
File size: 4,487 Bytes
b5e9da4 ce0bb81 54eeab0 ce0bb81 35a9d04 ce0bb81 243eb73 ce0bb81 24bb04d ce0bb81 eefc431 ce0bb81 eefc431 ce0bb81 eefc431 ce0bb81 659f73c ce0bb81 d817e85 dfb8cf3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
---
license: cc-by-4.0
---
<p align="center">
<img src="https://raw.githubusercontent.com/sy77777en/CameraBench/main/images/CameraBench.png" width="600">
</p>
## 📷 **CameraBench: Towards Understanding Camera Motions in Any Video**
[](https://arxiv.org/abs/2504.15376)
[](https://linzhiqiu.github.io/papers/camerabench/)
[](https://huggingface.co/datasets/syCen/CameraBench)
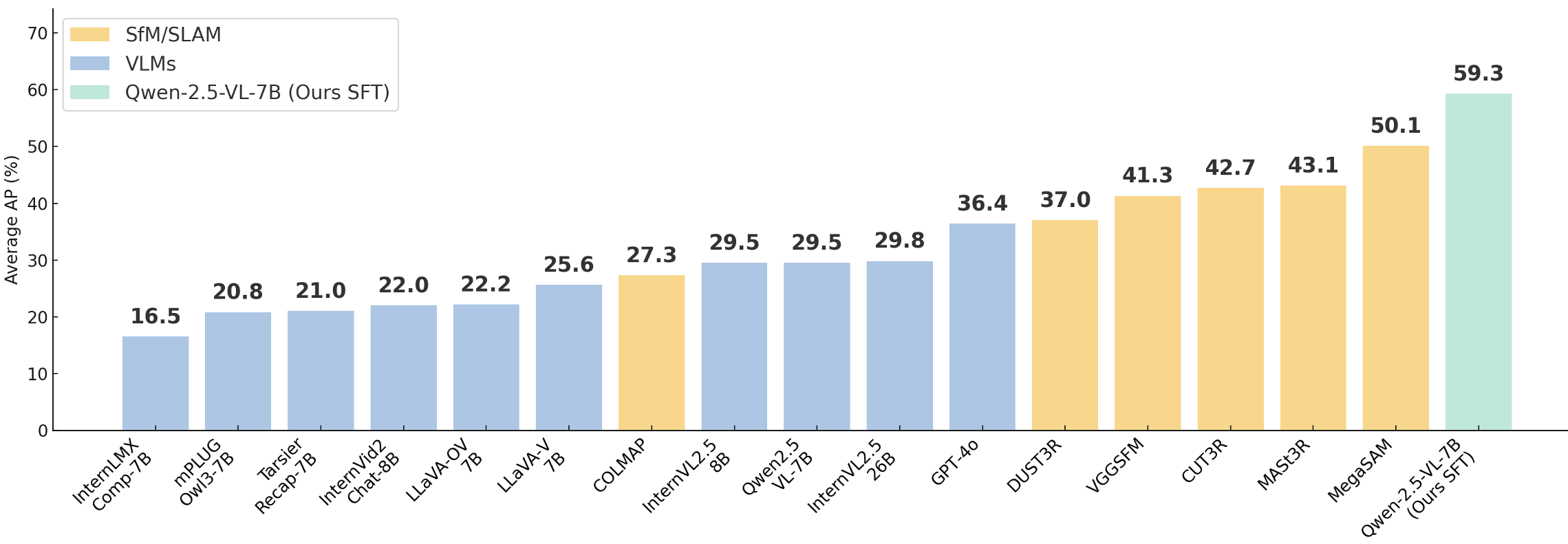
> **SfMs and VLMs performance on CameraBench**: Generative VLMs (evaluated with [VQAScore](https://linzhiqiu.github.io/papers/vqascore/)) trail classical SfM/SLAM in pure geometry, yet they outperform discriminative VLMs that rely on CLIPScore/ITMScore and—even better—capture scene‑aware semantic cues missed by SfM
> After simple supervised fine‑tuning (SFT) on ≈1,400 extra annotated clips, our 7B Qwen2.5‑VL doubles its AP, outperforming the current best MegaSAM.
## 📰 News
- **[2025/04/26]🔥** We open‑sourced our **fine‑tuned 7B model** and the public **test set**—1 000+ videos with expert labels & captions..
- **LLMs‑eval** integration is in progress—stay tuned!
- 32B & 72B checkpoints are on the way.
## 🌍 Explore More
- [🤗**CameraBench Testset**](https://huggingface.co/datasets/syCen/CameraBench): Download the testset.
- [🚀**Fine-tuned Model**](): Access model checkpoints.
- [🏠**Home Page**](https://linzhiqiu.github.io/papers/camerabench/): Demos & docs.
- [📖**Paper**](https://arxiv.org/abs/2504.15376): Detailed information about CameraBench.
- [📈**Leaderboard**](https://sy77777en.github.io/CameraBench/leaderboard/table.html): Explore the full leaderboard..
## ⚠️ Note
- If you are interested in accessing the dataset (including both training and testing splits), please contact us at [email protected].
## 🔎 VQA evaluation on VLMs
<table>
<tr>
<td>
<div style="display: flex; flex-direction: column; gap: 1em;">
<img src="https://raw.githubusercontent.com/sy77777en/CameraBench/main/images/VQA-leaderboard.png" width="440">
</div>
</td>
<td>
<div style="display: flex; flex-direction: column; gap: 1em;">
<div>
<img src="https://raw.githubusercontent.com/sy77777en/CameraBench/main/images/8-1.gif" width="405"><br>
🤔: Does the camera track the subject from a side view? <br>
🤖: ✅ 🙋: ✅
</div>
<div>
<img src="https://raw.githubusercontent.com/sy77777en/CameraBench/main/images/8-2.gif" width="405"><br>
🤔: Does the camera only move down during the video? <br>
🤖: ❌ 🙋: ✅
</div>
<div>
<img src="https://raw.githubusercontent.com/sy77777en/CameraBench/main/images/8-3.gif" width="405"><br>
🤔: Does the camera move backward while zooming in? <br>
🤖: ❌ 🙋: ✅
</div>
</div>
</td>
</tr>
</table>
## ⌚️ Motion Timeline
<div>
<img src="https://raw.githubusercontent.com/sy77777en/CameraBench/main/images/motion_timeline.gif" width="405"><br>
</div>
## ✏️ Citation
If you find this repository useful for your research, please use the following.
```
@article{lin2025towards,
title={Towards Understanding Camera Motions in Any Video},
author={Lin, Zhiqiu and Cen, Siyuan and Jiang, Daniel and Karhade, Jay and Wang, Hewei and Mitra, Chancharik and Ling, Tiffany and Huang, Yuhan and Liu, Sifan and Chen, Mingyu and Zawar, Rushikesh and Bai, Xue and Du, Yilun and Gan, Chuang and Ramanan, Deva},
journal={arXiv preprint arXiv:2504.15376},
year={2025},
}
```
We only provide a preview of these videos on this Hugging Face page to help researchers easily understand our labels and taxonomy. We do not publicly redistribute any videos. However, we keep a local copy of these video files for research purposes and can share them if you contact us at [email protected]. If you are the video creator and would like your video removed, please also contact us at [email protected]. |