
Update README.md
Browse files
README.md
CHANGED
|
@@ -8,4 +8,100 @@ tags:
|
|
| 8 |
- math
|
| 9 |
- reasoning
|
| 10 |
- thinking
|
| 11 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
- math
|
| 9 |
- reasoning
|
| 10 |
- thinking
|
| 11 |
+
---
|
| 12 |
+
Engineered to thrive where resources are scarce, these models are the solution for navigating the intricate pathways of sequential, logic-driven reasoning, especially when speed is critical. Their core function is to impose order on analytical chaos—from constructing rigorous mathematical proofs and manipulating symbolic equations to deciphering complex word problems. The architecture is built to connect information across a long chain of thought, ensuring the final output is not a guess, but a reliable and logically sound conclusion for any field demanding profound analytical capability.
|
| 13 |
+
|
| 14 |
+
في البيئات التي تعجز فيها الأنظمة التقليدية بسبب شح الموارد، تتألق هذه النماذج بقدرتها على اجتياز المسارات المعقدة للاستدلال المنطقي المتسلسل، خاصة عندما يكون عامل السرعة حاسماً. تكمن وظيفتها الأساسية في فرض النظام على الفوضى التحليلية؛ سواء كان ذلك ببناء البراهين الرياضية الصارمة، أو معالجة المعادلات الرمزية، أو فك شفرة المسائل الكلامية المعقدة. تم بناء بنيتها لربط المعلومات عبر سلسلة طويلة من التفكير، مما يضمن أن الناتج النهائي ليس مجرد تخمين، بل استنتاج موثوق وسليم منطقيًا لأي مجال يتطلب قدرة تحليلية فائقة.
|
| 15 |
+
|
| 16 |
+
To truly gauge the model's reasoning prowess, it was benchmarked against a competitive field of peers across a demanding suite of logical tests. Rather than relying on superficial metrics, our assessment methodology ensures precision by calculating the average Pass@1 accuracy from a substantial pool of samples—64 for the AIME benchmarks and 8 for Math500 and GPQA Diamond. The resulting performance landscape is detailed below:
|
| 17 |
+
|
| 18 |
+
لقياس براعة النموذج الاستدلالية بشكل حقيقي، تم وضعه في مواجهة تنافسية ضد مجموعة من النماذج الأخرى عبر باقة من الاختبارات المنطقية الصعبة. بدلاً من الاعتماد على مقاييس سطحية، تضمن منهجية التقييم لدينا الدقة من خلال حساب متوسط دقة Pass@1 من مجموعة كبيرة من العينات—64 عينة لمعايير AIME و 8 عينات لـ Math500 و GPQA Diamond. مشهد الأداء الناتج مفصل أدناه:
|
| 19 |
+
|
| 20 |
+
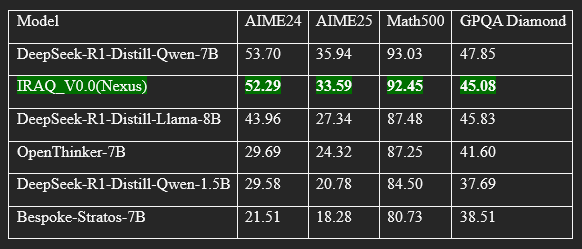
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
Model Performance Analysis
|
| 24 |
+
The model demonstrates highly competitive performance within its class, establishing it as a leading contender for complex reasoning tasks. It particularly excels on the advanced AIME24 and AIME25 mathematics benchmarks, achieving Pass@1 accuracy scores of 52.29% and 33.59%, respectively. These results place it in direct competition with the top-performing models, showcasing its exceptional capabilities in solving problems that require deep, multi-step logical thinking.
|
| 25 |
+
|
| 26 |
+
Furthermore, its robust performance on the Math500 test, with an accuracy of 92.45%, underscores a solid and versatile mathematical foundation. In the GPQA Diamond benchmark, which assesses reasoning on expert-level scientific questions, the model achieved a competitive score of 45.08%, proving its effectiveness in domains that demand deep analytical capabilities.
|
| 27 |
+
|
| 28 |
+
In summary, this analysis reveals the model to be a formidable contender, with a notable specialization in complex mathematical reasoning while maintaining excellent performance across a diverse range of analytical benchmarks.
|
| 29 |
+
|
| 30 |
+
يُظهر النموذج أداءً تنافسيًا عاليًا ضمن فئته، مما يضعه في مصاف النماذج الرائدة في مهام الاستدلال المعقد. يتألق النموذج بشكل خاص في معياري الرياضيات المتقدمة AIME24 و AIME25، حيث سجل دقة بلغت 52.29% و 33.59% على التوالي. تضعه هذه النتائج في منافسة مباشرة مع أفضل النماذج أداءً، مما يبرهن على قدراته الاستثنائية في حل المسائل التي تتطلب تفكيرًا منطقيًا عميقًا ومتعدد الخطوات.
|
| 31 |
+
|
| 32 |
+
بالإضافة إلى ذلك، يؤكد أداؤه القوي في اختبار Math500، بدرجة دقة 92.45%، على امتلاكه أساسًا رياضيًا متينًا وقدرة على التعامل مع مجموعة واسعة من المسائل الرياضية العامة. وفي اختبار GPQA Diamond الذي يقيس القدرة على الإجابة على أسئلة علمية متخصصة، حقق النموذج درجة تنافسية بلغت 45.08%، مما يثبت فعاليته في مجالات تتطلب فهمًا تحليليًا عميقًا.
|
| 33 |
+
|
| 34 |
+
بالمجمل، يُظهر التحليل أن هذا النموذج ليس فقط منافسًا قويًا، بل هو متخصص بشكل ملحوظ في الاستدلال الرياضي المعقد، مع الحفاظ على أداء ممتاز عبر مجموعة متنوعة من مهام التفكير التحليلي.
|
| 35 |
+
|
| 36 |
+
Input Formats
|
| 37 |
+
|
| 38 |
+
model is best suited for prompts using this specific chat format:
|
| 39 |
+
```[ <|user|>How to solve 3*x^2+4*x+5=1?<|end|><|assistant|> ]```
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Inference with transformers
|
| 43 |
+
|
| 44 |
+
List of required packages:
|
| 45 |
+
```
|
| 46 |
+
flash_attn==2.7.4.post1
|
| 47 |
+
torch==2.6.0
|
| 48 |
+
mamba-ssm==2.2.4 --no-build-isolation
|
| 49 |
+
causal-conv1d==1.5.0.post8
|
| 50 |
+
transformers==4.46.1
|
| 51 |
+
accelerate==1.4.0
|
| 52 |
+
```
|
| 53 |
+
How to use this model with python ?
|
| 54 |
+
|
| 55 |
+
after you install all the requirements packages with specified versions as above you can run this script:
|
| 56 |
+
|
| 57 |
+
```python
|
| 58 |
+
import torch
|
| 59 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
|
| 60 |
+
torch.random.manual_seed(0)
|
| 61 |
+
|
| 62 |
+
model_id = "barqahmed01/IRAQ_V0.0"
|
| 63 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 64 |
+
model_id,
|
| 65 |
+
device_map="cuda",
|
| 66 |
+
torch_dtype="auto",
|
| 67 |
+
trust_remote_code=True,
|
| 68 |
+
)
|
| 69 |
+
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
| 70 |
+
|
| 71 |
+
messages = [{
|
| 72 |
+
"role": "user",
|
| 73 |
+
"content": "How to solve x^3 - 7*x^2 + 14*x - 8 = 0?"
|
| 74 |
+
}]
|
| 75 |
+
inputs = tokenizer.apply_chat_template(
|
| 76 |
+
messages,
|
| 77 |
+
add_generation_prompt=True,
|
| 78 |
+
return_dict=True,
|
| 79 |
+
return_tensors="pt",
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
outputs = model.generate(
|
| 83 |
+
**inputs.to(model.device),
|
| 84 |
+
max_new_tokens=32768,
|
| 85 |
+
temperature=0.6,
|
| 86 |
+
top_p=0.95,
|
| 87 |
+
do_sample=True,
|
| 88 |
+
)
|
| 89 |
+
outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
* **Context length:** 64K tokens
|
| 93 |
+
* **GPUs:** Pre-training: 4070 TI SUPER; Reasoning training: 4070 TI SUPER
|
| 94 |
+
* **Training time:** 35 days; Reasoning training: 14 days
|
| 95 |
+
* **Training data:**3T tokens; Reasoning training: 150B tokens
|
| 96 |
+
* **Outputs:** Generated text
|
| 97 |
+
|
| 98 |
+
```The model is licensed under the MIT license.```
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
Custom Fine-Tuning & Support
|
| 102 |
+
|
| 103 |
+
You are welcome to use this model for your own projects. It is designed to be fine-tuned on custom datasets to meet your specific requirements.
|
| 104 |
+
|
| 105 |
+
If you encounter any issues, require a specialized model tailored to your data, or wish to discuss a collaboration, please do not hesitate to contact me at:
|
| 106 |
+
```[[email protected]]```
|
| 107 |
+
|