In-Depth Analysis of the Latest Deep Research Technology: Cutting-Edge Architecture, Core Technologies, and Future Prospects






I. Introduction
Recent Developments
Since OpenAI officially released Deep Research in February 2025, deep research/deep search (Deep Research / Deep Search) has been emerging as a new paradigm for information retrieval and knowledge work: systems driven by multi-step reasoning to conduct large-scale networked retrieval, cross-source evidence aggregation, and structured writing, producing research-grade results with citations. By the end of February, this feature was made available to Plus users; in April, a "lightweight version" was launched, covering Plus/Team/Pro tiers, further lowering the barrier to entry.
Meanwhile, Google advanced AI Mode from experimental to official capability at I/O 2025, introducing "Deep Search": providing comprehensive reports with traceable sources for complex questions, while adding "agentic" operational capabilities such as autonomously searching and guiding restaurant reservations. Starting in July, it has been deeply integrated with the Gemini 2.5 series and gradually rolled out to paid tiers. Overall, major players represented by OpenAI and Google have pushed Deep Research Agents capable of autonomous retrieval, synthesis, and subsequent task execution into the mainstream, reshaping search standards in 2025. This period has also witnessed the emergence of numerous startups, developer-contributed open-source projects, and research papers.
Of course, the new paradigm brings new requirements for methodology and engineering: how to ensure traceability of citations and fact verification, evidence selection under cross-source conflicts, and balancing cost and latency in long-chain reasoning. These issues will determine the reliability and usability of Deep Research Agents in real business scenarios.
What This Article Will Address
Question 1: What are the definition and capability boundaries of Deep Research / Deep Search?
Question 2: What is the core technical architecture of Deep Research? What kind of rapid iteration has it undergone?
Question 3: What are the characteristics and commonalities in the architecture and design of mainstream approaches? What insights can we derive?
Note that this article is not a comprehensive survey and may not cover all aspects of the work, nor can it provide in-depth insights into all directions. It merely organizes some potentially reusable conclusions from the perspective of an intelligent agent framework developer. We also welcome everyone to follow the agent framework Ms-Agent: Lightweight Framework for Empowering Agents with Autonomous Exploration in Complex Task Scenarios that ModelScope will continuously update in the near future.
II. What is a Deep Research Agent?
Core Definition
Version 1: An application system built around LLMs as the core, attempting to solve automation and capability enhancement problems for research (in a broad sense) tasks.
Version 2: "AI agents powered by LLMs, integrating dynamic reasoning, adaptive planning, multi-iteration external data retrieval and tool use, and comprehensive analytical report generation for informational research tasks."
Core Capabilities
Intelligent Knowledge Discovery: Autonomous literature review, hypothesis generation, and research pattern recognition across different data sources;
End-to-End Workflow Automation: Complete end-to-end solution design (experimental or investigative), data collection/analysis, and result report generation through an AI-driven pipeline;
Collaborative Intelligence Enhancement: Providing user-friendly interfaces to facilitate human-AI collaboration, including natural language-based interaction, visualization, and dynamic knowledge representation.
Definition Boundaries
Difference from General Models/Agents: Automated workflows, specialized research tools, and end-to-end research planning and orchestration capabilities;
Difference from Single-Function Research Tools: For example, citation managers, literature search engines, and data analysis tools are isolated components, while DR can combine the reasoning capabilities of models with the capabilities of individual tools, solving problems through orchestration and planning;
Compared to Simple LLM Applications: Compared to early applications that simply provided research-oriented prompts for language models, it possesses environmental interaction, tool integration, and workflow automation capabilities.
Demand Distribution
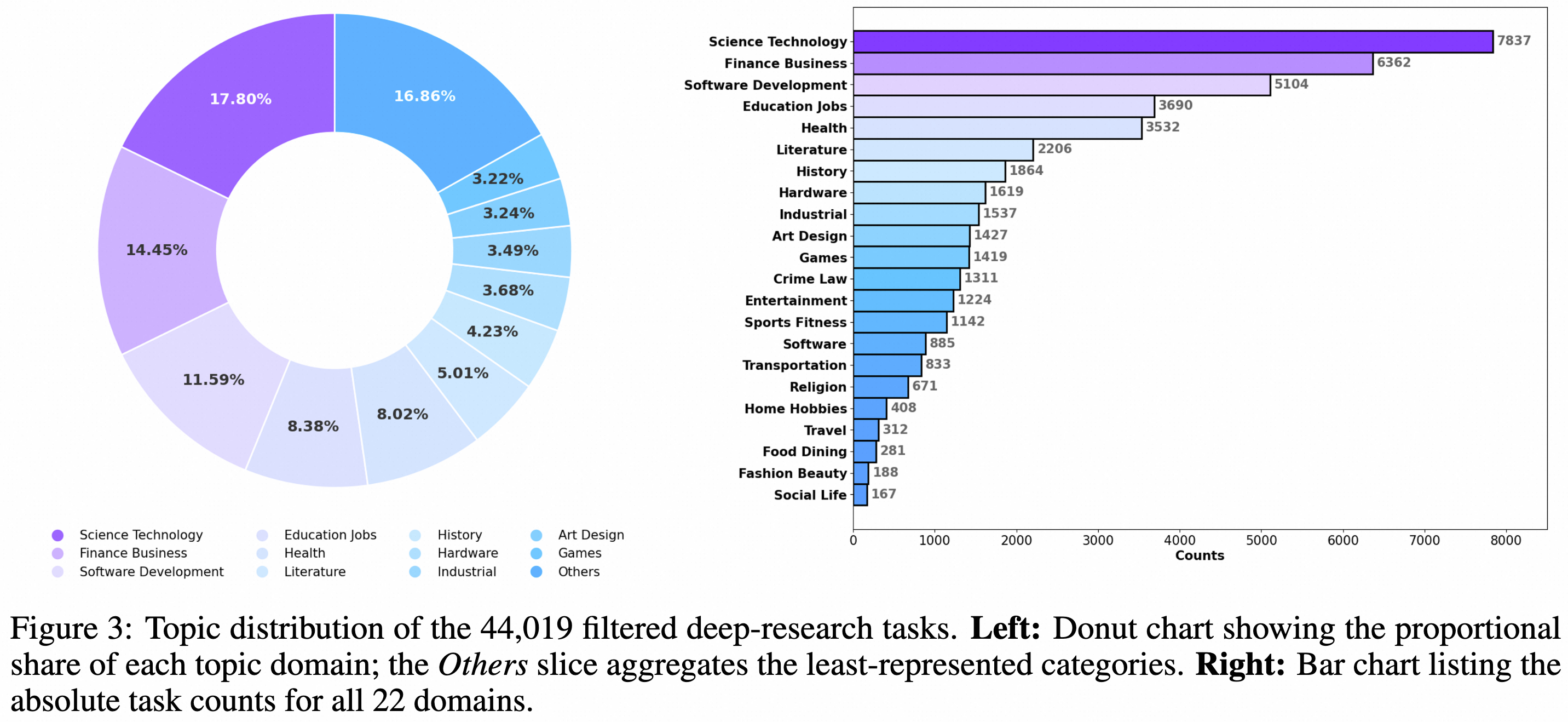

III. Core Technical Architecture of Deep Research Agent
Architecture & Workflow
As model capabilities continue to evolve, the design of agent architectures and workflows is also constantly developing. Based on the dependence on LLM's autonomous planning and dynamic adjustment capabilities, mainstream architectures can be broadly categorized into two types: static workflow and dynamic workflow.
Static Workflow
Static workflow primarily relies on human-defined task pipelines. For example, a research task is decomposed into four stages: requirement processing, information retrieval, content parsing, and summary output. Each stage predefines the tool components to be called and the sub-processes to be executed (such as conditional judgment, iterative optimization, etc.). Subsequently, agents are used to undertake part or all of the processes in each stage to obtain the final required output.
The advantages of static workflow lie in its clear structure and ease of implementation. Since each stage covers a limited scope of tasks, developers can more easily design good fault tolerance mechanisms to avoid the collapse of the entire workflow chain due to model capability instability. This approach has certain advantages in scenarios that require high task delivery stability, are not overly difficult, and have longer chains. Its disadvantages lie in limited generalization capability, as fixed processing steps prevent the workflow from effectively transferring to different task scenarios. For example, when facing work in different domains such as finance and computer science, it may be necessary to customize different pipelines separately.
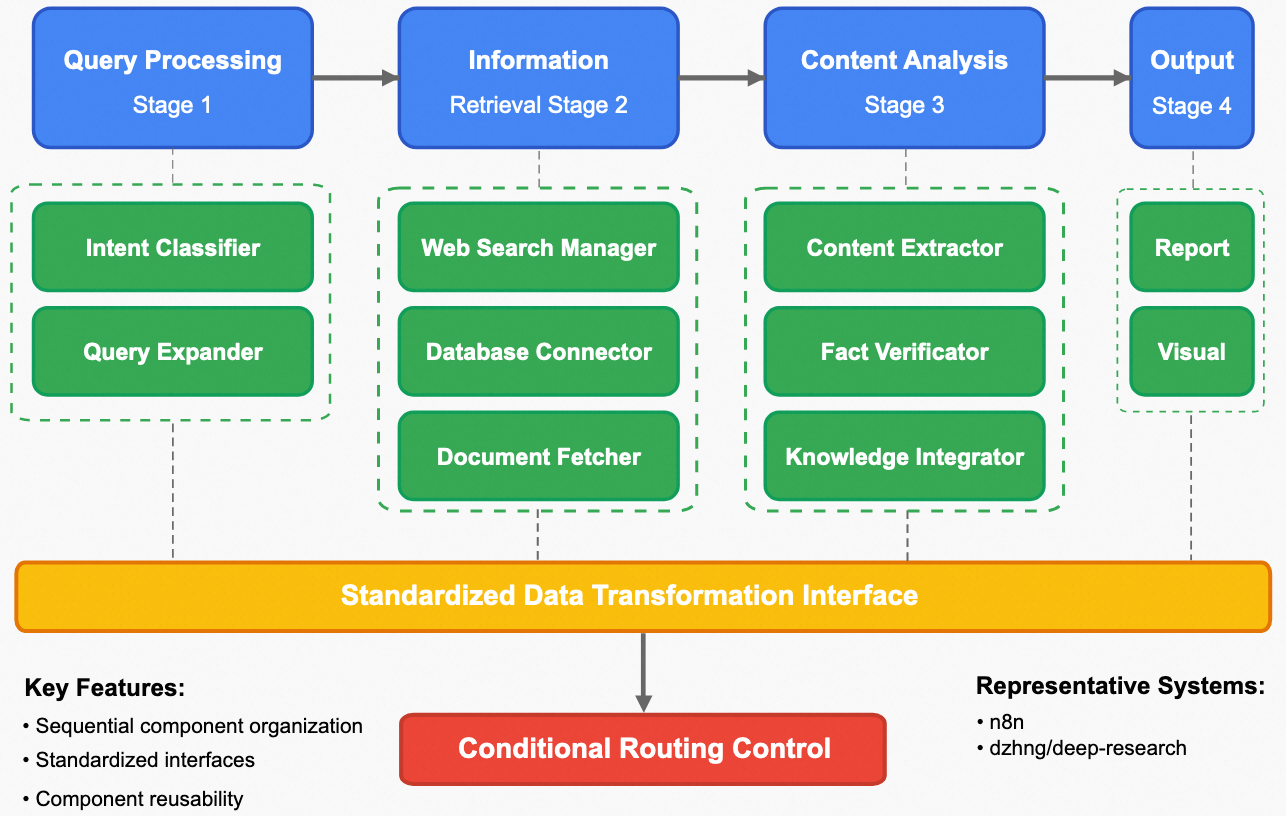
Dynamic Workflow
Dynamic workflow supports dynamic task planning, allowing agents to adjust future task execution steps based on feedback received during task execution and changing contexts. The model autonomously completes the closed-loop chain of task planning, execution, reflection, and adjustment, delivering final results.
The advantages of dynamic workflow lie in effectively solving the problems of static workflow in terms of flexibility and generalization capability, possessing stronger processing capabilities for complex tasks. Its disadvantages lie in the instability brought by higher requirements for LLM capabilities. Since the entire task is autonomously planned and executed by the model, developers will find it more difficult to design reasonable fault tolerance mechanisms to prevent task collapse, and the difficulty of troubleshooting errors will also increase.
In fact, in engineering practice, static pipelines and dynamic autonomous planning are not completely mutually exclusive. Properly coordinating the parts completed autonomously by agents and the parts with predefined processes in the agent framework can effectively balance the framework's stability and flexibility.
Furthermore, dynamic workflow can be subdivided into single-agent architecture and multi-agent architecture.
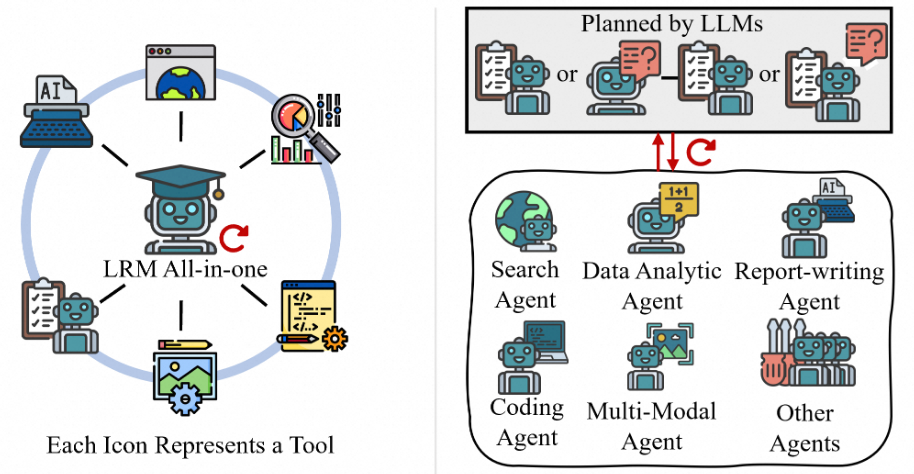
Single-Agent Architecture
Single-agent architecture completes tasks through the planning, execution, and reflection cycle of a single agent, typically relying on the model's own powerful reasoning capabilities and longer context windows. After receiving task requirements, the model autonomously decides all steps of the task and optimizes task planning, calls appropriate tools, and receives feedback based on the current context.
The advantages of single-agent architecture lie on one hand in its complete memory of contextual history, with no information opacity or coordination difficulties, and on the other hand in its support for end-to-end reinforcement learning, allowing the processes of reasoning, planning, and tool calling to be optimized. Its disadvantages lie in this paradigm placing higher requirements on foundational model capabilities, including the need for sufficiently long context windows, good context understanding/reasoning capabilities, stable tool calling capabilities, etc. Additionally, if one wants to optimize specific links or modules in a targeted manner, it becomes more difficult for this end-to-end black-box architecture.
Typical works such as Agent-R1, ReSearch, and Search-R1 all execute tasks based on reasoning, execution, and reflection cycles similar to the ReAct framework.
Multi-Agent Architecture
Multi-agent architecture achieves flexible task allocation through multiple specialized agents, distributing various aspects of task completion to different agents at a more granular level, simulating human team collaboration processes. For example, this architecture typically involves a planner agent for task understanding, decomposition, and allocation, followed by multiple sub-task agents (such as code, search, analysis, etc.) taking over the execution of sub-tasks, and finally specific agents delivering results in designated formats. The advantages of multi-agent architectures lie in their excellent scalability and flexibility. When handling complex tasks, different execution workflows can be selected based on task decomposition, achieving richer task orchestration through sequential or concurrent execution coordination. Under sufficient resource conditions, parallel processing by multiple sub-agents can also improve task completion efficiency. The disadvantages include, on one hand, the difficulty in designing coordination mechanisms between multiple agents - for example, since multiple agents cannot simultaneously share all contexts, designing reasonable context/memory management mechanisms is crucial for multi-agent collaboration processes. On the other hand, there are difficulties in end-to-end training optimization.
Typical works such as OpenManus and deerflow all adopt hierarchical planner-subtask executor architectures.
Tool Usage
Whether it's the previous tool call or the recently emerging mcp, developers have been continuously trying to enable models to handle complex real-world tasks through tool invocation processes similar to humans. The following introduces some commonly used tools, including search, code interpreters, multimodal processing, etc.
Web Search
For deep research tasks, search quality almost directly determines the quality and cost of generated reports. How to recall the most relevant, high-quality information at the lowest cost is the core issue that needs attention. The main ways models integrate search are through search APIs and browser simulation.
Based on Search APIs
By sending requests to search engines (Google, Bing, Tavily, etc.) or retrieval APIs provided by scientific databases, structured return data is directly obtained for subsequent processing. This usually includes website URLs and summaries associated with search requests, and requires payment of certain fees based on the number of calls. After obtaining search results, further filtering of URLs and requesting webpage content for specific URLs is needed. Some common solutions are summarized as follows:
| Work | API Solution | Characteristics |
|---|---|---|
| Gemini DR | Multi-source aggregation: Google Search API, arXiv API, etc. | 1. Multiple sources, wide range, multi-round recall (estimated total sources per retrieval > 50) |
| Grok DeepSearch | Continuously updates and maintains internal knowledge index through News-Outlet Feeds, Wikipedia API, and X's native interface, having LLM Agent decompose sub-queries for index and page crawling when needed | 1. Hybrid indexing system: traditional keyword search + vector-based semantic indexing 2. Requires real-time index updates 3. Does not retrieve real-time internet information but relies on preprocessed index 4. Recall scope is not very large (personal observation) |
| AgentLaboratory | arXiv API extracts paper metadata | 1. Few sources, stable, easy to parse |
| AI Scientist | Semantic Scholar API | 1. Can parse novelty and citation relationships of model-generated ideas |
| CoSearchAgent | SerpApi | 1. Essentially engines like Google, Bing, providing real-time engine retrieval 2. Based on Slack platform |
| DeepRetrieval | PubMed and ClinicalTrials.gov APIs | 1. Based on specific interfaces and reinforcement learning framework, specifically optimizes API-based queries to improve recall for biomedical tasks |
| Search-o1 | Bing Search API + Jina Reader API | 1. Directly completes parsing and returns reasoning-ready content 2. But depends on Jina Reader's parsing capabilities, not completely transparent |
Main disadvantages: Limited by the functionality provided by APIs and the format of returned data, unable to flexibly complete form filling and webpage operations, and cannot obtain content that requires dynamic loading.
Based on Browser Simulation
Directly simulating human operations in browsers running locally or in sandbox environments, simulating clicks, scrolling, form filling, JavaScript execution, and real-time extraction of webpage content. The figure below shows a schematic diagram of using sandbox browsers for retrieval in ChatGPT agent mode.

Main disadvantages: High resource consumption, high latency, and parsing dynamic, diverse webpage content is prone to bottlenecks.
Code Interpreter (Data Analysis)
Usually Python code is executed in a sandbox environment, providing intelligent agents with data processing, algorithm validation, and model simulation capabilities. Executable tasks include: automatically calculating mean, variance, median, etc.; creating charts, heatmaps, etc.; extracting metrics from text or tables and performing comparisons.
CoSearchAgent: Integrates SQL query capabilities to perform aggregated analysis on databases and generate reports.
AutoGLM: Can directly extract structured data from web tables and perform analysis.
Multimodal Processing and Generation
Supports processing of images, audio, and video, such as completing speech transcription, video summarization, image annotation and other tasks to meet subsequent task requirements. It can also implement various modal outputs based on TTS technology, text-to-image/video generation, and can utilize mermaid syntax to draw various common flowcharts and tables.
This functionality is currently supported by only a few mature commercial or open-source projects, such as Manus, OWL, OpenAI Deep Research, Gemini Deep Research, Grok DeepSearch, etc. However, most of them still cannot support end-to-end generation of multimodal reports. The Agentic Insight and Doc Research projects in the Ms-Agent project are among the few works in the open-source community that possess end-to-end text-image report generation capabilities. Their implementation is mainly based on a hierarchical information extraction strategy with charts as core nodes, which can effectively associate charts with context and produce high-quality text-image reports at low cost and high efficiency.
Optimization Methods
Prompt Engineering
The lowest-cost method with the fastest migration speed, but limited by the LLM's own generalization ability, it has limited robustness in complex and highly variable task settings. It is suitable for rapid prototyping but difficult to systematically optimize complex workflows, requiring repeated debugging.
- Common methods include ReAct (reasoning & acting), CoT (chain of thought), ToT (tree-of-thought), etc.
Supervised Fine-tuning
By constructing high-quality specialized fine-tuning data, it can specifically optimize the agent's performance in specific aspects of deep research, such as optimizing search query rewriting, tool invocation, and structured report generation capabilities.
Open-RAG: Incorporates different supervisory signals such as retrieval markers, relevance markers, grounding markers, and tool markers in data construction, improving the ability to filter irrelevant information through adversarial training.
AUTO-RAG: Constructs reasoning-based instruction datasets, enabling models to autonomously plan retrieval queries and execute multi-round interactions during generation.
DeepRAG: Adopts a binary tree-based search mechanism, recursively generating sub-queries and constructing multi-round retrieval trajectories, improving retrieval efficiency while balancing internal and external knowledge.
Uses rejection sampling-based fine-tuning methods to reduce dependence on SFT data, such as CoRAG, Start, and ATLAS, by extracting retrieval chains from existing Q&A data and monitoring tool invocation information during generation, encouraging models to learn autonomous tool invocation.
Reinforcement Learning
Optimizes the agent's information retrieval, dynamic tool invocation, and complex reasoning capabilities through real interaction with the environment and obtained reward signals.
Agent-R1: Represents a comprehensive framework for end-to-end RL training, supporting invocation of multiple tools such as APIs, search engines, and databases, achieving automated multi-step task execution and plan optimization.
WebThinker: Introduces a web resource retriever module for multi-hop web search, using Iterative Online DPO to achieve seamless interleaving of retrieval, navigation, and report writing.
Pangu DeepDiver: Adopts two-stage SFT+RL curriculum training, adaptively adjusting search depth in open web environments through a search intensity regulation mechanism.
In the selection of reward models, most open-source implementations use rule-based reward models, explicitly defining task-specific objectives such as retrieval relevance, information accuracy, and tool invocation success rate; some works also use policy optimization methods such as PPO and GRPO.
Non-parametric Continual Learning
Optimizes agent capabilities through continuous interaction to improve external memory banks, workflows, and tool configurations.
- CBR (Case-Based Reasoning): Agents retrieve, adapt, and reuse existing structured problem-solving trajectories from external case libraries. For example, DS-Agent introduces CBR in automated data science, performing approximate online retrieval from constructed case libraries; AgentRxiv simulates an updatable arXiv-style platform as a comprehensive case bank, allowing research agents to share and reuse previous research reports. Since no model parameter adjustment is required, CBR is particularly suitable for achieving continuous improvement of agent capabilities in scenarios with scarce data or limited computational resources.
IV. Analysis of Mainstream Closed/Open Source Works
Closed Source Works
| DR Agent | Base Model | Agent Architecture | SFT | RL | Key Feature | Generation Time |
|---|---|---|---|---|---|---|
| #### OpenAI Deep Research | GPT-O3 | Single-Agent | not present | detail unknown | 1. Intent-to-Planning: Proposes follow-up questions about the problem to help users clarify details, then proceeds with planning. 2. Iterative workflow optimization: Further clarifies requirements and conducts additional searches during the search process, gradually deepening and performing cross-comparisons, etc. 3. Strong contextual memory capability & supports multimodal understanding: Input and retrieval support multimodal understanding, with text modal output. 4. Comprehensive tool chain integration: Web search, built-in programming tools (less commonly used for general literature research tasks). |
5~30min |
| #### Gemini Deep Research | Gemini‑2.0‑Flash | Single-Agent | detail unknown | detail unknown | 1. Unified Intent-Planning: Generates a plan based on research requirements, then asks users to confirm whether to modify the plan. If modifications are needed, a new round of dialogue is initiated; in fact, this step can also require clarification of concepts and other elements, then generate a new plan. 2. Asynchronous task management: Uses asynchronous task management architecture to handle multiple simultaneous tasks. 3. Long context window RAG support: Supports multimodal input, text modal output. 4. High-speed adaptive retrieval: Implements fast, multi-round, more information-rich web retrieval. |
5~10min |
| #### Perplexity Deep Research | \ | \ | \ | \ | 1. Planning-only: Directly generates a plan based on the query and then executes it. 2. Iterative information retrieval: Does not have very fine-grained task decomposition, quickly begins multi-round searches on multiple sub-topics, with a large number of sources recalled per round (19, 20), conducting progressive retrieval. 3. Dynamic model (workflow) selection: Automatically selects reasonable architecture (model + workflow) based on requirements + context; can also manually specify specific search sources (entire web, academic...) and all categories (academic, financial, lifestyle) in advance. 4. Multimodal integration: Uses python to support chart generation, including roadmaps, csv files, etc. |
2~4min |
| #### Grok DeepSearch | Grok 3 | Single-Agent | not present | detail unknown | 1. Planning-only: Directly generates a plan based on the query and then executes it. The model's thinking process will clarify actual concepts and then proceed step by step. 2. Chunked processing workflow: 1. Single-round retrieval (it seems deepsee arch mode all recall 10 web pages); 2. Gradually analyze content based on content framework; 3. Finally integrate into a report. 3. Dynamic resource allocation (unverified): Adaptively switches between lightweight retrieval and intensive retrieval, integrates secure sandbox environment for computational verification. 4. Multimodal integration: Multimodal input, text modal output. |
Around 5min |
| #### Qwen Deep Research | Qwen3-235B-A22B | Single-Agent | \ | \ | 1. Intent-to-Planning: Proposes follow-up questions about the problem to help users clarify details, then proceeds with planning. 2. Concurrent task orchestration: Parallel retrieval verification analysis. 3. Not integrated multimodal: Single modal input, single modal output. |
10~20 minutes |
Open Source Work
A.deep research
Work Source
Author: David Zhang Co-founder & CEO @ Aomni (aomni.com)
github: https://github.com/dzhng/deep-research star 17.6k
Main Architecture
1) Basic Configuration
- Search Engine: Firecrawl API (for web search and content extraction)
- Model: OpenAI API (for o3 mini model)
2) Architecture Classification
- static workflow
3) Workflow
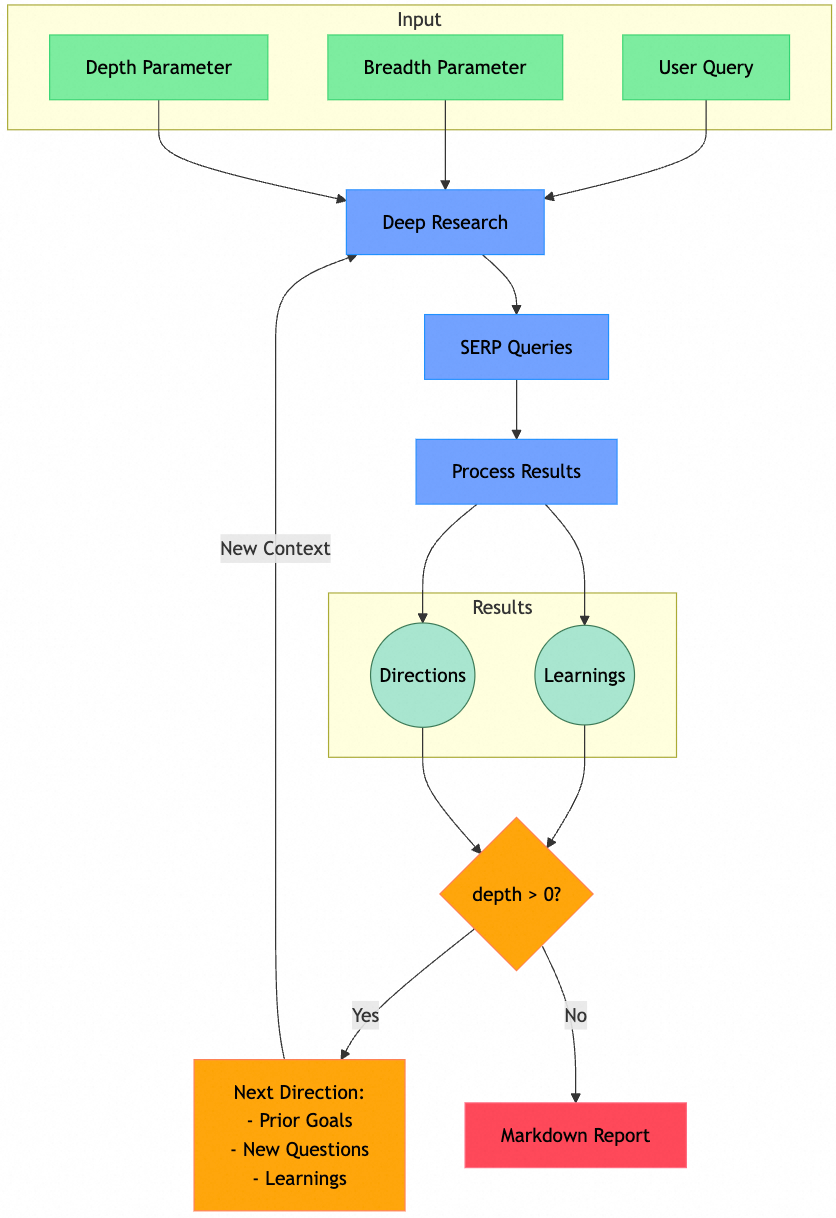
Query and Parameter Input:
- Requires input of query, depth (number of iterations), breadth (number of search queries per round), and isReport (report or simple answer).
Human-in-the-loop (report mode):
Calls the model to generate questions asking users to clarify research questions, with an upper limit on the number of questions;
Combines initial query, follow-up questions, and user answers as input query.
Deep Research Recursion
Search query generation: Input the aforementioned query and existing research learnings, requiring the model to generate serp search queries and corresponding research objectives, ensuring diversity and specificity while progressing with research depth;
Concurrent retrieval and parsing: Use firecrawl to search and crawl content, input to model requiring summarization of learnings and follow-up questions;
Manage depth and breadth states: depth = depth - 1; breadth = breadth / 2;
Generate new input query: Combine historical research objectives and generated follow-up questions;
Judge depth conditions: (1) If greater than 0, recursively call Deep Research; (2) If equal to 0, recursively return all learnings information and URL access history; (3) When errors occur, discard the node, and learnings information from predecessor nodes is returned by other nodes at the same level.
Post-processing
- Deduplication and merging: After the search tree is formed, retain all learnings and URL access history and deduplicate.
Result Generation
- Call model to generate report or direct reply: Input learnings, combined query obtained from human-in-the-loop stage, system prompts, historical URLs (not used in direct reply mode, mainly used for report generation citations).
Core Features
Iterative Search: Recursively build search trees based on custom depth and width, continuously generating search queries and crawling new content based on historical learnings;
Query Generation: Use agents to generate targeted search queries based on research objectives and previous learnings;
Depth/Breadth Control: Explicitly expose search tree parameters, allowing users to decide how to trade-off;
Concurrent Processing: Process multiple searches and result processing in parallel (but this is affected by API calls, non-paying users may not allow too high concurrency).
Summary
Using LLM to Summarize and Extract Learnings: Without excessive consideration of budget and possible hallucinations (assuming model capabilities meet requirements), independently summarizing large amounts of search results may reduce context pressure for final report generation, and can improve information coverage while delivering relatively clean context to the report generation stage, leading to improved generation effectiveness.
Building Search Trees: Methods to extend simple linear or loop-based search pipelines can reference recursive construction of search trees, using the same historical information and research objectives to automatically generate search queries during the process. The advantage is that tree-structured search history seems to have better diversity than loop optimization or linear search history, avoiding scenarios where ideal sources cannot be recalled; but the disadvantage is that massively growing search content may lead to context explosion, which must be combined with LLM summarization and extraction of learnings.
Exposing Control Options: Expose cost and time control options to users for trade-offs, avoiding difficulties in balancing token consumption, operational efficiency, and result quality.
Code Implementation: The author provides a very lightweight and concise implementation, supporting API and command-line calls.
B.DeerFlow
Work Source
- Author: ByteDance deerflow team
- github:https://github.com/bytedance/deer-flow star 16.7k
Main Architecture
1) Basic Configuration
Search Engine: Tavily (default), DuckDuckGo, Brave Search, Arxiv
Personal Knowledge Base: RAGFlow, vikingdb
Models: OpenAI-compatible API interface, open source models like Qwen, litellm integrable models
2) Architecture Classification
- Multi-Agent
3) Workflow
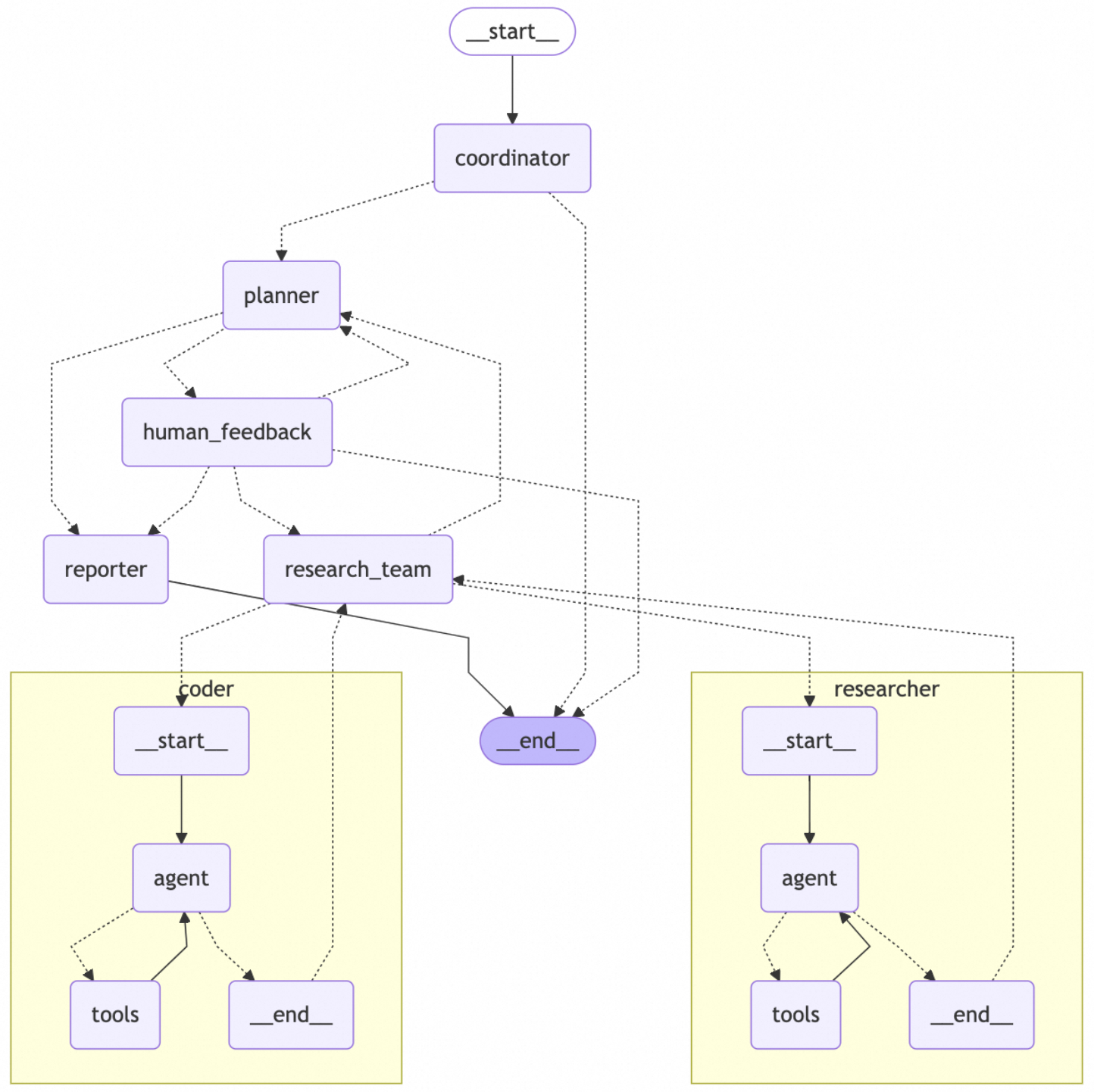
Coordinator Judgment:
Receives user questions for response and tool invocation
simple greeting or small talk: correct response;
security/moral risk: polite refusal;
needs more information: correct inquiry;
other situations: (1) call handoff_to_planner, generate research_topic and locale, without any further thinking; (2) if enable_background_investigation is set, then hands off to background_investigator.
Background_investigator Search
Search: uses the research topic passed by coordinator as query to directly perform search;
Transfer: hands off to planner after search completion.
Planner Determines Research Plan
Background information acquisition: if background_investigation exists, add it from state to context before inputting to planner;
Check loop boundary: check if plan count is greater than maximum count, otherwise hands off to reporter;
Plan generation: output plan in json format based on context, if json generation fails, decide whether to hands off to reporter or __end__ node based on whether there is contextual information;
Plan check: (1) if context is already sufficient to meet answer requirements, hands off to reporter; (2) otherwise hands off to human feedback (mandatory in normal execution flow, planner does not directly lead to researcher).
Human Feedback Modifies Plan
Reject plan: pass user feedback back to planner for plan regeneration, if generated normally then always return to human feedback;
Accept plan: check if the plan json in state can be loaded normally, if failed then decide whether to hands off to reporter or __end__ based on whether there is contextual information; if loaded normally then hands off to research team.
Research Team Executes Plan
If research plan parsing encounters problems, return to planner;
According to the step information in research plan, sequentially call researcher and coder for data collection or code execution, both are react-style agents; each time researcher or coder execution ends, return to research team, then decide which one to call next according to the plan: (1) researcher: web search, local database search; (2) coder: can execute python tools.
After completing the plan, hands off back to the planner's operational logic (above): (1) If the Planner considers the research complete, it will handoff to the Reporter; (2) Otherwise, it will continue planning (Re-plan) and handoff back to the Research Team for the next round of research iteration until final completion.
Reporter outputs report
- Obtains contextual information such as plan and observations (researcher and coder) to generate reports (supports multimodal).
Core Features
human-in-the-loop: Supports plan modification (similar to gemini deep research).
Report Post-Editing: Supports continued modification after report generation.
Content Generation: Supports multiple forms of output including podcasts and PPT presentations.
Summary
Tool Implementation Reference
Retrieval Tools: Only implemented simple search engine wrappers, with calls dependent on model capabilities to generate input parameters (prompts);
Content Parsing and Multimodal: (1) Relies on jina api for parsing to obtain text and image content, with the reporter model generating references to images; (2) jina can obtain image URLs and image descriptions, with models parsing this content rather than directly understanding images.
Global State Management: Uses a state to record core contextual information required and produced by each node, passed between all nodes;
Overall Evaluation: A multi-agent implementation centered on model capabilities, where tools are passed to react-style agents in tool form, providing extensive standardized prompts for reference.
C.sicra(mini-perplex)
Note
- Only the extreme search portion may be somewhat oriented toward deep search, while others are still relatively close to benchmarking against perplexity. However, the generation length of the extreme search portion is currently quite limited, with similar issues to those existing in perplexity.
Work Source
Author: Zaid Mukaddam (Independent Developer)
github: https://github.com/zaidmukaddam/scira star 10.5k
Main Architecture
1) Basic Configuration
Search: exa, tavily, x, reddit
Tools: Google Maps, OpenWeather, Daytona, TMDB, Aviation Stack
Models: xAI, Google, Anthropic, OpenAI, GRoq
2) Architecture Classification
- pipeline-based
3) Workflow (extreme mode)
Search Mode Grouping
Frontend explicitly specifies search mode and model to use;
Performs user information validation, model permission validation, etc.;
Allocates available tool groups and instructions according to search mode, such as using extreme search tools and corresponding sys prompts for extreme mode corresponding to deep search.
Model Streaming Call
- Passes in sys prompt, user query, and tools (e.g., Extreme Search Tool, requiring the model to immediately call the search tool without modifying user information).
Inside Extreme Search Tool
plan: Uses original prompt + built-in model scira-x-fast for breakdown.
Requires different key aspects that need to be researched under the topic
Requires generating specific, diverse search queries for each aspect
research: Use plan results + built-in model scira-x-fast-mini + tools (code and search) for search-driven research.
* Requires sequential execution of queries
* Requires a certain number of searches for the target topic
* Requires enriched research perspectives: broad overview → specific details → recent developments → expert opinions
* Requires specification of different categories: news, research papers, company info, financial reports, github
* Requires progressive search refinement
* Requires diversity and cross-validationsearch tool: Receives search query and category (possibly empty) to perform searches; parses URL content.
Search: exa + keyword
Parsing: exa's get_content interface
coding tool: Receives code and uses sandbox to run code and return results (visualization, mathematical computation, data analysis).
Core Features
Multiple search modes allocated for different needs: Web (general), Memory, Analysis, Chat, X, Reddit, Academic, YouTube, Extreme.
Tool adaptation provided for various functions: Core Search & Information, Academic & Research, Entertainment & Media, Financial & Data Analysis, Location & Travel, Productivity & Utilities.
Summary
Formulate search modes (tools, prompts, etc.) according to different scenarios: delegated to user specification, further matching targeted tools for scenarios; does not attempt to solve all scenario requirements with a single pipeline.
Framework relies on prompt engineering and simple model streaming calls for task layering, without involving frameworks like react:
Select models for different stages and components according to different principles, user-specified models (tool scheduling, analysis, report generation), models within tools (plan, research and other stages independently call LLM, also using only prompts, tools and regular generation);
Deep search functionality is toolified, using lower-cost, smaller models with decent specific capabilities to execute specific processes and provide context, using user-specified more capable models for analysis and invocation.
Search optimization logic may not rely solely on finding sufficiently powerful search engines:
Simple keyword search can also achieve good results when combined with prompts (diversity, category);
More dependent on Agent capabilities (prompts, reflection), simple API replacement or search engine replacement may not bring deterministic benefits;
Problems with clear scenarios can rely on specialized engines as supplements: arxiv, x, reddit, semantic scholar, etc.
D.open_deep_research
Work Source
Author: langchain-ai
github: https://github.com/langchain-ai/open_deep_research star 8.5k
Blog: https://blog.langchain.com/open-deep-research, https://rlancemartin.github.io/2025/07/30/bitter_lesson
Main Architecture
1) Basic Configuration
Search: Tavily (default), supports native web search for anthropic and openai, supports MCP
Tools: Supports extensive MCP tool compatibility
Models: Summarization (openai:gpt-4.1-mini), Research/Compression/Final Report Model (openai:gpt-4.1)
2) Architecture Classification
- Multi-Agent
3) Workflow

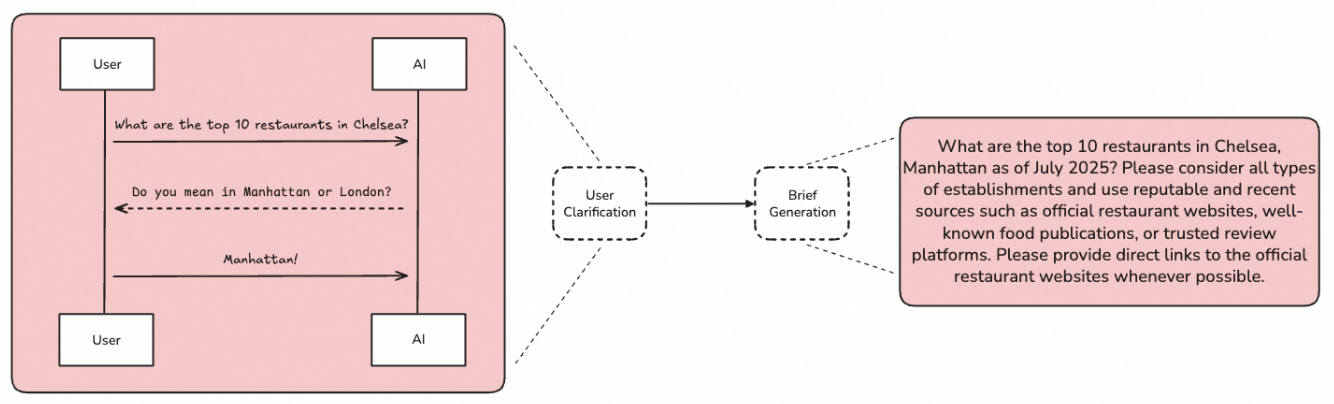
Research Scope -> Confirm Research Intent
User Intent Clarification: Requires the model to ask users for additional context to clarify (can be multi-turn, few-shot, etc.).
Research Summary Generation: Generates a summary covering research questions, research requirements, research approach, report requirements, etc., serving as a key summary to reference throughout the research process.
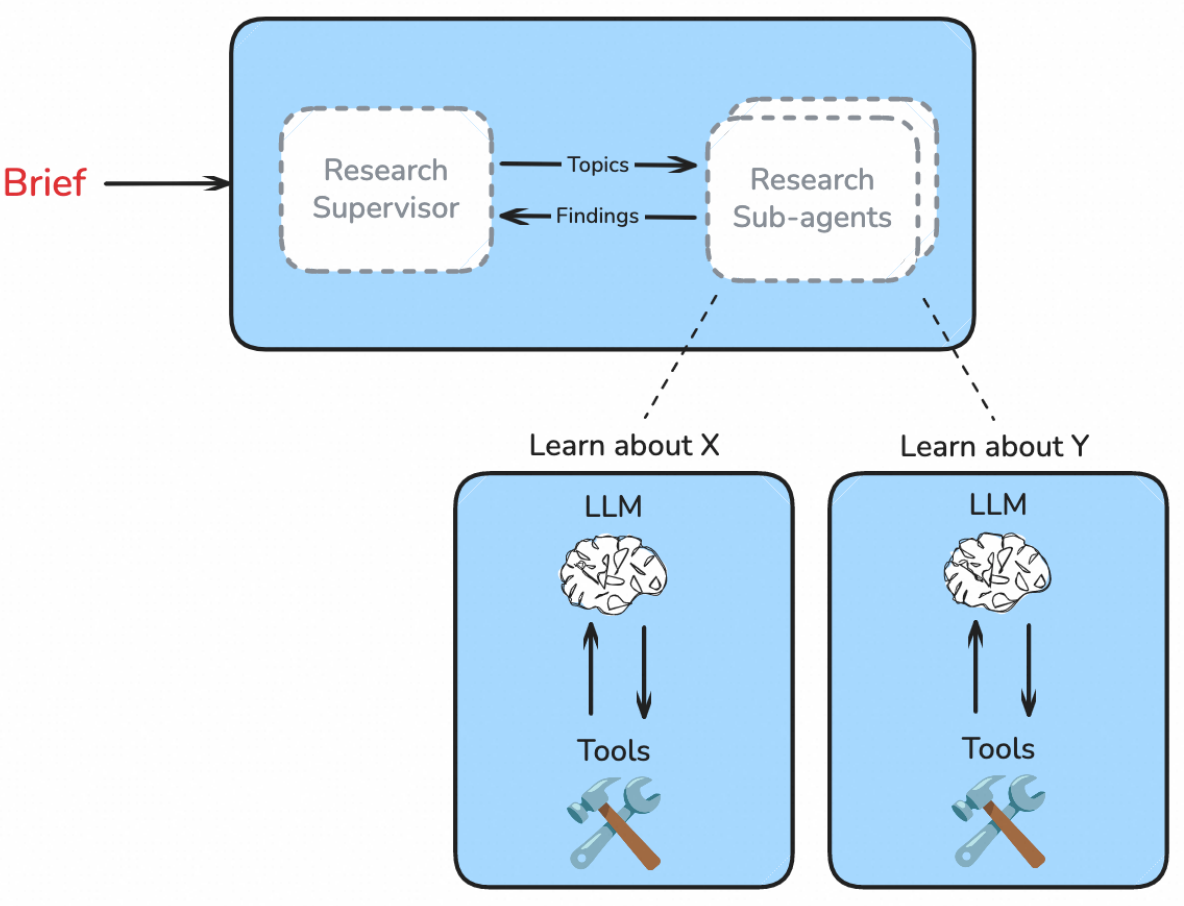
Execute Research -> Obtain Context
Research Supervisor: Receives the research summary and breaks it down into multiple independent sub-topics, with each sub-topic assigned to a sub-agent (context isolation) for parallel information collection.
Research Sub-Agents:
Based on sub-topics distributed by the Supervisor, conduct research through tool-calling loops (search tools or other MCP tools), without focusing on global information;
After completing research, summarize information and form findings with citations based on collected information (web pages, tool call information) and current topic questions to be solved, then return to Supervisor.
Research Supervisor Iteration: Reflects based on Sub-Agents' findings and research summary to determine whether further information collection is needed. If needed, generates sub-topics and distributes them until the task is completed.
Write Report -> Form Output
Based on the findings accumulated from the aforementioned process and the initial research summary, directly generates the final report.
Core Features
- Complete Research Intent Clarification: After asking questions in an OpenAI-like manner, proactively creates a summary and reflection that is not a breakdown plan.
- Cleaner context delivery: The three stages and agents interact through processed content. Specifically, the research intent confirmation stage delivers model-generated research summaries to the research execution stage, the supervisor receives research summaries and generates sub-topics to distribute to sub-agents, sub-agents summarize retrieved information with the purpose of responding to sub-topics and deliver learning summaries to the supervisor, and research summaries along with all learnings are delivered together to the agent responsible for report generation.
Summary
Maintaining the dynamic characteristics of deep research workflow: For problems of different difficulty and types, the architecture should ideally be configurable or capable of automatic expansion and dynamic adjustment, such as models autonomously adjusting the number of concurrent sub-topics and research depth.
Trade-off needed between tool-calling loops and workflow: Experiments are needed to verify the proportion and design approach of both. From the conclusions given by current work, allowing models to autonomously perform tool calling at the sub-agent level while maintaining supervisor planning and reflection at the global level can better balance stability and flexibility, representing a reasonable trade-off between static workflow and LLM autonomous tool calling loops. That is, having sub-task agents take complete control over small and focused tasks, while artificially defining processes at the global level.
Information isolation and result coherence issues among multi-agents can be solved by replacing intermediate deliverable content: The author's blog mentions that if each sub-agent independently completes a chapter and then attempts to merge them, it would be very difficult to coordinate coherence; however, if sub-agents only deliver searched and organized information, letting the final report generation agent write the article, the coherence problem would be resolved.
Reasonable context design can reduce excessive requirements for model capabilities and improve result quality: The operation where sub-agents provide learnings to the supervisor in this work is similar to David Zhang's deep research mentioned earlier. Combined with recent experimental observations of debugging agent performance in workflows, a preliminary conclusion is that clean, easily processable context design can improve the performance of models with insufficient capabilities, such as avoiding delivering logically confused and structurally chaotic contexts when generating reports to reduce report errors.
E.Open Deep Search
Work Source
Author: Sentient team (open-source AI platform)
github: https://github.com/sentient-agi/OpenDeepSearch?tab=readme-ov-file star 3.5k
Main Architecture
1) Basic Configuration
Search engines: serper.dev, SearXNG
Reranking: Jina AI, infinity+Qwen2-7B-instruct (self-deployed)
Models: OpenAI, Anthropic, Google (gemini), OpenRouter, HuggingFace, FireWorks
2) Architecture Classification
- Multi-Agent
3) Workflow
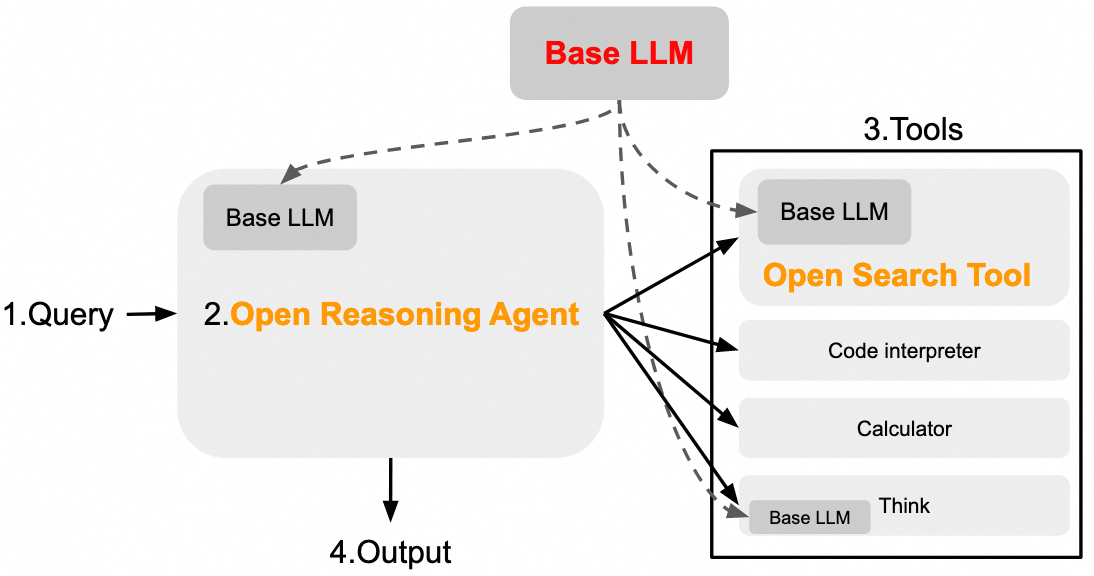
Open Search Tool Process
Query rewriting:
- Generate k search-optimized reconstructed queries based on the original query, requiring the model to maintain semantic context, adapt to search engines like Google, and narrow scope with clear objectives.
Web retrieval:
Use SERP (Google) for search recall and source legitimacy verification: (1) For non-pro mode, only process the first webpage from wiki sources; (2) For pro mode, process all accessible content from recalled sources.
* Retain metadata for subsequent generation: title, url, description, authorization date (if available).
* Emphasize in LLM system prompts to sort and use sources according to reliability.Content Parsing:
Use crawl4ai to parse information in various formats (multimodal information not used);
For the top m recalled webpages, perform rerank after each chunk (using similarity, topk);
All processed content is concatenated in order with content titles using '\n';
Emphasize consideration of content relevance in LLM system prompts.
Answer Generation:
- Use LLM to obtain all processed context and generate responses.
Open Reasoning Agent
ODS-v1 with ReAct Agent
React framework: Completely based on smolagents, directly using the ToolCallingAgent interface. When unable to generate normal replies, use Chain-of-Thought Self-Consistency to call r times, cluster, and randomly sample the largest cluster;
few-shot prompt design: Summarized and obtained from community activities (https://github.com/sentient-agi/OpenDeepSearch/blob/main/src/opendeepsearch/prompts.py);
Supports three tool actions: Continue thinking, Search internet (the aforementioned Open Search Tool), calculate (Wolfram Alpha).
ODS-v2 with CodeAct Agent
Codeact framework: Completely based on smolagents, directly using the CodeAgent interface, using Chain-of-Code;
few-shot prompt design: Uses the prompt from the built-in structured_code_agent.yaml in smolagents;
Supports one tool and built-in python interpreter: web_search (the aforementioned Open Search Tool).
Core Features
Semantic search: Uses Craw4AI and semantic search reranker (qwen2-7b-instruct or jina) to provide search results.
Mode selection:
Default mode: Fast and efficient search with minimal latency (overly shallow);
Pro mode: Requires additional processing time to obtain more in-depth and precise results (essentially the recall volume is not large either).
Can be integrated into Agents as a tool: Can seamlessly integrate with SmolAgents (such as CodeAgent).
Summary
- The search component is a concise pipeline with reference-worthy concepts: (1) Source sorting requirements and content relevance filtering in prompts: https://github.com/sentient-agi/OpenDeepSearch/blob/main/src/opendeepsearch/prompts.py; (2) Explicitly retain website metadata to assist source sorting.
- Reference the logic of React integration: In framework design, sub-task agents can be encapsulated as tools supporting tool calls or MCP to improve reusability and facilitate extension.
F.OpenDeepResearcher
Work Source
Author: Matt Shumer (AI application open-source contributor, CEO of HyperWriteAI/OthersideAI)
GitHub: https://github.com/mshumer/OpenDeepResearcher?tab=readme-ov-file star 2.7k
Main Architecture
1) Basic Configuration
Model Service: OpenRouter API (anthropic/claude-3.5-haiku)
Search Service: SERPAPI API
Parsing Service: Jina API
2) Architecture Classification
- static workflow
3) Workflow
Query Rewriting:
- Requires the model to generate 4 independent, precise search queries to cover comprehensive information.
Asynchronous Search
For each independent search query, uses SERP API to perform Google searches, maintaining a global search query list;
Aggregates all search results (by default should total 40 recalled sources) and performs source deduplication.
Content Acquisition and Processing
Acquisition: Uses Jina READER API to directly complete webpage parsing and content acquisition;
Filtering: Makes a separate LLM call to judge the relevance and usefulness of webpage content to the initial query, directly requiring the model to reply yes or no (note this is a new conversation without continuous context management);
Extraction: Requires LLM to individually extract relevant content/information from filtered (screened through the previous step) page content, requiring the model to make no comments, with user query, search query, and page content as inputs;
Memory: Merges extracted effective retrieval content (after acquisition, filtering, and extraction) into global memory (aggregated contexts).
Re-search
- Inputs memory, user query, and search query into the model to determine whether new searches are needed. If new searches are required, provides 4 new search queries and adds them to the search query list; otherwise, directly replies with "done" or similar content.
Iterative Loop
Returns to the "Asynchronous Search" phase;
Exit conditions: 1. Maximum iteration count or 2. LLM does not output new search queries.
Report Generation
- Inputs user query and aggregated contexts for report generation.
Core Features
Asynchronous search and extraction: Link deduplication, API content processing, relevance filtering, associated information extraction;
Iterative optimization: Maintains a global memory module to iteratively refine and record search-recalled content;
Report generation: Report generation depends on relevant search content recorded by the global memory module and user query.
Summary
Highly dependent on LLM capabilities: Search query rewriting, content extraction, iterative optimization, and other processes all depend on LLM capabilities.
Concise memory component: Does not involve retrospective management of past states, only maintains memory of search content, without global state context.
Simple pipeline design: Only performs search and summarization (no explicit planning phases).
V. Conclusion
Thus far, this paper has attempted to answer the three questions posed at the beginning. In Section IV, this paper mainly focuses on examining mainstream closed-source and open-source work in the Deep Research Agent field from an engineering framework perspective (currently insufficient research has been conducted on training, evaluation, and other aspects, so these will not be expanded upon). Several conclusions can be drawn as follows:
Understanding model capability boundaries and adjusting tasks promptly: In the early stages, due to limited model capabilities, manually defined processes and structures became important designs for ensuring stable agent outputs. However, with the enhancement of tool-calling capabilities and the development of technologies such as the MCP protocol, models now possess the ability to deliver good results at both global and many sub-task levels. Therefore, clarifying the structure of current designs, keeping up with model capability progress, rethinking which structures in the workflow should be completely taken over by the model, and making timely adjustments may be a key step in enabling agent frameworks to continuously benefit from model capability improvements.
Attempting to make search a "multi-round, progressive" pipeline: Query generation should always adaptively converge or diverge based on "learned learnings/findings," avoiding the one-time generation of a bunch of keywords that leads to the recall of large amounts of redundant information.
Attempting to deliver "cleaner" context at each stage: Most frameworks perform deduplication/reranking/refinement at each round, consolidating into structured learnings/findings, rather than stuffing entire pages of original text to the report model, resulting in better stability and lower costs.
Attempting to improve performance by changing the division of labor at each node: For example, in multi-agent architectures, if independent paragraphs produced by multiple agents are difficult to integrate together with logical coherence, trying to change the content delivered by each agent to the aforementioned learnings may effectively alleviate this issue.
Human-in-the-loop components are simple yet important: Most non-professional users may find it difficult to provide information-complete requirements in the first conversation. Designing reasonable intent clarification mechanisms that complement model capabilities is important, with typical approaches including asking users questions, generating and allowing users to modify plans, and combining both approaches.
Current-stage intelligent agents still need to learn to use tools well: Taking search engines as an example, there currently does not exist a search tool perfectly suited for intelligent agents. How to perform good query rewriting to collect appropriate information remains a factor that can be considered for optimization during design.
Although Deep Research Agents have already brought impressive performance in fields such as technology and finance, compared to leading players like OpenAI and Google, the open-source community still has a long way to go, and related technologies still have many areas that need exploration.
Reasonable and comprehensive evaluation benchmarks: Current Deep Research Agent research still lacks authoritative and comprehensive open-source evaluation benchmarks, mostly relying on QA, search, or agent capability-related benchmarks for assessment. Many QA datasets are increasingly easily solved by models' parametric knowledge, which also makes iterating Deep Research capabilities increasingly difficult. Designing end-to-end evaluation systems that align with the characteristics of Deep Research tasks has significant value for optimizing retrieval, reasoning, and report generation capabilities.
Expanding information sources and optimizing content parsing: Web search and content parsing play decisive roles in the Deep Research pipeline. Existing problems include, on one hand, limited accessible public web content, which may require support from richer MCP tools in the future to enable agents to access high-quality data from more professional databases, professional media, and academic websites. On the other hand, there are content parsing difficulties caused by the richness of web page structures, leading to missing content and format confusion in scraped content. Future development needs to design agent-native browsers to facilitate agent retrieval, navigation, and information scraping, such as providing explicit API hooks for clicking elements and filling forms.