Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
microsoft_WizardLM-2-7B - GGUF
- Model creator: https://huggingface.co/lucyknada/
- Original model: https://huggingface.co/lucyknada/microsoft_WizardLM-2-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [microsoft_WizardLM-2-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q2_K.gguf) | Q2_K | 2.53GB |
| [microsoft_WizardLM-2-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [microsoft_WizardLM-2-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [microsoft_WizardLM-2-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [microsoft_WizardLM-2-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [microsoft_WizardLM-2-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q3_K.gguf) | Q3_K | 3.28GB |
| [microsoft_WizardLM-2-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [microsoft_WizardLM-2-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [microsoft_WizardLM-2-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [microsoft_WizardLM-2-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q4_0.gguf) | Q4_0 | 3.83GB |
| [microsoft_WizardLM-2-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [microsoft_WizardLM-2-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [microsoft_WizardLM-2-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q4_K.gguf) | Q4_K | 4.07GB |
| [microsoft_WizardLM-2-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [microsoft_WizardLM-2-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q4_1.gguf) | Q4_1 | 4.24GB |
| [microsoft_WizardLM-2-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q5_0.gguf) | Q5_0 | 4.65GB |
| [microsoft_WizardLM-2-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [microsoft_WizardLM-2-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q5_K.gguf) | Q5_K | 4.78GB |
| [microsoft_WizardLM-2-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [microsoft_WizardLM-2-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q5_1.gguf) | Q5_1 | 5.07GB |
| [microsoft_WizardLM-2-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q6_K.gguf) | Q6_K | 5.53GB |
| [microsoft_WizardLM-2-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/lucyknada_-_microsoft_WizardLM-2-7B-gguf/blob/main/microsoft_WizardLM-2-7B.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: apache-2.0
---
🏠 WizardLM-2 Release Blog
🤗 HF Repo •🐱 Github Repo • 🐦 Twitter • 📃 [WizardLM] • 📃 [WizardCoder] • 📃 [WizardMath]
👋 Join our Discord
## News 🔥🔥🔥 [2024/04/15]
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models,
which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
- WizardLM-2 8x22B is our most advanced model, demonstrates highly competitive performance compared to those leading proprietary works
and consistently outperforms all the existing state-of-the-art opensource models.
- WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
- WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
For more details of WizardLM-2 please read our [release blog post](https://wizardlm.github.io/WizardLM2) and upcoming paper.
## Model Details
* **Model name**: WizardLM-2 7B
* **Developed by**: WizardLM@Microsoft AI
* **Base model**: [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* **Parameters**: 7B
* **Language(s)**: Multilingual
* **Blog**: [Introducing WizardLM-2](https://wizardlm.github.io/WizardLM2)
* **Repository**: [https://github.com/nlpxucan/WizardLM](https://github.com/nlpxucan/WizardLM)
* **Paper**: WizardLM-2 (Upcoming)
* **License**: Apache2.0
## Model Capacities
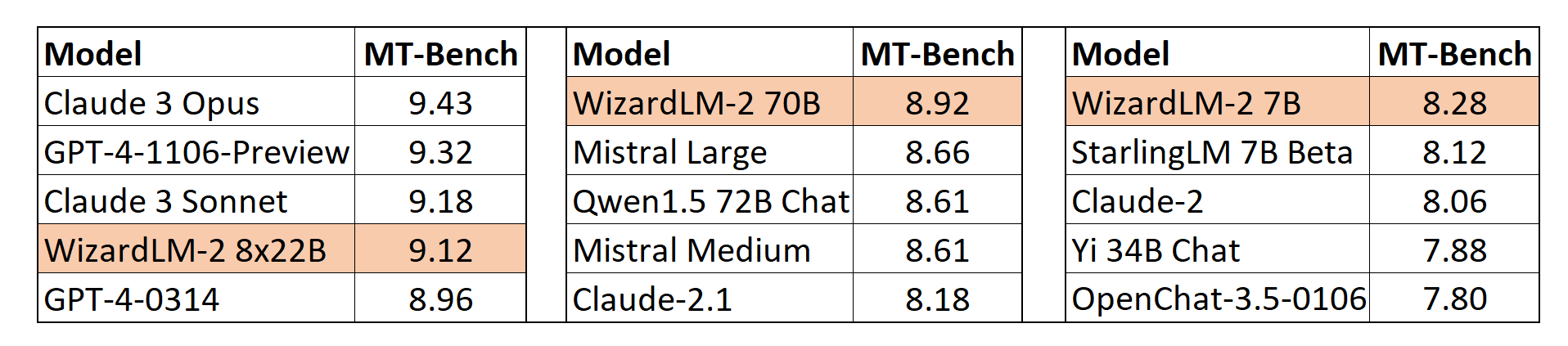
**MT-Bench**
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
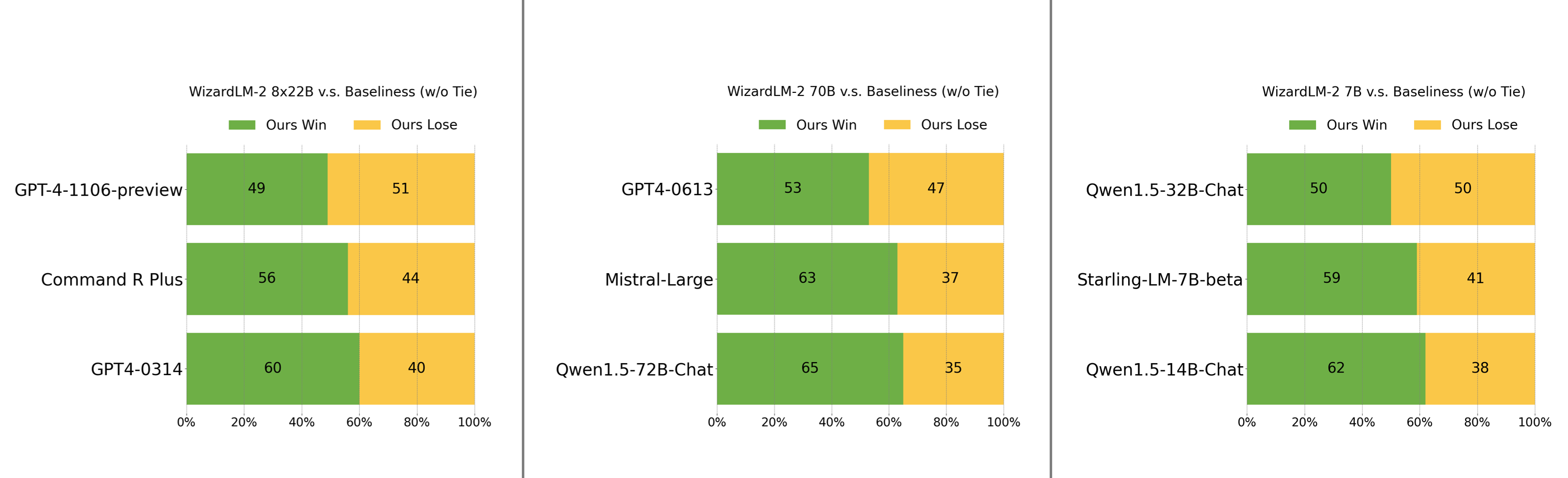
**Human Preferences Evaluation**
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual.
We report the win:loss rate without tie:
- WizardLM-2 8x22B is just slightly falling behind GPT-4-1106-preview, and significantly stronger than Command R Plus and GPT4-0314.
- WizardLM-2 70B is better than GPT4-0613, Mistral-Large, and Qwen1.5-72B-Chat.
- WizardLM-2 7B is comparable with Qwen1.5-32B-Chat, and surpasses Qwen1.5-14B-Chat and Starling-LM-7B-beta.
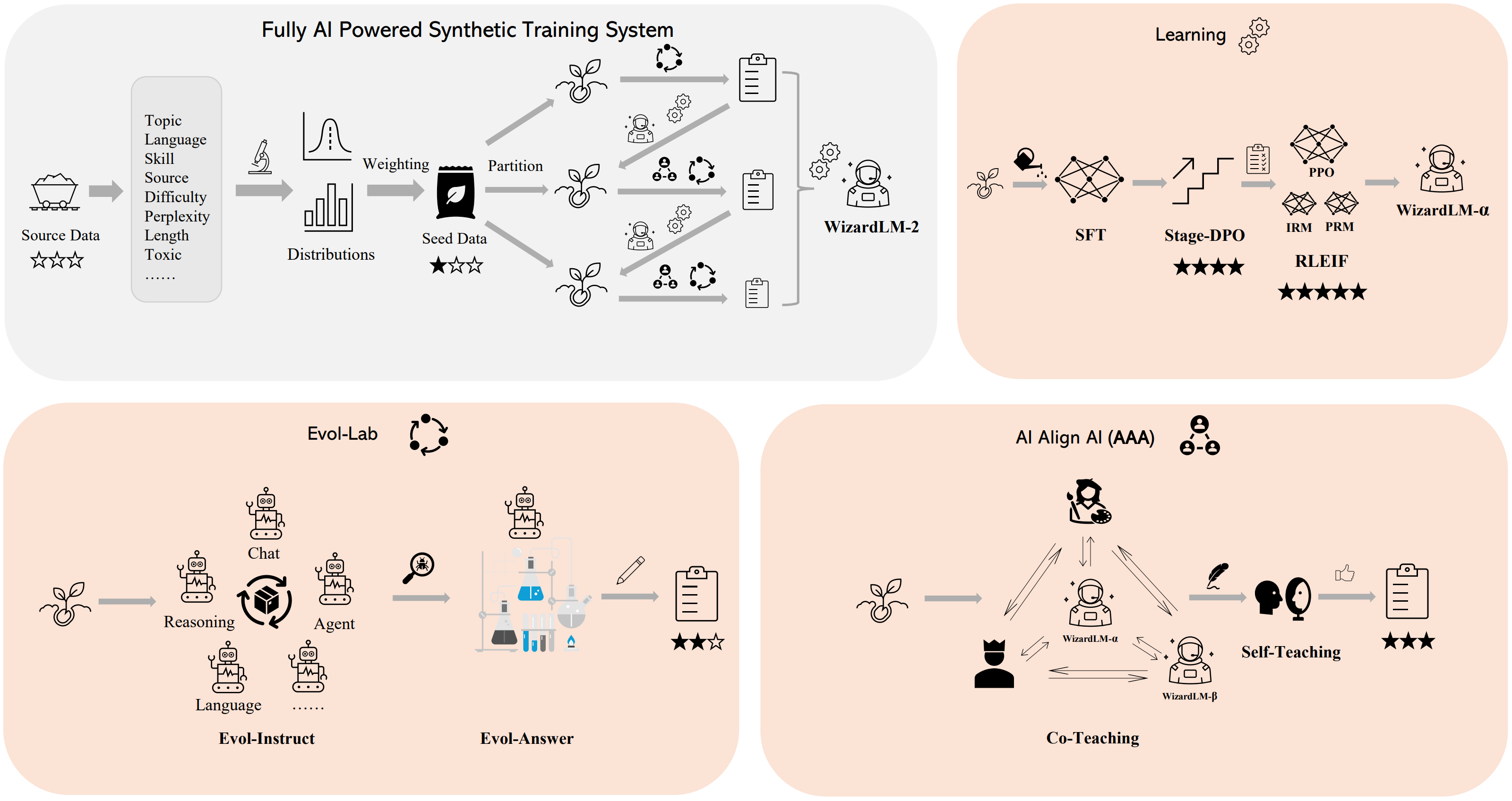
## Method Overview
We built a **fully AI powered synthetic training system** to train WizardLM-2 models, please refer to our [blog](https://wizardlm.github.io/WizardLM2) for more details of this system.
## Usage
❗Note for model system prompts usage:
WizardLM-2 adopts the prompt format from Vicuna and supports **multi-turn** conversation. The prompt should be as following:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.
USER: Who are you? ASSISTANT: I am WizardLM.......
```
Inference WizardLM-2 Demo Script
We provide a WizardLM-2 inference demo [code](https://github.com/nlpxucan/WizardLM/tree/main/demo) on our github.