
End of training
Browse files- README.md +5 -5
- all_results.json +19 -0
- egy_training_log.txt +2 -0
- eval_results.json +13 -0
- train_results.json +9 -0
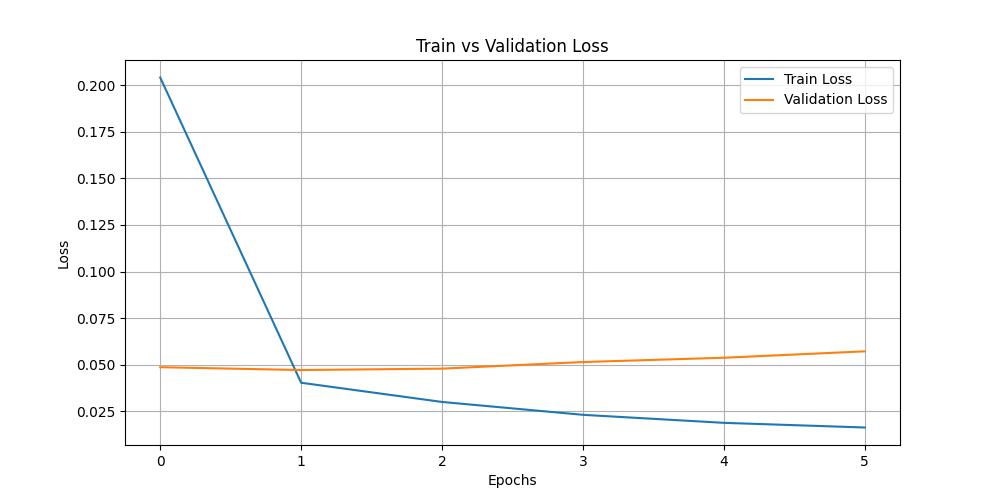
- train_vs_val_loss.png +0 -0
- trainer_state.json +184 -0
README.md
CHANGED
|
@@ -18,11 +18,11 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
-
- Bleu: 0.
|
| 23 |
-
- Rouge1: 0.
|
| 24 |
-
- Rouge2: 0.
|
| 25 |
-
- Rougel: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.0472
|
| 22 |
+
- Bleu: 0.0632
|
| 23 |
+
- Rouge1: 0.4039
|
| 24 |
+
- Rouge2: 0.1633
|
| 25 |
+
- Rougel: 0.4013
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
all_results.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"eval_bleu": 0.06321503399346401,
|
| 4 |
+
"eval_loss": 0.047215357422828674,
|
| 5 |
+
"eval_rouge1": 0.40393751877732786,
|
| 6 |
+
"eval_rouge2": 0.16331196085274022,
|
| 7 |
+
"eval_rougeL": 0.4013347547558428,
|
| 8 |
+
"eval_runtime": 342.1869,
|
| 9 |
+
"eval_samples": 1672,
|
| 10 |
+
"eval_samples_per_second": 4.886,
|
| 11 |
+
"eval_steps_per_second": 1.222,
|
| 12 |
+
"perplexity": 1.0483477542414168,
|
| 13 |
+
"total_flos": 2.03668247150592e+17,
|
| 14 |
+
"train_loss": 0.04967995416767697,
|
| 15 |
+
"train_runtime": 22443.4901,
|
| 16 |
+
"train_samples": 6685,
|
| 17 |
+
"train_samples_per_second": 5.957,
|
| 18 |
+
"train_steps_per_second": 1.49
|
| 19 |
+
}
|
egy_training_log.txt
CHANGED
|
@@ -568,3 +568,5 @@ INFO:root:Epoch 6.0: Train Loss = 0.0189, Eval Loss = 0.053812965750694275
|
|
| 568 |
INFO:absl:Using default tokenizer.
|
| 569 |
INFO:root:Epoch 7.0: Train Loss = 0.0164, Eval Loss = 0.05724157765507698
|
| 570 |
INFO:absl:Using default tokenizer.
|
|
|
|
|
|
|
|
|
| 568 |
INFO:absl:Using default tokenizer.
|
| 569 |
INFO:root:Epoch 7.0: Train Loss = 0.0164, Eval Loss = 0.05724157765507698
|
| 570 |
INFO:absl:Using default tokenizer.
|
| 571 |
+
INFO:__main__:*** Evaluate ***
|
| 572 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"eval_bleu": 0.06321503399346401,
|
| 4 |
+
"eval_loss": 0.047215357422828674,
|
| 5 |
+
"eval_rouge1": 0.40393751877732786,
|
| 6 |
+
"eval_rouge2": 0.16331196085274022,
|
| 7 |
+
"eval_rougeL": 0.4013347547558428,
|
| 8 |
+
"eval_runtime": 342.1869,
|
| 9 |
+
"eval_samples": 1672,
|
| 10 |
+
"eval_samples_per_second": 4.886,
|
| 11 |
+
"eval_steps_per_second": 1.222,
|
| 12 |
+
"perplexity": 1.0483477542414168
|
| 13 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"total_flos": 2.03668247150592e+17,
|
| 4 |
+
"train_loss": 0.04967995416767697,
|
| 5 |
+
"train_runtime": 22443.4901,
|
| 6 |
+
"train_samples": 6685,
|
| 7 |
+
"train_samples_per_second": 5.957,
|
| 8 |
+
"train_steps_per_second": 1.49
|
| 9 |
+
}
|
train_vs_val_loss.png
ADDED
|
trainer_state.json
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 0.047215357422828674,
|
| 3 |
+
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_gulf_aragpt2-large/checkpoint-3344",
|
| 4 |
+
"epoch": 7.0,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 11704,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 1.0,
|
| 13 |
+
"grad_norm": 0.7535182237625122,
|
| 14 |
+
"learning_rate": 4.822100789313904e-05,
|
| 15 |
+
"loss": 0.2041,
|
| 16 |
+
"step": 1672
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.0,
|
| 20 |
+
"eval_bleu": 0.04446881026937374,
|
| 21 |
+
"eval_loss": 0.04873450845479965,
|
| 22 |
+
"eval_rouge1": 0.3745425104768441,
|
| 23 |
+
"eval_rouge2": 0.13019286214073578,
|
| 24 |
+
"eval_rougeL": 0.37175423318625556,
|
| 25 |
+
"eval_runtime": 280.7972,
|
| 26 |
+
"eval_samples_per_second": 5.954,
|
| 27 |
+
"eval_steps_per_second": 1.489,
|
| 28 |
+
"step": 1672
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 2.0,
|
| 32 |
+
"grad_norm": 0.5986363887786865,
|
| 33 |
+
"learning_rate": 4.568306010928962e-05,
|
| 34 |
+
"loss": 0.0404,
|
| 35 |
+
"step": 3344
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"epoch": 2.0,
|
| 39 |
+
"eval_bleu": 0.06321503399346401,
|
| 40 |
+
"eval_loss": 0.047215357422828674,
|
| 41 |
+
"eval_rouge1": 0.40393751877732786,
|
| 42 |
+
"eval_rouge2": 0.16331196085274022,
|
| 43 |
+
"eval_rougeL": 0.4013347547558428,
|
| 44 |
+
"eval_runtime": 280.6911,
|
| 45 |
+
"eval_samples_per_second": 5.957,
|
| 46 |
+
"eval_steps_per_second": 1.489,
|
| 47 |
+
"step": 3344
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"epoch": 3.0,
|
| 51 |
+
"grad_norm": 0.6692299246788025,
|
| 52 |
+
"learning_rate": 4.3145112325440196e-05,
|
| 53 |
+
"loss": 0.0301,
|
| 54 |
+
"step": 5016
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"epoch": 3.0,
|
| 58 |
+
"eval_bleu": 0.07634204530814317,
|
| 59 |
+
"eval_loss": 0.047973889857530594,
|
| 60 |
+
"eval_rouge1": 0.43387069380649074,
|
| 61 |
+
"eval_rouge2": 0.20015750349405118,
|
| 62 |
+
"eval_rougeL": 0.4322337100043073,
|
| 63 |
+
"eval_runtime": 342.1899,
|
| 64 |
+
"eval_samples_per_second": 4.886,
|
| 65 |
+
"eval_steps_per_second": 1.222,
|
| 66 |
+
"step": 5016
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 4.0,
|
| 70 |
+
"grad_norm": 0.39187440276145935,
|
| 71 |
+
"learning_rate": 4.0607164541590774e-05,
|
| 72 |
+
"loss": 0.0232,
|
| 73 |
+
"step": 6688
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 4.0,
|
| 77 |
+
"eval_bleu": 0.08429412502024626,
|
| 78 |
+
"eval_loss": 0.05150514841079712,
|
| 79 |
+
"eval_rouge1": 0.45350332758712053,
|
| 80 |
+
"eval_rouge2": 0.2191636179696206,
|
| 81 |
+
"eval_rougeL": 0.45170908410677657,
|
| 82 |
+
"eval_runtime": 220.2929,
|
| 83 |
+
"eval_samples_per_second": 7.59,
|
| 84 |
+
"eval_steps_per_second": 1.897,
|
| 85 |
+
"step": 6688
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"epoch": 5.0,
|
| 89 |
+
"grad_norm": 0.7217269539833069,
|
| 90 |
+
"learning_rate": 3.806921675774135e-05,
|
| 91 |
+
"loss": 0.0189,
|
| 92 |
+
"step": 8360
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 5.0,
|
| 96 |
+
"eval_bleu": 0.08759878040919578,
|
| 97 |
+
"eval_loss": 0.053812965750694275,
|
| 98 |
+
"eval_rouge1": 0.4654488236955554,
|
| 99 |
+
"eval_rouge2": 0.22994914252764548,
|
| 100 |
+
"eval_rougeL": 0.46382599849734485,
|
| 101 |
+
"eval_runtime": 342.2351,
|
| 102 |
+
"eval_samples_per_second": 4.886,
|
| 103 |
+
"eval_steps_per_second": 1.221,
|
| 104 |
+
"step": 8360
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"epoch": 6.0,
|
| 108 |
+
"grad_norm": 0.5110601186752319,
|
| 109 |
+
"learning_rate": 3.553126897389193e-05,
|
| 110 |
+
"loss": 0.0164,
|
| 111 |
+
"step": 10032
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"epoch": 6.0,
|
| 115 |
+
"eval_bleu": 0.09295393672158372,
|
| 116 |
+
"eval_loss": 0.05724157765507698,
|
| 117 |
+
"eval_rouge1": 0.46747472033375215,
|
| 118 |
+
"eval_rouge2": 0.2370003193385344,
|
| 119 |
+
"eval_rougeL": 0.46529496417190075,
|
| 120 |
+
"eval_runtime": 342.1804,
|
| 121 |
+
"eval_samples_per_second": 4.886,
|
| 122 |
+
"eval_steps_per_second": 1.222,
|
| 123 |
+
"step": 10032
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 7.0,
|
| 127 |
+
"grad_norm": 0.23091594874858856,
|
| 128 |
+
"learning_rate": 3.2993321190042506e-05,
|
| 129 |
+
"loss": 0.0148,
|
| 130 |
+
"step": 11704
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"epoch": 7.0,
|
| 134 |
+
"eval_bleu": 0.0918093965340221,
|
| 135 |
+
"eval_loss": 0.05825383961200714,
|
| 136 |
+
"eval_rouge1": 0.46559708964007684,
|
| 137 |
+
"eval_rouge2": 0.2307789620256464,
|
| 138 |
+
"eval_rougeL": 0.46361556118175484,
|
| 139 |
+
"eval_runtime": 280.7351,
|
| 140 |
+
"eval_samples_per_second": 5.956,
|
| 141 |
+
"eval_steps_per_second": 1.489,
|
| 142 |
+
"step": 11704
|
| 143 |
+
},
|
| 144 |
+
{
|
| 145 |
+
"epoch": 7.0,
|
| 146 |
+
"step": 11704,
|
| 147 |
+
"total_flos": 2.03668247150592e+17,
|
| 148 |
+
"train_loss": 0.04967995416767697,
|
| 149 |
+
"train_runtime": 22443.4901,
|
| 150 |
+
"train_samples_per_second": 5.957,
|
| 151 |
+
"train_steps_per_second": 1.49
|
| 152 |
+
}
|
| 153 |
+
],
|
| 154 |
+
"logging_steps": 500,
|
| 155 |
+
"max_steps": 33440,
|
| 156 |
+
"num_input_tokens_seen": 0,
|
| 157 |
+
"num_train_epochs": 20,
|
| 158 |
+
"save_steps": 500,
|
| 159 |
+
"stateful_callbacks": {
|
| 160 |
+
"EarlyStoppingCallback": {
|
| 161 |
+
"args": {
|
| 162 |
+
"early_stopping_patience": 5,
|
| 163 |
+
"early_stopping_threshold": 0.0
|
| 164 |
+
},
|
| 165 |
+
"attributes": {
|
| 166 |
+
"early_stopping_patience_counter": 0
|
| 167 |
+
}
|
| 168 |
+
},
|
| 169 |
+
"TrainerControl": {
|
| 170 |
+
"args": {
|
| 171 |
+
"should_epoch_stop": false,
|
| 172 |
+
"should_evaluate": false,
|
| 173 |
+
"should_log": false,
|
| 174 |
+
"should_save": true,
|
| 175 |
+
"should_training_stop": true
|
| 176 |
+
},
|
| 177 |
+
"attributes": {}
|
| 178 |
+
}
|
| 179 |
+
},
|
| 180 |
+
"total_flos": 2.03668247150592e+17,
|
| 181 |
+
"train_batch_size": 4,
|
| 182 |
+
"trial_name": null,
|
| 183 |
+
"trial_params": null
|
| 184 |
+
}
|