
ffgcc
commited on
Commit
·
702abd3
1
Parent(s):
11f05fa
init
Browse files- .gitattributes +14 -0
- README.md +179 -0
- config.json +3 -0
- figure/LongMagpie.png +3 -0
- generation_config.json +3 -0
- model-00001-of-00007.safetensors +3 -0
- model-00002-of-00007.safetensors +3 -0
- model-00003-of-00007.safetensors +3 -0
- model-00004-of-00007.safetensors +3 -0
- model-00005-of-00007.safetensors +3 -0
- model-00006-of-00007.safetensors +3 -0
- model-00007-of-00007.safetensors +3 -0
- model.safetensors.index.json +3 -0
- special_tokens_map.json +3 -0
- tokenizer.json +3 -0
- tokenizer_config.json +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,17 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
model-00005-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
model-00006-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
model-00007-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
model-00001-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
model-00002-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
model-00003-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
model-00004-of-00007.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
config.json filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
generation_config.json filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
model.safetensors.index.json filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
special_tokens_map.json filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
tokenizer_config.json filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
figure/LongMagpie.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## LongMagpie: A Self-synthesis Method for Generating Large-scale Long-context Instructions
|
| 2 |
+
|
| 3 |
+
This repository contains the code, models and datasets for our paper [LongMagpie: A Self-synthesis Method for Generating Large-scale Long-context Instructions].
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
## Quick Links
|
| 7 |
+
|
| 8 |
+
- [Overview](#overview)
|
| 9 |
+
- [LongMagpie Models](#LongMagpie-models)
|
| 10 |
+
- [LongMagpie Datasets](#LongMagpie-datasets)
|
| 11 |
+
- [Datasets list](#datasets-list)
|
| 12 |
+
- [Train Llama-3-8B-LongMagpie-512K-Instruct](#train-LongMagpie512K)
|
| 13 |
+
- [Requirements](#requirements)
|
| 14 |
+
- [Evaluation](#evaluation)
|
| 15 |
+
- [Build your long-context instruction data](#build-long-data)
|
| 16 |
+
- [Bugs or Questions?](#bugs-or-questions)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
<a id="overview"></a>
|
| 20 |
+
|
| 21 |
+
## Overview
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
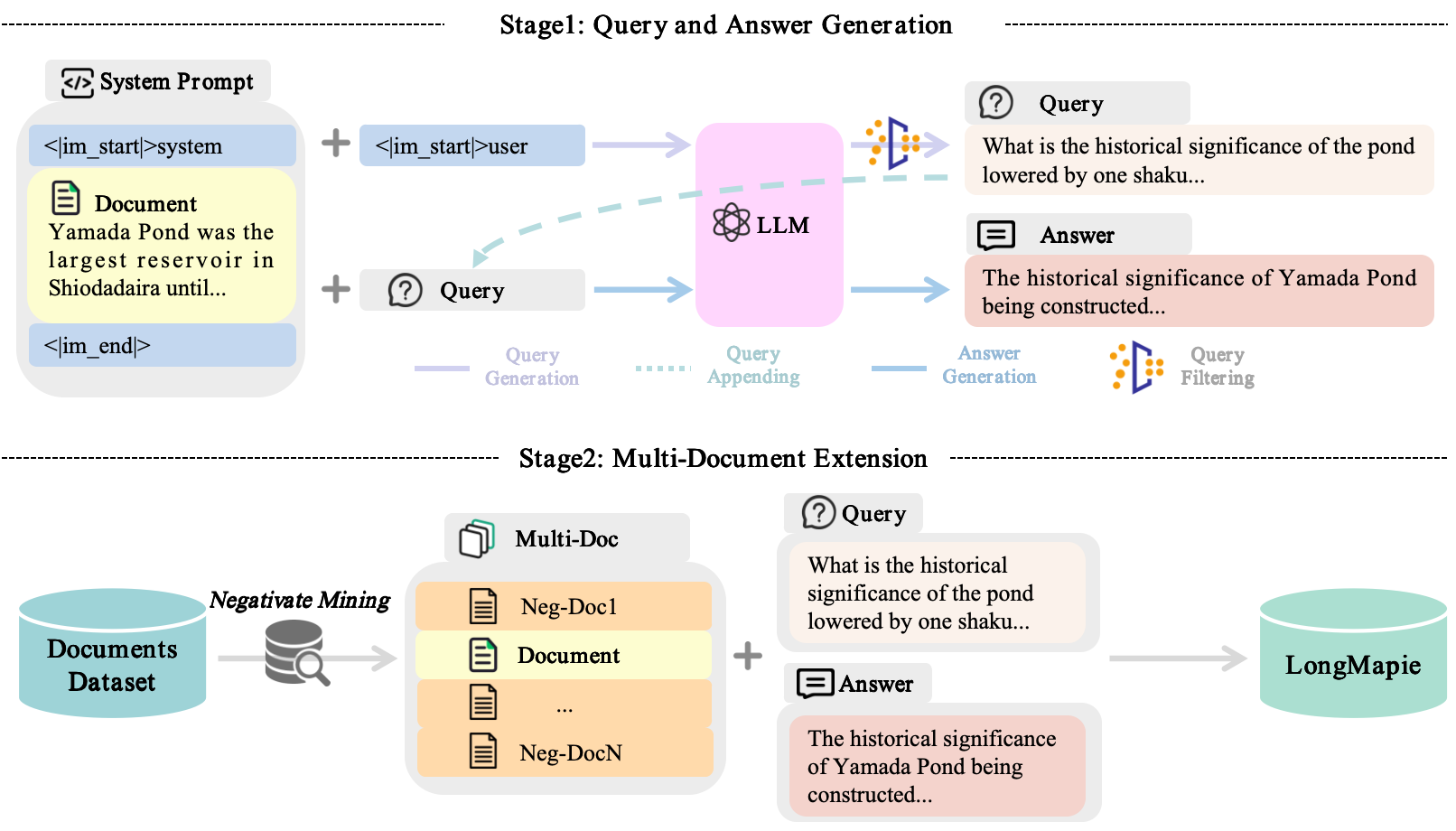
High-quality long-context instruction data is essential for aligning long-context large language models (LLMs). Despite the public release of models like Qwen and Llama, their long-context instruction data remains proprietary. Human annotation is costly and challenging, while template-based synthesis methods limit scale, diversity, and quality. We introduce LongMagpie, a self-synthesis framework that automatically generates large-scale long-context instruction data. Our key insight is that aligned long-context LLMs, when presented with a document followed by special tokens preceding a user turn, auto-regressively generate contextually relevant queries. By harvesting these document-query pairs and the model's responses, LongMagpie produces high-quality instructions without human effort. Experiments on HELMET, RULER, and Longbench v2 demonstrate that LongMagpie achieves leading performance on long-context tasks while maintaining competitive performance on short-context tasks, establishing it as a simple and effective approach for open, diverse, and scalable long-context instruction data synthesis.
|
| 25 |
+
|
| 26 |
+
<div style="text-align: center;">
|
| 27 |
+
<img src="figure/LongMagpie.png" width="700" height="350">
|
| 28 |
+
</div>
|
| 29 |
+
|
| 30 |
+
<a id="LongMagpie-models"></a>
|
| 31 |
+
|
| 32 |
+
## LongMagpie Models
|
| 33 |
+
|
| 34 |
+
Our released models are listed as follows. You can import these models by using [HuggingFace's Transformers](https://github.com/huggingface/transformers). All models are trained on long-context instruction data synthesized by [fineweb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu) and [Qwen/Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) model. In the following comparision, we choose [Llama-3-8B-NExtLong-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-NExtLong-512K-Instruct) as a baseline model, which is trained with [Magpie instruction data](https://huggingface.co/datasets/Magpie-Align/Magpie-Llama-3.3-Pro-1M-v0.1). In addition, to maintain short-text performance, we propose a p-mix strategy that combines LongMagpie and [UltraChat](https://huggingface.co/datasets/stingning/ultrachat) datasets, resulting in a performance-balanced model [Llama-3-8B-LongMagpie-p-mix-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-512K-Instruct).
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
#### The performance on [HELMET](https://github.com/princeton-nlp/HELMET) and [RULER](https://github.com/NVIDIA/RULER)
|
| 38 |
+
|
| 39 |
+
| Model | RULER Avg. | HELMET Avg. | HELMET Recall | HELMET RAG | HELMET ICL | HELMET Re-rank | HELMET LongQA |
|
| 40 |
+
|:-------------------------------|:-------:|:-------:|:------:|:-----:|:-----:|:-------:|:------:|
|
| 41 |
+
| [Llama-3-8B-NExtLong-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-NExtLong-512K-Instruct) | 88.00 | 59.92 | **98.63** | 62.70 | 81.00 | 26.41 | 30.89 |
|
| 42 |
+
| [Llama-3-8B-LongMagpie-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-512K-Instruct) | **91.17** | 62.10 | 97.53 | 63.37 | **85.84** | 28.60 | 35.16 |
|
| 43 |
+
| [Llama-3-8B-LongMagpie-p-mix-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-p-mix-512K-Instruct) | 89.70 | **62.11** | 95.96 | **64.17** | 85.12 | **29.61** | **35.71** |
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
#### The performance on [Longbench V2](https://github.com/THUDM/LongBench)
|
| 48 |
+
|
| 49 |
+
| Model | Overall (%) | Easy (%) | Hard (%) | Short (%) | Medium (%) | Long (%) |
|
| 50 |
+
|--------------------------------------------|-------------|----------|----------|-----------|------------|----------|
|
| 51 |
+
| [Llama-3-8B-NExtLong-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-NExtLong-512K-Instruct) | 30.8 | 33.9 | 28.9 | 37.8 | 27.4 | **25.9** |
|
| 52 |
+
| [Llama-3-8B-LongMagpie-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-512K-Instruct) | **34.4**| **38.5** |**31.8**| **41.7** |33 |25 |
|
| 53 |
+
| [Llama-3-8B-LongMagpie-p-mix-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-p-mix-512K-Instruct) | 33 | 35.9 |31.2 |37.2 |**34.9**| 22.2 |
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
#### The performance on Short-context Benchmarks
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
| Model | Avg. | Hel. | Lam. | AR-C. | AR-E. | PIQA | Win. | Logiqa | MMLU |
|
| 66 |
+
|----------------------------|-------|-----------|----------------|---------------|----------|-------|------------|--------|-------|
|
| 67 |
+
| [Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) | 0.6332 | 0.5773 | 0.7171 | 0.5316 | 0.8165 | 0.7889 | 0.7198 | 0.2765 | 0.6376 |
|
| 68 |
+
| [Llama-3-8B-NExtLong-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-NExtLong-512K-Instruct) | **0.6410** | **0.5953** | 0.7242 | 0.5188 | 0.8224 | **0.8079** | 0.7324 | **0.3041** | 0.6232 |
|
| 69 |
+
| [Llama-3-8B-LongMagpie-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-512K-Instruct) | 0.6237 |0.5803 |0.7025 |0.4804| 0.8047| 0.7938 |0.7293| 0.278 |0.6209 |
|
| 70 |
+
| [Llama-3-8B-LongMagpie-p-mix-512K-Instruct](https://huggingface.co/caskcsg/Llama-3-8B-LongMagpie-p-mix-512K-Instruct) | **0.6410** | 0.5893 | **0.7355**| **0.5282**| **0.8279**| 0.8052| **0.734**| 0.2842| **0.6236** |
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
<a id="LongMagpie-datasets"></a>
|
| 76 |
+
|
| 77 |
+
## LongMagpie Datasets
|
| 78 |
+
|
| 79 |
+
<a id="datasets-list"></a>
|
| 80 |
+
|
| 81 |
+
### Datasets list
|
| 82 |
+
|
| 83 |
+
Our released datasets are listed as follows. All datasets are synthesized from the short-text datasets [fineweb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu).
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
| Dataset | Description |
|
| 88 |
+
|:-------------------------------|:--------|
|
| 89 |
+
| [LongMagpie_singledoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_singledoc_longcontext_dataset) | Our synthesized 450k raw text files(refer to [infer_demo.py](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/infer_demo.py)). Each line of data contains context extracted from [fineweb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu), query generated by LongMapgie and answer. |
|
| 90 |
+
| [LongMagpie_multidoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_multidoc_longcontext_dataset) | Based on [LongMagpie_singledoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_singledoc_longcontext_dataset), we used the MultiDoc method (refer to [multidoc_format.py](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/multidoc_format.py)) to extend the context length and transformed it into SFT dialogue format. |
|
| 91 |
+
| [LongMagpie_64k_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_64k_dataset) | We tokenized [LongMagpie_multidoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_multidoc_longcontext_dataset) and concatenated it to a length of 64k (refer to [concat script](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/build_sft_data.py)), making it convenient to train using Document Mask technology. This dataset can be used to achieve the best long-text performance. |
|
| 92 |
+
| [LongMagpie_p-mix_64k_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_p-mix_64k_dataset) | To maintain short-text performance, we tokenized [LongMagpie_multidoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_multidoc_longcontext_dataset) and mixed it with [UltraChat](https://huggingface.co/datasets/stingning/ultrachat) using the p-mix strategy, concatenating to a length of 64k (refer to [p-mix.py](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/build_sft_data_p_mix.py)). This dataset can be used to achieve balanced long and short text performance. |
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
<a id="train-LongMagpie512K"></a>
|
| 96 |
+
|
| 97 |
+
## Train Llama-3-8B-LongMagpie-512K-Instruct
|
| 98 |
+
|
| 99 |
+
<a id="requirements"></a>
|
| 100 |
+
|
| 101 |
+
### Requirements
|
| 102 |
+
|
| 103 |
+
Run the following script to install the remaining dependencies and train the model.
|
| 104 |
+
|
| 105 |
+
```bash
|
| 106 |
+
pip install -r requirements.txt
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### Train
|
| 110 |
+
|
| 111 |
+
```bash
|
| 112 |
+
bash train_sft.sh
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
<a id="evaluation"></a>
|
| 117 |
+
|
| 118 |
+
## Evaluation
|
| 119 |
+
|
| 120 |
+
Refer to the [HELMET](https://github.com/princeton-nlp/HELMET), [RULER](https://github.com/NVIDIA/RULER), and [Longbench V2](https://github.com/THUDM/LongBench) to evaluate the Instruct model.
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
<a id="build-long-data"></a>
|
| 124 |
+
|
| 125 |
+
## Build your long-context instruction data
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
### 1. Synthesizing Single-Document Q&A Data
|
| 129 |
+
|
| 130 |
+
Refer to [infer_demo.py](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/infer_demo.py). Each line of data contains context extracted from [fineweb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu), query generated by LongMapgie and answer.
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
```bash
|
| 134 |
+
python longmagpie/infer_demo.py
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
### 2. Synthesizing Multi-Document Q&A Data
|
| 138 |
+
|
| 139 |
+
Based on [LongMagpie_singledoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_singledoc_longcontext_dataset), we used the MultiDoc method (refer to [multidoc_format.py](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/multidoc_format.py)) to extend the context length and transformed it into SFT dialogue format.
|
| 140 |
+
|
| 141 |
+
```bash
|
| 142 |
+
python longmagpie/multidoc_format.py
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
### 3. Dataset Concatenation
|
| 147 |
+
|
| 148 |
+
Following [ProLong](https://github.com/princeton-nlp/ProLong), we concatenate the datasets to a fixed 64k context length and train using Document Mask technology.
|
| 149 |
+
|
| 150 |
+
#### 3.1 Concatenating Document Q&A Datasets Only
|
| 151 |
+
|
| 152 |
+
We tokenized [LongMagpie_multidoc_longcontext_dataset](https://huggingface.co/datasets/caskcsg/LongMagpie_multidoc_longcontext_dataset) and concatenated it to a length of 64k (refer to [build_sft_data.py](https://github.com/caskcsg/longcontext/tree/main/LongMagpie/longmagpie/build_sft_data.py)), making it convenient to train using Document Mask technology. This dataset can be used to achieve the best long-text performance.
|
| 153 |
+
|
| 154 |
+
```bash
|
| 155 |
+
python longmagpie/build_sft_data.py
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
#### 3.2 Using p-mix Strategy
|
| 159 |
+
|
| 160 |
+
To balance these capabilities, we introduce \textit{p}-Mix, a novel instruction data hybridization strategy. The core idea is twofold. First, to emulate the typical non-contextual start of general tasks, we sample a short-context instruction at the beginning of each training sequence. Second, we append subsequent data segments probabilistically to construct a mixed-context sequence up to length $L_{max}$. With probability $P_L$, a long-context instruction (generated by LongMagpie) is chosen; otherwise, with probability $1-P_L$, another short-context sample is chosen. This process repeats until approaching the target sequence length, ensuring each instance starts with a short, context-free instruction followed by a dynamically mixed sequence of long and short segments.
|
| 161 |
+
|
| 162 |
+
```bash
|
| 163 |
+
python longmagpie/build_sft_data_p_mix.py
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
<a id="bugs-or-questions"></a>
|
| 168 |
+
|
| 169 |
+
## Bugs or questions?
|
| 170 |
+
|
| 171 |
+
If you have any questions related to the code or the paper, feel free to email Chaochen (`[email protected]`) and XingWu (`[email protected]`). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
|
| 172 |
+
|
| 173 |
+
<!-- ## Citation
|
| 174 |
+
|
| 175 |
+
Please cite our paper if you use LongMagpie in your work:
|
| 176 |
+
|
| 177 |
+
```bibtex
|
| 178 |
+
|
| 179 |
+
``` -->
|
config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4fc0d8f93206c0aafc94f170204edda028df2820bc4c78f84e66792305b192e3
|
| 3 |
+
size 771
|
figure/LongMagpie.png
ADDED
|
Git LFS Details
|
generation_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:88eac5bf673682f548fbf6e03281c033d882bcaf9166ba184a6c49014995cfcf
|
| 3 |
+
size 194
|
model-00001-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d907a7d0ca10194879d3518e4c05488d7dc874744c8336d1e0a8c6cadb12e94
|
| 3 |
+
size 4886466168
|
model-00002-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c5cc423509aeb7a9c5e8745537319350905ac0bba83956a0d5cee6dfc43ba22b
|
| 3 |
+
size 4832007448
|
model-00003-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5d6583ffcab682374a22ab02d3adb5de3c3784ab98fed5e59ad542ed06bd3ab2
|
| 3 |
+
size 4999813112
|
model-00004-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:96ddddb27f6b61dd68f141938828bc72c094993ad04b1dc3f307669487230322
|
| 3 |
+
size 4999813128
|
model-00005-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:50d7cdca0d81b1eb519e6eb1e24d35bdfa4d64550dfec0cc5c3681083d9d9010
|
| 3 |
+
size 4832007496
|
model-00006-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:39a49b903669bde90c8bcf5388363501c69701017322185fdd5c4906a179a47f
|
| 3 |
+
size 4999813120
|
model-00007-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c9bd47c5865d14ab8d6a4ae6307dcafe292f1db827f2657e4579455b4cd676a4
|
| 3 |
+
size 2571158184
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bb83c0dcc965cf42c5bc8fa1b1d88eae170b5beb5b705297c33a6399be9d0d2d
|
| 3 |
+
size 23950
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f38c73729248f6c127296386e3cdde96e254636cc58b4169d3fd32328d9a8ec
|
| 3 |
+
size 296
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3c5cf44023714fb39b05e71e425f8d7b92805ff73f7988b083b8c87f0bf87393
|
| 3 |
+
size 17209961
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:da0e3a7cce6e4d787e85eb1c24d548420e0d7fe2c7a214e192795c46e40d75bb
|
| 3 |
+
size 50977
|