StarCoder2 and The Stack v2











BigCode is releasing StarCoder2, the next generation of transparently trained open code LLMs. All StarCoder2 variants were trained on The Stack v2, a new large and high-quality code dataset. We release all models, datasets, and the processing as well as the training code. Check out the paper for details.
What is StarCoder2?
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
StarCoder2 offers three model sizes: a 3 billion-parameter model trained by ServiceNow, a 7 billion-parameter model trained by Hugging Face, and a 15 billion-parameter model trained by NVIDIA using NVIDIA NeMo on NVIDIA accelerated infrastructure:
- StarCoder2-3B was trained on 17 programming languages from The Stack v2 on 3+ trillion tokens.
- StarCoder2-7B was trained on 17 programming languages from The Stack v2 on 3.5+ trillion tokens.
- StarCoder2-15B was trained on 600+ programming languages from The Stack v2 on 4+ trillion tokens.
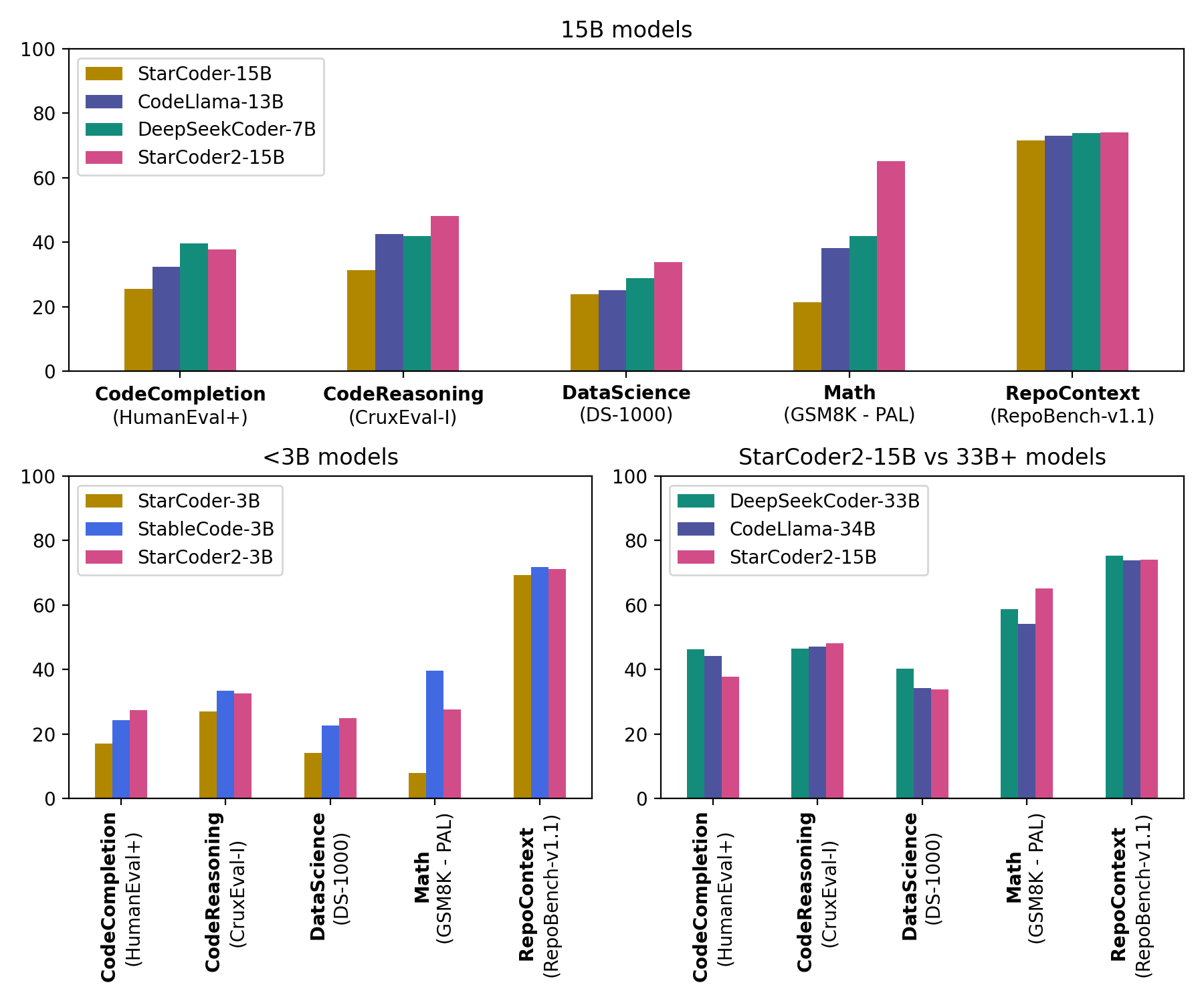
StarCoder2-15B is the best in its size class and matches 33B+ models on many evaluations. StarCoder2-3B matches the performance of StarCoder1-15B:
What is The Stack v2?

The Stack v2 is the largest open code dataset suitable for LLM pretraining. The Stack v2 is larger than The Stack v1, follows an improved language and license detection procedure, and better filtering heuristics. In addition, the training dataset is grouped by repositories, allowing to train models with repository context.
| The Stack v1 | The Stack v2 | |
|---|---|---|
| full | 6.4TB | 67.5TB |
| deduplicated | 2.9TB | 32.1TB |
| training dataset | ~200B tokens | ~900B tokens |
This dataset is derived from the Software Heritage archive, the largest public archive of software source code and accompanying development history. Software Heritage, launched by Inria in partnership with UNESCO, is an open, non-profit initiative to collect, preserve, and share the source code of all publicly available software. We are grateful to Software Heritage for providing access to this invaluable resource. For more details, visit the Software Heritage website.
The Stack v2 can be accessed through the Hugging Face Hub.
About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
Links
Models
- Paper: A technical report about StarCoder2 and The Stack v2.
- GitHub: All you need to know about using or fine-tuning StarCoder2.
- StarCoder2-3B: Small StarCoder2 model.
- StarCoder2-7B: Medium StarCoder2 model.
- StarCoder2-15B: Large StarCoder2 model.
Data & Governance
- StarCoder2 License Agreement: The model is licensed under the BigCode OpenRAIL-M v1 license agreement.
- StarCoder2 Search: Full-text search for code in the pretraining dataset.
- StarCoder2 Membership Test: Blazing fast check of code that was present in the pretraining dataset.
Others
- VSCode Extension: Code with StarCoder!
- Big Code Models Leaderboard
You can find all the resources and links at huggingface.co/bigcode!




