

Add `notebook.ipynb` demo to the HF model repo 🤗
Browse filesHey hey - VB from Hugging Face, congratulations on the release. I've opened this quick PR to add a `notebook.ipynb` which allows users to directly open your demo notebook from the model repo. Let me know if you have any questions.
Cheers!
VB
- notebook.ipynb +629 -0
notebook.ipynb
ADDED
|
@@ -0,0 +1,629 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"metadata": {
|
| 5 |
+
"id": "9HcmLuWtE213"
|
| 6 |
+
},
|
| 7 |
+
"cell_type": "markdown",
|
| 8 |
+
"source": [
|
| 9 |
+
"# Magenta RT: Streaming music generation!\n",
|
| 10 |
+
"\n",
|
| 11 |
+
"Note: Go to `Runtime` -> `Change Runtime type` -> Select `v2-8 TPU` 🤗\n",
|
| 12 |
+
"\n",
|
| 13 |
+
"Magenta RealTime is a Python library for streaming music audio generation on\n",
|
| 14 |
+
"your local device. It is the open weights / on device companion to\n",
|
| 15 |
+
"[MusicFX DJ Mode](https://labs.google/fx/tools/music-fx-dj) and the\n",
|
| 16 |
+
"[Lyria RealTime API](https://ai.google.dev/gemini-api/docs/music-generation).\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"- [Blog Post](https://g.co/magenta/rt)\n",
|
| 19 |
+
"- [Repository](https://github.com/magenta/magenta-realtime)\n",
|
| 20 |
+
"- [HuggingFace](https://huggingface.co/google/magenta-realtime)\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"### Generating audio with Magenta RT\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"Magenta RT generates audio in short chunks (2s) given a finite amount of past\n",
|
| 25 |
+
"context (10s). We use crossfading to mitigate boundary artifacts between chunks.\n",
|
| 26 |
+
"More details on our model are coming soon in a technical report!\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"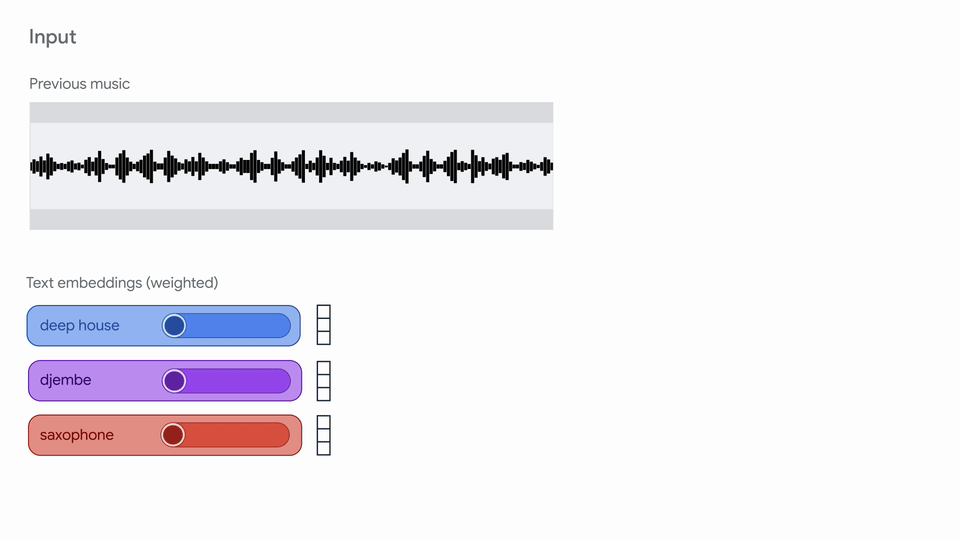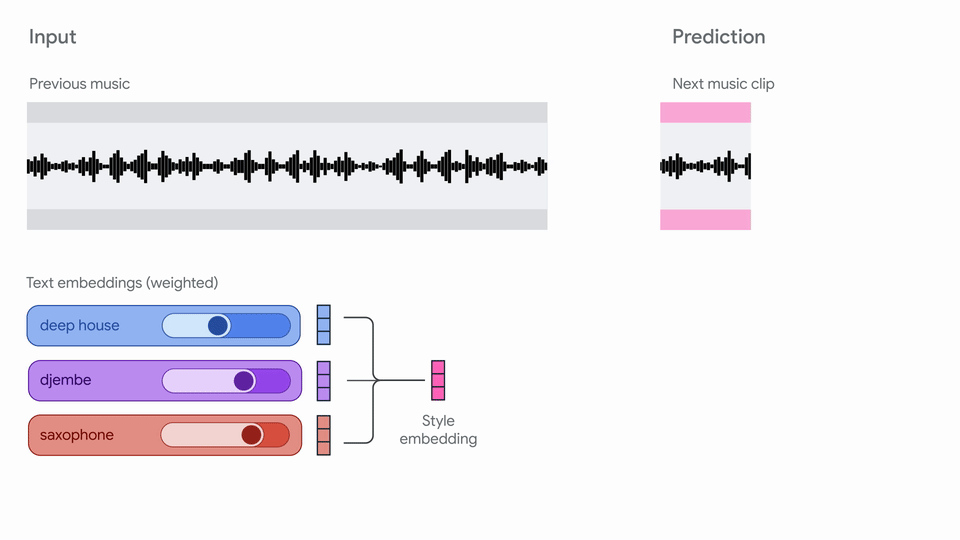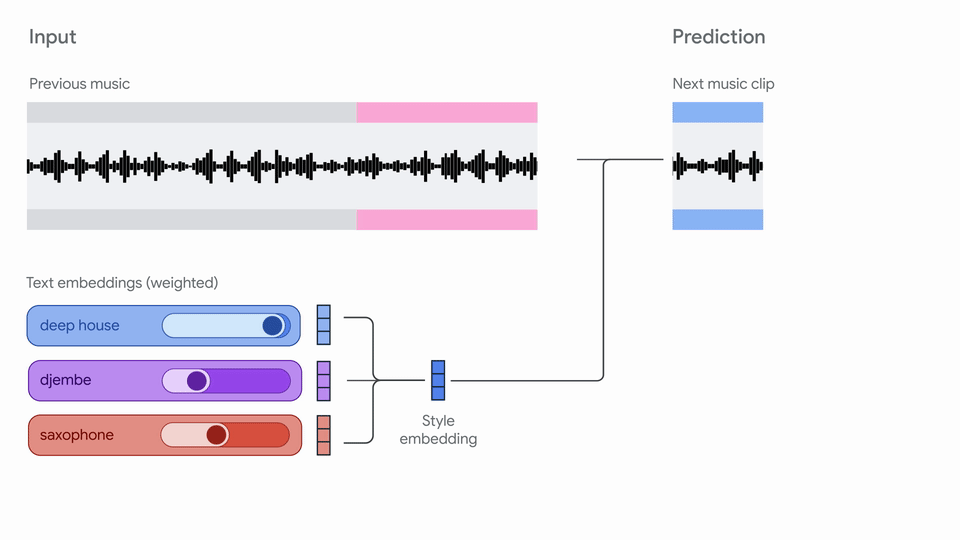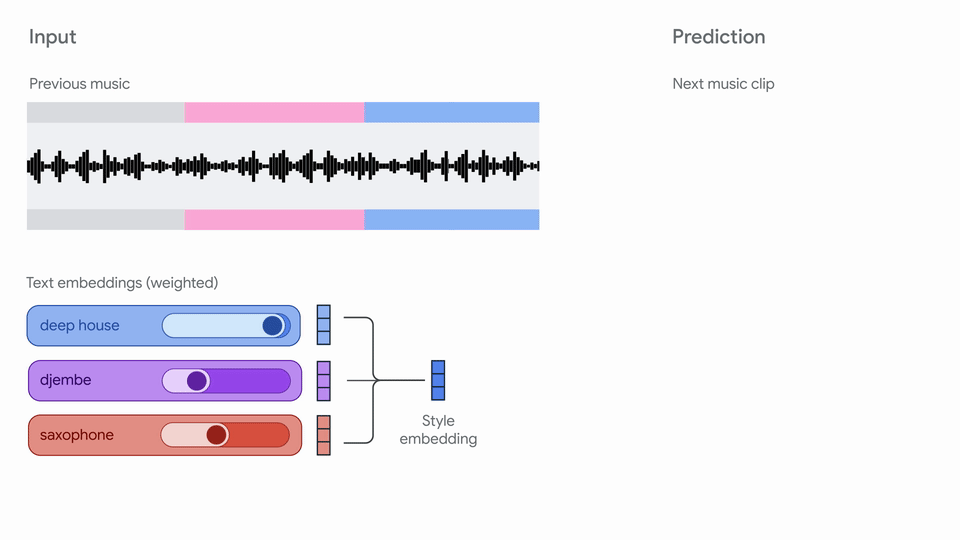"
|
| 29 |
+
]
|
| 30 |
+
},
|
| 31 |
+
{
|
| 32 |
+
"metadata": {
|
| 33 |
+
"id": "1l6sF-r_lISR"
|
| 34 |
+
},
|
| 35 |
+
"cell_type": "markdown",
|
| 36 |
+
"source": [
|
| 37 |
+
"# Step 1: 😴 One-time setup"
|
| 38 |
+
]
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"metadata": {
|
| 42 |
+
"cellView": "form",
|
| 43 |
+
"id": "6XAQy5V3pwzw"
|
| 44 |
+
},
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"source": [
|
| 47 |
+
"# @title **Run this cell** to install dependencies (~5 minutes)\n",
|
| 48 |
+
"# @markdown Make sure you are running on **`v2-8 TPU` runtime** via `Runtime > Change Runtime Type`\n",
|
| 49 |
+
"\n",
|
| 50 |
+
"# @markdown Colab may prompt you to restart session. **Wait until the cell finishes running to restart**!\n",
|
| 51 |
+
"\n",
|
| 52 |
+
"# Clone library\n",
|
| 53 |
+
"!git clone https://github.com/magenta/magenta-realtime.git\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"# Magenta RT requires nightly TF builds, but stable may be installed.\n",
|
| 56 |
+
"# Force nightly to take precedence by uninstalling and reinstalling.\n",
|
| 57 |
+
"# Temporary workaround until MusicCoCa supported by TF stable.\n",
|
| 58 |
+
"_all_tf = 'tensorflow tf-nightly tensorflow-cpu tf-nightly-cpu tensorflow-tpu tf-nightly-tpu tensorflow-hub tf-hub-nightly tensorflow-text tensorflow-text-nightly'\n",
|
| 59 |
+
"_nightly_tf = 'tf-nightly tensorflow-text-nightly tf-hub-nightly'\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"# Install library and dependencies\n",
|
| 62 |
+
"# If running on TPU (recommended, runs on free tier Colab TPUs):\n",
|
| 63 |
+
"!pip install -e magenta-realtime/[tpu] && pip uninstall -y {_all_tf} && pip install {_nightly_tf}\n",
|
| 64 |
+
"# Uncomment if running on GPU (requires A100 via Colab Pro):\n",
|
| 65 |
+
"# !pip install -e magenta-realtime/[gpu] && pip uninstall -y {_all_tf} && pip install {_nightly_tf}"
|
| 66 |
+
],
|
| 67 |
+
"outputs": [],
|
| 68 |
+
"execution_count": null
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"metadata": {
|
| 72 |
+
"cellView": "form",
|
| 73 |
+
"id": "1OI3L16olYQs"
|
| 74 |
+
},
|
| 75 |
+
"cell_type": "code",
|
| 76 |
+
"source": [
|
| 77 |
+
"# @title **Restart session (`Runtime > Restart Session`) and run this cell** to initialize model (~5 minutes)\n",
|
| 78 |
+
"\n",
|
| 79 |
+
"from magenta_rt import system\n",
|
| 80 |
+
"\n",
|
| 81 |
+
"# Fetch checkpoints and initialize model (may take up to 5 minutes)\n",
|
| 82 |
+
"MRT = system.MagentaRT(\n",
|
| 83 |
+
" tag=\"large\", device=\"tpu:v2-8\", skip_cache=True, lazy=False\n",
|
| 84 |
+
")"
|
| 85 |
+
],
|
| 86 |
+
"outputs": [],
|
| 87 |
+
"execution_count": null
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"metadata": {
|
| 91 |
+
"id": "00WPare9QS9O"
|
| 92 |
+
},
|
| 93 |
+
"cell_type": "markdown",
|
| 94 |
+
"source": [
|
| 95 |
+
"# Step 2: 🤘 Streaming music generation! 🎵"
|
| 96 |
+
]
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"metadata": {
|
| 100 |
+
"id": "uWm6bVv1U2f2"
|
| 101 |
+
},
|
| 102 |
+
"cell_type": "markdown",
|
| 103 |
+
"source": [
|
| 104 |
+
"**Run the cell below and click the `start` button to begin streaming!**\n",
|
| 105 |
+
"\n",
|
| 106 |
+
"**Instructions**. Type in text prompts to control the overall style of the generated music in real time. The sliders by the prompts change the influence of each text prompt on the overall output. The other controls change various aspects of the system behavior (expand below for additional information).\n",
|
| 107 |
+
"\n",
|
| 108 |
+
"**Disclaimer**. Magenta RT's training data primarily consists of Western instrumental music. As a consequence, Magenta RT has incomplete coverage of both vocal performance and the broader landscape of rich musical traditions worldwide. For real-time generation with broader style coverage, we refer users to our [Lyria RealTime API](g.co/magenta/lyria-realtime). See our [model card](https://huggingface.co/google/magenta-realtime) for more information.\n",
|
| 109 |
+
"\n",
|
| 110 |
+
"<details>\n",
|
| 111 |
+
" <summary>Click to expand for additional information on the controls</summary>\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"* **buffering_amount_seconds**: Increase this value if you experience audio\n",
|
| 114 |
+
" drops during generation. This will come at the expense of a greater latency,\n",
|
| 115 |
+
" but might help with internet connection issues. *You need to relaunch the\n",
|
| 116 |
+
" cell if you choose to modify this value*.\n",
|
| 117 |
+
"\n",
|
| 118 |
+
"* **sampling options**\n",
|
| 119 |
+
"\n",
|
| 120 |
+
" * **temperature**: This controls how *chaotic* the model behaves. Low\n",
|
| 121 |
+
" temperature values (e.g., 0.9) will make the model's choices more\n",
|
| 122 |
+
" predictable and stable. High values (e.g., 1.5) will encourage more\n",
|
| 123 |
+
" surprising and experimental musical ideas, but can also lead to\n",
|
| 124 |
+
" instability.\n",
|
| 125 |
+
"\n",
|
| 126 |
+
" * **topk**: This parameter filters the model's vocabulary at each step. It\n",
|
| 127 |
+
" forces the model to choose its next prediction only from the *k* most\n",
|
| 128 |
+
" likely options.\n",
|
| 129 |
+
"\n",
|
| 130 |
+
" * A **low `topk`** value (e.g., 40) restricts the model to a smaller,\n",
|
| 131 |
+
" safer palette of options. This leads to more coherent and\n",
|
| 132 |
+
" predictable music that is less likely to have dissonant errors, but\n",
|
| 133 |
+
" can sometimes feel repetitive.\n",
|
| 134 |
+
" * A **high `topk`** value gives the model a much wider range of\n",
|
| 135 |
+
" choices, allowing for more variety and unexpected turns. This can\n",
|
| 136 |
+
" make the output more creative, but also noisier.\n",
|
| 137 |
+
"\n",
|
| 138 |
+
" * **guidance**: This controls how strictly the generated music should\n",
|
| 139 |
+
" adhere to the **text prompts**.\n",
|
| 140 |
+
"\n",
|
| 141 |
+
" * A **higher value** will push the model to produce a textbook example\n",
|
| 142 |
+
" of the chosen style, emphasizing its key characteristics.\n",
|
| 143 |
+
" * A **lower value** will treat the text prompts more as a loose\n",
|
| 144 |
+
" inspiration, allowing the model more creative freedom to deviate and\n",
|
| 145 |
+
" blend other influences.\n",
|
| 146 |
+
"\n",
|
| 147 |
+
"* **Reset**: stop audio, and resets the model.\n",
|
| 148 |
+
"\n",
|
| 149 |
+
"* **Text prompts**: Next to each text prompt is a slider that controls how\n",
|
| 150 |
+
" much each prompt should be affecting the model. This allows the creation of\n",
|
| 151 |
+
" *mixed* embeddings (try mixing synthwave and flamenco guitar together !).\n",
|
| 152 |
+
" You can also type your own prompt and modify existing ones.\n",
|
| 153 |
+
"</details>"
|
| 154 |
+
]
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"metadata": {
|
| 158 |
+
"cellView": "form",
|
| 159 |
+
"id": "4taDDhwf9hvD"
|
| 160 |
+
},
|
| 161 |
+
"cell_type": "code",
|
| 162 |
+
"source": [
|
| 163 |
+
"# @title Run this cell to start demo\n",
|
| 164 |
+
"\n",
|
| 165 |
+
"import concurrent.futures\n",
|
| 166 |
+
"import functools\n",
|
| 167 |
+
"from typing import Any, Sequence\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"import IPython.display as ipd\n",
|
| 170 |
+
"import ipywidgets as ipw\n",
|
| 171 |
+
"import numpy as np\n",
|
| 172 |
+
"\n",
|
| 173 |
+
"from magenta_rt import system\n",
|
| 174 |
+
"from magenta_rt.colab import utils\n",
|
| 175 |
+
"from magenta_rt.colab import widgets\n",
|
| 176 |
+
"\n",
|
| 177 |
+
"buffering_amount_seconds = 0 # @param {\"type\":\"slider\",\"min\":0,\"max\":4,\"step\":0.1}\n",
|
| 178 |
+
"buffering_amount_samples = int(np.ceil(buffering_amount_seconds * 48000))\n",
|
| 179 |
+
"\n",
|
| 180 |
+
"\n",
|
| 181 |
+
"class AudioFade:\n",
|
| 182 |
+
" \"\"\"Handles the cross fade between audio chunks.\n",
|
| 183 |
+
"\n",
|
| 184 |
+
" Args:\n",
|
| 185 |
+
" chunk_size: Number of audio samples per predicted frame (current\n",
|
| 186 |
+
" SpectroStream models produces 25Hz frames corresponding to 1920 audio\n",
|
| 187 |
+
" samples at 48kHz)\n",
|
| 188 |
+
" num_chunks: Number of audio chunks to fade between.\n",
|
| 189 |
+
" stereo: Whether the predicted audio is stereo or mono.\n",
|
| 190 |
+
" \"\"\"\n",
|
| 191 |
+
"\n",
|
| 192 |
+
" def __init__(self, chunk_size: int, num_chunks: int, stereo: bool):\n",
|
| 193 |
+
" fade_size = chunk_size * num_chunks\n",
|
| 194 |
+
" self.fade_size = fade_size\n",
|
| 195 |
+
" self.num_chunks = num_chunks\n",
|
| 196 |
+
"\n",
|
| 197 |
+
" self.previous_chunk = np.zeros(fade_size)\n",
|
| 198 |
+
" self.ramp = np.sin(np.linspace(0, np.pi / 2, fade_size)) ** 2\n",
|
| 199 |
+
"\n",
|
| 200 |
+
" if stereo:\n",
|
| 201 |
+
" self.previous_chunk = self.previous_chunk[:, np.newaxis]\n",
|
| 202 |
+
" self.ramp = self.ramp[:, np.newaxis]\n",
|
| 203 |
+
"\n",
|
| 204 |
+
" def reset(self):\n",
|
| 205 |
+
" self.previous_chunk = np.zeros_like(self.previous_chunk)\n",
|
| 206 |
+
"\n",
|
| 207 |
+
" def __call__(self, chunk: np.ndarray) -> np.ndarray:\n",
|
| 208 |
+
" chunk[: self.fade_size] *= self.ramp\n",
|
| 209 |
+
" chunk[: self.fade_size] += self.previous_chunk\n",
|
| 210 |
+
" self.previous_chunk = chunk[-self.fade_size :] * np.flip(self.ramp)\n",
|
| 211 |
+
" return chunk[: -self.fade_size]\n",
|
| 212 |
+
"\n",
|
| 213 |
+
"\n",
|
| 214 |
+
"class MagentaRTStreamer:\n",
|
| 215 |
+
" \"\"\"Audio streamer class.\n",
|
| 216 |
+
"\n",
|
| 217 |
+
" This class holds a pretrained Magenta RT model, a cross fade state, a\n",
|
| 218 |
+
" generation state and an asynchronous executor to handle the embedding of text\n",
|
| 219 |
+
" prompt without interrupting the audio thread.\n",
|
| 220 |
+
"\n",
|
| 221 |
+
" Args:\n",
|
| 222 |
+
" system: A MagentaRTBase instance.\n",
|
| 223 |
+
" \"\"\"\n",
|
| 224 |
+
"\n",
|
| 225 |
+
" def __init__(self, system: system.MagentaRTBase):\n",
|
| 226 |
+
" self.system = system\n",
|
| 227 |
+
" self.fade = AudioFade(chunk_size=1920, num_chunks=1, stereo=True)\n",
|
| 228 |
+
" self.state = None\n",
|
| 229 |
+
" self.executor = concurrent.futures.ThreadPoolExecutor()\n",
|
| 230 |
+
" self.audio_streamer = None\n",
|
| 231 |
+
"\n",
|
| 232 |
+
" @functools.cache\n",
|
| 233 |
+
" def embed_style(self, style: str):\n",
|
| 234 |
+
" return self.executor.submit(self.system.embed_style, style)\n",
|
| 235 |
+
"\n",
|
| 236 |
+
" def get_style_embedding(\n",
|
| 237 |
+
" self, params: dict[str, Any], force_wait: bool = False\n",
|
| 238 |
+
" ):\n",
|
| 239 |
+
" num_prompts = sum(map(lambda s: \"prompt\" in s, params.keys()))\n",
|
| 240 |
+
"\n",
|
| 241 |
+
" weighted_embedding = np.zeros((768,), dtype=np.float32)\n",
|
| 242 |
+
" total_weight = 0.0\n",
|
| 243 |
+
"\n",
|
| 244 |
+
" for i in range(num_prompts):\n",
|
| 245 |
+
" weight = params[f\"prompt_{i}\"]\n",
|
| 246 |
+
" if not weight:\n",
|
| 247 |
+
" continue\n",
|
| 248 |
+
" text = params[f\"style_{i}\"]\n",
|
| 249 |
+
" embedding = self.embed_style(text)\n",
|
| 250 |
+
"\n",
|
| 251 |
+
" if force_wait:\n",
|
| 252 |
+
" embedding.result()\n",
|
| 253 |
+
"\n",
|
| 254 |
+
" if embedding.done():\n",
|
| 255 |
+
" weighted_embedding += embedding.result() * weight\n",
|
| 256 |
+
" total_weight += weight\n",
|
| 257 |
+
"\n",
|
| 258 |
+
" if total_weight:\n",
|
| 259 |
+
" weighted_embedding /= total_weight\n",
|
| 260 |
+
"\n",
|
| 261 |
+
" return weighted_embedding\n",
|
| 262 |
+
"\n",
|
| 263 |
+
" def __call__(self, inputs):\n",
|
| 264 |
+
" del inputs\n",
|
| 265 |
+
" ui_params = utils.Parameters.get_values()\n",
|
| 266 |
+
"\n",
|
| 267 |
+
" chunk, self.state = self.system.generate_chunk(\n",
|
| 268 |
+
" state=self.state,\n",
|
| 269 |
+
" style=self.get_style_embedding(ui_params),\n",
|
| 270 |
+
" seed=None,\n",
|
| 271 |
+
" **ui_params,\n",
|
| 272 |
+
" )\n",
|
| 273 |
+
" chunk = self.fade(chunk.samples)\n",
|
| 274 |
+
" return chunk\n",
|
| 275 |
+
"\n",
|
| 276 |
+
" def preflight(self):\n",
|
| 277 |
+
" ui_params = utils.Parameters.get_values()\n",
|
| 278 |
+
" self.get_style_embedding(ui_params, force_wait=False)\n",
|
| 279 |
+
" self.get_style_embedding(ui_params, force_wait=True)\n",
|
| 280 |
+
" self.audio_streamer.reset_ring_buffer()\n",
|
| 281 |
+
"\n",
|
| 282 |
+
" def reset(self):\n",
|
| 283 |
+
" self.state = None\n",
|
| 284 |
+
" self.fade.reset()\n",
|
| 285 |
+
" if self.audio_streamer is not None:\n",
|
| 286 |
+
" self.audio_streamer.reset_ring_buffer()\n",
|
| 287 |
+
"\n",
|
| 288 |
+
" def start(self):\n",
|
| 289 |
+
" self.audio_streamer = utils.AudioStreamer(\n",
|
| 290 |
+
" self,\n",
|
| 291 |
+
" rate=48000,\n",
|
| 292 |
+
" buffer_size=48000 * 2,\n",
|
| 293 |
+
" warmup=True,\n",
|
| 294 |
+
" num_output_channels=2,\n",
|
| 295 |
+
" additional_buffered_samples=buffering_amount_samples,\n",
|
| 296 |
+
" start_streaming_callback=self.preflight,\n",
|
| 297 |
+
" )\n",
|
| 298 |
+
" self.reset()\n",
|
| 299 |
+
"\n",
|
| 300 |
+
"\n",
|
| 301 |
+
"# BUILD UI\n",
|
| 302 |
+
"\n",
|
| 303 |
+
"\n",
|
| 304 |
+
"def build_prompt_ui(default_prompts: Sequence[str]):\n",
|
| 305 |
+
" \"\"\"Add interactive prompt widgets and register them.\"\"\"\n",
|
| 306 |
+
" prompts = []\n",
|
| 307 |
+
"\n",
|
| 308 |
+
" for p in default_prompts:\n",
|
| 309 |
+
" prompts.append(widgets.Prompt())\n",
|
| 310 |
+
" prompts[-1].text.value = p\n",
|
| 311 |
+
"\n",
|
| 312 |
+
" prompts[0].slider.value = 1.0\n",
|
| 313 |
+
"\n",
|
| 314 |
+
" utils.Parameters.register_ui_elements(\n",
|
| 315 |
+
" display=False,\n",
|
| 316 |
+
" **{f\"prompt_{i}\": p.slider for i, p in enumerate(prompts)},\n",
|
| 317 |
+
" **{f\"style_{i}\": p.text for i, p in enumerate(prompts)},\n",
|
| 318 |
+
" )\n",
|
| 319 |
+
" return [p.get_widget() for p in prompts]\n",
|
| 320 |
+
"\n",
|
| 321 |
+
"\n",
|
| 322 |
+
"def build_sampling_option_ui():\n",
|
| 323 |
+
" \"\"\"Add interactive sampling option widgets and register them.\"\"\"\n",
|
| 324 |
+
" options = {\n",
|
| 325 |
+
" \"temperature\": ipw.FloatSlider(\n",
|
| 326 |
+
" min=0.0,\n",
|
| 327 |
+
" max=4.0,\n",
|
| 328 |
+
" step=0.01,\n",
|
| 329 |
+
" value=1.3,\n",
|
| 330 |
+
" description=\"temperature\",\n",
|
| 331 |
+
" ),\n",
|
| 332 |
+
" \"topk\": ipw.IntSlider(\n",
|
| 333 |
+
" min=0,\n",
|
| 334 |
+
" max=1024,\n",
|
| 335 |
+
" step=1,\n",
|
| 336 |
+
" value=40,\n",
|
| 337 |
+
" description=\"topk\",\n",
|
| 338 |
+
" ),\n",
|
| 339 |
+
" \"guidance_weight\": ipw.FloatSlider(\n",
|
| 340 |
+
" min=0.0,\n",
|
| 341 |
+
" max=10.0,\n",
|
| 342 |
+
" step=0.01,\n",
|
| 343 |
+
" value=5.0,\n",
|
| 344 |
+
" description=\"guidance\",\n",
|
| 345 |
+
" ),\n",
|
| 346 |
+
" }\n",
|
| 347 |
+
"\n",
|
| 348 |
+
" utils.Parameters.register_ui_elements(display=False, **options)\n",
|
| 349 |
+
"\n",
|
| 350 |
+
" return list(options.values())\n",
|
| 351 |
+
"\n",
|
| 352 |
+
"\n",
|
| 353 |
+
"utils.Parameters.reset()\n",
|
| 354 |
+
"\n",
|
| 355 |
+
"\n",
|
| 356 |
+
"try:\n",
|
| 357 |
+
" MRT\n",
|
| 358 |
+
"except NameError:\n",
|
| 359 |
+
" print(\"Magenta RT not initialized. Please run the cell above.\")\n",
|
| 360 |
+
"\n",
|
| 361 |
+
"\n",
|
| 362 |
+
"streamer = MagentaRTStreamer(MRT)\n",
|
| 363 |
+
"\n",
|
| 364 |
+
"\n",
|
| 365 |
+
"def _reset_state(*args, **kwargs):\n",
|
| 366 |
+
" del args, kwargs\n",
|
| 367 |
+
" streamer.reset()\n",
|
| 368 |
+
"\n",
|
| 369 |
+
"\n",
|
| 370 |
+
"reset_button = ipw.Button(description=\"reset\")\n",
|
| 371 |
+
"reset_button.on_click(_reset_state)\n",
|
| 372 |
+
"\n",
|
| 373 |
+
"\n",
|
| 374 |
+
"# Building interactive UI\n",
|
| 375 |
+
"ipd.display(\n",
|
| 376 |
+
" ipw.VBox([\n",
|
| 377 |
+
" widgets.area(\n",
|
| 378 |
+
" \"sampling options\",\n",
|
| 379 |
+
" *build_sampling_option_ui(),\n",
|
| 380 |
+
" reset_button,\n",
|
| 381 |
+
" ),\n",
|
| 382 |
+
" widgets.area(\n",
|
| 383 |
+
" \"prompts\",\n",
|
| 384 |
+
" *build_prompt_ui([\n",
|
| 385 |
+
" \"synthwave\",\n",
|
| 386 |
+
" \"flamenco guitar\",\n",
|
| 387 |
+
" \"\",\n",
|
| 388 |
+
" \"\",\n",
|
| 389 |
+
" ]),\n",
|
| 390 |
+
" ),\n",
|
| 391 |
+
" ])\n",
|
| 392 |
+
")\n",
|
| 393 |
+
"\n",
|
| 394 |
+
"streamer.start()"
|
| 395 |
+
],
|
| 396 |
+
"outputs": [],
|
| 397 |
+
"execution_count": null
|
| 398 |
+
},
|
| 399 |
+
{
|
| 400 |
+
"metadata": {
|
| 401 |
+
"id": "RPJxjMnOqIU-"
|
| 402 |
+
},
|
| 403 |
+
"cell_type": "markdown",
|
| 404 |
+
"source": [
|
| 405 |
+
"# Step 3: Understand what is happening behind the hood"
|
| 406 |
+
]
|
| 407 |
+
},
|
| 408 |
+
{
|
| 409 |
+
"metadata": {
|
| 410 |
+
"id": "x_8cVQiQ34v9"
|
| 411 |
+
},
|
| 412 |
+
"cell_type": "markdown",
|
| 413 |
+
"source": [
|
| 414 |
+
"Let's start by generating a short (2s) chunk of synthwave"
|
| 415 |
+
]
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"metadata": {
|
| 419 |
+
"id": "BTzfxJ1fqQAF"
|
| 420 |
+
},
|
| 421 |
+
"cell_type": "code",
|
| 422 |
+
"source": [
|
| 423 |
+
"import IPython.display as ipd\n",
|
| 424 |
+
"\n",
|
| 425 |
+
"try:\n",
|
| 426 |
+
" model = MRT\n",
|
| 427 |
+
"except NameError:\n",
|
| 428 |
+
" model = system.MagentaRT(\n",
|
| 429 |
+
" tag=\"large\", device=\"tpu:v2-8\", skip_cache=True, lazy=False\n",
|
| 430 |
+
" )\n",
|
| 431 |
+
"\n",
|
| 432 |
+
"prompt = \"synthwave\"\n",
|
| 433 |
+
"embedding = model.embed_style(prompt)\n",
|
| 434 |
+
"\n",
|
| 435 |
+
"audio, state = model.generate_chunk(\n",
|
| 436 |
+
" state=None,\n",
|
| 437 |
+
" style=embedding,\n",
|
| 438 |
+
" seed=0,\n",
|
| 439 |
+
")\n",
|
| 440 |
+
"\n",
|
| 441 |
+
"ipd.display(ipd.Audio(audio.samples.T, rate=audio.sample_rate))"
|
| 442 |
+
],
|
| 443 |
+
"outputs": [],
|
| 444 |
+
"execution_count": null
|
| 445 |
+
},
|
| 446 |
+
{
|
| 447 |
+
"metadata": {
|
| 448 |
+
"id": "fGHSTwpCrsJx"
|
| 449 |
+
},
|
| 450 |
+
"cell_type": "markdown",
|
| 451 |
+
"source": [
|
| 452 |
+
"We can generate longer sequences by concatenating generations while keeping\n",
|
| 453 |
+
"track of the internal state of the model. We use a crossfade time of 40ms to\n",
|
| 454 |
+
"concatenate audio chunks as this is the frame length used by SpectroStream when\n",
|
| 455 |
+
"encoding audio."
|
| 456 |
+
]
|
| 457 |
+
},
|
| 458 |
+
{
|
| 459 |
+
"metadata": {
|
| 460 |
+
"id": "M2FDcW9prrWu"
|
| 461 |
+
},
|
| 462 |
+
"cell_type": "code",
|
| 463 |
+
"source": [
|
| 464 |
+
"from magenta_rt import audio\n",
|
| 465 |
+
"\n",
|
| 466 |
+
"num_chunks = 4\n",
|
| 467 |
+
"state = None\n",
|
| 468 |
+
"chunks = []\n",
|
| 469 |
+
"\n",
|
| 470 |
+
"for i in range(num_chunks):\n",
|
| 471 |
+
" chunk, state = model.generate_chunk(\n",
|
| 472 |
+
" state=state,\n",
|
| 473 |
+
" style=embedding,\n",
|
| 474 |
+
" seed=i,\n",
|
| 475 |
+
" )\n",
|
| 476 |
+
" chunks.append(chunk)\n",
|
| 477 |
+
"\n",
|
| 478 |
+
"concatenated_audio = audio.concatenate(\n",
|
| 479 |
+
" chunks,\n",
|
| 480 |
+
" crossfade_time=model.config.crossfade_length,\n",
|
| 481 |
+
")\n",
|
| 482 |
+
"ipd.display(\n",
|
| 483 |
+
" ipd.Audio(concatenated_audio.samples.T, rate=concatenated_audio.sample_rate)\n",
|
| 484 |
+
")"
|
| 485 |
+
],
|
| 486 |
+
"outputs": [],
|
| 487 |
+
"execution_count": null
|
| 488 |
+
},
|
| 489 |
+
{
|
| 490 |
+
"metadata": {
|
| 491 |
+
"id": "mKGsDvChsrr4"
|
| 492 |
+
},
|
| 493 |
+
"cell_type": "markdown",
|
| 494 |
+
"source": [
|
| 495 |
+
"At the core of Magenta RT lies the idea of changing the style embedding *during\n",
|
| 496 |
+
"generation* to enable smooth transitions between musical concepts. What about\n",
|
| 497 |
+
"transitioning from \"synthwave\" to \"disco funk\" ?"
|
| 498 |
+
]
|
| 499 |
+
},
|
| 500 |
+
{
|
| 501 |
+
"metadata": {
|
| 502 |
+
"id": "Zx_bEjtcs6yB"
|
| 503 |
+
},
|
| 504 |
+
"cell_type": "code",
|
| 505 |
+
"source": [
|
| 506 |
+
"state = None\n",
|
| 507 |
+
"chunks = []\n",
|
| 508 |
+
"\n",
|
| 509 |
+
"styles = [\n",
|
| 510 |
+
" \"synthwave\",\n",
|
| 511 |
+
" \"disco synthwave\",\n",
|
| 512 |
+
" \"disco\",\n",
|
| 513 |
+
" \"disco funk\",\n",
|
| 514 |
+
"]\n",
|
| 515 |
+
"\n",
|
| 516 |
+
"for i, style in enumerate(styles):\n",
|
| 517 |
+
" chunk, state = model.generate_chunk(\n",
|
| 518 |
+
" state=state,\n",
|
| 519 |
+
" style=model.embed_style(style),\n",
|
| 520 |
+
" seed=i,\n",
|
| 521 |
+
" guidance_weight=5.0,\n",
|
| 522 |
+
" temperature=1.3,\n",
|
| 523 |
+
" )\n",
|
| 524 |
+
" chunks.append(chunk)\n",
|
| 525 |
+
"\n",
|
| 526 |
+
"concatenated_audio = audio.concatenate(\n",
|
| 527 |
+
" chunks,\n",
|
| 528 |
+
" crossfade_time=model.config.crossfade_length,\n",
|
| 529 |
+
")\n",
|
| 530 |
+
"ipd.display(\n",
|
| 531 |
+
" ipd.Audio(concatenated_audio.samples.T, rate=concatenated_audio.sample_rate)\n",
|
| 532 |
+
")"
|
| 533 |
+
],
|
| 534 |
+
"outputs": [],
|
| 535 |
+
"execution_count": null
|
| 536 |
+
},
|
| 537 |
+
{
|
| 538 |
+
"metadata": {
|
| 539 |
+
"id": "-iiqJYDYxasB"
|
| 540 |
+
},
|
| 541 |
+
"cell_type": "markdown",
|
| 542 |
+
"source": [
|
| 543 |
+
"A simpler version can be done through the interpolation of musical genres in\n",
|
| 544 |
+
"*the embedding space*."
|
| 545 |
+
]
|
| 546 |
+
},
|
| 547 |
+
{
|
| 548 |
+
"metadata": {
|
| 549 |
+
"id": "n8Etm7CtxaRu"
|
| 550 |
+
},
|
| 551 |
+
"cell_type": "code",
|
| 552 |
+
"source": [
|
| 553 |
+
"import numpy as np\n",
|
| 554 |
+
"\n",
|
| 555 |
+
"state = None\n",
|
| 556 |
+
"chunks = []\n",
|
| 557 |
+
"\n",
|
| 558 |
+
"embed_a = model.embed_style(\"synthwave\")\n",
|
| 559 |
+
"embed_b = model.embed_style(\"disco funk\")\n",
|
| 560 |
+
"\n",
|
| 561 |
+
"weight = np.linspace(0, 1, 8, endpoint=True)\n",
|
| 562 |
+
"\n",
|
| 563 |
+
"embeddings = embed_a[None] + weight[:, None] * (embed_b - embed_a)\n",
|
| 564 |
+
"embeddings = embeddings.astype(np.float32)\n",
|
| 565 |
+
"\n",
|
| 566 |
+
"\n",
|
| 567 |
+
"for i, embedding in enumerate(embeddings):\n",
|
| 568 |
+
" chunk, state = model.generate_chunk(\n",
|
| 569 |
+
" state=state,\n",
|
| 570 |
+
" style=embedding,\n",
|
| 571 |
+
" seed=i,\n",
|
| 572 |
+
" guidance_weight=5.0,\n",
|
| 573 |
+
" temperature=1.3,\n",
|
| 574 |
+
" )\n",
|
| 575 |
+
" chunks.append(chunk)\n",
|
| 576 |
+
"\n",
|
| 577 |
+
"concatenated_audio = audio.concatenate(\n",
|
| 578 |
+
" chunks,\n",
|
| 579 |
+
" crossfade_time=model.config.crossfade_length,\n",
|
| 580 |
+
")\n",
|
| 581 |
+
"ipd.display(\n",
|
| 582 |
+
" ipd.Audio(concatenated_audio.samples.T, rate=concatenated_audio.sample_rate)\n",
|
| 583 |
+
")"
|
| 584 |
+
],
|
| 585 |
+
"outputs": [],
|
| 586 |
+
"execution_count": null
|
| 587 |
+
},
|
| 588 |
+
{
|
| 589 |
+
"metadata": {
|
| 590 |
+
"id": "xmvBk8UOphdL"
|
| 591 |
+
},
|
| 592 |
+
"cell_type": "markdown",
|
| 593 |
+
"source": [
|
| 594 |
+
"# License and terms\n",
|
| 595 |
+
"\n",
|
| 596 |
+
"Magenta RealTime is offered under a combination of licenses: the codebase is\n",
|
| 597 |
+
"licensed under\n",
|
| 598 |
+
"[Apache 2.0](https://github.com/magenta/magenta-realtime/blob/main/LICENSE), and\n",
|
| 599 |
+
"the model weights under\n",
|
| 600 |
+
"[Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/legalcode).\n",
|
| 601 |
+
"\n",
|
| 602 |
+
"In addition, we specify the following usage terms:\n",
|
| 603 |
+
"\n",
|
| 604 |
+
"Copyright 2025 Google LLC\n",
|
| 605 |
+
"\n",
|
| 606 |
+
"Use these materials responsibly and do not generate content, including outputs, that infringe or violate the rights of others, including rights in copyrighted content.\n",
|
| 607 |
+
"\n",
|
| 608 |
+
"Google claims no rights in outputs you generate using Magenta RealTime. You and your users are solely responsible for outputs and their subsequent uses.\n",
|
| 609 |
+
"\n",
|
| 610 |
+
"Unless required by applicable law or agreed to in writing, all software and materials distributed here under the Apache 2.0 or CC-BY licenses are distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the licenses for the specific language governing permissions and limitations under those licenses. You are solely responsible for determining the appropriateness of using, reproducing, modifying, performing, displaying or distributing the software and materials, and any outputs, and assume any and all risks associated with your use or distribution of any of the software and materials, and any outputs, and your exercise of rights and permissions under the licenses."
|
| 611 |
+
]
|
| 612 |
+
}
|
| 613 |
+
],
|
| 614 |
+
"metadata": {
|
| 615 |
+
"accelerator": "TPU",
|
| 616 |
+
"kernelspec": {
|
| 617 |
+
"display_name": "Python 3",
|
| 618 |
+
"name": "python3"
|
| 619 |
+
},
|
| 620 |
+
"language_info": {
|
| 621 |
+
"name": "python"
|
| 622 |
+
},
|
| 623 |
+
"colab": {
|
| 624 |
+
"provenance": []
|
| 625 |
+
}
|
| 626 |
+
},
|
| 627 |
+
"nbformat": 4,
|
| 628 |
+
"nbformat_minor": 0
|
| 629 |
+
}
|