Ultra-Long Sequence Parallelism: Ulysses + Ring-Attention Technical Principles and Implementation







Sequence Parallel (SP) technology can be used to reduce the dependency on large memory for long sequence training under multi-card or multi-machine conditions. Simply put, sequence parallelism can be defined by the following concept:
Sequence parallelism is the process of splitting an input sequence into several sub-sequences for parallel computation on different cards during training, thereby reducing the memory requirements for training.
Common sequence parallelism methods include the following:
- Ulysses
- Ring-Attention
- Megatron-SP/CP
Among these, both Ulysses and Ring-Attention are sequence parallelism solutions based on the Transformers ecosystem. We mainly introduce the technical principles and implementation of these two solutions here. Megatron-CP[1] and Ring-Attention can be considered as similar technologies, while Megatron-SP performs splitting on activation values and is generally used in conjunction with Megatron-TP. We will not elaborate on these here.
First, let's look at the memory reduction effects that can be achieved in long sequence training on the Qwen2.5-3B model after integrating both Ulysses and Ring-Attention training technologies:
| SP size | SP Strategy | GPU memory | training time |
|---|---|---|---|
| 8 | w/ ulysses=2 ring=4 | 17.92GiB | 1:07:20 |
| 4 | w/ ulysses=2 ring=2 | 27.78GiB | 37:48 |
| 2 | w/ ulysses=2 | 48.5GiB | 24:16 |
| 1 | w/o SP | 75.35GiB | 19:41 |
Note that due to increased communication volume and different GPU loads caused by sequence splitting, training time will be correspondingly extended.
When splitting into 2 sub-sequences, Ulysses was used; when splitting into 4/8 sub-sequences, Ulysses (split 2) + Ring-Attention (split 2 or 4) was used. Below we elaborate on the principles and implementation schemes of these two technologies.
Ulysses
Ulysses is a sequence parallelism algorithm developed by the DeepSpeed team[2]. The idea of Ulysses can be summarized in one sentence:
After the sequence is split into sub-sequences, activation value exchange is performed before Attention computation in each layer, allowing each card to combine into a complete sequence. Attention Heads are then distributed across different cards to achieve memory reduction. After computation is complete, they are exchanged back.
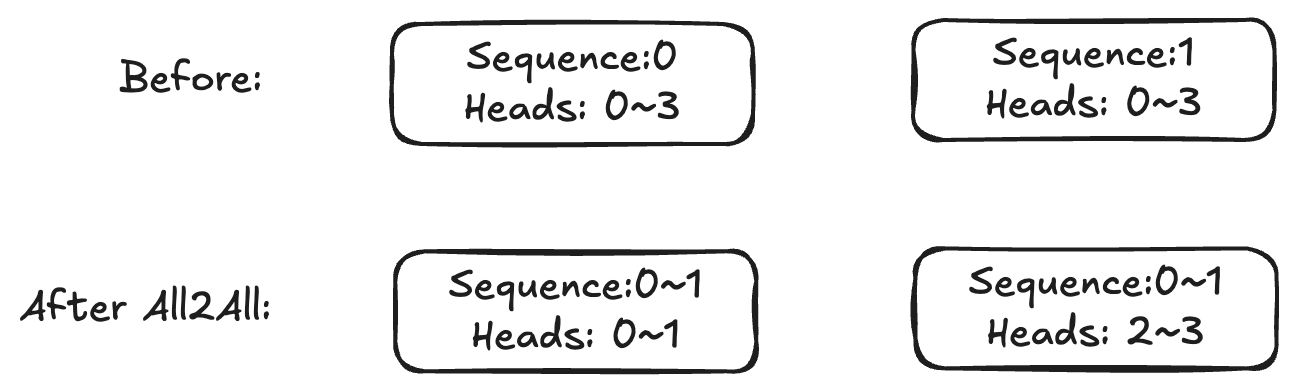
Through this approach, although QKV computation still involves O(N^2) activation values, memory usage is still reduced because each card has fewer Attention Heads. The following figure shows a simple example, assuming splitting into two sequences, each with two attention heads:
Here's the figure from the paper:
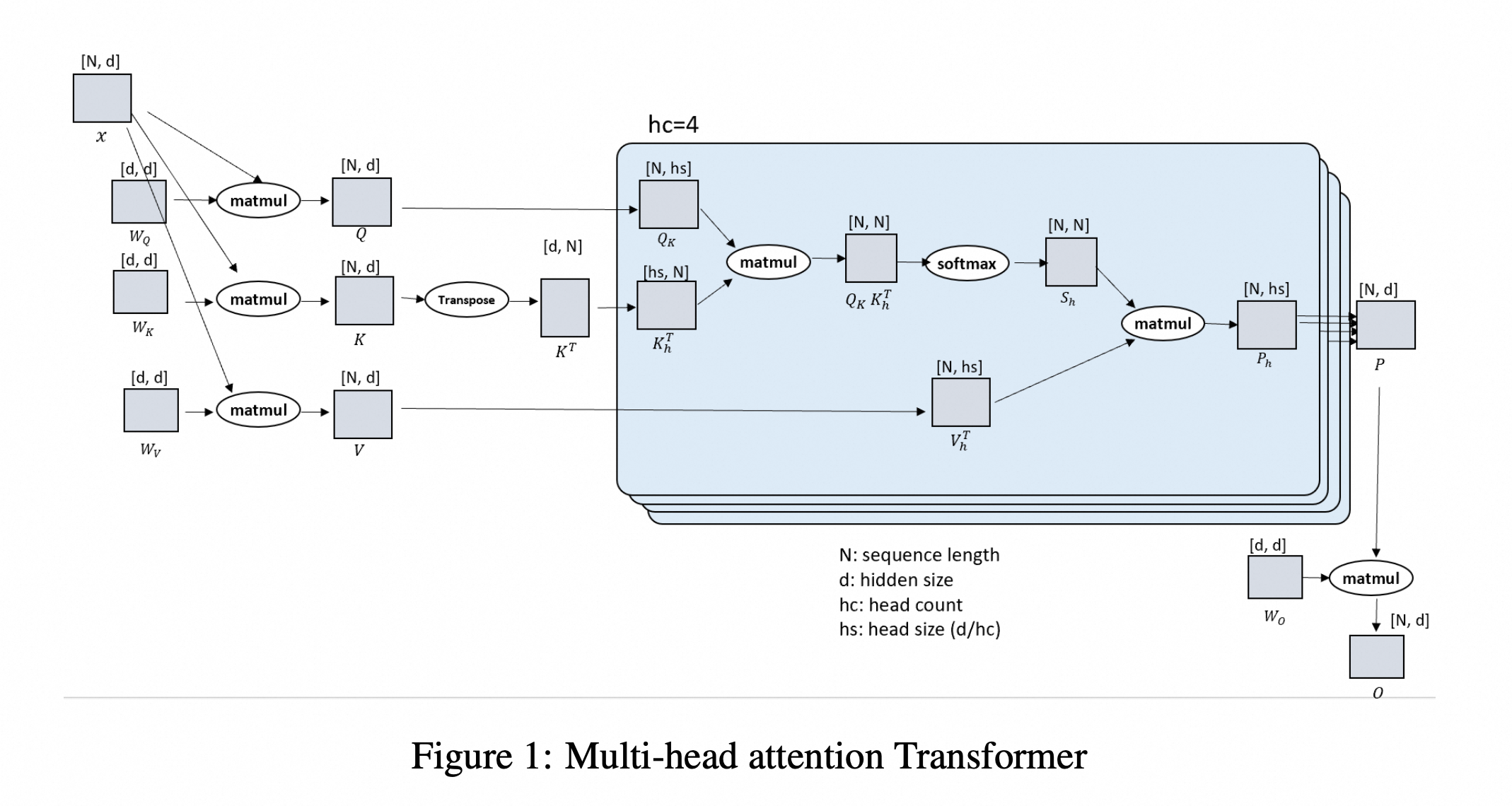
Where N represents sequence length, and d represents hidden_size, which can also be specifically understood as the number of Attention Heads * actual hidden_size.
State after Ulysses splitting:
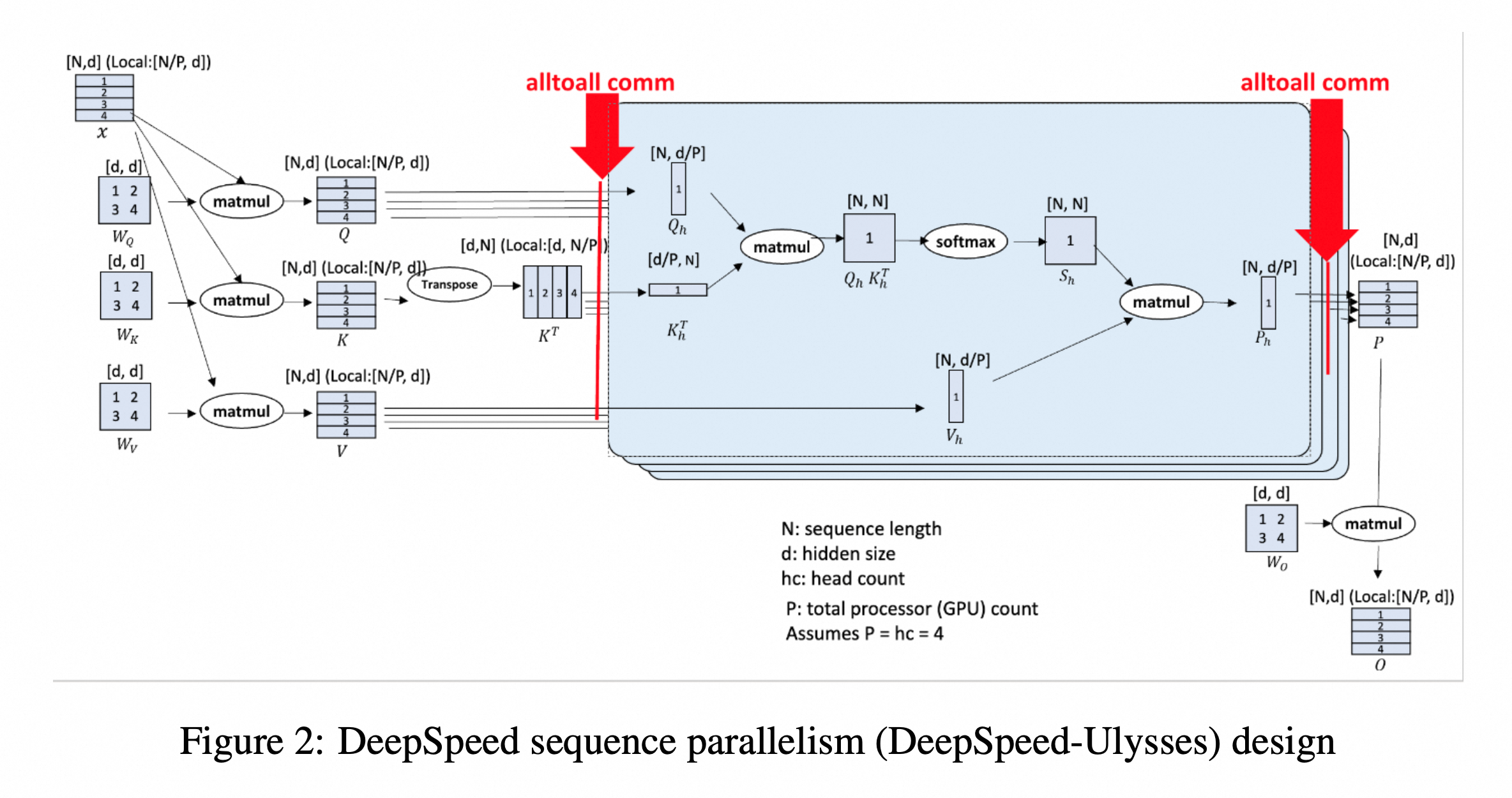 The technical principle of Ulysses is very clear, with the key point being the all-to-all communication from N/P to d/P. Since QKV is complete during Attention computation, and different Attention-Heads are distributed across different cards, it is universal in scenarios like GQA and MHA, and is fully compatible with various technologies such as flash-attn, SDPA, and padding_free. Of course, due to the existence of cross-card communication, the backward process requires additional handling.
The technical principle of Ulysses is very clear, with the key point being the all-to-all communication from N/P to d/P. Since QKV is complete during Attention computation, and different Attention-Heads are distributed across different cards, it is universal in scenarios like GQA and MHA, and is fully compatible with various technologies such as flash-attn, SDPA, and padding_free. Of course, due to the existence of cross-card communication, the backward process requires additional handling.
However, the limitations of Ulysses are also quite obvious, namely being constrained by the number of Attention Heads. Especially in GQA where the number of KV heads is much smaller than the number of Q heads, Ulysses may not be able to split across more cards.
Ring-Attention
Before discussing Ring-Attention, we need to briefly talk about Flash-Attention. The principle of Flash-Attention can also be explained in one sentence:
QKV and softmax can perform block-wise parallel computation and updates, maximizing the utilization of SRAM while reducing memory usage.
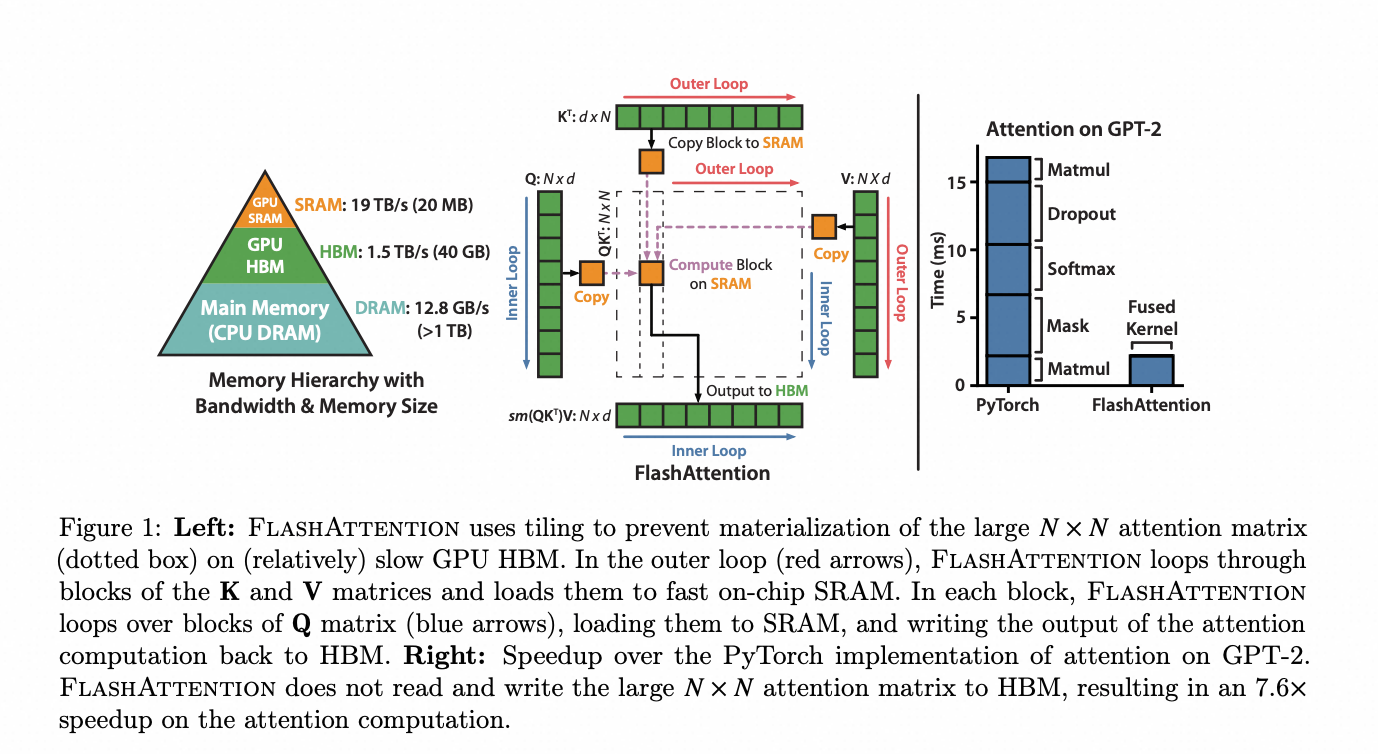
Pseudocode for flash-attention forward process:

Note the pseudocode in lines 10~12 of Algorithm1 above, this part performs merged updates on the block-wise LSE (log-sum-exp):
Where:
And Attention-Out are merged and updated, that is, after computing new blocks, the results of new blocks are merged with the results of old blocks to obtain complete results.
So, if each card carries a portion of the sequence length and computation results are passed across cards, can flash-attention work across cards? This is the basic idea of Ring-Attention.
Ring-Attention: Utilizing the principle that Attention computation can be performed in blocks, sequence blocks are split across multiple cards for separate computation, and then the computation results are merged to obtain the final result.
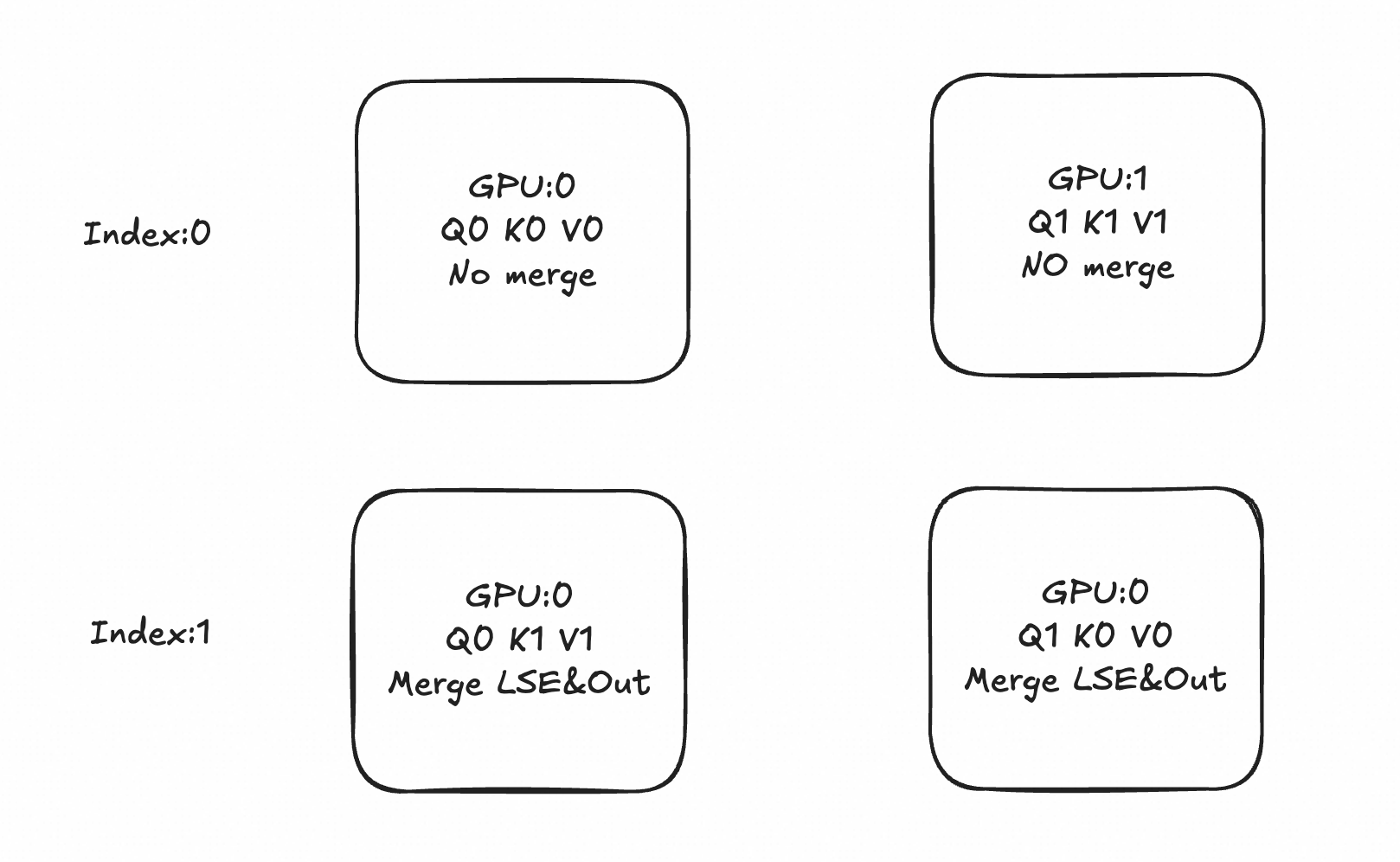
Assuming there are N blocks, consider the same Qi and K0n-1~ V0n-1~ that can communicate and flow between different blocks. First consider the Softmax part:
Where:
Generally, to avoid numerical instability, exponentials are not computed directly, but rather using numerically stable computation methods:
It can be seen that after expanding using the exponential formula, this method is equivalent to the original formula above.
Next, we need to derive the updates for LSE and Attention-Out recursively. Let's first look at LSE. Considering we already have previous accumulated results and current block results, the new LSE should be:
Then:
Where i represents the old accumulated value, and ij represents the current block value. Expanding the log on the right side:
Similarly, for numerical stability, we do not compute the exponential here, but merge the right side into the logsigmoid form. In PyTorch, the softplus operator of logsigmoid handles numerically stable computation:
This is the LSE update formula for Ring-Attention.
Next, let's consider Attention-Out. We currently have four values: block LSE, previous cumulative LSE, block Attention-Out, and previous cumulative Attention-Out. We need to use this information to recursively update the overall Attention-Out.
According to the Attention computation formula and block definition, assume the computation results of previous blocks:
The computation results of the current block:
Thus:
Using LSE to represent the above formula:
According to the Attention formula:
Substituting into the above:
Note that after splitting the numerator in the above formula, it can be transformed into the sum of two independent expressions, and these two expressions are respectively in sigmoid form, thus we obtain:
These two update formulas are equivalent to the recursive formulas given in the flash-attention paper, both following the approach of block updates and online-softmax.
The above derivation provides the forward computation formula for iterative updates, with the code located in update_out_and_lse:
Since there is a forward pass, there must be a backward pass. During backpropagation, we need to gradually restore from the final i-1 step back to step 0. Due to space constraints, the derivation of the backward formula is not expanded here, with the code located in lse_grad: https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L263: https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L263 https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L458: https://github.com/modelscope/ms-swift/blob/main/swift/trainers/sequence_parallel/zigzag_ring_attn.py#L458
Good, we have prepared the theory above and can now start implementing the code.
Note that Ring-Attention has multiple variant implementations, such as strip-ring-attention[3]. Among these implementations, the zigzag implementation is the most excellent in terms of load balancing. To understand the problem with the original Ring-Attention, let's look at the following figure:
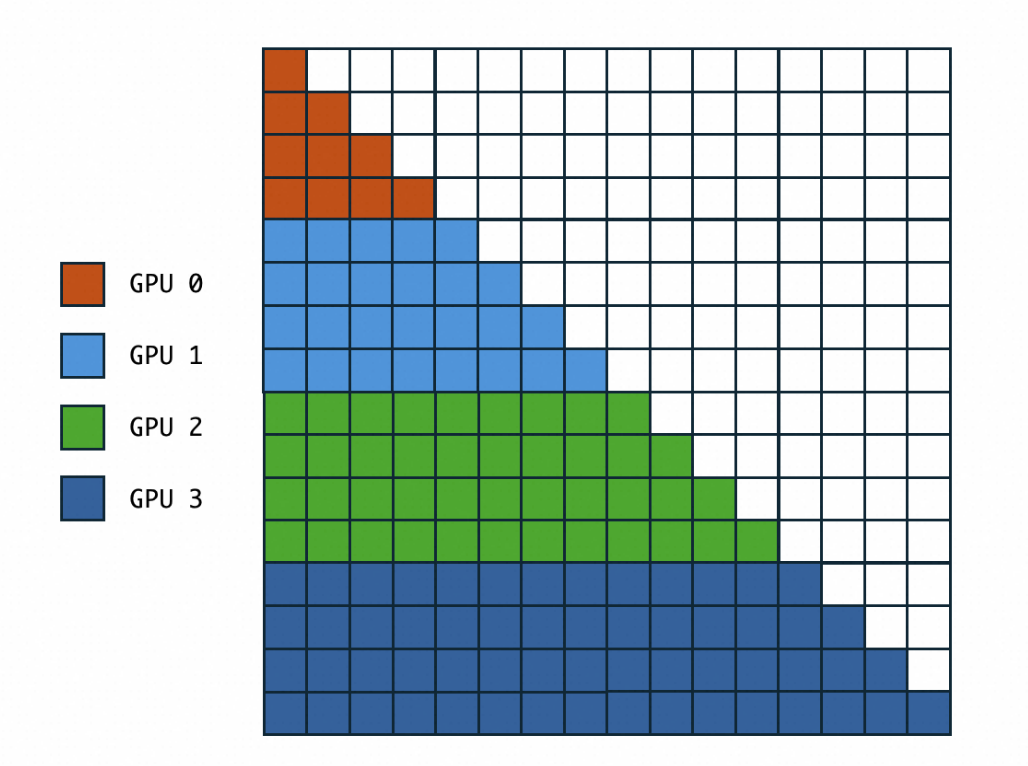
Since GPU 0 processes the front part of the sentence, when KV from other cards flows to GPU 0, the GPU cannot participate in computing the latter part of the sentence due to causal=True, while GPU 3 can compute the entire sequence from 0 to 2. Therefore, the computational load on each card is not consistent. Under this premise, Megatron-CP and some excellent implementations adopt zigzag partitioning:
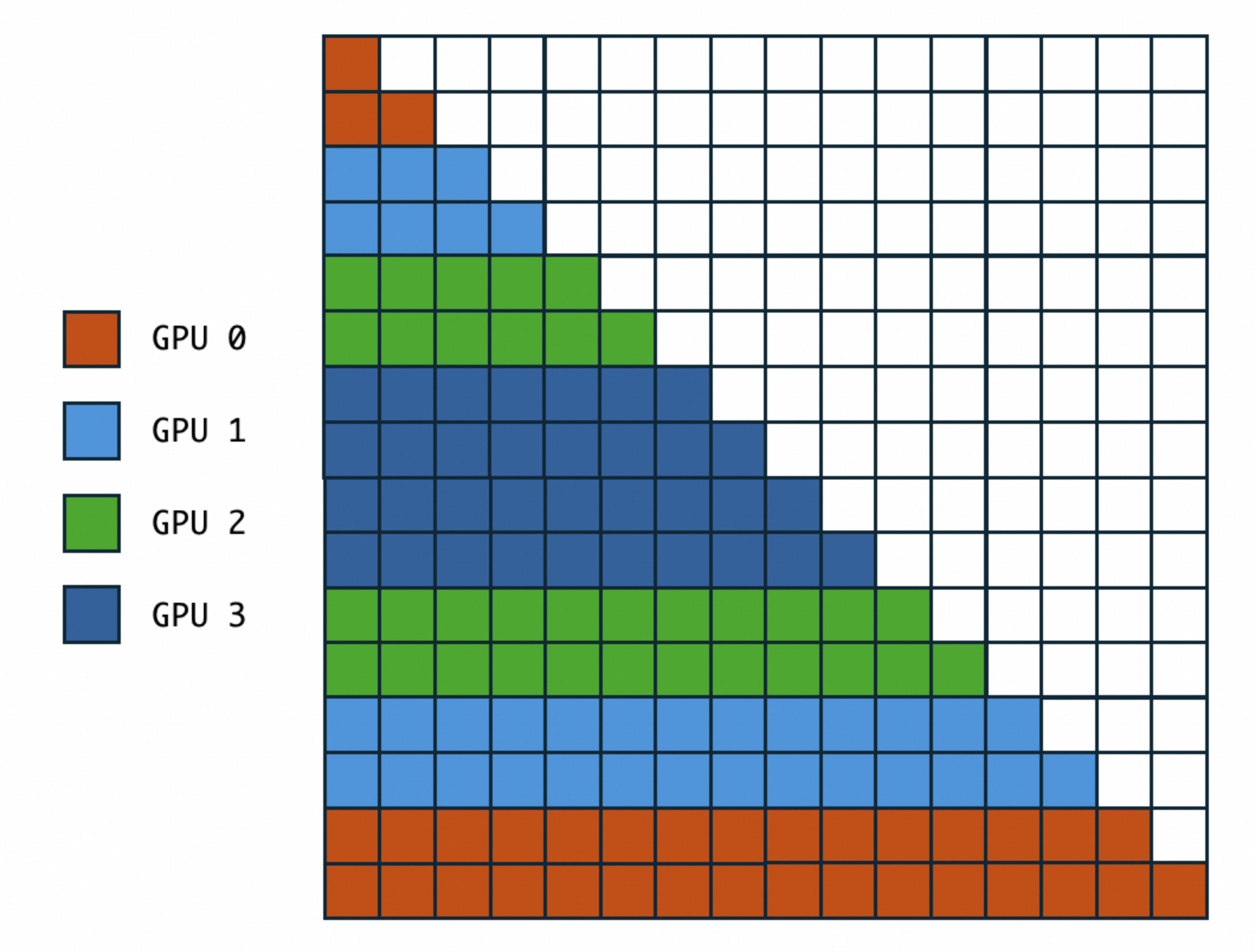
Assuming we need to partition across 4 cards, then under the condition that the sequence can be evenly divided into 8 pieces, we combine 0/7 together, 1/6 together, 2/5 and 3/4 respectively together. This ensures balanced computation. Moreover, this computation has another characteristic:
When computing QKV locally (sequence number 0), causal=True is computed directly
When the flow sequence number is less than or equal to the current rank, only the first half of KV needs to be computed
When the flow sequence number is greater than the current rank, only the second half of Q needs to be computed
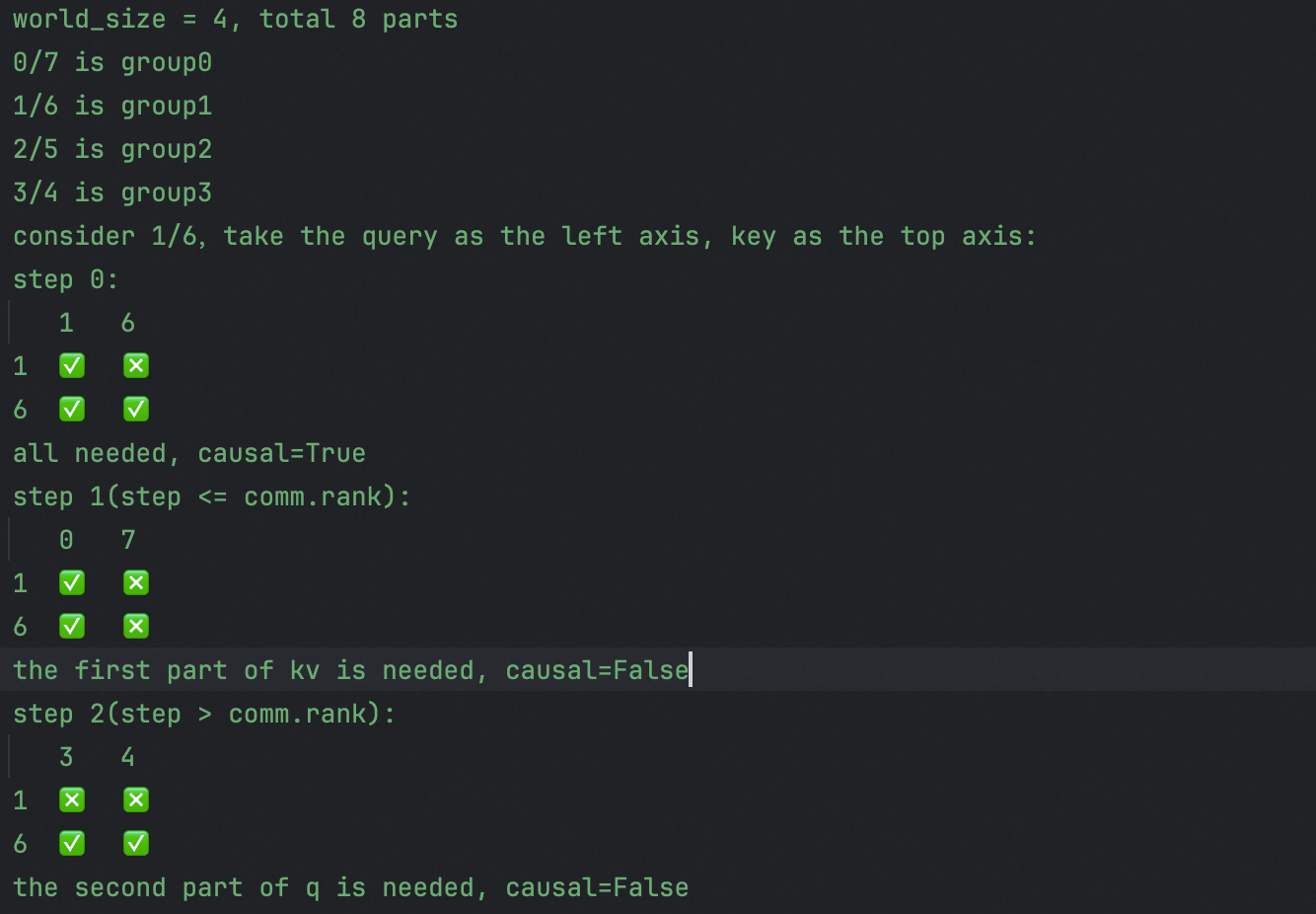
This further reduces the computational load. For code implementation, see:
Ulysses and Ring-Attention
It is not difficult to see that these two sequence parallelism schemes each have their own characteristics.
- Ulysses has relatively low communication overhead, but is limited by the number of Attention Heads, and all-to-all communication is sensitive to latency and has certain requirements for network topology.
- Ring-Attention's P2P ring communication has lower requirements, but has higher communication volume and is not limited by the number of Attention Heads.
From the above principles, we can see that Ulysses and Ring-Attention can actually be used in combination. We can first use Ulysses with lower communication volume for partitioning, and if the number of Attention Heads is insufficient (GQA), or the number of partitioned sequences is too large, then supplement with Ring-Attention.
SWIFT implements such a fusion computation technology, which is applicable to various scenarios including pure text, multimodal, SFT, DPO, GRPO, etc. In the basic code implementation, we adopted some excellent community open-source work[4][5] and rewrote parts of the code.
https://github.com/modelscope/ms-swift: https://github.com/modelscope/ms-swift
The usage is also very simple, just add an additional parameter in the command line:
--sequence_parallel_size N
The framework will automatically calculate the partitioning method, and can even support cases where the number of GPUs is not even (3, 5, 7, etc.).
Partitioning Method
The most natural approach is to first use Ulysses for local gather, then use Ring-Attention globally to compute global LSE and Attention-Out. Assuming partitioning into 4 subsequences (Ulysses world_size=2, Ring-Attention world_size=2), with model head=4:
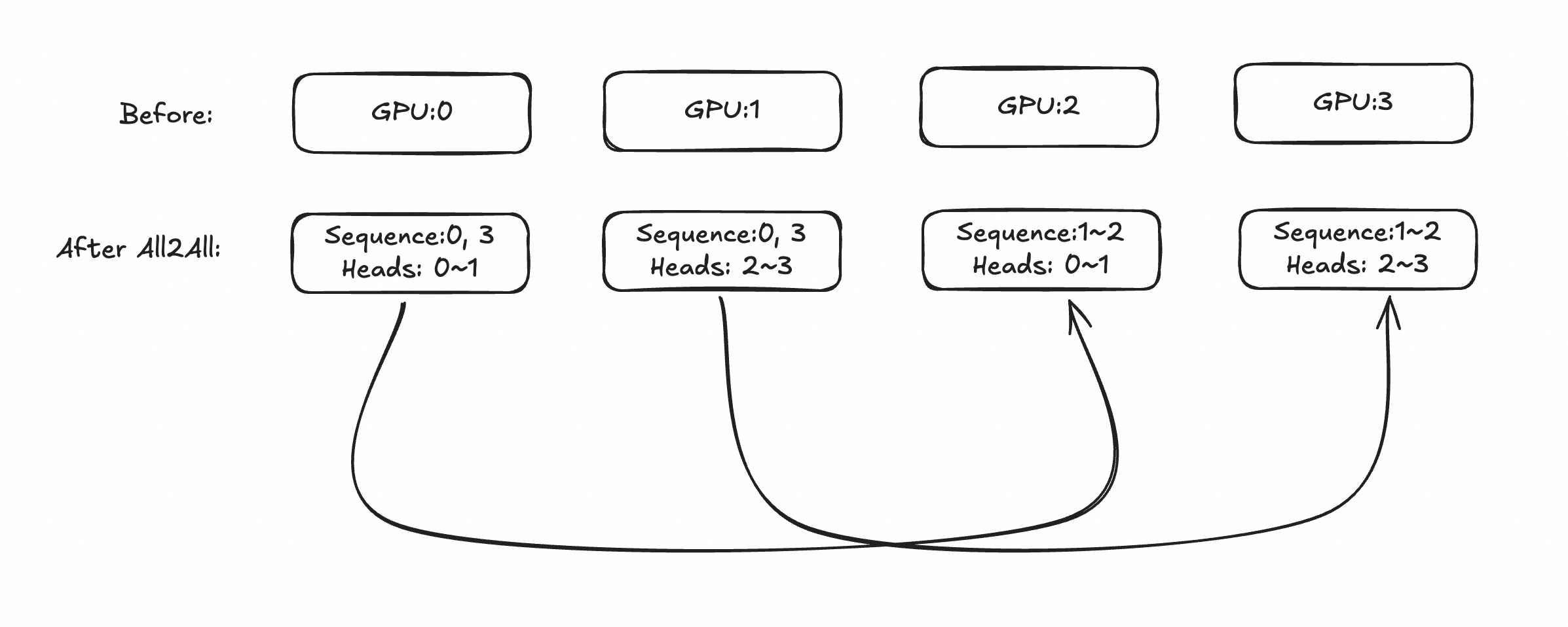
After Ulysses all-to-all communication, GPU0 and GPU1 as the same Ulysses group both hold sequences 0/3, but with different heads (first half and second half). GPU2 and GPU3 are similar. During Ring-Attention computation, GPU0 and GPU2 form a Ring-Attention group for ring communication, and GPU1 and GPU3 are similar.
Before partitioning, the sequence needs to be padded so that it can be divided by world_size*2 (multiplied by 2 because zigzag requires recombination of sub-blocks).
Multimodal Adaptation
Sequence partitioning adaptation for multimodal models is quite difficult, mainly due to:
The sequence length of multimodal models cannot be determined before actual forward pass. Some models only use a single
<image> tokento represent the multimodal part, and after ViT encodes the image, this token is replaced with a very long sequence.Some models' input sequences contain closure tags, such as
<image></image>, which cannot be partitioned before being replaced with actual image encoding, otherwise errors will be thrown directly.
Generally, multimodal LLMs contain inner and outer layers of models. The outer layer includes ViT processing and lm_head computation logic, while the inner layer computes decode_layers, which we call the backbone.
To adapt multimodal partitioning, SWIFT adopts an engineering trick during implementation: partitioning does not occur in the data preparation process (data_collator), but in the backbone's forward hook. This is because when entering the backbone, the multimodal encoding from the ViT part has already been fused with the pure text part, and the embedding obtained at this time has accurate length. Moreover, performing partitioning in the backbone's hook is also compatible with pure text models. This approach also allows the framework to avoid saving additional model code, preventing increased maintenance costs when original model code is updated.
Padding-free Adaptation
Padding-free can be understood as input format in flash-attention form: multiple sequences concatenated into one super-long sequence.
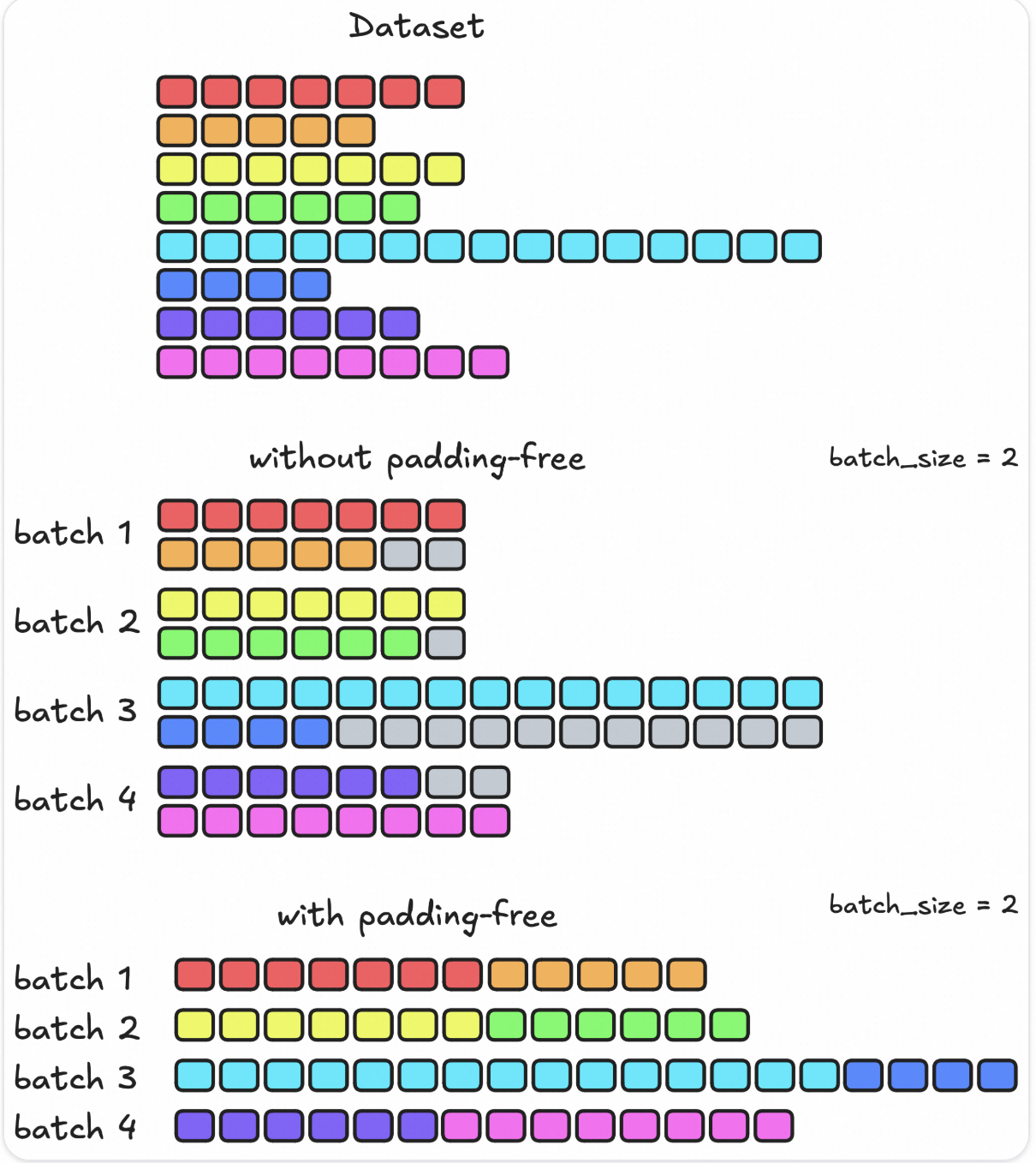
This approach brings trouble to actual engineering implementation. Therefore, in the implementation, SWIFT adopts the following engineering solution:
Decompose the original padding-free input, and perform padding (divisible by world_size*2) and separate partitioning for each sequence individually.
Before calculating attention, according to padding positions, set the padding of QV to 0 and the padding of K to extremely small values to prevent padding from adversely affecting attention computation.
Since GRPO and DPO final loss calculations require complete sequences, in padding_free, performing gather on logits first would increase communication volume, while performing gather later would cause abnormal loss calculations. Therefore, the loss calculation logic for each training method needs to be completely rewritten.
Since Q is only half-length when the communication sequence number is greater than rank, it needs to be restored to full length during backward gradient updates. Therefore, grad padding needs to be performed separately for each sequence, and LSE needs to be padded to extremely small values.
Backward Propagation
According to the formula derivation above, the backward propagation of LSE and Attention-Out block-wise updates needs to be performed sequentially and requires some forward information, such as block LSE, block Attention-Out, etc. Although this information can be obtained in the forward flash_attn_forward, saving it in ctx may consume additional memory. Therefore, we chose the approach of recalculating flash_attn_forward once during backward, then calculating lse_grad based on intermediate results, and subsequently performing actual backward on QKV.
Memory Optimization Results
We used a 3B model and tested the memory optimization effect on 8×A100 GPUs:
NPROC_PER_NODE=8 \
swift sft \
--model Qwen/Qwen2.5-3B-Instruct \
--dataset 'test.jsonl' \ # 9000 tokens per sequence
--train_type lora \
--torch_dtype bfloat16 \
--per_device_train_batch_size 4 \
--target_modules all-linear \
--gradient_accumulation_steps 8 \
--save_total_limit 2 \
--save_only_model true \
--save_steps 50 \
--max_length 65536 \
--warmup_ratio 0.05 \
--attn_impl flash_attn \
--sequence_parallel_size 8 \
--logging_steps 1 \
--use_logits_to_keep false \
--padding_free true
As shown at the beginning of the article, when split into 8 pieces, training memory usage decreased from nearly 80GiB to less than 20GiB, achieving the effect where ordinary commercial-grade graphics cards can perform training.
Outlook
This article explained the implementation of fused training capabilities combining Ulysses + Ring-Attention in the SWIFT framework. We are still continuing to explore further optimizations in this area, for example:
In backward, is recalculating flash_attention_forward the implementation that can achieve optimal speed?
There is still potential for continued optimization in P2P communication volume and asynchronous execution directions.
Developers interested in this can provide valuable suggestions to help SWIFT jointly improve large model training capabilities in long sequence scenarios.
References:








