
Description
Exllama 2 quant of Undi95/Emerhyst-20B
4 BPW, Head bit set to 8
I wanted to try to push context to 8k while still being able to load in 24gb of VRAM and in my so far very limited testing it seems to works fine.
VRAM
My VRAM usage with 20B models are:
| Bits per weight | Context | VRAM |
|---|---|---|
| 6bpw | 4k | 24gb |
| 4bpw | 4k | 18gb |
| 4bpw | 8k | 24gb |
| 3bpw | 4k | 16gb |
| 3bpw | 8k | 21gb |
| I have rounded up, these arent exact numbers, this is also on a windows machine. |
Prompt template
You can follow these instruction format settings in SillyTavern. Replace tiny with
your desired response length:
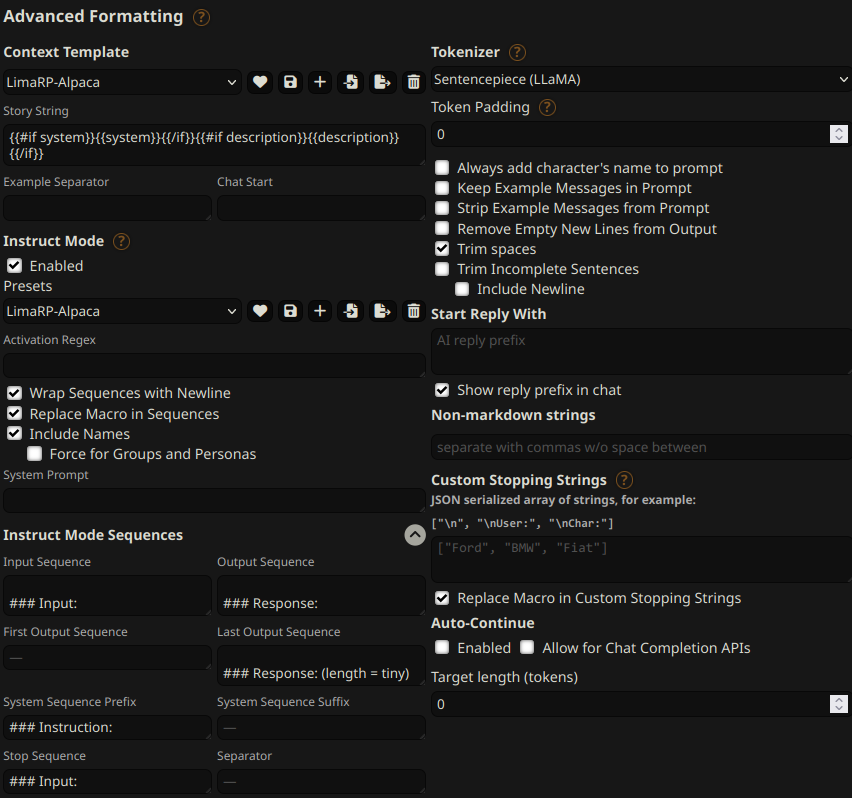
Message length control
Inspired by the previously named "Roleplay" preset in SillyTavern, starting from this version of LimaRP it is possible to append a length modifier to the response instruction sequence, like this:
### Input
User: {utterance}
### Response: (length = medium)
Character: {utterance}
This has an immediately noticeable effect on bot responses. The available lengths are:
tiny, short, medium, long, huge, humongous, extreme, unlimited. The
recommended starting length is medium. Keep in mind that the AI may ramble
or impersonate the user with very long messages.
The length control effect is reproducible, but the messages will not necessarily follow lengths very precisely, rather follow certain ranges on average, as seen in this table with data from tests made with one reply at the beginning of the conversation:
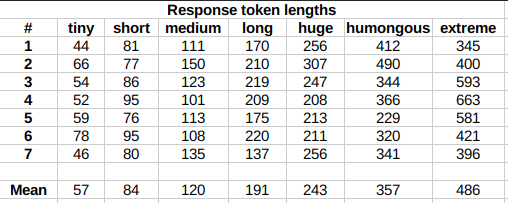
Response length control appears to work well also deep into the conversation.
- Downloads last month
- 15