
lescidium
commited on
Commit
·
4d1d982
1
Parent(s):
f1c103f
Add example usage
Browse filesSlightly change readme
- README.md +17 -5
- personal_mic_wer.png +3 -0
README.md
CHANGED
|
@@ -9,6 +9,7 @@ pretty_name: Audio Device
|
|
| 9 |
# Parallel Recordings
|
| 10 |
This dataset is a small corpus of audio recorded in parallel.
|
| 11 |
This data can be used to quantify the difference in recording quality between different audio devices.
|
|
|
|
| 12 |
|
| 13 |
## Organization
|
| 14 |
There are two separate experiments.
|
|
@@ -16,14 +17,13 @@ There are two separate experiments.
|
|
| 16 |
2) Speakerphone
|
| 17 |
|
| 18 |
The original data for both experiments are located in the`full_length_audio` directory.
|
| 19 |
-
|
| 20 |
-
## Methodology
|
| 21 |
Each experiment was performed by recording simultaneously on multiple devices.
|
| 22 |
Example sentences were prepared beforehand and read during the simultaneous recording.
|
|
|
|
| 23 |
|
| 24 |
### Personal Microphone
|
| 25 |
**Devices:**
|
| 26 |
-
* AT8: Audio Technica
|
| 27 |
* ATR: Audio Technica ATR4800-USB
|
| 28 |
* bltin: Built-In microphone on unknown laptop
|
| 29 |
* boya: Boya BY-W4, Ultracompact 2.4GHz Four-channel Wireless Microphone System
|
|
@@ -34,12 +34,24 @@ Each device was pointed in the same direction toward the speaker. The speaker re
|
|
| 34 |
* Indexes 30-39: Distance = 1 yard (914.4cm)
|
| 35 |
All other indexes correspond to user speaking to themselves at varying and inconsistent distances.
|
| 36 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 37 |
### Speakerphones
|
| 38 |
**Devices:**
|
| 39 |
* respeaker: SeeedStudio ReSpeaker USB Mic Array
|
| 40 |
-
* jabra: Jabra
|
| 41 |
* sanwa: Sanwa Supply 400-MC011
|
| 42 |
-
* yamaha: Yamaha Speakerphone
|
| 43 |
* ntt: NTT Advanced Technology FR-1100
|
| 44 |
|
| 45 |
Each device was placed in the same location in the center of the room. The speaker read sentences five at a time, moving position each time. The positions were roughly assigned and can be best described as close-rear-left, far-front-left, far-front-right, close-rear-right (in order). The final paragraph was read in the same location as the last 5 sentences (close-rear-right).
|
|
|
|
| 9 |
# Parallel Recordings
|
| 10 |
This dataset is a small corpus of audio recorded in parallel.
|
| 11 |
This data can be used to quantify the difference in recording quality between different audio devices.
|
| 12 |
+
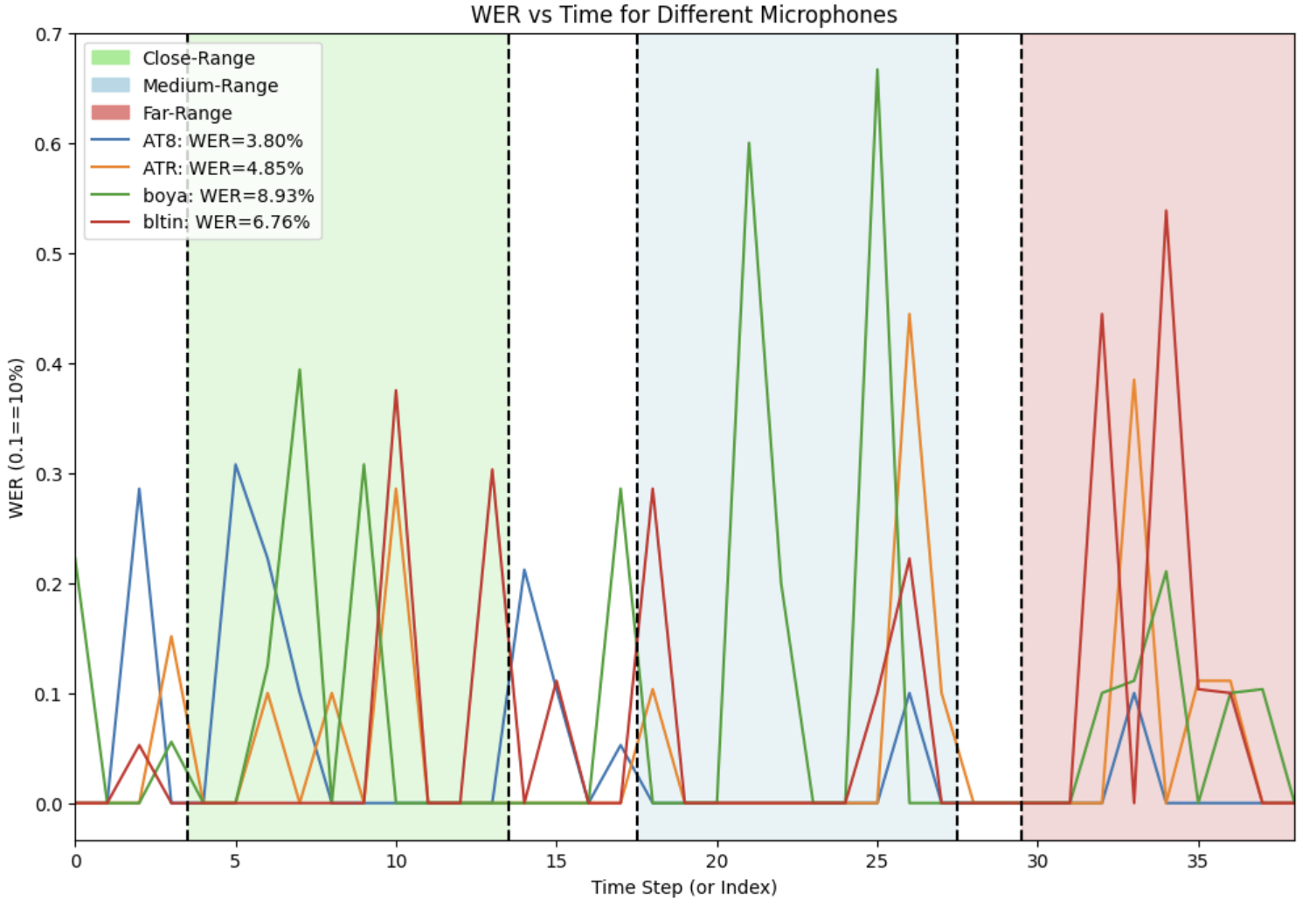
An example of this quantification using WER is [shown below](#example-of-usage).
|
| 13 |
|
| 14 |
## Organization
|
| 15 |
There are two separate experiments.
|
|
|
|
| 17 |
2) Speakerphone
|
| 18 |
|
| 19 |
The original data for both experiments are located in the`full_length_audio` directory.
|
|
|
|
|
|
|
| 20 |
Each experiment was performed by recording simultaneously on multiple devices.
|
| 21 |
Example sentences were prepared beforehand and read during the simultaneous recording.
|
| 22 |
+
The recordings were cut into bits that could fit within the context of most modern ASR models (ie. < 30s).
|
| 23 |
|
| 24 |
### Personal Microphone
|
| 25 |
**Devices:**
|
| 26 |
+
* AT8: Audio Technica Digital 2.4GHz System 10 + ATW-T1007 + AT857SL
|
| 27 |
* ATR: Audio Technica ATR4800-USB
|
| 28 |
* bltin: Built-In microphone on unknown laptop
|
| 29 |
* boya: Boya BY-W4, Ultracompact 2.4GHz Four-channel Wireless Microphone System
|
|
|
|
| 34 |
* Indexes 30-39: Distance = 1 yard (914.4cm)
|
| 35 |
All other indexes correspond to user speaking to themselves at varying and inconsistent distances.
|
| 36 |
|
| 37 |
+
#### Example of Usage
|
| 38 |
+
This data was used to measure microphone quality in the context of ASR. The metric used was WER from the output of `WhisperModel` from `faster_whisper`. The follow parameters were used:
|
| 39 |
+
```
|
| 40 |
+
whisper = WhisperModel(
|
| 41 |
+
model_size_or_path="deepdml/faster-whisper-large-v3-turbo-ct2",
|
| 42 |
+
device="cuda",
|
| 43 |
+
compute_type="float16",
|
| 44 |
+
)
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+

|
| 48 |
+
|
| 49 |
### Speakerphones
|
| 50 |
**Devices:**
|
| 51 |
* respeaker: SeeedStudio ReSpeaker USB Mic Array
|
| 52 |
+
* jabra: Jabra Speak2 75, PHS060Wa
|
| 53 |
* sanwa: Sanwa Supply 400-MC011
|
| 54 |
+
* yamaha: Yamaha Unified Communications Speakerphone YVC-330
|
| 55 |
* ntt: NTT Advanced Technology FR-1100
|
| 56 |
|
| 57 |
Each device was placed in the same location in the center of the room. The speaker read sentences five at a time, moving position each time. The positions were roughly assigned and can be best described as close-rear-left, far-front-left, far-front-right, close-rear-right (in order). The final paragraph was read in the same location as the last 5 sentences (close-rear-right).
|
personal_mic_wer.png
ADDED
|
Git LFS Details
|