
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
**Usage**
|
| 2 |
|
| 3 |
# 环境配置
|
|
|
|
| 1 |
+
# RLHF (Reinforcement Learning from Human Feedback)流程
|
| 2 |
+
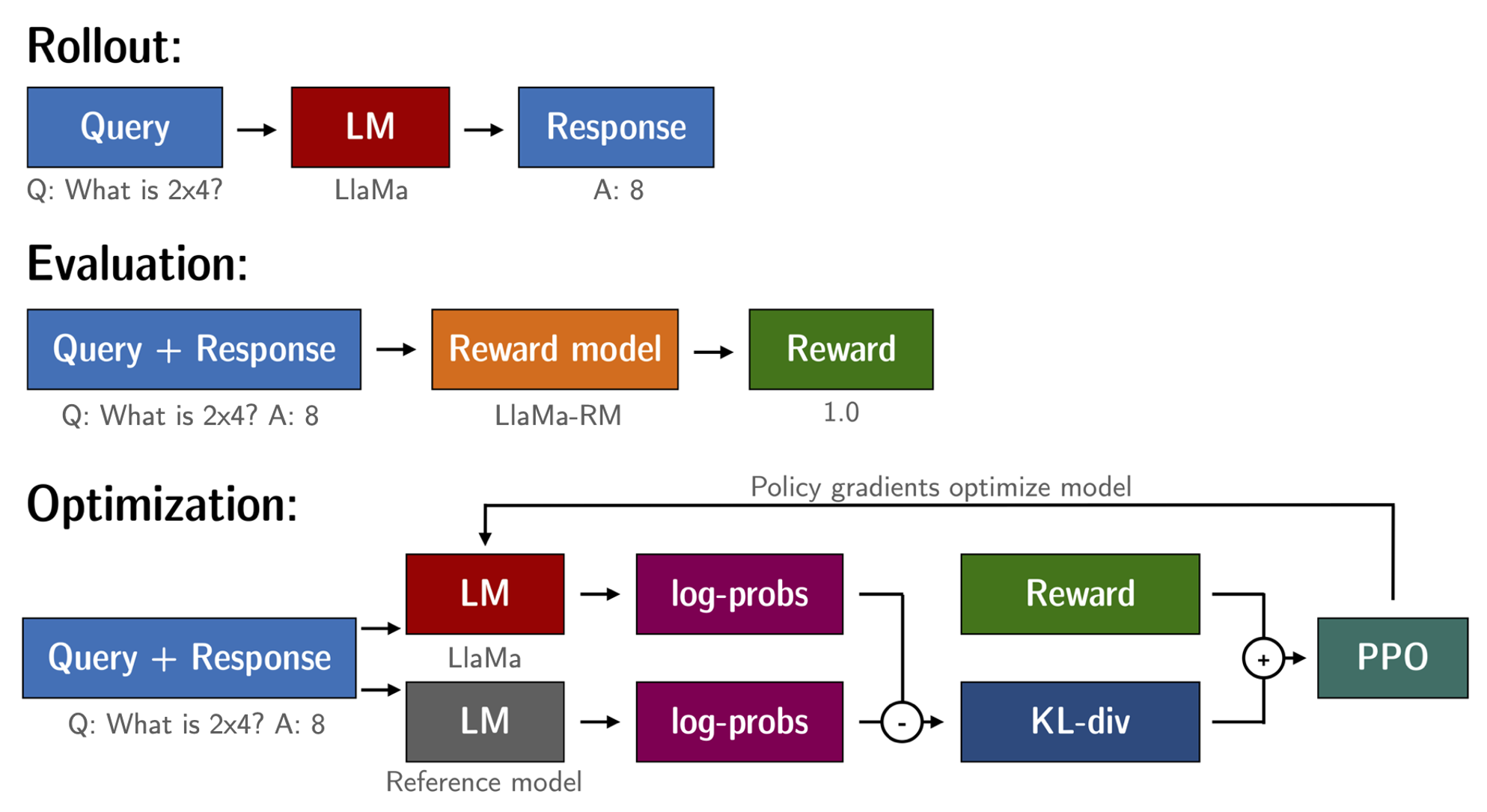
1. 首先采用监督学习的方式,使用人工标注的数据在预训练语言模型的基础上进行微调,得到一个初步的语言模型。
|
| 3 |
+
2. 然后收集人工反馈的数据,这些数据包含人工生成的文本及人工给出的评分。利用这些带评分的数据训练一个reward模型。
|
| 4 |
+
3. 最后,利用reward模型产生的奖励信号,采用强化学习的方式对第1步得到的语言模型进行优化。在这个步骤中,会生成大量文本,并采用reward模型给出的奖励进行更新。
|
| 5 |
+
所以整体流程分为监督微调、训练reward模型和强化学习三个阶段。首先利用有限的人工标注数据得到一个初步模型,然后利用更多的人工反馈文本训练reward模型,最后利用强化学习和reward模型的反馈不断优化和提高语言模型。
|
| 6 |
+
|
| 7 |
+
|
| 8 |
**Usage**
|
| 9 |
|
| 10 |
# 环境配置
|