---
base_model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
library_name: transformers
license: llama3.1
tags:
- deepseek
- transformers
- llama
- llama-3
- meta
- GGUF
---
# DeepSeek-R1-Distill-Llama-8B-NexaQuant
## Introduction
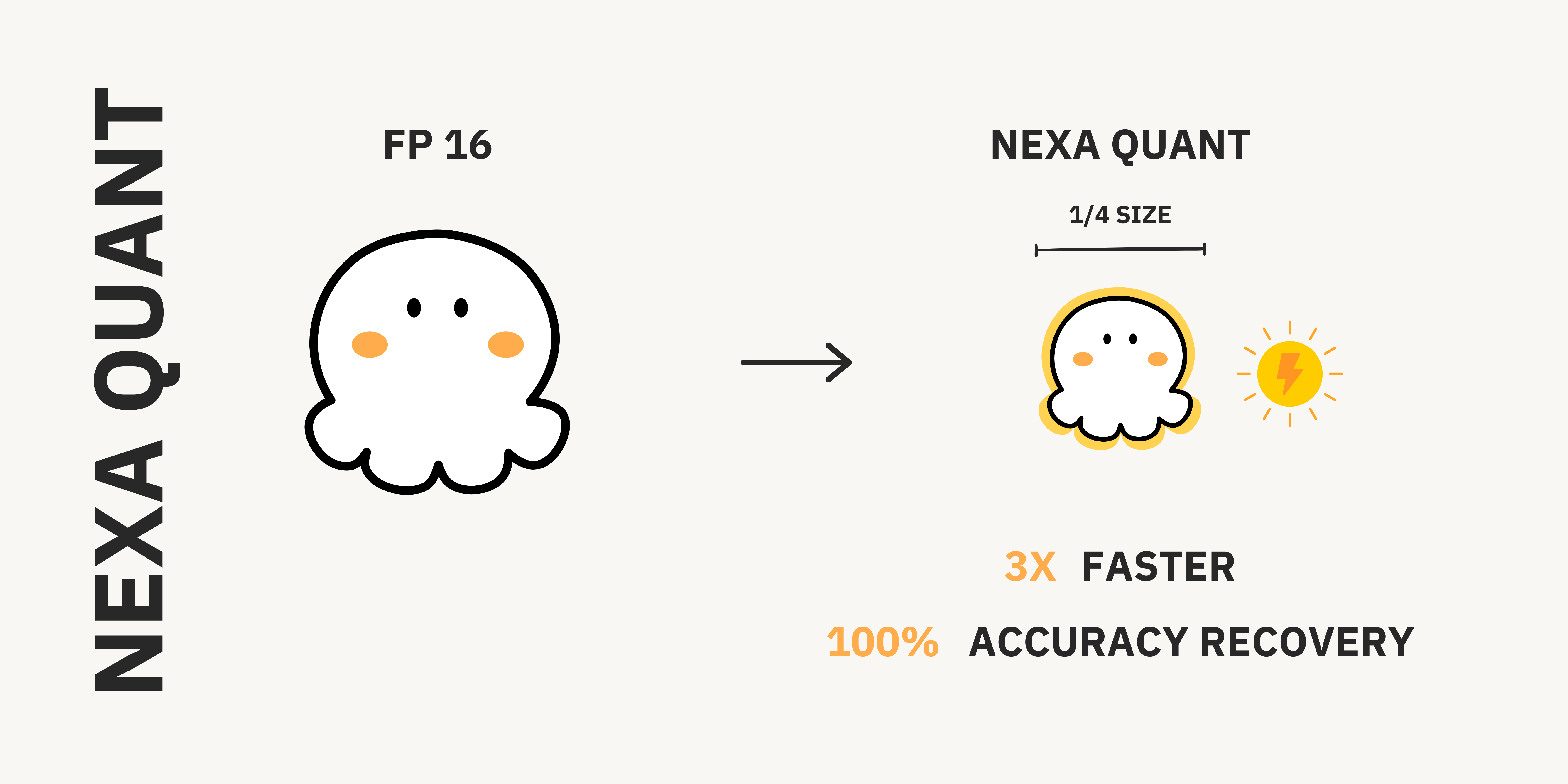
DeepSeek-R1 has been making headlines for rivaling OpenAI’s O1 reasoning model while remaining fully open-source. Many users want to run it locally to ensure data privacy, reduce latency, and maintain offline access. However, fitting such a large model onto personal devices typically requires quantization (e.g. Q4_K_M), which often sacrifices accuracy (up to ~22% accuracy loss) and undermines the benefits of the local reasoning model.
We’ve solved the trade-off by quantizing the DeepSeek R1 Distilled model to one-fourth its original file size—without losing any accuracy. Tests on an **HP Omnibook AIPC** with an **AMD Ryzen™ AI 9 HX 370 processor** showed a decoding speed of **17.20 tokens per second** and a peak RAM usage of just **5017 MB** in NexaQuant version—compared to only **5.30 tokens** per second and **15564 MB RAM** in the unquantized version—while NexaQuant **maintaining full precision model accuracy.**
## NexaQuant Use Case Demo
Here’s a comparison of how a standard Q4_K_M and NexaQuant-4Bit handle a common investment banking brain teaser question. NexaQuant excels in accuracy while shrinking the model file size by 4 times.
Prompt: A Common Investment Banking BrainTeaser Question
A stick is broken into 3 parts, by choosing 2 points randomly along its length. With what probability can it form a triangle?
Right Answer: 1/4

## Benchmarks
The benchmarks show that NexaQuant’s 4-bit model preserves the reasoning capacity of the original 16-bit model, delivering uncompromised performance in a significantly smaller memory & storage footprint.
**Reasoning Capacity:**

**General Capacity:**
| Benchmark | Full 16-bit | llama.cpp (4-bit) | NexaQuant (4-bit)|
|----------------------------|------------|-------------------|-------------------|
| **HellaSwag** | 57.07 | 52.12 | 54.56 |
| **MMLU** | 55.59 | 52.82 | 54.94 |
| **ARC Easy** | 74.49 | 69.32 | 71.72 |
| **MathQA** | 35.34 | 30.00 | 32.46 |
| **PIQA** | 78.56 | 76.09 | 77.68 |
| **IFEval** | 36.26 | 35.35 | 34.12 |
## Run locally
NexaQuant is compatible with **Nexa-SDK**, **Ollama**, **LM Studio**, **Llama.cpp**, and any llama.cpp based project. Below, we outline multiple ways to run the model locally.
#### Option 1: Using Nexa SDK
**Step 1: Install Nexa SDK**
Follow the installation instructions in Nexa SDK's [GitHub repository](https://github.com/NexaAI/nexa-sdk).
**Step 2: Run the model with Nexa**
Execute the following command in your terminal:
```bash
nexa run DeepSeek-R1-Distill-Llama-8B-NexaQuant:q4_0
```
#### Option 2: Using llama.cpp
**Step 1: Build llama.cpp on Your Device**
Follow the "Building the project" instructions in the llama.cpp [repository](https://github.com/ggerganov/llama.cpp) to build the project.
**Step 2: Run the Model with llama.cpp**
Once built, run `llama-cli` under `/bin/`:
```bash
./llama-cli \
--model your/local/path/to/DeepSeek-R1-Distill-Llama-8B-NexaQuant \
--prompt 'Provide step-by-step reasoning enclosed in tags, followed by the final answer enclosed in \boxed{} tags.' \
```
#### Option 3: Using LM Studio
**Step 1: Download and Install LM Studio**
Get the latest version from the [official website](https://lmstudio.ai/).
**Step 2: Load and Run the Model**
1. In LM Studio's top panel, search for and select `NexaAIDev/DeepSeek-R1-Distill-Llama-8B-NexaQuant`.
2. Click `Download` (if not already downloaded) and wait for the model to load.
3. Once loaded, go to the chat window and start a conversation.
---
## What's next
1. This model is built for complex problem-solving, which is why it sometimes takes a long thinking process even for simple questions. We recognized this and are working on improving it in the next update.
2. Inference Nexa Quantized Deepseek-R1 distilled model on NPU
### Follow us
If you liked our work, feel free to ⭐Star [Nexa's GitHub Repo](https://github.com/NexaAI/nexa-sdk).
Interested in running DeepSeek R1 on your own devices with optimized CPU, GPU, and NPU acceleration or compressing your finetuned DeepSeek-Distill-R1? [Let’s chat!](https://nexa.ai/book-a-call)
[Blogs](https://nexa.ai/blogs/deepseek-r1-nexaquant) | [Discord](https://discord.gg/nexa-ai) | [X(Twitter)](https://x.com/nexa_ai)
Join Discord server for help and discussion.