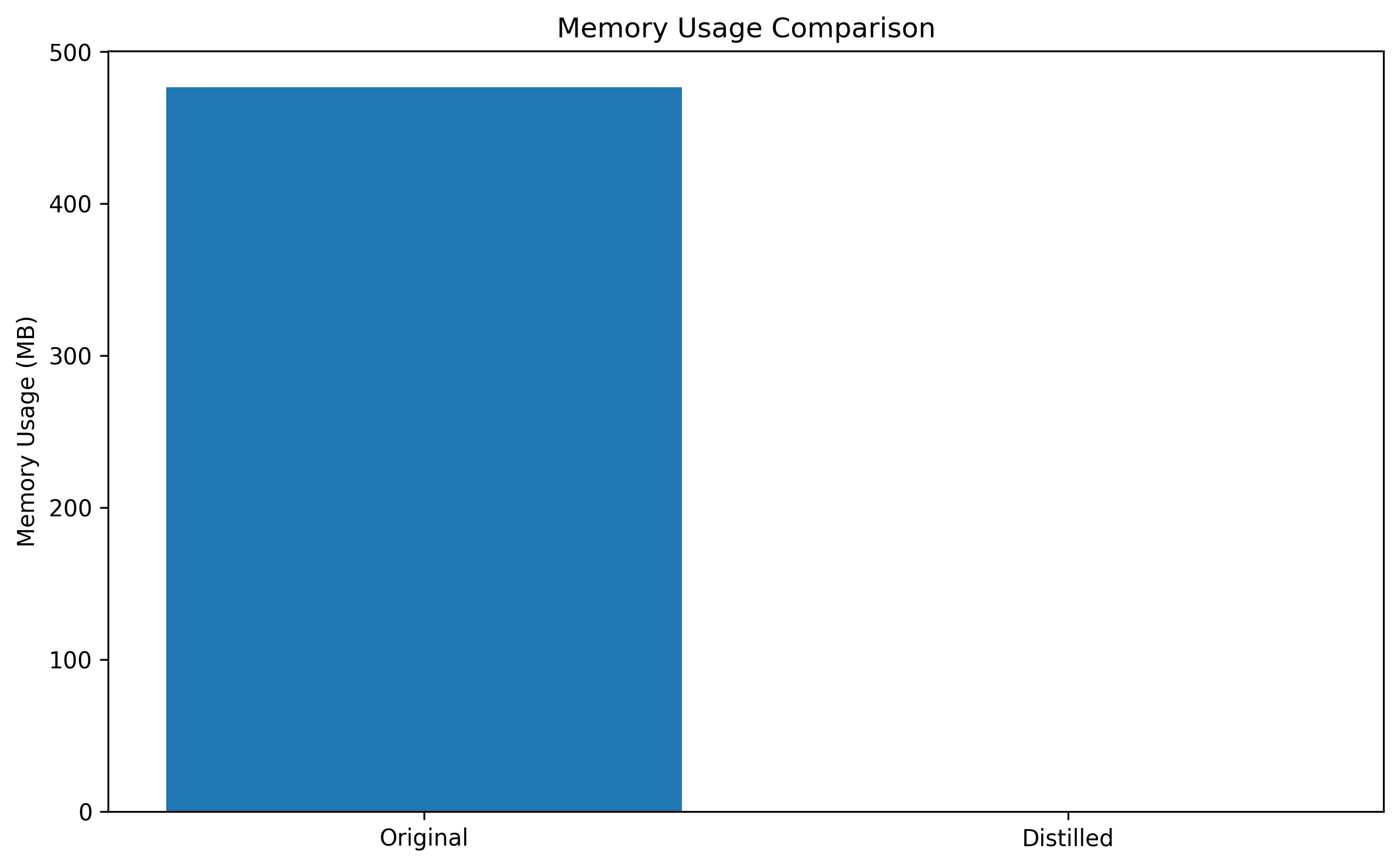
|
Git LFS Details
|
evaluation/similarity_matrix.png
ADDED
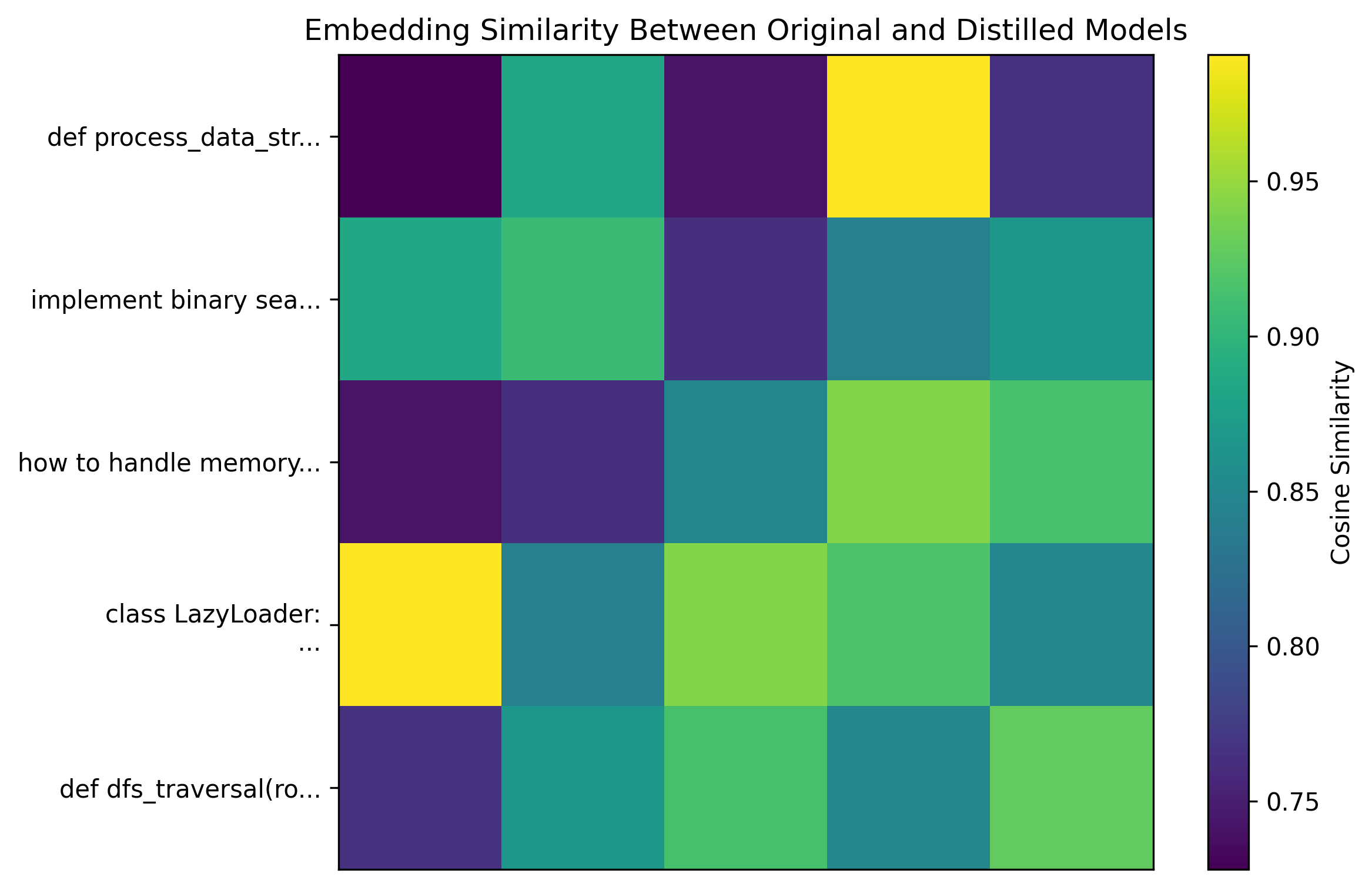
|
Git LFS Details
|
evaluation/size_comparison.png
ADDED
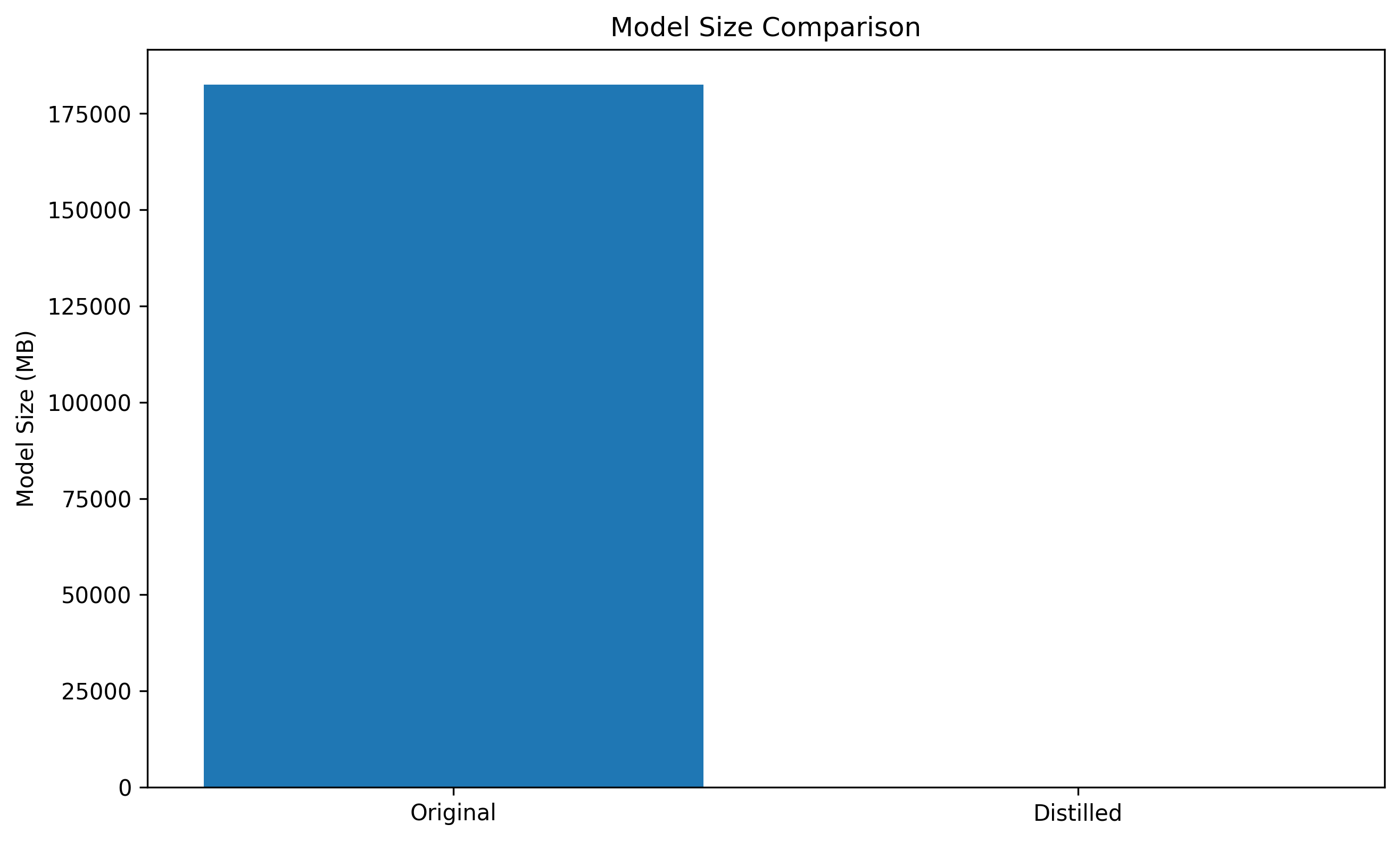
|
Git LFS Details
|
evaluation/speed_comparison.png
ADDED
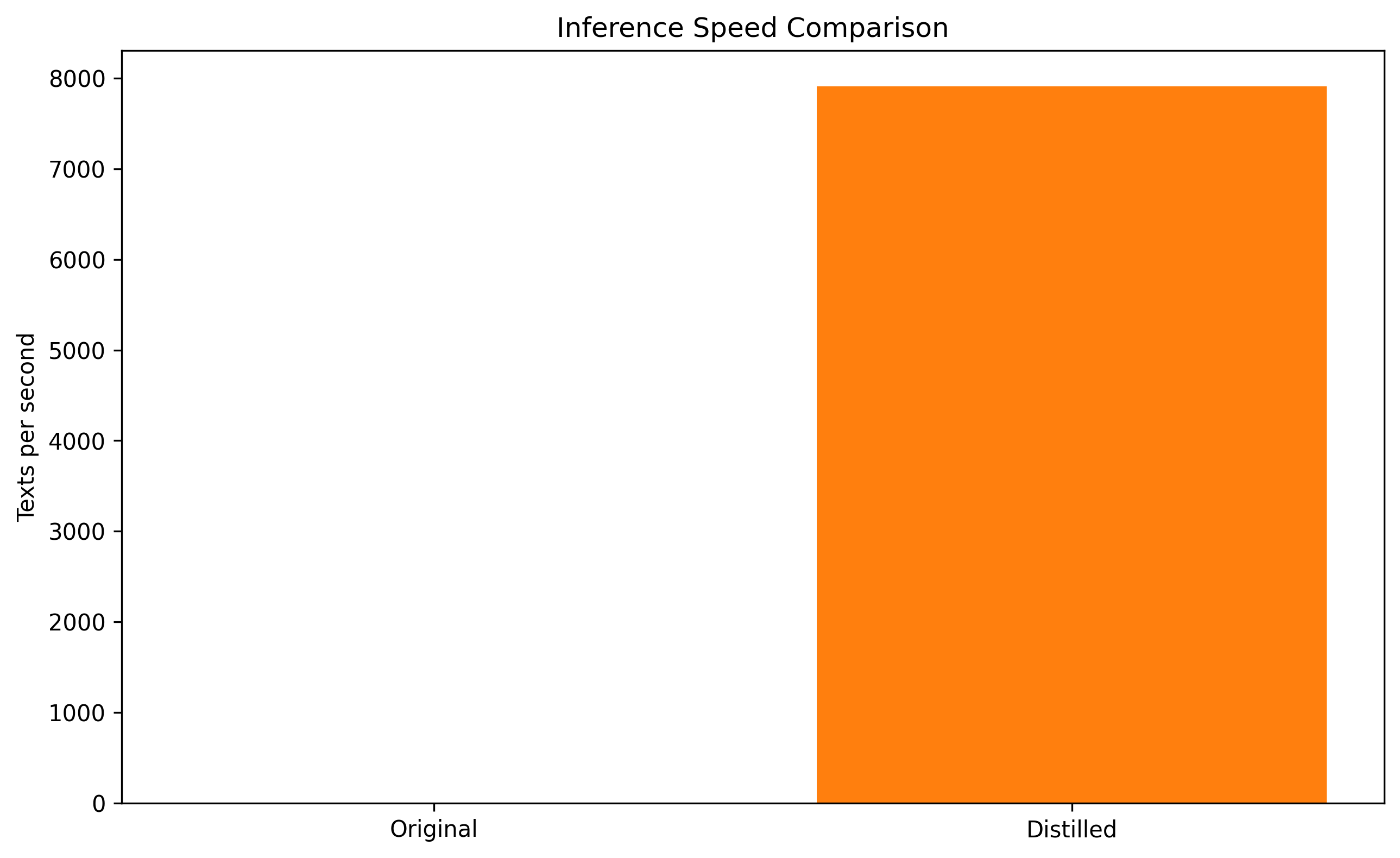
|
Git LFS Details
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9dc253eb31caa17834057d92999b03869cda542d5f70ecca3d4a5f03b3563b3f
|
| 3 |
+
size 155283544
|
modules.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": ".",
|
| 6 |
+
"type": "sentence_transformers.models.StaticEmbedding"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Normalize",
|
| 12 |
+
"type": "sentence_transformers.models.Normalize"
|
| 13 |
+
}
|
| 14 |
+
]
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/AmazonCounterfactualClassification.json
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_revision": "e8379541af4e31359cca9fbcf4b00f2671dba205",
|
| 3 |
+
"evaluation_time": 8.737873554229736,
|
| 4 |
+
"kg_co2_emissions": null,
|
| 5 |
+
"mteb_version": "1.14.15",
|
| 6 |
+
"scores": {
|
| 7 |
+
"test": [
|
| 8 |
+
{
|
| 9 |
+
"accuracy": 0.5690404797601201,
|
| 10 |
+
"ap": 0.13918928297805203,
|
| 11 |
+
"ap_weighted": 0.13918928297805203,
|
| 12 |
+
"f1": 0.47354721284407075,
|
| 13 |
+
"f1_weighted": 0.6484719142466673,
|
| 14 |
+
"hf_subset": "en-ext",
|
| 15 |
+
"languages": [
|
| 16 |
+
"eng-Latn"
|
| 17 |
+
],
|
| 18 |
+
"main_score": 0.5690404797601201,
|
| 19 |
+
"scores_per_experiment": [
|
| 20 |
+
{
|
| 21 |
+
"accuracy": 0.6041979010494752,
|
| 22 |
+
"ap": 0.1403174548244783,
|
| 23 |
+
"ap_weighted": 0.1403174548244783,
|
| 24 |
+
"f1": 0.49333755341034974,
|
| 25 |
+
"f1_weighted": 0.6809473724919468
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"accuracy": 0.6319340329835083,
|
| 29 |
+
"ap": 0.15145229144021116,
|
| 30 |
+
"ap_weighted": 0.15145229144021116,
|
| 31 |
+
"f1": 0.5150100219839455,
|
| 32 |
+
"f1_weighted": 0.7035165191069046
|
| 33 |
+
},
|
| 34 |
+
{
|
| 35 |
+
"accuracy": 0.6124437781109445,
|
| 36 |
+
"ap": 0.15370328203750555,
|
| 37 |
+
"ap_weighted": 0.15370328203750555,
|
| 38 |
+
"f1": 0.5069738581294719,
|
| 39 |
+
"f1_weighted": 0.6874863954073245
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"accuracy": 0.5712143928035982,
|
| 43 |
+
"ap": 0.13285280504159222,
|
| 44 |
+
"ap_weighted": 0.13285280504159222,
|
| 45 |
+
"f1": 0.471264367816092,
|
| 46 |
+
"f1_weighted": 0.6532423443450689
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"accuracy": 0.6101949025487257,
|
| 50 |
+
"ap": 0.1382528418572316,
|
| 51 |
+
"ap_weighted": 0.1382528418572316,
|
| 52 |
+
"f1": 0.49459093982420554,
|
| 53 |
+
"f1_weighted": 0.6859354298509973
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"accuracy": 0.5194902548725637,
|
| 57 |
+
"ap": 0.12777013417285304,
|
| 58 |
+
"ap_weighted": 0.12777013417285304,
|
| 59 |
+
"f1": 0.4405866978944166,
|
| 60 |
+
"f1_weighted": 0.6068983868543434
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"accuracy": 0.43778110944527737,
|
| 64 |
+
"ap": 0.11875450153550213,
|
| 65 |
+
"ap_weighted": 0.11875450153550213,
|
| 66 |
+
"f1": 0.3875609684433214,
|
| 67 |
+
"f1_weighted": 0.5263894210560583
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"accuracy": 0.6176911544227887,
|
| 71 |
+
"ap": 0.14128018744097307,
|
| 72 |
+
"ap_weighted": 0.14128018744097307,
|
| 73 |
+
"f1": 0.5005725863284003,
|
| 74 |
+
"f1_weighted": 0.6920233725631899
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"accuracy": 0.49025487256371814,
|
| 78 |
+
"ap": 0.14466447368521512,
|
| 79 |
+
"ap_weighted": 0.14466447368521512,
|
| 80 |
+
"f1": 0.43475703375805064,
|
| 81 |
+
"f1_weighted": 0.5749621002144737
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"accuracy": 0.5952023988005997,
|
| 85 |
+
"ap": 0.14284485774495798,
|
| 86 |
+
"ap_weighted": 0.14284485774495798,
|
| 87 |
+
"f1": 0.4908181008524535,
|
| 88 |
+
"f1_weighted": 0.6733178005763648
|
| 89 |
+
}
|
| 90 |
+
]
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"accuracy": 0.62,
|
| 94 |
+
"ap": 0.26415963699316264,
|
| 95 |
+
"ap_weighted": 0.26415963699316264,
|
| 96 |
+
"f1": 0.5644640290850564,
|
| 97 |
+
"f1_weighted": 0.6579491434972964,
|
| 98 |
+
"hf_subset": "en",
|
| 99 |
+
"languages": [
|
| 100 |
+
"eng-Latn"
|
| 101 |
+
],
|
| 102 |
+
"main_score": 0.62,
|
| 103 |
+
"scores_per_experiment": [
|
| 104 |
+
{
|
| 105 |
+
"accuracy": 0.5955223880597015,
|
| 106 |
+
"ap": 0.25283011702254965,
|
| 107 |
+
"ap_weighted": 0.25283011702254965,
|
| 108 |
+
"f1": 0.5461419440632507,
|
| 109 |
+
"f1_weighted": 0.637305840672083
|
| 110 |
+
},
|
| 111 |
+
{
|
| 112 |
+
"accuracy": 0.5835820895522388,
|
| 113 |
+
"ap": 0.26075921450734807,
|
| 114 |
+
"ap_weighted": 0.26075921450734807,
|
| 115 |
+
"f1": 0.5441743417924314,
|
| 116 |
+
"f1_weighted": 0.6257903879142659
|
| 117 |
+
},
|
| 118 |
+
{
|
| 119 |
+
"accuracy": 0.6029850746268657,
|
| 120 |
+
"ap": 0.24791359505097144,
|
| 121 |
+
"ap_weighted": 0.24791359505097144,
|
| 122 |
+
"f1": 0.5467492700989818,
|
| 123 |
+
"f1_weighted": 0.643970491486171
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"accuracy": 0.6029850746268657,
|
| 127 |
+
"ap": 0.26571020411740476,
|
| 128 |
+
"ap_weighted": 0.26571020411740476,
|
| 129 |
+
"f1": 0.5578808446455505,
|
| 130 |
+
"f1_weighted": 0.6438739560117962
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"accuracy": 0.6761194029850747,
|
| 134 |
+
"ap": 0.2747168088064611,
|
| 135 |
+
"ap_weighted": 0.2747168088064611,
|
| 136 |
+
"f1": 0.5995328480020714,
|
| 137 |
+
"f1_weighted": 0.7061789723470043
|
| 138 |
+
},
|
| 139 |
+
{
|
| 140 |
+
"accuracy": 0.6537313432835821,
|
| 141 |
+
"ap": 0.2721721103504757,
|
| 142 |
+
"ap_weighted": 0.2721721103504757,
|
| 143 |
+
"f1": 0.587775408670931,
|
| 144 |
+
"f1_weighted": 0.6881859359916834
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"accuracy": 0.6597014925373135,
|
| 148 |
+
"ap": 0.26444025941241256,
|
| 149 |
+
"ap_weighted": 0.26444025941241256,
|
| 150 |
+
"f1": 0.5851663570893213,
|
| 151 |
+
"f1_weighted": 0.692245002380803
|
| 152 |
+
},
|
| 153 |
+
{
|
| 154 |
+
"accuracy": 0.6149253731343284,
|
| 155 |
+
"ap": 0.23113683661630094,
|
| 156 |
+
"ap_weighted": 0.23113683661630094,
|
| 157 |
+
"f1": 0.538936721825689,
|
| 158 |
+
"f1_weighted": 0.6529196987886481
|
| 159 |
+
},
|
| 160 |
+
{
|
| 161 |
+
"accuracy": 0.5791044776119403,
|
| 162 |
+
"ap": 0.2786207978292612,
|
| 163 |
+
"ap_weighted": 0.2786207978292612,
|
| 164 |
+
"f1": 0.5501428571428572,
|
| 165 |
+
"f1_weighted": 0.6196507462686567
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"accuracy": 0.6313432835820896,
|
| 169 |
+
"ap": 0.29329642621844076,
|
| 170 |
+
"ap_weighted": 0.29329642621844076,
|
| 171 |
+
"f1": 0.5881396975194806,
|
| 172 |
+
"f1_weighted": 0.6693704031118514
|
| 173 |
+
}
|
| 174 |
+
]
|
| 175 |
+
}
|
| 176 |
+
]
|
| 177 |
+
},
|
| 178 |
+
"task_name": "AmazonCounterfactualClassification"
|
| 179 |
+
}
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/Banking77Classification.json
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_revision": "0fd18e25b25c072e09e0d92ab615fda904d66300",
|
| 3 |
+
"evaluation_time": 6.451777696609497,
|
| 4 |
+
"kg_co2_emissions": null,
|
| 5 |
+
"mteb_version": "1.14.15",
|
| 6 |
+
"scores": {
|
| 7 |
+
"test": [
|
| 8 |
+
{
|
| 9 |
+
"accuracy": 0.4396103896103896,
|
| 10 |
+
"f1": 0.4142711532114576,
|
| 11 |
+
"f1_weighted": 0.4142711532114576,
|
| 12 |
+
"hf_subset": "default",
|
| 13 |
+
"languages": [
|
| 14 |
+
"eng-Latn"
|
| 15 |
+
],
|
| 16 |
+
"main_score": 0.4396103896103896,
|
| 17 |
+
"scores_per_experiment": [
|
| 18 |
+
{
|
| 19 |
+
"accuracy": 0.4279220779220779,
|
| 20 |
+
"f1": 0.4030476288783657,
|
| 21 |
+
"f1_weighted": 0.4030476288783656
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"accuracy": 0.4211038961038961,
|
| 25 |
+
"f1": 0.39776168133611584,
|
| 26 |
+
"f1_weighted": 0.39776168133611584
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"accuracy": 0.45064935064935063,
|
| 30 |
+
"f1": 0.42872843564828145,
|
| 31 |
+
"f1_weighted": 0.42872843564828145
|
| 32 |
+
},
|
| 33 |
+
{
|
| 34 |
+
"accuracy": 0.4448051948051948,
|
| 35 |
+
"f1": 0.420756828398419,
|
| 36 |
+
"f1_weighted": 0.42075682839841905
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"accuracy": 0.44675324675324674,
|
| 40 |
+
"f1": 0.42100682221185654,
|
| 41 |
+
"f1_weighted": 0.42100682221185654
|
| 42 |
+
},
|
| 43 |
+
{
|
| 44 |
+
"accuracy": 0.45324675324675323,
|
| 45 |
+
"f1": 0.4392342490231314,
|
| 46 |
+
"f1_weighted": 0.4392342490231314
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"accuracy": 0.437012987012987,
|
| 50 |
+
"f1": 0.4056017558988273,
|
| 51 |
+
"f1_weighted": 0.40560175589882724
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"accuracy": 0.42337662337662335,
|
| 55 |
+
"f1": 0.39123709562594644,
|
| 56 |
+
"f1_weighted": 0.39123709562594655
|
| 57 |
+
},
|
| 58 |
+
{
|
| 59 |
+
"accuracy": 0.44512987012987015,
|
| 60 |
+
"f1": 0.41578171494860966,
|
| 61 |
+
"f1_weighted": 0.41578171494860966
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
"accuracy": 0.4461038961038961,
|
| 65 |
+
"f1": 0.4195553201450221,
|
| 66 |
+
"f1_weighted": 0.419555320145022
|
| 67 |
+
}
|
| 68 |
+
]
|
| 69 |
+
}
|
| 70 |
+
]
|
| 71 |
+
},
|
| 72 |
+
"task_name": "Banking77Classification"
|
| 73 |
+
}
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/CQADupstackProgrammersRetrieval.json
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_revision": "6184bc1440d2dbc7612be22b50686b8826d22b32",
|
| 3 |
+
"evaluation_time": 99.69791841506958,
|
| 4 |
+
"kg_co2_emissions": null,
|
| 5 |
+
"mteb_version": "1.14.15",
|
| 6 |
+
"scores": {
|
| 7 |
+
"test": [
|
| 8 |
+
{
|
| 9 |
+
"hf_subset": "default",
|
| 10 |
+
"languages": [
|
| 11 |
+
"eng-Latn"
|
| 12 |
+
],
|
| 13 |
+
"main_score": 0.0501,
|
| 14 |
+
"map_at_1": 0.02467,
|
| 15 |
+
"map_at_10": 0.03898,
|
| 16 |
+
"map_at_100": 0.04261,
|
| 17 |
+
"map_at_1000": 0.04333,
|
| 18 |
+
"map_at_20": 0.04068,
|
| 19 |
+
"map_at_3": 0.03388,
|
| 20 |
+
"map_at_5": 0.03693,
|
| 21 |
+
"mrr_at_1": 0.030821917808219176,
|
| 22 |
+
"mrr_at_10": 0.04904462926723201,
|
| 23 |
+
"mrr_at_100": 0.05339942610218758,
|
| 24 |
+
"mrr_at_1000": 0.05413492750157237,
|
| 25 |
+
"mrr_at_20": 0.05126402659708249,
|
| 26 |
+
"mrr_at_3": 0.04280821917808219,
|
| 27 |
+
"mrr_at_5": 0.04634703196347032,
|
| 28 |
+
"nauc_map_at_1000_diff1": 0.03644747951501248,
|
| 29 |
+
"nauc_map_at_1000_max": 0.2240572170754659,
|
| 30 |
+
"nauc_map_at_1000_std": -0.17708810912472517,
|
| 31 |
+
"nauc_map_at_100_diff1": 0.03759221625144172,
|
| 32 |
+
"nauc_map_at_100_max": 0.22324901446317413,
|
| 33 |
+
"nauc_map_at_100_std": -0.17630470695891512,
|
| 34 |
+
"nauc_map_at_10_diff1": 0.03906418656483989,
|
| 35 |
+
"nauc_map_at_10_max": 0.22061594321968936,
|
| 36 |
+
"nauc_map_at_10_std": -0.17777470317814356,
|
| 37 |
+
"nauc_map_at_1_diff1": 0.1731091343679673,
|
| 38 |
+
"nauc_map_at_1_max": 0.33459947679728974,
|
| 39 |
+
"nauc_map_at_1_std": -0.23115450977179597,
|
| 40 |
+
"nauc_map_at_20_diff1": 0.03795725531499195,
|
| 41 |
+
"nauc_map_at_20_max": 0.22396003211648763,
|
| 42 |
+
"nauc_map_at_20_std": -0.17867373725662639,
|
| 43 |
+
"nauc_map_at_3_diff1": 0.06042780588964212,
|
| 44 |
+
"nauc_map_at_3_max": 0.2486807528974488,
|
| 45 |
+
"nauc_map_at_3_std": -0.18512855007450404,
|
| 46 |
+
"nauc_map_at_5_diff1": 0.04407217741234605,
|
| 47 |
+
"nauc_map_at_5_max": 0.22647048266105405,
|
| 48 |
+
"nauc_map_at_5_std": -0.18107585673560017,
|
| 49 |
+
"nauc_mrr_at_1000_diff1": 0.033601872249839834,
|
| 50 |
+
"nauc_mrr_at_1000_max": 0.2523936325136619,
|
| 51 |
+
"nauc_mrr_at_1000_std": -0.19078164353963076,
|
| 52 |
+
"nauc_mrr_at_100_diff1": 0.03435870935950355,
|
| 53 |
+
"nauc_mrr_at_100_max": 0.2523932973431928,
|
| 54 |
+
"nauc_mrr_at_100_std": -0.1900913512193067,
|
| 55 |
+
"nauc_mrr_at_10_diff1": 0.03361519179733555,
|
| 56 |
+
"nauc_mrr_at_10_max": 0.25392922716866984,
|
| 57 |
+
"nauc_mrr_at_10_std": -0.1935061134919541,
|
| 58 |
+
"nauc_mrr_at_1_diff1": 0.1772995319079407,
|
| 59 |
+
"nauc_mrr_at_1_max": 0.35182174117717013,
|
| 60 |
+
"nauc_mrr_at_1_std": -0.24426280067522707,
|
| 61 |
+
"nauc_mrr_at_20_diff1": 0.03479828151019169,
|
| 62 |
+
"nauc_mrr_at_20_max": 0.25624951214228564,
|
| 63 |
+
"nauc_mrr_at_20_std": -0.19212268093923462,
|
| 64 |
+
"nauc_mrr_at_3_diff1": 0.06173430027850725,
|
| 65 |
+
"nauc_mrr_at_3_max": 0.26889485727748363,
|
| 66 |
+
"nauc_mrr_at_3_std": -0.19153801111553947,
|
| 67 |
+
"nauc_mrr_at_5_diff1": 0.036743759763164886,
|
| 68 |
+
"nauc_mrr_at_5_max": 0.253857849052297,
|
| 69 |
+
"nauc_mrr_at_5_std": -0.19604549670316734,
|
| 70 |
+
"nauc_ndcg_at_1000_diff1": -0.010372586628261796,
|
| 71 |
+
"nauc_ndcg_at_1000_max": 0.20925878430027478,
|
| 72 |
+
"nauc_ndcg_at_1000_std": -0.1717044268161809,
|
| 73 |
+
"nauc_ndcg_at_100_diff1": 0.0023309149151885546,
|
| 74 |
+
"nauc_ndcg_at_100_max": 0.20125970115134734,
|
| 75 |
+
"nauc_ndcg_at_100_std": -0.15865628929382014,
|
| 76 |
+
"nauc_ndcg_at_10_diff1": 0.0026192804576363727,
|
| 77 |
+
"nauc_ndcg_at_10_max": 0.19884193622357532,
|
| 78 |
+
"nauc_ndcg_at_10_std": -0.16919003671988075,
|
| 79 |
+
"nauc_ndcg_at_1_diff1": 0.1772995319079407,
|
| 80 |
+
"nauc_ndcg_at_1_max": 0.35182174117717013,
|
| 81 |
+
"nauc_ndcg_at_1_std": -0.24426280067522707,
|
| 82 |
+
"nauc_ndcg_at_20_diff1": 0.0031543394811079034,
|
| 83 |
+
"nauc_ndcg_at_20_max": 0.20925361343315524,
|
| 84 |
+
"nauc_ndcg_at_20_std": -0.17106125631597793,
|
| 85 |
+
"nauc_ndcg_at_3_diff1": 0.03670154146101528,
|
| 86 |
+
"nauc_ndcg_at_3_max": 0.23212930749840155,
|
| 87 |
+
"nauc_ndcg_at_3_std": -0.1728371812831961,
|
| 88 |
+
"nauc_ndcg_at_5_diff1": 0.0107566708693031,
|
| 89 |
+
"nauc_ndcg_at_5_max": 0.20474332948099355,
|
| 90 |
+
"nauc_ndcg_at_5_std": -0.1734952739301359,
|
| 91 |
+
"nauc_precision_at_1000_diff1": -0.07195606207962846,
|
| 92 |
+
"nauc_precision_at_1000_max": 0.2542912736794115,
|
| 93 |
+
"nauc_precision_at_1000_std": -0.1881459402790264,
|
| 94 |
+
"nauc_precision_at_100_diff1": -0.04518222914182943,
|
| 95 |
+
"nauc_precision_at_100_max": 0.22138981394024387,
|
| 96 |
+
"nauc_precision_at_100_std": -0.13384472263037697,
|
| 97 |
+
"nauc_precision_at_10_diff1": -0.052513811685878764,
|
| 98 |
+
"nauc_precision_at_10_max": 0.18962064467698705,
|
| 99 |
+
"nauc_precision_at_10_std": -0.14827004787357115,
|
| 100 |
+
"nauc_precision_at_1_diff1": 0.1772995319079407,
|
| 101 |
+
"nauc_precision_at_1_max": 0.35182174117717013,
|
| 102 |
+
"nauc_precision_at_1_std": -0.24426280067522707,
|
| 103 |
+
"nauc_precision_at_20_diff1": -0.040789324913047875,
|
| 104 |
+
"nauc_precision_at_20_max": 0.22086458009752882,
|
| 105 |
+
"nauc_precision_at_20_std": -0.14430508663959002,
|
| 106 |
+
"nauc_precision_at_3_diff1": -0.013044619440245884,
|
| 107 |
+
"nauc_precision_at_3_max": 0.21285488271783465,
|
| 108 |
+
"nauc_precision_at_3_std": -0.1483164417030193,
|
| 109 |
+
"nauc_precision_at_5_diff1": -0.05113181393685194,
|
| 110 |
+
"nauc_precision_at_5_max": 0.1756649379589832,
|
| 111 |
+
"nauc_precision_at_5_std": -0.15632134056178232,
|
| 112 |
+
"nauc_recall_at_1000_diff1": -0.047075752528689695,
|
| 113 |
+
"nauc_recall_at_1000_max": 0.16414155669676642,
|
| 114 |
+
"nauc_recall_at_1000_std": -0.1513320281746568,
|
| 115 |
+
"nauc_recall_at_100_diff1": -0.023004658252697183,
|
| 116 |
+
"nauc_recall_at_100_max": 0.14861973646512244,
|
| 117 |
+
"nauc_recall_at_100_std": -0.12240747671934184,
|
| 118 |
+
"nauc_recall_at_10_diff1": -0.051375323084735164,
|
| 119 |
+
"nauc_recall_at_10_max": 0.1384336247044034,
|
| 120 |
+
"nauc_recall_at_10_std": -0.14737738059263306,
|
| 121 |
+
"nauc_recall_at_1_diff1": 0.1731091343679673,
|
| 122 |
+
"nauc_recall_at_1_max": 0.33459947679728974,
|
| 123 |
+
"nauc_recall_at_1_std": -0.23115450977179597,
|
| 124 |
+
"nauc_recall_at_20_diff1": -0.03578815918976938,
|
| 125 |
+
"nauc_recall_at_20_max": 0.16386688869593355,
|
| 126 |
+
"nauc_recall_at_20_std": -0.1528456365862212,
|
| 127 |
+
"nauc_recall_at_3_diff1": -0.021696811828998432,
|
| 128 |
+
"nauc_recall_at_3_max": 0.1864107664448688,
|
| 129 |
+
"nauc_recall_at_3_std": -0.14586036842324565,
|
| 130 |
+
"nauc_recall_at_5_diff1": -0.0538517948884412,
|
| 131 |
+
"nauc_recall_at_5_max": 0.1453135254521713,
|
| 132 |
+
"nauc_recall_at_5_std": -0.1531619473747777,
|
| 133 |
+
"ndcg_at_1": 0.03082,
|
| 134 |
+
"ndcg_at_10": 0.0501,
|
| 135 |
+
"ndcg_at_100": 0.07072,
|
| 136 |
+
"ndcg_at_1000": 0.09327,
|
| 137 |
+
"ndcg_at_20": 0.05662,
|
| 138 |
+
"ndcg_at_3": 0.03989,
|
| 139 |
+
"ndcg_at_5": 0.04484,
|
| 140 |
+
"precision_at_1": 0.03082,
|
| 141 |
+
"precision_at_10": 0.00993,
|
| 142 |
+
"precision_at_100": 0.00241,
|
| 143 |
+
"precision_at_1000": 0.00052,
|
| 144 |
+
"precision_at_20": 0.00685,
|
| 145 |
+
"precision_at_3": 0.02017,
|
| 146 |
+
"precision_at_5": 0.0153,
|
| 147 |
+
"recall_at_1": 0.02467,
|
| 148 |
+
"recall_at_10": 0.07499,
|
| 149 |
+
"recall_at_100": 0.16969,
|
| 150 |
+
"recall_at_1000": 0.33718,
|
| 151 |
+
"recall_at_20": 0.09901,
|
| 152 |
+
"recall_at_3": 0.04648,
|
| 153 |
+
"recall_at_5": 0.05869
|
| 154 |
+
}
|
| 155 |
+
]
|
| 156 |
+
},
|
| 157 |
+
"task_name": "CQADupstackProgrammersRetrieval"
|
| 158 |
+
}
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/STSBenchmark.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_revision": "b0fddb56ed78048fa8b90373c8a3cfc37b684831",
|
| 3 |
+
"evaluation_time": 0.12331175804138184,
|
| 4 |
+
"kg_co2_emissions": null,
|
| 5 |
+
"mteb_version": "1.14.15",
|
| 6 |
+
"scores": {
|
| 7 |
+
"test": [
|
| 8 |
+
{
|
| 9 |
+
"cosine_pearson": 0.34632056143460516,
|
| 10 |
+
"cosine_spearman": 0.42973159111999676,
|
| 11 |
+
"euclidean_pearson": 0.4043313982401531,
|
| 12 |
+
"euclidean_spearman": 0.42973159111999676,
|
| 13 |
+
"hf_subset": "default",
|
| 14 |
+
"languages": [
|
| 15 |
+
"eng-Latn"
|
| 16 |
+
],
|
| 17 |
+
"main_score": 0.42973159111999676,
|
| 18 |
+
"manhattan_pearson": 0.511950240807258,
|
| 19 |
+
"manhattan_spearman": 0.5019330550880601,
|
| 20 |
+
"pearson": 0.34632056143460516,
|
| 21 |
+
"spearman": 0.42973159111999676
|
| 22 |
+
}
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
"task_name": "STSBenchmark"
|
| 26 |
+
}
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/SprintDuplicateQuestions.json
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_revision": "d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46",
|
| 3 |
+
"evaluation_time": 1.9629368782043457,
|
| 4 |
+
"kg_co2_emissions": null,
|
| 5 |
+
"mteb_version": "1.14.15",
|
| 6 |
+
"scores": {
|
| 7 |
+
"test": [
|
| 8 |
+
{
|
| 9 |
+
"cosine_accuracy": 0.9926237623762376,
|
| 10 |
+
"cosine_accuracy_threshold": 0.9106360077857971,
|
| 11 |
+
"cosine_ap": 0.4700755863552174,
|
| 12 |
+
"cosine_f1": 0.4925187032418952,
|
| 13 |
+
"cosine_f1_threshold": 0.8986777067184448,
|
| 14 |
+
"cosine_precision": 0.6539735099337748,
|
| 15 |
+
"cosine_recall": 0.395,
|
| 16 |
+
"dot_accuracy": 0.9926237623762376,
|
| 17 |
+
"dot_accuracy_threshold": 0.9106361269950867,
|
| 18 |
+
"dot_ap": 0.47007548398718707,
|
| 19 |
+
"dot_f1": 0.4925187032418952,
|
| 20 |
+
"dot_f1_threshold": 0.8986777663230896,
|
| 21 |
+
"dot_precision": 0.6539735099337748,
|
| 22 |
+
"dot_recall": 0.395,
|
| 23 |
+
"euclidean_accuracy": 0.9926237623762376,
|
| 24 |
+
"euclidean_accuracy_threshold": 0.42276236414909363,
|
| 25 |
+
"euclidean_ap": 0.47007558217981027,
|
| 26 |
+
"euclidean_f1": 0.4925187032418952,
|
| 27 |
+
"euclidean_f1_threshold": 0.4501606225967407,
|
| 28 |
+
"euclidean_precision": 0.6539735099337748,
|
| 29 |
+
"euclidean_recall": 0.395,
|
| 30 |
+
"hf_subset": "default",
|
| 31 |
+
"languages": [
|
| 32 |
+
"eng-Latn"
|
| 33 |
+
],
|
| 34 |
+
"main_score": 0.6386707007383838,
|
| 35 |
+
"manhattan_accuracy": 0.9939207920792079,
|
| 36 |
+
"manhattan_accuracy_threshold": 4.824772834777832,
|
| 37 |
+
"manhattan_ap": 0.6386707007383838,
|
| 38 |
+
"manhattan_f1": 0.6293103448275862,
|
| 39 |
+
"manhattan_f1_threshold": 5.194998741149902,
|
| 40 |
+
"manhattan_precision": 0.6822429906542056,
|
| 41 |
+
"manhattan_recall": 0.584,
|
| 42 |
+
"max_accuracy": 0.9939207920792079,
|
| 43 |
+
"max_ap": 0.6386707007383838,
|
| 44 |
+
"max_f1": 0.6293103448275862,
|
| 45 |
+
"max_precision": 0.6822429906542056,
|
| 46 |
+
"max_recall": 0.584,
|
| 47 |
+
"similarity_accuracy": 0.9926237623762376,
|
| 48 |
+
"similarity_accuracy_threshold": 0.9106360077857971,
|
| 49 |
+
"similarity_ap": 0.4700755863552174,
|
| 50 |
+
"similarity_f1": 0.4925187032418952,
|
| 51 |
+
"similarity_f1_threshold": 0.8986777067184448,
|
| 52 |
+
"similarity_precision": 0.6539735099337748,
|
| 53 |
+
"similarity_recall": 0.395
|
| 54 |
+
}
|
| 55 |
+
]
|
| 56 |
+
},
|
| 57 |
+
"task_name": "SprintDuplicateQuestions"
|
| 58 |
+
}
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/StackExchangeClustering.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dataset_revision": "6cbc1f7b2bc0622f2e39d2c77fa502909748c259",
|
| 3 |
+
"evaluation_time": 1075.5739603042603,
|
| 4 |
+
"kg_co2_emissions": null,
|
| 5 |
+
"mteb_version": "1.14.15",
|
| 6 |
+
"scores": {
|
| 7 |
+
"test": [
|
| 8 |
+
{
|
| 9 |
+
"hf_subset": "default",
|
| 10 |
+
"languages": [
|
| 11 |
+
"eng-Latn"
|
| 12 |
+
],
|
| 13 |
+
"main_score": 0.2747977935355363,
|
| 14 |
+
"v_measure": 0.2747977935355363,
|
| 15 |
+
"v_measure_std": 0.04408138950391278,
|
| 16 |
+
"v_measures": [
|
| 17 |
+
0.2671568735697825,
|
| 18 |
+
0.35324106044655595,
|
| 19 |
+
0.2134334295678833,
|
| 20 |
+
0.26069561242914296,
|
| 21 |
+
0.2360037867112385,
|
| 22 |
+
0.18352010080864292,
|
| 23 |
+
0.21227539957559294,
|
| 24 |
+
0.22564157353303899,
|
| 25 |
+
0.31014309699664405,
|
| 26 |
+
0.2792317143409387,
|
| 27 |
+
0.30736400840236383,
|
| 28 |
+
0.33654065468328326,
|
| 29 |
+
0.3375811203083562,
|
| 30 |
+
0.23635769205347795,
|
| 31 |
+
0.2889733490218442,
|
| 32 |
+
0.2628972368553193,
|
| 33 |
+
0.2892573063858698,
|
| 34 |
+
0.3093369539018476,
|
| 35 |
+
0.2778955236652676,
|
| 36 |
+
0.29489160764728006,
|
| 37 |
+
0.3092126928451642,
|
| 38 |
+
0.22100223054084894,
|
| 39 |
+
0.23711645754707986,
|
| 40 |
+
0.3264131545037563,
|
| 41 |
+
0.2937622020471872
|
| 42 |
+
]
|
| 43 |
+
}
|
| 44 |
+
]
|
| 45 |
+
},
|
| 46 |
+
"task_name": "StackExchangeClustering"
|
| 47 |
+
}
|
mteb_results/gte-Qwen2-7B-instruct-M2V-Distilled/distilled/model_meta.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"name": "gte-Qwen2-7B-instruct-M2V-Distilled", "revision": "distilled", "release_date": null, "languages": ["eng"], "n_parameters": null, "memory_usage": null, "max_tokens": null, "embed_dim": null, "license": null, "open_source": null, "similarity_fn_name": null, "framework": [], "loader": null}
|
mteb_results/mteb_parsed_results.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"gte-Qwen2-7B-instruct-M2V-Distilled": "ResultSet(datasets={'Banking77Classification': DatasetResult(scores=[0.4396103896103896], time=6.451777696609497), 'StackExchangeClustering': DatasetResult(scores=[0.2747977935355363], time=1075.5739603042603), 'STSBenchmark': DatasetResult(scores=[0.42973159111999676], time=0.12331175804138184), 'CQADupstackProgrammersRetrieval': DatasetResult(scores=[0.0501], time=99.69791841506958), 'SprintDuplicateQuestions': DatasetResult(scores=[0.6386707007383838], time=1.9629368782043457)})"
|
| 3 |
+
}
|
mteb_results/mteb_raw_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
"dataset_revision='0fd18e25b25c072e09e0d92ab615fda904d66300' task_name='Banking77Classification' mteb_version='1.14.15' scores={'test': [{'accuracy': 0.4396103896103896, 'f1': 0.4142711532114576, 'f1_weighted': 0.4142711532114576, 'scores_per_experiment': [{'accuracy': 0.4279220779220779, 'f1': 0.4030476288783657, 'f1_weighted': 0.4030476288783656}, {'accuracy': 0.4211038961038961, 'f1': 0.39776168133611584, 'f1_weighted': 0.39776168133611584}, {'accuracy': 0.45064935064935063, 'f1': 0.42872843564828145, 'f1_weighted': 0.42872843564828145}, {'accuracy': 0.4448051948051948, 'f1': 0.420756828398419, 'f1_weighted': 0.42075682839841905}, {'accuracy': 0.44675324675324674, 'f1': 0.42100682221185654, 'f1_weighted': 0.42100682221185654}, {'accuracy': 0.45324675324675323, 'f1': 0.4392342490231314, 'f1_weighted': 0.4392342490231314}, {'accuracy': 0.437012987012987, 'f1': 0.4056017558988273, 'f1_weighted': 0.40560175589882724}, {'accuracy': 0.42337662337662335, 'f1': 0.39123709562594644, 'f1_weighted': 0.39123709562594655}, {'accuracy': 0.44512987012987015, 'f1': 0.41578171494860966, 'f1_weighted': 0.41578171494860966}, {'accuracy': 0.4461038961038961, 'f1': 0.4195553201450221, 'f1_weighted': 0.419555320145022}], 'main_score': 0.4396103896103896, 'hf_subset': 'default', 'languages': ['eng-Latn']}]} evaluation_time=6.451777696609497 kg_co2_emissions=None",
|
| 3 |
+
"dataset_revision='6cbc1f7b2bc0622f2e39d2c77fa502909748c259' task_name='StackExchangeClustering' mteb_version='1.14.15' scores={'test': [{'v_measure': 0.2747977935355363, 'v_measure_std': 0.04408138950391278, 'v_measures': [0.2671568735697825, 0.35324106044655595, 0.2134334295678833, 0.26069561242914296, 0.2360037867112385, 0.18352010080864292, 0.21227539957559294, 0.22564157353303899, 0.31014309699664405, 0.2792317143409387, 0.30736400840236383, 0.33654065468328326, 0.3375811203083562, 0.23635769205347795, 0.2889733490218442, 0.2628972368553193, 0.2892573063858698, 0.3093369539018476, 0.2778955236652676, 0.29489160764728006, 0.3092126928451642, 0.22100223054084894, 0.23711645754707986, 0.3264131545037563, 0.2937622020471872], 'main_score': 0.2747977935355363, 'hf_subset': 'default', 'languages': ['eng-Latn']}]} evaluation_time=1075.5739603042603 kg_co2_emissions=None",
|
| 4 |
+
"dataset_revision='b0fddb56ed78048fa8b90373c8a3cfc37b684831' task_name='STSBenchmark' mteb_version='1.14.15' scores={'test': [{'pearson': 0.34632056143460516, 'spearman': 0.42973159111999676, 'cosine_pearson': 0.34632056143460516, 'cosine_spearman': 0.42973159111999676, 'manhattan_pearson': 0.511950240807258, 'manhattan_spearman': 0.5019330550880601, 'euclidean_pearson': 0.4043313982401531, 'euclidean_spearman': 0.42973159111999676, 'main_score': 0.42973159111999676, 'hf_subset': 'default', 'languages': ['eng-Latn']}]} evaluation_time=0.12331175804138184 kg_co2_emissions=None",
|
| 5 |
+
"dataset_revision='6184bc1440d2dbc7612be22b50686b8826d22b32' task_name='CQADupstackProgrammersRetrieval' mteb_version='1.14.15' scores={'test': [{'ndcg_at_1': 0.03082, 'ndcg_at_3': 0.03989, 'ndcg_at_5': 0.04484, 'ndcg_at_10': 0.0501, 'ndcg_at_20': 0.05662, 'ndcg_at_100': 0.07072, 'ndcg_at_1000': 0.09327, 'map_at_1': 0.02467, 'map_at_3': 0.03388, 'map_at_5': 0.03693, 'map_at_10': 0.03898, 'map_at_20': 0.04068, 'map_at_100': 0.04261, 'map_at_1000': 0.04333, 'recall_at_1': 0.02467, 'recall_at_3': 0.04648, 'recall_at_5': 0.05869, 'recall_at_10': 0.07499, 'recall_at_20': 0.09901, 'recall_at_100': 0.16969, 'recall_at_1000': 0.33718, 'precision_at_1': 0.03082, 'precision_at_3': 0.02017, 'precision_at_5': 0.0153, 'precision_at_10': 0.00993, 'precision_at_20': 0.00685, 'precision_at_100': 0.00241, 'precision_at_1000': 0.00052, 'mrr_at_1': 0.030821917808219176, 'mrr_at_3': 0.04280821917808219, 'mrr_at_5': 0.04634703196347032, 'mrr_at_10': 0.04904462926723201, 'mrr_at_20': 0.05126402659708249, 'mrr_at_100': 0.05339942610218758, 'mrr_at_1000': 0.05413492750157237, 'nauc_ndcg_at_1_max': 0.35182174117717013, 'nauc_ndcg_at_1_std': -0.24426280067522707, 'nauc_ndcg_at_1_diff1': 0.1772995319079407, 'nauc_ndcg_at_3_max': 0.23212930749840155, 'nauc_ndcg_at_3_std': -0.1728371812831961, 'nauc_ndcg_at_3_diff1': 0.03670154146101528, 'nauc_ndcg_at_5_max': 0.20474332948099355, 'nauc_ndcg_at_5_std': -0.1734952739301359, 'nauc_ndcg_at_5_diff1': 0.0107566708693031, 'nauc_ndcg_at_10_max': 0.19884193622357532, 'nauc_ndcg_at_10_std': -0.16919003671988075, 'nauc_ndcg_at_10_diff1': 0.0026192804576363727, 'nauc_ndcg_at_20_max': 0.20925361343315524, 'nauc_ndcg_at_20_std': -0.17106125631597793, 'nauc_ndcg_at_20_diff1': 0.0031543394811079034, 'nauc_ndcg_at_100_max': 0.20125970115134734, 'nauc_ndcg_at_100_std': -0.15865628929382014, 'nauc_ndcg_at_100_diff1': 0.0023309149151885546, 'nauc_ndcg_at_1000_max': 0.20925878430027478, 'nauc_ndcg_at_1000_std': -0.1717044268161809, 'nauc_ndcg_at_1000_diff1': -0.010372586628261796, 'nauc_map_at_1_max': 0.33459947679728974, 'nauc_map_at_1_std': -0.23115450977179597, 'nauc_map_at_1_diff1': 0.1731091343679673, 'nauc_map_at_3_max': 0.2486807528974488, 'nauc_map_at_3_std': -0.18512855007450404, 'nauc_map_at_3_diff1': 0.06042780588964212, 'nauc_map_at_5_max': 0.22647048266105405, 'nauc_map_at_5_std': -0.18107585673560017, 'nauc_map_at_5_diff1': 0.04407217741234605, 'nauc_map_at_10_max': 0.22061594321968936, 'nauc_map_at_10_std': -0.17777470317814356, 'nauc_map_at_10_diff1': 0.03906418656483989, 'nauc_map_at_20_max': 0.22396003211648763, 'nauc_map_at_20_std': -0.17867373725662639, 'nauc_map_at_20_diff1': 0.03795725531499195, 'nauc_map_at_100_max': 0.22324901446317413, 'nauc_map_at_100_std': -0.17630470695891512, 'nauc_map_at_100_diff1': 0.03759221625144172, 'nauc_map_at_1000_max': 0.2240572170754659, 'nauc_map_at_1000_std': -0.17708810912472517, 'nauc_map_at_1000_diff1': 0.03644747951501248, 'nauc_recall_at_1_max': 0.33459947679728974, 'nauc_recall_at_1_std': -0.23115450977179597, 'nauc_recall_at_1_diff1': 0.1731091343679673, 'nauc_recall_at_3_max': 0.1864107664448688, 'nauc_recall_at_3_std': -0.14586036842324565, 'nauc_recall_at_3_diff1': -0.021696811828998432, 'nauc_recall_at_5_max': 0.1453135254521713, 'nauc_recall_at_5_std': -0.1531619473747777, 'nauc_recall_at_5_diff1': -0.0538517948884412, 'nauc_recall_at_10_max': 0.1384336247044034, 'nauc_recall_at_10_std': -0.14737738059263306, 'nauc_recall_at_10_diff1': -0.051375323084735164, 'nauc_recall_at_20_max': 0.16386688869593355, 'nauc_recall_at_20_std': -0.1528456365862212, 'nauc_recall_at_20_diff1': -0.03578815918976938, 'nauc_recall_at_100_max': 0.14861973646512244, 'nauc_recall_at_100_std': -0.12240747671934184, 'nauc_recall_at_100_diff1': -0.023004658252697183, 'nauc_recall_at_1000_max': 0.16414155669676642, 'nauc_recall_at_1000_std': -0.1513320281746568, 'nauc_recall_at_1000_diff1': -0.047075752528689695, 'nauc_precision_at_1_max': 0.35182174117717013, 'nauc_precision_at_1_std': -0.24426280067522707, 'nauc_precision_at_1_diff1': 0.1772995319079407, 'nauc_precision_at_3_max': 0.21285488271783465, 'nauc_precision_at_3_std': -0.1483164417030193, 'nauc_precision_at_3_diff1': -0.013044619440245884, 'nauc_precision_at_5_max': 0.1756649379589832, 'nauc_precision_at_5_std': -0.15632134056178232, 'nauc_precision_at_5_diff1': -0.05113181393685194, 'nauc_precision_at_10_max': 0.18962064467698705, 'nauc_precision_at_10_std': -0.14827004787357115, 'nauc_precision_at_10_diff1': -0.052513811685878764, 'nauc_precision_at_20_max': 0.22086458009752882, 'nauc_precision_at_20_std': -0.14430508663959002, 'nauc_precision_at_20_diff1': -0.040789324913047875, 'nauc_precision_at_100_max': 0.22138981394024387, 'nauc_precision_at_100_std': -0.13384472263037697, 'nauc_precision_at_100_diff1': -0.04518222914182943, 'nauc_precision_at_1000_max': 0.2542912736794115, 'nauc_precision_at_1000_std': -0.1881459402790264, 'nauc_precision_at_1000_diff1': -0.07195606207962846, 'nauc_mrr_at_1_max': 0.35182174117717013, 'nauc_mrr_at_1_std': -0.24426280067522707, 'nauc_mrr_at_1_diff1': 0.1772995319079407, 'nauc_mrr_at_3_max': 0.26889485727748363, 'nauc_mrr_at_3_std': -0.19153801111553947, 'nauc_mrr_at_3_diff1': 0.06173430027850725, 'nauc_mrr_at_5_max': 0.253857849052297, 'nauc_mrr_at_5_std': -0.19604549670316734, 'nauc_mrr_at_5_diff1': 0.036743759763164886, 'nauc_mrr_at_10_max': 0.25392922716866984, 'nauc_mrr_at_10_std': -0.1935061134919541, 'nauc_mrr_at_10_diff1': 0.03361519179733555, 'nauc_mrr_at_20_max': 0.25624951214228564, 'nauc_mrr_at_20_std': -0.19212268093923462, 'nauc_mrr_at_20_diff1': 0.03479828151019169, 'nauc_mrr_at_100_max': 0.2523932973431928, 'nauc_mrr_at_100_std': -0.1900913512193067, 'nauc_mrr_at_100_diff1': 0.03435870935950355, 'nauc_mrr_at_1000_max': 0.2523936325136619, 'nauc_mrr_at_1000_std': -0.19078164353963076, 'nauc_mrr_at_1000_diff1': 0.033601872249839834, 'main_score': 0.0501, 'hf_subset': 'default', 'languages': ['eng-Latn']}]} evaluation_time=99.69791841506958 kg_co2_emissions=None",
|
| 6 |
+
"dataset_revision='d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46' task_name='SprintDuplicateQuestions' mteb_version='1.14.15' scores={'test': [{'similarity_accuracy': 0.9926237623762376, 'similarity_accuracy_threshold': 0.9106360077857971, 'similarity_f1': 0.4925187032418952, 'similarity_f1_threshold': 0.8986777067184448, 'similarity_precision': 0.6539735099337748, 'similarity_recall': 0.395, 'similarity_ap': 0.4700755863552174, 'cosine_accuracy': 0.9926237623762376, 'cosine_accuracy_threshold': 0.9106360077857971, 'cosine_f1': 0.4925187032418952, 'cosine_f1_threshold': 0.8986777067184448, 'cosine_precision': 0.6539735099337748, 'cosine_recall': 0.395, 'cosine_ap': 0.4700755863552174, 'manhattan_accuracy': 0.9939207920792079, 'manhattan_accuracy_threshold': 4.824772834777832, 'manhattan_f1': 0.6293103448275862, 'manhattan_f1_threshold': 5.194998741149902, 'manhattan_precision': 0.6822429906542056, 'manhattan_recall': 0.584, 'manhattan_ap': 0.6386707007383838, 'euclidean_accuracy': 0.9926237623762376, 'euclidean_accuracy_threshold': 0.42276236414909363, 'euclidean_f1': 0.4925187032418952, 'euclidean_f1_threshold': 0.4501606225967407, 'euclidean_precision': 0.6539735099337748, 'euclidean_recall': 0.395, 'euclidean_ap': 0.47007558217981027, 'dot_accuracy': 0.9926237623762376, 'dot_accuracy_threshold': 0.9106361269950867, 'dot_f1': 0.4925187032418952, 'dot_f1_threshold': 0.8986777663230896, 'dot_precision': 0.6539735099337748, 'dot_recall': 0.395, 'dot_ap': 0.47007548398718707, 'max_accuracy': 0.9939207920792079, 'max_f1': 0.6293103448275862, 'max_precision': 0.6822429906542056, 'max_recall': 0.584, 'max_ap': 0.6386707007383838, 'main_score': 0.6386707007383838, 'hf_subset': 'default', 'languages': ['eng-Latn']}]} evaluation_time=1.9629368782043457 kg_co2_emissions=None"
|
| 7 |
+
]
|
mteb_results/mteb_report.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
================================================================================
|
| 2 |
+
MTEB Evaluation Report
|
| 3 |
+
================================================================================
|
| 4 |
+
|
| 5 |
+
Model: gte-Qwen2-7B-instruct-M2V-Distilled
|
| 6 |
+
Model Path: .
|
| 7 |
+
Evaluation Time: 1235.71 seconds
|
| 8 |
+
Total Datasets: 1
|
| 9 |
+
|
| 10 |
+
Summary Statistics:
|
| 11 |
+
Average Score: 0.0501
|
| 12 |
+
Median Score: 0.0501
|
| 13 |
+
Standard Deviation: 0.0000
|
| 14 |
+
Score Range: 0.0501 - 0.0501
|
| 15 |
+
|
| 16 |
+
Detailed Results:
|
| 17 |
+
--------------------------------------------------
|
| 18 |
+
Model Average (All) Average (MTEB) Classification Clustering PairClassification Reranking Retrieval STS Summarization PEARL WordSim
|
| 19 |
+
gte-Qwen2-7B-instruct-M2V-Distilled nan nan nan nan nan nan 5.01 nan nan nan nan
|
| 20 |
+
|
| 21 |
+
================================================================================
|
mteb_results/mteb_summary.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model_name": "gte-Qwen2-7B-instruct-M2V-Distilled",
|
| 3 |
+
"evaluation_time_seconds": 1235.7057559490204,
|
| 4 |
+
"task_scores": {
|
| 5 |
+
"gte-Qwen2-7B-instruct-M2V-Distilled": {
|
| 6 |
+
"task_means": "Classification NaN\nClustering NaN\nPairClassification NaN\nReranking NaN\nRetrieval 0.0501\nSTS NaN\nSummarization NaN\nPEARL NaN\nWordSim NaN\ndtype: float64",
|
| 7 |
+
"dataset_scores": {
|
| 8 |
+
"CQADupstack": 0.0501
|
| 9 |
+
}
|
| 10 |
+
}
|
| 11 |
+
},
|
| 12 |
+
"summary_stats": {
|
| 13 |
+
"total_datasets": 1,
|
| 14 |
+
"average_score": 0.0501,
|
| 15 |
+
"median_score": 0.0501,
|
| 16 |
+
"std_dev": 0.0,
|
| 17 |
+
"min_score": 0.0501,
|
| 18 |
+
"max_score": 0.0501
|
| 19 |
+
}
|
| 20 |
+
}
|
pipeline.skops
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bd33bcb8eee34a4df1a0d5e7d22b1e2b241ea683750204be74f78055882c76c3
|
| 3 |
+
size 3843639
|
pyproject.toml
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[project]
|
| 2 |
+
name = "gte-qwen2-7b-instruct-m2v"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = "Add your description here"
|
| 5 |
+
readme = "README.md"
|
| 6 |
+
requires-python = ">=3.12"
|
| 7 |
+
dependencies = [
|
| 8 |
+
"datasets>=3.6.0",
|
| 9 |
+
"evaluation",
|
| 10 |
+
"iso639>=0.1.4",
|
| 11 |
+
"lightning>=2.5.1.post0",
|
| 12 |
+
"matplotlib>=3.10.3",
|
| 13 |
+
"model2vec[train]>=0.5.0",
|
| 14 |
+
"mteb>=1.14.15",
|
| 15 |
+
"psutil>=7.0.0",
|
| 16 |
+
"scikit-learn>=1.6.1",
|
| 17 |
+
"sentence-transformers>=4.1.0",
|
| 18 |
+
"torch>=2.7.0",
|
| 19 |
+
]
|
| 20 |
+
|
| 21 |
+
[dependency-groups]
|
| 22 |
+
dev = [
|
| 23 |
+
"mypy>=1.15.0",
|
| 24 |
+
"ruff>=0.11.6",
|
| 25 |
+
]
|
| 26 |
+
|
| 27 |
+
[tool.mypy]
|
| 28 |
+
exclude = [
|
| 29 |
+
".git",
|
| 30 |
+
".ruff_cache",
|
| 31 |
+
".venv",
|
| 32 |
+
"venv",
|
| 33 |
+
"__pycache__",
|
| 34 |
+
"build",
|
| 35 |
+
"dist",
|
| 36 |
+
"vendor",
|
| 37 |
+
]
|
| 38 |
+
follow_untyped_imports = true
|
| 39 |
+
|
| 40 |
+
[tool.ruff]
|
| 41 |
+
line-length = 120
|
| 42 |
+
target-version = "py312"
|
| 43 |
+
|
| 44 |
+
# Exclude files/directories
|
| 45 |
+
exclude = [
|
| 46 |
+
".git",
|
| 47 |
+
".ruff_cache",
|
| 48 |
+
".venv",
|
| 49 |
+
"venv",
|
| 50 |
+
"__pycache__",
|
| 51 |
+
"build",
|
| 52 |
+
"dist",
|
| 53 |
+
"vendor"
|
| 54 |
+
]
|
| 55 |
+
|
| 56 |
+
[tool.ruff.lint]
|
| 57 |
+
# Enable all rules by default, then selectively disable
|
| 58 |
+
select = ["ALL"]
|
| 59 |
+
ignore = [
|
| 60 |
+
# Rules that conflict with other tools/preferences
|
| 61 |
+
"D203", # one-blank-line-before-class
|
| 62 |
+
"D212", # multi-line-summary-first-line
|
| 63 |
+
"FBT001", # Boolean positional arg in function definition (required for typer)
|
| 64 |
+
"FBT002", # Boolean default value in function definition (required for typer)
|
| 65 |
+
"C901", # function too complex
|
| 66 |
+
"PLR0911", # too many return statements
|
| 67 |
+
"PLR0912", # too many branches
|
| 68 |
+
"PLR0913", # too many arguments in function definition
|
| 69 |
+
"PLR0915", # too many statements
|
| 70 |
+
"TRY300", # Consider moving this statement to an `else` block
|
| 71 |
+
"COM812", # Use a constant for the message in a raise statement
|
| 72 |
+
"TC001", # Move application import into a type-checking block
|
| 73 |
+
"ERA001", # Found commented-out code
|
| 74 |
+
"G004", # Logging statement uses f-string
|
| 75 |
+
"TD003", # Missing link in to-do
|
| 76 |
+
"TRY301", # Abstract raise to an inner function
|
| 77 |
+
# Disable rules that conflict with tab indentation
|
| 78 |
+
"E101", # Indentation contains mixed spaces and tabs
|
| 79 |
+
"W191", # indentation contains tabs
|
| 80 |
+
"D206", # indent with spaces, not tabs
|
| 81 |
+
]
|
| 82 |
+
|
| 83 |
+
[tool.ruff.lint.mccabe]
|
| 84 |
+
max-complexity = 10
|
| 85 |
+
|
| 86 |
+
[tool.ruff.lint.pylint]
|
| 87 |
+
max-args = 5
|
| 88 |
+
max-branches = 12
|
| 89 |
+
max-statements = 50
|
| 90 |
+
|
| 91 |
+
[tool.ruff.lint.pydocstyle]
|
| 92 |
+
convention = "google"
|
| 93 |
+
|
| 94 |
+
[tool.ruff.format]
|
| 95 |
+
quote-style = "double"
|
| 96 |
+
indent-style = "tab"
|
| 97 |
+
skip-magic-trailing-comma = false
|
| 98 |
+
line-ending = "auto"
|
| 99 |
+
|
| 100 |
+
[tool.uv.sources]
|
| 101 |
+
evaluation = { git = "https://github.com/MinishLab/evaluation.git", rev = "main" }
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e76d728582b9955c7afa6e5757b5b7825b3d40ef49d935b3cb7b148ad556dce4
|
| 3 |
+
size 11418179
|
train_code_classification.py
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
"""
|
| 3 |
+
Script to train a code classification model using CodeSearchNet dataset with Model2Vec.
|
| 4 |
+
|
| 5 |
+
This script performs the following operations:
|
| 6 |
+
1. Downloads the Alibaba-NLP/gte-Qwen2-7B-instruct model
|
| 7 |
+
2. Optionally distills it using Model2Vec to create a smaller, faster static model
|
| 8 |
+
3. Trains a programming language classifier on CodeSearchNet dataset
|
| 9 |
+
4. Evaluates the classifier and saves the trained model
|
| 10 |
+
|
| 11 |
+
Based on the official CodeSearchNet dataset: https://github.com/github/CodeSearchNet
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
import json
|
| 15 |
+
import logging
|
| 16 |
+
import re
|
| 17 |
+
import time
|
| 18 |
+
from pathlib import Path
|
| 19 |
+
from time import perf_counter
|
| 20 |
+
from typing import Any, cast
|
| 21 |
+
|
| 22 |
+
from datasets import Dataset, DatasetDict, load_dataset # type: ignore [import]
|
| 23 |
+
from model2vec.distill import distill
|
| 24 |
+
from model2vec.train import StaticModelForClassification
|
| 25 |
+
|
| 26 |
+
# =============================================================================
|
| 27 |
+
# CONFIGURATION CONSTANTS
|
| 28 |
+
# =============================================================================
|
| 29 |
+
|
| 30 |
+
# Model Configuration
|
| 31 |
+
MODEL_NAME = "Alibaba-NLP/gte-Qwen2-7B-instruct" # Source model to distill
|
| 32 |
+
OUTPUT_DIR = "." # Directory to save the trained model
|
| 33 |
+
|
| 34 |
+
# Distillation Configuration
|
| 35 |
+
SKIP_DISTILLATION = False # Set to True to skip distillation and use existing model
|
| 36 |
+
DISTILLED_MODEL_PATH = "." # Path to existing distilled model (if skipping distillation)
|
| 37 |
+
PCA_DIMS = 256 # Dimensions for PCA reduction (smaller = faster but less accurate)
|
| 38 |
+
|
| 39 |
+
# Dataset Configuration
|
| 40 |
+
DATASET_NAME = "code-search-net/code_search_net" # CodeSearchNet dataset
|
| 41 |
+
CLASSIFICATION_TASK = "language" # Task: classify programming language
|
| 42 |
+
MAX_SAMPLES_PER_LANGUAGE = 5000 # Limit samples per language for balanced training
|
| 43 |
+
MIN_CODE_LENGTH = 50 # Minimum code length in characters
|
| 44 |
+
MAX_CODE_LENGTH = 2000 # Maximum code length in characters (for memory efficiency)
|
| 45 |
+
|
| 46 |
+
# Text processing constants
|
| 47 |
+
MAX_COMMENT_LENGTH = 200 # Maximum length for comment lines before truncation
|
| 48 |
+
|
| 49 |
+
# Training Configuration
|
| 50 |
+
MAX_EPOCHS = 30 # Maximum number of training epochs
|
| 51 |
+
PATIENCE = 5 # Early stopping patience
|
| 52 |
+
BATCH_SIZE = 32 # Training batch size
|
| 53 |
+
LEARNING_RATE = 1e-3 # Learning rate
|
| 54 |
+
|
| 55 |
+
# Saving Configuration
|
| 56 |
+
SAVE_PIPELINE = True # Save as scikit-learn compatible pipeline
|
| 57 |
+
SAVE_TO_HUB = False # Whether to push the model to HuggingFace Hub
|
| 58 |
+
HUB_MODEL_ID = None # Model ID for HuggingFace Hub (if saving to hub)
|
| 59 |
+
|
| 60 |
+
# =============================================================================
|
| 61 |
+
|
| 62 |
+
# Configure logging
|
| 63 |
+
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 64 |
+
logger = logging.getLogger(__name__)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def clean_code_text(code: str) -> str:
|
| 68 |
+
"""Clean and normalize code text for better classification."""
|
| 69 |
+
if not code:
|
| 70 |
+
return ""
|
| 71 |
+
|
| 72 |
+
# Remove excessive whitespace while preserving structure
|
| 73 |
+
code = re.sub(r"\n\s*\n\s*\n", "\n\n", code) # Remove multiple empty lines
|
| 74 |
+
code = re.sub(r" +", " ", code) # Replace multiple spaces with single space
|
| 75 |
+
|
| 76 |
+
# Remove very long comments that might bias classification
|
| 77 |
+
lines = code.split("\n")
|
| 78 |
+
cleaned_lines = []
|
| 79 |
+
for original_line in lines:
|
| 80 |
+
line = original_line
|
| 81 |
+
# Keep comment lines but limit their length
|
| 82 |
+
if line.strip().startswith(("#", "//", "/*", "*", "--")) and len(line) > MAX_COMMENT_LENGTH:
|
| 83 |
+
line = line[:MAX_COMMENT_LENGTH] + "..."
|
| 84 |
+
cleaned_lines.append(line)
|
| 85 |
+
|
| 86 |
+
return "\n".join(cleaned_lines)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def load_codesearchnet_dataset() -> tuple[Dataset, Dataset, str, str]:
|
| 90 |
+
"""Load and preprocess the CodeSearchNet dataset for programming language classification."""
|
| 91 |
+
logger.info("Loading CodeSearchNet dataset...")
|
| 92 |
+
|
| 93 |
+
try:
|
| 94 |
+
# Load the dataset with trust_remote_code=True
|
| 95 |
+
logger.info("Downloading and loading CodeSearchNet data...")
|
| 96 |
+
ds = cast(
|
| 97 |
+
"DatasetDict",
|
| 98 |
+
load_dataset(
|
| 99 |
+
DATASET_NAME,
|
| 100 |
+
trust_remote_code=True,
|
| 101 |
+
# Load a reasonable sample for training
|
| 102 |
+
),
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
logger.info(f"Available splits: {list(ds.keys())}")
|
| 106 |
+
|
| 107 |
+
# Use train/test splits if available, otherwise split the data
|
| 108 |
+
if "train" in ds and "test" in ds:
|
| 109 |
+
train_dataset = ds["train"]
|
| 110 |
+
test_dataset = ds["test"]
|
| 111 |
+
elif "train" in ds:
|
| 112 |
+
# Split the train set
|
| 113 |
+
split_ds = ds["train"].train_test_split(test_size=0.2, seed=42)
|
| 114 |
+
train_dataset = split_ds["train"]
|
| 115 |
+
test_dataset = split_ds["test"]
|
| 116 |
+
else:
|
| 117 |
+
# Use all data and split
|
| 118 |
+
all_data = ds[next(iter(ds.keys()))]
|
| 119 |
+
split_ds = all_data.train_test_split(test_size=0.2, seed=42)
|
| 120 |
+
train_dataset = split_ds["train"]
|
| 121 |
+
test_dataset = split_ds["test"]
|
| 122 |
+
|
| 123 |
+
logger.info(f"Raw dataset sizes - Train: {len(train_dataset)}, Test: {len(test_dataset)}")
|
| 124 |
+
|
| 125 |
+
# Filter and preprocess the data
|
| 126 |
+
def filter_and_clean(dataset: Dataset) -> Dataset:
|
| 127 |
+
# Filter examples with valid code and language
|
| 128 |
+
filtered = dataset.filter(
|
| 129 |
+
lambda x: (
|
| 130 |
+
x["func_code_string"] is not None
|
| 131 |
+
and x["language"] is not None
|
| 132 |
+
and len(x["func_code_string"]) >= MIN_CODE_LENGTH
|
| 133 |
+
and len(x["func_code_string"]) <= MAX_CODE_LENGTH
|
| 134 |
+
and x["language"] in ["python", "java", "javascript", "go", "php", "ruby"]
|
| 135 |
+
)
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
# Balance the dataset by limiting samples per language
|
| 139 |
+
if len(filtered) > MAX_SAMPLES_PER_LANGUAGE * 6: # 6 languages
|
| 140 |
+
# Group by language and sample
|
| 141 |
+
language_samples: dict[str, list[dict[str, Any]]] = {}
|
| 142 |
+
for example in filtered:
|
| 143 |
+
lang = example["language"]
|
| 144 |
+
if lang not in language_samples:
|
| 145 |
+
language_samples[lang] = []
|
| 146 |
+
if len(language_samples[lang]) < MAX_SAMPLES_PER_LANGUAGE:
|
| 147 |
+
language_samples[lang].append(example)
|
| 148 |
+
|
| 149 |
+
# Combine all samples
|
| 150 |
+
balanced_examples = []
|
| 151 |
+
for lang_examples in language_samples.values():
|
| 152 |
+
balanced_examples.extend(lang_examples)
|
| 153 |
+
|
| 154 |
+
# Convert back to dataset format
|
| 155 |
+
if balanced_examples:
|
| 156 |
+
filtered = Dataset.from_list(balanced_examples)
|
| 157 |
+
|
| 158 |
+
# Clean the code text
|
| 159 |
+
def clean_example(example: dict[str, Any]) -> dict[str, Any]:
|
| 160 |
+
example["func_code_string"] = clean_code_text(example["func_code_string"])
|
| 161 |
+
return example
|
| 162 |
+
|
| 163 |
+
return filtered.map(clean_example)
|
| 164 |
+
|
| 165 |
+
train_dataset = filter_and_clean(train_dataset)
|
| 166 |
+
test_dataset = filter_and_clean(test_dataset)
|
| 167 |
+
|
| 168 |
+
logger.info(f"Filtered dataset sizes - Train: {len(train_dataset)}, Test: {len(test_dataset)}")
|
| 169 |
+
|
| 170 |
+
# Show language distribution
|
| 171 |
+
if len(train_dataset) > 0:
|
| 172 |
+
from collections import Counter
|
| 173 |
+
|
| 174 |
+
train_lang_dist = Counter(train_dataset["language"])
|
| 175 |
+
test_lang_dist = Counter(test_dataset["language"])
|
| 176 |
+
logger.info(f"Training language distribution: {dict(train_lang_dist)}")
|
| 177 |
+
logger.info(f"Test language distribution: {dict(test_lang_dist)}")
|
| 178 |
+
|
| 179 |
+
return train_dataset, test_dataset, "func_code_string", "language"
|
| 180 |
+
|
| 181 |
+
except Exception:
|
| 182 |
+
logger.exception("Error loading CodeSearchNet dataset")
|
| 183 |
+
raise
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def main() -> None:
|
| 187 |
+
"""Run the code classification training pipeline."""
|
| 188 |
+
# Create output directory if it doesn't exist
|
| 189 |
+
output_dir = Path(OUTPUT_DIR)
|
| 190 |
+
output_dir.mkdir(parents=True, exist_ok=True)
|
| 191 |
+
|
| 192 |
+
logger.info(f"Starting CodeSearchNet code classification pipeline for {MODEL_NAME}")
|
| 193 |
+
logger.info(f"Classification task: {CLASSIFICATION_TASK}")
|
| 194 |
+
logger.info(f"Trained model will be saved to {output_dir}")
|
| 195 |
+
|
| 196 |
+
# Record start time for benchmarking
|
| 197 |
+
total_start_time = time.time()
|
| 198 |
+
|
| 199 |
+
try:
|
| 200 |
+
# Step 1: Get the static model (either distill or load existing)
|
| 201 |
+
static_model = None
|
| 202 |
+
|
| 203 |
+
if SKIP_DISTILLATION:
|
| 204 |
+
if DISTILLED_MODEL_PATH:
|
| 205 |
+
logger.info(f"Loading existing distilled model from {DISTILLED_MODEL_PATH}")
|
| 206 |
+
# Note: We'll create the classifier from pretrained instead
|
| 207 |
+
else:
|
| 208 |
+
logger.error("DISTILLED_MODEL_PATH must be specified when SKIP_DISTILLATION is True")
|
| 209 |
+
return
|
| 210 |
+
else:
|
| 211 |
+
logger.info("Starting Model2Vec distillation...")
|
| 212 |
+
distill_start_time = time.time()
|
| 213 |
+
|
| 214 |
+
static_model = distill(
|
| 215 |
+
model_name=MODEL_NAME,
|
| 216 |
+
pca_dims=PCA_DIMS,
|
| 217 |
+
)
|
| 218 |
+
|
| 219 |
+
distill_time = time.time() - distill_start_time
|
| 220 |
+
logger.info(f"Distillation completed in {distill_time:.2f} seconds")
|
| 221 |
+
|
| 222 |
+
# Step 2: Create the classifier
|
| 223 |
+
logger.info("Creating classifier...")
|
| 224 |
+
|
| 225 |
+
if static_model is not None:
|
| 226 |
+
# From a distilled model
|
| 227 |
+
classifier = StaticModelForClassification.from_static_model(model=static_model)
|
| 228 |
+
else:
|
| 229 |
+
# From a pre-trained model path
|
| 230 |
+
classifier = StaticModelForClassification.from_pretrained(model_name=DISTILLED_MODEL_PATH)
|
| 231 |
+
|
| 232 |
+
# Step 3: Load the CodeSearchNet dataset
|
| 233 |
+
train_dataset, test_dataset, text_column, label_column = load_codesearchnet_dataset()
|
| 234 |
+
|
| 235 |
+
if len(train_dataset) == 0 or len(test_dataset) == 0:
|
| 236 |
+
logger.error("No valid data found after filtering. Please check dataset configuration.")
|
| 237 |
+
return
|
| 238 |
+
|
| 239 |
+
logger.info(f"Training dataset size: {len(train_dataset)}")
|
| 240 |
+
logger.info(f"Test dataset size: {len(test_dataset)}")
|
| 241 |
+
|
| 242 |
+
# Get unique languages for reference
|
| 243 |
+
unique_languages = sorted(set(train_dataset[label_column]))
|
| 244 |
+
logger.info(f"Programming languages to classify: {unique_languages}")
|
| 245 |
+
|
| 246 |
+
# Step 4: Train the classifier
|
| 247 |
+
logger.info("Starting training...")
|
| 248 |
+
train_start_time = perf_counter()
|
| 249 |
+
|
| 250 |
+
classifier = classifier.fit(
|
| 251 |
+
train_dataset[text_column],
|
| 252 |
+
train_dataset[label_column],
|
| 253 |
+
max_epochs=MAX_EPOCHS,
|
| 254 |
+
batch_size=BATCH_SIZE,
|
| 255 |
+
learning_rate=LEARNING_RATE,
|
| 256 |
+
early_stopping_patience=PATIENCE,
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
train_time = perf_counter() - train_start_time
|
| 260 |
+
logger.info(f"Training completed in {int(train_time)} seconds")
|
| 261 |
+
|
| 262 |
+
# Step 5: Evaluate the classifier
|
| 263 |
+
logger.info("Evaluating classifier...")
|
| 264 |
+
eval_start_time = perf_counter()
|
| 265 |
+
|
| 266 |
+
classification_report = classifier.evaluate(test_dataset[text_column], test_dataset[label_column])
|
| 267 |
+
|
| 268 |
+
eval_time = perf_counter() - eval_start_time
|
| 269 |
+
logger.info(f"Evaluation completed in {int(eval_time * 1000)} milliseconds")
|
| 270 |
+
logger.info(f"Classification results:\n{classification_report}")
|
| 271 |
+
|
| 272 |
+
# Step 6: Test with some examples
|
| 273 |
+
logger.info("Testing with sample code snippets...")
|
| 274 |
+
|
| 275 |
+
# Test examples for different languages
|
| 276 |
+
test_examples = [
|
| 277 |
+
'def hello_world():\n print("Hello, World!")\n return True', # Python
|
| 278 |
+
(
|
| 279 |
+
"public class HelloWorld {\n"
|
| 280 |
+
" public static void main(String[] args) {\n"
|
| 281 |
+
' System.out.println("Hello, World!");\n'
|
| 282 |
+
" }\n"
|
| 283 |
+
"}"
|
| 284 |
+
), # Java
|
| 285 |
+
'function helloWorld() {\n console.log("Hello, World!");\n return true;\n}', # JavaScript
|
| 286 |
+
'package main\n\nimport "fmt"\n\nfunc main() {\n fmt.Println("Hello, World!")\n}', # Go
|
| 287 |
+
'<?php\nfunction hello_world() {\n echo "Hello, World!";\n return true;\n}\n?>', # PHP
|
| 288 |
+
'def hello_world\n puts "Hello, World!"\n true\nend', # Ruby
|
| 289 |
+
]
|
| 290 |
+
|
| 291 |
+
predictions = classifier.predict(test_examples)
|
| 292 |
+
for i, (code, pred) in enumerate(zip(test_examples, predictions, strict=False)):
|
| 293 |
+
logger.info(f"Example {i + 1}: {pred}")
|
| 294 |
+
logger.info(f"Code snippet: {code[:100]}...")
|
| 295 |
+
|
| 296 |
+
# Step 7: Benchmark inference speed
|
| 297 |
+
logger.info("Benchmarking inference speed...")
|
| 298 |
+
inference_start_time = perf_counter()
|
| 299 |
+
_ = classifier.predict(test_dataset[text_column][:100]) # Test on first 100 samples
|
| 300 |
+
inference_time = perf_counter() - inference_start_time
|
| 301 |
+
logger.info(f"Inference took {int(inference_time * 1000)} milliseconds for 100 code snippets on CPU")
|
| 302 |
+
|
| 303 |
+
# Step 8: Save the model
|
| 304 |
+
if SAVE_PIPELINE:
|
| 305 |
+
logger.info("Converting to scikit-learn pipeline...")
|
| 306 |
+
pipeline = classifier.to_pipeline()
|
| 307 |
+
|
| 308 |
+
# Save locally
|
| 309 |
+
pipeline_path = output_dir / "pipeline"
|
| 310 |
+
pipeline.save_pretrained(str(pipeline_path))
|
| 311 |
+
logger.info(f"Pipeline saved to {pipeline_path}")
|
| 312 |
+
|
| 313 |
+
# Save additional metadata
|
| 314 |
+
metadata = {
|
| 315 |
+
"model_name": MODEL_NAME,
|
| 316 |
+
"dataset": DATASET_NAME,
|
| 317 |
+
"task": "programming_language_classification",
|
| 318 |
+
"languages": unique_languages,
|
| 319 |
+
"pca_dims": PCA_DIMS,
|
| 320 |
+
"train_samples": len(train_dataset),
|
| 321 |
+
"test_samples": len(test_dataset),
|
| 322 |
+
}
|
| 323 |
+
|
| 324 |
+
metadata_path = output_dir / "metadata.json"
|
| 325 |
+
with metadata_path.open("w") as f:
|
| 326 |
+
json.dump(metadata, f, indent=2)
|
| 327 |
+
logger.info("Metadata saved to metadata.json")
|
| 328 |
+
|
| 329 |
+
# Push to hub if requested
|
| 330 |
+
if SAVE_TO_HUB and HUB_MODEL_ID:
|
| 331 |
+
logger.info(f"Pushing pipeline to HuggingFace Hub as {HUB_MODEL_ID}")
|
| 332 |
+
pipeline.push_to_hub(HUB_MODEL_ID)
|
| 333 |
+
else:
|
| 334 |
+
# Save the classifier directly
|
| 335 |
+
classifier_path = output_dir / "classifier"
|
| 336 |
+
classifier_path.mkdir(exist_ok=True)
|
| 337 |
+
|
| 338 |
+
# Note: StaticModelForClassification might not have save_pretrained
|
| 339 |
+
# We'll save the underlying static model and create instructions
|
| 340 |
+
if static_model is not None:
|
| 341 |
+
static_model.save_pretrained(str(classifier_path / "static_model"))
|
| 342 |
+
|
| 343 |
+
logger.info(f"Classifier components saved to {classifier_path}")
|
| 344 |
+
|
| 345 |
+
# Summary
|
| 346 |
+
total_time = time.time() - total_start_time
|
| 347 |
+
logger.info("=" * 60)
|
| 348 |
+
logger.info("CODE CLASSIFICATION TRAINING COMPLETED SUCCESSFULLY!")
|
| 349 |
+
logger.info(f"Total time: {total_time:.2f} seconds")
|
| 350 |
+
if not SKIP_DISTILLATION:
|
| 351 |
+
logger.info(f"Distillation time: {distill_time:.2f} seconds")
|
| 352 |
+
logger.info(f"Training time: {int(train_time)} seconds")
|
| 353 |
+
logger.info(f"Dataset: {DATASET_NAME}")
|
| 354 |
+
logger.info("Task: Programming Language Classification")
|
| 355 |
+
logger.info(f"Languages: {', '.join(unique_languages)}")
|
| 356 |
+
logger.info(f"Model saved to: {output_dir}")
|
| 357 |
+
logger.info("=" * 60)
|
| 358 |
+
|
| 359 |
+
except Exception:
|
| 360 |
+
logger.exception("Error during code classification training pipeline")
|
| 361 |
+
raise
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
if __name__ == "__main__":
|
| 365 |
+
main()
|
uv.lock
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|