

Upload 5 files
Browse files- .gitattributes +1 -0
- BIAS.md +4 -0
- EXPLAINABILITY.md +13 -0
- PRIVACY.md +9 -0
- SAFETY.md +6 -0
- results.png +3 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
results.png filter=lfs diff=lfs merge=lfs -text
|
BIAS.md
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:---------------------------------------------------------------------------------------------------|:---------------
|
| 3 |
+
Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing: | None
|
| 4 |
+
Measures taken to mitigate against unwanted bias: | None
|
EXPLAINABILITY.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------
|
| 3 |
+
Intended Domain: | Text generation, reasoning, solving mathematical problems.
|
| 4 |
+
Model Type: | Text-to-text transformer
|
| 5 |
+
Intended Users: | This model is intended for developers, researchers, and customers building/utilizing LLMs.
|
| 6 |
+
Output: | Text String(s)
|
| 7 |
+
Describe how the model works: | Generates text by predicting the next word or token based on the context provided in the input sequence using multiple self-attention layers.
|
| 8 |
+
Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable
|
| 9 |
+
Technical Limitations & Mitigation: | The model was optimized for solving mathematical problems and thus might not be able to provide adequate answers for non-mathematical queries. The model was trained on questions with verifiable final answers, and thus may not be able to prove theorems.
|
| 10 |
+
Verified to have met prescribed NVIDIA quality standards: | Yes
|
| 11 |
+
Performance Metrics: | Accuracy
|
| 12 |
+
Potential Known Risks: | The model was optimized explicitly for solving mathematical problems and as such is more susceptible to prompt injection and jailbreaking in various forms as a result of its training. This means that the model should be paired with additional rails or system filtering to limit exposure to instructions from malicious sources -- either directly or indirectly by retrieval (e.g. via visiting a website) -- as they may yield outputs that can lead to harmful, system-level outcomes up to and including remote code execution in agentic systems when effective security controls including guardrails are not in place. The model was trained on data that contains toxic language and societal biases originally crawled from the internet. Therefore, the model may amplify those biases and return toxic responses especially when prompted with toxic prompts. The model may generate answers that may be inaccurate, omit key information, or include irrelevant or redundant text producing socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive.
|
| 13 |
+
Licensing: | Use of this model is governed by [CC-BY-4.0]((https://creativecommons.org/licenses/by/4.0/)) license. Additional Information: [Apache License Version 2.0](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B/blob/main/LICENSE)
|
PRIVACY.md
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:----------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------
|
| 3 |
+
Generatable or reverse engineerable personal data? | None
|
| 4 |
+
Personal data used to create this model? | None Known
|
| 5 |
+
How often is dataset reviewed? | Before Release
|
| 6 |
+
Is there provenance for all datasets used in training? | Yes
|
| 7 |
+
Does data labeling (annotation, metadata) comply with privacy laws? | Yes
|
| 8 |
+
Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data.
|
| 9 |
+
Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/
|
SAFETY.md
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:---------------------------------------------------|:----------------------------------
|
| 3 |
+
Model Application(s): | Text generation, reasoning, solving mathematical problems.
|
| 4 |
+
Use Case Restrictions: | Use of this model is governed by [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license
|
| 5 |
+
Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation. Restrictions enforce dataset access during training, and dataset license constraints adhered to. Model checkpoints are made available on Hugging Face.
|
| 6 |
+
Use Case Restrictions: | Use of this model is governed by [CC-BY-4.0]((https://creativecommons.org/licenses/by/4.0/)) license. Additional Information: [Apache License Version 2.0](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B/blob/main/LICENSE)
|
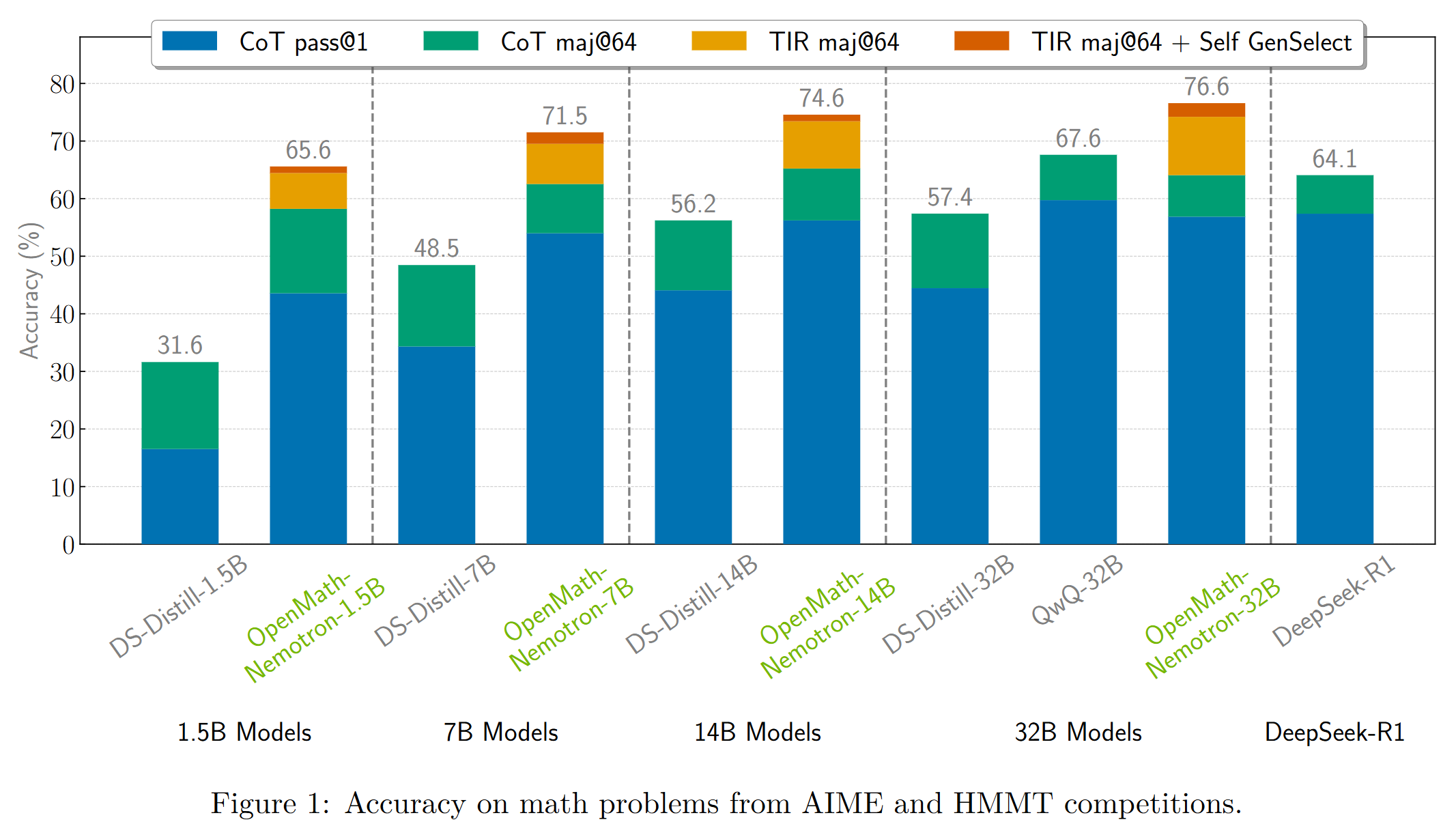
results.png
ADDED
|
Git LFS Details
|