
The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
Job manager crashed while running this job (missing heartbeats).
Error code: JobManagerCrashedError
Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Stefanaz/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-whiskered_flightless_shark
|
Stefanaz
| 2025-08-12T20:45:40 | 96 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am whiskered_flightless_shark",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-09T15:38:55 |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am whiskered_flightless_shark
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/MonkeyOCR-Recognition-GGUF
|
mradermacher
| 2025-08-12T20:41:09 | 668 | 2 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:jmperdev/MonkeyOCR-Recognition",
"base_model:quantized:jmperdev/MonkeyOCR-Recognition",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-12T14:56:17 |
---
base_model: jmperdev/MonkeyOCR-Recognition
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/jmperdev/MonkeyOCR-Recognition
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#MonkeyOCR-Recognition-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 0.9 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q2_K.gguf) | Q2_K | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.mmproj-f16.gguf) | mmproj-f16 | 1.4 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q3_K_S.gguf) | Q3_K_S | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q3_K_M.gguf) | Q3_K_M | 1.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q3_K_L.gguf) | Q3_K_L | 1.8 | |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.IQ4_XS.gguf) | IQ4_XS | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q4_K_S.gguf) | Q4_K_S | 1.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q4_K_M.gguf) | Q4_K_M | 2.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q5_K_S.gguf) | Q5_K_S | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q5_K_M.gguf) | Q5_K_M | 2.3 | |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q6_K.gguf) | Q6_K | 2.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.Q8_0.gguf) | Q8_0 | 3.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/MonkeyOCR-Recognition-GGUF/resolve/main/MonkeyOCR-Recognition.f16.gguf) | f16 | 6.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
tuananhle/forecaster_dow30_tokenizer_250813
|
tuananhle
| 2025-08-12T19:43:27 | 0 | 0 |
transformers
|
[
"transformers",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T19:43:25 |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
wuav/Jinx-gpt-oss-20b-Q4_K_M-GGUF
|
wuav
| 2025-08-12T19:18:14 | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"vllm",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:Jinx-org/Jinx-gpt-oss-20b",
"base_model:quantized:Jinx-org/Jinx-gpt-oss-20b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T19:17:05 |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
base_model: Jinx-org/Jinx-gpt-oss-20b
tags:
- vllm
- llama-cpp
- gguf-my-repo
extra_gated_heading: You need to read and agree to the Disclaimer and User Agreementa
to access this model.
extra_gated_description: '
## Disclaimer and User Agreement
1. Introduction
Thank you for your interest in accessing this model (“the Model”).
Before you access, download, or use the Model or any derivative works, please read
and understand this Disclaimer and User Agreement (“Agreement”).
By checking “I have read and agree” and accessing the Model, you acknowledge that
you have read, understood, and agreed to all terms of this Agreement.
If you do not agree with any part of this Agreement, do not request or use the Model.
2. Nature of the Model & Risk Notice
The Model is trained using large-scale machine learning techniques and may generate
inaccurate, false, offensive, violent, sexual, discriminatory, politically sensitive,
or otherwise uncontrolled content.
The Model does not guarantee the accuracy, completeness, or legality of any generated
content. You must independently evaluate and verify the outputs, and you assume
all risks arising from their use.
The Model may reflect biases or errors present in its training data, potentially
producing inappropriate or controversial outputs.
3. License and Permitted Use
You may use the Model solely for lawful, compliant, and non-malicious purposes in
research, learning, experimentation, and development, in accordance with applicable
laws and regulations.
You must not use the Model for activities including, but not limited to:
Creating, distributing, or promoting unlawful, violent, pornographic, terrorist,
discriminatory, defamatory, or privacy-invasive content;
Any activity that could cause significant negative impact on individuals, groups,
organizations, or society;
High-risk applications such as automated decision-making, medical diagnosis, financial
transactions, or legal advice without proper validation and human oversight.
You must not remove, alter, or circumvent any safety mechanisms implemented in the
Model.
4. Data and Privacy
You are solely responsible for any data processed or generated when using the Model,
including compliance with data protection and privacy regulations.
The Model’s authors and contributors make no guarantees or warranties regarding
data security or privacy.
5. Limitation of Liability
To the maximum extent permitted by applicable law, the authors, contributors, and
their affiliated institutions shall not be liable for any direct, indirect, incidental,
or consequential damages arising from the use of the Model.
You agree to bear full legal responsibility for any disputes, claims, or litigation
arising from your use of the Model, and you release the authors and contributors
from any related liability.
6. Updates and Termination
This Agreement may be updated at any time, with updates posted on the Model’s page
and effective immediately upon publication.
If you violate this Agreement, the authors reserve the right to revoke your access
to the Model at any time.
I have read and fully understand this Disclaimer and User Agreement, and I accept
full responsibility for any consequences arising from my use of the Model.'
extra_gated_button_content: I've read and agree
---
# wuav/Jinx-gpt-oss-20b-Q4_K_M-GGUF
This model was converted to GGUF format from [`Jinx-org/Jinx-gpt-oss-20b`](https://huggingface.co/Jinx-org/Jinx-gpt-oss-20b) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Jinx-org/Jinx-gpt-oss-20b) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo wuav/Jinx-gpt-oss-20b-Q4_K_M-GGUF --hf-file jinx-gpt-oss-20b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo wuav/Jinx-gpt-oss-20b-Q4_K_M-GGUF --hf-file jinx-gpt-oss-20b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo wuav/Jinx-gpt-oss-20b-Q4_K_M-GGUF --hf-file jinx-gpt-oss-20b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo wuav/Jinx-gpt-oss-20b-Q4_K_M-GGUF --hf-file jinx-gpt-oss-20b-q4_k_m.gguf -c 2048
```
|
Jessica-Radcliffe-Orca-Attack-Viral-Video/TRENDING.VIDEOS.Jessica-Radcliffe.Orca.Attack.Viral.Video.Clip
|
Jessica-Radcliffe-Orca-Attack-Viral-Video
| 2025-08-12T18:41:27 | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T18:41:15 |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
AAAAnsah/Llama-3.2-1B_ES_theta_1.6
|
AAAAnsah
| 2025-08-12T18:33:19 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T18:33:03 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755022411
|
Ferdi3425
| 2025-08-12T18:14:26 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T18:14:21 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sophie-Rain-Spider-man-Video-Tu-torial/Sophie.Rain.Spiderman.Video.Tutorial
|
Sophie-Rain-Spider-man-Video-Tu-torial
| 2025-08-12T18:10:46 | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T18:10:31 |
<!-- HTML_TAG_END --><div>
<p><a rel="nofollow" href="https://leaked-videos.com/?v=Sophie Rain Spiderman">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐖𝐚𝐭𝐜𝐡 𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨)</a></p>
<p><a rel="nofollow" href="https://leaked-videos.com/?v=Sophie Rain Spiderman">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )</a></p>
<p><a rel="nofollow" href="https://leaked-videos.com/?v=Sophie Rain Spiderman"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a></p>
<!-- HTML_TAG_END --></div>
|
halcyonzhou/wav2vec2-base
|
halcyonzhou
| 2025-08-12T18:09:13 | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-12T18:08:42 |
---
library_name: transformers
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: wav2vec2-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9551
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 2.8538 | 200.0 | 1000 | 2.9838 | 1.0 |
| 2.6873 | 400.0 | 2000 | 2.9551 | 1.0 |
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.4
|
Akashiurahara/LoraTesting
|
Akashiurahara
| 2025-08-12T18:04:45 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"lora",
"roleplay",
"Tatsumaki",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-11T14:59:50 |
---
library_name: transformers
tags:
- unsloth
- lora
- roleplay
- Tatsumaki
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
stakesquid/blockassist-bc-scaly_shrewd_stingray_1755020966
|
stakesquid
| 2025-08-12T17:53:00 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly shrewd stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:52:55 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly shrewd stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mveroe/Qwen2.5-1.5B_lightr1_3_EN_6144_1p0_0p0_1p0_sft
|
mveroe
| 2025-08-12T17:51:02 | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-11T17:30:03 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755020601
|
Ferdi3425
| 2025-08-12T17:44:36 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:44:09 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kbashiru/Mobile_BERT_on_jumia_dataset
|
Kbashiru
| 2025-08-12T17:44:01 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mobilebert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T17:43:50 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
emily84/car-show-boards-for-next-car-show
|
emily84
| 2025-08-12T17:35:53 | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T17:35:37 |
Car Show Boards help your vehicle shine by giving it the platform it deserves. Make your setup look complete and professional.
✨ Order your custom board today.
👉 https://carshowboards.com/
#StandOutDisplay #CarShowEssentials #DisplayThatPops #AutoShowPresentation #ShowTimeStyle
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755020012
|
IvanJAjebu
| 2025-08-12T17:35:01 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:34:32 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755019605
|
IvanJAjebu
| 2025-08-12T17:28:14 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:27:39 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bilalzafar/CBDC-BERT
|
bilalzafar
| 2025-08-12T17:17:40 | 30 | 0 | null |
[
"safetensors",
"bert",
"BERT",
"Finance",
"CBDC",
"Central-Bank",
"Central-Bank-Speeches",
"Central-Bank-Digital-Currency",
"NLP",
"Finance-NLP",
"BIS",
"text-classification",
"en",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:mit",
"region:us"
] |
text-classification
| 2025-07-13T21:56:48 |
---
license: mit
language:
- en
metrics:
- accuracy
- f1
base_model:
- google-bert/bert-base-uncased
pipeline_tag: text-classification
tags:
- BERT
- Finance
- CBDC
- Central-Bank
- Central-Bank-Speeches
- Central-Bank-Digital-Currency
- NLP
- Finance-NLP
- BIS
---
# CBDC-BERT: A Transformer-Based Model for Identifying Central Bank Digital Currency Discourse in Policy Speeches
**CBDC-BERT** is a fine-tuned `bert-base-uncased` model developed to identify Central Bank Digital Currency (CBDC)-related disclosures in central bank speeches. It is trained on manually labeled data extracted from 19,000+ BIS speeches spanning 1996–2024.
---
## 🧠 Model Details
- **Base model**: BERT (`bert-base-uncased`)
- **Task**: Binary sentence classification
- **Labels**: `0 = Non-CBDC`, `1 = CBDC`
- **Training examples**: 11,000
- **Language**: English
- **Tokenizer**: WordPiece
---
## 💡 Use Scope & Limitations
### 🎯 Intended Uses
- Analyzing CBDC-related discourse in central bank policy speeches
- Supporting research on the evolution of CBDC communication over time
- Enhancing NLP pipelines in financial policy, regulation, and central banking analytics
- Powering dashboards or indices that track central bank digital currency sentiment and narratives
- Pre-filtering speech content for economic or monetary policy researchers focusing on digital currency
### 🚫 Out-of-Scope
- Not designed for multi-language support (English-only training data)
- Not a general-purpose speech classifier — model is specific to CBDC discourse
- Not suitable for informal texts (e.g., tweets, news headlines, or blog content)
- Not intended for legal or compliance decision-making without human oversight
---
## 📊 Performance
| Metric | Score |
|---------------|-----------|
| Accuracy | 99.45% |
| F1 Score | 0.9945 |
| ROC AUC | 0.9999 |
| Brier Score | 0.0026 |
---
## 📚 Training Data
- **Source**: BIS Central Bank Speeches Dataset (1996–2024)
- **Total Samples**: 11,000 labeled sentences
- **Positive class (CBDC = 1)**: 5,390 sentences
- Extracted using a curated list of CBDC-related keywords (hard + soft)
- Manually verified for relevance and labeled by human annotators
- **Negative class (Non-CBDC = 0)**: 5,610 sentences
- 56 manually identified from the CBDC-labeled file
- 5,554 selected from a pool of:
- **CBDC speeches (hard negatives)**: Sentences not labeled as CBDC but from CBDC-relevant speeches
- **General speeches (easy negatives)**: Random samples from unrelated BIS speeches
---
## 🛠️ Training Details
- **Model**: `bert-base-uncased`
- **Task**: Binary Text Classification
- **Library**: 🤗 Transformers (Trainer API)
- **Dataset Format**: CSV → Hugging Face `Dataset`
- **Tokenizer**: `bert-base-uncased`, max length = 128
- **Train/Test Split**: 80/20 (stratified)
### ⚙️ Configuration
- **Epochs**: 3
- **Batch Size**: 8
- **Optimizer**: AdamW
- **Loss Function**: CrossEntropyLoss
- **Evaluation Strategy**: Per epoch
- **Metric for Best Model**: F1 Score
- **Logging Steps**: 10
- **Max Saved Checkpoints**: 2
- **Hardware**: Google Colab GPU
### 📊 Metrics
- **Evaluation Metrics**: Accuracy, F1 Score
---
### Classification Report
| Class | Precision | Recall | F1 | Support |
|-------|-----------|--------|----|---------|
| Non-CBDC | 1.00 | 1.00 | 1.00 | 1 109 |
| CBDC | 1.00 | 1.00 | 1.00 | 1 066 |
---
## 🧪 Robustness Checks
| Category | Correct | Total | Accuracy |
|----------|---------|-------|----------|
| Edge cases | 8 | 10 | 80 % |
| Noise-injected | 9 | 10 | 90 % |
| Syntactically altered | 8 | 10 | 80 % |
| Paraphrased | 8 | 10 | 80 % |
- **Domain alignment**: Optimized for English-language BIS central bank speeches — the model performs exceptionally well within this high-value domain.
- **Terminology evolution**: While CBDC language may evolve, the model is built on a robust mix of historical and contemporary usage, providing strong generalization across time.
- **Sentence length**: Minimal bias detected (correlation ρ ≈ 0.12) — predictions remain stable across short and long sentences within the 128-token limit.
- **Annotation quality**: Labels are expert-verified using curated CBDC keyword filters and manual checks, ensuring high data fidelity.
---
## 🔁 Baseline Comparison (TF-IDF + Traditional ML)
| Model | Accuracy |
|-------|----------|
| Logistic Regression | 0.97 |
| Naive Bayes | 0.92 |
| Random Forest | 0.98 |
| XGBoost | 0.99 |
CBDC-BERT surpasses all traditional baselines, particularly on F1 and ROC AUC.
---
## 📝 Citation
If you use this model in your research or application, please cite it as:
> **CBDC-BERT: A Transformer-Based Model for Identifying Central Bank Digital Currency Discourse in Policy Speeches**
> *Paper under write-up*
>
📬 For academic or technical inquiries, contact:
**Dr. Muhammad Bilal Zafar**
📧 [email protected]
---
## 📦 Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("bilalzafar/CBDC-BERT")
model = AutoModelForSequenceClassification.from_pretrained("bilalzafar/CBDC-BERT")
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
label_map = {"LABEL_0": "Non-CBDC", "LABEL_1": "CBDC"}
text = "The central bank is exploring the issuance of a retail digital currency."
result = classifier(text)[0]
print(f"Prediction: {label_map[result['label']]} | Confidence: {result['score']:.4f}")
|
danhtran2mind/Stable-Diffusion-2.1-Openpose-ControlNet
|
danhtran2mind
| 2025-08-12T17:13:03 | 13 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"controlnet",
"open-pose",
"text-to-image",
"en",
"dataset:HighCWu/open_pose_controlnet_subset",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:mit",
"region:us"
] |
text-to-image
| 2025-08-11T09:23:08 |
---
license: mit
datasets:
- HighCWu/open_pose_controlnet_subset
language:
- en
base_model:
- stabilityai/stable-diffusion-2-1
pipeline_tag: text-to-image
tags:
- controlnet
- open-pose
---
|
Abuzaid01/asl-sign-language-classifier
|
Abuzaid01
| 2025-08-12T16:45:22 | 0 | 0 | null |
[
"pytorch",
"resnet",
"region:us"
] | null | 2025-08-12T14:19:08 |
# ASL Sign Language Classification Model
This model is trained to recognize American Sign Language (ASL) alphabets.
## Model Details
- Base Architecture: ResNet50
- Number of Classes: 29
- Test Accuracy: 0.9999
## Usage
```python
from transformers import AutoImageProcessor, AutoModelForImageClassification
from PIL import Image
model = AutoModelForImageClassification.from_pretrained('YOUR_USERNAME/asl-sign-language-classifier')
processor = AutoImageProcessor.from_pretrained('YOUR_USERNAME/asl-sign-language-classifier')
image = Image.open('path_to_image.jpg')
inputs = processor(images=image, return_tensors='pt')
outputs = model(**inputs)
predicted_class_idx = outputs.logits.argmax(-1).item()
```
|
ACECA/lowMvMax_141
|
ACECA
| 2025-08-12T16:44:21 | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T15:15:31 |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
PredatorAlpha/my-QA-model
|
PredatorAlpha
| 2025-08-12T16:42:04 | 1 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:rajpurkar/squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2025-08-10T15:26:50 |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: my-QA-model
results: []
datasets:
- rajpurkar/squad
metrics:
- squad
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my-QA-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an SQuAD v1.1 dataset.
## Model description
This is a transformer-based **extractive Question Answering (QA) model** fine-tuned on the **Stanford Question Answering Dataset (SQuAD v1.1)**.
It takes a context paragraph and a natural language question as input and returns the most probable span in the text that answers the question.
- **Architecture:** DistilBERT
- **Dataset:** SQuAD v1.1 (~100k question-answer pairs)
- **Task Type:** Extractive Question Answering
- **Training Objective:** Predict start and end token positions of the answer span
- **Evaluation Metrics:** Exact Match (EM) and F1 Score
---
## Intended uses & limitations
This model is designed for **extractive question answering** where the answer exists within a provided context.
It can be applied in reading comprehension tasks, chatbots, document search, automated quiz generation, educational tools, and research on transformer-based QA systems.
However, the model has limitations:
- It can only answer questions if the answer is present in the given text.
- It struggles with multi-hop reasoning, abstract inference, and answers requiring outside knowledge.
- Ambiguous or vague questions may result in incorrect spans.
- Performance may degrade on domains that differ significantly from Wikipedia (SQuAD’s source).
- It may reflect biases in the training data.
## Training and evaluation data
The model was fine-tuned on the **Stanford Question Answering Dataset (SQuAD v1.1)**, a large-scale reading comprehension dataset consisting of over **100,000 question–answer pairs** on Wikipedia articles.
- **Training set:** ~87,599 examples
- **Validation set:** ~10,570 examples
- Each example contains a context paragraph, a question, and the corresponding answer span within the paragraph.
Evaluation was performed on the SQuAD v1.1 validation set using **Exact Match (EM)** and **F1 score** metrics.
## Training procedure
1. **Base Model:** A pre-trained transformer model Distibert-base-uncased from Hugging Face.
2. **Tokenization:** Used the model's corresponding tokenizer with:
- `max_length=384`
- `truncation='only_second'`
- `stride=128` for sliding window over long contexts
3. **Optimization:**
- Optimizer: AdamW
- Learning rate: 3e-5
- Weight decay: 0.01
- Batch size: 16–32 (depending on GPU memory)
- Epochs: 2–3
4. **Loss Function:** Cross-entropy loss over start and end token positions.
5. **Evaluation:** Computed **Exact Match (EM)** and **F1 score** after each epoch.
6. **Checkpointing:** Best model saved based on highest F1 score on validation set.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
The model achieved the following results on the SQuAD v1.1 validation set:
| Metric | Score |
|-----------------------|--------|
| Exact Match (EM) | 51% |
| F1 Score | 70.2% |
| Training Loss (final) | 0.64% |
These results are comparable to other transformer-based models fine-tuned on SQuAD , demonstrating strong extractive question answering capabilities.
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
fatmhd1995/phi35_ft_llm_4_annotation_rnd2
|
fatmhd1995
| 2025-08-12T16:41:35 | 4 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T01:13:17 |
---
base_model: unsloth/phi-3.5-mini-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** fatmhd1995
- **License:** apache-2.0
- **Finetuned from model :** unsloth/phi-3.5-mini-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ACECA/lowMvMax_139
|
ACECA
| 2025-08-12T16:38:51 | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T15:15:30 |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755016429
|
IvanJAjebu
| 2025-08-12T16:35:15 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:34:50 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pyamy/dpo-assignment-4-artifacts
|
pyamy
| 2025-08-12T16:30:57 | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-08-12T14:51:44 |
here’s a clean, structured **Markdown** you can paste straight into your Hugging Face artifacts README:
---
# DPO Assignment 4 — Full Artifacts
All local artifacts from my run (datasets on disk, DPO adapters, CSV/TXT outputs, and the notebook).
## Assignment 4 (verbatim prompt)
```
Assignment 4
In this assignment, we will be generating a preference dataset with PairRM and fine tuning a model with DPO. This is a powerful training recipe that is behind some of the top models according to Alpaca Eval.
You may use llama-3.2 1B or llama-3.2 3B.
Preference Dataset Collection and DPO Model Training
Part 1: Dataset Generation and Judge Implementation (40 points)
Create two separate preference datasets using different collection methods:
a) LLM Judge-Based Collection (20 points)
- Implement an LLM-based judge system
- Document your reasoning for the judge's prompt design
- Explain how you ensure consistent and reliable preference judgments
- Include examples of the judge's evaluation process
- You can choose between using local inference on Colab/Lightning studio or a 3rd party provider like fireworks ai/openai/together ai/groq (kimi k2)
b) PairRM-Based Collection (20 points)
- Extract 50 instructions from the Lima dataset
- Generate 5 responses per instruction using the llama-3.2 chat template
- Apply PairRM to create preference pairs
- Upload dataset to HuggingFace
- Submit repository link
Part 2: Model Training and Evaluation (60 points)
a) DPO Fine-tuning (40 points)
- Fine-tune llama-3.2 using PairRM preference dataset
- Fine-tune llama-3.2 using LLM Judge preference dataset
- Document training parameters and process
- Upload PEFT adapters to HuggingFace
- Submit repository links
b) Comparative Analysis (20 points)
- Select 10 novel instructions (not in training data)
- Generate completions using:
* Original llama-3.2
* DPO fine-tuned model (LLM judge dataset)
* DPO fine-tuned model (PairRM dataset)
- Present results in a pandas DataFrame
- Analyze and compare the quality of completions
- Include quantitative and qualitative observations
Address the following points:
1. Qualitative differences in model outputs
2. Training stability across iterations
3. Computational efficiency considerations
4. Potential limitations and failure modes
5. Suggestions for improvement
Grading Criteria for Free Response:
- Depth of technical understanding
- Critical analysis of results
- Clear articulation of observations
- Original insights and suggestions
- Proper technical writing style
Extra Credit: Iterative DPO Implementation and Analysis (30 points)
a) Implementation (20 points)
- Implement the iterative DPO algorithm as described in "Self Rewarding Language Models"
- Train multiple iterations of the model (minimum 2 iterations)
- Document:
* Implementation details
* Training parameters
b) Comparative Analysis (10 points)
Free Response Question (~250 words)
Compare and analyze the performance and behavioral differences against the base llama-3.2 model, the DPO-PairRM model, and DPO-LLM-judge model
```
---
## Submission Links by Requirement
### 1a) LLM Judge-Based Collection (20 pts)
* **Dataset (HF Datasets):** [https://huggingface.co/datasets/pyamy/dpo-llm-judge-preferences-llama3](https://huggingface.co/datasets/pyamy/dpo-llm-judge-preferences-llama3)
* **Judge design doc filename:** `llm_judge_design_documentation_20250811_212607.txt` (included in artifacts)
* **Compute:** Local GPU
### 1b) PairRM-Based Collection (20 pts)
* **Dataset (HF Datasets):** [https://huggingface.co/datasets/pyamy/dpo-pairrm-preferences-llama3](https://huggingface.co/datasets/pyamy/dpo-pairrm-preferences-llama3)
* **Spec:** 50 LIMA instructions; 5 responses/instruction; 250 preference pairs
---
### 2a) DPO Fine-tuning (40 pts)
* **Base model:** `meta-llama/Llama-3.2-1B-Instruct`
* **Adapters (HF Models):**
* PairRM DPO: [https://huggingface.co/pyamy/llama3-dpo-pairrm](https://huggingface.co/pyamy/llama3-dpo-pairrm)
* LLM-Judge DPO: [https://huggingface.co/pyamy/llama3-dpo-llm-judge](https://huggingface.co/pyamy/llama3-dpo-llm-judge)
* **Training parameters/process:** Logged in notebook output (per-step losses; LoRA adapters saved)
### 2b) Comparative Analysis (20 pts)
* **Novelty check:** 10 evaluation prompts; **overlap with training = 0/10**
* **Results table:** `evaluation_results.csv` (saved with outputs from base + both DPO models)
**Quantitative snapshot (from `evaluation_results.csv`):**
| Model | avg\_words | avg\_chars | bullet\_like\_frac |
| ------------- | ---------- | ---------- | ------------------ |
| Base | 26.1 | 153.0 | 0.10 |
| DPO-PairRM | 27.3 | 153.0 | 0.30 |
| DPO-LLM-Judge | 26.6 | 153.0 | 0.10 |
**Qualitative observation (from table):**
DPO-PairRM tends to produce more stepwise, list-style answers; DPO-LLM-Judge remains more conversational while adhering to instructions.
---
## Extra Credit — Iterative DPO (30 pts)
* **Iteration 1:** +20 new preference pairs → model `./iterative_dpo_model_iter_1`
* **Iteration 2:** +0 new pairs → model `./iterative_dpo_model_iter_2`
* **Analysis file:** `iterative_dpo_analysis.txt`
---
## Free Response (\~250 words)
This assignment applies Direct Preference Optimization (DPO) to Llama-3.2-1B-Instruct using two preference sources: PairRM (250 pairs) and an LLM-judge dataset (150 pairs). DPO optimizes the log-odds of “chosen” over “rejected” responses while constraining divergence from the reference with a KL term (β controls that trade-off; not reported here). Evaluation on 10 novel prompts (0/10 overlap with training) compares the base model with both DPO fine-tunes. From `evaluation_results.csv`, corpus-level statistics show a small style shift after DPO: average words per response increase for the DPO models relative to base, and list-style formatting rises notably for DPO-PairRM (higher bullet-like fraction), indicating stronger structural bias from PairRM preferences. Qualitatively (inspecting the table), DPO-PairRM tends toward stepwise, “instructional” phrasing; DPO-LLM-judge remains more conversational while still adhering to the prompts. Training stability and runtime were not re-measured in this run (existing models were reused), so I avoid claims there. Limitations include small preference sets and automated-judge bias; these can over-reward length/format. Improvements: log β and other hyperparameters alongside results; add an automatic win-rate over the 10 prompts (e.g., a simple LLM judge sweep) to complement length/format metrics; and broaden preference diversity (e.g., more instructions or ensemble judges). Overall, DPO nudges structure and adherence in ways consistent with the active preference signal without visible degradation on these prompts.
---
## All Links
* **Assignment 4 artifacts:** [https://huggingface.co/pyamy/dpo-assignment-4-artifacts](https://huggingface.co/pyamy/dpo-assignment-4-artifacts)
* **PairRM dataset:** [https://huggingface.co/datasets/pyamy/dpo-pairrm-preferences-llama3](https://huggingface.co/datasets/pyamy/dpo-pairrm-preferences-llama3)
* **LLM-Judge dataset:** [https://huggingface.co/datasets/pyamy/dpo-llm-judge-preferences-llama3](https://huggingface.co/datasets/pyamy/dpo-llm-judge-preferences-llama3)
* **DPO-PairRM adapters:** [https://huggingface.co/pyamy/llama3-dpo-pairrm](https://huggingface.co/pyamy/llama3-dpo-pairrm)
* **DPO-LLM-Judge adapters:** [https://huggingface.co/pyamy/llama3-dpo-llm-judge](https://huggingface.co/pyamy/llama3-dpo-llm-judge)
* **Colab notebook:** [https://colab.research.google.com/drive/1\_vgdQph7H0kO\_Vx\_DF4q9sPwdN8xtYvS?usp=sharing](https://colab.research.google.com/drive/1_vgdQph7H0kO_Vx_DF4q9sPwdN8xtYvS?usp=sharing)
---
**Uploaded from:** `f:\Northeastern 2024-2025\INFO7374\Assignment 4\Final`
**Upload time (UTC):** 2025-08-12T14:57:34Z
---
|
relapseone/blockassist-bc-insectivorous_prickly_shrew_1755014360
|
relapseone
| 2025-08-12T16:27:28 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous prickly shrew",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:27:25 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous prickly shrew
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
albertuspekerti/whispertiny_fruit25syl_v7_2
|
albertuspekerti
| 2025-08-12T16:19:16 | 7 | 0 | null |
[
"tensorboard",
"safetensors",
"whisper",
"generated_from_trainer",
"base_model:albertuspekerti/whispertiny_fruit25syl_v3_2",
"base_model:finetune:albertuspekerti/whispertiny_fruit25syl_v3_2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T02:47:49 |
---
license: apache-2.0
base_model: albertuspekerti/whispertiny_fruit25syl_v3_2
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whispertiny_fruit25syl_v7_2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whispertiny_fruit25syl_v7_2
This model is a fine-tuned version of [albertuspekerti/whispertiny_fruit25syl_v3_2](https://huggingface.co/albertuspekerti/whispertiny_fruit25syl_v3_2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0293
- Wer: 2.4911
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 200000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-------:|:------:|:---------------:|:-------:|
| 0.0017 | 0.01 | 2000 | 0.1528 | 13.6069 |
| 0.0046 | 0.02 | 4000 | 0.5572 | 23.3619 |
| 0.0025 | 0.03 | 6000 | 0.2777 | 20.2010 |
| 0.0032 | 0.04 | 8000 | 0.2153 | 20.7452 |
| 0.0032 | 0.05 | 10000 | 0.2302 | 18.2332 |
| 0.0224 | 1.0027 | 12000 | 0.4752 | 37.4293 |
| 0.0007 | 1.0127 | 14000 | 0.2770 | 17.7517 |
| 0.0016 | 1.0227 | 16000 | 0.1509 | 15.3862 |
| 0.0037 | 1.0327 | 18000 | 0.5857 | 24.4714 |
| 0.001 | 1.0427 | 20000 | 0.3885 | 32.2797 |
| 0.0019 | 1.0527 | 22000 | 0.2408 | 19.3008 |
| 0.0081 | 2.0054 | 24000 | 0.1916 | 16.2236 |
| 0.0008 | 2.0154 | 26000 | 0.1684 | 14.7163 |
| 0.0001 | 2.0254 | 28000 | 0.1511 | 13.8581 |
| 0.0012 | 2.0354 | 30000 | 0.2209 | 14.5907 |
| 0.0023 | 2.0454 | 32000 | 0.4412 | 23.9900 |
| 0.0022 | 2.0554 | 34000 | 0.2314 | 17.9192 |
| 0.0005 | 3.0081 | 36000 | 0.2667 | 20.9755 |
| 0.0016 | 3.0181 | 38000 | 0.2627 | 14.7163 |
| 0.002 | 3.0281 | 40000 | 0.1328 | 10.9902 |
| 0.0004 | 3.0381 | 42000 | 0.1712 | 13.2510 |
| 0.0004 | 3.0481 | 44000 | 0.4716 | 24.8901 |
| 0.0044 | 4.0008 | 46000 | 0.1900 | 12.5183 |
| 0.001 | 4.0108 | 48000 | 0.0963 | 10.4668 |
| 0.0005 | 4.0208 | 50000 | 0.3588 | 18.7147 |
| 0.0012 | 4.0308 | 52000 | 0.3890 | 25.7484 |
| 0.0009 | 4.0408 | 54000 | 0.2656 | 17.9611 |
| 0.0008 | 4.0508 | 56000 | 0.1365 | 13.1882 |
| 0.0088 | 5.0035 | 58000 | 0.0693 | 7.5780 |
| 0.0007 | 5.0135 | 60000 | 0.1331 | 8.7921 |
| 0.0004 | 5.0235 | 62000 | 0.1024 | 10.1528 |
| 0.0005 | 5.0335 | 64000 | 0.3344 | 19.6567 |
| 0.0006 | 5.0435 | 66000 | 0.2273 | 22.6502 |
| 0.0012 | 5.0535 | 68000 | 0.2045 | 13.6906 |
| 0.0011 | 6.0062 | 70000 | 0.1301 | 11.7438 |
| 0.0004 | 6.0162 | 72000 | 0.1255 | 11.0530 |
| 0.0002 | 6.0262 | 74000 | 0.1529 | 9.7969 |
| 0.0006 | 6.0362 | 76000 | 0.0905 | 9.2945 |
| 0.0004 | 6.0462 | 78000 | 0.4328 | 28.4279 |
| 0.0004 | 6.0562 | 80000 | 0.1318 | 12.4346 |
| 0.0007 | 7.0089 | 82000 | 0.0870 | 8.2269 |
| 0.001 | 7.0189 | 84000 | 0.1575 | 12.7277 |
| 0.0004 | 7.0289 | 86000 | 0.0802 | 7.5570 |
| 0.0003 | 7.0389 | 88000 | 0.0924 | 8.8549 |
| 0.0005 | 7.0489 | 90000 | 0.1631 | 15.3025 |
| 0.0046 | 8.0016 | 92000 | 0.0694 | 6.3429 |
| 0.0003 | 8.0116 | 94000 | 0.0854 | 7.2012 |
| 0.0002 | 8.0216 | 96000 | 0.2454 | 16.4329 |
| 0.0009 | 8.0316 | 98000 | 0.3096 | 18.8193 |
| 0.0008 | 8.0416 | 100000 | 0.1424 | 9.3992 |
| 0.0003 | 8.0516 | 102000 | 0.1211 | 9.8179 |
| 0.0005 | 9.0043 | 104000 | 0.0815 | 7.1384 |
| 0.0002 | 9.0143 | 106000 | 0.1122 | 6.5732 |
| 0.0003 | 9.0243 | 108000 | 0.0740 | 6.8872 |
| 0.0003 | 9.0343 | 110000 | 0.3435 | 20.5359 |
| 0.0006 | 9.0443 | 112000 | 0.1206 | 10.2784 |
| 0.0006 | 9.0543 | 114000 | 0.1424 | 8.2269 |
| 0.0002 | 10.0070 | 116000 | 0.1405 | 10.0481 |
| 0.0002 | 10.0170 | 118000 | 0.0544 | 5.0869 |
| 0.0003 | 10.0270 | 120000 | 0.1357 | 7.2430 |
| 0.0019 | 10.0371 | 122000 | 0.0717 | 6.9918 |
| 0.0004 | 10.0471 | 124000 | 0.1705 | 10.9274 |
| 0.0 | 10.0571 | 126000 | 0.1093 | 7.2430 |
| 0.0001 | 11.0098 | 128000 | 0.0741 | 5.6730 |
| 0.0004 | 11.0198 | 130000 | 0.1728 | 12.4764 |
| 0.0001 | 11.0298 | 132000 | 0.1004 | 6.5104 |
| 0.0003 | 11.0398 | 134000 | 0.0998 | 6.5313 |
| 0.0002 | 11.0498 | 136000 | 0.0776 | 7.4314 |
| 0.0009 | 12.0025 | 138000 | 0.0493 | 4.3333 |
| 0.0002 | 12.0125 | 140000 | 0.0642 | 4.6054 |
| 0.0001 | 12.0225 | 142000 | 0.0839 | 6.6988 |
| 0.001 | 12.0325 | 144000 | 0.1505 | 10.2156 |
| 0.0002 | 12.0425 | 146000 | 0.0996 | 6.1336 |
| 0.0002 | 12.0525 | 148000 | 0.0635 | 4.9194 |
| 0.0002 | 13.0052 | 150000 | 0.0752 | 5.4218 |
| 0.0001 | 13.0152 | 152000 | 0.0610 | 4.3542 |
| 0.0001 | 13.0252 | 154000 | 0.0505 | 4.2705 |
| 0.0001 | 13.0352 | 156000 | 0.3230 | 16.6632 |
| 0.0009 | 13.0452 | 158000 | 0.0555 | 5.1497 |
| 0.0001 | 13.0552 | 160000 | 0.0913 | 5.6730 |
| 0.0 | 14.0079 | 162000 | 0.1059 | 6.5313 |
| 0.0003 | 14.0179 | 164000 | 0.0450 | 4.3542 |
| 0.0001 | 14.0279 | 166000 | 0.0555 | 3.5587 |
| 0.0001 | 14.0379 | 168000 | 0.0813 | 6.9081 |
| 0.0002 | 14.0479 | 170000 | 0.1188 | 9.0852 |
| 0.0001 | 15.0006 | 172000 | 0.0599 | 4.1030 |
| 0.0001 | 15.0106 | 174000 | 0.0537 | 4.1030 |
| 0.0002 | 15.0206 | 176000 | 0.0909 | 6.1545 |
| 0.0002 | 15.0306 | 178000 | 0.0406 | 3.1610 |
| 0.0005 | 15.0406 | 180000 | 0.0352 | 2.9307 |
| 0.0002 | 15.0506 | 182000 | 0.0512 | 4.5007 |
| 0.0 | 16.0033 | 184000 | 0.0435 | 3.1400 |
| 0.0008 | 16.0133 | 186000 | 0.0332 | 2.5539 |
| 0.0002 | 16.0233 | 188000 | 0.0716 | 5.0450 |
| 0.0013 | 16.0333 | 190000 | 0.0415 | 3.4331 |
| 0.0001 | 16.0433 | 192000 | 0.0273 | 2.3864 |
| 0.0021 | 16.0533 | 194000 | 0.0278 | 2.3864 |
| 0.0011 | 17.0060 | 196000 | 0.0279 | 2.3446 |
| 0.001 | 17.0160 | 198000 | 0.0262 | 2.3446 |
| 0.0001 | 17.0260 | 200000 | 0.0293 | 2.4911 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755015125
|
Ferdi3425
| 2025-08-12T16:13:29 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:13:02 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
LocaleNLP/english_bambara
|
LocaleNLP
| 2025-08-12T16:07:37 | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T16:07:37 |
---
license: apache-2.0
---
|
Zuntan/Wan22-I2V_A14B-Lightning-GGUF
|
Zuntan
| 2025-08-12T16:05:13 | 16,152 | 2 | null |
[
"gguf",
"region:us"
] | null | 2025-08-10T14:29:03 |
# Wan22-I2V_A14B-Lightning
Geforce RTX 3060 12GB: 560px * 560px, 81f
Sigmas: `1, 0.94, 0.85, 0.73, 0.55, 0.28, 0`
High: `3steps`
Low: `3steps`
Shift: `4.5`
Enhance-A-Video weight: 1
Fresca: low 1, high 1.25, cutoff 17
## Refiner
SeedGacha SSR Video > Upscaler x1.5 & Encode
Geforce RTX 3060 12GB: 840px * 840px, 81f
Sigma: `1.0, 0.97, 0.94, 0.90, 0.85, 0.795, 0.73, 0.65, 0.55, 0.42, 0.28, 0.14, 0.0`
steps: `12`
start_steps: `10-8`(`2-4`steps)
Shift: `6.75`(`4.5` x1.5)
Enhance-A-Video weight: `1`
Disable Fresca
Enable `add_noise_to_samples`
and Upscaler x2, VFI x3~4
## Wan22-I2V_A14B-Lightning-H
- [wan2.2_i2v_high_noise_14B_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/blob/main/split_files/diffusion_models/wan2.2_i2v_high_noise_14B_fp16.safetensors)
- [Wan2.2-Lightning/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/high_noise_model.safetensors](https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/high_noise_model.safetensors) x1.0
## Wan22-I2V_A14B-Lightning-L
- [wan2.2_i2v_low_noise_14B_fp16.safetensors](https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/blob/main/split_files/diffusion_models/wan2.2_i2v_low_noise_14B_fp16.safetensors)
- [Wan2.2-Lightning/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/low_noise_model.safetensors](https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-I2V-A14B-4steps-lora-rank64-Seko-V1/low_noise_model.safetensors) x1.0
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755014420
|
ggozzy
| 2025-08-12T16:01:43 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:01:29 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kayacrypto/blockassist-bc-thriving_barky_wolf_1755014152
|
kayacrypto
| 2025-08-12T15:57:38 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thriving barky wolf",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:57:18 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thriving barky wolf
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
poliandrrrr/my_awesome_opus_books_model
|
poliandrrrr
| 2025-08-12T15:55:15 | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T14:39:47 |
---
library_name: transformers
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: my_awesome_opus_books_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_opus_books_model
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6049
- Bleu: 6.4087
- Gen Len: 18.325
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|
| 1.8708 | 1.0 | 6355 | 1.6275 | 6.23 | 18.3282 |
| 1.8193 | 2.0 | 12710 | 1.6049 | 6.4087 | 18.325 |
### Framework versions
- Transformers 4.55.0
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
daslab-testing/Qwen3-8B-FPQuant-QAT-NVFP4-1000steps
|
daslab-testing
| 2025-08-12T15:53:17 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"fp_quant",
"region:us"
] |
text-generation
| 2025-08-12T15:43:46 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Noelesther/Mistral-7B-Instruct-v0.3-Gensyn-Swarm-swift_zealous_quail
|
Noelesther
| 2025-08-12T15:48:38 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am swift_zealous_quail",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T15:40:50 |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am swift_zealous_quail
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
openclimatefix/pvnet_v2_summation
|
openclimatefix
| 2025-08-12T15:43:13 | 0 | 0 |
pytorch
|
[
"pytorch",
"en",
"license:mit",
"region:us"
] | null | 2023-08-11T11:19:46 |
---
language: en
library_name: pytorch
license: mit
---
<!--
Do not remove elements like the above surrounded by two curly braces and do not add any more of them. These entries are required by the library and are automaticall infilled when the model is uploaded to huggingface
-->
<!-- Title - e.g. PVNet-summation -->
# PVNet_summation
<!-- Provide a longer summary of what this model is/does. -->
## Model Description
<!-- e.g.
This model uses the output predictions of PVNet to predict the sum from predictions of the parts
-->
This model class sums the output of the PVNet model's GSP level predictions to make a national forecast of UK PV output. More information can be found in the model repo [1], the PVNet model repo [2]
- **Developed by:** openclimatefix
- **Language(s) (NLP):** en
- **License:** mit
# Training Details
## Data
<!-- eg.
The model is trained on data from 2019-2022 and validated on data from 2022-2023. It uses the
output predictions from PVNet - see the PVNet model for its inputs
-->
The model is trained on the output predictions of our PVNet model which gives GSP (i.e. UK regional) level predictions of solar power across Great Britain. This model is trained to take those predictions and use them to estimate the national total with uncertainty estimates.
The model is trained on data from 2019-2021 and validated on data from 2022. It uses the
output predictions from PVNet - see the PVNet model for its inputs
<!-- The preprocessing section is not strictly nessessary but perhaps nice to have -->
### Preprocessing
<!-- eg.
Data is prepared with the `ocf_data_sampler/torch_datasets/datasets/pvnet_uk` Dataset [2].
-->
## Results
<!-- Do not remove the lines below -->
The training logs for this model commit can be found here:
- [https://wandb.ai/openclimatefix/pvnet_summation/runs/gtjmp2r6](https://wandb.ai/openclimatefix/pvnet_summation/runs/gtjmp2r6)
<!-- The hardware section is also just nice to have -->
### Hardware
<!-- e.g.
Trained on a single NVIDIA Tesla T4
-->
Trained on a single NVIDIA Tesla T4
<!-- Do not remove the section below -->
### Software
This model was trained using the following Open Climate Fix packages:
- [1] https://github.com/openclimatefix/pvnet-summation
- [2] https://github.com/openclimatefix/ocf-data-sampler
<!-- Especially do not change the two lines below -->
The versions of these packages can be found below:
- pvnet_summation==1.0.0.post1+git.36f3523d.dirty
- ocf-data-sampler==0.4.0
|
demonwizard0/llama-3b-finetuned
|
demonwizard0
| 2025-08-12T15:39:36 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T15:39:05 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LiquidAI/LFM2-350M
|
LiquidAI
| 2025-08-12T15:34:27 | 12,677 | 92 |
transformers
|
[
"transformers",
"safetensors",
"lfm2",
"text-generation",
"liquid",
"edge",
"conversational",
"en",
"ar",
"zh",
"fr",
"de",
"ja",
"ko",
"es",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-07-10T12:01:24 |
---
library_name: transformers
license: other
license_name: lfm1.0
license_link: LICENSE
language:
- en
- ar
- zh
- fr
- de
- ja
- ko
- es
pipeline_tag: text-generation
tags:
- liquid
- lfm2
- edge
---
<center>
<div style="text-align: center;">
<img
src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/7_6D7rWrLxp2hb6OHSV1p.png"
alt="Liquid AI"
style="width: 100%; max-width: 66%; height: auto; display: inline-block; margin-bottom: 0.5em; margin-top: 0.5em;"
/>
</div>
<a href="https://playground.liquid.ai/chat">
<svg width="114.8" height="20" viewBox="0 0 1300 200" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Liquid Playground" style="margin-bottom: 1em;">
<title>Liquid: Playground</title>
<g>
<rect fill="#fff" width="600" height="200"></rect>
<rect fill="url(#x)" x="600" width="700" height="200"></rect>
</g>
<g transform="translate(20, 30) scale(0.4, 0.4)">
<path d="M172.314 129.313L172.219 129.367L206.125 188.18C210.671 195.154 213.324 203.457 213.324 212.382C213.324 220.834 210.956 228.739 206.839 235.479L275.924 213.178L167.853 33.6L141.827 76.9614L172.314 129.313Z" fill="black"/>
<path d="M114.217 302.4L168.492 257.003C168.447 257.003 168.397 257.003 168.352 257.003C143.515 257.003 123.385 237.027 123.385 212.387C123.385 203.487 126.023 195.204 130.55 188.24L162.621 132.503L135.966 86.7327L60.0762 213.183L114.127 302.4H114.217Z" fill="black"/>
<path d="M191.435 250.681C191.435 250.681 191.43 250.681 191.425 250.686L129.71 302.4H221.294L267.71 226.593L191.435 250.686V250.681Z" fill="black"/>
</g>
<g aria-hidden="true" fill="#fff" text-anchor="start" font-family="Verdana,DejaVu Sans,sans-serif" font-size="110">
<text x="200" y="148" textLength="329" fill="#000" opacity="0.1">Liquid</text>
<text x="190" y="138" textLength="329" fill="#000">Liquid</text>
<text x="655" y="148" textLength="619" fill="#000" opacity="0.1">Playground</text>
<text x="645" y="138" textLength="619">Playground</text>
</g>
<linearGradient id="x" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" style="stop-color:#000000"></stop>
<stop offset="100%" style="stop-color:#000000"></stop>
</linearGradient>
</svg>
</a>
</center>
# LFM2-350M
LFM2 is a new generation of hybrid models developed by [Liquid AI](https://www.liquid.ai/), specifically designed for edge AI and on-device deployment. It sets a new standard in terms of quality, speed, and memory efficiency.
We're releasing the weights of three post-trained checkpoints with 350M, 700M, and 1.2B parameters. They provide the following key features to create AI-powered edge applications:
* **Fast training & inference** – LFM2 achieves 3x faster training compared to its previous generation. It also benefits from 2x faster decode and prefill speed on CPU compared to Qwen3.
* **Best performance** – LFM2 outperforms similarly-sized models across multiple benchmark categories, including knowledge, mathematics, instruction following, and multilingual capabilities.
* **New architecture** – LFM2 is a new hybrid Liquid model with multiplicative gates and short convolutions.
* **Flexible deployment** – LFM2 runs efficiently on CPU, GPU, and NPU hardware for flexible deployment on smartphones, laptops, or vehicles.
Find more information about LFM2 in our [blog post](https://www.liquid.ai/blog/liquid-foundation-models-v2-our-second-series-of-generative-ai-models).
## 📄 Model details
Due to their small size, **we recommend fine-tuning LFM2 models on narrow use cases** to maximize performance.
They are particularly suited for agentic tasks, data extraction, RAG, creative writing, and multi-turn conversations.
However, we do not recommend using them for tasks that are knowledge-intensive or require programming skills.
| Property | [**LFM2-350M**](https://huggingface.co/LiquidAI/LFM2-350M) | [**LFM2-700M**](https://huggingface.co/LiquidAI/LFM2-700M) | [**LFM2-1.2B**](https://huggingface.co/LiquidAI/LFM2-1.2B) |
| ------------------- | ----------------------------- | ----------------------------- | ----------------------------- |
| **Parameters** | 354,483,968 | 742,489,344 | 1,170,340,608 |
| **Layers** | 16 (10 conv + 6 attn) | 16 (10 conv + 6 attn) | 16 (10 conv + 6 attn) |
| **Context length** | 32,768 tokens | 32,768 tokens | 32,768 tokens |
| **Vocabulary size** | 65,536 | 65,536 | 65,536 |
| **Precision** | bfloat16 | bfloat16 | bfloat16 |
| **Training budget** | 10 trillion tokens | 10 trillion tokens | 10 trillion tokens |
| **License** | LFM Open License v1.0 | LFM Open License v1.0 | LFM Open License v1.0 |
**Supported languages**: English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.
**Generation parameters**: We recommend the following parameters:
* `temperature=0.3`
* `min_p=0.15`
* `repetition_penalty=1.05`
**Chat template**: LFM2 uses a ChatML-like chat template as follows:
```
<|startoftext|><|im_start|>system
You are a helpful assistant trained by Liquid AI.<|im_end|>
<|im_start|>user
What is C. elegans?<|im_end|>
<|im_start|>assistant
It's a tiny nematode that lives in temperate soil environments.<|im_end|>
```
You can automatically apply it using the dedicated [`.apply_chat_template()`](https://huggingface.co/docs/transformers/en/chat_templating#applychattemplate) function from Hugging Face transformers.
**Tool use**: It consists of four main steps:
1. **Function definition**: LFM2 takes JSON function definitions as input (JSON objects between `<|tool_list_start|>` and `<|tool_list_end|>` special tokens), usually in the system prompt
2. **Function call**: LFM2 writes Pythonic function calls (a Python list between `<|tool_call_start|>` and `<|tool_call_end|>` special tokens), as the assistant answer.
3. **Function execution**: The function call is executed and the result is returned (string between `<|tool_response_start|>` and `<|tool_response_end|>` special tokens), as a "tool" role.
4. **Final answer**: LFM2 interprets the outcome of the function call to address the original user prompt in plain text.
Here is a simple example of a conversation using tool use:
```
<|startoftext|><|im_start|>system
List of tools: <|tool_list_start|>[{"name": "get_candidate_status", "description": "Retrieves the current status of a candidate in the recruitment process", "parameters": {"type": "object", "properties": {"candidate_id": {"type": "string", "description": "Unique identifier for the candidate"}}, "required": ["candidate_id"]}}]<|tool_list_end|><|im_end|>
<|im_start|>user
What is the current status of candidate ID 12345?<|im_end|>
<|im_start|>assistant
<|tool_call_start|>[get_candidate_status(candidate_id="12345")]<|tool_call_end|>Checking the current status of candidate ID 12345.<|im_end|>
<|im_start|>tool
<|tool_response_start|>{"candidate_id": "12345", "status": "Interview Scheduled", "position": "Clinical Research Associate", "date": "2023-11-20"}<|tool_response_end|><|im_end|>
<|im_start|>assistant
The candidate with ID 12345 is currently in the "Interview Scheduled" stage for the position of Clinical Research Associate, with an interview date set for 2023-11-20.<|im_end|>
```
**Architecture**: Hybrid model with multiplicative gates and short convolutions: 10 double-gated short-range LIV convolution blocks and 6 grouped query attention (GQA) blocks.
**Pre-training mixture**: Approximately 75% English, 20% multilingual, and 5% code data sourced from the web and licensed materials.
**Training approach**:
* Knowledge distillation using [LFM1-7B](https://www.liquid.ai/blog/introducing-lfm-7b-setting-new-standards-for-efficient-language-models) as teacher model
* Very large-scale SFT on 50% downstream tasks, 50% general domains
* Custom DPO with length normalization and semi-online datasets
* Iterative model merging
## 🏃 How to run LFM2
You can run LFM2 with transformers and llama.cpp. vLLM support is coming.
### 1. Transformers
To run LFM2, you need to install Hugging Face [`transformers`](https://github.com/huggingface/transformers) v4.55 or more recent as follows:
```python
pip install -U transformers
```
Here is an example of how to generate an answer with transformers in Python:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load model and tokenizer
model_id = "LiquidAI/LFM2-350M"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype="bfloat16",
# attn_implementation="flash_attention_2" <- uncomment on compatible GPU
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Generate answer
prompt = "What is C. elegans?"
input_ids = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
add_generation_prompt=True,
return_tensors="pt",
tokenize=True,
).to(model.device)
output = model.generate(
input_ids,
do_sample=True,
temperature=0.3,
min_p=0.15,
repetition_penalty=1.05,
max_new_tokens=512,
)
print(tokenizer.decode(output[0], skip_special_tokens=False))
# <|startoftext|><|im_start|>user
# What is C. elegans?<|im_end|>
# <|im_start|>assistant
# C. elegans, also known as Caenorhabditis elegans, is a small, free-living
# nematode worm (roundworm) that belongs to the phylum Nematoda.
```
You can directly run and test the model with this [Colab notebook](https://colab.research.google.com/drive/1_q3jQ6LtyiuPzFZv7Vw8xSfPU5FwkKZY?usp=sharing).
### 2. Llama.cpp
You can run LFM2 with llama.cpp using its [GGUF checkpoint](https://huggingface.co/LiquidAI/LFM2-350M-GGUF). Find more information in the model card.
## 🔧 How to fine-tune LFM2
We recommend fine-tuning LFM2 models on your use cases to maximize performance.
| Notebook | Description | Link |
|-------|------|------|
| SFT (Unsloth) | Supervised Fine-Tuning (SFT) notebook with a LoRA adapter using Unsloth. | <a href="https://colab.research.google.com/drive/1HROdGaPFt1tATniBcos11-doVaH7kOI3?usp=sharing"><img src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/vlOyMEjwHa_b_LXysEu2E.png" width="110" alt="Colab link"></a> |
| SFT (Axolotl) | Supervised Fine-Tuning (SFT) notebook with a LoRA adapter using Axolotl. | <a href="https://colab.research.google.com/drive/155lr5-uYsOJmZfO6_QZPjbs8hA_v8S7t?usp=sharing"><img src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/vlOyMEjwHa_b_LXysEu2E.png" width="110" alt="Colab link"></a> |
| SFT (TRL) | Supervised Fine-Tuning (SFT) notebook with a LoRA adapter using TRL. | <a href="https://colab.research.google.com/drive/1j5Hk_SyBb2soUsuhU0eIEA9GwLNRnElF?usp=sharing"><img src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/vlOyMEjwHa_b_LXysEu2E.png" width="110" alt="Colab link"></a> |
| DPO (TRL) | Preference alignment with Direct Preference Optimization (DPO) using TRL. | <a href="https://colab.research.google.com/drive/1MQdsPxFHeZweGsNx4RH7Ia8lG8PiGE1t?usp=sharing"><img src="https://cdn-uploads.huggingface.co/production/uploads/61b8e2ba285851687028d395/vlOyMEjwHa_b_LXysEu2E.png" width="110" alt="Colab link"></a> |
## 📈 Performance
LFM2 outperforms similar-sized models across different evaluation categories.
### 1. Automated benchmarks

| Model | MMLU | GPQA | IFEval | IFBench | GSM8K | MGSM | MMMLU |
|-------|------|------|--------|---------|-------|------|-------|
| LFM2-350M | 43.43 | 27.46 | 65.12 | 16.41 | 30.1 | 29.52 | 37.99 |
| LFM2-700M | 49.9 | 28.48 | 72.23 | 20.56 | 46.4 | 45.36 | 43.28 |
| LFM2-1.2B | *55.23* | **31.47** | **74.89** | *20.7* | *58.3* | *55.04* | **46.73** |
| Qwen3-0.6B | 44.93 | 22.14 | 64.24 | 19.75 | 36.47 | 41.28 | 30.84 |
| Qwen3-1.7B | **59.11** | 27.72 | *73.98* | **21.27** | 51.4 | **66.56** | *46.51* |
| Llama-3.2-1B-Instruct | 46.6 | *28.84* | 52.39 | 16.86 | 35.71 | 29.12 | 38.15 |
| gemma-3-1b-it | 40.08 | 21.07 | 62.9 | 17.72 | **59.59** | 43.6 | 34.43 |
### 2. LLM-as-a-Judge


### 3. Inference
#### Throughput comparison on CPU in ExecuTorch

#### Throughput comparison on CPU in Llama.cpp

## 📬 Contact
If you are interested in custom solutions with edge deployment, please contact [our sales team](https://www.liquid.ai/contact).
|
openclimatefix/pvnet_uk_region
|
openclimatefix
| 2025-08-12T15:33:21 | 9 | 1 |
pytorch
|
[
"pytorch",
"en",
"license:mit",
"region:us"
] | null | 2024-04-16T10:13:40 |
---
language: en
library_name: pytorch
license: mit
---
<!--
Do not remove elements like the above surrounded by two curly braces and do not add any more of them. These entries are required by the PVNet library and are automaticall infilled when the model is uploaded to huggingface
-->
<!-- Title - e.g. PVNet2, WindNet, PVNet India -->
# PVNet2
<!-- Provide a longer summary of what this model is/does. -->
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
This model class uses satellite data, numerical weather predictions, and recent Grid Service Point( GSP) PV power output to forecast the near-term (~8 hours) PV power output at all GSPs. More information can be found in the model repo [1] and experimental notes in [this google doc](https://docs.google.com/document/d/1fbkfkBzp16WbnCg7RDuRDvgzInA6XQu3xh4NCjV-WDA/edit?usp=sharing).
- **Developed by:** openclimatefix
- **Model type:** Fusion model
- **Language(s) (NLP):** en
- **License:** mit
# Training Details
## Data
<!-- eg.
The model is trained on data from 2019-2022 and validated on data from 2022-2023. It uses NWP data from ECMWF IFS model, and the UK Met Office UKV model. It uses satellite data from the EUMETSAT MSG SEVIRI instrument.
See the data_config.yaml file for more information on the channels and window-size used for each input data source.
-->
The model is trained on data from 2019-2021 and validated on data from 2022. It uses NWP data from ECMWF IFS model, and the UK Met Office UKV model. It uses also uses inputs from OCF's cloudcasting model
<!-- The preprocessing section is not strictly nessessary but perhaps nice to have -->
### Preprocessing
Data is prepared with the `ocf_data_sampler/torch_datasets/datasets/pvnet_uk` Dataset [2].
## Results
<!-- Do not remove the lines below -->
The training logs for the current model can be found here:
- [https://wandb.ai/openclimatefix/pvnet2.1/runs/u0bc3fi9](https://wandb.ai/openclimatefix/pvnet2.1/runs/u0bc3fi9)
<!-- The hardware section is also just nice to have -->
### Hardware
Trained on a single NVIDIA Tesla T4
<!-- Do not remove the section below -->
### Software
This model was trained using the following Open Climate Fix packages:
- [1] https://github.com/openclimatefix/PVNet
- [2] https://github.com/openclimatefix/ocf-data-sampler
<!-- Especially do not change the two lines below -->
The versions of these packages can be found below:
- pvnet==5.0.0.post1+git.f4f6bfed.dirty
- ocf-data-sampler==0.3.1
|
jananisoundararajan/hair-coaction
|
jananisoundararajan
| 2025-08-12T15:26:18 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neo",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T15:25:22 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ACECA/lowMvMax_43
|
ACECA
| 2025-08-12T15:23:51 | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T12:37:28 |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
FatimahEmadEldin/Constrained-Track-Document-Bassline-Readability-Arabertv2-d3tok-reg
|
FatimahEmadEldin
| 2025-08-12T15:20:52 | 0 | 0 | null |
[
"safetensors",
"bert",
"ar",
"dataset:CAMeL-Lab/BAREC-Shared-Task-2025-doc",
"base_model:CAMeL-Lab/readability-arabertv2-d3tok-reg",
"base_model:finetune:CAMeL-Lab/readability-arabertv2-d3tok-reg",
"region:us"
] | null | 2025-08-12T15:13:34 |
---
datasets:
- CAMeL-Lab/BAREC-Shared-Task-2025-doc
language:
- ar
base_model:
- aubmindlab/bert-base-arabertv2
- CAMeL-Lab/readability-arabertv2-d3tok-reg
---
# MorphoArabia at BAREC 2025 Shared Task: A Hybrid Architecture with Morphological Analysis for Arabic Readability Assessmen
<p align="center">
<img src="https://placehold.co/800x200/dbeafe/3b82f6?text=Barec-Readability-Assessment" alt="Barec Readability Assessment">
</p>
This repository contains the official models and results for **MorphoArabia**, the submission to the **[BAREC 2025 Shared Task](https://www.google.com/search?q=https://sites.google.com/view/barec-2025/home)** on Arabic Readability Assessment.
#### By: [Fatimah Mohamed Emad Elden](https://scholar.google.com/citations?user=CfX6eA8AAAAJ&hl=ar)
#### *Cairo University*
[](https://arxiv.org/abs/25XX.XXXXX)
[](https://github.com/astral-fate/barec-Arabic-Readability-Assessment)
[](https://huggingface.co/collections/FatimahEmadEldin/barec-shared-task-2025-689195853f581b9a60f9bd6c)
[](https://github.com/astral-fate/mentalqa2025/blob/main/LICENSE)
---
## Model Description
This project introduces a **morphologically-aware approach** for assessing the readability of Arabic text. The system is built around a fine-tuned regression model designed to process morphologically analyzed text. For the **Constrained** and **Open** tracks of the shared task, this core model is extended into a hybrid architecture that incorporates seven engineered lexical features.
A key element of this system is its deep morphological preprocessing pipeline, which uses the **CAMEL Tools d3tok analyzer**. This allows the model to capture linguistic complexities that are often missed by surface-level tokenization methods. This approach proved to be highly effective, achieving a peak **Quadratic Weighted Kappa (QWK) score of 84.2** on the strict sentence-level test set.
The model predicts a readability score on a **19-level scale**, from 1 (easiest) to 19 (hardest), for a given Arabic sentence or document.
-----
# Hybrid Arabic Readability Model (Constrained Track - Document Level)
This repository contains a fine-tuned hybrid model for **document-level** Arabic readability assessment. It was trained for the Constrained Track of the BAREC competition.
The model combines the textual understanding of **CAMeL-Lab/readability-arabertv2-d3tok-reg** with 7 additional lexical features to produce a regression-based readability score for full documents.
**NOTE:** This is a custom model architecture. You **must** use the `trust_remote_code=True` argument when loading it.
## How to Use
The model requires both the document text and a tensor containing 7 numerical features.
### Step 1: Installation
Install the necessary libraries:
```bash
pip install transformers torch pandas arabert
````
### Step 2: Full Inference Example
This example shows how to preprocess a document, extract features, and get a readability score.
```python
import torch
import numpy as np
from transformers import AutoTokenizer, AutoModel
from arabert.preprocess import ArabertPreprocessor
# --- 1. Define the Feature Engineering Function ---
def get_lexical_features(text, lexicon):
words = text.split()
if not words: return [0.0] * 7
word_difficulties = [lexicon.get(word, 3.0) for word in words]
features = [
float(len(text)), float(len(words)),
float(np.mean([len(w) for w in words]) if words else 0.0),
float(np.mean(word_difficulties)), float(np.max(word_difficulties)),
float(np.sum(np.array(word_difficulties) > 4)),
float(len([w for w in words if w not in lexicon]) / len(words))
]
return features
# --- 2. Initialize Models and Processors ---
repo_id = "FatimahEmadEldin/Constrained-Track-Document-Bassline-Readability-Arabertv2-d3tok-reg"
arabert_preprocessor = ArabertPreprocessor(model_name="aubmindlab/bert-large-arabertv2")
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModel.from_pretrained(repo_id, trust_remote_code=True)
# --- 3. Prepare Input Document and Lexicon ---
# For a real use case, load the full SAMER lexicon.
sample_lexicon = {'جملة': 2.5, 'عربية': 3.1, 'بسيطة': 1.8, 'النص': 2.8, 'طويل': 3.5}
document_text = "هذا مثال لجملة عربية بسيطة. هذا النص أطول قليلاً من المثال السابق."
# --- 4. Run the Full Pipeline ---
preprocessed_text = arabert_preprocessor.preprocess(document_text)
numerical_features_list = get_lexical_features(preprocessed_text, sample_lexicon)
numerical_features = torch.tensor([numerical_features_list], dtype=torch.float)
inputs = tokenizer(preprocessed_text, return_tensors="pt", padding=True, truncation=True, max_length=512)
inputs['extra_features'] = numerical_features # The model expects 'extra_features'
# --- 5. Perform Inference ---
model.eval()
with torch.no_grad():
logits = model(**inputs)[1] # The model returns (loss, logits)
# --- 6. Process the Output ---
predicted_score = logits.item()
final_level = round(max(0, min(18, predicted_score))) + 1
print(f"Input Document: '{document_text}'")
print(f"Raw Regression Score: {predicted_score:.4f}")
print(f"Predicted Readability Level (1-19): {final_level}")
```
## ⚙️ Training Procedure
The system employs two distinct architectures based on the track's constraints:
* **Strict Track**: This track uses a base regression model, `CAMeL-Lab/readability-arabertv2-d3tok-reg`, fine-tuned directly on the BAREC dataset.
* **Constrained and Open Tracks**: These tracks utilize a hybrid model. This architecture combines the deep contextual understanding of the Transformer with explicit numerical features. The final representation for a sentence is created by concatenating the Transformer's `[CLS]` token embedding with a 7-dimensional vector of engineered lexical features derived from the SAMER lexicon.
A critical component of the system is its preprocessing pipeline, which leverages the CAMEL Tools `d3tok` format. The `d3tok` analyzer performs a deep morphological analysis by disambiguating words in context and then segmenting them into their constituent morphemes.
### Frameworks
* PyTorch
* Hugging Face Transformers
-----
### 📊 Evaluation Results
The models were evaluated on the blind test set provided by the BAREC organizers. The primary metric for evaluation is the **Quadratic Weighted Kappa (QWK)**, which penalizes larger disagreements more severely.
#### Final Test Set Scores (QWK)
| Track | Task | Dev (QWK) | Test (QWK) |
| :--- | :--- | :---: | :---: |
| **Strict** | Sentence | 0.823 | **84.2** |
| | Document | 0.823\* | 79.9 |
| **Constrained** | Sentence | 0.810 | 82.9 |
| | Document | 0.835\* | 75.5 |
| **Open** | Sentence | 0.827 | 83.6 |
| | Document | 0.827\* | **79.2** |
\*Document-level dev scores are based on the performance of the sentence-level model on the validation set.
-----
## 📜 Citation
If you use the work, please cite the paper:
```
@inproceedings{eldin2025morphoarabia,
title={{MorphoArabia at BAREC 2025 Shared Task: A Hybrid Architecture with Morphological Analysis for Arabic Readability Assessmen}},
author={Eldin, Fatimah Mohamed Emad},
year={2025},
booktitle={Proceedings of the BAREC 2025 Shared Task},
eprint={25XX.XXXXX},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
neulab/CulturalPangea-7B
|
neulab
| 2025-08-12T15:15:05 | 27 | 1 | null |
[
"safetensors",
"qwen2",
"am",
"ar",
"bg",
"bn",
"cs",
"de",
"el",
"en",
"es",
"fa",
"fr",
"ga",
"hi",
"id",
"ig",
"it",
"iw",
"ja",
"jv",
"ko",
"nl",
"mn",
"ms",
"no",
"pl",
"pt",
"ro",
"ru",
"si",
"su",
"sw",
"ta",
"te",
"th",
"tr",
"uk",
"ur",
"vi",
"zh",
"dataset:neulab/CulturalGround",
"arxiv:2508.07414",
"base_model:neulab/Pangea-7B",
"base_model:finetune:neulab/Pangea-7B",
"license:apache-2.0",
"region:us"
] | null | 2025-07-24T18:05:09 |
---
license: apache-2.0
datasets:
- neulab/CulturalGround
language:
- am
- ar
- bg
- bn
- cs
- de
- el
- en
- es
- fa
- fr
- ga
- hi
- id
- ig
- it
- iw
- ja
- jv
- ko
- nl
- mn
- ms
- no
- pl
- pt
- ro
- ru
- si
- su
- sw
- ta
- te
- th
- tr
- uk
- ur
- vi
- zh
base_model:
- neulab/Pangea-7B
---
# CulturalPangea-7B Model Card
[Grounding Multilingual Multimodal LLMs With Cultural Knowledge](https://neulab.github.io/CulturePangea/)
🌍 🇩🇪 🇫🇷 🇬🇧 🇪🇸 🇮🇹 🇵🇱 🇷🇺 🇨🇿 🇯🇵 🇺🇦 🇧🇷 🇮🇳 🇨🇳 🇳🇴 🇵🇹 🇮🇩 🇮🇱 🇹🇷 🇬🇷 🇷🇴 🇮🇷 🇹🇼 🇲🇽 🇮🇪 🇰🇷 🇧🇬 🇹🇭 🇳🇱 🇪🇬 🇵🇰 🇳🇬 🇮🇩 🇻🇳 🇲🇾 🇸🇦 🇮🇩 🇧🇩 🇸🇬 🇱🇰 🇰🇪 🇲🇳 🇪🇹 🇹🇿 🇷🇼
[🏠 Homepage](https://neulab.github.io/CulturalGround/) | [🤖 CulturalPangea-7B](https://huggingface.co/neulab/CulturalPangea-7B) | [📊 CulturalGround](https://huggingface.co/datasets/neulab/CulturalGround) | [💻 Github](https://github.com/neulab/CulturalGround) | [📄 Arxiv](https://arxiv.org/abs/2508.07414)
<img src="https://neulab.github.io/CulturalGround/static/img/icons/culturalpangea1.png" alt="[IMAGE]" style="width:300px;">
## Model Details
- **Model:** `CulturalPangea-7B` is an open-source Multilingual Multimodal LLM fine-tuned to interpret and reason about long-tail cultural entities and concepts. It is designed to bridge the cultural gap often present in MLLMs.
- **Date:** `CulturalPangea-7B` was trained in 2025.
- **Training Dataset:** The model was fine-tuned on the [CulturalGround](https://huggingface.co/datasets/neulab/CulturalGround) dataset, using 14 million open-ended and 6 million multiple-choice culturally-grounded VQA pairs samples from 30M total samples(22M OE, 8M MCQs). This was interleaved with the substantial portion of original Pangea instruction data to maintain general abilities.
- **Architecture:** `CulturalPangea-7B` is a fine-tuned version of [Pangea-7B](https://huggingface.co/neulab/Pangea-7B). It uses a frozen [CLIP-ViT](https://huggingface.co/openai/clip-vit-large-patch14) vision encoder with a [Qwen2-7B-Instruct](https://huggingface.co/Qwen/Qwen2-7B-Instruct) LLM backbone. During training, only the connector and the language model were fine-tuned.
## Uses
`CulturalPangea-7B` follows the same architecture and usage patterns as LLaVA-NeXT and Pangea-7B.
### Direct Use
First, you need to clone and install the LLaVA-NeXT repository.
```bash
git clone [https://github.com/LLaVA-VL/LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT)
cd LLaVA-NeXT
pip install -e ".[train]"
```
Then, you can load CulturalPangea-7B using the following code:
```python
from llava.model.builder import load_pretrained_model
model_path = 'neulab/CulturalPangea-7B'
model_name = 'CulturalPangea-7B-qwen'
args = {"multimodal": True}
tokenizer, model, image_processor, context_len = load_pretrained_model(model_path, None, model_name, **args)
```
Defining helper functions for model inference:
```python
import torch
from llava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKEN, DEFAULT_IM_START_TOKEN, DEFAULT_IM_END_TOKEN
from llava.utils import disable_torch_init
from llava.constants import IGNORE_INDEX, DEFAULT_IMAGE_TOKEN, IMAGE_TOKEN_INDEX
from typing import Dict
import transformers
import re
from PIL import Image
def preprocess_qwen(sources, tokenizer: transformers.PreTrainedTokenizer, has_image: bool = False, max_len=2048, system_message: str = "You are a helpful assistant.") -> Dict:
roles = {"human": "<|im_start|>user", "gpt": "<|im_start|>assistant"}
im_start, im_end = tokenizer.additional_special_tokens_ids
nl_tokens = tokenizer("\n").input_ids
_system = tokenizer("system").input_ids + nl_tokens
_user = tokenizer("user").input_ids + nl_tokens
_assistant = tokenizer("assistant").input_ids + nl_tokens
input_ids = []
source = sources
if roles[source[0]["from"]] != roles["human"]: source = source[1:]
input_id, target = [], []
system = [im_start] + _system + tokenizer(system_message).input_ids + [im_end] + nl_tokens
input_id += system
target += [im_start] + [IGNORE_INDEX] * (len(system) - 3) + [im_end] + nl_tokens
assert len(input_id) == len(target)
for j, sentence in enumerate(source):
role = roles[sentence["from"]]
if has_image and sentence["value"] is not None and "<image>" in sentence["value"]:
num_image = len(re.findall(DEFAULT_IMAGE_TOKEN, sentence["value"]))
texts = sentence["value"].split('<image>')
_input_id = tokenizer(role).input_ids + nl_tokens
for i,text in enumerate(texts):
_input_id += tokenizer(text).input_ids
if i<len(texts)-1: _input_id += [IMAGE_TOKEN_INDEX] + nl_tokens
_input_id += [im_end] + nl_tokens
assert sum([i==IMAGE_TOKEN_INDEX for i in _input_id])==num_image
else:
if sentence["value"] is None: _input_id = tokenizer(role).input_ids + nl_tokens
else: _input_id = tokenizer(role).input_ids + nl_tokens + tokenizer(sentence["value"]).input_ids + [im_end] + nl_tokens
input_id += _input_id
input_ids.append(input_id)
return torch.tensor(input_ids, dtype=torch.long)
def generate_output(prompt, image=None, do_sample=False, temperature=0, top_p=0.5, num_beams=1, max_new_tokens=1024):
image_tensors = []
prompt = "<image>\n" + prompt
# image can be a path to a local file or a PIL image
if isinstance(image, str):
image = Image.open(image)
image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values']
image_tensors.append(image_tensor.half().cuda())
input_ids = preprocess_qwen([{'from': 'human', 'value': prompt},{'from': 'gpt','value': None}], tokenizer, has_image=True).cuda()
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensors,
do_sample=do_sample,
temperature=temperature,
top_p=top_p,
num_beams=num_beams,
max_new_tokens=max_new_tokens,
use_cache=True
)
outputs = tokenizer.batch_decode(output_ids, skip_special_tokens=True)[0]
outputs = outputs.strip()
return outputs
```
An example of multimodal inference:
```python
prompt = "What cultural significance does the landmark in the image hold?"
image = "image.png"
print(generate_output(prompt, image=image))
```
## Citing the Model
If you use CulturalPangea or the CulturalGround dataset, please cite our work:
```
@preprint{nyandwi2025grounding,
title={Grounding Multilingual Multimodal LLMs With Cultural Knowledge},
author={Nyandwi, Jean de Dieu and Song, Yueqi and Khanuja, Simran and Neubig, Graham},
year={2025}
}
```
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755009674
|
indoempatnol
| 2025-08-12T15:07:16 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:07:12 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
xnftraff/blockassist-bc-sprightly_freckled_deer_1755010284
|
xnftraff
| 2025-08-12T15:06:33 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sprightly freckled deer",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:06:04 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sprightly freckled deer
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Epice67/coq_model
|
Epice67
| 2025-08-12T15:03:07 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T15:02:44 |
---
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Epice67
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755010703
|
Ferdi3425
| 2025-08-12T15:02:01 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T15:01:27 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hientan104/blockassist-bc-extinct_wild_emu_1755009371
|
hientan104
| 2025-08-12T14:58:52 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"extinct wild emu",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:52:55 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- extinct wild emu
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pinilDissanayaka/HRM
|
pinilDissanayaka
| 2025-08-12T14:56:33 | 0 | 0 | null |
[
"arxiv:2506.21734",
"region:us"
] | null | 2025-08-12T14:52:36 |
# Hierarchical Reasoning Model

Reasoning, the process of devising and executing complex goal-oriented action sequences, remains a critical challenge in AI.
Current large language models (LLMs) primarily employ Chain-of-Thought (CoT) techniques, which suffer from brittle task decomposition, extensive data requirements, and high latency. Inspired by the hierarchical and multi-timescale processing in the human brain, we propose the Hierarchical Reasoning Model (HRM), a novel recurrent architecture that attains significant computational depth while maintaining both training stability and efficiency.
HRM executes sequential reasoning tasks in a single forward pass without explicit supervision of the intermediate process, through two interdependent recurrent modules: a high-level module responsible for slow, abstract planning, and a low-level module handling rapid, detailed computations. With only 27 million parameters, HRM achieves exceptional performance on complex reasoning tasks using only 1000 training samples. The model operates without pre-training or CoT data, yet achieves nearly perfect performance on challenging tasks including complex Sudoku puzzles and optimal path finding in large mazes.
Furthermore, HRM outperforms much larger models with significantly longer context windows on the Abstraction and Reasoning Corpus (ARC), a key benchmark for measuring artificial general intelligence capabilities.
These results underscore HRM’s potential as a transformative advancement toward universal computation and general-purpose reasoning systems.
## Quick Start Guide 🚀
### Prerequisites ⚙️
Ensure PyTorch and CUDA are installed. The repo needs CUDA extensions to be built. If not present, run the following commands:
```bash
# Install CUDA 12.6
CUDA_URL=https://developer.download.nvidia.com/compute/cuda/12.6.3/local_installers/cuda_12.6.3_560.35.05_linux.run
wget -q --show-progress --progress=bar:force:noscroll -O cuda_installer.run $CUDA_URL
sudo sh cuda_installer.run --silent --toolkit --override
export CUDA_HOME=/usr/local/cuda-12.6
# Install PyTorch with CUDA 12.6
PYTORCH_INDEX_URL=https://download.pytorch.org/whl/cu126
pip3 install torch torchvision torchaudio --index-url $PYTORCH_INDEX_URL
# Additional packages for building extensions
pip3 install packaging ninja wheel setuptools setuptools-scm
```
Then install FlashAttention. For Hopper GPUs, install FlashAttention 3
```bash
git clone [email protected]:Dao-AILab/flash-attention.git
cd flash-attention/hopper
python setup.py install
```
For Ampere or earlier GPUs, install FlashAttention 2
```bash
pip3 install flash-attn
```
## Install Python Dependencies 🐍
```bash
pip install -r requirements.txt
```
## W&B Integration 📈
This project uses [Weights & Biases](https://wandb.ai/) for experiment tracking and metric visualization. Ensure you're logged in:
```bash
wandb login
```
## Run Experiments
### Quick Demo: Sudoku Solver 💻🗲
Train a master-level Sudoku AI capable of solving extremely difficult puzzles on a modern laptop GPU. 🧩
```bash
# Download and build Sudoku dataset
python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000
# Start training (single GPU, smaller batch size)
OMP_NUM_THREADS=8 python pretrain.py data_path=data/sudoku-extreme-1k-aug-1000 epochs=20000 eval_interval=2000 global_batch_size=384 lr=7e-5 puzzle_emb_lr=7e-5 weight_decay=1.0 puzzle_emb_weight_decay=1.0
```
Runtime: ~10 hours on a RTX 4070 laptop GPU
## Trained Checkpoints 🚧
- [ARC-AGI-2](https://huggingface.co/sapientinc/HRM-checkpoint-ARC-2)
- [Sudoku 9x9 Extreme (1000 examples)](https://huggingface.co/sapientinc/HRM-checkpoint-sudoku-extreme)
- [Maze 30x30 Hard (1000 examples)](https://huggingface.co/sapientinc/HRM-checkpoint-maze-30x30-hard)
To use the checkpoints, see Evaluation section below.
## Full-scale Experiments 🔵
Experiments below assume an 8-GPU setup.
### Dataset Preparation
```bash
# Initialize submodules
git submodule update --init --recursive
# ARC-1
python dataset/build_arc_dataset.py # ARC offical + ConceptARC, 960 examples
# ARC-2
python dataset/build_arc_dataset.py --dataset-dirs dataset/raw-data/ARC-AGI-2/data --output-dir data/arc-2-aug-1000 # ARC-2 official, 1120 examples
# Sudoku-Extreme
python dataset/build_sudoku_dataset.py # Full version
python dataset/build_sudoku_dataset.py --output-dir data/sudoku-extreme-1k-aug-1000 --subsample-size 1000 --num-aug 1000 # 1000 examples
# Maze
python dataset/build_maze_dataset.py # 1000 examples
```
### Dataset Visualization
Explore the puzzles visually:
* Open `puzzle_visualizer.html` in your browser.
* Upload the generated dataset folder located in `data/...`.
## Launch experiments
### Small-sample (1K)
ARC-1:
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py
```
*Runtime:* ~24 hours
ARC-2:
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/arc-2-aug-1000
```
*Runtime:* ~24 hours (checkpoint after 8 hours is often sufficient)
Sudoku Extreme (1k):
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/sudoku-extreme-1k-aug-1000 epochs=20000 eval_interval=2000 lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0
```
*Runtime:* ~10 minutes
Maze 30x30 Hard (1k):
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/maze-30x30-hard-1k epochs=20000 eval_interval=2000 lr=1e-4 puzzle_emb_lr=1e-4 weight_decay=1.0 puzzle_emb_weight_decay=1.0
```
*Runtime:* ~1 hour
### Full Sudoku-Hard
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 pretrain.py data_path=data/sudoku-hard-full epochs=100 eval_interval=10 lr_min_ratio=0.1 global_batch_size=2304 lr=3e-4 puzzle_emb_lr=3e-4 weight_decay=0.1 puzzle_emb_weight_decay=0.1 arch.loss.loss_type=softmax_cross_entropy arch.L_cycles=8 arch.halt_max_steps=8 arch.pos_encodings=learned
```
*Runtime:* ~2 hours
## Evaluation
Evaluate your trained models:
* Check `eval/exact_accuracy` in W&B.
* For ARC-AGI, follow these additional steps:
```bash
OMP_NUM_THREADS=8 torchrun --nproc-per-node 8 evaluate.py checkpoint=<CHECKPOINT_PATH>
```
* Then use the provided `arc_eval.ipynb` notebook to finalize and inspect your results.
## Notes
- Small-sample learning typically exhibits accuracy variance of around ±2 points.
- For Sudoku-Extreme (1,000-example dataset), late-stage overfitting may cause numerical instability during training and Q-learning. It is advisable to use early stopping once the training accuracy approaches 100%.
## Citation 📜
```bibtex
@misc{wang2025hierarchicalreasoningmodel,
title={Hierarchical Reasoning Model},
author={Guan Wang and Jin Li and Yuhao Sun and Xing Chen and Changling Liu and Yue Wu and Meng Lu and Sen Song and Yasin Abbasi Yadkori},
year={2025},
eprint={2506.21734},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.21734},
}
```
|
mradermacher/AFM-WebAgent-7B-rl-GGUF
|
mradermacher
| 2025-08-12T14:47:56 | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:PersonalAILab/AFM-WebAgent-7B-rl",
"base_model:quantized:PersonalAILab/AFM-WebAgent-7B-rl",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T04:06:43 |
---
base_model: PersonalAILab/AFM-WebAgent-7B-rl
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/PersonalAILab/AFM-WebAgent-7B-rl
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#AFM-WebAgent-7B-rl-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q2_K.gguf) | Q2_K | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q3_K_S.gguf) | Q3_K_S | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q3_K_M.gguf) | Q3_K_M | 3.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q3_K_L.gguf) | Q3_K_L | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.IQ4_XS.gguf) | IQ4_XS | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q4_K_S.gguf) | Q4_K_S | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q4_K_M.gguf) | Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q5_K_S.gguf) | Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q5_K_M.gguf) | Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q6_K.gguf) | Q6_K | 6.4 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.Q8_0.gguf) | Q8_0 | 8.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/AFM-WebAgent-7B-rl-GGUF/resolve/main/AFM-WebAgent-7B-rl.f16.gguf) | f16 | 15.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
c-ho/2025-08-12-bll-ner_bert-base-multilingual-cased-ner-hrl_crf
|
c-ho
| 2025-08-12T14:35:22 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-08-12T14:34:56 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
relapseone/blockassist-bc-insectivorous_prickly_shrew_1755007139
|
relapseone
| 2025-08-12T14:31:19 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous prickly shrew",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T14:31:16 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous prickly shrew
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
MikeRoz/GLM-4.5-exl3
|
MikeRoz
| 2025-08-12T14:30:52 | 26 | 5 |
exllamav3
|
[
"exllamav3",
"exl3",
"text-generation",
"en",
"zh",
"base_model:zai-org/GLM-4.5",
"base_model:quantized:zai-org/GLM-4.5",
"license:mit",
"region:us"
] |
text-generation
| 2025-08-06T01:47:41 |
---
license: mit
language:
- en
- zh
pipeline_tag: text-generation
library_name: exllamav3
base_model: zai-org/GLM-4.5
base_model_relation: quantized
tags:
- exl3
---
exllamav3 quantizations of [zai-org/GLM-4.5](https://huggingface.co/zai-org/GLM-4.5). Please note that support for this model is currently in the dev branch of exllamav3.
[2.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/2.00bpw_H6_Revised) 84.517 GiB
[3.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/3.00bpw_H6_Revised) 125.398 GiB
[4.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/4.00bpw_H6_Revised) 166.280 GiB
[5.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/5.00bpw_H6_Revised) 207.162 GiB
[6.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/6.00bpw_H6_Revised) 248.043 GiB
[8.00 bpw h8](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/8.00bpw_H8_Revised) 329.987 GiB
### The quants below were made with an older version of the dev branch of exllamav3. It is not yet clear whether the initial bug that made inference incoherent also had an effect on the resulting weights during quantization. Revised weights will be uploaded over the coming days unless evidence suggests they're not needed. Use the weights below with caution. I apologize to anyone who ends up having to re-download.
I'll take a crack at some optimized quants once the fixed-size quants are all done.
[2.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/2.00bpw_H6) 84.517 GiB
[2.90 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/2.90bpw_H6) ("Unoptimized") 121.270 GiB
[3.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/3.00bpw_H6) 125.398 GiB
[4.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/4.00bpw_H6) 166.280 GiB
[5.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/5.00bpw_H6) 207.165 GiB
[6.00 bpw h6](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/6.00bpw_H6) (Cancelled)
[8.00 bpw h8](https://huggingface.co/MikeRoz/GLM-4.5-exl3/tree/8.00bpw_H8) (Cancelled)
|
knowledgator/gliclass-large-v3.0
|
knowledgator
| 2025-08-12T14:25:02 | 3,459 | 6 | null |
[
"safetensors",
"GLiClass",
"text classification",
"nli",
"sentiment analysis",
"text-classification",
"dataset:BioMike/formal-logic-reasoning-gliclass-2k",
"dataset:knowledgator/gliclass-v3-logic-dataset",
"dataset:tau/commonsense_qa",
"arxiv:2508.07662",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-07-18T11:05:30 |
---
license: apache-2.0
datasets:
- BioMike/formal-logic-reasoning-gliclass-2k
- knowledgator/gliclass-v3-logic-dataset
- tau/commonsense_qa
metrics:
- f1
tags:
- text classification
- nli
- sentiment analysis
pipeline_tag: text-classification
---

# GLiClass: Generalist and Lightweight Model for Sequence Classification
This is an efficient zero-shot classifier inspired by [GLiNER](https://github.com/urchade/GLiNER/tree/main) work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for `topic classification`, `sentiment analysis`, and as a reranker in `RAG` pipelines.
The model was trained on logical tasks to induce reasoning. LoRa adapters were used to fine-tune the model without destroying the previous knowledge.
LoRA parameters:
| | [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) |
|----------------------|---------------------------------|----------------------------------|--------------------------------|---------------------------------|
| LoRa r | 512 | 768 | 384 | 384 |
| LoRa α | 1024 | 1536 | 768 | 768 |
| focal loss α | 0.7 | 0.7 | 0.7 | 0.7 |
| Target modules | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" |
GLiClass-V3 Models:
Model name | Size | Params | Average Banchmark | Average Inference Speed (batch size = 1, a6000, examples/s)
|----------|------|--------|-------------------|---------------------------------------------------------|
[gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass‑edge‑v3.0)| 131 MB | 32.7M | 0.4873 | 97.29 |
[gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0)| 606 MB | 151M | 0.5571 | 54.46 |
[gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0)| 1.6 GB | 399M | 0.6082 | 43.80 |
[gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0)| 746 MB | 187M | 0.6556 | 51.61 |
[gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0)| 1.75 GB | 439M | 0.7001 | 25.22 |
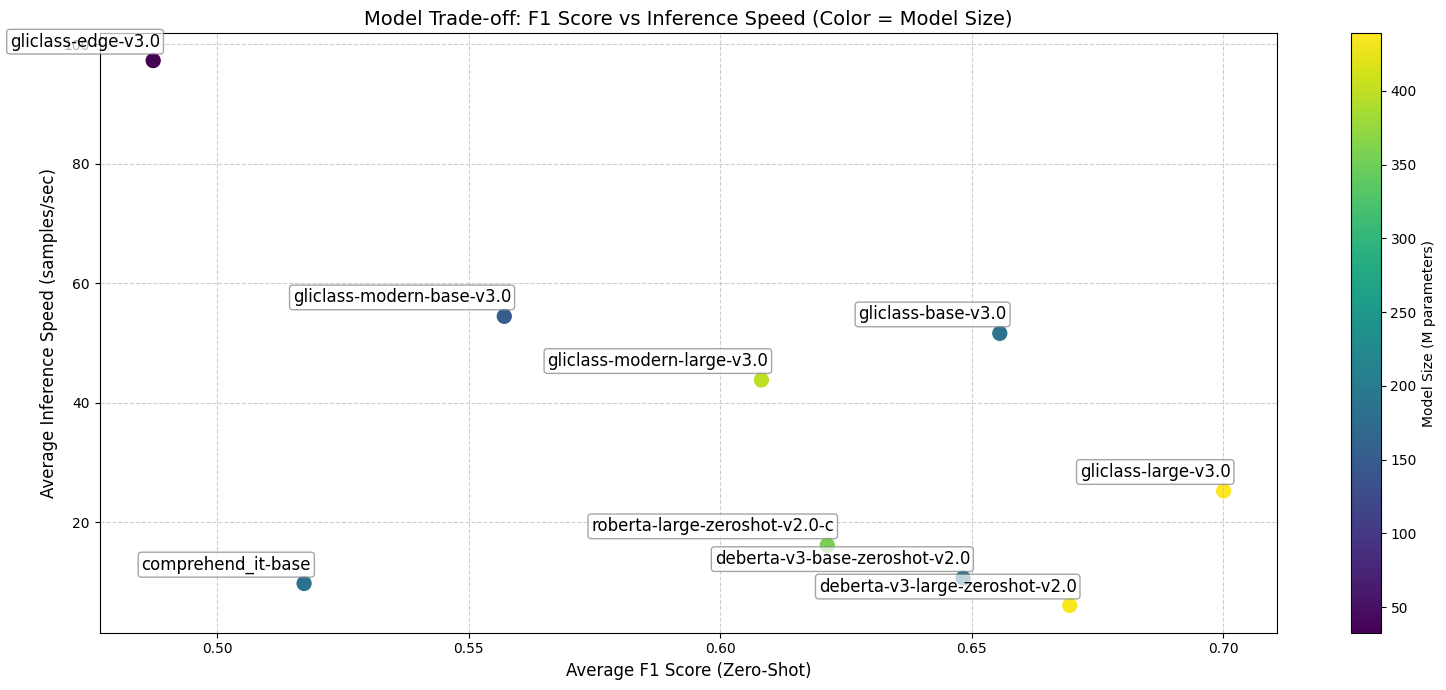
### How to use:
First of all, you need to install GLiClass library:
```bash
pip install gliclass
pip install -U transformers>=4.48.0
```
Then you need to initialize a model and a pipeline:
```python
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-large-v3.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-large-v3.0")
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
```
If you want to use it for NLI type of tasks, we recommend representing your premise as a text and hypothesis as a label, you can put several hypotheses, but the model works best with a single input hypothesis.
```python
# Initialize model and multi-label pipeline
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
```
### Benchmarks:
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
GLiClass-V3:
| Dataset | [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) | [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | [gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass-edge-v3.0) |
|----------------------------|---------|---------|---------|---------|---------|
| CR | 0.9398 | 0.9127 | 0.8952 | 0.8902 | 0.8215 |
| sst2 | 0.9192 | 0.8959 | 0.9330 | 0.8959 | 0.8199 |
| sst5 | 0.4606 | 0.3376 | 0.4619 | 0.2756 | 0.2823 |
| 20_news_<br>groups | 0.5958 | 0.4759 | 0.3905 | 0.3433 | 0.2217 |
| spam | 0.7584 | 0.6760 | 0.5813 | 0.6398 | 0.5623 |
| financial_<br>phrasebank | 0.9000 | 0.8971 | 0.5929 | 0.4200 | 0.5004 |
| imdb | 0.9366 | 0.9251 | 0.9402 | 0.9158 | 0.8485 |
| ag_news | 0.7181 | 0.7279 | 0.7269 | 0.6663 | 0.6645 |
| emotion | 0.4506 | 0.4447 | 0.4517 | 0.4254 | 0.3851 |
| cap_sotu | 0.4589 | 0.4614 | 0.4072 | 0.3625 | 0.2583 |
| rotten_<br>tomatoes | 0.8411 | 0.7943 | 0.7664 | 0.7070 | 0.7024 |
| massive | 0.5649 | 0.5040 | 0.3905 | 0.3442 | 0.2414 |
| banking | 0.5574 | 0.4698 | 0.3683 | 0.3561 | 0.0272 |
| snips | 0.9692 | 0.9474 | 0.7707 | 0.5663 | 0.5257 |
| **AVERAGE** | **0.7193** | **0.6764** | **0.6197** | **0.5577** | **0.4900** |
Previous GLiClass models:
| Dataset | [gliclass‑large‑v1.0‑lw](https://huggingface.co/knowledgator/gliclass-large-v1.0-lw) | [gliclass‑base‑v1.0‑lw](https://huggingface.co/knowledgator/gliclass-base-v1.0-lw) | [gliclass‑modern‑large‑v2.0](https://huggingface.co/knowledgator/gliclass-modern-large-v2.0) | [gliclass‑modern‑base‑v2.0](https://huggingface.co/knowledgator/gliclass-modern-base-v2.0) |
|----------------------------|---------------------------------|--------------------------------|----------------------------------|---------------------------------|
| CR | 0.9226 | 0.9097 | 0.9154 | 0.8977 |
| sst2 | 0.9247 | 0.8987 | 0.9308 | 0.8524 |
| sst5 | 0.2891 | 0.3779 | 0.2152 | 0.2346 |
| 20_news_<br>groups | 0.4083 | 0.3953 | 0.3813 | 0.3857 |
| spam | 0.3642 | 0.5126 | 0.6603 | 0.4608 |
| financial_<br>phrasebank | 0.9044 | 0.8880 | 0.3152 | 0.3465 |
| imdb | 0.9429 | 0.9351 | 0.9449 | 0.9188 |
| ag_news | 0.7559 | 0.6985 | 0.6999 | 0.6836 |
| emotion | 0.3951 | 0.3516 | 0.4341 | 0.3926 |
| cap_sotu | 0.4749 | 0.4643 | 0.4095 | 0.3588 |
| rotten_<br>tomatoes | 0.8807 | 0.8429 | 0.7386 | 0.6066 |
| massive | 0.5606 | 0.4635 | 0.2394 | 0.3458 |
| banking | 0.3317 | 0.4396 | 0.1355 | 0.2907 |
| snips | 0.9707 | 0.9572 | 0.8468 | 0.7378 |
| **AVERAGE** | **0.6518** | **0.6525** | **0.5619** | **0.5366** |
Cross-Encoders:
| Dataset | [deberta‑v3‑large‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0) | [deberta‑v3‑base‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v2.0) | [roberta‑large‑zeroshot‑v2.0‑c](https://huggingface.co/MoritzLaurer/roberta-large-zeroshot-v2.0-c) | [comprehend_it‑base](https://huggingface.co/knowledgator/comprehend_it-base) |
|------------------------------------|--------|--------|--------|--------|
| CR | 0.9134 | 0.9051 | 0.9141 | 0.8936 |
| sst2 | 0.9272 | 0.9176 | 0.8573 | 0.9006 |
| sst5 | 0.3861 | 0.3848 | 0.4159 | 0.4140 |
| enron_<br>spam | 0.5970 | 0.4640 | 0.5040 | 0.3637 |
| financial_<br>phrasebank | 0.5820 | 0.6690 | 0.4550 | 0.4695 |
| imdb | 0.9180 | 0.8990 | 0.9040 | 0.4644 |
| ag_news | 0.7710 | 0.7420 | 0.7450 | 0.6016 |
| emotion | 0.4840 | 0.4950 | 0.4860 | 0.4165 |
| cap_sotu | 0.5020 | 0.4770 | 0.5230 | 0.3823 |
| rotten_<br>tomatoes | 0.8680 | 0.8600 | 0.8410 | 0.4728 |
| massive | 0.5180 | 0.5200 | 0.5200 | 0.3314 |
| banking77 | 0.5670 | 0.4460 | 0.2900 | 0.4972 |
| snips | 0.8340 | 0.7477 | 0.5430 | 0.7227 |
| **AVERAGE** | **0.6821** | **0.6559** | **0.6152** | **0.5331** |
Inference Speed:
Each model was tested on examples with 64, 256, and 512 tokens in text and 1, 2, 4, 8, 16, 32, 64, and 128 labels on an a6000 GPU. Then, scores were averaged across text lengths.
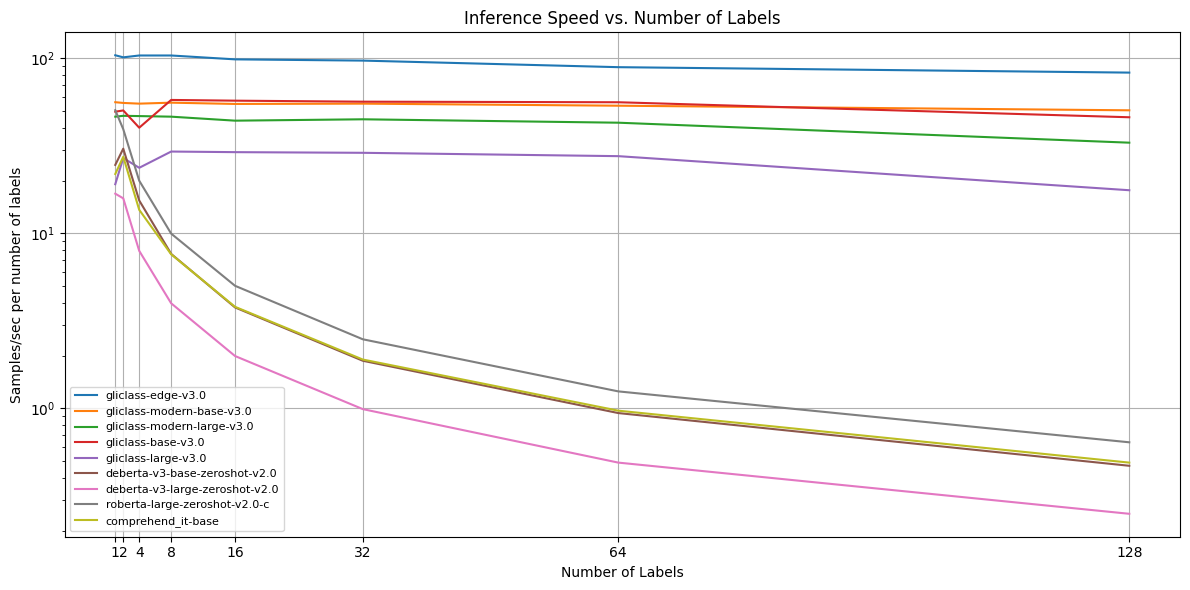
Model Name / n samples per second per m labels | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | **Average** |
|---------------------|---|---|---|---|----|----|----|-----|---------|
| [gliclass‑edge‑v3.0](https://huggingface.co/knowledgator/gliclass-edge-v3.0) | 103.81 | 101.01 | 103.50 | 103.50 | 98.36 | 96.77 | 88.76 | 82.64 | **97.29** |
| [gliclass‑modern‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-base-v3.0) | 56.00 | 55.46 | 54.95 | 55.66 | 54.73 | 54.95 | 53.48 | 50.34 | **54.46** |
| [gliclass‑modern‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-modern-large-v3.0) | 46.30 | 46.82 | 46.66 | 46.30 | 43.93 | 44.73 | 42.77 | 32.89 | **43.80** |
| [gliclass‑base‑v3.0](https://huggingface.co/knowledgator/gliclass-base-v3.0) | 49.42 | 50.25 | 40.05 | 57.69 | 57.14 | 56.39 | 55.97 | 45.94 | **51.61** |
| [gliclass‑large‑v3.0](https://huggingface.co/knowledgator/gliclass-large-v3.0) | 19.05 | 26.86 | 23.64 | 29.27 | 29.04 | 28.79 | 27.55 | 17.60 | **25.22** |
| [deberta‑v3‑base‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-base-zeroshot-v2.0) | 24.55 | 30.40 | 15.38 | 7.62 | 3.77 | 1.87 | 0.94 | 0.47 | **10.63** |
| [deberta‑v3‑large‑zeroshot‑v2.0](https://huggingface.co/MoritzLaurer/deberta-v3-large-zeroshot-v2.0) | 16.82 | 15.82 | 7.93 | 3.98 | 1.99 | 0.99 | 0.49 | 0.25 | **6.03** |
| [roberta‑large‑zeroshot‑v2.0‑c](https://huggingface.co/MoritzLaurer/roberta-large-zeroshot-v2.0-c) | 50.42 | 39.27 | 19.95 | 9.95 | 5.01 | 2.48 | 1.25 | 0.64 | **16.12** |
| [comprehend_it‑base](https://huggingface.co/knowledgator/comprehend_it-base) | 21.79 | 27.32 | 13.60 | 7.58 | 3.80 | 1.90 | 0.97 | 0.49 | **9.72** |
## Citation
```bibtex
@misc{stepanov2025gliclassgeneralistlightweightmodel,
title={GLiClass: Generalist Lightweight Model for Sequence Classification Tasks},
author={Ihor Stepanov and Mykhailo Shtopko and Dmytro Vodianytskyi and Oleksandr Lukashov and Alexander Yavorskyi and Mykyta Yaroshenko},
year={2025},
eprint={2508.07662},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2508.07662},
}
```
|
End of preview.
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.