

Upload folder using huggingface_hub
Browse files- .gitattributes +3 -0
- README.md +202 -3
- config.json +29 -0
- generation_config.json +9 -0
- images/general_score.png +3 -0
- images/writingbench_score.png +3 -0
- model.safetensors.index.json +586 -0
- special_tokens_map.json +23 -0
- tokenizer.json +3 -0
- tokenizer_config.json +199 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/general_score.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/writingbench_score.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,202 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- Congliu/Chinese-DeepSeek-R1-Distill-data-110k
|
| 5 |
+
- cognitivecomputations/dolphin-r1
|
| 6 |
+
- open-thoughts/OpenThoughts-114k
|
| 7 |
+
- qihoo360/Light-R1-SFTData
|
| 8 |
+
- qihoo360/Light-R1-DPOData
|
| 9 |
+
language:
|
| 10 |
+
- zh
|
| 11 |
+
- en
|
| 12 |
+
base_model:
|
| 13 |
+
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
|
| 14 |
+
tags:
|
| 15 |
+
- qwen2
|
| 16 |
+
---
|
| 17 |
+
# Zhi-writing-dsr1-14b
|
| 18 |
+
|
| 19 |
+
## 1. Introduction
|
| 20 |
+
|
| 21 |
+
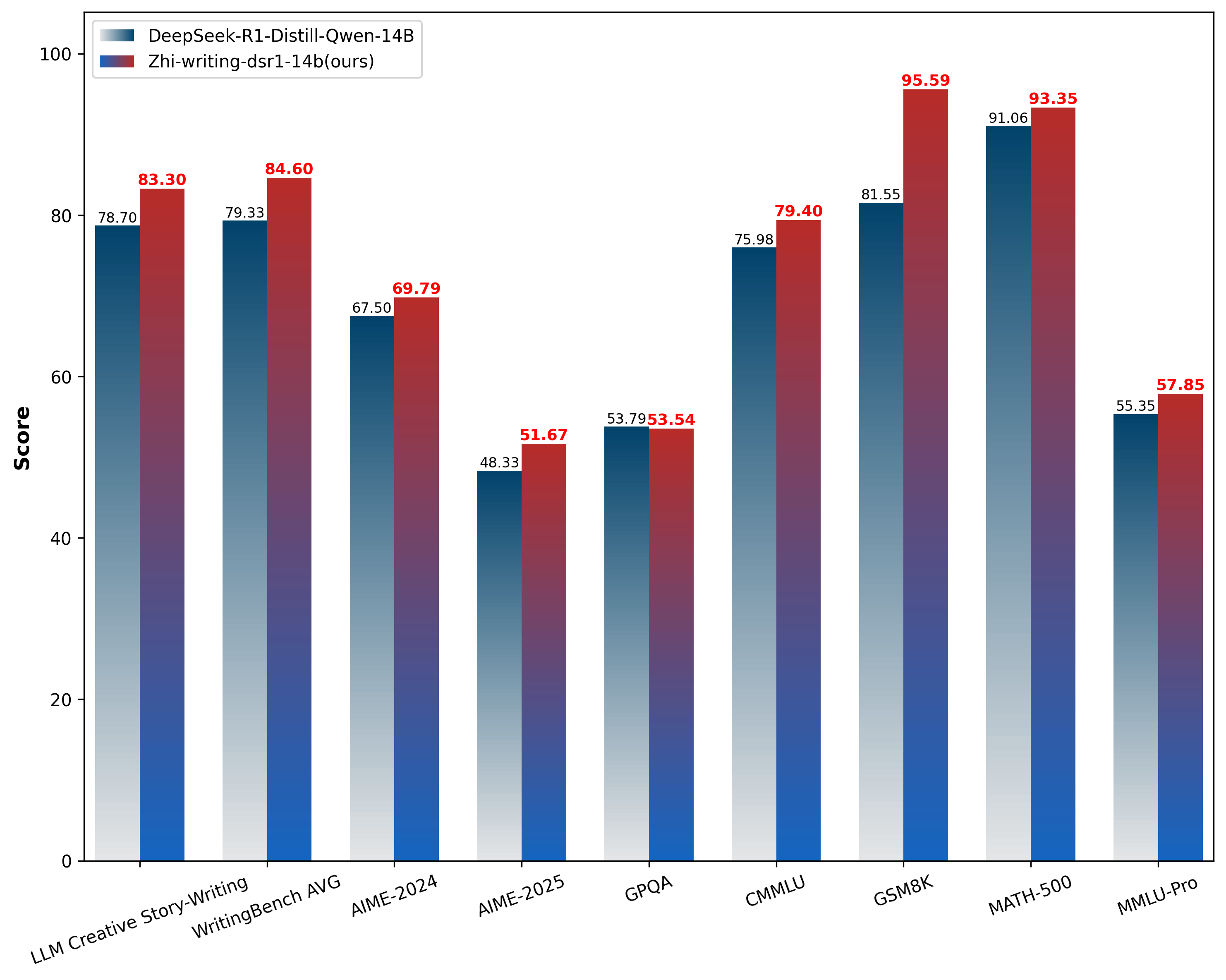
Zhi-writing-dsr1-14b is a fine-tuned model based on DeepSeek-R1-Distill-Qwen-14B, specifically optimized for enhanced creative writing capabilities. Several benchmark evaluations indicate the model's improved creative writing performance.
|
| 22 |
+
|
| 23 |
+
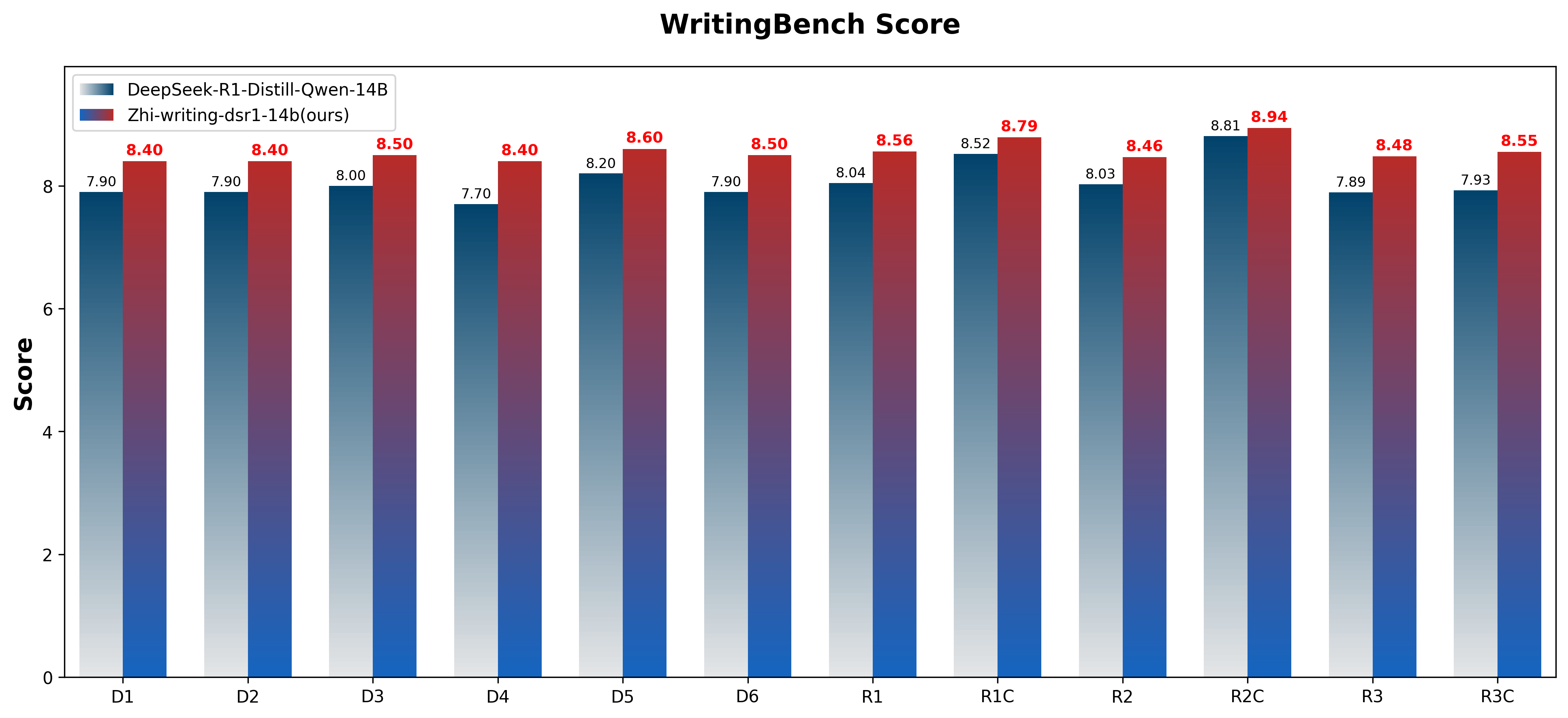
In the [LLM Creative Story-Writing Benchmark](https://github.com/lechmazur/writing), the model achieved a score of **8.33** compared to its base model's **7.8**. In the [WritingBench](https://github.com/X-PLUG/WritingBench) evaluation framework, it scored **8.46**, showing improvement over DeepSeek-R1-Distill-Qwen-14B's **7.93**. The model was also evaluated using GPT-4o on the AlpacaEval dataset, achieving an **82.6%** win rate when compared with the base model.
|
| 24 |
+
|
| 25 |
+
The figure below shows the performance comparison across different domains in WritingBench:
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
<figcaption style="text-align:center; font-size:0.9em; color:#666">
|
| 30 |
+
Figure 1: WritingBench performance of Zhi-writing-dsr1-14b and DeepSeek-R1-Distill-Qwen-14B across 6 domains and 3 writing requirements evaluated with WritingBench critic model (scale: 1-10). The six domains include: (D1) Academic & Engineering, (D2) Finance & Business, (D3) Politics & Law, (D4) Literature & Art, (D5) Education, and (D6) Advertising & Marketing. The three writing requirements assessed are: (R1) Style, (R2) Format, and (R3) Length. Here, "C" indicates category-specific scores.
|
| 31 |
+
</figcaption>
|
| 32 |
+
|
| 33 |
+
## 2. Training Process
|
| 34 |
+
|
| 35 |
+
### Data
|
| 36 |
+
|
| 37 |
+
The model's training corpus comprises three primary data sources: rigorously filtered open-source datasets, chain-of-thought reasoning corpora, and curated question-answer pairs from Zhihu.
|
| 38 |
+
|
| 39 |
+
To achieve optimal domain coverage, we meticulously balanced the distribution of various datasets, including [Dolphin-r1](https://huggingface.co/datasets/cognitivecomputations/dolphin-r1), [Congliu/Chinese-DeepSeek-R1-Distill-data-110k](https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k), [OpenThoughts-114k](https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k), [Light-R1-SFTData](https://huggingface.co/datasets/qihoo360/Light-R1-SFTData), and [Light-R1-DPOData](https://huggingface.co/datasets/qihoo360/Light-R1-DPOData), alongside high-quality content from Zhihu. All datasets underwent comprehensive quality assurance through our Reward Model (RM) filtering pipeline.
|
| 40 |
+
|
| 41 |
+
### Training
|
| 42 |
+
**Supervised Fine-tuning (SFT)**: We employed a curriculum learning strategy for supervised fine-tuning. This methodical approach systematically enhances creative writing capabilities while incorporating diverse domain data to maintain core competencies and mitigate catastrophic forgetting.
|
| 43 |
+
|
| 44 |
+
**Direct Preference Optimization (DPO)**: For scenarios involving minimal edit distances, we utilized Step-DPO ([arxiv:2406.18629](https://arxiv.org/abs/2406.18629)) to selectively penalize incorrect tokens, while incorporating positive constraints in the loss function as proposed in DPOP ([arXiv:2402.13228](https://arxiv.org/abs/2402.13228)).
|
| 45 |
+
|
| 46 |
+
## 3. Evaluation Results
|
| 47 |
+
|
| 48 |
+
Our evaluation results suggest promising improvements in the model's creative writing capabilities. In the LLM Creative Story-Writing Benchmark evaluation, the model achieved a score of **8.33**, showing an improvement from the base model's **7.87**. When assessed on WritingBench, a comprehensive framework for evaluating large language model writing abilities, the model attained a score of **8.46**. This places it in proximity to DeepSeek-R1's performance and represents an advancement over DeepSeek-R1-Distill-Qwen-14B's score of 7.93.
|
| 49 |
+
|
| 50 |
+
With respect to general capabilities, evaluations indicate modest improvements of **2%–5% in knowledge and reasoning tasks (CMMLU, MMLU-Pro)**, alongside encouraging progress in mathematical reasoning as measured by benchmarks such as **AIME-2024, AIME-2025, and GSM8K**. The results suggest that the model maintains a balanced performance profile, with improvements observed across creative writing, knowledge/reasoning, and mathematical tasks compared to DeepSeek-R1-Distill-Qwen-14B. These characteristics potentially make it suitable for a range of general-purpose applications.
|
| 51 |
+
|
| 52 |
+

|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## 4. How to Run Locally
|
| 56 |
+
|
| 57 |
+
Zhi-writing-dsr1-14b can be deployed on various hardware configurations, including GPUs with 80GB memory, a single H20/A800/H800, or dual RTX 4090. Additionally, the INT4 quantized version Zhi-writing-dsr1-14b-gptq-int4 can be deployed on a single RTX 4090.
|
| 58 |
+
|
| 59 |
+
### Transformers
|
| 60 |
+
|
| 61 |
+
```python
|
| 62 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 63 |
+
from transformers.generation import GenerationConfig
|
| 64 |
+
|
| 65 |
+
MODEL_NAME = "Zhihu-ai/Zhi-writing-dsr1-14b"
|
| 66 |
+
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
|
| 67 |
+
|
| 68 |
+
# use bf16
|
| 69 |
+
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto", trust_remote_code=True, bf16=True).eval()
|
| 70 |
+
# use fp16
|
| 71 |
+
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto", trust_remote_code=True, fp16=True).eval()
|
| 72 |
+
# use cpu only
|
| 73 |
+
# model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="cpu", trust_remote_code=True).eval()
|
| 74 |
+
# use auto mode, automatically select precision based on the device.
|
| 75 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 76 |
+
MODEL_NAME,
|
| 77 |
+
device_map="auto",
|
| 78 |
+
trust_remote_code=True
|
| 79 |
+
).eval()
|
| 80 |
+
|
| 81 |
+
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
|
| 82 |
+
# model.generation_config = GenerationConfig.from_pretrained(MODEL_NAME, trust_remote_code=True)
|
| 83 |
+
|
| 84 |
+
generate_configs = {
|
| 85 |
+
"temperature": 0.6,
|
| 86 |
+
"do_sample": True,
|
| 87 |
+
"top_p": 0.95,
|
| 88 |
+
"max_new_tokens": 4096
|
| 89 |
+
}
|
| 90 |
+
|
| 91 |
+
prompt = "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章"
|
| 92 |
+
messages = [
|
| 93 |
+
{"role": "user", "content": prompt}
|
| 94 |
+
]
|
| 95 |
+
text = tokenizer.apply_chat_template(
|
| 96 |
+
messages,
|
| 97 |
+
tokenize=False,
|
| 98 |
+
add_generation_prompt=True
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 102 |
+
|
| 103 |
+
generated_ids = model.generate(
|
| 104 |
+
**model_inputs,
|
| 105 |
+
**generate_configs
|
| 106 |
+
)
|
| 107 |
+
generated_ids = [
|
| 108 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 109 |
+
]
|
| 110 |
+
|
| 111 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 112 |
+
print(response)
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
### vllm
|
| 116 |
+
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm)
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
# install vllm
|
| 120 |
+
pip install vllm>=0.6.4.post1
|
| 121 |
+
|
| 122 |
+
# huggingface model id
|
| 123 |
+
vllm serve Zhihu-ai/Zhi-writing-dsr1-14b --served-model-name Zhi-writing-dsr1-14b --port 8000
|
| 124 |
+
|
| 125 |
+
# local path
|
| 126 |
+
vllm serve /path/to/model --served-model-name Zhi-writing-dsr1-14b --port 8000
|
| 127 |
+
|
| 128 |
+
curl http://localhost:8000/v1/completions \
|
| 129 |
+
-H "Content-Type: application/json" \
|
| 130 |
+
-d '{
|
| 131 |
+
"model": "Zhi-writing-dsr1-14b",
|
| 132 |
+
"prompt": "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章",
|
| 133 |
+
"max_tokens": 4096,
|
| 134 |
+
"temperature": 0.6,
|
| 135 |
+
"top_p": 0.95
|
| 136 |
+
}'
|
| 137 |
+
```
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
### SGLang
|
| 141 |
+
|
| 142 |
+
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
|
| 143 |
+
```python
|
| 144 |
+
# install SGLang
|
| 145 |
+
pip install "sglang[all]>=0.4.5" --find-links https://flashinfer.ai/whl/cu124/torch2.5/flashinfer-python
|
| 146 |
+
|
| 147 |
+
# huggingface model id
|
| 148 |
+
python -m sglang.launch_server --model-path Zhi-writing-dsr1-14b --served-model-name Zhi-writing-dsr1-14b --port 8000
|
| 149 |
+
|
| 150 |
+
# local path
|
| 151 |
+
python -m sglang.launch_server --model-path /path/to/model --served-model-name Zhi-writing-dsr1-14b --port 8000
|
| 152 |
+
|
| 153 |
+
# send request
|
| 154 |
+
curl http://localhost:8000/v1/completions \
|
| 155 |
+
-H "Content-Type: application/json" \
|
| 156 |
+
-d '{
|
| 157 |
+
"model": "Zhi-writing-dsr1-14b",
|
| 158 |
+
"prompt": "请你以鲁迅的口吻,写一篇介绍西湖醋鱼的文章",
|
| 159 |
+
"max_tokens": 4096,
|
| 160 |
+
"temperature": 0.6,
|
| 161 |
+
"top_p": 0.95
|
| 162 |
+
}'
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
### ollama
|
| 166 |
+
|
| 167 |
+
You can download ollama using [this](https://ollama.com/download/)
|
| 168 |
+
* quantization: Q4_K_M
|
| 169 |
+
```bash
|
| 170 |
+
ollama run zhihu/zhi-writing-dsr1-14b
|
| 171 |
+
```
|
| 172 |
+
* bf16
|
| 173 |
+
```bash
|
| 174 |
+
ollama run zhihu/zhi-writing-dsr1-14b:bf16
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
## 5. Usage Recommendations
|
| 178 |
+
|
| 179 |
+
We recommend adhering to the following configurations when utilizing the Zhi-writing-dsr1-14b, including benchmarking, to achieve the expected performance:
|
| 180 |
+
|
| 181 |
+
* Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
|
| 182 |
+
|
| 183 |
+
* When evaluating model performance, it is recommended to conduct multiple tests and average the results. (We use `n=16` for mathematical tasks and `n=2` for others)
|
| 184 |
+
|
| 185 |
+
* To ensure that the model engages in thorough reasoning like DeepSeek-R1 series models, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.
|
| 186 |
+
|
| 187 |
+
## 6. Citation
|
| 188 |
+
|
| 189 |
+
```text
|
| 190 |
+
@misc{Zhi-writing-dsr1-14b,
|
| 191 |
+
title={Zhi-writing-dsr1-14b: Curriculum Reinforcement and Direct Preference Optimization for Robust Creative Writing in LLMs},
|
| 192 |
+
author={Jiewu Wang, Xu Chen, Wenyuan Su, Chao Huang, Hongkui Gao, Lin Feng, Shan Wang, Lu Xu, Penghe Liu, Zebin Ou},
|
| 193 |
+
year={2025},
|
| 194 |
+
eprint={},
|
| 195 |
+
archivePrefix={},
|
| 196 |
+
url={https://huggingface.co/Zhihu-ai/Zhi-writing-dsr1-14b},
|
| 197 |
+
}
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
## 7. Contact
|
| 201 |
+
|
| 202 |
+
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen2ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 151643,
|
| 7 |
+
"eos_token_id": 151643,
|
| 8 |
+
"hidden_act": "silu",
|
| 9 |
+
"hidden_size": 5120,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 13824,
|
| 12 |
+
"max_position_embeddings": 131072,
|
| 13 |
+
"max_window_layers": 48,
|
| 14 |
+
"model_type": "qwen2",
|
| 15 |
+
"num_attention_heads": 40,
|
| 16 |
+
"num_hidden_layers": 48,
|
| 17 |
+
"num_key_value_heads": 8,
|
| 18 |
+
"pad_token_id": 151643,
|
| 19 |
+
"rms_norm_eps": 1e-05,
|
| 20 |
+
"rope_scaling": null,
|
| 21 |
+
"rope_theta": 1000000.0,
|
| 22 |
+
"sliding_window": null,
|
| 23 |
+
"tie_word_embeddings": false,
|
| 24 |
+
"torch_dtype": "bfloat16",
|
| 25 |
+
"transformers_version": "4.49.0",
|
| 26 |
+
"use_cache": false,
|
| 27 |
+
"use_sliding_window": false,
|
| 28 |
+
"vocab_size": 152064
|
| 29 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151646,
|
| 3 |
+
"eos_token_id": 151643,
|
| 4 |
+
"pad_token_id": 151643,
|
| 5 |
+
"max_new_tokens": 4096,
|
| 6 |
+
"temperature": 0.6,
|
| 7 |
+
"top_p": 0.95,
|
| 8 |
+
"transformers_version": "4.49.0"
|
| 9 |
+
}
|
images/general_score.png
ADDED
|
Git LFS Details
|
images/writingbench_score.png
ADDED
|
Git LFS Details
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,586 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 29540067328
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00006-of-00006.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00006.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 20 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 21 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 22 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 23 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 24 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 27 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 28 |
+
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 29 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 30 |
+
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 31 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 32 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 33 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 34 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 35 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 36 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 37 |
+
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 38 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 39 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 40 |
+
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 41 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 42 |
+
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 43 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 44 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 45 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 46 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 47 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 48 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 49 |
+
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 50 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 51 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 52 |
+
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 53 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 54 |
+
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 55 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 56 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 57 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 58 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 59 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 60 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 61 |
+
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 62 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 63 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 64 |
+
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 65 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 66 |
+
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 67 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 68 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 69 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 70 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 71 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 72 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 73 |
+
"model.layers.13.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 74 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 75 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 76 |
+
"model.layers.13.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 77 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 78 |
+
"model.layers.13.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 79 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 80 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 81 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 82 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 83 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 84 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 85 |
+
"model.layers.14.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 86 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 87 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 88 |
+
"model.layers.14.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 89 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 90 |
+
"model.layers.14.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 91 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 92 |
+
"model.layers.15.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 93 |
+
"model.layers.15.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 94 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 95 |
+
"model.layers.15.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 96 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 97 |
+
"model.layers.15.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 98 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 99 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 100 |
+
"model.layers.15.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 101 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 102 |
+
"model.layers.15.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 103 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 104 |
+
"model.layers.16.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 105 |
+
"model.layers.16.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 106 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 107 |
+
"model.layers.16.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 108 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 109 |
+
"model.layers.16.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 110 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 111 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 112 |
+
"model.layers.16.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 113 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 114 |
+
"model.layers.16.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 115 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 116 |
+
"model.layers.17.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 117 |
+
"model.layers.17.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 118 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 119 |
+
"model.layers.17.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 120 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 121 |
+
"model.layers.17.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 122 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 123 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 124 |
+
"model.layers.17.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 125 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 126 |
+
"model.layers.17.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 127 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 128 |
+
"model.layers.18.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 129 |
+
"model.layers.18.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 130 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 131 |
+
"model.layers.18.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 132 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 133 |
+
"model.layers.18.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 134 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 135 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 136 |
+
"model.layers.18.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 137 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 138 |
+
"model.layers.18.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 139 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 140 |
+
"model.layers.19.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 141 |
+
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 142 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 143 |
+
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 144 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 145 |
+
"model.layers.19.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 146 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 147 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 148 |
+
"model.layers.19.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 149 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 150 |
+
"model.layers.19.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 151 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 152 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 153 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 154 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 155 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 156 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 157 |
+
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 158 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 159 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 160 |
+
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 161 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 162 |
+
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 163 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 164 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 165 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 166 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 167 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 168 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 169 |
+
"model.layers.20.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 170 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 171 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 172 |
+
"model.layers.20.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 173 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 174 |
+
"model.layers.20.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 175 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 176 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 177 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 178 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 179 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 180 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 181 |
+
"model.layers.21.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 182 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 183 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 184 |
+
"model.layers.21.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 185 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 186 |
+
"model.layers.21.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 187 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 188 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 189 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 190 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 191 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 192 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 193 |
+
"model.layers.22.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 194 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 195 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 196 |
+
"model.layers.22.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 197 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 198 |
+
"model.layers.22.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 199 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 200 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 201 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00006.safetensors",
|
| 202 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00006.safetensors",
|
| 203 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00006.safetensors",
|
| 204 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00006.safetensors",
|
| 205 |
+
"model.layers.23.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 206 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 207 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 208 |
+
"model.layers.23.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 209 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 210 |
+
"model.layers.23.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 211 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 212 |
+
"model.layers.24.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 213 |
+
"model.layers.24.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 214 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 215 |
+
"model.layers.24.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 216 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 217 |
+
"model.layers.24.self_attn.k_proj.bias": "model-00003-of-00006.safetensors",
|
| 218 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00006.safetensors",
|
| 219 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00006.safetensors",
|
| 220 |
+
"model.layers.24.self_attn.q_proj.bias": "model-00003-of-00006.safetensors",
|
| 221 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00006.safetensors",
|
| 222 |
+
"model.layers.24.self_attn.v_proj.bias": "model-00003-of-00006.safetensors",
|
| 223 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00006.safetensors",
|
| 224 |
+
"model.layers.25.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 225 |
+
"model.layers.25.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 226 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 227 |
+
"model.layers.25.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 228 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 229 |
+
"model.layers.25.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 230 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 231 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 232 |
+
"model.layers.25.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 233 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 234 |
+
"model.layers.25.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 235 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 236 |
+
"model.layers.26.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 237 |
+
"model.layers.26.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 238 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 239 |
+
"model.layers.26.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 240 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 241 |
+
"model.layers.26.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 242 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 243 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 244 |
+
"model.layers.26.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 245 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 246 |
+
"model.layers.26.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 247 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 248 |
+
"model.layers.27.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 249 |
+
"model.layers.27.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 250 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 251 |
+
"model.layers.27.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 252 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 253 |
+
"model.layers.27.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 254 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 255 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 256 |
+
"model.layers.27.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 257 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 258 |
+
"model.layers.27.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 259 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 260 |
+
"model.layers.28.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 261 |
+
"model.layers.28.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 262 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 263 |
+
"model.layers.28.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 264 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 265 |
+
"model.layers.28.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 266 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 267 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 268 |
+
"model.layers.28.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 269 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 270 |
+
"model.layers.28.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 271 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 272 |
+
"model.layers.29.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 273 |
+
"model.layers.29.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 274 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 275 |
+
"model.layers.29.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 276 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 277 |
+
"model.layers.29.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 278 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 279 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 280 |
+
"model.layers.29.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 281 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 282 |
+
"model.layers.29.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 283 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 284 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 285 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 286 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 287 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 288 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 289 |
+
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 290 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 291 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 292 |
+
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 293 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 294 |
+
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 295 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 296 |
+
"model.layers.30.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 297 |
+
"model.layers.30.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 298 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 299 |
+
"model.layers.30.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 300 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 301 |
+
"model.layers.30.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 302 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 303 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 304 |
+
"model.layers.30.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 305 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 306 |
+
"model.layers.30.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 307 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 308 |
+
"model.layers.31.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 309 |
+
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 310 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 311 |
+
"model.layers.31.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 312 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 313 |
+
"model.layers.31.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 314 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 315 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 316 |
+
"model.layers.31.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 317 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 318 |
+
"model.layers.31.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 319 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 320 |
+
"model.layers.32.input_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 321 |
+
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00006.safetensors",
|
| 322 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00004-of-00006.safetensors",
|
| 323 |
+
"model.layers.32.mlp.up_proj.weight": "model-00004-of-00006.safetensors",
|
| 324 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00006.safetensors",
|
| 325 |
+
"model.layers.32.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 326 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 327 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 328 |
+
"model.layers.32.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 329 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 330 |
+
"model.layers.32.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 331 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 332 |
+
"model.layers.33.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 333 |
+
"model.layers.33.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 334 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 335 |
+
"model.layers.33.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 336 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 337 |
+
"model.layers.33.self_attn.k_proj.bias": "model-00004-of-00006.safetensors",
|
| 338 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00006.safetensors",
|
| 339 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00006.safetensors",
|
| 340 |
+
"model.layers.33.self_attn.q_proj.bias": "model-00004-of-00006.safetensors",
|
| 341 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00006.safetensors",
|
| 342 |
+
"model.layers.33.self_attn.v_proj.bias": "model-00004-of-00006.safetensors",
|
| 343 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00006.safetensors",
|
| 344 |
+
"model.layers.34.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 345 |
+
"model.layers.34.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 346 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 347 |
+
"model.layers.34.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 348 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 349 |
+
"model.layers.34.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 350 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 351 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 352 |
+
"model.layers.34.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 353 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 354 |
+
"model.layers.34.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 355 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 356 |
+
"model.layers.35.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 357 |
+
"model.layers.35.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 358 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 359 |
+
"model.layers.35.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 360 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 361 |
+
"model.layers.35.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 362 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 363 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 364 |
+
"model.layers.35.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 365 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 366 |
+
"model.layers.35.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 367 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 368 |
+
"model.layers.36.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 369 |
+
"model.layers.36.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 370 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 371 |
+
"model.layers.36.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 372 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 373 |
+
"model.layers.36.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 374 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 375 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 376 |
+
"model.layers.36.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 377 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 378 |
+
"model.layers.36.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 379 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 380 |
+
"model.layers.37.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 381 |
+
"model.layers.37.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 382 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 383 |
+
"model.layers.37.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 384 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 385 |
+
"model.layers.37.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 386 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 387 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 388 |
+
"model.layers.37.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 389 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 390 |
+
"model.layers.37.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 391 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 392 |
+
"model.layers.38.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 393 |
+
"model.layers.38.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 394 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 395 |
+
"model.layers.38.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 396 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 397 |
+
"model.layers.38.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 398 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 399 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 400 |
+
"model.layers.38.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 401 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 402 |
+
"model.layers.38.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 403 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 404 |
+
"model.layers.39.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 405 |
+
"model.layers.39.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 406 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 407 |
+
"model.layers.39.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 408 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 409 |
+
"model.layers.39.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 410 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 411 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 412 |
+
"model.layers.39.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 413 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 414 |
+
"model.layers.39.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 415 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 416 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 417 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 418 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 419 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 420 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 421 |
+
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 422 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 423 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 424 |
+
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 425 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 426 |
+
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 427 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 428 |
+
"model.layers.40.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 429 |
+
"model.layers.40.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 430 |
+
"model.layers.40.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 431 |
+
"model.layers.40.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 432 |
+
"model.layers.40.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 433 |
+
"model.layers.40.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 434 |
+
"model.layers.40.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 435 |
+
"model.layers.40.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 436 |
+
"model.layers.40.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 437 |
+
"model.layers.40.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 438 |
+
"model.layers.40.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 439 |
+
"model.layers.40.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 440 |
+
"model.layers.41.input_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 441 |
+
"model.layers.41.mlp.down_proj.weight": "model-00005-of-00006.safetensors",
|
| 442 |
+
"model.layers.41.mlp.gate_proj.weight": "model-00005-of-00006.safetensors",
|
| 443 |
+
"model.layers.41.mlp.up_proj.weight": "model-00005-of-00006.safetensors",
|
| 444 |
+
"model.layers.41.post_attention_layernorm.weight": "model-00005-of-00006.safetensors",
|
| 445 |
+
"model.layers.41.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 446 |
+
"model.layers.41.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 447 |
+
"model.layers.41.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 448 |
+
"model.layers.41.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 449 |
+
"model.layers.41.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 450 |
+
"model.layers.41.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 451 |
+
"model.layers.41.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 452 |
+
"model.layers.42.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 453 |
+
"model.layers.42.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 454 |
+
"model.layers.42.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 455 |
+
"model.layers.42.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 456 |
+
"model.layers.42.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 457 |
+
"model.layers.42.self_attn.k_proj.bias": "model-00005-of-00006.safetensors",
|
| 458 |
+
"model.layers.42.self_attn.k_proj.weight": "model-00005-of-00006.safetensors",
|
| 459 |
+
"model.layers.42.self_attn.o_proj.weight": "model-00005-of-00006.safetensors",
|
| 460 |
+
"model.layers.42.self_attn.q_proj.bias": "model-00005-of-00006.safetensors",
|
| 461 |
+
"model.layers.42.self_attn.q_proj.weight": "model-00005-of-00006.safetensors",
|
| 462 |
+
"model.layers.42.self_attn.v_proj.bias": "model-00005-of-00006.safetensors",
|
| 463 |
+
"model.layers.42.self_attn.v_proj.weight": "model-00005-of-00006.safetensors",
|
| 464 |
+
"model.layers.43.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 465 |
+
"model.layers.43.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 466 |
+
"model.layers.43.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 467 |
+
"model.layers.43.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 468 |
+
"model.layers.43.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 469 |
+
"model.layers.43.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 470 |
+
"model.layers.43.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 471 |
+
"model.layers.43.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 472 |
+
"model.layers.43.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 473 |
+
"model.layers.43.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 474 |
+
"model.layers.43.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 475 |
+
"model.layers.43.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 476 |
+
"model.layers.44.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 477 |
+
"model.layers.44.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 478 |
+
"model.layers.44.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 479 |
+
"model.layers.44.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 480 |
+
"model.layers.44.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 481 |
+
"model.layers.44.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 482 |
+
"model.layers.44.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 483 |
+
"model.layers.44.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 484 |
+
"model.layers.44.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 485 |
+
"model.layers.44.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 486 |
+
"model.layers.44.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 487 |
+
"model.layers.44.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 488 |
+
"model.layers.45.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 489 |
+
"model.layers.45.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 490 |
+
"model.layers.45.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 491 |
+
"model.layers.45.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 492 |
+
"model.layers.45.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 493 |
+
"model.layers.45.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 494 |
+
"model.layers.45.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 495 |
+
"model.layers.45.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 496 |
+
"model.layers.45.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 497 |
+
"model.layers.45.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 498 |
+
"model.layers.45.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 499 |
+
"model.layers.45.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 500 |
+
"model.layers.46.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 501 |
+
"model.layers.46.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 502 |
+
"model.layers.46.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 503 |
+
"model.layers.46.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 504 |
+
"model.layers.46.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 505 |
+
"model.layers.46.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 506 |
+
"model.layers.46.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 507 |
+
"model.layers.46.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 508 |
+
"model.layers.46.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 509 |
+
"model.layers.46.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 510 |
+
"model.layers.46.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 511 |
+
"model.layers.46.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 512 |
+
"model.layers.47.input_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 513 |
+
"model.layers.47.mlp.down_proj.weight": "model-00006-of-00006.safetensors",
|
| 514 |
+
"model.layers.47.mlp.gate_proj.weight": "model-00006-of-00006.safetensors",
|
| 515 |
+
"model.layers.47.mlp.up_proj.weight": "model-00006-of-00006.safetensors",
|
| 516 |
+
"model.layers.47.post_attention_layernorm.weight": "model-00006-of-00006.safetensors",
|
| 517 |
+
"model.layers.47.self_attn.k_proj.bias": "model-00006-of-00006.safetensors",
|
| 518 |
+
"model.layers.47.self_attn.k_proj.weight": "model-00006-of-00006.safetensors",
|
| 519 |
+
"model.layers.47.self_attn.o_proj.weight": "model-00006-of-00006.safetensors",
|
| 520 |
+
"model.layers.47.self_attn.q_proj.bias": "model-00006-of-00006.safetensors",
|
| 521 |
+
"model.layers.47.self_attn.q_proj.weight": "model-00006-of-00006.safetensors",
|
| 522 |
+
"model.layers.47.self_attn.v_proj.bias": "model-00006-of-00006.safetensors",
|
| 523 |
+
"model.layers.47.self_attn.v_proj.weight": "model-00006-of-00006.safetensors",
|
| 524 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 525 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00006.safetensors",
|
| 526 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00006.safetensors",
|
| 527 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00006.safetensors",
|
| 528 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00006.safetensors",
|
| 529 |
+
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 530 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 531 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 532 |
+
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 533 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 534 |
+
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 535 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 536 |
+
"model.layers.6.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 537 |
+
"model.layers.6.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 538 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 539 |
+
"model.layers.6.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 540 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 541 |
+
"model.layers.6.self_attn.k_proj.bias": "model-00001-of-00006.safetensors",
|
| 542 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00006.safetensors",
|
| 543 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00006.safetensors",
|
| 544 |
+
"model.layers.6.self_attn.q_proj.bias": "model-00001-of-00006.safetensors",
|
| 545 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00006.safetensors",
|
| 546 |
+
"model.layers.6.self_attn.v_proj.bias": "model-00001-of-00006.safetensors",
|
| 547 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00006.safetensors",
|
| 548 |
+
"model.layers.7.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 549 |
+
"model.layers.7.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 550 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 551 |
+
"model.layers.7.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 552 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 553 |
+
"model.layers.7.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 554 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 555 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 556 |
+
"model.layers.7.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 557 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 558 |
+
"model.layers.7.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 559 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 560 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 561 |
+
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 562 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 563 |
+
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 564 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 565 |
+
"model.layers.8.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 566 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 567 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 568 |
+
"model.layers.8.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 569 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 570 |
+
"model.layers.8.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 571 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 572 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 573 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00006.safetensors",
|
| 574 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00006.safetensors",
|
| 575 |
+
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00006.safetensors",
|
| 576 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00006.safetensors",
|
| 577 |
+
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00006.safetensors",
|
| 578 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00006.safetensors",
|
| 579 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00006.safetensors",
|
| 580 |
+
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00006.safetensors",
|
| 581 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00006.safetensors",
|
| 582 |
+
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00006.safetensors",
|
| 583 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00006.safetensors",
|
| 584 |
+
"model.norm.weight": "model-00006-of-00006.safetensors"
|
| 585 |
+
}
|
| 586 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin▁of▁sentence|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end▁of▁sentence|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|end▁of▁sentence|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5150c03d259d53983eceee63b352ef718b9f8c04a53382a35f6a22744674ce0e
|
| 3 |
+
size 11422877
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": null,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"151643": {
|
| 7 |
+
"content": "<|end▁of▁sentence|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"151644": {
|
| 15 |
+
"content": "<|User|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": false
|
| 21 |
+
},
|
| 22 |
+
"151645": {
|
| 23 |
+
"content": "<|Assistant|>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": false
|
| 29 |
+
},
|
| 30 |
+
"151646": {
|
| 31 |
+
"content": "<|begin▁of▁sentence|>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": true
|
| 37 |
+
},
|
| 38 |
+
"151647": {
|
| 39 |
+
"content": "<|EOT|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": false
|
| 45 |
+
},
|
| 46 |
+
"151648": {
|
| 47 |
+
"content": "<think>",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": false,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": false
|
| 53 |
+
},
|
| 54 |
+
"151649": {
|
| 55 |
+
"content": "</think>",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": false,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": false
|
| 61 |
+
},
|
| 62 |
+
"151650": {
|
| 63 |
+
"content": "<|quad_start|>",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": false,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": true
|
| 69 |
+
},
|
| 70 |
+
"151651": {
|
| 71 |
+
"content": "<|quad_end|>",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": false,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": true
|
| 77 |
+
},
|
| 78 |
+
"151652": {
|
| 79 |
+
"content": "<|vision_start|>",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": false,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": true
|
| 85 |
+
},
|
| 86 |
+
"151653": {
|
| 87 |
+
"content": "<|vision_end|>",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": false,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": true
|
| 93 |
+
},
|
| 94 |
+
"151654": {
|
| 95 |
+
"content": "<|vision_pad|>",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": false,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": true
|
| 101 |
+
},
|
| 102 |
+
"151655": {
|
| 103 |
+
"content": "<|image_pad|>",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": false,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": true
|
| 109 |
+
},
|
| 110 |
+
"151656": {
|
| 111 |
+
"content": "<|video_pad|>",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": false,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": true
|
| 117 |
+
},
|
| 118 |
+
"151657": {
|
| 119 |
+
"content": "<tool_call>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": false
|
| 125 |
+
},
|
| 126 |
+
"151658": {
|
| 127 |
+
"content": "</tool_call>",
|
| 128 |
+
"lstrip": false,
|
| 129 |
+
"normalized": false,
|
| 130 |
+
"rstrip": false,
|
| 131 |
+
"single_word": false,
|
| 132 |
+
"special": false
|
| 133 |
+
},
|
| 134 |
+
"151659": {
|
| 135 |
+
"content": "<|fim_prefix|>",
|
| 136 |
+
"lstrip": false,
|
| 137 |
+
"normalized": false,
|
| 138 |
+
"rstrip": false,
|
| 139 |
+
"single_word": false,
|
| 140 |
+
"special": false
|
| 141 |
+
},
|
| 142 |
+
"151660": {
|
| 143 |
+
"content": "<|fim_middle|>",
|
| 144 |
+
"lstrip": false,
|
| 145 |
+
"normalized": false,
|
| 146 |
+
"rstrip": false,
|
| 147 |
+
"single_word": false,
|
| 148 |
+
"special": false
|
| 149 |
+
},
|
| 150 |
+
"151661": {
|
| 151 |
+
"content": "<|fim_suffix|>",
|
| 152 |
+
"lstrip": false,
|
| 153 |
+
"normalized": false,
|
| 154 |
+
"rstrip": false,
|
| 155 |
+
"single_word": false,
|
| 156 |
+
"special": false
|
| 157 |
+
},
|
| 158 |
+
"151662": {
|
| 159 |
+
"content": "<|fim_pad|>",
|
| 160 |
+
"lstrip": false,
|
| 161 |
+
"normalized": false,
|
| 162 |
+
"rstrip": false,
|
| 163 |
+
"single_word": false,
|
| 164 |
+
"special": false
|
| 165 |
+
},
|
| 166 |
+
"151663": {
|
| 167 |
+
"content": "<|repo_name|>",
|
| 168 |
+
"lstrip": false,
|
| 169 |
+
"normalized": false,
|
| 170 |
+
"rstrip": false,
|
| 171 |
+
"single_word": false,
|
| 172 |
+
"special": false
|
| 173 |
+
},
|
| 174 |
+
"151664": {
|
| 175 |
+
"content": "<|file_sep|>",
|
| 176 |
+
"lstrip": false,
|
| 177 |
+
"normalized": false,
|
| 178 |
+
"rstrip": false,
|
| 179 |
+
"single_word": false,
|
| 180 |
+
"special": false
|
| 181 |
+
}
|
| 182 |
+
},
|
| 183 |
+
"bos_token": "<|begin▁of▁sentence|>",
|
| 184 |
+
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin��>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\\n' + '```json' + '\\n' + tool['function']['arguments'] + '\\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|><think>\\n'}}{% endif %}",
|
| 185 |
+
"clean_up_tokenization_spaces": false,
|
| 186 |
+
"eos_token": "<|end▁of▁sentence|>",
|
| 187 |
+
"extra_special_tokens": {},
|
| 188 |
+
"legacy": true,
|
| 189 |
+
"max_length": 8096,
|
| 190 |
+
"model_max_length": 16384,
|
| 191 |
+
"pad_token": "<|end▁of▁sentence|>",
|
| 192 |
+
"sp_model_kwargs": {},
|
| 193 |
+
"stride": 0,
|
| 194 |
+
"tokenizer_class": "LlamaTokenizerFast",
|
| 195 |
+
"truncation_side": "right",
|
| 196 |
+
"truncation_strategy": "longest_first",
|
| 197 |
+
"unk_token": null,
|
| 198 |
+
"use_default_system_prompt": false
|
| 199 |
+
}
|