

Commit
·
a41139f
1
Parent(s):
c55421c
init upload
Browse files- .gitattributes +0 -2
- README.md +18 -14
- assets/.DS_Store +0 -3
- assets/comp_effic.png +2 -2
- assets/input.png +0 -3
- assets/vben_vs_sota.png +2 -2
- assets/video_vae_res.jpg +2 -2
.gitattributes
CHANGED
|
@@ -37,7 +37,6 @@ google/umt5-xxl/tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
|
| 37 |
assets/comp_effic.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
assets/data_for_diff_stage.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
assets/i2v_res.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
-
assets/input.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
assets/logo.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
assets/t2v_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
assets/vben_vs_sota.png filter=lfs diff=lfs merge=lfs -text
|
|
@@ -45,5 +44,4 @@ assets/vben_vs_sota_t2i.jpg filter=lfs diff=lfs merge=lfs -text
|
|
| 45 |
assets/video_dit_arch.jpg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
assets/video_vae_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 47 |
examples/i2v_input.JPG filter=lfs diff=lfs merge=lfs -text
|
| 48 |
-
assets/.DS_Store filter=lfs diff=lfs merge=lfs -text
|
| 49 |
assets/vben_1.3b_vs_sota.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 37 |
assets/comp_effic.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
assets/data_for_diff_stage.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
assets/i2v_res.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 40 |
assets/logo.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
assets/t2v_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
assets/vben_vs_sota.png filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 44 |
assets/video_dit_arch.jpg filter=lfs diff=lfs merge=lfs -text
|
| 45 |
assets/video_vae_res.jpg filter=lfs diff=lfs merge=lfs -text
|
| 46 |
examples/i2v_input.JPG filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 47 |
assets/vben_1.3b_vs_sota.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -5,12 +5,12 @@
|
|
| 5 |
<p>
|
| 6 |
|
| 7 |
<p align="center">
|
| 8 |
-
💜 <a href=""><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.1">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="">Paper</a>    |    📑 <a href="">Blog</a>    |   💬 <a href="">WeChat
|
| 9 |
<br>
|
| 10 |
|
| 11 |
-----
|
| 12 |
|
| 13 |
-
[**Wan: Open and Advanced Large-Scale Video Generative Models**]("
|
| 14 |
|
| 15 |
In this repository, we present **Wan2.1**, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. **Wan2.1** offers these key features:
|
| 16 |
- 👍 **SOTA Performance**: **Wan2.1** consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
|
|
@@ -19,7 +19,6 @@ In this repository, we present **Wan2.1**, a comprehensive and open suite of vid
|
|
| 19 |
- 👍 **Visual Text Generation**: **Wan2.1** is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
|
| 20 |
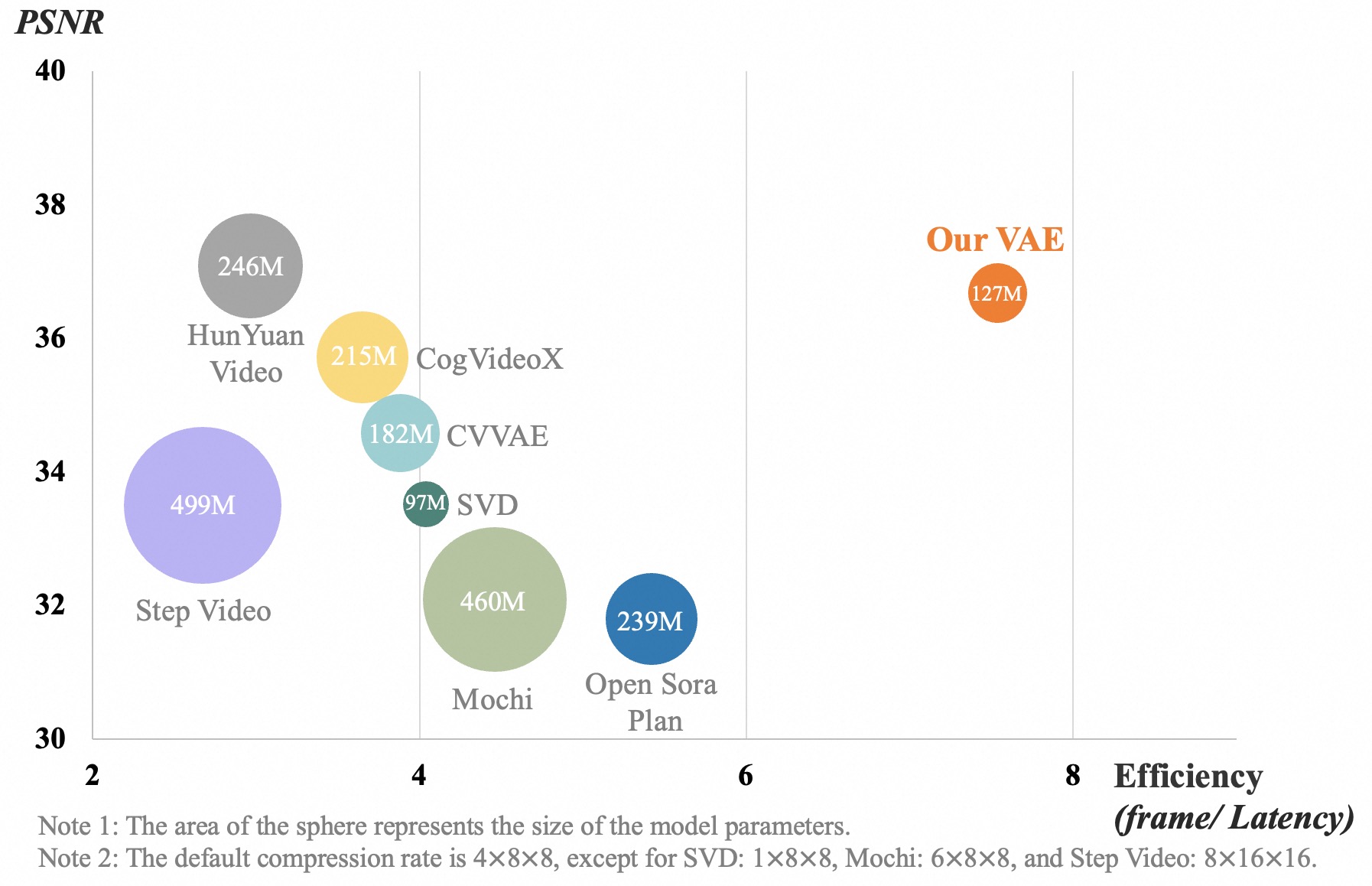
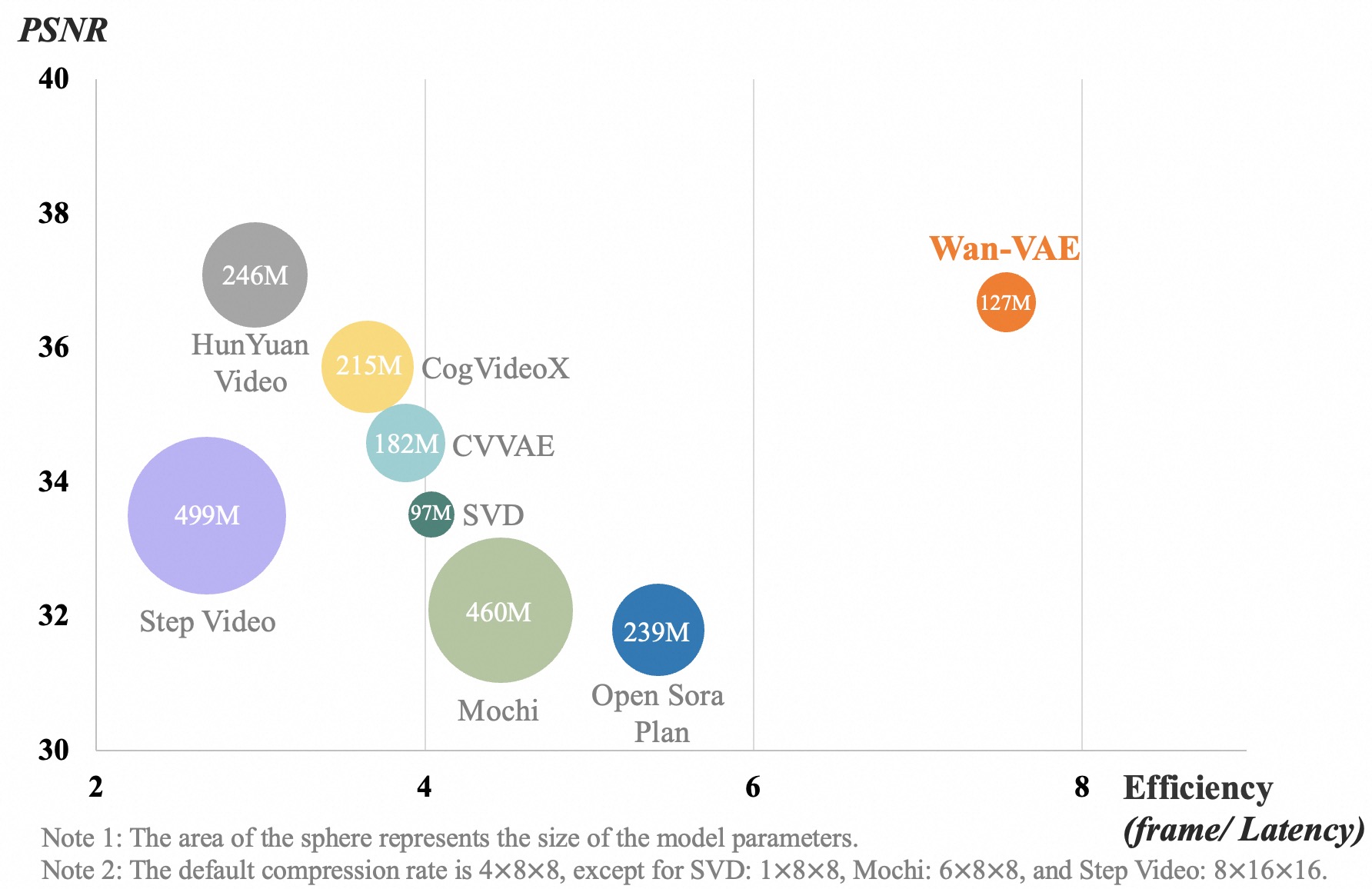
- 👍 **Powerful Video VAE**: **Wan-VAE** delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
|
| 21 |
|
| 22 |
-
|
| 23 |
This repository features our T2V-14B model, which establishes a new SOTA performance benchmark among both open-source and closed-source models. It demonstrates exceptional capabilities in generating high-quality visuals with significant motion dynamics. It is also the only video model capable of producing both Chinese and English text and supports video generation at both 480P and 720P resolutions.
|
| 24 |
|
| 25 |
|
|
@@ -72,10 +71,10 @@ pip install -r requirements.txt
|
|
| 72 |
|
| 73 |
| Models | Download Link | Notes |
|
| 74 |
| --------------|-------------------------------------------------------------------------------|-------------------------------|
|
| 75 |
-
| T2V-14B | [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B)
|
| 76 |
-
| I2V-14B-720P | [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P)
|
| 77 |
-
| I2V-14B-480P | [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P)
|
| 78 |
-
| T2V-1.3B | [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B)
|
| 79 |
|
| 80 |
> 💡Note: The 1.3B model is capable of generating videos at 720P resolution. However, due to limited training at this resolution, the results are generally less stable compared to 480P. For optimal performance, we recommend using 480P resolution.
|
| 81 |
|
|
@@ -83,7 +82,7 @@ pip install -r requirements.txt
|
|
| 83 |
Download models using huggingface-cli:
|
| 84 |
```
|
| 85 |
pip install "huggingface_hub[cli]"
|
| 86 |
-
huggingface-cli download
|
| 87 |
```
|
| 88 |
|
| 89 |
#### Run Text-to-Video Generation
|
|
@@ -135,7 +134,8 @@ If you encounter OOM (Out-of-Memory) issues, you can use the `--offload_model Tr
|
|
| 135 |
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 136 |
```
|
| 137 |
|
| 138 |
-
> 💡Note: If you
|
|
|
|
| 139 |
|
| 140 |
- Multi-GPU inference using FSDP + xDiT USP
|
| 141 |
|
|
@@ -150,8 +150,8 @@ torchrun --nproc_per_node=8 generate.py --task t2v-14B --size 1280*720 --ckpt_di
|
|
| 150 |
Extending the prompts can effectively enrich the details in the generated videos, further enhancing the video quality. Therefore, we recommend enabling prompt extension. We provide the following two methods for prompt extension:
|
| 151 |
|
| 152 |
- Use the Dashscope API for extension.
|
| 153 |
-
- Apply for a `dashscope.api_key` in advance ([
|
| 154 |
-
- Configure the environment variable `DASH_API_KEY` to specify the Dashscope API key. For users of Alibaba Cloud's international site, you also need to set the environment variable `DASH_API_URL` to 'https://dashscope-intl.aliyuncs.com/api/v1'. For more detailed instructions, please refer to the [dashscope document](https://www.alibabacloud.com/help/en/model-studio/
|
| 155 |
- Use the `qwen-plus` model for text-to-video tasks and `qwen-vl-max` for image-to-video tasks.
|
| 156 |
- You can modify the model used for extension with the parameter `--prompt_extend_model`. For example:
|
| 157 |
```
|
|
@@ -208,6 +208,10 @@ We test the computational efficiency of different **Wan2.1** models on different
|
|
| 208 |
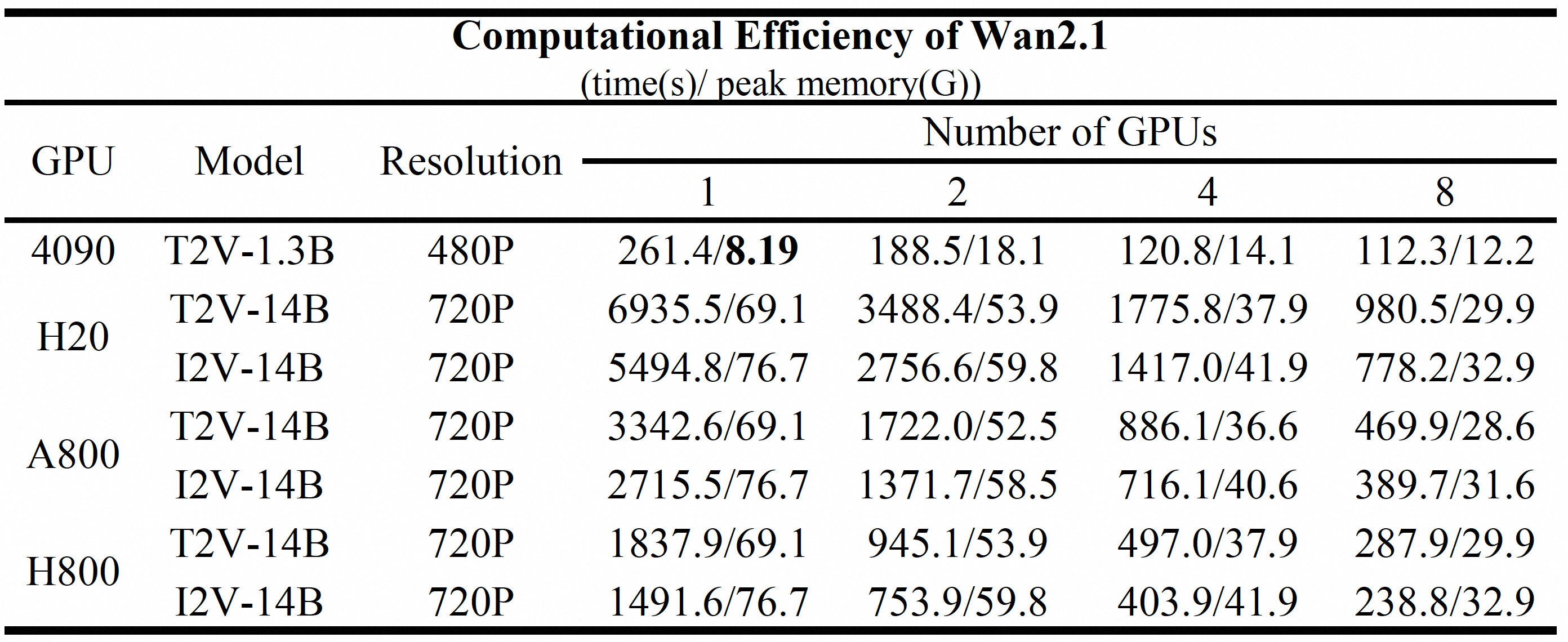
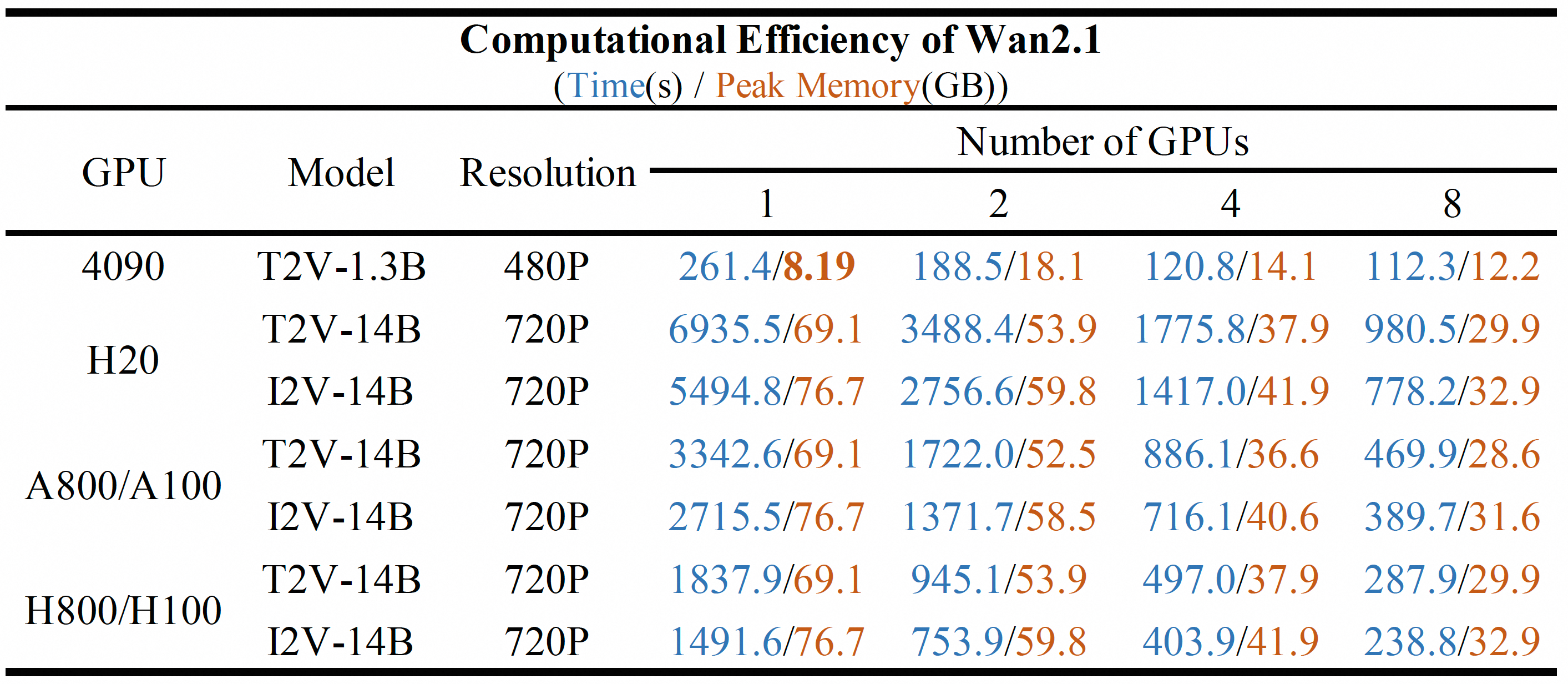
> (3) For the 1.3B model on a single 4090 GPU, set `--offload_model True --t5_cpu`;
|
| 209 |
> (4) For all testings, no prompt extension was applied, meaning `--use_prompt_extend` was not enabled.
|
| 210 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 211 |
-------
|
| 212 |
|
| 213 |
## Introduction of Wan2.1
|
|
@@ -248,7 +252,7 @@ We curated and deduplicated a candidate dataset comprising a vast amount of imag
|
|
| 248 |
|
| 249 |
|
| 250 |
##### Comparisons to SOTA
|
| 251 |
-
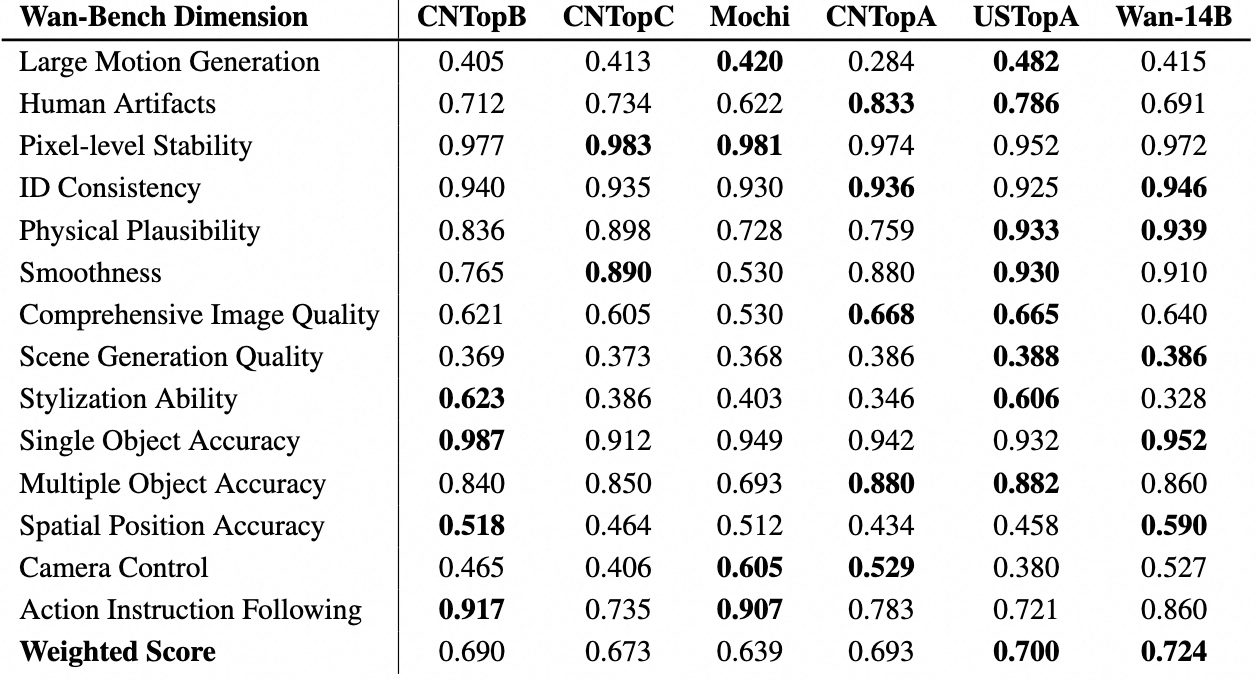
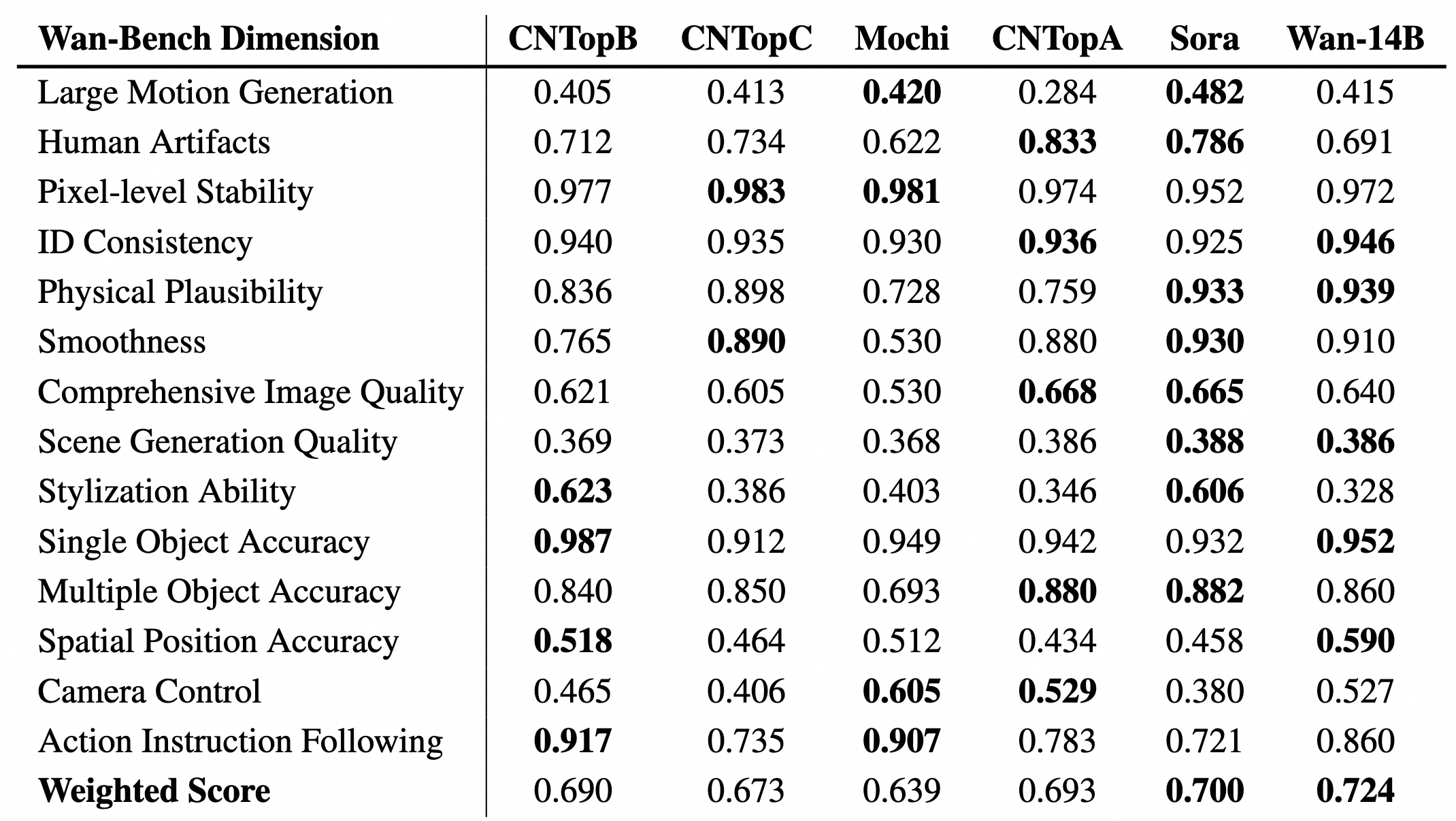
We compared **Wan2.1** with leading open-source and closed-source models to evaluate the performace. Using our carefully designed set of 1,035 internal prompts, we tested across 14 major dimensions and 26 sub-dimensions.
|
| 252 |
|
| 253 |

|
| 254 |
|
|
@@ -271,9 +275,9 @@ The models in this repository are licensed under the Apache 2.0 License. We clai
|
|
| 271 |
|
| 272 |
## Acknowledgements
|
| 273 |
|
| 274 |
-
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [
|
| 275 |
|
| 276 |
|
| 277 |
|
| 278 |
## Contact Us
|
| 279 |
-
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/p5XbdQV7) or [WeChat groups]()!
|
|
|
|
| 5 |
<p>
|
| 6 |
|
| 7 |
<p align="center">
|
| 8 |
+
💜 <a href=""><b>Wan</b></a>    |    🖥️ <a href="https://github.com/Wan-Video/Wan2.1">GitHub</a>    |   🤗 <a href="https://huggingface.co/Wan-AI/">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/organization/Wan-AI">ModelScope</a>   |    📑 <a href="">Paper (Coming soon)</a>    |    📑 <a href="https://wanxai.com">Blog</a>    |   💬 <a href="https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg">WeChat Group</a>   |    📖 <a href="https://discord.gg/p5XbdQV7">Discord</a>  
|
| 9 |
<br>
|
| 10 |
|
| 11 |
-----
|
| 12 |
|
| 13 |
+
[**Wan: Open and Advanced Large-Scale Video Generative Models**]("") <be>
|
| 14 |
|
| 15 |
In this repository, we present **Wan2.1**, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. **Wan2.1** offers these key features:
|
| 16 |
- 👍 **SOTA Performance**: **Wan2.1** consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
|
|
|
|
| 19 |
- 👍 **Visual Text Generation**: **Wan2.1** is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
|
| 20 |
- 👍 **Powerful Video VAE**: **Wan-VAE** delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
|
| 21 |
|
|
|
|
| 22 |
This repository features our T2V-14B model, which establishes a new SOTA performance benchmark among both open-source and closed-source models. It demonstrates exceptional capabilities in generating high-quality visuals with significant motion dynamics. It is also the only video model capable of producing both Chinese and English text and supports video generation at both 480P and 720P resolutions.
|
| 23 |
|
| 24 |
|
|
|
|
| 71 |
|
| 72 |
| Models | Download Link | Notes |
|
| 73 |
| --------------|-------------------------------------------------------------------------------|-------------------------------|
|
| 74 |
+
| T2V-14B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | Supports both 480P and 720P
|
| 75 |
+
| I2V-14B-720P | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | Supports 720P
|
| 76 |
+
| I2V-14B-480P | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | Supports 480P
|
| 77 |
+
| T2V-1.3B | 🤗 [Huggingface](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) 🤖 [ModelScope](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | Supports 480P
|
| 78 |
|
| 79 |
> 💡Note: The 1.3B model is capable of generating videos at 720P resolution. However, due to limited training at this resolution, the results are generally less stable compared to 480P. For optimal performance, we recommend using 480P resolution.
|
| 80 |
|
|
|
|
| 82 |
Download models using huggingface-cli:
|
| 83 |
```
|
| 84 |
pip install "huggingface_hub[cli]"
|
| 85 |
+
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
|
| 86 |
```
|
| 87 |
|
| 88 |
#### Run Text-to-Video Generation
|
|
|
|
| 134 |
python generate.py --task t2v-1.3B --size 832*480 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --prompt "Two anthropomorphic cats in comfy boxing gear and bright gloves fight intensely on a spotlighted stage."
|
| 135 |
```
|
| 136 |
|
| 137 |
+
> 💡Note: If you are using the `T2V-1.3B` model, we recommend setting the parameter `--sample_guide_scale 6`. The `--sample_shift parameter` can be adjusted within the range of 8 to 12 based on the performance.
|
| 138 |
+
|
| 139 |
|
| 140 |
- Multi-GPU inference using FSDP + xDiT USP
|
| 141 |
|
|
|
|
| 150 |
Extending the prompts can effectively enrich the details in the generated videos, further enhancing the video quality. Therefore, we recommend enabling prompt extension. We provide the following two methods for prompt extension:
|
| 151 |
|
| 152 |
- Use the Dashscope API for extension.
|
| 153 |
+
- Apply for a `dashscope.api_key` in advance ([EN](https://www.alibabacloud.com/help/en/model-studio/getting-started/first-api-call-to-qwen) | [CN](https://help.aliyun.com/zh/model-studio/getting-started/first-api-call-to-qwen)).
|
| 154 |
+
- Configure the environment variable `DASH_API_KEY` to specify the Dashscope API key. For users of Alibaba Cloud's international site, you also need to set the environment variable `DASH_API_URL` to 'https://dashscope-intl.aliyuncs.com/api/v1'. For more detailed instructions, please refer to the [dashscope document](https://www.alibabacloud.com/help/en/model-studio/developer-reference/use-qwen-by-calling-api?spm=a2c63.p38356.0.i1).
|
| 155 |
- Use the `qwen-plus` model for text-to-video tasks and `qwen-vl-max` for image-to-video tasks.
|
| 156 |
- You can modify the model used for extension with the parameter `--prompt_extend_model`. For example:
|
| 157 |
```
|
|
|
|
| 208 |
> (3) For the 1.3B model on a single 4090 GPU, set `--offload_model True --t5_cpu`;
|
| 209 |
> (4) For all testings, no prompt extension was applied, meaning `--use_prompt_extend` was not enabled.
|
| 210 |
|
| 211 |
+
|
| 212 |
+
## Community Contributions
|
| 213 |
+
- [DiffSynth-Studio](https://github.com/modelscope/DiffSynth-Studio) provides more support for Wan, including video-to-video, FP8 quantization, VRAM optimization, LoRA training, and more. Please refer to [their examples](https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/wanvideo).
|
| 214 |
+
|
| 215 |
-------
|
| 216 |
|
| 217 |
## Introduction of Wan2.1
|
|
|
|
| 252 |
|
| 253 |
|
| 254 |
##### Comparisons to SOTA
|
| 255 |
+
We compared **Wan2.1** with leading open-source and closed-source models to evaluate the performace. Using our carefully designed set of 1,035 internal prompts, we tested across 14 major dimensions and 26 sub-dimensions. We then compute the total score by performing a weighted calculation on the scores of each dimension, utilizing weights derived from human preferences in the matching process. The detailed results are shown in the table below. These results demonstrate our model's superior performance compared to both open-source and closed-source models.
|
| 256 |
|
| 257 |

|
| 258 |
|
|
|
|
| 275 |
|
| 276 |
## Acknowledgements
|
| 277 |
|
| 278 |
+
We would like to thank the contributors to the [SD3](https://huggingface.co/stabilityai/stable-diffusion-3-medium), [Qwen](https://huggingface.co/Qwen), [umt5-xxl](https://huggingface.co/google/umt5-xxl), [diffusers](https://github.com/huggingface/diffusers) and [HuggingFace](https://huggingface.co) repositories, for their open research.
|
| 279 |
|
| 280 |
|
| 281 |
|
| 282 |
## Contact Us
|
| 283 |
+
If you would like to leave a message to our research or product teams, feel free to join our [Discord](https://discord.gg/p5XbdQV7) or [WeChat groups](https://gw.alicdn.com/imgextra/i2/O1CN01tqjWFi1ByuyehkTSB_!!6000000000015-0-tps-611-1279.jpg)!
|
assets/.DS_Store
DELETED
|
@@ -1,3 +0,0 @@
|
|
| 1 |
-
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:d65165279105ca6773180500688df4bdc69a2c7b771752f0a46ef120b7fd8ec3
|
| 3 |
-
size 6148
|
|
|
|
|
|
|
|
|
|
|
|
assets/comp_effic.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
assets/input.png
DELETED
Git LFS Details
|
assets/vben_vs_sota.png
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|
assets/video_vae_res.jpg
CHANGED
|
Git LFS Details
|
|
Git LFS Details
|