
End of training
Browse files- README.md +5 -5
- all_results.json +19 -0
- egy_training_log.txt +2 -0
- eval_results.json +13 -0
- train_results.json +9 -0
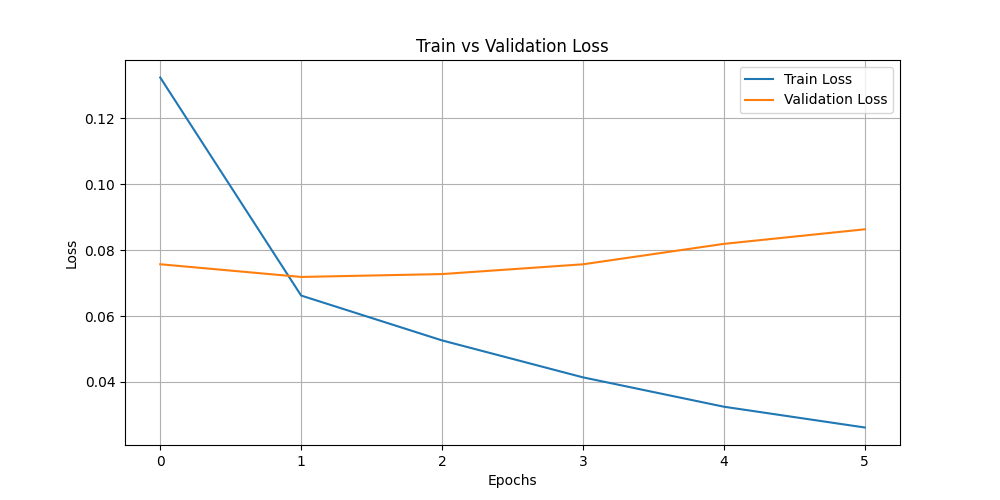
- train_vs_val_loss.png +0 -0
- trainer_state.json +184 -0
README.md
CHANGED
|
@@ -18,11 +18,11 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
-
- Loss: 0.
|
| 22 |
-
- Bleu: 0.
|
| 23 |
-
- Rouge1: 0.
|
| 24 |
-
- Rouge2: 0.
|
| 25 |
-
- Rougel: 0.
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
|
|
|
| 18 |
|
| 19 |
This model is a fine-tuned version of [aubmindlab/aragpt2-large](https://huggingface.co/aubmindlab/aragpt2-large) on an unknown dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.0718
|
| 22 |
+
- Bleu: 0.1063
|
| 23 |
+
- Rouge1: 0.4552
|
| 24 |
+
- Rouge2: 0.2232
|
| 25 |
+
- Rougel: 0.4516
|
| 26 |
|
| 27 |
## Model description
|
| 28 |
|
all_results.json
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"eval_bleu": 0.10627535338849203,
|
| 4 |
+
"eval_loss": 0.07183855026960373,
|
| 5 |
+
"eval_rouge1": 0.45517089056426413,
|
| 6 |
+
"eval_rouge2": 0.2232454846856679,
|
| 7 |
+
"eval_rougeL": 0.4515800058148628,
|
| 8 |
+
"eval_runtime": 828.4394,
|
| 9 |
+
"eval_samples": 5380,
|
| 10 |
+
"eval_samples_per_second": 6.494,
|
| 11 |
+
"eval_steps_per_second": 1.624,
|
| 12 |
+
"perplexity": 1.0744818552534834,
|
| 13 |
+
"total_flos": 6.528656496918528e+17,
|
| 14 |
+
"train_loss": 0.0533416826159377,
|
| 15 |
+
"train_runtime": 67570.4522,
|
| 16 |
+
"train_samples": 21429,
|
| 17 |
+
"train_samples_per_second": 6.343,
|
| 18 |
+
"train_steps_per_second": 1.586
|
| 19 |
+
}
|
egy_training_log.txt
CHANGED
|
@@ -568,3 +568,5 @@ INFO:root:Epoch 6.0: Train Loss = 0.0325, Eval Loss = 0.08186400681734085
|
|
| 568 |
INFO:absl:Using default tokenizer.
|
| 569 |
INFO:root:Epoch 7.0: Train Loss = 0.0262, Eval Loss = 0.08628461509943008
|
| 570 |
INFO:absl:Using default tokenizer.
|
|
|
|
|
|
|
|
|
| 568 |
INFO:absl:Using default tokenizer.
|
| 569 |
INFO:root:Epoch 7.0: Train Loss = 0.0262, Eval Loss = 0.08628461509943008
|
| 570 |
INFO:absl:Using default tokenizer.
|
| 571 |
+
INFO:__main__:*** Evaluate ***
|
| 572 |
+
INFO:absl:Using default tokenizer.
|
eval_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"eval_bleu": 0.10627535338849203,
|
| 4 |
+
"eval_loss": 0.07183855026960373,
|
| 5 |
+
"eval_rouge1": 0.45517089056426413,
|
| 6 |
+
"eval_rouge2": 0.2232454846856679,
|
| 7 |
+
"eval_rougeL": 0.4515800058148628,
|
| 8 |
+
"eval_runtime": 828.4394,
|
| 9 |
+
"eval_samples": 5380,
|
| 10 |
+
"eval_samples_per_second": 6.494,
|
| 11 |
+
"eval_steps_per_second": 1.624,
|
| 12 |
+
"perplexity": 1.0744818552534834
|
| 13 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 7.0,
|
| 3 |
+
"total_flos": 6.528656496918528e+17,
|
| 4 |
+
"train_loss": 0.0533416826159377,
|
| 5 |
+
"train_runtime": 67570.4522,
|
| 6 |
+
"train_samples": 21429,
|
| 7 |
+
"train_samples_per_second": 6.343,
|
| 8 |
+
"train_steps_per_second": 1.586
|
| 9 |
+
}
|
train_vs_val_loss.png
ADDED
|
trainer_state.json
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 0.07183855026960373,
|
| 3 |
+
"best_model_checkpoint": "/home/iais_marenpielka/Bouthaina/res_nw_dj_aragpt2-large/checkpoint-10716",
|
| 4 |
+
"epoch": 7.0,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 37506,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 1.0,
|
| 13 |
+
"grad_norm": 1.1402301788330078,
|
| 14 |
+
"learning_rate": 4.772267016688543e-05,
|
| 15 |
+
"loss": 0.1323,
|
| 16 |
+
"step": 5358
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 1.0,
|
| 20 |
+
"eval_bleu": 0.08300663646266425,
|
| 21 |
+
"eval_loss": 0.07568918913602829,
|
| 22 |
+
"eval_rouge1": 0.4072217751588082,
|
| 23 |
+
"eval_rouge2": 0.18254715184887235,
|
| 24 |
+
"eval_rougeL": 0.4034974548012786,
|
| 25 |
+
"eval_runtime": 706.7922,
|
| 26 |
+
"eval_samples_per_second": 7.612,
|
| 27 |
+
"eval_steps_per_second": 1.903,
|
| 28 |
+
"step": 5358
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"epoch": 2.0,
|
| 32 |
+
"grad_norm": 0.7255021929740906,
|
| 33 |
+
"learning_rate": 4.521095068441778e-05,
|
| 34 |
+
"loss": 0.0662,
|
| 35 |
+
"step": 10716
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"epoch": 2.0,
|
| 39 |
+
"eval_bleu": 0.10627535338849203,
|
| 40 |
+
"eval_loss": 0.07183855026960373,
|
| 41 |
+
"eval_rouge1": 0.45517089056426413,
|
| 42 |
+
"eval_rouge2": 0.2232454846856679,
|
| 43 |
+
"eval_rougeL": 0.4515800058148628,
|
| 44 |
+
"eval_runtime": 715.8215,
|
| 45 |
+
"eval_samples_per_second": 7.516,
|
| 46 |
+
"eval_steps_per_second": 1.879,
|
| 47 |
+
"step": 10716
|
| 48 |
+
},
|
| 49 |
+
{
|
| 50 |
+
"epoch": 3.0,
|
| 51 |
+
"grad_norm": 0.5735991597175598,
|
| 52 |
+
"learning_rate": 4.269923120195012e-05,
|
| 53 |
+
"loss": 0.0526,
|
| 54 |
+
"step": 16074
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"epoch": 3.0,
|
| 58 |
+
"eval_bleu": 0.11970864457422921,
|
| 59 |
+
"eval_loss": 0.07271187007427216,
|
| 60 |
+
"eval_rouge1": 0.47525716850104355,
|
| 61 |
+
"eval_rouge2": 0.25197591385088847,
|
| 62 |
+
"eval_rougeL": 0.47186762638658064,
|
| 63 |
+
"eval_runtime": 766.9396,
|
| 64 |
+
"eval_samples_per_second": 7.015,
|
| 65 |
+
"eval_steps_per_second": 1.754,
|
| 66 |
+
"step": 16074
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"epoch": 4.0,
|
| 70 |
+
"grad_norm": 0.9193664789199829,
|
| 71 |
+
"learning_rate": 4.018751171948247e-05,
|
| 72 |
+
"loss": 0.0414,
|
| 73 |
+
"step": 21432
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"epoch": 4.0,
|
| 77 |
+
"eval_bleu": 0.12737868761714774,
|
| 78 |
+
"eval_loss": 0.07567169517278671,
|
| 79 |
+
"eval_rouge1": 0.4894464779386084,
|
| 80 |
+
"eval_rouge2": 0.2644220876804199,
|
| 81 |
+
"eval_rougeL": 0.48620236061532013,
|
| 82 |
+
"eval_runtime": 767.056,
|
| 83 |
+
"eval_samples_per_second": 7.014,
|
| 84 |
+
"eval_steps_per_second": 1.753,
|
| 85 |
+
"step": 21432
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"epoch": 5.0,
|
| 89 |
+
"grad_norm": 1.2567533254623413,
|
| 90 |
+
"learning_rate": 3.7675792237014815e-05,
|
| 91 |
+
"loss": 0.0325,
|
| 92 |
+
"step": 26790
|
| 93 |
+
},
|
| 94 |
+
{
|
| 95 |
+
"epoch": 5.0,
|
| 96 |
+
"eval_bleu": 0.12904171218936847,
|
| 97 |
+
"eval_loss": 0.08186400681734085,
|
| 98 |
+
"eval_rouge1": 0.4910163857094879,
|
| 99 |
+
"eval_rouge2": 0.26712580782902845,
|
| 100 |
+
"eval_rougeL": 0.4874926457795191,
|
| 101 |
+
"eval_runtime": 767.2369,
|
| 102 |
+
"eval_samples_per_second": 7.012,
|
| 103 |
+
"eval_steps_per_second": 1.753,
|
| 104 |
+
"step": 26790
|
| 105 |
+
},
|
| 106 |
+
{
|
| 107 |
+
"epoch": 6.0,
|
| 108 |
+
"grad_norm": 1.125952124595642,
|
| 109 |
+
"learning_rate": 3.516407275454716e-05,
|
| 110 |
+
"loss": 0.0262,
|
| 111 |
+
"step": 32148
|
| 112 |
+
},
|
| 113 |
+
{
|
| 114 |
+
"epoch": 6.0,
|
| 115 |
+
"eval_bleu": 0.12974770289755774,
|
| 116 |
+
"eval_loss": 0.08628461509943008,
|
| 117 |
+
"eval_rouge1": 0.4922385680285879,
|
| 118 |
+
"eval_rouge2": 0.26649486337370165,
|
| 119 |
+
"eval_rougeL": 0.4887932180100094,
|
| 120 |
+
"eval_runtime": 828.4635,
|
| 121 |
+
"eval_samples_per_second": 6.494,
|
| 122 |
+
"eval_steps_per_second": 1.623,
|
| 123 |
+
"step": 32148
|
| 124 |
+
},
|
| 125 |
+
{
|
| 126 |
+
"epoch": 7.0,
|
| 127 |
+
"grad_norm": 0.9687314629554749,
|
| 128 |
+
"learning_rate": 3.26523532720795e-05,
|
| 129 |
+
"loss": 0.0221,
|
| 130 |
+
"step": 37506
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"epoch": 7.0,
|
| 134 |
+
"eval_bleu": 0.13258665968806682,
|
| 135 |
+
"eval_loss": 0.09302929788827896,
|
| 136 |
+
"eval_rouge1": 0.4960344976284088,
|
| 137 |
+
"eval_rouge2": 0.2712943985267227,
|
| 138 |
+
"eval_rougeL": 0.4923109277459174,
|
| 139 |
+
"eval_runtime": 828.274,
|
| 140 |
+
"eval_samples_per_second": 6.495,
|
| 141 |
+
"eval_steps_per_second": 1.624,
|
| 142 |
+
"step": 37506
|
| 143 |
+
},
|
| 144 |
+
{
|
| 145 |
+
"epoch": 7.0,
|
| 146 |
+
"step": 37506,
|
| 147 |
+
"total_flos": 6.528656496918528e+17,
|
| 148 |
+
"train_loss": 0.0533416826159377,
|
| 149 |
+
"train_runtime": 67570.4522,
|
| 150 |
+
"train_samples_per_second": 6.343,
|
| 151 |
+
"train_steps_per_second": 1.586
|
| 152 |
+
}
|
| 153 |
+
],
|
| 154 |
+
"logging_steps": 500,
|
| 155 |
+
"max_steps": 107160,
|
| 156 |
+
"num_input_tokens_seen": 0,
|
| 157 |
+
"num_train_epochs": 20,
|
| 158 |
+
"save_steps": 500,
|
| 159 |
+
"stateful_callbacks": {
|
| 160 |
+
"EarlyStoppingCallback": {
|
| 161 |
+
"args": {
|
| 162 |
+
"early_stopping_patience": 5,
|
| 163 |
+
"early_stopping_threshold": 0.0
|
| 164 |
+
},
|
| 165 |
+
"attributes": {
|
| 166 |
+
"early_stopping_patience_counter": 0
|
| 167 |
+
}
|
| 168 |
+
},
|
| 169 |
+
"TrainerControl": {
|
| 170 |
+
"args": {
|
| 171 |
+
"should_epoch_stop": false,
|
| 172 |
+
"should_evaluate": false,
|
| 173 |
+
"should_log": false,
|
| 174 |
+
"should_save": true,
|
| 175 |
+
"should_training_stop": true
|
| 176 |
+
},
|
| 177 |
+
"attributes": {}
|
| 178 |
+
}
|
| 179 |
+
},
|
| 180 |
+
"total_flos": 6.528656496918528e+17,
|
| 181 |
+
"train_batch_size": 4,
|
| 182 |
+
"trial_name": null,
|
| 183 |
+
"trial_params": null
|
| 184 |
+
}
|