

update
Browse files- .gitattributes +13 -0
- Llama-3.1-8B-UltraLong-1M-Instruct.png +0 -0
- README.md +80 -3
- config.json +3 -0
- generation_config.json +3 -0
- long_benchmark.png +0 -0
- model-00001-of-00007.safetensors +3 -0
- model-00002-of-00007.safetensors +3 -0
- model-00003-of-00007.safetensors +3 -0
- model-00004-of-00007.safetensors +3 -0
- model-00005-of-00007.safetensors +3 -0
- model-00006-of-00007.safetensors +3 -0
- model-00007-of-00007.safetensors +3 -0
- model.safetensors.index.json +3 -0
- special_tokens_map.json +3 -0
- standard_benchmark.png +0 -0
- tokenizer.json +3 -0
- tokenizer_config.json +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,16 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
model-00002-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
model-00003-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
model-00004-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
model-00005-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
model-00006-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
model-00007-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
model-00001-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
model.safetensors.index.json filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
special_tokens_map.json filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
tokenizer_config.json filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
config.json filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
generation_config.json filter=lfs diff=lfs merge=lfs -text
|
Llama-3.1-8B-UltraLong-1M-Instruct.png
ADDED

|
README.md
CHANGED
|
@@ -1,3 +1,80 @@
|
|
| 1 |
-
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
# Model Information
|
| 8 |
+
|
| 9 |
+
We introduce **UltraLong-8B**, a series of ultra-long context language models designed to process extensive sequences of text (up to 1M, 2M, and 4M tokens) while maintaining competitive performance on standard benchmarks. Built on the Llama-3.1, UltraLong-8B leverages a systematic training recipe that combines efficient continued pretraining with instruction tuning to enhance long-context understanding and instruction-following capabilities. This approach enables our models to efficiently scale their context windows without sacrificing general performance.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
## The UltraLong Models
|
| 13 |
+
|
| 14 |
+
- [ultralong/Llama-3.1-8B-UltraLong-1M-Instruct](https://huggingface.co/ultralong/Llama-3.1-8B-UltraLong-1M-Instruct)
|
| 15 |
+
- [ultralong/Llama-3.1-8B-UltraLong-2M-Instruct](https://huggingface.co/ultralong/Llama-3.1-8B-UltraLong-2M-Instruct)
|
| 16 |
+
- [ultralong/Llama-3.1-8B-UltraLong-4M-Instruct](https://huggingface.co/ultralong/Llama-3.1-8B-UltraLong-4M-Instruct)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
## Uses
|
| 20 |
+
|
| 21 |
+
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
|
| 22 |
+
|
| 23 |
+
Make sure to update your transformers installation via `pip install --upgrade transformers`.
|
| 24 |
+
|
| 25 |
+
```python
|
| 26 |
+
import transformers
|
| 27 |
+
import torch
|
| 28 |
+
|
| 29 |
+
model_id = "ultralong/Llama-3.1-8B-UltraLong-1M-Instruct"
|
| 30 |
+
|
| 31 |
+
pipeline = transformers.pipeline(
|
| 32 |
+
"text-generation",
|
| 33 |
+
model=model_id,
|
| 34 |
+
model_kwargs={"torch_dtype": torch.bfloat16},
|
| 35 |
+
device_map="auto",
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
messages = [
|
| 39 |
+
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
|
| 40 |
+
{"role": "user", "content": "Who are you?"},
|
| 41 |
+
]
|
| 42 |
+
|
| 43 |
+
outputs = pipeline(
|
| 44 |
+
messages,
|
| 45 |
+
max_new_tokens=256,
|
| 46 |
+
)
|
| 47 |
+
print(outputs[0]["generated_text"][-1])
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
## Model Card
|
| 51 |
+
|
| 52 |
+
* Base model: [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
|
| 53 |
+
* Continued Pretraining: 1B tokens on 1M Per-source upsampled SlimPajama data.
|
| 54 |
+
* Supervised fine-tuning (SFT): 1B tokens on open-source instruction datasets across general, mathematics, and code domains.
|
| 55 |
+
* Maximum context window: 1M tokens
|
| 56 |
+
|
| 57 |
+
## Evaluation Results
|
| 58 |
+
|
| 59 |
+
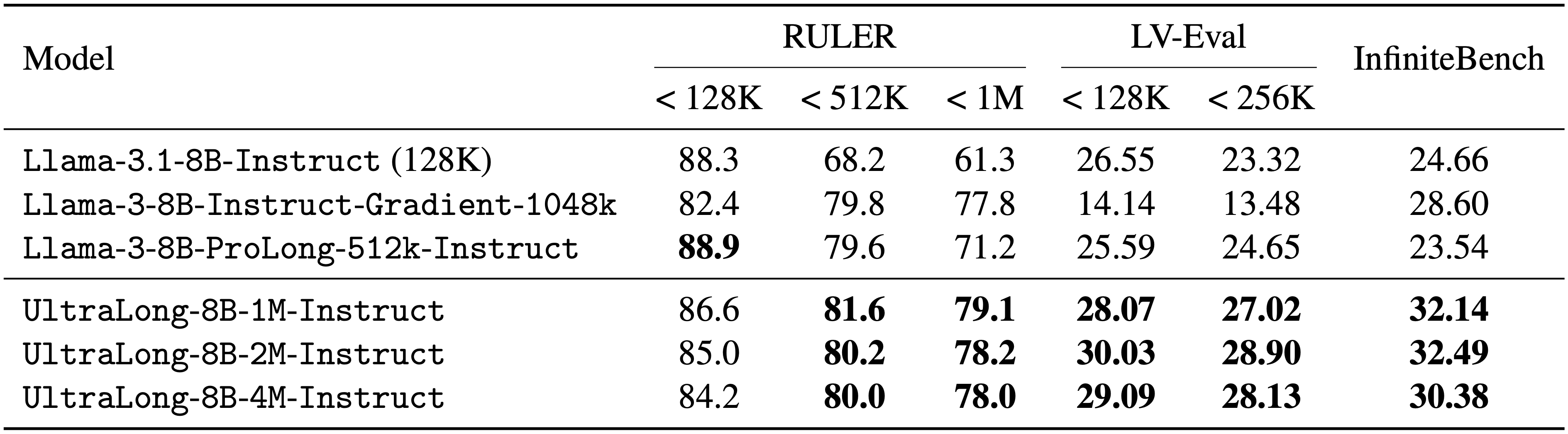
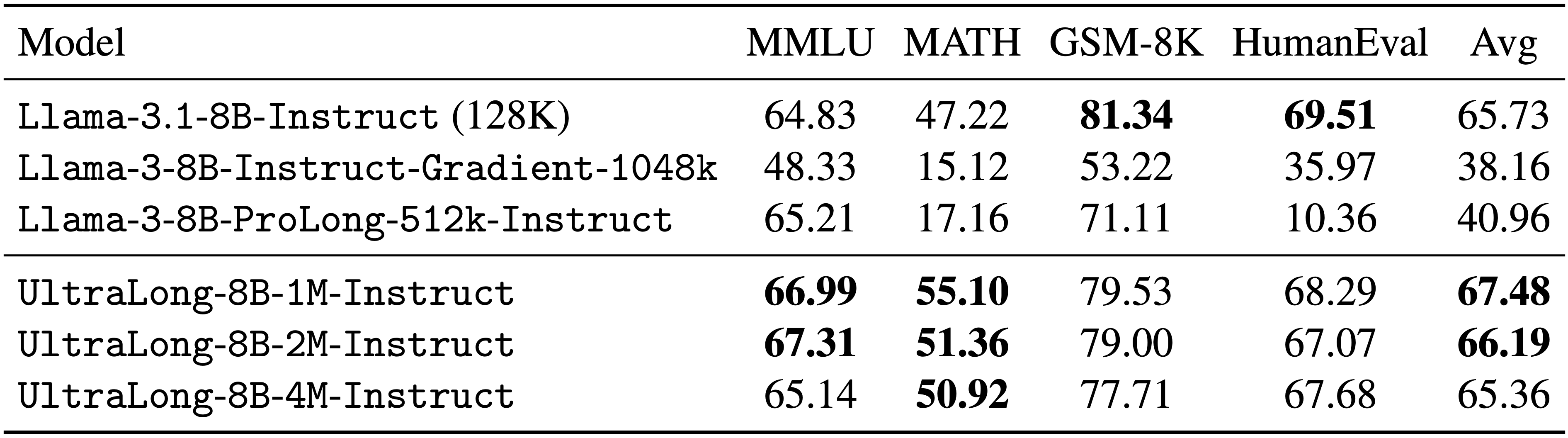
We evaluate UltraLong-8B on a diverse set of benchmarks, including long-context tasks (e.g., RULER, LV-Eval, and InfiniteBench) and standard tasks (e.g., MMLU, MATH, GSM-8K, and HumanEval). UltraLong-8B achieves superior performance on ultra-long context tasks while maintaining competitive results on standard benchmarks.
|
| 60 |
+
|
| 61 |
+
### Needle in a Haystack
|
| 62 |
+
|
| 63 |
+
<img width="80%" alt="image" src="Llama-3.1-8B-UltraLong-1M-Instruct.png">
|
| 64 |
+
|
| 65 |
+
### Long context evaluation
|
| 66 |
+
|
| 67 |
+
<img width="80%" alt="image" src="long_benchmark.png">
|
| 68 |
+
|
| 69 |
+
### Standard capability evaluation
|
| 70 |
+
|
| 71 |
+
<img width="80%" alt="image" src="standard_benchmark.png">
|
| 72 |
+
|
| 73 |
+
## Correspondence to
|
| 74 |
+
Chejian Xu ([email protected]), Wei Ping ([email protected])
|
| 75 |
+
|
| 76 |
+
## Citation
|
| 77 |
+
|
| 78 |
+
<pre>
|
| 79 |
+
|
| 80 |
+
</pre>
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:737698662db1457b8280fa8d5bbd542a19012ced204761129e518c9fbbef780a
|
| 3 |
+
size 897
|
generation_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4abcf8ce084298b021f1d6f42b4c08d141d1897eff20428e987a9e8dbcfd2e42
|
| 3 |
+
size 121
|
long_benchmark.png
ADDED
|
model-00001-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:19715f8e4d923e046ca58fc49749ff6fd8bd5d0cff7afbb2171ac160a443ea2d
|
| 3 |
+
size 4899049080
|
model-00002-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f247116125f57168497e3c542c647a288df9b9351bc51903c750eedd75f51122
|
| 3 |
+
size 4832007448
|
model-00003-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7b32a6b1393d5731ffcbc96ccc94db72b851953bace5edbab84a722b8f85a34c
|
| 3 |
+
size 4999813112
|
model-00004-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0cc5f81ff2afe5203e4c13d41c7d3c88cd2f74469a30dd4d9dcad685a1177f63
|
| 3 |
+
size 4999813128
|
model-00005-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0d0a113738d298f983e4e1db2c6902f7667e14c563c8bc470c183110286a89a
|
| 3 |
+
size 4832007496
|
model-00006-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e21734608eef2fc2c1571632db0c8fbda3c6aeb233eda54e41a30365dd9beefc
|
| 3 |
+
size 4999813120
|
model-00007-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c2ccf616750c9d349d4056a55ee661f77e88fbd8cb707fe87bc892b07bfd8798
|
| 3 |
+
size 2583741096
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0fde2fcc0ec44f067e7429e647bfbeeb159a649a8fd9f209ff315ec5411af6b4
|
| 3 |
+
size 23950
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f38c73729248f6c127296386e3cdde96e254636cc58b4169d3fd32328d9a8ec
|
| 3 |
+
size 296
|
standard_benchmark.png
ADDED
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6b9e4e7fb171f92fd137b777cc2714bf87d11576700a1dcd7a399e7bbe39537b
|
| 3 |
+
size 17209920
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c5965bf8c62811c97bff003a2198c7ccb5c0589ae9310e9c796a008a336e1c9
|
| 3 |
+
size 55377
|