

update README
Browse files- .gitattributes +3 -0
- README.md +44 -0
- assets/costs-1.5b.png +3 -0
- assets/costs-7b.png +3 -0
- assets/performances.png +3 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/costs-1.5b.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/costs-7b.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/performances.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model Summary
|
| 2 |
+
|
| 3 |
+
This repository hosts model for the **Open RS** project, accompanying the paper *Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t*. The project explores enhancing reasoning capabilities in small large language models (LLMs) using reinforcement learning (RL) under resource-constrained conditions.
|
| 4 |
+
|
| 5 |
+
We focus on a 1.5-billion-parameter model, `DeepSeek-R1-Distill-Qwen-1.5B`, trained on 4 NVIDIA A40 GPUs (48 GB VRAM each) within 24 hours. By adapting the Group Relative Policy Optimization (GRPO) algorithm and leveraging a curated, compact mathematical reasoning dataset, we conducted three experiments to assess performance and behavior. Key findings include:
|
| 6 |
+
|
| 7 |
+
- Significant reasoning improvements, e.g., AMC23 accuracy rising from 63% to 80% and AIME24 reaching 46.7%, outperforming `o1-preview`.
|
| 8 |
+
- Efficient training with just 7,000 samples at a cost of $42, compared to thousands of dollars for baseline models.
|
| 9 |
+
- Challenges like optimization instability and length constraints with extended training.
|
| 10 |
+
|
| 11 |
+
These results showcase RL-based fine-tuning as a cost-effective approach for small LLMs, making reasoning capabilities accessible in resource-limited settings. We open-source our code, models, and datasets to support further research.
|
| 12 |
+
|
| 13 |
+
For more details, please refer our [github](https://github.com/knoveleng/open-rs).
|
| 14 |
+
|
| 15 |
+
## Evaluation
|
| 16 |
+
### Performance Highlights
|
| 17 |
+
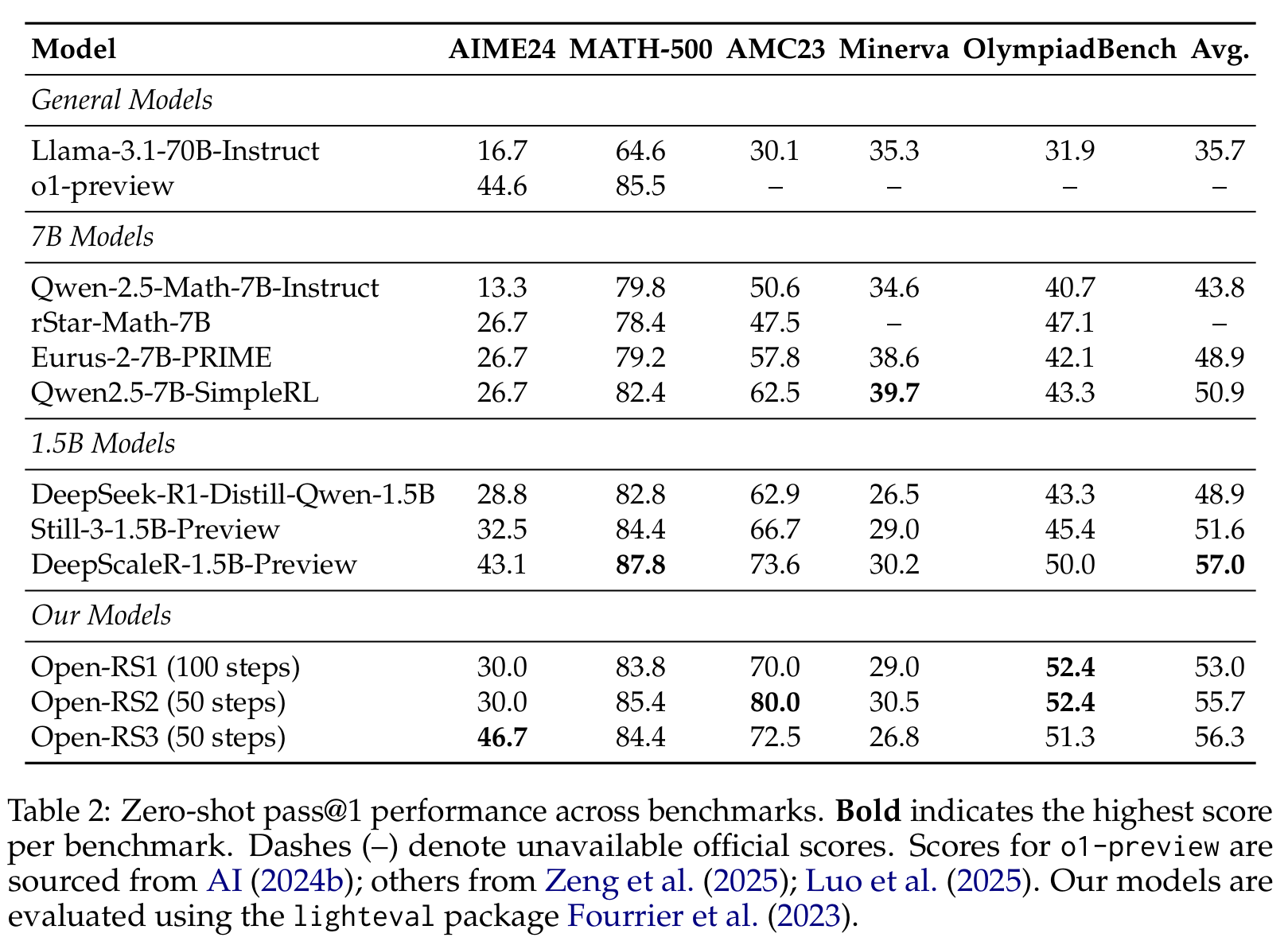
- **Open-RS1**: 53.0% avg. score
|
| 18 |
+
- **Open-RS2**: 55.7% avg. score, 80.0% on AMC23
|
| 19 |
+
- **Open-RS3**: 56.3% avg. score, 46.7% on AIME24 (outperforms `o1-preview` at 44.6%)
|
| 20 |
+
- Competitive MATH-500 scores; Minerva lags behind 7B models.
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
### Cost Efficiency
|
| 25 |
+
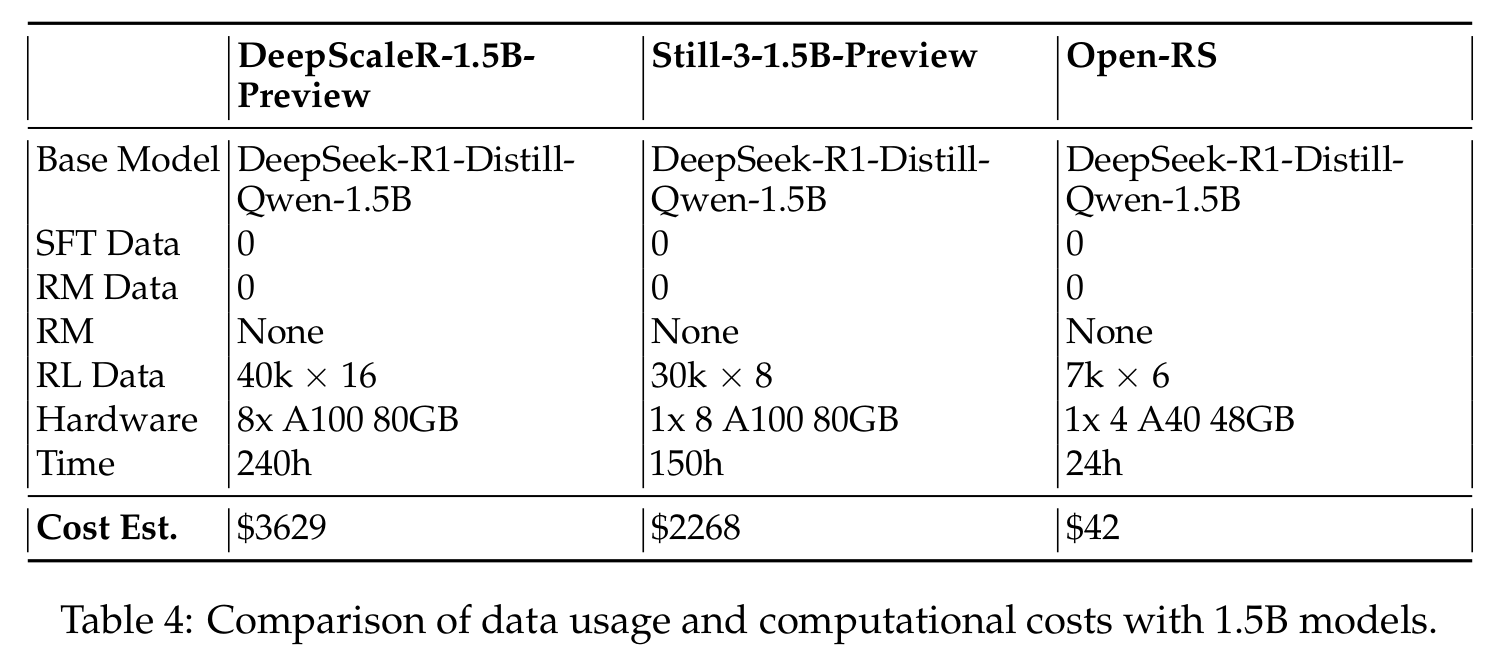
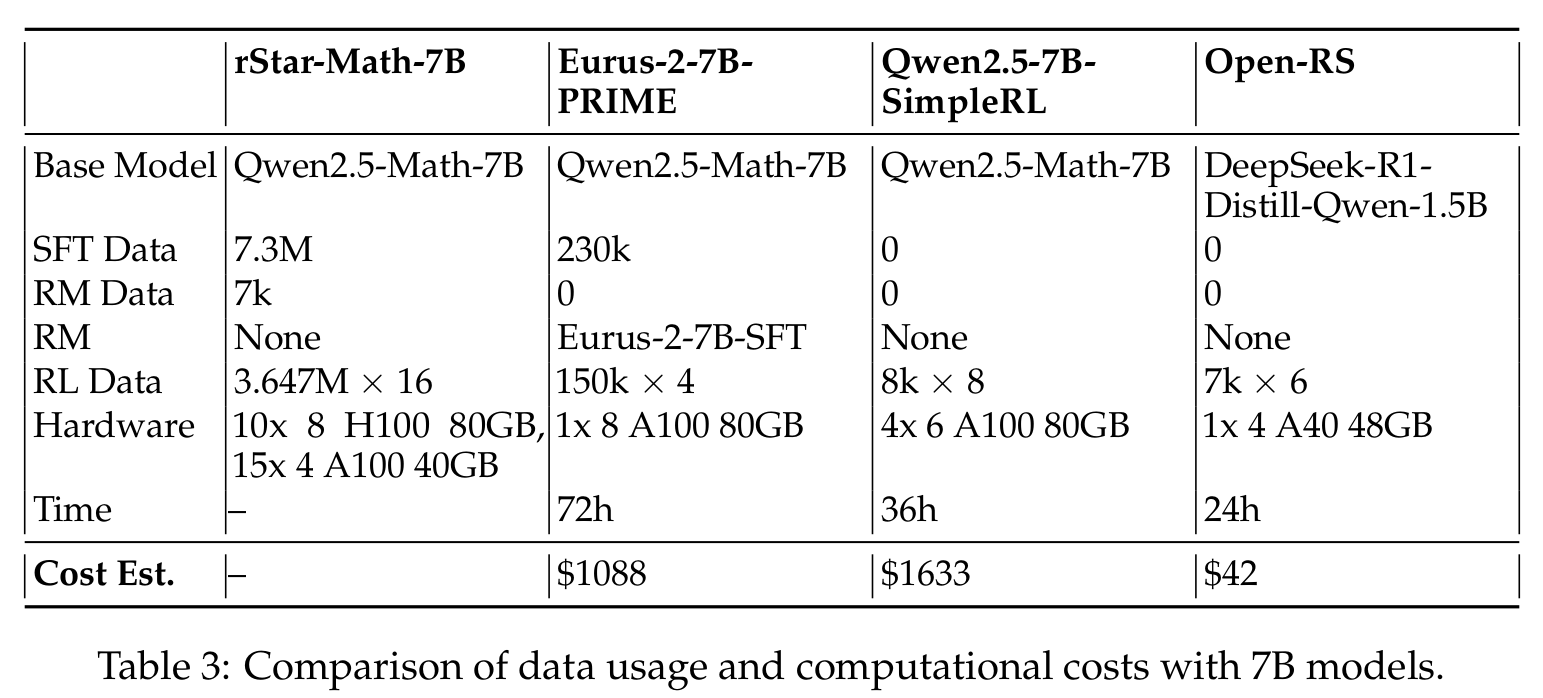
Our approach uses 7,000 samples (42,000 total outputs) and costs ~$42 on 4x A40 GPUs in 24 hours, compared to:
|
| 26 |
+
- 7B models: `Qwen2.5-7B-SimpleRL` ($1,633), `Eurus-2-7B-PRIME` ($1,088)
|
| 27 |
+
- 1.5B models: `DeepScaleR-1.5B-Preview` ($3,629), `Still-3-1.5B-Preview` ($2,268)
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+

|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
## Citation
|
| 34 |
+
If this project aids your work, please cite it as:
|
| 35 |
+
```
|
| 36 |
+
@misc{open-rs,
|
| 37 |
+
title = {Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't},
|
| 38 |
+
url = {https://github.com/knoveleng/open-rs},
|
| 39 |
+
author = {Quy-Anh Dang, Chris Ngo},
|
| 40 |
+
month = {March},
|
| 41 |
+
year = {2025}
|
| 42 |
+
}
|
| 43 |
+
```
|
| 44 |
+
|
assets/costs-1.5b.png
ADDED
|
Git LFS Details
|
assets/costs-7b.png
ADDED
|
Git LFS Details
|
assets/performances.png
ADDED
|
Git LFS Details
|