OpenReasoning-Nemotron: A Family of State-of-the-Art Distilled Reasoning Models











Today, we announce the release of OpenReasoning-Nemotron: a suite of reasoning-capable large language models (LLMs) which have been distilled from the DeepSeek R1 0528 671B model. Trained on a massive, high-quality dataset distilled from the new DeepSeek R1 0528, our 7B, 14B, and 32B models achieve state-of-the-art performance on a wide range of reasoning benchmarks for their respective sizes in the domain of mathematics, science and code. These models, which will be available for download on Hugging Face (1.5B, 7B, 14B, 32B), may enable further research on RL for Reasoning on top of far stronger baselines. These models can serve as a good starting point for research on techniques to improve reasoning efficiency by reducing the amount of tokens consumed or customizing these models to specific tasks. Furthermore, while these models are not general-purpose chat assistants, research on preference optimization with or without verified rewards while preserving their benchmark scores may unlock new applications of this model.
Large-Scale Data Distillation
The foundation of these models is their dataset. We generated 5 million high-quality reasoning-based solutions by leveraging the powerful DeepSeek R1 0528 model across the domains of mathematics, coding, and science. This dataset will be released in the coming months, enabling all models to improve their reasoning capabilities on these domains. While the dataset is not immediately available, the code to generate the dataset, train and evaluate models is available at NeMo-Skills.
Effectiveness of Data Distillation
To enable researchers with varying compute capabilities, we are releasing four models based on the Qwen 2.5 architecture. While the original DeepSeek R1 671B model were accompanied with distilled models of various sizes, the new DeepSeek R1 0528 671B model was released with just the 8B distilled model. Considering the limits this places on research for reasoning, we developed models of 4 sizes to accommodate research.
Over the past year, we released OpenMathReasoning and OpenCodeReasoning datasets, which enable public models to attain state-of-the-art scores on various math and coding benchmarks via reasoning. A key factor of this work is the scale of SFT data used for distillation - we generated and trained on several million samples of R1 distilled data. As such, we find that our data distilled models on each of these domains far surpass the original Distilled R1 models released.
The models are created using NeMo-Skills for all steps, including data generation, dataset pre- and post-processing, model conversion, training, as well as evaluation on all these benchmarks.
Benchmark Results: Setting a New Standard
Our models demonstrate exceptional performance across a suite of challenging reasoning benchmarks. The 7B, 14B, and 32B models consistently set new state-of-the-art records for their size classes.
Scores on Reasoning Benchmarks
All evaluation results in this plot and the table below are pass@1.
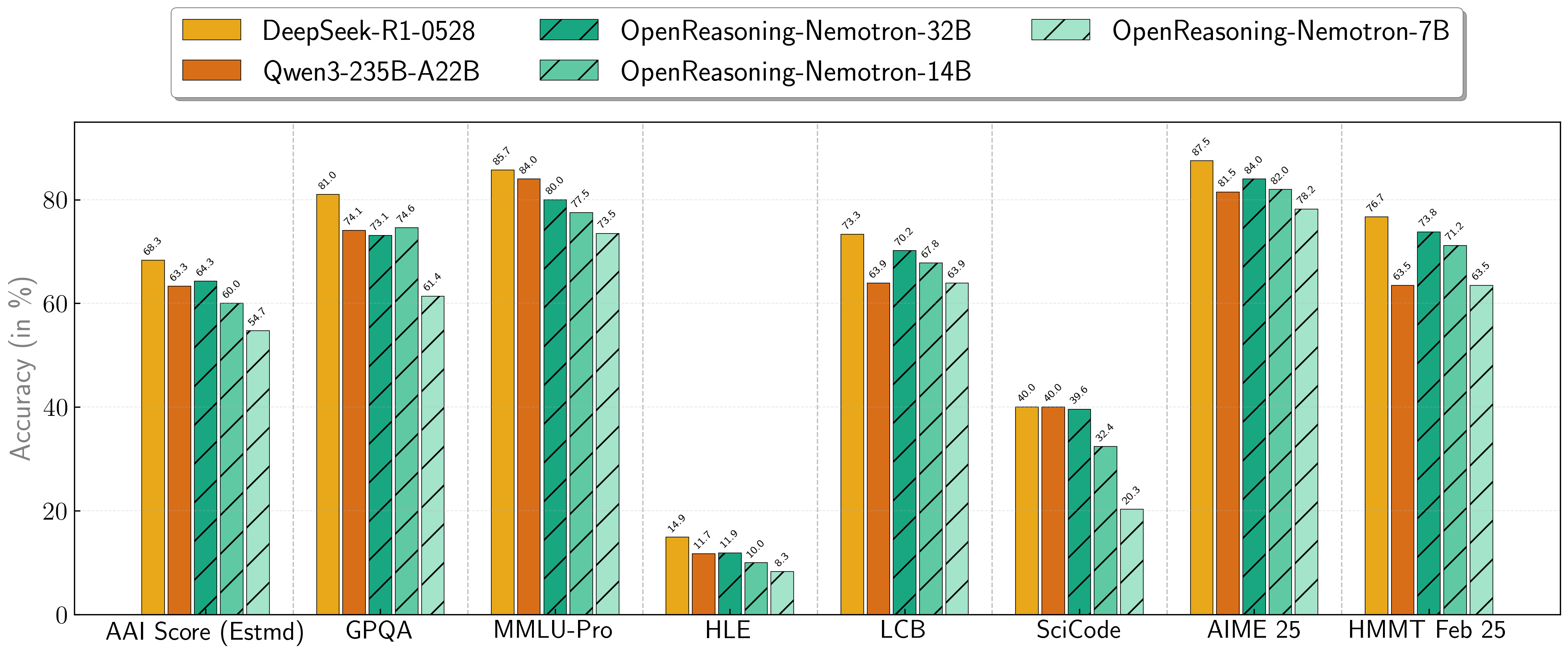
| Model | AritificalAnalysisIndex* | GPQA | MMLU-PRO | HLE | LiveCodeBench* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* This is our estimation of the Artificial Analysis Intelligence Index, not an official score.
* LiveCodeBench version 6, date range 2408-2505.
Combining the work of multiple agents
OpenReasoning-Nemotron models can be used in a "heavy" mode by starting multiple parallel generations and combining them together via generative solution selection (GenSelect). To add this "skill", we follow the original GenSelect training pipeline, except we do not train on the selection summary but use the full reasoning trace of DeepSeek R1 0528 671B instead. We only train models to select the best solution for math problems, but surprisingly find that this capability directly generalizes to code questions! With this "heavy" GenSelect inference mode, the OpenReasoning-Nemotron-32B model approaches and sometimes exceeds o3 (High) scores on math and coding benchmarks.
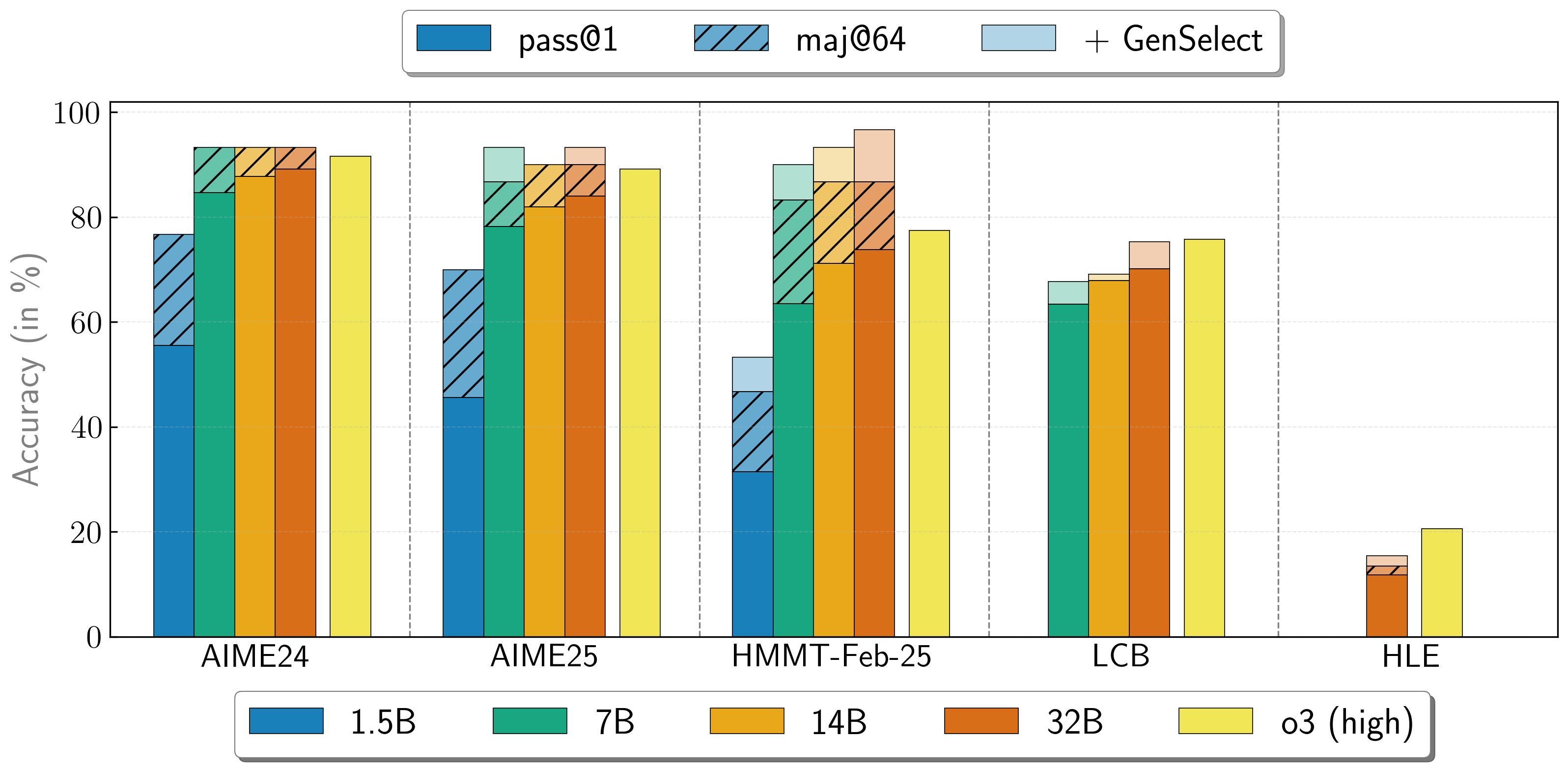
| Model | Pass@1 (Avg@64) | Majority@64 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408-2505 | 63.4 | n/a | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408-2505 | 67.9 | n/a | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408-2505 | 70.2 | n/a | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
* We apply GenSelect@64 for math and GenSelect@16 for science and coding.
A Strong Foundation for Future Research
A key aspect of this release is our training methodology. These models are trained using Supervised Fine-Tuning (SFT) distillation only, with no Reinforcement Learning (RL) applied. This deliberate choice showcases how far we can go via just data distillation and provides the research community with a great starting point for reasoning-based RL techniques. Recent work from AceReasoning-Nemotron has shown that a schedule of Curriculum RL, and the sequential inclusion of Math and Code RL shows much more stable training of reasoning models. We therefore combine the data for the domains of Mathematics, Science, and Code and regenerate the solutions using the latest R1, providing a strong baseline on which further RL research can be conducted, starting from near state-of-the-art scores.
You can find the checkpoints for these models in the OpenReasoning-Nemotron collection








