![]()
🤗 Hugging Face | 🤖 ModelScope | 📑 Paper | 🖥️ Demo
WeChat (微信) | Discord | API
For position encoding, FFN activation function, and normalization methods, we adopt the prevalent practices, i.e., RoPE relative position encoding, SwiGLU for activation function, and RMSNorm for normalization (optional installation of flash-attention for acceleration).
For tokenization, compared to the current mainstream open-source models based on Chinese and English vocabularies, Qwen-1.8B uses a vocabulary of over 150K tokens. It first considers efficient encoding of Chinese, English, and code data, and is also more friendly to multilingual languages, enabling users to directly enhance the capability of some languages without expanding the vocabulary. It segments numbers by single digit, and calls the [tiktoken](https://github.com/openai/tiktoken) tokenizer library for efficient tokenization.
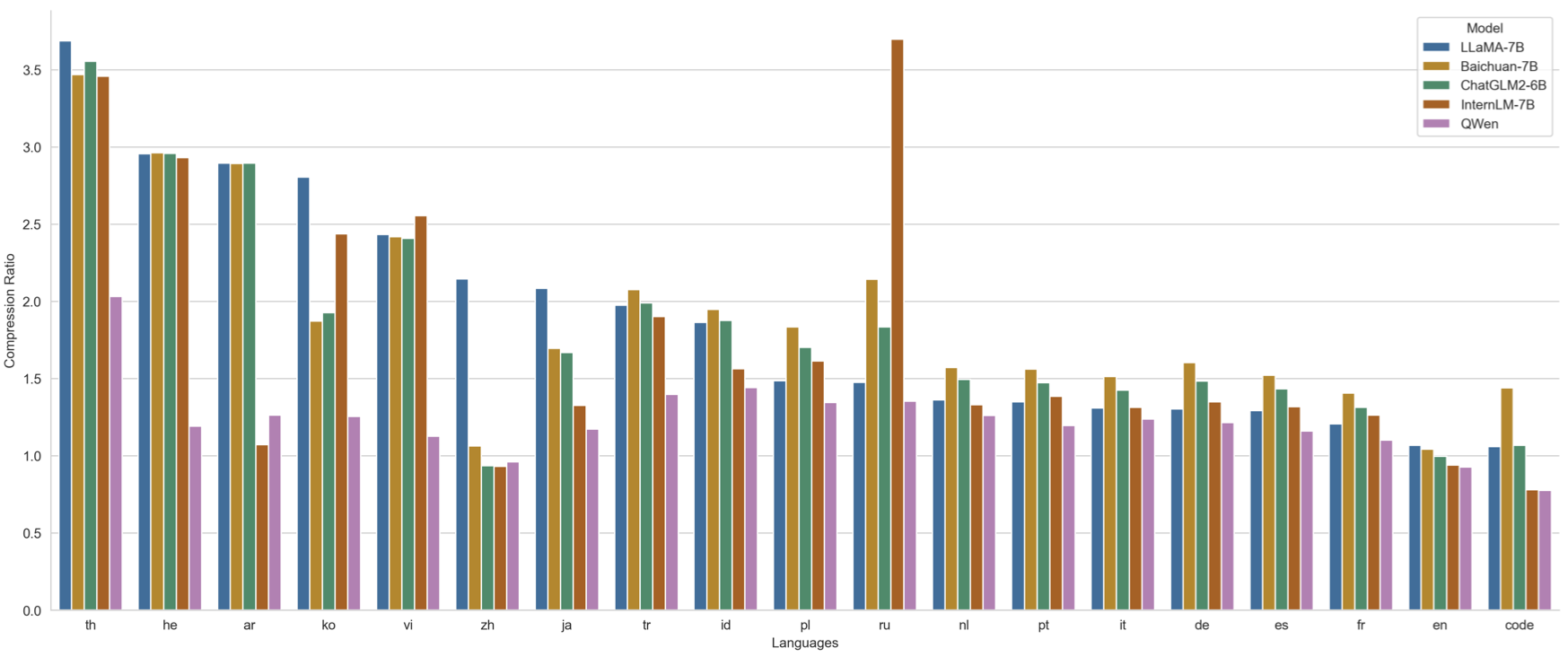
We randomly selected 1 million document corpus of each language to test and compare the encoding compression rates of different models (with XLM-R, which supports 100 languages, as the base value 1). The specific performance is shown in the figure above.
As can be seen, while ensuring the efficient decoding of Chinese, English, and code, Qwen-1.8B also achieves a high compression rate for many other languages (such as th, he, ar, ko, vi, ja, tr, id, pl, ru, nl, pt, it, de, es, fr etc.), equipping the model with strong scalability as well as high training and inference efficiency in these languages.
For pre-training data, on the one hand, Qwen-1.8B uses part of the open-source generic corpus. On the other hand, it uses a massive amount of accumulated web corpus and high-quality text content. The scale of corpus reaches over 2.2T tokens after deduplication and filtration, encompassing web text, encyclopedias, books, code, mathematics, and various domain.
## 评测效果(Evaluation)
### 中文评测(Chinese Evaluation)
#### C-Eval
[C-Eval](https://arxiv.org/abs/2305.08322)是评测预训练模型中文常识能力的常用测评框架,覆盖人文、社科、理工、其他专业四个大方向共52个学科。
我们按照标准做法,以开发集样本作为few-shot来源,评价Qwen-1.8B预训练模型的5-shot验证集与测试集准确率。
[C-Eval](https://arxiv.org/abs/2305.08322) is a common evaluation benchmark for testing the common sense capability of pre-trained models in Chinese. It covers 52 subjects in four major directions: humanities, social sciences, STEM, and other specialties. According to the standard practice, we use the development set samples as the source of few-shot, to evaluate the 5-shot validation set and test set accuracy of the Qwen-1.8B pre-trained model.
在C-Eval验证集、测试集上,Qwen-1.8B模型和其他模型的准确率对比如下:
The accuracy comparison of Qwen-1.8B and the other models on the C-Eval validation set is shown as follows:
| Model | Avg. (Val) | Avg. (Test) |
|:--------------|:----------:|:-----------:|
| Bloom-1B7 | 23.8 | - |
| Bloomz-1B7 | 29.6 | - |
| Bloom-3B | 25.8 | - |
| Bloomz-3B | 32.5 | - |
| MiLM-1.3B | - | 45.8 |
| **Qwen-1.8B** | **56.1** | **56.2** |
### 英文评测(English Evaluation)
#### MMLU
[MMLU](https://arxiv.org/abs/2009.03300)是目前评测英文综合能力最权威的基准评测之一,同样覆盖了不同学科领域、不同难度层级的57个子任务。
Qwen-1.8B在MMLU 5-shot准确率表现如下表:
[MMLU](https://arxiv.org/abs/2009.03300) is currently one of the most recognized benchmarks for evaluating English comprehension abilities, covering 57 subtasks across different academic fields and difficulty levels. The MMLU 5-shot accuracy performance of Qwen-1.8B is shown in the following table:
| Model | Avg. |
|:--------------|:--------:|
| GPT-Neo-1.3B | 24.6 |
| OPT-1.3B | 25.1 |
| Pythia-1B | 26.6 |
| Bloom-1.1B | 26.7 |
| Bloom-1.7B | 27.7 |
| Bloomz-1.7B | 30.7 |
| Bloomz-3B | 33.3 |
| **Qwen-1.8B** | **45.3** |
### 代码评测(Coding Evaluation)
我们在[HumanEval](https://github.com/openai/human-eval)(0-shot)上对比预训练模型的代码能力,结果如下:
We compared the code capabilities of pre-trained models on [HumanEval](https://github.com/openai/human-eval), and the results are as follows:
| Model | Pass@1 |
|:--------------|:--------:|
| GPT-Neo-1.3B | 3.66 |
| GPT-Neo-2.7B | 7.93 |
| Pythia-1B | 3.67 |
| Pythia-2.8B | 5.49 |
| Bloom-1.1B | 2.48 |
| Bloom-1.7B | 4.03 |
| Bloom-3B | 6.48 |
| Bloomz-1.7B | 4.38 |
| Bloomz-3B | 6.71 |
| **Qwen-1.8B** | **15.2** |
### 数学评测(Mathematics Evaluation)
数学能力使用常用的[GSM8K](https://github.com/openai/grade-school-math)数据集(8-shot)评价:
We compared the math capabilities of pre-trained models on [GSM8K](https://github.com/openai/grade-school-math) (8-shot), and the results are as follows:
| Model | Acc. |
|:--------------|:--------:|
| GPT-Neo-1.3B | 1.97 |
| GPT-Neo-2.7B | 1.74 |
| Pythia-1B | 2.20 |
| Pythia-2.8B | 3.11 |
| Openllama-3B | 3.11 |
| Bloom-1.1B | 1.82 |
| Bloom-1.7B | 2.05 |
| Bloom-3B | 1.82 |
| Bloomz-1.7B | 2.05 |
| Bloomz-3B | 3.03 |
| **Qwen-1.8B** | **32.3** |
## 评测复现(Reproduction)
我们提供了评测脚本,方便大家复现模型效果,详见[链接](https://github.com/QwenLM/Qwen/tree/main/eval)。提示:由于硬件和框架造成的舍入误差,复现结果如有小幅波动属于正常现象。
We have provided evaluation scripts to reproduce the performance of our model, details as [link](https://github.com/QwenLM/Qwen/tree/main/eval).
## FAQ
如遇到问题,敬请查阅[FAQ](https://github.com/QwenLM/Qwen/blob/main/FAQ_zh.md)以及issue区,如仍无法解决再提交issue。
If you meet problems, please refer to [FAQ](https://github.com/QwenLM/Qwen/blob/main/FAQ.md) and the issues first to search a solution before you launch a new issue.
## 引用 (Citation)
如果你觉得我们的工作对你有帮助,欢迎引用!
If you find our work helpful, feel free to give us a cite.
```
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
```
## 使用协议(License Agreement)
我们的代码和模型权重对学术研究完全开放。请查看[LICENSE](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20RESEARCH%20LICENSE%20AGREEMENT)文件了解具体的开源协议细节。如需商用,请联系我们。
Our code and checkpoints are open to research purpose. Check the [LICENSE](https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20RESEARCH%20LICENSE%20AGREEMENT) for more details about the license. For commercial use, please contact us.
## 联系我们(Contact Us)
如果你想给我们的研发团队和产品团队留言,欢迎加入我们的微信群、钉钉群以及Discord!同时,也欢迎通过邮件(qianwen_opensource@alibabacloud.com)联系我们。
If you are interested to leave a message to either our research team or product team, join our Discord or WeChat groups! Also, feel free to send an email to qianwen_opensource@alibabacloud.com.
{kind=link}