
File size: 24,499 Bytes
8dfda6c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 |
{
"cells": [
{
"metadata": {
"id": "9HcmLuWtE213"
},
"cell_type": "markdown",
"source": [
"# Magenta RT: Streaming music generation!\n",
"\n",
"Note: Go to `Runtime` -> `Change Runtime type` -> Select `v2-8 TPU` 🤗\n",
"\n",
"Magenta RealTime is a Python library for streaming music audio generation on\n",
"your local device. It is the open weights / on device companion to\n",
"[MusicFX DJ Mode](https://labs.google/fx/tools/music-fx-dj) and the\n",
"[Lyria RealTime API](https://ai.google.dev/gemini-api/docs/music-generation).\n",
"\n",
"- [Blog Post](https://g.co/magenta/rt)\n",
"- [Repository](https://github.com/magenta/magenta-realtime)\n",
"- [HuggingFace](https://huggingface.co/google/magenta-realtime)\n",
"\n",
"### Generating audio with Magenta RT\n",
"\n",
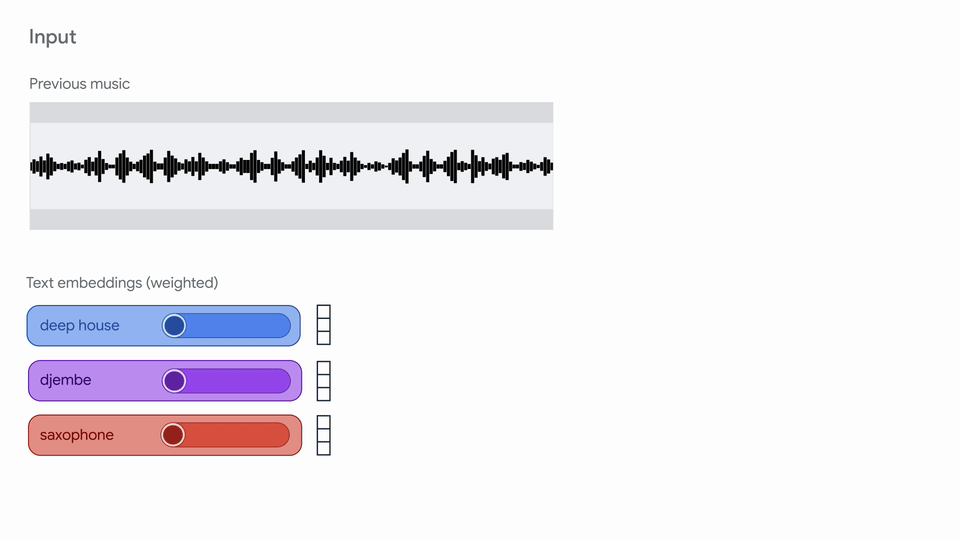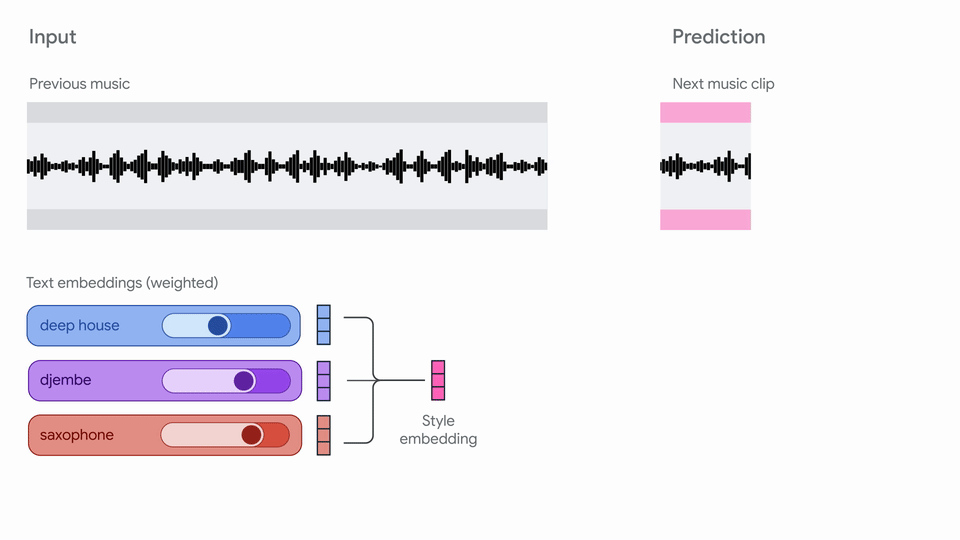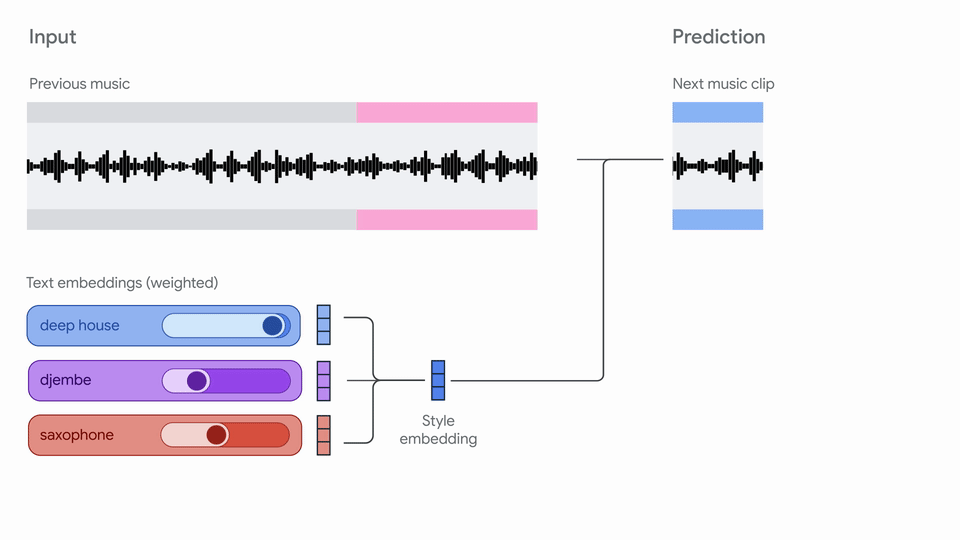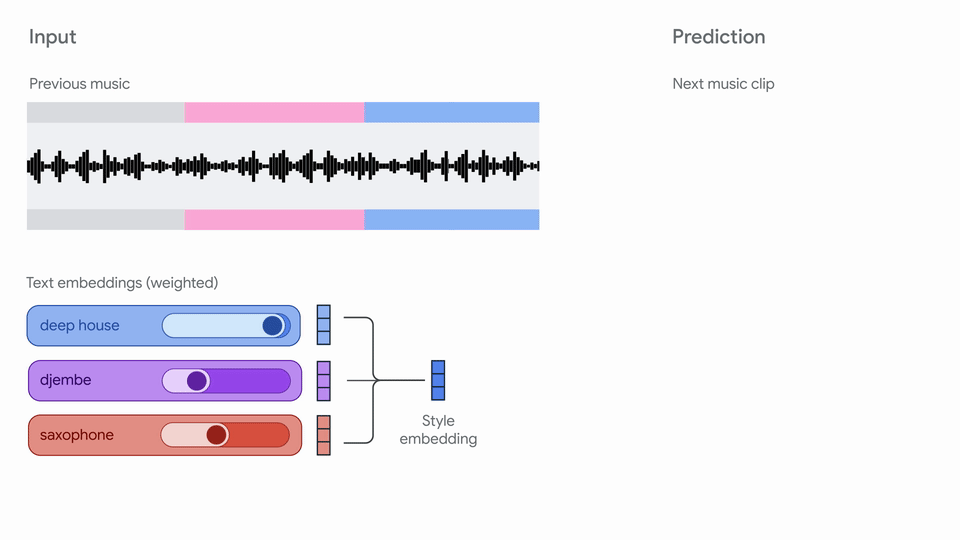
"Magenta RT generates audio in short chunks (2s) given a finite amount of past\n",
"context (10s). We use crossfading to mitigate boundary artifacts between chunks.\n",
"More details on our model are coming soon in a technical report!\n",
"\n",
""
]
},
{
"metadata": {
"id": "1l6sF-r_lISR"
},
"cell_type": "markdown",
"source": [
"# Step 1: 😴 One-time setup"
]
},
{
"metadata": {
"cellView": "form",
"id": "6XAQy5V3pwzw"
},
"cell_type": "code",
"source": [
"# @title **Run this cell** to install dependencies (~5 minutes)\n",
"# @markdown Make sure you are running on **`v2-8 TPU` runtime** via `Runtime > Change Runtime Type`\n",
"\n",
"# @markdown Colab may prompt you to restart session. **Wait until the cell finishes running to restart**!\n",
"\n",
"# Clone library\n",
"!git clone https://github.com/magenta/magenta-realtime.git\n",
"\n",
"# Magenta RT requires nightly TF builds, but stable may be installed.\n",
"# Force nightly to take precedence by uninstalling and reinstalling.\n",
"# Temporary workaround until MusicCoCa supported by TF stable.\n",
"_all_tf = 'tensorflow tf-nightly tensorflow-cpu tf-nightly-cpu tensorflow-tpu tf-nightly-tpu tensorflow-hub tf-hub-nightly tensorflow-text tensorflow-text-nightly'\n",
"_nightly_tf = 'tf-nightly tensorflow-text-nightly tf-hub-nightly'\n",
"\n",
"# Install library and dependencies\n",
"# If running on TPU (recommended, runs on free tier Colab TPUs):\n",
"!pip install -e magenta-realtime/[tpu] && pip uninstall -y {_all_tf} && pip install {_nightly_tf}\n",
"# Uncomment if running on GPU (requires A100 via Colab Pro):\n",
"# !pip install -e magenta-realtime/[gpu] && pip uninstall -y {_all_tf} && pip install {_nightly_tf}"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"cellView": "form",
"id": "1OI3L16olYQs"
},
"cell_type": "code",
"source": [
"# @title **Restart session (`Runtime > Restart Session`) and run this cell** to initialize model (~5 minutes)\n",
"\n",
"from magenta_rt import system\n",
"\n",
"# Fetch checkpoints and initialize model (may take up to 5 minutes)\n",
"MRT = system.MagentaRT(\n",
" tag=\"large\", device=\"tpu:v2-8\", skip_cache=True, lazy=False\n",
")"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"id": "00WPare9QS9O"
},
"cell_type": "markdown",
"source": [
"# Step 2: 🤘 Streaming music generation! 🎵"
]
},
{
"metadata": {
"id": "uWm6bVv1U2f2"
},
"cell_type": "markdown",
"source": [
"**Run the cell below and click the `start` button to begin streaming!**\n",
"\n",
"**Instructions**. Type in text prompts to control the overall style of the generated music in real time. The sliders by the prompts change the influence of each text prompt on the overall output. The other controls change various aspects of the system behavior (expand below for additional information).\n",
"\n",
"**Disclaimer**. Magenta RT's training data primarily consists of Western instrumental music. As a consequence, Magenta RT has incomplete coverage of both vocal performance and the broader landscape of rich musical traditions worldwide. For real-time generation with broader style coverage, we refer users to our [Lyria RealTime API](g.co/magenta/lyria-realtime). See our [model card](https://huggingface.co/google/magenta-realtime) for more information.\n",
"\n",
"<details>\n",
" <summary>Click to expand for additional information on the controls</summary>\n",
"\n",
"* **buffering_amount_seconds**: Increase this value if you experience audio\n",
" drops during generation. This will come at the expense of a greater latency,\n",
" but might help with internet connection issues. *You need to relaunch the\n",
" cell if you choose to modify this value*.\n",
"\n",
"* **sampling options**\n",
"\n",
" * **temperature**: This controls how *chaotic* the model behaves. Low\n",
" temperature values (e.g., 0.9) will make the model's choices more\n",
" predictable and stable. High values (e.g., 1.5) will encourage more\n",
" surprising and experimental musical ideas, but can also lead to\n",
" instability.\n",
"\n",
" * **topk**: This parameter filters the model's vocabulary at each step. It\n",
" forces the model to choose its next prediction only from the *k* most\n",
" likely options.\n",
"\n",
" * A **low `topk`** value (e.g., 40) restricts the model to a smaller,\n",
" safer palette of options. This leads to more coherent and\n",
" predictable music that is less likely to have dissonant errors, but\n",
" can sometimes feel repetitive.\n",
" * A **high `topk`** value gives the model a much wider range of\n",
" choices, allowing for more variety and unexpected turns. This can\n",
" make the output more creative, but also noisier.\n",
"\n",
" * **guidance**: This controls how strictly the generated music should\n",
" adhere to the **text prompts**.\n",
"\n",
" * A **higher value** will push the model to produce a textbook example\n",
" of the chosen style, emphasizing its key characteristics.\n",
" * A **lower value** will treat the text prompts more as a loose\n",
" inspiration, allowing the model more creative freedom to deviate and\n",
" blend other influences.\n",
"\n",
"* **Reset**: stop audio, and resets the model.\n",
"\n",
"* **Text prompts**: Next to each text prompt is a slider that controls how\n",
" much each prompt should be affecting the model. This allows the creation of\n",
" *mixed* embeddings (try mixing synthwave and flamenco guitar together !).\n",
" You can also type your own prompt and modify existing ones.\n",
"</details>"
]
},
{
"metadata": {
"cellView": "form",
"id": "4taDDhwf9hvD"
},
"cell_type": "code",
"source": [
"# @title Run this cell to start demo\n",
"\n",
"import concurrent.futures\n",
"import functools\n",
"from typing import Any, Sequence\n",
"\n",
"import IPython.display as ipd\n",
"import ipywidgets as ipw\n",
"import numpy as np\n",
"\n",
"from magenta_rt import system\n",
"from magenta_rt.colab import utils\n",
"from magenta_rt.colab import widgets\n",
"\n",
"buffering_amount_seconds = 0 # @param {\"type\":\"slider\",\"min\":0,\"max\":4,\"step\":0.1}\n",
"buffering_amount_samples = int(np.ceil(buffering_amount_seconds * 48000))\n",
"\n",
"\n",
"class AudioFade:\n",
" \"\"\"Handles the cross fade between audio chunks.\n",
"\n",
" Args:\n",
" chunk_size: Number of audio samples per predicted frame (current\n",
" SpectroStream models produces 25Hz frames corresponding to 1920 audio\n",
" samples at 48kHz)\n",
" num_chunks: Number of audio chunks to fade between.\n",
" stereo: Whether the predicted audio is stereo or mono.\n",
" \"\"\"\n",
"\n",
" def __init__(self, chunk_size: int, num_chunks: int, stereo: bool):\n",
" fade_size = chunk_size * num_chunks\n",
" self.fade_size = fade_size\n",
" self.num_chunks = num_chunks\n",
"\n",
" self.previous_chunk = np.zeros(fade_size)\n",
" self.ramp = np.sin(np.linspace(0, np.pi / 2, fade_size)) ** 2\n",
"\n",
" if stereo:\n",
" self.previous_chunk = self.previous_chunk[:, np.newaxis]\n",
" self.ramp = self.ramp[:, np.newaxis]\n",
"\n",
" def reset(self):\n",
" self.previous_chunk = np.zeros_like(self.previous_chunk)\n",
"\n",
" def __call__(self, chunk: np.ndarray) -> np.ndarray:\n",
" chunk[: self.fade_size] *= self.ramp\n",
" chunk[: self.fade_size] += self.previous_chunk\n",
" self.previous_chunk = chunk[-self.fade_size :] * np.flip(self.ramp)\n",
" return chunk[: -self.fade_size]\n",
"\n",
"\n",
"class MagentaRTStreamer:\n",
" \"\"\"Audio streamer class.\n",
"\n",
" This class holds a pretrained Magenta RT model, a cross fade state, a\n",
" generation state and an asynchronous executor to handle the embedding of text\n",
" prompt without interrupting the audio thread.\n",
"\n",
" Args:\n",
" system: A MagentaRTBase instance.\n",
" \"\"\"\n",
"\n",
" def __init__(self, system: system.MagentaRTBase):\n",
" self.system = system\n",
" self.fade = AudioFade(chunk_size=1920, num_chunks=1, stereo=True)\n",
" self.state = None\n",
" self.executor = concurrent.futures.ThreadPoolExecutor()\n",
" self.audio_streamer = None\n",
"\n",
" @functools.cache\n",
" def embed_style(self, style: str):\n",
" return self.executor.submit(self.system.embed_style, style)\n",
"\n",
" def get_style_embedding(\n",
" self, params: dict[str, Any], force_wait: bool = False\n",
" ):\n",
" num_prompts = sum(map(lambda s: \"prompt\" in s, params.keys()))\n",
"\n",
" weighted_embedding = np.zeros((768,), dtype=np.float32)\n",
" total_weight = 0.0\n",
"\n",
" for i in range(num_prompts):\n",
" weight = params[f\"prompt_{i}\"]\n",
" if not weight:\n",
" continue\n",
" text = params[f\"style_{i}\"]\n",
" embedding = self.embed_style(text)\n",
"\n",
" if force_wait:\n",
" embedding.result()\n",
"\n",
" if embedding.done():\n",
" weighted_embedding += embedding.result() * weight\n",
" total_weight += weight\n",
"\n",
" if total_weight:\n",
" weighted_embedding /= total_weight\n",
"\n",
" return weighted_embedding\n",
"\n",
" def __call__(self, inputs):\n",
" del inputs\n",
" ui_params = utils.Parameters.get_values()\n",
"\n",
" chunk, self.state = self.system.generate_chunk(\n",
" state=self.state,\n",
" style=self.get_style_embedding(ui_params),\n",
" seed=None,\n",
" **ui_params,\n",
" )\n",
" chunk = self.fade(chunk.samples)\n",
" return chunk\n",
"\n",
" def preflight(self):\n",
" ui_params = utils.Parameters.get_values()\n",
" self.get_style_embedding(ui_params, force_wait=False)\n",
" self.get_style_embedding(ui_params, force_wait=True)\n",
" self.audio_streamer.reset_ring_buffer()\n",
"\n",
" def reset(self):\n",
" self.state = None\n",
" self.fade.reset()\n",
" if self.audio_streamer is not None:\n",
" self.audio_streamer.reset_ring_buffer()\n",
"\n",
" def start(self):\n",
" self.audio_streamer = utils.AudioStreamer(\n",
" self,\n",
" rate=48000,\n",
" buffer_size=48000 * 2,\n",
" warmup=True,\n",
" num_output_channels=2,\n",
" additional_buffered_samples=buffering_amount_samples,\n",
" start_streaming_callback=self.preflight,\n",
" )\n",
" self.reset()\n",
"\n",
"\n",
"# BUILD UI\n",
"\n",
"\n",
"def build_prompt_ui(default_prompts: Sequence[str]):\n",
" \"\"\"Add interactive prompt widgets and register them.\"\"\"\n",
" prompts = []\n",
"\n",
" for p in default_prompts:\n",
" prompts.append(widgets.Prompt())\n",
" prompts[-1].text.value = p\n",
"\n",
" prompts[0].slider.value = 1.0\n",
"\n",
" utils.Parameters.register_ui_elements(\n",
" display=False,\n",
" **{f\"prompt_{i}\": p.slider for i, p in enumerate(prompts)},\n",
" **{f\"style_{i}\": p.text for i, p in enumerate(prompts)},\n",
" )\n",
" return [p.get_widget() for p in prompts]\n",
"\n",
"\n",
"def build_sampling_option_ui():\n",
" \"\"\"Add interactive sampling option widgets and register them.\"\"\"\n",
" options = {\n",
" \"temperature\": ipw.FloatSlider(\n",
" min=0.0,\n",
" max=4.0,\n",
" step=0.01,\n",
" value=1.3,\n",
" description=\"temperature\",\n",
" ),\n",
" \"topk\": ipw.IntSlider(\n",
" min=0,\n",
" max=1024,\n",
" step=1,\n",
" value=40,\n",
" description=\"topk\",\n",
" ),\n",
" \"guidance_weight\": ipw.FloatSlider(\n",
" min=0.0,\n",
" max=10.0,\n",
" step=0.01,\n",
" value=5.0,\n",
" description=\"guidance\",\n",
" ),\n",
" }\n",
"\n",
" utils.Parameters.register_ui_elements(display=False, **options)\n",
"\n",
" return list(options.values())\n",
"\n",
"\n",
"utils.Parameters.reset()\n",
"\n",
"\n",
"try:\n",
" MRT\n",
"except NameError:\n",
" print(\"Magenta RT not initialized. Please run the cell above.\")\n",
"\n",
"\n",
"streamer = MagentaRTStreamer(MRT)\n",
"\n",
"\n",
"def _reset_state(*args, **kwargs):\n",
" del args, kwargs\n",
" streamer.reset()\n",
"\n",
"\n",
"reset_button = ipw.Button(description=\"reset\")\n",
"reset_button.on_click(_reset_state)\n",
"\n",
"\n",
"# Building interactive UI\n",
"ipd.display(\n",
" ipw.VBox([\n",
" widgets.area(\n",
" \"sampling options\",\n",
" *build_sampling_option_ui(),\n",
" reset_button,\n",
" ),\n",
" widgets.area(\n",
" \"prompts\",\n",
" *build_prompt_ui([\n",
" \"synthwave\",\n",
" \"flamenco guitar\",\n",
" \"\",\n",
" \"\",\n",
" ]),\n",
" ),\n",
" ])\n",
")\n",
"\n",
"streamer.start()"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"id": "RPJxjMnOqIU-"
},
"cell_type": "markdown",
"source": [
"# Step 3: Understand what is happening behind the hood"
]
},
{
"metadata": {
"id": "x_8cVQiQ34v9"
},
"cell_type": "markdown",
"source": [
"Let's start by generating a short (2s) chunk of synthwave"
]
},
{
"metadata": {
"id": "BTzfxJ1fqQAF"
},
"cell_type": "code",
"source": [
"import IPython.display as ipd\n",
"\n",
"try:\n",
" model = MRT\n",
"except NameError:\n",
" model = system.MagentaRT(\n",
" tag=\"large\", device=\"tpu:v2-8\", skip_cache=True, lazy=False\n",
" )\n",
"\n",
"prompt = \"synthwave\"\n",
"embedding = model.embed_style(prompt)\n",
"\n",
"audio, state = model.generate_chunk(\n",
" state=None,\n",
" style=embedding,\n",
" seed=0,\n",
")\n",
"\n",
"ipd.display(ipd.Audio(audio.samples.T, rate=audio.sample_rate))"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"id": "fGHSTwpCrsJx"
},
"cell_type": "markdown",
"source": [
"We can generate longer sequences by concatenating generations while keeping\n",
"track of the internal state of the model. We use a crossfade time of 40ms to\n",
"concatenate audio chunks as this is the frame length used by SpectroStream when\n",
"encoding audio."
]
},
{
"metadata": {
"id": "M2FDcW9prrWu"
},
"cell_type": "code",
"source": [
"from magenta_rt import audio\n",
"\n",
"num_chunks = 4\n",
"state = None\n",
"chunks = []\n",
"\n",
"for i in range(num_chunks):\n",
" chunk, state = model.generate_chunk(\n",
" state=state,\n",
" style=embedding,\n",
" seed=i,\n",
" )\n",
" chunks.append(chunk)\n",
"\n",
"concatenated_audio = audio.concatenate(\n",
" chunks,\n",
" crossfade_time=model.config.crossfade_length,\n",
")\n",
"ipd.display(\n",
" ipd.Audio(concatenated_audio.samples.T, rate=concatenated_audio.sample_rate)\n",
")"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"id": "mKGsDvChsrr4"
},
"cell_type": "markdown",
"source": [
"At the core of Magenta RT lies the idea of changing the style embedding *during\n",
"generation* to enable smooth transitions between musical concepts. What about\n",
"transitioning from \"synthwave\" to \"disco funk\" ?"
]
},
{
"metadata": {
"id": "Zx_bEjtcs6yB"
},
"cell_type": "code",
"source": [
"state = None\n",
"chunks = []\n",
"\n",
"styles = [\n",
" \"synthwave\",\n",
" \"disco synthwave\",\n",
" \"disco\",\n",
" \"disco funk\",\n",
"]\n",
"\n",
"for i, style in enumerate(styles):\n",
" chunk, state = model.generate_chunk(\n",
" state=state,\n",
" style=model.embed_style(style),\n",
" seed=i,\n",
" guidance_weight=5.0,\n",
" temperature=1.3,\n",
" )\n",
" chunks.append(chunk)\n",
"\n",
"concatenated_audio = audio.concatenate(\n",
" chunks,\n",
" crossfade_time=model.config.crossfade_length,\n",
")\n",
"ipd.display(\n",
" ipd.Audio(concatenated_audio.samples.T, rate=concatenated_audio.sample_rate)\n",
")"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"id": "-iiqJYDYxasB"
},
"cell_type": "markdown",
"source": [
"A simpler version can be done through the interpolation of musical genres in\n",
"*the embedding space*."
]
},
{
"metadata": {
"id": "n8Etm7CtxaRu"
},
"cell_type": "code",
"source": [
"import numpy as np\n",
"\n",
"state = None\n",
"chunks = []\n",
"\n",
"embed_a = model.embed_style(\"synthwave\")\n",
"embed_b = model.embed_style(\"disco funk\")\n",
"\n",
"weight = np.linspace(0, 1, 8, endpoint=True)\n",
"\n",
"embeddings = embed_a[None] + weight[:, None] * (embed_b - embed_a)\n",
"embeddings = embeddings.astype(np.float32)\n",
"\n",
"\n",
"for i, embedding in enumerate(embeddings):\n",
" chunk, state = model.generate_chunk(\n",
" state=state,\n",
" style=embedding,\n",
" seed=i,\n",
" guidance_weight=5.0,\n",
" temperature=1.3,\n",
" )\n",
" chunks.append(chunk)\n",
"\n",
"concatenated_audio = audio.concatenate(\n",
" chunks,\n",
" crossfade_time=model.config.crossfade_length,\n",
")\n",
"ipd.display(\n",
" ipd.Audio(concatenated_audio.samples.T, rate=concatenated_audio.sample_rate)\n",
")"
],
"outputs": [],
"execution_count": null
},
{
"metadata": {
"id": "xmvBk8UOphdL"
},
"cell_type": "markdown",
"source": [
"# License and terms\n",
"\n",
"Magenta RealTime is offered under a combination of licenses: the codebase is\n",
"licensed under\n",
"[Apache 2.0](https://github.com/magenta/magenta-realtime/blob/main/LICENSE), and\n",
"the model weights under\n",
"[Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0/legalcode).\n",
"\n",
"In addition, we specify the following usage terms:\n",
"\n",
"Copyright 2025 Google LLC\n",
"\n",
"Use these materials responsibly and do not generate content, including outputs, that infringe or violate the rights of others, including rights in copyrighted content.\n",
"\n",
"Google claims no rights in outputs you generate using Magenta RealTime. You and your users are solely responsible for outputs and their subsequent uses.\n",
"\n",
"Unless required by applicable law or agreed to in writing, all software and materials distributed here under the Apache 2.0 or CC-BY licenses are distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the licenses for the specific language governing permissions and limitations under those licenses. You are solely responsible for determining the appropriateness of using, reproducing, modifying, performing, displaying or distributing the software and materials, and any outputs, and assume any and all risks associated with your use or distribution of any of the software and materials, and any outputs, and your exercise of rights and permissions under the licenses."
]
}
],
"metadata": {
"accelerator": "TPU",
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
},
"colab": {
"provenance": []
}
},
"nbformat": 4,
"nbformat_minor": 0
} |