---
tags:
- clip
license: apache-2.0
language:
- en
library_name: transformers
pipeline_tag: zero-shot-image-classification
---
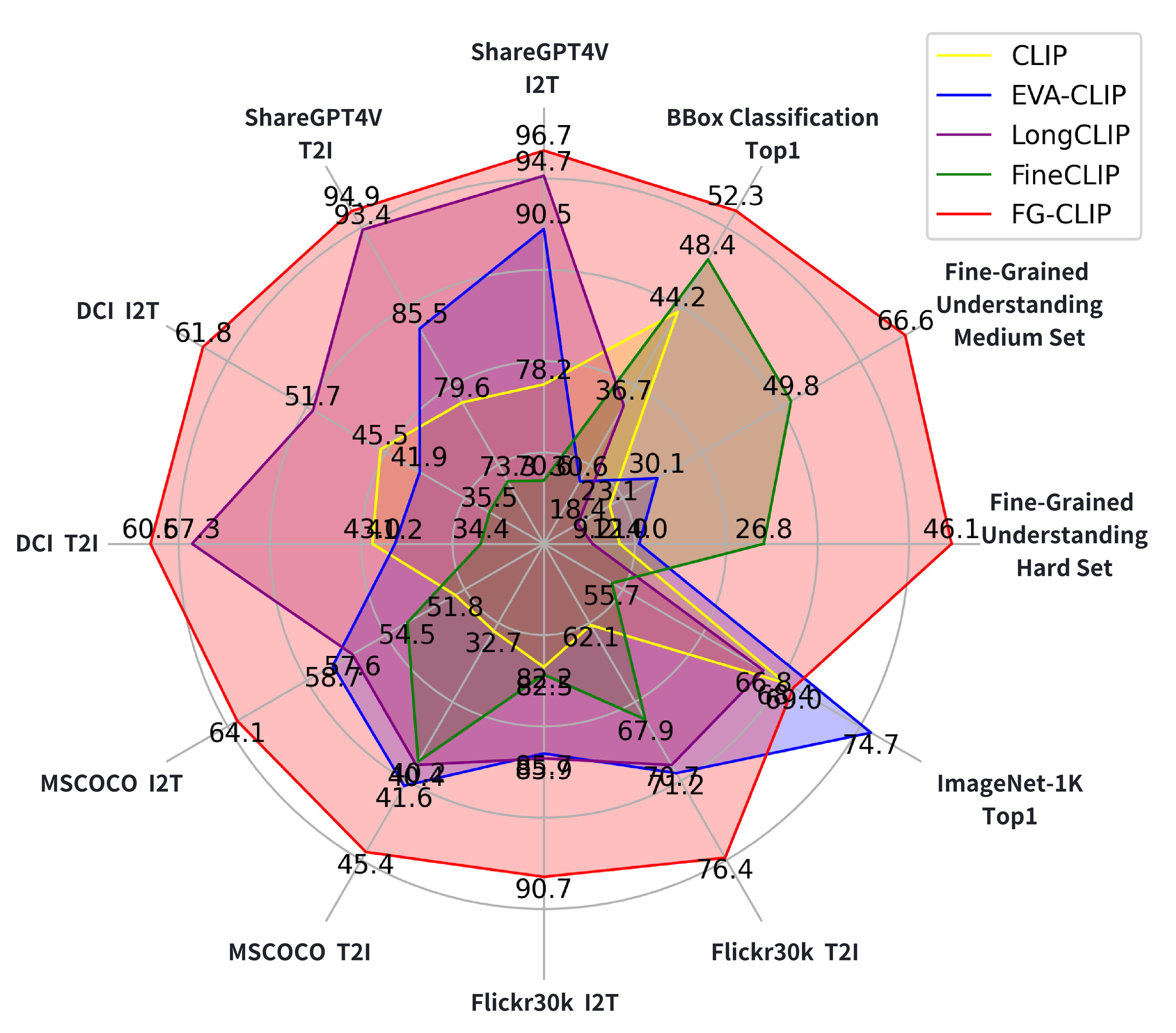
# FG-CLIP: Fine-Grained Visual and Textual Alignment
**[FG-CLIP: Fine-Grained Visual and Textual Alignment](https://arxiv.org/abs/2505.05071)**
Chunyu Xie*, Bin Wang*, Fanjing Kong, Jincheng Li, Dawei Liang, Gengshen Zhang, Dawei Leng†, Yuhui Yin(*Equal Contribution, ✝Corresponding Author)
[](https://arxiv.org/abs/2505.05071)
[](https://icml.cc/Conferences/2025)
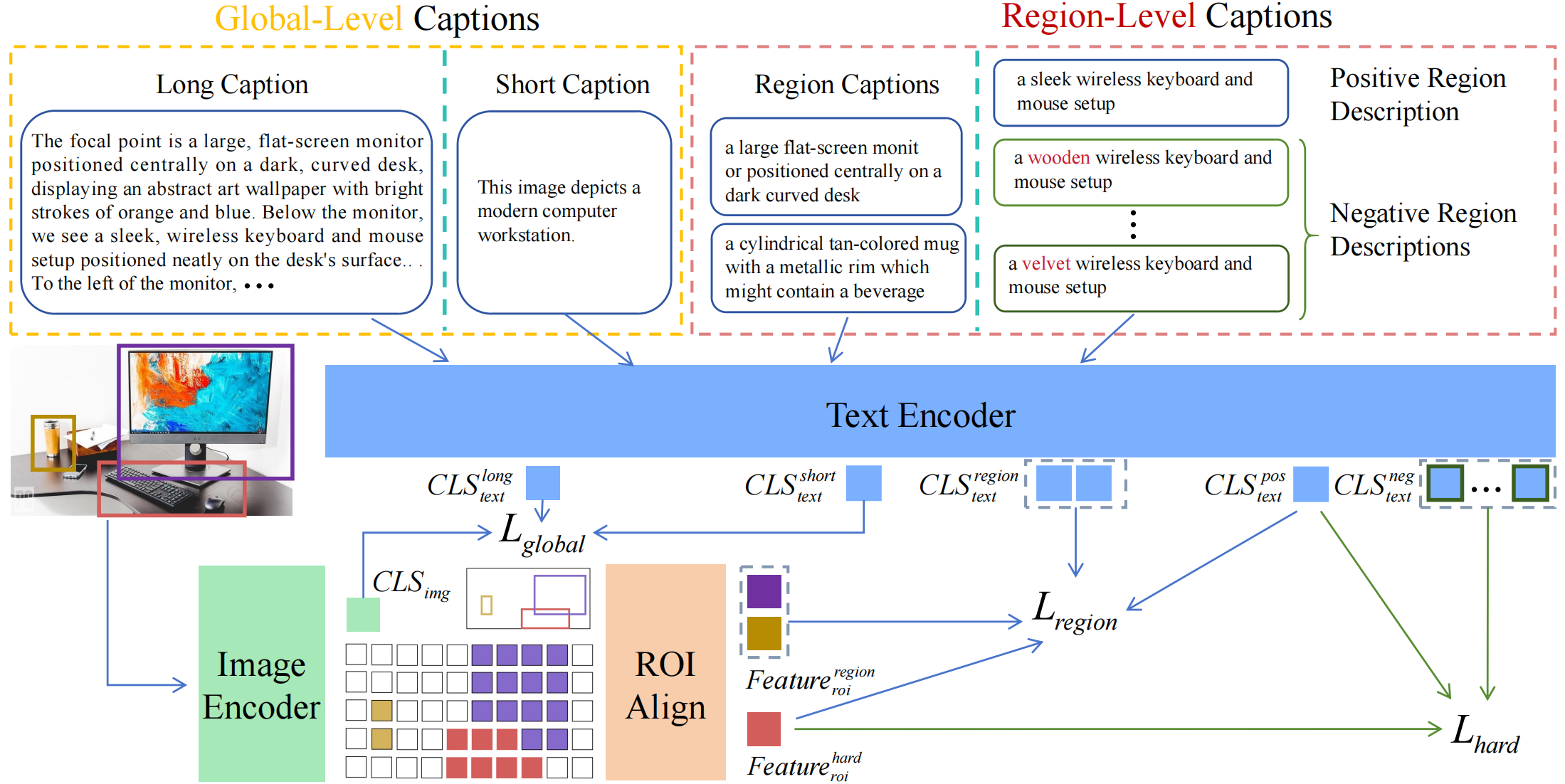
## Model Framework
FG-CLIP’s training proceeds in two stages: the first stage leverages
global-level caption-image pairs to achieve initial fine-grained alignment, while the second stage supplements these with additional
region-level captions, including detailed region captions and positive/negative region descriptions to further refine the alignment.
## Quick Start 🤗
### Load Model
```Shell
import torch
from PIL import Image
from transformers import (
AutoImageProcessor,
AutoTokenizer,
AutoModelForCausalLM,
)
model_root = "qihoo360/fg-clip-large"
image_size=336
model = AutoModelForCausalLM.from_pretrained(model_root,trust_remote_code=True).cuda()
device = model.device
tokenizer = AutoTokenizer.from_pretrained(model_root)
image_processor = AutoImageProcessor.from_pretrained(model_root)
```
### Retrieval
```Shell
img_root = "FG-CLIP/use_imgs/cat_dfclor.jpg"
image = Image.open(img_root).convert("RGB")
image = image.resize((image_size,image_size))
image_input = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(device)
# NOTE Short captions: max_length=77 && walk_short_pos=True
walk_short_pos = True
captions=["a photo of a cat", "a photo of a dog"]
caption_input = torch.tensor(tokenizer(captions, max_length=77, padding="max_length", truncation=True).input_ids, dtype=torch.long, device=device)
# NOTE Long captions: max_length=248 && walk_short_pos=False
# ......
with torch.no_grad():
image_feature = model.get_image_features(image_input)
text_feature = model.get_text_features(caption_input,walk_short_pos=walk_short_pos)
image_feature = image_feature / image_feature.norm(dim=1, keepdim=True)
text_feature = text_feature / text_feature.norm(dim=1, keepdim=True)
logits_per_image = image_feature @ text_feature.T
probs = logits_per_image.softmax(dim=1)
print(probs)
```
### Dense feature effect display
```Shell
import math
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
img_root = "FG-CLIP/use_imgs/cat_dfclor.jpg"
image = Image.open(img_root).convert("RGB")
image = image.resize((image_size,image_size))
image_input = image_processor.preprocess(image, return_tensors='pt')['pixel_values'].to(device)
with torch.no_grad():
dense_image_feature = model.get_image_dense_features(image_input)
captions = ["white cat"]
caption_input = torch.tensor(tokenizer(captions, max_length=77, padding="max_length", truncation=True).input_ids, dtype=torch.long, device=device)
text_feature = model.get_text_features(caption_input,walk_short_pos=True)
text_feature = text_feature / text_feature.norm(dim=1, keepdim=True)
dense_image_feature = dense_image_feature / dense_image_feature.norm(dim=1, keepdim=True)
similarity = dense_image_feature.squeeze() @ text_feature.squeeze().T
similarity = similarity.cpu().numpy()
patch_size = int(math.sqrt(similarity.shape[0]))
original_shape = (patch_size, patch_size)
show_image = similarity.reshape(original_shape)
plt.figure(figsize=(6, 6))
plt.imshow(show_image)
plt.title('similarity Visualization')
plt.axis('off')
plt.savefig("FG-CLIP/use_imgs/FGCLIP_dfcolor_cat.png")
```

## Citation
If you find FG-CLIP useful for your research and applications, please cite using this BibTeX:
```
@article{xie2025fgclip,
title={FG-CLIP: Fine-Grained Visual and Textual Alignment},
author={Chunyu Xie and Bin Wang and Fanjing Kong and Jincheng Li and Dawei Liang and Gengshen Zhang and Dawei Leng and Yuhui Yin},
year={2025},
eprint={2505.05071},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.05071},
}
```
## License
This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses.
The content of this project itself is licensed under the [Apache license 2.0](./LICENSE).