
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,32 +1,36 @@
|
|
| 1 |
-
|
| 2 |
-
tags:
|
| 3 |
-
- generated_from_trainer
|
| 4 |
-
model-index:
|
| 5 |
-
- name: home/suika/bin/axolotl/OUT-perscengen/
|
| 6 |
-
results: []
|
| 7 |
-
---
|
| 8 |
|
| 9 |
-
|
| 10 |
-
|
|
|
|
| 11 |
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
| 14 |
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
|
| 19 |
-
|
|
|
|
|
|
|
| 20 |
|
| 21 |
-
|
|
|
|
| 22 |
|
| 23 |
-
|
| 24 |
|
| 25 |
-
|
|
|
|
| 26 |
|
| 27 |
-
##
|
| 28 |
-
|
| 29 |
-
|
|
|
|
|
|
|
|
|
|
| 30 |
|
| 31 |
## Training procedure
|
| 32 |
|
|
|
|
| 1 |
+
# LimaRP Persona-Scenario Generator (v5, Alpaca)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
|
| 3 |
+
A previously unpublished LoRA adapter for [Yarn-Llama-2-7B-64k](https://huggingface.co/NousResearch/Yarn-Llama-2-7b-64k) made
|
| 4 |
+
for internal use. Its primary purpose is generating Persona and Scenario (summary) from LimaRP `yaml` source data.
|
| 5 |
+
To some extent it can work with different text types, however.
|
| 6 |
|
| 7 |
+
## Prompt format
|
| 8 |
+
```
|
| 9 |
+
### Input:
|
| 10 |
+
{Your text here}
|
| 11 |
|
| 12 |
+
### Response:
|
| 13 |
+
Charactername's Persona: {output goes here}
|
| 14 |
+
```
|
| 15 |
|
| 16 |
+
Replace `Charactername` with the name of the character you want to infer a Persona for.
|
| 17 |
+
By default this LoRA looks for the placeholder names `<FIRST>` and `<SECOND>` (in this
|
| 18 |
+
respective order) but it can work with proper names as well.
|
| 19 |
|
| 20 |
+
## Example
|
| 21 |
+
This image shows what would happen (red box) after adding data in the format shown in the left pane.
|
| 22 |
|
| 23 |
+
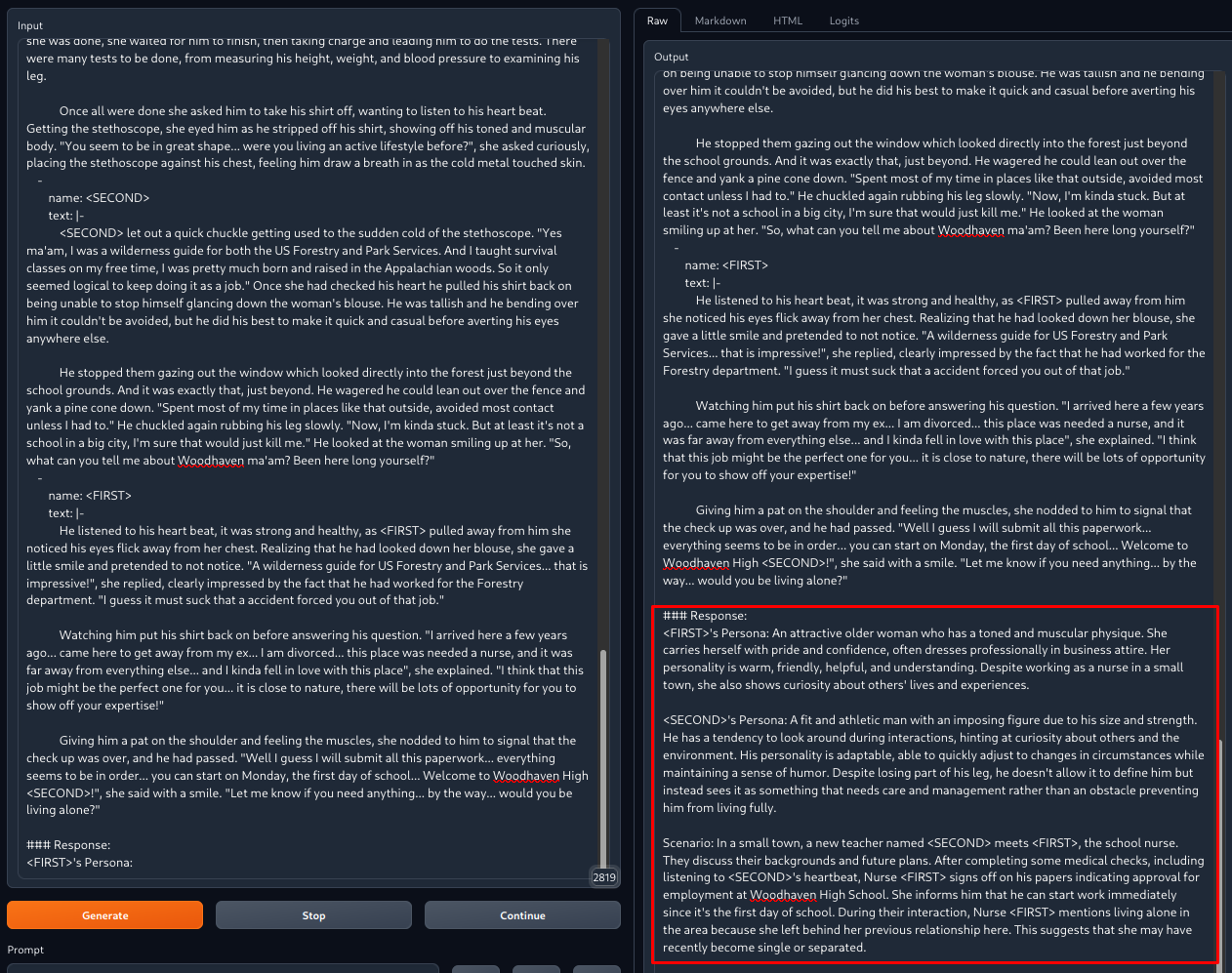
|
| 24 |
|
| 25 |
+
In practice the results would be double-checked and manually tweaked to diversify the
|
| 26 |
+
outputs and adding character quirks, peculiarities or traits that the model couldn't catch.
|
| 27 |
|
| 28 |
+
## Known issues
|
| 29 |
+
- While the scenario/summary is often remarkably accurate, personas don't show a very high accuracy and can be repetitive.
|
| 30 |
+
- Persona and Scenario may exhibit `gpt`-isms.
|
| 31 |
+
- Peculiar character quirks may not be observed by the model.
|
| 32 |
+
- The LoRA hasn't been extensively tested with different input formats.
|
| 33 |
+
- This LoRA hasn't been updated in a good while.
|
| 34 |
|
| 35 |
## Training procedure
|
| 36 |
|