---
license: apache-2.0
datasets:
- Congliu/Chinese-DeepSeek-R1-Distill-data-110k
- cognitivecomputations/dolphin-r1
- open-thoughts/OpenThoughts-114k
- qihoo360/Light-R1-SFTData
- qihoo360/Light-R1-DPOData
language:
- zh
- en
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
tags:
- qwen2
---
# Zhi-writing-dsr1-14b
## 1. Introduction
Zhi-writing-dsr1-14b is a fine-tuned model based on DeepSeek-R1-Distill-Qwen-14B, specifically optimized for enhanced creative writing capabilities. Several benchmark evaluations indicate the model's improved creative writing performance.
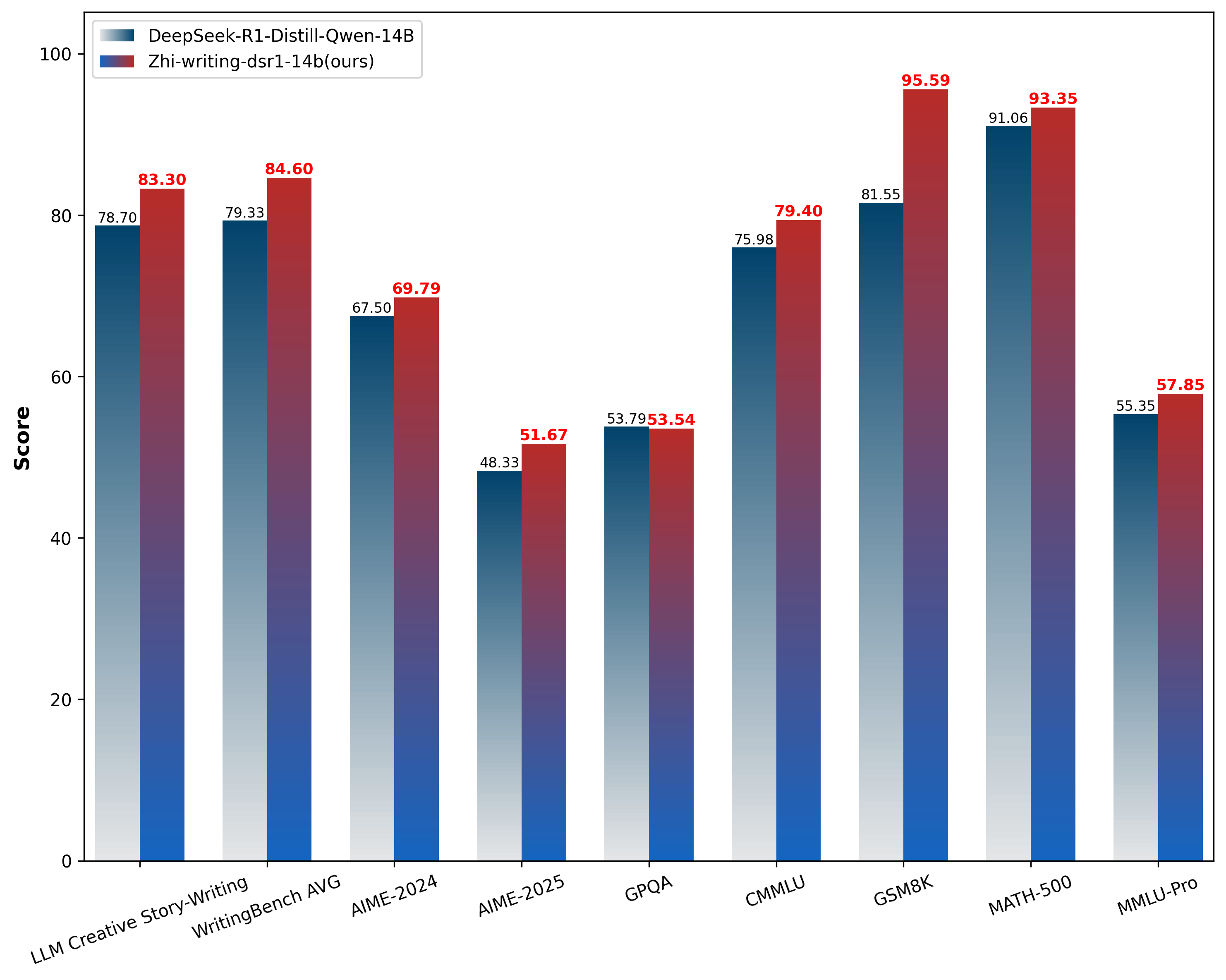
In the [LLM Creative Story-Writing Benchmark](https://github.com/lechmazur/writing), the model achieved a score of **8.33** compared to its base model's **7.8**. In the [WritingBench](https://github.com/X-PLUG/WritingBench) evaluation framework, it scored **8.46**, showing improvement over DeepSeek-R1-Distill-Qwen-14B's **7.93**. The model was also evaluated using GPT-4o on the AlpacaEval dataset, achieving an **82.6%** win rate when compared with the base model.
The figure below shows the performance comparison across different domains in WritingBench:
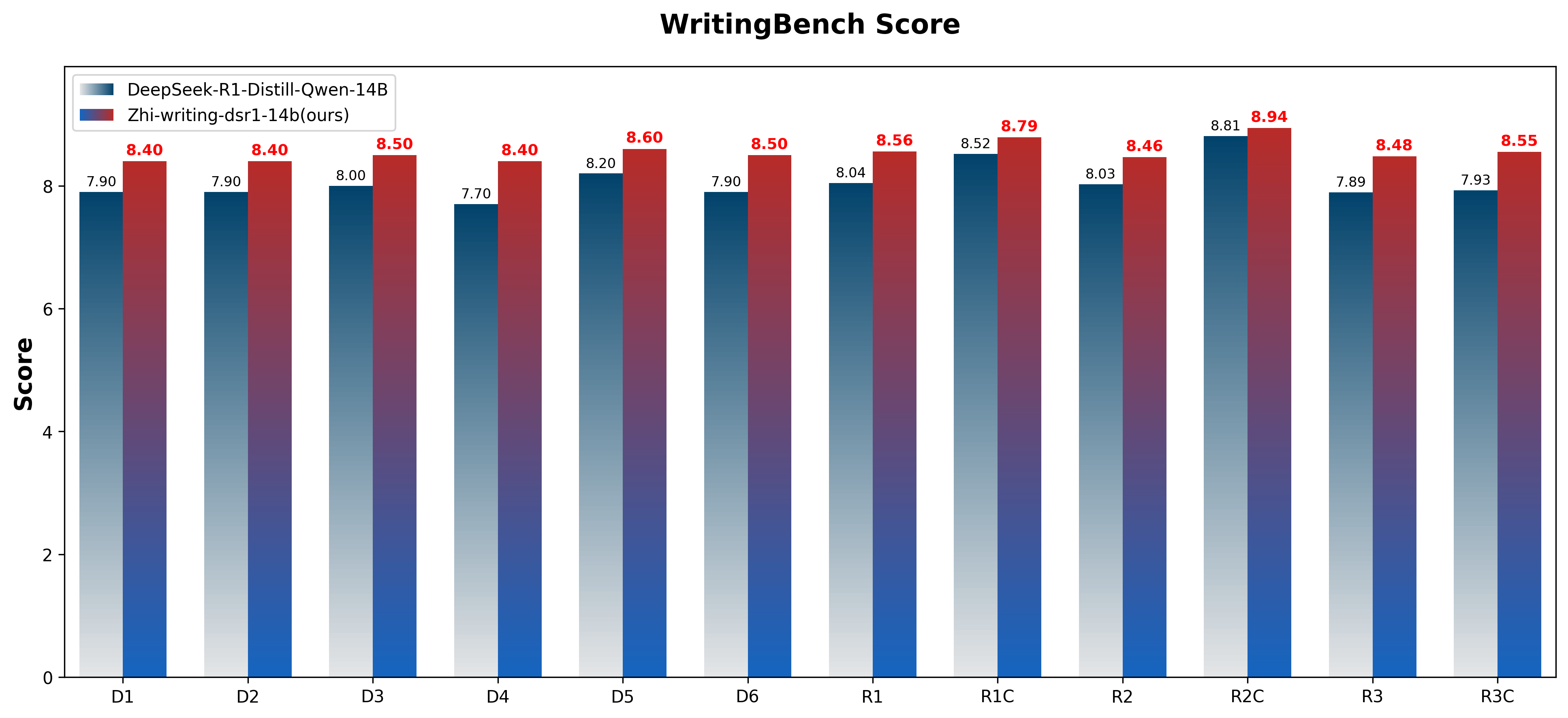
Figure 1: WritingBench performance of Zhi-writing-dsr1-14b and DeepSeek-R1-Distill-Qwen-14B across 6 domains and 3 writing requirements evaluated with WritingBench critic model (scale: 1-10). The six domains include: (D1) Academic & Engineering, (D2) Finance & Business, (D3) Politics & Law, (D4) Literature & Art, (D5) Education, and (D6) Advertising & Marketing. The three writing requirements assessed are: (R1) Style, (R2) Format, and (R3) Length. Here, "C" indicates category-specific scores.
## 2. Training Process
### Data
The model's training corpus comprises three primary data sources: rigorously filtered open-source datasets, chain-of-thought reasoning corpora, and curated question-answer pairs from Zhihu.
To achieve optimal domain coverage, we meticulously balanced the distribution of various datasets, including [Dolphin-r1](https://huggingface.co/datasets/cognitivecomputations/dolphin-r1), [Congliu/Chinese-DeepSeek-R1-Distill-data-110k](https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k), [OpenThoughts-114k](https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k), [Light-R1-SFTData](https://huggingface.co/datasets/qihoo360/Light-R1-SFTData), and [Light-R1-DPOData](https://huggingface.co/datasets/qihoo360/Light-R1-DPOData), alongside high-quality content from Zhihu. All datasets underwent comprehensive quality assurance through our Reward Model (RM) filtering pipeline.
### Training
**Supervised Fine-tuning (SFT)**: We employed a curriculum learning strategy for supervised fine-tuning. This methodical approach systematically enhances creative writing capabilities while incorporating diverse domain data to maintain core competencies and mitigate catastrophic forgetting.
**Direct Preference Optimization (DPO)**: For scenarios involving minimal edit distances, we utilized Step-DPO ([arxiv:2406.18629](https://arxiv.org/abs/2406.18629)) to selectively penalize incorrect tokens, while incorporating positive constraints in the loss function as proposed in DPOP ([arXiv:2402.13228](https://arxiv.org/abs/2402.13228)).
## 3. Evaluation Results
Our evaluation results suggest promising improvements in the model's creative writing capabilities. In the LLM Creative Story-Writing Benchmark evaluation, the model achieved a score of **8.33**, showing an improvement from the base model's **7.87**. When assessed on WritingBench, a comprehensive framework for evaluating large language model writing abilities, the model attained a score of **8.46**. This places it in proximity to DeepSeek-R1's performance and represents an advancement over DeepSeek-R1-Distill-Qwen-14B's score of 7.93.
With respect to general capabilities, evaluations indicate modest improvements of **2%–5% in knowledge and reasoning tasks (CMMLU, MMLU-Pro)**, alongside encouraging progress in mathematical reasoning as measured by benchmarks such as **AIME-2024, AIME-2025, and GSM8K**. The results suggest that the model maintains a balanced performance profile, with improvements observed across creative writing, knowledge/reasoning, and mathematical tasks compared to DeepSeek-R1-Distill-Qwen-14B. These characteristics potentially make it suitable for a range of general-purpose applications.
## 4. How to Run Locally
Zhi-writing-dsr1-14b can be deployed on various hardware configurations, including GPUs with 80GB memory, a single H20/A800/H800, or dual RTX 4090. Additionally, the INT4 quantized version Zhi-writing-dsr1-14b-gptq-int4 can be deployed on a single RTX 4090.
### Transformers
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
MODEL_NAME = "Zhihu-ai/Zhi-writing-dsr1-14b"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
device_map="auto",
trust_remote_code=True
).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained(MODEL_NAME, trust_remote_code=True)
generate_configs = {
"temperature": 0.6,
"do_sample": True,
"top_p": 0.95,
"max_new_tokens": 4096
}
prompt = "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
**generate_configs
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
### vllm
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm)
```python
# install vllm
pip install vllm>=0.6.4.post1
# huggingface model id
vllm serve Zhihu-ai/Zhi-writing-dsr1-14b --served-model-name Zhi-writing-dsr1-14b --port 8000
# local path
vllm serve /path/to/model --served-model-name Zhi-writing-dsr1-14b --port 8000
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Zhi-writing-dsr1-14b",
"prompt": "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章",
"max_tokens": 4096,
"temperature": 0.6,
"top_p": 0.95
}'
```
### SGLang
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```python
# install SGLang
pip install "sglang[all]>=0.4.5" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer-python
# huggingface model id
python -m sglang.launch_server --model-path Zhi-writing-dsr1-14b --served-model-name Zhi-writing-dsr1-14b --port 8000
# local path
python -m sglang.launch_server --model-path /path/to/model --served-model-name Zhi-writing-dsr1-14b --port 8000
# send request
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Zhi-writing-dsr1-14b",
"prompt": "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章",
"max_tokens": 4096,
"temperature": 0.6,
"top_p": 0.95
}'
```
### ollama
You can download ollama using [this](https://ollama.com/download/)
* quantization: Q4_K_M
```bash
ollama run zhihu/zhi-writing-dsr1-14b
```
* bf16
```bash
ollama run zhihu/zhi-writing-dsr1-14b:bf16
```
## 5. Usage Recommendations
We recommend adhering to the following configurations when utilizing the Zhi-writing-dsr1-14b, including benchmarking, to achieve the expected performance:
* Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
* When evaluating model performance, it is recommended to conduct multiple tests and average the results. (We use `n=16` for mathematical tasks and `n=2` for others)
* To ensure that the model engages in thorough reasoning like DeepSeek-R1 series models, we recommend enforcing the model to initiate its response with "\\n" at the beginning of every output.
## 6. Citation
```text
@misc{Zhi-writing-dsr1-14b,
title={Zhi-writing-dsr1-14b: Curriculum Reinforcement and Direct Preference Optimization for Robust Creative Writing in LLMs},
author={Jiewu Wang, Xu Chen, Wenyuan Su, Chao Huang, Hongkui Gao, Lin Feng, Shan Wang, Lu Xu, Penghe Liu, Zebin Ou},
year={2025},
eprint={},
archivePrefix={},
url={https://huggingface.co/Zhihu-ai/Zhi-writing-dsr1-14b},
}
```
## 7. Contact
If you have any questions, please raise an issue or contact us at [ai@zhihu.com](mailto:ai@zhihu.com).