
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,128 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
# LimaRP-Mistral-7B-v0.1 (Alpaca, 8-bit LoRA adapter)
|
| 6 |
+
|
| 7 |
+
This is an experimental version of LimaRP for [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) with
|
| 8 |
+
about 1800 training samples _up to_ 4k tokens length. Contrarily to the previously released "v3" version for Llama-2, this one does
|
| 9 |
+
not include a preliminary finetuning pass on several thousands story. Initial testing has shown Mistral to be capable of
|
| 10 |
+
generating on its own the kind of stories that were included there
|
| 11 |
+
|
| 12 |
+
Due to software limitations, finetuning didn't take advantage yet of the Sliding Window Attention (SWA) which would have allowed
|
| 13 |
+
to use longer conversations in the training data. Thus, this version of LimaRP could be considered an initial attempt.
|
| 14 |
+
|
| 15 |
+
For more details about LimaRP, see the model page for the [previously released version for Llama-2](https://huggingface.co/lemonilia/limarp-llama2-v2).
|
| 16 |
+
Most details written there apply for this version as well. Generally speaking, LimaRP is a longform-oriented, novel-style
|
| 17 |
+
roleplaying chat model intended to replicate the experience of 1-on-1 roleplay on Internet forums. Short-form,
|
| 18 |
+
IRC/Discord-style RP (aka "Markdown format") is not supported yet. The model does not include instruction tuning,
|
| 19 |
+
only conversations with persona and scenario data.
|
| 20 |
+
|
| 21 |
+
## Important notes on generation settings
|
| 22 |
+
It's recommended not to go overboard with low tail-free-sampling (TFS) values. From previous testing with Llama-2,
|
| 23 |
+
decreasing it too much appeared to easily yield rather repetitive responses. Extensive testing with Mistral has not
|
| 24 |
+
been performed yet, but suggested starting generation settings are:
|
| 25 |
+
|
| 26 |
+
- TFS = 0.92~0.95
|
| 27 |
+
- Temperature = 0.70~0.85
|
| 28 |
+
- Repetition penalty = 1.05~1.10
|
| 29 |
+
- top-k = 0 (disabled)
|
| 30 |
+
- top-p = 1 (disabled)
|
| 31 |
+
|
| 32 |
+
## Prompt format
|
| 33 |
+
Same as before. It uses the [extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
|
| 34 |
+
with `### Input:` immediately preceding user inputs and `### Response:` immediately preceding
|
| 35 |
+
model outputs. While Alpaca wasn't originally intended for multi-turn responses, in practice this
|
| 36 |
+
is not a problem; the format follows a pattern already used by other models.
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
### Instruction:
|
| 40 |
+
Character's Persona: {bot character description}
|
| 41 |
+
|
| 42 |
+
User's Persona: {user character description}
|
| 43 |
+
|
| 44 |
+
Scenario: {what happens in the story}
|
| 45 |
+
|
| 46 |
+
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
|
| 47 |
+
|
| 48 |
+
### Input:
|
| 49 |
+
User: {utterance}
|
| 50 |
+
|
| 51 |
+
### Response:
|
| 52 |
+
Character: {utterance}
|
| 53 |
+
|
| 54 |
+
### Input
|
| 55 |
+
User: {utterance}
|
| 56 |
+
|
| 57 |
+
### Response:
|
| 58 |
+
Character: {utterance}
|
| 59 |
+
|
| 60 |
+
(etc.)
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
You should:
|
| 64 |
+
- Replace all text in curly braces (curly braces included) with your own text.
|
| 65 |
+
- Replace `User` and `Character` with appropriate names.
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
### Message length control
|
| 69 |
+
Inspired by the previously named "Roleplay" preset in SillyTavern, starting from this
|
| 70 |
+
version of LimaRP it is possible to append a length modifier to the response instruction
|
| 71 |
+
sequence, like this:
|
| 72 |
+
|
| 73 |
+
```
|
| 74 |
+
### Input
|
| 75 |
+
User: {utterance}
|
| 76 |
+
|
| 77 |
+
### Response: (length = medium)
|
| 78 |
+
Character: {utterance}
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
This has an immediately noticeable effect on bot responses. The available lengths are:
|
| 82 |
+
`tiny`, `short`, `medium`, `long`, `huge`, `humongous`, `extreme`, `unlimited`. **The
|
| 83 |
+
recommended starting length is `medium`**. Keep in mind that the AI may ramble
|
| 84 |
+
or impersonate the user with very long messages.
|
| 85 |
+
|
| 86 |
+
The length control effect is reproducible, but the messages will not necessarily follow
|
| 87 |
+
lengths very precisely, rather follow certain ranges on average, as seen in this table
|
| 88 |
+
with data from tests made with one reply at the beginning of the conversation:
|
| 89 |
+
|
| 90 |
+
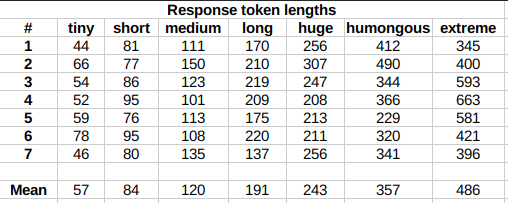
|
| 91 |
+
|
| 92 |
+
Response length control appears to work well also deep into the conversation.
|
| 93 |
+
|
| 94 |
+
## Suggested settings
|
| 95 |
+
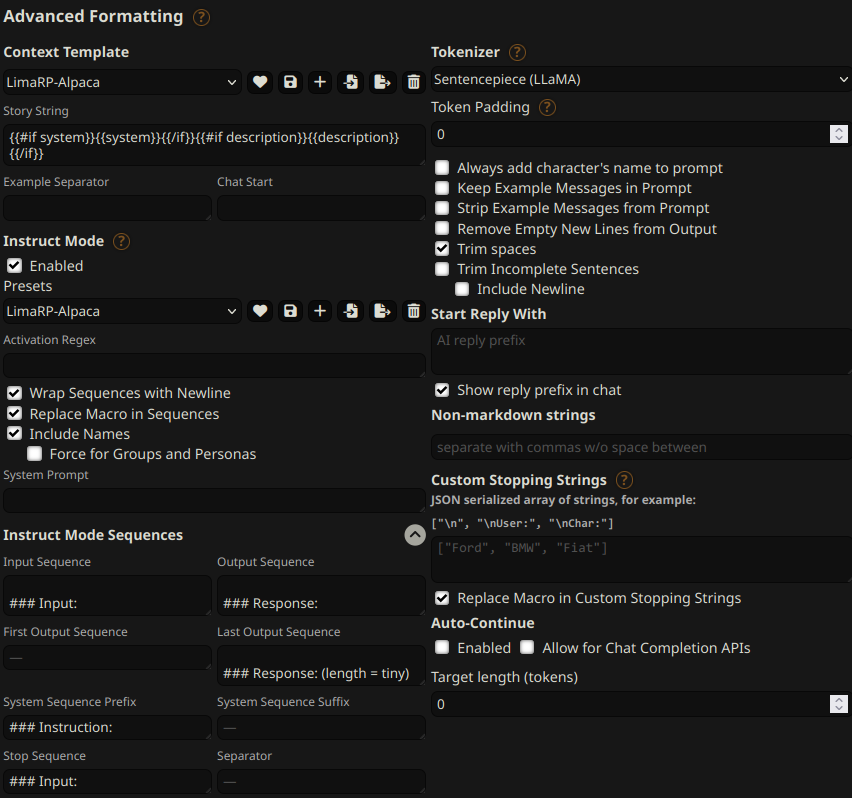
You can follow these instruction format settings in SillyTavern. Replace `tiny` with
|
| 96 |
+
your desired response length:
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
## Training procedure
|
| 101 |
+
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
|
| 102 |
+
on a 2x NVidia A40 GPU cluster.
|
| 103 |
+
|
| 104 |
+
The A40 GPU cluster has been graciously provided by [Arc Compute](https://www.arccompute.io/).
|
| 105 |
+
|
| 106 |
+
The model has been trained as an 8-bit LoRA adapter, and
|
| 107 |
+
it's so large because a LoRA rank of 256 was also used. The reasoning was that this
|
| 108 |
+
might have helped the model internalize any newly acquired information, making the
|
| 109 |
+
training process closer to a full finetune. It's suggested to merge the adapter to
|
| 110 |
+
the base Mistral-7B-v0.1 model.
|
| 111 |
+
|
| 112 |
+
### Training hyperparameters
|
| 113 |
+
- learning_rate: 0.0010
|
| 114 |
+
- lr_scheduler_type: cosine
|
| 115 |
+
- lora_r: 256
|
| 116 |
+
- lora_alpha: 16
|
| 117 |
+
- lora_dropout: 0.05
|
| 118 |
+
- lora_target_linear: True
|
| 119 |
+
- num_epochs: 2
|
| 120 |
+
- bf16: True
|
| 121 |
+
- tf32: True
|
| 122 |
+
- load_in_8bit: True
|
| 123 |
+
- adapter: lora
|
| 124 |
+
- micro_batch_size: 1
|
| 125 |
+
- gradient_accumulation_steps: 16
|
| 126 |
+
- optimizer: adamw_torch
|
| 127 |
+
|
| 128 |
+
Using 2 GPUs, the effective global batch size would have been 32.
|