Datasets:

Tasks:
Text Generation
Formats:
parquet
Sub-tasks:
language-modeling
Languages:
Danish
Size:
10M - 100M
ArXiv:
DOI:
License:

Add Grundtvigs works (#79)
Browse files- ## [v1.2.7] - 2025-07-22 (f4994c5e82d3bfcc0eea53752c40b12dfb15ac74)
- CHANGELOG.md +8 -0
- CONTRIBUTING.md +1 -1
- README.md +79 -64
- data/grundtvig/create.py +85 -0
- data/grundtvig/descriptive_stats.json +6 -0
- data/grundtvig/grundtvig.log +10 -0
- data/grundtvig/grundtvig.md +185 -0
- data/grundtvig/grundtvig.parquet +3 -0
- data/grundtvig/images/dist_document_length.png +3 -0
- descriptive_stats.json +4 -4
- images/dist_document_length.png +2 -2
- images/domain_distribution.png +2 -2
- images/tokens_over_time.html +1 -1
- images/tokens_over_time.svg +1 -1
- pyproject.toml +1 -1
CHANGELOG.md
CHANGED
|
@@ -5,6 +5,14 @@ All notable changes to this project will be documented in this file.
|
|
| 5 |
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
## [v1.2.6] - 2025-07-21
|
| 9 |
|
| 10 |
### Added
|
|
|
|
| 5 |
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
| 8 |
+
|
| 9 |
+
## [v1.2.7] - 2025-07-22
|
| 10 |
+
|
| 11 |
+
### Added
|
| 12 |
+
|
| 13 |
+
- Added dataset: Grundtvigs Works (`grundtvig`)
|
| 14 |
+
- Added bias and risk section to the README
|
| 15 |
+
|
| 16 |
## [v1.2.6] - 2025-07-21
|
| 17 |
|
| 18 |
### Added
|
CONTRIBUTING.md
CHANGED
|
@@ -72,7 +72,7 @@ Before you make the PR do be sure to make sure that you have completed the follo
|
|
| 72 |
### Checklist
|
| 73 |
|
| 74 |
- [ ] I have run the test suite using `make test` and all tests pass
|
| 75 |
-
- [ ] I have added/changed a dataset
|
| 76 |
- [ ] I have updated descriptive statistics using `make update-descriptive-statistics`
|
| 77 |
- [ ] I have bumped the version use `make bump-version`
|
| 78 |
- [ ] If I have added a `create.py` script I have added the [script dependencies](https://docs.astral.sh/uv/guides/scripts/#declaring-script-dependencies) required to run that script.
|
|
|
|
| 72 |
### Checklist
|
| 73 |
|
| 74 |
- [ ] I have run the test suite using `make test` and all tests pass
|
| 75 |
+
- [ ] I have added/changed a dataset:
|
| 76 |
- [ ] I have updated descriptive statistics using `make update-descriptive-statistics`
|
| 77 |
- [ ] I have bumped the version use `make bump-version`
|
| 78 |
- [ ] If I have added a `create.py` script I have added the [script dependencies](https://docs.astral.sh/uv/guides/scripts/#declaring-script-dependencies) required to run that script.
|
README.md
CHANGED
|
@@ -13,6 +13,10 @@ configs:
|
|
| 13 |
data_files:
|
| 14 |
- split: train
|
| 15 |
path: data/cellar/*.parquet
|
|
|
|
|
|
|
|
|
|
|
|
|
| 16 |
- config_name: danske-taler
|
| 17 |
data_files:
|
| 18 |
- split: train
|
|
@@ -182,7 +186,7 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 182 |
<!-- START README TABLE -->
|
| 183 |
| | |
|
| 184 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 185 |
-
| **Version**
|
| 186 |
| **Language** | dan, dansk, Danish |
|
| 187 |
| **License** | Openly Licensed, See the respective dataset |
|
| 188 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
@@ -215,15 +219,16 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 215 |
- [Citation Information](#citation-information)
|
| 216 |
- [License information](#license-information)
|
| 217 |
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
|
|
|
| 218 |
- [Notice and takedown policy](#notice-and-takedown-policy)
|
| 219 |
|
| 220 |
## Dataset Description
|
| 221 |
|
| 222 |
<!-- START-DESC-STATS -->
|
| 223 |
- **Language**: dan, dansk, Danish
|
| 224 |
-
- **Number of samples**: 960.
|
| 225 |
-
- **Number of tokens (Llama 3)**: 4.
|
| 226 |
-
- **Average document length (characters)**:
|
| 227 |
<!-- END-DESC-STATS -->
|
| 228 |
|
| 229 |
|
|
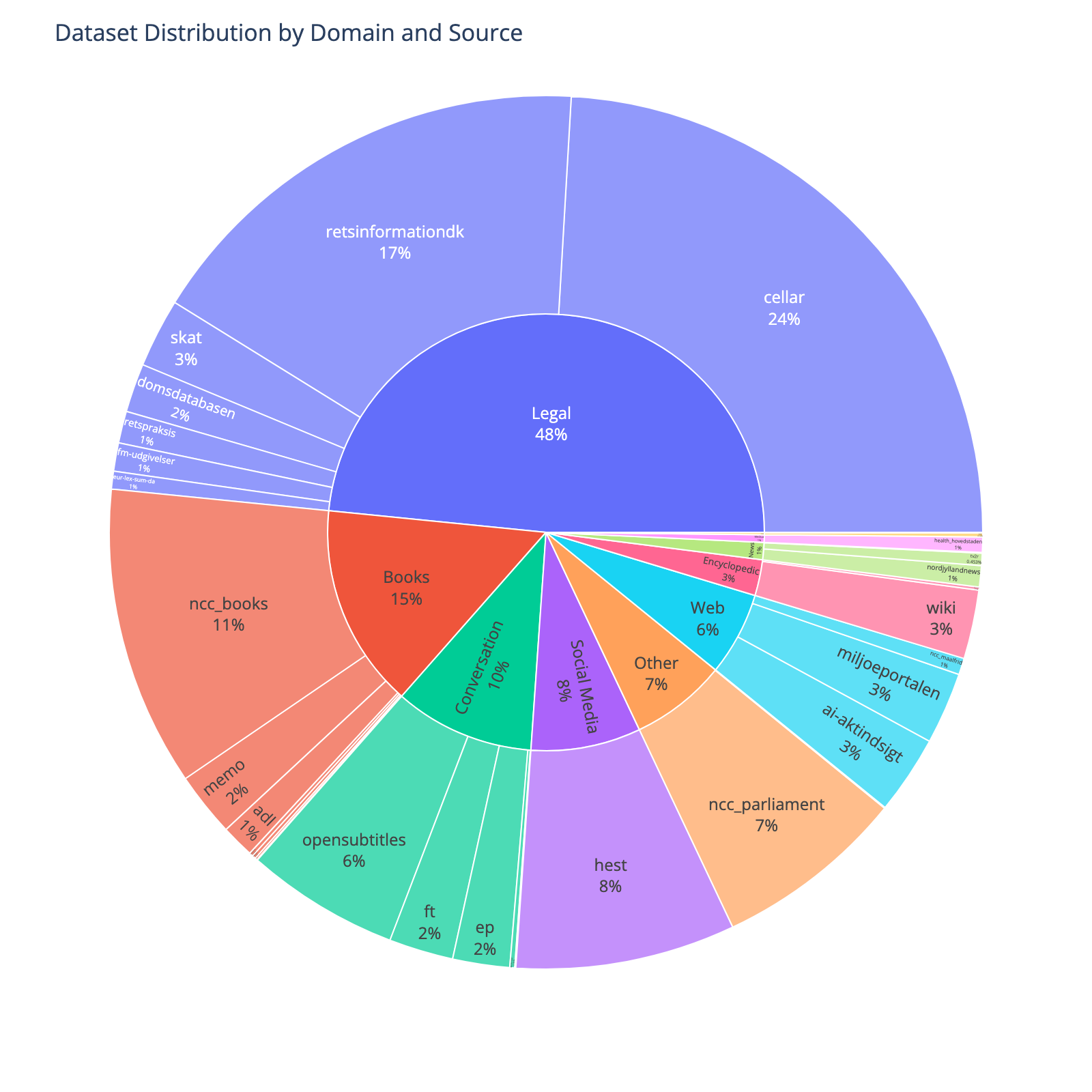
@@ -283,23 +288,24 @@ This dynaword consist of data from various domains (e.g., legal, books, social m
|
|
| 283 |
|
| 284 |
|
| 285 |
<!-- START-DOMAIN TABLE -->
|
| 286 |
-
| Domain | Sources | N. Tokens
|
| 287 |
-
|
| 288 |
-
| Legal | [cellar], [eur-lex-sum-da], [fm-udgivelser], [retsinformationdk], [skat], [retspraksis], [domsdatabasen] | 2.32B
|
| 289 |
-
| Books | [ncc_books], [memo], [adl], [wikibooks], [jvj], [gutenberg], [relig]
|
| 290 |
-
| Conversation | [danske-taler], [opensubtitles], [ep], [ft], [spont], [naat] | 497.09M
|
| 291 |
-
| Social Media | [hest] | 389.32M
|
| 292 |
-
| Other | [ncc_parliament], [dannet], [depbank], [synne] | 340.59M
|
| 293 |
-
| Web | [ai-aktindsigt], [ncc_maalfrid], [miljoeportalen] | 295.87M
|
| 294 |
-
| Encyclopedic | [wikisource], [wiki] | 127.35M
|
| 295 |
-
| News | [ncc_newspaper], [tv2r], [nordjyllandnews] | 60.63M
|
| 296 |
-
| Medical | [health_hovedstaden] | 27.07M
|
| 297 |
-
| Readaloud | [nota] | 7.30M
|
| 298 |
-
| Dialect | [botxt] | 847.97K
|
| 299 |
-
| **Total** | | 4.
|
| 300 |
|
| 301 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 302 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 303 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 304 |
[ncc_books]: data/ncc_books/ncc_books.md
|
| 305 |
[ncc_newspaper]: data/ncc_newspaper/ncc_newspaper.md
|
|
@@ -355,16 +361,17 @@ The following gives an overview of the licensing in the Dynaword. To get the exa
|
|
| 355 |
These license is applied to the constituent data, i.e., the text. The collection of datasets (metadata, quality control, etc.) is licensed under [CC-0](https://creativecommons.org/publicdomain/zero/1.0/legalcode.en).
|
| 356 |
|
| 357 |
<!-- START-LICENSE TABLE -->
|
| 358 |
-
| License | Sources
|
| 359 |
-
|
| 360 |
-
| CC-0 | [danske-taler], [ncc_books], [ncc_newspaper], [miljoeportalen], [opensubtitles], [ep], [ft], [wikisource], [spont], [adl], [hest], [skat], [retspraksis], [wikibooks], [botxt], [naat], [synne], [wiki], [nordjyllandnews], [relig], [nota], [health_hovedstaden] |
|
| 361 |
-
| CC-BY-SA 4.0 | [cellar], [eur-lex-sum-da], [fm-udgivelser], [memo], [tv2r], [jvj], [depbank]
|
| 362 |
-
| Other (No attribution required) | [retsinformationdk], [domsdatabasen]
|
| 363 |
-
| Other (Attribution required) | [ai-aktindsigt], [ncc_maalfrid], [ncc_parliament], [dannet], [gutenberg]
|
| 364 |
-
| **Total** |
|
| 365 |
|
| 366 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 367 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 368 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 369 |
[ncc_books]: data/ncc_books/ncc_books.md
|
| 370 |
[ncc_newspaper]: data/ncc_newspaper/ncc_newspaper.md
|
|
@@ -462,48 +469,50 @@ Below follows a brief overview of the sources in the corpus along with their ind
|
|
| 462 |
You can learn more about each dataset by pressing the link in the first column.
|
| 463 |
|
| 464 |
<!-- START-MAIN TABLE -->
|
| 465 |
-
| Source | Description | Domain | N. Tokens
|
| 466 |
-
|
| 467 |
-
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B
|
| 468 |
-
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 818.25M
|
| 469 |
-
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M
|
| 470 |
-
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M
|
| 471 |
-
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M
|
| 472 |
-
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M
|
| 473 |
-
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M
|
| 474 |
-
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M
|
| 475 |
-
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M
|
| 476 |
-
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M
|
| 477 |
-
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M
|
| 478 |
-
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M
|
| 479 |
-
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M
|
| 480 |
-
| [domsdatabasen] | [Domsdatabasen.dk](https://domsdatabasen.dk/) is a public database containing selected judgments from the Danish courts | Legal | 86.35M
|
| 481 |
-
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M
|
| 482 |
-
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M
|
| 483 |
-
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M
|
| 484 |
-
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M
|
| 485 |
-
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M
|
| 486 |
-
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M
|
| 487 |
-
| [health_hovedstaden] | Guidelines and informational documents for healthcare professionals from the Capital Region | Medical | 27.07M
|
| 488 |
-
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M
|
| 489 |
-
| [
|
| 490 |
-
| [
|
| 491 |
-
| [
|
| 492 |
-
| [
|
| 493 |
-
| [
|
| 494 |
-
| [
|
| 495 |
-
| [
|
| 496 |
-
| [
|
| 497 |
-
| [
|
| 498 |
-
| [
|
| 499 |
-
| [
|
| 500 |
-
| [
|
| 501 |
-
| [
|
| 502 |
-
| [
|
| 503 |
-
|
|
|
|
|
| 504 |
|
| 505 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 506 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 507 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 508 |
[ncc_books]: data/ncc_books/ncc_books.md
|
| 509 |
[ncc_newspaper]: data/ncc_newspaper/ncc_newspaper.md
|
|
@@ -614,6 +623,12 @@ The license for each constituent dataset is supplied in the [Source data](#sourc
|
|
| 614 |
|
| 615 |
As far as we are aware the dataset does not contain information identifying sexual orientation, political beliefs, religion, or health connected with utterer ID. In case that such information is present in the data we have been removed utterer information from social media content.
|
| 616 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 617 |
### Notice and takedown policy
|
| 618 |
We redistribute files shared with us under a license permitting such redistribution. If you have concerns about the licensing of these files, please [contact us](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/discussions/new). If you consider that the data contains material that infringe your copyright, please:
|
| 619 |
- Clearly identify yourself with detailed contact information such as an address, a telephone number, or an email address at which you can be contacted.
|
|
|
|
| 13 |
data_files:
|
| 14 |
- split: train
|
| 15 |
path: data/cellar/*.parquet
|
| 16 |
+
- config_name: grundtvig
|
| 17 |
+
data_files:
|
| 18 |
+
- split: train
|
| 19 |
+
path: data/grundtvig/*.parquet
|
| 20 |
- config_name: danske-taler
|
| 21 |
data_files:
|
| 22 |
- split: train
|
|
|
|
| 186 |
<!-- START README TABLE -->
|
| 187 |
| | |
|
| 188 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 189 |
+
| **Version** | 1.2.7 ([Changelog](/CHANGELOG.md)) |
|
| 190 |
| **Language** | dan, dansk, Danish |
|
| 191 |
| **License** | Openly Licensed, See the respective dataset |
|
| 192 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
|
|
| 219 |
- [Citation Information](#citation-information)
|
| 220 |
- [License information](#license-information)
|
| 221 |
- [Personal and Sensitive Information](#personal-and-sensitive-information)
|
| 222 |
+
- [Bias, Risks, and Limitations](#bias-risks-and-limitations)
|
| 223 |
- [Notice and takedown policy](#notice-and-takedown-policy)
|
| 224 |
|
| 225 |
## Dataset Description
|
| 226 |
|
| 227 |
<!-- START-DESC-STATS -->
|
| 228 |
- **Language**: dan, dansk, Danish
|
| 229 |
+
- **Number of samples**: 960.99K
|
| 230 |
+
- **Number of tokens (Llama 3)**: 4.80B
|
| 231 |
+
- **Average document length (characters)**: 15322.53
|
| 232 |
<!-- END-DESC-STATS -->
|
| 233 |
|
| 234 |
|
|
|
|
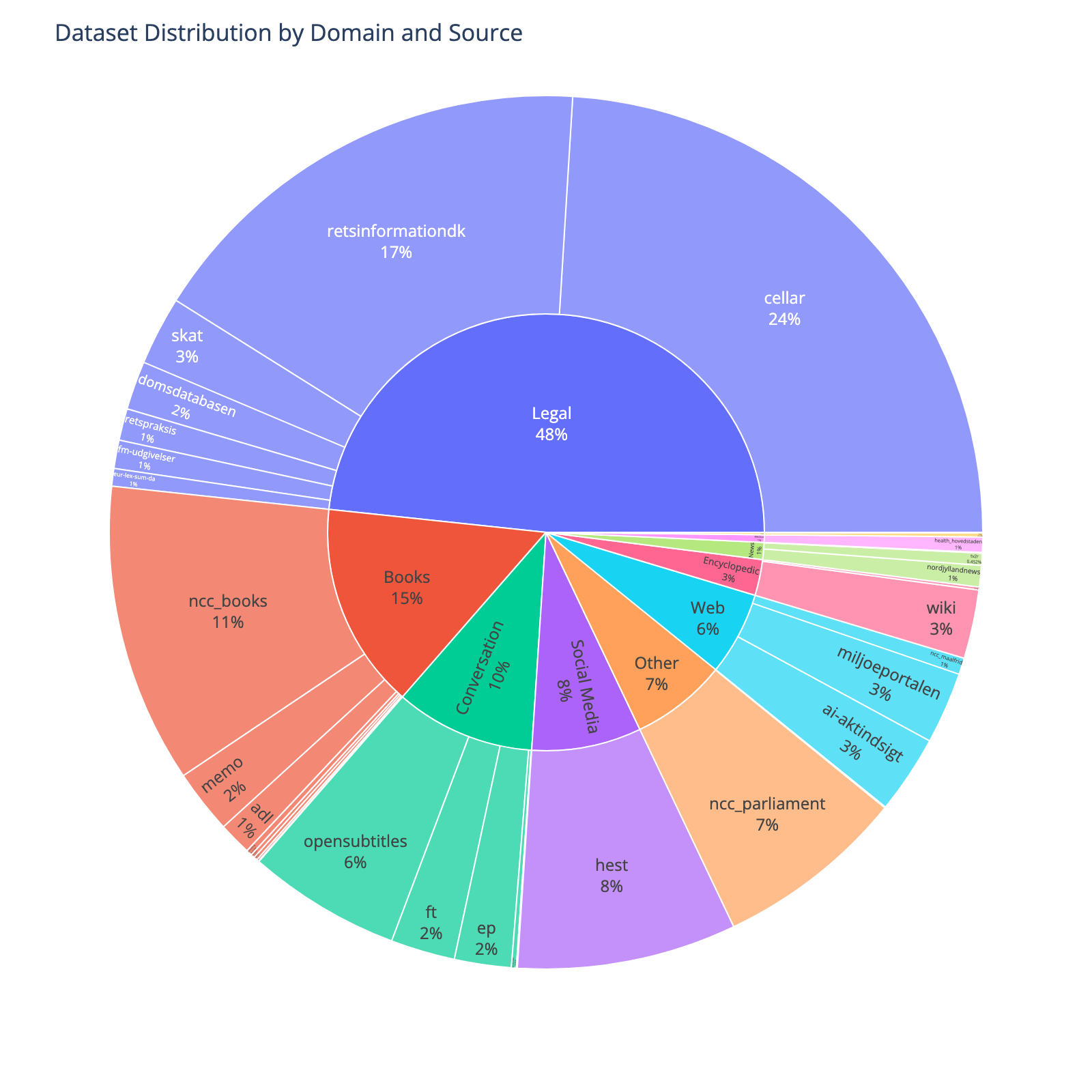
| 288 |
|
| 289 |
|
| 290 |
<!-- START-DOMAIN TABLE -->
|
| 291 |
+
| Domain | Sources | N. Tokens |
|
| 292 |
+
| :----------- | :------------------------------------------------------------------------------------------------------- | :-------- |
|
| 293 |
+
| Legal | [cellar], [eur-lex-sum-da], [fm-udgivelser], [retsinformationdk], [skat], [retspraksis], [domsdatabasen] | 2.32B |
|
| 294 |
+
| Books | [grundtvig], [ncc_books], [memo], [adl], [wikibooks], [jvj], [gutenberg], [relig] | 732.52M |
|
| 295 |
+
| Conversation | [danske-taler], [opensubtitles], [ep], [ft], [spont], [naat] | 497.09M |
|
| 296 |
+
| Social Media | [hest] | 389.32M |
|
| 297 |
+
| Other | [ncc_parliament], [dannet], [depbank], [synne] | 340.59M |
|
| 298 |
+
| Web | [ai-aktindsigt], [ncc_maalfrid], [miljoeportalen] | 295.87M |
|
| 299 |
+
| Encyclopedic | [wikisource], [wiki] | 127.35M |
|
| 300 |
+
| News | [ncc_newspaper], [tv2r], [nordjyllandnews] | 60.63M |
|
| 301 |
+
| Medical | [health_hovedstaden] | 27.07M |
|
| 302 |
+
| Readaloud | [nota] | 7.30M |
|
| 303 |
+
| Dialect | [botxt] | 847.97K |
|
| 304 |
+
| **Total** | | 4.80B |
|
| 305 |
|
| 306 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 307 |
[cellar]: data/cellar/cellar.md
|
| 308 |
+
[grundtvig]: data/grundtvig/grundtvig.md
|
| 309 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 310 |
[ncc_books]: data/ncc_books/ncc_books.md
|
| 311 |
[ncc_newspaper]: data/ncc_newspaper/ncc_newspaper.md
|
|
|
|
| 361 |
These license is applied to the constituent data, i.e., the text. The collection of datasets (metadata, quality control, etc.) is licensed under [CC-0](https://creativecommons.org/publicdomain/zero/1.0/legalcode.en).
|
| 362 |
|
| 363 |
<!-- START-LICENSE TABLE -->
|
| 364 |
+
| License | Sources | N. Tokens |
|
| 365 |
+
| :------------------------------ | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-------- |
|
| 366 |
+
| CC-0 | [grundtvig], [danske-taler], [ncc_books], [ncc_newspaper], [miljoeportalen], [opensubtitles], [ep], [ft], [wikisource], [spont], [adl], [hest], [skat], [retspraksis], [wikibooks], [botxt], [naat], [synne], [wiki], [nordjyllandnews], [relig], [nota], [health_hovedstaden] | 2.00B |
|
| 367 |
+
| CC-BY-SA 4.0 | [cellar], [eur-lex-sum-da], [fm-udgivelser], [memo], [tv2r], [jvj], [depbank] | 1.37B |
|
| 368 |
+
| Other (No attribution required) | [retsinformationdk], [domsdatabasen] | 904.61M |
|
| 369 |
+
| Other (Attribution required) | [ai-aktindsigt], [ncc_maalfrid], [ncc_parliament], [dannet], [gutenberg] | 515.61M |
|
| 370 |
+
| **Total** | | 4.80B |
|
| 371 |
|
| 372 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 373 |
[cellar]: data/cellar/cellar.md
|
| 374 |
+
[grundtvig]: data/grundtvig/grundtvig.md
|
| 375 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 376 |
[ncc_books]: data/ncc_books/ncc_books.md
|
| 377 |
[ncc_newspaper]: data/ncc_newspaper/ncc_newspaper.md
|
|
|
|
| 469 |
You can learn more about each dataset by pressing the link in the first column.
|
| 470 |
|
| 471 |
<!-- START-MAIN TABLE -->
|
| 472 |
+
| Source | Description | Domain | N. Tokens | License |
|
| 473 |
+
| :------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :----------- | :-------- | :--------------------- |
|
| 474 |
+
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B | [CC-BY-SA 4.0] |
|
| 475 |
+
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 818.25M | [Danish Copyright Law] |
|
| 476 |
+
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M | [CC-0] |
|
| 477 |
+
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M | [CC-0] |
|
| 478 |
+
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M | [NLOD 2.0] |
|
| 479 |
+
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M | [CC-0] |
|
| 480 |
+
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M | [Apache 2.0] |
|
| 481 |
+
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M | [CC-0] |
|
| 482 |
+
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M | [CC-0] |
|
| 483 |
+
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M | [CC-0] |
|
| 484 |
+
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M | [CC-0] |
|
| 485 |
+
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M | [CC-BY-SA 4.0] |
|
| 486 |
+
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M | [CC-0] |
|
| 487 |
+
| [domsdatabasen] | [Domsdatabasen.dk](https://domsdatabasen.dk/) is a public database containing selected judgments from the Danish courts | Legal | 86.35M | [Danish Copyright Law] |
|
| 488 |
+
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M | [CC-0] |
|
| 489 |
+
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M | [CC-0] |
|
| 490 |
+
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M | [CC-BY-SA 4.0] |
|
| 491 |
+
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 492 |
+
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 493 |
+
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 494 |
+
| [health_hovedstaden] | Guidelines and informational documents for healthcare professionals from the Capital Region | Medical | 27.07M | [CC-0] |
|
| 495 |
+
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 496 |
+
| [grundtvig] | The complete collection of [Grundtvig](https://en.wikipedia.org/wiki/N._F._S._Grundtvig) (1783-1872) one of Denmark’s most influential figures | Books | 10.53M | [CC-0] |
|
| 497 |
+
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.72M | [CC-0] |
|
| 498 |
+
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
| 499 |
+
| [gutenberg] | The Danish subsection from Project [Gutenberg](https://www.gutenberg.org) | Books | 6.76M | [Gutenberg] |
|
| 500 |
+
| [wikibooks] | The Danish Subsection of [Wikibooks](https://www.wikibooks.org) | Books | 6.24M | [CC-0] |
|
| 501 |
+
| [wikisource] | The Danish subsection of [Wikisource](https://en.wikisource.org/wiki/Main_Page) | Encyclopedic | 5.34M | [CC-0] |
|
| 502 |
+
| [jvj] | The works of the Danish author and poet, [Johannes V. Jensen](https://da.wikipedia.org/wiki/Johannes_V._Jensen) | Books | 3.55M | [CC-BY-SA 4.0] |
|
| 503 |
+
| [spont] | Conversational samples collected as a part of research projects at Aarhus University | Conversation | 1.56M | [CC-0] |
|
| 504 |
+
| [dannet] | [DanNet](https://cst.ku.dk/projekter/dannet) is a Danish WordNet | Other | 1.48M | [DanNet 1.0] |
|
| 505 |
+
| [relig] | Danish religious text from the 1700-2022 | Books | 1.24M | [CC-0] |
|
| 506 |
+
| [ncc_newspaper] | OCR'd Newspapers derived from [NCC](https://huggingface.co/datasets/NbAiLab/NCC) | News | 1.05M | [CC-0] |
|
| 507 |
+
| [botxt] | The Bornholmsk Ordbog Dictionary Project | Dialect | 847.97K | [CC-0] |
|
| 508 |
+
| [naat] | Danish speeches from 1930-2022 | Conversation | 286.68K | [CC-0] |
|
| 509 |
+
| [depbank] | The Danish subsection of the [Universal Dependencies Treebank](https://github.com/UniversalDependencies/UD_Danish-DDT) | Other | 185.45K | [CC-BY-SA 4.0] |
|
| 510 |
+
| [synne] | Dataset collected from [synnejysk forening's website](https://www.synnejysk.dk), covering the Danish dialect sønderjysk | Other | 52.02K | [CC-0] |
|
| 511 |
+
| **Total** | | | 4.80B | |
|
| 512 |
|
| 513 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 514 |
[cellar]: data/cellar/cellar.md
|
| 515 |
+
[grundtvig]: data/grundtvig/grundtvig.md
|
| 516 |
[danske-taler]: data/danske-taler/danske-taler.md
|
| 517 |
[ncc_books]: data/ncc_books/ncc_books.md
|
| 518 |
[ncc_newspaper]: data/ncc_newspaper/ncc_newspaper.md
|
|
|
|
| 623 |
|
| 624 |
As far as we are aware the dataset does not contain information identifying sexual orientation, political beliefs, religion, or health connected with utterer ID. In case that such information is present in the data we have been removed utterer information from social media content.
|
| 625 |
|
| 626 |
+
### Bias, Risks, and Limitations
|
| 627 |
+
|
| 628 |
+
Certain works in this collection are historical works and thus reflects the linguistic, cultural, and ideological norms of its time.
|
| 629 |
+
As such, it includes perspectives, assumptions, and biases characteristic of the period. For instance the works of N.F.S. Grundtvig (`grundtvig`) was known to nationalistic views and critical stances toward specific groups – such as Germans – which may be considered offensive or exclusionary by contemporary standards.
|
| 630 |
+
|
| 631 |
+
|
| 632 |
### Notice and takedown policy
|
| 633 |
We redistribute files shared with us under a license permitting such redistribution. If you have concerns about the licensing of these files, please [contact us](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/discussions/new). If you consider that the data contains material that infringe your copyright, please:
|
| 634 |
- Clearly identify yourself with detailed contact information such as an address, a telephone number, or an email address at which you can be contacted.
|
data/grundtvig/create.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# /// script
|
| 2 |
+
# requires-python = ">=3.12"
|
| 3 |
+
# dependencies = [
|
| 4 |
+
# "datasets",
|
| 5 |
+
# "dynaword",
|
| 6 |
+
# ]
|
| 7 |
+
#
|
| 8 |
+
# [tool.uv.sources]
|
| 9 |
+
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword" }
|
| 10 |
+
# ///
|
| 11 |
+
|
| 12 |
+
"""
|
| 13 |
+
Script for downloading and processing the dataset
|
| 14 |
+
|
| 15 |
+
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
GIT_LFS_SKIP_SMUDGE=1 uv run data/grundtvig/create.py
|
| 19 |
+
```
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
import logging
|
| 23 |
+
from datetime import date
|
| 24 |
+
from pathlib import Path
|
| 25 |
+
from typing import Any, cast
|
| 26 |
+
|
| 27 |
+
from datasets import Dataset, load_dataset
|
| 28 |
+
|
| 29 |
+
from dynaword.process_dataset import (
|
| 30 |
+
add_token_count,
|
| 31 |
+
ensure_column_order,
|
| 32 |
+
remove_duplicate_text,
|
| 33 |
+
remove_empty_texts,
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger(__name__)
|
| 37 |
+
|
| 38 |
+
SOURCE = "grundtvig"
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def reformat_samples(example: dict[str, Any]) -> dict[str, Any]:
|
| 42 |
+
year_of_creation = example["id"].split("_")[0]
|
| 43 |
+
# Reformatting the date to YYYY-MM-DD format
|
| 44 |
+
start = f"{year_of_creation}-01-01"
|
| 45 |
+
end = f"{year_of_creation}-12-31"
|
| 46 |
+
return {
|
| 47 |
+
"id": f"grundtvig_{example['id']}",
|
| 48 |
+
"text": example["md"],
|
| 49 |
+
"source": SOURCE,
|
| 50 |
+
"added": date.today().strftime("%Y-%m-%d"),
|
| 51 |
+
"created": f"{start}, {end}",
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def main():
|
| 56 |
+
dataset = load_dataset(
|
| 57 |
+
"chcaa/grundtvigs-works",
|
| 58 |
+
split="train",
|
| 59 |
+
revision="945dd72c1e902632ed581d90c8ff1571ef211a63",
|
| 60 |
+
)
|
| 61 |
+
dataset = cast(Dataset, dataset)
|
| 62 |
+
|
| 63 |
+
dataset = dataset.map(reformat_samples)
|
| 64 |
+
|
| 65 |
+
dataset = remove_empty_texts(dataset) # remove rows with empty text
|
| 66 |
+
dataset = remove_duplicate_text(dataset) # remove rows with duplicate text
|
| 67 |
+
dataset = add_token_count(dataset)
|
| 68 |
+
dataset = ensure_column_order(dataset)
|
| 69 |
+
|
| 70 |
+
dataset.to_parquet(
|
| 71 |
+
Path(__file__).parent / f"{SOURCE}.parquet",
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
log_path = Path(__file__).parent / f"{SOURCE}.log"
|
| 77 |
+
logging.basicConfig(
|
| 78 |
+
level=logging.INFO,
|
| 79 |
+
format="%(asctime)s - %(levelname)s - %(message)s",
|
| 80 |
+
handlers=[
|
| 81 |
+
logging.StreamHandler(),
|
| 82 |
+
logging.FileHandler(log_path),
|
| 83 |
+
],
|
| 84 |
+
)
|
| 85 |
+
main()
|
data/grundtvig/descriptive_stats.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"number_of_samples": 632,
|
| 3 |
+
"average_document_length": 46944.920886075946,
|
| 4 |
+
"number_of_tokens": 10525393,
|
| 5 |
+
"revision": "300716355eb49b3b6ad14f0b0d4f1507c713ab88"
|
| 6 |
+
}
|
data/grundtvig/grundtvig.log
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
2025-07-21 22:26:35,895 - INFO - Removing empty texts
|
| 2 |
+
2025-07-21 22:26:36,148 - INFO - Filtered 0 empty examples
|
| 3 |
+
2025-07-21 22:26:36,148 - INFO - Removing duplicate texts
|
| 4 |
+
2025-07-21 22:26:36,292 - INFO - Filtered 0 duplicate examples
|
| 5 |
+
2025-07-21 22:26:42,922 - INFO - Ensuring columns are in the correct order and are present
|
| 6 |
+
2025-07-21 22:27:36,078 - INFO - Removing empty texts
|
| 7 |
+
2025-07-21 22:27:36,086 - INFO - Filtered 0 empty examples
|
| 8 |
+
2025-07-21 22:27:36,086 - INFO - Removing duplicate texts
|
| 9 |
+
2025-07-21 22:27:36,088 - INFO - Filtered 0 duplicate examples
|
| 10 |
+
2025-07-21 22:27:36,848 - INFO - Ensuring columns are in the correct order and are present
|
data/grundtvig/grundtvig.md
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
pretty_name: Grundtvig's Works
|
| 3 |
+
language:
|
| 4 |
+
- da
|
| 5 |
+
license: cc0-1.0
|
| 6 |
+
license_name: CC-0
|
| 7 |
+
task_categories:
|
| 8 |
+
- text-generation
|
| 9 |
+
- fill-mask
|
| 10 |
+
task_ids:
|
| 11 |
+
- language-modeling
|
| 12 |
+
domains:
|
| 13 |
+
- Books
|
| 14 |
+
source_datasets:
|
| 15 |
+
- chcaa/grundtvigs-works
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
# Dataset Card for Grundtvig's Works
|
| 19 |
+
|
| 20 |
+
<!-- START-SHORT DESCRIPTION -->
|
| 21 |
+
The complete collection of [Grundtvig](https://en.wikipedia.org/wiki/N._F._S._Grundtvig) (1783-1872) one of Denmark’s most influential figures.
|
| 22 |
+
<!-- END-SHORT DESCRIPTION -->
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
Grundtvig's Works is a comprehensive digital humanities dataset containing the complete collected writings of
|
| 26 |
+
[Nicolai Frederik Severin Grundtvig](https://en.wikipedia.org/wiki/N._F._S._Grundtvig) (1783-1872) was one of Denmark’s most influential cultural and intellectual figures.
|
| 27 |
+
As a critical edition, it includes editorial commentary by philologists and is continually updated.
|
| 28 |
+
The project is scheduled for completion in 2030 and will comprise 1,000 individual works spanning 35,000 pages. The complete edition is freely available online.
|
| 29 |
+
|
| 30 |
+
## Dataset Description
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
<!-- START-DESC-STATS -->
|
| 34 |
+
- **Language**: dan, dansk, Danish
|
| 35 |
+
- **Domains**: Books
|
| 36 |
+
- **Number of samples**: 632
|
| 37 |
+
- **Number of tokens (Llama 3)**: 10.53M
|
| 38 |
+
- **Average document length (characters)**: 46944.92
|
| 39 |
+
<!-- END-DESC-STATS -->
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
This dataset represents version 1.25 (updated May 2025) of the digital scholarly edition of Grundtvig’s Works, comprising 632 texts by N.F.S. Grundtvig.
|
| 43 |
+
All texts have been OCR-scanned, and each is processed through three separate textual collations. We compare three different first editions, identify variants between them,
|
| 44 |
+
and incorporate their differences into the digitized version.
|
| 45 |
+
|
| 46 |
+
Following collation, we enrich the texts with several layers of annotation, marked up in XML according to TEI P5 guidelines.
|
| 47 |
+
|
| 48 |
+
These include:
|
| 49 |
+
|
| 50 |
+
- *Explanatory commentaries* – clarifying older words or shifts in meaning
|
| 51 |
+
- *Named entities* – identifying people, places, titles, and mythological figures
|
| 52 |
+
- *Emendations* – documenting any corrections (no silent changes are made)
|
| 53 |
+
- *Bible references* - allusions, quotations, and explicit references are identified and categorized according to type and source
|
| 54 |
+
-
|
| 55 |
+
We also provide introductory texts and textual essays to offer historical and interpretive context. Before publication, each text undergoes a triple review process.
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
### Dataset Sources
|
| 60 |
+
|
| 61 |
+
- **Dataset Website:** [www.grundtvigsværker.dk](https://www.grundtvigsværker.dk)
|
| 62 |
+
|
| 63 |
+
## Uses
|
| 64 |
+
|
| 65 |
+
This dataset represents a major digital preservation effort of Denmark's literary and intellectual heritage, providing structured access to works that shaped Danish theology, education, democracy, and cultural identity. It's valuable for research in digital humanities, Scandinavian studies, religious history, and 19th-century European thought.
|
| 66 |
+
|
| 67 |
+
In addition, this dataset is also a part of [Danish Dynaword](https://huggingface.co/datasets/danish-foundation-models/danish-dynaword), a collection of dataset intended for training language models, thus integrating Danish Cultural Heritage into the next generation of digital technologies.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Dataset Structure
|
| 72 |
+
An example from the dataset looks as follows.
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
<!-- START-SAMPLE -->
|
| 76 |
+
```py
|
| 77 |
+
{
|
| 78 |
+
"id": "grundtvig_1824_392_txt",
|
| 79 |
+
"text": "---\ntitle: Søgubrot med Efterklang\nauthor: Nicolai Frederik Severin Grundtvig\ndate: 2019-12-03\npubli[...]",
|
| 80 |
+
"source": "grundtvig",
|
| 81 |
+
"added": "2025-07-21",
|
| 82 |
+
"created": "1824-01-01, 1824-12-31",
|
| 83 |
+
"token_count": 4106
|
| 84 |
+
}
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
### Data Fields
|
| 88 |
+
|
| 89 |
+
An entry in the dataset consists of the following fields:
|
| 90 |
+
|
| 91 |
+
- `id` (`str`): An unique identifier for each document.
|
| 92 |
+
- `text`(`str`): The content of the document.
|
| 93 |
+
- `source` (`str`): The source of the document (see [Source Data](#source-data)).
|
| 94 |
+
- `added` (`str`): An date for when the document was added to this collection.
|
| 95 |
+
- `created` (`str`): An date range for when the document was originally created.
|
| 96 |
+
- `token_count` (`int`): The number of tokens in the sample computed using the Llama 8B tokenizer
|
| 97 |
+
<!-- END-SAMPLE -->
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
### Dataset Statistics
|
| 101 |
+
|
| 102 |
+
<!-- START-DATASET PLOTS -->
|
| 103 |
+
<p align="center">
|
| 104 |
+
<img src="./images/dist_document_length.png" width="600" style="margin-right: 10px;" />
|
| 105 |
+
</p>
|
| 106 |
+
<!-- END-DATASET PLOTS -->
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
## Dataset Creation
|
| 111 |
+
|
| 112 |
+
### Curation Rationale
|
| 113 |
+
|
| 114 |
+
The digital scholarly edition of Grundtvig’s Works was created to provide open, reliable, and annotated access to the entire published oeuvre of N.F.S. Grundtvig (1783–1872), one of Denmark’s most influential thinkers. The rationale behind this effort is twofold: public accessibility and scholarly accuracy.
|
| 115 |
+
|
| 116 |
+
On the one hand, the edition enables the general public to read Grundtvig’s works on their own terms, supported by textual commentary that helps decode complex 19th-century language and theological or philosophical concepts. On the other, the edition serves as a scholarly tool, offering a searchable, critically edited, and TEI-encoded corpus that facilitates in-depth research across disciplines.
|
| 117 |
+
|
| 118 |
+
Grundtvig’s writings have had a lasting influence on Danish culture, education, and national identity. They are frequently referenced in contemporary political and cultural debates. However, many of his texts have until now only existed in fragile first editions or scattered, outdated collections. By digitizing, editing, and annotating his complete published works – including posthumous publications central to his public image – the project ensures both preservation and access.
|
| 119 |
+
|
| 120 |
+
The primary motivation behind creating this dataset was to bridge the gap between Grundtvig’s historical significance and the limited access to his writings. By offering a freely accessible digital edition, the project not only preserves a vital part of Danish cultural heritage but also democratizes access to foundational texts in Danish intellectual history. This aligns with both public interest and scholarly needs: to make Grundtvig’s complex legacy understandable, searchable, and usable in modern contexts.
|
| 121 |
+
|
| 122 |
+
The edition was launched in 2010 by the Center for Grundtvig Studies and is scheduled for completion in 2030. It is funded by the Danish Finance Act, ensuring its continued development as a national cultural and scholarly resource.
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
#### Data Collection and Processing
|
| 126 |
+
|
| 127 |
+
All texts in the Grundtvig’s Works dataset originate from printed first editions of N.F.S. Grundtvig’s published writings. The digitization process begins with OCR (optical character recognition) scanning of the original editions. Following OCR, each text undergoes three separate textual collations: we compare three different first editions of the same work to identify textual variants. Differences are systematically incorporated into the digitized version to ensure accuracy and representational fidelity.
|
| 128 |
+
|
| 129 |
+
After collation, the editorial team performs further corrections based on internal editorial review. The final result is a fully digitized, TEI P5 XML–encoded version of each text.
|
| 130 |
+
On top of this, all works are accompanied by facsimiles – high-resolution images of the first printed editions – allowing users to view the original sources alongside the transcribed and annotated texts.
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
Before upload the dataset was provided as XML and .txt files. The XML files were converted to .md and uploaded to Huggingface. The scripts for conversion and upload can be found [here](https://huggingface.co/datasets/chcaa/grundtvigs-works/tree/main/src) and a [.lock](https://huggingface.co/datasets/chcaa/grundtvigs-works/tree/main) file specifying the version can be found here.
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
#### Who are the source data producers?
|
| 137 |
+
|
| 138 |
+
N.F.S. Grundtvig is the author of the source material. The Center for Grundtvig Studies at Aarhus University curates, digitizes, and maintains the dataset.
|
| 139 |
+
|
| 140 |
+
### Annotations
|
| 141 |
+
|
| 142 |
+
We annotate explanatory commentaries, named entities (people, places, titles, and mythological figures), biblical references and emendations (documenting corrections). Only emendations are part of this dataset.
|
| 143 |
+
The annotation process began in 2010 and will continue until 2030.
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
#### Who are the annotators?
|
| 147 |
+
|
| 148 |
+
The editorial team consists of 12 philologists and 5 student assistants and one editor in chief.
|
| 149 |
+
|
| 150 |
+
As of 2025, the team includes 13 female and 5 male staff members.
|
| 151 |
+
|
| 152 |
+
### Formatting
|
| 153 |
+
|
| 154 |
+
The samples are currently formatted as markdown using a frontmatter which contain information about the author, year of digitization etc.
|
| 155 |
+
|
| 156 |
+
#### Personal and Sensitive Information
|
| 157 |
+
|
| 158 |
+
This dataset contains no personal or sensitive information.
|
| 159 |
+
|
| 160 |
+
## Bias, Risks, and Limitations
|
| 161 |
+
|
| 162 |
+
The Grundtvig’s Works dataset contains texts written in 19th-century Danish and reflects the linguistic, cultural, and ideological norms of its time.
|
| 163 |
+
As such, it includes perspectives, assumptions, and biases characteristic of the period.
|
| 164 |
+
Readers should be aware that the author, N.F.S. Grundtvig, expressed strong personal and political opinions,
|
| 165 |
+
including nationalistic views and critical stances toward specific groups – such as Germans – which may be considered offensive or exclusionary by contemporary standards.
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
### License Information
|
| 169 |
+
|
| 170 |
+
N.F.S. Grundtvig's works fall under Public Domain (CC0)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
### Citation Information
|
| 174 |
+
|
| 175 |
+
Studies where the dataset from Grundtvig’s Works has been used:
|
| 176 |
+
|
| 177 |
+
- Baunvig, K. F., & Nielbo, K. L. (2022). Mermaids are Birds: Embedding N.F.S. Grundtvig’s Bestiary. I K. Berglund, M. La Mela, & I. Zwart (red.), Proceedings of the 6th Digital Humanities in the Nordic and Baltic Countries Conference (DHNB 2022) (Bind 3232, s. 23-32). CEUR-WS.org. http://ceur-ws.org/Vol-3232/paper02.pdf
|
| 178 |
+
- Baunvig, K. F., Jarvis, O., & Nielbo, K. L. (2021). Emotional Imprints: Exclamation Marks in N.F.S. Grundtvig's Writings. I S. Reinsone, I. Skadiņa, J. Daugavietis, & A. Baklāne (red.), Post-Proceedings of the 5th Conference Digital Humanities in the Nordic Countries (DHN 2020) (s. 156-169) http://ceur-ws.org/Vol-2865/short7.pdf
|
| 179 |
+
- Nielbo, K.L., Baunvig, K. F., Liu, B., & Gao, J. (2019). A Curious Case of Entropic Decay: Persistent Complexity in Textual Cultural Heritage. Digital Scholarship in the Humanities, Volume 34, Issue 3, September 2019, Pages 542–557, https://doi.org/10.1093/llc/fqy054.
|
| 180 |
+
|
| 181 |
+
## More Information
|
| 182 |
+
|
| 183 |
+
For questions related to the dataset, curation, and annotation we please contact [Center for Grundtvig Studies](https://grundtvigcenteret.au.dk/)
|
| 184 |
+
|
| 185 |
+
The edition is funded by the Danish Finance Act
|
data/grundtvig/grundtvig.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5242e74ddc101d6b57c77be29a1cac7f4b80dc0b3399d71a8703aeb7ae2acce6
|
| 3 |
+
size 18711422
|
data/grundtvig/images/dist_document_length.png
ADDED
|
Git LFS Details
|
descriptive_stats.json
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
{
|
| 2 |
-
"number_of_samples":
|
| 3 |
-
"average_document_length":
|
| 4 |
-
"number_of_tokens":
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"number_of_samples": 960989,
|
| 3 |
+
"average_document_length": 15322.534747015834,
|
| 4 |
+
"number_of_tokens": 4795348963,
|
| 5 |
+
"revision": "300716355eb49b3b6ad14f0b0d4f1507c713ab88"
|
| 6 |
}
|
images/dist_document_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
images/domain_distribution.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
images/tokens_over_time.html
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
<head><meta charset="utf-8" /></head>
|
| 3 |
<body>
|
| 4 |
<div> <script type="text/javascript">window.PlotlyConfig = {MathJaxConfig: 'local'};</script>
|
| 5 |
-
<script charset="utf-8" src="https://cdn.plot.ly/plotly-3.0.1.min.js"></script> <div id="5b08e3f1-a9bd-44ac-afab-f0bde51525e6" class="plotly-graph-div" style="height:400px; width:600px;"></div> <script type="text/javascript"> window.PLOTLYENV=window.PLOTLYENV || {}; if (document.getElementById("5b08e3f1-a9bd-44ac-afab-f0bde51525e6")) { Plotly.newPlot( "5b08e3f1-a9bd-44ac-afab-f0bde51525e6", [{"hovertemplate":"%{text}\u003cextra\u003e\u003c\u002fextra\u003e","line":{"color":"#DC2626","width":3},"marker":{"color":"#DC2626","size":5},"mode":"lines+markers","name":"Tokens","text":["Date: 2025-01-02\u003cbr\u003eTokens: 1.57G\u003cbr\u003eSamples: 546,769\u003cbr\u003eCommit: 9c15515d\u003cbr\u003eMessage: Added number of llama3 tokens to desc stats","Date: 2025-01-03\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +271.89M\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 38b692a5\u003cbr\u003eMessage: Added automatically updated samples to update_descriptive_stats.py","Date: 2025-01-04\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 546c3b35\u003cbr\u003eMessage: update opensubtitles","Date: 2025-01-05\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +5.40M\u003cbr\u003eSamples: 588,476\u003cbr\u003eCommit: 0cef3177\u003cbr\u003eMessage: Added distribution plot for number of tokens","Date: 2025-02-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +7.30M\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 97b3aa5d\u003cbr\u003eMessage: Add Nota-tekster (#41)","Date: 2025-03-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 5affec72\u003cbr\u003eMessage: add_memo (#42)","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +1.51G\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 65faa6e2\u003cbr\u003eMessage: a lot of improvements","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 43d839aa\u003cbr\u003eMessage: updates sheets","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 060c4430\u003cbr\u003eMessage: Updated changelog","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: c9397c44\u003cbr\u003eMessage: reformatted the readme","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +901.15M\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: d36009a4\u003cbr\u003eMessage: update desc stats","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 91cd694a\u003cbr\u003eMessage: docs: minor fixes to datasheets","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 2453a15a\u003cbr\u003eMessage: updated datasheet","Date: 2025-06-23\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +104.46M\u003cbr\u003eSamples: 891,094\u003cbr\u003eCommit: 16931a4c\u003cbr\u003eMessage: Fix memo (#68)","Date: 2025-06-25\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +581.06k\u003cbr\u003eSamples: 891,348\u003cbr\u003eCommit: 2c91001b\u003cbr\u003eMessage: Fix Danske Taler (#69)","Date: 2025-06-30\u003cbr\u003eTokens: 4.40G\u003cbr\u003eChange: +26.49M\u003cbr\u003eSamples: 915,090\u003cbr\u003eCommit: 7df022e7\u003cbr\u003eMessage: Adding Scrape Hovedstaden (#70)","Date: 2025-07-01\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +302.40M\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 6a2c8fbf\u003cbr\u003eMessage: update-retsinformationdk (#72)","Date: 2025-07-08\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 0cdc88c0\u003cbr\u003eMessage: Add tokens over time (+ rename scrape_hovedstaten) (#73)","Date: 2025-07-11\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +86.35M\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: dd36adfe\u003cbr\u003eMessage: Add domsdatabasen (#74)","Date: 2025-07-21\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: d06be7ce\u003cbr\u003eMessage: Updating readme and graphs after merging with main."],"x":["2025-01-02T00:00:00.000000000","2025-01-03T00:00:00.000000000","2025-01-04T00:00:00.000000000","2025-01-05T00:00:00.000000000","2025-02-10T00:00:00.000000000","2025-03-10T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-06-23T00:00:00.000000000","2025-06-25T00:00:00.000000000","2025-06-30T00:00:00.000000000","2025-07-01T00:00:00.000000000","2025-07-08T00:00:00.000000000","2025-07-11T00:00:00.000000000","2025-07-21T00:00:00.000000000"],"y":[1567706760,1839599769,1839599769,1844994816,1852293828,1852293828,3363395483,3363395483,3363395483,3363395483,4264549097,4264549097,4264549097,4369008328,4369589385,4396075044,4698470546,4698470546,4784823570,4784823570],"type":"scatter"}], {"template":{"data":{"histogram2dcontour":[{"type":"histogram2dcontour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"choropleth":[{"type":"choropleth","colorbar":{"outlinewidth":0,"ticks":""}}],"histogram2d":[{"type":"histogram2d","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"heatmap":[{"type":"heatmap","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"contourcarpet":[{"type":"contourcarpet","colorbar":{"outlinewidth":0,"ticks":""}}],"contour":[{"type":"contour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"surface":[{"type":"surface","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"mesh3d":[{"type":"mesh3d","colorbar":{"outlinewidth":0,"ticks":""}}],"scatter":[{"fillpattern":{"fillmode":"overlay","size":10,"solidity":0.2},"type":"scatter"}],"parcoords":[{"type":"parcoords","line":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolargl":[{"type":"scatterpolargl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"bar":[{"error_x":{"color":"#2a3f5f"},"error_y":{"color":"#2a3f5f"},"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"bar"}],"scattergeo":[{"type":"scattergeo","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolar":[{"type":"scatterpolar","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"histogram":[{"marker":{"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"histogram"}],"scattergl":[{"type":"scattergl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatter3d":[{"type":"scatter3d","line":{"colorbar":{"outlinewidth":0,"ticks":""}},"marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermap":[{"type":"scattermap","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermapbox":[{"type":"scattermapbox","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterternary":[{"type":"scatterternary","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattercarpet":[{"type":"scattercarpet","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"carpet":[{"aaxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"baxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"type":"carpet"}],"table":[{"cells":{"fill":{"color":"#EBF0F8"},"line":{"color":"white"}},"header":{"fill":{"color":"#C8D4E3"},"line":{"color":"white"}},"type":"table"}],"barpolar":[{"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"barpolar"}],"pie":[{"automargin":true,"type":"pie"}]},"layout":{"autotypenumbers":"strict","colorway":["#636efa","#EF553B","#00cc96","#ab63fa","#FFA15A","#19d3f3","#FF6692","#B6E880","#FF97FF","#FECB52"],"font":{"color":"#2a3f5f"},"hovermode":"closest","hoverlabel":{"align":"left"},"paper_bgcolor":"white","plot_bgcolor":"#E5ECF6","polar":{"bgcolor":"#E5ECF6","angularaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"radialaxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"ternary":{"bgcolor":"#E5ECF6","aaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"baxis":{"gridcolor":"white","linecolor":"white","ticks":""},"caxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"coloraxis":{"colorbar":{"outlinewidth":0,"ticks":""}},"colorscale":{"sequential":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"sequentialminus":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"diverging":[[0,"#8e0152"],[0.1,"#c51b7d"],[0.2,"#de77ae"],[0.3,"#f1b6da"],[0.4,"#fde0ef"],[0.5,"#f7f7f7"],[0.6,"#e6f5d0"],[0.7,"#b8e186"],[0.8,"#7fbc41"],[0.9,"#4d9221"],[1,"#276419"]]},"xaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"yaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"scene":{"xaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"yaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"zaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2}},"shapedefaults":{"line":{"color":"#2a3f5f"}},"annotationdefaults":{"arrowcolor":"#2a3f5f","arrowhead":0,"arrowwidth":1},"geo":{"bgcolor":"white","landcolor":"#E5ECF6","subunitcolor":"white","showland":true,"showlakes":true,"lakecolor":"white"},"title":{"x":0.05},"mapbox":{"style":"light"}}},"shapes":[{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":300000000,"y1":300000000,"yref":"y"},{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":1000000000,"y1":1000000000,"yref":"y"}],"annotations":[{"font":{"color":"gray","size":12},"showarrow":false,"text":"Common Corpus (dan) (Langlais et al., 2025)","x":0,"xanchor":"left","xref":"x domain","y":300000000,"yanchor":"bottom","yref":"y"},{"font":{"color":"gray","size":12},"showarrow":false,"text":"Danish Gigaword (Derczynski et al., 2021)","x":0,"xanchor":"left","xref":"x domain","y":1000000000,"yanchor":"bottom","yref":"y"}],"title":{"text":"Number of Tokens Over Time in Danish Dynaword"},"xaxis":{"title":{"text":"Date"}},"yaxis":{"title":{"text":"Number of Tokens (Llama 3)"},"tickformat":".2s","ticksuffix":""},"hovermode":"closest","width":600,"height":400,"showlegend":false,"plot_bgcolor":"rgba(0,0,0,0)","paper_bgcolor":"rgba(0,0,0,0)"}, {"responsive": true} ) }; </script> </div>
|
| 6 |
</body>
|
| 7 |
</html>
|
|
|
|
| 2 |
<head><meta charset="utf-8" /></head>
|
| 3 |
<body>
|
| 4 |
<div> <script type="text/javascript">window.PlotlyConfig = {MathJaxConfig: 'local'};</script>
|
| 5 |
+
<script charset="utf-8" src="https://cdn.plot.ly/plotly-3.0.1.min.js"></script> <div id="cbff9399-9d83-4378-9a08-8dcd2e1ed656" class="plotly-graph-div" style="height:400px; width:600px;"></div> <script type="text/javascript"> window.PLOTLYENV=window.PLOTLYENV || {}; if (document.getElementById("cbff9399-9d83-4378-9a08-8dcd2e1ed656")) { Plotly.newPlot( "cbff9399-9d83-4378-9a08-8dcd2e1ed656", [{"hovertemplate":"%{text}\u003cextra\u003e\u003c\u002fextra\u003e","line":{"color":"#DC2626","width":3},"marker":{"color":"#DC2626","size":5},"mode":"lines+markers","name":"Tokens","text":["Date: 2025-01-02\u003cbr\u003eTokens: 1.57G\u003cbr\u003eSamples: 546,769\u003cbr\u003eCommit: 9c15515d\u003cbr\u003eMessage: Added number of llama3 tokens to desc stats","Date: 2025-01-03\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +271.89M\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 38b692a5\u003cbr\u003eMessage: Added automatically updated samples to update_descriptive_stats.py","Date: 2025-01-04\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 546c3b35\u003cbr\u003eMessage: update opensubtitles","Date: 2025-01-05\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +5.40M\u003cbr\u003eSamples: 588,476\u003cbr\u003eCommit: 0cef3177\u003cbr\u003eMessage: Added distribution plot for number of tokens","Date: 2025-02-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +7.30M\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 97b3aa5d\u003cbr\u003eMessage: Add Nota-tekster (#41)","Date: 2025-03-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 5affec72\u003cbr\u003eMessage: add_memo (#42)","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +1.51G\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 65faa6e2\u003cbr\u003eMessage: a lot of improvements","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 43d839aa\u003cbr\u003eMessage: updates sheets","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 060c4430\u003cbr\u003eMessage: Updated changelog","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: c9397c44\u003cbr\u003eMessage: reformatted the readme","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +901.15M\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: d36009a4\u003cbr\u003eMessage: update desc stats","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 91cd694a\u003cbr\u003eMessage: docs: minor fixes to datasheets","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 2453a15a\u003cbr\u003eMessage: updated datasheet","Date: 2025-06-23\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +104.46M\u003cbr\u003eSamples: 891,094\u003cbr\u003eCommit: 16931a4c\u003cbr\u003eMessage: Fix memo (#68)","Date: 2025-06-25\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +581.06k\u003cbr\u003eSamples: 891,348\u003cbr\u003eCommit: 2c91001b\u003cbr\u003eMessage: Fix Danske Taler (#69)","Date: 2025-06-30\u003cbr\u003eTokens: 4.40G\u003cbr\u003eChange: +26.49M\u003cbr\u003eSamples: 915,090\u003cbr\u003eCommit: 7df022e7\u003cbr\u003eMessage: Adding Scrape Hovedstaden (#70)","Date: 2025-07-01\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +302.40M\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 6a2c8fbf\u003cbr\u003eMessage: update-retsinformationdk (#72)","Date: 2025-07-08\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 0cdc88c0\u003cbr\u003eMessage: Add tokens over time (+ rename scrape_hovedstaten) (#73)","Date: 2025-07-11\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +86.35M\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: dd36adfe\u003cbr\u003eMessage: Add domsdatabasen (#74)","Date: 2025-07-21\u003cbr\u003eTokens: 4.78G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 960,357\u003cbr\u003eCommit: 30071635\u003cbr\u003eMessage: restructuring-main-table (#75)"],"x":["2025-01-02T00:00:00.000000000","2025-01-03T00:00:00.000000000","2025-01-04T00:00:00.000000000","2025-01-05T00:00:00.000000000","2025-02-10T00:00:00.000000000","2025-03-10T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-06-23T00:00:00.000000000","2025-06-25T00:00:00.000000000","2025-06-30T00:00:00.000000000","2025-07-01T00:00:00.000000000","2025-07-08T00:00:00.000000000","2025-07-11T00:00:00.000000000","2025-07-21T00:00:00.000000000"],"y":[1567706760,1839599769,1839599769,1844994816,1852293828,1852293828,3363395483,3363395483,3363395483,3363395483,4264549097,4264549097,4264549097,4369008328,4369589385,4396075044,4698470546,4698470546,4784823570,4784823570],"type":"scatter"}], {"template":{"data":{"histogram2dcontour":[{"type":"histogram2dcontour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"choropleth":[{"type":"choropleth","colorbar":{"outlinewidth":0,"ticks":""}}],"histogram2d":[{"type":"histogram2d","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"heatmap":[{"type":"heatmap","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"contourcarpet":[{"type":"contourcarpet","colorbar":{"outlinewidth":0,"ticks":""}}],"contour":[{"type":"contour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"surface":[{"type":"surface","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"mesh3d":[{"type":"mesh3d","colorbar":{"outlinewidth":0,"ticks":""}}],"scatter":[{"fillpattern":{"fillmode":"overlay","size":10,"solidity":0.2},"type":"scatter"}],"parcoords":[{"type":"parcoords","line":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolargl":[{"type":"scatterpolargl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"bar":[{"error_x":{"color":"#2a3f5f"},"error_y":{"color":"#2a3f5f"},"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"bar"}],"scattergeo":[{"type":"scattergeo","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolar":[{"type":"scatterpolar","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"histogram":[{"marker":{"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"histogram"}],"scattergl":[{"type":"scattergl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatter3d":[{"type":"scatter3d","line":{"colorbar":{"outlinewidth":0,"ticks":""}},"marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermap":[{"type":"scattermap","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermapbox":[{"type":"scattermapbox","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterternary":[{"type":"scatterternary","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattercarpet":[{"type":"scattercarpet","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"carpet":[{"aaxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"baxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"type":"carpet"}],"table":[{"cells":{"fill":{"color":"#EBF0F8"},"line":{"color":"white"}},"header":{"fill":{"color":"#C8D4E3"},"line":{"color":"white"}},"type":"table"}],"barpolar":[{"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"barpolar"}],"pie":[{"automargin":true,"type":"pie"}]},"layout":{"autotypenumbers":"strict","colorway":["#636efa","#EF553B","#00cc96","#ab63fa","#FFA15A","#19d3f3","#FF6692","#B6E880","#FF97FF","#FECB52"],"font":{"color":"#2a3f5f"},"hovermode":"closest","hoverlabel":{"align":"left"},"paper_bgcolor":"white","plot_bgcolor":"#E5ECF6","polar":{"bgcolor":"#E5ECF6","angularaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"radialaxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"ternary":{"bgcolor":"#E5ECF6","aaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"baxis":{"gridcolor":"white","linecolor":"white","ticks":""},"caxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"coloraxis":{"colorbar":{"outlinewidth":0,"ticks":""}},"colorscale":{"sequential":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"sequentialminus":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"diverging":[[0,"#8e0152"],[0.1,"#c51b7d"],[0.2,"#de77ae"],[0.3,"#f1b6da"],[0.4,"#fde0ef"],[0.5,"#f7f7f7"],[0.6,"#e6f5d0"],[0.7,"#b8e186"],[0.8,"#7fbc41"],[0.9,"#4d9221"],[1,"#276419"]]},"xaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"yaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"scene":{"xaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"yaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"zaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2}},"shapedefaults":{"line":{"color":"#2a3f5f"}},"annotationdefaults":{"arrowcolor":"#2a3f5f","arrowhead":0,"arrowwidth":1},"geo":{"bgcolor":"white","landcolor":"#E5ECF6","subunitcolor":"white","showland":true,"showlakes":true,"lakecolor":"white"},"title":{"x":0.05},"mapbox":{"style":"light"}}},"shapes":[{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":300000000,"y1":300000000,"yref":"y"},{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":1000000000,"y1":1000000000,"yref":"y"}],"annotations":[{"font":{"color":"gray","size":12},"showarrow":false,"text":"Common Corpus (dan) (Langlais et al., 2025)","x":0,"xanchor":"left","xref":"x domain","y":300000000,"yanchor":"bottom","yref":"y"},{"font":{"color":"gray","size":12},"showarrow":false,"text":"Danish Gigaword (Derczynski et al., 2021)","x":0,"xanchor":"left","xref":"x domain","y":1000000000,"yanchor":"bottom","yref":"y"}],"title":{"text":"Number of Tokens Over Time in Danish Dynaword"},"xaxis":{"title":{"text":"Date"}},"yaxis":{"title":{"text":"Number of Tokens (Llama 3)"},"tickformat":".2s","ticksuffix":""},"hovermode":"closest","width":600,"height":400,"showlegend":false,"plot_bgcolor":"rgba(0,0,0,0)","paper_bgcolor":"rgba(0,0,0,0)"}, {"responsive": true} ) }; </script> </div>
|
| 6 |
</body>
|
| 7 |
</html>
|
images/tokens_over_time.svg
CHANGED

|

|
pyproject.toml
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
-
version = "1.2.
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
|
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
+
version = "1.2.7"
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|