The case for specialized pre-training: ultra-fast foundation models for dedicated tasks







Pre-training foundation models is generally thought to be the exclusive domain of a handful of AI labs and big tech companies. This is changing. Thanks to more powerful GPUs, optimized programming frameworks (like llm.c) and better datasets, pre-training is becoming affordable and a competitive alternative to fine-tuning.
At PleIAs we are successfully experimenting with a new category of models: specialized pre-training. Theses models are designed from the ground up for specific tasks, exclusively trained on a large custom instruction dataset (at least 5-10B tokens) and, so far, yielding performance comparable to much larger generalist models.
Pretraining an OCR correction model
While specialized pretrained models have been existing for some time, in areas like automated translation, they have not been commonly acknowledged as their own specific subcategory.
We release a new example of specialized pre-training, OCRonos-Vintage. It's a 124 million parameter model trained on 18 billion tokens from cultural heritage archives to perform OCR correction. Despite an extremely small size and lack of generalist capacities, OCRonos-Vintage is currently one the best available model for this task. We are currently deploying it at scale to pre-process a large cultural heritage corpus of more than 700 billion tokens.
OCRonos-Vintage was trained on the new H100 cluster on Jean Zay (compute grant n°GC011015451) with llm.c, the new pre-training library originally developed by Andrej Karpathy for pegagogic purposes. Thanks to the unprecedented performance of llm.c, the multiple past experiments released over the past weeks by Yuchen Jin (Hyperbolic Labs) and our advanced data preprocessing pipelines, training from scratch was as easy, short and eventless as a llama fine-tune.
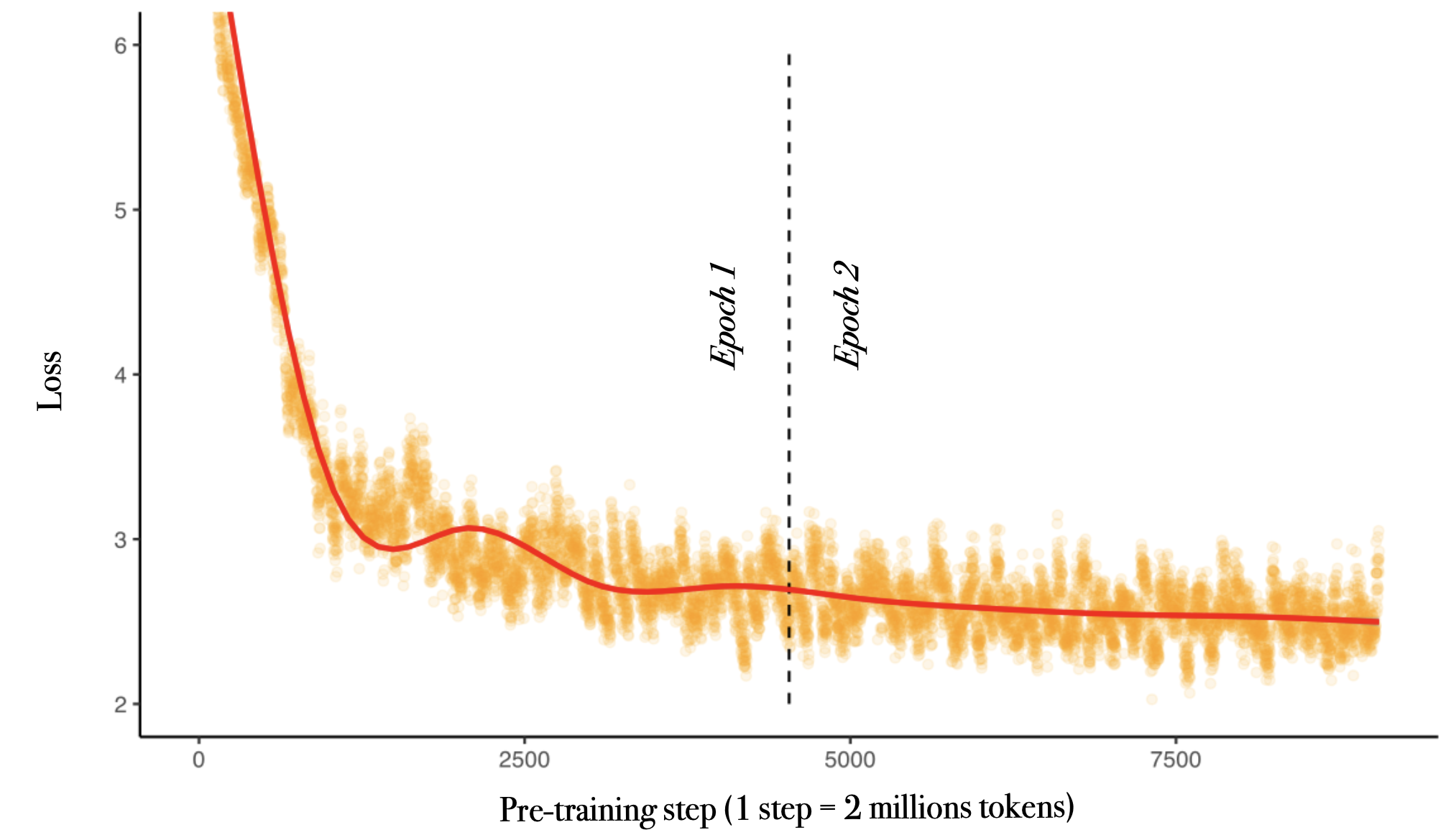
Over the next weeks, we are going to iterate multiple experiments on other, more common LLM tasks like summarization, RAG or classification. Overall the big question is: how well could a tiny model overperform on reasoning-intensive use cases. Extremely small models are usually lacking in logical consistency and it is generally thought that this capacity is unlocked through more parameters. Unless it is fundamentally an alignment problem, and tiny performant reasoning machines are within reach.
In the process, we will additionally release a range of LLM research artifact to assist future similar projects, including pre-tokenized and tokenized datasets as well dedicated code. We are now convinced that llm.c and its nascent ecosystem have an incredible potential to support projects in this line.
The case for language model specialization
Specialized pre-training is to a large extent a "natural" development in the field. Over the past few months, SLMs and LLMs have been increasingly specialized for end use cases, with the overall objective of trading generalist capacities for better focused performance. A typical example is the Cohere line of Command-R models optimized for RAG. In a wider sense, a model like Phi-3 trained on millions of synthetic data examples can be conceived as an aggregate of common use cases for LLM deployment.
Specialized pre-training is an attractive solution for multiple reasons:
- Low-cost and frugal inference. With 100-300 million parameters, models can be deployed as they are on most CPU infrastructures without requiring any adaptation or quantization. In a GPU environment, the models can provide a much higher throughput. This was our primary motivation for the training of OCRonos-Vintage as we needed to process a vast amount of cultural heritage archives with noisy OCR.
- Increased customization. The architecture and the tokenizer can be especially rethought with the tasks or the processed data in mind. For OCR correction, our preliminary studies show that a tokenizer volontarily trained on a small sample of noisy data is much more competitive. In practice, this means that a specialized pre-train could opt for a Mamba architecture to deal better with long context or be optimized for fast inference and enhanced comprehension in a local non-English language. Inference of specialized models is potentially so fast even letter or byte-level tokenization can be contemplated for some use cases.
- Full control over the data. In regulated contexts, the deployment or fine-tuning of existing models raises many issues of liabilities. Specialized pre-trained are trained end-to-end and do not include any other dataset than the one selected for training. OCRonos-Vintage is consequently an example of "open" models in the strong sense of the word, only trained on permissible data under public domain.
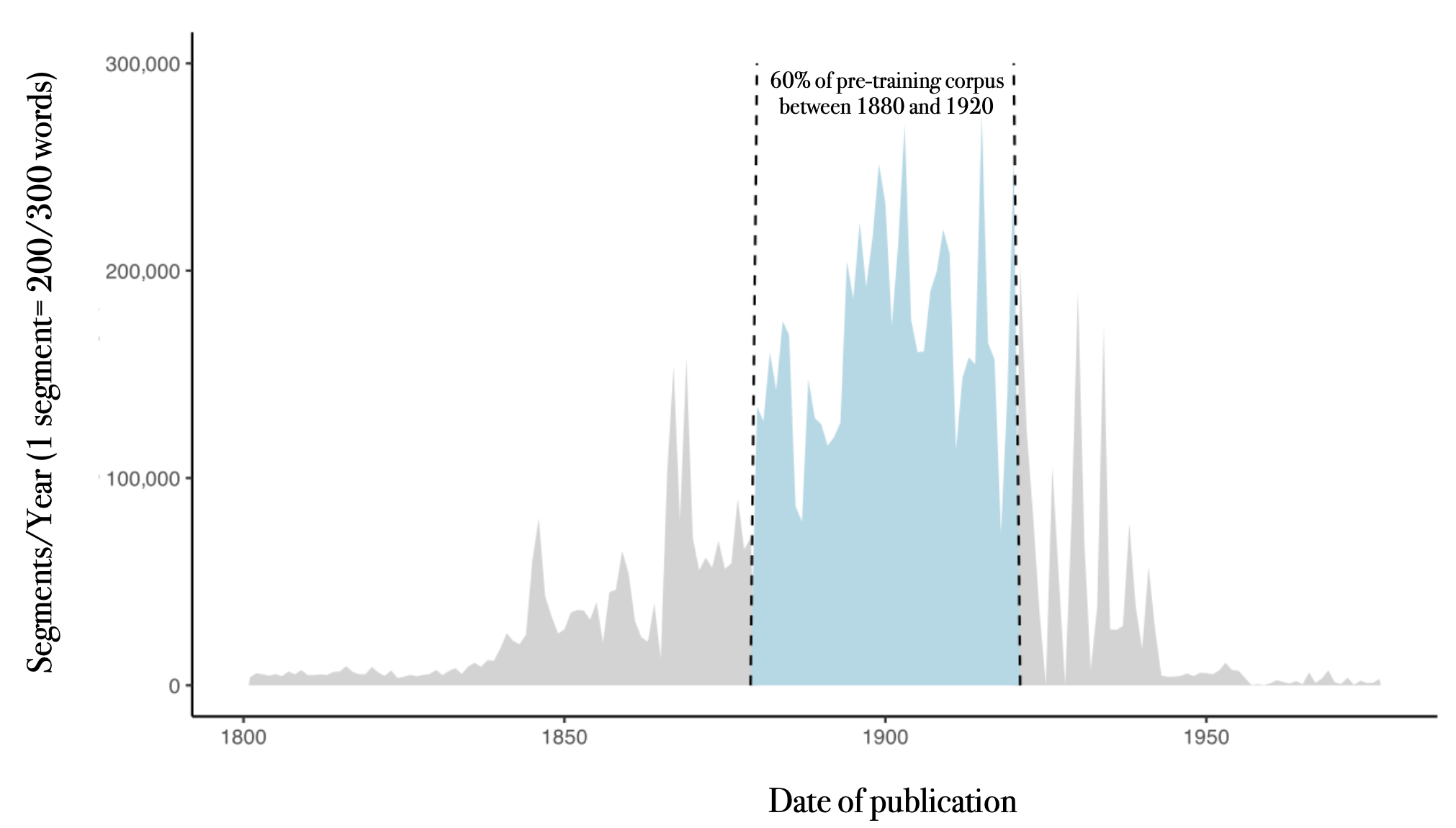
The main requirement for specialized pre-training is the dataset. We have been seeing strong performance gain while expanding the OCR dataset from 5 billion tokens (1 epoch) to 18 billion tokens (2 epochs, so 9 billion unique ones). While not comparable to generalist pre-training, this is still a considerably larger scale than fine-tuning. We believe the size requirements can be tackled thanks to the falling costs of synthetic data and the increased availability of big pretraining dataset. Typically, for summarization, there are already millions of couples of texts with their associated summaries.
The very unusual collection of open dataset we have been curating for pre-training turns out to be a fitting resource for theses experiments. Most datasets happen to be exactly in the desired range (from 2 to 20B tokens) and incorporate a range of additional metadata that can be repurposed for designing a task.





