Datasets:

Tasks:
Text Generation
Formats:
parquet
Sub-tasks:
language-modeling
Languages:
Danish
Size:
10M - 100M
ArXiv:
DOI:
License:

Add tokens over time (+ rename scrape_hovedstaten) (#73)
Browse files- updated logo (2d31a537efd08700abc0924c1e9df83d3849db46)
- renamed scrape-hovedstaden to follow pretty name (7ad37693d49a38be7dc02e8c20e3b1a152ba3241)
- added tokens over time plot (a8901d31007c5854021a37ed43d3f0f0a6da696a)
- run make test, lint and bump_version (b711cf03f901568ac03052aae8a1e2d086fdc05e)
- delete tokens_over_time.png (e18bfe8d089ea9fc3686a802eb0f8067b4cb0e2c)
- fix changelog (3732914093b098f9eb9aa4d148e2bedbd5f4d376)
- CHANGELOG.md +11 -0
- README.md +56 -46
- data/{scrape_hovedstaden → health_hovedstaden}/create.py +8 -10
- data/{scrape_hovedstaden → health_hovedstaden}/descriptive_stats.json +1 -1
- data/{scrape_hovedstaden/scrape_hovedstaden.md → health_hovedstaden/health_hovedstaden.md} +4 -4
- data/{scrape_hovedstaden/scrape_hovedstaden.parquet → health_hovedstaden/health_hovedstaden.parquet} +1 -1
- data/{scrape_hovedstaden → health_hovedstaden}/images/dist_document_length.png +2 -2
- descriptive_stats.json +1 -1
- docs/icon.png +2 -2
- images/dist_document_length.png +2 -2
- images/domain_distribution.png +2 -2
- images/tokens_over_time.html +7 -0
- images/tokens_over_time.svg +1 -0
- pyproject.toml +1 -1
- src/dynaword/plot_tokens_over_time.py +241 -0
- src/dynaword/update_descriptive_statistics.py +2 -0
- test_results.log +4 -3
- uv.lock +0 -0
CHANGELOG.md
CHANGED
|
@@ -5,6 +5,17 @@ All notable changes to this project will be documented in this file.
|
|
| 5 |
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
## [v1.2.3] - 2025-06-30
|
| 9 |
|
| 10 |
### Added
|
|
|
|
| 5 |
|
| 6 |
The format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/).
|
| 7 |
|
| 8 |
+
## [v1.2.4] - 2025-07-08
|
| 9 |
+
|
| 10 |
+
### Added
|
| 11 |
+
|
| 12 |
+
- Add a plot for tokens over time to see how the dataset develops
|
| 13 |
+
- Minor documentation improvements in the main readme
|
| 14 |
+
|
| 15 |
+
### Changed
|
| 16 |
+
|
| 17 |
+
- Rename `scrape_hovedstaden` to `health_hovedstaden` avoid confusion with its pretty name
|
| 18 |
+
|
| 19 |
## [v1.2.3] - 2025-06-30
|
| 20 |
|
| 21 |
### Added
|
README.md
CHANGED
|
@@ -141,10 +141,10 @@ configs:
|
|
| 141 |
data_files:
|
| 142 |
- split: train
|
| 143 |
path: data/nota/*.parquet
|
| 144 |
-
- config_name:
|
| 145 |
data_files:
|
| 146 |
- split: train
|
| 147 |
-
path: data/
|
| 148 |
annotations_creators:
|
| 149 |
- no-annotation
|
| 150 |
language_creators:
|
|
@@ -178,7 +178,7 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 178 |
<!-- START README TABLE -->
|
| 179 |
| | |
|
| 180 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 181 |
-
| **Version** | 1.2.
|
| 182 |
| **Language** | dan, dansk, Danish |
|
| 183 |
| **License** | Openly Licensed, See the respective dataset |
|
| 184 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
@@ -223,8 +223,10 @@ https://github.com/huggingface/datasets/blob/main/templates/README_guide.md
|
|
| 223 |
|
| 224 |
### Dataset Summary
|
| 225 |
|
| 226 |
-
The Danish dynaword is a
|
|
|
|
| 227 |
|
|
|
|
| 228 |
|
| 229 |
### Loading the dataset
|
| 230 |
|
|
@@ -304,7 +306,9 @@ The entire corpus is provided in the `train` split.
|
|
| 304 |
|
| 305 |
### Curation Rationale
|
| 306 |
|
| 307 |
-
These datasets were collected and curated with the intention of making openly license Danish data available. While this was collected with the intention of developing language models it is likely to have multiple other uses such as examining language development and differences across domains.
|
|
|
|
|
|
|
| 308 |
|
| 309 |
### Annotations
|
| 310 |
|
|
@@ -315,44 +319,44 @@ This data generally contains no annotation besides the metadata attached to each
|
|
| 315 |
Below follows a brief overview of the sources in the corpus along with their individual license.
|
| 316 |
|
| 317 |
<!-- START-MAIN TABLE -->
|
| 318 |
-
| Source | Description | Domain | N. Tokens
|
| 319 |
-
|
| 320 |
-
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B
|
| 321 |
-
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 818.25M
|
| 322 |
-
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M
|
| 323 |
-
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M
|
| 324 |
-
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M
|
| 325 |
-
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M
|
| 326 |
-
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M
|
| 327 |
-
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M
|
| 328 |
-
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M
|
| 329 |
-
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M
|
| 330 |
-
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M
|
| 331 |
-
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M
|
| 332 |
-
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M
|
| 333 |
-
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M
|
| 334 |
-
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M
|
| 335 |
-
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M
|
| 336 |
-
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M
|
| 337 |
-
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M
|
| 338 |
-
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M
|
| 339 |
-
| [
|
| 340 |
-
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M
|
| 341 |
-
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.72M
|
| 342 |
-
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M
|
| 343 |
-
| [gutenberg] | The Danish subsection from Project [Gutenberg](https://www.gutenberg.org) | Books | 6.76M
|
| 344 |
-
| [wikibooks] | The Danish Subsection of [Wikibooks](https://www.wikibooks.org) | Books | 6.24M
|
| 345 |
-
| [wikisource] | The Danish subsection of [Wikisource](https://en.wikisource.org/wiki/Main_Page) | Encyclopedic | 5.34M
|
| 346 |
-
| [jvj] | The works of the Danish author and poet, [Johannes V. Jensen](https://da.wikipedia.org/wiki/Johannes_V._Jensen) | Books | 3.55M
|
| 347 |
-
| [spont] | Conversational samples collected as a part of research projects at Aarhus University | Conversation | 1.56M
|
| 348 |
-
| [dannet] | [DanNet](https://cst.ku.dk/projekter/dannet) is a Danish WordNet | Other | 1.48M
|
| 349 |
-
| [relig] | Danish religious text from the 1700-2022 | Books | 1.24M
|
| 350 |
-
| [ncc_newspaper] | OCR'd Newspapers derived from [NCC](https://huggingface.co/datasets/NbAiLab/NCC) | News | 1.05M
|
| 351 |
-
| [botxt] | The Bornholmsk Ordbog Dictionary Project | Dialect | 847.97K
|
| 352 |
-
| [naat] | Danish speeches from 1930-2022 | Conversation | 286.68K
|
| 353 |
-
| [depbank] | The Danish subsection of the [Universal Dependencies Treebank](https://github.com/UniversalDependencies/UD_Danish-DDT) | Other | 185.45K
|
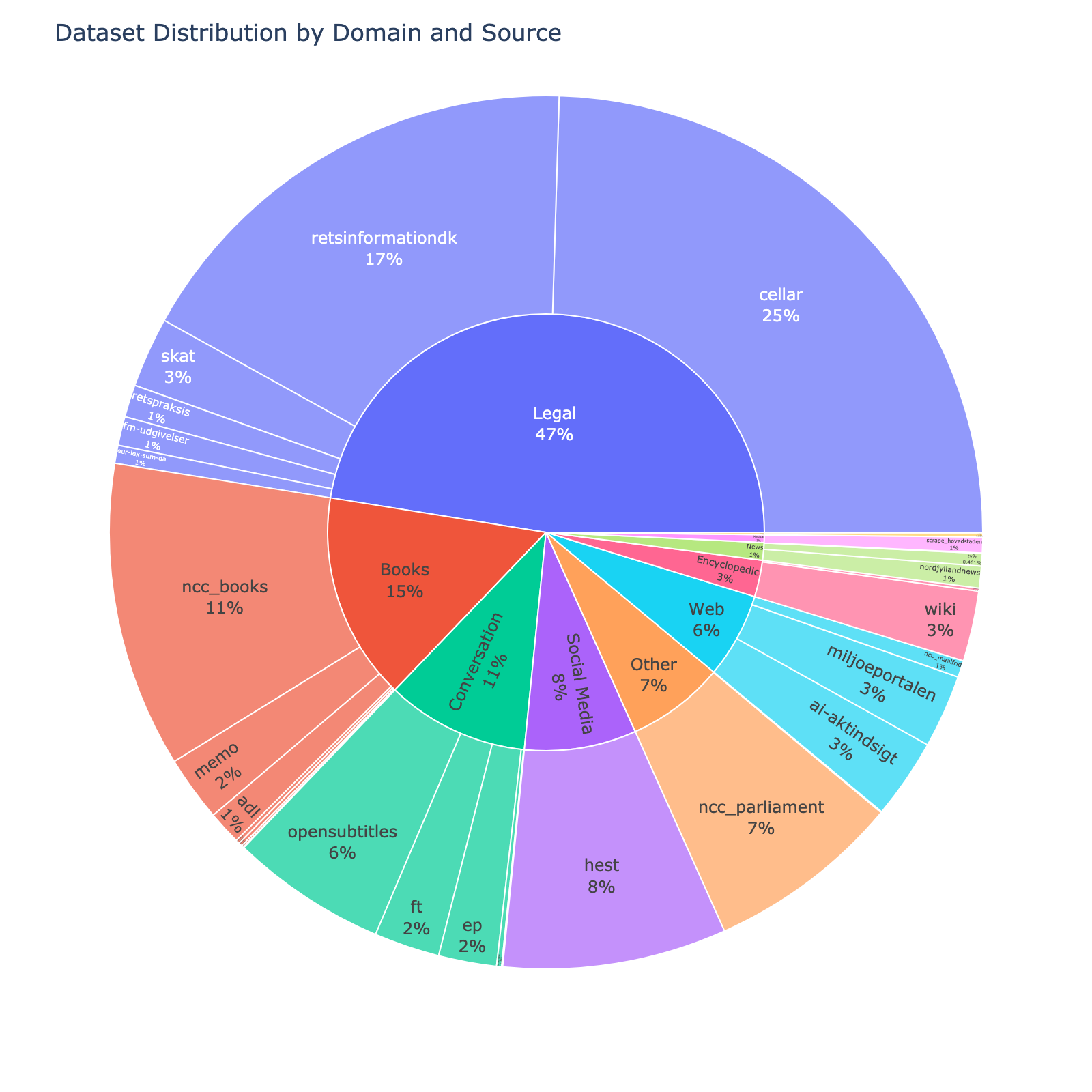
| 354 |
-
| [synne] | Dataset collected from [synnejysk forening's website](https://www.synnejysk.dk), covering the Danish dialect sønderjysk | Other | 52.02K
|
| 355 |
-
| **Total** | | | 4.70B
|
| 356 |
|
| 357 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 358 |
[cellar]: data/cellar/cellar.md
|
|
@@ -388,7 +392,7 @@ Below follows a brief overview of the sources in the corpus along with their ind
|
|
| 388 |
[nordjyllandnews]: data/nordjyllandnews/nordjyllandnews.md
|
| 389 |
[relig]: data/relig/relig.md
|
| 390 |
[nota]: data/nota/nota.md
|
| 391 |
-
[
|
| 392 |
|
| 393 |
|
| 394 |
[CC-0]: https://creativecommons.org/publicdomain/zero/1.0/legalcode.en
|
|
@@ -407,11 +411,18 @@ You can learn more about each dataset by pressing the link in the first column.
|
|
| 407 |
|
| 408 |
### Data Collection and Processing
|
| 409 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 410 |
The data collection and processing varies depending on the dataset and is documentationed the individual datasheets, which is linked in the above table. If possible the collection is documented both in the datasheet and in the reproducible script (`data/{dataset}/create.py`).
|
| 411 |
|
| 412 |
In addition to data specific processing we also run a series automated quality checks to ensure formatting (e.g. ensuring correctly formatted columns and unique IDs), quality checks (e.g. duplicate and empty string detection) and datasheet documentation checks. These checks are there to ensure a high quality of documentation and a minimal level of quality. To allow for the development of novel cleaning methodologies we do not provide more extensive cleaning.
|
| 413 |
|
| 414 |
|
|
|
|
| 415 |
### Dataset Statistics
|
| 416 |
The following plot show the domains distribution of the following within the dynaword:
|
| 417 |
|
|
@@ -419,8 +430,6 @@ The following plot show the domains distribution of the following within the dyn
|
|
| 419 |
<img src="./images/domain_distribution.png" width="400" style="margin-right: 10px;" />
|
| 420 |
</p>
|
| 421 |
|
| 422 |
-
|
| 423 |
-
|
| 424 |
<details>
|
| 425 |
<summary>Per dataset histograms</summary>
|
| 426 |
<!-- START-DATASET PLOTS -->
|
|
@@ -433,6 +442,7 @@ The following plot show the domains distribution of the following within the dyn
|
|
| 433 |
|
| 434 |
|
| 435 |
|
|
|
|
| 436 |
### Contributing to the dataset
|
| 437 |
|
| 438 |
We welcome contributions to the dataset such as new sources, better data filtering and so on. To get started on contributing please see [the contribution guidelines](CONTRIBUTING.md)
|
|
|
|
| 141 |
data_files:
|
| 142 |
- split: train
|
| 143 |
path: data/nota/*.parquet
|
| 144 |
+
- config_name: health_hovedstaden
|
| 145 |
data_files:
|
| 146 |
- split: train
|
| 147 |
+
path: data/health_hovedstaden/*.parquet
|
| 148 |
annotations_creators:
|
| 149 |
- no-annotation
|
| 150 |
language_creators:
|
|
|
|
| 178 |
<!-- START README TABLE -->
|
| 179 |
| | |
|
| 180 |
| ------------ | ----------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
| 181 |
+
| **Version** | 1.2.4 ([Changelog](/CHANGELOG.md)) |
|
| 182 |
| **Language** | dan, dansk, Danish |
|
| 183 |
| **License** | Openly Licensed, See the respective dataset |
|
| 184 |
| **Models** | For model trained used this data see [danish-foundation-models](https://huggingface.co/danish-foundation-models) |
|
|
|
|
| 223 |
|
| 224 |
### Dataset Summary
|
| 225 |
|
| 226 |
+
The Danish dynaword is a collection of Danish free-form text datasets from various domains. All of the datasets in Danish Dynaword are openly licensed
|
| 227 |
+
and deemed permissible for training large language models.
|
| 228 |
|
| 229 |
+
Danish Dynaword is continually developed, which means that the dataset will actively be updated as new datasets become available. If you would like to contribute a dataset see the [contribute section](#contributing-to-the-dataset).
|
| 230 |
|
| 231 |
### Loading the dataset
|
| 232 |
|
|
|
|
| 306 |
|
| 307 |
### Curation Rationale
|
| 308 |
|
| 309 |
+
These datasets were collected and curated with the intention of making openly license Danish data available. While this was collected with the intention of developing language models it is likely to have multiple other uses such as examining language development and differences across domains.
|
| 310 |
+
|
| 311 |
+
|
| 312 |
|
| 313 |
### Annotations
|
| 314 |
|
|
|
|
| 319 |
Below follows a brief overview of the sources in the corpus along with their individual license.
|
| 320 |
|
| 321 |
<!-- START-MAIN TABLE -->
|
| 322 |
+
| Source | Description | Domain | N. Tokens | License |
|
| 323 |
+
| :------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :----------- | :-------- | :--------------------- |
|
| 324 |
+
| [cellar] | The official digital repository for European Union legal documents and open data | Legal | 1.15B | [CC-BY-SA 4.0] |
|
| 325 |
+
| [retsinformationdk] | [retsinformation.dk](https://www.retsinformation.dk) (legal-information.dk) the official legal information system of Denmark | Legal | 818.25M | [Danish Copyright Law] |
|
| 326 |
+
| [ncc_books] | Danish books extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from OCR | Books | 531.97M | [CC-0] |
|
| 327 |
+
| [hest] | Samples from the Danish debate forum www.heste-nettet.dk | Social Media | 389.32M | [CC-0] |
|
| 328 |
+
| [ncc_parliament] | Collections from the Norwegian parliament in Danish. Extracted from the [Norwegian Colossal Corpus](https://huggingface.co/datasets/NbAiLab/NCC) derived from ocr | Other | 338.87M | [NLOD 2.0] |
|
| 329 |
+
| [opensubtitles] | Danish subsection of [OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) | Conversation | 271.60M | [CC-0] |
|
| 330 |
+
| [ai-aktindsigt] | Multiple web scrapes from municipality websites collected as a part of the [AI-aktindsigt](https://ai-aktindsigt.dk) project | Web | 139.23M | [Apache 2.0] |
|
| 331 |
+
| [miljoeportalen] | Data from [Danmarks Miljøportalen](https://www.miljoeportal.dk/om-danmarks-miljoeportal/) (Denmark's Environment Portal) | Web | 127.38M | [CC-0] |
|
| 332 |
+
| [skat] | Skat is the Danish tax authority. This dataset contains content from its website skat.dk | Legal | 122.11M | [CC-0] |
|
| 333 |
+
| [wiki] | The Danish subsection of [wikipedia](https://en.wikipedia.org/wiki/Main_Page) | Encyclopedic | 122.00M | [CC-0] |
|
| 334 |
+
| [ft] | Records from all meetings of The Danish parliament (Folketinget) in the parliament hall | Conversation | 114.09M | [CC-0] |
|
| 335 |
+
| [memo] | The MeMo corpus comprising almost all Danish novels from the period 1870-1899, known as the Modern Breakthrough | Books | 113.74M | [CC-BY-SA 4.0] |
|
| 336 |
+
| [ep] | The Danish subsection of [Europarl](https://aclanthology.org/2005.mtsummit-papers.11/) | Conversation | 100.84M | [CC-0] |
|
| 337 |
+
| [adl] | Danish literature from 1700-2023 from the [Archive for Danish Literature](https://tekster.kb.dk/text?editorial=no&f%5Bsubcollection_ssi%5D%5B%5D=adl&match=one&search_field=Alt) (ADL) | Books | 58.49M | [CC-0] |
|
| 338 |
+
| [retspraksis] | Case law or judical practice in Denmark derived from [Retspraksis](https://da.wikipedia.org/wiki/Retspraksis) | Legal | 56.26M | [CC-0] |
|
| 339 |
+
| [fm-udgivelser] | The official publication series of the Danish Ministry of Finance containing economic analyses, budget proposals, and fiscal policy documents | Legal | 50.34M | [CC-BY-SA 4.0] |
|
| 340 |
+
| [nordjyllandnews] | Articles from the Danish Newspaper [TV2 Nord](https://www.tv2nord.dk) | News | 37.90M | [CC-0] |
|
| 341 |
+
| [eur-lex-sum-da] | The Danish subsection of EUR-lex SUM consisting of EU legislation paired with professionally written summaries | Legal | 31.37M | [CC-BY-SA 4.0] |
|
| 342 |
+
| [ncc_maalfrid] | Danish content from Norwegian institutions websites | Web | 29.26M | [NLOD 2.0] |
|
| 343 |
+
| [health_hovedstaden] | Guidelines and informational documents for healthcare professionals from the Capital Region | Medical | 27.07M | [CC-0] |
|
| 344 |
+
| [tv2r] | Contemporary Danish newswire articles published between 2010 and 2019 | News | 21.67M | [CC-BY-SA 4.0] |
|
| 345 |
+
| [danske-taler] | Danish Speeches from [dansketaler.dk](https://www.dansketaler.dk) | Conversation | 8.72M | [CC-0] |
|
| 346 |
+
| [nota] | The text only part of the [Nota lyd- og tekstdata](https://sprogteknologi.dk/dataset/nota-lyd-og-tekstdata) dataset | Readaloud | 7.30M | [CC-0] |
|
| 347 |
+
| [gutenberg] | The Danish subsection from Project [Gutenberg](https://www.gutenberg.org) | Books | 6.76M | [Gutenberg] |
|
| 348 |
+
| [wikibooks] | The Danish Subsection of [Wikibooks](https://www.wikibooks.org) | Books | 6.24M | [CC-0] |
|
| 349 |
+
| [wikisource] | The Danish subsection of [Wikisource](https://en.wikisource.org/wiki/Main_Page) | Encyclopedic | 5.34M | [CC-0] |
|
| 350 |
+
| [jvj] | The works of the Danish author and poet, [Johannes V. Jensen](https://da.wikipedia.org/wiki/Johannes_V._Jensen) | Books | 3.55M | [CC-BY-SA 4.0] |
|
| 351 |
+
| [spont] | Conversational samples collected as a part of research projects at Aarhus University | Conversation | 1.56M | [CC-0] |
|
| 352 |
+
| [dannet] | [DanNet](https://cst.ku.dk/projekter/dannet) is a Danish WordNet | Other | 1.48M | [DanNet 1.0] |
|
| 353 |
+
| [relig] | Danish religious text from the 1700-2022 | Books | 1.24M | [CC-0] |
|
| 354 |
+
| [ncc_newspaper] | OCR'd Newspapers derived from [NCC](https://huggingface.co/datasets/NbAiLab/NCC) | News | 1.05M | [CC-0] |
|
| 355 |
+
| [botxt] | The Bornholmsk Ordbog Dictionary Project | Dialect | 847.97K | [CC-0] |
|
| 356 |
+
| [naat] | Danish speeches from 1930-2022 | Conversation | 286.68K | [CC-0] |
|
| 357 |
+
| [depbank] | The Danish subsection of the [Universal Dependencies Treebank](https://github.com/UniversalDependencies/UD_Danish-DDT) | Other | 185.45K | [CC-BY-SA 4.0] |
|
| 358 |
+
| [synne] | Dataset collected from [synnejysk forening's website](https://www.synnejysk.dk), covering the Danish dialect sønderjysk | Other | 52.02K | [CC-0] |
|
| 359 |
+
| **Total** | | | 4.70B | |
|
| 360 |
|
| 361 |
[ai-aktindsigt]: data/ai-aktindsigt/ai-aktindsigt.md
|
| 362 |
[cellar]: data/cellar/cellar.md
|
|
|
|
| 392 |
[nordjyllandnews]: data/nordjyllandnews/nordjyllandnews.md
|
| 393 |
[relig]: data/relig/relig.md
|
| 394 |
[nota]: data/nota/nota.md
|
| 395 |
+
[health_hovedstaden]: data/health_hovedstaden/health_hovedstaden.md
|
| 396 |
|
| 397 |
|
| 398 |
[CC-0]: https://creativecommons.org/publicdomain/zero/1.0/legalcode.en
|
|
|
|
| 411 |
|
| 412 |
### Data Collection and Processing
|
| 413 |
|
| 414 |
+
Danish Dynaword is continually developed, which means that the dataset will actively be updated as new datasets become available. This means that the size of Dynaword increases over time as seen in the following plot:
|
| 415 |
+
|
| 416 |
+
<p align="center">
|
| 417 |
+
<img src="./images/tokens_over_time.svg" width="600" style="margin-right: 10px;" />
|
| 418 |
+
</p>
|
| 419 |
+
|
| 420 |
The data collection and processing varies depending on the dataset and is documentationed the individual datasheets, which is linked in the above table. If possible the collection is documented both in the datasheet and in the reproducible script (`data/{dataset}/create.py`).
|
| 421 |
|
| 422 |
In addition to data specific processing we also run a series automated quality checks to ensure formatting (e.g. ensuring correctly formatted columns and unique IDs), quality checks (e.g. duplicate and empty string detection) and datasheet documentation checks. These checks are there to ensure a high quality of documentation and a minimal level of quality. To allow for the development of novel cleaning methodologies we do not provide more extensive cleaning.
|
| 423 |
|
| 424 |
|
| 425 |
+
|
| 426 |
### Dataset Statistics
|
| 427 |
The following plot show the domains distribution of the following within the dynaword:
|
| 428 |
|
|
|
|
| 430 |
<img src="./images/domain_distribution.png" width="400" style="margin-right: 10px;" />
|
| 431 |
</p>
|
| 432 |
|
|
|
|
|
|
|
| 433 |
<details>
|
| 434 |
<summary>Per dataset histograms</summary>
|
| 435 |
<!-- START-DATASET PLOTS -->
|
|
|
|
| 442 |
|
| 443 |
|
| 444 |
|
| 445 |
+
|
| 446 |
### Contributing to the dataset
|
| 447 |
|
| 448 |
We welcome contributions to the dataset such as new sources, better data filtering and so on. To get started on contributing please see [the contribution guidelines](CONTRIBUTING.md)
|
data/{scrape_hovedstaden → health_hovedstaden}/create.py
RENAMED
|
@@ -8,22 +8,20 @@
|
|
| 8 |
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword", rev = "00e7f2aee7f7ad2da423419f77ecbb9c0536de0d" }
|
| 9 |
# ///
|
| 10 |
"""
|
| 11 |
-
Script for downloading and processing
|
| 12 |
|
| 13 |
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 14 |
|
| 15 |
```bash
|
| 16 |
-
GIT_LFS_SKIP_SMUDGE=1 uv run data/
|
| 17 |
```
|
| 18 |
"""
|
| 19 |
|
| 20 |
import logging
|
| 21 |
-
import subprocess
|
| 22 |
from datetime import datetime
|
| 23 |
from pathlib import Path
|
| 24 |
-
from typing import
|
| 25 |
|
| 26 |
-
import pandas as pd
|
| 27 |
from datasets import Dataset, load_dataset
|
| 28 |
|
| 29 |
from dynaword.process_dataset import (
|
|
@@ -39,7 +37,7 @@ download_path = Path(__file__).parent / "tmp"
|
|
| 39 |
|
| 40 |
|
| 41 |
def main():
|
| 42 |
-
save_path = Path(__file__).parent / "
|
| 43 |
# Download data from repo: Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 44 |
ds = load_dataset(
|
| 45 |
"Den-Intelligente-Patientjournal/region_hovedstaden_text", split="train"
|
|
@@ -55,11 +53,11 @@ def main():
|
|
| 55 |
dataset = dataset.add_column(
|
| 56 |
"added", [datetime.today().date().strftime("%Y-%m-%d")] * len(dataset)
|
| 57 |
) # type: ignore
|
| 58 |
-
# Add source column:
|
| 59 |
-
dataset = dataset.add_column("source", ["
|
| 60 |
-
# Add id column:
|
| 61 |
dataset = dataset.add_column(
|
| 62 |
-
"id", [f"
|
| 63 |
) # type: ignore
|
| 64 |
|
| 65 |
# quality checks and processing
|
|
|
|
| 8 |
# dynaword = { git = "https://huggingface.co/datasets/danish-foundation-models/danish-dynaword", rev = "00e7f2aee7f7ad2da423419f77ecbb9c0536de0d" }
|
| 9 |
# ///
|
| 10 |
"""
|
| 11 |
+
Script for downloading and processing Health Hovedstaden texts.
|
| 12 |
|
| 13 |
Note: To run this script, you need to set `GIT_LFS_SKIP_SMUDGE=1` to be able to install dynaword:
|
| 14 |
|
| 15 |
```bash
|
| 16 |
+
GIT_LFS_SKIP_SMUDGE=1 uv run data/health_hovedstaden/create.py
|
| 17 |
```
|
| 18 |
"""
|
| 19 |
|
| 20 |
import logging
|
|
|
|
| 21 |
from datetime import datetime
|
| 22 |
from pathlib import Path
|
| 23 |
+
from typing import cast
|
| 24 |
|
|
|
|
| 25 |
from datasets import Dataset, load_dataset
|
| 26 |
|
| 27 |
from dynaword.process_dataset import (
|
|
|
|
| 37 |
|
| 38 |
|
| 39 |
def main():
|
| 40 |
+
save_path = Path(__file__).parent / "health_hovedstaden.parquet"
|
| 41 |
# Download data from repo: Den-Intelligente-Patientjournal/region_hovedstaden_text
|
| 42 |
ds = load_dataset(
|
| 43 |
"Den-Intelligente-Patientjournal/region_hovedstaden_text", split="train"
|
|
|
|
| 53 |
dataset = dataset.add_column(
|
| 54 |
"added", [datetime.today().date().strftime("%Y-%m-%d")] * len(dataset)
|
| 55 |
) # type: ignore
|
| 56 |
+
# Add source column: health_hovedstaden
|
| 57 |
+
dataset = dataset.add_column("source", ["health_hovedstaden"] * len(dataset)) # type: ignore
|
| 58 |
+
# Add id column: health_hovedstaden_{idx}
|
| 59 |
dataset = dataset.add_column(
|
| 60 |
+
"id", [f"health_hovedstaden_{i}" for i in range(len(dataset))]
|
| 61 |
) # type: ignore
|
| 62 |
|
| 63 |
# quality checks and processing
|
data/{scrape_hovedstaden → health_hovedstaden}/descriptive_stats.json
RENAMED
|
@@ -2,5 +2,5 @@
|
|
| 2 |
"number_of_samples": 23996,
|
| 3 |
"average_document_length": 3329.0515919319887,
|
| 4 |
"number_of_tokens": 27066716,
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 2 |
"number_of_samples": 23996,
|
| 3 |
"average_document_length": 3329.0515919319887,
|
| 4 |
"number_of_tokens": 27066716,
|
| 5 |
+
"revision": "2d31a537efd08700abc0924c1e9df83d3849db46"
|
| 6 |
}
|
data/{scrape_hovedstaden/scrape_hovedstaden.md → health_hovedstaden/health_hovedstaden.md}
RENAMED
|
@@ -26,7 +26,7 @@ The document collection consists of guidelines and informational documents for h
|
|
| 26 |
|
| 27 |
The corpus was created based on the texts in the document collection and has been post-processed so that the texts can be used for the development of language technology.
|
| 28 |
|
| 29 |
-
Martin Sundahl Laursen and Thiusius R. Savarimuthu from the University of Southern Denmark have assisted the Danish Agency for Digital Government with the post-processing of the data. Read their joint paper on "Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text."
|
| 30 |
|
| 31 |
|
| 32 |
|
|
@@ -48,10 +48,10 @@ An example from the dataset looks as follows.
|
|
| 48 |
<!-- START-SAMPLE -->
|
| 49 |
```py
|
| 50 |
{
|
| 51 |
-
"id": "
|
| 52 |
"text": "Acetylsalicylsyre - Aspirin, Akutlægebil\n\nMålgrupper og anvendelsesområde\nDefinitioner\nFremgangsmåde[...]",
|
| 53 |
-
"source": "
|
| 54 |
-
"added": "2025-
|
| 55 |
"created": "2015-01-01, 2020-12-31",
|
| 56 |
"token_count": 766
|
| 57 |
}
|
|
|
|
| 26 |
|
| 27 |
The corpus was created based on the texts in the document collection and has been post-processed so that the texts can be used for the development of language technology.
|
| 28 |
|
| 29 |
+
Martin Sundahl Laursen and Thiusius R. Savarimuthu from the University of Southern Denmark have assisted the Danish Agency for Digital Government with the post-processing of the data. Read their joint paper on "[Automatic Annotation of Training Data for Deep Learning Based De-identification of Narrative Clinical Text](https://ceur-ws.org/Vol-3416/paper_5.pdf)."
|
| 30 |
|
| 31 |
|
| 32 |
|
|
|
|
| 48 |
<!-- START-SAMPLE -->
|
| 49 |
```py
|
| 50 |
{
|
| 51 |
+
"id": "health_hovedstaden_0",
|
| 52 |
"text": "Acetylsalicylsyre - Aspirin, Akutlægebil\n\nMålgrupper og anvendelsesområde\nDefinitioner\nFremgangsmåde[...]",
|
| 53 |
+
"source": "health_hovedstaden",
|
| 54 |
+
"added": "2025-07-07",
|
| 55 |
"created": "2015-01-01, 2020-12-31",
|
| 56 |
"token_count": 766
|
| 57 |
}
|
data/{scrape_hovedstaden/scrape_hovedstaden.parquet → health_hovedstaden/health_hovedstaden.parquet}
RENAMED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 41434842
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dd95bbe8f9fc0b8ec530b0d0b9ba1ea51b4e7ec509a599a13dc3ec0aeac6c6d2
|
| 3 |
size 41434842
|
data/{scrape_hovedstaden → health_hovedstaden}/images/dist_document_length.png
RENAMED
|
File without changes
|
descriptive_stats.json
CHANGED
|
@@ -2,5 +2,5 @@
|
|
| 2 |
"number_of_samples": 951889,
|
| 3 |
"average_document_length": 15168.871661506751,
|
| 4 |
"number_of_tokens": 4698470546,
|
| 5 |
-
"revision": "
|
| 6 |
}
|
|
|
|
| 2 |
"number_of_samples": 951889,
|
| 3 |
"average_document_length": 15168.871661506751,
|
| 4 |
"number_of_tokens": 4698470546,
|
| 5 |
+
"revision": "2d31a537efd08700abc0924c1e9df83d3849db46"
|
| 6 |
}
|
docs/icon.png
CHANGED
|
|
Git LFS Details
|
|
|
Git LFS Details
|
images/dist_document_length.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
images/domain_distribution.png
CHANGED
|
Git LFS Details
|

|
Git LFS Details
|
images/tokens_over_time.html
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<html>
|
| 2 |
+
<head><meta charset="utf-8" /></head>
|
| 3 |
+
<body>
|
| 4 |
+
<div> <script type="text/javascript">window.PlotlyConfig = {MathJaxConfig: 'local'};</script>
|
| 5 |
+
<script charset="utf-8" src="https://cdn.plot.ly/plotly-3.0.1.min.js"></script> <div id="a8776fd6-9bc6-41ad-94a0-22c4d1eaf95e" class="plotly-graph-div" style="height:400px; width:600px;"></div> <script type="text/javascript"> window.PLOTLYENV=window.PLOTLYENV || {}; if (document.getElementById("a8776fd6-9bc6-41ad-94a0-22c4d1eaf95e")) { Plotly.newPlot( "a8776fd6-9bc6-41ad-94a0-22c4d1eaf95e", [{"hovertemplate":"%{text}\u003cextra\u003e\u003c\u002fextra\u003e","line":{"color":"#DC2626","width":3},"marker":{"color":"#DC2626","size":5},"mode":"lines+markers","name":"Tokens","text":["Date: 2025-01-02\u003cbr\u003eTokens: 1.57G\u003cbr\u003eSamples: 546,769\u003cbr\u003eCommit: 9c15515d\u003cbr\u003eMessage: Added number of llama3 tokens to desc stats","Date: 2025-01-03\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +271.89M\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 38b692a5\u003cbr\u003eMessage: Added automatically updated samples to update_descriptive_stats.py","Date: 2025-01-04\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 576,589\u003cbr\u003eCommit: 546c3b35\u003cbr\u003eMessage: update opensubtitles","Date: 2025-01-05\u003cbr\u003eTokens: 1.84G\u003cbr\u003eChange: +5.40M\u003cbr\u003eSamples: 588,476\u003cbr\u003eCommit: 0cef3177\u003cbr\u003eMessage: Added distribution plot for number of tokens","Date: 2025-02-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +7.30M\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 97b3aa5d\u003cbr\u003eMessage: Add Nota-tekster (#41)","Date: 2025-03-10\u003cbr\u003eTokens: 1.85G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 588,922\u003cbr\u003eCommit: 5affec72\u003cbr\u003eMessage: add_memo (#42)","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +1.51G\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 65faa6e2\u003cbr\u003eMessage: a lot of improvements","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 43d839aa\u003cbr\u003eMessage: updates sheets","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: 060c4430\u003cbr\u003eMessage: Updated changelog","Date: 2025-04-29\u003cbr\u003eTokens: 3.36G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 846,387\u003cbr\u003eCommit: c9397c44\u003cbr\u003eMessage: reformatted the readme","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +901.15M\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: d36009a4\u003cbr\u003eMessage: update desc stats","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 2453a15a\u003cbr\u003eMessage: updated datasheet","Date: 2025-05-12\u003cbr\u003eTokens: 4.26G\u003cbr\u003eChange: +0\u003cbr\u003eSamples: 891,075\u003cbr\u003eCommit: 91cd694a\u003cbr\u003eMessage: docs: minor fixes to datasheets","Date: 2025-06-23\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +104.46M\u003cbr\u003eSamples: 891,094\u003cbr\u003eCommit: 16931a4c\u003cbr\u003eMessage: Fix memo (#68)","Date: 2025-06-25\u003cbr\u003eTokens: 4.37G\u003cbr\u003eChange: +581.06k\u003cbr\u003eSamples: 891,348\u003cbr\u003eCommit: 2c91001b\u003cbr\u003eMessage: Fix Danske Taler (#69)","Date: 2025-06-30\u003cbr\u003eTokens: 4.40G\u003cbr\u003eChange: +26.49M\u003cbr\u003eSamples: 915,090\u003cbr\u003eCommit: 7df022e7\u003cbr\u003eMessage: Adding Scrape Hovedstaden (#70)","Date: 2025-07-01\u003cbr\u003eTokens: 4.70G\u003cbr\u003eChange: +302.40M\u003cbr\u003eSamples: 951,889\u003cbr\u003eCommit: 6a2c8fbf\u003cbr\u003eMessage: update-retsinformationdk (#72)"],"x":["2025-01-02T00:00:00.000000000","2025-01-03T00:00:00.000000000","2025-01-04T00:00:00.000000000","2025-01-05T00:00:00.000000000","2025-02-10T00:00:00.000000000","2025-03-10T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-04-29T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-05-12T00:00:00.000000000","2025-06-23T00:00:00.000000000","2025-06-25T00:00:00.000000000","2025-06-30T00:00:00.000000000","2025-07-01T00:00:00.000000000"],"y":[1567706760,1839599769,1839599769,1844994816,1852293828,1852293828,3363395483,3363395483,3363395483,3363395483,4264549097,4264549097,4264549097,4369008328,4369589385,4396075044,4698470546],"type":"scatter"}], {"template":{"data":{"histogram2dcontour":[{"type":"histogram2dcontour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"choropleth":[{"type":"choropleth","colorbar":{"outlinewidth":0,"ticks":""}}],"histogram2d":[{"type":"histogram2d","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"heatmap":[{"type":"heatmap","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"contourcarpet":[{"type":"contourcarpet","colorbar":{"outlinewidth":0,"ticks":""}}],"contour":[{"type":"contour","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"surface":[{"type":"surface","colorbar":{"outlinewidth":0,"ticks":""},"colorscale":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]]}],"mesh3d":[{"type":"mesh3d","colorbar":{"outlinewidth":0,"ticks":""}}],"scatter":[{"fillpattern":{"fillmode":"overlay","size":10,"solidity":0.2},"type":"scatter"}],"parcoords":[{"type":"parcoords","line":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolargl":[{"type":"scatterpolargl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"bar":[{"error_x":{"color":"#2a3f5f"},"error_y":{"color":"#2a3f5f"},"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"bar"}],"scattergeo":[{"type":"scattergeo","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterpolar":[{"type":"scatterpolar","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"histogram":[{"marker":{"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"histogram"}],"scattergl":[{"type":"scattergl","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatter3d":[{"type":"scatter3d","line":{"colorbar":{"outlinewidth":0,"ticks":""}},"marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermap":[{"type":"scattermap","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattermapbox":[{"type":"scattermapbox","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scatterternary":[{"type":"scatterternary","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"scattercarpet":[{"type":"scattercarpet","marker":{"colorbar":{"outlinewidth":0,"ticks":""}}}],"carpet":[{"aaxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"baxis":{"endlinecolor":"#2a3f5f","gridcolor":"white","linecolor":"white","minorgridcolor":"white","startlinecolor":"#2a3f5f"},"type":"carpet"}],"table":[{"cells":{"fill":{"color":"#EBF0F8"},"line":{"color":"white"}},"header":{"fill":{"color":"#C8D4E3"},"line":{"color":"white"}},"type":"table"}],"barpolar":[{"marker":{"line":{"color":"#E5ECF6","width":0.5},"pattern":{"fillmode":"overlay","size":10,"solidity":0.2}},"type":"barpolar"}],"pie":[{"automargin":true,"type":"pie"}]},"layout":{"autotypenumbers":"strict","colorway":["#636efa","#EF553B","#00cc96","#ab63fa","#FFA15A","#19d3f3","#FF6692","#B6E880","#FF97FF","#FECB52"],"font":{"color":"#2a3f5f"},"hovermode":"closest","hoverlabel":{"align":"left"},"paper_bgcolor":"white","plot_bgcolor":"#E5ECF6","polar":{"bgcolor":"#E5ECF6","angularaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"radialaxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"ternary":{"bgcolor":"#E5ECF6","aaxis":{"gridcolor":"white","linecolor":"white","ticks":""},"baxis":{"gridcolor":"white","linecolor":"white","ticks":""},"caxis":{"gridcolor":"white","linecolor":"white","ticks":""}},"coloraxis":{"colorbar":{"outlinewidth":0,"ticks":""}},"colorscale":{"sequential":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"sequentialminus":[[0.0,"#0d0887"],[0.1111111111111111,"#46039f"],[0.2222222222222222,"#7201a8"],[0.3333333333333333,"#9c179e"],[0.4444444444444444,"#bd3786"],[0.5555555555555556,"#d8576b"],[0.6666666666666666,"#ed7953"],[0.7777777777777778,"#fb9f3a"],[0.8888888888888888,"#fdca26"],[1.0,"#f0f921"]],"diverging":[[0,"#8e0152"],[0.1,"#c51b7d"],[0.2,"#de77ae"],[0.3,"#f1b6da"],[0.4,"#fde0ef"],[0.5,"#f7f7f7"],[0.6,"#e6f5d0"],[0.7,"#b8e186"],[0.8,"#7fbc41"],[0.9,"#4d9221"],[1,"#276419"]]},"xaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"yaxis":{"gridcolor":"white","linecolor":"white","ticks":"","title":{"standoff":15},"zerolinecolor":"white","automargin":true,"zerolinewidth":2},"scene":{"xaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"yaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2},"zaxis":{"backgroundcolor":"#E5ECF6","gridcolor":"white","linecolor":"white","showbackground":true,"ticks":"","zerolinecolor":"white","gridwidth":2}},"shapedefaults":{"line":{"color":"#2a3f5f"}},"annotationdefaults":{"arrowcolor":"#2a3f5f","arrowhead":0,"arrowwidth":1},"geo":{"bgcolor":"white","landcolor":"#E5ECF6","subunitcolor":"white","showland":true,"showlakes":true,"lakecolor":"white"},"title":{"x":0.05},"mapbox":{"style":"light"}}},"shapes":[{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":300000000,"y1":300000000,"yref":"y"},{"line":{"color":"gray","dash":"dash","width":1},"type":"line","x0":0,"x1":1,"xref":"x domain","y0":1000000000,"y1":1000000000,"yref":"y"}],"annotations":[{"font":{"color":"gray","size":12},"showarrow":false,"text":"Common Corpus (dan) (Langlais et al., 2025)","x":0,"xanchor":"left","xref":"x domain","y":300000000,"yanchor":"bottom","yref":"y"},{"font":{"color":"gray","size":12},"showarrow":false,"text":"Danish Gigaword (Derczynski et al., 2021)","x":0,"xanchor":"left","xref":"x domain","y":1000000000,"yanchor":"bottom","yref":"y"}],"title":{"text":"Number of Tokens Over Time in Danish Dynaword"},"xaxis":{"title":{"text":"Date"}},"yaxis":{"title":{"text":"Number of Tokens (Llama 3)"},"tickformat":".2s","ticksuffix":""},"hovermode":"closest","width":600,"height":400,"showlegend":false,"plot_bgcolor":"rgba(0,0,0,0)","paper_bgcolor":"rgba(0,0,0,0)"}, {"responsive": true} ) }; </script> </div>
|
| 6 |
+
</body>
|
| 7 |
+
</html>
|
images/tokens_over_time.svg
ADDED

|
pyproject.toml
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
-
version = "1.2.
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
|
|
|
| 1 |
[project]
|
| 2 |
name = "dynaword"
|
| 3 |
+
version = "1.2.4"
|
| 4 |
description = "project code for the danish dynaword project"
|
| 5 |
readme = "README.md"
|
| 6 |
requires-python = ">=3.12,<3.13" # 3.13 have issues with spacy and pytorch
|
src/dynaword/plot_tokens_over_time.py
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import logging
|
| 3 |
+
import subprocess
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import plotly.graph_objects as go
|
| 9 |
+
|
| 10 |
+
from dynaword.paths import repo_path
|
| 11 |
+
|
| 12 |
+
# Configure logging
|
| 13 |
+
logging.basicConfig(
|
| 14 |
+
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
|
| 15 |
+
)
|
| 16 |
+
logger = logging.getLogger(__name__)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_file_history(
|
| 20 |
+
filename: str = "descriptive_stats.json",
|
| 21 |
+
) -> List[Tuple[str, str, str]]:
|
| 22 |
+
"""Get commit history for a file with commit messages"""
|
| 23 |
+
logger.info(f"Retrieving git history for {filename}")
|
| 24 |
+
|
| 25 |
+
cmd = [
|
| 26 |
+
"git",
|
| 27 |
+
"log",
|
| 28 |
+
"--format=%H|%ci|%s", # commit hash | commit date | subject
|
| 29 |
+
"--",
|
| 30 |
+
filename,
|
| 31 |
+
]
|
| 32 |
+
|
| 33 |
+
try:
|
| 34 |
+
result = subprocess.run(
|
| 35 |
+
cmd, capture_output=True, text=True, cwd=repo_path, check=True
|
| 36 |
+
)
|
| 37 |
+
commits = []
|
| 38 |
+
|
| 39 |
+
for line in result.stdout.strip().split("\n"):
|
| 40 |
+
if line:
|
| 41 |
+
parts = line.split("|", 2) # Split on first 2 pipes only
|
| 42 |
+
if len(parts) == 3:
|
| 43 |
+
commit_hash, date_str, message = parts
|
| 44 |
+
commits.append((commit_hash, date_str, message))
|
| 45 |
+
|
| 46 |
+
logger.info(f"Found {len(commits)} commits for {filename}")
|
| 47 |
+
return commits
|
| 48 |
+
|
| 49 |
+
except subprocess.CalledProcessError as e:
|
| 50 |
+
logger.error(f"Failed to get git history: {e}")
|
| 51 |
+
return []
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def get_file_at_commit(commit_hash: str, filename: str) -> Optional[Dict[str, Any]]:
|
| 55 |
+
"""Get file content at specific commit"""
|
| 56 |
+
cmd = ["git", "show", f"{commit_hash}:{filename}"]
|
| 57 |
+
|
| 58 |
+
try:
|
| 59 |
+
result = subprocess.run(
|
| 60 |
+
cmd, capture_output=True, text=True, cwd=repo_path, check=True
|
| 61 |
+
)
|
| 62 |
+
return json.loads(result.stdout)
|
| 63 |
+
except (subprocess.CalledProcessError, json.JSONDecodeError) as e:
|
| 64 |
+
logger.warning(f"Failed to parse {filename} at commit {commit_hash[:8]}: {e}")
|
| 65 |
+
return None
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def create_token_dataframe(filename: str = "descriptive_stats.json") -> pd.DataFrame:
|
| 69 |
+
"""Create DataFrame with token history from git commits"""
|
| 70 |
+
logger.info("Building token history dataframe from git commits")
|
| 71 |
+
|
| 72 |
+
commits = get_file_history(filename)
|
| 73 |
+
if not commits:
|
| 74 |
+
logger.warning("No commits found")
|
| 75 |
+
return pd.DataFrame()
|
| 76 |
+
|
| 77 |
+
data = []
|
| 78 |
+
for commit_hash, date_str, commit_message in commits:
|
| 79 |
+
file_data = get_file_at_commit(commit_hash, filename)
|
| 80 |
+
if file_data and "number_of_tokens" in file_data:
|
| 81 |
+
try:
|
| 82 |
+
date = datetime.fromisoformat(date_str.split(" ")[0])
|
| 83 |
+
data.append(
|
| 84 |
+
{
|
| 85 |
+
"date": date,
|
| 86 |
+
"tokens": file_data["number_of_tokens"],
|
| 87 |
+
"samples": file_data.get("number_of_samples", 0),
|
| 88 |
+
"avg_length": file_data.get("average_document_length", 0),
|
| 89 |
+
"commit": commit_hash,
|
| 90 |
+
"commit_short": commit_hash[:8],
|
| 91 |
+
"commit_message": commit_message,
|
| 92 |
+
}
|
| 93 |
+
)
|
| 94 |
+
except ValueError as e:
|
| 95 |
+
logger.warning(f"Failed to parse date {date_str}: {e}")
|
| 96 |
+
|
| 97 |
+
# Convert to DataFrame and sort by date
|
| 98 |
+
df = pd.DataFrame(data)
|
| 99 |
+
if df.empty:
|
| 100 |
+
logger.warning("No valid data found in commits")
|
| 101 |
+
return df
|
| 102 |
+
|
| 103 |
+
df = df.sort_values("date").reset_index(drop=True)
|
| 104 |
+
|
| 105 |
+
# Calculate token changes
|
| 106 |
+
if len(df) > 1:
|
| 107 |
+
df["token_change"] = df["tokens"].diff()
|
| 108 |
+
|
| 109 |
+
logger.info(
|
| 110 |
+
f"Created dataframe with {len(df)} data points spanning {df['date'].min().date()} to {df['date'].max().date()}"
|
| 111 |
+
)
|
| 112 |
+
return df
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def _format_tokens(value: float) -> str:
|
| 116 |
+
"""Format tokens with human-readable suffixes"""
|
| 117 |
+
if value >= 1e12:
|
| 118 |
+
return f"{value/1e12:.2f}T"
|
| 119 |
+
elif value >= 1e9:
|
| 120 |
+
return f"{value/1e9:.2f}G"
|
| 121 |
+
elif value >= 1e6:
|
| 122 |
+
return f"{value/1e6:.2f}M"
|
| 123 |
+
elif value >= 1e3:
|
| 124 |
+
return f"{value/1e3:.2f}k"
|
| 125 |
+
else:
|
| 126 |
+
return f"{value:.0f}"
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def _create_hover_text(df: pd.DataFrame) -> List[str]:
|
| 130 |
+
"""Create hover text for each data point"""
|
| 131 |
+
hover_text = []
|
| 132 |
+
for _, row in df.iterrows():
|
| 133 |
+
hover_info = (
|
| 134 |
+
f"Date: {row['date'].strftime('%Y-%m-%d')}<br>"
|
| 135 |
+
f"Tokens: {_format_tokens(row['tokens'])}<br>"
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
if pd.notna(row.get("token_change")):
|
| 139 |
+
change_sign = "+" if row["token_change"] >= 0 else ""
|
| 140 |
+
hover_info += (
|
| 141 |
+
f"Change: {change_sign}{_format_tokens(abs(row['token_change']))}<br>"
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
hover_info += (
|
| 145 |
+
f"Samples: {row['samples']:,}<br>"
|
| 146 |
+
f"Commit: {row['commit_short']}<br>"
|
| 147 |
+
f"Message: {row['commit_message']}"
|
| 148 |
+
)
|
| 149 |
+
hover_text.append(hover_info)
|
| 150 |
+
|
| 151 |
+
return hover_text
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def _add_reference_lines(fig: go.Figure) -> None:
|
| 155 |
+
"""Add reference lines for other Danish corpora"""
|
| 156 |
+
references = [
|
| 157 |
+
(300_000_000, "Common Corpus (dan) (Langlais et al., 2025)"),
|
| 158 |
+
(1_000_000_000, "Danish Gigaword (Derczynski et al., 2021)"),
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
for y_value, annotation in references:
|
| 162 |
+
fig.add_hline(
|
| 163 |
+
y=y_value,
|
| 164 |
+
line_dash="dash",
|
| 165 |
+
line_color="gray",
|
| 166 |
+
line_width=1,
|
| 167 |
+
annotation_text=annotation,
|
| 168 |
+
annotation_position="top left",
|
| 169 |
+
annotation_font_size=12,
|
| 170 |
+
annotation_font_color="gray",
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def plot_tokens_over_time(
|
| 175 |
+
df: pd.DataFrame, width: int = 600, height: int = 400
|
| 176 |
+
) -> go.Figure:
|
| 177 |
+
"""Plot tokens over time using Plotly with interactive hover info"""
|
| 178 |
+
hover_text = _create_hover_text(df)
|
| 179 |
+
|
| 180 |
+
# Create the plot
|
| 181 |
+
fig = go.Figure()
|
| 182 |
+
|
| 183 |
+
# Add main data line
|
| 184 |
+
fig.add_trace(
|
| 185 |
+
go.Scatter(
|
| 186 |
+
x=df["date"],
|
| 187 |
+
y=df["tokens"],
|
| 188 |
+
mode="lines+markers",
|
| 189 |
+
name="Tokens",
|
| 190 |
+
line=dict(width=3, color="#DC2626"), # Saturated red
|
| 191 |
+
marker=dict(size=5, color="#DC2626"),
|
| 192 |
+
hovertemplate="%{text}<extra></extra>",
|
| 193 |
+
text=hover_text,
|
| 194 |
+
)
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
# Add reference lines
|
| 198 |
+
_add_reference_lines(fig)
|
| 199 |
+
|
| 200 |
+
# Update layout
|
| 201 |
+
fig.update_layout(
|
| 202 |
+
title="Number of Tokens Over Time in Danish Dynaword",
|
| 203 |
+
xaxis_title="Date",
|
| 204 |
+
yaxis_title="Number of Tokens (Llama 3)",
|
| 205 |
+
hovermode="closest",
|
| 206 |
+
width=width,
|
| 207 |
+
height=height,
|
| 208 |
+
showlegend=False,
|
| 209 |
+
plot_bgcolor="rgba(0,0,0,0)", # Transparent plot background
|
| 210 |
+
paper_bgcolor="rgba(0,0,0,0)", # Transparent paper background
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
# Set x-axis and y-axis properties
|
| 214 |
+
# x_min = df["date"].min() - pd.Timedelta(days=)
|
| 215 |
+
# x_max = df["date"].max() + pd.Timedelta(days=1)
|
| 216 |
+
|
| 217 |
+
# Format y-axis
|
| 218 |
+
fig.update_yaxes(tickformat=".2s", ticksuffix="")
|
| 219 |
+
# fig.update_xaxes(range=[x_min, x_max]) # Explicitly set x-axis range
|
| 220 |
+
return fig
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def create_tokens_over_time_plot() -> None:
|
| 224 |
+
"""Main function to create DataFrame and plot tokens over time"""
|
| 225 |
+
df = create_token_dataframe()
|
| 226 |
+
if not df.empty:
|
| 227 |
+
logger.info("Generating interactive plot")
|
| 228 |
+
fig = plot_tokens_over_time(df)
|
| 229 |
+
else:
|
| 230 |
+
logger.warning("No data available to plot")
|
| 231 |
+
|
| 232 |
+
save_path = repo_path / "images" / "tokens_over_time.html"
|
| 233 |
+
save_path_svg = repo_path / "images" / "tokens_over_time.svg"
|
| 234 |
+
|
| 235 |
+
save_path.parent.mkdir(parents=True, exist_ok=True)
|
| 236 |
+
fig.write_html(save_path, include_plotlyjs="cdn")
|
| 237 |
+
fig.write_image(save_path_svg)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
if __name__ == "__main__":
|
| 241 |
+
create_tokens_over_time_plot()
|
src/dynaword/update_descriptive_statistics.py
CHANGED
|
@@ -23,6 +23,7 @@ from dynaword.git_utilities import (
|
|
| 23 |
get_latest_revision,
|
| 24 |
)
|
| 25 |
from dynaword.paths import repo_path
|
|
|
|
| 26 |
from dynaword.tables import create_overview_table, create_overview_table_str
|
| 27 |
|
| 28 |
logger = logging.getLogger(__name__)
|
|
@@ -106,6 +107,7 @@ def update_dataset(
|
|
| 106 |
package = create_overview_table_str()
|
| 107 |
sheet.body = sheet.replace_tag(package=package, tag="MAIN TABLE")
|
| 108 |
create_domain_distribution_plot()
|
|
|
|
| 109 |
|
| 110 |
sheet.write_to_path()
|
| 111 |
|
|
|
|
| 23 |
get_latest_revision,
|
| 24 |
)
|
| 25 |
from dynaword.paths import repo_path
|
| 26 |
+
from dynaword.plot_tokens_over_time import create_tokens_over_time_plot
|
| 27 |
from dynaword.tables import create_overview_table, create_overview_table_str
|
| 28 |
|
| 29 |
logger = logging.getLogger(__name__)
|
|
|
|
| 107 |
package = create_overview_table_str()
|
| 108 |
sheet.body = sheet.replace_tag(package=package, tag="MAIN TABLE")
|
| 109 |
create_domain_distribution_plot()
|
| 110 |
+
create_tokens_over_time_plot()
|
| 111 |
|
| 112 |
sheet.write_to_path()
|
| 113 |
|
test_results.log
CHANGED
|
@@ -1,7 +1,8 @@
|
|
| 1 |
============================= test session starts ==============================
|
| 2 |
platform darwin -- Python 3.12.0, pytest-8.3.4, pluggy-1.5.0
|
| 3 |
-
rootdir: /Users/
|
| 4 |
configfile: pyproject.toml
|
|
|
|
| 5 |
collected 319 items
|
| 6 |
|
| 7 |
src/tests/test_dataset_schema.py ....................................... [ 12%]
|
|
@@ -18,7 +19,7 @@ src/tests/test_unique_ids.py . [100%]
|
|
| 18 |
|
| 19 |
=============================== warnings summary ===============================
|
| 20 |
src/tests/test_quality/test_short_texts.py: 35 warnings
|
| 21 |
-
/Users/
|
| 22 |
|
| 23 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 24 |
-
|
|
|
|
| 1 |
============================= test session starts ==============================
|
| 2 |
platform darwin -- Python 3.12.0, pytest-8.3.4, pluggy-1.5.0
|
| 3 |
+
rootdir: /Users/au561649/Github/danish-dynaword
|
| 4 |
configfile: pyproject.toml
|
| 5 |
+
plugins: anyio-4.9.0
|
| 6 |
collected 319 items
|
| 7 |
|
| 8 |
src/tests/test_dataset_schema.py ....................................... [ 12%]
|
|
|
|
| 19 |
|
| 20 |
=============================== warnings summary ===============================
|
| 21 |
src/tests/test_quality/test_short_texts.py: 35 warnings
|
| 22 |
+
/Users/au561649/Github/danish-dynaword/.venv/lib/python3.12/site-packages/datasets/utils/_dill.py:385: DeprecationWarning: co_lnotab is deprecated, use co_lines instead.
|
| 23 |
|
| 24 |
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
|
| 25 |
+
============ 318 passed, 1 skipped, 35 warnings in 81.92s (0:01:21) ============
|
uv.lock
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|