---
license: apache-2.0
base_model:
- Qwen/Qwen3-32B
library_name: transformers
---
| | |
|-|-|
| [](https://github.com/inclusionAI/AWorld/tree/main/train) | [](https://arxiv.org/abs/2508.20404) |
# Qwen3-32B-AWorld
## Model Description
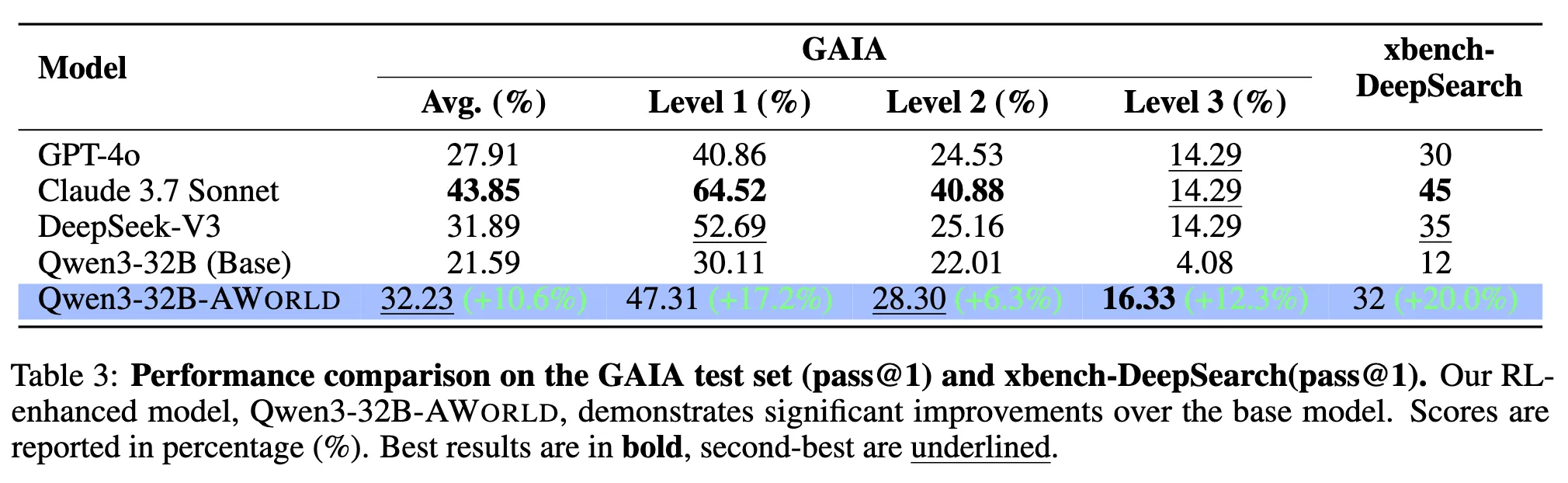
**Qwen3-32B-AWorld** is a large language model fine-tuned from `Qwen3-32B`, specializing in agent capabilities and proficient tool usage. The model excels at complex agent-based tasks through precise integration with external tools, achieving a pass@1 score on the GAIA benchmark that surpasses GPT-4o and is comparable to DeepSeek-V3.
 ## Quick Start
This guide provides instructions for quickly deploying and running inference with `Qwen3-32B-AWorld` using vLLM.
### Deployment with vLLM
To deploy the model, use the following `vllm serve` command:
```bash
vllm serve inclusionAI/Qwen3-32B-AWorld \
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' \
--max-model-len 131072 \
--gpu-memory-utilization 0.85 \
--dtype bfloat16 \
--tensor-parallel-size 8 \
--enable-auto-tool-choice \
--tool-call-parser hermes
```
**Key Configuration:**
* **Deployment Recommendation:** We recommend deploying the model on **8 GPUs** to enhance concurrency. The `tensor-parallel-size` argument should be set to the number of GPUs you are using (e.g., `8` in the command above).
* **Tool Usage Flags:** To enable the model's tool-calling capabilities, it is crucial to include the `--enable-auto-tool-choice` and `--tool-call-parser hermes` flags. These ensure that the model can correctly process tool calls and parse the results.
### Making Inference Calls
When making an inference request, you must include the `tools` you want the model to use. The format should follow the official OpenAI API specification.
Here is a complete Python example for making an API call to the deployed model using the requests library. This example demonstrates how to query the model with a specific tool.
```python
import requests
import json
# Define the tools available for the model to use
tools = [
{
"type": "function",
"function": {
"name": "mcp__google-search__search",
"description": "Perform a web search query",
"parameters": {
"type": "object",
"properties": {
"query": {
"description": "Search query",
"type": "string"
},
"num": {
"description": "Number of results (1-10)",
"type": "number"
}
},
"required": [
"query"
]
}
}
}
]
# Define the user's prompt
messages = [
{
"role": "user",
"content": "Search for hangzhou's weather today."
}
]
# Set generation parameters
temperature = 0.6
top_p = 0.95
top_k = 20
min_p = 0
# Prepare the request payload
data = {
"messages": messages,
"tools": tools,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"min_p": min_p,
}
# The endpoint for the vLLM OpenAI-compatible server
# Replace {your_ip} and {your_port} with the actual IP address and port of your server.
url = "http://{your_ip}:{your_port}/v1/chat/completions"
# Send the POST request
response = requests.post(
url,
headers={"Content-Type": "application/json"},
data=json.dumps(data)
)
# Print the response from the server
print("Status Code:", response.status_code)
print("Response Body:", response.text)
```
**Note:**
* Remember to replace `{your_ip}` and `{your_port}` in the `url` variable with the actual IP address and port where your vLLM server is running. The default port is typically `8000`.
## Quick Start
This guide provides instructions for quickly deploying and running inference with `Qwen3-32B-AWorld` using vLLM.
### Deployment with vLLM
To deploy the model, use the following `vllm serve` command:
```bash
vllm serve inclusionAI/Qwen3-32B-AWorld \
--rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' \
--max-model-len 131072 \
--gpu-memory-utilization 0.85 \
--dtype bfloat16 \
--tensor-parallel-size 8 \
--enable-auto-tool-choice \
--tool-call-parser hermes
```
**Key Configuration:**
* **Deployment Recommendation:** We recommend deploying the model on **8 GPUs** to enhance concurrency. The `tensor-parallel-size` argument should be set to the number of GPUs you are using (e.g., `8` in the command above).
* **Tool Usage Flags:** To enable the model's tool-calling capabilities, it is crucial to include the `--enable-auto-tool-choice` and `--tool-call-parser hermes` flags. These ensure that the model can correctly process tool calls and parse the results.
### Making Inference Calls
When making an inference request, you must include the `tools` you want the model to use. The format should follow the official OpenAI API specification.
Here is a complete Python example for making an API call to the deployed model using the requests library. This example demonstrates how to query the model with a specific tool.
```python
import requests
import json
# Define the tools available for the model to use
tools = [
{
"type": "function",
"function": {
"name": "mcp__google-search__search",
"description": "Perform a web search query",
"parameters": {
"type": "object",
"properties": {
"query": {
"description": "Search query",
"type": "string"
},
"num": {
"description": "Number of results (1-10)",
"type": "number"
}
},
"required": [
"query"
]
}
}
}
]
# Define the user's prompt
messages = [
{
"role": "user",
"content": "Search for hangzhou's weather today."
}
]
# Set generation parameters
temperature = 0.6
top_p = 0.95
top_k = 20
min_p = 0
# Prepare the request payload
data = {
"messages": messages,
"tools": tools,
"temperature": temperature,
"top_p": top_p,
"top_k": top_k,
"min_p": min_p,
}
# The endpoint for the vLLM OpenAI-compatible server
# Replace {your_ip} and {your_port} with the actual IP address and port of your server.
url = "http://{your_ip}:{your_port}/v1/chat/completions"
# Send the POST request
response = requests.post(
url,
headers={"Content-Type": "application/json"},
data=json.dumps(data)
)
# Print the response from the server
print("Status Code:", response.status_code)
print("Response Body:", response.text)
```
**Note:**
* Remember to replace `{your_ip}` and `{your_port}` in the `url` variable with the actual IP address and port where your vLLM server is running. The default port is typically `8000`.