nablaNABLA: Neighborhood Adaptive Block-Level Attention
 korviakov
korviakov







Abstract
NABLA, a dynamic block-level attention mechanism, improves video diffusion transformers by enhancing computational efficiency without sacrificing generative quality.
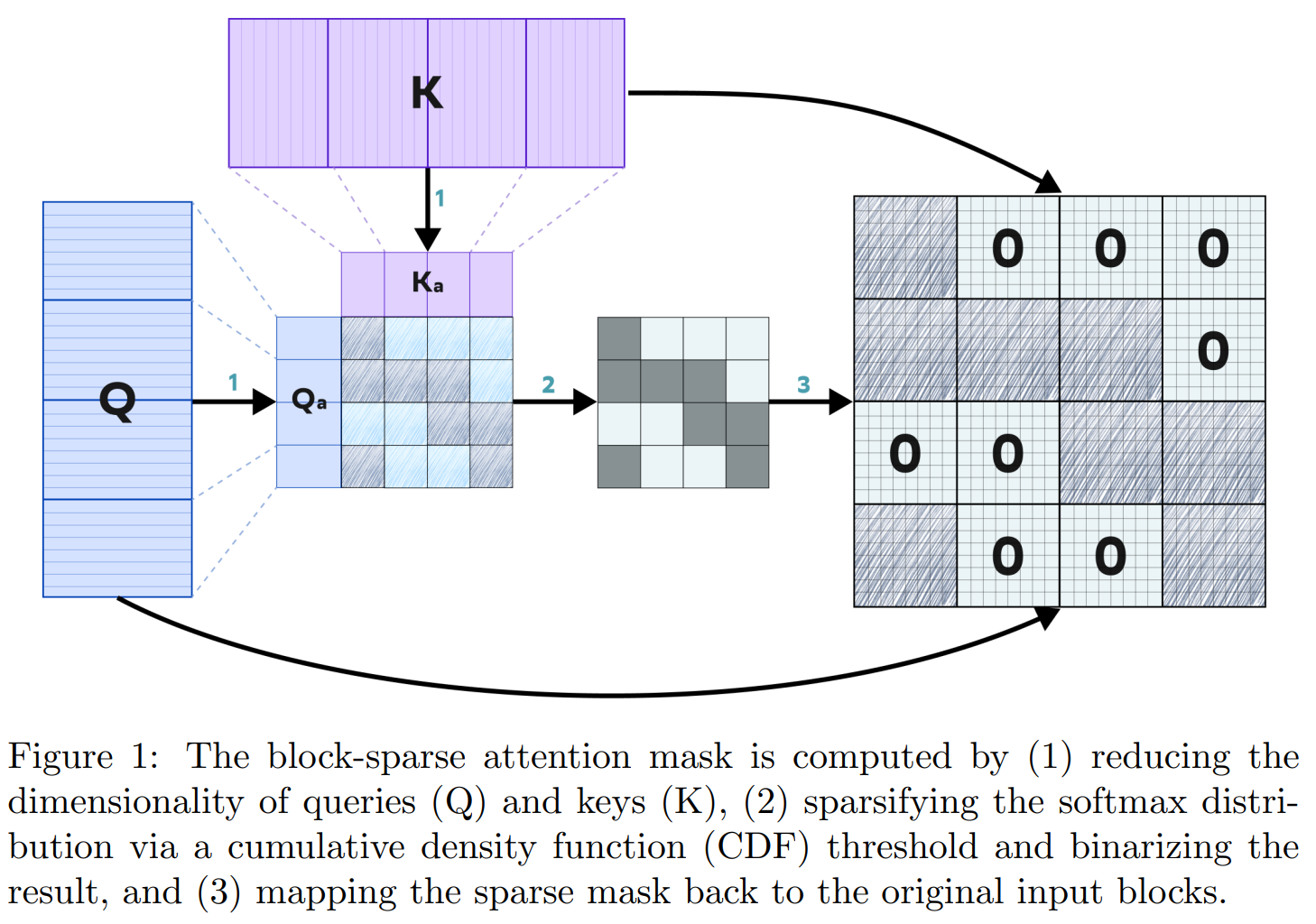
Recent progress in transformer-based architectures has demonstrated remarkable success in video generation tasks. However, the quadratic complexity of full attention mechanisms remains a critical bottleneck, particularly for high-resolution and long-duration video sequences. In this paper, we propose NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality. Our method does not require custom low-level operator design and can be seamlessly integrated with PyTorch's Flex Attention operator. Experiments demonstrate that NABLA achieves up to 2.7x faster training and inference compared to baseline almost without compromising quantitative metrics (CLIP score, VBench score, human evaluation score) and visual quality drop. The code and model weights are available here: https://github.com/gen-ai-team/Wan2.1-NABLA
Community
This paper proposes NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality.
Github: https://github.com/gen-ai-team/Wan2.1-NABLA

arXiv explained breakdown of this paper 👉 https://arxivexplained.com/papers/nablanabla-neighborhood-adaptive-block-level-attention

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion (2025)
- VMoBA: Mixture-of-Block Attention for Video Diffusion Models (2025)
- Sparse-vDiT: Unleashing the Power of Sparse Attention to Accelerate Video Diffusion Transformers (2025)
- Chipmunk: Training-Free Acceleration of Diffusion Transformers with Dynamic Column-Sparse Deltas (2025)
- PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models (2025)
- DAM: Dynamic Attention Mask for Long-Context Large Language Model Inference Acceleration (2025)
- Iwin Transformer: Hierarchical Vision Transformer using Interleaved Windows (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend




Models citing this paper 3
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper