Datasets:

Tasks:
Text Generation
Formats:
parquet
Sub-tasks:
language-modeling
Languages:
Danish
Size:
10M - 100M
ArXiv:
DOI:
License:
Kenneth Enevoldsen
commited on
Added dataset: Enevældens Nyheder Online
Browse files## [v1.2.8] - 2025-08-05
### Added
- Added dataset: Enevældens Nyheder Online (`enevaeldens_nyheder`). This brings us to >5B tokens!
## Checklist
- [x] I have run the test suite using `make test` and all tests pass
- [x] I have added/changed a dataset:
- [x] I have updated descriptive statistics using `make update-descriptive-statistics`
- [x] I have bumped the version use `make bump-version`
- [x] If I have added a `create.py` script I have added the [script dependencies](https://docs.astral.sh/uv/guides/scripts/#declaring-script-dependencies) required to run that script.
- [x] I have updated the CHANGELOG.md if appropriate
- CHANGELOG.md +6 -0
- README.md +73 -65
- data/enevaeldens_nyheder/create.py +96 -0
- data/enevaeldens_nyheder/descriptive_stats.json +6 -0
- data/enevaeldens_nyheder/enevaeldens_nyheder.log +9 -0
- data/enevaeldens_nyheder/enevaeldens_nyheder.md +149 -0
- data/enevaeldens_nyheder/enevaeldens_nyheder.parquet +3 -0
- data/enevaeldens_nyheder/images/coverage-of-newspapers.jpeg +3 -0
- data/enevaeldens_nyheder/images/dist_document_length.png +3 -0
- data/enevaeldens_nyheder/images/distribution-pr-year.jpeg +3 -0
- data/enevaeldens_nyheder/images/header_img.jpeg +3 -0
- descriptive_stats.json +4 -4
- images/dist_document_length.png +2 -2
- images/domain_distribution.png +2 -2
- images/tokens_over_time.html +1 -1
- images/tokens_over_time.svg +1 -1
- pyproject.toml +1 -1
- test_results.log +10 -9
- uv.lock +1 -1
CHANGELOG.md
CHANGED
|
@@ -6,6 +6,12 @@ All notable changes to this project will be documented in this file.
|
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
| 8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
## [v1.2.7] - 2025-07-22
|
| 10 |
|
| 11 |
### Added
|
|
|
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
| 8 |
|
| 9 |
+
## [v1.2.8] - 2025-08-05
|
| 10 |
+
|
| 11 |
+
### Added
|
| 12 |
+
|
| 13 |
+
- Added dataset: Enevældens Nyheder Online (`enevaeldens_nyheder`). This brings us to >5B tokens!
|
| 14 |
+
|
| 15 |
## [v1.2.7] - 2025-07-22
|
| 16 |
|
| 17 |
### Added
|
README.md
CHANGED
|
@@ -13,6 +13,10 @@ configs:
|
|
| 13 |
data_files:
|
| 14 |
- split: train
|
| 15 |
path: data/cellar/*.parquet
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
- config_name: grundtvig
|
| 17 |
data_files:
|
| 18 |
- split: train
|
|
@@ -186,7 +190,7 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 186 |
<!-- START README TABLE -->
|
| 187 |
| | |
|
| 188 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 189 |
-
| **Version**
|
| 190 |
| **Language** | dan, dansk, Danish |
|
| 191 |
| **License** | Openly Licensed, See the respective dataset |
|
| 192 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
@@ -226,9 +230,9 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 226 |
|
| 227 |
<!-- START-DESC-STATS -->
|
| 228 |
- **Language**: dan, dansk, Danish
|
| 229 |
-
- **Number of samples**:
|
| 230 |
-
- **Number of tokens (Llama 3)**:
|
| 231 |
-
- **Average document length (characters)**:
|
| 232 |
<!-- END-DESC-STATS -->
|
| 233 |
|
| 234 |
|
|
@@ -288,23 +292,24 @@ This dynaword consist of data from various domains (e.g., legal, books, social m
|
|
| 288 |
|
| 289 |
|
| 290 |
<!-- START-DOMAIN TABLE -->
|
| 291 |
-
| Domain | Sources | N. Tokens
|
| 292 |
-
|
| 293 |
-
| Legal | [cellar], [eur-lex-sum-da], [fm-udgivelser], [retsinformationdk], [skat], [retspraksis], [domsdatabasen] | 2.32B
|
| 294 |
-
|
|
| 295 |
-
|
|
| 296 |
-
|
|
| 297 |
-
|
|
| 298 |
-
|
|
| 299 |
-
|
|
| 300 |
-
|
|
| 301 |
-
| Medical | [health_hovedstaden] | 27.07M
|
| 302 |
-
| Readaloud | [nota] | 7.30M
|
| 303 |
-
| Dialect | [botxt] | 847.97K
|
| 304 |
-
| **Total** | |
|
| 305 |
|
| 306 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 307 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 308 |
[grundtvig]: data/grundtvig/grundtvig.md
|
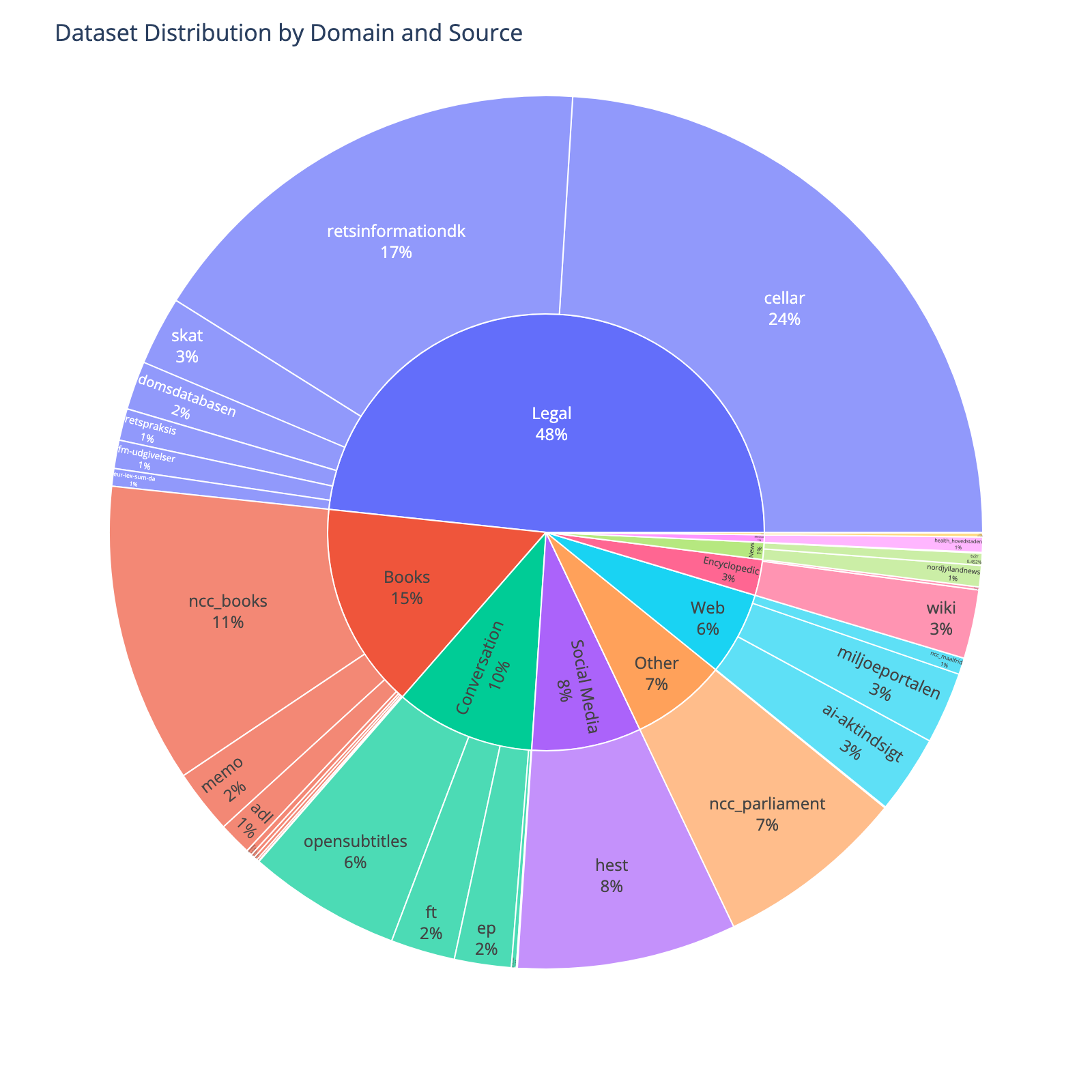
| 309 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 310 |
[ncc_books]: data/ncc_books/ncc_books.md
|
|
@@ -361,16 +366,17 @@ The following gives an overview of the licensing in the Dynaword. To get the exa
|
|
| 361 |
These license is applied to the constituent data, i.e., the text. The collection of datasets (metadata, quality control, etc.) is licensed under [CC-0](https://creativecommons.org/publicdomain/zero/1.0/legalcode.en).
|
| 362 |
|
| 363 |
<!-- START-LICENSE TABLE -->
|
| 364 |
-
| License | Sources
|
| 365 |
-
|
| 366 |
-
| CC-0 | [grundtvig], [danske-taler], [ncc_books], [ncc_newspaper], [miljoeportalen], [opensubtitles], [ep], [ft], [wikisource], [spont], [adl], [hest], [skat], [retspraksis], [wikibooks], [botxt], [naat], [synne], [wiki], [nordjyllandnews], [relig], [nota], [health_hovedstaden] |
|
| 367 |
-
| CC-BY-SA 4.0 | [cellar], [eur-lex-sum-da], [fm-udgivelser], [memo], [tv2r], [jvj], [depbank]
|
| 368 |
-
| Other (No attribution required) | [retsinformationdk], [domsdatabasen]
|
| 369 |
-
| Other (Attribution required) | [ai-aktindsigt], [ncc_maalfrid], [ncc_parliament], [dannet], [gutenberg]
|
| 370 |
-
| **Total** |
|
| 371 |
|
| 372 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 373 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 374 |
[grundtvig]: data/grundtvig/grundtvig.md
|
| 375 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 376 |
[ncc_books]: data/ncc_books/ncc_books.md
|
|
@@ -469,49 +475,51 @@ Below follows a brief overview of the sources in the corpus along with their ind
|
|
| 469 |
You can learn more about each dataset by pressing the link in the first column.
|
| 470 |
|
| 471 |
<!-- START-MAIN TABLE -->
|
| 472 |
-
| Source
|
| 473 |
-
|
| 474 |
-
| [cellar]
|
| 475 |
-
| [
|
| 476 |
-
| [
|
| 477 |
-
| [
|
| 478 |
-
| [
|
| 479 |
-
| [
|
| 480 |
-
| [
|
| 481 |
-
| [
|
| 482 |
-
| [
|
| 483 |
-
| [
|
| 484 |
-
| [
|
| 485 |
-
| [
|
| 486 |
-
| [
|
| 487 |
-
| [
|
| 488 |
-
| [
|
| 489 |
-
| [
|
| 490 |
-
| [
|
| 491 |
-
| [
|
| 492 |
-
| [
|
| 493 |
-
| [
|
| 494 |
-
| [
|
| 495 |
-
| [
|
| 496 |
-
| [
|
| 497 |
-
| [
|
| 498 |
-
| [
|
| 499 |
-
| [
|
| 500 |
-
| [
|
| 501 |
-
| [
|
| 502 |
-
| [
|
| 503 |
-
| [
|
| 504 |
-
| [
|
| 505 |
-
| [
|
| 506 |
-
| [
|
| 507 |
-
| [
|
| 508 |
-
| [
|
| 509 |
-
| [
|
| 510 |
-
| [
|
| 511 |
-
|
|
|
|
|
| 512 |
|
| 513 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 514 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 515 |
[grundtvig]: data/grundtvig/grundtvig.md
|
| 516 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 517 |
[ncc_books]: data/ncc_books/ncc_books.md
|
|
|
|
| 13 |
data_files:
|
| 14 |
- split: train
|
| 15 |
path: data/cellar/*.parquet
|
| 16 |
+
- config_name: enevaeldens_nyheder
|
| 17 |
+
data_files:
|
| 18 |
+
- split: train
|
| 19 |
+
path: data/enevaeldens_nyheder/*.parquet
|
| 20 |
- config_name: grundtvig
|
| 21 |
data_files:
|
| 22 |
- split: train
|
|
|
|
| 190 |
<!-- START README TABLE -->
|
| 191 |
| | |
|
| 192 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 193 |
+
| **Version** | 1.2.8 ([Changelog](/CHANGELOG.md)) |
|
| 194 |
| **Language** | dan, dansk, Danish |
|
| 195 |
| **License** | Openly Licensed, See the respective dataset |
|
| 196 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
|
|
| 230 |
|
| 231 |
<!-- START-DESC-STATS -->
|
| 232 |
- **Language**: dan, dansk, Danish
|
| 233 |
+
- **Number of samples**: 5.55M
|
| 234 |
+
- **Number of tokens (Llama 3)**: 5.83B
|
| 235 |
+
- **Average document length (characters)**: 3171.33
|
| 236 |
<!-- END-DESC-STATS -->
|
| 237 |
|
| 238 |
|
|
|
|
| 292 |
|
| 293 |
|
| 294 |
<!-- START-DOMAIN TABLE -->
|
| 295 |
+
| Domain | Sources | N. Tokens |
|
| 296 |
+
|:-------------|:---------------------------------------------------------------------------------------------------------|:------------|
|
| 297 |
+
| Legal | [cellar], [eur-lex-sum-da], [fm-udgivelser], [retsinformationdk], [skat], [retspraksis], [domsdatabasen] | 2.32B |
|
| 298 |
+
| News | [enevaeldens_nyheder], [ncc_newspaper], [tv2r], [nordjyllandnews] | 1.09B |
|
| 299 |
+
| Books | [grundtvig], [ncc_books], [memo], [adl], [wikibooks], [jvj], [gutenberg], [relig] | 732.52M |
|
| 300 |
+
| Conversation | [danske-taler], [opensubtitles], [ep], [ft], [spont], [naat] | 497.09M |
|
| 301 |
+
| Social Media | [hest] | 389.32M |
|
| 302 |
+
| Other | [ncc_parliament], [dannet], [depbank], [synne] | 340.59M |
|
| 303 |
+
| Web | [ai-aktindsigt], [ncc_maalfrid], [miljoeportalen] | 295.87M |
|
| 304 |
+
| Encyclopedic | [wikisource], [wiki] | 127.35M |
|
| 305 |
+
| Medical | [health_hovedstaden] | 27.07M |
|
| 306 |
+
| Readaloud | [nota] | 7.30M |
|
| 307 |
+
| Dialect | [botxt] | 847.97K |
|
| 308 |
+
| **Total** | | 5.83B |
|
| 309 |
|
| 310 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 311 |
[cellar]: data/cellar/cellar.md
|
| 312 |
+
[enevaeldens_nyheder]: data/enevaeldens_nyheder/enevaeldens_nyheder.md
|
| 313 |
[grundtvig]: data/grundtvig/grundtvig.md
|
| 314 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 315 |
[ncc_books]: data/ncc_books/ncc_books.md
|
|
|
|
| 366 |
These license is applied to the constituent data, i.e., the text. The collection of datasets (metadata, quality control, etc.) is licensed under [CC-0](https://creativecommons.org/publicdomain/zero/1.0/legalcode.en).
|
| 367 |
|
| 368 |
<!-- START-LICENSE TABLE -->
|
| 369 |
+
| License | Sources | N. Tokens |
|
| 370 |
+
|:--------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------|
|
| 371 |
+
| CC-0 | [enevaeldens_nyheder], [grundtvig], [danske-taler], [ncc_books], [ncc_newspaper], [miljoeportalen], [opensubtitles], [ep], [ft], [wikisource], [spont], [adl], [hest], [skat], [retspraksis], [wikibooks], [botxt], [naat], [synne], [wiki], [nordjyllandnews], [relig], [nota], [health_hovedstaden] | 3.04B |
|
| 372 |
+
| CC-BY-SA 4.0 | [cellar], [eur-lex-sum-da], [fm-udgivelser], [memo], [tv2r], [jvj], [depbank] | 1.37B |
|
| 373 |
+
| Other (No attribution required) | [retsinformationdk], [domsdatabasen] | 904.61M |
|
| 374 |
+
| Other (Attribution required) | [ai-aktindsigt], [ncc_maalfrid], [ncc_parliament], [dannet], [gutenberg] | 515.61M |
|
| 375 |
+
| **Total** | | 5.83B |
|
| 376 |
|
| 377 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 378 |
[cellar]: data/cellar/cellar.md
|
| 379 |
+
[enevaeldens_nyheder]: data/enevaeldens_nyheder/enevaeldens_nyheder.md
|
| 380 |
[grundtvig]: data/grundtvig/grundtvig.md
|
| 381 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 382 |
[ncc_books]: data/ncc_books/ncc_books.md
|
|
|
|
| 475 |
You can learn more about each dataset by pressing the link in the first column.
|
| 476 |
|
| 477 |
<!-- START-MAIN TABLE -->
|
| 478 |
+
| Source | Description | Domain | N. Tokens | License |
|
| 479 |
+
|:----------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-------------|:------------|:-----------------------|
|
| 480 |
+
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B | [CC-BY-SA 4.0] |
|
| 481 |
+
| [enevaeldens_nyheder] | High quality OCR'd texts from Danish and Norwegian newspapers during the period of constitutional absolutism in Denmark (1660–1849) | News | 1.03B | [CC-0] |
|
| 482 |
+
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 818.25M | [Danish Copyright Law] |
|
| 483 |
+
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M | [CC-0] |
|
| 484 |
+
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M | [CC-0] |
|
| 485 |
+
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M | [NLOD 2.0] |
|
| 486 |
+
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M | [CC-0] |
|
| 487 |
+
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M | [Apache 2.0] |
|
| 488 |
+
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M | [CC-0] |
|
| 489 |
+
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M | [CC-0] |
|
| 490 |
+
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M | [CC-0] |
|
| 491 |
+
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M | [CC-0] |
|
| 492 |
+
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M | [CC-BY-SA 4.0] |
|
| 493 |
+
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M | [CC-0] |
|
| 494 |
+
| [domsdatabasen] | [Domsdatabasen.dk](https://domsdatabasen.dk/) is a public database containing selected judgments from the Danish courts | Legal | 86.35M | [Danish Copyright Law] |
|
| 495 |
+
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M | [CC-0] |
|
| 496 |
+
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M | [CC-0] |
|
| 497 |
+
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M | [CC-BY-SA 4.0] |
|
| 498 |
+
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 499 |
+
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 500 |
+
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 501 |
+
| [health_hovedstaden] | Guidelines and informational documents for healthcare professionals from the Capital Region | Medical | 27.07M | [CC-0] |
|
| 502 |
+
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 503 |
+
| [grundtvig] | The complete collection of [Grundtvig](https://en.wikipedia.org/wiki/N._F._S._Grundtvig) (1783-1872) one of Denmark’s most influential figures | Books | 10.53M | [CC-0] |
|
| 504 |
+
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.72M | [CC-0] |
|
| 505 |
+
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
| 506 |
+
| [gutenberg] | The Danish subsection from Project [Gutenberg](https://www.gutenberg.org) | Books | 6.76M | [Gutenberg] |
|
| 507 |
+
| [wikibooks] | The Danish Subsection of [Wikibooks](https://www.wikibooks.org) | Books | 6.24M | [CC-0] |
|
| 508 |
+
| [wikisource] | The Danish subsection of [Wikisource](https://en.wikisource.org/wiki/Main_Page) | Encyclopedic | 5.34M | [CC-0] |
|
| 509 |
+
| [jvj] | The works of the Danish author and poet, [Johannes V. Jensen](https://da.wikipedia.org/wiki/Johannes_V._Jensen) | Books | 3.55M | [CC-BY-SA 4.0] |
|
| 510 |
+
| [spont] | Conversational samples collected as a part of research projects at Aarhus University | Conversation | 1.56M | [CC-0] |
|
| 511 |
+
| [dannet] | [DanNet](https://cst.ku.dk/projekter/dannet) is a Danish WordNet | Other | 1.48M | [DanNet 1.0] |
|
| 512 |
+
| [relig] | Danish religious text from the 1700-2022 | Books | 1.24M | [CC-0] |
|
| 513 |
+
| [ncc_newspaper] | OCR'd Newspapers derived from [NCC](https://huggingface.co/datasets/NbAiLab/NCC) | News | 1.05M | [CC-0] |
|
| 514 |
+
| [botxt] | The Bornholmsk Ordbog Dictionary Project | Dialect | 847.97K | [CC-0] |
|
| 515 |
+
| [naat] | Danish speeches from 1930-2022 | Conversation | 286.68K | [CC-0] |
|
| 516 |
+
| [depbank] | The Danish subsection of the [Universal Dependencies Treebank](https://github.com/UniversalDependencies/UD_Danish-DDT) | Other | 185.45K | [CC-BY-SA 4.0] |
|
| 517 |
+
| [synne] | Dataset collected from [synnejysk forening's website](https://www.synnejysk.dk), covering the Danish dialect sønderjysk | Other | 52.02K | [CC-0] |
|
| 518 |
+
| **Total** | | | 5.83B | |
|
| 519 |
|
| 520 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 521 |
[cellar]: data/cellar/cellar.md
|
| 522 |
+
[enevaeldens_nyheder]: data/enevaeldens_nyheder/enevaeldens_nyheder.md
|
| 523 |
[grundtvig]: data/grundtvig/grundtvig.md
|
| 524 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 525 |
[ncc_books]: data/ncc_books/ncc_books.md
|
data/enevaeldens_nyheder/create.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# /// script
|
| 2 |
+
# requires-python = ">=3.12"
|
| 3 |
+
# dependencies = [
|
| 4 |
+
# "datasets",
|
| 5 |
+
# "dynaword",
|
| 6 |
+
# ]
|
| 7 |
+
#
|
| 8 |
+
# [tool.uv.sources]
|
| 9 |
+
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword" }
|
| 10 |
+
# ///
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
Script for downloading and processing the dataset
|
| 14 |
+
|
| 15 |
+
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
GIT_LFS_SKIP_SMUDGE=1 uv run data/enevaeldens_nyheder/create.py
|
| 19 |
+
```
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
import logging
|
| 23 |
+
from datetime import date
|
| 24 |
+
from pathlib import Path
|
| 25 |
+
from typing import Any, cast
|
| 26 |
+
|
| 27 |
+
from datasets import Dataset, load_dataset
|
| 28 |
+
|
| 29 |
+
from dynaword.process_dataset import (
|
| 30 |
+
add_token_count,
|
| 31 |
+
ensure_column_order,
|
| 32 |
+
remove_duplicate_text,
|
| 33 |
+
remove_empty_texts,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
SOURCE = "enevaeldens_nyheder"
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def reformat_samples(example: dict[str, Any]) -> dict[str, Any]:
|
| 42 |
+
creation_date = example["date"]
|
| 43 |
+
# Reformatting the date to YYYY-MM-DD format
|
| 44 |
+
start = creation_date
|
| 45 |
+
end = creation_date
|
| 46 |
+
return {
|
| 47 |
+
"id": f"{SOURCE}_{example['id']}",
|
| 48 |
+
"text": example["text"],
|
| 49 |
+
"source": SOURCE,
|
| 50 |
+
"added": date.today().strftime("%Y-%m-%d"),
|
| 51 |
+
"created": f"{start}, {end}",
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def main():
|
| 56 |
+
dataset = load_dataset(
|
| 57 |
+
"JohanHeinsen/ENO",
|
| 58 |
+
split="train",
|
| 59 |
+
revision="009f45ef63a1a41705781840807eb620f380d17d",
|
| 60 |
+
)
|
| 61 |
+
dataset = cast(Dataset, dataset)
|
| 62 |
+
|
| 63 |
+
logger.info("Removing 1 word texts")
|
| 64 |
+
len_ds = len(dataset)
|
| 65 |
+
dataset = dataset.filter(
|
| 66 |
+
lambda x: len(x["text"].split()) >= 2
|
| 67 |
+
) # require at least 2 word in the text
|
| 68 |
+
logger.info(f"Filtered {len_ds - len(dataset)} 1 word examples")
|
| 69 |
+
|
| 70 |
+
logger.info("Filtering out texts with predicted word acuracy < 0.7")
|
| 71 |
+
dataset = dataset.filter(lambda x: x["pwa"] >= 0.7)
|
| 72 |
+
logger.info(f"Filtered {len_ds - len(dataset)} low accuracy examples")
|
| 73 |
+
|
| 74 |
+
dataset = dataset.map(reformat_samples)
|
| 75 |
+
|
| 76 |
+
dataset = remove_empty_texts(dataset) # remove rows with empty text
|
| 77 |
+
dataset = remove_duplicate_text(dataset) # remove rows with duplicate text
|
| 78 |
+
dataset = add_token_count(dataset)
|
| 79 |
+
dataset = ensure_column_order(dataset)
|
| 80 |
+
|
| 81 |
+
dataset.to_parquet(
|
| 82 |
+
Path(__file__).parent / f"{SOURCE}.parquet",
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
if __name__ == "__main__":
|
| 87 |
+
log_path = Path(__file__).parent / f"{SOURCE}.log"
|
| 88 |
+
logging.basicConfig(
|
| 89 |
+
level=logging.INFO,
|
| 90 |
+
format="%(asctime)s - %(levelname)s - %(message)s",
|
| 91 |
+
handlers=[
|
| 92 |
+
logging.StreamHandler(),
|
| 93 |
+
logging.FileHandler(log_path),
|
| 94 |
+
],
|
| 95 |
+
)
|
| 96 |
+
main()
|
data/enevaeldens_nyheder/descriptive_stats.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"number_of_samples": 4593228,
|
| 3 |
+
"average_document_length": 629.0663916531032,
|
| 4 |
+
"number_of_tokens": 1034308344,
|
| 5 |
+
"revision": "14e79bd9ddcf790f41259971134ccacc1be2a60d"
|
| 6 |
+
}
|
data/enevaeldens_nyheder/enevaeldens_nyheder.log
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
2025-08-05 13:09:29,533 - INFO - Removing 1 word texts
|
| 2 |
+
2025-08-05 13:10:14,475 - INFO - Filtered 42635 1 word examples
|
| 3 |
+
2025-08-05 13:10:14,475 - INFO - Filtering out texts with predicted word acuracy < 0.7
|
| 4 |
+
2025-08-05 13:11:24,300 - INFO - Filtered 76655 low accuracy examples
|
| 5 |
+
2025-08-05 13:15:33,389 - INFO - Removing empty texts
|
| 6 |
+
2025-08-05 13:15:50,876 - INFO - Filtered 0 empty examples
|
| 7 |
+
2025-08-05 13:15:50,876 - INFO - Removing duplicate texts
|
| 8 |
+
2025-08-05 13:19:48,194 - INFO - Filtered 161196 duplicate examples
|
| 9 |
+
2025-08-05 13:32:46,967 - INFO - Ensuring columns are in the correct order and are present
|
data/enevaeldens_nyheder/enevaeldens_nyheder.md
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: "Enev\xE6ldens Nyheder Online"
|
| 3 |
+
language:
|
| 4 |
+
- da
|
| 5 |
+
license: cc0-1.0
|
| 6 |
+
license_name: CC-0
|
| 7 |
+
task_categories:
|
| 8 |
+
- text-generation
|
| 9 |
+
- fill-mask
|
| 10 |
+
task_ids:
|
| 11 |
+
- language-modeling
|
| 12 |
+
domains:
|
| 13 |
+
- News
|
| 14 |
+
source_datasets:
|
| 15 |
+
- JohanHeinsen/ENO
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
# Dataset Card for Enevældens Nyheder Online
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
<!-- START-SHORT DESCRIPTION -->
|
| 22 |
+
High quality OCR'd texts from Danish and Norwegian newspapers during the period of constitutional absolutism in Denmark (1660–1849).
|
| 23 |
+
<!-- END-SHORT DESCRIPTION -->
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
During the eighteenth century, newspapers became a ubiquitous medium. They informed a relatively large reading public about everything from high politics to the mundanities of local markets.
|
| 27 |
+
The dataset was created by re-processing over 550.000 digital images scanned from microfilm and held in the Danish Royal Library's collection. They had initially been OCR-processed, but the results were generally unreadable. ENO reprocessed the images using tailored pylaia models in Transkribus. The OCR-quality is generally high, despite the difficult state of the original images.
|
| 28 |
+
The newspaper editions have been segmented into individual texts using a model designed by the project team. Such texts are the base entity of the dataset. They include mainly two genres: news items and advertisements.
|
| 29 |
+
|
| 30 |
+
## Dataset Description
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
<!-- START-DESC-STATS -->
|
| 34 |
+
- **Language**: dan, dansk, Danish
|
| 35 |
+
- **Domains**: News
|
| 36 |
+
- **Number of samples**: 4.59M
|
| 37 |
+
- **Number of tokens (Llama 3)**: 1.03B
|
| 38 |
+
- **Average document length (characters)**: 629.07
|
| 39 |
+
<!-- END-DESC-STATS -->
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
* **Curated by**: Johan Heinsen and Camilla Bøgeskov, Historisk Datalaboratorium, Aalborg University. With assistance from Sofus Landor Dam, Anders Birkemose, Kamilla Matthiassen and Louise Karoline Sort.
|
| 43 |
+
* **Funded by**: MASSHINE, Aalborg University.
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
The dataset contains a wide range of newspapers. The total distribution can be studied here. They cover most of Denmark as well as the three oldest newspapers of Norway, running until the separation of the Danish-Norwegian conglomerate in 1814. This dataset represents version 0.9 (updated 5th of August 2025).
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
### Dataset Sources
|
| 50 |
+
|
| 51 |
+
The sources of the dataset can be studied in more detail at the [project website](https://hislab.quarto.pub/eno/).
|
| 52 |
+
Most of the original image material is available in [LOAR](https://loar.kb.dk/handle/1902/7803) – a data repository of the Danish Royal Library. The Norwegian material was downloaded via the API of Nettbiblioteket. The scans of Nyeste Skilderie af Kjøbenhavn were taken from the Internet Archive repository of [Niels Jensen](https://archive.org/details/@uforbederlig). The scans for Politivennen stem from [Københavns Biblioteker](https://bibliotek.kk.dk/din/bag-om-kobenhavn/politivennen). Some early newspapers come from recent scans made available to the project by the Danish Royal Library. These are not yet available online.
|
| 53 |
+
|
| 54 |
+
## Uses
|
| 55 |
+
|
| 56 |
+
This dataset represents an effort to enable analysis of Denmark-Norway in the seventeenth, eighteenth, and nineteenth centuries. The data can be used to study and model sentiments, political and cultural currents, and the minutiae of urban life.
|
| 57 |
+
|
| 58 |
+
In addition, this dataset is part of Danish Dynaword, a collection of datasets intended for training language models, thereby integrating Danish cultural heritage into the next generation of digital technologies.
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
## Dataset Structure
|
| 63 |
+
An example from the dataset looks as follows.
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
<!-- START-SAMPLE -->
|
| 67 |
+
```py
|
| 68 |
+
{
|
| 69 |
+
"id": "enevaeldens_nyheder_aalborg1767_1767-01-02_1000001",
|
| 70 |
+
"text": "Et Menneske er skabt ey for sig selv allene: Hvert Lem paa Legemet det heele tiene maae, En Stolpes [...]",
|
| 71 |
+
"source": "enevaeldens_nyheder",
|
| 72 |
+
"added": "2025-08-05",
|
| 73 |
+
"created": "1767-01-02, 1767-01-02",
|
| 74 |
+
"token_count": 2377
|
| 75 |
+
}
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### Data Fields
|
| 79 |
+
|
| 80 |
+
An entry in the dataset consists of the following fields:
|
| 81 |
+
|
| 82 |
+
- `id` (`str`): An unique identifier for each document.
|
| 83 |
+
- `text`(`str`): The content of the document.
|
| 84 |
+
- `source` (`str`): The source of the document (see [Source Data](#source-data)).
|
| 85 |
+
- `added` (`str`): An date for when the document was added to this collection.
|
| 86 |
+
- `created` (`str`): An date range for when the document was originally created.
|
| 87 |
+
- `token_count` (`int`): The number of tokens in the sample computed using the Llama 8B tokenizer
|
| 88 |
+
<!-- END-SAMPLE -->
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
## Dataset Creation
|
| 93 |
+
|
| 94 |
+
### Curation Rationale
|
| 95 |
+
|
| 96 |
+
The newspapers in the dataset generally represent the longest-running newspaper series in the Danish and Norwegian libraries. We prioritised long-running newspapers to enable historical analysis of changes over time. As historians, this was our initial ambition: to allow us to get quality serial text data.
|
| 97 |
+
We also prioritised geographical diversity, representing different regions of Denmark-Norway. Of course, this varies over time, as newspapers were most common in Copenhagen until the late eighteenth century.
|
| 98 |
+
Since the newspapers of Denmark's Caribbean colonies were primarily in English, they are not included. The text recognition model designed for the project struggles with English text.
|
| 99 |
+
Besides long-running series, we also included a few smaller newspaper series, mainly with an eye towards diversity of subject matter. These include Politivennen, which was concerned with very local news from Copenhagen and carried a lot of reader contributions, offering a unique insight into urban sentiments at the time. A similar inclusion was made with Jyllandsposten (of 1838), which was defined by a somewhat radical rural horizon.
|
| 100 |
+
|
| 101 |
+
As a rule of thumb, publications have been digitised in total, as they exist in their respective collections.
|
| 102 |
+
This means that they sometimes include appendices and sometimes do not, depending on whether these exist. Holes in the dataset mirror holes in the archival collections.
|
| 103 |
+
The one exception to this rule is the newspaper Københavns Adresseavis. This advertisement paper has survived continuously from its inception in 1759, but from 1804 onwards, it is only included here with samples every fifth year.
|
| 104 |
+
The reason for sampling is a combination of the massive extent of this advertisement paper and the poor condition of the digital images available for this specific period. Combined this meant that the results of the text recognition process were not entirely satisfying relative to the resources necessary for the effort. Therefore, we decided to prioritize other publications that would yield better quality text.
|
| 105 |
+
|
| 106 |
+
Most publications contain title page marginalia (date, title, etc.). Because these were set with large ornamental types, they are typically recognised with much less accuracy than the regular text. We are currently working on implementing a step in the workflow to identify and filter out these elements.
|
| 107 |
+
|
| 108 |
+
### Data Collection and Processing
|
| 109 |
+
|
| 110 |
+
The text recognition model used to create the dataset is available via [Transkribus](https://app.transkribus.org/models/public/text/danish-newspapers-1750-1850). A description of the text segmentation process can be found [here](https://hislab.quarto.pub/eno/dokumentation.html). Besides segmentation into separate news items / advertisements, no further processing of the text has taken place. We are currently experimenting with automated error correction using decoder-models.
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
### Dataset Statistics
|
| 114 |
+
|
| 115 |
+
<!-- START-DATASET PLOTS -->
|
| 116 |
+
<p align="center">
|
| 117 |
+
<img src="./images/dist_document_length.png" width="600" style="margin-right: 10px;" />
|
| 118 |
+
</p>
|
| 119 |
+
<!-- END-DATASET PLOTS -->
|
| 120 |
+
|
| 121 |
+
The coverage of the newspapers included can be seen here:
|
| 122 |
+
|
| 123 |
+

|
| 124 |
+
|
| 125 |
+
The distribution of texts pr. year is as follows:
|
| 126 |
+
|
| 127 |
+

|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
## Personal and Sensitive Information
|
| 131 |
+
|
| 132 |
+
Due to the historical nature of the data, ENO contains no personal or sensitive information.
|
| 133 |
+
|
| 134 |
+
## Bias, Risks, and Limitations
|
| 135 |
+
|
| 136 |
+
The data reflects the time of its initial creation. This means that it mirrors and describes a deeply hierarchical society that was structured by deep-seated biases and forms of discrimination that are alien even to some of the worst among the living today. For example, the material contains racist language in describing contemporary phenomena such as the Transatlantic slave trade and the persecution of Jewish diasporas. Use cases which might relay or perpetuate such sentiments should be aware of these risks. It is a historical text corpora, warts and all.
|
| 137 |
+
|
| 138 |
+
Please also note that, although the newspapers are all in Danish, they do contain intermittent passages in German and Latin.
|
| 139 |
+
|
| 140 |
+
Some advertisements were reprinted verbatim. The dataset, therefore, includes occasional duplicate texts.
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
### License Information
|
| 144 |
+
|
| 145 |
+
The dataset is licensed under CC BY-SA 4.0. Please note that this license only pertains to the digitised text and dataset curation, not the original images. The original images of all material stemming from The Danish Royal Library, Nettbiblioteket, Københavns Biblioteker as well as the scans of Nyeste Skilderie af Kiøbenhavn made available by Niels Jensen are all in the public domain.
|
| 146 |
+
|
| 147 |
+
## More Information
|
| 148 |
+
|
| 149 |
+
For questions related to the dataset, curation, and annotation we please contact Johan Heinsen, Aalborg University <[email protected]>
|
data/enevaeldens_nyheder/enevaeldens_nyheder.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f0ccbf865189f37c9735e001219ef85da11ea3b5849621993a995f138c7f51d
|
| 3 |
+
size 1856788258
|
data/enevaeldens_nyheder/images/coverage-of-newspapers.jpeg
ADDED

|
Git LFS Details
|
data/enevaeldens_nyheder/images/dist_document_length.png
ADDED
|
Git LFS Details
|
data/enevaeldens_nyheder/images/distribution-pr-year.jpeg
ADDED

|
Git LFS Details
|
data/enevaeldens_nyheder/images/header_img.jpeg
ADDED
|
Git LFS Details
|
descriptive_stats.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
-
"number_of_samples":
|
| 3 |
-
"average_document_length":
|
| 4 |
-
"number_of_tokens":
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"number_of_samples": 5554217,
|
| 3 |
+
"average_document_length": 3171.325986723241,
|
| 4 |
+
"number_of_tokens": 5829657307,
|
| 5 |
+
"revision": "14e79bd9ddcf790f41259971134ccacc1be2a60d"
|
| 6 |
}
|
images/dist_document_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
images/domain_distribution.png
CHANGED
|
Git LFS Details
|

|
Git LFS Details
|
images/tokens_over_time.html
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
<head><meta charset="utf-8" /></head>
|
| 3 |
<body>
|
| 4 |
<div> <script type="text/javascript">window.PlotlyConfig = {MathJaxConfig: 'local'};</script>
|
| 5 |
-
<script charset="utf-8" src="https://cdn.plot.ly/plotly-3.0.1.min.js"></script> <div id="cbff9399-9d83-4378-9a08-8dcd2e1ed656" class="plotly-graph-div" style="height:400px; width:600px;"></div> <script type="text/javascript"> window.PLOTLYENV=window.PLOTLYENV || {}; if (document.getElementById("cbff9399-9d83-4378-9a08-8dcd2e1ed656")) { Plotly.newPlot( "cbff9399-9d83-4378-9a08-8dcd2e1ed656", [{"hovertemplate":"%{text}\u003cextra\u003e\u003c\u002fextra\u003e","line":{"color":"#DC2626","width":3},"marker":{"color":"#DC2626","size":5},"mode":"lines+markers","name":"Tokens","text":["Date: 2025-01-02\u003cbr\u003eTokens: 1.57G\u003cbr\u003eSamples: 546,769\u003cbr\u003eCommit: 9c15515d\u003cbr\u003eMessage: Added number of llama3 tokens to desc stats","Date: 2025-01-03\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +271.89M\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 38b692a5\u003cbr\u003eMessage: Added automatically updated samples to update_descriptive_stats.py","Date: 2025-01-04\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 546c3b35\u003cbr\u003eMessage: update opensubtitles","Date: 2025-01-05\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +5.40M\u003cbr\u003eSamples: 588,476\u003cbr\u003eCommit: 0cef3177\u003cbr\u003eMessage: Added distribution plot for number of tokens","Date: 2025-02-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +7.30M\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 97b3aa5d\u003cbr\u003eMessage: Add Nota-tekster (#41)","Date: 2025-03-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 5affec72\u003cbr\u003eMessage: add_memo (#42)","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +1.51G\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 65faa6e2\u003cbr\u003eMessage: a lot of improvements","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 43d839aa\u003cbr\u003eMessage: updates sheets","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 060c4430\u003cbr\u003eMessage: Updated changelog","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: c9397c44\u003cbr\u003eMessage: reformatted the readme","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +901.15M\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: d36009a4\u003cbr\u003eMessage: update desc stats","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 91cd694a\u003cbr\u003eMessage: docs: minor fixes to datasheets","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 2453a15a\u003cbr\u003eMessage: updated datasheet","Date: 2025-06-23\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +104.46M\u003cbr\u003eSamples: 891,094\u003cbr\u003eCommit: 16931a4c\u003cbr\u003eMessage: Fix memo (#68)","Date: 2025-06-25\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +581.06k\u003cbr\u003eSamples: 891,348\u003cbr\u003eCommit: 2c91001b\u003cbr\u003eMessage: Fix Danske Taler (#69)","Date: 2025-06-30\u003cbr\u003eTokens: 4.40G\u003cbr\u003eChange: +26.49M\u003cbr\u003eSamples: 915,090\u003cbr\u003eCommit: 7df022e7\u003cbr\u003eMessage: Adding Scrape Hovedstaden (#70)","Date: 2025-07-01\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +302.40M\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 6a2c8fbf\u003cbr\u003eMessage: update-retsinformationdk (#72)","Date: 2025-07-08\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 0cdc88c0\u003cbr\u003eMessage: Add tokens over time (+ rename scrape_hovedstaten) (#73)","Date: 2025-07-11\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +86.35M\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: dd36adfe\u003cbr\u003eMessage: Add domsdatabasen (#74)","Date: 2025-07-21\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: 30071635\u003cbr\u003eMessage: restructuring-main-table (#75)"],"x":["2025-01-02T00:00:00.000000000","2025-01-03T00:00:00.000000000","2025-01-04T00:00:00.000000000","2025-01-05T00:00:00.000000000","2025-02-10T00:00:00.000000000","2025-03-10T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-06-23T00:00:00.000000000","2025-06-25T00:00:00.000000000","2025-06-30T00:00:00.000000000","2025-07-01T00:00:00.000000000","2025-07-08T00:00:00.000000000","2025-07-11T00:00:00.000000000","2025-07-21T00:00:00.000000000"],"y":[1567706760,1839599769,1839599769,1844994816,1852293828,1852293828,3363395483,3363395483,3363395483,3363395483,4264549097,4264549097,4264549097,4369008328,4369589385,4396075044,4698470546,4698470546,4784823570,4784823570],"type":"scatter"}], {"template":{"data":{"histogram2dcontour":[{"type":"histogram2dcontour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"choropleth":[{"type":"choropleth","colorbar":{"outlinewidth":0,"ticks":""}}],"histogram2d":[{"type":"histogram2d","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"heatmap":[{"type":"heatmap","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"contourcarpet":[{"type":"contourcarpet","colorbar":{"outlinewidth":0,"ticks":""}}],"contour":[{"type":"contour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"surface":[{"type":"surface","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"mesh3d":[{"type":"mesh3d","colorbar":{"outlinewidth":0,"ticks":""}}],"scatter":[{"fillpattern":{"fillmode":"overlay","size":10,"solidity":0.2},"type":"scatter"}],"parcoords":[{"type":"parcoords","line":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolargl":[{"type":"scatterpolargl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"bar":[{"error_x":{"color":"#2a3f5f"},"error_y":{"color":"#2a3f5f"},"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"bar"}],"scattergeo":[{"type":"scattergeo","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolar":[{"type":"scatterpolar","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"histogram":[{"marker":{"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"histogram"}],"scattergl":[{"type":"scattergl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatter3d":[{"type":"scatter3d","line":{"colorbar":{"outlinewidth":0,"ticks":""}},"marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermap":[{"type":"scattermap","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermapbox":[{"type":"scattermapbox","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterternary":[{"type":"scatterternary","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattercarpet":[{"type":"scattercarpet","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"carpet":[{"aaxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"baxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"type":"carpet"}],"table":[{"cells":{"fill":{"color":"#EBF0F8"},"line":{"color":"white"}},"header":{"fill":{"color":"#C8D4E3"},"line":{"color":"white"}},"type":"table"}],"barpolar":[{"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"barpolar"}],"pie":[{"automargin":true,"type":"pie"}]},"layout":{"autotypenumbers":"strict","colorway":["#636efa","#EF553B","#00cc96","#ab63fa","#FFA15A","#19d3f3","#FF6692","#B6E880","#FF97FF","#FECB52"],"font":{"color":"#2a3f5f"},"hovermode":"closest","hoverlabel":{"align":"left"},"paper_bgcolor":"white","plot_bgcolor":"#E5ECF6","polar":{"bgcolor":"#E5ECF6","angularaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"radialaxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"ternary":{"bgcolor":"#E5ECF6","aaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"baxis":{"gridcolor":"white","linecolor":"white","ticks":""},"caxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"coloraxis":{"colorbar":{"outlinewidth":0,"ticks":""}},"colorscale":{"sequential":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"sequentialminus":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"diverging":[[0,"#8e0152"],[0.1,"#c51b7d"],[0.2,"#de77ae"],[0.3,"#f1b6da"],[0.4,"#fde0ef"],[0.5,"#f7f7f7"],[0.6,"#e6f5d0"],[0.7,"#b8e186"],[0.8,"#7fbc41"],[0.9,"#4d9221"],[1,"#276419"]]},"xaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"yaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"scene":{"xaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"yaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"zaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2}},"shapedefaults":{"line":{"color":"#2a3f5f"}},"annotationdefaults":{"arrowcolor":"#2a3f5f","arrowhead":0,"arrowwidth":1},"geo":{"bgcolor":"white","landcolor":"#E5ECF6","subunitcolor":"white","showland":true,"showlakes":true,"lakecolor":"white"},"title":{"x":0.05},"mapbox":{"style":"light"}}},"shapes":[{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":300000000,"y1":300000000,"yref":"y"},{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":1000000000,"y1":1000000000,"yref":"y"}],"annotations":[{"font":{"color":"gray","size":12},"showarrow":false,"text":"Common Corpus (dan) (Langlais et al., 2025)","x":0,"xanchor":"left","xref":"x domain","y":300000000,"yanchor":"bottom","yref":"y"},{"font":{"color":"gray","size":12},"showarrow":false,"text":"Danish Gigaword (Derczynski et al., 2021)","x":0,"xanchor":"left","xref":"x domain","y":1000000000,"yanchor":"bottom","yref":"y"}],"title":{"text":"Number of Tokens Over Time in Danish Dynaword"},"xaxis":{"title":{"text":"Date"}},"yaxis":{"title":{"text":"Number of Tokens (Llama 3)"},"tickformat":".2s","ticksuffix":""},"hovermode":"closest","width":600,"height":400,"showlegend":false,"plot_bgcolor":"rgba(0,0,0,0)","paper_bgcolor":"rgba(0,0,0,0)"}, {"responsive": true} ) }; </script> </div>
|
| 6 |
</body>
|
| 7 |
</html>
|
|
|
|
| 2 |
<head><meta charset="utf-8" /></head>
|
| 3 |
<body>
|
| 4 |
<div> <script type="text/javascript">window.PlotlyConfig = {MathJaxConfig: 'local'};</script>
|
| 5 |
+
<script charset="utf-8" src="https://cdn.plot.ly/plotly-3.0.1.min.js"></script> <div id="9b1eef65-0ffe-44ad-b754-45027d3ce6df" class="plotly-graph-div" style="height:400px; width:600px;"></div> <script type="text/javascript"> window.PLOTLYENV=window.PLOTLYENV || {}; if (document.getElementById("9b1eef65-0ffe-44ad-b754-45027d3ce6df")) { Plotly.newPlot( "9b1eef65-0ffe-44ad-b754-45027d3ce6df", [{"hovertemplate":"%{text}\u003cextra\u003e\u003c\u002fextra\u003e","line":{"color":"#DC2626","width":3},"marker":{"color":"#DC2626","size":5},"mode":"lines+markers","name":"Tokens","text":["Date: 2025-01-02\u003cbr\u003eTokens: 1.57G\u003cbr\u003eSamples: 546,769\u003cbr\u003eCommit: 9c15515d\u003cbr\u003eMessage: Added number of llama3 tokens to desc stats","Date: 2025-01-03\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +271.89M\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 38b692a5\u003cbr\u003eMessage: Added automatically updated samples to update_descriptive_stats.py","Date: 2025-01-04\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 546c3b35\u003cbr\u003eMessage: update opensubtitles","Date: 2025-01-05\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +5.40M\u003cbr\u003eSamples: 588,476\u003cbr\u003eCommit: 0cef3177\u003cbr\u003eMessage: Added distribution plot for number of tokens","Date: 2025-02-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +7.30M\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 97b3aa5d\u003cbr\u003eMessage: Add Nota-tekster (#41)","Date: 2025-03-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 5affec72\u003cbr\u003eMessage: add_memo (#42)","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +1.51G\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 65faa6e2\u003cbr\u003eMessage: a lot of improvements","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 43d839aa\u003cbr\u003eMessage: updates sheets","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 060c4430\u003cbr\u003eMessage: Updated changelog","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: c9397c44\u003cbr\u003eMessage: reformatted the readme","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +901.15M\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: d36009a4\u003cbr\u003eMessage: update desc stats","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 91cd694a\u003cbr\u003eMessage: docs: minor fixes to datasheets","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 2453a15a\u003cbr\u003eMessage: updated datasheet","Date: 2025-06-23\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +104.46M\u003cbr\u003eSamples: 891,094\u003cbr\u003eCommit: 16931a4c\u003cbr\u003eMessage: Fix memo (#68)","Date: 2025-06-25\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +581.06k\u003cbr\u003eSamples: 891,348\u003cbr\u003eCommit: 2c91001b\u003cbr\u003eMessage: Fix Danske Taler (#69)","Date: 2025-06-30\u003cbr\u003eTokens: 4.40G\u003cbr\u003eChange: +26.49M\u003cbr\u003eSamples: 915,090\u003cbr\u003eCommit: 7df022e7\u003cbr\u003eMessage: Adding Scrape Hovedstaden (#70)","Date: 2025-07-01\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +302.40M\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 6a2c8fbf\u003cbr\u003eMessage: update-retsinformationdk (#72)","Date: 2025-07-08\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 0cdc88c0\u003cbr\u003eMessage: Add tokens over time (+ rename scrape_hovedstaten) (#73)","Date: 2025-07-11\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +86.35M\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: dd36adfe\u003cbr\u003eMessage: Add domsdatabasen (#74)","Date: 2025-07-21\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: 30071635\u003cbr\u003eMessage: restructuring-main-table (#75)","Date: 2025-07-22\u003cbr\u003eTokens: 4.80G\u003cbr\u003eChange: +10.53M\u003cbr\u003eSamples: 960,989\u003cbr\u003eCommit: 439e14c0\u003cbr\u003eMessage: Add Grundtvigs works (#79)"],"x":["2025-01-02T00:00:00.000000000","2025-01-03T00:00:00.000000000","2025-01-04T00:00:00.000000000","2025-01-05T00:00:00.000000000","2025-02-10T00:00:00.000000000","2025-03-10T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-06-23T00:00:00.000000000","2025-06-25T00:00:00.000000000","2025-06-30T00:00:00.000000000","2025-07-01T00:00:00.000000000","2025-07-08T00:00:00.000000000","2025-07-11T00:00:00.000000000","2025-07-21T00:00:00.000000000","2025-07-22T00:00:00.000000000"],"y":[1567706760,1839599769,1839599769,1844994816,1852293828,1852293828,3363395483,3363395483,3363395483,3363395483,4264549097,4264549097,4264549097,4369008328,4369589385,4396075044,4698470546,4698470546,4784823570,4784823570,4795348963],"type":"scatter"}], {"template":{"data":{"histogram2dcontour":[{"type":"histogram2dcontour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"choropleth":[{"type":"choropleth","colorbar":{"outlinewidth":0,"ticks":""}}],"histogram2d":[{"type":"histogram2d","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"heatmap":[{"type":"heatmap","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"contourcarpet":[{"type":"contourcarpet","colorbar":{"outlinewidth":0,"ticks":""}}],"contour":[{"type":"contour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"surface":[{"type":"surface","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"mesh3d":[{"type":"mesh3d","colorbar":{"outlinewidth":0,"ticks":""}}],"scatter":[{"fillpattern":{"fillmode":"overlay","size":10,"solidity":0.2},"type":"scatter"}],"parcoords":[{"type":"parcoords","line":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolargl":[{"type":"scatterpolargl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"bar":[{"error_x":{"color":"#2a3f5f"},"error_y":{"color":"#2a3f5f"},"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"bar"}],"scattergeo":[{"type":"scattergeo","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolar":[{"type":"scatterpolar","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"histogram":[{"marker":{"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"histogram"}],"scattergl":[{"type":"scattergl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatter3d":[{"type":"scatter3d","line":{"colorbar":{"outlinewidth":0,"ticks":""}},"marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermap":[{"type":"scattermap","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermapbox":[{"type":"scattermapbox","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterternary":[{"type":"scatterternary","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattercarpet":[{"type":"scattercarpet","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"carpet":[{"aaxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"baxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"type":"carpet"}],"table":[{"cells":{"fill":{"color":"#EBF0F8"},"line":{"color":"white"}},"header":{"fill":{"color":"#C8D4E3"},"line":{"color":"white"}},"type":"table"}],"barpolar":[{"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"barpolar"}],"pie":[{"automargin":true,"type":"pie"}]},"layout":{"autotypenumbers":"strict","colorway":["#636efa","#EF553B","#00cc96","#ab63fa","#FFA15A","#19d3f3","#FF6692","#B6E880","#FF97FF","#FECB52"],"font":{"color":"#2a3f5f"},"hovermode":"closest","hoverlabel":{"align":"left"},"paper_bgcolor":"white","plot_bgcolor":"#E5ECF6","polar":{"bgcolor":"#E5ECF6","angularaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"radialaxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"ternary":{"bgcolor":"#E5ECF6","aaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"baxis":{"gridcolor":"white","linecolor":"white","ticks":""},"caxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"coloraxis":{"colorbar":{"outlinewidth":0,"ticks":""}},"colorscale":{"sequential":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"sequentialminus":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"diverging":[[0,"#8e0152"],[0.1,"#c51b7d"],[0.2,"#de77ae"],[0.3,"#f1b6da"],[0.4,"#fde0ef"],[0.5,"#f7f7f7"],[0.6,"#e6f5d0"],[0.7,"#b8e186"],[0.8,"#7fbc41"],[0.9,"#4d9221"],[1,"#276419"]]},"xaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"yaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"scene":{"xaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"yaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"zaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2}},"shapedefaults":{"line":{"color":"#2a3f5f"}},"annotationdefaults":{"arrowcolor":"#2a3f5f","arrowhead":0,"arrowwidth":1},"geo":{"bgcolor":"white","landcolor":"#E5ECF6","subunitcolor":"white","showland":true,"showlakes":true,"lakecolor":"white"},"title":{"x":0.05},"mapbox":{"style":"light"}}},"shapes":[{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":300000000,"y1":300000000,"yref":"y"},{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":1000000000,"y1":1000000000,"yref":"y"}],"annotations":[{"font":{"color":"gray","size":12},"showarrow":false,"text":"Common Corpus (dan) (Langlais et al., 2025)","x":0,"xanchor":"left","xref":"x domain","y":300000000,"yanchor":"bottom","yref":"y"},{"font":{"color":"gray","size":12},"showarrow":false,"text":"Danish Gigaword (Derczynski et al., 2021)","x":0,"xanchor":"left","xref":"x domain","y":1000000000,"yanchor":"bottom","yref":"y"}],"title":{"text":"Number of Tokens Over Time in Danish Dynaword"},"xaxis":{"title":{"text":"Date"}},"yaxis":{"title":{"text":"Number of Tokens (Llama 3)"},"tickformat":".2s","ticksuffix":""},"hovermode":"closest","width":600,"height":400,"showlegend":false,"plot_bgcolor":"rgba(0,0,0,0)","paper_bgcolor":"rgba(0,0,0,0)"}, {"responsive": true} ) }; </script> </div>
|
| 6 |
</body>
|
| 7 |
</html>
|
images/tokens_over_time.svg
CHANGED

|

|
pyproject.toml
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
-
version = "1.2.
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
|
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
+
version = "1.2.8"
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
test_results.log
CHANGED
|
@@ -3,23 +3,24 @@ platform darwin -- Python 3.12.0, pytest-8.3.4, pluggy-1.5.0
|
|
| 3 |
rootdir: /Users/au561649/Github/danish-dynaword
|
| 4 |
configfile: pyproject.toml
|
| 5 |
plugins: anyio-4.9.0
|
| 6 |
-
collected
|
| 7 |
|
| 8 |
src/tests/test_dataset_schema.py ....................................... [ 11%]
|
| 9 |
-
|
| 10 |
-
src/tests/test_datasheets.py ........................................... [
|
| 11 |
-
........................................................................ [
|
| 12 |
-
|
|
|
|
| 13 |
src/tests/test_load.py .. [ 77%]
|
| 14 |
src/tests/test_quality/test_duplicates.py .............................. [ 86%]
|
| 15 |
-
|
| 16 |
src/tests/test_quality/test_short_texts.py ............................. [ 97%]
|
| 17 |
-
|
| 18 |
src/tests/test_unique_ids.py . [100%]
|
| 19 |
|
| 20 |
=============================== warnings summary ===============================
|
| 21 |
-
src/tests/test_quality/test_short_texts.py:
|
| 22 |
/Users/au561649/Github/danish-dynaword/.venv/lib/python3.12/site-packages/datasets/utils/_dill.py:385: DeprecationWarning: co_lnotab is deprecated, use co_lines instead.
|
| 23 |
|
| 24 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 25 |
-
|
|
|
|
| 3 |
rootdir: /Users/au561649/Github/danish-dynaword
|
| 4 |
configfile: pyproject.toml
|
| 5 |
plugins: anyio-4.9.0
|
| 6 |
+
collected 346 items
|
| 7 |
|
| 8 |
src/tests/test_dataset_schema.py ....................................... [ 11%]
|
| 9 |
+
..................................... [ 21%]
|
| 10 |
+
src/tests/test_datasheets.py ........................................... [ 34%]
|
| 11 |
+
........................................................................ [ 55%]
|
| 12 |
+
........................................................................ [ 76%]
|
| 13 |
+
... [ 76%]
|
| 14 |
src/tests/test_load.py .. [ 77%]
|
| 15 |
src/tests/test_quality/test_duplicates.py .............................. [ 86%]
|
| 16 |
+
........s [ 88%]
|
| 17 |
src/tests/test_quality/test_short_texts.py ............................. [ 97%]
|
| 18 |
+
......... [ 99%]
|
| 19 |
src/tests/test_unique_ids.py . [100%]
|
| 20 |
|
| 21 |
=============================== warnings summary ===============================
|
| 22 |
+
src/tests/test_quality/test_short_texts.py: 38 warnings
|
| 23 |
/Users/au561649/Github/danish-dynaword/.venv/lib/python3.12/site-packages/datasets/utils/_dill.py:385: DeprecationWarning: co_lnotab is deprecated, use co_lines instead.
|
| 24 |
|
| 25 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 26 |
+
=========== 345 passed, 1 skipped, 38 warnings in 111.50s (0:01:51) ============
|
uv.lock
CHANGED
|
@@ -258,7 +258,7 @@ wheels = [
|
|
| 258 |
|
| 259 |
[[package]]
|
| 260 |
name = "dynaword"
|
| 261 |
-
version = "1.2.
|
| 262 |
source = { editable = "." }
|
| 263 |
dependencies = [
|
| 264 |
{ name = "datasets" },
|
|
|
|
| 258 |
|
| 259 |
[[package]]
|
| 260 |
name = "dynaword"
|
| 261 |
+
version = "1.2.8"
|
| 262 |
source = { editable = "." }
|
| 263 |
dependencies = [
|
| 264 |
{ name = "datasets" },
|