---
license: cc-by-4.0
base_model:
- Qwen/Qwen2.5-Math-7B
datasets:
- nvidia/OpenMathReasoning
language:
- en
tags:
- nvidia
- math
library_name: transformers
---
# OpenMath-Nemotron-7B
OpenMath-Nemotron-7B is created by finetuning [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning) dataset.
This model is ready for commercial use.
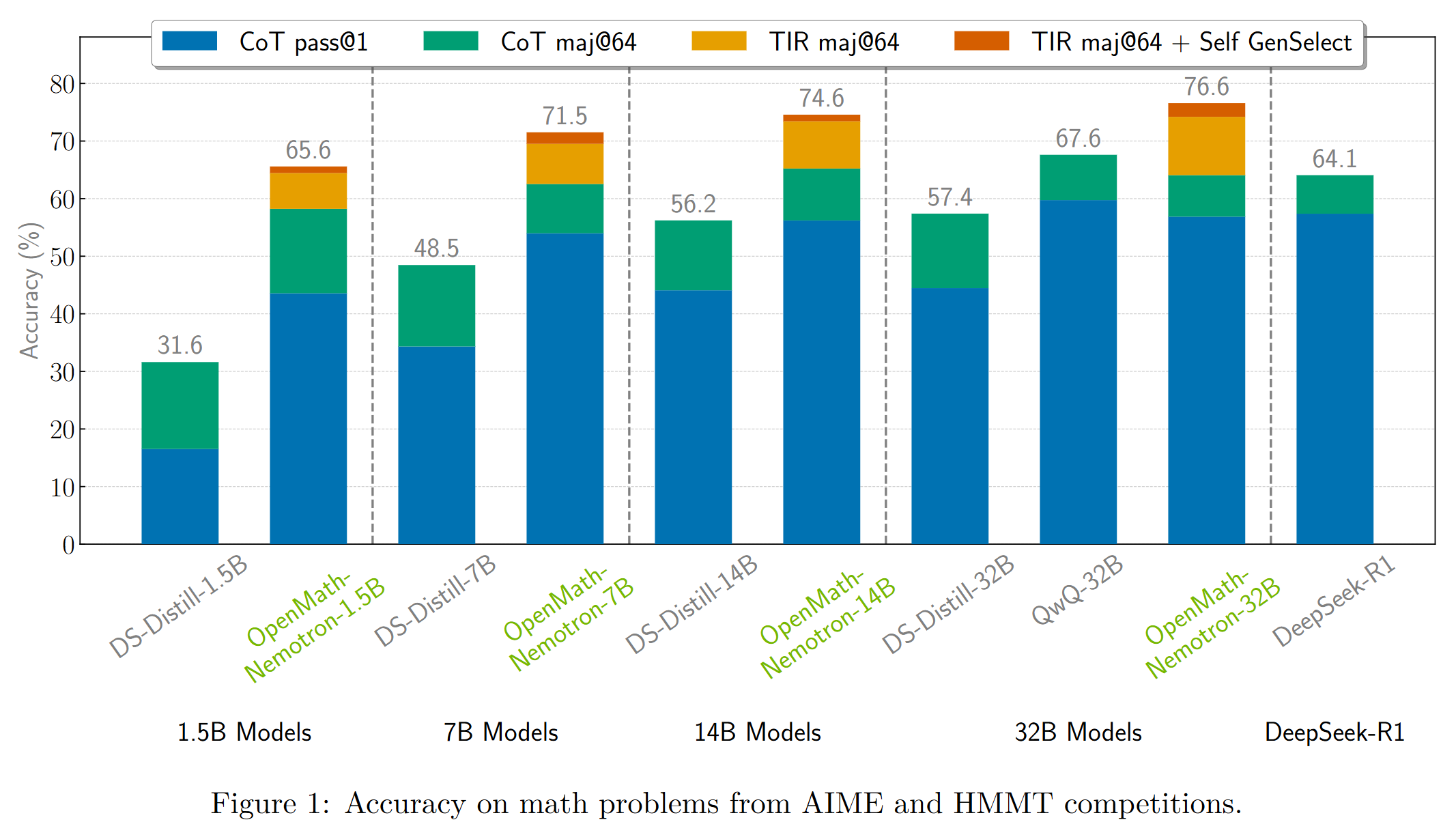
OpenMath-Nemotron models achieve state-of-the-art results on popular mathematical benchmarks. We present metrics as pass@1 (maj@64) where pass@1
is an average accuracy across 64 generations and maj@64 is the result of majority voting.
Please see our [paper](TODO) for more details on the evaluation setup.
| Model | AIME24 | AIME25 | HMMT-24-25 | HLE-Math |
|-------------------------------|-----------------|-------|-------|-------------|
| DeepSeek-R1-Distill-Qwen-1.5B | 26.8 (60.0) | 21.4 (36.7) | 14.2 (26.5) | 2.9 (5.0) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) CoT | 61.6 (80.0) | 49.5 (66.7) | 39.9 (53.6) | 5.4 (5.4) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) TIR | 52.0 (83.3) | 39.7 (70.0) | 37.2 (60.7) | 2.5 (6.2) |
| + Self GenSelect | 83.3 | 70.0 | 62.2 | 7.9 |
| + 32B GenSelect | 83.3 | 70.0 | 62.8 | 8.3 |
| DeepSeek-R1-Distill-Qwen-7B | 54.4 (80.0) | 38.6 (53.3) | 30.6 (42.9) | 3.3 (5.2) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) CoT | 74.8 (80.0) | 61.2 (76.7) | 49.7 (57.7) | 6.6 (6.6) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) TIR | 72.9 (83.3) | 57.5 (76.7) | 54.6 (66.3) | 7.8 (10.8) |
| + Self GenSelect | 86.7 | 76.7 | 68.4 | 11.5 |
| + 32B GenSelect | 86.7 | 76.7 | 69.9 | 11.9 |
| DeepSeek-R1-Distill-Qwen-14B | 65.8 (80.0) | 48.4 (60.0) | 40.1 (52.0) | 4.2 (4.8) |
| [OpenMath-Nemotron-14B-MIX (kaggle)](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) | 73.7 (86.7) | 57.9 (73.3) | 50.5 (64.8) | 5.7 (6.5) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) CoT | 76.3 (83.3) | 63.0 (76.7) | 52.1 (60.7) | 7.5 (7.6) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) TIR | 76.3 (86.7) | 61.3 (76.7) | 58.6 (70.9) | 9.5 (11.5) |
| + Self GenSelect | 86.7 | 76.7 | 72.4 | 14.1 |
| + 32B GenSelect | 90.0 | 76.7 | 71.9 | 13.7 |
| QwQ-32B | 78.1 (86.7) | 66.5 (76.7) | 55.9 (63.3) | 9.0 (9.5) |
| DeepSeek-R1-Distill-Qwen-32B | 66.9 (83.3) | 51.8 (73.3) | 39.9 (51.0) | 4.8 (6.0) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) CoT | 76.5 (86.7) | 62.5 (73.3) | 53.0 (59.2) | 8.3 (8.3) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) TIR | 78.4 (93.3) | 64.2 (76.7) | 59.7 (70.9) | 9.2 (12.5) |
| + Self GenSelect | 93.3 | 80.0 | 73.5 | 15.7 |
| DeepSeek-R1 | 79.1 (86.7) | 64.3 (73.3) | 53.0 (59.2) | 10.5 (11.4) |
We used [a version of OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) model to secure
the first place in AIMO-2 Kaggle competition!
## Reproducing our results
The pipeline we used to produce the data and models is fully open-sourced!
- [Code](https://github.com/NVIDIA/NeMo-Skills)
- [Models](https://huggingface.co/collections/nvidia/openmathreasoning-68072c0154a5099573d2e730)
- [Dataset](https://huggingface.co/datasets/nvidia/OpenMathReasoning)
We provide [all instructions](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/)
to fully reproduce our results, including data generation.
# How to use the models?
Our models can be used in 3 inference modes: chain-of-thought (CoT), tool-integrated reasoning (TIR) and generative solution selection (GenSelect).
To run inference with CoT mode, you can use this example code snippet.
```python
import transformers
import torch
model_id = "nvidia/OpenMath-Nemotron-7B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{
"role": "user",
"content": "Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.\n\n" +
"What is the minimum value of $a^2+6a-7$?"},
]
outputs = pipeline(
messages,
max_new_tokens=4096,
)
print(outputs[0]["generated_text"][-1]['content'])
```
To run inference with TIR or GenSelect modes, we highly recommend to use our
[reference implementation in NeMo-Skills](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/evaluation/).
Please note that these models have not been instruction tuned on general data and thus might not provide good answers outside of math domain.
## Citation
If you find our work useful, please consider citing us!
TODO
## Additional information
### License/Terms of Use:
GOVERNING TERMS: Use of this model is governed by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/legalcode.en).
Additional Information: [Apache License Version 2.0](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B/blob/main/LICENSE).
### Deployment Geography:
Global
### Use Case:
This model is intended to facilitate research in the area of mathematical reasoning.
### Release Date:
Huggingface 04/23/2025
## Model Architecture:
**Architecture Type:** Transformer decoder-only language model
**Network Architecture:** Qwen2.5
**This model was developed based on Qwen2.5-1.5B
** This model has 1.5B of model parameters.
## Input:
**Input Type(s):** Text
**Input Format(s):** String
**Input Parameters:** One-Dimensional (1D)
**Other Properties Related to Input:** Context length up to 131,072 tokens
## Output:
**Output Type(s):** Text
**Output Format:** String
**Output Parameters:** One-Dimensional (1D)
**Other Properties Related to Output:** Context length up to 131,072 tokens
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions.
## Software Integration :
**Runtime Engine(s):**
* Tensor RT / Triton
**Supported Hardware Microarchitecture Compatibility:**
* NVIDIA Ampere
* NVIDIA Hopper
**Preferred Operating System(s):**
* Linux
## Model Version(s):
[OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B)
[OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B)
[OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B)
[OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B)
# Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](./EXPLAINABILITY.md), [Bias](./BIAS.md), [Safety & Security](./SAFETY.md), and [Privacy](./PRIVACY.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).