The AI Paradigm Shift Is Here: 4 Disruptive Trends from the Top 50 Hugging Face Papers of Q2 2025


The race for sheer scale is over. The race for intelligence has just begun. We break down the four key trends in RL, efficiency, agents, and data that are redefining the future of AI.
If you’ve been following AI, you might think the story is simple: bigger models, more parameters, better performance. But the latest wave of research from Q2 2025 tells a different, more nuanced story. The frantic race to scale model size is cooling, and a new, more profound competition is heating up—one focused on efficiency, deep reasoning, and intelligent design.
The most-voted papers on Hugging Face are no longer just about breaking parameter records. Instead, they're asking fundamental questions: Is Reinforcement Learning (RL) truly creating new knowledge, or just polishing existing capabilities? Where is the real computational bottleneck, if not in the model's size? How do we build agents that don't just "emerge" with skills but are systematically aligned with core reasoning principles? And most importantly, what if data isn't just fuel, but the algorithm itself?
In this post, we dive deep into the 50 most popular papers of the quarter to uncover the paradigm shifts that are reshaping the AI landscape. First, we'll present a curated list of these groundbreaking studies. Then, we'll synthesize our findings into four key insights that reveal where AI is heading next.
🚀 The Top 50 Papers of Q2 2025 (Ranked by Votes)
Here are the papers that captured the community's attention, presented in descending order of votes.
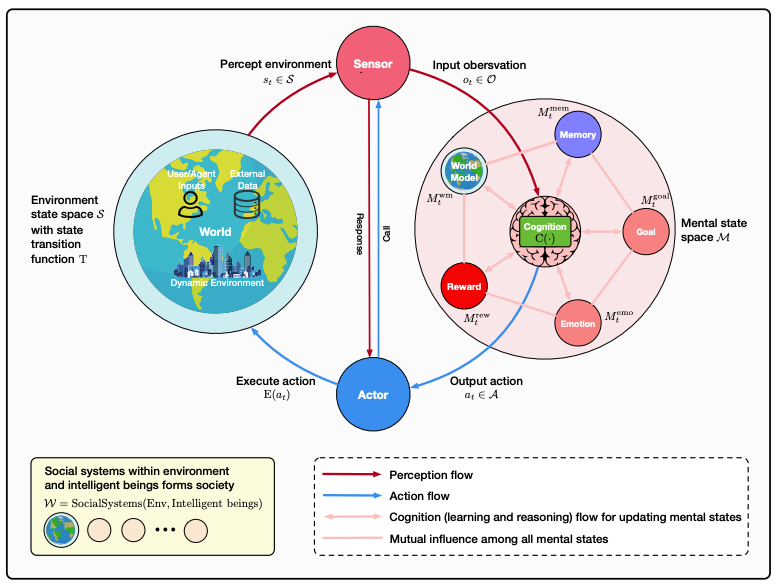
(1) Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems (293 votes)
Paper Link: https://huggingface.co/papers/2504.01990
Brief Introduction:
Proposed by a massive collaboration including MetaGPT, Université de Montréal, Mila, NTU, Microsoft Research Asia, and DeepMind, this paper provides a comprehensive survey on Foundation Agents. It frames intelligent agents within a modular, brain-inspired architecture, systematically exploring their cognitive, perceptual, and operational modules, while delving into challenges like self-enhancement, collaboration, and safety.
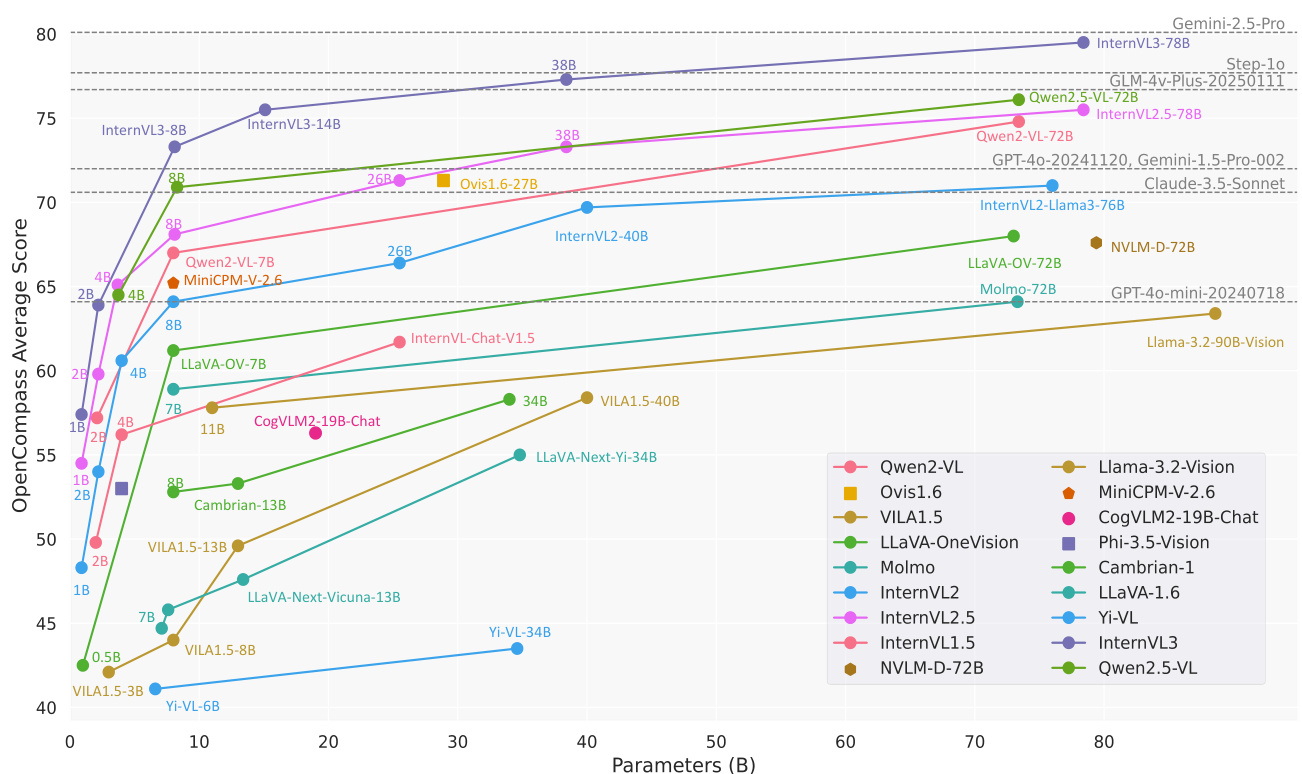
(2) InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models (276 votes)
Paper Link: https://huggingface.co/papers/2504.10479
Brief Introduction:
From Shanghai AI Laboratory, SenseTime, Tsinghua University, and others, InternVL3 introduces a native multimodal pre-training paradigm. Instead of retrofitting a text-only LLM, it jointly acquires multimodal and linguistic capabilities from the start. It achieves state-of-the-art performance on benchmarks like MMMU, rivaling proprietary models like ChatGPT-4o.
Core Image:
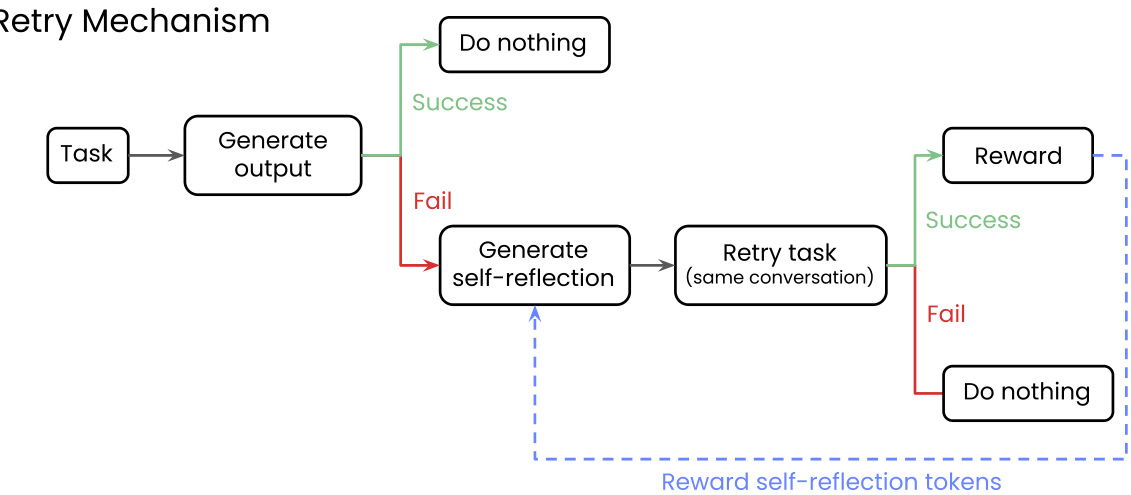
(3) Reflect, Retry, Reward: Self-Improving LLMs via Reinforcement Learning (256 votes)
Paper Link: https://huggingface.co/papers/2505.24726
Brief Introduction:
Writer, Inc. proposes the "Reflect, Retry, Reward" framework for LLM self-improvement. When a model fails, it generates a self-reflection. If a subsequent attempt succeeds, the reflection process is rewarded via RL. This method enhances performance on complex tasks using only binary feedback, without needing synthetic data.
Core Image:
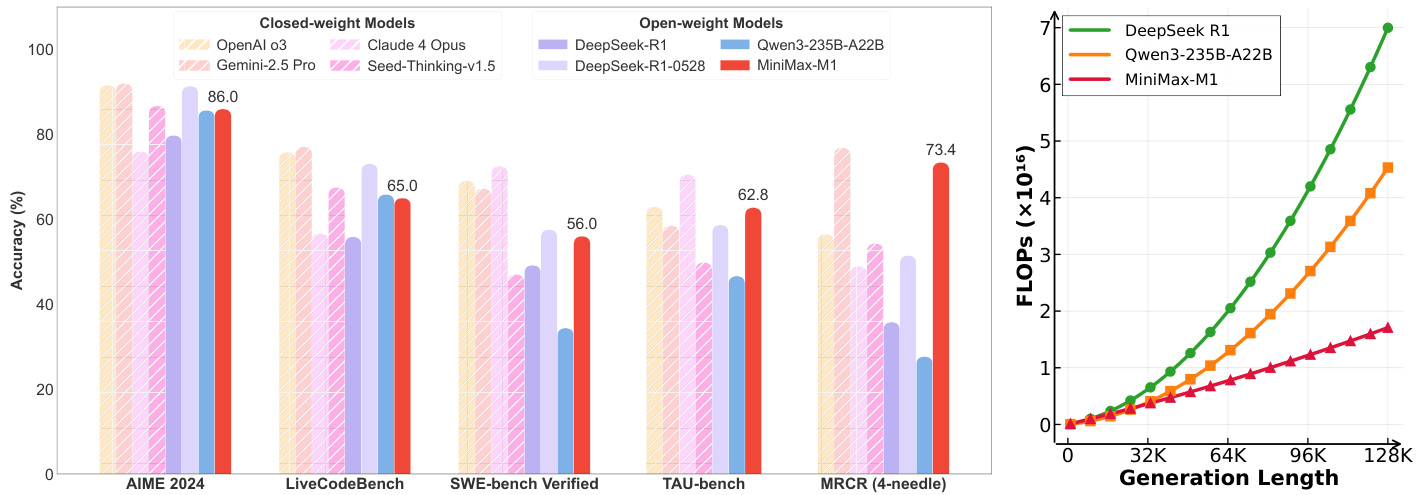
(4) MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention (249 votes)
Paper Link: https://huggingface.co/papers/2506.13585
Brief Introduction:
MiniMax introduces MiniMax-M1, the first open-weight, large-scale hybrid-attention reasoning model. It combines a Mixture-of-Experts (MoE) architecture with Lightning Attention, supporting a 1M token context. With its novel RL algorithm, CISPO, it achieves superior performance on complex tasks while significantly reducing training costs.
Core Image:
(5) Reinforcement Pre-Training (238 votes)
Paper Link: https://huggingface.co/papers/2506.08007
Brief Introduction:
Microsoft Research, Peking University, and Tsinghua University introduce Reinforcement Pre-Training (RPT), a new paradigm for scaling LLMs. It reframes next-token prediction as a reasoning task trained with RL, where the model receives verifiable rewards for correct predictions. RPT leverages vast text data for general-purpose RL, improving accuracy and providing a strong foundation for fine-tuning.
Core Image:
(The remaining 45 papers follow the same format) ...
(6) Mutarjim: Advancing Bidirectional Arabic-English Translation with a Small Language Model (217 votes)
Paper Link: https://huggingface.co/papers/2505.17894
Brief Introduction:
Proposed by MISRAJA, Mutarjim is a compact yet powerful model for bidirectional Arabic-English translation. Based on the 1.5B Kuwain model, it outperforms models 20x larger and even rivals GPT-4o mini on some benchmarks, thanks to an optimized two-phase training approach.
Core Image: 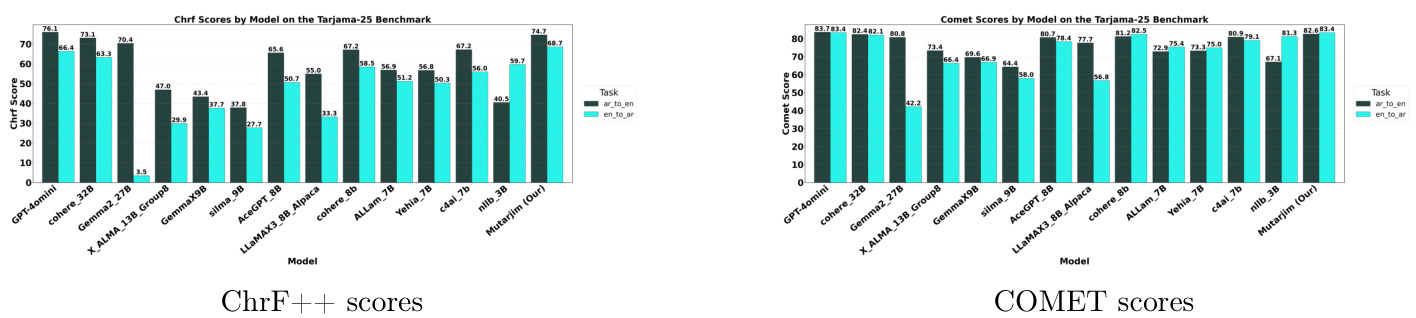
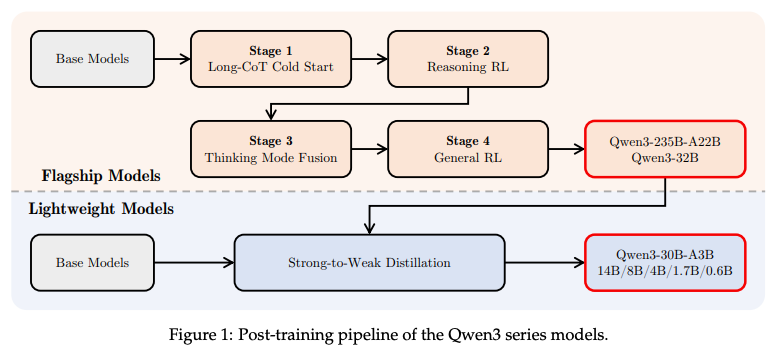
(7) Qwen3 Technical Report (209 votes)
Paper Link: https://huggingface.co/papers/2505.09388
Brief Introduction: The Qwen Team presents the Qwen3 model family, featuring both dense and MoE architectures from 0.6B to 235B parameters. A key innovation is the unified framework integrating a "thinking mode" for complex reasoning and a "non-thinking mode" for rapid responses.
(8) SmolVLM: Redefining small and efficient multimodal models (192 votes)
Paper Link: https://huggingface.co/papers/2504.05299
Brief Introduction:
Hugging Face and Stanford University introduce SmolVLM, a series of compact multimodal models designed for resource-efficient inference. The smallest 256M model uses less than 1GB of GPU memory and outperforms the 300-times larger Idefics-80B, enabling on-device deployment.
Core Image: 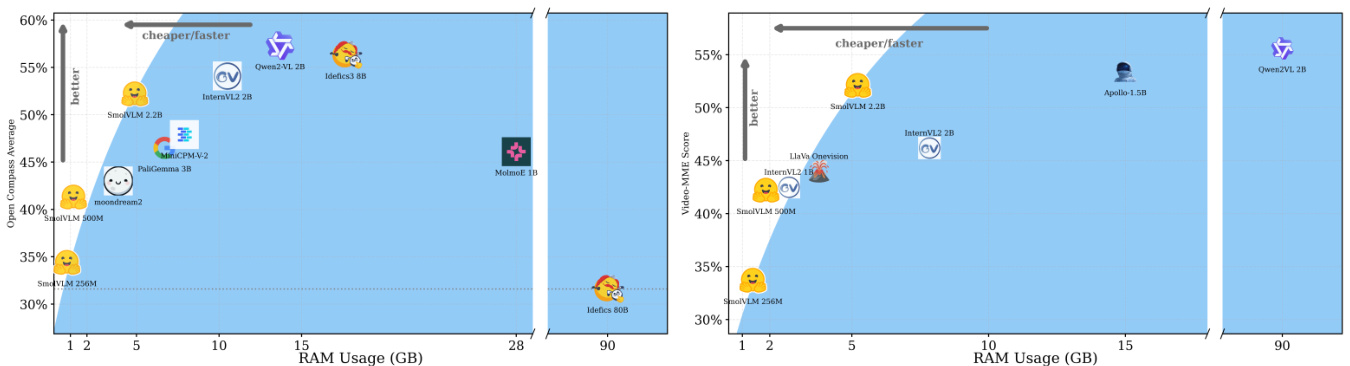
(9) Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models (178 votes)
Paper Link: https://huggingface.co/papers/2505.04921
Brief Introduction:
Harbin Institute of Technology (Shenzhen) provides a comprehensive survey of Large Multimodal Reasoning Models (LMRMs). It outlines a four-stage developmental roadmap, from modular pipelines to unified, language-centric frameworks, and looks ahead to native, agentic reasoning models.
Core Image: 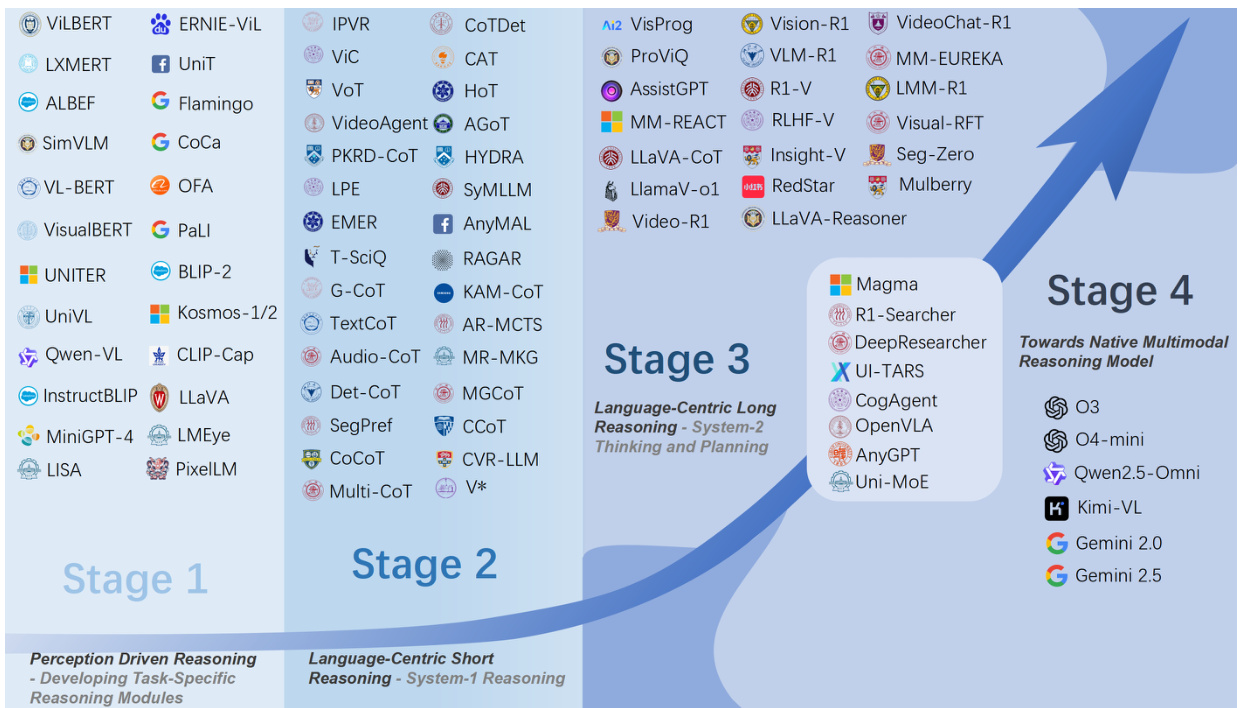
(10) Absolute Zero: Reinforced Self-play Reasoning with Zero Data (177 votes)
Paper Link: https://huggingface.co/papers/2505.03335
Brief Introduction:
Tsinghua University and others propose Absolute Zero, a new RL paradigm where a model learns by proposing and solving its own tasks without any external data. Their system, AZR, achieves SOTA performance on coding and math reasoning, proving that general reasoning skills can emerge from self-play.
Core Image: 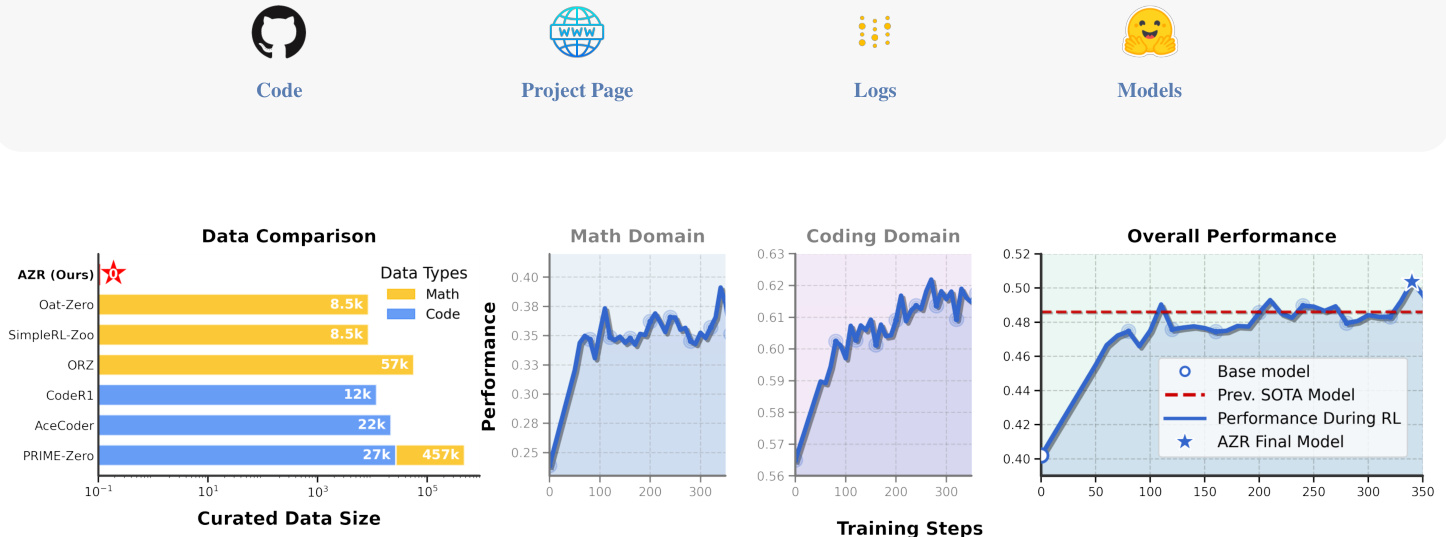
(11) OmniSVG: A Unified Scalable Vector Graphics Generation Model (171 votes)
Paper Link: https://huggingface.co/papers/2504.06263
Brief Introduction:
Fudan University and StepFun present OmniSVG, a unified framework for end-to-end multimodal SVG generation. Using pre-trained VLMs, it can generate high-quality, complex SVGs from simple icons to intricate anime characters, and introduces a new 2M-asset dataset, MMSVG-2M.
Core Image: 
(12) Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning (165 votes)
Paper Link: https://huggingface.co/papers/2506.01939
Brief Introduction:
The Alibaba Qwen Team and Tsinghua University find that a small fraction of high-entropy tokens ("forking tokens") are the primary drivers of performance gains in RL for LLM reasoning. Training only on these critical 20% of tokens can match or even exceed the performance of full-gradient updates.
Core Image: 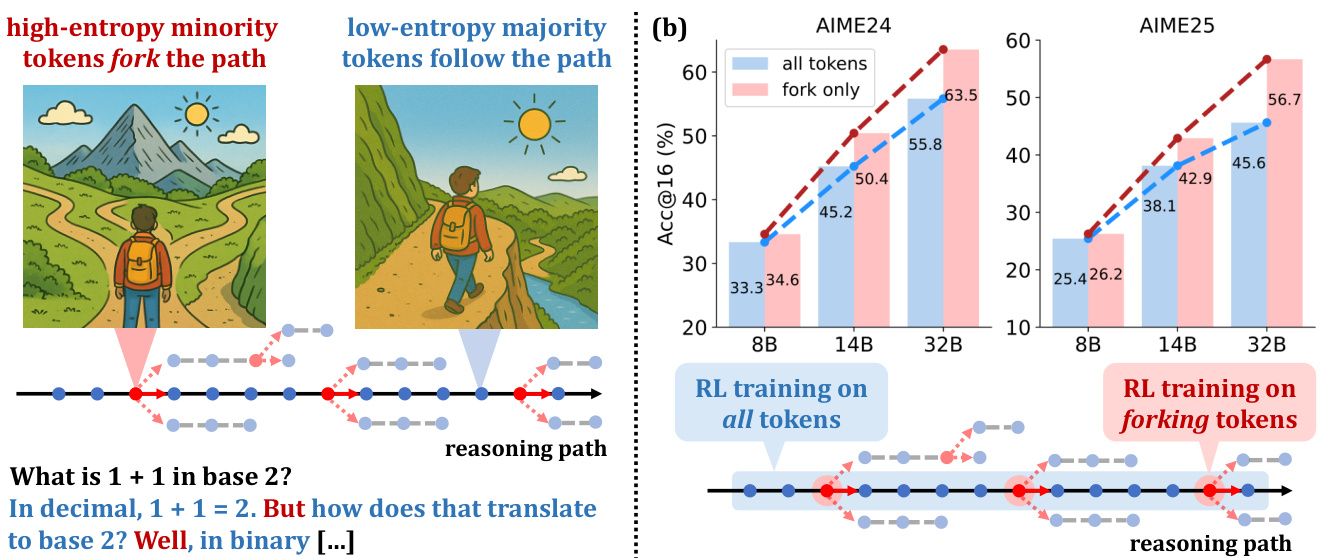
(13) Towards Understanding Camera Motions in Any Video (157 votes)
Paper Link: https://huggingface.co/papers/2504.15376
Brief Introduction:
CMU, UMass Amherst, and others introduce CameraBench, a large-scale dataset and benchmark for understanding camera motion. Designed with cinematographers, it features a new taxonomy and expert annotations to help models differentiate between geometric and semantic camera movements.
Core Image: 
(14) Seed1.5-VL Technical Report (146 votes)
Paper Link: https://huggingface.co/papers/2505.07062
Brief Introduction:
The ByteDance Seed team presents Seed1.5-VL, a vision-language foundation model with a 532M vision encoder and a 20B active-parameter MoE LLM. Despite its compact size, it achieves SOTA on 38 out of 60 public benchmarks and excels at agent-centric tasks like GUI control.
Core Image: 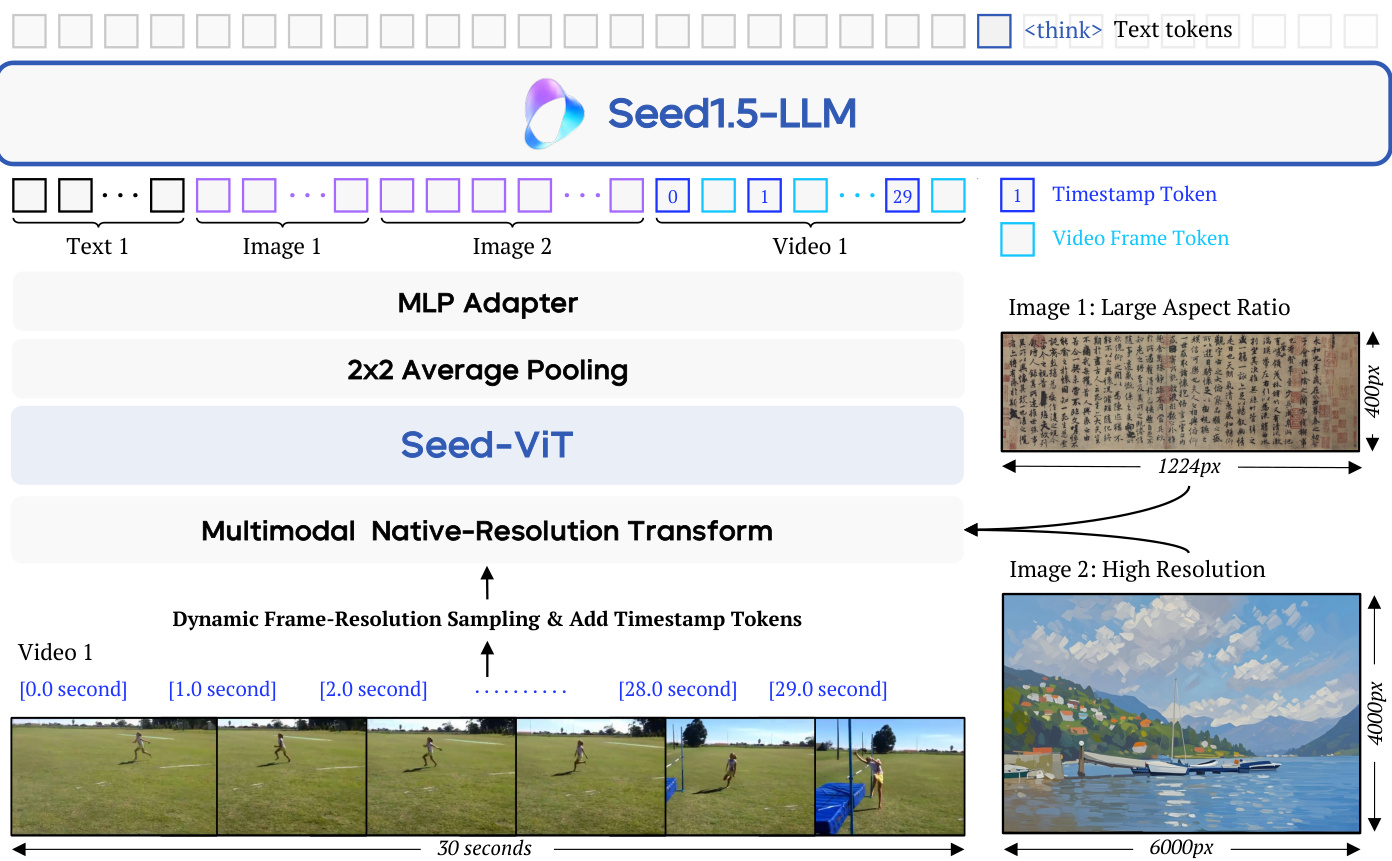
(15) Shifting AI Efficiency From Model-Centric to Data-Centric Compression (145 votes)
Paper Link: https://huggingface.co/papers/2505.19147
Brief Introduction:
This position paper from Shanghai Jiao Tong University and others argues that the focus of AI efficiency research is shifting from model-centric to data-centric compression. As model sizes plateau, the key bottleneck is now the quadratic cost of attention over long token sequences, making token compression the new frontier.
Core Image: 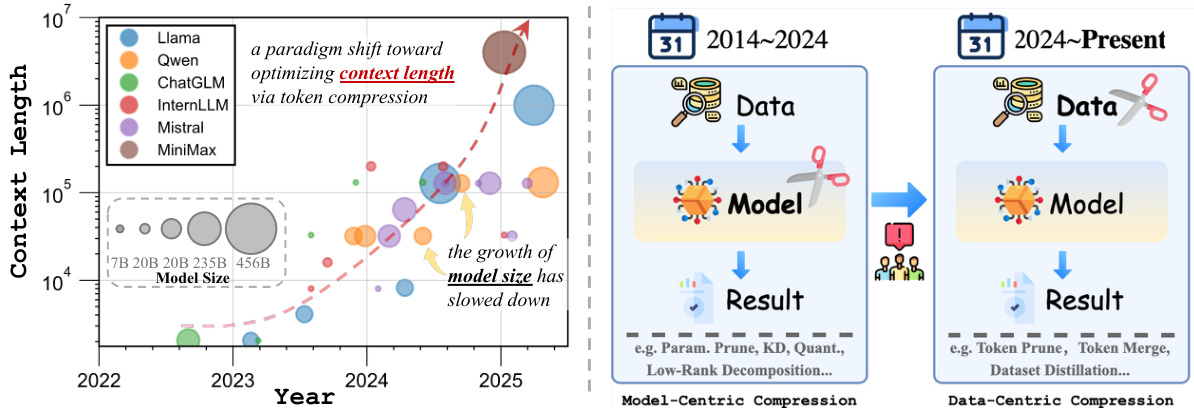
(16) Will It Still Be True Tomorrow? Multilingual Evergreen Question Classification to Improve Trustworthy QA (134 votes)
Paper Link: https://huggingface.co/papers/2505.21115
Brief Introduction:
Skoltech and AIRI tackle LLM hallucination by focusing on the temporality of questions. They introduce EverGreenQA, the first multilingual dataset with "evergreen" labels, to train a classifier that can distinguish between questions with stable vs. changing answers, thereby improving QA trustworthiness.
Core Image: 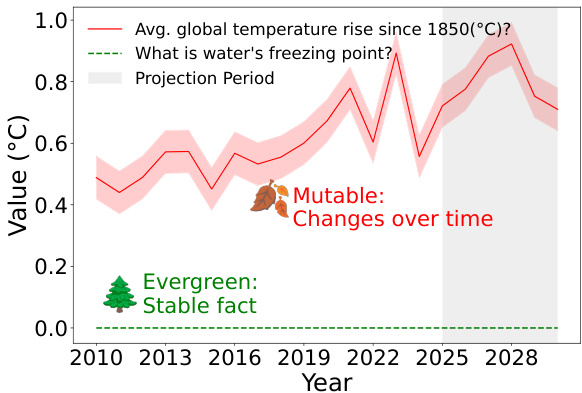
(17) PRIMA.CPP: Speeding Up 70B-Scale LLM Inference on Low-Resource Everyday Home Clusters (133 votes)
Paper Link: https://huggingface.co/papers/2504.08791
Brief Introduction: This work introduces prima.cpp, a distributed inference system that runs 70B-scale models on everyday home devices (laptops, phones) over Wi-Fi. It uses a novel piped-ring parallelism with prefetching to hide disk latency and an intelligent algorithm to optimally assign layers to heterogeneous devices.
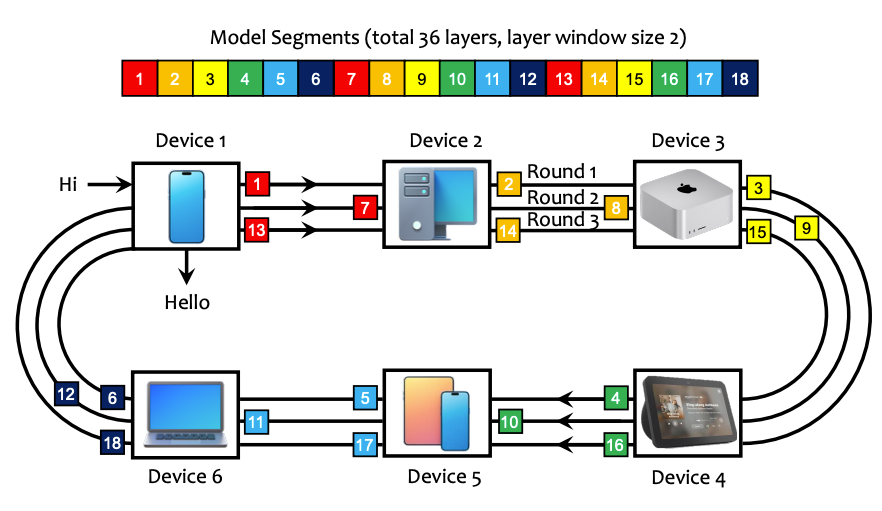
(18) ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models (132 votes)
Paper Link: https://huggingface.co/papers/2505.24864
Brief Introduction:
NVIDIA challenges the assumption that RL only amplifies existing abilities. They introduce ProRL, a methodology for prolonged RL training, and show that with sufficient training time, models can discover novel reasoning strategies that are inaccessible to the base models, genuinely expanding their reasoning boundaries.
Core Image: 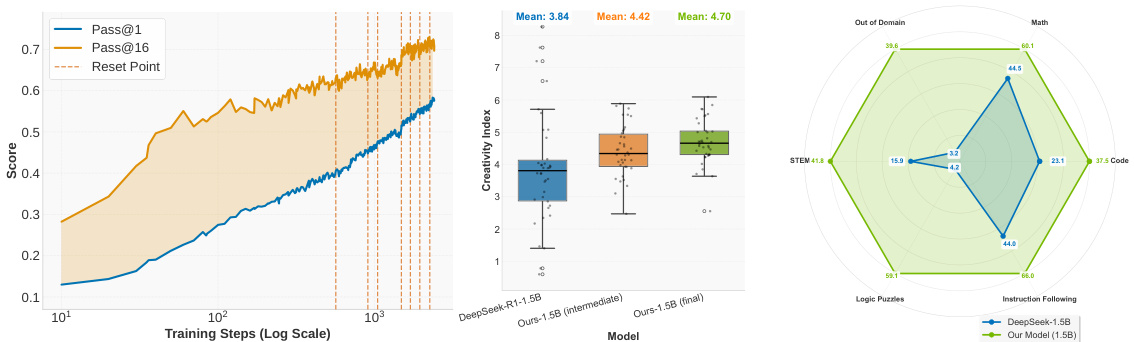
(19) Kimi-VL Technical Report (130 votes)
Paper Link: https://huggingface.co/papers/2504.07491
Brief Introduction:
The Kimi Team presents Kimi-VL, an efficient open-source MoE vision-language model activating only 2.8B parameters. It excels in multimodal reasoning, long-context understanding (128K window), and agent capabilities, setting a new standard for efficient yet powerful multimodal models.
Core Image: 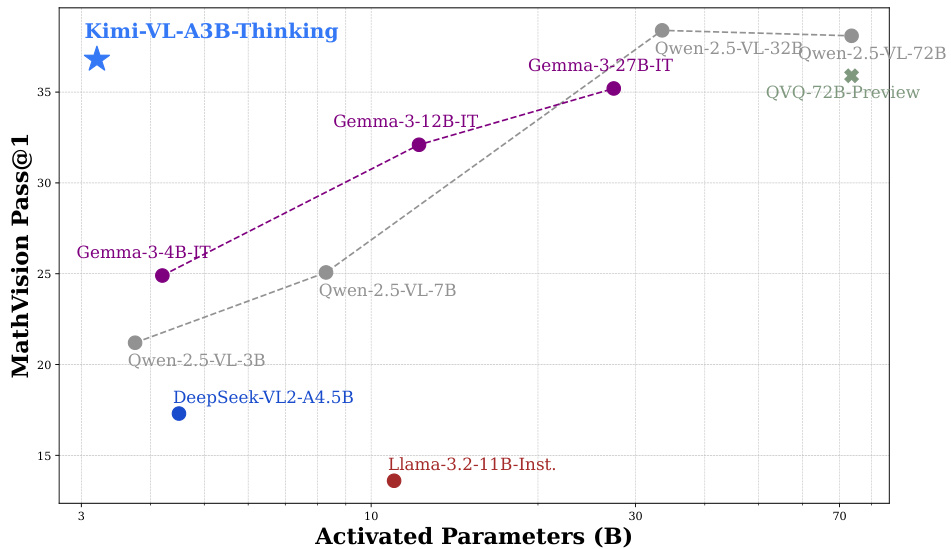
(20) Emerging Properties in Unified Multimodal Pretraining (130 votes)
Paper Link: https://huggingface.co/papers/2505.14683
Brief Introduction:
ByteDance Seed and others introduce BAGEL, a unified, decoder-only model pretrained on trillions of interleaved text, image, video, and web tokens. When scaled with such diverse data, BAGEL exhibits emerging abilities in complex reasoning like free-form image manipulation and world navigation.
Core Image: 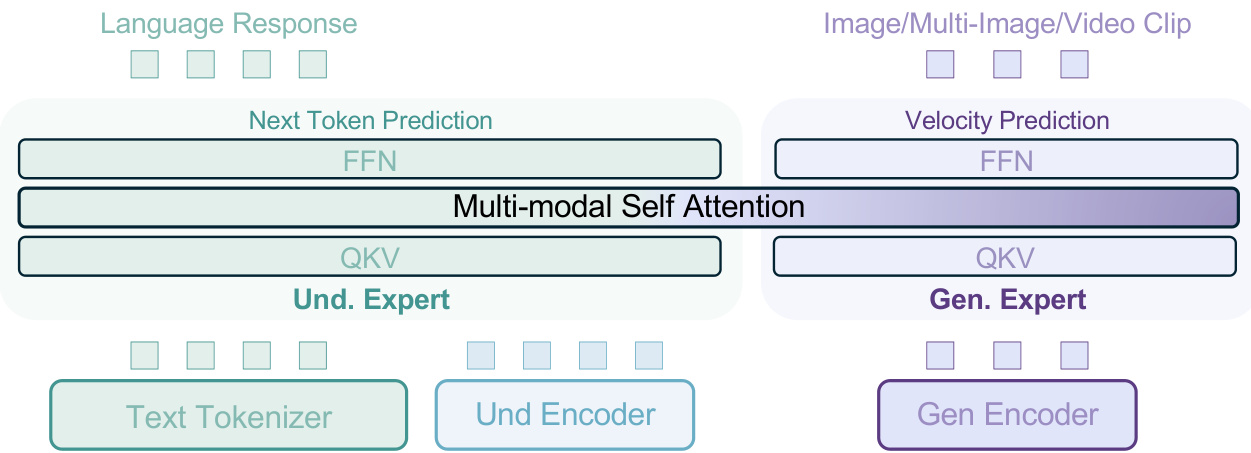
(21) Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model (129 votes)
Paper Link: https://huggingface.co/papers/2504.08685
Brief Introduction: The ByteDance Seed team presents a technical report on a cost-efficient strategy for training a video generation model. Their 7B parameter model, Seaweed-7B, was trained with moderate resources but demonstrates competitive performance against much larger models, highlighting the importance of design choices.
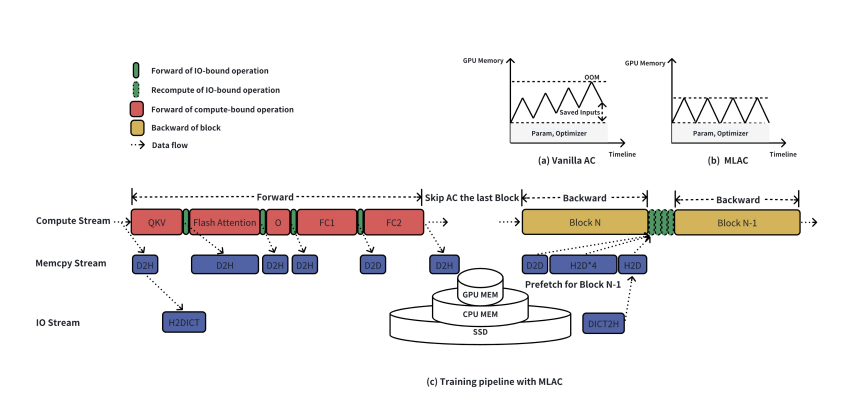
(22) Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? (129 votes)
Paper Link: https://huggingface.co/papers/2504.13837
Brief Introduction:
This critical study from Tsinghua University re-examines the impact of RLVR. Using pass@k metrics with large k, they find that while RL-trained models are more efficient, their base models often have a comparable or even higher reasoning capability boundary. This suggests RLVR primarily biases the model toward rewarded paths rather than creating new abilities.
Core Image: 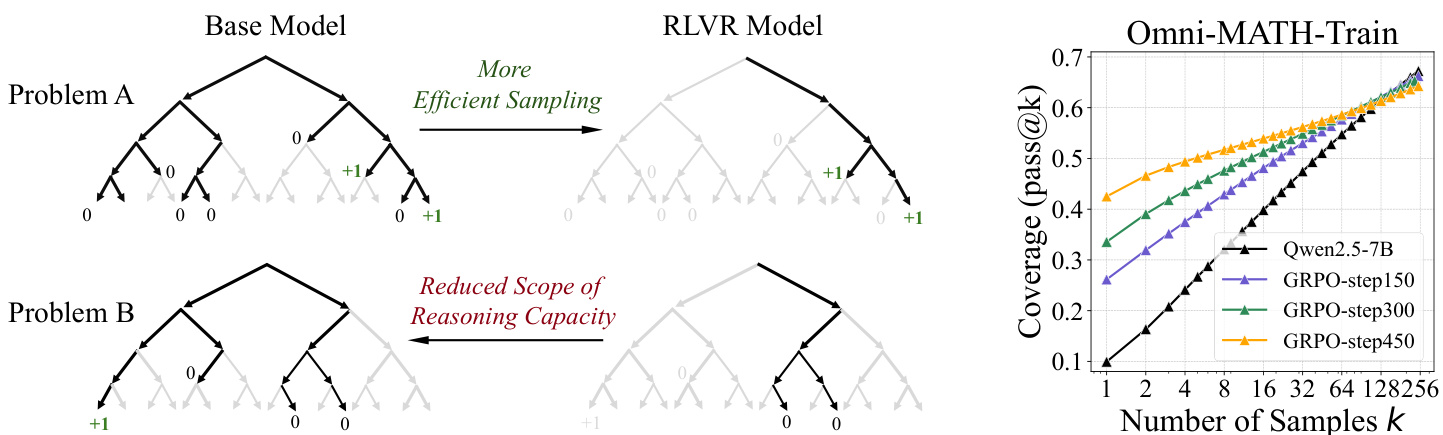
(23) MiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder (125 votes)
Paper Link: https://huggingface.co/papers/2505.07916
Brief Introduction:
MiniMax introduces MiniMax-Speech, an autoregressive TTS model with a key innovation: a learnable speaker encoder. This allows it to extract timbre from reference audio without transcription, enabling high-quality, expressive zero-shot speech synthesis and one-shot voice cloning in 32 languages.
Core Image: 
(24) Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models (124 votes)
Paper Link: https://huggingface.co/papers/2506.06395
Brief Introduction:
AIRI and Skoltech propose Reinforcement Learning via Self-Confidence (RLSC), a novel method that uses the model's own confidence as a reward signal. This eliminates the need for labels or reward engineering. With just 16 samples per question and a few training steps, RLSC significantly improves reasoning accuracy.
Core Image: 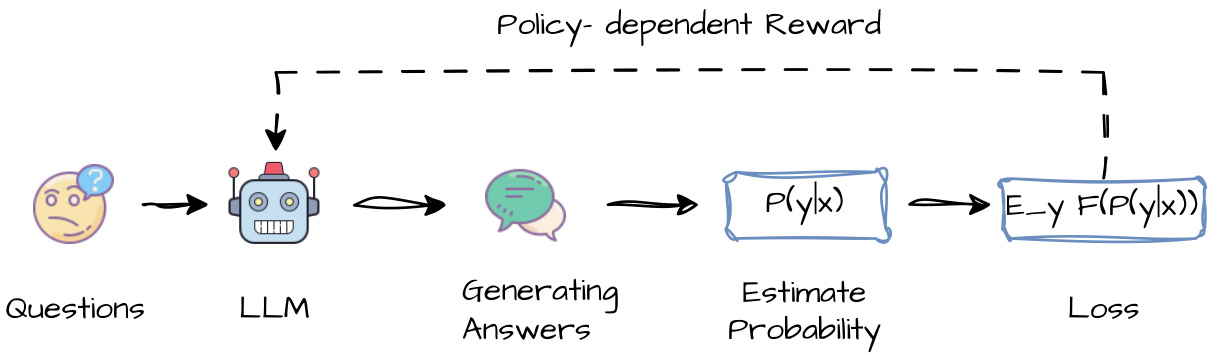
(25) The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models (123 votes)
Paper Link: https://huggingface.co/papers/2505.22617
Brief Introduction:
Shanghai AI Lab, Tsinghua University, and others investigate the phenomenon of "entropy collapse" in RL for reasoning LLMs. They find performance is bottlenecked by the exhaustion of policy entropy and propose new methods, Clip-Cov and KL-Cov, to control entropy and escape this trap, leading to better performance.
Core Image: 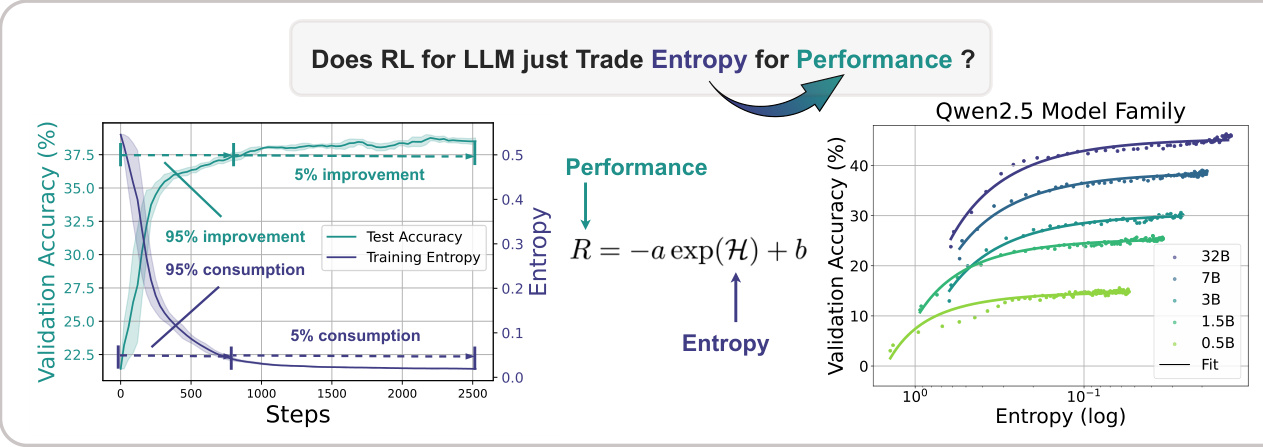
(26) Kuwain 1.5B: An Arabic SLM via Language Injection (121 votes)
Paper Link: https://huggingface.co/papers/2504.15120
Brief Introduction:
MISRAJA introduces Kuwain 1.5B, demonstrating a novel method to inject a new language (Arabic) into an existing English-centric model without compromising its original knowledge. This cost-effective approach offers a powerful alternative to training bilingual models from scratch.
Core Image: 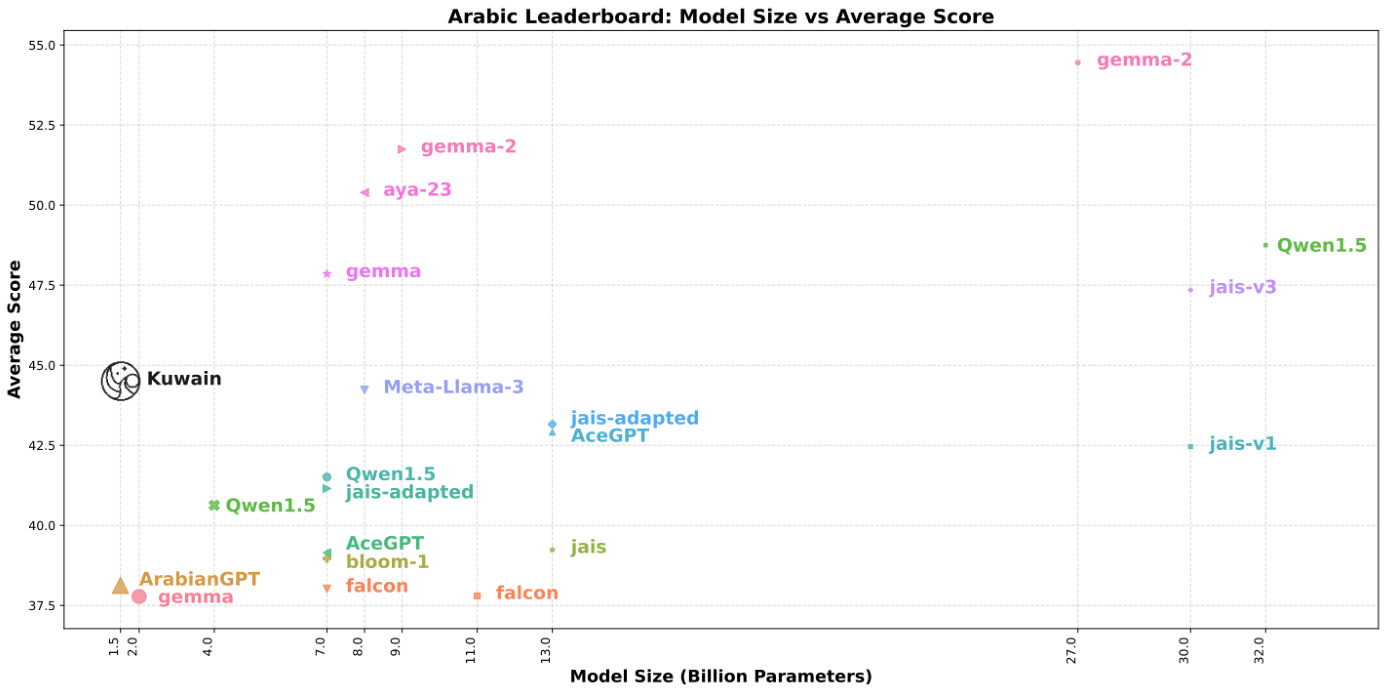
(27) Beyond 'Aha!': Toward Systematic Meta-Abilities Alignment in Large Reasoning Models (119 votes)
Paper Link: https://huggingface.co/papers/2505.10554
Brief Introduction:
National University of Singapore, Tsinghua, and Salesforce AI Research argue for moving beyond reliance on emergent "aha moments" in reasoning models. They propose explicitly aligning models with three meta-abilities—deduction, induction, and abduction—offering a more scalable and dependable foundation for reasoning.
Core Image: 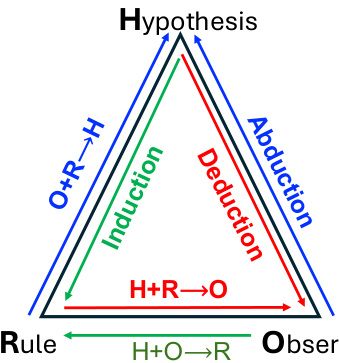
(28) Chain-of-Model Learning for Language Model (119 votes)
Paper Link: https://huggingface.co/papers/2505.11820
Brief Introduction:
Microsoft Research and others propose "Chain-of-Model" (CoM), a novel learning paradigm that introduces a causal, chain-style relationship into the hidden states of each layer. This allows for progressive model scaling and flexible, elastic inference by activating a variable number of "chains."
Core Image: 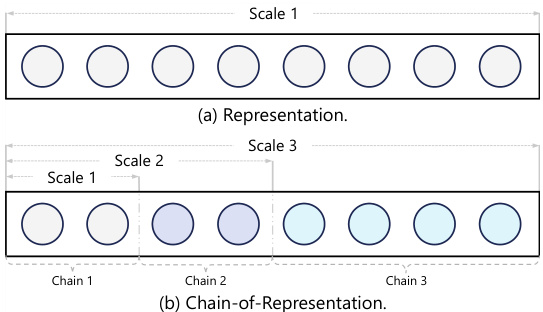
(29) NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification (118 votes)
Paper Link: https://huggingface.co/papers/2505.16938
Brief Introduction:
The NovelSeek Team at Shanghai AI Lab introduces a unified, closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR). NovelSeek automates the entire research pipeline from hypothesis to verification, demonstrating significant performance gains in fields like chemistry and biology in a fraction of the time required by humans.
Core Image: 
(30) TTRL: Test-Time Reinforcement Learning (116 votes)
Paper Link: https://huggingface.co/papers/2504.16084
Brief Introduction:
Tsinghua University and Shanghai AI Lab introduce Test-Time Reinforcement Learning (TTRL), a method for training LLMs on unlabeled data. TTRL uses strategies like majority voting to estimate rewards during inference, enabling self-evolution and consistent performance improvements on new, unlabeled test data.
Core Image: 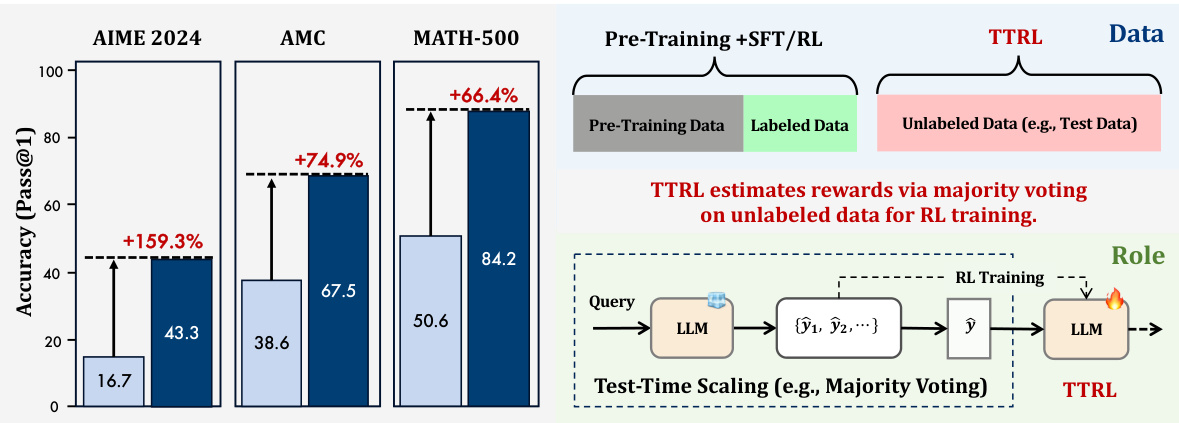
(31) Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights (113 votes)
Paper Link: https://huggingface.co/papers/2506.16406
Brief Introduction:
This work from NUS, UT Austin, and Oxford introduces Drag-and-Drop LLMs (DnD), a prompt-conditioned parameter generator that eliminates per-task training. It maps a few unlabeled prompts directly to LoRA weights in seconds, achieving up to 30% performance gains on unseen tasks with 12,000x lower overhead.
Core Image: 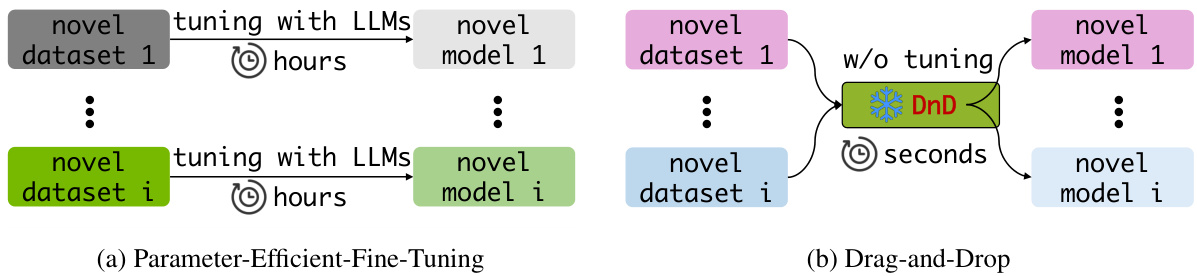
(32) Paper2Code: Automating Code Generation from Scientific Papers in Machine Learning (112 votes)
Paper Link: https://huggingface.co/papers/2504.17192
Brief Introduction:
KAIST and DeepAuto.ai introduce PaperCoder, a multi-agent LLM framework that transforms machine learning papers into functional code repositories. It mimics the human developer lifecycle with three stages: planning, analysis, and generation, effectively addressing the reproducibility crisis in ML research.
Core Image: 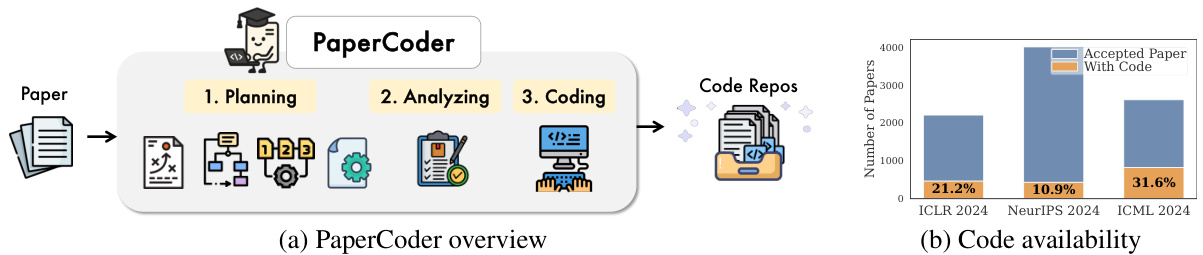
(33) TabSTAR: A Foundation Tabular Model With Semantically Target-Aware Representations (111 votes)
Paper Link: https://huggingface.co/papers/2505.18125
Brief Introduction: Technion - IIT introduces TabSTAR, a foundation model for tabular data with textual features. It unfreezes a pretrained text encoder and uses target-aware tokens to learn task-specific embeddings, achieving SOTA performance on classification benchmarks and outperforming traditional GBDTs. (No core image in the paper)
(34) Hogwild! Inference: Parallel LLM Generation via Concurrent Attention (110 votes)
Paper Link: https://huggingface.co/papers/2504.06261
Brief Introduction:
Yandex, HSE University, and IST Austria propose Hogwild! Inference, a parallel LLM generation engine. Instead of a fixed collaboration framework, it runs multiple LLM "workers" in parallel, allowing them to synchronize and develop their own collaboration strategies via a concurrently-updated attention cache.
Core Image: 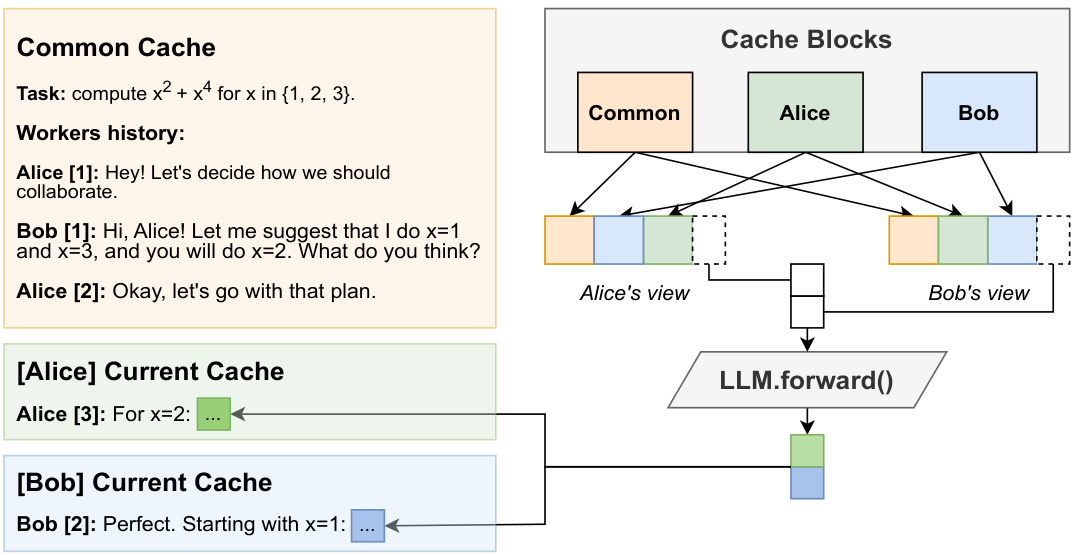
(35) One-Minute Video Generation with Test-Time Training (106 votes)
Paper Link: https://huggingface.co/papers/2504.05298
Brief Introduction:
NVIDIA, Stanford, UCSD, and others introduce a method to generate one-minute videos using Test-Time Training (TTT) layers. These layers use neural networks as hidden states, making them more expressive than standard RNNs and enabling a pretrained Transformer to generate coherent, long-form videos.
Core Image: 
(36) SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics (106 votes)
Paper Link: https://huggingface.co/papers/2506.01844
Brief Introduction:
Hugging Face, Sorbonne University, and others present SmolVLA, a small, efficient, and community-driven Vision-Language-Action (VLA) model for robotics. Designed to be trained on a single GPU, it achieves performance comparable to VLAs 10x larger, making advanced robotics more accessible.
Core Image: 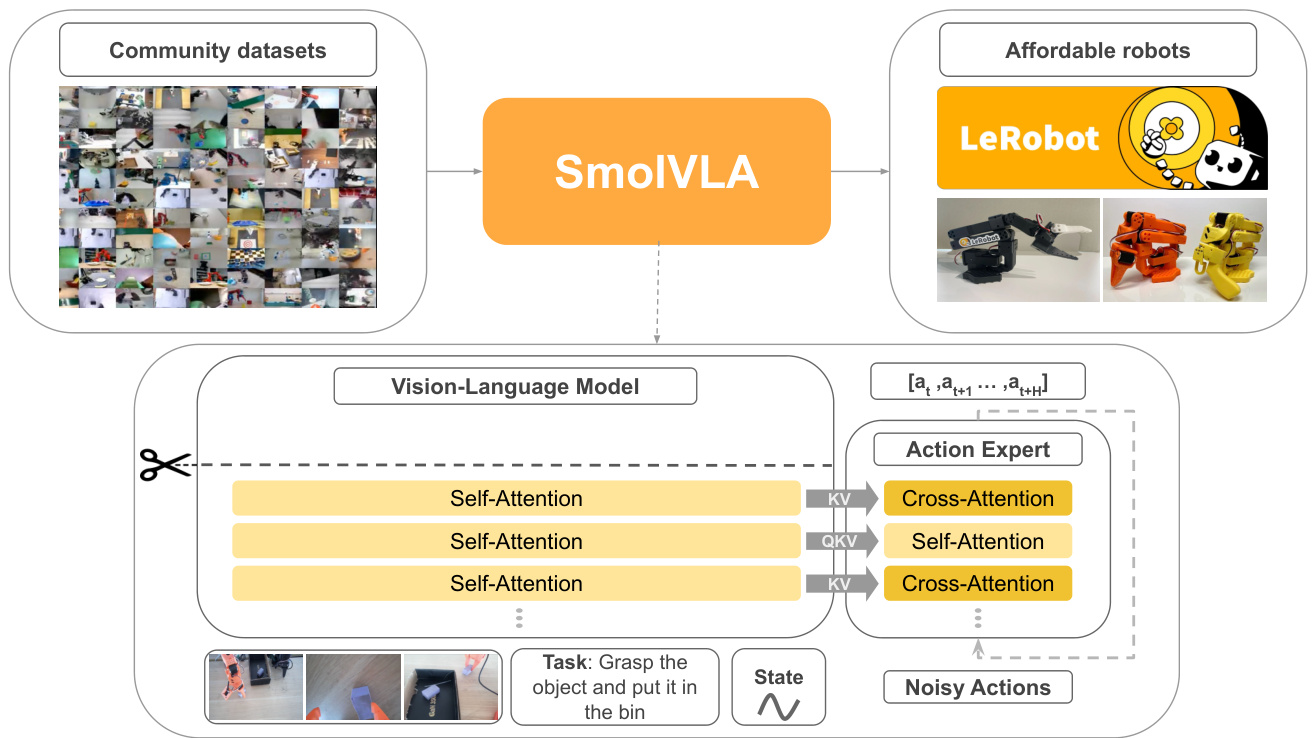
(37) Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning (106 votes)
Paper Link: https://huggingface.co/papers/2506.07044
Brief Introduction:
The LASA Team at Alibaba DAMO Academy introduces Lingshu, a generalist foundation model for medical understanding and reasoning. It is trained on a meticulously curated multimodal dataset to address the limitations of general MLLMs in the medical domain, such as hallucinations and lack of specific knowledge.
Core Image: 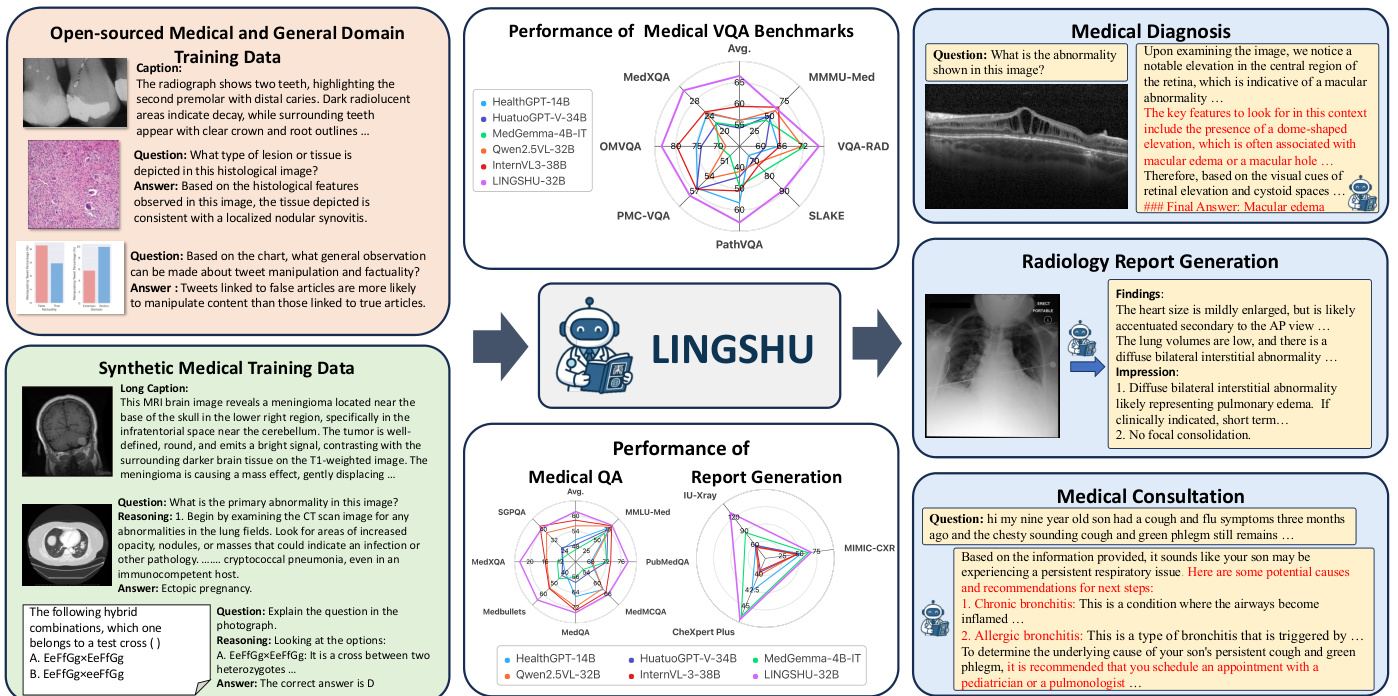
(38) Web-Shepherd: Advancing PRMs for Reinforcing Web Agents (102 votes)
Paper Link: https://huggingface.co/papers/2505.15277
Brief Introduction:
Yonsei University and Carnegie Mellon introduce Web-Shepherd, the first process reward model (PRM) specifically for web navigation. By training on a large-scale dataset of step-level preference pairs, Web-Shepherd provides more precise, robust, and cost-effective guidance for web agents than using prompted MLLMs.
Core Image: 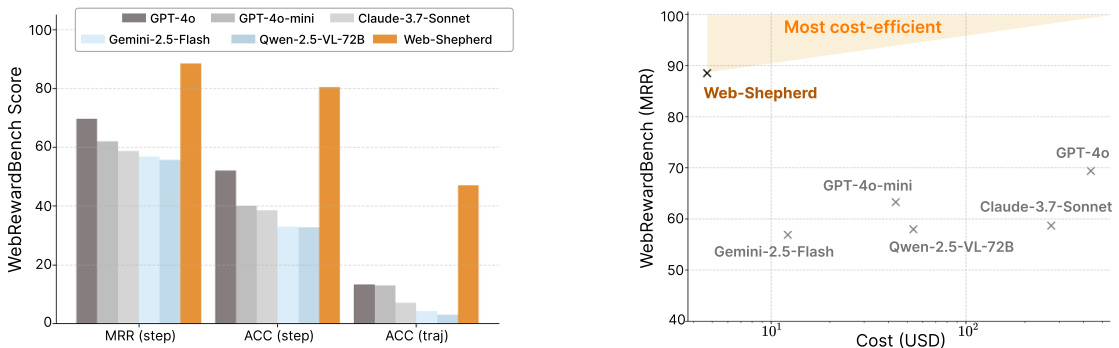
(39) ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows (102 votes)
Paper Link: https://huggingface.co/papers/2505.19897
Brief Introduction:
The University of Hong Kong, Shanghai AI Lab, and others introduce ScienceBoard, a benchmark and environment for evaluating autonomous agents in scientific workflows. It features a suite of professional software and 169 real-world tasks, revealing that even SOTA agents struggle with complex scientific tasks.
Core Image: 
(40) Reinforcement Learning for Reasoning in Large Language Models with One Training Example (95 votes)
Paper Link: https://huggingface.co/papers/2504.20571
Brief Introduction:
This surprising study from the University of Washington, USC, and Microsoft shows that RLVR with just one training example can be highly effective. They found a single example that boosted a model's math reasoning performance on MATH500 from 36.0% to 73.6%, matching results from a 1.2k-example dataset.
Core Image: 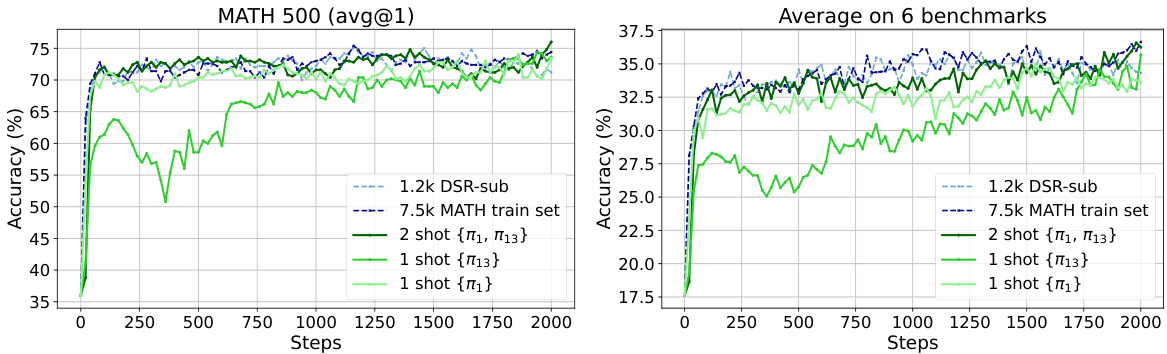
(41) AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time (95 votes)
Paper Link: https://huggingface.co/papers/2505.24863
Brief Introduction:
UIUC and UC Berkeley present AlphaOne (α1), a universal framework for modulating reasoning speed in LRMs at test time. It introduces an "alpha moment" to scale the thinking phase, dynamically scheduling slow-to-fast thinking transitions to improve reasoning capability and efficiency.
Core Image: 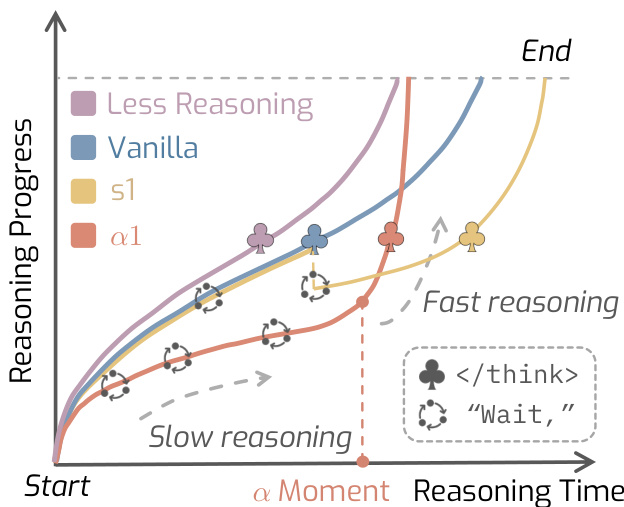
(42) ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical Reasoning (95 votes)
Paper Link: https://huggingface.co/papers/2506.09513
Brief Introduction:
Alibaba DAMO Academy and others introduce ReasonMed, the largest medical reasoning dataset with 370k high-quality examples. It was constructed via a multi-agent verification and refinement process. Their model, ReasonMed-7B, sets a new benchmark for sub-10B models, even outperforming LLaMA3.1-70B on PubMedQA.
Core Image: 
(43) BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset (94 votes)
Paper Link: https://huggingface.co/papers/2505.09568
Brief Introduction:
Salesforce Research and others introduce BLIP3-o, a family of state-of-the-art unified multimodal models. Their comprehensive study explores optimal architectures for both image understanding and generation, finding that using a diffusion transformer on semantic CLIP features with a sequential training strategy yields the best results.
Core Image: 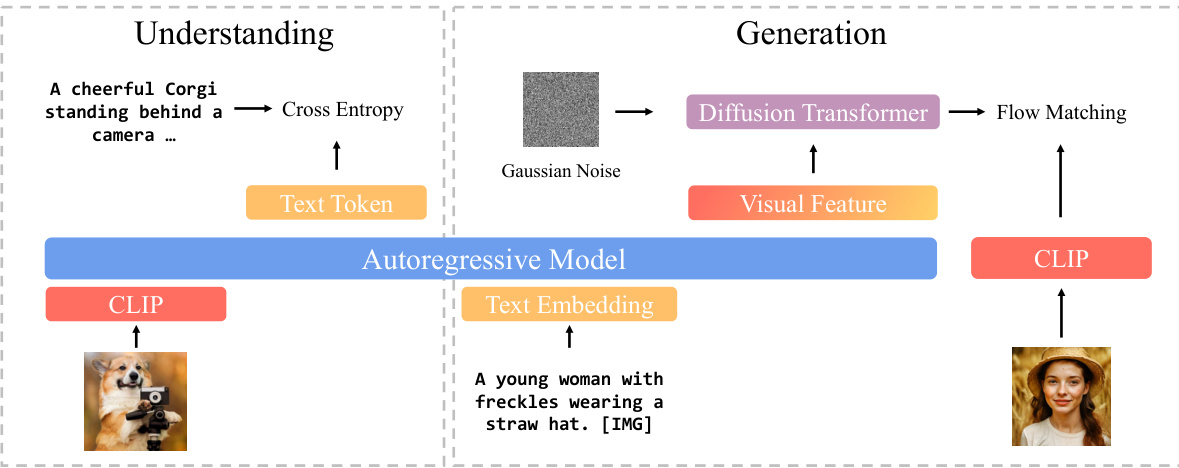
(44) MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization (93 votes)
Paper Link: https://huggingface.co/papers/2504.00999
Brief Introduction:
Zhejiang University, Tsinghua University, and others propose MergeVQ, a unified framework that incorporates token merging techniques into VQ-based generative models. It bridges the gap between generation and representation learning by decoupling high-level semantics from fine-grained details during pre-training.
Core Image: 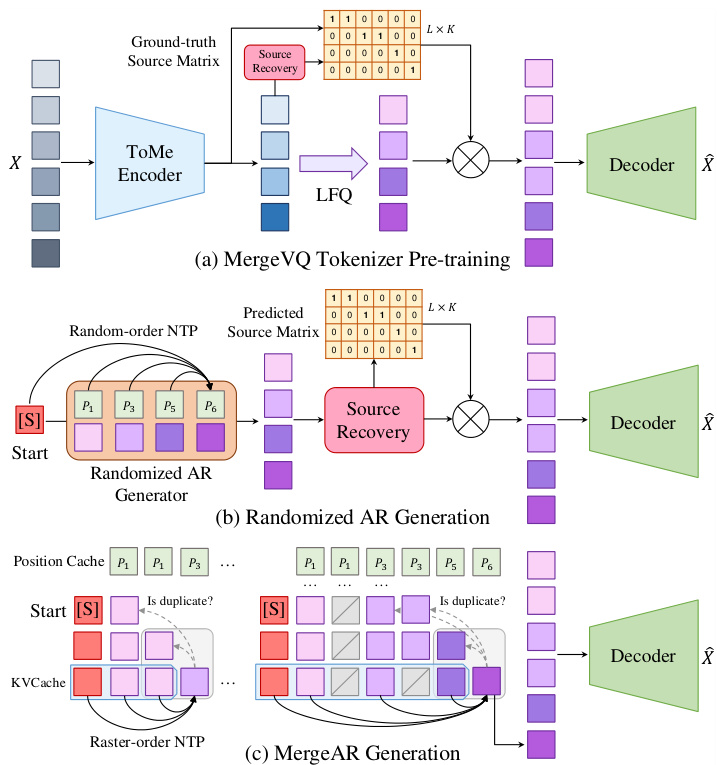
(45) Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning (93 votes)
Paper Link: https://huggingface.co/papers/2505.03318
Brief Introduction:
Fudan University, Shanghai AI Lab, and Tencent Hunyuan propose UnifiedReward-Think, the first unified multimodal CoT-based reward model. It uses an exploration-driven RL approach to elicit and incentivize long-chain reasoning for both visual understanding and generation reward tasks, improving reward signal accuracy.
Core Image: 
(46) CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training (92 votes)
Paper Link: https://huggingface.co/papers/2504.13161
Brief Introduction:
NVIDIA introduces CLIMB, an automated framework that discovers, evaluates, and refines data mixtures for pre-training. It embeds and clusters large-scale datasets, then iteratively searches for optimal mixtures. Their 1B model, trained on a CLIMB-optimized mixture, surpasses the SOTA Llama-3.2-1B.
Core Image: 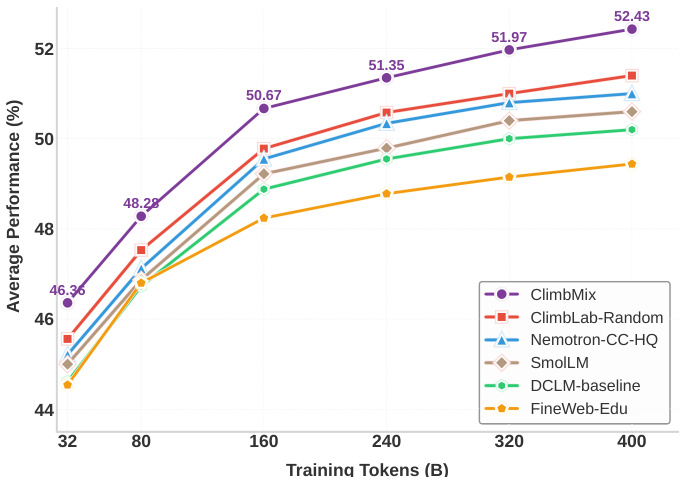
(47) Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers (91 votes)
Paper Link: https://huggingface.co/papers/2504.20752
Brief Introduction:
This work extends the "grokking" phenomenon to real-world factual data for the first time. By augmenting knowledge graphs with synthetic data to increase the ratio of inferred-to-atomic facts, they enable Transformers to transition from memorization to generalization, achieving near-perfect accuracy on multi-hop QA tasks.
Core Image: 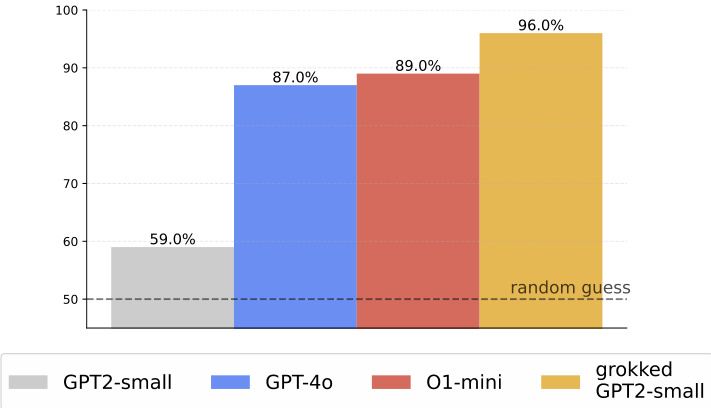
(48) Seedance 1.0: Exploring the Boundaries of Video Generation Models (91 votes)
Paper Link: https://huggingface.co/papers/2506.09113
Brief Introduction:
The ByteDance Seed team introduces Seedance 1.0, a high-performance and efficient video generation model. It integrates multi-source data curation, an efficient architecture supporting multi-shot generation, and video-specific RLHF to balance prompt following, motion plausibility, and visual quality.
Core Image: 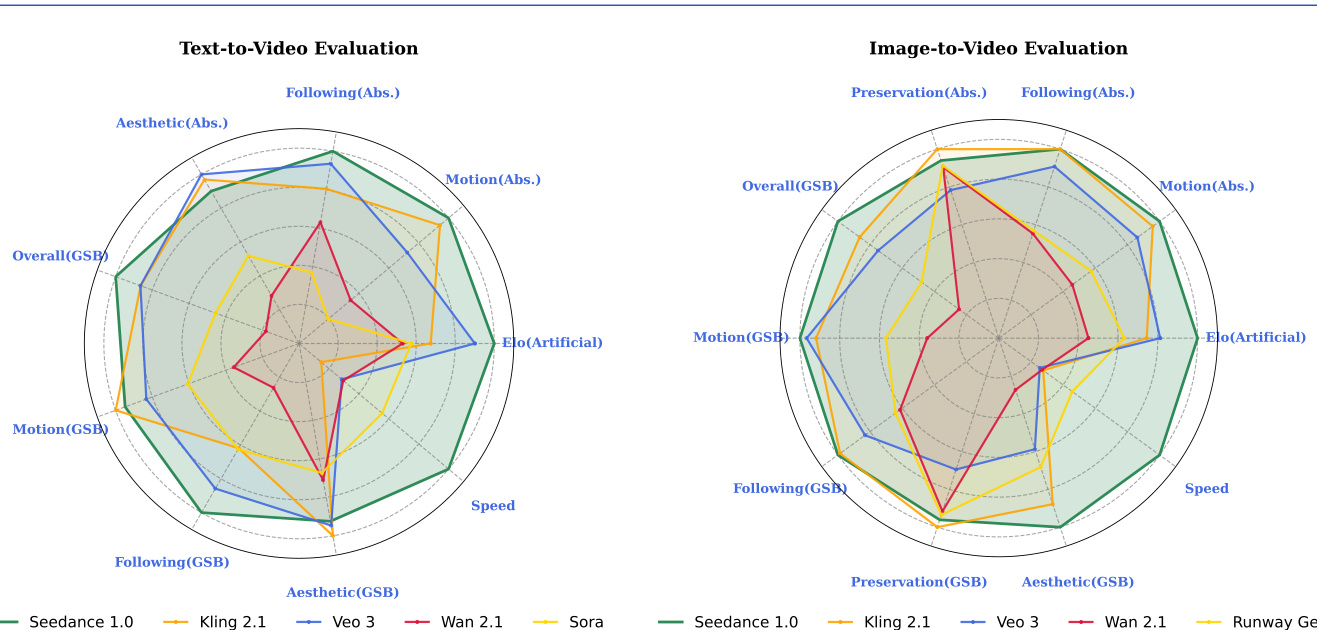
(49) MultiFinBen: A Multilingual, Multimodal, and Difficulty-Aware Benchmark for Financial LLM Evaluation (90 votes)
Paper Link: https://huggingface.co/papers/2506.14028
Brief Introduction:
A large consortium of universities and The FinAI introduce MultiFinBen, the first multilingual, multimodal, and difficulty-aware benchmark for financial LLMs. It includes novel tasks like multilingual financial QA and OCR-embedded QA, revealing that even the strongest models struggle with complex, real-world financial tasks.
Core Image: 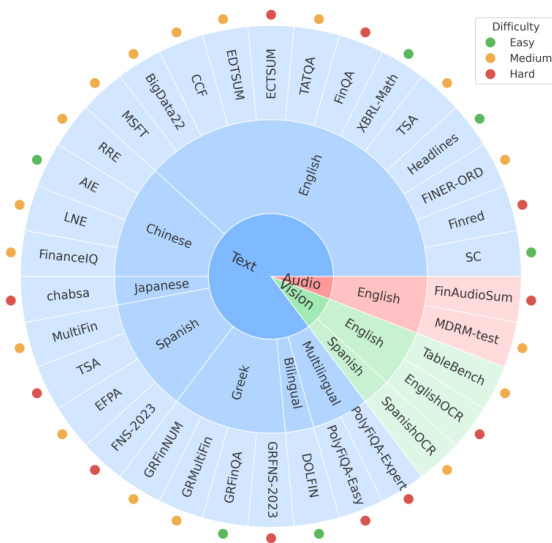
(50) ZClip: Adaptive Spike Mitigation for LLM Pre-Training (89 votes)
Paper Link: https://huggingface.co/papers/2504.02507
Brief Introduction:
BluOrion proposes ZClip, an adaptive gradient clipping algorithm to mitigate loss spikes during LLM pre-training. Unlike fixed thresholds, ZClip dynamically adjusts the clipping threshold based on z-score anomaly detection of gradient norms, proactively preventing training divergence without manual intervention.
Core Image: 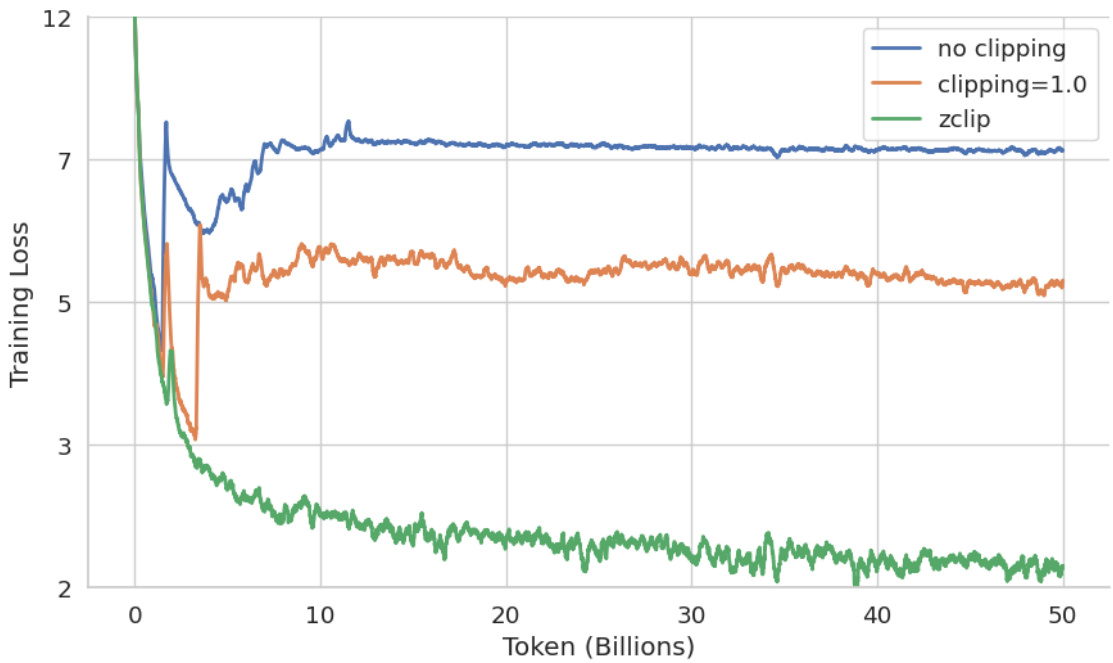
🔥 Final Insights: The Four Paradigm Shifts Redefining AI
After journeying through these 50 pioneering studies, it's clear that the AI landscape is undergoing a profound transformation. The narrative is no longer just about scale, but about intelligence, efficiency, and design. Here are the four key insights that define this new era:
1. The Great RL Debate: Gilding vs. Alchemy Reinforcement Learning (RL) was the undisputed star of the quarter, but its role is now being critically re-examined. On one hand, work like ProRL and One-Shot RLVR demonstrates its incredible power to unlock latent reasoning capabilities. On the other, papers like "Does Reinforcement Learning Really Incentivize..." pose a crucial question: Is RL creating fundamentally new abilities (alchemy), or is it just making models more efficient at sampling what they already know (gilding)? The answer seems to lie in a deeper understanding of its mechanisms, focusing on key decision points (High-Entropy Minority Tokens) and managing policy entropy (The Entropy Mechanism).
- The Trend: Research is moving beyond if RL works to how and why it works. The future lies in creating more explainable, controllable, and efficient RL paradigms.
2. The Great Migration: From Model-Centric to Data- & Compute-Centric Efficiency The era of "brute-force scaling" of model parameters is giving way to a new focus on efficiency at the data and compute level.
- The Shift: As highlighted in "Shifting AI Efficiency...," the primary bottleneck is no longer model size but the cost of processing vast token sequences. This has made "token compression" (MergeVQ) and efficient inference-time computation (MiniMax-M1, Hogwild! Inference) the new frontiers. Meanwhile, "small-but-mighty" models like SmolVLM and low-resource deployment frameworks like PRIMA.CPP prove that top-tier performance can be achieved without massive hardware.
- The Trend: AI's "Moore's Law" will now be measured in efficiency gains. The next breakthroughs will come from smarter data processing, novel attention mechanisms, and powerful models that can run anywhere.
3. The Dawn of the Generalist Agent: Beyond "Aha!" Moments Intelligent Agents are moving from niche concepts to system-level foundational capabilities.
- The Unification: A unified architecture is becoming standard, as seen in the survey on Foundation Agents and models like BAGEL and Qwen3. Agents are being designed to tackle real-world workflows, from autonomous scientific discovery (NovelSeek, ScienceBoard) to everyday tasks (Web-Shepherd, SmolVLA).
- The Alignment: Crucially, the field is moving beyond relying on emergent "aha moments." Instead, as "Beyond 'Aha!'" suggests, the focus is on systematically aligning agents with core "meta-abilities" like deduction and induction, building a more reliable and controllable foundation for reasoning.
- The Trend: The next generation of AI will be defined by its ability to act. The challenge is to integrate perception, language, and planning into a seamless, goal-driven system that is both capable and trustworthy.
4. Data as the New Algorithm: The Rise of Curated Intelligence Data is no longer passive fuel; it's an active, programmable component for shaping model intelligence.
- The Curation: High-quality, domain-specific datasets are now recognized as a prerequisite for success. Whether it's ReasonMed for medicine or Web-Shepherd for web navigation, curated data is the key to unlocking breakthrough performance.
- The Automation: Frameworks like CLIMB are turning data mixing from an art into a science, using AI to automatically discover the optimal pre-training "recipe."
- The Induction: Most profoundly, "Grokking in the Wild" shows that data augmentation can be used as a tool to induce generalizable reasoning circuits in a model, forcing it to learn underlying logic rather than just memorizing facts.
- The Trend: Data engineering is becoming as critical as model architecture. The competitive edge will belong to those who can build superior pipelines for data generation, filtering, mixing, and augmentation, creating a powerful self-improvement loop for AI.
This is not just a technological iteration; it's an evolution in thinking. It demands that we, as practitioners and researchers, see ourselves not just as trainers of models, but as designers of their cognitive processes and architects of their capabilities. The next "aha moment" in AI may not come from a larger model, but from a smarter insight into these very trends. Let's keep exploring.