

Upload folder using huggingface_hub
Browse files- .gitattributes +7 -0
- README.md +659 -3
- assets/comp_effic.png +3 -0
- assets/data_for_diff_stage.jpg +3 -0
- assets/i2v_res.png +3 -0
- assets/logo.png +0 -0
- assets/t2v_res.jpg +3 -0
- assets/vben_vs_sota.png +3 -0
- assets/video_dit_arch.jpg +3 -0
- assets/video_vae_res.jpg +3 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,10 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
google/umt5-xxl/tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
google/umt5-xxl/tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/comp_effic.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/data_for_diff_stage.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/i2v_res.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/t2v_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/vben_vs_sota.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/video_dit_arch.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
assets/video_vae_res.jpg filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,659 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Wan2.1
|
| 2 |
+
|
| 3 |
+
<p align="center">
|
| 4 |
+
<img src="assets/logo.png" width="400"/>
|
| 5 |
+
<p>
|
| 6 |
+
|
| 7 |
+
<p align="center">
|
| 8 |
+
💜 <a href="https://wan.video"><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.1">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="https://arxiv.org/abs/2503.20314">Technical Report</a>    |    📑 <a href="https://wan.video/welcome?spm=a2ty_o02.30011076.0.0.6c9ee41eCcluqg">Blog</a>    |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat Group</a>   |    📖 <a href="https://discord.gg/AKNgpMK4Yj">Discord</a>  
|
| 9 |
+
<br>
|
| 10 |
+
|
| 11 |
+
-----
|
| 12 |
+
|
| 13 |
+
[**Wan: Open and Advanced Large-Scale Video Generative Models**](https://arxiv.org/abs/2503.20314) <be>
|
| 14 |
+
|
| 15 |
+
In this repository, we present **Wan2.1**, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. **Wan2.1** offers these key features:
|
| 16 |
+
- 👍 **SOTA Performance**: **Wan2.1** consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
|
| 17 |
+
- 👍 **Supports Consumer-grade GPUs**: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
|
| 18 |
+
- 👍 **Multiple Tasks**: **Wan2.1** excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
|
| 19 |
+
- 👍 **Visual Text Generation**: **Wan2.1** is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
|
| 20 |
+
- 👍 **Powerful Video VAE**: **Wan-VAE** delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
|
| 21 |
+
|
| 22 |
+
## Video Demos
|
| 23 |
+
|
| 24 |
+
<div align="center">
|
| 25 |
+
<video src="https://github.com/user-attachments/assets/4aca6063-60bf-4953-bfb7-e265053f49ef" width="70%" poster=""> </video>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
## 🔥 Latest News!!
|
| 29 |
+
|
| 30 |
+
* May 14, 2025: 👋 We introduce **Wan2.1** [VACE](https://github.com/ali-vilab/VACE), an all-in-one model for video creation and editing, along with its [inference code](#run-vace), [weights](#model-download), and [technical report](https://arxiv.org/abs/2503.07598)!
|
| 31 |
+
* Apr 17, 2025: 👋 We introduce **Wan2.1** [FLF2V](#run-first-last-frame-to-video-generation) with its inference code and weights!
|
| 32 |
+
* Mar 21, 2025: 👋 We are excited to announce the release of the **Wan2.1** [technical report](https://files.alicdn.com/tpsservice/5c9de1c74de03972b7aa657e5a54756b.pdf). We welcome discussions and feedback!
|
| 33 |
+
* Mar 3, 2025: 👋 **Wan2.1**'s T2V and I2V have been integrated into Diffusers ([T2V](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wan#diffusers.WanPipeline) | [I2V](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wan#diffusers.WanImageToVideoPipeline)). Feel free to give it a try!
|
| 34 |
+
* Feb 27, 2025: 👋 **Wan2.1** has been integrated into [ComfyUI](https://comfyanonymous.github.io/ComfyUI_examples/wan/). Enjoy!
|
| 35 |
+
* Feb 25, 2025: 👋 We've released the inference code and weights of **Wan2.1**.
|
| 36 |
+
|
| 37 |
+
## Community Works
|
| 38 |
+
If your work has improved **Wan2.1** and you would like more people to see it, please inform us.
|
| 39 |
+
- [Phantom](https://github.com/Phantom-video/Phantom) has developed a unified video generation framework for single and multi-subject references based on **Wan2.1-T2V-1.3B**. Please refer to [their examples](https://github.com/Phantom-video/Phantom).
|
| 40 |
+
- [UniAnimate-DiT](https://github.com/ali-vilab/UniAnimate-DiT), based on **Wan2.1-14B-I2V**, has trained a Human image animation model and has open-sourced the inference and training code. Feel free to enjoy it!
|
| 41 |
+
- [CFG-Zero](https://github.com/WeichenFan/CFG-Zero-star) enhances **Wan2.1** (covering both T2V and I2V models) from the perspective of CFG.
|
| 42 |
+
- [TeaCache](https://github.com/ali-vilab/TeaCache) now supports **Wan2.1** acceleration, capable of increasing speed by approximately 2x. Feel free to give it a try!
|
| 43 |
+
- [DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio) provides more support for **Wan2.1**, including video-to-video, FP8 quantization, VRAM optimization, LoRA training, and more. Please refer to [their examples](https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/wanvideo).
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
## 📑 Todo List
|
| 47 |
+
- Wan2.1 Text-to-Video
|
| 48 |
+
- [x] Multi-GPU Inference code of the 14B and 1.3B models
|
| 49 |
+
- [x] Checkpoints of the 14B and 1.3B models
|
| 50 |
+
- [x] Gradio demo
|
| 51 |
+
- [x] ComfyUI integration
|
| 52 |
+
- [x] Diffusers integration
|
| 53 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 54 |
+
- Wan2.1 Image-to-Video
|
| 55 |
+
- [x] Multi-GPU Inference code of the 14B model
|
| 56 |
+
- [x] Checkpoints of the 14B model
|
| 57 |
+
- [x] Gradio demo
|
| 58 |
+
- [x] ComfyUI integration
|
| 59 |
+
- [x] Diffusers integration
|
| 60 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 61 |
+
- Wan2.1 First-Last-Frame-to-Video
|
| 62 |
+
- [x] Multi-GPU Inference code of the 14B model
|
| 63 |
+
- [x] Checkpoints of the 14B model
|
| 64 |
+
- [x] Gradio demo
|
| 65 |
+
- [ ] ComfyUI integration
|
| 66 |
+
- [ ] Diffusers integration
|
| 67 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 68 |
+
- Wan2.1 VACE
|
| 69 |
+
- [x] Multi-GPU Inference code of the 14B and 1.3B models
|
| 70 |
+
- [x] Checkpoints of the 14B and 1.3B models
|
| 71 |
+
- [x] Gradio demo
|
| 72 |
+
- [x] ComfyUI integration
|
| 73 |
+
- [ ] Diffusers integration
|
| 74 |
+
- [ ] Diffusers + Multi-GPU Inference
|
| 75 |
+
|
| 76 |
+
## Quickstart
|
| 77 |
+
|
| 78 |
+
#### Installation
|
| 79 |
+
Clone the repo:
|
| 80 |
+
```sh
|
| 81 |
+
git clone https://github.com/Wan-Video/Wan2.1.git
|
| 82 |
+
cd Wan2.1
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
Install dependencies:
|
| 86 |
+
```sh
|
| 87 |
+
# Ensure torch >= 2.4.0
|
| 88 |
+
pip install -r requirements.txt
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
#### Model Download
|
| 93 |
+
|
| 94 |
+
| Models | Download Link | Notes |
|
| 95 |
+
|--------------|---------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------|
|
| 96 |
+
| T2V-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | Supports both 480P and 720P
|
| 97 |
+
| I2V-14B-720P | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | Supports 720P
|
| 98 |
+
| I2V-14B-480P | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | Supports 480P
|
| 99 |
+
| T2V-1.3B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | Supports 480P
|
| 100 |
+
| FLF2V-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-FLF2V-14B-720P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-FLF2V-14B-720P) | Supports 720P
|
| 101 |
+
| VACE-1.3B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-VACE-1.3B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-VACE-1.3B) | Supports 480P
|
| 102 |
+
| VACE-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-VACE-14B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-VACE-14B) | Supports both 480P and 720P
|
| 103 |
+
|
| 104 |
+
> 💡Note:
|
| 105 |
+
> * The 1.3B model is capable of generating videos at 720P resolution. However, due to limited training at this resolution, the results are generally less stable compared to 480P. For optimal performance, we recommend using 480P resolution.
|
| 106 |
+
> * For the first-last frame to video generation, we train our model primarily on Chinese text-video pairs. Therefore, we recommend using Chinese prompt to achieve better results.
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
Download models using huggingface-cli:
|
| 110 |
+
``` sh
|
| 111 |
+
pip install "huggingface_hub[cli]"
|
| 112 |
+
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
Download models using modelscope-cli:
|
| 116 |
+
``` sh
|
| 117 |
+
pip install modelscope
|
| 118 |
+
modelscope download Wan-AI/Wan2.1-T2V-14B --local_dir ./Wan2.1-T2V-14B
|
| 119 |
+
```
|
| 120 |
+
#### Run Text-to-Video Generation
|
| 121 |
+
|
| 122 |
+
This repository supports two Text-to-Video models (1.3B and 14B) and two resolutions (480P and 720P). The parameters and configurations for these models are as follows:
|
| 123 |
+
|
| 124 |
+
<table>
|
| 125 |
+
<thead>
|
| 126 |
+
<tr>
|
| 127 |
+
<th rowspan="2">Task</th>
|
| 128 |
+
<th colspan="2">Resolution</th>
|
| 129 |
+
<th rowspan="2">Model</th>
|
| 130 |
+
</tr>
|
| 131 |
+
<tr>
|
| 132 |
+
<th>480P</th>
|
| 133 |
+
<th>720P</th>
|
| 134 |
+
</tr>
|
| 135 |
+
</thead>
|
| 136 |
+
<tbody>
|
| 137 |
+
<tr>
|
| 138 |
+
<td>t2v-14B</td>
|
| 139 |
+
<td style="color: green;">✔️</td>
|
| 140 |
+
<td style="color: green;">✔️</td>
|
| 141 |
+
<td>Wan2.1-T2V-14B</td>
|
| 142 |
+
</tr>
|
| 143 |
+
<tr>
|
| 144 |
+
<td>t2v-1.3B</td>
|
| 145 |
+
<td style="color: green;">✔️</td>
|
| 146 |
+
<td style="color: red;">❌</td>
|
| 147 |
+
<td>Wan2.1-T2V-1.3B</td>
|
| 148 |
+
</tr>
|
| 149 |
+
</tbody>
|
| 150 |
+
</table>
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
##### (1) Without Prompt Extension
|
| 154 |
+
|
| 155 |
+
To facilitate implementation, we will start with a basic version of the inference process that skips the [prompt extension](#2-using-prompt-extention) step.
|
| 156 |
+
|
| 157 |
+
- Single-GPU inference
|
| 158 |
+
|
| 159 |
+
``` sh
|
| 160 |
+
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
If you encounter OOM (Out-of-Memory) issues, you can use the `--offload_model True` and `--t5_cpu` options to reduce GPU memory usage. For example, on an RTX 4090 GPU:
|
| 164 |
+
|
| 165 |
+
``` sh
|
| 166 |
+
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
> 💡Note: If you are using the `T2V-1.3B` model, we recommend setting the parameter `--sample_guide_scale 6`. The `--sample_shift parameter` can be adjusted within the range of 8 to 12 based on the performance.
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 173 |
+
|
| 174 |
+
We use FSDP and [xDiT](https://github.com/xdit-project/xDiT) USP to accelerate inference.
|
| 175 |
+
|
| 176 |
+
* Ulysess Strategy
|
| 177 |
+
|
| 178 |
+
If you want to use [`Ulysses`](https://arxiv.org/abs/2309.14509) strategy, you should set `--ulysses_size $GPU_NUMS`. Note that the `num_heads` should be divisible by `ulysses_size` if you wish to use `Ulysess` strategy. For the 1.3B model, the `num_heads` is `12` which can't be divided by 8 (as most multi-GPU machines have 8 GPUs). Therefore, it is recommended to use `Ring Strategy` instead.
|
| 179 |
+
|
| 180 |
+
* Ring Strategy
|
| 181 |
+
|
| 182 |
+
If you want to use [`Ring`](https://arxiv.org/pdf/2310.01889) strategy, you should set `--ring_size $GPU_NUMS`. Note that the `sequence length` should be divisible by `ring_size` when using the `Ring` strategy.
|
| 183 |
+
|
| 184 |
+
Of course, you can also combine the use of `Ulysses` and `Ring` strategies.
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
``` sh
|
| 188 |
+
pip install "xfuser>=0.4.1"
|
| 189 |
+
torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 190 |
+
```
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
##### (2) Using Prompt Extension
|
| 194 |
+
|
| 195 |
+
Extending the prompts can effectively enrich the details in the generated videos, further enhancing the video quality. Therefore, we recommend enabling prompt extension. We provide the following two methods for prompt extension:
|
| 196 |
+
|
| 197 |
+
- Use the Dashscope API for extension.
|
| 198 |
+
- Apply for a `dashscope.api_key` in advance ([EN](https://www.alibabacloud.com/help/en/model-studio/getting-started/first-api-call-to-qwen) | [CN](https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen)).
|
| 199 |
+
- Configure the environment variable `DASH_API_KEY` to specify the Dashscope API key. For users of Alibaba Cloud's international site, you also need to set the environment variable `DASH_API_URL` to 'https://dashscope-intl.aliyuncs.com/api/v1'. For more detailed instructions, please refer to the [dashscope document](https://www.alibabacloud.com/help/en/model-studio/developer-reference/use-qwen-by-calling-api?spm=a2c63.p38356.0.i1).
|
| 200 |
+
- Use the `qwen-plus` model for text-to-video tasks and `qwen-vl-max` for image-to-video tasks.
|
| 201 |
+
- You can modify the model used for extension with the parameter `--prompt_extend_model`. For example:
|
| 202 |
+
```sh
|
| 203 |
+
DASH_API_KEY=your_key python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh'
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
- Using a local model for extension.
|
| 207 |
+
|
| 208 |
+
- By default, the Qwen model on HuggingFace is used for this extension. Users can choose Qwen models or other models based on the available GPU memory size.
|
| 209 |
+
- For text-to-video tasks, you can use models like `Qwen/Qwen2.5-14B-Instruct`, `Qwen/Qwen2.5-7B-Instruct` and `Qwen/Qwen2.5-3B-Instruct`.
|
| 210 |
+
- For image-to-video or first-last-frame-to-video tasks, you can use models like `Qwen/Qwen2.5-VL-7B-Instruct` and `Qwen/Qwen2.5-VL-3B-Instruct`.
|
| 211 |
+
- Larger models generally provide better extension results but require more GPU memory.
|
| 212 |
+
- You can modify the model used for extension with the parameter `--prompt_extend_model` , allowing you to specify either a local model path or a Hugging Face model. For example:
|
| 213 |
+
|
| 214 |
+
``` sh
|
| 215 |
+
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_target_lang 'zh'
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
##### (3) Running with Diffusers
|
| 220 |
+
|
| 221 |
+
You can easily inference **Wan2.1**-T2V using Diffusers with the following command:
|
| 222 |
+
``` python
|
| 223 |
+
import torch
|
| 224 |
+
from diffusers.utils import export_to_video
|
| 225 |
+
from diffusers import AutoencoderKLWan, WanPipeline
|
| 226 |
+
from diffusers.schedulers.scheduling_unipc_multistep import UniPCMultistepScheduler
|
| 227 |
+
|
| 228 |
+
# Available models: Wan-AI/Wan2.1-T2V-14B-Diffusers, Wan-AI/Wan2.1-T2V-1.3B-Diffusers
|
| 229 |
+
model_id = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
|
| 230 |
+
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
|
| 231 |
+
flow_shift = 5.0 # 5.0 for 720P, 3.0 for 480P
|
| 232 |
+
scheduler = UniPCMultistepScheduler(prediction_type='flow_prediction', use_flow_sigmas=True, num_train_timesteps=1000, flow_shift=flow_shift)
|
| 233 |
+
pipe = WanPipeline.from_pretrained(model_id, vae=vae, torch_dtype=torch.bfloat16)
|
| 234 |
+
pipe.scheduler = scheduler
|
| 235 |
+
pipe.to("cuda")
|
| 236 |
+
|
| 237 |
+
prompt = "A cat and a dog baking a cake together in a kitchen. The cat is carefully measuring flour, while the dog is stirring the batter with a wooden spoon. The kitchen is cozy, with sunlight streaming through the window."
|
| 238 |
+
negative_prompt = "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards"
|
| 239 |
+
|
| 240 |
+
output = pipe(
|
| 241 |
+
prompt=prompt,
|
| 242 |
+
negative_prompt=negative_prompt,
|
| 243 |
+
height=720,
|
| 244 |
+
width=1280,
|
| 245 |
+
num_frames=81,
|
| 246 |
+
guidance_scale=5.0,
|
| 247 |
+
).frames[0]
|
| 248 |
+
export_to_video(output, "output.mp4", fps=16)
|
| 249 |
+
```
|
| 250 |
+
> 💡Note: Please note that this example does not integrate Prompt Extension and distributed inference. We will soon update with the integrated prompt extension and multi-GPU version of Diffusers.
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
##### (4) Running local gradio
|
| 254 |
+
|
| 255 |
+
``` sh
|
| 256 |
+
cd gradio
|
| 257 |
+
# if one uses dashscope’s API for prompt extension
|
| 258 |
+
DASH_API_KEY=your_key python t2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir ./Wan2.1-T2V-14B
|
| 259 |
+
|
| 260 |
+
# if one uses a local model for prompt extension
|
| 261 |
+
python t2v_14B_singleGPU.py --prompt_extend_method 'local_qwen' --ckpt_dir ./Wan2.1-T2V-14B
|
| 262 |
+
```
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
#### Run Image-to-Video Generation
|
| 267 |
+
|
| 268 |
+
Similar to Text-to-Video, Image-to-Video is also divided into processes with and without the prompt extension step. The specific parameters and their corresponding settings are as follows:
|
| 269 |
+
<table>
|
| 270 |
+
<thead>
|
| 271 |
+
<tr>
|
| 272 |
+
<th rowspan="2">Task</th>
|
| 273 |
+
<th colspan="2">Resolution</th>
|
| 274 |
+
<th rowspan="2">Model</th>
|
| 275 |
+
</tr>
|
| 276 |
+
<tr>
|
| 277 |
+
<th>480P</th>
|
| 278 |
+
<th>720P</th>
|
| 279 |
+
</tr>
|
| 280 |
+
</thead>
|
| 281 |
+
<tbody>
|
| 282 |
+
<tr>
|
| 283 |
+
<td>i2v-14B</td>
|
| 284 |
+
<td style="color: green;">❌</td>
|
| 285 |
+
<td style="color: green;">✔️</td>
|
| 286 |
+
<td>Wan2.1-I2V-14B-720P</td>
|
| 287 |
+
</tr>
|
| 288 |
+
<tr>
|
| 289 |
+
<td>i2v-14B</td>
|
| 290 |
+
<td style="color: green;">✔️</td>
|
| 291 |
+
<td style="color: red;">❌</td>
|
| 292 |
+
<td>Wan2.1-T2V-14B-480P</td>
|
| 293 |
+
</tr>
|
| 294 |
+
</tbody>
|
| 295 |
+
</table>
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
##### (1) Without Prompt Extension
|
| 299 |
+
|
| 300 |
+
- Single-GPU inference
|
| 301 |
+
```sh
|
| 302 |
+
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 303 |
+
```
|
| 304 |
+
|
| 305 |
+
> 💡For the Image-to-Video task, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 309 |
+
|
| 310 |
+
```sh
|
| 311 |
+
pip install "xfuser>=0.4.1"
|
| 312 |
+
torchrun --nproc_per_node=8 generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
##### (2) Using Prompt Extension
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
The process of prompt extension can be referenced [here](#2-using-prompt-extention).
|
| 319 |
+
|
| 320 |
+
Run with local prompt extension using `Qwen/Qwen2.5-VL-7B-Instruct`:
|
| 321 |
+
```
|
| 322 |
+
python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 323 |
+
```
|
| 324 |
+
|
| 325 |
+
Run with remote prompt extension using `dashscope`:
|
| 326 |
+
```
|
| 327 |
+
DASH_API_KEY=your_key python generate.py --task i2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-I2V-14B-720P --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_method 'dashscope' --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."
|
| 328 |
+
```
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
##### (3) Running with Diffusers
|
| 332 |
+
|
| 333 |
+
You can easily inference **Wan2.1**-I2V using Diffusers with the following command:
|
| 334 |
+
``` python
|
| 335 |
+
import torch
|
| 336 |
+
import numpy as np
|
| 337 |
+
from diffusers import AutoencoderKLWan, WanImageToVideoPipeline
|
| 338 |
+
from diffusers.utils import export_to_video, load_image
|
| 339 |
+
from transformers import CLIPVisionModel
|
| 340 |
+
|
| 341 |
+
# Available models: Wan-AI/Wan2.1-I2V-14B-480P-Diffusers, Wan-AI/Wan2.1-I2V-14B-720P-Diffusers
|
| 342 |
+
model_id = "Wan-AI/Wan2.1-I2V-14B-720P-Diffusers"
|
| 343 |
+
image_encoder = CLIPVisionModel.from_pretrained(model_id, subfolder="image_encoder", torch_dtype=torch.float32)
|
| 344 |
+
vae = AutoencoderKLWan.from_pretrained(model_id, subfolder="vae", torch_dtype=torch.float32)
|
| 345 |
+
pipe = WanImageToVideoPipeline.from_pretrained(model_id, vae=vae, image_encoder=image_encoder, torch_dtype=torch.bfloat16)
|
| 346 |
+
pipe.to("cuda")
|
| 347 |
+
|
| 348 |
+
image = load_image(
|
| 349 |
+
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg"
|
| 350 |
+
)
|
| 351 |
+
max_area = 720 * 1280
|
| 352 |
+
aspect_ratio = image.height / image.width
|
| 353 |
+
mod_value = pipe.vae_scale_factor_spatial * pipe.transformer.config.patch_size[1]
|
| 354 |
+
height = round(np.sqrt(max_area * aspect_ratio)) // mod_value * mod_value
|
| 355 |
+
width = round(np.sqrt(max_area / aspect_ratio)) // mod_value * mod_value
|
| 356 |
+
image = image.resize((width, height))
|
| 357 |
+
prompt = (
|
| 358 |
+
"An astronaut hatching from an egg, on the surface of the moon, the darkness and depth of space realised in "
|
| 359 |
+
"the background. High quality, ultrarealistic detail and breath-taking movie-like camera shot."
|
| 360 |
+
)
|
| 361 |
+
negative_prompt = "Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards"
|
| 362 |
+
|
| 363 |
+
output = pipe(
|
| 364 |
+
image=image,
|
| 365 |
+
prompt=prompt,
|
| 366 |
+
negative_prompt=negative_prompt,
|
| 367 |
+
height=height, width=width,
|
| 368 |
+
num_frames=81,
|
| 369 |
+
guidance_scale=5.0
|
| 370 |
+
).frames[0]
|
| 371 |
+
export_to_video(output, "output.mp4", fps=16)
|
| 372 |
+
|
| 373 |
+
```
|
| 374 |
+
> 💡Note: Please note that this example does not integrate Prompt Extension and distributed inference. We will soon update with the integrated prompt extension and multi-GPU version of Diffusers.
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
##### (4) Running local gradio
|
| 378 |
+
|
| 379 |
+
```sh
|
| 380 |
+
cd gradio
|
| 381 |
+
# if one only uses 480P model in gradio
|
| 382 |
+
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_480p ./Wan2.1-I2V-14B-480P
|
| 383 |
+
|
| 384 |
+
# if one only uses 720P model in gradio
|
| 385 |
+
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_720p ./Wan2.1-I2V-14B-720P
|
| 386 |
+
|
| 387 |
+
# if one uses both 480P and 720P models in gradio
|
| 388 |
+
DASH_API_KEY=your_key python i2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_480p ./Wan2.1-I2V-14B-480P --ckpt_dir_720p ./Wan2.1-I2V-14B-720P
|
| 389 |
+
```
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
#### Run First-Last-Frame-to-Video Generation
|
| 393 |
+
|
| 394 |
+
First-Last-Frame-to-Video is also divided into processes with and without the prompt extension step. Currently, only 720P is supported. The specific parameters and corresponding settings are as follows:
|
| 395 |
+
<table>
|
| 396 |
+
<thead>
|
| 397 |
+
<tr>
|
| 398 |
+
<th rowspan="2">Task</th>
|
| 399 |
+
<th colspan="2">Resolution</th>
|
| 400 |
+
<th rowspan="2">Model</th>
|
| 401 |
+
</tr>
|
| 402 |
+
<tr>
|
| 403 |
+
<th>480P</th>
|
| 404 |
+
<th>720P</th>
|
| 405 |
+
</tr>
|
| 406 |
+
</thead>
|
| 407 |
+
<tbody>
|
| 408 |
+
<tr>
|
| 409 |
+
<td>flf2v-14B</td>
|
| 410 |
+
<td style="color: green;">❌</td>
|
| 411 |
+
<td style="color: green;">✔️</td>
|
| 412 |
+
<td>Wan2.1-FLF2V-14B-720P</td>
|
| 413 |
+
</tr>
|
| 414 |
+
</tbody>
|
| 415 |
+
</table>
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
##### (1) Without Prompt Extension
|
| 419 |
+
|
| 420 |
+
- Single-GPU inference
|
| 421 |
+
```sh
|
| 422 |
+
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 423 |
+
```
|
| 424 |
+
|
| 425 |
+
> 💡Similar to Image-to-Video, the `size` parameter represents the area of the generated video, with the aspect ratio following that of the original input image.
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 429 |
+
|
| 430 |
+
```sh
|
| 431 |
+
pip install "xfuser>=0.4.1"
|
| 432 |
+
torchrun --nproc_per_node=8 generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 433 |
+
```
|
| 434 |
+
|
| 435 |
+
##### (2) Using Prompt Extension
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
The process of prompt extension can be referenced [here](#2-using-prompt-extention).
|
| 439 |
+
|
| 440 |
+
Run with local prompt extension using `Qwen/Qwen2.5-VL-7B-Instruct`:
|
| 441 |
+
```
|
| 442 |
+
python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --use_prompt_extend --prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 443 |
+
```
|
| 444 |
+
|
| 445 |
+
Run with remote prompt extension using `dashscope`:
|
| 446 |
+
```
|
| 447 |
+
DASH_API_KEY=your_key python generate.py --task flf2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-FLF2V-14B-720P --first_frame examples/flf2v_input_first_frame.png --last_frame examples/flf2v_input_last_frame.png --use_prompt_extend --prompt_extend_method 'dashscope' --prompt "CG animation style, a small blue bird takes off from the ground, flapping its wings. The bird’s feathers are delicate, with a unique pattern on its chest. The background shows a blue sky with white clouds under bright sunshine. The camera follows the bird upward, capturing its flight and the vastness of the sky from a close-up, low-angle perspective."
|
| 448 |
+
```
|
| 449 |
+
|
| 450 |
+
|
| 451 |
+
##### (3) Running local gradio
|
| 452 |
+
|
| 453 |
+
```sh
|
| 454 |
+
cd gradio
|
| 455 |
+
# use 720P model in gradio
|
| 456 |
+
DASH_API_KEY=your_key python flf2v_14B_singleGPU.py --prompt_extend_method 'dashscope' --ckpt_dir_720p ./Wan2.1-FLF2V-14B-720P
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
|
| 460 |
+
#### Run VACE
|
| 461 |
+
|
| 462 |
+
[VACE](https://github.com/ali-vilab/VACE) now supports two models (1.3B and 14B) and two main resolutions (480P and 720P).
|
| 463 |
+
The input supports any resolution, but to achieve optimal results, the video size should fall within a specific range.
|
| 464 |
+
The parameters and configurations for these models are as follows:
|
| 465 |
+
|
| 466 |
+
<table>
|
| 467 |
+
<thead>
|
| 468 |
+
<tr>
|
| 469 |
+
<th rowspan="2">Task</th>
|
| 470 |
+
<th colspan="2">Resolution</th>
|
| 471 |
+
<th rowspan="2">Model</th>
|
| 472 |
+
</tr>
|
| 473 |
+
<tr>
|
| 474 |
+
<th>480P(~81x480x832)</th>
|
| 475 |
+
<th>720P(~81x720x1280)</th>
|
| 476 |
+
</tr>
|
| 477 |
+
</thead>
|
| 478 |
+
<tbody>
|
| 479 |
+
<tr>
|
| 480 |
+
<td>VACE</td>
|
| 481 |
+
<td style="color: green; text-align: center; vertical-align: middle;">✔️</td>
|
| 482 |
+
<td style="color: green; text-align: center; vertical-align: middle;">✔️</td>
|
| 483 |
+
<td>Wan2.1-VACE-14B</td>
|
| 484 |
+
</tr>
|
| 485 |
+
<tr>
|
| 486 |
+
<td>VACE</td>
|
| 487 |
+
<td style="color: green; text-align: center; vertical-align: middle;">✔️</td>
|
| 488 |
+
<td style="color: red; text-align: center; vertical-align: middle;">❌</td>
|
| 489 |
+
<td>Wan2.1-VACE-1.3B</td>
|
| 490 |
+
</tr>
|
| 491 |
+
</tbody>
|
| 492 |
+
</table>
|
| 493 |
+
|
| 494 |
+
In VACE, users can input text prompt and optional video, mask, and image for video generation or editing. Detailed instructions for using VACE can be found in the [User Guide](https://github.com/ali-vilab/VACE/blob/main/UserGuide.md).
|
| 495 |
+
The execution process is as follows:
|
| 496 |
+
|
| 497 |
+
##### (1) Preprocessing
|
| 498 |
+
|
| 499 |
+
User-collected materials needs to be preprocessed into VACE-recognizable inputs, including `src_video`, `src_mask`, `src_ref_images`, and `prompt`.
|
| 500 |
+
For R2V (Reference-to-Video Generation), you may skip this preprocessing, but for V2V (Video-to-Video Editing) and MV2V (Masked Video-to-Video Editing) tasks, additional preprocessing is required to obtain video with conditions such as depth, pose or masked regions.
|
| 501 |
+
For more details, please refer to [vace_preproccess](https://github.com/ali-vilab/VACE/blob/main/vace/vace_preproccess.py).
|
| 502 |
+
|
| 503 |
+
##### (2) cli inference
|
| 504 |
+
|
| 505 |
+
- Single-GPU inference
|
| 506 |
+
```sh
|
| 507 |
+
python generate.py --task vace-1.3B --size 832*480 --ckpt_dir ./Wan2.1-VACE-1.3B --src_ref_images examples/girl.png,examples/snake.png --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩���快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
|
| 508 |
+
```
|
| 509 |
+
|
| 510 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 511 |
+
|
| 512 |
+
```sh
|
| 513 |
+
torchrun --nproc_per_node=8 generate.py --task vace-14B --size 1280*720 --ckpt_dir ./Wan2.1-VACE-14B --dit_fsdp --t5_fsdp --ulysses_size 8 --src_ref_images examples/girl.png,examples/snake.png --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"
|
| 514 |
+
```
|
| 515 |
+
|
| 516 |
+
##### (3) Running local gradio
|
| 517 |
+
|
| 518 |
+
```sh
|
| 519 |
+
cd gradio
|
| 520 |
+
python vace_1.3B_singleGPU.py --ckpt_dir_720p ./Wan2.1-VACE-1.3B # use 480P model in gradio
|
| 521 |
+
```
|
| 522 |
+
|
| 523 |
+
#### Run Text-to-Image Generation
|
| 524 |
+
|
| 525 |
+
Wan2.1 is a unified model for both image and video generation. Since it was trained on both types of data, it can also generate images. The command for generating images is similar to video generation, as follows:
|
| 526 |
+
|
| 527 |
+
##### (1) Without Prompt Extension
|
| 528 |
+
|
| 529 |
+
- Single-GPU inference
|
| 530 |
+
```sh
|
| 531 |
+
python generate.py --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人'
|
| 532 |
+
```
|
| 533 |
+
|
| 534 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 535 |
+
|
| 536 |
+
```sh
|
| 537 |
+
torchrun --nproc_per_node=8 generate.py --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 0 --frame_num 1 --task t2i-14B --size 1024*1024 --prompt '一个朴素端庄的美人' --ckpt_dir ./Wan2.1-T2V-14B
|
| 538 |
+
```
|
| 539 |
+
|
| 540 |
+
##### (2) With Prompt Extention
|
| 541 |
+
|
| 542 |
+
- Single-GPU inference
|
| 543 |
+
```sh
|
| 544 |
+
python generate.py --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人' --use_prompt_extend
|
| 545 |
+
```
|
| 546 |
+
|
| 547 |
+
- Multi-GPU inference using FSDP + xDiT USP
|
| 548 |
+
```sh
|
| 549 |
+
torchrun --nproc_per_node=8 generate.py --dit_fsdp --t5_fsdp --ulysses_size 8 --base_seed 0 --frame_num 1 --task t2i-14B --size 1024*1024 --ckpt_dir ./Wan2.1-T2V-14B --prompt '一个朴素端庄的美人' --use_prompt_extend
|
| 550 |
+
```
|
| 551 |
+
|
| 552 |
+
|
| 553 |
+
## Manual Evaluation
|
| 554 |
+
|
| 555 |
+
##### (1) Text-to-Video Evaluation
|
| 556 |
+
|
| 557 |
+
Through manual evaluation, the results generated after prompt extension are superior to those from both closed-source and open-source models.
|
| 558 |
+
|
| 559 |
+
<div align="center">
|
| 560 |
+
<img src="assets/t2v_res.jpg" alt="" style="width: 80%;" />
|
| 561 |
+
</div>
|
| 562 |
+
|
| 563 |
+
|
| 564 |
+
##### (2) Image-to-Video Evaluation
|
| 565 |
+
|
| 566 |
+
We also conducted extensive manual evaluations to evaluate the performance of the Image-to-Video model, and the results are presented in the table below. The results clearly indicate that **Wan2.1** outperforms both closed-source and open-source models.
|
| 567 |
+
|
| 568 |
+
<div align="center">
|
| 569 |
+
<img src="assets/i2v_res.png" alt="" style="width: 80%;" />
|
| 570 |
+
</div>
|
| 571 |
+
|
| 572 |
+
|
| 573 |
+
## Computational Efficiency on Different GPUs
|
| 574 |
+
|
| 575 |
+
We test the computational efficiency of different **Wan2.1** models on different GPUs in the following table. The results are presented in the format: **Total time (s) / peak GPU memory (GB)**.
|
| 576 |
+
|
| 577 |
+
|
| 578 |
+
<div align="center">
|
| 579 |
+
<img src="assets/comp_effic.png" alt="" style="width: 80%;" />
|
| 580 |
+
</div>
|
| 581 |
+
|
| 582 |
+
> The parameter settings for the tests presented in this table are as follows:
|
| 583 |
+
> (1) For the 1.3B model on 8 GPUs, set `--ring_size 8` and `--ulysses_size 1`;
|
| 584 |
+
> (2) For the 14B model on 1 GPU, use `--offload_model True`;
|
| 585 |
+
> (3) For the 1.3B model on a single 4090 GPU, set `--offload_model True --t5_cpu`;
|
| 586 |
+
> (4) For all testings, no prompt extension was applied, meaning `--use_prompt_extend` was not enabled.
|
| 587 |
+
|
| 588 |
+
> 💡Note: T2V-14B is slower than I2V-14B because the former samples 50 steps while the latter uses 40 steps.
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
-------
|
| 592 |
+
|
| 593 |
+
## Introduction of Wan2.1
|
| 594 |
+
|
| 595 |
+
**Wan2.1** is designed on the mainstream diffusion transformer paradigm, achieving significant advancements in generative capabilities through a series of innovations. These include our novel spatio-temporal variational autoencoder (VAE), scalable training strategies, large-scale data construction, and automated evaluation metrics. Collectively, these contributions enhance the model’s performance and versatility.
|
| 596 |
+
|
| 597 |
+
|
| 598 |
+
##### (1) 3D Variational Autoencoders
|
| 599 |
+
We propose a novel 3D causal VAE architecture, termed **Wan-VAE** specifically designed for video generation. By combining multiple strategies, we improve spatio-temporal compression, reduce memory usage, and ensure temporal causality. **Wan-VAE** demonstrates significant advantages in performance efficiency compared to other open-source VAEs. Furthermore, our **Wan-VAE** can encode and decode unlimited-length 1080P videos without losing historical temporal information, making it particularly well-suited for video generation tasks.
|
| 600 |
+
|
| 601 |
+
|
| 602 |
+
<div align="center">
|
| 603 |
+
<img src="assets/video_vae_res.jpg" alt="" style="width: 80%;" />
|
| 604 |
+
</div>
|
| 605 |
+
|
| 606 |
+
|
| 607 |
+
##### (2) Video Diffusion DiT
|
| 608 |
+
|
| 609 |
+
**Wan2.1** is designed using the Flow Matching framework within the paradigm of mainstream Diffusion Transformers. Our model's architecture uses the T5 Encoder to encode multilingual text input, with cross-attention in each transformer block embedding the text into the model structure. Additionally, we employ an MLP with a Linear layer and a SiLU layer to process the input time embeddings and predict six modulation parameters individually. This MLP is shared across all transformer blocks, with each block learning a distinct set of biases. Our experimental findings reveal a significant performance improvement with this approach at the same parameter scale.
|
| 610 |
+
|
| 611 |
+
<div align="center">
|
| 612 |
+
<img src="assets/video_dit_arch.jpg" alt="" style="width: 80%;" />
|
| 613 |
+
</div>
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
| Model | Dimension | Input Dimension | Output Dimension | Feedforward Dimension | Frequency Dimension | Number of Heads | Number of Layers |
|
| 617 |
+
|--------|-----------|-----------------|------------------|-----------------------|---------------------|-----------------|------------------|
|
| 618 |
+
| 1.3B | 1536 | 16 | 16 | 8960 | 256 | 12 | 30 |
|
| 619 |
+
| 14B | 5120 | 16 | 16 | 13824 | 256 | 40 | 40 |
|
| 620 |
+
|
| 621 |
+
|
| 622 |
+
|
| 623 |
+
##### Data
|
| 624 |
+
|
| 625 |
+
We curated and deduplicated a candidate dataset comprising a vast amount of image and video data. During the data curation process, we designed a four-step data cleaning process, focusing on fundamental dimensions, visual quality and motion quality. Through the robust data processing pipeline, we can easily obtain high-quality, diverse, and large-scale training sets of images and videos.
|
| 626 |
+
|
| 627 |
+

|
| 628 |
+
|
| 629 |
+
|
| 630 |
+
##### Comparisons to SOTA
|
| 631 |
+
We compared **Wan2.1** with leading open-source and closed-source models to evaluate the performance. Using our carefully designed set of 1,035 internal prompts, we tested across 14 major dimensions and 26 sub-dimensions. We then compute the total score by performing a weighted calculation on the scores of each dimension, utilizing weights derived from human preferences in the matching process. The detailed results are shown in the table below. These results demonstrate our model's superior performance compared to both open-source and closed-source models.
|
| 632 |
+
|
| 633 |
+

|
| 634 |
+
|
| 635 |
+
|
| 636 |
+
## Citation
|
| 637 |
+
If you find our work helpful, please cite us.
|
| 638 |
+
|
| 639 |
+
```
|
| 640 |
+
@article{wan2025,
|
| 641 |
+
title={Wan: Open and Advanced Large-Scale Video Generative Models},
|
| 642 |
+
author={Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
|
| 643 |
+
journal = {arXiv preprint arXiv:2503.20314},
|
| 644 |
+
year={2025}
|
| 645 |
+
}
|
| 646 |
+
```
|
| 647 |
+
|
| 648 |
+
## License Agreement
|
| 649 |
+
The models in this repository are licensed under the Apache 2.0 License. We claim no rights over the your generated contents, granting you the freedom to use them while ensuring that your usage complies with the provisions of this license. You are fully accountable for your use of the models, which must not involve sharing any content that violates applicable laws, causes harm to individuals or groups, disseminates personal information intended for harm, spreads misinformation, or targets vulnerable populations. For a complete list of restrictions and details regarding your rights, please refer to the full text of the [license](LICENSE.txt).
|
| 650 |
+
|
| 651 |
+
|
| 652 |
+
## Acknowledgements
|
| 653 |
+
|
| 654 |
+
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
|
| 655 |
+
|
| 656 |
+
|
| 657 |
+
|
| 658 |
+
## Contact Us
|
| 659 |
+
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/AKNgpMK4Yj) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
assets/comp_effic.png
ADDED

|
Git LFS Details
|
assets/data_for_diff_stage.jpg
ADDED
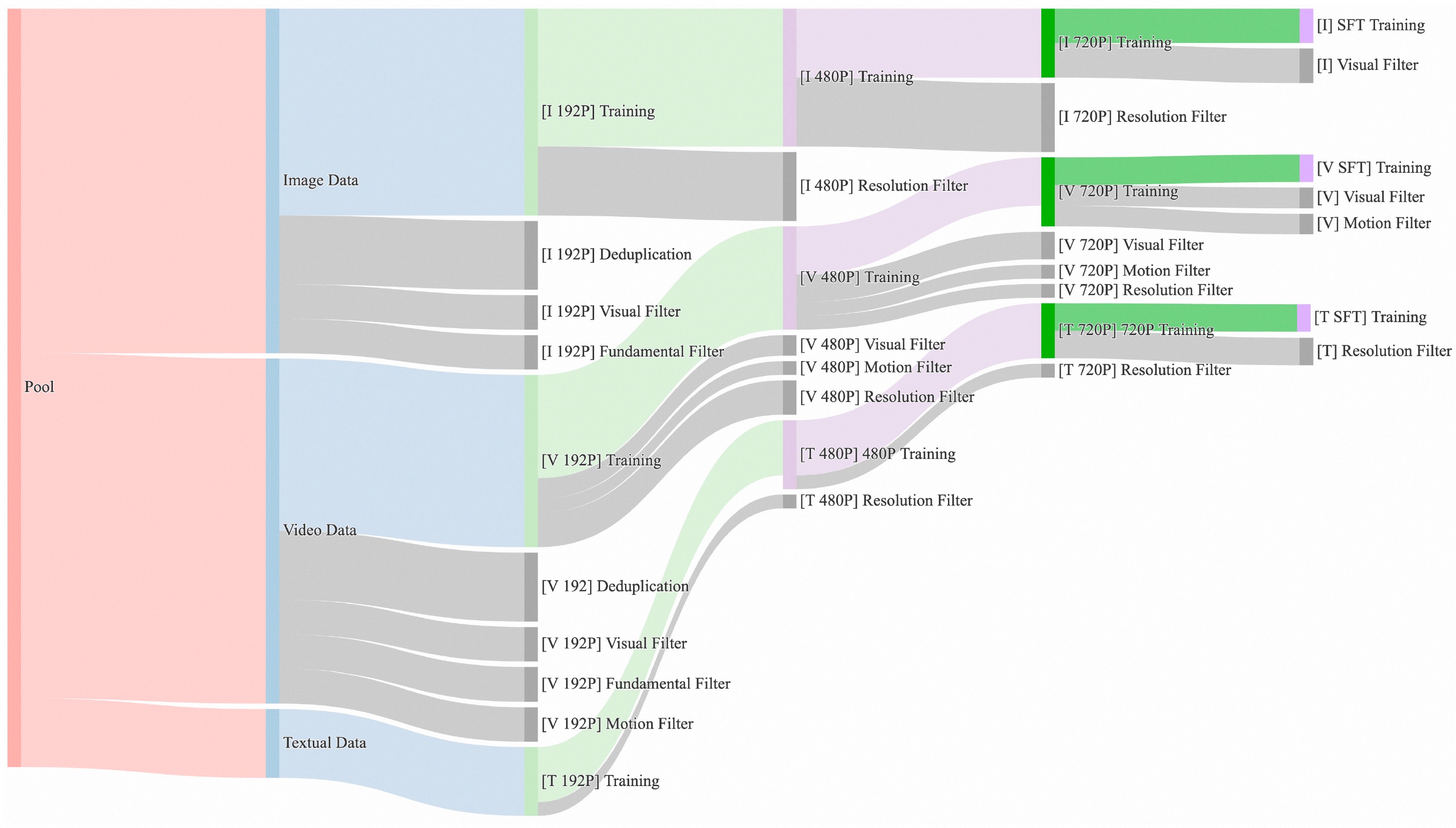
|
Git LFS Details
|
assets/i2v_res.png
ADDED
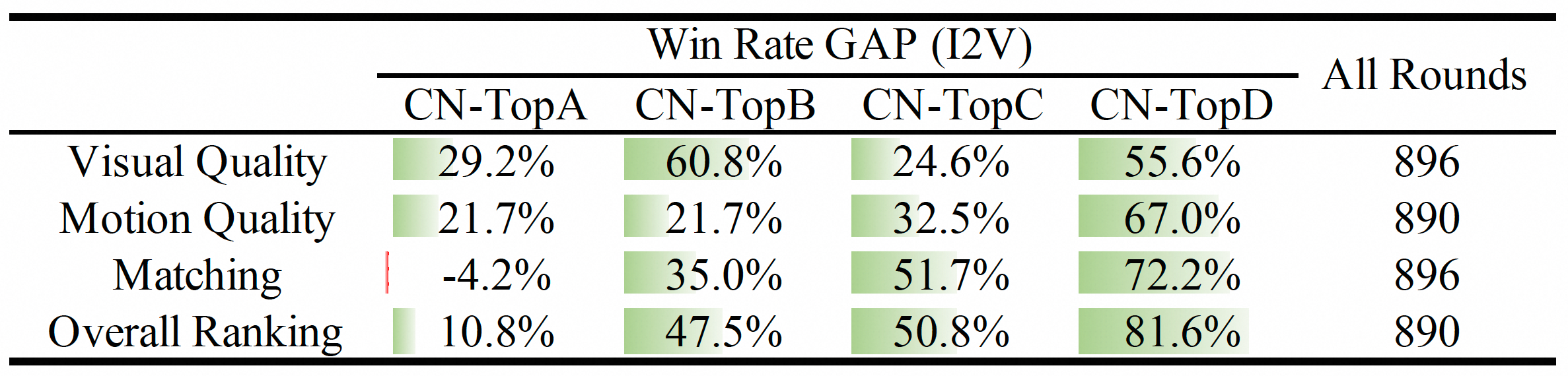
|
Git LFS Details
|
assets/logo.png
ADDED
|
|
assets/t2v_res.jpg
ADDED

|
Git LFS Details
|
assets/vben_vs_sota.png
ADDED

|
Git LFS Details
|
assets/video_dit_arch.jpg
ADDED

|
Git LFS Details
|
assets/video_vae_res.jpg
ADDED

|
Git LFS Details
|