

Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- .ipynb_checkpoints/README-checkpoint.md +213 -0
- README.md +213 -3
- added_tokens.json +16 -0
- chat_template.json +3 -0
- config.json +48 -0
- cover.png +0 -0
- generation_config.json +14 -0
- merges.txt +0 -0
- model.safetensors +3 -0
- preprocessor_config.json +29 -0
- special_tokens_map.json +31 -0
- tokenizer.json +3 -0
- tokenizer_config.json +147 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
.ipynb_checkpoints/README-checkpoint.md
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- it
|
| 6 |
+
- fr
|
| 7 |
+
- de
|
| 8 |
+
- es
|
| 9 |
+
base_model:
|
| 10 |
+
- MrLight/dse-qwen2-2b-mrl-v1
|
| 11 |
+
tags:
|
| 12 |
+
- transformers
|
| 13 |
+
- Qwen2-VL
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# vdr-2b-multi-v1
|
| 17 |
+
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
vdr-2b-multi-v1 is a multilingual model designed for visual document retrieval across multiple languages and domains. This model is designed to encode document page screenshots into dense single-vector representations, this will effectively allow to search and query visually rich multilingual documents without the need for any OCR, data extraction pipelines, chunking...
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
- **Trained on 🇮🇹 Italian, 🇪🇸 Spanish, 🇬🇧 English, 🇫🇷 French and 🇩🇪 German:** together they form a new large, open-source, multilingual training dataset of 500k high-quality samples.
|
| 24 |
+
|
| 25 |
+
- **Low VRAM and Faster Inference**: english model achieves better results on synthetic vidore benchmarks with just 30% of the base model image resolution. This results in 3x faster inference and much lower VRAM usage.
|
| 26 |
+
|
| 27 |
+
- **Cross-lingual Retrieval**: substantially better on real-world scenarios. For example, this allows for searching german documents with italian queries.
|
| 28 |
+
|
| 29 |
+
- **Matryoshka Representation Learning**: You can reduce the vectors size 3x and still keep 98% of the embeddings quality.
|
| 30 |
+
|
| 31 |
+
# Usage
|
| 32 |
+
|
| 33 |
+
**Initialize model and processor**
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
|
| 37 |
+
from PIL import Image
|
| 38 |
+
import torch
|
| 39 |
+
import math
|
| 40 |
+
|
| 41 |
+
# more pixels -> better embeddings -> more VRAM -> slower inference
|
| 42 |
+
# From my experience, 768 image patches is the right spot for compute efficient embeddings.
|
| 43 |
+
max_pixels = 768 * 28 * 28
|
| 44 |
+
min_pixels = 1 * 28 * 28
|
| 45 |
+
|
| 46 |
+
# Load the embedding model and processor
|
| 47 |
+
model = Qwen2VLForConditionalGeneration.from_pretrained(
|
| 48 |
+
'llamaindex/vdr-2b-multi-v1',
|
| 49 |
+
attn_implementation="flash_attention_2",
|
| 50 |
+
torch_dtype=torch.bfloat16,
|
| 51 |
+
device_map="cuda:0"
|
| 52 |
+
).eval()
|
| 53 |
+
|
| 54 |
+
processor = AutoProcessor.from_pretrained(
|
| 55 |
+
'llamaindex/vdr-2b-multi-v1',
|
| 56 |
+
min_pixels=min_pixels,
|
| 57 |
+
max_pixels=max_pixels
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
model.padding_side = "left"
|
| 61 |
+
processor.tokenizer.padding_side = "left"
|
| 62 |
+
|
| 63 |
+
document_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>What is shown in this image?<|im_end|>\n<|endoftext|>"
|
| 64 |
+
|
| 65 |
+
query_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Query: %s<|im_end|>\n<|endoftext|>"
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
**Encode queries**
|
| 69 |
+
|
| 70 |
+
```python
|
| 71 |
+
def encode_queries(queries: list[str], dimension: int) -> torch.Tensor:
|
| 72 |
+
"""
|
| 73 |
+
Encode a list of queries into a tensor of embeddings.
|
| 74 |
+
|
| 75 |
+
Args:
|
| 76 |
+
queries: A list of strings, each representing a query.
|
| 77 |
+
dimension: The desired dimension of the output embeddings.
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
A tensor of shape (num_queries, dimension) containing the encoded queries.
|
| 81 |
+
"""
|
| 82 |
+
|
| 83 |
+
dummy_image = Image.new('RGB', (56, 56))
|
| 84 |
+
inputs = processor(
|
| 85 |
+
text=[query_prompt % x for x in queries],
|
| 86 |
+
images=[dummy_image for _ in queries],
|
| 87 |
+
videos=None,
|
| 88 |
+
padding='longest',
|
| 89 |
+
return_tensors='pt'
|
| 90 |
+
).to('cuda:0')
|
| 91 |
+
|
| 92 |
+
cache_position = torch.arange(0, len(queries))
|
| 93 |
+
inputs = model.prepare_inputs_for_generation(
|
| 94 |
+
**inputs, cache_position=cache_position, use_cache=False)
|
| 95 |
+
|
| 96 |
+
with torch.no_grad():
|
| 97 |
+
output = self.model(
|
| 98 |
+
**inputs,
|
| 99 |
+
return_dict=True,
|
| 100 |
+
output_hidden_states=True
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
embeddings = output.hidden_states[-1][:, -1]
|
| 104 |
+
return torch.nn.functional.normalize(embeddings[:, :dimension], p=2, dim=-1)
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
**Encode documents**
|
| 108 |
+
```python
|
| 109 |
+
def round_by_factor(number: float, factor: int) -> int:
|
| 110 |
+
return round(number / factor) * factor
|
| 111 |
+
|
| 112 |
+
def ceil_by_factor(number: float, factor: int) -> int:
|
| 113 |
+
return math.ceil(number / factor) * factor
|
| 114 |
+
|
| 115 |
+
def floor_by_factor(number: float, factor: int) -> int:
|
| 116 |
+
return math.floor(number / factor) * factor
|
| 117 |
+
|
| 118 |
+
def smart_resize(height: int, width: int) -> tuple[int, int]:
|
| 119 |
+
h_bar = max(28, round_by_factor(height, 28))
|
| 120 |
+
w_bar = max(28, round_by_factor(width, 28))
|
| 121 |
+
if h_bar * w_bar > max_pixels:
|
| 122 |
+
beta = math.sqrt((height * width) / max_pixels)
|
| 123 |
+
h_bar = floor_by_factor(height / beta, 28)
|
| 124 |
+
w_bar = floor_by_factor(width / beta, 28)
|
| 125 |
+
elif h_bar * w_bar < min_pixels:
|
| 126 |
+
beta = math.sqrt(min_pixels / (height * width))
|
| 127 |
+
h_bar = ceil_by_factor(height * beta, 28)
|
| 128 |
+
w_bar = ceil_by_factor(width * beta, 28)
|
| 129 |
+
return w_bar, h_bar
|
| 130 |
+
|
| 131 |
+
def resize(image: Image.Image):
|
| 132 |
+
new_size = smart_resize(image.height, image.width)
|
| 133 |
+
return image.resize(new_size)
|
| 134 |
+
|
| 135 |
+
def encode_documents(documents: list[Image.Image], dimension: int):
|
| 136 |
+
"""
|
| 137 |
+
Encode a list of images into a tensor of embeddings.
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
documents: A list of PIL Image objects.
|
| 141 |
+
dimension: The desired dimension of the output embeddings.
|
| 142 |
+
|
| 143 |
+
Returns:
|
| 144 |
+
A tensor of shape (num_documents, dimension) containing the encoded images.
|
| 145 |
+
"""
|
| 146 |
+
|
| 147 |
+
inputs = processor(
|
| 148 |
+
text=[document_prompt] * len(documents),
|
| 149 |
+
images=[resize(x) for x in documents],
|
| 150 |
+
videos=None,
|
| 151 |
+
padding='longest',
|
| 152 |
+
return_tensors='pt'
|
| 153 |
+
).to('cuda:0')
|
| 154 |
+
|
| 155 |
+
cache_position = torch.arange(0, len(queries))
|
| 156 |
+
inputs = model.prepare_inputs_for_generation(
|
| 157 |
+
**inputs, cache_position=cache_position, use_cache=False)
|
| 158 |
+
|
| 159 |
+
with torch.no_grad():
|
| 160 |
+
output = self.model(
|
| 161 |
+
**inputs,
|
| 162 |
+
return_dict=True,
|
| 163 |
+
output_hidden_states=True
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
embeddings = output.hidden_states[-1][:, -1]
|
| 167 |
+
return torch.nn.functional.normalize(embeddings[:, :dimension], p=2, dim=-1)
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
# Training
|
| 171 |
+
|
| 172 |
+
The model is based on [MrLight/dse-qwen2-2b-mrl-v1](https://huggingface.co/MrLight/dse-qwen2-2b-mrl-v1) and it was trained on the new [vdr-multilingual-train](https://huggingface.co/datasets/llamaindex/vdr-multilingual-train) dataset that consinsists of 500k high quality, multilingual query image pairs. It was trained for 1 epoch using the [DSE approach](https://arxiv.org/abs/2406.11251), with a batch size of 128 and hard-mined negatives.
|
| 173 |
+
|
| 174 |
+
# Results
|
| 175 |
+
|
| 176 |
+
The model has been evaluated on the Vidore benchmark and on custom-built evaluation sets that allow testing its multilingual capabilities on text-only, visual-only and mixed page screenshots. The evaluation dataset is publicly available [here on HuggingFace](https://huggingface.co/datasets/llamaindex/vdr-multilingual-test).
|
| 177 |
+
|
| 178 |
+
All evaluations are performed by calculating **NDCG@5** scores using **1536 dimensions** vectors and an image resolution that can be represented with **maximum 768 tokens**.
|
| 179 |
+
|
| 180 |
+
| | Avg | Italian (text) | Italian (visual) | Italian (mix) |
|
| 181 |
+
|---------------------|----------|----------------|------------------|---------------|
|
| 182 |
+
| dse-qwen2-2b-mrl-v1 | 95.1 | 95.1 | 94 | 96.2 |
|
| 183 |
+
| vdr-2b-multi-v1 | **97.0** | **96.4** | **96.3** | **98.4** |
|
| 184 |
+
| | **+2%** | | | |
|
| 185 |
+
|
| 186 |
+
| | Avg | French (text) | French (visual) | French (mix) |
|
| 187 |
+
|---------------------|-----------|---------------|-----------------|--------------|
|
| 188 |
+
| dse-qwen2-2b-mrl-v1 | 93.5 | 94.7 | 90.8 | 95.1 |
|
| 189 |
+
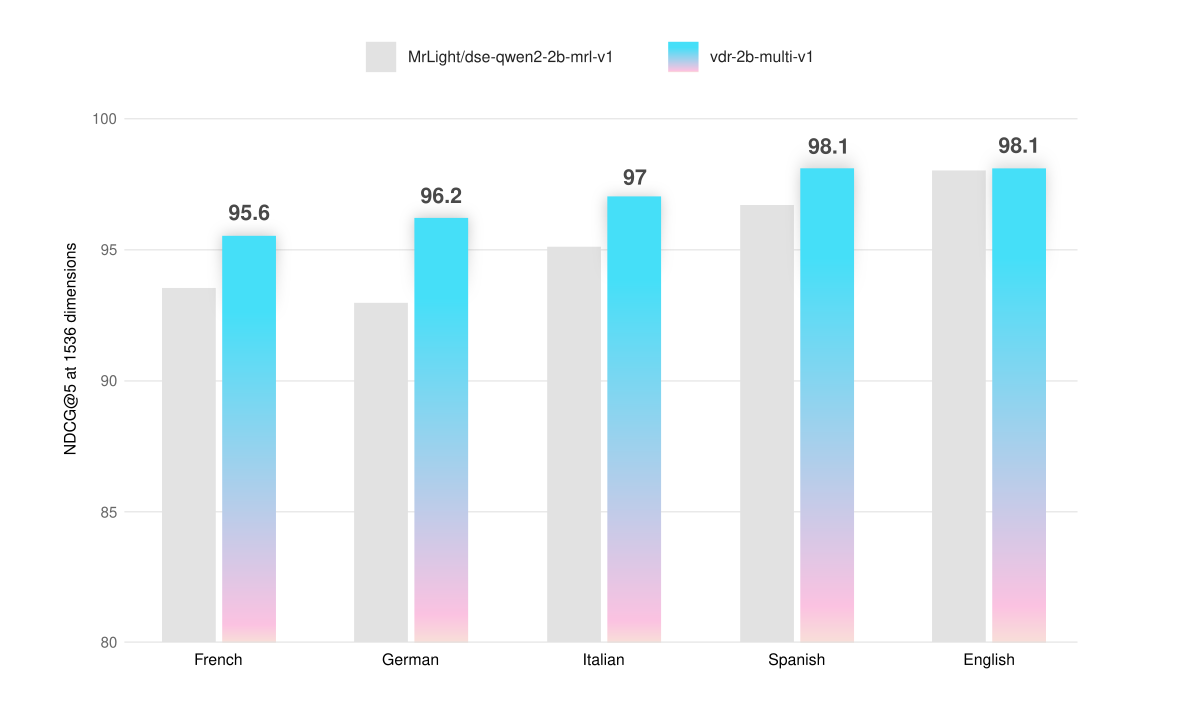
| vdr-2b-multi-v1 | **95.6** | **95.6** | **93.3** | **97.9** |
|
| 190 |
+
| | **+2.2%** | | | |
|
| 191 |
+
|
| 192 |
+
| | Avg | Spanish (text) | Spanish (visual) | Spanish (mix) |
|
| 193 |
+
|---------------------|-----------|----------------|------------------|---------------|
|
| 194 |
+
| dse-qwen2-2b-mrl-v1 | 96.7 | 97.2 | 94.7 | 98.2 |
|
| 195 |
+
| vdr-2b-multi-v1 | **98.1** | **98.3** | **96.9** | **99.1** |
|
| 196 |
+
| | **+1.4%** | | | |
|
| 197 |
+
|
| 198 |
+
| | Avg | German (text) | German (visual) | German (mix) |
|
| 199 |
+
|---------------------|-----------|---------------|-----------------|--------------|
|
| 200 |
+
| dse-qwen2-2b-mrl-v1 | 93.0 | 93.4 | 90 | 95.5 |
|
| 201 |
+
| vdr-2b-multi-v1 | **96.2** | **94.8** | **95.7** | **98.1** |
|
| 202 |
+
| | **+3.4%** | | | |
|
| 203 |
+
|
| 204 |
+
| | Avg | English (text) | English (visual) | English (mix) |
|
| 205 |
+
|---------------------|-----------|----------------|------------------|---------------|
|
| 206 |
+
| dse-qwen2-2b-mrl-v1 | 98.0 | **98.3** | 98.5 | 97.1 |
|
| 207 |
+
| vdr-2b-multi-v1 | **98.1** | 97.9 | **99.1** | **97.3** |
|
| 208 |
+
| | **+0.1%** | | | |
|
| 209 |
+
|
| 210 |
+
| | **Avg** | **shiftproject** | **government** | **healthcare** | **energy** | **ai** | **docvqa** | **arxivqa** | **tatdqa** | **infovqa** | **tabfquad** |
|
| 211 |
+
|--------------------:|---------:|-----------------:|---------------:|---------------:|-----------:|-----------:|-----------:|------------:|-----------:|------------:|-------------:|
|
| 212 |
+
| dse-qwen2-2b-mrl-v1 | 83.6 | 79.8 | **95.7** | **96.9** | **92** | 98.2 | 56.3 | **85.2** | **53.9** | **87.5** | 90.3 |
|
| 213 |
+
| vdr-2b-multi-v1 | **84.0** | **82.4** | 95.5 | 96.5 | 91.2 | **98.5** | **58.5** | 84.7 | 53.6 | 87.1 | **92.2** |
|
README.md
CHANGED
|
@@ -1,3 +1,213 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- it
|
| 6 |
+
- fr
|
| 7 |
+
- de
|
| 8 |
+
- es
|
| 9 |
+
base_model:
|
| 10 |
+
- MrLight/dse-qwen2-2b-mrl-v1
|
| 11 |
+
tags:
|
| 12 |
+
- transformers
|
| 13 |
+
- Qwen2-VL
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
# vdr-2b-multi-v1
|
| 17 |
+
|
| 18 |
+

|
| 19 |
+
|
| 20 |
+
vdr-2b-multi-v1 is a multilingual model designed for visual document retrieval across multiple languages and domains. This model is designed to encode document page screenshots into dense single-vector representations, this will effectively allow to search and query visually rich multilingual documents without the need for any OCR, data extraction pipelines, chunking...
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
- **Trained on 🇮🇹 Italian, 🇪🇸 Spanish, 🇬🇧 English, 🇫🇷 French and 🇩🇪 German:** together they form a new large, open-source, multilingual training dataset of 500k high-quality samples.
|
| 24 |
+
|
| 25 |
+
- **Low VRAM and Faster Inference**: english model achieves better results on synthetic vidore benchmarks with just 30% of the base model image resolution. This results in 3x faster inference and much lower VRAM usage.
|
| 26 |
+
|
| 27 |
+
- **Cross-lingual Retrieval**: substantially better on real-world scenarios. For example, this allows for searching german documents with italian queries.
|
| 28 |
+
|
| 29 |
+
- **Matryoshka Representation Learning**: You can reduce the vectors size 3x and still keep 98% of the embeddings quality.
|
| 30 |
+
|
| 31 |
+
# Usage
|
| 32 |
+
|
| 33 |
+
**Initialize model and processor**
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
|
| 37 |
+
from PIL import Image
|
| 38 |
+
import torch
|
| 39 |
+
import math
|
| 40 |
+
|
| 41 |
+
# more pixels -> better embeddings -> more VRAM -> slower inference
|
| 42 |
+
# From my experience, 768 image patches is the right spot for compute efficient embeddings.
|
| 43 |
+
max_pixels = 768 * 28 * 28
|
| 44 |
+
min_pixels = 1 * 28 * 28
|
| 45 |
+
|
| 46 |
+
# Load the embedding model and processor
|
| 47 |
+
model = Qwen2VLForConditionalGeneration.from_pretrained(
|
| 48 |
+
'llamaindex/vdr-2b-multi-v1',
|
| 49 |
+
attn_implementation="flash_attention_2",
|
| 50 |
+
torch_dtype=torch.bfloat16,
|
| 51 |
+
device_map="cuda:0"
|
| 52 |
+
).eval()
|
| 53 |
+
|
| 54 |
+
processor = AutoProcessor.from_pretrained(
|
| 55 |
+
'llamaindex/vdr-2b-multi-v1',
|
| 56 |
+
min_pixels=min_pixels,
|
| 57 |
+
max_pixels=max_pixels
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
model.padding_side = "left"
|
| 61 |
+
processor.tokenizer.padding_side = "left"
|
| 62 |
+
|
| 63 |
+
document_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>What is shown in this image?<|im_end|>\n<|endoftext|>"
|
| 64 |
+
|
| 65 |
+
query_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Query: %s<|im_end|>\n<|endoftext|>"
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
**Encode queries**
|
| 69 |
+
|
| 70 |
+
```python
|
| 71 |
+
def encode_queries(queries: list[str], dimension: int) -> torch.Tensor:
|
| 72 |
+
"""
|
| 73 |
+
Encode a list of queries into a tensor of embeddings.
|
| 74 |
+
|
| 75 |
+
Args:
|
| 76 |
+
queries: A list of strings, each representing a query.
|
| 77 |
+
dimension: The desired dimension of the output embeddings.
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
A tensor of shape (num_queries, dimension) containing the encoded queries.
|
| 81 |
+
"""
|
| 82 |
+
|
| 83 |
+
dummy_image = Image.new('RGB', (56, 56))
|
| 84 |
+
inputs = processor(
|
| 85 |
+
text=[query_prompt % x for x in queries],
|
| 86 |
+
images=[dummy_image for _ in queries],
|
| 87 |
+
videos=None,
|
| 88 |
+
padding='longest',
|
| 89 |
+
return_tensors='pt'
|
| 90 |
+
).to('cuda:0')
|
| 91 |
+
|
| 92 |
+
cache_position = torch.arange(0, len(queries))
|
| 93 |
+
inputs = model.prepare_inputs_for_generation(
|
| 94 |
+
**inputs, cache_position=cache_position, use_cache=False)
|
| 95 |
+
|
| 96 |
+
with torch.no_grad():
|
| 97 |
+
output = self.model(
|
| 98 |
+
**inputs,
|
| 99 |
+
return_dict=True,
|
| 100 |
+
output_hidden_states=True
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
embeddings = output.hidden_states[-1][:, -1]
|
| 104 |
+
return torch.nn.functional.normalize(embeddings[:, :dimension], p=2, dim=-1)
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
**Encode documents**
|
| 108 |
+
```python
|
| 109 |
+
def round_by_factor(number: float, factor: int) -> int:
|
| 110 |
+
return round(number / factor) * factor
|
| 111 |
+
|
| 112 |
+
def ceil_by_factor(number: float, factor: int) -> int:
|
| 113 |
+
return math.ceil(number / factor) * factor
|
| 114 |
+
|
| 115 |
+
def floor_by_factor(number: float, factor: int) -> int:
|
| 116 |
+
return math.floor(number / factor) * factor
|
| 117 |
+
|
| 118 |
+
def smart_resize(height: int, width: int) -> tuple[int, int]:
|
| 119 |
+
h_bar = max(28, round_by_factor(height, 28))
|
| 120 |
+
w_bar = max(28, round_by_factor(width, 28))
|
| 121 |
+
if h_bar * w_bar > max_pixels:
|
| 122 |
+
beta = math.sqrt((height * width) / max_pixels)
|
| 123 |
+
h_bar = floor_by_factor(height / beta, 28)
|
| 124 |
+
w_bar = floor_by_factor(width / beta, 28)
|
| 125 |
+
elif h_bar * w_bar < min_pixels:
|
| 126 |
+
beta = math.sqrt(min_pixels / (height * width))
|
| 127 |
+
h_bar = ceil_by_factor(height * beta, 28)
|
| 128 |
+
w_bar = ceil_by_factor(width * beta, 28)
|
| 129 |
+
return w_bar, h_bar
|
| 130 |
+
|
| 131 |
+
def resize(image: Image.Image):
|
| 132 |
+
new_size = smart_resize(image.height, image.width)
|
| 133 |
+
return image.resize(new_size)
|
| 134 |
+
|
| 135 |
+
def encode_documents(documents: list[Image.Image], dimension: int):
|
| 136 |
+
"""
|
| 137 |
+
Encode a list of images into a tensor of embeddings.
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
documents: A list of PIL Image objects.
|
| 141 |
+
dimension: The desired dimension of the output embeddings.
|
| 142 |
+
|
| 143 |
+
Returns:
|
| 144 |
+
A tensor of shape (num_documents, dimension) containing the encoded images.
|
| 145 |
+
"""
|
| 146 |
+
|
| 147 |
+
inputs = processor(
|
| 148 |
+
text=[document_prompt] * len(documents),
|
| 149 |
+
images=[resize(x) for x in documents],
|
| 150 |
+
videos=None,
|
| 151 |
+
padding='longest',
|
| 152 |
+
return_tensors='pt'
|
| 153 |
+
).to('cuda:0')
|
| 154 |
+
|
| 155 |
+
cache_position = torch.arange(0, len(queries))
|
| 156 |
+
inputs = model.prepare_inputs_for_generation(
|
| 157 |
+
**inputs, cache_position=cache_position, use_cache=False)
|
| 158 |
+
|
| 159 |
+
with torch.no_grad():
|
| 160 |
+
output = self.model(
|
| 161 |
+
**inputs,
|
| 162 |
+
return_dict=True,
|
| 163 |
+
output_hidden_states=True
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
embeddings = output.hidden_states[-1][:, -1]
|
| 167 |
+
return torch.nn.functional.normalize(embeddings[:, :dimension], p=2, dim=-1)
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
# Training
|
| 171 |
+
|
| 172 |
+
The model is based on [MrLight/dse-qwen2-2b-mrl-v1](https://huggingface.co/MrLight/dse-qwen2-2b-mrl-v1) and it was trained on the new [vdr-multilingual-train](https://huggingface.co/datasets/llamaindex/vdr-multilingual-train) dataset that consinsists of 500k high quality, multilingual query image pairs. It was trained for 1 epoch using the [DSE approach](https://arxiv.org/abs/2406.11251), with a batch size of 128 and hard-mined negatives.
|
| 173 |
+
|
| 174 |
+
# Results
|
| 175 |
+
|
| 176 |
+
The model has been evaluated on the Vidore benchmark and on custom-built evaluation sets that allow testing its multilingual capabilities on text-only, visual-only and mixed page screenshots. The evaluation dataset is publicly available [here on HuggingFace](https://huggingface.co/datasets/llamaindex/vdr-multilingual-test).
|
| 177 |
+
|
| 178 |
+
All evaluations are performed by calculating **NDCG@5** scores using **1536 dimensions** vectors and an image resolution that can be represented with **maximum 768 tokens**.
|
| 179 |
+
|
| 180 |
+
| | Avg | Italian (text) | Italian (visual) | Italian (mix) |
|
| 181 |
+
|---------------------|----------|----------------|------------------|---------------|
|
| 182 |
+
| dse-qwen2-2b-mrl-v1 | 95.1 | 95.1 | 94 | 96.2 |
|
| 183 |
+
| vdr-2b-multi-v1 | **97.0** | **96.4** | **96.3** | **98.4** |
|
| 184 |
+
| | **+2%** | | | |
|
| 185 |
+
|
| 186 |
+
| | Avg | French (text) | French (visual) | French (mix) |
|
| 187 |
+
|---------------------|-----------|---------------|-----------------|--------------|
|
| 188 |
+
| dse-qwen2-2b-mrl-v1 | 93.5 | 94.7 | 90.8 | 95.1 |
|
| 189 |
+
| vdr-2b-multi-v1 | **95.6** | **95.6** | **93.3** | **97.9** |
|
| 190 |
+
| | **+2.2%** | | | |
|
| 191 |
+
|
| 192 |
+
| | Avg | Spanish (text) | Spanish (visual) | Spanish (mix) |
|
| 193 |
+
|---------------------|-----------|----------------|------------------|---------------|
|
| 194 |
+
| dse-qwen2-2b-mrl-v1 | 96.7 | 97.2 | 94.7 | 98.2 |
|
| 195 |
+
| vdr-2b-multi-v1 | **98.1** | **98.3** | **96.9** | **99.1** |
|
| 196 |
+
| | **+1.4%** | | | |
|
| 197 |
+
|
| 198 |
+
| | Avg | German (text) | German (visual) | German (mix) |
|
| 199 |
+
|---------------------|-----------|---------------|-----------------|--------------|
|
| 200 |
+
| dse-qwen2-2b-mrl-v1 | 93.0 | 93.4 | 90 | 95.5 |
|
| 201 |
+
| vdr-2b-multi-v1 | **96.2** | **94.8** | **95.7** | **98.1** |
|
| 202 |
+
| | **+3.4%** | | | |
|
| 203 |
+
|
| 204 |
+
| | Avg | English (text) | English (visual) | English (mix) |
|
| 205 |
+
|---------------------|-----------|----------------|------------------|---------------|
|
| 206 |
+
| dse-qwen2-2b-mrl-v1 | 98.0 | **98.3** | 98.5 | 97.1 |
|
| 207 |
+
| vdr-2b-multi-v1 | **98.1** | 97.9 | **99.1** | **97.3** |
|
| 208 |
+
| | **+0.1%** | | | |
|
| 209 |
+
|
| 210 |
+
| | **Avg** | **shiftproject** | **government** | **healthcare** | **energy** | **ai** | **docvqa** | **arxivqa** | **tatdqa** | **infovqa** | **tabfquad** |
|
| 211 |
+
|--------------------:|---------:|-----------------:|---------------:|---------------:|-----------:|-----------:|-----------:|------------:|-----------:|------------:|-------------:|
|
| 212 |
+
| dse-qwen2-2b-mrl-v1 | 83.6 | 79.8 | **95.7** | **96.9** | **92** | 98.2 | 56.3 | **85.2** | **53.9** | **87.5** | 90.3 |
|
| 213 |
+
| vdr-2b-multi-v1 | **84.0** | **82.4** | 95.5 | 96.5 | 91.2 | **98.5** | **58.5** | 84.7 | 53.6 | 87.1 | **92.2** |
|
added_tokens.json
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|box_end|>": 151649,
|
| 3 |
+
"<|box_start|>": 151648,
|
| 4 |
+
"<|endoftext|>": 151643,
|
| 5 |
+
"<|im_end|>": 151645,
|
| 6 |
+
"<|im_start|>": 151644,
|
| 7 |
+
"<|image_pad|>": 151655,
|
| 8 |
+
"<|object_ref_end|>": 151647,
|
| 9 |
+
"<|object_ref_start|>": 151646,
|
| 10 |
+
"<|quad_end|>": 151651,
|
| 11 |
+
"<|quad_start|>": 151650,
|
| 12 |
+
"<|video_pad|>": 151656,
|
| 13 |
+
"<|vision_end|>": 151653,
|
| 14 |
+
"<|vision_pad|>": 151654,
|
| 15 |
+
"<|vision_start|>": 151652
|
| 16 |
+
}
|
chat_template.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_template": "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{% for message in messages %}{% if loop.first and message['role'] != 'system' %}<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n{% endif %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}<|im_end|>\n{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}<|im_end|>\n{% endif %}{% endfor %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}"
|
| 3 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "MrLight/dse-qwen2-2b-mrl-v1",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2VLForConditionalGeneration"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151645,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 1536,
|
| 11 |
+
"image_token_id": 151655,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 8960,
|
| 14 |
+
"max_position_embeddings": 32768,
|
| 15 |
+
"max_window_layers": 28,
|
| 16 |
+
"model_type": "qwen2_vl",
|
| 17 |
+
"num_attention_heads": 12,
|
| 18 |
+
"num_hidden_layers": 28,
|
| 19 |
+
"num_key_value_heads": 2,
|
| 20 |
+
"rms_norm_eps": 1e-06,
|
| 21 |
+
"rope_scaling": {
|
| 22 |
+
"mrope_section": [
|
| 23 |
+
16,
|
| 24 |
+
24,
|
| 25 |
+
24
|
| 26 |
+
],
|
| 27 |
+
"rope_type": "default",
|
| 28 |
+
"type": "default"
|
| 29 |
+
},
|
| 30 |
+
"rope_theta": 1000000.0,
|
| 31 |
+
"sliding_window": 32768,
|
| 32 |
+
"tie_word_embeddings": true,
|
| 33 |
+
"torch_dtype": "bfloat16",
|
| 34 |
+
"transformers_version": "4.47.1",
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"use_sliding_window": false,
|
| 37 |
+
"video_token_id": 151656,
|
| 38 |
+
"vision_config": {
|
| 39 |
+
"hidden_size": 1536,
|
| 40 |
+
"in_chans": 3,
|
| 41 |
+
"model_type": "qwen2_vl",
|
| 42 |
+
"spatial_patch_size": 14
|
| 43 |
+
},
|
| 44 |
+
"vision_end_token_id": 151653,
|
| 45 |
+
"vision_start_token_id": 151652,
|
| 46 |
+
"vision_token_id": 151654,
|
| 47 |
+
"vocab_size": 151936
|
| 48 |
+
}
|
cover.png
ADDED
|
generation_config.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"attn_implementation": "flash_attention_2",
|
| 3 |
+
"bos_token_id": 151643,
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": [
|
| 6 |
+
151645,
|
| 7 |
+
151643
|
| 8 |
+
],
|
| 9 |
+
"pad_token_id": 151643,
|
| 10 |
+
"temperature": 0.01,
|
| 11 |
+
"top_k": 1,
|
| 12 |
+
"top_p": 0.001,
|
| 13 |
+
"transformers_version": "4.47.1"
|
| 14 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f44d6a049be8cfa671c99e936d8cdcd6878f5db3ccf998aca6423abdd31604cd
|
| 3 |
+
size 4418050848
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"do_convert_rgb": true,
|
| 3 |
+
"do_normalize": true,
|
| 4 |
+
"do_rescale": true,
|
| 5 |
+
"do_resize": true,
|
| 6 |
+
"image_mean": [
|
| 7 |
+
0.48145466,
|
| 8 |
+
0.4578275,
|
| 9 |
+
0.40821073
|
| 10 |
+
],
|
| 11 |
+
"image_processor_type": "Qwen2VLImageProcessor",
|
| 12 |
+
"image_std": [
|
| 13 |
+
0.26862954,
|
| 14 |
+
0.26130258,
|
| 15 |
+
0.27577711
|
| 16 |
+
],
|
| 17 |
+
"max_pixels": 602112,
|
| 18 |
+
"merge_size": 2,
|
| 19 |
+
"min_pixels": 784,
|
| 20 |
+
"patch_size": 14,
|
| 21 |
+
"processor_class": "Qwen2VLProcessor",
|
| 22 |
+
"resample": 3,
|
| 23 |
+
"rescale_factor": 0.00392156862745098,
|
| 24 |
+
"size": {
|
| 25 |
+
"max_pixels": 12845056,
|
| 26 |
+
"min_pixels": 3136
|
| 27 |
+
},
|
| 28 |
+
"temporal_patch_size": 2
|
| 29 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:091aa7594dc2fcfbfa06b9e3c22a5f0562ac14f30375c13af7309407a0e67b8a
|
| 3 |
+
size 11420371
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"151646": {
|
| 29 |
+
"content": "<|object_ref_start|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"151647": {
|
| 37 |
+
"content": "<|object_ref_end|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"151648": {
|
| 45 |
+
"content": "<|box_start|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"151649": {
|
| 53 |
+
"content": "<|box_end|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"151650": {
|
| 61 |
+
"content": "<|quad_start|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"151651": {
|
| 69 |
+
"content": "<|quad_end|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"151652": {
|
| 77 |
+
"content": "<|vision_start|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"151653": {
|
| 85 |
+
"content": "<|vision_end|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"151654": {
|
| 93 |
+
"content": "<|vision_pad|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"151655": {
|
| 101 |
+
"content": "<|image_pad|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"151656": {
|
| 109 |
+
"content": "<|video_pad|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
}
|
| 116 |
+
},
|
| 117 |
+
"additional_special_tokens": [
|
| 118 |
+
"<|im_start|>",
|
| 119 |
+
"<|im_end|>",
|
| 120 |
+
"<|object_ref_start|>",
|
| 121 |
+
"<|object_ref_end|>",
|
| 122 |
+
"<|box_start|>",
|
| 123 |
+
"<|box_end|>",
|
| 124 |
+
"<|quad_start|>",
|
| 125 |
+
"<|quad_end|>",
|
| 126 |
+
"<|vision_start|>",
|
| 127 |
+
"<|vision_end|>",
|
| 128 |
+
"<|vision_pad|>",
|
| 129 |
+
"<|image_pad|>",
|
| 130 |
+
"<|video_pad|>"
|
| 131 |
+
],
|
| 132 |
+
"bos_token": null,
|
| 133 |
+
"chat_template": "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{% for message in messages %}{% if loop.first and message['role'] != 'system' %}<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n{% endif %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}<|im_end|>\n{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}<|im_end|>\n{% endif %}{% endfor %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}",
|
| 134 |
+
"clean_up_tokenization_spaces": false,
|
| 135 |
+
"eos_token": "<|im_end|>",
|
| 136 |
+
"errors": "replace",
|
| 137 |
+
"extra_special_tokens": {},
|
| 138 |
+
"max_pixels": 602112,
|
| 139 |
+
"min_pixels": 784,
|
| 140 |
+
"model_max_length": 32768,
|
| 141 |
+
"pad_token": "<|endoftext|>",
|
| 142 |
+
"padding_side": "left",
|
| 143 |
+
"processor_class": "Qwen2VLProcessor",
|
| 144 |
+
"split_special_tokens": false,
|
| 145 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 146 |
+
"unk_token": null
|
| 147 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|