Datasets:

admin
commited on
Commit
·
28a70bf
1
Parent(s):
5537d0b
Update README.md
Browse files
README.md
CHANGED
|
@@ -24,7 +24,7 @@ In the original dataset, the labels were stored in a separate CSV file. This pos
|
|
| 24 |
We performed data processing and constructed the [default subset](#default-subset) of the current integrated version of the dataset, and the details of its data structure can be viewed through the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/Guzheng_Tech99/dataPeview). In light of the fact that the current dataset has been referenced and evaluated in a published article, we transcribe here the details of the dataset processing during the evaluation in the said article: each audio clip is a 3-second segment sampled at 44,100Hz, which is then converted into a log Constant-Q Transform (CQT) spectrogram. A CQT accompanied by a label constitutes a single data entry, forming the first and second columns, respectively. The CQT is a 3-dimensional array with dimensions of 88x258x1, representing the frequency-time structure of the audio. The label, on the other hand, is a 2-dimensional array with dimensions of 7x258, indicating the presence of seven distinct techniques across each time frame. Ultimately, given that the original dataset has already been divided into train, valid, and test sets, we have integrated the feature extraction method mentioned in this article's evaluation process into the API, thereby constructing the [eval subset](#eval-subset), which is not embodied in our paper.
|
| 25 |
|
| 26 |
## Statistics
|
| 27 |
-
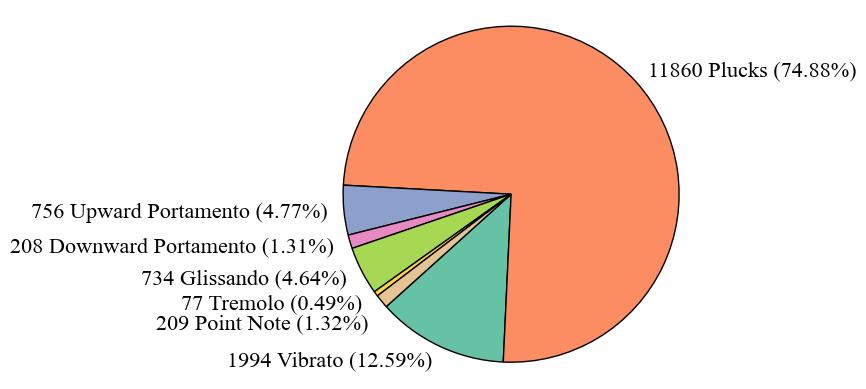
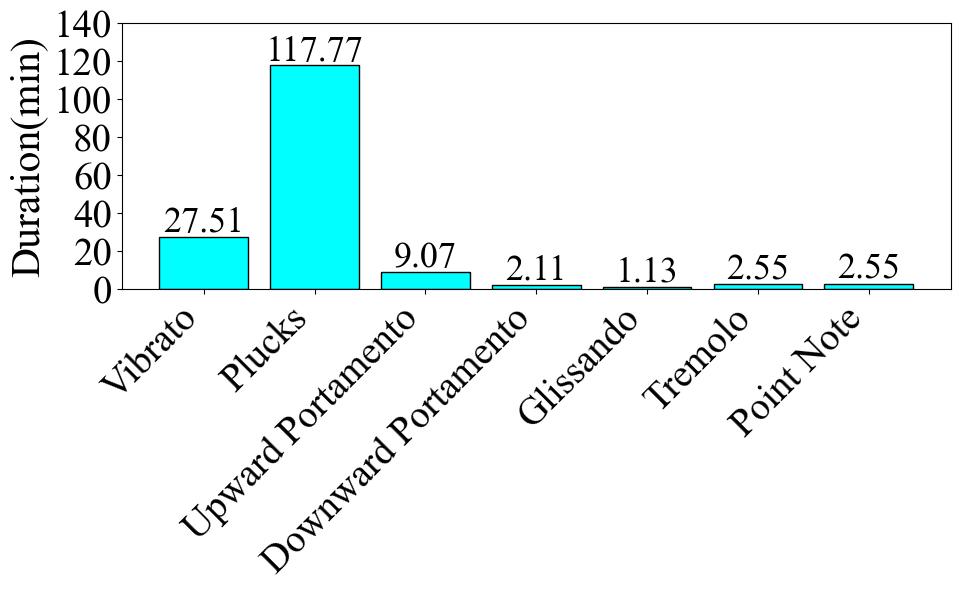
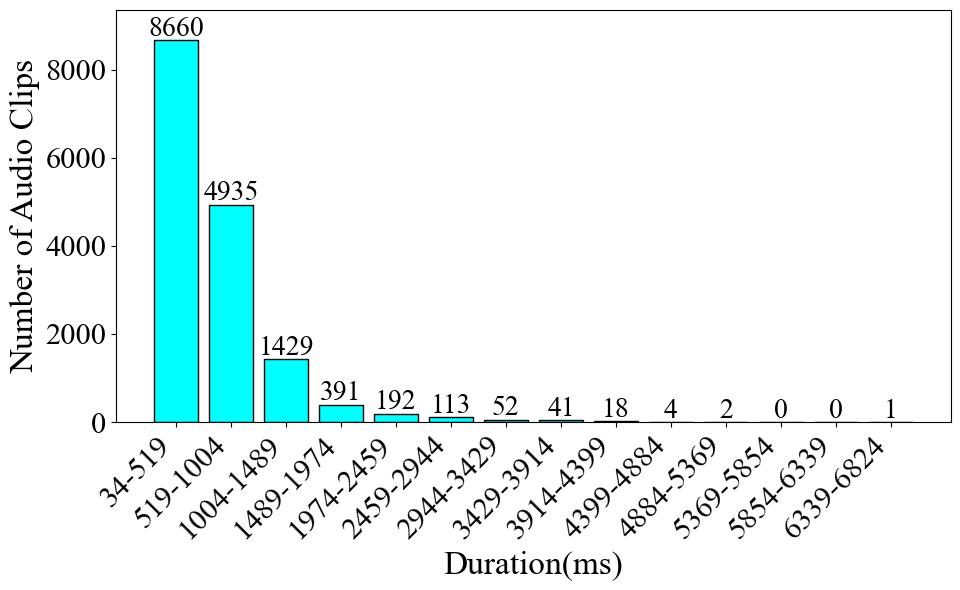
In this part, we present statistics at the label-level. The number of audio clips is equivalent to the count of either onset or offset occurrences. The duration of an audio clip is determined by calculating the offset time minus the onset time. At this level, the
|
| 28 |
|
| 29 |
|  |  |  |
|
| 30 |
| :--------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------: |
|
|
|
|
| 24 |
We performed data processing and constructed the [default subset](#default-subset) of the current integrated version of the dataset, and the details of its data structure can be viewed through the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/Guzheng_Tech99/dataPeview). In light of the fact that the current dataset has been referenced and evaluated in a published article, we transcribe here the details of the dataset processing during the evaluation in the said article: each audio clip is a 3-second segment sampled at 44,100Hz, which is then converted into a log Constant-Q Transform (CQT) spectrogram. A CQT accompanied by a label constitutes a single data entry, forming the first and second columns, respectively. The CQT is a 3-dimensional array with dimensions of 88x258x1, representing the frequency-time structure of the audio. The label, on the other hand, is a 2-dimensional array with dimensions of 7x258, indicating the presence of seven distinct techniques across each time frame. Ultimately, given that the original dataset has already been divided into train, valid, and test sets, we have integrated the feature extraction method mentioned in this article's evaluation process into the API, thereby constructing the [eval subset](#eval-subset), which is not embodied in our paper.
|
| 25 |
|
| 26 |
## Statistics
|
| 27 |
+
In this part, we present statistics at the label-level. The number of audio clips is equivalent to the count of either onset or offset occurrences. The duration of an audio clip is determined by calculating the offset time minus the onset time. At this level, the number of clips is 15,838, and the total duration is 162.69 minutes.
|
| 28 |
|
| 29 |
|  |  |  |
|
| 30 |
| :--------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------: |
|