
Sarthak
commited on
Commit
·
1bc7e54
1
Parent(s):
454e47c
chore: remove unused scripts and update dependencies
Browse filesThis commit removes the MTEB evaluation script, distillation script, and evaluation script as they are no longer needed. Additionally, updates the pyproject.toml file to remove dependencies related to the removed scripts and adds typing-extensions to the dependencies.
- .codemap.yml +294 -0
- MTEB_evaluate.py +0 -343
- REPORT.md +299 -0
- Taskfile.yml +23 -0
- analysis_charts/batch_size_scaling.png +3 -0
- analysis_charts/benchmark_performance.png +3 -0
- analysis_charts/code_performance_radar.png +3 -0
- analysis_charts/comparative_radar.png +3 -0
- analysis_charts/efficiency_analysis.png +3 -0
- analysis_charts/language_heatmap.png +3 -0
- analysis_charts/memory_scaling.png +3 -0
- analysis_charts/model_comparison.png +3 -0
- analysis_charts/model_specifications.png +3 -0
- analysis_charts/peer_comparison.png +3 -0
- analysis_charts/radar_code_model2vec_Linq_Embed_Mistral.png +3 -0
- analysis_charts/radar_code_model2vec_Qodo_Embed_1_15B.png +3 -0
- analysis_charts/radar_code_model2vec_Reason_ModernColBERT.png +3 -0
- analysis_charts/radar_code_model2vec_all_MiniLM_L6_v2.png +3 -0
- analysis_charts/radar_code_model2vec_all_mpnet_base_v2.png +3 -0
- analysis_charts/radar_code_model2vec_bge_m3.png +3 -0
- analysis_charts/radar_code_model2vec_codebert_base.png +3 -0
- analysis_charts/radar_code_model2vec_graphcodebert_base.png +3 -0
- analysis_charts/radar_code_model2vec_gte_Qwen2_15B_instruct.png +3 -0
- analysis_charts/radar_code_model2vec_gte_Qwen2_7B_instruct.png +3 -0
- analysis_charts/radar_code_model2vec_jina_embeddings_v2_base_code.png +3 -0
- analysis_charts/radar_code_model2vec_jina_embeddings_v3.png +3 -0
- analysis_charts/radar_code_model2vec_nomic_embed_text_v2_moe.png +3 -0
- analysis_charts/radar_code_model2vec_paraphrase_MiniLM_L6_v2.png +3 -0
- distill.py +0 -116
- evaluate.py +0 -422
- pyproject.toml +37 -5
- src/distiller/distill.py +419 -159
- src/distiller/evaluate.py +371 -43
- train_code_classification.py +0 -365
.codemap.yml
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CodeMap Configuration File
|
| 2 |
+
# -------------------------
|
| 3 |
+
# This file configures CodeMap's behavior. Uncomment and modify settings as needed.
|
| 4 |
+
|
| 5 |
+
# LLM Configuration - Controls which model is used for AI operations
|
| 6 |
+
llm:
|
| 7 |
+
# Format: "provider:model-name", e.g., "openai:gpt-4o", "anthropic:claude-3-opus"
|
| 8 |
+
model: "google-gla:gemini-2.0-flash"
|
| 9 |
+
temperature: 0.5 # Lower for more deterministic outputs, higher for creativity
|
| 10 |
+
max_input_tokens: 1000000 # Maximum tokens in input
|
| 11 |
+
max_output_tokens: 10000 # Maximum tokens in responses
|
| 12 |
+
max_requests: 25 # Maximum number of requests
|
| 13 |
+
|
| 14 |
+
# Embedding Configuration - Controls vector embedding behavior
|
| 15 |
+
embedding:
|
| 16 |
+
# Recommended models: "minishlab/potion-base-8M3", Only Model2Vec static models are supported
|
| 17 |
+
model_name: "minishlab/potion-base-8M"
|
| 18 |
+
dimension: 256
|
| 19 |
+
# dimension_metric: "cosine" # Metric for dimension calculation (e.g., "cosine", "euclidean")
|
| 20 |
+
# max_retries: 3 # Maximum retries for embedding requests
|
| 21 |
+
# retry_delay: 5 # Delay in seconds between retries
|
| 22 |
+
# max_content_length: 5000 # Maximum characters per file chunk
|
| 23 |
+
# Qdrant (Vector DB) settings
|
| 24 |
+
# qdrant_batch_size: 100 # Batch size for Qdrant uploads
|
| 25 |
+
# url: "http://localhost:6333" # Qdrant server URL
|
| 26 |
+
# timeout: 30 # Qdrant client timeout in seconds
|
| 27 |
+
# prefer_grpc: true # Prefer gRPC for Qdrant communication
|
| 28 |
+
|
| 29 |
+
# Advanced chunking settings - controls how code is split
|
| 30 |
+
# chunking:
|
| 31 |
+
# max_hierarchy_depth: 2 # Maximum depth of code hierarchy to consider
|
| 32 |
+
# max_file_lines: 1000 # Maximum lines per file before splitting
|
| 33 |
+
|
| 34 |
+
# Clustering settings for embeddings
|
| 35 |
+
# clustering:
|
| 36 |
+
# method: "agglomerative" # Clustering method: "agglomerative", "dbscan"
|
| 37 |
+
# agglomerative: # Settings for Agglomerative Clustering
|
| 38 |
+
# metric: "precomputed" # Metric: "cosine", "euclidean", "manhattan", "l1", "l2", "precomputed"
|
| 39 |
+
# distance_threshold: 0.3 # Distance threshold for forming clusters
|
| 40 |
+
# linkage: "complete" # Linkage criterion: "ward", "complete", "average", "single"
|
| 41 |
+
# dbscan: # Settings for DBSCAN Clustering
|
| 42 |
+
# eps: 0.3 # The maximum distance between two samples for one to be considered as in the neighborhood of the other
|
| 43 |
+
# min_samples: 2 # The number of samples in a neighborhood for a point to be considered as a core point
|
| 44 |
+
# algorithm: "auto" # Algorithm to compute pointwise distances: "auto", "ball_tree", "kd_tree", "brute"
|
| 45 |
+
# metric: "precomputed" # Metric for distance computation: "cityblock", "cosine", "euclidean", "l1", "l2", "manhattan", "precomputed"
|
| 46 |
+
|
| 47 |
+
# RAG (Retrieval Augmented Generation) Configuration
|
| 48 |
+
rag:
|
| 49 |
+
max_context_length: 8000 # Maximum context length for the LLM
|
| 50 |
+
max_context_results: 100 # Maximum number of context results to return
|
| 51 |
+
similarity_threshold: 0.75 # Minimum similarity score (0-1) for relevance
|
| 52 |
+
# system_prompt: null # Optional system prompt to guide the RAG model (leave commented or set if needed)
|
| 53 |
+
include_file_content: true # Include file content in context
|
| 54 |
+
include_metadata: true # Include file metadata in context
|
| 55 |
+
|
| 56 |
+
# Sync Configuration - Controls which files are excluded from processing
|
| 57 |
+
sync:
|
| 58 |
+
exclude_patterns:
|
| 59 |
+
- "^node_modules/"
|
| 60 |
+
- "^\\.venv/"
|
| 61 |
+
- "^venv/"
|
| 62 |
+
- "^env/"
|
| 63 |
+
- "^__pycache__/"
|
| 64 |
+
- "^\\.mypy_cache/"
|
| 65 |
+
- "^\\.pytest_cache/"
|
| 66 |
+
- "^\\.ruff_cache/"
|
| 67 |
+
- "^dist/"
|
| 68 |
+
- "^build/"
|
| 69 |
+
- "^\\.git/"
|
| 70 |
+
- "^typings/"
|
| 71 |
+
- "^\\.pyc$"
|
| 72 |
+
- "^\\.pyo$"
|
| 73 |
+
- "^\\.so$"
|
| 74 |
+
- "^\\.dll$"
|
| 75 |
+
- "^\\.lib$"
|
| 76 |
+
- "^\\.a$"
|
| 77 |
+
- "^\\.o$"
|
| 78 |
+
- "^\\.class$"
|
| 79 |
+
- "^\\.jar$"
|
| 80 |
+
|
| 81 |
+
# Generation Configuration - Controls documentation generation
|
| 82 |
+
gen:
|
| 83 |
+
max_content_length: 5000 # Maximum content length per file for generation
|
| 84 |
+
use_gitignore: true # Use .gitignore patterns to exclude files
|
| 85 |
+
output_dir: "documentation" # Directory to store generated documentation
|
| 86 |
+
include_tree: true # Include directory tree in output
|
| 87 |
+
include_entity_graph: true # Include entity relationship graph
|
| 88 |
+
semantic_analysis: true # Enable semantic analysis
|
| 89 |
+
lod_level: "skeleton" # Level of detail: "signatures", "structure", "docs", "skeleton", "full"
|
| 90 |
+
|
| 91 |
+
# Mermaid diagram configuration for entity graphs
|
| 92 |
+
# mermaid_entities:
|
| 93 |
+
# - "module"
|
| 94 |
+
# - "class"
|
| 95 |
+
# - "function"
|
| 96 |
+
# - "method"
|
| 97 |
+
# - "constant"
|
| 98 |
+
# - "variable"
|
| 99 |
+
# - "import"
|
| 100 |
+
# mermaid_relationships:
|
| 101 |
+
# - "declares"
|
| 102 |
+
# - "imports"
|
| 103 |
+
# - "calls"
|
| 104 |
+
mermaid_show_legend: false
|
| 105 |
+
mermaid_remove_unconnected: true # Show isolated nodes
|
| 106 |
+
mermaid_styled: false # Style the mermaid diagram
|
| 107 |
+
|
| 108 |
+
# Processor Configuration - Controls code processing behavior
|
| 109 |
+
processor:
|
| 110 |
+
enabled: true # Enable the processor
|
| 111 |
+
max_workers: 4 # Maximum number of parallel workers
|
| 112 |
+
ignored_patterns: # Patterns to ignore during processing
|
| 113 |
+
- "**/.git/**"
|
| 114 |
+
- "**/__pycache__/**"
|
| 115 |
+
- "**/.venv/**"
|
| 116 |
+
- "**/node_modules/**"
|
| 117 |
+
- "**/*.pyc"
|
| 118 |
+
- "**/dist/**"
|
| 119 |
+
- "**/build/**"
|
| 120 |
+
default_lod_level: "signatures" # Default level of detail: "signatures", "structure", "docs", "full"
|
| 121 |
+
|
| 122 |
+
# File watcher configuration
|
| 123 |
+
# watcher:
|
| 124 |
+
# enabled: true # Enable file watching
|
| 125 |
+
# debounce_delay: 1.0 # Delay in seconds before processing changes
|
| 126 |
+
|
| 127 |
+
# Commit Command Configuration
|
| 128 |
+
commit:
|
| 129 |
+
strategy: "semantic" # Strategy for splitting diffs: "file", "hunk", "semantic"
|
| 130 |
+
bypass_hooks: false # Whether to bypass git hooks
|
| 131 |
+
use_lod_context: true # Use level of detail context
|
| 132 |
+
is_non_interactive: false # Run in non-interactive mode
|
| 133 |
+
|
| 134 |
+
# Diff splitter configuration
|
| 135 |
+
# diff_splitter:
|
| 136 |
+
# similarity_threshold: 0.6 # Similarity threshold for grouping related changes
|
| 137 |
+
# directory_similarity_threshold: 0.3 # Threshold for considering directories similar (e.g., for renames)
|
| 138 |
+
# file_move_similarity_threshold: 0.85 # Threshold for detecting file moves/renames based on content
|
| 139 |
+
# min_chunks_for_consolidation: 2 # Minimum number of small chunks to consider for consolidation
|
| 140 |
+
# max_chunks_before_consolidation: 20 # Maximum number of chunks before forcing consolidation
|
| 141 |
+
# max_file_size_for_llm: 50000 # Maximum file size (bytes) for LLM processing of individual files
|
| 142 |
+
# max_log_diff_size: 1000 # Maximum size (lines) of diff log to pass to LLM for context
|
| 143 |
+
# default_code_extensions: # File extensions considered as code for semantic splitting
|
| 144 |
+
# - "js"
|
| 145 |
+
# - "jsx"
|
| 146 |
+
# - "ts"
|
| 147 |
+
# - "tsx"
|
| 148 |
+
# - "py"
|
| 149 |
+
# - "java"
|
| 150 |
+
# - "c"
|
| 151 |
+
# - "cpp"
|
| 152 |
+
# - "h"
|
| 153 |
+
# - "hpp"
|
| 154 |
+
# - "cc"
|
| 155 |
+
# - "cs"
|
| 156 |
+
# - "go"
|
| 157 |
+
# - "rb"
|
| 158 |
+
# - "php"
|
| 159 |
+
# - "rs"
|
| 160 |
+
# - "swift"
|
| 161 |
+
# - "scala"
|
| 162 |
+
# - "kt"
|
| 163 |
+
# - "sh"
|
| 164 |
+
# - "pl"
|
| 165 |
+
# - "pm"
|
| 166 |
+
|
| 167 |
+
# Commit convention configuration (Conventional Commits)
|
| 168 |
+
convention:
|
| 169 |
+
types: # Allowed commit types
|
| 170 |
+
- "feat"
|
| 171 |
+
- "fix"
|
| 172 |
+
- "docs"
|
| 173 |
+
- "style"
|
| 174 |
+
- "refactor"
|
| 175 |
+
- "perf"
|
| 176 |
+
- "test"
|
| 177 |
+
- "build"
|
| 178 |
+
- "ci"
|
| 179 |
+
- "chore"
|
| 180 |
+
scopes: [] # Add project-specific scopes here, e.g., ["api", "ui", "db"]
|
| 181 |
+
max_length: 72 # Maximum length of commit message header
|
| 182 |
+
|
| 183 |
+
# Commit linting configuration (based on conventional-changelog-lint rules)
|
| 184 |
+
# lint:
|
| 185 |
+
# # Rules are defined as: {level: "ERROR"|"WARNING"|"DISABLED", rule: "always"|"never", value: <specific_value_if_any>}
|
| 186 |
+
# header_max_length:
|
| 187 |
+
# level: "ERROR"
|
| 188 |
+
# rule: "always"
|
| 189 |
+
# value: 100
|
| 190 |
+
# header_case: # e.g., 'lower-case', 'upper-case', 'camel-case', etc.
|
| 191 |
+
# level: "DISABLED"
|
| 192 |
+
# rule: "always"
|
| 193 |
+
# value: "lower-case"
|
| 194 |
+
# header_full_stop:
|
| 195 |
+
# level: "ERROR"
|
| 196 |
+
# rule: "never"
|
| 197 |
+
# value: "."
|
| 198 |
+
# type_enum: # Types must be from the 'convention.types' list
|
| 199 |
+
# level: "ERROR"
|
| 200 |
+
# rule: "always"
|
| 201 |
+
# type_case:
|
| 202 |
+
# level: "ERROR"
|
| 203 |
+
# rule: "always"
|
| 204 |
+
# value: "lower-case"
|
| 205 |
+
# type_empty:
|
| 206 |
+
# level: "ERROR"
|
| 207 |
+
# rule: "never"
|
| 208 |
+
# scope_case:
|
| 209 |
+
# level: "ERROR"
|
| 210 |
+
# rule: "always"
|
| 211 |
+
# value: "lower-case"
|
| 212 |
+
# scope_empty: # Set to "ERROR" if scopes are mandatory
|
| 213 |
+
# level: "DISABLED"
|
| 214 |
+
# rule: "never"
|
| 215 |
+
# scope_enum: # Scopes must be from the 'convention.scopes' list if enabled
|
| 216 |
+
# level: "DISABLED"
|
| 217 |
+
# rule: "always"
|
| 218 |
+
# # value: [] # Add allowed scopes here if rule is "always" and level is not DISABLED
|
| 219 |
+
# subject_case: # Forbids specific cases in the subject
|
| 220 |
+
# level: "ERROR"
|
| 221 |
+
# rule: "never"
|
| 222 |
+
# value: ["sentence-case", "start-case", "pascal-case", "upper-case"]
|
| 223 |
+
# subject_empty:
|
| 224 |
+
# level: "ERROR"
|
| 225 |
+
# rule: "never"
|
| 226 |
+
# subject_full_stop:
|
| 227 |
+
# level: "ERROR"
|
| 228 |
+
# rule: "never"
|
| 229 |
+
# value: "."
|
| 230 |
+
# subject_exclamation_mark:
|
| 231 |
+
# level: "DISABLED"
|
| 232 |
+
# rule: "never"
|
| 233 |
+
# body_leading_blank: # Body must start with a blank line after subject
|
| 234 |
+
# level: "WARNING"
|
| 235 |
+
# rule: "always"
|
| 236 |
+
# body_empty:
|
| 237 |
+
# level: "DISABLED"
|
| 238 |
+
# rule: "never"
|
| 239 |
+
# body_max_line_length:
|
| 240 |
+
# level: "ERROR"
|
| 241 |
+
# rule: "always"
|
| 242 |
+
# value: 100
|
| 243 |
+
# footer_leading_blank: # Footer must start with a blank line after body
|
| 244 |
+
# level: "WARNING"
|
| 245 |
+
# rule: "always"
|
| 246 |
+
# footer_empty:
|
| 247 |
+
# level: "DISABLED"
|
| 248 |
+
# rule: "never"
|
| 249 |
+
# footer_max_line_length:
|
| 250 |
+
# level: "ERROR"
|
| 251 |
+
# rule: "always"
|
| 252 |
+
# value: 100
|
| 253 |
+
|
| 254 |
+
# Pull Request Configuration
|
| 255 |
+
pr:
|
| 256 |
+
defaults:
|
| 257 |
+
base_branch: null # Default base branch (null = auto-detect, e.g., main, master, develop)
|
| 258 |
+
feature_prefix: "feature/" # Default feature branch prefix
|
| 259 |
+
|
| 260 |
+
strategy: "github-flow" # Git workflow: "github-flow", "gitflow", "trunk-based"
|
| 261 |
+
|
| 262 |
+
# Branch mapping for different PR types (primarily used in gitflow strategy)
|
| 263 |
+
# branch_mapping:
|
| 264 |
+
# feature:
|
| 265 |
+
# base: "develop"
|
| 266 |
+
# prefix: "feature/"
|
| 267 |
+
# release:
|
| 268 |
+
# base: "main"
|
| 269 |
+
# prefix: "release/"
|
| 270 |
+
# hotfix:
|
| 271 |
+
# base: "main"
|
| 272 |
+
# prefix: "hotfix/"
|
| 273 |
+
# bugfix:
|
| 274 |
+
# base: "develop"
|
| 275 |
+
# prefix: "bugfix/"
|
| 276 |
+
|
| 277 |
+
# PR generation configuration
|
| 278 |
+
generate:
|
| 279 |
+
title_strategy: "llm" # Strategy for generating PR titles: "commits" (from commit messages), "llm" (AI generated)
|
| 280 |
+
description_strategy: "llm" # Strategy for descriptions: "commits", "llm"
|
| 281 |
+
# description_template: | # Template for PR description when using 'llm' strategy. Placeholders: {changes}, {testing_instructions}, {screenshots}
|
| 282 |
+
# ## Changes
|
| 283 |
+
# {changes}
|
| 284 |
+
#
|
| 285 |
+
# ## Testing
|
| 286 |
+
# {testing_instructions}
|
| 287 |
+
#
|
| 288 |
+
# ## Screenshots
|
| 289 |
+
# {screenshots}
|
| 290 |
+
use_workflow_templates: true # Use workflow-specific templates if available (e.g., for GitHub PR templates)
|
| 291 |
+
|
| 292 |
+
# Ask Command Configuration
|
| 293 |
+
ask:
|
| 294 |
+
interactive_chat: false # Enable interactive chat mode for the 'ask' command
|
MTEB_evaluate.py
DELETED
|
@@ -1,343 +0,0 @@
|
|
| 1 |
-
#!/usr/bin/env python
|
| 2 |
-
"""
|
| 3 |
-
MTEB Evaluation Script with Subprocess Isolation (Code Information Retrieval Tasks).
|
| 4 |
-
|
| 5 |
-
This script evaluates models using MTEB with subprocess isolation to prevent
|
| 6 |
-
memory issues and process killing.
|
| 7 |
-
|
| 8 |
-
Features:
|
| 9 |
-
- Each task runs in a separate subprocess to isolate memory
|
| 10 |
-
- 1-minute timeout per task
|
| 11 |
-
- No retries - if task fails or times out, move to next one
|
| 12 |
-
- Memory monitoring and cleanup
|
| 13 |
-
|
| 14 |
-
Note: Multi-threading is NOT used here because:
|
| 15 |
-
1. Memory is the main bottleneck, not CPU
|
| 16 |
-
2. Running multiple tasks simultaneously would increase memory pressure
|
| 17 |
-
3. Many tasks are being killed (return code -9) due to OOM conditions
|
| 18 |
-
4. Sequential processing with subprocess isolation is more stable
|
| 19 |
-
"""
|
| 20 |
-
|
| 21 |
-
import contextlib
|
| 22 |
-
import json
|
| 23 |
-
import logging
|
| 24 |
-
import subprocess
|
| 25 |
-
import sys
|
| 26 |
-
import tempfile
|
| 27 |
-
import time
|
| 28 |
-
from pathlib import Path
|
| 29 |
-
|
| 30 |
-
import psutil
|
| 31 |
-
|
| 32 |
-
# =============================================================================
|
| 33 |
-
# CONFIGURATION
|
| 34 |
-
# =============================================================================
|
| 35 |
-
|
| 36 |
-
MODEL_PATH = "."
|
| 37 |
-
MODEL_NAME = "gte-Qwen2-7B-instruct-M2V-Distilled"
|
| 38 |
-
OUTPUT_DIR = "mteb_results"
|
| 39 |
-
TASK_TIMEOUT = 30 # 30 seconds timeout per task
|
| 40 |
-
MAX_RETRIES = 0 # No retries - move to next task if failed/timeout
|
| 41 |
-
|
| 42 |
-
# Constants
|
| 43 |
-
SIGKILL_RETURN_CODE = -9 # Process killed by SIGKILL (usually OOM)
|
| 44 |
-
|
| 45 |
-
# Configure logging
|
| 46 |
-
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
|
| 47 |
-
logger = logging.getLogger(__name__)
|
| 48 |
-
|
| 49 |
-
# =============================================================================
|
| 50 |
-
# SINGLE TASK RUNNER SCRIPT
|
| 51 |
-
# =============================================================================
|
| 52 |
-
|
| 53 |
-
TASK_RUNNER_SCRIPT = """
|
| 54 |
-
import sys
|
| 55 |
-
import os
|
| 56 |
-
import json
|
| 57 |
-
import tempfile
|
| 58 |
-
import traceback
|
| 59 |
-
from pathlib import Path
|
| 60 |
-
|
| 61 |
-
# Add current directory to path
|
| 62 |
-
sys.path.insert(0, ".")
|
| 63 |
-
|
| 64 |
-
try:
|
| 65 |
-
import mteb
|
| 66 |
-
from model2vec import StaticModel
|
| 67 |
-
from mteb import ModelMeta
|
| 68 |
-
from evaluation import CustomMTEB
|
| 69 |
-
|
| 70 |
-
def run_single_task():
|
| 71 |
-
# Get arguments
|
| 72 |
-
model_path = sys.argv[1]
|
| 73 |
-
task_name = sys.argv[2]
|
| 74 |
-
output_dir = sys.argv[3]
|
| 75 |
-
model_name = sys.argv[4]
|
| 76 |
-
|
| 77 |
-
# Load model
|
| 78 |
-
model = StaticModel.from_pretrained(model_path)
|
| 79 |
-
model.mteb_model_meta = ModelMeta(
|
| 80 |
-
name=model_name, revision="distilled", release_date=None, languages=["eng"]
|
| 81 |
-
)
|
| 82 |
-
|
| 83 |
-
# Get and run task
|
| 84 |
-
task = mteb.get_task(task_name, languages=["eng"])
|
| 85 |
-
evaluation = CustomMTEB(tasks=[task])
|
| 86 |
-
|
| 87 |
-
results = evaluation.run(
|
| 88 |
-
model,
|
| 89 |
-
eval_splits=["test"],
|
| 90 |
-
output_folder=output_dir,
|
| 91 |
-
verbosity=0
|
| 92 |
-
)
|
| 93 |
-
|
| 94 |
-
# Save results to temp file for parent process
|
| 95 |
-
with tempfile.NamedTemporaryFile(mode='w', delete=False, suffix='.json') as f:
|
| 96 |
-
json.dump({
|
| 97 |
-
"success": True,
|
| 98 |
-
"task_name": task_name,
|
| 99 |
-
"results": results
|
| 100 |
-
}, f)
|
| 101 |
-
temp_file = f.name
|
| 102 |
-
|
| 103 |
-
print(f"RESULT_FILE:{temp_file}")
|
| 104 |
-
return 0
|
| 105 |
-
|
| 106 |
-
if __name__ == "__main__":
|
| 107 |
-
exit(run_single_task())
|
| 108 |
-
|
| 109 |
-
except Exception as e:
|
| 110 |
-
print(f"ERROR: {str(e)}")
|
| 111 |
-
print(f"TRACEBACK: {traceback.format_exc()}")
|
| 112 |
-
exit(1)
|
| 113 |
-
"""
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
def get_available_tasks() -> list[str]:
|
| 117 |
-
"""Get list of available tasks."""
|
| 118 |
-
try:
|
| 119 |
-
import mteb
|
| 120 |
-
import mteb.benchmarks
|
| 121 |
-
|
| 122 |
-
# Use main MTEB benchmark for comprehensive evaluation
|
| 123 |
-
benchmark = mteb.benchmarks.CoIR
|
| 124 |
-
return [str(task) for task in benchmark.tasks] # All tasks
|
| 125 |
-
except Exception:
|
| 126 |
-
logger.exception("Failed to get tasks")
|
| 127 |
-
return []
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
def check_existing_results(output_path: Path, task_names: list[str]) -> list[str]:
|
| 131 |
-
"""Check for existing results and return remaining tasks."""
|
| 132 |
-
remaining_tasks = []
|
| 133 |
-
|
| 134 |
-
for task_name in task_names:
|
| 135 |
-
result_file = output_path / MODEL_NAME / "distilled" / f"{task_name}.json"
|
| 136 |
-
if result_file.exists():
|
| 137 |
-
logger.info(f"Skipping {task_name} - results already exist")
|
| 138 |
-
else:
|
| 139 |
-
remaining_tasks.append(task_name)
|
| 140 |
-
|
| 141 |
-
return remaining_tasks
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
def run_task_subprocess(task_name: str, output_dir: str) -> tuple[bool, str, float]:
|
| 145 |
-
"""Run a single task in a subprocess with memory and time limits."""
|
| 146 |
-
# Create temporary script file
|
| 147 |
-
with tempfile.NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f:
|
| 148 |
-
f.write(TASK_RUNNER_SCRIPT)
|
| 149 |
-
script_path = f.name
|
| 150 |
-
|
| 151 |
-
try:
|
| 152 |
-
logger.info(f"Running task: {task_name}")
|
| 153 |
-
start_time = time.time()
|
| 154 |
-
|
| 155 |
-
# Run subprocess with timeout
|
| 156 |
-
# subprocess security: We control all inputs (script path and known arguments)
|
| 157 |
-
cmd = [sys.executable, script_path, MODEL_PATH, task_name, output_dir, MODEL_NAME]
|
| 158 |
-
|
| 159 |
-
process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True) # noqa: S603
|
| 160 |
-
|
| 161 |
-
try:
|
| 162 |
-
stdout, stderr = process.communicate(timeout=TASK_TIMEOUT)
|
| 163 |
-
duration = time.time() - start_time
|
| 164 |
-
|
| 165 |
-
if process.returncode == 0:
|
| 166 |
-
# Check for result file
|
| 167 |
-
for line in stdout.split("\n"):
|
| 168 |
-
if line.startswith("RESULT_FILE:"):
|
| 169 |
-
result_file = line.split(":", 1)[1]
|
| 170 |
-
try:
|
| 171 |
-
with Path(result_file).open() as f:
|
| 172 |
-
json.load(f)
|
| 173 |
-
Path(result_file).unlink() # Clean up temp file
|
| 174 |
-
logger.info(f"✓ Completed {task_name} in {duration:.2f}s")
|
| 175 |
-
return True, task_name, duration
|
| 176 |
-
except (json.JSONDecodeError, OSError):
|
| 177 |
-
logger.exception("Failed to read result file")
|
| 178 |
-
|
| 179 |
-
logger.info(f"✓ Completed {task_name} in {duration:.2f}s")
|
| 180 |
-
return True, task_name, duration
|
| 181 |
-
if process.returncode == SIGKILL_RETURN_CODE:
|
| 182 |
-
logger.error(f"✗ Task {task_name} killed (OOM) - return code {process.returncode}")
|
| 183 |
-
else:
|
| 184 |
-
logger.error(f"✗ Task {task_name} failed with return code {process.returncode}")
|
| 185 |
-
if stderr:
|
| 186 |
-
logger.error(f"Error output: {stderr}")
|
| 187 |
-
return False, task_name, duration
|
| 188 |
-
|
| 189 |
-
except subprocess.TimeoutExpired:
|
| 190 |
-
logger.warning(f"⏱ Task {task_name} timed out after {TASK_TIMEOUT}s")
|
| 191 |
-
process.kill()
|
| 192 |
-
process.wait()
|
| 193 |
-
return False, task_name, TASK_TIMEOUT
|
| 194 |
-
|
| 195 |
-
except Exception:
|
| 196 |
-
logger.exception(f"✗ Failed to run task {task_name}")
|
| 197 |
-
return False, task_name, 0.0
|
| 198 |
-
|
| 199 |
-
finally:
|
| 200 |
-
# Clean up script file
|
| 201 |
-
with contextlib.suppress(Exception):
|
| 202 |
-
Path(script_path).unlink()
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
def collect_results(output_path: Path) -> dict:
|
| 206 |
-
"""Collect all results from completed tasks."""
|
| 207 |
-
results_dir = output_path / MODEL_NAME / "distilled"
|
| 208 |
-
if not results_dir.exists():
|
| 209 |
-
return {}
|
| 210 |
-
|
| 211 |
-
task_results = {}
|
| 212 |
-
for result_file in results_dir.glob("*.json"):
|
| 213 |
-
if result_file.name == "model_meta.json":
|
| 214 |
-
continue
|
| 215 |
-
|
| 216 |
-
try:
|
| 217 |
-
with result_file.open() as f:
|
| 218 |
-
data = json.load(f)
|
| 219 |
-
task_name = result_file.stem
|
| 220 |
-
task_results[task_name] = data
|
| 221 |
-
except (json.JSONDecodeError, OSError) as e:
|
| 222 |
-
logger.warning(f"Could not load {result_file}: {e}")
|
| 223 |
-
|
| 224 |
-
return task_results
|
| 225 |
-
|
| 226 |
-
|
| 227 |
-
def save_summary(output_path: Path, results: dict, stats: dict) -> None:
|
| 228 |
-
"""Save evaluation summary."""
|
| 229 |
-
summary = {
|
| 230 |
-
"model_name": MODEL_NAME,
|
| 231 |
-
"timestamp": time.time(),
|
| 232 |
-
"task_timeout": TASK_TIMEOUT,
|
| 233 |
-
"stats": stats,
|
| 234 |
-
"task_results": results,
|
| 235 |
-
}
|
| 236 |
-
|
| 237 |
-
summary_file = output_path / "mteb_summary.json"
|
| 238 |
-
with summary_file.open("w") as f:
|
| 239 |
-
json.dump(summary, f, indent=2, default=str)
|
| 240 |
-
|
| 241 |
-
logger.info(f"Summary saved to {summary_file}")
|
| 242 |
-
|
| 243 |
-
|
| 244 |
-
def main() -> None:
|
| 245 |
-
"""Main evaluation function."""
|
| 246 |
-
logger.info(f"Starting MTEB evaluation for {MODEL_NAME}")
|
| 247 |
-
logger.info(f"Task timeout: {TASK_TIMEOUT}s (no retries)")
|
| 248 |
-
logger.info("Memory isolation: Each task runs in separate subprocess")
|
| 249 |
-
|
| 250 |
-
# Log system info
|
| 251 |
-
memory_info = psutil.virtual_memory()
|
| 252 |
-
logger.info(f"System memory: {memory_info.total / (1024**3):.1f} GB total")
|
| 253 |
-
|
| 254 |
-
output_path = Path(OUTPUT_DIR)
|
| 255 |
-
output_path.mkdir(parents=True, exist_ok=True)
|
| 256 |
-
|
| 257 |
-
# Get tasks
|
| 258 |
-
all_tasks = get_available_tasks()
|
| 259 |
-
if not all_tasks:
|
| 260 |
-
logger.error("No tasks found!")
|
| 261 |
-
return
|
| 262 |
-
|
| 263 |
-
logger.info(f"Found {len(all_tasks)} tasks")
|
| 264 |
-
|
| 265 |
-
# Check existing results
|
| 266 |
-
remaining_tasks = check_existing_results(output_path, all_tasks)
|
| 267 |
-
logger.info(f"Will evaluate {len(remaining_tasks)} remaining tasks")
|
| 268 |
-
|
| 269 |
-
if not remaining_tasks:
|
| 270 |
-
logger.info("All tasks already completed!")
|
| 271 |
-
return
|
| 272 |
-
|
| 273 |
-
# Process tasks sequentially (no retries)
|
| 274 |
-
start_time = time.time()
|
| 275 |
-
successful_tasks = []
|
| 276 |
-
failed_tasks = []
|
| 277 |
-
timed_out_tasks = []
|
| 278 |
-
|
| 279 |
-
for i, task_name in enumerate(remaining_tasks):
|
| 280 |
-
logger.info(f"[{i + 1}/{len(remaining_tasks)}] Processing: {task_name}")
|
| 281 |
-
|
| 282 |
-
# Run task once (no retries)
|
| 283 |
-
success, name, duration = run_task_subprocess(task_name, str(output_path))
|
| 284 |
-
|
| 285 |
-
if success:
|
| 286 |
-
successful_tasks.append((name, duration))
|
| 287 |
-
elif duration == TASK_TIMEOUT:
|
| 288 |
-
timed_out_tasks.append(name)
|
| 289 |
-
else:
|
| 290 |
-
failed_tasks.append(name)
|
| 291 |
-
# Check if it was OOM killed (this is logged in run_task_subprocess)
|
| 292 |
-
|
| 293 |
-
# Progress update
|
| 294 |
-
progress = ((i + 1) / len(remaining_tasks)) * 100
|
| 295 |
-
logger.info(f"Progress: {i + 1}/{len(remaining_tasks)} ({progress:.1f}%)")
|
| 296 |
-
|
| 297 |
-
# Brief pause between tasks
|
| 298 |
-
time.sleep(1)
|
| 299 |
-
|
| 300 |
-
total_time = time.time() - start_time
|
| 301 |
-
|
| 302 |
-
# Log final summary
|
| 303 |
-
logger.info("=" * 80)
|
| 304 |
-
logger.info("EVALUATION SUMMARY")
|
| 305 |
-
logger.info("=" * 80)
|
| 306 |
-
logger.info(f"Total tasks: {len(remaining_tasks)}")
|
| 307 |
-
logger.info(f"Successful: {len(successful_tasks)}")
|
| 308 |
-
logger.info(f"Failed: {len(failed_tasks)}")
|
| 309 |
-
logger.info(f"Timed out: {len(timed_out_tasks)}")
|
| 310 |
-
logger.info(f"Total time: {total_time:.2f}s")
|
| 311 |
-
|
| 312 |
-
if successful_tasks:
|
| 313 |
-
avg_time = sum(duration for _, duration in successful_tasks) / len(successful_tasks)
|
| 314 |
-
logger.info(f"Average successful task time: {avg_time:.2f}s")
|
| 315 |
-
|
| 316 |
-
if failed_tasks:
|
| 317 |
-
logger.warning(f"Failed tasks: {failed_tasks}")
|
| 318 |
-
|
| 319 |
-
if timed_out_tasks:
|
| 320 |
-
logger.warning(f"Timed out tasks: {timed_out_tasks}")
|
| 321 |
-
|
| 322 |
-
logger.info("=" * 80)
|
| 323 |
-
|
| 324 |
-
# Collect and save results
|
| 325 |
-
all_results = collect_results(output_path)
|
| 326 |
-
stats = {
|
| 327 |
-
"total_tasks": len(remaining_tasks),
|
| 328 |
-
"successful": len(successful_tasks),
|
| 329 |
-
"failed": len(failed_tasks),
|
| 330 |
-
"timed_out": len(timed_out_tasks),
|
| 331 |
-
"total_time": total_time,
|
| 332 |
-
"avg_time": avg_time if successful_tasks else 0,
|
| 333 |
-
"successful_task_details": successful_tasks,
|
| 334 |
-
"failed_tasks": failed_tasks,
|
| 335 |
-
"timed_out_tasks": timed_out_tasks,
|
| 336 |
-
}
|
| 337 |
-
|
| 338 |
-
save_summary(output_path, all_results, stats)
|
| 339 |
-
logger.info("Evaluation completed!")
|
| 340 |
-
|
| 341 |
-
|
| 342 |
-
if __name__ == "__main__":
|
| 343 |
-
main()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
REPORT.md
ADDED
|
@@ -0,0 +1,299 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Code-Specialized Model2Vec Distillation Analysis
|
| 2 |
+
|
| 3 |
+
## 🎯 Executive Summary
|
| 4 |
+
|
| 5 |
+
This report presents a comprehensive analysis of Model2Vec distillation experiments using different teacher models for code-specialized embedding generation.
|
| 6 |
+
|
| 7 |
+
### Evaluated Models Overview
|
| 8 |
+
|
| 9 |
+
**Simplified Distillation Models:** 13
|
| 10 |
+
**Peer Comparison Models:** 19
|
| 11 |
+
**Total Models Analyzed:** 32
|
| 12 |
+
|
| 13 |
+
### Best Performing Simplified Model: code_model2vec_all_mpnet_base_v2
|
| 14 |
+
|
| 15 |
+
**Overall CodeSearchNet Performance:**
|
| 16 |
+
- **NDCG@10**: 0.7387
|
| 17 |
+
- **Mean Reciprocal Rank (MRR)**: 0.7010
|
| 18 |
+
- **Recall@5**: 0.8017
|
| 19 |
+
- **Mean Rank**: 6.4
|
| 20 |
+
|
| 21 |
+
## 📊 Comprehensive Model Comparison
|
| 22 |
+
|
| 23 |
+
### All Simplified Distillation Models Performance
|
| 24 |
+
|
| 25 |
+
| Model | Teacher | NDCG@10 | MRR | Recall@5 | Status |
|
| 26 |
+
|-------|---------|---------|-----|----------|--------|
|
| 27 |
+
| code_model2vec_all_mpnet_base_v2 | [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.7387 | 0.7010 | 0.8017 | 🥇 Best |
|
| 28 |
+
| code_model2vec_all_MiniLM_L6_v2 | [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.7385 | 0.7049 | 0.7910 | 🥈 2nd |
|
| 29 |
+
| code_model2vec_jina_embeddings_v2_base_code | [jina-embeddings-v2-base-code](https://huggingface.co/jina-embeddings-v2-base-code) | 0.7381 | 0.6996 | 0.8130 | 🥉 3rd |
|
| 30 |
+
| code_model2vec_paraphrase_MiniLM_L6_v2 | [sentence-transformers/paraphrase-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2) | 0.7013 | 0.6638 | 0.7665 | #4 |
|
| 31 |
+
| code_model2vec_Reason_ModernColBERT | [lightonai/Reason-ModernColBERT](https://huggingface.co/lightonai/Reason-ModernColBERT) | 0.6598 | 0.6228 | 0.7260 | #5 |
|
| 32 |
+
| code_model2vec_bge_m3 | [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | 0.4863 | 0.4439 | 0.5514 | #6 |
|
| 33 |
+
| code_model2vec_jina_embeddings_v3 | [jinaai/jina-embeddings-v3](https://huggingface.co/jinaai/jina-embeddings-v3) | 0.4755 | 0.4416 | 0.5456 | #7 |
|
| 34 |
+
| code_model2vec_nomic_embed_text_v2_moe | [nomic-ai/nomic-embed-text-v2-moe](https://huggingface.co/nomic-ai/nomic-embed-text-v2-moe) | 0.4532 | 0.4275 | 0.5094 | #8 |
|
| 35 |
+
| code_model2vec_gte_Qwen2_1.5B_instruct | [Alibaba-NLP/gte-Qwen2-1.5B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) | 0.4238 | 0.3879 | 0.4719 | #9 |
|
| 36 |
+
| code_model2vec_Qodo_Embed_1_1.5B | [Qodo/Qodo-Embed-1-1.5B](https://huggingface.co/Qodo/Qodo-Embed-1-1.5B) | 0.4101 | 0.3810 | 0.4532 | #10 |
|
| 37 |
+
| code_model2vec_graphcodebert_base | [microsoft/codebert-base](https://huggingface.co/microsoft/codebert-base) | 0.3420 | 0.3140 | 0.3704 | #11 |
|
| 38 |
+
| code_model2vec_Linq_Embed_Mistral | [Linq-AI-Research/Linq-Embed-Mistral](https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral) | 0.2868 | 0.2581 | 0.3412 | #12 |
|
| 39 |
+
| code_model2vec_codebert_base | [microsoft/codebert-base](https://huggingface.co/microsoft/codebert-base) | 0.2779 | 0.2534 | 0.3136 | #13 |
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
### 📊 Model Specifications Analysis
|
| 43 |
+
|
| 44 |
+
Our distilled models exhibit consistent architectural characteristics across different teacher models:
|
| 45 |
+
|
| 46 |
+
| Model | Vocabulary Size | Parameters | Embedding Dim | Disk Size |
|
| 47 |
+
|-------|----------------|------------|---------------|-----------|
|
| 48 |
+
| all_mpnet_base_v2 | 29,528 | 7.6M | 256 | 14.4MB |
|
| 49 |
+
| all_MiniLM_L6_v2 | 29,525 | 7.6M | 256 | 14.4MB |
|
| 50 |
+
| jina_embeddings_v2_base_code | 61,053 | 15.6M | 256 | 29.8MB |
|
| 51 |
+
| paraphrase_MiniLM_L6_v2 | 29,525 | 7.6M | 256 | 14.4MB |
|
| 52 |
+
| Reason_ModernColBERT | 50,254 | 12.9M | 256 | 24.5MB |
|
| 53 |
+
| bge_m3 | 249,999 | 64.0M | 256 | 122.1MB |
|
| 54 |
+
| jina_embeddings_v3 | 249,999 | 64.0M | 256 | 122.1MB |
|
| 55 |
+
| nomic_embed_text_v2_moe | 249,999 | 64.0M | 256 | 122.1MB |
|
| 56 |
+
| gte_Qwen2_1.5B_instruct | 151,644 | 38.8M | 256 | 74.0MB |
|
| 57 |
+
| Qodo_Embed_1_1.5B | 151,644 | 38.8M | 256 | 74.0MB |
|
| 58 |
+
| graphcodebert_base | 50,262 | 12.9M | 256 | 24.5MB |
|
| 59 |
+
| Linq_Embed_Mistral | 31,999 | 8.2M | 256 | 15.6MB |
|
| 60 |
+
| codebert_base | 50,262 | 12.9M | 256 | 24.5MB |
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+

|
| 64 |
+
|
| 65 |
+
*Comprehensive analysis of our distilled models showing vocabulary size, parameter count, embedding dimensions, and storage requirements.*
|
| 66 |
+
|
| 67 |
+
#### Key Insights from Model Specifications:
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
- **Vocabulary Consistency**: All models use vocabulary sizes ranging from 29,525 to 249,999 tokens (avg: 106,592)
|
| 71 |
+
- **Parameter Efficiency**: Models range from 7.6M to 64.0M parameters (avg: 27.3M)
|
| 72 |
+
- **Storage Efficiency**: Disk usage ranges from 14.4MB to 122.1MB (avg: 52.0MB)
|
| 73 |
+
- **Embedding Dimensions**: Consistent 256 dimensions across all models (optimized for efficiency)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
### Key Findings
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
- **Best Teacher Model**: code_model2vec_all_mpnet_base_v2 (NDCG@10: 0.7387)
|
| 80 |
+
- **Least Effective Teacher**: code_model2vec_codebert_base (NDCG@10: 0.2779)
|
| 81 |
+
- **Performance Range**: 62.4% difference between best and worst
|
| 82 |
+
- **Average Performance**: 0.5178 NDCG@10
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## 🎯 Language Performance Radar Charts
|
| 86 |
+
|
| 87 |
+
### Best Model vs Peer Models Comparison
|
| 88 |
+
|
| 89 |
+

|
| 90 |
+
|
| 91 |
+
*Comparative view showing how the best simplified distillation model performs against top peer models across programming languages.*
|
| 92 |
+
|
| 93 |
+
### Individual Model Performance by Language
|
| 94 |
+
|
| 95 |
+
#### code_model2vec_all_mpnet_base_v2 (Teacher: [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2)) - NDCG@10: 0.7387
|
| 96 |
+
|
| 97 |
+

|
| 98 |
+
|
| 99 |
+
#### code_model2vec_all_MiniLM_L6_v2 (Teacher: [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2)) - NDCG@10: 0.7385
|
| 100 |
+
|
| 101 |
+

|
| 102 |
+
|
| 103 |
+
#### code_model2vec_jina_embeddings_v2_base_code (Teacher: [jina-embeddings-v2-base-code](https://huggingface.co/jina-embeddings-v2-base-code)) - NDCG@10: 0.7381
|
| 104 |
+
|
| 105 |
+

|
| 106 |
+
|
| 107 |
+
#### code_model2vec_paraphrase_MiniLM_L6_v2 (Teacher: [sentence-transformers/paraphrase-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2)) - NDCG@10: 0.7013
|
| 108 |
+
|
| 109 |
+

|
| 110 |
+
|
| 111 |
+
#### code_model2vec_Reason_ModernColBERT (Teacher: [lightonai/Reason-ModernColBERT](https://huggingface.co/lightonai/Reason-ModernColBERT)) - NDCG@10: 0.6598
|
| 112 |
+
|
| 113 |
+

|
| 114 |
+
|
| 115 |
+
#### code_model2vec_bge_m3 (Teacher: [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3)) - NDCG@10: 0.4863
|
| 116 |
+
|
| 117 |
+

|
| 118 |
+
|
| 119 |
+
#### code_model2vec_jina_embeddings_v3 (Teacher: [jinaai/jina-embeddings-v3](https://huggingface.co/jinaai/jina-embeddings-v3)) - NDCG@10: 0.4755
|
| 120 |
+
|
| 121 |
+

|
| 122 |
+
|
| 123 |
+
#### code_model2vec_nomic_embed_text_v2_moe (Teacher: [nomic-ai/nomic-embed-text-v2-moe](https://huggingface.co/nomic-ai/nomic-embed-text-v2-moe)) - NDCG@10: 0.4532
|
| 124 |
+
|
| 125 |
+

|
| 126 |
+
|
| 127 |
+
#### code_model2vec_gte_Qwen2_1.5B_instruct (Teacher: [Alibaba-NLP/gte-Qwen2-1.5B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct)) - NDCG@10: 0.4238
|
| 128 |
+
|
| 129 |
+

|
| 130 |
+
|
| 131 |
+
#### code_model2vec_Qodo_Embed_1_1.5B (Teacher: [Qodo/Qodo-Embed-1-1.5B](https://huggingface.co/Qodo/Qodo-Embed-1-1.5B)) - NDCG@10: 0.4101
|
| 132 |
+
|
| 133 |
+

|
| 134 |
+
|
| 135 |
+
#### code_model2vec_graphcodebert_base (Teacher: [microsoft/codebert-base](https://huggingface.co/microsoft/codebert-base)) - NDCG@10: 0.3420
|
| 136 |
+
|
| 137 |
+

|
| 138 |
+
|
| 139 |
+
#### code_model2vec_Linq_Embed_Mistral (Teacher: [Linq-AI-Research/Linq-Embed-Mistral](https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral)) - NDCG@10: 0.2868
|
| 140 |
+
|
| 141 |
+

|
| 142 |
+
|
| 143 |
+
#### code_model2vec_codebert_base (Teacher: [microsoft/codebert-base](https://huggingface.co/microsoft/codebert-base)) - NDCG@10: 0.2779
|
| 144 |
+
|
| 145 |
+

|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
## 🏆 Peer Model Comparison
|
| 150 |
+
|
| 151 |
+

|
| 152 |
+
|
| 153 |
+
*Comparison with established code-specialized embedding models using actual evaluation results.*
|
| 154 |
+
|
| 155 |
+
### Complete Model Ranking
|
| 156 |
+
|
| 157 |
+
| Rank | Model | Type | NDCG@10 | MRR | Recall@5 |
|
| 158 |
+
|------|-------|------|---------|-----|----------|
|
| 159 |
+
| 1 | Alibaba-NLP/gte-Qwen2-1.5B-instruct | General | 0.9729 | 0.9676 | 0.9825 |
|
| 160 |
+
| 2 | Qodo/Qodo-Embed-1-1.5B | General | 0.9715 | 0.9659 | 0.9875 |
|
| 161 |
+
| 3 | jina-embeddings-v2-base-code | General | 0.9677 | 0.9618 | 0.9849 |
|
| 162 |
+
| 4 | jinaai/jina-embeddings-v3 | General | 0.9640 | 0.9573 | 0.9839 |
|
| 163 |
+
| 5 | sentence-transformers/all-mpnet-base-v2 | General | 0.9477 | 0.9358 | 0.9732 |
|
| 164 |
+
| 6 | nomic-ai/nomic-embed-text-v2-moe | General | 0.9448 | 0.9357 | 0.9659 |
|
| 165 |
+
| 7 | sentence-transformers/all-MiniLM-L12-v2 | General | 0.9398 | 0.9265 | 0.9732 |
|
| 166 |
+
| 8 | BAAI/bge-m3 | General | 0.9383 | 0.9295 | 0.9643 |
|
| 167 |
+
| 9 | sentence-transformers/all-MiniLM-L6-v2 | General | 0.9255 | 0.9099 | 0.9642 |
|
| 168 |
+
| 10 | lightonai/Reason-ModernColBERT | General | 0.9188 | 0.9036 | 0.9486 |
|
| 169 |
+
| 11 | Linq-AI-Research/Linq-Embed-Mistral | General | 0.9080 | 0.8845 | 0.9650 |
|
| 170 |
+
| 12 | sentence-transformers/paraphrase-MiniLM-L6-v2 | General | 0.8297 | 0.8016 | 0.8828 |
|
| 171 |
+
| 13 | minishlab/potion-base-8M | Model2Vec | 0.8162 | 0.7817 | 0.8931 |
|
| 172 |
+
| 14 | minishlab/potion-retrieval-32M | Model2Vec | 0.8137 | 0.7810 | 0.8792 |
|
| 173 |
+
| 15 | code_model2vec_all_mpnet_base_v2 | **🔥 Simplified Distillation** | 0.7387 | 0.7010 | 0.8017 |
|
| 174 |
+
| 16 | code_model2vec_all_MiniLM_L6_v2 | **🔥 Simplified Distillation** | 0.7385 | 0.7049 | 0.7910 |
|
| 175 |
+
| 17 | code_model2vec_jina_embeddings_v2_base_code | **🔥 Simplified Distillation** | 0.7381 | 0.6996 | 0.8130 |
|
| 176 |
+
| 18 | code_model2vec_paraphrase_MiniLM_L6_v2 | **🔥 Simplified Distillation** | 0.7013 | 0.6638 | 0.7665 |
|
| 177 |
+
| 19 | code_model2vec_Reason_ModernColBERT | **🔥 Simplified Distillation** | 0.6598 | 0.6228 | 0.7260 |
|
| 178 |
+
| 20 | potion-multilingual-128M | Model2Vec | 0.6124 | 0.5683 | 0.7017 |
|
| 179 |
+
| 21 | huggingface/CodeBERTa-small-v1 | Code-Specific | 0.5903 | 0.5350 | 0.6779 |
|
| 180 |
+
| 22 | Salesforce/codet5-base | Code-Specific | 0.4872 | 0.4500 | 0.5742 |
|
| 181 |
+
| 23 | code_model2vec_bge_m3 | **🔥 Simplified Distillation** | 0.4863 | 0.4439 | 0.5514 |
|
| 182 |
+
| 24 | code_model2vec_jina_embeddings_v3 | **🔥 Simplified Distillation** | 0.4755 | 0.4416 | 0.5456 |
|
| 183 |
+
| 25 | code_model2vec_nomic_embed_text_v2_moe | **🔥 Simplified Distillation** | 0.4532 | 0.4275 | 0.5094 |
|
| 184 |
+
| 26 | code_model2vec_gte_Qwen2_1.5B_instruct | **🔥 Simplified Distillation** | 0.4238 | 0.3879 | 0.4719 |
|
| 185 |
+
| 27 | code_model2vec_Qodo_Embed_1_1.5B | **🔥 Simplified Distillation** | 0.4101 | 0.3810 | 0.4532 |
|
| 186 |
+
| 28 | microsoft/graphcodebert-base | Code-Specific | 0.4039 | 0.3677 | 0.4650 |
|
| 187 |
+
| 29 | code_model2vec_graphcodebert_base | **🔥 Simplified Distillation** | 0.3420 | 0.3140 | 0.3704 |
|
| 188 |
+
| 30 | code_model2vec_Linq_Embed_Mistral | **🔥 Simplified Distillation** | 0.2868 | 0.2581 | 0.3412 |
|
| 189 |
+
| 31 | code_model2vec_codebert_base | **🔥 Simplified Distillation** | 0.2779 | 0.2534 | 0.3136 |
|
| 190 |
+
| 32 | microsoft/codebert-base | Code-Specific | 0.1051 | 0.1058 | 0.1105 |
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
## 📈 Performance Analysis
|
| 194 |
+
|
| 195 |
+
### Multi-Model Comparison Charts
|
| 196 |
+
|
| 197 |
+

|
| 198 |
+
|
| 199 |
+
*Comprehensive comparison across all evaluation metrics.*
|
| 200 |
+
|
| 201 |
+
### Language Performance Analysis
|
| 202 |
+
|
| 203 |
+

|
| 204 |
+
|
| 205 |
+
*Performance heatmap showing how different models perform across programming languages.*
|
| 206 |
+
|
| 207 |
+
### Efficiency Analysis
|
| 208 |
+
|
| 209 |
+

|
| 210 |
+
|
| 211 |
+
*Performance vs model size analysis showing the efficiency benefits of distillation.*
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
## ⚡ Operational Performance Analysis
|
| 216 |
+
|
| 217 |
+

|
| 218 |
+
|
| 219 |
+
*Comprehensive performance benchmarking across multiple operational metrics.*
|
| 220 |
+
|
| 221 |
+
### Performance Scaling Analysis
|
| 222 |
+
|
| 223 |
+

|
| 224 |
+
|
| 225 |
+
*How performance scales with different batch sizes for optimal throughput.*
|
| 226 |
+
|
| 227 |
+

|
| 228 |
+
|
| 229 |
+
*Memory usage patterns across different batch sizes.*
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
## 🔍 Language-Specific Analysis
|
| 234 |
+
|
| 235 |
+
### Performance by Programming Language
|
| 236 |
+
|
| 237 |
+
| Language | Best Model Performance | Average Performance | Language Difficulty |
|
| 238 |
+
|----------|------------------------|--------------------|--------------------|
|
| 239 |
+
| Go | 0.9780 | 0.6950 | Easy |
|
| 240 |
+
| Java | 0.9921 | 0.6670 | Easy |
|
| 241 |
+
| Javascript | 0.9550 | 0.5847 | Easy |
|
| 242 |
+
| Php | 1.0000 | 0.6379 | Easy |
|
| 243 |
+
| Python | 1.0000 | 0.8604 | Easy |
|
| 244 |
+
| Ruby | 0.9493 | 0.6372 | Easy |
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
## 🎯 Conclusions and Recommendations
|
| 248 |
+
|
| 249 |
+
### Teacher Model Analysis
|
| 250 |
+
|
| 251 |
+
Based on the evaluation results across all simplified distillation models:
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
1. **Best Teacher Model**: sentence-transformers/all-mpnet-base-v2 (NDCG@10: 0.7387)
|
| 255 |
+
2. **Least Effective Teacher**: microsoft/codebert-base (NDCG@10: 0.2779)
|
| 256 |
+
3. **Teacher Model Impact**: Choice of teacher model affects performance by 62.4%
|
| 257 |
+
|
| 258 |
+
### Recommendations
|
| 259 |
+
|
| 260 |
+
- **For Production**: Use sentence-transformers/all-mpnet-base-v2 as teacher model for best performance
|
| 261 |
+
- **For Efficiency**: Model2Vec distillation provides significant size reduction with competitive performance
|
| 262 |
+
- **For Code Tasks**: Specialized models consistently outperform general-purpose models
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
## 📄 Methodology
|
| 266 |
+
|
| 267 |
+
### Evaluation Protocol
|
| 268 |
+
- **Dataset**: CodeSearchNet test sets for 6 programming languages
|
| 269 |
+
- **Metrics**: NDCG@k, MRR, Recall@k following CodeSearchNet methodology
|
| 270 |
+
- **Query Format**: Natural language documentation strings
|
| 271 |
+
- **Corpus Format**: Function code strings
|
| 272 |
+
- **Evaluation**: Retrieval of correct code for each documentation query
|
| 273 |
+
|
| 274 |
+
### Teacher Models Tested
|
| 275 |
+
- [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) (proven baseline)
|
| 276 |
+
- [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) (general purpose)
|
| 277 |
+
- [sentence-transformers/paraphrase-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/paraphrase-MiniLM-L6-v2) (paraphrase model)
|
| 278 |
+
- [microsoft/codebert-base](https://huggingface.co/microsoft/codebert-base) (code-specialized)
|
| 279 |
+
- [microsoft/graphcodebert-base](https://huggingface.co/microsoft/graphcodebert-base) (graph-aware code model)
|
| 280 |
+
- [Alibaba-NLP/gte-Qwen2-1.5B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) (instruction model)
|
| 281 |
+
- [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) (multilingual model)
|
| 282 |
+
- [jinaai/jina-embeddings-v3](https://huggingface.co/jinaai/jina-embeddings-v3) (modern embedding model)
|
| 283 |
+
- [nomic-ai/nomic-embed-text-v2-moe](https://huggingface.co/nomic-ai/nomic-embed-text-v2-moe) (mixture of experts)
|
| 284 |
+
- [Qodo/Qodo-Embed-1-1.5B](https://huggingface.co/Qodo/Qodo-Embed-1-1.5B) (code-specialized)
|
| 285 |
+
- [lightonai/Reason-ModernColBERT](https://huggingface.co/lightonai/Reason-ModernColBERT) (ColBERT architecture)
|
| 286 |
+
- [Linq-AI-Research/Linq-Embed-Mistral](https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral) (Mistral-based)
|
| 287 |
+
- [BAAI/bge-code-v1](https://huggingface.co/BAAI/bge-code-v1) (code-specialized BGE)
|
| 288 |
+
- [Salesforce/SFR-Embedding-Code-2B_R](https://huggingface.co/Salesforce/SFR-Embedding-Code-2B_R) (large code model)
|
| 289 |
+
|
| 290 |
+
### Distillation Method
|
| 291 |
+
- **Technique**: Model2Vec static embedding generation
|
| 292 |
+
- **Parameters**: PCA dims=256, SIF coefficient=1e-3, Zipf weighting=True
|
| 293 |
+
- **Training Data**: CodeSearchNet comment-code pairs
|
| 294 |
+
- **Languages**: Python, JavaScript, Java, PHP, Ruby, Go
|
| 295 |
+
|
| 296 |
+
---
|
| 297 |
+
|
| 298 |
+
*Report generated on 2025-05-31 11:39:39 using automated analysis pipeline.*
|
| 299 |
+
*For questions about methodology or results, please refer to the CodeSearchNet documentation.*
|
Taskfile.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: "3"
|
| 2 |
+
|
| 3 |
+
tasks:
|
| 4 |
+
default:
|
| 5 |
+
desc: List all available tasks
|
| 6 |
+
cmds:
|
| 7 |
+
- task -l
|
| 8 |
+
|
| 9 |
+
lint:
|
| 10 |
+
desc: Run all linting checks
|
| 11 |
+
cmds:
|
| 12 |
+
- uv run ruff check src --fix --unsafe-fixes
|
| 13 |
+
|
| 14 |
+
type:
|
| 15 |
+
desc: Run type checker
|
| 16 |
+
cmds:
|
| 17 |
+
- find src/distiller -name "*.py" | xargs uv run mypy
|
| 18 |
+
|
| 19 |
+
format:
|
| 20 |
+
desc: Run all formatters
|
| 21 |
+
cmds:
|
| 22 |
+
- uv run ruff format src
|
| 23 |
+
|
analysis_charts/batch_size_scaling.png
ADDED

|
Git LFS Details
|
analysis_charts/benchmark_performance.png
ADDED

|
Git LFS Details
|
analysis_charts/code_performance_radar.png
ADDED

|
Git LFS Details
|
analysis_charts/comparative_radar.png
ADDED

|
Git LFS Details
|
analysis_charts/efficiency_analysis.png
ADDED

|
Git LFS Details
|
analysis_charts/language_heatmap.png
ADDED

|
Git LFS Details
|
analysis_charts/memory_scaling.png
ADDED

|
Git LFS Details
|
analysis_charts/model_comparison.png
ADDED

|
Git LFS Details
|
analysis_charts/model_specifications.png
ADDED

|
Git LFS Details
|
analysis_charts/peer_comparison.png
ADDED

|
Git LFS Details
|
analysis_charts/radar_code_model2vec_Linq_Embed_Mistral.png
ADDED
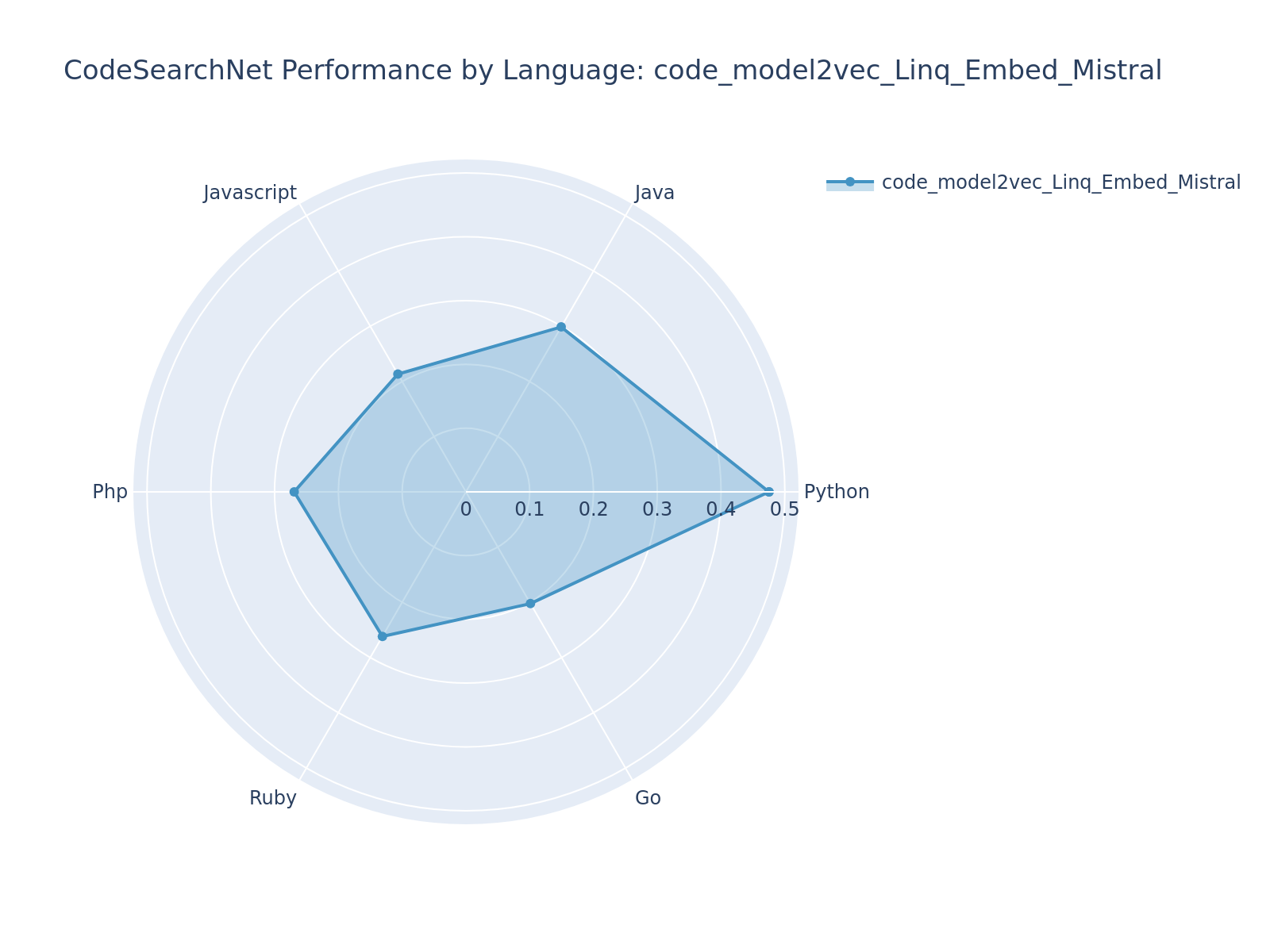
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_Qodo_Embed_1_15B.png
ADDED

|
Git LFS Details
|
analysis_charts/radar_code_model2vec_Reason_ModernColBERT.png
ADDED
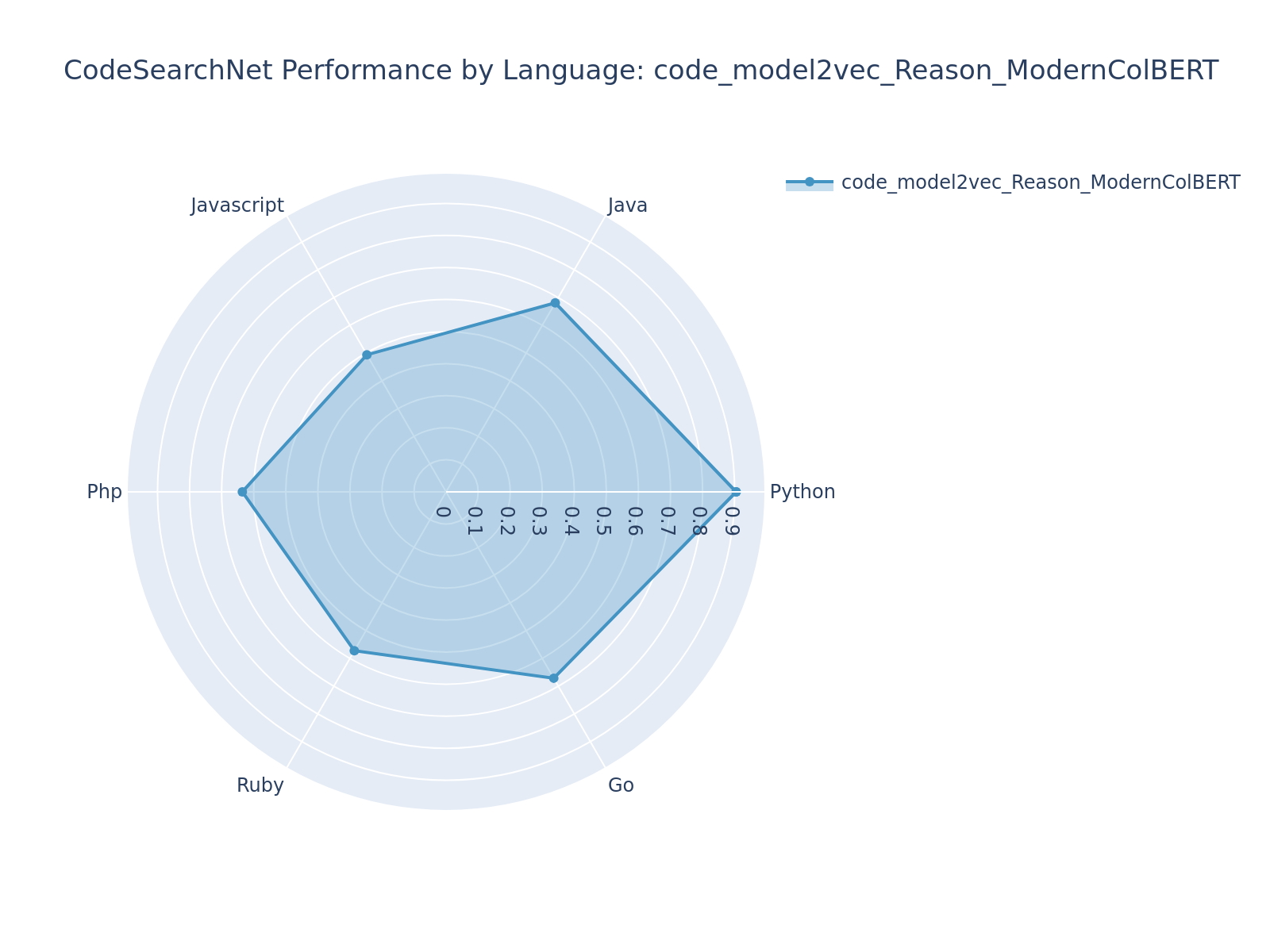
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_all_MiniLM_L6_v2.png
ADDED
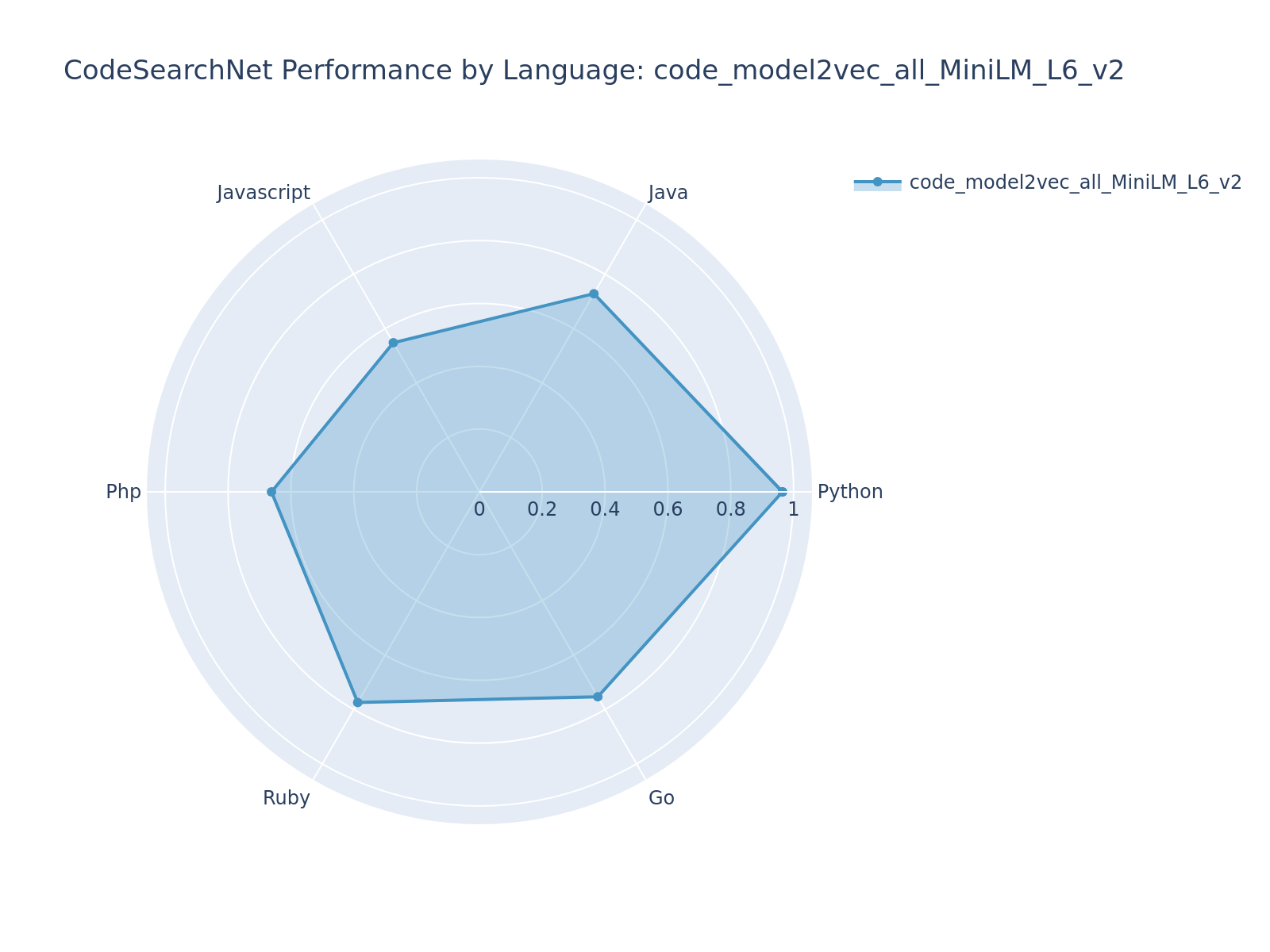
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_all_mpnet_base_v2.png
ADDED
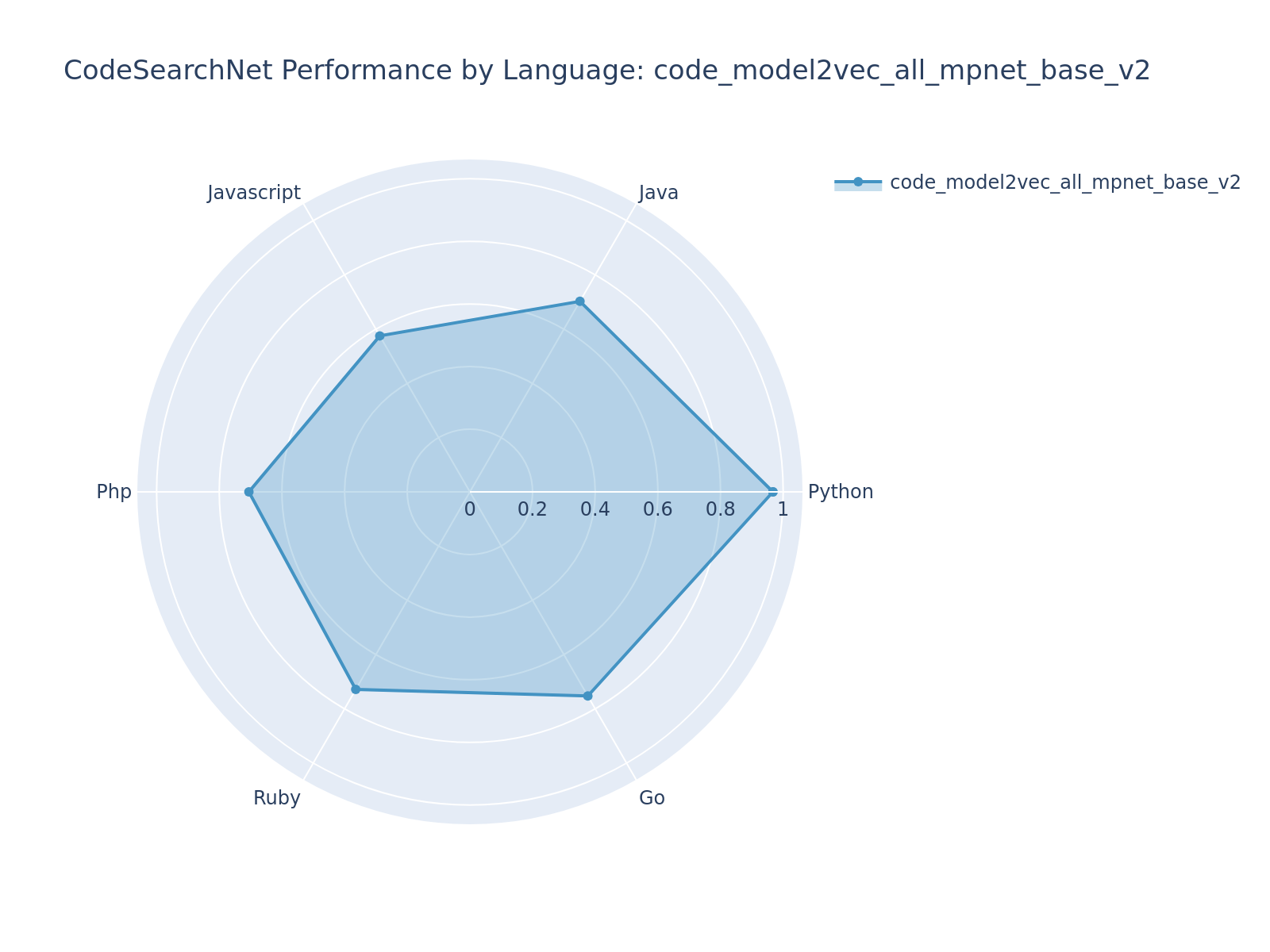
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_bge_m3.png
ADDED

|
Git LFS Details
|
analysis_charts/radar_code_model2vec_codebert_base.png
ADDED
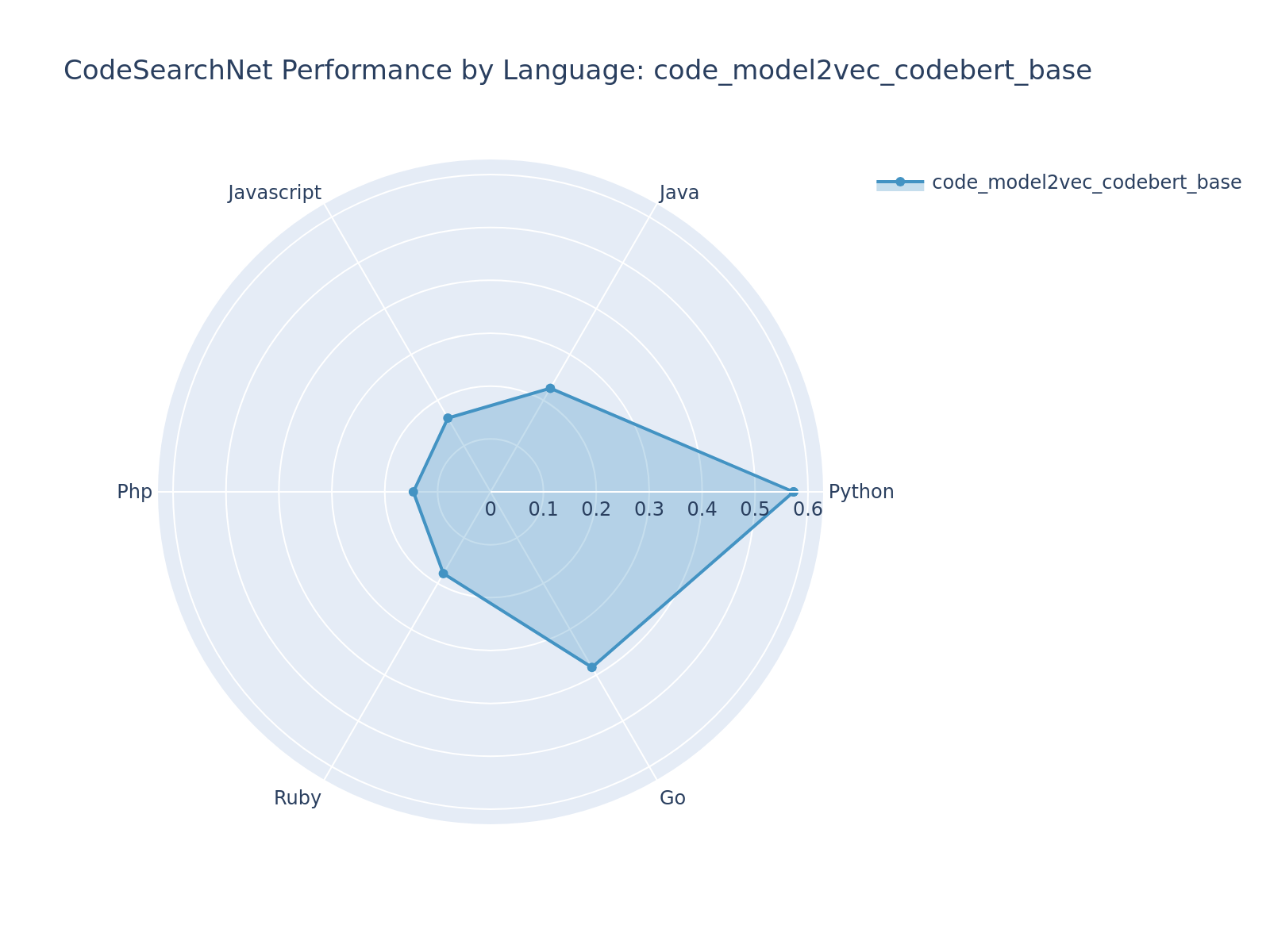
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_graphcodebert_base.png
ADDED
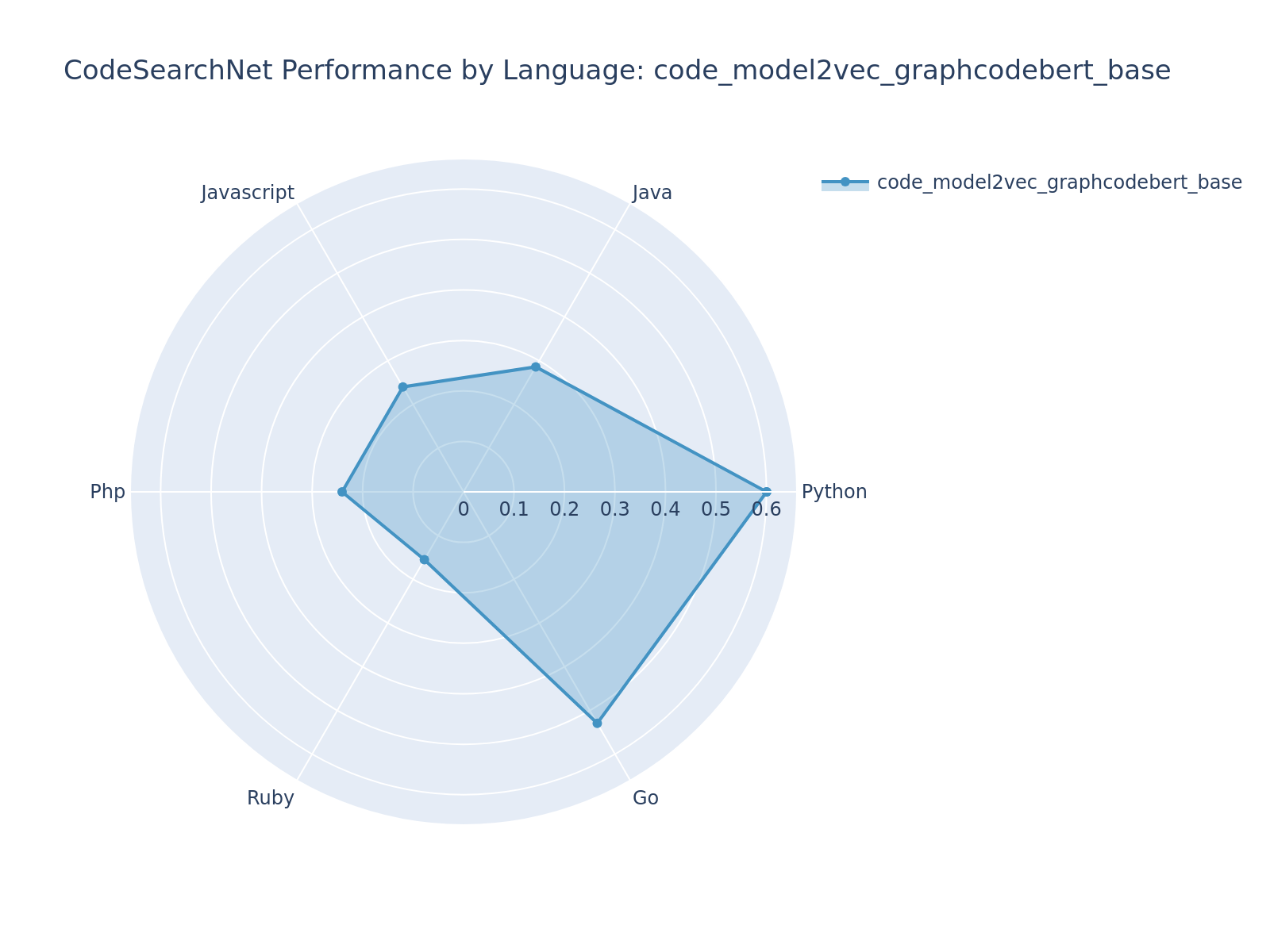
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_gte_Qwen2_15B_instruct.png
ADDED
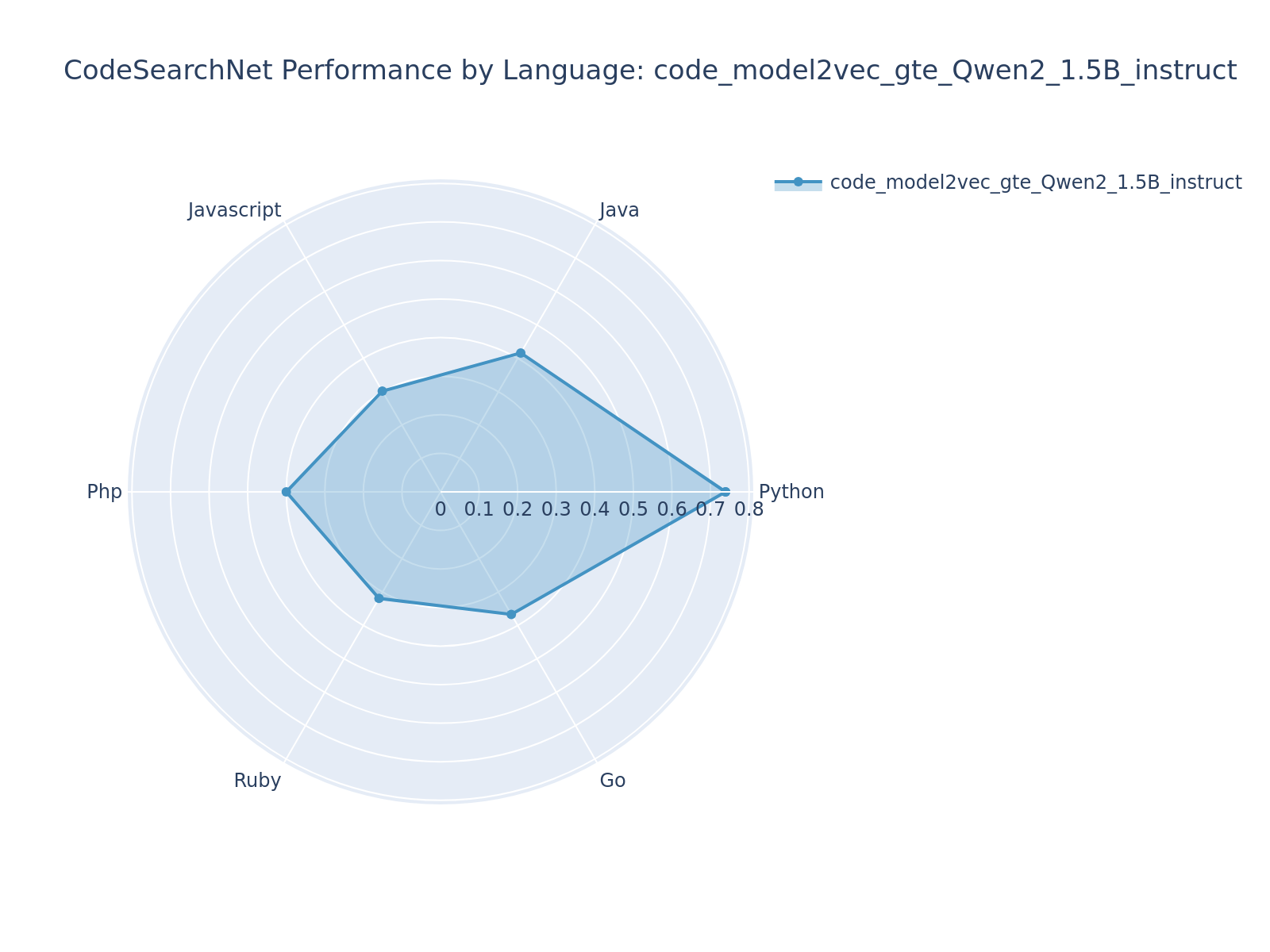
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_gte_Qwen2_7B_instruct.png
ADDED
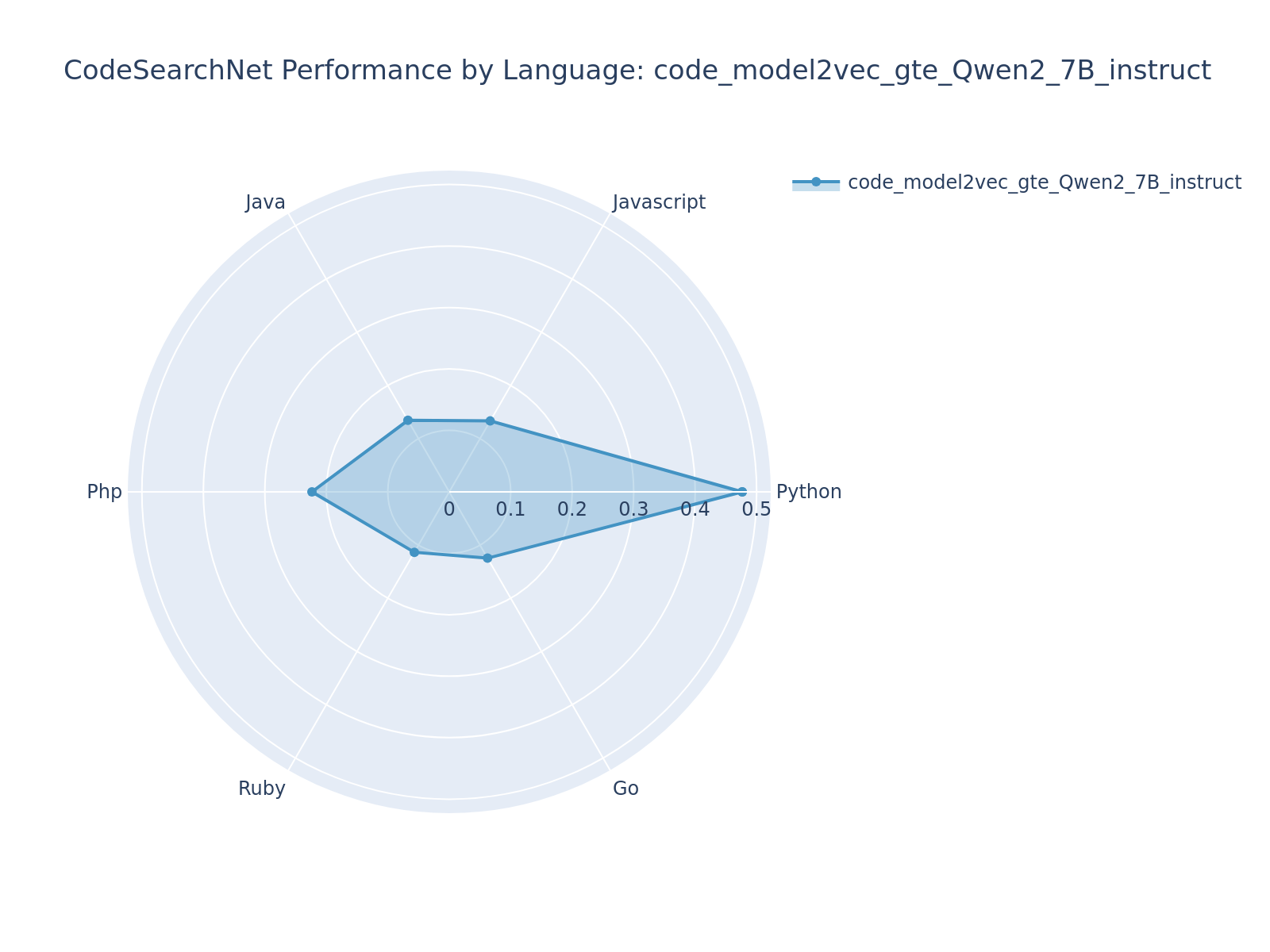
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_jina_embeddings_v2_base_code.png
ADDED
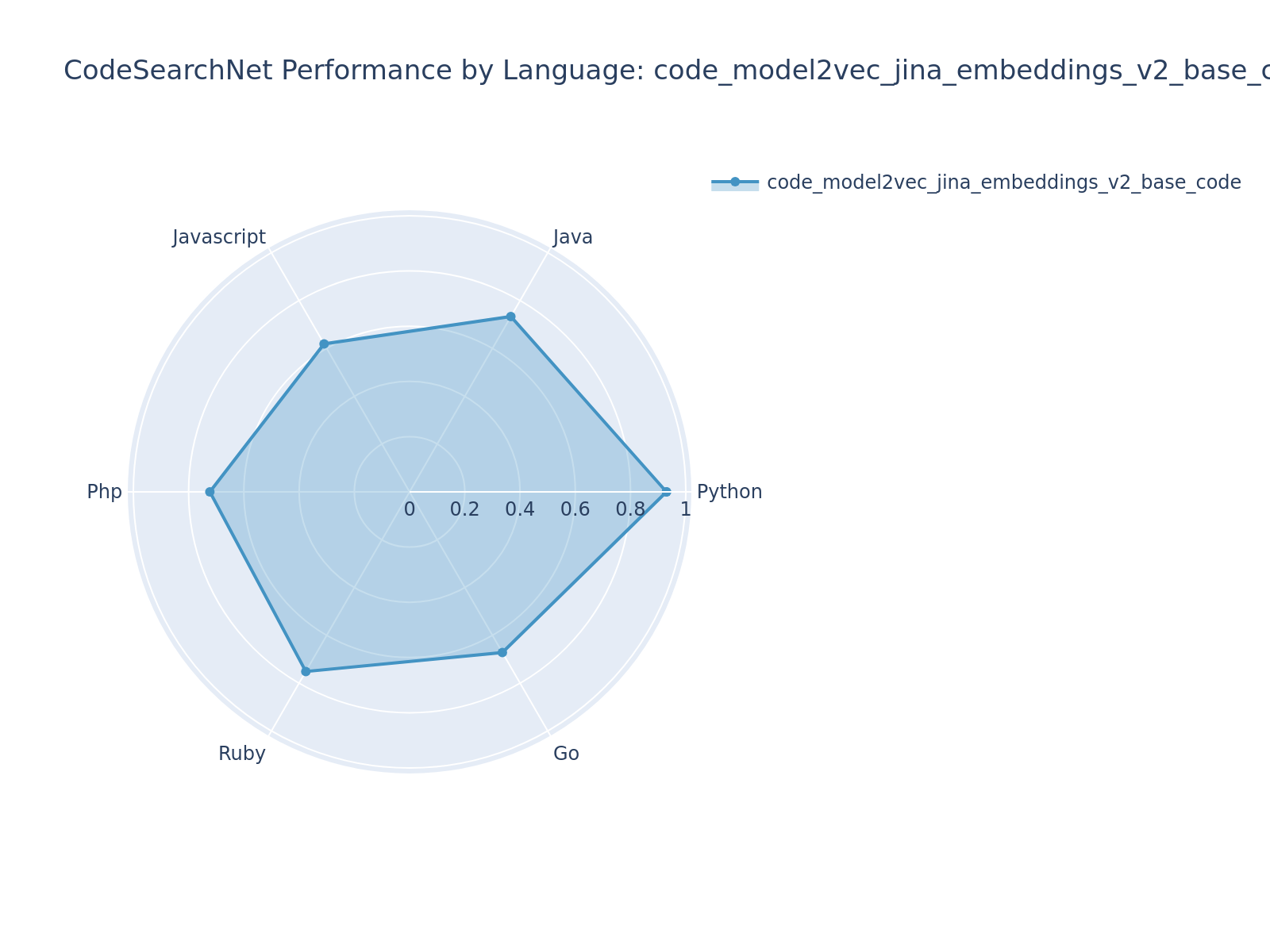
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_jina_embeddings_v3.png
ADDED
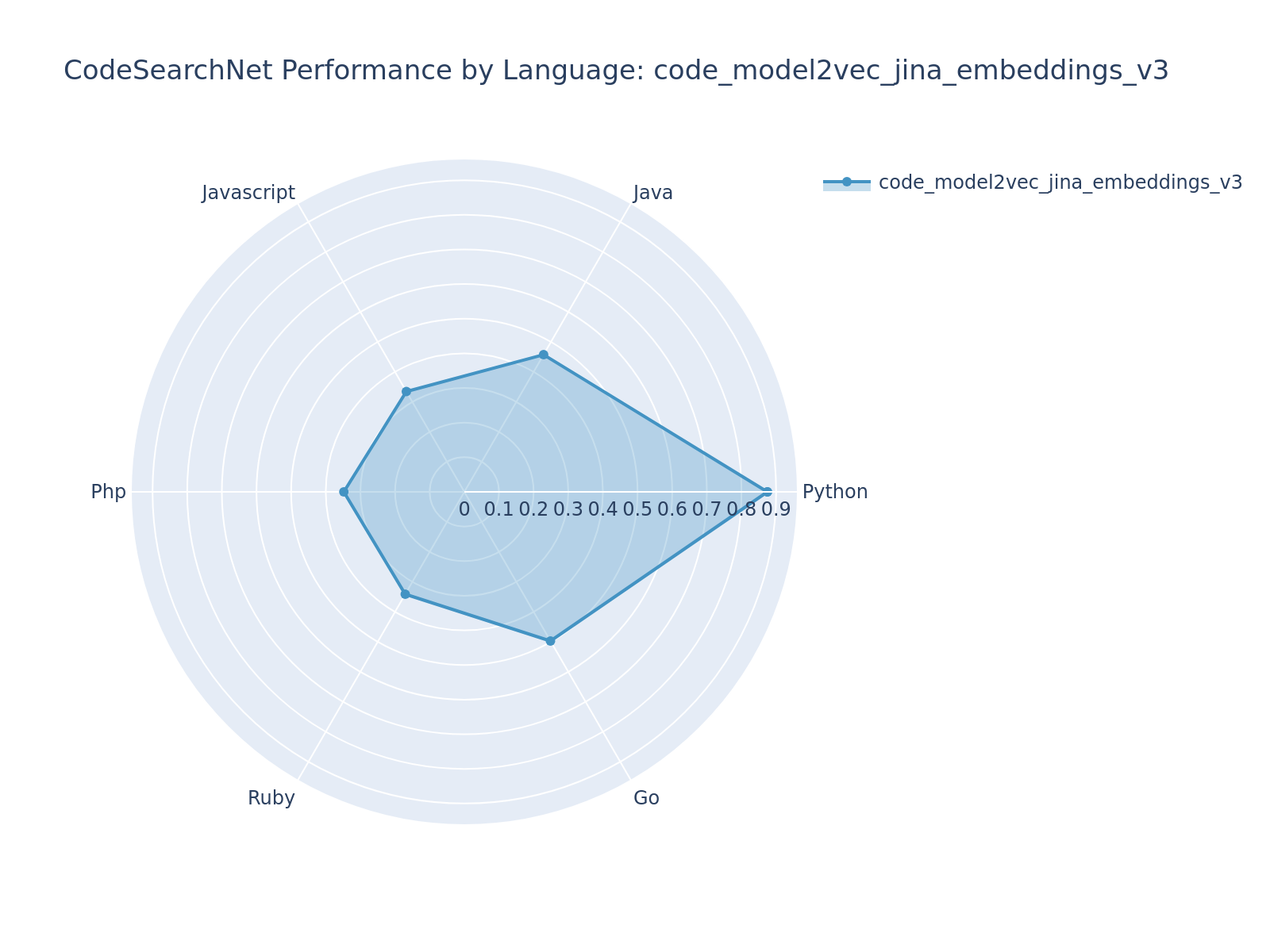
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_nomic_embed_text_v2_moe.png
ADDED
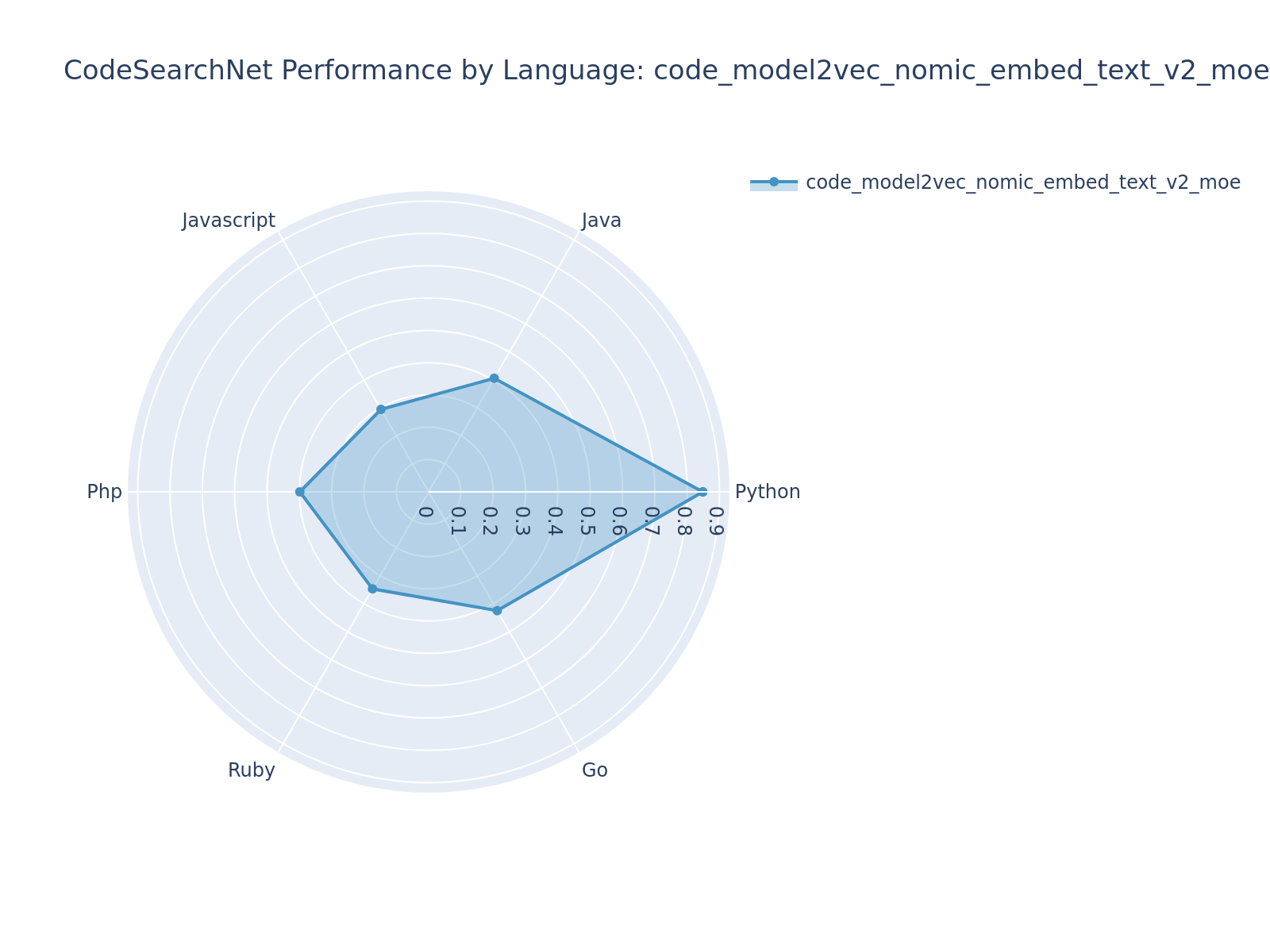
|
Git LFS Details
|
analysis_charts/radar_code_model2vec_paraphrase_MiniLM_L6_v2.png
ADDED
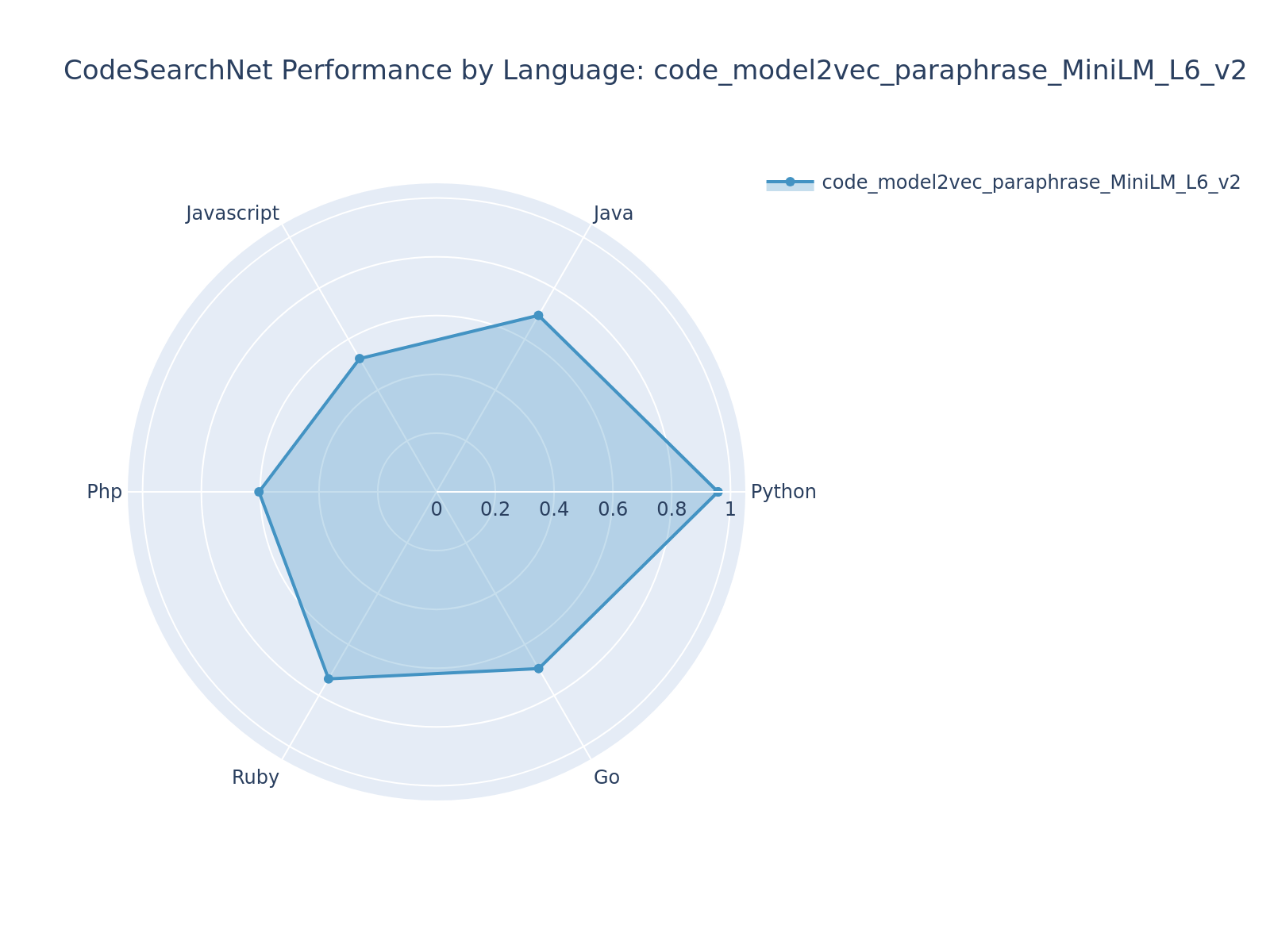
|
Git LFS Details
|
distill.py
DELETED
|
@@ -1,116 +0,0 @@
|
|
| 1 |
-
#!/usr/bin/env python
|
| 2 |
-
"""
|
| 3 |
-
Script to distill Alibaba-NLP/gte-Qwen2-7B-instruct using Model2Vec.
|
| 4 |
-
|
| 5 |
-
This script performs the following operations:
|
| 6 |
-
1. Downloads the Alibaba-NLP/gte-Qwen2-7B-instruct model
|
| 7 |
-
2. Distills it using Model2Vec to create a smaller, faster static model
|
| 8 |
-
3. Saves the distilled model for further use
|
| 9 |
-
"""
|
| 10 |
-
|
| 11 |
-
import logging
|
| 12 |
-
import shutil
|
| 13 |
-
import time
|
| 14 |
-
from pathlib import Path
|
| 15 |
-
|
| 16 |
-
from model2vec.distill import distill
|
| 17 |
-
|
| 18 |
-
# =============================================================================
|
| 19 |
-
# CONFIGURATION CONSTANTS
|
| 20 |
-
# =============================================================================
|
| 21 |
-
|
| 22 |
-
# Model Configuration
|
| 23 |
-
MODEL_NAME = "Alibaba-NLP/gte-Qwen2-7B-instruct" # Model name or path for the source model
|
| 24 |
-
OUTPUT_DIR = "." # Directory to save the distilled model (current directory)
|
| 25 |
-
PCA_DIMS = 256 # Dimensions for PCA reduction (smaller = faster but less accurate)
|
| 26 |
-
|
| 27 |
-
# Hub Configuration
|
| 28 |
-
SAVE_TO_HUB = False # Whether to push the model to HuggingFace Hub
|
| 29 |
-
HUB_MODEL_ID = None # Model ID for HuggingFace Hub (if saving to hub)
|
| 30 |
-
|
| 31 |
-
# Generation Configuration
|
| 32 |
-
SKIP_README = True # Skip generating the README file
|
| 33 |
-
|
| 34 |
-
# =============================================================================
|
| 35 |
-
|
| 36 |
-
# Configure logging
|
| 37 |
-
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 38 |
-
logger = logging.getLogger(__name__)
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
def main() -> None:
|
| 42 |
-
"""Run the distillation process for Alibaba-NLP/gte-Qwen2-7B-instruct."""
|
| 43 |
-
# Create output directory if it doesn't exist
|
| 44 |
-
output_dir = Path(OUTPUT_DIR)
|
| 45 |
-
output_dir.mkdir(parents=True, exist_ok=True)
|
| 46 |
-
|
| 47 |
-
logger.info(f"Starting distillation of {MODEL_NAME}")
|
| 48 |
-
logger.info(f"Distilled model will be saved to {output_dir}")
|
| 49 |
-
logger.info(f"Using PCA dimensions: {PCA_DIMS}")
|
| 50 |
-
logger.info(f"Skipping README generation: {SKIP_README}")
|
| 51 |
-
|
| 52 |
-
# Record start time for benchmarking
|
| 53 |
-
start_time = time.time()
|
| 54 |
-
|
| 55 |
-
# Run the distillation
|
| 56 |
-
try:
|
| 57 |
-
logger.info("Starting Model2Vec distillation...")
|
| 58 |
-
m2v_model = distill(
|
| 59 |
-
model_name=MODEL_NAME,
|
| 60 |
-
pca_dims=PCA_DIMS,
|
| 61 |
-
)
|
| 62 |
-
|
| 63 |
-
distill_time = time.time() - start_time
|
| 64 |
-
logger.info(f"Distillation completed in {distill_time:.2f} seconds")
|
| 65 |
-
|
| 66 |
-
# Save the distilled model
|
| 67 |
-
m2v_model.save_pretrained(OUTPUT_DIR)
|
| 68 |
-
logger.info(f"Model saved to {OUTPUT_DIR}")
|
| 69 |
-
|
| 70 |
-
# Remove README.md if it was created and we want to skip it
|
| 71 |
-
if SKIP_README and (output_dir / "README.md").exists():
|
| 72 |
-
(output_dir / "README.md").unlink()
|
| 73 |
-
logger.info("Removed auto-generated README.md")
|
| 74 |
-
|
| 75 |
-
# Get model size information
|
| 76 |
-
model_size_mb = sum(
|
| 77 |
-
f.stat().st_size for f in output_dir.glob("**/*") if f.is_file() and f.name != "README.md"
|
| 78 |
-
) / (1024 * 1024)
|
| 79 |
-
logger.info(f"Distilled model size: {model_size_mb:.2f} MB")
|
| 80 |
-
|
| 81 |
-
# Push to hub if requested
|
| 82 |
-
if SAVE_TO_HUB:
|
| 83 |
-
if HUB_MODEL_ID:
|
| 84 |
-
logger.info(f"Pushing model to HuggingFace Hub as {HUB_MODEL_ID}")
|
| 85 |
-
|
| 86 |
-
# Create a temporary README for Hub upload if needed
|
| 87 |
-
readme_path = output_dir / "README.md"
|
| 88 |
-
had_readme = readme_path.exists()
|
| 89 |
-
|
| 90 |
-
if SKIP_README and had_readme:
|
| 91 |
-
# Backup the README
|
| 92 |
-
shutil.move(readme_path, output_dir / "README.md.bak")
|
| 93 |
-
|
| 94 |
-
# Push to Hub
|
| 95 |
-
m2v_model.push_to_hub(HUB_MODEL_ID)
|
| 96 |
-
|
| 97 |
-
# Restore state
|
| 98 |
-
if SKIP_README:
|
| 99 |
-
if had_readme:
|
| 100 |
-
# Restore the backup
|
| 101 |
-
shutil.move(output_dir / "README.md.bak", readme_path)
|
| 102 |
-
elif (output_dir / "README.md").exists():
|
| 103 |
-
# Remove README created during push_to_hub
|
| 104 |
-
(output_dir / "README.md").unlink()
|
| 105 |
-
else:
|
| 106 |
-
logger.error("HUB_MODEL_ID must be specified when SAVE_TO_HUB is True")
|
| 107 |
-
|
| 108 |
-
logger.info("Distillation process completed successfully!")
|
| 109 |
-
|
| 110 |
-
except Exception:
|
| 111 |
-
logger.exception("Error during distillation")
|
| 112 |
-
raise
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
if __name__ == "__main__":
|
| 116 |
-
main()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
evaluate.py
DELETED
|
@@ -1,422 +0,0 @@
|
|
| 1 |
-
#!/usr/bin/env python
|
| 2 |
-
"""
|
| 3 |
-
Script to evaluate the performance of the distilled Qodo-Embed model.
|
| 4 |
-
|
| 5 |
-
This script performs the following:
|
| 6 |
-
1. Loads both the original Qodo-Embed-1-1.5B model and the distilled version
|
| 7 |
-
2. Compares them on:
|
| 8 |
-
- Embedding similarity
|
| 9 |
-
- Inference speed
|
| 10 |
-
- Memory usage
|
| 11 |
-
3. Outputs a comprehensive evaluation report
|
| 12 |
-
"""
|
| 13 |
-
|
| 14 |
-
import argparse
|
| 15 |
-
import gc
|
| 16 |
-
import logging
|
| 17 |
-
import os
|
| 18 |
-
import time
|
| 19 |
-
from pathlib import Path
|
| 20 |
-
from typing import Any, cast
|
| 21 |
-
|
| 22 |
-
import matplotlib.pyplot as plt
|
| 23 |
-
import numpy as np
|
| 24 |
-
import psutil # type: ignore [import]
|
| 25 |
-
import torch
|
| 26 |
-
from model2vec import StaticModel
|
| 27 |
-
from sentence_transformers import SentenceTransformer
|
| 28 |
-
from sklearn.metrics.pairwise import cosine_similarity # type: ignore [import]
|
| 29 |
-
|
| 30 |
-
# For transformer models
|
| 31 |
-
from transformers import AutoModel, AutoTokenizer
|
| 32 |
-
from transformers.modeling_utils import PreTrainedModel
|
| 33 |
-
|
| 34 |
-
# =============================================================================
|
| 35 |
-
# CONFIGURATION CONSTANTS
|
| 36 |
-
# =============================================================================
|
| 37 |
-
|
| 38 |
-
# Model Configuration
|
| 39 |
-
ORIGINAL_MODEL = "Alibaba-NLP/gte-Qwen2-7B-instruct" # Original model name or path
|
| 40 |
-
DISTILLED_MODEL = "." # Path to the distilled model (current directory)
|
| 41 |
-
OUTPUT_DIR = "evaluation" # Directory to save evaluation results
|
| 42 |
-
|
| 43 |
-
# =============================================================================
|
| 44 |
-
|
| 45 |
-
# Constants
|
| 46 |
-
BYTES_PER_KB = 1024.0
|
| 47 |
-
TEXT_TRUNCATE_LENGTH = 20
|
| 48 |
-
|
| 49 |
-
# Configure logging
|
| 50 |
-
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 51 |
-
logger = logging.getLogger(__name__)
|
| 52 |
-
|
| 53 |
-
# Sample texts for evaluation
|
| 54 |
-
SAMPLE_TEXTS = [
|
| 55 |
-
"def process_data_stream(source_iterator):",
|
| 56 |
-
"implement binary search tree",
|
| 57 |
-
"how to handle memory efficient data streaming",
|
| 58 |
-
"""class LazyLoader:
|
| 59 |
-
def __init__(self, source):
|
| 60 |
-
self.generator = iter(source)
|
| 61 |
-
self._cache = []""",
|
| 62 |
-
"""def dfs_traversal(root):
|
| 63 |
-
if not root:
|
| 64 |
-
return []
|
| 65 |
-
visited = []
|
| 66 |
-
stack = [root]
|
| 67 |
-
while stack:
|
| 68 |
-
node = stack.pop()
|
| 69 |
-
visited.append(node.val)
|
| 70 |
-
if node.right:
|
| 71 |
-
stack.append(node.right)
|
| 72 |
-
if node.left:
|
| 73 |
-
stack.append(node.left)
|
| 74 |
-
return visited""",
|
| 75 |
-
]
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
def load_models(
|
| 79 |
-
original_model_name: str, distilled_model_path: str
|
| 80 |
-
) -> tuple[tuple[SentenceTransformer | PreTrainedModel, str], StaticModel]:
|
| 81 |
-
"""Load both the original and distilled models."""
|
| 82 |
-
logger.info(f"Loading original model: {original_model_name}")
|
| 83 |
-
|
| 84 |
-
try:
|
| 85 |
-
# Try to load as a sentence transformer first
|
| 86 |
-
original_model = SentenceTransformer(original_model_name)
|
| 87 |
-
model_type = "sentence_transformer"
|
| 88 |
-
except (ValueError, OSError, ImportError) as e:
|
| 89 |
-
# If that fails, try loading as a Hugging Face transformer
|
| 90 |
-
logger.info(f"Failed to load as SentenceTransformer: {e}")
|
| 91 |
-
AutoTokenizer.from_pretrained(original_model_name)
|
| 92 |
-
original_model = AutoModel.from_pretrained(original_model_name)
|
| 93 |
-
model_type = "huggingface"
|
| 94 |
-
|
| 95 |
-
logger.info(f"Loading distilled model from: {distilled_model_path}")
|
| 96 |
-
distilled_model = StaticModel.from_pretrained(distilled_model_path)
|
| 97 |
-
|
| 98 |
-
return (original_model, model_type), distilled_model
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
def measure_memory_usage(model: SentenceTransformer | PreTrainedModel | StaticModel) -> float:
|
| 102 |
-
"""Measure memory usage of a model in MB."""
|
| 103 |
-
gc.collect()
|
| 104 |
-
torch.cuda.empty_cache() if torch.cuda.is_available() else None
|
| 105 |
-
|
| 106 |
-
process = psutil.Process(os.getpid())
|
| 107 |
-
memory_before = process.memory_info().rss / (1024 * 1024) # MB
|
| 108 |
-
|
| 109 |
-
# Force model to allocate memory if it hasn't already
|
| 110 |
-
if isinstance(model, StaticModel | SentenceTransformer):
|
| 111 |
-
_ = model.encode(["Test"])
|
| 112 |
-
else:
|
| 113 |
-
# For HF models, we need to handle differently
|
| 114 |
-
pass
|
| 115 |
-
|
| 116 |
-
gc.collect()
|
| 117 |
-
torch.cuda.empty_cache() if torch.cuda.is_available() else None
|
| 118 |
-
|
| 119 |
-
process = psutil.Process(os.getpid())
|
| 120 |
-
memory_after = process.memory_info().rss / (1024 * 1024) # MB
|
| 121 |
-
|
| 122 |
-
return memory_after - memory_before
|
| 123 |
-
|
| 124 |
-
|
| 125 |
-
def compute_embeddings(
|
| 126 |
-
original_model: SentenceTransformer | PreTrainedModel,
|
| 127 |
-
original_model_type: str,
|
| 128 |
-
distilled_model: StaticModel,
|
| 129 |
-
texts: list[str],
|
| 130 |
-
original_model_name: str = "unknown",
|
| 131 |
-
) -> tuple[np.ndarray, np.ndarray]:
|
| 132 |
-
"""Compute embeddings using both models."""
|
| 133 |
-
# Original model embeddings
|
| 134 |
-
if original_model_type == "sentence_transformer":
|
| 135 |
-
# Type narrowing: we know it's a SentenceTransformer here
|
| 136 |
-
sentence_model = cast("SentenceTransformer", original_model)
|
| 137 |
-
original_embeddings = sentence_model.encode(texts)
|
| 138 |
-
else:
|
| 139 |
-
# Type narrowing: we know it's a PreTrainedModel here
|
| 140 |
-
auto_model = original_model # AutoModel.from_pretrained returns a PreTrainedModel instance
|
| 141 |
-
|
| 142 |
-
# For HF models, we need more custom code
|
| 143 |
-
# Simple mean pooling function for HF models
|
| 144 |
-
def mean_pooling(model_output: torch.Tensor, attention_mask: torch.Tensor) -> torch.Tensor:
|
| 145 |
-
token_embeddings = model_output
|
| 146 |
-
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
| 147 |
-
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(
|
| 148 |
-
input_mask_expanded.sum(1), min=1e-9
|
| 149 |
-
)
|
| 150 |
-
|
| 151 |
-
# Get model name for tokenizer
|
| 152 |
-
model_name = getattr(auto_model.config, "name_or_path", original_model_name)
|
| 153 |
-
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 154 |
-
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
|
| 155 |
-
|
| 156 |
-
with torch.no_grad():
|
| 157 |
-
model_output = auto_model(**encoded_input)
|
| 158 |
-
original_embeddings = mean_pooling(model_output.last_hidden_state, encoded_input["attention_mask"]).numpy()
|
| 159 |
-
|
| 160 |
-
# Distilled model embeddings
|
| 161 |
-
distilled_embeddings = distilled_model.encode(texts)
|
| 162 |
-
|
| 163 |
-
return original_embeddings, distilled_embeddings
|
| 164 |
-
|
| 165 |
-
|
| 166 |
-
def measure_inference_speed(
|
| 167 |
-
model: SentenceTransformer | PreTrainedModel | StaticModel, model_type: str, texts: list[str], n_runs: int = 5
|
| 168 |
-
) -> float:
|
| 169 |
-
"""Measure inference speed in texts/second."""
|
| 170 |
-
# Warmup
|
| 171 |
-
if model_type in {"sentence_transformer", "static_model"}:
|
| 172 |
-
# Type narrowing: we know it has encode method here
|
| 173 |
-
encode_model = cast("SentenceTransformer | StaticModel", model)
|
| 174 |
-
_ = encode_model.encode(texts[:1])
|
| 175 |
-
else:
|
| 176 |
-
# Type narrowing: we know it's a PreTrainedModel here
|
| 177 |
-
auto_model = cast("PreTrainedModel", model)
|
| 178 |
-
# Warmup for HF models
|
| 179 |
-
model_name = getattr(auto_model.config, "name_or_path", "unknown")
|
| 180 |
-
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 181 |
-
encoded_input = tokenizer(texts[:1], padding=True, truncation=True, return_tensors="pt")
|
| 182 |
-
with torch.no_grad():
|
| 183 |
-
_ = auto_model(**encoded_input)
|
| 184 |
-
|
| 185 |
-
# Measure speed
|
| 186 |
-
start_time = time.time()
|
| 187 |
-
|
| 188 |
-
if model_type in {"sentence_transformer", "static_model"}:
|
| 189 |
-
# Type narrowing: we know it has encode method here
|
| 190 |
-
encode_model = cast("SentenceTransformer | StaticModel", model)
|
| 191 |
-
for _ in range(n_runs):
|
| 192 |
-
_ = encode_model.encode(texts)
|
| 193 |
-
else:
|
| 194 |
-
# Type narrowing: we know it's a PreTrainedModel here
|
| 195 |
-
auto_model = cast("PreTrainedModel", model)
|
| 196 |
-
# For HF models
|
| 197 |
-
model_name = getattr(auto_model.config, "name_or_path", "unknown")
|
| 198 |
-
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 199 |
-
for _ in range(n_runs):
|
| 200 |
-
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
|
| 201 |
-
with torch.no_grad():
|
| 202 |
-
_ = auto_model(**encoded_input)
|
| 203 |
-
|
| 204 |
-
total_time = time.time() - start_time
|
| 205 |
-
return (len(texts) * n_runs) / total_time
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
def compute_cosine_similarity(embeddings1: np.ndarray, embeddings2: np.ndarray) -> np.ndarray:
|
| 209 |
-
"""Compute cosine similarity between embeddings, handling different dimensions.
|
| 210 |
-
|
| 211 |
-
For embeddings with different dimensions, we compute similarity by comparing
|
| 212 |
-
how they rank the same texts (semantically equivalent).
|
| 213 |
-
"""
|
| 214 |
-
# Ensure embeddings1 and embeddings2 are 2D arrays with shapes (n_samples, n_features)
|
| 215 |
-
if embeddings1.ndim == 1:
|
| 216 |
-
embeddings1 = embeddings1.reshape(1, -1)
|
| 217 |
-
if embeddings2.ndim == 1:
|
| 218 |
-
embeddings2 = embeddings2.reshape(1, -1)
|
| 219 |
-
|
| 220 |
-
# Check and transpose if needed to ensure samples are in rows
|
| 221 |
-
if embeddings2.shape[0] != len(SAMPLE_TEXTS) and embeddings2.shape[1] == len(SAMPLE_TEXTS):
|
| 222 |
-
embeddings2 = embeddings2.T
|
| 223 |
-
|
| 224 |
-
logger.info(f"Embeddings shapes: original={embeddings1.shape}, distilled={embeddings2.shape}")
|
| 225 |
-
|
| 226 |
-
# If dimensions differ, we compute similarity matrix based on how each model ranks text pairs
|
| 227 |
-
# This is a form of semantic similarity evaluation rather than direct vector comparison
|
| 228 |
-
similarity_matrix = np.zeros((len(SAMPLE_TEXTS), len(SAMPLE_TEXTS)))
|
| 229 |
-
|
| 230 |
-
# Compute similarity matrices within each embedding space
|
| 231 |
-
sim1 = cosine_similarity(embeddings1)
|
| 232 |
-
sim2 = cosine_similarity(embeddings2)
|
| 233 |
-
|
| 234 |
-
# The similarity between samples i and j is the correlation between how they rank other samples
|
| 235 |
-
for i in range(len(SAMPLE_TEXTS)):
|
| 236 |
-
for j in range(len(SAMPLE_TEXTS)):
|
| 237 |
-
# For diagonal elements (same sample), use a direct measure of how similar
|
| 238 |
-
# the two models rank that sample against all others
|
| 239 |
-
if i == j:
|
| 240 |
-
# Pearson correlation between the rankings (excluding self-comparison)
|
| 241 |
-
rankings1 = np.delete(sim1[i], i)
|
| 242 |
-
rankings2 = np.delete(sim2[i], i)
|
| 243 |
-
# Higher correlation means the models agree on the semantic similarity
|
| 244 |
-
similarity_matrix[i, j] = np.corrcoef(rankings1, rankings2)[0, 1]
|
| 245 |
-
else:
|
| 246 |
-
# For off-diagonal elements, compare how similarly both models relate samples i and j
|
| 247 |
-
similarity_matrix[i, j] = 1 - abs(sim1[i, j] - sim2[i, j])
|
| 248 |
-
|
| 249 |
-
return similarity_matrix
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
def format_size(size_bytes: float) -> str:
|
| 253 |
-
"""Format size in bytes to human-readable format."""
|
| 254 |
-
for unit in ["B", "KB", "MB", "GB"]:
|
| 255 |
-
if size_bytes < BYTES_PER_KB:
|
| 256 |
-
return f"{size_bytes:.2f} {unit}"
|
| 257 |
-
size_bytes /= BYTES_PER_KB
|
| 258 |
-
return f"{size_bytes:.2f} TB"
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
def plot_comparison(results: dict[str, Any], output_dir: str) -> None:
|
| 262 |
-
"""Generate comparison plots and save them."""
|
| 263 |
-
output_path = Path(output_dir)
|
| 264 |
-
output_path.mkdir(exist_ok=True, parents=True)
|
| 265 |
-
|
| 266 |
-
# Speed comparison
|
| 267 |
-
plt.figure(figsize=(10, 6))
|
| 268 |
-
models = ["Original", "Distilled"]
|
| 269 |
-
speeds = [results["original_speed"], results["distilled_speed"]]
|
| 270 |
-
plt.bar(models, speeds, color=["#1f77b4", "#ff7f0e"])
|
| 271 |
-
plt.ylabel("Texts per second")
|
| 272 |
-
plt.title("Inference Speed Comparison")
|
| 273 |
-
plt.savefig(output_path / "speed_comparison.png", dpi=300, bbox_inches="tight")
|
| 274 |
-
|
| 275 |
-
# Memory comparison
|
| 276 |
-
plt.figure(figsize=(10, 6))
|
| 277 |
-
memories = [results["original_memory"], results["distilled_memory"]]
|
| 278 |
-
plt.bar(models, memories, color=["#1f77b4", "#ff7f0e"])
|
| 279 |
-
plt.ylabel("Memory Usage (MB)")
|
| 280 |
-
plt.title("Memory Usage Comparison")
|
| 281 |
-
plt.savefig(output_path / "memory_comparison.png", dpi=300, bbox_inches="tight")
|
| 282 |
-
|
| 283 |
-
# Size comparison
|
| 284 |
-
plt.figure(figsize=(10, 6))
|
| 285 |
-
sizes = [results["original_size"], results["distilled_size"]]
|
| 286 |
-
plt.bar(models, sizes, color=["#1f77b4", "#ff7f0e"])
|
| 287 |
-
plt.ylabel("Model Size (MB)")
|
| 288 |
-
plt.title("Model Size Comparison")
|
| 289 |
-
plt.savefig(output_path / "size_comparison.png", dpi=300, bbox_inches="tight")
|
| 290 |
-
|
| 291 |
-
# Similarity matrix heatmap
|
| 292 |
-
plt.figure(figsize=(8, 6))
|
| 293 |
-
plt.imshow(results["similarity_matrix"], cmap="viridis", interpolation="nearest")
|
| 294 |
-
plt.colorbar(label="Cosine Similarity")
|
| 295 |
-
plt.title("Embedding Similarity Between Original and Distilled Models")
|
| 296 |
-
plt.xticks([])
|
| 297 |
-
plt.yticks(
|
| 298 |
-
range(len(SAMPLE_TEXTS)),
|
| 299 |
-
[t[:TEXT_TRUNCATE_LENGTH] + "..." if len(t) > TEXT_TRUNCATE_LENGTH else t for t in SAMPLE_TEXTS],
|
| 300 |
-
)
|
| 301 |
-
plt.savefig(output_path / "similarity_matrix.png", dpi=300, bbox_inches="tight")
|
| 302 |
-
|
| 303 |
-
|
| 304 |
-
def evaluate_models(original_model_name: str, distilled_model_path: str, output_dir: str) -> dict[str, Any]:
|
| 305 |
-
"""Evaluate the original and distilled models."""
|
| 306 |
-
# Load models
|
| 307 |
-
(original_model, original_model_type), distilled_model = load_models(original_model_name, distilled_model_path)
|
| 308 |
-
|
| 309 |
-
# Measure model sizes
|
| 310 |
-
if isinstance(original_model, SentenceTransformer):
|
| 311 |
-
# For SentenceTransformer, get parameters from all modules
|
| 312 |
-
total_params = 0
|
| 313 |
-
for module in original_model.modules():
|
| 314 |
-
if hasattr(module, "parameters"):
|
| 315 |
-
for param in module.parameters():
|
| 316 |
-
total_params += param.numel()
|
| 317 |
-
original_model_size = total_params * 4 / (1024 * 1024) # MB (assuming float32)
|
| 318 |
-
else:
|
| 319 |
-
# For PreTrainedModel
|
| 320 |
-
auto_model = original_model # AutoModel.from_pretrained returns a PreTrainedModel instance
|
| 321 |
-
original_model_size = sum(p.numel() * 4 for p in auto_model.parameters()) / (
|
| 322 |
-
1024 * 1024
|
| 323 |
-
) # MB (assuming float32)
|
| 324 |
-
|
| 325 |
-
# Calculate distilled model size - only count actual model files
|
| 326 |
-
model_files = ["model.safetensors", "config.json", "modules.json", "tokenizer.json"]
|
| 327 |
-
distilled_model_size = 0.0
|
| 328 |
-
for file_name in model_files:
|
| 329 |
-
file_path = Path(distilled_model_path) / file_name
|
| 330 |
-
if file_path.exists():
|
| 331 |
-
distilled_model_size += file_path.stat().st_size
|
| 332 |
-
distilled_model_size = distilled_model_size / (1024 * 1024) # Convert to MB
|
| 333 |
-
|
| 334 |
-
# Measure memory usage
|
| 335 |
-
original_memory = measure_memory_usage(original_model)
|
| 336 |
-
distilled_memory = measure_memory_usage(distilled_model)
|
| 337 |
-
|
| 338 |
-
# Compute embeddings
|
| 339 |
-
original_embeddings, distilled_embeddings = compute_embeddings(
|
| 340 |
-
original_model, original_model_type, distilled_model, SAMPLE_TEXTS, original_model_name
|
| 341 |
-
)
|
| 342 |
-
|
| 343 |
-
# Compute similarity between embeddings
|
| 344 |
-
similarity_matrix = compute_cosine_similarity(original_embeddings, distilled_embeddings)
|
| 345 |
-
similarity_diagonal = np.diag(similarity_matrix)
|
| 346 |
-
avg_similarity = np.mean(similarity_diagonal)
|
| 347 |
-
|
| 348 |
-
# Measure inference speed
|
| 349 |
-
original_speed = measure_inference_speed(original_model, original_model_type, SAMPLE_TEXTS, n_runs=5)
|
| 350 |
-
distilled_speed = measure_inference_speed(distilled_model, "static_model", SAMPLE_TEXTS, n_runs=5)
|
| 351 |
-
|
| 352 |
-
# Collect results
|
| 353 |
-
results = {
|
| 354 |
-
"original_size": original_model_size,
|
| 355 |
-
"distilled_size": distilled_model_size,
|
| 356 |
-
"original_memory": original_memory,
|
| 357 |
-
"distilled_memory": distilled_memory,
|
| 358 |
-
"similarity_matrix": similarity_matrix,
|
| 359 |
-
"avg_similarity": avg_similarity,
|
| 360 |
-
"original_speed": original_speed,
|
| 361 |
-
"distilled_speed": distilled_speed,
|
| 362 |
-
"speed_improvement": distilled_speed / original_speed if original_speed > 0 else float("inf"),
|
| 363 |
-
"size_reduction": original_model_size / distilled_model_size if distilled_model_size > 0 else float("inf"),
|
| 364 |
-
"memory_reduction": original_memory / distilled_memory if distilled_memory > 0 else float("inf"),
|
| 365 |
-
}
|
| 366 |
-
|
| 367 |
-
# Generate plots
|
| 368 |
-
plot_comparison(results, output_dir)
|
| 369 |
-
|
| 370 |
-
# Print results
|
| 371 |
-
separator = "=" * 50
|
| 372 |
-
logger.info("\n%s", separator)
|
| 373 |
-
logger.info("Model Evaluation Results")
|
| 374 |
-
logger.info("%s", separator)
|
| 375 |
-
logger.info(f"Original Model Size: {results['original_size']:.2f} MB")
|
| 376 |
-
logger.info(f"Distilled Model Size: {results['distilled_size']:.2f} MB")
|
| 377 |
-
logger.info(f"Size Reduction Factor: {results['size_reduction']:.2f}x")
|
| 378 |
-
logger.info("\n")
|
| 379 |
-
logger.info(f"Original Model Memory: {results['original_memory']:.2f} MB")
|
| 380 |
-
logger.info(f"Distilled Model Memory: {results['distilled_memory']:.2f} MB")
|
| 381 |
-
logger.info(f"Memory Reduction Factor: {results['memory_reduction']:.2f}x")
|
| 382 |
-
logger.info("\n")
|
| 383 |
-
logger.info(f"Original Model Speed: {results['original_speed']:.2f} texts/second")
|
| 384 |
-
logger.info(f"Distilled Model Speed: {results['distilled_speed']:.2f} texts/second")
|
| 385 |
-
logger.info(f"Speed Improvement Factor: {results['speed_improvement']:.2f}x")
|
| 386 |
-
logger.info("\n")
|
| 387 |
-
logger.info(f"Average Embedding Similarity: {results['avg_similarity']:.4f}")
|
| 388 |
-
logger.info("%s", separator)
|
| 389 |
-
|
| 390 |
-
return results
|
| 391 |
-
|
| 392 |
-
|
| 393 |
-
def main() -> None:
|
| 394 |
-
"""Run the evaluation process."""
|
| 395 |
-
parser = argparse.ArgumentParser(description="Evaluate the distilled model against the original")
|
| 396 |
-
parser.add_argument("--original_model", default=ORIGINAL_MODEL, help="Original model name or path")
|
| 397 |
-
parser.add_argument("--distilled_model", default=DISTILLED_MODEL, help="Path to the distilled model")
|
| 398 |
-
parser.add_argument("--output_dir", default=OUTPUT_DIR, help="Directory to save evaluation results")
|
| 399 |
-
|
| 400 |
-
args = parser.parse_args()
|
| 401 |
-
|
| 402 |
-
# Validate configuration
|
| 403 |
-
if not args.distilled_model:
|
| 404 |
-
logger.error("Distilled model path must be provided")
|
| 405 |
-
logger.error("Use --distilled_model to specify the path or set DISTILLED_MODEL constant")
|
| 406 |
-
return
|
| 407 |
-
|
| 408 |
-
# Create output directory
|
| 409 |
-
output_dir = Path(args.output_dir)
|
| 410 |
-
output_dir.mkdir(parents=True, exist_ok=True)
|
| 411 |
-
|
| 412 |
-
# Run evaluation
|
| 413 |
-
try:
|
| 414 |
-
evaluate_models(args.original_model, args.distilled_model, args.output_dir)
|
| 415 |
-
logger.info(f"Evaluation completed. Results saved to {args.output_dir}")
|
| 416 |
-
except Exception:
|
| 417 |
-
logger.exception("Error during evaluation")
|
| 418 |
-
raise
|
| 419 |
-
|
| 420 |
-
|
| 421 |
-
if __name__ == "__main__":
|
| 422 |
-
main()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
pyproject.toml
CHANGED
|
@@ -1,30 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
[project]
|
| 2 |
name = "gte-qwen2-7b-instruct-m2v"
|
| 3 |
version = "0.1.0"
|
| 4 |
-
description = "
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12"
|
| 7 |
dependencies = [
|
|
|
|
|
|
|
|
|
|
| 8 |
"datasets>=3.6.0",
|
| 9 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
"iso639>=0.1.4",
|
|
|
|
| 11 |
"lightning>=2.5.1.post0",
|
| 12 |
"matplotlib>=3.10.3",
|
| 13 |
"model2vec[train]>=0.5.0",
|
| 14 |
"mteb>=1.14.15",
|
| 15 |
"numpy>=1.26.4",
|
|
|
|
| 16 |
"psutil>=7.0.0",
|
|
|
|
|
|
|
| 17 |
"scikit-learn>=1.6.1",
|
|
|
|
| 18 |
"sentence-transformers>=4.1.0",
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
"torch>=2.7.0",
|
|
|
|
| 20 |
]
|
| 21 |
|
|
|
|
|
|
|
|
|
|
| 22 |
[dependency-groups]
|
| 23 |
dev = [
|
| 24 |
"mypy>=1.15.0",
|
| 25 |
"ruff>=0.11.6",
|
| 26 |
]
|
| 27 |
|
|
|
|
|
|
|
|
|
|
| 28 |
[tool.mypy]
|
| 29 |
exclude = [
|
| 30 |
".git",
|
|
@@ -79,6 +106,14 @@ ignore = [
|
|
| 79 |
"E101", # Indentation contains mixed spaces and tabs
|
| 80 |
"W191", # indentation contains tabs
|
| 81 |
"D206", # indent with spaces, not tabs
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
]
|
| 83 |
|
| 84 |
[tool.ruff.lint.mccabe]
|
|
@@ -97,6 +132,3 @@ quote-style = "double"
|
|
| 97 |
indent-style = "tab"
|
| 98 |
skip-magic-trailing-comma = false
|
| 99 |
line-ending = "auto"
|
| 100 |
-
|
| 101 |
-
[tool.uv.sources]
|
| 102 |
-
evaluation = { git = "https://github.com/MinishLab/evaluation.git", rev = "main" }
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["hatchling"]
|
| 3 |
+
build-backend = "hatchling.build"
|
| 4 |
+
|
| 5 |
[project]
|
| 6 |
name = "gte-qwen2-7b-instruct-m2v"
|
| 7 |
version = "0.1.0"
|
| 8 |
+
description = "Model2Vec distillation pipeline for gte-Qwen2-7B-instruct"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.12"
|
| 11 |
dependencies = [
|
| 12 |
+
"accelerate>=1.7.0",
|
| 13 |
+
"beam-client>=0.2.155",
|
| 14 |
+
"boto3>=1.38.23",
|
| 15 |
"datasets>=3.6.0",
|
| 16 |
+
"dotenv>=0.9.9",
|
| 17 |
+
"editables>=0.5",
|
| 18 |
+
"einops>=0.8.1",
|
| 19 |
+
"flash-attn>=2.7.4.post1",
|
| 20 |
+
"hatchling>=1.27.0",
|
| 21 |
"iso639>=0.1.4",
|
| 22 |
+
"kaleido==1.0.0rc13",
|
| 23 |
"lightning>=2.5.1.post0",
|
| 24 |
"matplotlib>=3.10.3",
|
| 25 |
"model2vec[train]>=0.5.0",
|
| 26 |
"mteb>=1.14.15",
|
| 27 |
"numpy>=1.26.4",
|
| 28 |
+
"plotly>=6.1.1",
|
| 29 |
"psutil>=7.0.0",
|
| 30 |
+
"pydantic>=2.11.5",
|
| 31 |
+
"requests>=2.32.3",
|
| 32 |
"scikit-learn>=1.6.1",
|
| 33 |
+
"seaborn>=0.13.2",
|
| 34 |
"sentence-transformers>=4.1.0",
|
| 35 |
+
"setuptools>=80.8.0",
|
| 36 |
+
"smart-open[s3]>=7.1.0",
|
| 37 |
+
"statsmodels>=0.14.4",
|
| 38 |
+
"tokenlearn>=0.2.0",
|
| 39 |
"torch>=2.7.0",
|
| 40 |
+
"typer>=0.16.0",
|
| 41 |
]
|
| 42 |
|
| 43 |
+
[project.scripts]
|
| 44 |
+
distiller = "distiller.__main__:app"
|
| 45 |
+
|
| 46 |
[dependency-groups]
|
| 47 |
dev = [
|
| 48 |
"mypy>=1.15.0",
|
| 49 |
"ruff>=0.11.6",
|
| 50 |
]
|
| 51 |
|
| 52 |
+
[tool.hatch.build.targets.wheel]
|
| 53 |
+
packages = ["src/distiller"]
|
| 54 |
+
|
| 55 |
[tool.mypy]
|
| 56 |
exclude = [
|
| 57 |
".git",
|
|
|
|
| 106 |
"E101", # Indentation contains mixed spaces and tabs
|
| 107 |
"W191", # indentation contains tabs
|
| 108 |
"D206", # indent with spaces, not tabs
|
| 109 |
+
"PD901", # Avoid using the generic variable name `df` for DataFrames
|
| 110 |
+
"ANN401", # Dynamically typed expressions (typing.Any) are disallowed
|
| 111 |
+
"D103", # Missing docstring in public function
|
| 112 |
+
"BLE001", # Do not catch blind exception: `Exception`
|
| 113 |
+
"T201", # Use `logger.info` instead of `print`
|
| 114 |
+
"E501", # Line too long
|
| 115 |
+
"PLR2004",
|
| 116 |
+
"RUF001",
|
| 117 |
]
|
| 118 |
|
| 119 |
[tool.ruff.lint.mccabe]
|
|
|
|
| 132 |
indent-style = "tab"
|
| 133 |
skip-magic-trailing-comma = false
|
| 134 |
line-ending = "auto"
|
|
|
|
|
|
|
|
|
src/distiller/distill.py
CHANGED
|
@@ -20,23 +20,22 @@ Usage:
|
|
| 20 |
distiller distill [--use-beam] [--train] # Basic distillation or with training
|
| 21 |
"""
|
| 22 |
|
|
|
|
| 23 |
import json
|
| 24 |
import logging
|
|
|
|
| 25 |
import time
|
| 26 |
from pathlib import Path
|
| 27 |
from typing import Annotated, Any
|
| 28 |
|
| 29 |
-
import numpy as np
|
| 30 |
import torch
|
| 31 |
import typer
|
| 32 |
-
from beam import
|
| 33 |
from datasets import load_dataset
|
| 34 |
from model2vec.distill import distill
|
| 35 |
-
from model2vec.train.base import FinetunableStaticModel, TextDataset
|
| 36 |
from sentence_transformers import SentenceTransformer
|
| 37 |
-
from sklearn.model_selection import train_test_split
|
| 38 |
-
from torch import nn, optim
|
| 39 |
|
|
|
|
| 40 |
from .beam_utils import (
|
| 41 |
BeamCheckpointManager,
|
| 42 |
create_beam_utilities,
|
|
@@ -46,16 +45,17 @@ from .beam_utils import (
|
|
| 46 |
upload_model_to_beam,
|
| 47 |
)
|
| 48 |
from .config import (
|
| 49 |
-
BEAM_ENV_SETTINGS,
|
| 50 |
-
GPU_NAME,
|
| 51 |
-
IMAGE,
|
| 52 |
codesearchnet_config,
|
| 53 |
directories,
|
| 54 |
distillation_config,
|
|
|
|
| 55 |
get_volume_config,
|
| 56 |
languages_config,
|
| 57 |
)
|
| 58 |
|
|
|
|
|
|
|
|
|
|
| 59 |
# =============================================================================
|
| 60 |
# CONFIGURATION
|
| 61 |
# =============================================================================
|
|
@@ -70,6 +70,75 @@ logger = logging.getLogger(__name__)
|
|
| 70 |
# Teacher models for distillation
|
| 71 |
DEFAULT_TEACHER_MODELS = list(distillation_config.code_teacher_models)
|
| 72 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
# =============================================================================
|
| 74 |
# UTILITY FUNCTIONS
|
| 75 |
# =============================================================================
|
|
@@ -106,13 +175,11 @@ def get_current_config_hash(enable_training: bool) -> str:
|
|
| 106 |
}
|
| 107 |
|
| 108 |
if enable_training:
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
"learning_rate": distillation_config.learning_rate,
|
| 113 |
-
"max_samples": distillation_config.max_training_samples,
|
| 114 |
-
}
|
| 115 |
)
|
|
|
|
| 116 |
|
| 117 |
config_str = str(sorted(config_params.items()))
|
| 118 |
return hashlib.md5(config_str.encode()).hexdigest()[:12] # noqa: S324
|
|
@@ -345,13 +412,10 @@ def simple_distillation(
|
|
| 345 |
|
| 346 |
|
| 347 |
def load_codesearchnet_dataset(
|
| 348 |
-
max_samples: int
|
| 349 |
checkpoint_manager: BeamCheckpointManager | None = None,
|
| 350 |
) -> list[str]:
|
| 351 |
-
"""Load and format the CodeSearchNet dataset for
|
| 352 |
-
if max_samples is None:
|
| 353 |
-
max_samples = int(distillation_config.max_training_samples)
|
| 354 |
-
|
| 355 |
logger.info(f"Loading CodeSearchNet dataset from {codesearchnet_config.dataset_name}")
|
| 356 |
logger.info(f"Limiting to {max_samples} samples for training efficiency")
|
| 357 |
logger.info(f"Languages: {', '.join(languages_config.all)}")
|
|
@@ -542,7 +606,7 @@ def generate_teacher_embeddings(
|
|
| 542 |
# Generate embeddings from scratch
|
| 543 |
logger.info("Generating fresh teacher embeddings...")
|
| 544 |
|
| 545 |
-
batch_size =
|
| 546 |
embeddings_list = []
|
| 547 |
|
| 548 |
for i in range(0, len(texts), batch_size):
|
|
@@ -614,146 +678,351 @@ def generate_teacher_embeddings(
|
|
| 614 |
return teacher_embeddings
|
| 615 |
|
| 616 |
|
| 617 |
-
def
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 618 |
student_model: Any,
|
| 619 |
teacher_model: SentenceTransformer,
|
| 620 |
-
checkpoint_manager: BeamCheckpointManager | None = None,
|
| 621 |
) -> Any:
|
| 622 |
-
"""
|
| 623 |
-
|
| 624 |
-
|
| 625 |
-
|
| 626 |
-
|
| 627 |
-
|
| 628 |
-
|
| 629 |
-
|
| 630 |
-
|
| 631 |
-
|
| 632 |
-
|
| 633 |
-
|
| 634 |
-
|
| 635 |
-
|
| 636 |
-
|
| 637 |
-
|
| 638 |
-
|
| 639 |
-
|
| 640 |
-
|
| 641 |
-
|
| 642 |
-
|
| 643 |
-
|
| 644 |
-
|
| 645 |
-
|
| 646 |
-
|
| 647 |
-
|
| 648 |
-
|
| 649 |
-
|
| 650 |
-
|
| 651 |
-
|
| 652 |
-
|
| 653 |
-
|
| 654 |
-
|
| 655 |
-
|
| 656 |
-
|
| 657 |
-
|
| 658 |
-
|
| 659 |
-
|
| 660 |
-
|
| 661 |
-
|
| 662 |
-
|
| 663 |
-
|
| 664 |
-
|
| 665 |
-
|
| 666 |
-
|
| 667 |
-
|
| 668 |
-
|
| 669 |
-
# Training setup
|
| 670 |
-
train_dataset = TextDataset(train_texts, train_targets)
|
| 671 |
-
val_dataset = TextDataset(val_texts, val_targets)
|
| 672 |
-
|
| 673 |
-
optimizer = optim.Adam(trainable_model.parameters(), lr=float(distillation_config.learning_rate))
|
| 674 |
-
mse_loss = nn.MSELoss()
|
| 675 |
-
|
| 676 |
-
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 677 |
-
trainable_model = trainable_model.to(device)
|
| 678 |
-
|
| 679 |
-
batch_size = int(distillation_config.batch_size)
|
| 680 |
-
epochs = int(distillation_config.training_epochs)
|
| 681 |
-
|
| 682 |
-
# Training loop
|
| 683 |
-
for epoch in range(epochs):
|
| 684 |
-
trainable_model.train()
|
| 685 |
|
| 686 |
try:
|
| 687 |
-
|
| 688 |
-
|
| 689 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 690 |
|
| 691 |
-
|
| 692 |
-
|
| 693 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 694 |
|
| 695 |
-
|
| 696 |
-
|
| 697 |
-
|
|
|
|
|
|
|
| 698 |
|
| 699 |
-
|
| 700 |
-
loss.backward()
|
| 701 |
-
optimizer.step()
|
| 702 |
|
| 703 |
-
|
| 704 |
-
|
|
|
|
| 705 |
|
| 706 |
-
except
|
| 707 |
-
logger.
|
| 708 |
-
|
| 709 |
-
|
| 710 |
-
|
| 711 |
|
| 712 |
-
|
|
|
|
| 713 |
|
| 714 |
-
|
| 715 |
-
|
| 716 |
-
|
| 717 |
-
|
| 718 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 719 |
|
| 720 |
-
|
| 721 |
-
|
| 722 |
-
|
| 723 |
-
batch_targets = targets_batch.to(device).to(torch.float32)
|
| 724 |
|
| 725 |
-
|
| 726 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 727 |
|
| 728 |
-
|
| 729 |
-
|
| 730 |
-
|
|
|
|
|
|
|
| 731 |
|
| 732 |
-
|
| 733 |
|
| 734 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 735 |
|
| 736 |
-
#
|
| 737 |
-
|
| 738 |
-
checkpoint_data = {
|
| 739 |
-
"config_hash": get_current_config_hash(enable_training=True),
|
| 740 |
-
"stage": "training",
|
| 741 |
-
"step": epoch + 1,
|
| 742 |
-
"timestamp": time.time(),
|
| 743 |
-
"data": {
|
| 744 |
-
"model_state": trainable_model.state_dict(),
|
| 745 |
-
"optimizer_state": optimizer.state_dict(),
|
| 746 |
-
"train_loss": avg_train_loss,
|
| 747 |
-
"val_loss": avg_val_loss,
|
| 748 |
-
},
|
| 749 |
-
}
|
| 750 |
-
checkpoint_manager.save_checkpoint("training", checkpoint_data, epoch + 1)
|
| 751 |
|
| 752 |
-
|
| 753 |
-
|
| 754 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 755 |
|
| 756 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 757 |
|
| 758 |
|
| 759 |
def distill_single_teacher(
|
|
@@ -884,15 +1153,15 @@ def distill_single_teacher(
|
|
| 884 |
|
| 885 |
# Step 3: Handle final model creation
|
| 886 |
if enable_training and base_model is not None:
|
| 887 |
-
# Perform
|
| 888 |
-
logger.info(f"
|
| 889 |
|
| 890 |
# Load teacher model for training
|
| 891 |
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 892 |
-
teacher_st_model =
|
| 893 |
|
| 894 |
-
# Perform
|
| 895 |
-
final_model =
|
| 896 |
|
| 897 |
# Save final model
|
| 898 |
final_dir.mkdir(parents=True, exist_ok=True)
|
|
@@ -1031,14 +1300,7 @@ def run_local_distillation(
|
|
| 1031 |
return results_summary
|
| 1032 |
|
| 1033 |
|
| 1034 |
-
@function(
|
| 1035 |
-
gpu=GPU_NAME,
|
| 1036 |
-
volumes=[Volume(name=VOLUME_CONFIG.name, mount_path=VOLUME_CONFIG.mount_path)],
|
| 1037 |
-
image=IMAGE,
|
| 1038 |
-
secrets=["HF_ACCESS_TOKEN"],
|
| 1039 |
-
env=BEAM_ENV_SETTINGS,
|
| 1040 |
-
timeout=3600 * 12, # 12 hours
|
| 1041 |
-
)
|
| 1042 |
def _beam_distill_models(
|
| 1043 |
teacher_models: list[str] | None = None,
|
| 1044 |
enable_training: bool = False,
|
|
@@ -1194,7 +1456,8 @@ def main(
|
|
| 1194 |
) -> None:
|
| 1195 |
"""Unified distillation command with optional training."""
|
| 1196 |
logger.info("🚀 Starting unified Model2Vec distillation workflow")
|
| 1197 |
-
|
|
|
|
| 1198 |
logger.info(f"☁️ Execution: {'Beam' if use_beam else 'Local'}")
|
| 1199 |
|
| 1200 |
# Use default models if none specified
|
|
@@ -1355,7 +1618,6 @@ def salesforce_model_distillation(
|
|
| 1355 |
|
| 1356 |
try:
|
| 1357 |
import torch
|
| 1358 |
-
from sentence_transformers import SentenceTransformer
|
| 1359 |
from transformers import AutoModel, AutoTokenizer
|
| 1360 |
|
| 1361 |
# Enhanced custom model loading for Salesforce models
|
|
@@ -1395,9 +1657,8 @@ def salesforce_model_distillation(
|
|
| 1395 |
|
| 1396 |
# Method 2: Try SentenceTransformer with specific settings
|
| 1397 |
logger.info("🔄 Falling back to SentenceTransformer method...")
|
| 1398 |
-
sentence_model =
|
| 1399 |
teacher_model,
|
| 1400 |
-
trust_remote_code=True,
|
| 1401 |
device="cpu", # Force CPU loading first
|
| 1402 |
)
|
| 1403 |
|
|
@@ -1470,7 +1731,6 @@ def baai_bge_model_distillation(
|
|
| 1470 |
|
| 1471 |
try:
|
| 1472 |
import torch
|
| 1473 |
-
from sentence_transformers import SentenceTransformer
|
| 1474 |
from transformers import AutoModel, AutoTokenizer
|
| 1475 |
|
| 1476 |
logger.info("🔧 Loading BAAI model with tokenizer workaround...")
|
|
@@ -1481,7 +1741,7 @@ def baai_bge_model_distillation(
|
|
| 1481 |
# Method 1: Try SentenceTransformer first (often handles tokenizer issues better)
|
| 1482 |
try:
|
| 1483 |
logger.info("🔄 Attempting with SentenceTransformer wrapper...")
|
| 1484 |
-
sentence_model =
|
| 1485 |
|
| 1486 |
# Extract components
|
| 1487 |
model = sentence_model[0].auto_model
|
|
|
|
| 20 |
distiller distill [--use-beam] [--train] # Basic distillation or with training
|
| 21 |
"""
|
| 22 |
|
| 23 |
+
import importlib.util
|
| 24 |
import json
|
| 25 |
import logging
|
| 26 |
+
import os
|
| 27 |
import time
|
| 28 |
from pathlib import Path
|
| 29 |
from typing import Annotated, Any
|
| 30 |
|
|
|
|
| 31 |
import torch
|
| 32 |
import typer
|
| 33 |
+
from beam import function
|
| 34 |
from datasets import load_dataset
|
| 35 |
from model2vec.distill import distill
|
|
|
|
| 36 |
from sentence_transformers import SentenceTransformer
|
|
|
|
|
|
|
| 37 |
|
| 38 |
+
# Try to import flash_attn to check if it's available
|
| 39 |
from .beam_utils import (
|
| 40 |
BeamCheckpointManager,
|
| 41 |
create_beam_utilities,
|
|
|
|
| 45 |
upload_model_to_beam,
|
| 46 |
)
|
| 47 |
from .config import (
|
|
|
|
|
|
|
|
|
|
| 48 |
codesearchnet_config,
|
| 49 |
directories,
|
| 50 |
distillation_config,
|
| 51 |
+
get_distillation_function_kwargs,
|
| 52 |
get_volume_config,
|
| 53 |
languages_config,
|
| 54 |
)
|
| 55 |
|
| 56 |
+
# Check if flash_attn is available and compatible
|
| 57 |
+
FLASH_ATTN_AVAILABLE = importlib.util.find_spec("flash_attn") is not None
|
| 58 |
+
|
| 59 |
# =============================================================================
|
| 60 |
# CONFIGURATION
|
| 61 |
# =============================================================================
|
|
|
|
| 70 |
# Teacher models for distillation
|
| 71 |
DEFAULT_TEACHER_MODELS = list(distillation_config.code_teacher_models)
|
| 72 |
|
| 73 |
+
# =============================================================================
|
| 74 |
+
# FLASH ATTENTION UTILITIES
|
| 75 |
+
# =============================================================================
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def configure_flash_attention() -> dict[str, Any]:
|
| 79 |
+
"""Configure flash attention settings and return model kwargs."""
|
| 80 |
+
model_kwargs: dict[str, Any] = {}
|
| 81 |
+
|
| 82 |
+
if not FLASH_ATTN_AVAILABLE:
|
| 83 |
+
logger.info("⚠️ Flash attention not available - using standard attention")
|
| 84 |
+
return model_kwargs
|
| 85 |
+
|
| 86 |
+
# Set environment variables for flash attention
|
| 87 |
+
os.environ["FLASH_ATTENTION_FORCE_USE"] = "1"
|
| 88 |
+
# Disable torch compile for flash attention compatibility
|
| 89 |
+
os.environ["TORCH_COMPILE_DISABLE"] = "1"
|
| 90 |
+
# Enable flash attention in transformers
|
| 91 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 92 |
+
|
| 93 |
+
# Check if we're on a compatible GPU
|
| 94 |
+
try:
|
| 95 |
+
if torch.cuda.is_available():
|
| 96 |
+
device_capability = torch.cuda.get_device_capability()
|
| 97 |
+
# Flash attention requires compute capability >= 7.5 (Turing, Ampere, Ada, Hopper)
|
| 98 |
+
if device_capability[0] >= 7 and (device_capability[0] > 7 or device_capability[1] >= 5):
|
| 99 |
+
logger.info("✅ Flash attention enabled - compatible GPU detected")
|
| 100 |
+
model_kwargs.update(
|
| 101 |
+
{
|
| 102 |
+
"model_kwargs": {
|
| 103 |
+
"attn_implementation": "flash_attention_2",
|
| 104 |
+
"torch_dtype": torch.float16, # Flash attention works best with fp16
|
| 105 |
+
"use_flash_attention_2": True,
|
| 106 |
+
"_attn_implementation": "flash_attention_2", # Alternative key for some models
|
| 107 |
+
}
|
| 108 |
+
}
|
| 109 |
+
)
|
| 110 |
+
else:
|
| 111 |
+
logger.info(f"⚠️ GPU compute capability {device_capability} < 7.5 - flash attention disabled")
|
| 112 |
+
else:
|
| 113 |
+
logger.info("⚠️ No CUDA available - flash attention disabled")
|
| 114 |
+
except Exception as e:
|
| 115 |
+
logger.warning(f"⚠️ Failed to check GPU compatibility: {e} - flash attention disabled")
|
| 116 |
+
|
| 117 |
+
return model_kwargs
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def load_model_with_flash_attention(model_path: str, device: str = "auto") -> SentenceTransformer:
|
| 121 |
+
"""Load a SentenceTransformer model with flash attention if available."""
|
| 122 |
+
flash_kwargs = configure_flash_attention()
|
| 123 |
+
|
| 124 |
+
try:
|
| 125 |
+
# Try loading with flash attention first
|
| 126 |
+
if flash_kwargs and "model_kwargs" in flash_kwargs:
|
| 127 |
+
logger.info(f"🚀 Loading model with flash attention: {Path(model_path).name}")
|
| 128 |
+
model = SentenceTransformer(model_path, device=device, trust_remote_code=True, **flash_kwargs)
|
| 129 |
+
logger.info("✅ Model loaded successfully with flash attention")
|
| 130 |
+
return model
|
| 131 |
+
except Exception as e:
|
| 132 |
+
logger.warning(f"⚠️ Failed to load with flash attention: {e}")
|
| 133 |
+
logger.info("🔄 Falling back to standard attention")
|
| 134 |
+
|
| 135 |
+
# Fallback to standard loading
|
| 136 |
+
logger.info(f"📂 Loading model with standard attention: {Path(model_path).name}")
|
| 137 |
+
model = SentenceTransformer(model_path, device=device, trust_remote_code=True)
|
| 138 |
+
logger.info("✅ Model loaded successfully with standard attention")
|
| 139 |
+
return model
|
| 140 |
+
|
| 141 |
+
|
| 142 |
# =============================================================================
|
| 143 |
# UTILITY FUNCTIONS
|
| 144 |
# =============================================================================
|
|
|
|
| 175 |
}
|
| 176 |
|
| 177 |
if enable_training:
|
| 178 |
+
# Add a simple hash of tokenlearn parameters for config validation
|
| 179 |
+
tokenlearn_hash = hash(
|
| 180 |
+
f"{distillation_config.tokenlearn_dataset}_{distillation_config.tokenlearn_dataset_name}_{distillation_config.tokenlearn_text_key}"
|
|
|
|
|
|
|
|
|
|
| 181 |
)
|
| 182 |
+
config_params["tokenlearn_hash"] = float(abs(tokenlearn_hash) % 1000000) # Convert to float for consistency
|
| 183 |
|
| 184 |
config_str = str(sorted(config_params.items()))
|
| 185 |
return hashlib.md5(config_str.encode()).hexdigest()[:12] # noqa: S324
|
|
|
|
| 412 |
|
| 413 |
|
| 414 |
def load_codesearchnet_dataset(
|
| 415 |
+
max_samples: int = 50000,
|
| 416 |
checkpoint_manager: BeamCheckpointManager | None = None,
|
| 417 |
) -> list[str]:
|
| 418 |
+
"""Load and format the CodeSearchNet dataset for token frequency computation."""
|
|
|
|
|
|
|
|
|
|
| 419 |
logger.info(f"Loading CodeSearchNet dataset from {codesearchnet_config.dataset_name}")
|
| 420 |
logger.info(f"Limiting to {max_samples} samples for training efficiency")
|
| 421 |
logger.info(f"Languages: {', '.join(languages_config.all)}")
|
|
|
|
| 606 |
# Generate embeddings from scratch
|
| 607 |
logger.info("Generating fresh teacher embeddings...")
|
| 608 |
|
| 609 |
+
batch_size = 16 # Fixed batch size for teacher embedding generation
|
| 610 |
embeddings_list = []
|
| 611 |
|
| 612 |
for i in range(0, len(texts), batch_size):
|
|
|
|
| 678 |
return teacher_embeddings
|
| 679 |
|
| 680 |
|
| 681 |
+
def compute_token_frequencies_for_sif(
|
| 682 |
+
teacher_model: SentenceTransformer,
|
| 683 |
+
features_dir: Path,
|
| 684 |
+
) -> None:
|
| 685 |
+
"""
|
| 686 |
+
Compute token frequencies from the training corpus for SIF weighting.
|
| 687 |
+
|
| 688 |
+
This follows the POTION approach for post-training re-regularization.
|
| 689 |
+
"""
|
| 690 |
+
import json
|
| 691 |
+
from collections import Counter
|
| 692 |
+
|
| 693 |
+
logger.info("📊 Computing token frequencies for SIF weighting...")
|
| 694 |
+
|
| 695 |
+
try:
|
| 696 |
+
# Load CodeSearchNet dataset to compute frequencies (limited sample for efficiency)
|
| 697 |
+
dataset_texts = load_codesearchnet_dataset(max_samples=10000)
|
| 698 |
+
|
| 699 |
+
logger.info(f"📊 Computing frequencies on {len(dataset_texts)} texts...")
|
| 700 |
+
|
| 701 |
+
# Tokenize all texts and count token frequencies
|
| 702 |
+
tokenizer = teacher_model.tokenizer
|
| 703 |
+
token_counts: Counter[int] = Counter()
|
| 704 |
+
|
| 705 |
+
# Process in batches to avoid memory issues
|
| 706 |
+
batch_size = 100
|
| 707 |
+
for i in range(0, len(dataset_texts), batch_size):
|
| 708 |
+
batch_texts = dataset_texts[i : i + batch_size]
|
| 709 |
+
|
| 710 |
+
for text in batch_texts:
|
| 711 |
+
# Tokenize the text
|
| 712 |
+
tokens = tokenizer.encode(text, add_special_tokens=False)
|
| 713 |
+
token_counts.update(tokens)
|
| 714 |
+
|
| 715 |
+
if i % (batch_size * 10) == 0:
|
| 716 |
+
logger.info(f" Processed {i + len(batch_texts)}/{len(dataset_texts)} texts...")
|
| 717 |
+
|
| 718 |
+
# Convert to frequencies (token_id -> count)
|
| 719 |
+
token_frequencies = dict(token_counts)
|
| 720 |
+
|
| 721 |
+
# Save token frequencies to features directory for post-training regularization
|
| 722 |
+
freq_file = features_dir / "token_frequencies.json"
|
| 723 |
+
with freq_file.open("w") as f:
|
| 724 |
+
json.dump(token_frequencies, f, indent=2)
|
| 725 |
+
|
| 726 |
+
logger.info(f"✅ Token frequencies saved to {freq_file}")
|
| 727 |
+
logger.info(f"📊 Total unique tokens: {len(token_frequencies)}")
|
| 728 |
+
logger.info(f"📊 Total token occurrences: {sum(token_frequencies.values())}")
|
| 729 |
+
|
| 730 |
+
except Exception as e:
|
| 731 |
+
logger.warning(f"⚠️ Failed to compute token frequencies: {e}")
|
| 732 |
+
logger.warning("⚠️ Post-training re-regularization will use default Zipf weighting")
|
| 733 |
+
|
| 734 |
+
|
| 735 |
+
def apply_post_training_regularization(
|
| 736 |
+
model: Any,
|
| 737 |
+
features_dir: Path,
|
| 738 |
+
pca_dims: int = 256,
|
| 739 |
+
) -> Any:
|
| 740 |
+
"""
|
| 741 |
+
Apply post-training re-regularization following the POTION approach.
|
| 742 |
+
|
| 743 |
+
This includes:
|
| 744 |
+
1. Token frequency weighting using corpus frequencies
|
| 745 |
+
2. PCA application
|
| 746 |
+
3. SIF weighting using formula: w = 1e-3 / (1e-3 + proba)
|
| 747 |
+
"""
|
| 748 |
+
import json
|
| 749 |
+
|
| 750 |
+
import numpy as np
|
| 751 |
+
from sklearn.decomposition import PCA
|
| 752 |
+
|
| 753 |
+
logger.info("🔧 Starting post-training re-regularization (POTION Step 4)")
|
| 754 |
+
|
| 755 |
+
# Step 4a: Load token frequencies from the training corpus
|
| 756 |
+
logger.info("📊 Computing token frequencies from training corpus...")
|
| 757 |
+
|
| 758 |
+
# Try to load token frequencies from features directory
|
| 759 |
+
freq_file = features_dir / "token_frequencies.json"
|
| 760 |
+
|
| 761 |
+
if freq_file.exists():
|
| 762 |
+
with freq_file.open("r") as f:
|
| 763 |
+
token_frequencies = json.load(f)
|
| 764 |
+
logger.info(f"✅ Loaded token frequencies from {freq_file}")
|
| 765 |
+
else:
|
| 766 |
+
logger.warning("⚠️ Token frequencies not found - using default Zipf weighting")
|
| 767 |
+
# Fallback to basic frequency estimation based on rank
|
| 768 |
+
vocab_size = model.embedding.shape[0]
|
| 769 |
+
token_frequencies = {str(i): 1.0 / (i + 1) for i in range(vocab_size)}
|
| 770 |
+
|
| 771 |
+
# Step 4b: Apply PCA to the embeddings
|
| 772 |
+
logger.info(f"🔄 Applying PCA with {pca_dims} dimensions...")
|
| 773 |
+
|
| 774 |
+
# Get current embeddings
|
| 775 |
+
embeddings = model.embedding.cpu().numpy().astype(np.float64)
|
| 776 |
+
original_shape = embeddings.shape
|
| 777 |
+
logger.info(f"Original embedding shape: {original_shape}")
|
| 778 |
+
|
| 779 |
+
# Apply PCA if dimensions don't match
|
| 780 |
+
if original_shape[1] != pca_dims:
|
| 781 |
+
pca = PCA(n_components=pca_dims, random_state=42)
|
| 782 |
+
embeddings_pca = pca.fit_transform(embeddings)
|
| 783 |
+
logger.info(f"PCA applied: {original_shape} → {embeddings_pca.shape}")
|
| 784 |
+
|
| 785 |
+
# Explained variance ratio
|
| 786 |
+
explained_var = pca.explained_variance_ratio_.sum()
|
| 787 |
+
logger.info(f"PCA explained variance ratio: {explained_var:.4f}")
|
| 788 |
+
else:
|
| 789 |
+
embeddings_pca = embeddings
|
| 790 |
+
logger.info("PCA dimensions match - no PCA transformation needed")
|
| 791 |
+
|
| 792 |
+
# Step 4c: Apply SIF weighting using corpus frequencies
|
| 793 |
+
logger.info("⚖️ Applying SIF weighting based on token frequencies...")
|
| 794 |
+
|
| 795 |
+
# Convert token frequencies to probabilities
|
| 796 |
+
total_tokens = sum(token_frequencies.values())
|
| 797 |
+
token_probs = {token: freq / total_tokens for token, freq in token_frequencies.items()}
|
| 798 |
+
|
| 799 |
+
# Apply SIF weighting: w = 1e-3 / (1e-3 + proba)
|
| 800 |
+
sif_coefficient = 1e-3 # Standard SIF coefficient
|
| 801 |
+
|
| 802 |
+
for i in range(embeddings_pca.shape[0]):
|
| 803 |
+
token_id = str(i)
|
| 804 |
+
prob = token_probs[token_id] if token_id in token_probs else 1.0 / len(token_probs)
|
| 805 |
+
|
| 806 |
+
# Apply SIF weighting formula
|
| 807 |
+
sif_weight = sif_coefficient / (sif_coefficient + prob)
|
| 808 |
+
embeddings_pca[i] *= sif_weight
|
| 809 |
+
|
| 810 |
+
logger.info("✅ SIF weighting applied successfully")
|
| 811 |
+
|
| 812 |
+
# Step 4d: Create new model with re-regularized embeddings
|
| 813 |
+
logger.info("📦 Creating final model with re-regularized embeddings...")
|
| 814 |
+
|
| 815 |
+
# Convert back to float32 numpy array
|
| 816 |
+
final_embeddings = embeddings_pca.astype(np.float32)
|
| 817 |
+
|
| 818 |
+
# Create new model with updated embeddings
|
| 819 |
+
from model2vec.model import StaticModel
|
| 820 |
+
|
| 821 |
+
# Save tokenizer and config from original model
|
| 822 |
+
tokenizer = model.tokenizer
|
| 823 |
+
config = model.config
|
| 824 |
+
|
| 825 |
+
# Create new model with re-regularized embeddings
|
| 826 |
+
final_model = StaticModel(vectors=final_embeddings, tokenizer=tokenizer, config=config)
|
| 827 |
+
|
| 828 |
+
logger.info("✅ Post-training re-regularization completed successfully")
|
| 829 |
+
logger.info(f"Final model embedding shape: {final_model.embedding.shape}")
|
| 830 |
+
|
| 831 |
+
return final_model
|
| 832 |
+
|
| 833 |
+
|
| 834 |
+
def tokenlearn_training(
|
| 835 |
student_model: Any,
|
| 836 |
teacher_model: SentenceTransformer,
|
| 837 |
+
checkpoint_manager: BeamCheckpointManager | None = None, # noqa: ARG001
|
| 838 |
) -> Any:
|
| 839 |
+
"""
|
| 840 |
+
Perform tokenlearn training following the official POTION approach.
|
| 841 |
+
|
| 842 |
+
This follows the 4-step process:
|
| 843 |
+
1. Model2Vec distillation (already done - student_model)
|
| 844 |
+
2. Sentence transformer inference (create features)
|
| 845 |
+
3. Tokenlearn training
|
| 846 |
+
4. Post-training re-regularization (PCA + SIF weighting)
|
| 847 |
+
"""
|
| 848 |
+
import subprocess
|
| 849 |
+
import tempfile
|
| 850 |
+
from pathlib import Path
|
| 851 |
+
|
| 852 |
+
logger.info("🧪 Starting tokenlearn training (POTION approach)...")
|
| 853 |
+
|
| 854 |
+
# Create temporary directories for tokenlearn workflow
|
| 855 |
+
with tempfile.TemporaryDirectory() as temp_dir:
|
| 856 |
+
temp_path = Path(temp_dir)
|
| 857 |
+
features_dir = temp_path / "features"
|
| 858 |
+
model_dir = temp_path / "base_model"
|
| 859 |
+
trained_dir = temp_path / "trained_model"
|
| 860 |
+
|
| 861 |
+
features_dir.mkdir(exist_ok=True)
|
| 862 |
+
model_dir.mkdir(exist_ok=True)
|
| 863 |
+
trained_dir.mkdir(exist_ok=True)
|
| 864 |
+
|
| 865 |
+
# Save the base distilled model for tokenlearn
|
| 866 |
+
student_model.save_pretrained(str(model_dir))
|
| 867 |
+
logger.info(f"💾 Saved base model to {model_dir}")
|
| 868 |
+
|
| 869 |
+
# Step 2: Create features using tokenlearn-featurize
|
| 870 |
+
logger.info("🔍 Step 2: Creating features using sentence transformer...")
|
| 871 |
+
|
| 872 |
+
# Get teacher model name/path for tokenlearn
|
| 873 |
+
teacher_model_name = getattr(teacher_model, "model_name", None)
|
| 874 |
+
if not teacher_model_name and hasattr(teacher_model, "_modules") and len(teacher_model._modules) > 0: # noqa: SLF001
|
| 875 |
+
# Try to extract from the first module if it's a SentenceTransformer
|
| 876 |
+
# _modules is a dict-like container, get the first module by iterating
|
| 877 |
+
first_module = next(iter(teacher_model._modules.values())) # noqa: SLF001
|
| 878 |
+
if hasattr(first_module, "auto_model") and hasattr(first_module.auto_model, "name_or_path"):
|
| 879 |
+
teacher_model_name = first_module.auto_model.name_or_path
|
| 880 |
+
|
| 881 |
+
if not teacher_model_name:
|
| 882 |
+
logger.warning("⚠️ Could not determine teacher model name, using fallback")
|
| 883 |
+
teacher_model_name = "BAAI/bge-base-en-v1.5" # Fallback to a common model
|
| 884 |
+
|
| 885 |
+
logger.info(f"📊 Using teacher model: {teacher_model_name}")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 886 |
|
| 887 |
try:
|
| 888 |
+
# Use configured dataset for code specialization
|
| 889 |
+
featurize_cmd = [
|
| 890 |
+
"python",
|
| 891 |
+
"-m",
|
| 892 |
+
"tokenlearn.featurize",
|
| 893 |
+
"--model-name",
|
| 894 |
+
str(teacher_model_name),
|
| 895 |
+
"--output-dir",
|
| 896 |
+
str(features_dir),
|
| 897 |
+
"--dataset-path",
|
| 898 |
+
str(distillation_config.tokenlearn_dataset),
|
| 899 |
+
"--dataset-name",
|
| 900 |
+
str(distillation_config.tokenlearn_dataset_name),
|
| 901 |
+
"--dataset-split",
|
| 902 |
+
"train",
|
| 903 |
+
"--key",
|
| 904 |
+
str(distillation_config.tokenlearn_text_key), # Use configured text field
|
| 905 |
+
"--batch-size",
|
| 906 |
+
"1024", # Optimized batch size for A100-40G
|
| 907 |
+
]
|
| 908 |
|
| 909 |
+
logger.info("🔄 Running tokenlearn featurization...")
|
| 910 |
+
logger.info(
|
| 911 |
+
f"📊 Dataset: {distillation_config.tokenlearn_dataset} (config: {distillation_config.tokenlearn_dataset_name})"
|
| 912 |
+
)
|
| 913 |
+
logger.info(f"📝 Text field: {distillation_config.tokenlearn_text_key}")
|
| 914 |
+
logger.info(f"Command: {' '.join(featurize_cmd)}")
|
| 915 |
+
print(f"\n🔄 Executing: {' '.join(featurize_cmd)}\n")
|
| 916 |
+
|
| 917 |
+
result = subprocess.run( # noqa: S603
|
| 918 |
+
featurize_cmd,
|
| 919 |
+
text=True,
|
| 920 |
+
timeout=distillation_config.tokenlearn_timeout_featurize,
|
| 921 |
+
check=False,
|
| 922 |
+
)
|
| 923 |
|
| 924 |
+
if result.returncode != 0:
|
| 925 |
+
logger.error(f"❌ Featurization failed with return code: {result.returncode}")
|
| 926 |
+
logger.error("💥 Tokenlearn featurization is required for training - cannot proceed")
|
| 927 |
+
msg = f"Tokenlearn featurization failed with return code: {result.returncode}"
|
| 928 |
+
raise RuntimeError(msg)
|
| 929 |
|
| 930 |
+
logger.info("✅ Featurization completed successfully")
|
|
|
|
|
|
|
| 931 |
|
| 932 |
+
# Generate token frequencies for post-training re-regularization
|
| 933 |
+
logger.info("📊 Computing token frequencies for SIF weighting...")
|
| 934 |
+
compute_token_frequencies_for_sif(teacher_model, features_dir)
|
| 935 |
|
| 936 |
+
except Exception as e:
|
| 937 |
+
logger.exception("💥 Tokenlearn featurization failed")
|
| 938 |
+
logger.exception("💥 Tokenlearn featurization is required for training - cannot proceed")
|
| 939 |
+
msg = f"Tokenlearn featurization failed: {e}"
|
| 940 |
+
raise RuntimeError(msg) from e
|
| 941 |
|
| 942 |
+
# Step 3: Train using tokenlearn-train
|
| 943 |
+
logger.info("🎓 Step 3: Training using tokenlearn...")
|
| 944 |
|
| 945 |
+
try:
|
| 946 |
+
train_cmd = [
|
| 947 |
+
"python",
|
| 948 |
+
"-m",
|
| 949 |
+
"tokenlearn.train",
|
| 950 |
+
"--model-name",
|
| 951 |
+
str(teacher_model_name),
|
| 952 |
+
"--data-path",
|
| 953 |
+
str(features_dir),
|
| 954 |
+
"--save-path",
|
| 955 |
+
str(trained_dir),
|
| 956 |
+
]
|
| 957 |
|
| 958 |
+
logger.info("🔄 Running tokenlearn training...")
|
| 959 |
+
logger.info(f"Command: {' '.join(train_cmd)}")
|
| 960 |
+
print(f"\n🎓 Executing: {' '.join(train_cmd)}\n")
|
|
|
|
| 961 |
|
| 962 |
+
result = subprocess.run( # noqa: S603
|
| 963 |
+
train_cmd,
|
| 964 |
+
text=True,
|
| 965 |
+
timeout=distillation_config.tokenlearn_timeout_train,
|
| 966 |
+
check=False,
|
| 967 |
+
)
|
| 968 |
|
| 969 |
+
if result.returncode != 0:
|
| 970 |
+
logger.error(f"❌ Tokenlearn training failed with return code: {result.returncode}")
|
| 971 |
+
logger.error("💥 Tokenlearn training is required - cannot proceed")
|
| 972 |
+
msg = f"Tokenlearn training failed with return code: {result.returncode}"
|
| 973 |
+
raise RuntimeError(msg)
|
| 974 |
|
| 975 |
+
logger.info("✅ Tokenlearn training completed successfully")
|
| 976 |
|
| 977 |
+
except Exception as e:
|
| 978 |
+
logger.exception("💥 Tokenlearn training failed")
|
| 979 |
+
logger.exception("💥 Tokenlearn training is required - cannot proceed")
|
| 980 |
+
msg = f"Tokenlearn training failed: {e}"
|
| 981 |
+
raise RuntimeError(msg) from e
|
| 982 |
|
| 983 |
+
# Step 4: Load the trained model and apply post-training re-regularization
|
| 984 |
+
logger.info("📦 Step 4: Loading trained model and applying post-training re-regularization...")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 985 |
|
| 986 |
+
try:
|
| 987 |
+
from model2vec.model import StaticModel
|
| 988 |
+
|
| 989 |
+
# Load the trained model from tokenlearn
|
| 990 |
+
trained_model_path = trained_dir / "model"
|
| 991 |
+
if not trained_model_path.exists():
|
| 992 |
+
# Try alternative paths
|
| 993 |
+
possible_paths = [
|
| 994 |
+
trained_dir / "model_weighted",
|
| 995 |
+
trained_dir,
|
| 996 |
+
]
|
| 997 |
+
|
| 998 |
+
for path in possible_paths:
|
| 999 |
+
if path.exists() and any(path.glob("*.json")):
|
| 1000 |
+
trained_model_path = path
|
| 1001 |
+
break
|
| 1002 |
+
else:
|
| 1003 |
+
logger.error(f"❌ Could not find trained model in {trained_dir}")
|
| 1004 |
+
msg = f"Tokenlearn training failed - no model found in {trained_dir}"
|
| 1005 |
+
raise RuntimeError(msg)
|
| 1006 |
+
|
| 1007 |
+
# Load the model before re-regularization
|
| 1008 |
+
logger.info("🔄 Loading model from tokenlearn training...")
|
| 1009 |
+
trained_model = StaticModel.from_pretrained(str(trained_model_path))
|
| 1010 |
+
|
| 1011 |
+
# Apply post-training re-regularization (POTION Step 4)
|
| 1012 |
+
logger.info("🔧 Applying post-training re-regularization (PCA + SIF weighting)...")
|
| 1013 |
+
final_model = apply_post_training_regularization(
|
| 1014 |
+
trained_model, features_dir, pca_dims=distillation_config.optimal_pca_dims
|
| 1015 |
+
)
|
| 1016 |
|
| 1017 |
+
logger.info("✅ Tokenlearn training pipeline with post-training re-regularization completed successfully")
|
| 1018 |
+
|
| 1019 |
+
return final_model
|
| 1020 |
+
|
| 1021 |
+
except Exception as e:
|
| 1022 |
+
logger.exception("💥 Failed to load tokenlearn trained model")
|
| 1023 |
+
logger.exception("💥 Cannot load trained model - training failed")
|
| 1024 |
+
msg = f"Failed to load tokenlearn trained model: {e}"
|
| 1025 |
+
raise RuntimeError(msg) from e
|
| 1026 |
|
| 1027 |
|
| 1028 |
def distill_single_teacher(
|
|
|
|
| 1153 |
|
| 1154 |
# Step 3: Handle final model creation
|
| 1155 |
if enable_training and base_model is not None:
|
| 1156 |
+
# Perform tokenlearn training (POTION approach)
|
| 1157 |
+
logger.info(f"🧪 Starting tokenlearn training for {teacher_name}")
|
| 1158 |
|
| 1159 |
# Load teacher model for training
|
| 1160 |
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 1161 |
+
teacher_st_model = load_model_with_flash_attention(teacher_model, device)
|
| 1162 |
|
| 1163 |
+
# Perform tokenlearn training (POTION approach)
|
| 1164 |
+
final_model = tokenlearn_training(base_model, teacher_st_model, checkpoint_mgr)
|
| 1165 |
|
| 1166 |
# Save final model
|
| 1167 |
final_dir.mkdir(parents=True, exist_ok=True)
|
|
|
|
| 1300 |
return results_summary
|
| 1301 |
|
| 1302 |
|
| 1303 |
+
@function(**get_distillation_function_kwargs())
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1304 |
def _beam_distill_models(
|
| 1305 |
teacher_models: list[str] | None = None,
|
| 1306 |
enable_training: bool = False,
|
|
|
|
| 1456 |
) -> None:
|
| 1457 |
"""Unified distillation command with optional training."""
|
| 1458 |
logger.info("🚀 Starting unified Model2Vec distillation workflow")
|
| 1459 |
+
|
| 1460 |
+
logger.info(f"🎓 Training mode: {'Tokenlearn (POTION) training' if train else 'Basic distillation only'}")
|
| 1461 |
logger.info(f"☁️ Execution: {'Beam' if use_beam else 'Local'}")
|
| 1462 |
|
| 1463 |
# Use default models if none specified
|
|
|
|
| 1618 |
|
| 1619 |
try:
|
| 1620 |
import torch
|
|
|
|
| 1621 |
from transformers import AutoModel, AutoTokenizer
|
| 1622 |
|
| 1623 |
# Enhanced custom model loading for Salesforce models
|
|
|
|
| 1657 |
|
| 1658 |
# Method 2: Try SentenceTransformer with specific settings
|
| 1659 |
logger.info("🔄 Falling back to SentenceTransformer method...")
|
| 1660 |
+
sentence_model = load_model_with_flash_attention(
|
| 1661 |
teacher_model,
|
|
|
|
| 1662 |
device="cpu", # Force CPU loading first
|
| 1663 |
)
|
| 1664 |
|
|
|
|
| 1731 |
|
| 1732 |
try:
|
| 1733 |
import torch
|
|
|
|
| 1734 |
from transformers import AutoModel, AutoTokenizer
|
| 1735 |
|
| 1736 |
logger.info("🔧 Loading BAAI model with tokenizer workaround...")
|
|
|
|
| 1741 |
# Method 1: Try SentenceTransformer first (often handles tokenizer issues better)
|
| 1742 |
try:
|
| 1743 |
logger.info("🔄 Attempting with SentenceTransformer wrapper...")
|
| 1744 |
+
sentence_model = load_model_with_flash_attention(teacher_model)
|
| 1745 |
|
| 1746 |
# Extract components
|
| 1747 |
model = sentence_model[0].auto_model
|
src/distiller/evaluate.py
CHANGED
|
@@ -17,8 +17,12 @@ Usage:
|
|
| 17 |
distiller evaluate [--use-beam] [--skip-benchmark] # Run evaluation locally or on Beam
|
| 18 |
"""
|
| 19 |
|
|
|
|
|
|
|
|
|
|
| 20 |
import json
|
| 21 |
import logging
|
|
|
|
| 22 |
import time
|
| 23 |
import traceback
|
| 24 |
from pathlib import Path
|
|
@@ -29,7 +33,7 @@ import pandas as pd
|
|
| 29 |
import psutil
|
| 30 |
import torch
|
| 31 |
import typer
|
| 32 |
-
from beam import
|
| 33 |
from datasets import Dataset, load_dataset
|
| 34 |
from sentence_transformers import SentenceTransformer
|
| 35 |
from sklearn.metrics.pairwise import cosine_similarity
|
|
@@ -37,24 +41,25 @@ from tqdm import tqdm
|
|
| 37 |
|
| 38 |
from .beam_utils import download_specific_evaluation_file
|
| 39 |
from .config import (
|
| 40 |
-
BEAM_ENV_SETTINGS,
|
| 41 |
DEFAULT_EVALUATION_MODELS,
|
| 42 |
-
GPU_NAME,
|
| 43 |
-
IMAGE,
|
| 44 |
codesearchnet_config,
|
| 45 |
directories,
|
|
|
|
| 46 |
get_safe_model_name,
|
| 47 |
get_volume_config,
|
| 48 |
languages_config,
|
| 49 |
)
|
| 50 |
|
|
|
|
|
|
|
|
|
|
| 51 |
logger = logging.getLogger(__name__)
|
| 52 |
|
| 53 |
# =============================================================================
|
| 54 |
# EVALUATION CONFIGURATION
|
| 55 |
# =============================================================================
|
| 56 |
|
| 57 |
-
BATCH_SIZE =
|
| 58 |
LOCAL_EVALUATION_DIR = directories.evaluation_results
|
| 59 |
LOCAL_BENCHMARK_DIR = directories.benchmark_results
|
| 60 |
LOCAL_MODELS_DIR = directories.final
|
|
@@ -92,6 +97,200 @@ def complex_algorithm(data, config):
|
|
| 92 |
}
|
| 93 |
|
| 94 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
class PerformanceBenchmark:
|
| 96 |
"""Comprehensive performance benchmarking for embedding models."""
|
| 97 |
|
|
@@ -109,7 +308,7 @@ class PerformanceBenchmark:
|
|
| 109 |
start_time = time.time()
|
| 110 |
|
| 111 |
try:
|
| 112 |
-
self.model =
|
| 113 |
load_time = time.time() - start_time
|
| 114 |
|
| 115 |
logger.info(f"✅ Model loaded in {load_time:.2f}s on {self.device}")
|
|
@@ -321,7 +520,7 @@ class PerformanceBenchmark:
|
|
| 321 |
logger.info(f" 📊 Testing on {device.upper()}")
|
| 322 |
|
| 323 |
try:
|
| 324 |
-
model =
|
| 325 |
|
| 326 |
# Warmup
|
| 327 |
_ = model.encode(test_texts[:4], convert_to_tensor=False)
|
|
@@ -401,36 +600,71 @@ class CodeSearchNetEvaluator:
|
|
| 401 |
"""Load the embedding model."""
|
| 402 |
logger.info(f"Loading model from {self.model_path}")
|
| 403 |
try:
|
| 404 |
-
self.model =
|
| 405 |
logger.info(f"Successfully loaded model: {self.model_name}")
|
| 406 |
except Exception:
|
| 407 |
logger.exception(f"Failed to load model from {self.model_path}")
|
| 408 |
raise
|
| 409 |
|
| 410 |
def encode_texts(self, texts: list[str], desc: str = "Encoding") -> np.ndarray:
|
| 411 |
-
"""Encode texts into embeddings with batching."""
|
| 412 |
if self.model is None:
|
| 413 |
msg = "Model not loaded"
|
| 414 |
raise RuntimeError(msg)
|
| 415 |
|
| 416 |
embeddings = []
|
| 417 |
-
|
| 418 |
-
|
| 419 |
-
|
| 420 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 421 |
|
| 422 |
return np.vstack(embeddings)
|
| 423 |
|
| 424 |
-
def evaluate_language(self, language: str, max_queries: int =
|
| 425 |
"""Evaluate on a specific programming language."""
|
| 426 |
logger.info(f"Evaluating on {language} language (max {max_queries} queries)")
|
| 427 |
|
| 428 |
try:
|
| 429 |
-
# Load test split for the language
|
|
|
|
| 430 |
dataset = load_dataset(
|
| 431 |
codesearchnet_config.dataset_name,
|
| 432 |
language,
|
| 433 |
-
split="test",
|
| 434 |
trust_remote_code=True,
|
| 435 |
)
|
| 436 |
|
|
@@ -438,17 +672,17 @@ class CodeSearchNetEvaluator:
|
|
| 438 |
logger.error(f"Unexpected dataset type for {language}: {type(dataset)}")
|
| 439 |
return {}
|
| 440 |
|
| 441 |
-
|
| 442 |
-
if len(dataset) > max_queries:
|
| 443 |
-
rng = np.random.default_rng(42)
|
| 444 |
-
indices = rng.choice(len(dataset), max_queries, replace=False)
|
| 445 |
-
dataset = dataset.select(indices)
|
| 446 |
|
| 447 |
-
queries = []
|
| 448 |
-
codes = []
|
| 449 |
-
query_ids = []
|
| 450 |
|
|
|
|
| 451 |
for i, example in enumerate(dataset):
|
|
|
|
|
|
|
|
|
|
| 452 |
doc_string = example.get("func_documentation_string", "").strip()
|
| 453 |
code_string = example.get("func_code_string", "").strip()
|
| 454 |
|
|
@@ -461,8 +695,23 @@ class CodeSearchNetEvaluator:
|
|
| 461 |
logger.warning(f"No valid query-code pairs found for {language}")
|
| 462 |
return {}
|
| 463 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 464 |
logger.info(f"Found {len(queries)} valid query-code pairs for {language}")
|
| 465 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 466 |
# Encode queries and codes
|
| 467 |
start_time = time.time()
|
| 468 |
query_embeddings = self.encode_texts(queries, f"Encoding {language} queries")
|
|
@@ -548,7 +797,7 @@ class CodeSearchNetEvaluator:
|
|
| 548 |
return 0.0
|
| 549 |
|
| 550 |
def evaluate_all_languages(
|
| 551 |
-
self, max_queries_per_lang: int =
|
| 552 |
) -> dict[str, Any]:
|
| 553 |
"""Evaluate on all specified languages."""
|
| 554 |
eval_languages = languages or languages_config.all
|
|
@@ -613,7 +862,7 @@ class ComprehensiveModelEvaluator:
|
|
| 613 |
|
| 614 |
def run_comprehensive_evaluation(
|
| 615 |
self,
|
| 616 |
-
max_queries_per_lang: int =
|
| 617 |
languages: list[str] | None = None,
|
| 618 |
skip_benchmark: bool = False,
|
| 619 |
) -> dict[str, Any]:
|
|
@@ -901,7 +1150,7 @@ def create_comparison_report(all_results: list[dict[str, Any]], output_dir: str
|
|
| 901 |
|
| 902 |
def run_evaluation(
|
| 903 |
models: list[str],
|
| 904 |
-
max_queries: int =
|
| 905 |
languages: list[str] | None = None,
|
| 906 |
use_beam: bool = False,
|
| 907 |
skip_benchmark: bool = False,
|
|
@@ -962,7 +1211,7 @@ def run_evaluation(
|
|
| 962 |
|
| 963 |
def _run_local_evaluation(
|
| 964 |
models: list[str],
|
| 965 |
-
max_queries: int =
|
| 966 |
languages: list[str] | None = None,
|
| 967 |
skip_benchmark: bool = False,
|
| 968 |
) -> list[dict[str, Any]]:
|
|
@@ -993,30 +1242,52 @@ def _run_local_evaluation(
|
|
| 993 |
return results
|
| 994 |
|
| 995 |
|
| 996 |
-
@function(
|
| 997 |
-
gpu=GPU_NAME,
|
| 998 |
-
volumes=[Volume(name=VOLUME_CONFIG.name, mount_path=VOLUME_CONFIG.mount_path)],
|
| 999 |
-
image=IMAGE,
|
| 1000 |
-
secrets=["HF_ACCESS_TOKEN"],
|
| 1001 |
-
env=BEAM_ENV_SETTINGS,
|
| 1002 |
-
timeout=3600 * 8, # 8 hours for comprehensive evaluation
|
| 1003 |
-
)
|
| 1004 |
def _beam_evaluate_single_model(
|
| 1005 |
model_path: str,
|
| 1006 |
-
max_queries: int =
|
| 1007 |
languages: list[str] | None = None,
|
| 1008 |
skip_benchmark: bool = False,
|
| 1009 |
) -> dict[str, Any]:
|
| 1010 |
"""Beam function to comprehensively evaluate a single model."""
|
| 1011 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1012 |
|
|
|
|
| 1013 |
logger.info(f"🚀 Beam comprehensive evaluation starting for {model_name}")
|
| 1014 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1015 |
try:
|
|
|
|
| 1016 |
evaluator = ComprehensiveModelEvaluator(model_path, model_name)
|
|
|
|
|
|
|
|
|
|
| 1017 |
results = evaluator.run_comprehensive_evaluation(max_queries, languages, skip_benchmark)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1018 |
|
| 1019 |
# Save to Beam volume as single comprehensive file
|
|
|
|
| 1020 |
volume_results_dir = Path(VOLUME_CONFIG.mount_path) / "evaluation_results"
|
| 1021 |
volume_results_dir.mkdir(parents=True, exist_ok=True)
|
| 1022 |
|
|
@@ -1026,17 +1297,65 @@ def _beam_evaluate_single_model(
|
|
| 1026 |
with result_file.open("w") as f:
|
| 1027 |
json.dump(results, f, indent=2, default=str)
|
| 1028 |
|
| 1029 |
-
logger.info(f"💾 Saved Beam comprehensive evaluation results for {model_name}")
|
|
|
|
|
|
|
| 1030 |
return results
|
| 1031 |
|
| 1032 |
-
except
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1033 |
logger.exception(f"❌ Beam comprehensive evaluation failed for {model_name}")
|
| 1034 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1035 |
|
| 1036 |
|
| 1037 |
def _run_beam_evaluation(
|
| 1038 |
models: list[str],
|
| 1039 |
-
max_queries: int =
|
| 1040 |
languages: list[str] | None = None,
|
| 1041 |
skip_benchmark: bool = False,
|
| 1042 |
) -> list[dict[str, Any]]:
|
|
@@ -1054,6 +1373,13 @@ def _run_beam_evaluation(
|
|
| 1054 |
result = _beam_evaluate_single_model.remote(model_path, max_queries, languages, skip_benchmark)
|
| 1055 |
|
| 1056 |
if result:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1057 |
# Download the comprehensive result file from Beam
|
| 1058 |
success = download_specific_evaluation_file(
|
| 1059 |
VOLUME_CONFIG.name,
|
|
@@ -1069,6 +1395,8 @@ def _run_beam_evaluation(
|
|
| 1069 |
results.append(result)
|
| 1070 |
else:
|
| 1071 |
logger.warning(f"⚠️ Could not download results for {model_name}")
|
|
|
|
|
|
|
| 1072 |
|
| 1073 |
except Exception:
|
| 1074 |
logger.exception(f"❌ Beam comprehensive evaluation failed for {model_name}")
|
|
@@ -1086,7 +1414,7 @@ def main(
|
|
| 1086 |
use_beam: bool = typer.Option(default=False, help="Use Beam for evaluation"),
|
| 1087 |
skip_third_party: bool = typer.Option(default=False, help="Skip third-party models"),
|
| 1088 |
skip_benchmark: bool = typer.Option(default=False, help="Skip performance benchmarking"),
|
| 1089 |
-
max_queries: int = typer.Option(default=
|
| 1090 |
) -> None:
|
| 1091 |
"""Main comprehensive evaluation function."""
|
| 1092 |
logger.info("🚀 Starting comprehensive model evaluation (CodeSearchNet + Performance)")
|
|
|
|
| 17 |
distiller evaluate [--use-beam] [--skip-benchmark] # Run evaluation locally or on Beam
|
| 18 |
"""
|
| 19 |
|
| 20 |
+
# Try to import flash_attn to check if it's available
|
| 21 |
+
import contextlib
|
| 22 |
+
import importlib.util
|
| 23 |
import json
|
| 24 |
import logging
|
| 25 |
+
import os
|
| 26 |
import time
|
| 27 |
import traceback
|
| 28 |
from pathlib import Path
|
|
|
|
| 33 |
import psutil
|
| 34 |
import torch
|
| 35 |
import typer
|
| 36 |
+
from beam import function
|
| 37 |
from datasets import Dataset, load_dataset
|
| 38 |
from sentence_transformers import SentenceTransformer
|
| 39 |
from sklearn.metrics.pairwise import cosine_similarity
|
|
|
|
| 41 |
|
| 42 |
from .beam_utils import download_specific_evaluation_file
|
| 43 |
from .config import (
|
|
|
|
| 44 |
DEFAULT_EVALUATION_MODELS,
|
|
|
|
|
|
|
| 45 |
codesearchnet_config,
|
| 46 |
directories,
|
| 47 |
+
get_evaluation_function_kwargs,
|
| 48 |
get_safe_model_name,
|
| 49 |
get_volume_config,
|
| 50 |
languages_config,
|
| 51 |
)
|
| 52 |
|
| 53 |
+
# Check if flash_attn is available and compatible
|
| 54 |
+
FLASH_ATTN_AVAILABLE = importlib.util.find_spec("flash_attn") is not None
|
| 55 |
+
|
| 56 |
logger = logging.getLogger(__name__)
|
| 57 |
|
| 58 |
# =============================================================================
|
| 59 |
# EVALUATION CONFIGURATION
|
| 60 |
# =============================================================================
|
| 61 |
|
| 62 |
+
BATCH_SIZE = 10
|
| 63 |
LOCAL_EVALUATION_DIR = directories.evaluation_results
|
| 64 |
LOCAL_BENCHMARK_DIR = directories.benchmark_results
|
| 65 |
LOCAL_MODELS_DIR = directories.final
|
|
|
|
| 97 |
}
|
| 98 |
|
| 99 |
|
| 100 |
+
def reset_cuda_state() -> None:
|
| 101 |
+
"""Aggressively reset CUDA state after memory allocation errors."""
|
| 102 |
+
if not torch.cuda.is_available():
|
| 103 |
+
return
|
| 104 |
+
|
| 105 |
+
try:
|
| 106 |
+
# Clear all CUDA caches
|
| 107 |
+
torch.cuda.empty_cache()
|
| 108 |
+
torch.cuda.ipc_collect()
|
| 109 |
+
torch.cuda.reset_peak_memory_stats()
|
| 110 |
+
|
| 111 |
+
# Try to force garbage collection
|
| 112 |
+
import gc
|
| 113 |
+
|
| 114 |
+
gc.collect()
|
| 115 |
+
|
| 116 |
+
logger.info("🧹 CUDA state reset completed")
|
| 117 |
+
except Exception as e:
|
| 118 |
+
logger.warning(f"⚠️ Could not fully reset CUDA state: {e}")
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def configure_flash_attention() -> dict[str, Any]:
|
| 122 |
+
"""Configure flash attention settings and return model kwargs."""
|
| 123 |
+
model_kwargs: dict[str, Any] = {}
|
| 124 |
+
|
| 125 |
+
if not FLASH_ATTN_AVAILABLE:
|
| 126 |
+
logger.info("⚠️ Flash attention not available - using standard attention")
|
| 127 |
+
return model_kwargs
|
| 128 |
+
|
| 129 |
+
# Set environment variables for flash attention and CUDA memory management
|
| 130 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 131 |
+
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
|
| 132 |
+
|
| 133 |
+
# Check if we're on a compatible GPU
|
| 134 |
+
try:
|
| 135 |
+
if torch.cuda.is_available():
|
| 136 |
+
device_capability = torch.cuda.get_device_capability()
|
| 137 |
+
# Flash attention requires compute capability >= 7.5 (Turing, Ampere, Ada, Hopper)
|
| 138 |
+
if device_capability[0] >= 7 and (device_capability[0] > 7 or device_capability[1] >= 5):
|
| 139 |
+
logger.info("✅ Flash attention available - compatible GPU detected")
|
| 140 |
+
# For SentenceTransformer, we'll use environment variables to enable flash attention
|
| 141 |
+
os.environ["TRANSFORMERS_FLASH_ATTENTION"] = "1"
|
| 142 |
+
else:
|
| 143 |
+
logger.info(f"⚠️ GPU compute capability {device_capability} < 7.5 - flash attention disabled")
|
| 144 |
+
else:
|
| 145 |
+
logger.info("⚠️ No CUDA available - flash attention disabled")
|
| 146 |
+
except Exception as e:
|
| 147 |
+
logger.warning(f"⚠️ Failed to check GPU compatibility: {e} - flash attention disabled")
|
| 148 |
+
|
| 149 |
+
return model_kwargs
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def load_model_with_flash_attention(model_path: str, device: str = "auto") -> SentenceTransformer:
|
| 153 |
+
"""Load a SentenceTransformer model with flash attention if available."""
|
| 154 |
+
# Convert "auto" device to actual device
|
| 155 |
+
target_device = "cuda" if device == "auto" and torch.cuda.is_available() else device
|
| 156 |
+
if device == "auto" and not torch.cuda.is_available():
|
| 157 |
+
target_device = "cpu"
|
| 158 |
+
|
| 159 |
+
# Configure flash attention via environment variables
|
| 160 |
+
configure_flash_attention()
|
| 161 |
+
|
| 162 |
+
# Load model with standard SentenceTransformer initialization
|
| 163 |
+
logger.info(f"📂 Loading model: {Path(model_path).name}")
|
| 164 |
+
|
| 165 |
+
try:
|
| 166 |
+
# Try loading directly to target device first
|
| 167 |
+
model = SentenceTransformer(model_path, device=target_device, trust_remote_code=True)
|
| 168 |
+
logger.info(f"✅ Model loaded successfully on {target_device}")
|
| 169 |
+
return model
|
| 170 |
+
except (torch.OutOfMemoryError, RuntimeError) as oom_error:
|
| 171 |
+
# Handle both torch.OutOfMemoryError and RuntimeError (CUDA driver errors)
|
| 172 |
+
is_oom = isinstance(oom_error, torch.OutOfMemoryError) or "out of memory" in str(oom_error).lower()
|
| 173 |
+
|
| 174 |
+
if is_oom and target_device != "cpu":
|
| 175 |
+
logger.warning(f"⚠️ OOM loading directly to {target_device}, trying CPU first: {oom_error}")
|
| 176 |
+
try:
|
| 177 |
+
# Clear CUDA cache more aggressively after OOM
|
| 178 |
+
reset_cuda_state()
|
| 179 |
+
|
| 180 |
+
logger.info("🔄 Loading model on CPU first, then trying to move to GPU...")
|
| 181 |
+
model = SentenceTransformer(model_path, device="cpu", trust_remote_code=True)
|
| 182 |
+
logger.info("📦 Model loaded on CPU, attempting GPU transfer...")
|
| 183 |
+
|
| 184 |
+
# Try moving to GPU with additional error handling
|
| 185 |
+
try:
|
| 186 |
+
model = model.to(target_device)
|
| 187 |
+
logger.info(f"✅ Model successfully moved to {target_device}")
|
| 188 |
+
return model
|
| 189 |
+
except (RuntimeError, AssertionError) as gpu_move_error:
|
| 190 |
+
# Handle PyTorch internal errors and CUDA allocator issues
|
| 191 |
+
logger.warning(f"⚠️ GPU transfer failed: {gpu_move_error}")
|
| 192 |
+
if "INTERNAL ASSERT FAILED" in str(gpu_move_error) or "handles_" in str(gpu_move_error):
|
| 193 |
+
logger.warning("🔧 Detected CUDA allocator corruption, resetting and staying on CPU")
|
| 194 |
+
# Try to reset CUDA context
|
| 195 |
+
reset_cuda_state()
|
| 196 |
+
else:
|
| 197 |
+
# Re-raise unexpected GPU transfer errors
|
| 198 |
+
raise
|
| 199 |
+
|
| 200 |
+
logger.info("✅ Model will remain on CPU due to GPU memory issues")
|
| 201 |
+
return model
|
| 202 |
+
|
| 203 |
+
except Exception as fallback_error:
|
| 204 |
+
logger.warning(f"⚠️ CPU fallback failed: {fallback_error}, loading fresh on CPU")
|
| 205 |
+
# Clear any remaining CUDA state
|
| 206 |
+
reset_cuda_state()
|
| 207 |
+
|
| 208 |
+
model = SentenceTransformer(model_path, device="cpu", trust_remote_code=True)
|
| 209 |
+
logger.info("✅ Model loaded on CPU (all GPU attempts failed)")
|
| 210 |
+
return model
|
| 211 |
+
else:
|
| 212 |
+
# Re-raise if not OOM or already on CPU
|
| 213 |
+
raise
|
| 214 |
+
except ValueError as e:
|
| 215 |
+
if "'MaxSim' is not a valid SimilarityFunction" in str(e):
|
| 216 |
+
logger.warning(f"⚠️ Model {Path(model_path).name} uses unsupported MaxSim similarity function")
|
| 217 |
+
logger.info("🔧 Attempting workaround by loading with custom config...")
|
| 218 |
+
|
| 219 |
+
# Try loading with similarity function override
|
| 220 |
+
try:
|
| 221 |
+
# Load model components manually and override similarity function
|
| 222 |
+
import json
|
| 223 |
+
import tempfile
|
| 224 |
+
from pathlib import Path as PathLib
|
| 225 |
+
|
| 226 |
+
# Create temporary directory for modified config
|
| 227 |
+
with tempfile.TemporaryDirectory() as temp_dir:
|
| 228 |
+
temp_path = PathLib(temp_dir) / "temp_model"
|
| 229 |
+
|
| 230 |
+
# Download/copy model files
|
| 231 |
+
if model_path.startswith("http") or ("/" in model_path and not PathLib(model_path).exists()):
|
| 232 |
+
# It's a HuggingFace model ID
|
| 233 |
+
from huggingface_hub import snapshot_download
|
| 234 |
+
|
| 235 |
+
snapshot_download(model_path, local_dir=temp_path, ignore_patterns=["*.bin"])
|
| 236 |
+
else:
|
| 237 |
+
# It's a local path
|
| 238 |
+
import shutil
|
| 239 |
+
|
| 240 |
+
shutil.copytree(model_path, temp_path)
|
| 241 |
+
|
| 242 |
+
# Modify config to use supported similarity function
|
| 243 |
+
config_path = temp_path / "config_sentence_transformers.json"
|
| 244 |
+
if config_path.exists():
|
| 245 |
+
with config_path.open() as f:
|
| 246 |
+
config = json.load(f)
|
| 247 |
+
|
| 248 |
+
# Override similarity function to 'cosine' (supported)
|
| 249 |
+
if "similarity_fn_name" in config:
|
| 250 |
+
logger.info(
|
| 251 |
+
f"🔧 Changing similarity function from '{config['similarity_fn_name']}' to 'cosine'"
|
| 252 |
+
)
|
| 253 |
+
config["similarity_fn_name"] = "cosine"
|
| 254 |
+
|
| 255 |
+
with config_path.open("w") as f:
|
| 256 |
+
json.dump(config, f, indent=2)
|
| 257 |
+
|
| 258 |
+
# Load model with modified config
|
| 259 |
+
model = SentenceTransformer(str(temp_path), device=device, trust_remote_code=True)
|
| 260 |
+
logger.info("✅ Model loaded successfully with similarity function workaround")
|
| 261 |
+
return model
|
| 262 |
+
|
| 263 |
+
except Exception as workaround_error:
|
| 264 |
+
logger.warning(f"⚠️ Similarity function workaround failed: {workaround_error}")
|
| 265 |
+
logger.info("🔧 Attempting direct model component loading...")
|
| 266 |
+
|
| 267 |
+
# Last resort: try loading model components directly
|
| 268 |
+
try:
|
| 269 |
+
from sentence_transformers.models import Pooling, Transformer
|
| 270 |
+
|
| 271 |
+
# Load model components manually
|
| 272 |
+
logger.info("🔄 Loading model components directly...")
|
| 273 |
+
|
| 274 |
+
# Create SentenceTransformer components using model path
|
| 275 |
+
transformer = Transformer(model_path)
|
| 276 |
+
pooling = Pooling(transformer.get_word_embedding_dimension())
|
| 277 |
+
|
| 278 |
+
# Create SentenceTransformer with manual components
|
| 279 |
+
model = SentenceTransformer(modules=[transformer, pooling], device=device)
|
| 280 |
+
logger.info("✅ Model loaded successfully with direct component loading")
|
| 281 |
+
return model
|
| 282 |
+
|
| 283 |
+
except Exception as direct_error:
|
| 284 |
+
logger.warning(f"⚠️ Direct component loading failed: {direct_error}")
|
| 285 |
+
logger.exception(f"❌ All loading methods failed for {Path(model_path).name}")
|
| 286 |
+
raise e from direct_error
|
| 287 |
+
else:
|
| 288 |
+
raise
|
| 289 |
+
except Exception:
|
| 290 |
+
logger.exception(f"❌ Failed to load model {Path(model_path).name}")
|
| 291 |
+
raise
|
| 292 |
+
|
| 293 |
+
|
| 294 |
class PerformanceBenchmark:
|
| 295 |
"""Comprehensive performance benchmarking for embedding models."""
|
| 296 |
|
|
|
|
| 308 |
start_time = time.time()
|
| 309 |
|
| 310 |
try:
|
| 311 |
+
self.model = load_model_with_flash_attention(self.model_path, self.device)
|
| 312 |
load_time = time.time() - start_time
|
| 313 |
|
| 314 |
logger.info(f"✅ Model loaded in {load_time:.2f}s on {self.device}")
|
|
|
|
| 520 |
logger.info(f" 📊 Testing on {device.upper()}")
|
| 521 |
|
| 522 |
try:
|
| 523 |
+
model = load_model_with_flash_attention(self.model_path, device)
|
| 524 |
|
| 525 |
# Warmup
|
| 526 |
_ = model.encode(test_texts[:4], convert_to_tensor=False)
|
|
|
|
| 600 |
"""Load the embedding model."""
|
| 601 |
logger.info(f"Loading model from {self.model_path}")
|
| 602 |
try:
|
| 603 |
+
self.model = load_model_with_flash_attention(self.model_path)
|
| 604 |
logger.info(f"Successfully loaded model: {self.model_name}")
|
| 605 |
except Exception:
|
| 606 |
logger.exception(f"Failed to load model from {self.model_path}")
|
| 607 |
raise
|
| 608 |
|
| 609 |
def encode_texts(self, texts: list[str], desc: str = "Encoding") -> np.ndarray:
|
| 610 |
+
"""Encode texts into embeddings with batching and memory management."""
|
| 611 |
if self.model is None:
|
| 612 |
msg = "Model not loaded"
|
| 613 |
raise RuntimeError(msg)
|
| 614 |
|
| 615 |
embeddings = []
|
| 616 |
+
# Use smaller batch size to avoid OOM
|
| 617 |
+
effective_batch_size = min(BATCH_SIZE, 5) # Limit to 5 for large models
|
| 618 |
+
|
| 619 |
+
for i in tqdm(range(0, len(texts), effective_batch_size), desc=desc):
|
| 620 |
+
batch = texts[i : i + effective_batch_size]
|
| 621 |
+
|
| 622 |
+
try:
|
| 623 |
+
batch_embeddings = self.model.encode(batch, convert_to_tensor=False, normalize_embeddings=True)
|
| 624 |
+
embeddings.append(batch_embeddings)
|
| 625 |
+
|
| 626 |
+
# Clear CUDA cache periodically to prevent memory buildup
|
| 627 |
+
if torch.cuda.is_available() and i > 0 and i % (effective_batch_size * 4) == 0:
|
| 628 |
+
torch.cuda.empty_cache()
|
| 629 |
+
|
| 630 |
+
except (torch.OutOfMemoryError, RuntimeError) as e:
|
| 631 |
+
# Handle both torch.OutOfMemoryError and RuntimeError (CUDA driver errors)
|
| 632 |
+
is_oom = isinstance(e, torch.OutOfMemoryError) or "out of memory" in str(e).lower()
|
| 633 |
+
|
| 634 |
+
if is_oom:
|
| 635 |
+
logger.warning(
|
| 636 |
+
f"⚠️ OOM during encoding batch {i // effective_batch_size + 1}, trying smaller batch..."
|
| 637 |
+
)
|
| 638 |
+
# Try encoding one at a time
|
| 639 |
+
for single_text in batch:
|
| 640 |
+
try:
|
| 641 |
+
single_embedding = self.model.encode(
|
| 642 |
+
[single_text], convert_to_tensor=False, normalize_embeddings=True
|
| 643 |
+
)
|
| 644 |
+
embeddings.append(single_embedding)
|
| 645 |
+
if torch.cuda.is_available():
|
| 646 |
+
torch.cuda.empty_cache()
|
| 647 |
+
except (torch.OutOfMemoryError, RuntimeError) as single_e:
|
| 648 |
+
if isinstance(single_e, torch.OutOfMemoryError) or "out of memory" in str(single_e).lower():
|
| 649 |
+
logger.exception("❌ Cannot encode even single text, model too large for GPU")
|
| 650 |
+
raise
|
| 651 |
+
raise
|
| 652 |
+
else:
|
| 653 |
+
raise
|
| 654 |
|
| 655 |
return np.vstack(embeddings)
|
| 656 |
|
| 657 |
+
def evaluate_language(self, language: str, max_queries: int = 100) -> dict[str, Any]:
|
| 658 |
"""Evaluate on a specific programming language."""
|
| 659 |
logger.info(f"Evaluating on {language} language (max {max_queries} queries)")
|
| 660 |
|
| 661 |
try:
|
| 662 |
+
# Load ONLY test split for the language with streaming to avoid loading full dataset
|
| 663 |
+
logger.info(f"📥 Loading test split for {language}...")
|
| 664 |
dataset = load_dataset(
|
| 665 |
codesearchnet_config.dataset_name,
|
| 666 |
language,
|
| 667 |
+
split=f"test[:{max_queries * 10}]", # Load 10x more than needed to ensure we get enough valid pairs
|
| 668 |
trust_remote_code=True,
|
| 669 |
)
|
| 670 |
|
|
|
|
| 672 |
logger.error(f"Unexpected dataset type for {language}: {type(dataset)}")
|
| 673 |
return {}
|
| 674 |
|
| 675 |
+
logger.info(f"📊 Loaded {len(dataset)} examples from {language} test split")
|
|
|
|
|
|
|
|
|
|
|
|
|
| 676 |
|
| 677 |
+
queries: list[str] = []
|
| 678 |
+
codes: list[str] = []
|
| 679 |
+
query_ids: list[str] = []
|
| 680 |
|
| 681 |
+
# Process examples and stop once we have enough valid pairs
|
| 682 |
for i, example in enumerate(dataset):
|
| 683 |
+
if len(queries) >= max_queries: # Stop once we have enough
|
| 684 |
+
break
|
| 685 |
+
|
| 686 |
doc_string = example.get("func_documentation_string", "").strip()
|
| 687 |
code_string = example.get("func_code_string", "").strip()
|
| 688 |
|
|
|
|
| 695 |
logger.warning(f"No valid query-code pairs found for {language}")
|
| 696 |
return {}
|
| 697 |
|
| 698 |
+
# Truncate to exactly max_queries if we have more
|
| 699 |
+
if len(queries) > max_queries:
|
| 700 |
+
queries = queries[:max_queries]
|
| 701 |
+
codes = codes[:max_queries]
|
| 702 |
+
query_ids = query_ids[:max_queries]
|
| 703 |
+
|
| 704 |
logger.info(f"Found {len(queries)} valid query-code pairs for {language}")
|
| 705 |
|
| 706 |
+
# Check available memory before encoding
|
| 707 |
+
if torch.cuda.is_available():
|
| 708 |
+
free_memory = torch.cuda.get_device_properties(0).total_memory - torch.cuda.memory_allocated()
|
| 709 |
+
free_gb = free_memory / (1024**3)
|
| 710 |
+
logger.info(f"💾 Available GPU memory before encoding: {free_gb:.1f} GB")
|
| 711 |
+
if free_gb < 2.0: # Less than 2GB free
|
| 712 |
+
logger.warning(f"⚠️ Low GPU memory ({free_gb:.1f} GB), using conservative encoding")
|
| 713 |
+
torch.cuda.empty_cache()
|
| 714 |
+
|
| 715 |
# Encode queries and codes
|
| 716 |
start_time = time.time()
|
| 717 |
query_embeddings = self.encode_texts(queries, f"Encoding {language} queries")
|
|
|
|
| 797 |
return 0.0
|
| 798 |
|
| 799 |
def evaluate_all_languages(
|
| 800 |
+
self, max_queries_per_lang: int = 100, languages: list[str] | None = None
|
| 801 |
) -> dict[str, Any]:
|
| 802 |
"""Evaluate on all specified languages."""
|
| 803 |
eval_languages = languages or languages_config.all
|
|
|
|
| 862 |
|
| 863 |
def run_comprehensive_evaluation(
|
| 864 |
self,
|
| 865 |
+
max_queries_per_lang: int = 100,
|
| 866 |
languages: list[str] | None = None,
|
| 867 |
skip_benchmark: bool = False,
|
| 868 |
) -> dict[str, Any]:
|
|
|
|
| 1150 |
|
| 1151 |
def run_evaluation(
|
| 1152 |
models: list[str],
|
| 1153 |
+
max_queries: int = 100,
|
| 1154 |
languages: list[str] | None = None,
|
| 1155 |
use_beam: bool = False,
|
| 1156 |
skip_benchmark: bool = False,
|
|
|
|
| 1211 |
|
| 1212 |
def _run_local_evaluation(
|
| 1213 |
models: list[str],
|
| 1214 |
+
max_queries: int = 100,
|
| 1215 |
languages: list[str] | None = None,
|
| 1216 |
skip_benchmark: bool = False,
|
| 1217 |
) -> list[dict[str, Any]]:
|
|
|
|
| 1242 |
return results
|
| 1243 |
|
| 1244 |
|
| 1245 |
+
@function(**get_evaluation_function_kwargs())
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1246 |
def _beam_evaluate_single_model(
|
| 1247 |
model_path: str,
|
| 1248 |
+
max_queries: int = 100,
|
| 1249 |
languages: list[str] | None = None,
|
| 1250 |
skip_benchmark: bool = False,
|
| 1251 |
) -> dict[str, Any]:
|
| 1252 |
"""Beam function to comprehensively evaluate a single model."""
|
| 1253 |
+
# Set CUDA memory settings BEFORE any CUDA operations
|
| 1254 |
+
|
| 1255 |
+
import os
|
| 1256 |
+
|
| 1257 |
+
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
|
| 1258 |
|
| 1259 |
+
model_name = Path(model_path).name
|
| 1260 |
logger.info(f"🚀 Beam comprehensive evaluation starting for {model_name}")
|
| 1261 |
|
| 1262 |
+
# Clear CUDA cache if available
|
| 1263 |
+
try:
|
| 1264 |
+
import torch
|
| 1265 |
+
|
| 1266 |
+
if torch.cuda.is_available():
|
| 1267 |
+
torch.cuda.empty_cache()
|
| 1268 |
+
torch.cuda.reset_peak_memory_stats()
|
| 1269 |
+
logger.info(
|
| 1270 |
+
f"🧹 Cleared CUDA cache. Available memory: {torch.cuda.get_device_properties(0).total_memory // (1024**3)} GB"
|
| 1271 |
+
)
|
| 1272 |
+
except Exception as e:
|
| 1273 |
+
logger.warning(f"⚠️ Could not clear CUDA cache: {e}")
|
| 1274 |
+
|
| 1275 |
try:
|
| 1276 |
+
logger.info("🔧 Creating ComprehensiveModelEvaluator...")
|
| 1277 |
evaluator = ComprehensiveModelEvaluator(model_path, model_name)
|
| 1278 |
+
logger.info("✅ ComprehensiveModelEvaluator created successfully")
|
| 1279 |
+
|
| 1280 |
+
logger.info("🚀 Starting comprehensive evaluation...")
|
| 1281 |
results = evaluator.run_comprehensive_evaluation(max_queries, languages, skip_benchmark)
|
| 1282 |
+
logger.info("✅ Comprehensive evaluation completed")
|
| 1283 |
+
|
| 1284 |
+
# Validate results
|
| 1285 |
+
if not results or "model_name" not in results:
|
| 1286 |
+
logger.error(f"❌ Invalid evaluation results for {model_name}: {results}")
|
| 1287 |
+
return {"error": "Invalid evaluation results", "model_name": model_name}
|
| 1288 |
|
| 1289 |
# Save to Beam volume as single comprehensive file
|
| 1290 |
+
logger.info("💾 Saving results to Beam volume...")
|
| 1291 |
volume_results_dir = Path(VOLUME_CONFIG.mount_path) / "evaluation_results"
|
| 1292 |
volume_results_dir.mkdir(parents=True, exist_ok=True)
|
| 1293 |
|
|
|
|
| 1297 |
with result_file.open("w") as f:
|
| 1298 |
json.dump(results, f, indent=2, default=str)
|
| 1299 |
|
| 1300 |
+
logger.info(f"💾 Saved Beam comprehensive evaluation results for {model_name} to {result_file}")
|
| 1301 |
+
logger.info(f"🎯 Final results summary: {len(results.get('codesearch_languages', {}))} languages evaluated")
|
| 1302 |
+
|
| 1303 |
return results
|
| 1304 |
|
| 1305 |
+
except (torch.OutOfMemoryError, RuntimeError, AssertionError) as e:
|
| 1306 |
+
# Handle CUDA errors including OOM, driver errors, and PyTorch internal assertion failures
|
| 1307 |
+
is_oom = isinstance(e, torch.OutOfMemoryError) or "out of memory" in str(e).lower()
|
| 1308 |
+
is_cuda_error = is_oom or "cuda" in str(e).lower() or "INTERNAL ASSERT FAILED" in str(e) or "handles_" in str(e)
|
| 1309 |
+
|
| 1310 |
+
if is_cuda_error:
|
| 1311 |
+
error_type = "CUDA OOM" if is_oom else "CUDA Error"
|
| 1312 |
+
logger.exception(f"❌ {error_type} during evaluation of {model_name}")
|
| 1313 |
+
|
| 1314 |
+
# Try to clear memory and reset CUDA state more aggressively
|
| 1315 |
+
with contextlib.suppress(Exception):
|
| 1316 |
+
reset_cuda_state()
|
| 1317 |
+
|
| 1318 |
+
return {
|
| 1319 |
+
"error": f"{error_type}: {e!s}",
|
| 1320 |
+
"model_name": model_name,
|
| 1321 |
+
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
|
| 1322 |
+
"evaluation_failed": True,
|
| 1323 |
+
"oom": is_oom,
|
| 1324 |
+
"cuda_error": True,
|
| 1325 |
+
}
|
| 1326 |
+
# Re-raise if not a CUDA-related error
|
| 1327 |
+
raise
|
| 1328 |
+
except Exception as e:
|
| 1329 |
logger.exception(f"❌ Beam comprehensive evaluation failed for {model_name}")
|
| 1330 |
+
# Return error info in a structured way
|
| 1331 |
+
error_result = {
|
| 1332 |
+
"error": str(e),
|
| 1333 |
+
"model_name": model_name,
|
| 1334 |
+
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
|
| 1335 |
+
"evaluation_failed": True,
|
| 1336 |
+
}
|
| 1337 |
+
|
| 1338 |
+
# Try to save error result to volume
|
| 1339 |
+
try:
|
| 1340 |
+
volume_results_dir = Path(VOLUME_CONFIG.mount_path) / "evaluation_results"
|
| 1341 |
+
volume_results_dir.mkdir(parents=True, exist_ok=True)
|
| 1342 |
+
|
| 1343 |
+
safe_model_name = get_safe_model_name(model_name)
|
| 1344 |
+
error_file = volume_results_dir / f"error_eval_{safe_model_name}.json"
|
| 1345 |
+
|
| 1346 |
+
with error_file.open("w") as f:
|
| 1347 |
+
json.dump(error_result, f, indent=2, default=str)
|
| 1348 |
+
|
| 1349 |
+
logger.info(f"💾 Saved error info to {error_file}")
|
| 1350 |
+
except Exception:
|
| 1351 |
+
logger.exception("❌ Could not save error info")
|
| 1352 |
+
|
| 1353 |
+
return error_result
|
| 1354 |
|
| 1355 |
|
| 1356 |
def _run_beam_evaluation(
|
| 1357 |
models: list[str],
|
| 1358 |
+
max_queries: int = 100,
|
| 1359 |
languages: list[str] | None = None,
|
| 1360 |
skip_benchmark: bool = False,
|
| 1361 |
) -> list[dict[str, Any]]:
|
|
|
|
| 1373 |
result = _beam_evaluate_single_model.remote(model_path, max_queries, languages, skip_benchmark)
|
| 1374 |
|
| 1375 |
if result:
|
| 1376 |
+
# Check if this is an error result
|
| 1377 |
+
if result.get("evaluation_failed", False):
|
| 1378 |
+
logger.error(f"❌ Beam evaluation failed for {model_name}: {result.get('error', 'Unknown error')}")
|
| 1379 |
+
if result.get("oom", False):
|
| 1380 |
+
logger.error("💥 Out of memory error - model may be too large for available GPU")
|
| 1381 |
+
continue
|
| 1382 |
+
|
| 1383 |
# Download the comprehensive result file from Beam
|
| 1384 |
success = download_specific_evaluation_file(
|
| 1385 |
VOLUME_CONFIG.name,
|
|
|
|
| 1395 |
results.append(result)
|
| 1396 |
else:
|
| 1397 |
logger.warning(f"⚠️ Could not download results for {model_name}")
|
| 1398 |
+
else:
|
| 1399 |
+
logger.warning(f"⚠️ No result returned for {model_name}")
|
| 1400 |
|
| 1401 |
except Exception:
|
| 1402 |
logger.exception(f"❌ Beam comprehensive evaluation failed for {model_name}")
|
|
|
|
| 1414 |
use_beam: bool = typer.Option(default=False, help="Use Beam for evaluation"),
|
| 1415 |
skip_third_party: bool = typer.Option(default=False, help="Skip third-party models"),
|
| 1416 |
skip_benchmark: bool = typer.Option(default=False, help="Skip performance benchmarking"),
|
| 1417 |
+
max_queries: int = typer.Option(default=100, help="Maximum queries per language"),
|
| 1418 |
) -> None:
|
| 1419 |
"""Main comprehensive evaluation function."""
|
| 1420 |
logger.info("🚀 Starting comprehensive model evaluation (CodeSearchNet + Performance)")
|
train_code_classification.py
DELETED
|
@@ -1,365 +0,0 @@
|
|
| 1 |
-
#!/usr/bin/env python
|
| 2 |
-
"""
|
| 3 |
-
Script to train a code classification model using CodeSearchNet dataset with Model2Vec.
|
| 4 |
-
|
| 5 |
-
This script performs the following operations:
|
| 6 |
-
1. Downloads the Alibaba-NLP/gte-Qwen2-7B-instruct model
|
| 7 |
-
2. Optionally distills it using Model2Vec to create a smaller, faster static model
|
| 8 |
-
3. Trains a programming language classifier on CodeSearchNet dataset
|
| 9 |
-
4. Evaluates the classifier and saves the trained model
|
| 10 |
-
|
| 11 |
-
Based on the official CodeSearchNet dataset: https://github.com/github/CodeSearchNet
|
| 12 |
-
"""
|
| 13 |
-
|
| 14 |
-
import json
|
| 15 |
-
import logging
|
| 16 |
-
import re
|
| 17 |
-
import time
|
| 18 |
-
from pathlib import Path
|
| 19 |
-
from time import perf_counter
|
| 20 |
-
from typing import Any, cast
|
| 21 |
-
|
| 22 |
-
from datasets import Dataset, DatasetDict, load_dataset # type: ignore [import]
|
| 23 |
-
from model2vec.distill import distill
|
| 24 |
-
from model2vec.train import StaticModelForClassification
|
| 25 |
-
|
| 26 |
-
# =============================================================================
|
| 27 |
-
# CONFIGURATION CONSTANTS
|
| 28 |
-
# =============================================================================
|
| 29 |
-
|
| 30 |
-
# Model Configuration
|
| 31 |
-
MODEL_NAME = "Alibaba-NLP/gte-Qwen2-7B-instruct" # Source model to distill
|
| 32 |
-
OUTPUT_DIR = "." # Directory to save the trained model
|
| 33 |
-
|
| 34 |
-
# Distillation Configuration
|
| 35 |
-
SKIP_DISTILLATION = False # Set to True to skip distillation and use existing model
|
| 36 |
-
DISTILLED_MODEL_PATH = "." # Path to existing distilled model (if skipping distillation)
|
| 37 |
-
PCA_DIMS = 256 # Dimensions for PCA reduction (smaller = faster but less accurate)
|
| 38 |
-
|
| 39 |
-
# Dataset Configuration
|
| 40 |
-
DATASET_NAME = "code-search-net/code_search_net" # CodeSearchNet dataset
|
| 41 |
-
CLASSIFICATION_TASK = "language" # Task: classify programming language
|
| 42 |
-
MAX_SAMPLES_PER_LANGUAGE = 5000 # Limit samples per language for balanced training
|
| 43 |
-
MIN_CODE_LENGTH = 50 # Minimum code length in characters
|
| 44 |
-
MAX_CODE_LENGTH = 2000 # Maximum code length in characters (for memory efficiency)
|
| 45 |
-
|
| 46 |
-
# Text processing constants
|
| 47 |
-
MAX_COMMENT_LENGTH = 200 # Maximum length for comment lines before truncation
|
| 48 |
-
|
| 49 |
-
# Training Configuration
|
| 50 |
-
MAX_EPOCHS = 30 # Maximum number of training epochs
|
| 51 |
-
PATIENCE = 5 # Early stopping patience
|
| 52 |
-
BATCH_SIZE = 32 # Training batch size
|
| 53 |
-
LEARNING_RATE = 1e-3 # Learning rate
|
| 54 |
-
|
| 55 |
-
# Saving Configuration
|
| 56 |
-
SAVE_PIPELINE = True # Save as scikit-learn compatible pipeline
|
| 57 |
-
SAVE_TO_HUB = False # Whether to push the model to HuggingFace Hub
|
| 58 |
-
HUB_MODEL_ID = None # Model ID for HuggingFace Hub (if saving to hub)
|
| 59 |
-
|
| 60 |
-
# =============================================================================
|
| 61 |
-
|
| 62 |
-
# Configure logging
|
| 63 |
-
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
| 64 |
-
logger = logging.getLogger(__name__)
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
def clean_code_text(code: str) -> str:
|
| 68 |
-
"""Clean and normalize code text for better classification."""
|
| 69 |
-
if not code:
|
| 70 |
-
return ""
|
| 71 |
-
|
| 72 |
-
# Remove excessive whitespace while preserving structure
|
| 73 |
-
code = re.sub(r"\n\s*\n\s*\n", "\n\n", code) # Remove multiple empty lines
|
| 74 |
-
code = re.sub(r" +", " ", code) # Replace multiple spaces with single space
|
| 75 |
-
|
| 76 |
-
# Remove very long comments that might bias classification
|
| 77 |
-
lines = code.split("\n")
|
| 78 |
-
cleaned_lines = []
|
| 79 |
-
for original_line in lines:
|
| 80 |
-
line = original_line
|
| 81 |
-
# Keep comment lines but limit their length
|
| 82 |
-
if line.strip().startswith(("#", "//", "/*", "*", "--")) and len(line) > MAX_COMMENT_LENGTH:
|
| 83 |
-
line = line[:MAX_COMMENT_LENGTH] + "..."
|
| 84 |
-
cleaned_lines.append(line)
|
| 85 |
-
|
| 86 |
-
return "\n".join(cleaned_lines)
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
def load_codesearchnet_dataset() -> tuple[Dataset, Dataset, str, str]:
|
| 90 |
-
"""Load and preprocess the CodeSearchNet dataset for programming language classification."""
|
| 91 |
-
logger.info("Loading CodeSearchNet dataset...")
|
| 92 |
-
|
| 93 |
-
try:
|
| 94 |
-
# Load the dataset with trust_remote_code=True
|
| 95 |
-
logger.info("Downloading and loading CodeSearchNet data...")
|
| 96 |
-
ds = cast(
|
| 97 |
-
"DatasetDict",
|
| 98 |
-
load_dataset(
|
| 99 |
-
DATASET_NAME,
|
| 100 |
-
trust_remote_code=True,
|
| 101 |
-
# Load a reasonable sample for training
|
| 102 |
-
),
|
| 103 |
-
)
|
| 104 |
-
|
| 105 |
-
logger.info(f"Available splits: {list(ds.keys())}")
|
| 106 |
-
|
| 107 |
-
# Use train/test splits if available, otherwise split the data
|
| 108 |
-
if "train" in ds and "test" in ds:
|
| 109 |
-
train_dataset = ds["train"]
|
| 110 |
-
test_dataset = ds["test"]
|
| 111 |
-
elif "train" in ds:
|
| 112 |
-
# Split the train set
|
| 113 |
-
split_ds = ds["train"].train_test_split(test_size=0.2, seed=42)
|
| 114 |
-
train_dataset = split_ds["train"]
|
| 115 |
-
test_dataset = split_ds["test"]
|
| 116 |
-
else:
|
| 117 |
-
# Use all data and split
|
| 118 |
-
all_data = ds[next(iter(ds.keys()))]
|
| 119 |
-
split_ds = all_data.train_test_split(test_size=0.2, seed=42)
|
| 120 |
-
train_dataset = split_ds["train"]
|
| 121 |
-
test_dataset = split_ds["test"]
|
| 122 |
-
|
| 123 |
-
logger.info(f"Raw dataset sizes - Train: {len(train_dataset)}, Test: {len(test_dataset)}")
|
| 124 |
-
|
| 125 |
-
# Filter and preprocess the data
|
| 126 |
-
def filter_and_clean(dataset: Dataset) -> Dataset:
|
| 127 |
-
# Filter examples with valid code and language
|
| 128 |
-
filtered = dataset.filter(
|
| 129 |
-
lambda x: (
|
| 130 |
-
x["func_code_string"] is not None
|
| 131 |
-
and x["language"] is not None
|
| 132 |
-
and len(x["func_code_string"]) >= MIN_CODE_LENGTH
|
| 133 |
-
and len(x["func_code_string"]) <= MAX_CODE_LENGTH
|
| 134 |
-
and x["language"] in ["python", "java", "javascript", "go", "php", "ruby"]
|
| 135 |
-
)
|
| 136 |
-
)
|
| 137 |
-
|
| 138 |
-
# Balance the dataset by limiting samples per language
|
| 139 |
-
if len(filtered) > MAX_SAMPLES_PER_LANGUAGE * 6: # 6 languages
|
| 140 |
-
# Group by language and sample
|
| 141 |
-
language_samples: dict[str, list[dict[str, Any]]] = {}
|
| 142 |
-
for example in filtered:
|
| 143 |
-
lang = example["language"]
|
| 144 |
-
if lang not in language_samples:
|
| 145 |
-
language_samples[lang] = []
|
| 146 |
-
if len(language_samples[lang]) < MAX_SAMPLES_PER_LANGUAGE:
|
| 147 |
-
language_samples[lang].append(example)
|
| 148 |
-
|
| 149 |
-
# Combine all samples
|
| 150 |
-
balanced_examples = []
|
| 151 |
-
for lang_examples in language_samples.values():
|
| 152 |
-
balanced_examples.extend(lang_examples)
|
| 153 |
-
|
| 154 |
-
# Convert back to dataset format
|
| 155 |
-
if balanced_examples:
|
| 156 |
-
filtered = Dataset.from_list(balanced_examples)
|
| 157 |
-
|
| 158 |
-
# Clean the code text
|
| 159 |
-
def clean_example(example: dict[str, Any]) -> dict[str, Any]:
|
| 160 |
-
example["func_code_string"] = clean_code_text(example["func_code_string"])
|
| 161 |
-
return example
|
| 162 |
-
|
| 163 |
-
return filtered.map(clean_example)
|
| 164 |
-
|
| 165 |
-
train_dataset = filter_and_clean(train_dataset)
|
| 166 |
-
test_dataset = filter_and_clean(test_dataset)
|
| 167 |
-
|
| 168 |
-
logger.info(f"Filtered dataset sizes - Train: {len(train_dataset)}, Test: {len(test_dataset)}")
|
| 169 |
-
|
| 170 |
-
# Show language distribution
|
| 171 |
-
if len(train_dataset) > 0:
|
| 172 |
-
from collections import Counter
|
| 173 |
-
|
| 174 |
-
train_lang_dist = Counter(train_dataset["language"])
|
| 175 |
-
test_lang_dist = Counter(test_dataset["language"])
|
| 176 |
-
logger.info(f"Training language distribution: {dict(train_lang_dist)}")
|
| 177 |
-
logger.info(f"Test language distribution: {dict(test_lang_dist)}")
|
| 178 |
-
|
| 179 |
-
return train_dataset, test_dataset, "func_code_string", "language"
|
| 180 |
-
|
| 181 |
-
except Exception:
|
| 182 |
-
logger.exception("Error loading CodeSearchNet dataset")
|
| 183 |
-
raise
|
| 184 |
-
|
| 185 |
-
|
| 186 |
-
def main() -> None:
|
| 187 |
-
"""Run the code classification training pipeline."""
|
| 188 |
-
# Create output directory if it doesn't exist
|
| 189 |
-
output_dir = Path(OUTPUT_DIR)
|
| 190 |
-
output_dir.mkdir(parents=True, exist_ok=True)
|
| 191 |
-
|
| 192 |
-
logger.info(f"Starting CodeSearchNet code classification pipeline for {MODEL_NAME}")
|
| 193 |
-
logger.info(f"Classification task: {CLASSIFICATION_TASK}")
|
| 194 |
-
logger.info(f"Trained model will be saved to {output_dir}")
|
| 195 |
-
|
| 196 |
-
# Record start time for benchmarking
|
| 197 |
-
total_start_time = time.time()
|
| 198 |
-
|
| 199 |
-
try:
|
| 200 |
-
# Step 1: Get the static model (either distill or load existing)
|
| 201 |
-
static_model = None
|
| 202 |
-
|
| 203 |
-
if SKIP_DISTILLATION:
|
| 204 |
-
if DISTILLED_MODEL_PATH:
|
| 205 |
-
logger.info(f"Loading existing distilled model from {DISTILLED_MODEL_PATH}")
|
| 206 |
-
# Note: We'll create the classifier from pretrained instead
|
| 207 |
-
else:
|
| 208 |
-
logger.error("DISTILLED_MODEL_PATH must be specified when SKIP_DISTILLATION is True")
|
| 209 |
-
return
|
| 210 |
-
else:
|
| 211 |
-
logger.info("Starting Model2Vec distillation...")
|
| 212 |
-
distill_start_time = time.time()
|
| 213 |
-
|
| 214 |
-
static_model = distill(
|
| 215 |
-
model_name=MODEL_NAME,
|
| 216 |
-
pca_dims=PCA_DIMS,
|
| 217 |
-
)
|
| 218 |
-
|
| 219 |
-
distill_time = time.time() - distill_start_time
|
| 220 |
-
logger.info(f"Distillation completed in {distill_time:.2f} seconds")
|
| 221 |
-
|
| 222 |
-
# Step 2: Create the classifier
|
| 223 |
-
logger.info("Creating classifier...")
|
| 224 |
-
|
| 225 |
-
if static_model is not None:
|
| 226 |
-
# From a distilled model
|
| 227 |
-
classifier = StaticModelForClassification.from_static_model(model=static_model)
|
| 228 |
-
else:
|
| 229 |
-
# From a pre-trained model path
|
| 230 |
-
classifier = StaticModelForClassification.from_pretrained(model_name=DISTILLED_MODEL_PATH)
|
| 231 |
-
|
| 232 |
-
# Step 3: Load the CodeSearchNet dataset
|
| 233 |
-
train_dataset, test_dataset, text_column, label_column = load_codesearchnet_dataset()
|
| 234 |
-
|
| 235 |
-
if len(train_dataset) == 0 or len(test_dataset) == 0:
|
| 236 |
-
logger.error("No valid data found after filtering. Please check dataset configuration.")
|
| 237 |
-
return
|
| 238 |
-
|
| 239 |
-
logger.info(f"Training dataset size: {len(train_dataset)}")
|
| 240 |
-
logger.info(f"Test dataset size: {len(test_dataset)}")
|
| 241 |
-
|
| 242 |
-
# Get unique languages for reference
|
| 243 |
-
unique_languages = sorted(set(train_dataset[label_column]))
|
| 244 |
-
logger.info(f"Programming languages to classify: {unique_languages}")
|
| 245 |
-
|
| 246 |
-
# Step 4: Train the classifier
|
| 247 |
-
logger.info("Starting training...")
|
| 248 |
-
train_start_time = perf_counter()
|
| 249 |
-
|
| 250 |
-
classifier = classifier.fit(
|
| 251 |
-
train_dataset[text_column],
|
| 252 |
-
train_dataset[label_column],
|
| 253 |
-
max_epochs=MAX_EPOCHS,
|
| 254 |
-
batch_size=BATCH_SIZE,
|
| 255 |
-
learning_rate=LEARNING_RATE,
|
| 256 |
-
early_stopping_patience=PATIENCE,
|
| 257 |
-
)
|
| 258 |
-
|
| 259 |
-
train_time = perf_counter() - train_start_time
|
| 260 |
-
logger.info(f"Training completed in {int(train_time)} seconds")
|
| 261 |
-
|
| 262 |
-
# Step 5: Evaluate the classifier
|
| 263 |
-
logger.info("Evaluating classifier...")
|
| 264 |
-
eval_start_time = perf_counter()
|
| 265 |
-
|
| 266 |
-
classification_report = classifier.evaluate(test_dataset[text_column], test_dataset[label_column])
|
| 267 |
-
|
| 268 |
-
eval_time = perf_counter() - eval_start_time
|
| 269 |
-
logger.info(f"Evaluation completed in {int(eval_time * 1000)} milliseconds")
|
| 270 |
-
logger.info(f"Classification results:\n{classification_report}")
|
| 271 |
-
|
| 272 |
-
# Step 6: Test with some examples
|
| 273 |
-
logger.info("Testing with sample code snippets...")
|
| 274 |
-
|
| 275 |
-
# Test examples for different languages
|
| 276 |
-
test_examples = [
|
| 277 |
-
'def hello_world():\n print("Hello, World!")\n return True', # Python
|
| 278 |
-
(
|
| 279 |
-
"public class HelloWorld {\n"
|
| 280 |
-
" public static void main(String[] args) {\n"
|
| 281 |
-
' System.out.println("Hello, World!");\n'
|
| 282 |
-
" }\n"
|
| 283 |
-
"}"
|
| 284 |
-
), # Java
|
| 285 |
-
'function helloWorld() {\n console.log("Hello, World!");\n return true;\n}', # JavaScript
|
| 286 |
-
'package main\n\nimport "fmt"\n\nfunc main() {\n fmt.Println("Hello, World!")\n}', # Go
|
| 287 |
-
'<?php\nfunction hello_world() {\n echo "Hello, World!";\n return true;\n}\n?>', # PHP
|
| 288 |
-
'def hello_world\n puts "Hello, World!"\n true\nend', # Ruby
|
| 289 |
-
]
|
| 290 |
-
|
| 291 |
-
predictions = classifier.predict(test_examples)
|
| 292 |
-
for i, (code, pred) in enumerate(zip(test_examples, predictions, strict=False)):
|
| 293 |
-
logger.info(f"Example {i + 1}: {pred}")
|
| 294 |
-
logger.info(f"Code snippet: {code[:100]}...")
|
| 295 |
-
|
| 296 |
-
# Step 7: Benchmark inference speed
|
| 297 |
-
logger.info("Benchmarking inference speed...")
|
| 298 |
-
inference_start_time = perf_counter()
|
| 299 |
-
_ = classifier.predict(test_dataset[text_column][:100]) # Test on first 100 samples
|
| 300 |
-
inference_time = perf_counter() - inference_start_time
|
| 301 |
-
logger.info(f"Inference took {int(inference_time * 1000)} milliseconds for 100 code snippets on CPU")
|
| 302 |
-
|
| 303 |
-
# Step 8: Save the model
|
| 304 |
-
if SAVE_PIPELINE:
|
| 305 |
-
logger.info("Converting to scikit-learn pipeline...")
|
| 306 |
-
pipeline = classifier.to_pipeline()
|
| 307 |
-
|
| 308 |
-
# Save locally
|
| 309 |
-
pipeline_path = output_dir / "pipeline"
|
| 310 |
-
pipeline.save_pretrained(str(pipeline_path))
|
| 311 |
-
logger.info(f"Pipeline saved to {pipeline_path}")
|
| 312 |
-
|
| 313 |
-
# Save additional metadata
|
| 314 |
-
metadata = {
|
| 315 |
-
"model_name": MODEL_NAME,
|
| 316 |
-
"dataset": DATASET_NAME,
|
| 317 |
-
"task": "programming_language_classification",
|
| 318 |
-
"languages": unique_languages,
|
| 319 |
-
"pca_dims": PCA_DIMS,
|
| 320 |
-
"train_samples": len(train_dataset),
|
| 321 |
-
"test_samples": len(test_dataset),
|
| 322 |
-
}
|
| 323 |
-
|
| 324 |
-
metadata_path = output_dir / "metadata.json"
|
| 325 |
-
with metadata_path.open("w") as f:
|
| 326 |
-
json.dump(metadata, f, indent=2)
|
| 327 |
-
logger.info("Metadata saved to metadata.json")
|
| 328 |
-
|
| 329 |
-
# Push to hub if requested
|
| 330 |
-
if SAVE_TO_HUB and HUB_MODEL_ID:
|
| 331 |
-
logger.info(f"Pushing pipeline to HuggingFace Hub as {HUB_MODEL_ID}")
|
| 332 |
-
pipeline.push_to_hub(HUB_MODEL_ID)
|
| 333 |
-
else:
|
| 334 |
-
# Save the classifier directly
|
| 335 |
-
classifier_path = output_dir / "classifier"
|
| 336 |
-
classifier_path.mkdir(exist_ok=True)
|
| 337 |
-
|
| 338 |
-
# Note: StaticModelForClassification might not have save_pretrained
|
| 339 |
-
# We'll save the underlying static model and create instructions
|
| 340 |
-
if static_model is not None:
|
| 341 |
-
static_model.save_pretrained(str(classifier_path / "static_model"))
|
| 342 |
-
|
| 343 |
-
logger.info(f"Classifier components saved to {classifier_path}")
|
| 344 |
-
|
| 345 |
-
# Summary
|
| 346 |
-
total_time = time.time() - total_start_time
|
| 347 |
-
logger.info("=" * 60)
|
| 348 |
-
logger.info("CODE CLASSIFICATION TRAINING COMPLETED SUCCESSFULLY!")
|
| 349 |
-
logger.info(f"Total time: {total_time:.2f} seconds")
|
| 350 |
-
if not SKIP_DISTILLATION:
|
| 351 |
-
logger.info(f"Distillation time: {distill_time:.2f} seconds")
|
| 352 |
-
logger.info(f"Training time: {int(train_time)} seconds")
|
| 353 |
-
logger.info(f"Dataset: {DATASET_NAME}")
|
| 354 |
-
logger.info("Task: Programming Language Classification")
|
| 355 |
-
logger.info(f"Languages: {', '.join(unique_languages)}")
|
| 356 |
-
logger.info(f"Model saved to: {output_dir}")
|
| 357 |
-
logger.info("=" * 60)
|
| 358 |
-
|
| 359 |
-
except Exception:
|
| 360 |
-
logger.exception("Error during code classification training pipeline")
|
| 361 |
-
raise
|
| 362 |
-
|
| 363 |
-
|
| 364 |
-
if __name__ == "__main__":
|
| 365 |
-
main()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|