
Add files using upload-large-folder tool
Browse files- .gitattributes +1 -0
- README.md +65 -0
- all_results.json +12 -0
- config.json +30 -0
- eval_results.json +7 -0
- generation_config.json +9 -0
- model.safetensors +3 -0
- special_tokens_map.json +23 -0
- tokenizer.json +3 -0
- tokenizer_config.json +196 -0
- train_results.json +8 -0
- trainer_log.jsonl +1 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license: other
|
| 4 |
+
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
|
| 5 |
+
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- full
|
| 8 |
+
- generated_from_trainer
|
| 9 |
+
model-index:
|
| 10 |
+
- name: Distill_DeepScaleR_7B_Preview
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# Distill_DeepScaleR_7B_Preview
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) on the Distill_DeepScaleR_7B_Preview dataset.
|
| 20 |
+
It achieves the following results on the evaluation set:
|
| 21 |
+
- Loss: 0.3696
|
| 22 |
+
|
| 23 |
+
## Model description
|
| 24 |
+
|
| 25 |
+
More information needed
|
| 26 |
+
|
| 27 |
+
## Intended uses & limitations
|
| 28 |
+
|
| 29 |
+
More information needed
|
| 30 |
+
|
| 31 |
+
## Training and evaluation data
|
| 32 |
+
|
| 33 |
+
More information needed
|
| 34 |
+
|
| 35 |
+
## Training procedure
|
| 36 |
+
|
| 37 |
+
### Training hyperparameters
|
| 38 |
+
|
| 39 |
+
The following hyperparameters were used during training:
|
| 40 |
+
- learning_rate: 1e-05
|
| 41 |
+
- train_batch_size: 1
|
| 42 |
+
- eval_batch_size: 1
|
| 43 |
+
- seed: 42
|
| 44 |
+
- distributed_type: multi-GPU
|
| 45 |
+
- num_devices: 4
|
| 46 |
+
- total_train_batch_size: 4
|
| 47 |
+
- total_eval_batch_size: 4
|
| 48 |
+
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 49 |
+
- lr_scheduler_type: cosine
|
| 50 |
+
- num_epochs: 2
|
| 51 |
+
|
| 52 |
+
### Training results
|
| 53 |
+
|
| 54 |
+
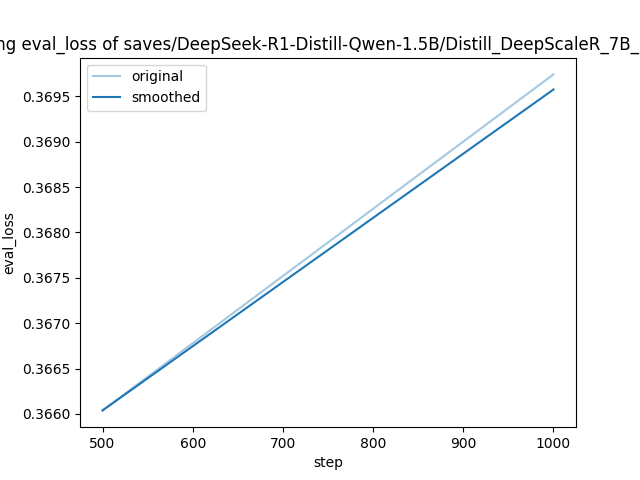
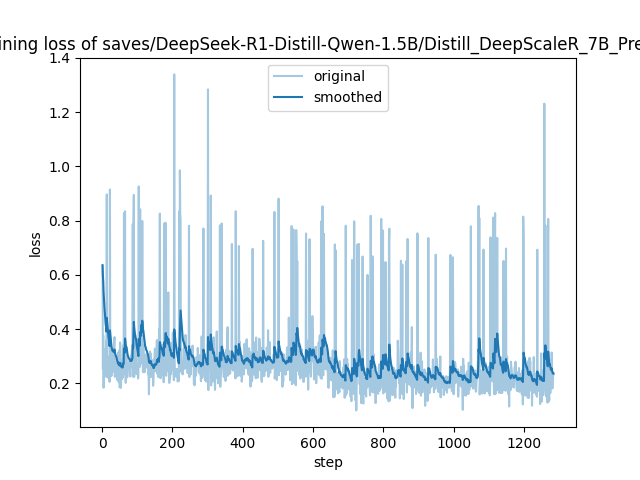
| Training Loss | Epoch | Step | Validation Loss |
|
| 55 |
+
|:-------------:|:------:|:----:|:---------------:|
|
| 56 |
+
| 0.3007 | 0.7788 | 500 | 0.3660 |
|
| 57 |
+
| 0.1601 | 1.5576 | 1000 | 0.3697 |
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
### Framework versions
|
| 61 |
+
|
| 62 |
+
- Transformers 4.46.1
|
| 63 |
+
- Pytorch 2.6.0+cu124
|
| 64 |
+
- Datasets 3.1.0
|
| 65 |
+
- Tokenizers 0.20.3
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"eval_loss": 0.3695966303348541,
|
| 4 |
+
"eval_runtime": 2.67,
|
| 5 |
+
"eval_samples_per_second": 9.738,
|
| 6 |
+
"eval_steps_per_second": 2.622,
|
| 7 |
+
"total_flos": 17255618273280.0,
|
| 8 |
+
"train_loss": 0.27858535300162723,
|
| 9 |
+
"train_runtime": 1476.77,
|
| 10 |
+
"train_samples_per_second": 3.477,
|
| 11 |
+
"train_steps_per_second": 0.869
|
| 12 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Qwen2ForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 151643,
|
| 8 |
+
"eos_token_id": 151643,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 1536,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 8960,
|
| 13 |
+
"max_position_embeddings": 131072,
|
| 14 |
+
"max_window_layers": 21,
|
| 15 |
+
"model_type": "qwen2",
|
| 16 |
+
"num_attention_heads": 12,
|
| 17 |
+
"num_hidden_layers": 28,
|
| 18 |
+
"num_key_value_heads": 2,
|
| 19 |
+
"rms_norm_eps": 1e-06,
|
| 20 |
+
"rope_scaling": null,
|
| 21 |
+
"rope_theta": 10000,
|
| 22 |
+
"sliding_window": null,
|
| 23 |
+
"tie_word_embeddings": false,
|
| 24 |
+
"torch_dtype": "bfloat16",
|
| 25 |
+
"transformers_version": "4.46.1",
|
| 26 |
+
"use_cache": false,
|
| 27 |
+
"use_mrope": false,
|
| 28 |
+
"use_sliding_window": false,
|
| 29 |
+
"vocab_size": 151936
|
| 30 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"eval_loss": 0.3695966303348541,
|
| 4 |
+
"eval_runtime": 2.67,
|
| 5 |
+
"eval_samples_per_second": 9.738,
|
| 6 |
+
"eval_steps_per_second": 2.622
|
| 7 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 151646,
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": 151643,
|
| 6 |
+
"temperature": 0.6,
|
| 7 |
+
"top_p": 0.95,
|
| 8 |
+
"transformers_version": "4.46.1"
|
| 9 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a2ced59a0360cb29733fbbcf670c57c934fe552130408af710d284698761038d
|
| 3 |
+
size 3554214752
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin▁of▁sentence|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end▁of▁sentence|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|end▁of▁sentence|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e20ddafc659ba90242154b55275402edeca0715e5dbb30f56815a4ce081f4893
|
| 3 |
+
size 11422778
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": null,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"151643": {
|
| 7 |
+
"content": "<|end▁of▁sentence|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"151644": {
|
| 15 |
+
"content": "<|User|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": false
|
| 21 |
+
},
|
| 22 |
+
"151645": {
|
| 23 |
+
"content": "<|Assistant|>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": false
|
| 29 |
+
},
|
| 30 |
+
"151646": {
|
| 31 |
+
"content": "<|begin▁of▁sentence|>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": true
|
| 37 |
+
},
|
| 38 |
+
"151647": {
|
| 39 |
+
"content": "<|EOT|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": false
|
| 45 |
+
},
|
| 46 |
+
"151648": {
|
| 47 |
+
"content": "<think>",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": false,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": false
|
| 53 |
+
},
|
| 54 |
+
"151649": {
|
| 55 |
+
"content": "</think>",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": false,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": false
|
| 61 |
+
},
|
| 62 |
+
"151650": {
|
| 63 |
+
"content": "<|quad_start|>",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": false,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": true
|
| 69 |
+
},
|
| 70 |
+
"151651": {
|
| 71 |
+
"content": "<|quad_end|>",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": false,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": true
|
| 77 |
+
},
|
| 78 |
+
"151652": {
|
| 79 |
+
"content": "<|vision_start|>",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": false,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": true
|
| 85 |
+
},
|
| 86 |
+
"151653": {
|
| 87 |
+
"content": "<|vision_end|>",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": false,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": true
|
| 93 |
+
},
|
| 94 |
+
"151654": {
|
| 95 |
+
"content": "<|vision_pad|>",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": false,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": true
|
| 101 |
+
},
|
| 102 |
+
"151655": {
|
| 103 |
+
"content": "<|image_pad|>",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": false,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": true
|
| 109 |
+
},
|
| 110 |
+
"151656": {
|
| 111 |
+
"content": "<|video_pad|>",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": false,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": true
|
| 117 |
+
},
|
| 118 |
+
"151657": {
|
| 119 |
+
"content": "<tool_call>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": false
|
| 125 |
+
},
|
| 126 |
+
"151658": {
|
| 127 |
+
"content": "</tool_call>",
|
| 128 |
+
"lstrip": false,
|
| 129 |
+
"normalized": false,
|
| 130 |
+
"rstrip": false,
|
| 131 |
+
"single_word": false,
|
| 132 |
+
"special": false
|
| 133 |
+
},
|
| 134 |
+
"151659": {
|
| 135 |
+
"content": "<|fim_prefix|>",
|
| 136 |
+
"lstrip": false,
|
| 137 |
+
"normalized": false,
|
| 138 |
+
"rstrip": false,
|
| 139 |
+
"single_word": false,
|
| 140 |
+
"special": false
|
| 141 |
+
},
|
| 142 |
+
"151660": {
|
| 143 |
+
"content": "<|fim_middle|>",
|
| 144 |
+
"lstrip": false,
|
| 145 |
+
"normalized": false,
|
| 146 |
+
"rstrip": false,
|
| 147 |
+
"single_word": false,
|
| 148 |
+
"special": false
|
| 149 |
+
},
|
| 150 |
+
"151661": {
|
| 151 |
+
"content": "<|fim_suffix|>",
|
| 152 |
+
"lstrip": false,
|
| 153 |
+
"normalized": false,
|
| 154 |
+
"rstrip": false,
|
| 155 |
+
"single_word": false,
|
| 156 |
+
"special": false
|
| 157 |
+
},
|
| 158 |
+
"151662": {
|
| 159 |
+
"content": "<|fim_pad|>",
|
| 160 |
+
"lstrip": false,
|
| 161 |
+
"normalized": false,
|
| 162 |
+
"rstrip": false,
|
| 163 |
+
"single_word": false,
|
| 164 |
+
"special": false
|
| 165 |
+
},
|
| 166 |
+
"151663": {
|
| 167 |
+
"content": "<|repo_name|>",
|
| 168 |
+
"lstrip": false,
|
| 169 |
+
"normalized": false,
|
| 170 |
+
"rstrip": false,
|
| 171 |
+
"single_word": false,
|
| 172 |
+
"special": false
|
| 173 |
+
},
|
| 174 |
+
"151664": {
|
| 175 |
+
"content": "<|file_sep|>",
|
| 176 |
+
"lstrip": false,
|
| 177 |
+
"normalized": false,
|
| 178 |
+
"rstrip": false,
|
| 179 |
+
"single_word": false,
|
| 180 |
+
"special": false
|
| 181 |
+
}
|
| 182 |
+
},
|
| 183 |
+
"bos_token": "<|begin▁of▁sentence|>",
|
| 184 |
+
"chat_template": "{{ '<|begin▁of▁sentence|>' }}{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in loop_messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|User|>' + content + '<|Assistant|>' }}{% elif message['role'] == 'assistant' %}{{ content + '<|end▁of▁sentence|>' }}{% endif %}{% endfor %}",
|
| 185 |
+
"clean_up_tokenization_spaces": false,
|
| 186 |
+
"eos_token": "<|end▁of▁sentence|>",
|
| 187 |
+
"legacy": true,
|
| 188 |
+
"model_max_length": 16384,
|
| 189 |
+
"pad_token": "<|end▁of▁sentence|>",
|
| 190 |
+
"padding_side": "right",
|
| 191 |
+
"sp_model_kwargs": {},
|
| 192 |
+
"split_special_tokens": false,
|
| 193 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 194 |
+
"unk_token": null,
|
| 195 |
+
"use_default_system_prompt": false
|
| 196 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"total_flos": 17255618273280.0,
|
| 4 |
+
"train_loss": 0.27858535300162723,
|
| 5 |
+
"train_runtime": 1476.77,
|
| 6 |
+
"train_samples_per_second": 3.477,
|
| 7 |
+
"train_steps_per_second": 0.869
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 1, "total_steps": 1284, "loss": 8.7188, "lr": 9.999985033870806e-06, "epoch": 0.001557632398753894, "percentage": 0.08, "elapsed_time": "0:00:02", "remaining_time": "0:58:02"}
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3fd3267f097a30875fbf6acb1eb33f7254f4804fa072ffa279b19b6fa55f4c29
|
| 3 |
+
size 7224
|
training_eval_loss.png
ADDED
|
training_loss.png
ADDED
|